
1. 事前準備
本程式碼研究室是以本系列先前程式碼研究室的最終結果為基礎,使用 TensorFlow.js 偵測垃圾留言。
在上一個程式碼研究室中,您為虛構的影音網誌建立了功能齊全的網頁。在將留言傳送至伺服器儲存以供儲存或其他已連結的用戶端之前,你能先篩選垃圾留言,方法是在瀏覽器中使用採用 TensorFlow.js 的預先訓練垃圾留言偵測模型。
本程式碼研究室最終結果如下:
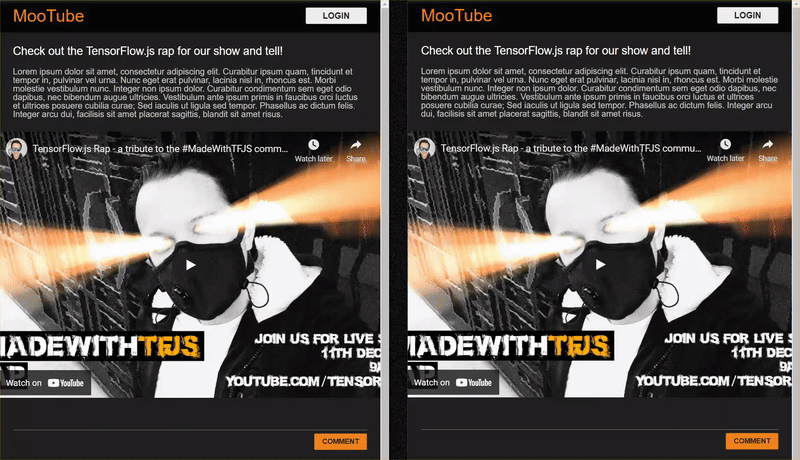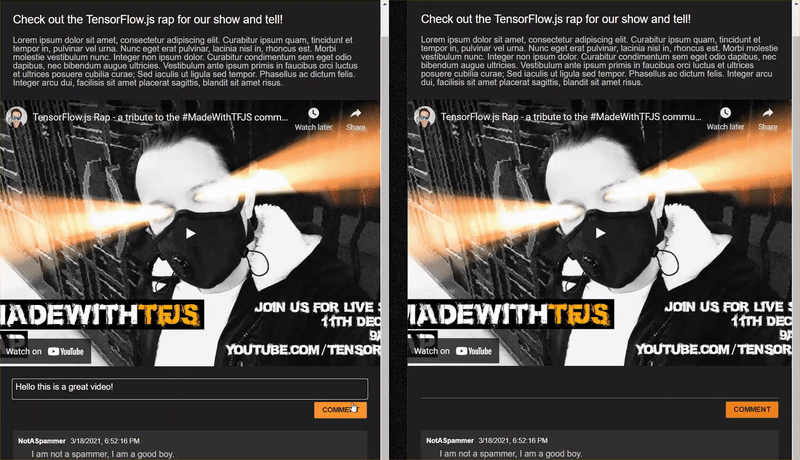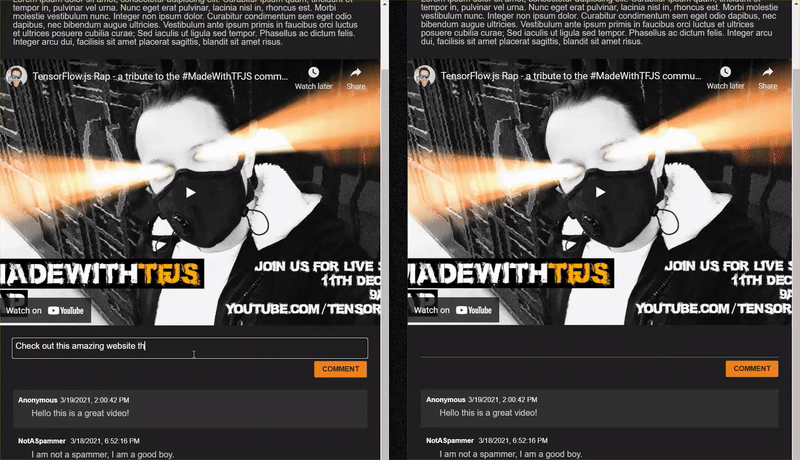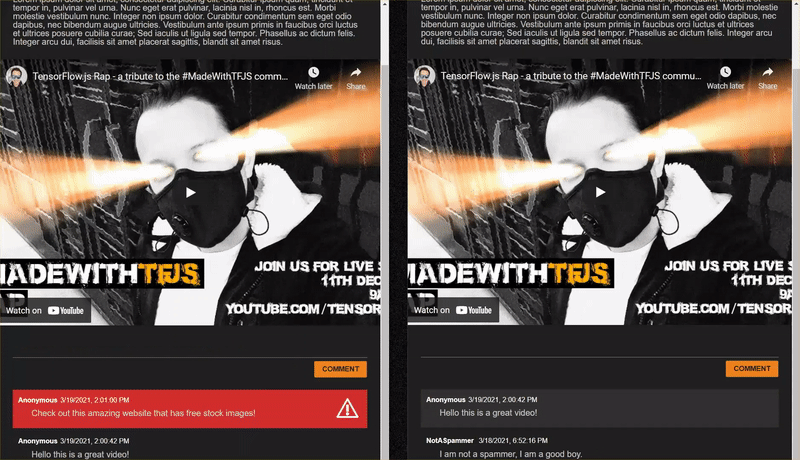
雖然這種做法看起來非常好,但還是有一些極端案例無法被發現。針對無法處理的情況,您可以重新訓練模型。
本程式碼研究室著重於使用自然語言處理 (就電腦理解人類語言的藝術),並說明如何修改您建立的現有網頁應用程式 (強烈建議您遵循程式碼研究室),解決垃圾留言的真正問題,許多網頁開發人員都會在處理垃圾留言時遇到的難題。
在這個程式碼研究室中,您將更進一步重新訓練機器學習模型,以因應垃圾郵件內容的變化。這類訊息可能會根據當前趨勢或熱門討論主題而隨著時間變動,讓模型保持最新狀態,並因應這類變化。
必要條件
- 已完成本系列中的第一個程式碼研究室。
- 具備網頁技術 (包括 HTML、CSS 和 JavaScript) 的基本知識。
建構項目
您將重複使用先前建構的網站,建立含有即時留言區的虛構影音網誌,並透過 TensorFlow.js 載入經過訓練的自訂版本垃圾內容偵測模型,讓先前無法成功載入的極端案例表現得更好。您當然可以在網頁程式開發人員和工程師中,變更這種假設的使用者體驗,以便在日常工作中重複使用,並依據各種客戶用途調整解決方案,例如網誌、論壇或某些形式的 CMS (例如 Drupal)。
開始入侵吧...
課程內容
您將學會以下內容:
- 找出預先訓練模型失敗的邊緣案例
- 重新訓練使用 Model Maker 建立的垃圾郵件分類模型。
- 將這個以 Python 為基礎的模型匯出為 TensorFlow.js 格式,以便在瀏覽器中使用。
- 使用新訓練的模型更新託管模型及其字典,然後查看結果
本研究室假設您已熟悉 HTML5、CSS 和 JavaScript。您還會透過「co Lab」執行一些 Python 程式碼來重新訓練模型。
2. 設定程式碼
再次提醒您,您將使用 Glitch.com 代管及修改網頁應用程式。如果您尚未完成事前準備程式碼研究室,可以複製這裡的最終結果做為起點。如果對程式碼的運作方式有任何疑問,強烈建議您完成先前的程式碼研究室,逐步瞭解如何建構可正常運作的網頁應用程式,然後再繼續操作。
在 Glitch 上,點選「重混這個」按鈕就能建立分支,並建立一組可編輯的檔案。
3. 探索先前解決方案中的極端案例
如果您開啟剛剛複製的完成網站並嘗試輸入一些留言,就會發現網站長時間正常運作、封鎖看似垃圾留言的留言,並且允許合法回應。
不過,如果您有足夠的精力和語句來破壞模型,可能在特定時間點還是有可能成功。經過些許測試和錯誤時,您可以自行建立範例,如下所示。請嘗試將下列內容貼到現有的網頁應用程式,檢查控制台,看看留言是否為垃圾留言的機率會出現什麼情況:
張貼正當且沒有問題的正當留言 (真陰性):
- 「哇,影片,超棒的!」機率垃圾郵件:47.91854%
- 「非常喜歡這些示範!想瞭解更多資訊嗎?」機率垃圾郵件:47.15898%
- 「我可以前往哪個網站瞭解詳情?」機率垃圾郵件:15.32495%
這非常好,上述所有資訊的機率都很低,成功通過預設 SPAM_THRESHOLD 後,即成功採用最低可能性最低 75% 的機率 (在先前程式碼研究室的 script.js 程式碼中定義)。
現在讓我們試著撰寫一些較常見且被標記為垃圾的留言,即使留言並非垃圾內容...
標示為垃圾內容的合法留言 (偽陽性):
- 「有人可以連結自己穿著口罩的網站嗎?」機率垃圾郵件:98.46466%
- 「我可以在 Spotify 上購買這首歌曲嗎?有人請告訴我!」機率垃圾郵件:94.40953%
- 「有人可以與我聯絡,並詳細說明如何下載 TensorFlow.js 嗎?」機率垃圾郵件:83.20084%
糟糕!系統已將這些合法留言標示為垃圾留言,但其實可以將其標示為垃圾內容。該如何修正這個問題?
其中一個簡單的做法是,將 SPAM_THRESHOLD 提升至超過 98.5% 的信心值。在這種情況下,這些分類錯誤的留言就會張貼。瞭解這點後,讓我們繼續嘗試下列其他可能的結果...
標示為垃圾內容的垃圾內容留言 (是正面的):
- 「這是很酷的,但快去看看我網站上的下載連結,或許更適合你!」機率垃圾郵件:99.77873%
- 「我知道有些人可以買一些藥品,只要前往我的 pr0file 就能瞭解詳情」:可能性垃圾內容:98.46955%
- 「查看我的個人資料並下載更多令人驚豔的影片!http://example.com" 機率垃圾郵件:96.26383%
好的,這是正常的 75% 門檻,不過在上一個步驟中,您已將 SPAM_THRESHOLD 變更為 98.5% 以上的信心值,這意味著這裡有 2 個範例可以通過,因此門檻可能過高。也許 96% 才比較好?但如果您這麼做,前一節的其中一則留言 (偽陽性) 的評分為 98.46466% 時,系統會將其標示為垃圾內容。
在此情況下,最好能攔截所有這些真實的垃圾意見,只需針對上述失敗情形進行重新訓練即可。將門檻設為 96% 後,系統仍會擷取所有真陽性,並消除上述 2 個偽陽性的情形。只更改一個號碼也沒關係,
繼續...
允許張貼的垃圾留言 (偽陰性):
- 「查看我的個人資料,下載更精彩的影片!」機率垃圾郵件:7.54926%
- 「享有健身房訓練課程的折扣,請參閱 pr0file!」機率垃圾郵件:17.49849%
- "「天啊, GOOG 的股票剛剛射門了!」早點入手!」機率垃圾郵件:20.42894%
如果不想處理這些註解,只要進一步變更 SPAM_THRESHOLD 值即可。如果將垃圾郵件門檻從 96% 降至約 9%,我們就有可能將真正的留言標示為垃圾內容,即使這類留言是正常行為,也會獲得 58% 的評分。處理這類留言的唯一方法,就是在訓練資料中使用這類極端案例重新訓練模型,讓模型學習調整其對於垃圾內容的認知。
雖然現在唯一的選項是重新訓練模型,但您已瞭解如何調整判定呼叫垃圾來電的時機門檻,進而改善成效。身為人類,75% 似乎很有信心,但以這個模型來說,您需要將幅度增加到 81.5%,才能運用範例資料提升效率。
雖然沒有一個神奇價值適用於各種模型,而且要測試實際資料並找出成效良好的部分,然後為每個模型設定這個門檻值。
在某些情況下 (例如醫療產業中),有誤判 (或負面) 可能會受到嚴重後果 (例如醫療產業),因此您可以將門檻調整為非常高,針對未達到門檻的人士申請更多人工審查。您選為開發人員,但需要做一些實驗。
4. 重新訓練垃圾留言偵測模型
在前一節中,您已發現一些模型因這些情況而重新訓練模型而失敗。在實際工作環境系統中,由於使用者手動檢舉留言為垃圾內容,導致這些留言遭到檢舉,或管理員審核遭檢舉的留言,指出有些不是垃圾內容,且可能會將這類留言標示為需要重新訓練。假設您已經針對這些極端案例收集到大量的新資料 (為盡可能取得最佳結果,請盡可能讓這些新的句子出現變化),而我們現在也會說明如何運用這些極端情況重新訓練模型。
預製模型重點回顧
您使用的預建模型是由第三方透過模型製作工具建立的模型,這類模型使用「平均字詞嵌入」才能運作
由於這個模型是以 Model Maker 建立而成,因此你必須短暫切換至 Python 來重新訓練模型,然後將建立的模型匯出為 TensorFlow.js 格式,以便在瀏覽器中使用。值得慶幸的是,模型製作工具讓模型的使用方式變得非常簡單,跟您一樣很容易上手,我們也會引導您完成整個程序,因此如果您從未使用過 Python,請不用擔心!
哥倫比亞
在本程式碼研究室中,您不會擔心想設定 Linux 伺服器並安裝各種 Python 公用程式,因此只要使用網路瀏覽器,就能透過「Colab Notebook」執行程式碼。這些筆記本可連結至「後端」,不過是已預先安裝部分內容的伺服器,您可以在網路瀏覽器中執行任意程式碼並查看結果。無論是快速設計原型,還是用於這類教學課程,這項功能都非常實用。
只要前往 colab.research.google.com,就會看到歡迎畫面,如下所示:
現在請點選彈出式視窗右下方的「新增筆記本」按鈕,畫面上應會顯示一個空白 Colab,如下所示:
太好了!接著是將前端 Colab 連線至某些後端伺服器,以便執行您將編寫的 Python 程式碼。按一下右上方的「Connect」(連線),然後選取「Connect to Hosting Runtime」(連線至代管的執行階段) 即可。
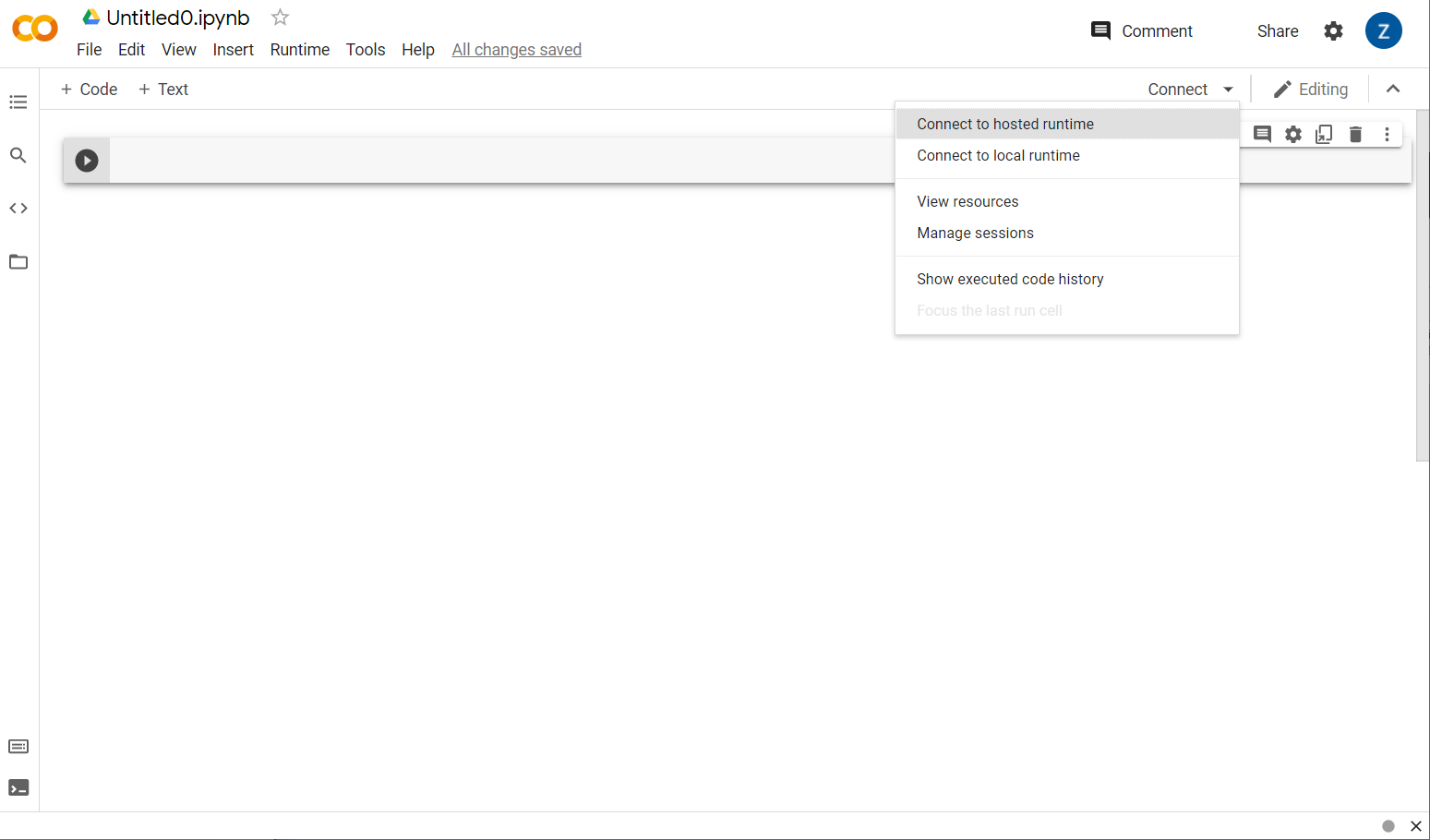
完成連接後,您應該會在其位置看到 RAM 和「磁碟」圖示,如下所示:
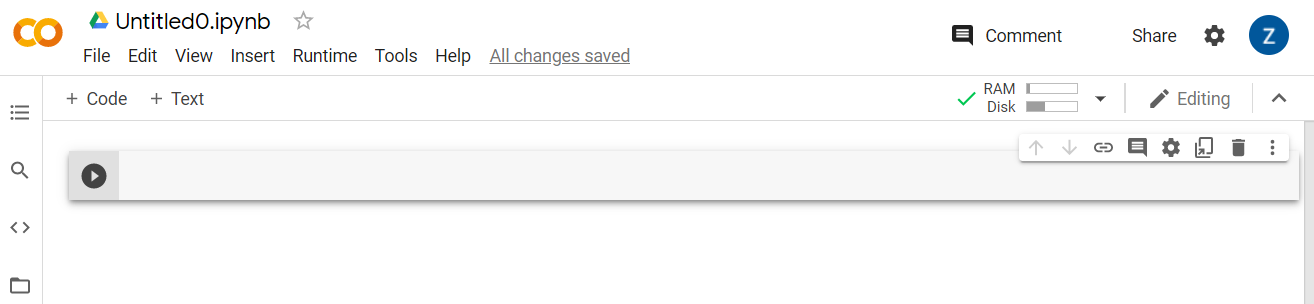
太棒了!您現在可以開始在 Python 中編寫程式碼,重新訓練 Model Maker 模型。只要按照下列步驟進行即可。
步驟 1
在目前空白的第一個儲存格中,複製下方的程式碼。系統會使用 Python 的套件管理工具「pip」,為您安裝 TensorFlow Lite Model Maker(與 npm 類似,此程式碼研究室的多數讀者可能會對 JS 生態系統更熟悉):
!apt-get install libasound-dev portaudio19-dev libportaudio2 libportaudiocpp0
!pip install -q tflite-model-maker
不過,將程式碼貼入儲存格並不會執行該程式碼。接著,將滑鼠遊標移至您貼上上述程式碼的灰色儲存格上,然後選取一個小小的「播放」儲存格左方將顯示如下的圖示:
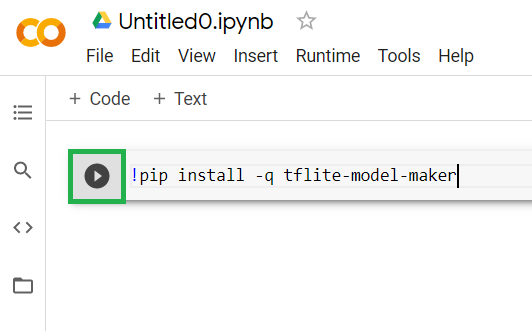 按一下播放按鈕,即可執行剛剛在儲存格中輸入的程式碼。
按一下播放按鈕,即可執行剛剛在儲存格中輸入的程式碼。
現在,您會看到模型製作工具的安裝完成:
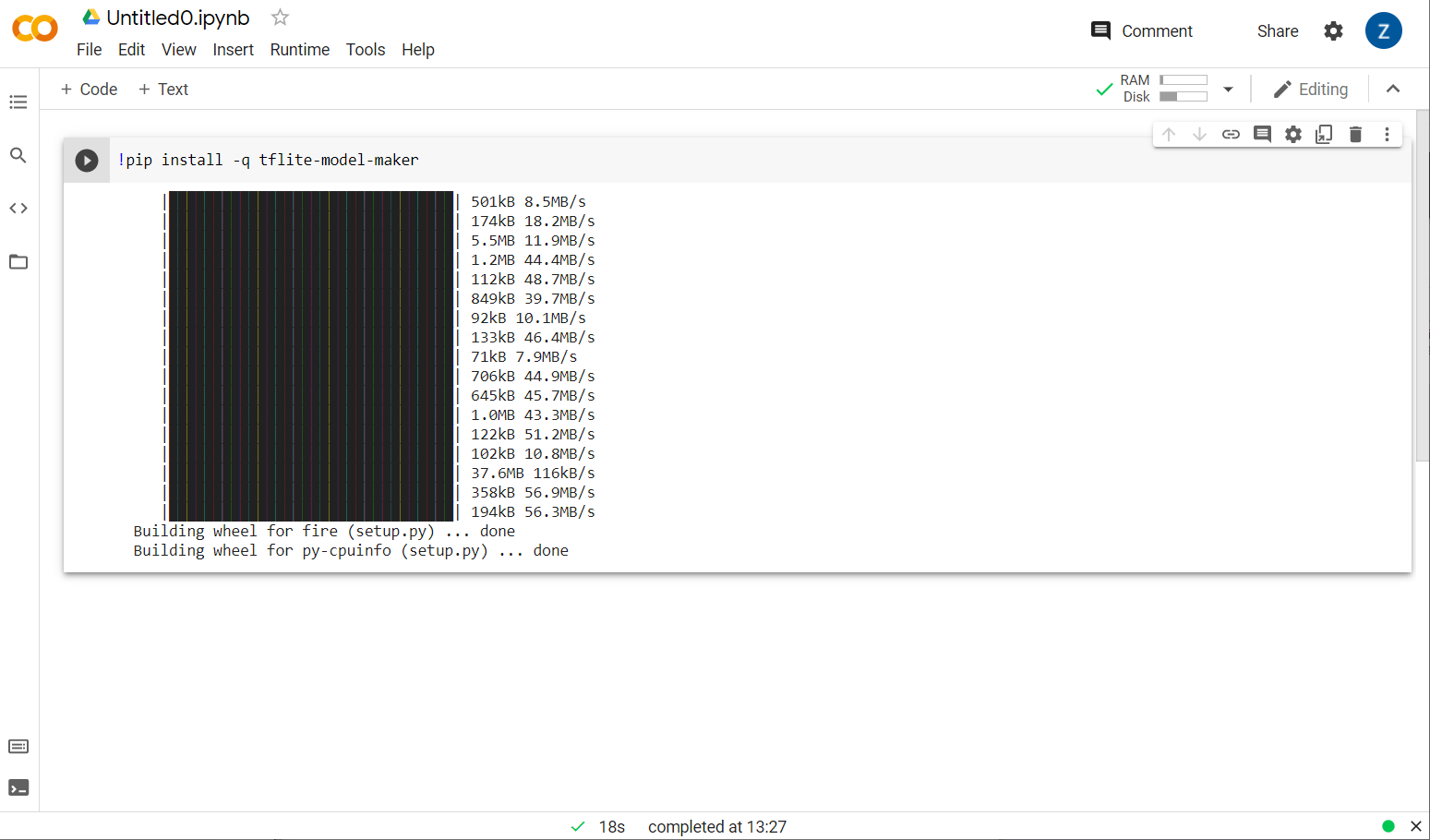
這個儲存格的執行作業完成 (如圖所示) 後,請繼續下一步驟。
步驟 2
接下來,新增程式碼儲存格 (如下所示),以便在第一個儲存格後方貼上其他程式碼,並分別執行:
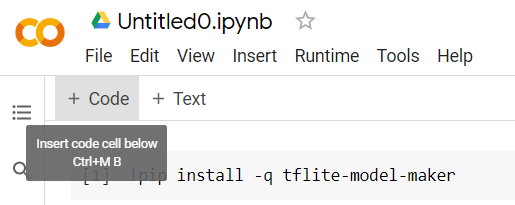
下一個執行的儲存格會顯示一些匯入作業,筆記本其餘部分的程式碼需要使用這些匯入內容。請複製下方文字並貼到新建的儲存格中:
import numpy as np
import os
from tflite_model_maker import configs
from tflite_model_maker import ExportFormat
from tflite_model_maker import model_spec
from tflite_model_maker import text_classifier
from tflite_model_maker.text_classifier import DataLoader
import tensorflow as tf
assert tf.__version__.startswith('2')
tf.get_logger().setLevel('ERROR')
就算您不熟悉 Python,也能照常使用。你即將匯入垃圾郵件分類器所需的部分公用程式和 Model Maker 功能,系統也會檢查您是否執行的是 TensorFlow 2.x,這是使用 Model Maker 的必要條件。
最後,和先前一樣,按下「播放」按鈕執行儲存格圖示,請將滑鼠懸停在儲存格上,然後新增程式碼儲存格,以便進行下一個步驟。
步驟 3
接下來,請將遠端伺服器中的資料下載至裝置,並將 training_data 變數設為所產生本機檔案的下載路徑:
data_file = tf.keras.utils.get_file(fname='comment-spam-extras.csv', origin='https://storage.googleapis.com/jmstore/TensorFlowJS/EdX/code/6.5/jm_blog_comments_extras.csv', extract=False)
Model Maker 可用簡單的 CSV 檔案來訓練模型,例如下載的檔案。您只需指定包含文字的欄,並指定要保留標籤的資料欄。步驟 5 將顯示操作方式。如有需要,您可以直接下載 CSV 檔案,查看檔案內容。
您正注意到這個檔案的名稱是 jm_blog_comments_extras.csv,這個檔案只是我們產生第一個垃圾留言模型時的原始訓練資料,會與您發現的新極端案例資料合併,讓這個檔案全都集中在一個檔案中。除了您想從中學習的新語句,還需要用來訓練模型的原始訓練資料。
選用:如果您下載這個 CSV 檔案並檢查最後幾行,就會看到先前無法正常運作的極端情況示例。這些訓練資料現已新增至現有訓練資料的結尾,這是預建模型用來自我訓練的模型。
請執行這個儲存格,並在執行完畢後新增儲存格,然後前往步驟 4。
步驟 4
使用 Model Maker 時,您不必從頭開始建構模型,您通常會使用現有模型,然後根據自身需求自訂。
模型製作工具提供一些您可以使用的預先學習模型嵌入,但最簡單的入門就是在先前的程式碼研究室中用來建構網站的 average_word_vec。程式碼如下:
spec = model_spec.get('average_word_vec')
spec.num_words = 2000
spec.seq_len = 20
spec.wordvec_dim = 7
請將儲存格貼到新的儲存格中,直接執行該指令。
瞭解
num_words
參數
這是您希望模型使用的字詞數。您可能認為越多越好,但一般而言,還是會根據每個字詞的使用頻率做出最佳選擇。如果使用整個語料庫中的每個字詞,模型可能會試圖學習和平衡只使用一次的字詞,這樣就沒有幫助。許多文字語料庫中只會出現一或兩次的字詞,在模型中使用這些字詞對整體情緒的影響微乎其微,因此通常不值得。因此,您可以使用 num_words 參數,針對需要的字數調整模型。這個數字越小,模型越短越好,但可能因為辨識出較少字詞而較不準確。這裡的數字越大,模型越大且速度可能較慢。找出最佳時機很重要,您須仰賴機器學習工程師,才能找出最適合自己的用途。
瞭解
wordvec_dim
參數
wordvec_dim 參數是指您要用於每個字詞向量的維度數量。這些維度基本上是不同的特徵 (訓練時由機器學習演算法建立),程式會使用任何指定字詞來衡量該字詞,並以有意義的方式將相似字詞建立關聯。
舉例來說,假設你設定的維度是「醫療」也就是「藥丸」等字詞在這個維度中,分數可能較高,並與「xray」和「貓」等其他高分字詞建立關聯。會使此維度的分數偏低圖表的「醫療維度」結合其他潛在維度時,有助於確定垃圾內容。
如果「醫療維度」中獲得高分的字詞可能會發現用字詞與人體關聯的第 2 維度可能會有幫助「leg」、「arm」、「Neck」等字詞在這裡的得分可能很高,在醫療領域也相當高
之後,模型就能根據這些維度偵測可能與垃圾郵件相關的字詞。也許垃圾電子郵件容易包含醫療和身體部位兩者的字詞。
根據研究判斷,經驗法則是指字詞數量的第四根對這個參數有效。如果我輸入的是 2000 個字,可以從 7 個維度著手,如果您變更了使用的字詞數量,也可以進行變更。
瞭解
seq_len
參數
關於輸入值,模型通常都相當嚴謹。對語言模型而言,這表示語言模型可分類特定、靜態長度的語句。此設定取決於 seq_len 參數,其中表示「sequence 長度」。當您將字詞轉換為數字 (或符記) 時,一個句子會成為這些符記的序列。因此,您的模型經過訓練 (在本範例中),分類及辨識含有 20 個符記的句子。如果句子長超過此長度,將遭到截斷。如果篇幅較短,則會填充,就像本系列的第一個程式碼研究室一樣。
步驟 5:載入訓練資料
您先前下載了 CSV 檔案。接下來請使用資料載入器,將上述值轉換為模型可識別的訓練資料。
data = DataLoader.from_csv(
filename=data_file,
text_column='commenttext',
label_column='spam',
model_spec=spec,
delimiter=',',
shuffle=True,
is_training=True)
train_data, test_data = data.split(0.9)
在編輯器中開啟 CSV 檔案時,您會發現每一行都有兩個值,而這些項目的第一行將以文字描述。一般來說,每個項目都會視為「資料欄」。您會看到第一欄的描述元是 commenttext,而每一行的第一個項目就是註解的文字。
同樣地,第二欄的描述元是 spam,您會看到每一行的第二個項目是 TRUE 或 FALSE,表示該文字是否屬於垃圾評論。其他屬性則設定您在步驟 4 建立的模型規格,以及分隔符號字元 (在本範例中為以半形逗號分隔檔案)。此外,您也可以設定重組參數來隨機重新排列訓練資料,讓可能類似或一起收集的資料隨機分散在資料集中。
接著,您會使用 data.split() 將資料拆分為訓練和測試資料。0.9 代表 90% 的資料集將用於訓練,其餘部分則用於測試。
步驟 6:建構模型
新增另一個儲存格,用於新增程式碼來建構模型:
model = text_classifier.create(train_data, model_spec=spec, epochs=50)
這項操作會使用 Model Maker 建立文字分類器模型,指定要使用的訓練資料 (步驟 4 已定義)、模型規格 (在步驟 4 中也一併設定),以及多個訓練週期 (本例為 50)。
機器學習的基本原則是模式比對的形式。一開始,它會為字詞載入預先訓練的權重,並嘗試使用「Predict」(預測結果) 將資料分組在一起以及未歸為垃圾郵件的群組。第一次使用時,可能非常接近 50:50,因為模型的入門程度如下所示:

接著再評估預測結果,然後調整模型權重以調整預測結果,然後再試一次。這是一個週期只要指定 epochs=50,就會進入該「迴圈」50 次,如下所示:

因此,等到第 50 個週期時,模型的準確率就會提高。在本例中是 99.1%!
步驟 7:匯出模型
訓練完成後,即可匯出模型。TensorFlow 會以自己的格式訓練模型,因此必須轉換成 TensorFlow.js 格式,才能在網頁上使用。方法很簡單,只要在新的儲存格中貼上下列程式碼,然後執行即可:
model.export(export_dir="/js_export/", export_format=[ExportFormat.TFJS, ExportFormat.LABEL, ExportFormat.VOCAB])
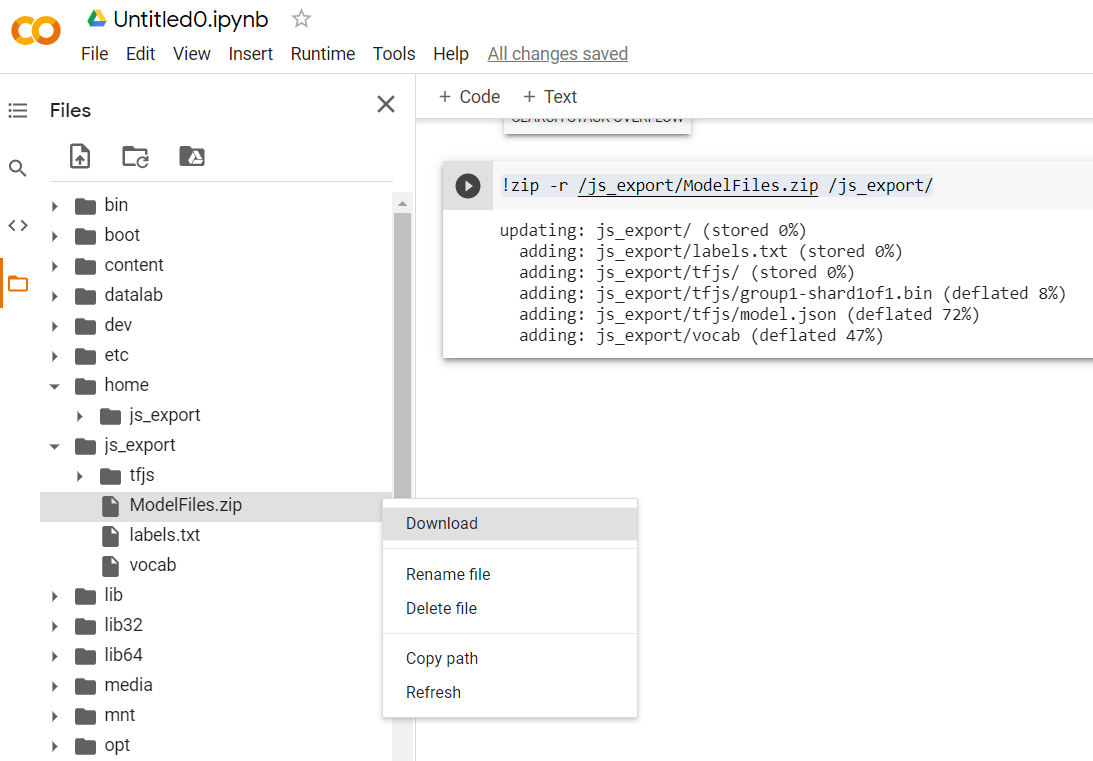
!zip -r /js_export/ModelFiles.zip /js_export/
執行這個程式碼後,只要點選 Colab 左側的小型資料夾圖示,即可前往上方匯出的資料夾 (位於根目錄中,您可能需要上更高層級),並找出 ModelFiles.zip 內含所匯出檔案的 ZIP 套件。
立即將這個 ZIP 檔案下載至電腦,就像第一個程式碼研究室中一樣可以使用這些檔案:
太好了!Python 部分已經結束,您現在可以回到您熟悉且喜愛的 JavaScript 土地。太好了!
5. 提供新的機器學習模型
您現在即將可以載入模型。在這之前,您必須先上傳先前在程式碼研究室中下載的新模型檔案,以便讓模型代管並在程式碼中使用。
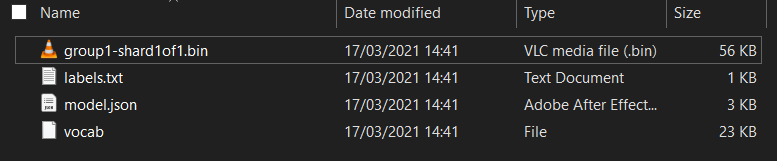
首先,如果您尚未從剛才執行的 Model Maker Colab 筆記本,將模型的檔案解壓縮,請先進行解壓縮。您會在各個資料夾中看到下列檔案:
你在這裡做什麼?
model.json- 這是構成訓練 TensorFlow.js 模型的其中一個檔案。您可以在 JS 程式碼中參照這個特定檔案。group1-shard1of1.bin:這個二進位檔案包含許多匯出的 TensorFlow.js 模型已儲存的資料,需託管於伺服器中的某個位置,才能下載與上述model.json相同的目錄。vocab- 這個沒有副檔名的奇怪檔案來自 Model Maker 的部分,它讓我們知道該如何將語句中的字詞編碼,讓模型瞭解如何使用它們。我們將在下一節深入探討。labels.txt- 這只包含模型將預測產生的類別名稱。如果您是使用文字編輯器開啟這個檔案,這個模型只會含有「false」和「true」標示「非垃圾郵件」或「垃圾內容」做為預測輸出
託管 TensorFlow.js 模型檔案
首先,請放置網路伺服器產生的 model.json 和 *.bin 檔案,以便透過網頁存取。
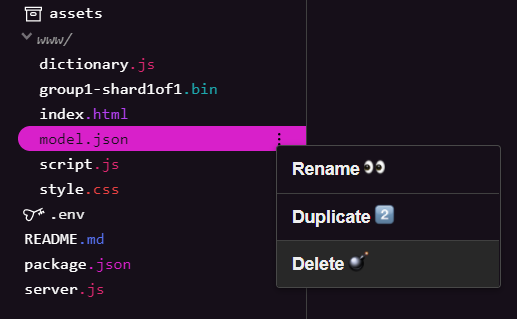
刪除現有的模型檔案
您在本系列第一個程式碼研究室結束時,必須刪除已上傳的現有模型檔案。如果您使用的是 Glitch.com,只需查看左側的檔案面板是否有 model.json 和 group1-shard1of1.bin,請按一下每個檔案的三點下拉式選單,然後選取「delete」,如下所示:
將新檔案上傳至 Glitch
太好了!現在請上傳新檔案:
- 在 Glitch 專案的左側面板中開啟 assets 資料夾,然後刪除先前上傳相同名稱的舊資產。
- 按一下「上傳素材資源」,然後選取要上傳至這個資料夾的
group1-shard1of1.bin。上傳完成後,畫面應該會如下所示:
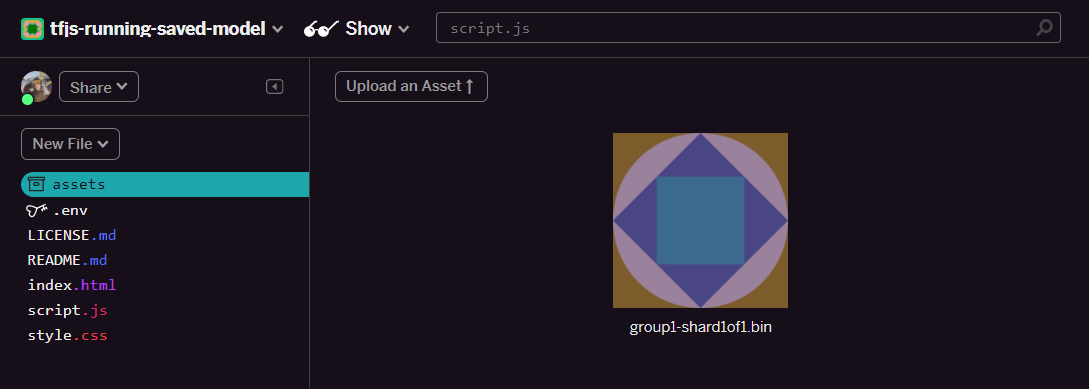
- 太好了!接著對 model.json 檔案執行相同操作,因此素材資源資料夾中應有 2 個檔案,如下所示:
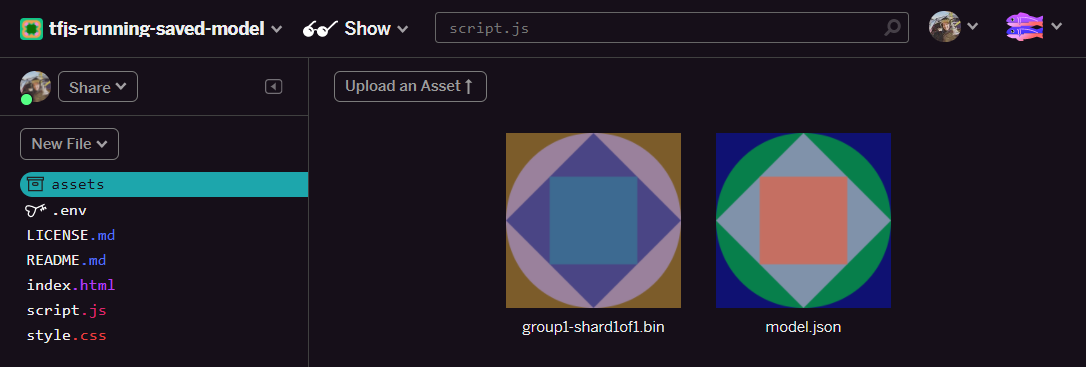
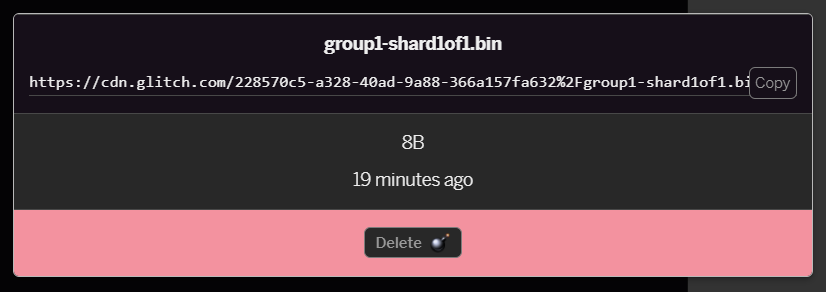
- 按一下剛上傳的
group1-shard1of1.bin檔案,即可將網址複製到該檔案的位置。現在請複製這個路徑,如下所示:
- 現在,按一下畫面左下方的「工具」>終端機。等待終端機視窗載入。
- 載入以下內容後,請按下 Enter 鍵,將目錄變更為
www資料夾:
終端機:
cd www
- 接著,請使用
wget下載剛才上傳的 2 個檔案,方法是將下列網址替換成您在 Glitch 上素材資源資料夾為檔案產生的網址 (請查看素材資源資料夾,瞭解每個檔案的自訂網址)。
請注意,這兩個網址之間的距離與您要使用的網址不同,但看起來會很類似:
終端機
wget https://cdn.glitch.com/1cb82939-a5dd-42a2-9db9-0c42cab7e407%2Fmodel.json?v=1616111344958 https://cdn.glitch.com/1cb82939-a5dd-42a2-9db9-0c42cab7e407%2Fgroup1-shard1of1.bin?v=1616017964562
超級!您現在已經複製上傳到「www」資料夾的檔案了。
不過,目前下載時會使用奇怪的名稱。如果您在終端機中輸入 ls 並按下 Enter 鍵,就會看到如下內容:

- 使用
mv指令重新命名檔案。在控制台中輸入以下內容,並在每行輸入一個後按下 Enter 鍵:
終端機:
mv *group1-shard1of1.bin* group1-shard1of1.bin
mv *model.json* model.json
- 最後,在終端機中輸入
refresh並按下 Enter 鍵,即可重新整理 Glitch 專案:
終端機:
refresh
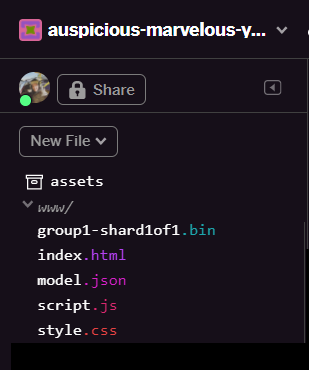
重新整理後,您應該會在使用者介面的 www 資料夾中看到 model.json 和 group1-shard1of1.bin:
太好了!最後一個步驟是更新 dictionary.js 檔案。
- 透過文字編輯器手動將新下載的 WordPress 檔案轉換為正確的 JS 格式,或者使用這項工具,然後將產生的輸出結果儲存為
www資料夾的dictionary.js。如果已經有dictionary.js檔案,只要複製新內容並貼到該檔案上,即可儲存檔案。
太厲害了!您已成功更新所有已變更的檔案,現在嘗試使用網站時,會發現重新訓練模型如何充分考慮發現的邊緣案例,如圖所示:
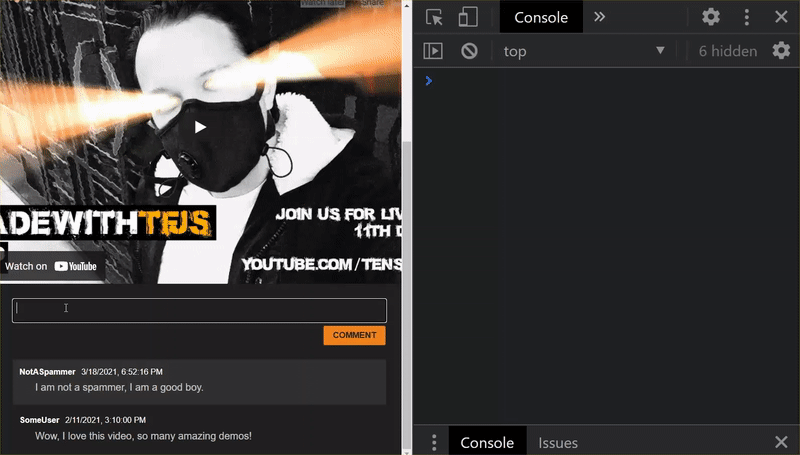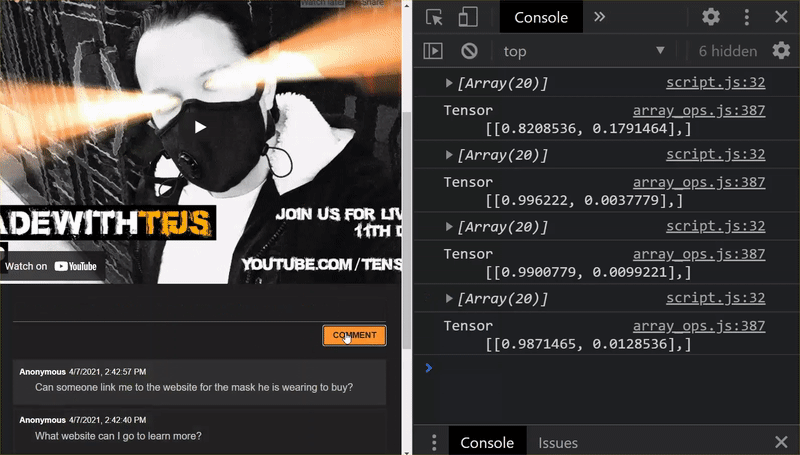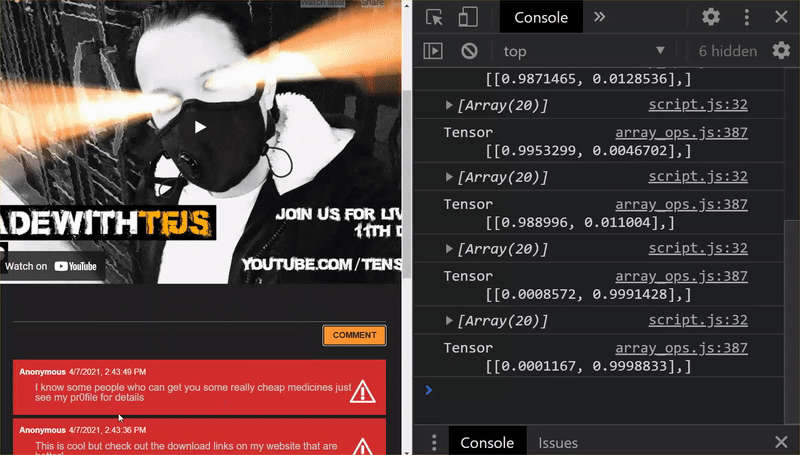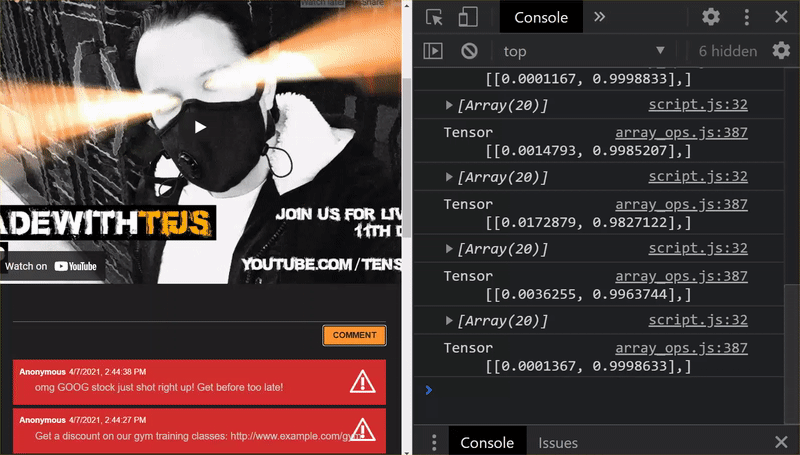
如您所見,前 6 個群組已正確歸類為非垃圾郵件,第 2 批則全部歸類為垃圾郵件。太完美了!
我們同時嘗試一些變化,看看能否妥善通用。原本就有一段失敗的句子,例如:
「omg GOOG 的股票剛剛開球!即刻入手!」
系統目前已正確歸類為垃圾郵件,但如果您將此狀態變更為:
「因此 XYZ 股票的價值增加了!把握時間,搶先購買一些商品!」
這裡會顯示 98% 的垃圾郵件預測,即使你變更了股票符號和遣詞用字,這個結果仍然正確無誤。
當然,如果您確實嘗試破壞這個新模型,您將能夠並收集更多的訓練資料,以盡可能從您可能遇到的網路常見情境擷取更多獨特的變化。在日後的程式碼研究室中,我們會說明如何使用遭到標記的即時資料,持續改善模型。
6. 恭喜!
恭喜!您已順利重新訓練現有的機器學習模型,讓模型能夠配合各種極端情況進行更新,並運用 TensorFlow.js 將這些變更部署至瀏覽器,以實際應用在現實世界中。
重點回顧
在本程式碼研究室中,您已完成以下事項:
- 發現使用預製垃圾留言模型時無法運作的極端案例
- 重新訓練模型,將發現的邊緣案例納入考量
- 將經過訓練的新模型匯出為 TensorFlow.js 格式
- 已更新網頁應用程式,以便使用新檔案
後續步驟
這種更新非常好,但如同其他網頁應用程式,更新也會與時俱進。如果應用程式能隨時間自動持續改進,則不必每次都手動改進。您能否思考一下,您該如何自動化這些步驟,讓模型在模型分類後自動重新訓練模型 (例如有 100 則標示為錯誤分類的新留言)?建議您以平時的網頁工程策略,思考如何建立能自動達成這個目標的管道。如果還不熟悉,請參考本系列的下一個程式碼研究室,瞭解實際操作方式。
分享您的成果
此外,你可以輕鬆將今日成果拓展至其他創意用途,建議跳脫傳統思維並持續嘗試入侵。
別忘了在社群媒體上標記我們,並加上 #MadeWithTFJS 主題標記,你的專案就有機會登上 TensorFlow 網誌,甚至是日後的活動。我們很期待看到你的作品。
更多 TensorFlow.js 程式碼研究室可深入探索
建議結帳網站
- TensorFlow.js 官方網站
- TensorFlow.js 預建模型
- TensorFlow.js API
- TensorFlow.js 展示與分享 - 汲取靈感,並瞭解其他創作者的創意作品。