
1. Avant de commencer
Cet atelier de programmation s'appuie sur le résultat de l'atelier de programmation précédent de cette série concernant la détection du spam dans les commentaires à l'aide de TensorFlow.js.
Dans le dernier atelier de programmation, vous avez créé une page Web entièrement fonctionnelle pour un blog vidéo fictif. Vous avez pu filtrer les commentaires pour détecter le spam avant qu'ils ne soient envoyés au serveur à des fins de stockage ou à d'autres clients connectés, à l'aide d'un modèle pré-entraîné de détection du spam dans les commentaires, fourni par TensorFlow.js dans le navigateur.
Le résultat final de cet atelier de programmation est présenté ci-dessous:
Bien que cela ait fonctionné très bien, il existe des cas limites à explorer qu'il n'a pas été en mesure de détecter. Vous pouvez réentraîner le modèle pour tenir compte des situations qu'il n'a pas pu gérer.
Cet atelier de programmation se concentre sur l'utilisation du traitement du langage naturel (l'art de comprendre le langage humain avec un ordinateur) et vous montre comment modifier une application Web existante que vous avez créée (nous vous recommandons vivement de suivre les ateliers de programmation dans l'ordre) pour résoudre le problème bien réel du spam dans les commentaires, que de nombreux développeurs Web rencontreront certainement lorsqu'ils travailleront sur l'une des applications Web populaires actuelles, toujours plus nombreuses.
Dans cet atelier de programmation, vous allez encore plus loin en entraînant de nouveau votre modèle de ML à tenir compte des changements dans le contenu des messages de spam qui peuvent évoluer au fil du temps, en fonction des tendances actuelles ou des sujets de discussion populaires. Vous pourrez ainsi garder le modèle à jour et tenir compte de ces changements.
Prérequis
- Vous avez suivi le premier atelier de programmation de cette série.
- Connaissances de base des technologies Web, y compris HTML, CSS et JavaScript
Objectifs de l'atelier
Vous allez réutiliser le site Web créé précédemment pour un blog vidéo fictif avec une section de commentaires en temps réel et le mettre à niveau pour charger une version entraînée personnalisée du modèle de détection de spam à l'aide de TensorFlow.js, afin qu'il fonctionne mieux sur les cas limites sur lesquels il aurait auparavant échoué. Bien entendu, en tant que développeurs et ingénieurs Web, vous pouvez modifier cette expérience utilisateur hypothétique pour la réutiliser sur n'importe quel site Web sur lequel vous travaillez au quotidien et adapter la solution à n'importe quel cas d'utilisation client, comme un blog, un forum ou une forme de CMS, comme Drupal par exemple.
Allons pirater...
Points abordés
Vous découvrirez comment :
- Identifier les cas limites sur lesquels le modèle pré-entraîné échouait
- Réentraînez le modèle de classification du spam créé à l'aide de Model Maker.
- Exportez ce modèle basé sur Python au format TensorFlow.js pour l'utiliser dans des navigateurs.
- Mettre à jour le modèle hébergé et son dictionnaire avec le nouveau modèle entraîné, puis vérifier les résultats
Pour cet atelier, vous devez avoir des connaissances de base en HTML5, CSS et JavaScript. Vous exécuterez également du code Python via un atelier collaboratif. pour réentraîner le modèle créé à l'aide de Model Maker, mais aucune connaissance de Python n'est requise pour cela.
2. Préparez-vous au code
Là encore, vous utiliserez Glitch.com pour héberger et modifier l'application Web. Si vous n'avez pas encore terminé l'atelier de programmation préalable, vous pouvez cloner le résultat final ici comme point de départ. Si vous avez des questions sur le fonctionnement du code, nous vous recommandons vivement de suivre l'atelier de programmation précédent, qui vous a montré comment créer cette application Web fonctionnelle avant de continuer.
Dans Glitch, il vous suffit de cliquer sur le bouton remixer pour dupliquer le fichier et créer un nouvel ensemble de fichiers que vous pourrez modifier.
3. Découvrir les cas limites avec la solution précédente
Si vous ouvrez le site Web finalisé que vous venez de cloner et que vous essayez de saisir des commentaires, vous remarquerez que la plupart du temps, cela fonctionne comme prévu. Cela permet de bloquer les commentaires qui ressemblent à du spam et d'autoriser l'envoi de réponses légitimes.
Cependant, si vous êtes ingénieux et que vous essayez de formuler des éléments pour briser le modèle, vous réussirez probablement à un moment donné. Après quelques essais et erreurs, vous pouvez créer manuellement des exemples comme ceux présentés ci-dessous. Essayez de les coller dans l'application Web existante, consultez la console et consultez les probabilités que cela indique si le commentaire est un spam:
Commentaires légitimes publiés sans problème (vrais négatifs):
- "Wow, j'adore cette vidéo, super travail." Spam de probabilité: 47,91854%
- "J'ai adoré ces démonstrations ! Souhaitez-vous en savoir plus ?" Spam de probabilité: 47,15898%
- "Quel site Web puis-je consulter pour en savoir plus ?" Spam de probabilité: 15,32495%
C'est génial. Les probabilités pour toutes les propositions ci-dessus sont assez faibles et elles parviennent à passer avec la SPAM_THRESHOLD par défaut d'une probabilité minimale de 75% avant que l'action ne soit effectuée (définie dans le code script.js de l'atelier de programmation précédent).
Essayons maintenant de rédiger des commentaires plus avant-gardistes qui seront marqués comme spam, même s'ils ne sont pas...
Commentaires légitimes marqués comme spam (faux positifs):
- "Quelqu'un peut-il ajouter un lien vers le site Web du masque qu'il porte ?" Probabilité de spam: 98,46466%
- "Puis-je acheter cette chanson sur Spotify ? N'hésitez pas à me contacter." Spam de probabilité: 94,40953%
- "Est-ce que quelqu'un peut me contacter pour m'expliquer comment télécharger TensorFlow.js ?" Spam de probabilité: 83,20084%
Oh non ! Il semble que ces commentaires légitimes soient marqués comme spam alors qu'ils devraient être autorisés. Comment résoudre ce problème ?
Une option simple consiste à augmenter la SPAM_THRESHOLD pour qu'elle atteigne un niveau de confiance supérieur à 98,5 %. Dans ce cas, ces commentaires mal classés sont alors publiés. En gardant cela à l'esprit, continuons avec les autres résultats possibles ci-dessous...
Commentaires indésirables marqués comme spam (vrais positifs):
- "C'est cool, mais regardez les liens de téléchargement sur mon site Web qui sont meilleurs !" Spam de probabilité: 99,77873%
- "Je connais des personnes qui peuvent vous prendre des médicaments. Pour en savoir plus, consultez mon fichier .pr0file." Probabilité de spam: 98,46955%
- "Consultez mon profil pour télécharger d'autres vidéos incroyables, encore meilleures ! http://example.com" Spam de probabilité: 96,26383%
Cela fonctionne comme prévu avec notre seuil initial de 75 %. Toutefois, étant donné qu'à l'étape précédente, vous avez modifié SPAM_THRESHOLD pour une confiance supérieure à 98, 5 %, deux exemples seraient acceptés. Le seuil est donc peut-être trop élevé. Un taux de 96% est peut-être mieux ? En revanche, l'un des commentaires de la section précédente (faux positifs) serait marqué comme spam s'il était légitime, car il a été évalué à 98,46466%.
Dans ce cas, il est probablement préférable de capturer tous ces commentaires de spam réel et simplement de procéder à un réentraînement pour les échecs ci-dessus. Si vous définissez le seuil sur 96 %, tous les vrais positifs sont toujours capturés et vous éliminez deux des faux positifs ci-dessus. Pas trop mal pour ne changer qu'un seul numéro.
Continuons...
Spam dans les commentaires qui ont été autorisés à être publiés (faux négatifs):
- "Consultez mon profil pour télécharger des vidéos encore plus incroyables !" Spam de probabilité: 7,54926%
- "Profitez d'une remise sur nos cours d'entraînement à la salle de sport, consultez le fichier pr0file !" Spam de probabilité: 17,49849%
- "Oh mon Dieu, la bourse GOOG vient de grimper tout de suite ! Ne tardez pas trop tard !" Spam de probabilité: 20,42894%
Pour ces commentaires, vous ne pouvez rien faire en modifiant davantage la valeur SPAM_THRESHOLD. Si vous diminuez le seuil de spam de 96% à environ 9 %, les commentaires authentiques seront marqués comme spam. L'un d'entre eux obtient une note de 58 %, même s'il est légitime. La seule façon de gérer de tels commentaires est de réentraîner le modèle en incluant ces cas limites dans les données d'entraînement, afin qu'il apprenne à ajuster sa vision du monde pour identifier les spams ou non.
Bien que la seule option possible pour le moment soit de réentraîner le modèle, vous avez également vu comment affiner le seuil à partir duquel vous décidez d'appeler un élément indésirable afin d'améliorer également les performances. En tant qu'humain, 75% semble assez confiant, mais pour ce modèle, vous avez dû vous rapprocher de 81,5% pour être plus efficace avec des exemples d'entrées.
Il n'existe pas de valeur magique unique qui fonctionne bien d'un modèle à l'autre. Vous devez définir cette valeur seuil pour chaque modèle après avoir testé des données réelles afin d'identifier ce qui fonctionne bien.
Dans certains cas, un faux positif (ou un faux négatif) peut avoir de graves conséquences (dans le secteur médical, par exemple). Vous pouvez donc ajuster votre seuil afin qu'il soit très élevé et demander davantage d'examens manuels pour ceux qui n'atteignent pas le seuil. C'est votre choix en tant que développeur et nécessite quelques tests.
4. Réentraîner le modèle de détection de spam dans les commentaires
Dans la section précédente, vous avez identifié un certain nombre de cas limites qui échouaient pour le modèle, où la seule option était de réentraîner le modèle pour tenir compte de ces situations. Dans un système de production, vous pouvez les repérer au fil du temps lorsque les utilisateurs signalent manuellement un commentaire comme étant du spam et que les modérateurs qui examinent les commentaires signalés se rendent compte que certains ne sont pas réellement du spam et peuvent le marquer pour une nouvelle formation. En supposant que vous ayez recueilli de nombreuses nouvelles données pour ces cas limites (pour de meilleurs résultats, vous devriez avoir des variantes de ces nouvelles phrases si possible), nous allons maintenant vous montrer comment réentraîner le modèle en tenant compte de ces cas limites.
Résumé du modèle prédéfini
Le modèle prédéfini que vous avez utilisé a été créé par un tiers via Model Maker et utilise une "représentation vectorielle continue de mots". pour qu'il fonctionne.
Comme le modèle a été créé avec Model Maker, vous devez passer brièvement à Python pour le réentraîner, puis exporter le modèle créé au format TensorFlow.js afin de pouvoir l'utiliser dans votre navigateur. Heureusement, Model Maker facilite l'utilisation de ses modèles. Cela devrait donc être facile à suivre. Nous vous guiderons tout au long du processus, donc ne vous inquiétez pas si vous n'avez jamais utilisé Python auparavant.
Colabs
Dans cet atelier de programmation, vous n'êtes pas trop préoccupé par la configuration d'un serveur Linux sur lequel tous les utilitaires Python sont installés. Il vous suffit donc d'exécuter du code via le navigateur Web à l'aide d'un "notebook Colab". Ces notebooks peuvent se connecter à un "backend" . Il s'agit simplement d'un serveur sur lequel vous avez pré-installé des éléments, à partir duquel vous pouvez exécuter du code arbitraire dans le navigateur Web et voir les résultats. Ceci est très utile pour un prototypage rapide ou pour une utilisation dans des tutoriels comme celui-ci.
Il vous suffit d'accéder à la page colab.research.google.com pour afficher un écran de bienvenue comme celui-ci:
Cliquez sur le bouton New Notebook (Nouveau notebook) en bas à droite de la fenêtre pop-up. Un Colab vide semblable à celui-ci doit s'afficher:
Parfait ! L'étape suivante consiste à connecter le Colab frontend à un serveur backend afin de pouvoir exécuter le code Python que vous allez écrire. Pour ce faire, cliquez sur Se connecter en haut à droite, puis sélectionnez Se connecter à un environnement d'exécution hébergé.
Une fois la connexion établie, les icônes de RAM et de disque devraient apparaître à la place, comme ceci:
Bravo ! Vous pouvez maintenant commencer à coder en Python pour réentraîner le modèle Model Maker. Il vous suffit de procéder comme suit :
Étape 1
Dans la première cellule actuellement vide, copiez le code ci-dessous. Il installera automatiquement TensorFlow Lite Model Maker à l'aide du gestionnaire de packages de Python appelé "pip". (il est semblable à npm, que la plupart des lecteurs de cet atelier de programmation connaissent peut-être plus dans l'écosystème JS):
!apt-get install libasound-dev portaudio19-dev libportaudio2 libportaudiocpp0
!pip install -q tflite-model-maker
Toutefois, le fait de coller du code dans la cellule ne permet pas de l'exécuter. Ensuite, placez le pointeur de la souris sur la cellule grise dans laquelle vous avez collé le code ci-dessus. s'affiche à gauche de la cellule, comme illustré ci-dessous:
 Cliquez sur le bouton de lecture pour exécuter le code que vous venez de saisir dans la cellule.
Cliquez sur le bouton de lecture pour exécuter le code que vous venez de saisir dans la cellule.
L'installation de Model Maker s'affiche:
Une fois l'exécution de cette cellule terminée comme indiqué, passez à l'étape suivante ci-dessous.
Étape 2
Ensuite, ajoutez une nouvelle cellule de code comme indiqué ci-dessous afin de pouvoir coller du code après la première cellule et l'exécuter séparément:
La prochaine cellule exécutée comportera un certain nombre d'importations que le code du reste du notebook devra utiliser. Copiez et collez le texte ci-dessous dans la nouvelle cellule créée:
import numpy as np
import os
from tflite_model_maker import configs
from tflite_model_maker import ExportFormat
from tflite_model_maker import model_spec
from tflite_model_maker import text_classifier
from tflite_model_maker.text_classifier import DataLoader
import tensorflow as tf
assert tf.__version__.startswith('2')
tf.get_logger().setLevel('ERROR')
C'est un processus assez standard, même si vous ne maîtrisez pas Python. Vous n'avez qu'à importer quelques utilitaires et les fonctions Model Maker nécessaires au classificateur de spam. Cela vous permet également de vérifier que vous exécutez TensorFlow 2.x, ce qui est nécessaire pour utiliser Model Maker.
Enfin, comme précédemment, exécutez la cellule en appuyant sur la touche de lecture. lorsque vous pointez sur la cellule, puis ajoutez une nouvelle cellule de code pour l'étape suivante.
Étape 3
Vous allez maintenant télécharger les données d'un serveur distant sur votre appareil et définir la variable training_data comme étant le chemin d'accès au fichier local téléchargé:
data_file = tf.keras.utils.get_file(fname='comment-spam-extras.csv', origin='https://storage.googleapis.com/jmstore/TensorFlowJS/EdX/code/6.5/jm_blog_comments_extras.csv', extract=False)
Model Maker peut entraîner des modèles à partir de fichiers CSV simples comme celui téléchargé. Il vous suffit de spécifier les colonnes qui contiennent le texte et celles qui contiennent les libellés. La procédure à suivre est décrite à l'étape 5. Si vous le souhaitez, vous pouvez télécharger directement le fichier CSV vous-même pour en consulter le contenu.
Vous remarquerez que ce fichier s'appelle jm_blog_comments_extras.csv. Il s'agit simplement des données d'entraînement d'origine que nous avons utilisées pour générer le premier modèle de spam dans les commentaires combiné avec les nouvelles données de cas particuliers que vous avez découvertes. Le tout se trouve dans un seul et même fichier. Vous avez également besoin des données d'entraînement d'origine utilisées pour entraîner le modèle, en plus des nouvelles phrases que vous souhaitez utiliser.
Facultatif:si vous téléchargez ce fichier CSV et que vous consultez les dernières lignes, vous verrez des exemples de cas spéciaux qui ne fonctionnaient pas correctement auparavant. Elles viennent d'être ajoutées à la fin des données d'entraînement existantes que le modèle prédéfini a utilisé pour s'entraîner.
Exécutez cette cellule. Une fois l'exécution terminée, ajoutez-en une nouvelle et passez à l'étape 4.
Étape 4
Lorsque vous utilisez Model Maker, vous ne créez pas de modèles à partir de zéro. Vous utilisez généralement des modèles existants que vous personnaliserez ensuite en fonction de vos besoins.
Model Maker propose plusieurs représentations vectorielles continues de modèles pré-entraînés que vous pouvez utiliser, mais la plus simple et la plus rapide pour commencer est average_word_vec, qui est l'outil que vous avez utilisé dans l'atelier de programmation précédent pour créer votre site Web. Voici le code :
spec = model_spec.get('average_word_vec')
spec.num_words = 2000
spec.seq_len = 20
spec.wordvec_dim = 7
Exécutez cette commande une fois que vous l'avez collée dans la nouvelle cellule.
Comprendre les
num_words
paramètre
Il s'agit du nombre de mots que le modèle doit utiliser. Vous pensez peut-être que plus il y en a, mieux c'est, mais il y a généralement une marge d'erreur basée sur la fréquence à laquelle chaque mot est utilisé. Si vous reteniez tous les mots du corpus, le modèle pourrait essayer d'apprendre et d'équilibrer la pondération de mots qui ne sont utilisés qu'une seule fois, ce qui n'est pas très utile. Dans un corpus de textes, vous constaterez que de nombreux mots ne sont utilisés qu'une ou deux fois et qu'il n'est généralement pas utile de les utiliser dans votre modèle, car ils ont un impact négligeable sur le sentiment général. Vous pouvez donc ajuster votre modèle en fonction du nombre de mots de votre choix à l'aide du paramètre num_words. Un plus petit nombre dans ce cas aura un modèle plus petit et plus rapide, mais il pourrait être moins précis, car il reconnaît moins de mots. Plus le nombre est élevé, plus le modèle sera volumineux et potentiellement plus lent. En tant qu'ingénieur en machine learning, il est essentiel de trouver le bon compromis. C'est à vous de déterminer ce qui convient le mieux à votre cas d'utilisation.
Comprendre les
wordvec_dim
paramètre
Le paramètre wordvec_dim correspond au nombre de dimensions que vous souhaitez utiliser pour le vecteur de chaque mot. Ces dimensions sont essentiellement les différentes caractéristiques (créées par l'algorithme de machine learning lors de l'entraînement) que le programme peut utiliser pour mesurer un mot donné afin d'essayer d'associer au mieux des mots similaires d'une manière significative.
Par exemple, si vous avez défini la dimension "médicale" un mot était, un mot comme « pilules » peut obtenir un score élevé pour cette dimension et être associé à d'autres mots ayant des scores élevés, comme "rayon X", mais "chat" un score faible pour cette dimension. Il se peut qu'une « dimension médicale » est utile pour identifier les spams lorsque ceux-ci sont combinés à d'autres dimensions potentielles importantes.
Lorsque des mots obtiennent un score élevé dans la "dimension médicale" il peut se rendre compte qu'une deuxième dimension qui établit une corrélation entre les mots et le corps humain pourrait être utile. Mots comme "jambe", "bras", "cou" peut obtenir de bons résultats ici, mais aussi assez haut dans la dimension médicale.
Le modèle peut utiliser ces dimensions pour qu'il puisse ensuite détecter les mots plus susceptibles d'être associés au spam. Les spams sont peut-être plus susceptibles de contenir des mots qui désignent à la fois des parties médicales et du corps humain.
D'après des recherches, la règle d'or est que la quatrième racine du nombre de mots fonctionne bien pour ce paramètre. Si j'utilise 2 000 mots, 7 dimensions de départ sont un bon point de départ. Vous pouvez également modifier le nombre de mots utilisés.
Comprendre les
seq_len
paramètre
Les modèles sont généralement très rigides en ce qui concerne les valeurs d'entrée. Dans le cas d'un modèle de langage, cela signifie qu'il peut classifier des phrases d'une longueur statique particulière. Ce paramètre est déterminé par le paramètre seq_len, qui signifie "longueur de la séquence". Lorsque vous convertissez des mots en nombres (ou jetons), une phrase devient une séquence de ces jetons. Votre modèle sera donc entraîné (ici) à classer et à reconnaître les phrases comportant 20 jetons. Si la phrase est plus longue, elle sera tronquée. S'il est plus court, il sera complété, comme dans le premier atelier de programmation de cette série.
Étape 5 : Chargez les données d'entraînement
Précédemment, vous avez téléchargé le fichier CSV. Il est maintenant temps d'utiliser un chargeur de données pour les transformer en données d'entraînement reconnues par le modèle.
data = DataLoader.from_csv(
filename=data_file,
text_column='commenttext',
label_column='spam',
model_spec=spec,
delimiter=',',
shuffle=True,
is_training=True)
train_data, test_data = data.split(0.9)
Si vous ouvrez le fichier CSV dans un éditeur, vous pouvez voir que chaque ligne comporte deux valeurs et un texte de description sur la première ligne du fichier. Généralement, chaque entrée est considérée comme une "colonne". Notez que le descripteur de la première colonne est commenttext et que la première entrée de chaque ligne est le texte du commentaire.
De même, le descripteur de la deuxième colonne est spam, et vous verrez que la deuxième entrée de chaque ligne est TRUE ou FALSE pour indiquer si ce texte est considéré comme du spam dans les commentaires ou non. Les autres propriétés définissent la spécification de modèle que vous avez créée à l'étape 4, ainsi qu'un caractère délimiteur. Dans ce cas, il s'agit d'une virgule, car le fichier est séparé par une virgule. Vous allez également définir un paramètre de brassage pour réorganiser les données d'entraînement de manière aléatoire, afin que les éléments ayant pu être similaires ou collectés ensemble soient répartis de manière aléatoire dans l'ensemble de données.
Vous utiliserez ensuite data.split() pour diviser les données en données d'entraînement et de test. La valeur 0,9 indique que 90% de l'ensemble de données sera utilisé pour l'entraînement, le reste pour les tests.
Étape 6 : Créez le modèle
Ajoutez une autre cellule dans laquelle nous allons ajouter du code pour créer le modèle:
model = text_classifier.create(train_data, model_spec=spec, epochs=50)
Un modèle de classificateur de texte est alors créé à l'aide de Model Maker. Vous devez spécifier les données d'entraînement que vous souhaitez utiliser (définies à l'étape 4), la spécification du modèle (également configurée à l'étape 4) et un nombre d'époques, dans ce cas 50.
Le principe de base du machine learning est qu'il s'agit d'une forme de correspondance de modèles. Dans un premier temps, il chargera les pondérations pré-entraînées pour les mots et tentera de les regrouper dans une "prédiction" de ceux qui, lorsqu'ils sont regroupés, indiquent du spam et ceux qui ne le sont pas. La première fois, il devrait se rapprocher des 50 min 50 s, car le modèle ne fait que commencer, comme illustré ci-dessous :

Il mesurera ensuite les résultats et modifiera les pondérations du modèle pour ajuster sa prédiction. Il effectuera une nouvelle tentative. Chaque séquence représente une époque. Si vous spécifiez "epochs=50", la boucle 50 fois comme indiqué:

Ainsi, lorsque vous atteignez la 50e époque, le niveau de précision du modèle est bien supérieur. Dans ce cas, il s'agit de 99,1 %.
Étape 7 : Exportez le modèle
Une fois l'entraînement terminé, vous pouvez exporter le modèle. TensorFlow entraîne un modèle dans son propre format, qui doit être converti au format TensorFlow.js pour être utilisé sur une page Web. Il vous suffit de coller le code suivant dans une nouvelle cellule et de l'exécuter:
model.export(export_dir="/js_export/", export_format=[ExportFormat.TFJS, ExportFormat.LABEL, ExportFormat.VOCAB])
!zip -r /js_export/ModelFiles.zip /js_export/
Après avoir exécuté ce code, si vous cliquez sur la petite icône de dossier à gauche de Colab, vous pouvez accéder au dossier que vous avez exporté ci-dessus (dans le répertoire racine, vous devrez peut-être remonter d'un niveau) et trouver le dossier ZIP des fichiers exportés contenus dans ModelFiles.zip.
Téléchargez ce fichier ZIP sur votre ordinateur dès maintenant, car vous l'utiliserez comme dans le premier atelier de programmation:
Parfait ! La partie Python étant terminée, vous pouvez à présent revenir à JavaScript, que vous connaissez et appréciez déjà. Ouf !
5. Inférence du nouveau modèle de machine learning
Vous êtes presque prêt à charger le modèle. Toutefois, vous devez d'abord importer les nouveaux fichiers de modèle téléchargés précédemment dans l'atelier de programmation afin qu'ils soient hébergés et utilisables dans votre code.
Si vous ne l'avez pas déjà fait, décompressez les fichiers du modèle que vous venez de télécharger à partir du notebook Colab Model Maker que vous venez d'exécuter. Vous devriez voir les fichiers suivants contenus dans ses différents dossiers:
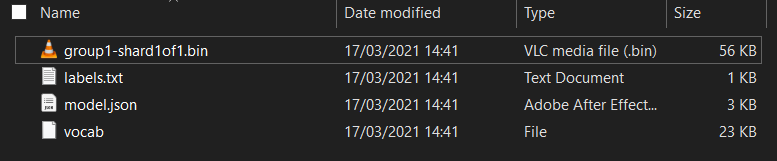
Qu'y a-t-il ici ?
model.json: il s'agit de l'un des fichiers qui constituent le modèle TensorFlow.js entraîné. Vous ferez référence à ce fichier spécifique dans le code JS.group1-shard1of1.bin: fichier binaire contenant la plupart des données enregistrées pour le modèle TensorFlow.js exporté. Il doit être hébergé sur votre serveur pour être téléchargé dans le même répertoire quemodel.jsonci-dessus.vocab: ce fichier étrange sans extension provient de Model Maker. Il nous montre comment encoder les mots dans les phrases afin que le modèle comprenne comment les utiliser. Nous aborderons ce point plus en détail dans la section suivante.labels.txt: contient simplement les noms de classe résultants que le modèle va prédire. Pour ce modèle, si vous ouvrez ce fichier dans votre éditeur de texte, il contient simplement "false" et "true" répertorié comme "non-spam" ou "spam" comme sortie de prédiction.
Héberger les fichiers du modèle TensorFlow.js
Commencez par placer les fichiers model.json et *.bin qui ont été générés sur un serveur Web afin de pouvoir y accéder via votre page Web.
Supprimer des fichiers de modèle existants
Au fur et à mesure que vous vous basez sur le résultat final du premier atelier de programmation de cette série, vous devez d'abord supprimer les fichiers de modèle existants que vous avez importés. Si vous utilisez Glitch.com, recherchez simplement model.json et group1-shard1of1.bin dans le panneau de fichiers à gauche, cliquez sur le menu à trois points pour chaque fichier, puis sélectionnez delete (supprimer) comme indiqué ci-dessous:
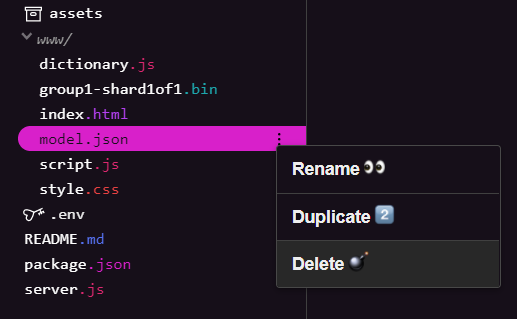
Importer de nouveaux fichiers dans Glitch
Parfait ! À présent, importez les nouveaux enregistrements:
- Ouvrez le dossier assets dans le panneau de gauche de votre projet Glitch et supprimez tous les anciens assets importés s'ils portent le même nom.
- Cliquez sur Importer un asset et sélectionnez
group1-shard1of1.binpour l'importer dans ce dossier. Une fois l'importation terminée, l'application devrait ressembler à ceci:
- Parfait ! Procédez de la même façon pour le fichier model.json afin que votre dossier "assets" contienne deux fichiers comme suit:
- Si vous cliquez sur le fichier
group1-shard1of1.binque vous venez d'importer, vous pourrez copier l'URL à son emplacement. Copiez maintenant ce chemin d'accès comme indiqué ci-dessous:
- En bas à gauche de l'écran, cliquez sur Outils > Terminal. Attendez que la fenêtre du terminal se charge.
- Une fois le chargement terminé, saisissez la commande suivante, puis appuyez sur Entrée pour remplacer le répertoire par le dossier
www:
terminal:
cd www
- Ensuite, utilisez
wgetpour télécharger les deux fichiers que vous venez d'importer en remplaçant les URL ci-dessous par celles que vous avez générées pour les fichiers du dossier d'éléments sur Glitch (vérifiez le dossier des éléments pour l'URL personnalisée de chaque fichier).
Notez l'espace entre les deux URL et que les URL que vous devrez utiliser seront différentes de celles affichées, mais seront similaires:
terminal
wget https://cdn.glitch.com/1cb82939-a5dd-42a2-9db9-0c42cab7e407%2Fmodel.json?v=1616111344958 https://cdn.glitch.com/1cb82939-a5dd-42a2-9db9-0c42cab7e407%2Fgroup1-shard1of1.bin?v=1616017964562
Super ! Vous avez maintenant créé une copie des fichiers importés dans le dossier www.
Cependant, pour le moment, ils sont téléchargés avec des noms étranges. Si vous saisissez ls dans le terminal et appuyez sur Entrée, un résultat semblable à celui-ci s'affiche:

- Renommez les fichiers à l'aide de la commande
mv. Saisissez la commande suivante dans la console et appuyez sur Entrée après chaque ligne:
terminal:
mv *group1-shard1of1.bin* group1-shard1of1.bin
mv *model.json* model.json
- Enfin, actualisez le projet Glitch en saisissant
refreshdans le terminal et en appuyant sur Entrée:
terminal:
refresh
Après l'actualisation, vous devriez maintenant voir model.json et group1-shard1of1.bin dans le dossier www de l'interface utilisateur:
Parfait ! La dernière étape consiste à mettre à jour le fichier dictionary.js.
- Convertissez le nouveau fichier de vocabulaire téléchargé au format JS approprié manuellement via votre éditeur de texte ou à l'aide de cet outil, puis enregistrez le résultat obtenu au format
dictionary.jsdans votre dossierwww. Si vous disposez déjà d'un fichierdictionary.js, il vous suffit de copier et coller le nouveau contenu, puis d'enregistrer le fichier.
Excellent ! Vous avez mis à jour tous les fichiers modifiés. Si vous essayez maintenant d'utiliser le site Web, vous remarquerez que le modèle réentraîné doit pouvoir tenir compte des cas limites découverts et appris, comme illustré ci-dessous:
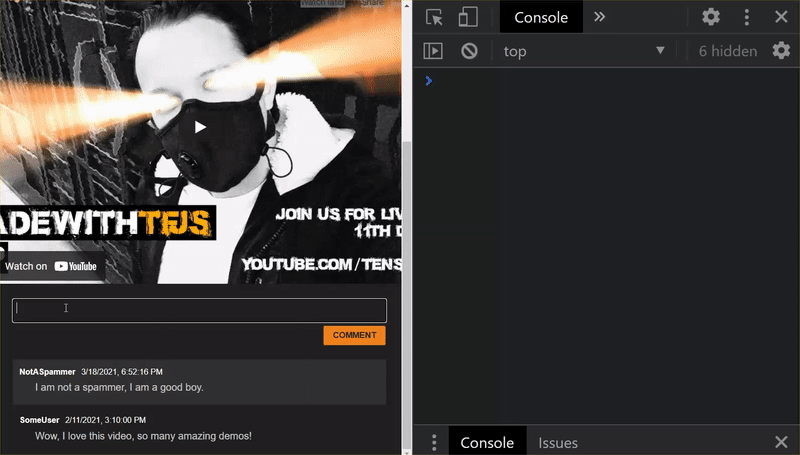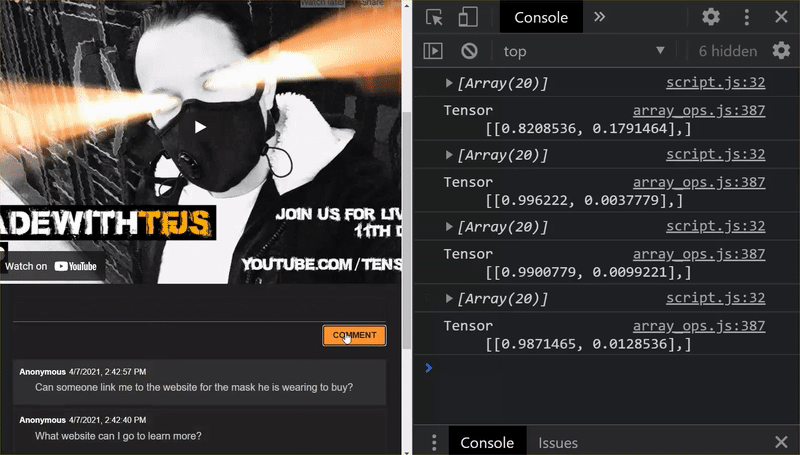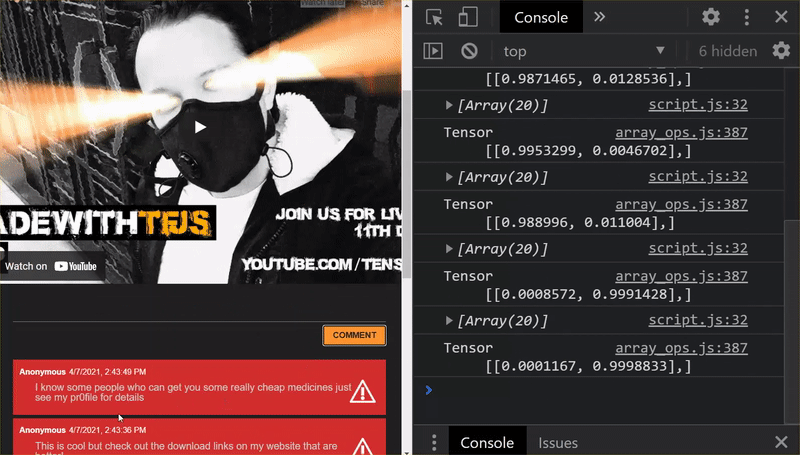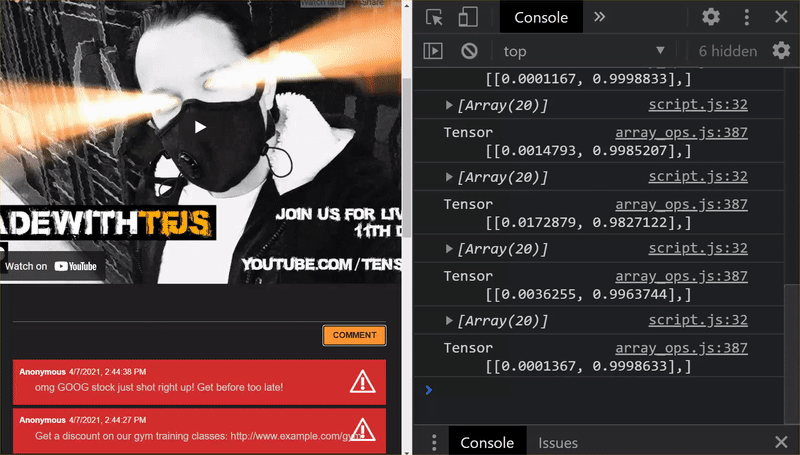
Comme vous pouvez le constater, les six premiers sont désormais classés comme non-spam, et les six premiers sont identifiés comme spam. Parfait !
Essayons également quelques variantes pour voir si cela se généralise correctement. À l'origine, il y avait une dénonciation non conforme telle que:
"Oh mon Dieu, le cours de la bourse GOOG vient de grimper tout de suite ! Allez-y avant trop tard !"
Ce message est à présent correctement classé comme spam, mais que se passe-t-il si vous la remplacez par:
"La valeur de l'action XYZ a donc augmenté ! Achetez-en avant qu'il ne soit trop tard !"
Vous obtenez ici une prédiction de 98% de probabilité d'être du spam, ce qui est correct même si vous avez légèrement modifié le symbole boursier et la formulation.
Bien entendu, si vous essayez réellement de casser ce nouveau modèle, vous pourrez le faire, et vous devrez collecter encore plus de données d'entraînement pour avoir la meilleure chance de capturer des variantes plus spécifiques pour les situations courantes que vous êtes susceptible de rencontrer en ligne. Dans un prochain atelier de programmation, nous vous montrerons comment améliorer en permanence votre modèle avec des données actives lorsqu'elles sont signalées.
6. Félicitations !
Félicitations ! Vous avez réussi à réentraîner un modèle de machine learning existant pour qu'il se mette à jour afin qu'il fonctionne avec les cas limites que vous avez détectés et vous avez déployé ces modifications dans le navigateur avec TensorFlow.js pour une application réelle.
Résumé
Dans cet atelier de programmation, vous avez découvert :
- Détection de cas limites qui ne fonctionnaient pas avec le modèle prédéfini de spam dans les commentaires
- Réentraînement du modèle Model Maker pour prendre en compte les cas limites que vous avez découverts
- le nouveau modèle entraîné a été exporté au format TensorFlow.js.
- Mise à jour de votre application Web pour utiliser les nouveaux fichiers
Et ensuite ?
Cette mise à jour fonctionne donc très bien, mais comme pour toute application Web, des changements se produiront au fil du temps. Ce serait beaucoup mieux que l'application s'améliore constamment au fil du temps, plutôt que de devoir le faire manuellement à chaque fois. Pouvez-vous imaginer comment vous avez automatisé ces étapes pour réentraîner automatiquement un modèle après avoir, par exemple, 100 nouveaux commentaires marqués comme mal classés ? Mettez-vous à la place de l'ingénieur Web pour savoir comment créer un pipeline afin d'effectuer cette opération automatiquement. Si ce n'est pas le cas, ne vous inquiétez pas. L'atelier de programmation suivant de la série vous expliquera comment procéder.
Partagez vos créations
Vous pouvez facilement étendre ce que vous avez réalisé aujourd'hui à d'autres cas d'utilisation créatifs. Nous vous encourageons à sortir des sentiers battus et à continuer à pirater.
N'oubliez pas de nous taguer sur les réseaux sociaux avec le hashtag #MadeWithTFJS. Votre projet sera peut-être mis en avant sur le blog TensorFlow, voire dans le cadre d'événements à venir. Nous serions ravis de découvrir vos créations.
Autres ateliers de programmation TensorFlow.js pour aller plus loin
- Utilisez l'hébergement Firebase pour déployer et héberger un modèle TensorFlow.js à grande échelle.
- Créer une webcam intelligente à l'aide d'un modèle de détection d'objets prédéfini avec TensorFlow.js
Sites Web à consulter
- Site Web officiel de TensorFlow.js
- Modèles prédéfinis TensorFlow.js
- API TensorFlow.js
- TensorFlow.js Show & Racontez : trouvez l'inspiration et découvrez les créations des autres.