
1. शुरू करने से पहले
इस कोडलैब को इस सीरीज़ में, पिछले कोडलैब के आखिरी नतीजे के आधार पर बनाया गया है. इसकी मदद से, TensorFlow.js का इस्तेमाल करके टिप्पणियों का पता लगाया जाता है.
पिछले कोडलैब में, आपने एक काल्पनिक वीडियो ब्लॉग के लिए, पूरी तरह से काम करने वाला वेबपेज बनाया है. आपके पास स्पैम वाली टिप्पणियों को स्टोरेज के लिए सर्वर पर या कनेक्ट किए गए अन्य क्लाइंट को भेजने से पहले, उन्हें फ़िल्टर करने की सुविधा थी. इसके लिए, ब्राउज़र में TensorFlow.js की मदद से, स्पैम की पहचान करने वाले, पहले से ट्रेन किए गए मॉडल का इस्तेमाल किया गया था.
उस कोडलैब का आखिरी नतीजा नीचे दिखाया गया है:
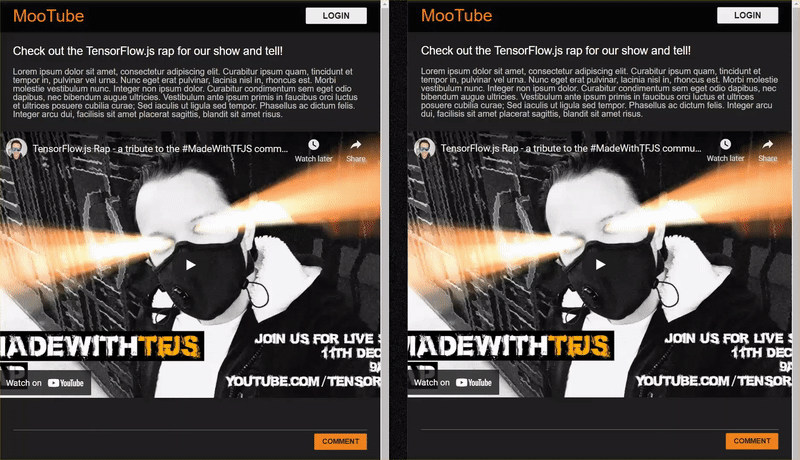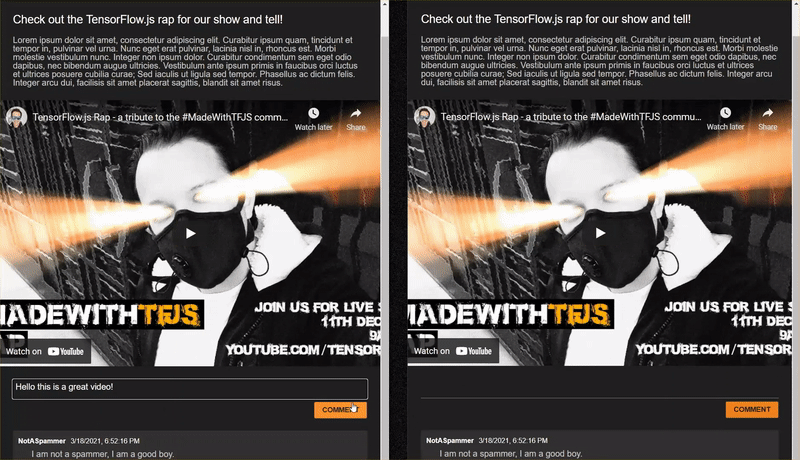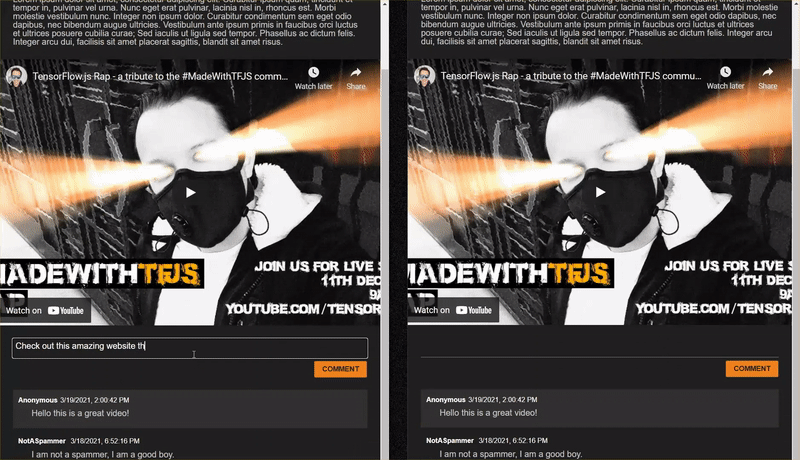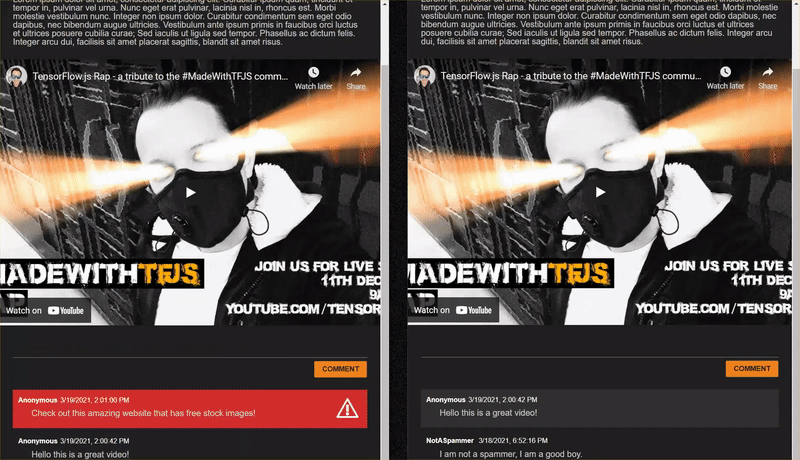
हालांकि, यह काफ़ी अच्छी तरह से काम करता है, लेकिन कुछ ऐसे किनारे हैं जिनका पता नहीं लगाया जा सका. मॉडल को उन स्थितियों के लिए फिर से ट्रेनिंग दी जा सकती है जिन्हें वह मैनेज नहीं कर पाया.
यह कोडलैब, नैचुरल लैंग्वेज प्रोसेसिंग (कंप्यूटर पर इंसानों की भाषा को समझने की कला) के इस्तेमाल पर फ़ोकस करता है. साथ ही, यह बताता है कि अपने बनाए गए मौजूदा वेब ऐप्लिकेशन में बदलाव कैसे किया जाए (आपको कोडलैब को क्रम से लगाना चाहिए). ऐसा करके, स्पैम वाली टिप्पणियों की असल समस्या को हल किया जा सकता है. आज के समय में कई वेब डेवलपर, सबसे लोकप्रिय वेब ऐप्लिकेशन में से किसी एक पर काम करेंगे.
इस कोडलैब में, मशीन लर्निंग मॉडल को फिर से ट्रेनिंग दी जा सकती है, ताकि मौजूदा रुझानों या चर्चा के लोकप्रिय विषयों के आधार पर स्पैम मैसेज के कॉन्टेंट में समय के साथ होने वाले बदलावों का पता लगाया जा सके. इससे आपको मॉडल को अप-टू-डेट रखने और ऐसे बदलावों के हिसाब से खातों को तैयार करने में मदद मिलती है.
ज़रूरी शर्तें
- इस सीरीज़ का पहला कोडलैब पूरा किया गया.
- एचटीएमएल, सीएसएस, और JavaScript जैसी वेब टेक्नोलॉजी की बुनियादी जानकारी.
आपको क्या बनाना होगा
आपको किसी काल्पनिक वीडियो ब्लॉग के लिए, टिप्पणी वाले रीयल टाइम सेक्शन के साथ पहले से बनी वेबसाइट का फिर से इस्तेमाल करना होगा. साथ ही, TensorFlow.js का इस्तेमाल करके, स्पैम का पता लगाने वाले मॉडल का कस्टम ट्रेन वाला वर्शन लोड करने के लिए, उस वेबसाइट को अपग्रेड किया जाएगा. इससे, उन मामलों में वेबसाइट बेहतर परफ़ॉर्म करेगी जिन पर वह शायद पहले काम नहीं करता था. वेब डेवलपर और इंजीनियर होने के नाते आप इस काल्पनिक UX को बदलकर किसी भी वेबसाइट पर दोबारा इस्तेमाल कर सकते हैं, जिस पर आप रोज़मर्रा के काम कर सकते हैं. साथ ही, क्लाइंट के काम के हिसाब से इस समाधान को बदल सकते हैं - उदाहरण के लिए, यह ब्लॉग, फ़ोरम या कॉन्टेंट मैनेजमेंट सिस्टम का कोई तरीका हो सकता है, जैसे कि Drupal.
चलो हैक हो जाते हैं...
आपको इनके बारे में जानकारी मिलेगी
ऐसा करने पर:
- उन किनारे के मामलों की पहचान करना जिनमें पहले से ट्रेन किया गया मॉडल काम नहीं कर रहा था
- Model Maker का इस्तेमाल करके बनाए गए स्पैम क्लासिफ़िकेशन मॉडल को फिर से ट्रेनिंग दें.
- ब्राउज़र में इस्तेमाल करने के लिए, Python पर आधारित इस मॉडल को TensorFlow.js फ़ॉर्मैट में एक्सपोर्ट करें.
- होस्ट किए गए मॉडल और उसके डिक्शनरी को, नए ट्रेन किए गए मॉडल से अपडेट करें और नतीजे देखें
इस लैब के लिए यह माना जाता है कि HTML5, सीएसएस, और JavaScript की जानकारी है. आप "co lab" के ज़रिए भी कुछ Python कोड चला सकते हैं Notebook का इस्तेमाल करके, Model Maker का इस्तेमाल करके बनाए गए मॉडल की फिर से ट्रेनिंग करें. हालांकि, ऐसा करने के लिए Python की जानकारी होना ज़रूरी नहीं है.
2. कोड सेट अप करें
एक बार फिर से आप Glitch.com का इस्तेमाल करके, वेब ऐप्लिकेशन को होस्ट और उसमें बदलाव करेंगे. अगर आपने कोडलैब के लिए ज़रूरी कोड को पहले से पूरा नहीं किया है, तो शुरुआत की जगह के तौर पर यहां आखिरी नतीजे का क्लोन बनाएं. अगर कोड के काम करने के तरीके के बारे में आपका कोई सवाल है, तो हमारी सलाह है कि आप पिछले कोडलैब को पूरा कर लें. इसमें बताया गया है कि आगे बढ़ने से पहले, काम करने वाले इस वेब ऐप्लिकेशन को कैसे बनाना है.
Glitch पर जाकर, इसे रीमिक्स करें बटन पर क्लिक करके, इसे फ़ोर्क करें और फ़ाइलों का ऐसा नया सेट बनाएं जिसमें बदलाव किया जा सके.
3. पहले वाले समाधान में किनारे के केस का पता लगाएं
अगर आप पूरी की गई उस वेबसाइट को खोलते हैं जिसे आपने अभी-अभी क्लोन किया है और कुछ टिप्पणियां टाइप करने की कोशिश की है, तो देखें कि यह काफ़ी समय तक काम करती हुई दिखती है. साथ ही, इससे आपको स्पैम जैसी लगने वाली टिप्पणियों को ब्लॉक करने और सही जवाब देने में मदद मिलती है.
हालांकि, अगर आप उसमें कुछ नया करने की कोशिश करते हैं और मॉडल को तोड़ने की कोशिश करते हैं, तो मुमकिन है कि कुछ समय बाद आप कामयाबी हासिल कर लें. थोड़े से परीक्षण और गड़बड़ी के साथ आप मैन्युअल रूप से नीचे दिखाए गए उदाहरण जैसे उदाहरण बना सकते हैं. इन्हें मौजूदा वेब ऐप्लिकेशन में चिपकाकर देखें और कंसोल की जांच करें. साथ ही, देखें कि टिप्पणी के स्पैम होने पर क्या होता है:
बिना किसी समस्या के पोस्ट की गई कानूनी टिप्पणियां (गलत टिप्पणियां):
- "वाह, मुझे यह वीडियो पसंद है, बहुत बढ़िया." स्पैम की संभावना: 47.91854%
- "ये डेमो बहुत पसंद आए! क्या आपके पास और जानकारी है?" स्पैम की संभावना: 47.15898%
- "ज़्यादा जानकारी के लिए किस वेबसाइट पर जा सकता/सकती हूं?" स्पैम की संभावना: 15.32495%
यह बहुत अच्छी बात है. ऊपर बताई गई सभी चीज़ों की संभावना बहुत कम है. साथ ही, कार्रवाई होने से पहले, 75% कम से कम संभावना के डिफ़ॉल्ट SPAM_THRESHOLD के ज़रिए सही नतीजे हासिल कर लिए जाते हैं. इस बारे में, पिछले कोडलैब के script.js कोड में बताया गया है.
आइए, अब कुछ और तीखी टिप्पणियां लिखने की कोशिश करते हैं, जो स्पैम के रूप में चिह्नित की जाती हैं, भले ही वे...
कानूनी टिप्पणियों को स्पैम के तौर पर मार्क किया गया है (गलत टिप्पणियां):
- "क्या कोई व्यक्ति उस मास्क की वेबसाइट को लिंक कर सकता है जिसने वह मास्क पहना हुआ है?" स्पैम की संभावना: 98.46466%
- "क्या Spotify पर यह गाना ख़रीदा जा सकता है? कृपया मुझे बताएं!" स्पैम की संभावना: 94.40953%
- "क्या TensorFlow.js को डाउनलोड करने का तरीका जानने के लिए, कोई मुझसे संपर्क कर सकता है?" स्पैम की संभावना: 83.20084%
अरे नहीं! ऐसा लगता है कि इन मान्य टिप्पणियों को स्पैम के तौर पर तब मार्क किया जा रहा है, जब इनकी अनुमति होनी चाहिए. इसे कैसे ठीक किया जा सकता है?
एक आसान विकल्प यह है कि SPAM_THRESHOLD को बढ़ाकर 98.5% से ज़्यादा आत्मविश्वास के साथ बात करें. इस स्थिति में, गलत कैटगरी में रखी गई इन टिप्पणियों को पोस्ट कर दिया जाएगा. इसे ध्यान में रखते हुए, चलिए नीचे दिए गए अन्य संभावित नतीजों पर फ़ोकस करते हैं...
स्पैम टिप्पणियां, जिन्हें स्पैम के तौर पर मार्क किया गया है (ट्रू पॉज़िटिव):
- "यह काफ़ी मज़ेदार है, लेकिन मेरी वेबसाइट पर मौजूद बेहतर डाउनलोड लिंक देखें!" स्पैम की संभावना: 99.77873%
- "मैं कुछ ऐसे लोगों को जानती हूं जो आपको कुछ दवाएं ले सकते हैं, बस ज़्यादा जानकारी के लिए मेरी pr0file देखें" संभावित स्पैम: 98.46955%
- "शानदार वीडियो डाउनलोड करने के लिए मेरी प्रोफ़ाइल देखें! http://example.com" स्पैम की संभावना: 96.26383%
ठीक है, यह हमारे मूल 75% थ्रेशोल्ड के साथ उम्मीद के मुताबिक काम कर रहा है. हालांकि, पिछले चरण में आपने SPAM_THRESHOLD को बदलकर 98.5% से ज़्यादा भरोसा किया है, इसका मतलब यह होगा कि यहां दो उदाहरण शामिल किए जा सकेंगे. इसलिए, हो सकता है कि यह थ्रेशोल्ड बहुत ज़्यादा हो. शायद 96% बेहतर है? हालांकि, ऐसा करने पर, पिछले सेक्शन में किसी टिप्पणी (फ़ॉल्स पॉज़िटिव) को स्पैम के तौर पर मार्क किया जाएगा. हालांकि, इसके लिए ज़रूरी है कि वह टिप्पणी सही हो, क्योंकि उसकी रेटिंग 98.46466% थी.
इस मामले में, इन सभी स्पैम टिप्पणियों को कैप्चर करना और ऊपर बताई गई गड़बड़ियों के लिए फिर से ट्रेनिंग देना सबसे अच्छा रहता है. थ्रेशोल्ड को 96% पर सेट करने पर, सभी ट्रू पॉज़िटिव कैप्चर होते हैं और आपने ऊपर दिए गए दो फ़ॉल्स पॉज़िटिव को हटा दिया है. सिर्फ़ एक नंबर बदलना भी ठीक नहीं है.
आइए, जारी रखें...
ऐसी स्पैम टिप्पणियां जिन्हें पोस्ट करने की अनुमति दी गई थी (गलत टिप्पणियां):
- "इसके अलावा, और भी शानदार वीडियो डाउनलोड करने के लिए मेरी प्रोफ़ाइल देखें!" स्पैम की संभावना: 7.54926%
- "हमारी जिम प्रशिक्षण क्लास पर छूट पाएं! pr0file देखें!" स्पैम की संभावना: 17.49849%
- "Google के स्टॉक ने अभी-अभी खरीदारी की है! देर हो जाए!" स्पैम की संभावना: 20.42894%
इन टिप्पणियों के लिए, SPAM_THRESHOLD की वैल्यू में और बदलाव करके कुछ नहीं किया जा सकता. स्पैम के लिए थ्रेशोल्ड को 96% से घटाकर ~9% करने से, असली टिप्पणियों को स्पैम के तौर पर मार्क किया जाएगा. इनमें से एक टिप्पणी को 58% रेटिंग मिली है, भले ही वह मान्य हो. इस तरह की टिप्पणियों से निपटने के लिए, मॉडल को ट्रेनिंग डेटा में शामिल किए गए ऐसे किनारे के केस के साथ फिर से ट्रेनिंग देनी होगी. इससे, मॉडल को यह समझने में मदद मिलती है कि दुनिया को किस तरह से दिखाया जाए कि यह स्पैम है या नहीं.
फ़िलहाल, सिर्फ़ एक विकल्प बचा है और मॉडल को फिर से ट्रेनिंग दें. साथ ही, आपने यह भी देखा कि स्पैम को कॉल करने का थ्रेशोल्ड तय करने के लिए, उसे बेहतर कैसे बनाया जा सकता है. एक इंसान के तौर पर, 75% काफ़ी आत्मविश्वासी लगती है, लेकिन इस मॉडल के लिए आपको उदाहरण के इनपुट की मदद से ज़्यादा असरदार बनने के लिए 81.5% के करीब जाना होगा.
कोई एक जादुई वैल्यू नहीं है जो अलग-अलग मॉडल में अच्छी तरह से काम करती हो. साथ ही, सही थ्रेशोल्ड वैल्यू को असल दुनिया के डेटा के साथ एक्सपेरिमेंट करने के बाद, हर मॉडल के हिसाब से सेट किया जाना चाहिए.
कुछ मामलों में, फ़ॉल्स पॉज़िटिव या नेगेटिव होने के गंभीर नतीजे हो सकते हैं. उदाहरण के लिए, मेडिकल इंडस्ट्री में. ऐसे में, थ्रेशोल्ड को बहुत ज़्यादा पर सेट किया जा सकता है. साथ ही, उन मामलों को मैन्युअल तौर पर समीक्षा के लिए अनुरोध किया जा सकता है जो थ्रेशोल्ड को पूरा नहीं करते हैं. डेवलपर के तौर पर यह आपकी मर्ज़ी है और इसे आज़माने की ज़रूरत है.
4. स्पैम टिप्पणी का पता लगाने वाले मॉडल को फिर से ट्रेनिंग दें
पिछले सेक्शन में, आपने मॉडल के लिए काम न करने वाले किनारे के कई मामलों की पहचान की थी. इनमें सिर्फ़ एक विकल्प यह था कि इन स्थितियों के लिए मॉडल को फिर से ट्रेनिंग दें. प्रोडक्शन सिस्टम में आपको पता चल सकता है कि समय के साथ लोग किसी ऐसी टिप्पणी को स्पैम के तौर पर फ़्लैग कर देते हैं जो मैन्युअल तरीके से स्पैम के तौर पर मार्क हो जाती है. इसके अलावा, फ़्लैग की गई टिप्पणियों की समीक्षा करने वाले मॉडरेटर को लगता है कि उनमें से कुछ टिप्पणियां स्पैम नहीं हैं. ऐसे में, लोगों को इस तरह की टिप्पणियों को फिर से ट्रेनिंग देने के लिए मार्क किया जा सकता है. यह मानते हुए कि आपने इन किनारे वाले मामलों के लिए बहुत सारे नए डेटा इकट्ठा किए हैं (सबसे अच्छे नतीजों के लिए, अगर हो सके, तो आपके इन नए वाक्यों के कुछ वैरिएशन होने चाहिए), अब हम आपको उन किनारे वाले मामलों को ध्यान में रखकर मॉडल को फिर से तैयार करने के तरीके के बारे में बताएंगे.
पहले से बनाए गए मॉडल का रीकैप
आपने पहले से बनाया हुआ मॉडल एक ऐसा मॉडल बनाया था जिसे किसी तीसरे पक्ष ने Model Maker के ज़रिए बनाया था. इसमें "औसत शब्द एम्बेड करने" का इस्तेमाल होता है मॉडल का इस्तेमाल करें.
इस मॉडल को Model Maker की मदद से बनाया गया है. इसलिए, आपको कुछ समय के लिए Python में स्विच करना होगा. इसके बाद ही, आपको इस मॉडल को फिर से ट्रेनिंग देनी होगी. इसके बाद, बनाए गए मॉडल को TensorFlow.js फ़ॉर्मैट में एक्सपोर्ट करना होगा, ताकि आप इसे ब्राउज़र में इस्तेमाल कर सकें. अच्छी बात यह है कि Model Maker अपने मॉडल का इस्तेमाल करना बहुत आसान बना देता है. इसलिए, इसे इस्तेमाल करना काफ़ी आसान होना चाहिए. हम इस प्रोसेस को पूरा करने में आपकी मदद करेंगे. अगर आपने पहले कभी Python इस्तेमाल नहीं किया है, तो चिंता न करें!
Colab
अगर आपको इस कोडलैब के बारे में ज़्यादा चिंता नहीं है और आपको Python की सभी अलग-अलग सुविधाओं के साथ Linux सर्वर सेट अप करना है, तो आपके पास "Colab Notebook" का इस्तेमाल करके, वेब ब्राउज़र से कोड चलाने का विकल्प है. ये नोटबुक किसी "बैकएंड" से कनेक्ट हो सकती हैं - जो सामान्य तौर पर एक ऐसा सर्वर है, जिसमें कुछ सामग्री पहले से इंस्टॉल होती है, जिससे आप फिर वेब ब्राउज़र में आर्बिट्रेरी कोड निष्पादित कर सकते हैं और परिणाम देख सकते हैं. यह तुरंत प्रोटोटाइप बनाने या इस तरह के ट्यूटोरियल में इस्तेमाल के लिए बहुत काम का है.
इसके लिए, colab.research.google.com पर जाएं. इसके बाद, आपको वेलकम स्क्रीन दिखेगी. यह स्क्रीन इस तरह दिखेगी:
अब पॉप-अप विंडो के सबसे नीचे दाईं ओर, नई नोटबुक बटन पर क्लिक करें. इसके बाद, आपको ऐसा खाली कोलैब दिखेगा:
बढ़िया! अगला चरण कुछ बैकएंड सर्वर से फ़्रंटएंड कोलैब कनेक्ट करना है, ताकि आप लिखे जाने वाले Python कोड को एक्ज़ीक्यूट कर सकें. इसके लिए, सबसे ऊपर दाईं ओर मौजूद कनेक्ट करें पर क्लिक करें. इसके बाद, होस्ट किए गए रनटाइम से कनेक्ट करें को चुनें.
कनेक्ट होने के बाद, आपको उसकी जगह पर रैम और डिस्क आइकॉन दिखेंगे, जैसे कि:
बहुत खूब! अब Python में कोडिंग शुरू करके, Model Maker मॉडल को फिर से ट्रेनिंग दी जा सकती है. बस नीचे दिए चरणों का अनुसरण करें.
कदम 1
फ़िलहाल खाली पहली सेल में, नीचे दिया गया कोड कॉपी करें. यह Python के "pip" नाम के पैकेज मैनेजर का इस्तेमाल करके, आपके लिए TensorFlow Lite Model Maker इंस्टॉल करेगा (यह npm के जैसा है जिसके बारे में इस कोड लैब के ज़्यादातर पाठक JS नेटवर्क से ज़्यादा जानकारी पा सकते हैं):
!apt-get install libasound-dev portaudio19-dev libportaudio2 libportaudiocpp0
!pip install -q tflite-model-maker
हालांकि, सेल में कोड चिपकाने से वह लागू नहीं होगा. इसके बाद, अपने माउस को उस स्लेटी सेल पर घुमाएं जिसमें आपने ऊपर दिया गया कोड चिपकाया था और एक छोटा सा "चलाएं" बटन दबाएं आइकन सेल की बाईं ओर दिखाई देगा, जैसा कि नीचे हाइलाइट किया गया है:
 सेल में अभी टाइप किए गए कोड को चलाने के लिए, 'चलाएं' बटन पर क्लिक करें.
सेल में अभी टाइप किए गए कोड को चलाने के लिए, 'चलाएं' बटन पर क्लिक करें.
अब आपको दिखेगा कि मॉडल मेकर इंस्टॉल हो रहा है:
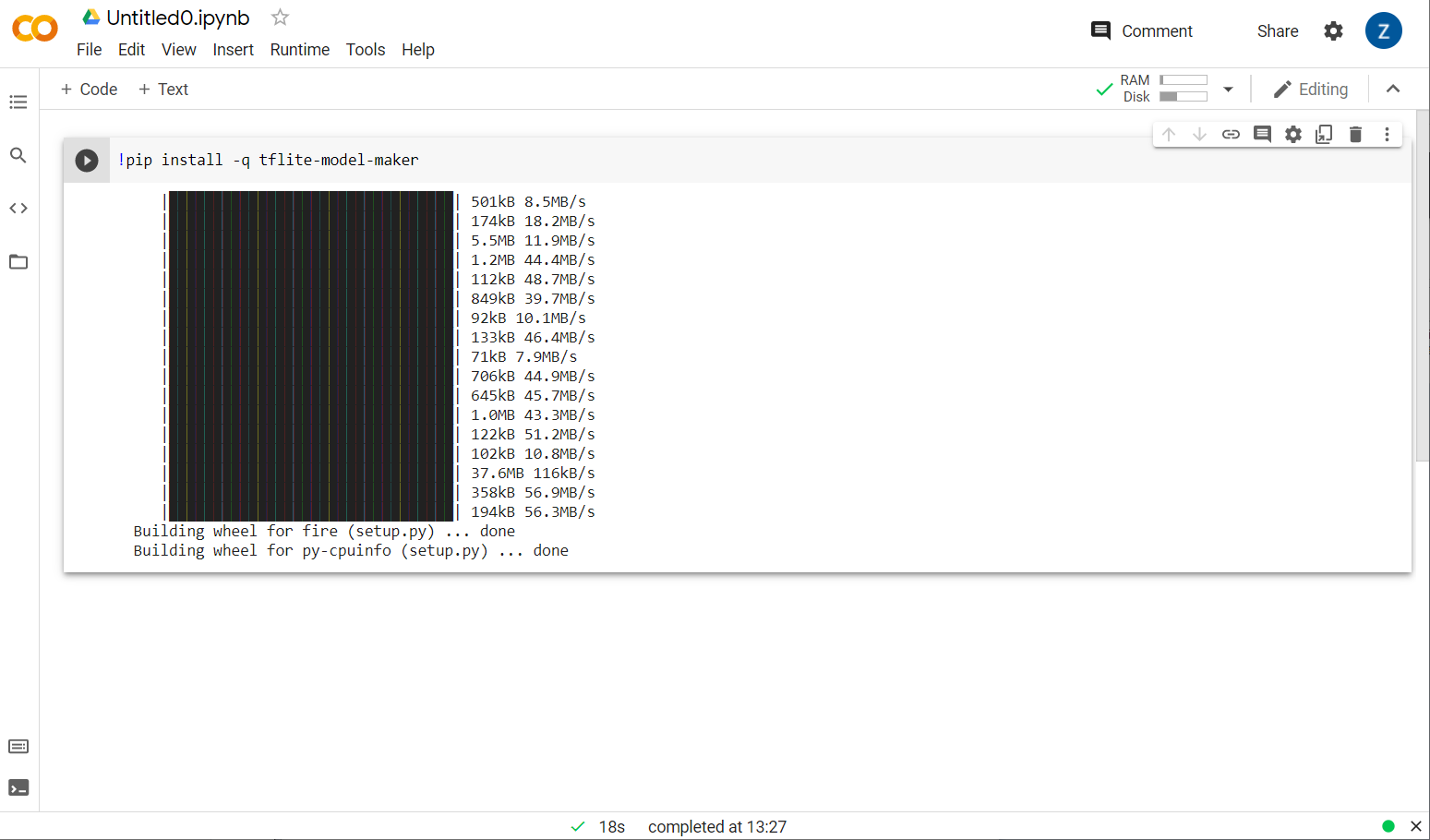
दिखाए गए तरीके से इस सेल का एक्ज़ीक्यूशन पूरा होने के बाद, नीचे दिए गए अगले चरण पर जाएं.
दूसरा चरण
इसके बाद, दिखाए गए तरीके से नया कोड सेल जोड़ें, ताकि आप पहली सेल के बाद कुछ और कोड चिपका सकें और उसे अलग से एक्ज़ीक्यूट कर सकें:
लागू किए गए अगले सेल में ऐसे कई इंपोर्ट होंगे जिनका इस्तेमाल, बाकी नोटबुक में मौजूद कोड को करना होगा. नीचे दी गई सेल को कॉपी करके, बनाए गए नए सेल में चिपकाएं:
import numpy as np
import os
from tflite_model_maker import configs
from tflite_model_maker import ExportFormat
from tflite_model_maker import model_spec
from tflite_model_maker import text_classifier
from tflite_model_maker.text_classifier import DataLoader
import tensorflow as tf
assert tf.__version__.startswith('2')
tf.get_logger().setLevel('ERROR')
यह काफ़ी स्टैंडर्ड कॉन्टेंट है, भले ही आप Python के बारे में न जानते हों. आप बस कुछ उपयोगिताएं आयात कर रहे हैं और स्पैम वर्गीकारक के लिए आवश्यक Model Maker फ़ंक्शन आयात कर रहे हैं. इससे यह भी जांच की जाएगी कि क्या TensorFlow 2.x चलाया जा रहा है, जो कि Model Maker का इस्तेमाल करने के लिए ज़रूरी है.
आखिर में, पहले की तरह, "चलाएं" दबाकर सेल चलाने के लिए आइकॉन पर टैप करें. इसके बाद, अगले चरण के लिए नया कोड सेल जोड़ें.
चरण 3
इसके बाद, आपको रिमोट सर्वर से अपने डिवाइस पर डेटा डाउनलोड करना होगा. साथ ही, डाउनलोड की गई लोकल फ़ाइल के पाथ के तौर पर training_data वैरिएबल को सेट करना होगा:
data_file = tf.keras.utils.get_file(fname='comment-spam-extras.csv', origin='https://storage.googleapis.com/jmstore/TensorFlowJS/EdX/code/6.5/jm_blog_comments_extras.csv', extract=False)
मॉडल मेकर सामान्य CSV फ़ाइलों से मॉडल को ट्रेनिंग दे सकता है, जैसे कि डाउनलोड की गई फ़ाइल. आपको सिर्फ़ यह बताना होगा कि कौनसे कॉलम में टेक्स्ट है और कौनसे लेबल हैं. इसका तरीका आपको पांचवें चरण में बताया गया है. इस CSV फ़ाइल को डाउनलोड करके देखें कि इसमें क्या-क्या है.
आप पूरी तरह से ध्यान देंगे कि इस फ़ाइल का नाम jm_blog_comments_extras.csv है - यह फ़ाइल सिर्फ़ मूल ट्रेनिंग डेटा है, जिसका इस्तेमाल हमने सबसे पहले स्पैम टिप्पणी वाले मॉडल को जनरेट करने के लिए किया था. इसे आपके खोजे गए नए किनारे के केस डेटा के साथ सं साथ दिया गया था, ताकि यह पूरी फ़ाइल एक फ़ाइल में मौजूद हो. आपको सीखे जाने वाले नए वाक्यों के अलावा, मॉडल को ट्रेनिंग देने के लिए भी ओरिजनल ट्रेनिंग डेटा की ज़रूरत होगी.
ज़रूरी नहीं: इस CSV फ़ाइल को डाउनलोड करने और आखिरी कुछ लाइनों को देखने पर, आपको ऐसे किनारे के उदाहरण दिखेंगे जो पहले ठीक से काम नहीं कर रहे थे. इन्हें हाल ही में, मौजूदा ट्रेनिंग डेटा के आखिर में जोड़ा गया है. इस मॉडल का इस्तेमाल, खुद को ट्रेनिंग देने के लिए किया जाता है.
इस सेल को एक्ज़ीक्यूट करें. इसके बाद, एक नया सेल जोड़ें और चौथे चरण पर जाएं.
चौथा चरण
Model Maker का इस्तेमाल करते समय, आपको मॉडल शुरुआत से नहीं बनाए जाते हैं. आम तौर पर, उन मॉडल का इस्तेमाल किया जाता है जिन्हें बाद में अपनी ज़रूरत के हिसाब से बनाया जा सकता है.
मॉडल मेकर, पहले से सीखी गई कई मॉडल की एम्बेडिंग की सुविधा देता है, जिसका आप इस्तेमाल कर सकते हैं. हालांकि, शुरुआत करने के लिए सबसे आसान और सबसे तेज़ मॉडल average_word_vec है, जिसका इस्तेमाल आपने अपनी वेबसाइट बनाने के लिए पिछले कोडलैब में किया था. कोड यहाँ है:
spec = model_spec.get('average_word_vec')
spec.num_words = 2000
spec.seq_len = 20
spec.wordvec_dim = 7
आगे बढ़ें और इसे नए सेल में चिपकाने के बाद चलाएं.
इन बातों को समझना
num_words
पैरामीटर
मॉडल को इतने शब्दों का इस्तेमाल करना चाहिए. आपको लग सकता है कि जितना बेहतर होगा उतना बेहतर होगा, लेकिन कोई भी शब्द कितनी बार इस्तेमाल किया गया है, इसे देखकर ही अच्छा फ़ैसला लिया जा सकता है. अगर आपके पूरे संग्रह में हर शब्द का इस्तेमाल किया जाता है, तो हो सकता है कि मॉडल, सिर्फ़ एक बार इस्तेमाल किए गए शब्दों की अहमियत को समझता हो और उन्हें संतुलित कर दे. यह बहुत काम का नहीं है. आपको किसी भी टेक्स्ट कॉर्पस में मिलेगा कि कई शब्दों का इस्तेमाल सिर्फ़ एक या दो बार किया जाता है. साथ ही, आम तौर पर इनका इस्तेमाल अपने मॉडल में नहीं करना चाहिए, क्योंकि इससे लोगों पर थोड़ा असर पड़ता है. इसलिए, num_words पैरामीटर का इस्तेमाल करके, अपने मॉडल को अपने हिसाब से शब्दों की संख्या के हिसाब से बदला जा सकता है. यहां छोटी संख्या का मॉडल छोटा और ज़्यादा तेज़ होगा. हालांकि, यह कम सटीक हो सकता है, क्योंकि यह कम शब्दों को पहचानता है. यहां बड़ी संख्या का बड़ा और संभावित रूप से धीमा मॉडल होगा. सबसे सही कीवर्ड का पता लगाना सबसे ज़रूरी है. मशीन लर्निंग इंजीनियर के तौर पर, आपको यह पता करना होता है कि आपके काम के लिए कौनसा तरीका सबसे सही रहेगा.
इन बातों को समझना
wordvec_dim
पैरामीटर
wordvec_dim पैरामीटर उन डाइमेंशन की संख्या है जिनका इस्तेमाल आपको हर शब्द के वेक्टर के लिए करना है. ये डाइमेंशन ज़रूरी अलग-अलग विशेषताएं हैं. ये ट्रेनिंग के दौरान मशीन लर्निंग एल्गोरिदम की मदद से बनाए जाते हैं. इनकी मदद से प्रोग्राम, उन शब्दों को आज़माता है जो एक जैसे शब्दों को सबसे सही तरीके से जोड़ते हैं.
उदाहरण के लिए, अगर आपके पास "मेडिकल" क्षेत्र के बारे में कोई डाइमेंशन होता एक शब्द था, "गोलियां" जैसा एक शब्द इस आयाम में यहां उच्च स्कोर कर सकता है और अन्य उच्च स्कोरिंग शब्दों के साथ संबद्ध हो सकता है, जैसे "xray", लेकिन "cat" इस डाइमेंशन पर स्कोर कम हो जाएगा. यह भी पता चल सकता है कि "मेडिकल डाइमेंशन" इससे स्पैम का पता लगाने में मदद मिलती है. हालांकि, इसे ऐसे अन्य संभावित डाइमेंशन के साथ मिलाकर जाना जा सकता है जिनका इस्तेमाल करना ज़रूरी है.
अगर "मेडिकल डाइमेंशन" में सबसे ज़्यादा स्कोर पाने वाले शब्दों के मामले में, यह समझ सकता है कि शब्दों को मानव शरीर से जोड़ने वाला दूसरा डाइमेंशन मददगार हो सकता है. "पैर", "हाथ", "गला" जैसे शब्द वे यहां अच्छा स्कोर हासिल कर सकते हैं. साथ ही, मेडिकल डाइमेंशन में भी काफ़ी ज़्यादा स्कोर कर सकते हैं.
यह मॉडल इन डाइमेंशन का इस्तेमाल करके, उन शब्दों का पता लगाता है जिनकी स्पैम से ज़्यादा संभावना होती है. हो सकता है कि स्पैम ईमेल में ऐसे शब्द हों जो चिकित्सा और मानव शरीर के अंगों, दोनों से जुड़े हों.
रिसर्च से तय किया गया नियम यह है कि शब्दों की संख्या का चौथा मूल इस पैरामीटर के लिए अच्छा काम करता है. अगर मेरे पास 2,000 शब्द हैं, तो इसके लिए सबसे अच्छा शुरुआती पॉइंट 7 डाइमेंशन हैं. अगर शब्दों की संख्या बदली जाती है, तो यह सेटिंग भी बदली जा सकती है.
इन बातों को समझना
seq_len
पैरामीटर
आम तौर पर, इनपुट वैल्यू के मामले में मॉडल बहुत सख्त होते हैं. लैंग्वेज मॉडल के लिए, इसका मतलब है कि लैंग्वेज मॉडल, किसी खास, स्थिर, और लंबे वाक्य के वाक्यों की कैटगरी तय कर सकता है. इसे seq_len पैरामीटर से तय किया जाता है. इसमें इसका मतलब 'क्रम की लंबाई' से है. जब शब्दों को संख्याओं (या टोकन) में बदला जाता है, तो कोई वाक्य इन टोकन का क्रम बन जाता है. इस तरह, आपके मॉडल को (इस मामले में) ऐसे वाक्यों की कैटगरी तय करने और पहचानने की ट्रेनिंग दी जाएगी जिनमें 20 टोकन हैं. अगर वाक्य इससे लंबा है, तो उसमें काट-छांट की जाएगी. अगर यह छोटा है, तो इसे पैड कर दिया जाएगा - ठीक उसी तरह, जैसे इस सीरीज़ के पहले कोडलैब में होता है.
पांचवां चरण - ट्रेनिंग का डेटा लोड करना
इससे पहले आपने CSV फ़ाइल डाउनलोड की थी. अब इसे डेटा लोड करने वाले किसी ट्रेनिंग डेटा में बदलने का समय आ गया है, ताकि मॉडल उसकी पहचान कर सके.
data = DataLoader.from_csv(
filename=data_file,
text_column='commenttext',
label_column='spam',
model_spec=spec,
delimiter=',',
shuffle=True,
is_training=True)
train_data, test_data = data.split(0.9)
CSV फ़ाइल को एडिटर में खोलने पर, आपको दिखेगा कि हर लाइन में दो वैल्यू हैं. इनके बारे में, फ़ाइल की पहली लाइन में टेक्स्ट से बताया गया है. आम तौर पर, हर एंट्री को एक 'कॉलम' माना जाता है. आप देखेंगे कि पहले कॉलम का डिस्क्रिप्टर commenttext है और हर लाइन में पहली एंट्री, टिप्पणी का टेक्स्ट है.
इसी तरह, दूसरे कॉलम का डिस्क्रिप्टर spam है. यहां आपको दिखेगा कि हर लाइन में दूसरी एंट्री TRUE या FALSE है, ताकि यह पता चल सके कि टेक्स्ट को स्पैम टिप्पणी माना जाता है या नहीं. अन्य प्रॉपर्टी, डेलिमिटर वर्ण के साथ चरण 4 में बनाए गए मॉडल की खास जानकारी सेट करती हैं. इस मामले में, यह एक कॉमा है, क्योंकि फ़ाइल को कॉमा लगाकर अलग किया जाता है. ट्रेनिंग डेटा को फिर से व्यवस्थित करने के लिए, शफ़ल पैरामीटर भी सेट किया जा सकता है. इससे, इकट्ठा की गई चीज़ों या उनसे मिलती-जुलती चीज़ों को, पूरे डेटा सेट में बिना किसी क्रम के व्यवस्थित किया जा सकता है.
इसके बाद, डेटा को ट्रेनिंग और टेस्ट डेटा में बांटने के लिए, data.split() का इस्तेमाल करें. .9 से पता चलता है कि 90% डेटासेट का इस्तेमाल ट्रेनिंग के लिए और बाकी का इस्तेमाल टेस्टिंग के लिए किया जाएगा.
छठा चरण - मॉडल बनाना
एक और सेल जोड़ें, जहां हम मॉडल बनाने के लिए कोड जोड़ेंगे:
model = text_classifier.create(train_data, model_spec=spec, epochs=50)
इससे, Model Maker में टेक्स्ट क्लासिफ़ायर का मॉडल बन जाता है और आपको इस्तेमाल किया जाने वाला ट्रेनिंग डेटा (जिसकी जानकारी चौथे चरण में दी गई थी), मॉडल की खास बातों (जिसे चौथे चरण में भी सेट अप किया गया था), और epoch की संख्या, इस मामले में 50 होती है.
मशीन लर्निंग का बुनियादी सिद्धांत है कि यह पैटर्न मैचिंग का एक तरीका है. शुरुआत में, यह शब्दों के लिए पहले से ट्रेन किए गए वेट लोड करेगा और 'अनुमान' की मदद से उन्हें एक साथ ग्रुप करने की कोशिश करेगा कौनसे ईमेल एक साथ ग्रुप किए जाते हैं, यह स्पैम बताते हैं और कौनसे नहीं. पहली बार, इसके 50:50 के करीब होने की संभावना हो सकती है, क्योंकि मॉडल नीचे दिखाए गए तरीके से ही शुरू हो रहा है:

इसके बाद, एआई इस मॉडल के नतीजों को मेज़र करेगा और अपने अनुमान में बदलाव करने के लिए, मॉडल के वेट में बदलाव करेगा. इसके बाद, यह फिर से कोशिश करेगा. यह एक युग है. इसलिए, epochs=50 तय करने पर, यह उस 'लूप' से होकर गुज़रेगा 50 बार दिखाया गया है:

इसलिए, 50वें युग तक पहुंचने से पहले, यह मॉडल ज़्यादा सटीक नतीजे दिखाएगा. इस मामले में 99.1%!
सातवां चरण - मॉडल एक्सपोर्ट करना
ट्रेनिंग पूरी होने के बाद, मॉडल को एक्सपोर्ट किया जा सकता है. TensorFlow, मॉडल को उसके फ़ॉर्मैट में ट्रेनिंग देता है. इसे वेब पेज पर इस्तेमाल करने के लिए, TensorFlow.js फ़ॉर्मैट में बदलना होगा. नई सेल में इन्हें चिपकाएं और एक्ज़ीक्यूट करें:
model.export(export_dir="/js_export/", export_format=[ExportFormat.TFJS, ExportFormat.LABEL, ExportFormat.VOCAB])
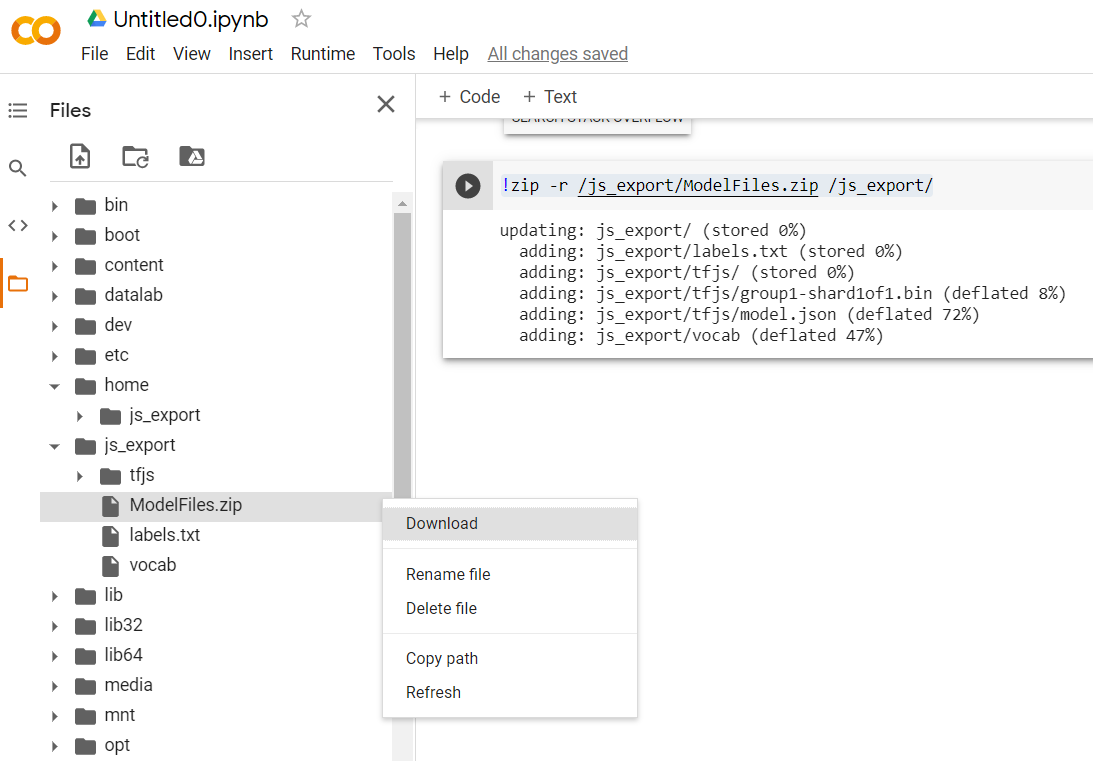
!zip -r /js_export/ModelFiles.zip /js_export/
इस कोड को इस्तेमाल करने के बाद, Colab की बाईं ओर छोटे फ़ोल्डर आइकॉन पर क्लिक करने पर, ऊपर एक्सपोर्ट किए गए फ़ोल्डर (रूट डायरेक्ट्री में आपको एक लेवल ऊपर जाना पड़ सकता है) पर जाएं. इसके बाद, ModelFiles.zip में एक्सपोर्ट की गई फ़ाइलों का ज़िप बंडल ढूंढें.
इस ज़िप फ़ाइल को अपने कंप्यूटर पर अभी डाउनलोड करें, क्योंकि आप इन फ़ाइलों का इस्तेमाल पहले कोडलैब की तरह ही करेंगे:
बढ़िया! Python का पार्ट खत्म हो गया है. अब आपके पास JavaScript लैंड में वापस जाने का विकल्प है जो आपको पसंद है और जिसे आपको पसंद है. वाह!
5. नया मशीन लर्निंग मॉडल इस्तेमाल करना
अब आप मॉडल लोड करने के लिए करीब-करीब तैयार हैं. ऐसा करने से पहले, आपको कोडलैब में पहले से डाउनलोड की गई नई मॉडल फ़ाइलें अपलोड करनी होंगी, ताकि यह आपके कोड में होस्ट की जा सके और इस्तेमाल की जा सके.
सबसे पहले, अगर आपने अभी तक ऐसा नहीं किया है, तो मॉडल मेकर Colab notebook से अभी-अभी डाउनलोड किए गए मॉडल की फ़ाइलों को अनज़िप करें. आपको इसके अलग-अलग फ़ोल्डर में मौजूद ये फ़ाइलें दिखेंगी:
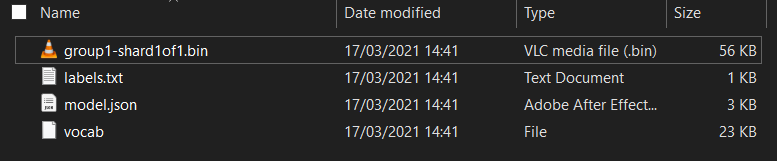
आपके यहां क्या मिलता है?
model.json- यह उन फ़ाइलों में से एक है जिनसे TensorFlow.js का एक मॉडल तैयार किया गया है. आप JS कोड में इस खास फ़ाइल का रेफ़रंस देंगे.group1-shard1of1.bin- यह एक बाइनरी फ़ाइल है, जिसमें एक्सपोर्ट किए गए TensorFlow.js मॉडल का काफ़ी सारा डेटा मौजूद है. इसे ऊपरmodel.jsonकी डायरेक्ट्री में डाउनलोड करने के लिए, सर्वर पर कहीं भी होस्ट करना होगा.vocab- यह अजीब फ़ाइल बिना किसी एक्सटेंशन के होती है, जो हमें Model Maker की ओर से दिखाई गई फ़ाइल है. इससे हमें पता चलता है कि वाक्यों में शब्दों को कैसे कोड में बदला जाए, ताकि मॉडल समझ सके कि उनका इस्तेमाल कैसे करना है. अगले सेक्शन में, आपको इस बारे में ज़्यादा जानकारी मिलेगी.labels.txt- इसमें बस नतीजे के तौर पर मिलने वाले ऐसे क्लास नेम शामिल होते हैं जिनके बारे में मॉडल अनुमान लगाएगा. इस मॉडल के लिए, अगर इस फ़ाइल को टेक्स्ट एडिटर में खोला जाता है, तो इसमें "गलत" दिखेगा और "सही" "स्पैम नहीं है" दिखाने वाली सूची या "स्पैम" किया जाता है.
TensorFlow.js मॉडल फ़ाइलें होस्ट करें
सबसे पहले वेब सर्वर पर जनरेट की गई model.json और *.bin फ़ाइलें रखें, ताकि आप अपने वेब पेज से उन तक पहुंच सकें.
मौजूदा मॉडल फ़ाइलें मिटाना
इस सीरीज़ के पहले कोडलैब के नतीजे के आधार पर तैयार करते समय, आपको पहले अपलोड की गई मौजूदा मॉडल फ़ाइलें मिटानी होंगी. अगर Glitch.com का इस्तेमाल किया जा रहा है, तो model.json और group1-shard1of1.bin के लिए बाईं ओर मौजूद फ़ाइल पैनल को देखें. हर फ़ाइल के लिए, तीन बिंदु वाले मेन्यू ड्रॉपडाउन पर क्लिक करें और मिटाएं को चुनें:
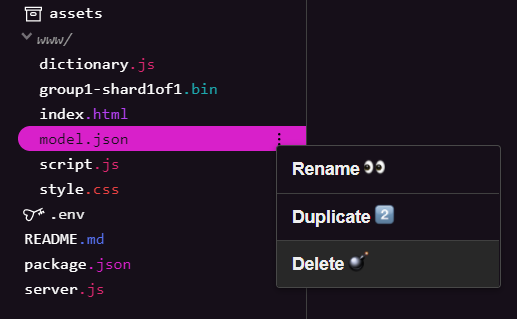
glitch पर नई फ़ाइलें अपलोड करना
बढ़िया! अब नए अपलोड करें:
- अपने Glitch प्रोजेक्ट की बाईं ओर मौजूद पैनल में ऐसेट फ़ोल्डर खोलें. अगर ऐसेट के नाम एक जैसे हैं, तो अपलोड की गई पुरानी ऐसेट मिटाएं.
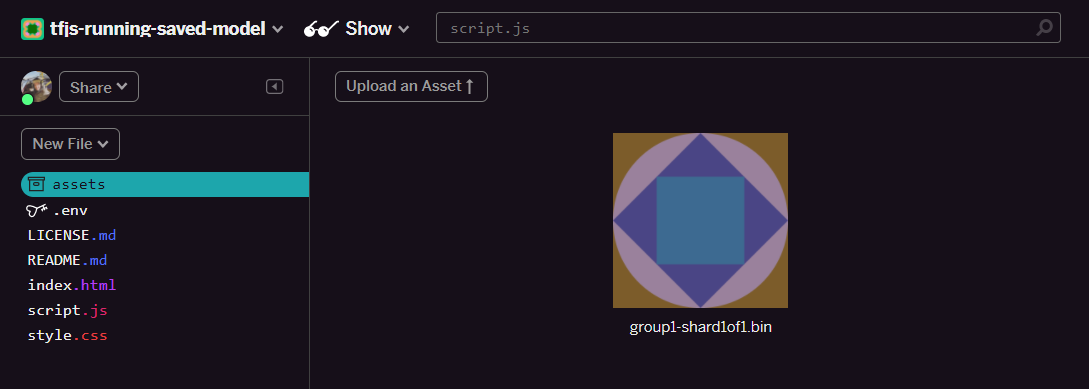
- कोई ऐसेट अपलोड करें पर क्लिक करें और इस फ़ोल्डर में अपलोड करने के लिए
group1-shard1of1.binचुनें. अपलोड हो जाने के बाद, यह कुछ ऐसा दिखेगा:
- बढ़िया! अब Model.json फ़ाइल के लिए भी ऐसा ही करें, ताकि आपके एसेट फ़ोल्डर में दो फ़ाइलें इस तरह से हों:
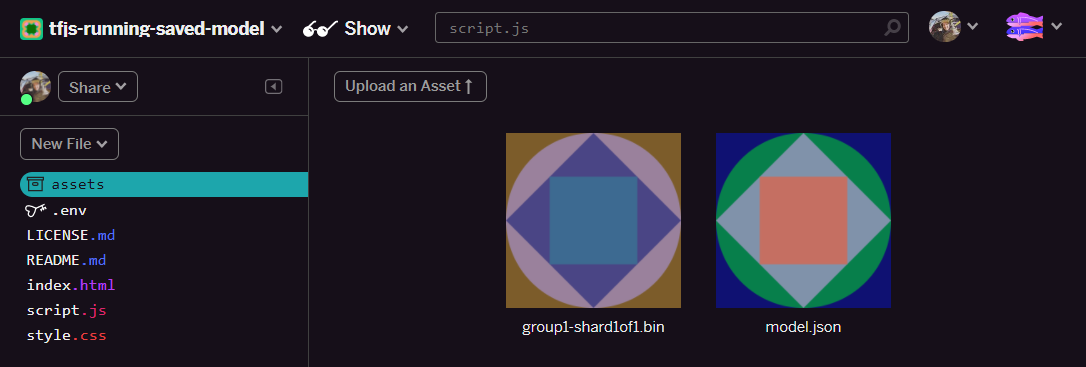
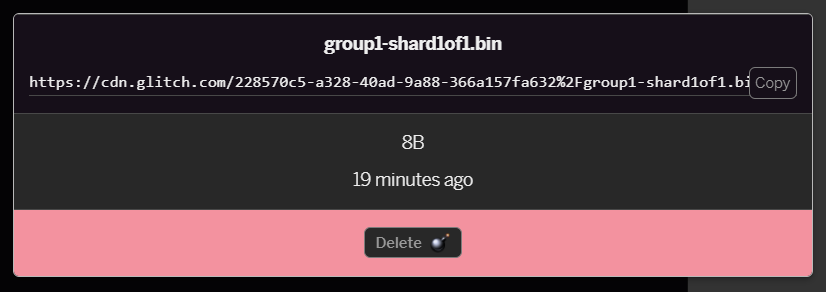
- आपने अभी-अभी जो
group1-shard1of1.binफ़ाइल अपलोड की है उस पर क्लिक करने से, यूआरएल उसकी जगह पर कॉपी हो जाएगा. इस पाथ को अभी कॉपी करें, जैसा कि दिखाया गया है:
- अब स्क्रीन के नीचे बाईं ओर, टूल क्लिक करें > Terminal. टर्मिनल विंडो के लोड होने का इंतज़ार करें.
- लोड होने के बाद, यह टाइप करें और फिर डायरेक्ट्री को
wwwफ़ोल्डर में बदलने के लिए, Enter दबाएं:
टर्मिनल:
cd www
- इसके बाद, अभी अपलोड की गई दो फ़ाइलें डाउनलोड करने के लिए,
wgetका इस्तेमाल करें. इसके लिए, यहां दिए गए यूआरएल को उन यूआरएल से बदलें जो आपने Glitch पर मौजूद ऐसेट फ़ोल्डर में फ़ाइलों के लिए जनरेट किए हों. हर फ़ाइल के कस्टम यूआरएल के लिए ऐसेट फ़ोल्डर देखें.
ध्यान दें कि दोनों यूआरएल के बीच स्पेस और आपको जिन यूआरएल का इस्तेमाल करना है वे दिखाए गए यूआरएल से अलग होंगे, लेकिन वे एक जैसे दिखेंगे:
टर्मिनल
wget https://cdn.glitch.com/1cb82939-a5dd-42a2-9db9-0c42cab7e407%2Fmodel.json?v=1616111344958 https://cdn.glitch.com/1cb82939-a5dd-42a2-9db9-0c42cab7e407%2Fgroup1-shard1of1.bin?v=1616017964562
बहुत बढ़िया! अब आपने www फ़ोल्डर में अपलोड की गई फ़ाइलों की एक कॉपी बना ली है.
हालांकि, अभी उन्हें अजीब नामों से डाउनलोड किया जाएगा. अगर आप टर्मिनल में ls टाइप करते हैं और Enter दबाते हैं, तो आपको कुछ ऐसा दिखेगा:

mvनिर्देश का इस्तेमाल करके, फ़ाइलों का नाम बदला जा सकता है. कंसोल में यह टाइप करें और हर लाइन के बाद Enter दबाएं:
टर्मिनल:
mv *group1-shard1of1.bin* group1-shard1of1.bin
mv *model.json* model.json
- आखिर में, टर्मिनल में
refreshटाइप करके Glitch प्रोजेक्ट को रीफ़्रेश करें और Enter दबाएं:
टर्मिनल:
refresh
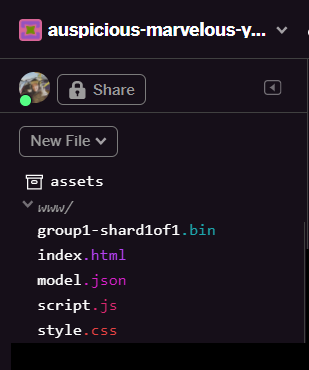
रीफ़्रेश करने पर, अब आपको यूज़र इंटरफ़ेस के www फ़ोल्डर में model.json और group1-shard1of1.bin दिखेंगे:
बढ़िया! आखिरी चरण dictionary.js फ़ाइल को अपडेट करना है.
- अपनी डाउनलोड की गई वोकेब फ़ाइल को मैन्युअल रूप से अपने टेक्स्ट एडिटर के ज़रिए मैन्युअल रूप से या इस टूल का इस्तेमाल करके सही JS फ़ॉर्मैट में बदलें. इसके बाद मिलने वाले आउटपुट को
wwwफ़ोल्डर मेंdictionary.jsके तौर पर सेव करें. अगर आपके पास पहले से कोईdictionary.jsफ़ाइल है, तो नए कॉन्टेंट को कॉपी करके उस पर चिपकाएं और फ़ाइल को सेव करें.
बहुत बढ़िया! आपने सभी बदली गई फ़ाइलों को अपडेट कर दिया है. साथ ही, वेबसाइट को इस्तेमाल करके देखने पर, आपको यह पता चलेगा कि आगे जिस मॉडल को ट्रेनिंग दी गई है वह किनारे वाले मामलों की जांच कर सकती है और सीखी गई है. इनके बारे में नीचे बताया गया है:
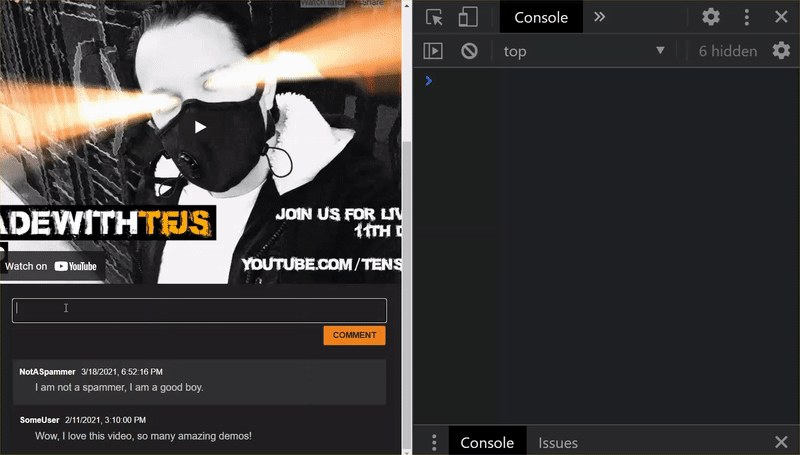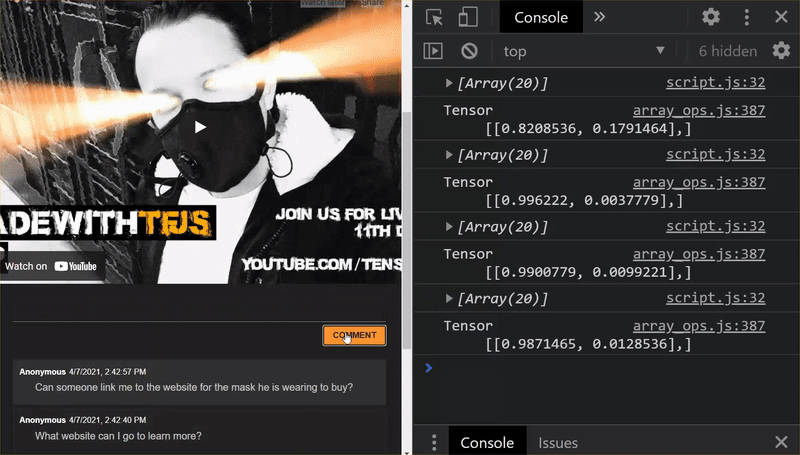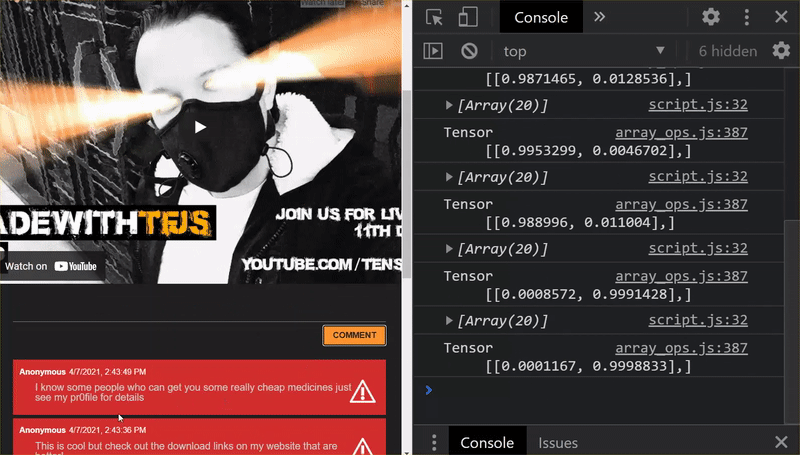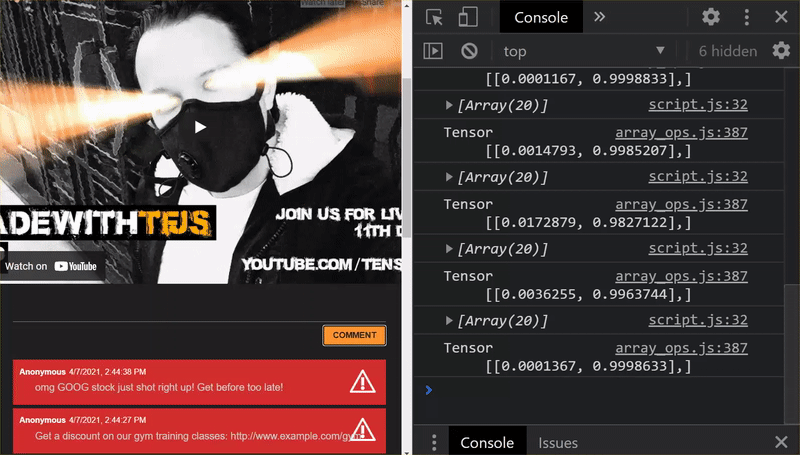
जैसा कि आपको दिख रहा है, पहले छह को 'स्पैम नहीं है' के तौर पर सही कैटगरी में रखा गया है और छह के दूसरे बैच की पहचान स्पैम के तौर पर की गई है. बढ़िया!
आइए, कुछ वैरिएशन भी आज़माते हैं, ताकि यह देख सकें कि वे सही हैं या नहीं. मूल रूप से इसमें एक ऐसा वाक्य मौजूद नहीं था जिसमें यह काम न करे, जैसे कि:
"" देर हो जाए!"
अब इसे सही ढंग से स्पैम के रूप में वर्गीकृत कर दिया गया है, लेकिन अगर आप इसे बदलकर यह करते हैं, तो क्या होता है:
"इसलिए, XYZ के स्टॉक की कीमत बढ़ गई है! देर होने से पहले, कुछ खरीद लें!"
यहां आपको 98% स्पैम होने की संभावना का अनुमान मिलता है जो सही है, भले ही आपने स्टॉक सिंबल और शब्दों में थोड़ा-बहुत बदलाव किया हो.
बेशक, अगर आप वाकई इस नए मॉडल को आज़माने की कोशिश करते हैं, तो आपको ऑनलाइन मिलने वाली आम परिस्थितियों के लिए ज़्यादा यूनीक वैरिएशन कैप्चर करने का सबसे अच्छा मौका मिलेगा. इसके अलावा, आपको और ज़्यादा ट्रेनिंग डेटा इकट्ठा करने में मदद मिलेगी. आने वाले समय में कोडलैब का इस्तेमाल करके, हम आपको बताएंगे कि लाइव डेटा के साथ अपने मॉडल को लगातार बेहतर कैसे बनाएं, क्योंकि यह फ़्लैग किया गया है.
6. बधाई हो!
बधाई हो, आपने अपने मौजूदा मशीन लर्निंग मॉडल को फिर से ट्रेनिंग दी है, ताकि वह अपने-आप अपडेट हो जाए, ताकि आपके बताए गए किनारे के मामलों के हिसाब से काम कर सके. साथ ही, आपने उन बदलावों को असल दुनिया में इस्तेमाल होने वाले ऐप्लिकेशन के लिए, TensorFlow.js की मदद से ब्राउज़र में डिप्लॉय किया.
रीकैप
इस कोडलैब में:
- ऐसे मामलों का पता चला जो टिप्पणी वाले स्पैम के पहले से बने मॉडल का इस्तेमाल करते समय काम नहीं कर रहे थे
- आपके खोजे गए किनारे के केस को ध्यान में रखने के लिए, मॉडल मेकर मॉडल को फिर से ट्रेनिंग दी गई
- नए प्रशिक्षित मॉडल को TensorFlow.js फ़ॉर्मैट में एक्सपोर्ट किया गया
- नई फ़ाइलों का इस्तेमाल करने के लिए, अपने वेब ऐप्लिकेशन को अपडेट किया गया है
आगे क्या होगा?
इसलिए, यह अपडेट बेहतरीन तरीके से काम करता है. हालांकि, किसी भी अन्य वेब ऐप्लिकेशन की तरह इसमें भी समय-समय पर बदलाव होते रहेंगे. यह ज़्यादा बेहतर होगा अगर ऐप्लिकेशन समय-समय पर अपने-आप बेहतर होता जाए, न कि मैन्युअल तौर पर हर बार ऐसा करना पड़े. क्या आप सोच सकते हैं कि आपने मॉडल को फिर से प्रशिक्षण देने के लिए इन चरणों को कैसे ऑटोमेट किया है, उदाहरण के लिए, 100 नई टिप्पणियों को गलत कैटगरी में रखा गया है? अपनी नियमित वेब इंजीनियरिंग हैट पहनें और शायद आप यह पता लगा सकते हैं कि इसे अपने आप करने के लिए पाइपलाइन कैसे बनाएं. अगर ऐसा नहीं है, तो चिंता न करें. सीरीज़ में अगली कोडलैब वाली फ़ाइल देखें. इसमें आपको इसका तरीका बताया जाएगा.
आप जो भी बनाते हैं उसे हमारे साथ शेयर करें
आपने आज जो बनाया है उसे अन्य क्रिएटिव कामों के लिए भी आसानी से इस्तेमाल किया जा सकता है. हमारा सुझाव है कि आप कुछ नया करें और हैकिंग करते रहें.
अपने प्रोजेक्ट को TensorFlow ब्लॉग या आने वाले इवेंट में दिखाने का मौका पाने के लिए, #MadeWithTFJS हैशटैग का इस्तेमाल करके, हमें सोशल मीडिया पर टैग करना न भूलें. हम जानना चाहेंगे कि आप क्या बनाते हैं.
ज़्यादा जानकारी के लिए, TensorFlow.js कोडलैब की ज़्यादा सुविधा
- बड़े पैमाने पर TensorFlow.js मॉडल को डिप्लॉय और होस्ट करने के लिए, Firebase होस्टिंग का इस्तेमाल करें.
- TensorFlow.js की मदद से, पहले से बने ऑब्जेक्ट डिटेक्शन मॉडल का इस्तेमाल करके स्मार्ट वेबकैम बनाना
इन वेबसाइटों पर पैसे चुकाएं
- TensorFlow.js की आधिकारिक वेबसाइट
- TensorFlow.js के पहले से बने मॉडल
- TensorFlow.js एपीआई
- TensorFlow.js शो और बताएं - इस बात से प्रेरणा लें और देखें कि दूसरे लोगों ने क्या बनाया है.