
1. ก่อนเริ่มต้น
Codelab นี้ออกแบบมาเพื่อสร้างขึ้นจากผลลัพธ์สุดท้ายของ Codelab ก่อนหน้านี้ในซีรีส์นี้ เพื่อตรวจจับสแปมความคิดเห็นโดยใช้ TensorFlow.js
ใน Codelab ล่าสุด คุณได้สร้างหน้าเว็บที่ใช้งานได้เต็มรูปแบบสำหรับบล็อกวิดีโอสมมติ คุณสามารถกรองความคิดเห็นเพื่อหาสแปมก่อนส่งไปยังเซิร์ฟเวอร์เพื่อเก็บข้อมูลหรือไคลเอ็นต์ที่เชื่อมต่ออื่นๆ ได้โดยใช้โมเดลการตรวจจับสแปมความคิดเห็นที่ฝึกไว้แล้วล่วงหน้าซึ่งขับเคลื่อนโดย TensorFlow.js ในเบราว์เซอร์
ผลลัพธ์สุดท้ายของ Codelab จะปรากฏด้านล่าง
แม้ว่าการดำเนินการนี้จะดีมาก แต่ก็ยังมีกรณีพิเศษอื่นๆ ที่ไม่สามารถตรวจพบได้ คุณสามารถฝึกโมเดลอีกครั้งเพื่อให้พิจารณาสถานการณ์ที่ไม่สามารถรับมือได้
Codelab นี้เน้นการใช้การประมวลผลภาษาธรรมชาติ (ศาสตร์ในการทำความเข้าใจภาษามนุษย์ด้วยคอมพิวเตอร์) และแสดงวิธีแก้ไขเว็บแอปที่มีอยู่ที่คุณสร้างขึ้น (เราขอแนะนำอย่างยิ่งให้คุณใช้ Codelab ตามลำดับ) เพื่อจัดการกับปัญหาที่แท้จริงของสแปมความคิดเห็น ซึ่งนักพัฒนาเว็บจำนวนมากจะต้องพบเจอในขณะใช้งานเว็บแอปยอดนิยมแอปหนึ่งที่มีจำนวนเพิ่มขึ้นเรื่อยๆ ในปัจจุบัน
ใน Codelab นี้ คุณจะก้าวไปอีกขั้นโดยการฝึกโมเดล ML อีกครั้งให้คำนึงถึงการเปลี่ยนแปลงของเนื้อหาข้อความสแปมที่อาจมีการพัฒนาเมื่อเวลาผ่านไป โดยอิงตามแนวโน้มปัจจุบันหรือหัวข้อการพูดคุยยอดนิยม ซึ่งช่วยให้โมเดลอัปเดตอยู่เสมอและรองรับการเปลี่ยนแปลงดังกล่าว
ข้อกำหนดเบื้องต้น
- Codelab แรกในชุดนี้เสร็จสมบูรณ์แล้ว
- ความรู้พื้นฐานเกี่ยวกับเทคโนโลยีเว็บ ซึ่งรวมถึง HTML, CSS และ JavaScript
สิ่งที่คุณจะสร้าง
คุณจะนำเว็บไซต์ที่สร้างขึ้นก่อนหน้านี้มาใช้ซ้ำสำหรับวิดีโอบล็อกที่สมมติขึ้นพร้อมกับส่วนความคิดเห็นแบบเรียลไทม์ และอัปเกรดเว็บไซต์ให้โหลดโมเดลตรวจจับสแปมเวอร์ชันที่ผ่านการฝึกที่กำหนดเองโดยใช้ TensorFlow.js เพื่อให้มีประสิทธิภาพดีกว่าในกรณี Edge ที่ก่อนหน้านี้อาจทำไม่สำเร็จ แน่นอนว่าในฐานะนักพัฒนาเว็บและวิศวกร คุณสามารถเปลี่ยน UX สมมตินี้เพื่อนำมาใช้ใหม่ในเว็บไซต์ใดๆ ที่คุณอาจใช้งานอยู่ในแต่ละวัน และปรับเปลี่ยนโซลูชันให้เหมาะกับการใช้งานของลูกค้าทุกกรณี อาจเป็นบล็อก ฟอรัม หรือ CMS บางรูปแบบ เช่น Drupal
มาเริ่มแฮ็กกันเลย...
สิ่งที่คุณจะได้เรียนรู้
คุณจะ:
- ระบุขอบกรณีที่โมเดลที่ฝึกล่วงหน้าทำงานไม่สำเร็จ
- ฝึกโมเดลการจัดประเภทสแปมที่สร้างขึ้นโดยใช้ Model Maker อีกครั้ง
- ส่งออกโมเดลที่ใช้ Python นี้เป็นรูปแบบ TensorFlow.js สำหรับใช้ในเบราว์เซอร์
- อัปเดตโมเดลที่โฮสต์และพจนานุกรมของโมเดลด้วยโมเดลที่ผ่านการฝึกใหม่ แล้วตรวจสอบผลลัพธ์
ห้องทดลองนี้มีความคุ้นเคยกับ HTML5, CSS และ JavaScript คุณจะเรียกใช้โค้ด Python ผ่าน "co lab" ได้ด้วย ในการฝึกโมเดลที่สร้างโดยใช้เครื่องสร้างโมเดลอีกครั้ง แต่ยังไม่คุ้นเคยกับ Python ต้องทำเช่นนี้
2. เตรียมเขียนโค้ด
คุณจะใช้ Glitch.com เพื่อโฮสต์และแก้ไขเว็บแอปพลิเคชันได้อีกครั้ง หากคุณยังไม่ได้ทำ Codelab เบื้องต้น คุณสามารถโคลนผลลัพธ์สุดท้ายที่นี่เป็นจุดเริ่มต้น หากคุณมีข้อสงสัยเกี่ยวกับวิธีการทำงานของโค้ด เราขอแนะนำอย่างยิ่งให้คุณทำ Codelab ก่อนหน้านี้ให้เสร็จสิ้นซึ่งแนะนำวิธีสร้างเว็บแอปที่ทำงานได้อย่างละเอียดก่อนดำเนินการต่อ
ใน Glitch ให้คลิกปุ่มรีมิกซ์นี้เพื่อแยกและสร้างชุดไฟล์ใหม่ที่แก้ไขได้
3. ค้นพบกรณีปัญหาในโซลูชันก่อนหน้านี้
ถ้าคุณเปิดเว็บไซต์ที่เสร็จสมบูรณ์ที่คุณเพิ่งโคลน และลองพิมพ์ความคิดเห็นบางอย่าง คุณจะสังเกตเห็นว่าส่วนใหญ่แล้วจะทำงานตามที่ตั้งใจไว้ บล็อกความคิดเห็นที่ดูเหมือนสแปมตามที่คาดไว้ และปล่อยให้มีคำตอบที่ถูกต้อง
อย่างไรก็ตาม หากคุณมีทักษะด้านการสร้างสรรค์แล้วพยายามใช้ถ้อยคำที่จะฉีกรูปแบบจากรูปแบบเดิม คุณก็อาจประสบความสำเร็จได้ในบางเวลา การลองผิดลองถูกเล็กน้อยจะช่วยให้คุณสร้างตัวอย่างได้ด้วยตนเองดังตัวอย่างด้านล่าง ลองวางข้อมูลเหล่านี้ลงในเว็บแอปที่มีอยู่ ตรวจสอบคอนโซล และดูความเป็นไปได้ที่จะกลับมาเมื่อความคิดเห็นเป็นสแปม
ความคิดเห็นที่ชอบด้วยกฎหมายที่โพสต์โดยไม่มีปัญหา (เชิงลบจริง)
- "ว้าว ฉันชื่นชอบวิดีโอนี้มากๆ เลย เยี่ยมมาก" ความน่าจะเป็นสแปม: 47.91854%
- "ชอบเดโมเหล่านี้มาก มีรายละเอียดเพิ่มเติมอีกไหม" ความน่าจะเป็นสแปม: 47.15898%
- "ฉันจะดูข้อมูลเพิ่มเติมได้ที่เว็บไซต์ใด" ความน่าจะเป็นสแปม: 15.32495%
ซึ่งดีมาก ความน่าจะเป็นสำหรับทั้งหมดข้างต้นค่อนข้างต่ำ และทำสำเร็จผ่าน SPAM_THRESHOLD ตามค่าเริ่มต้นของความน่าจะเป็นขั้นต่ำ 75% ก่อนที่จะดำเนินการ (ระบุไว้ในโค้ด script.js จาก Codelab ก่อนหน้านี้)
ทีนี้ก็มาลองเขียนความคิดเห็นที่แปลกๆ ที่ถูกทำเครื่องหมายว่าเป็นสแปม แม้ว่าความคิดเห็นเหล่านั้นจะไม่ใช่...
ความคิดเห็นที่ชอบด้วยกฎหมายที่ทำเครื่องหมายว่าเป็นสแปม (การตรวจสอบที่ผิดพลาด):
- "บุคคลอื่นสามารถลิงก์เว็บไซต์หน้ากากอนามัยที่เขาสวมใส่ได้หรือไม่" ความน่าจะเป็นสแปม: 98.46466%
- "ฉันซื้อเพลงนี้ใน Spotify ได้ไหม มีคนช่วยแจ้งฉันด้วยนะ" ความน่าจะเป็นสแปม: 94.40953%
- "ใครสักคนติดต่อฉันพร้อมรายละเอียดเกี่ยวกับวิธีดาวน์โหลด TensorFlow.js ได้ไหม" ความน่าจะเป็นสแปม: 83.20084%
ขออภัย ดูเหมือนว่าระบบจะทำเครื่องหมายความคิดเห็นที่ถูกต้องเหล่านี้ว่าเป็นสแปมทั้งๆ ที่ได้รับอนุญาต จะแก้ไขได้อย่างไร
ทางเลือกง่ายๆ อย่างหนึ่งคือการเพิ่ม SPAM_THRESHOLD ให้มีความมั่นใจมากกว่า 98.5% ในกรณีดังกล่าว ระบบจะโพสต์ความคิดเห็นที่มีการจัดประเภทไม่ถูกต้องเหล่านี้ ดังนั้น เรามาดูผลลัพธ์ที่เป็นไปได้อื่นๆ ด้านล่างกัน...
ความคิดเห็นที่เป็นสแปมที่ทำเครื่องหมายว่าเป็นสแปม (ผลบวกจริง):
- "เยี่ยมไปเลย แต่ลองดูลิงก์ดาวน์โหลดบนเว็บไซต์ของฉัน ดีกว่า" ความน่าจะเป็นสแปม: 99.77873%
- "ฉันรู้จักคนที่สามารถรับยาบางอย่างให้คุณได้ดูรายละเอียดในไฟล์ pr00 ของฉัน" จดหมายขยะที่น่าจะเป็น: 98.46955%
- "ดูโปรไฟล์ของฉันเพื่อดาวน์โหลดวิดีโอที่เจ๋งกว่าเดิมซึ่งดียิ่งกว่า http://example.com" ความน่าจะเป็นที่เป็นสแปม: 96.26383%
โอเค เกณฑ์นี้ทำงานตามที่คาดไว้ด้วยเกณฑ์ 75% เดิม แต่เนื่องจากในขั้นตอนก่อนหน้าคุณได้เปลี่ยน SPAM_THRESHOLD ให้มั่นใจมากกว่า 98.5% นั่นหมายความว่ามีตัวอย่าง 2 รายการที่จะปล่อยผ่าน ดังนั้นเกณฑ์อาจสูงเกินไป อีก 96% อาจจะดีกว่าไหม แต่หากคุณดำเนินการดังกล่าว ความคิดเห็นรายการใดรายการหนึ่งในส่วนก่อนหน้านี้ (การตรวจสอบที่ผิดพลาด) จะถูกทำเครื่องหมายว่าเป็นสแปมเมื่อความคิดเห็นนั้นถูกต้อง เนื่องจากมีการให้คะแนนที่ 98.46466%
ในกรณีนี้ วิธีที่ดีที่สุดคือรวบรวมความคิดเห็นที่เป็นสแปมที่แท้จริงเหล่านี้ แล้วฝึกอีกครั้งสำหรับความล้มเหลวข้างต้น เมื่อคุณกำหนดเกณฑ์เป็น 96% ผลบวกจริงทั้งหมดจะยังคงมีผลอยู่ และคุณสามารถกำจัดผลบวกลวง 2 ข้อข้างต้น การเปลี่ยนตัวเลขเพียงตัวเดียวก็ไม่แย่นัก
ไปต่อกันเลย...
ความคิดเห็นที่เป็นสแปมที่ได้รับอนุญาตให้โพสต์ (ผลลบลวง):
- "ดูโปรไฟล์ของฉันเพื่อดาวน์โหลดวิดีโอเจ๋งๆ ที่ดียิ่งขึ้นไปอีก" ความน่าจะเป็นสแปม: 7.54926%
- "รับส่วนลดสำหรับคลาสออกกำลังกายในยิมของเรา ดูไฟล์ pr0!" ความน่าจะเป็นสแปม: 17.49849%
- "โอ้ หุ้น GOOG เพิ่งพุ่งตัวไป รีบไปก่อน!" ความน่าจะเป็นสแปม: 20.42894%
สำหรับความคิดเห็นเหล่านี้ คุณเพียงแค่เปลี่ยนค่า SPAM_THRESHOLD เองเท่านั้น การลดเกณฑ์สำหรับสแปมจาก 96% เป็นประมาณ 9% จะทำให้ความคิดเห็นจริงได้รับการทำเครื่องหมายว่าเป็นสแปม โดยหนึ่งในความคิดเห็นนั้นจะได้คะแนน 58% แม้ว่าจะถูกต้องก็ตาม วิธีเดียวในการจัดการกับความคิดเห็นเช่นนี้คือการฝึกโมเดลอีกครั้งโดยระบุกรณีที่เป็นปัญหาที่สุดในข้อมูลการฝึก เพื่อที่โมเดลจะเรียนรู้ในการปรับมุมมองใหม่ว่าสิ่งใดเป็นสแปมหรือไม่
แม้ว่าตัวเลือกเดียวที่เหลืออยู่ในตอนนี้คือการฝึกโมเดลอีกครั้ง แต่คุณยังได้เห็นว่าคุณสามารถปรับแต่งเกณฑ์ของเวลาในการเรียกสแปมเพื่อปรับปรุงประสิทธิภาพได้ด้วย ในฐานะมนุษย์ ดูเหมือนว่า 75% ค่อนข้างมั่นใจ แต่สำหรับโมเดลนี้ คุณต้องเพิ่มจำนวนใกล้เคียงเป็น 81.5% เพื่อให้มีประสิทธิภาพมากขึ้นเมื่อใช้อินพุตตัวอย่าง
ไม่มีค่ามหัศจรรย์ค่าใดค่าหนึ่งที่ใช้ได้ผลดีในรูปแบบต่างๆ และต้องตั้งค่าเกณฑ์มาตรฐานนี้ตามโมเดลหลังจากทดสอบกับข้อมูลในโลกแห่งความเป็นจริงว่าสิ่งใดทำงานได้ดี
อาจมีบางกรณีที่ผลบวกลวง (หรือเชิงลบ) อาจส่งผลกระทบร้ายแรงตามมา (เช่น ในอุตสาหกรรมการแพทย์) อาจทำให้คุณปรับเกณฑ์ให้สูงมากและขอรับการตรวจสอบโดยเจ้าหน้าที่มากขึ้นสำหรับผู้ที่ไม่เป็นไปตามเกณฑ์ นี่คือทางเลือกของคุณในฐานะนักพัฒนาซอฟต์แวร์และต้องมีการทดลอง
4. ฝึกโมเดลการตรวจหาสแปมความคิดเห็นอีกครั้ง
ในส่วนก่อนหน้านี้ คุณได้ระบุกรณีปัญหาที่อาจไม่สำเร็จสำหรับโมเดลนี้จำนวนหนึ่ง ซึ่งมีตัวเลือกเดียวคือให้ฝึกโมเดลอีกครั้งให้คำนึงถึงสถานการณ์เหล่านี้ ในระบบการผลิต คุณสามารถพบความคิดเห็นเหล่านี้ได้เมื่อเวลาผ่านไป เพราะผู้ใช้แจ้งความคิดเห็นนั้นเป็นสแปมด้วยตนเอง แต่ผู้ดูแลตรวจสอบความคิดเห็นที่ได้รับแจ้งว่าไม่เหมาะสมแล้วพบว่าความคิดเห็นเหล่านั้นไม่ใช่สแปมจริงๆ และสามารถทำเครื่องหมายความคิดเห็นเหล่านั้นเพื่อฝึกฝนอีกครั้ง สมมติว่าคุณได้รวบรวมข้อมูลใหม่จำนวนมากสำหรับกรณีที่เป็นปัญหาขั้นสูงเหล่านี้แล้ว (เพื่อผลลัพธ์ที่ดีที่สุด คุณควรมีรูปแบบประโยคใหม่เหล่านี้หากทำได้) ตอนนี้เราจะแสดงวิธีฝึกโมเดลอีกครั้งโดยคำนึงถึงกรณีปัญหาหลักเหล่านั้น
สรุปโมเดลที่สร้างไว้ล่วงหน้า
โมเดลสำเร็จรูปที่คุณใช้เป็นโมเดลที่บุคคลที่สามสร้างขึ้นผ่าน Model Maker โดยใช้ "การฝังคำโดยเฉลี่ย" โมเดลที่จะทำงาน
เนื่องจากโมเดลสร้างขึ้นด้วยเครื่องสร้างโมเดล คุณจะต้องเปลี่ยนไปใช้ Python สั้นๆ เพื่อฝึกโมเดลอีกครั้ง จากนั้นให้ส่งออกโมเดลที่สร้างเป็นรูปแบบ TensorFlow.js เพื่อให้คุณใช้งานในเบราว์เซอร์ได้ โชคดีที่เครื่องมือสร้างโมเดลทำให้การใช้โมเดลของพวกเขาเป็นไปอย่างง่ายดาย วิธีนี้จึงน่าจะทำตามได้ง่ายๆ และเราจะแนะนำคุณไปตลอดทุกขั้นตอน ดังนั้นไม่ต้องกังวลหากไม่เคยใช้ Python มาก่อน
Colab
เนื่องจากคุณไม่ค่อยกังวลกับ Codelab ที่ต้องการตั้งค่าเซิร์ฟเวอร์ Linux ที่มีการติดตั้งยูทิลิตี Python ต่างๆ ไว้ คุณแค่ต้องเรียกใช้โค้ดผ่านเว็บเบราว์เซอร์โดยใช้ "Colab Notebook" สมุดบันทึกเหล่านี้เชื่อมต่อกับ "แบ็กเอนด์" ได้ - ซึ่งเป็นเซิร์ฟเวอร์ที่มีบางสิ่งติดตั้งไว้ล่วงหน้า ซึ่งคุณสามารถเรียกใช้โค้ดที่กำหนดเองภายในเว็บเบราว์เซอร์และดูผลลัพธ์ได้ ซึ่งมีประโยชน์มากสำหรับการสร้างต้นแบบอย่างรวดเร็วหรือสำหรับใช้ในบทแนะนำนี้
โปรดไปที่ colab.research.google.com แล้วคุณจะเห็นหน้าจอต้อนรับดังตัวอย่างต่อไปนี้
จากนั้นคลิกปุ่มสมุดบันทึกใหม่ที่ด้านล่างขวาของหน้าต่างป๊อปอัป แล้วคุณจะเห็น Colab เปล่าแบบนี้
เยี่ยม! ขั้นตอนถัดไปคือการเชื่อมต่อ Colab ฟรอนท์เอนด์ไปยังเซิร์ฟเวอร์แบ็กเอนด์บางเซิร์ฟเวอร์ เพื่อให้คุณสามารถเรียกใช้โค้ด Python ที่จะเขียนได้ โดยคลิกเชื่อมต่อที่ด้านขวาบน แล้วเลือกเชื่อมต่อกับรันไทม์ที่โฮสต์ไว้
เมื่อเชื่อมต่อแล้ว คุณจะเห็นไอคอน RAM และดิสก์ปรากฏขึ้นในลักษณะดังนี้
เยี่ยมมาก ตอนนี้คุณสามารถเริ่มเขียนโค้ดใน Python เพื่อฝึกโมเดล Model Maker อีกครั้งได้แล้ว โปรดดำเนินการตามขั้นตอนด้านล่าง
ขั้นตอนที่ 1
คัดลอกโค้ดด้านล่างในเซลล์แรกที่ว่างอยู่ การดำเนินการนี้จะติดตั้ง TensorFlow Lite Model Maker ให้คุณโดยใช้โปรแกรมจัดการแพ็กเกจของ Python ที่ชื่อ "pip" (คล้ายกับ npm ซึ่งผู้อ่าน Code Lab นี้ส่วนใหญ่อาจคุ้นเคยมากกว่าจากระบบนิเวศของ JS):
!apt-get install libasound-dev portaudio19-dev libportaudio2 libportaudiocpp0
!pip install -q tflite-model-maker
แต่การวางโค้ดลงในเซลล์จะไม่เรียกใช้โค้ด จากนั้น ให้วางเมาส์เหนือเซลล์สีเทาที่คุณวางโค้ดด้านบนไว้ จากนั้นปุ่ม "เล่น" เล็กๆ จะปรากฏทางด้านซ้ายของเซลล์ตามที่ไฮไลต์ด้านล่าง
 คลิกปุ่มเล่นเพื่อเรียกใช้โค้ดที่เพิ่งพิมพ์ลงในเซลล์
คลิกปุ่มเล่นเพื่อเรียกใช้โค้ดที่เพิ่งพิมพ์ลงในเซลล์
ตอนนี้ คุณจะเห็นว่าระบบกำลังติดตั้งเครื่องสร้างโมเดล:
เมื่อการดำเนินการของเซลล์นี้เสร็จสมบูรณ์ดังที่แสดงแล้ว ให้ไปยังขั้นตอนถัดไปด้านล่าง
ขั้นตอนที่ 2
จากนั้น เพิ่มเซลล์โค้ดใหม่ตามที่แสดงเพื่อวางเซลล์โค้ดเพิ่มเติมหลังเซลล์แรกและเรียกใช้แยกต่างหาก
เซลล์ถัดไปที่เรียกใช้จะมีการนำเข้าจำนวนหนึ่งที่โค้ดในส่วนที่เหลือของสมุดบันทึกจะต้องใช้ คัดลอกและวางด้านล่างนี้ในเซลล์ใหม่ที่สร้าง
import numpy as np
import os
from tflite_model_maker import configs
from tflite_model_maker import ExportFormat
from tflite_model_maker import model_spec
from tflite_model_maker import text_classifier
from tflite_model_maker.text_classifier import DataLoader
import tensorflow as tf
assert tf.__version__.startswith('2')
tf.get_logger().setLevel('ERROR')
เป็นเรื่องที่ทุกคนเข้าใจได้ แม้คุณจะไม่คุ้นเคยกับ Python คุณเพียงแค่นำเข้ายูทิลิตีบางอย่างและฟังก์ชัน Model Maker ที่จำเป็นสำหรับตัวแยกประเภทสแปม การดำเนินการนี้จะตรวจสอบว่าคุณได้เรียกใช้ TensorFlow 2.x หรือไม่ ซึ่งเป็นข้อกำหนดในการใช้ Model Maker
สุดท้าย เรียกใช้เซลล์โดยการกด "เล่น" เช่นเดียวกับก่อนหน้านี้ เมื่อวางเมาส์เหนือเซลล์ ให้เพิ่มเซลล์โค้ดใหม่สำหรับขั้นตอนถัดไป
ขั้นตอนที่ 3
ถัดไป คุณจะดาวน์โหลดข้อมูลจากเซิร์ฟเวอร์ระยะไกลลงในอุปกรณ์ และตั้งค่าตัวแปร training_data เป็นเส้นทางของไฟล์ในเครื่องที่ได้ดาวน์โหลด ดังนี้
data_file = tf.keras.utils.get_file(fname='comment-spam-extras.csv', origin='https://storage.googleapis.com/jmstore/TensorFlowJS/EdX/code/6.5/jm_blog_comments_extras.csv', extract=False)
เครื่องสร้างแบบจำลองสามารถฝึกแบบจำลองจากไฟล์ CSV แบบธรรมดาๆ เช่นที่ดาวน์โหลดมาได้ คุณเพียงแค่ต้องระบุคอลัมน์ที่จะเก็บรักษาข้อความและคอลัมน์ใดที่เก็บป้ายกำกับ ซึ่งคุณจะเห็นวิธีการในขั้นตอนที่ 5 คุณสามารถดาวน์โหลดไฟล์ CSV ด้วยตนเองเพื่อดูไฟล์นั้นๆ ได้ด้วยตนเองหากต้องการ
เมื่อให้ความสนใจเป็นพิเศษ คุณจะสังเกตเห็นว่าชื่อไฟล์นี้คือ jm_blog_comments_extras.csv ไฟล์นี้เป็นเพียงข้อมูลการฝึกฝนเดิมที่เราใช้ในการสร้างโมเดลสแปมความคิดเห็นรูปแบบแรกที่รวมไว้กับข้อมูลเคส Edge Case ใหม่ที่คุณค้นพบ ทั้งหมดนี้จึงรวมอยู่ในไฟล์เดียว คุณจำเป็นต้องใช้ข้อมูลการฝึกต้นฉบับที่ใช้ฝึกโมเดลด้วย นอกเหนือจากประโยคใหม่ที่ต้องการเรียนรู้
ไม่บังคับ: หากคุณดาวน์โหลดไฟล์ CSV นี้และตรวจสอบ 2-3 บรรทัดสุดท้าย คุณจะเห็นตัวอย่างสำหรับกรณี Edge ที่ทำงานผิดปกติก่อนหน้านี้ เพิ่งมีการเพิ่มผลลัพธ์เหล่านี้ลงในส่วนท้ายของข้อมูลการฝึกที่มีอยู่ ซึ่งเป็นโมเดลที่สร้างไว้ล่วงหน้าซึ่งใช้ในการฝึกตนเอง
เรียกใช้เซลล์นี้ เมื่อเสร็จสิ้นการดำเนินการแล้ว ให้เพิ่มเซลล์ใหม่และไปยังขั้นตอนที่ 4
ขั้นตอนที่ 4
เมื่อใช้เครื่องสร้างโมเดล คุณไม่ต้องสร้างโมเดลเองตั้งแต่ต้น โดยทั่วไปแล้วคุณจะใช้โมเดลที่มีอยู่ แล้วปรับแต่งให้ตรงตามความต้องการ
เครื่องสร้างแบบจำลองมีการฝังโมเดลก่อนเรียนรู้หลายอย่างที่คุณสามารถใช้ได้ แต่วิธีที่ง่ายที่สุดและรวดเร็วที่สุดคือ average_word_vec ซึ่งเป็นสิ่งที่คุณใช้ในการสร้างเว็บไซต์ใน Codelab ก่อนหน้านี้ ต่อไปนี้เป็นรหัส:
spec = model_spec.get('average_word_vec')
spec.num_words = 2000
spec.seq_len = 20
spec.wordvec_dim = 7
คุณสามารถเรียกใช้ได้ทันทีเมื่อวางลงในเซลล์ใหม่
การทำความเข้าใจ
num_words
พารามิเตอร์
นี่คือจำนวนคำที่คุณต้องการให้โมเดลใช้ คุณอาจคิดว่ายิ่งเยอะยิ่งดี แต่โดยทั่วไปแล้วก็มีจุดที่น่าสนใจตามความถี่ในการใช้แต่ละคำ หากคุณใช้ทุกคำทั้งคลัง ก็อาจสุดท้ายแล้วโมเดลจะพยายามเรียนรู้และหาสมดุลระหว่างคำที่ใช้เพียงครั้งเดียว ซึ่งไม่ค่อยมีประโยชน์เท่าไหร่นัก คุณจะเจอในคลังข้อความว่าคำจำนวนมากมีการใช้เพียงครั้งเดียวหรือ 2 ครั้งเท่านั้น และโดยทั่วไปก็ไม่คุ้มกับการใช้คำเหล่านั้นในโมเดลของคุณเนื่องจากคำเหล่านั้นมีผลกระทบต่อความรู้สึกโดยรวมเพียงเล็กน้อย เพื่อให้คุณปรับแต่งโมเดลตามจำนวนคำที่ต้องการได้โดยใช้พารามิเตอร์ num_words จำนวนที่น้อยกว่าจะมีรูปแบบที่เล็กกว่าและเร็วกว่า แต่ก็อาจมีความแม่นยำน้อยลงเนื่องจากจดจำคำได้น้อยกว่า จำนวนที่สูงที่นี่จะมีโมเดลที่ใหญ่กว่าและอาจช้ากว่า การค้นหาจุดที่เหมาะสมคือกุญแจสำคัญและขึ้นอยู่กับคุณในฐานะวิศวกรแมชชีนเลิร์นนิงที่จะพิจารณาว่าวิธีใดเหมาะกับกรณีการใช้งานของคุณที่สุด
การทำความเข้าใจ
wordvec_dim
พารามิเตอร์
พารามิเตอร์ wordvec_dim คือจำนวนมิติข้อมูลที่คุณต้องการใช้สำหรับเวกเตอร์ของแต่ละคำ โดยพื้นฐานแล้วมิติข้อมูลเหล่านี้เป็นลักษณะเฉพาะที่แตกต่างกัน (ซึ่งอัลกอริทึมของแมชชีนเลิร์นนิงสร้างขึ้นเมื่อทำการฝึก) ที่โปรแกรมจะใช้วัดคำที่กำหนดเพื่อพยายามเชื่อมโยงคำที่คล้ายกันให้มีความหมายที่สุด
เช่น หากคุณมีมิติข้อมูลว่า "การแพทย์" คำก็คือ คำอย่างเช่น "ยา" อาจมีคะแนนสูงในมิติข้อมูลนี้ และเชื่อมโยงกับคำที่ได้คะแนนสูงอื่นๆ เช่น "xray" แต่ "cat" จะทำคะแนนได้ต่ำสำหรับมิติข้อมูลนี้ อาจกลายเป็นว่า "มิติข้อมูลทางการแพทย์" มีประโยชน์ในการระบุสแปมเมื่อรวมกับมิติข้อมูลอื่นๆ ที่อาจเลือกใช้ซึ่งมีความสำคัญ
ในกรณีของคำที่ได้รับคะแนนสูงใน "มิติข้อมูลทางการแพทย์" ก็อาจพบว่ามิติที่ 2 ที่สัมพันธ์กับร่างกายมนุษย์อาจเป็นประโยชน์ คำอย่างเช่น "ขา" "แขน" "คอ" อาจได้คะแนนสูงที่นี่ และในด้านการแพทย์ก็ค่อนข้างสูงเช่นกัน
โมเดลจะใช้มิติข้อมูลเหล่านี้เพื่อเปิดใช้การตรวจจับคำที่มีแนวโน้มจะเชื่อมโยงกับสแปมมากขึ้นได้ บางทีอีเมลสแปมมักจะมีคำที่เป็นทั้งอวัยวะทางการแพทย์และร่างกายมนุษย์
หลักการทั่วไปที่ได้จากการวิจัยคือรากที่ 4 ของจำนวนคำทำงานได้ดีสำหรับพารามิเตอร์นี้ ดังนั้น หากผมใช้ 2, 000 คำ จุดเริ่มต้นที่ดีในกรณีนี้คือ 7 มิติ หากเปลี่ยนจำนวนคำที่ใช้ เธอก็เปลี่ยนค่านี้ได้เช่นกัน
การทำความเข้าใจ
seq_len
พารามิเตอร์
โดยทั่วไปแล้ว โมเดลจะมีความเข้มงวดมากในแง่ของค่าอินพุต สำหรับโมเดลภาษา หมายความว่าโมเดลภาษาสามารถจำแนกประโยคที่มีความยาวคงที่ได้ ซึ่งกำหนดโดยพารามิเตอร์ seq_len โดยค่านี้ย่อมาจาก "ความยาวของลำดับ" เมื่อคุณแปลงคำเป็นตัวเลข (หรือโทเค็น) ประโยคจะกลายเป็นลำดับของโทเค็นเหล่านี้ ดังนั้นโมเดลของคุณจะได้รับการฝึก (ในกรณีนี้) ให้แยกประเภทและจดจำประโยคที่มี 20 โทเค็น ถ้าประโยคยาวเกินกว่านี้ จะถูกตัดออก หากสั้นกว่านั้น ก็จะมีการเพิ่มเข้าไปอีก - เช่นเดียวกับใน Codelab แรกของซีรีส์นี้
ขั้นตอนที่ 5 - โหลดข้อมูลการฝึก
คุณดาวน์โหลดไฟล์ CSV ไว้ก่อนหน้านี้ ตอนนี้ถึงเวลาใช้ตัวโหลดข้อมูลเพื่อเปลี่ยนข้อมูลนี้เป็นข้อมูลการฝึกที่โมเดลจดจำได้
data = DataLoader.from_csv(
filename=data_file,
text_column='commenttext',
label_column='spam',
model_spec=spec,
delimiter=',',
shuffle=True,
is_training=True)
train_data, test_data = data.split(0.9)
หากเปิดไฟล์ CSV ในเครื่องมือแก้ไข คุณจะเห็นว่าแต่ละบรรทัดมีเพียง 2 ค่า และอธิบายด้วยข้อความในบรรทัดแรกของไฟล์ โดยทั่วไป แต่ละรายการจะถือว่าเป็น "คอลัมน์" คุณจะเห็นว่าข้อบ่งชี้สำหรับคอลัมน์แรกคือ commenttext และรายการแรกในแต่ละบรรทัดจะเป็นข้อความของความคิดเห็น
ในทำนองเดียวกัน ข้อบ่งชี้สำหรับคอลัมน์ที่ 2 คือ spam และคุณจะเห็นว่ารายการที่ 2 ในแต่ละบรรทัดเป็น TRUE หรือ FALSE เพื่อระบุว่าข้อความนั้นเป็นสแปมความคิดเห็นหรือไม่ ส่วนพร็อพเพอร์ตี้อื่นๆ จะตั้งข้อมูลจำเพาะของโมเดลที่คุณสร้างขึ้นในขั้นตอนที่ 4 พร้อมกับอักขระตัวคั่น ซึ่งในกรณีนี้จะเป็นเครื่องหมายจุลภาคเนื่องจากไฟล์มีการคั่นด้วยเครื่องหมายจุลภาค นอกจากนี้ คุณยังตั้งค่าพารามิเตอร์การสุ่มเพลงเพื่อสุ่มจัดเรียงข้อมูลการฝึกใหม่เพื่อให้สิ่งต่างๆ ที่อาจคล้ายคลึงหรือเก็บรวบรวมไว้ด้วยกันแบบสุ่มกระจายทั่วทั้งชุดข้อมูล
จากนั้นจะใช้ data.split() เพื่อแยกข้อมูลออกเป็นข้อมูลการฝึกและการทดสอบ ค่า .9 บ่งชี้ว่า 90% ของชุดข้อมูลจะใช้สำหรับการฝึก ส่วนที่เหลือสำหรับการทดสอบ
ขั้นตอนที่ 6 - สร้างโมเดล
เพิ่มเซลล์อื่นที่เราจะเพิ่มโค้ดเพื่อสร้างโมเดล ดังนี้
model = text_classifier.create(train_data, model_spec=spec, epochs=50)
วิธีนี้จะสร้างโมเดลตัวแยกประเภทข้อความด้วย Model Maker และคุณระบุข้อมูลการฝึกฝนที่ต้องการใช้ (ซึ่งกำหนดไว้ในขั้นตอนที่ 4) ข้อมูลจำเพาะของโมเดล (ซึ่งตั้งค่าไว้ในขั้นตอนที่ 4 ด้วย) และจำนวน Epoch ในกรณีดังนี้ 50
หลักการพื้นฐานของแมชชีนเลิร์นนิงคือรูปแบบหนึ่งของการจับคู่รูปแบบ ในขั้นต้น ระบบจะโหลดน้ำหนักที่ฝึกสอนมาล่วงหน้าของคำ และพยายามจับกลุ่มคำเหล่านั้นเข้าด้วยกันโดยใช้ "การคาดคะเน" ว่าข้อความใดบ้างเมื่อจับกลุ่มกันแล้ว ระบุว่าเป็นจดหมายขยะหรือไม่ ในช่วงแรก ก็น่าจะใกล้เคียงกับ 50:50 เนื่องจากโมเดลเพิ่งเริ่มต้นเท่านั้น ดังที่แสดงด้านล่าง

จากนั้นโมเดลจะวัดผลลัพธ์ของสิ่งนี้ และเปลี่ยนน้ำหนักของโมเดลเพื่อปรับการคาดการณ์ และจะพยายามอีกครั้ง นี่คือ Epoch ดังนั้น เมื่อระบุ epochs=50 พารามิเตอร์จะผ่าน "loop" นั้น 50 ครั้งตามที่แสดง:

ดังนั้น เมื่อถึงตอนที่ 50 โมเดลจะรายงานระดับความแม่นยำที่สูงขึ้นมาก ในกรณีนี้ ผลลัพธ์จะแสดงเป็น 99.1%!
ขั้นตอนที่ 7 - ส่งออกโมเดล
เมื่อการฝึกเสร็จสมบูรณ์ คุณจะส่งออกโมเดลได้ TensorFlow จะฝึกโมเดลในรูปแบบของตัวเองและต้องแปลงเป็นรูปแบบ TensorFlow.js เพื่อนำไปใช้บนหน้าเว็บ เพียงวางข้อมูลต่อไปนี้ลงในเซลล์ใหม่และเรียกใช้
model.export(export_dir="/js_export/", export_format=[ExportFormat.TFJS, ExportFormat.LABEL, ExportFormat.VOCAB])
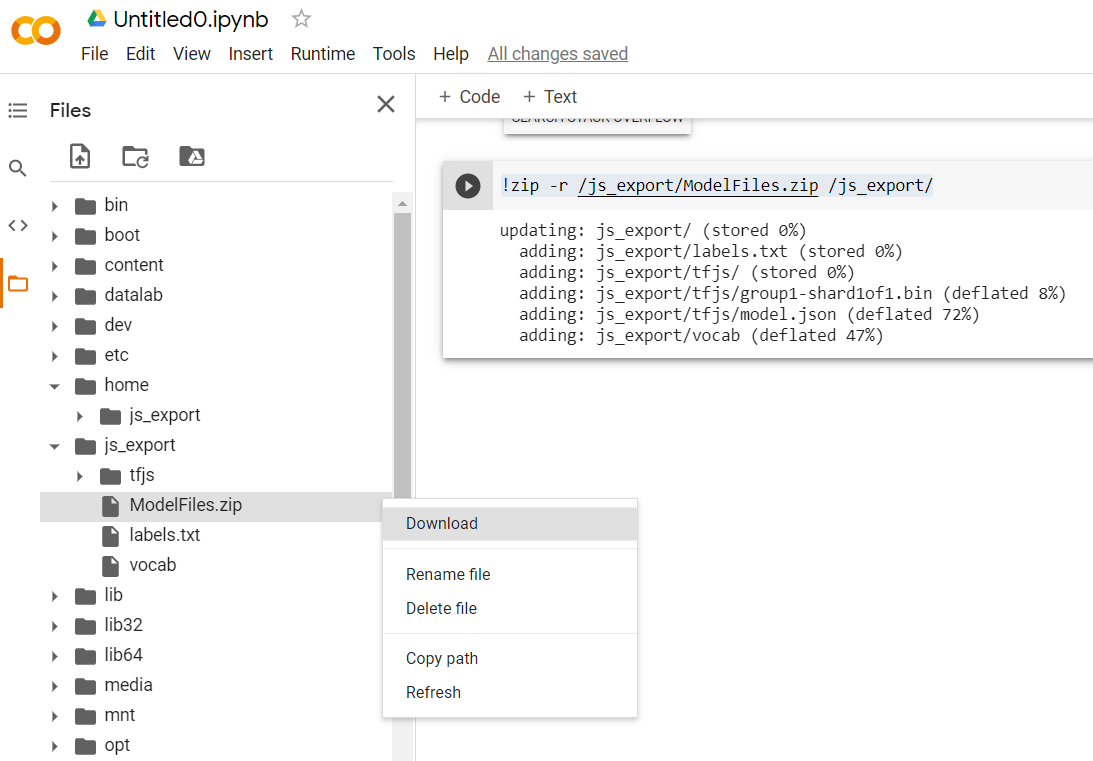
!zip -r /js_export/ModelFiles.zip /js_export/
หลังจากเรียกใช้โค้ดนี้ หากคุณคลิกไอคอนโฟลเดอร์ขนาดเล็กทางด้านซ้ายของ Colab คุณจะไปยังโฟลเดอร์ที่คุณส่งออกไปด้านบนได้ (ในไดเรกทอรีราก คุณอาจต้องเลื่อนขึ้น 1 ระดับ) และค้นหาชุดไฟล์ ZIP ของไฟล์ที่ส่งออกซึ่งมีอยู่ใน ModelFiles.zip
ดาวน์โหลดไฟล์ ZIP นี้ลงในคอมพิวเตอร์ทันที เนื่องจากคุณจะใช้ไฟล์เหมือนกับใน Codelab แรก:
เยี่ยม! ส่วน Python จบลงแล้ว ตอนนี้คุณสามารถกลับไปยังพื้นที่ JavaScript ที่คุณรู้จักและชื่นชอบได้แล้ว ในที่สุด
5. การใช้งานโมเดลแมชชีนเลิร์นนิงใหม่
ขณะนี้เกือบพร้อมที่จะโหลดโมเดลแล้ว โดยก่อนที่จะทำเช่นนั้นได้ คุณต้องอัปโหลดไฟล์โมเดลใหม่ที่ดาวน์โหลดมาก่อนหน้านี้ใน Codelab เพื่อให้มีโฮสต์และใช้งานได้ภายในโค้ดของคุณ
ก่อนอื่น ให้แตกไฟล์ของโมเดลที่เพิ่งดาวน์โหลดจากสมุดบันทึก Colab Maker Code ที่คุณเพิ่งเรียกใช้ หากยังไม่ได้ดำเนินการ คุณควรเห็นไฟล์ต่อไปนี้อยู่ในโฟลเดอร์ต่างๆ
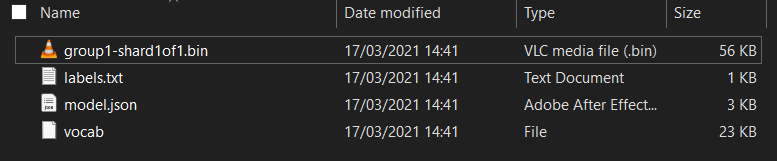
ที่นี่มีอะไร
model.json- ไฟล์นี้เป็นหนึ่งในไฟล์ที่ประกอบขึ้นเป็นโมเดล TensorFlow.js ที่ผ่านการฝึกแล้ว คุณจะอ้างอิงไฟล์นี้ในโค้ด JSgroup1-shard1of1.bin- ไฟล์นี้เป็นไฟล์ไบนารีที่มีข้อมูลที่บันทึกไว้ส่วนใหญ่สำหรับโมเดล TensorFlow.js ที่ส่งออกและจะต้องโฮสต์ไว้ที่ใดที่หนึ่งบนเซิร์ฟเวอร์เพื่อดาวน์โหลดในไดเรกทอรีเดียวกับที่model.jsonด้านบนvocab- ไฟล์แปลกๆ ที่ไม่มีนามสกุลนี้มาจากเครื่องมือสร้างโมเดลที่แสดงให้เห็นวิธีเข้ารหัสคำในประโยคเพื่อให้โมเดลเข้าใจวิธีใช้ คุณจะเจาะลึกเรื่องนี้มากขึ้นในส่วนถัดไปlabels.txt- ซึ่งมีเพียงชื่อคลาสที่โมเดลจะคาดการณ์ สำหรับโมเดลนี้ หากคุณเปิดไฟล์นี้ในเครื่องมือแก้ไขข้อความจะมีค่าเป็น "false" และ "จริง" ระบุว่า "ไม่ใช่สแปม" หรือ "สแปม" เป็นเอาต์พุตการคาดการณ์
โฮสต์ไฟล์โมเดล TensorFlow.js
ก่อนอื่นให้วางไฟล์ model.json และ *.bin ที่สร้างขึ้นในเว็บเซิร์ฟเวอร์เพื่อให้คุณเข้าถึงได้ผ่านหน้าเว็บ
ลบไฟล์โมเดลที่มีอยู่
ขณะที่คุณสร้างผลลัพธ์สุดท้ายของ Codelab แรกในชุดนี้ คุณจะต้องลบไฟล์โมเดลที่มีอยู่ซึ่งอัปโหลดแล้วก่อน หากคุณใช้ Glitch.com เพียงตรวจสอบแผงไฟล์ทางด้านซ้ายสำหรับ model.json และ group1-shard1of1.bin คลิกเมนูแบบเลื่อนลง 3 จุดสำหรับแต่ละไฟล์ แล้วเลือกลบตามที่แสดง
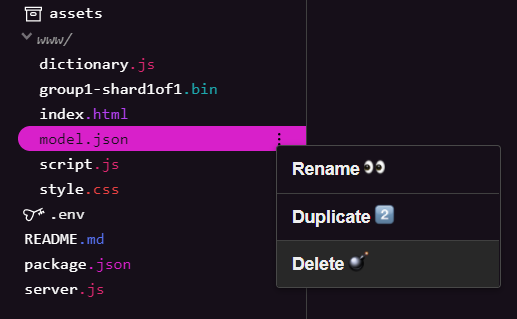
การอัปโหลดไฟล์ใหม่ไปยัง Glitch
เยี่ยม! จากนั้นอัปโหลดไฟล์ใหม่:
- เปิดโฟลเดอร์ assets ในแผงด้านซ้ายของโปรเจ็กต์ Glitch และลบเนื้อหาเก่าที่อัปโหลดหากมีชื่อเดียวกัน
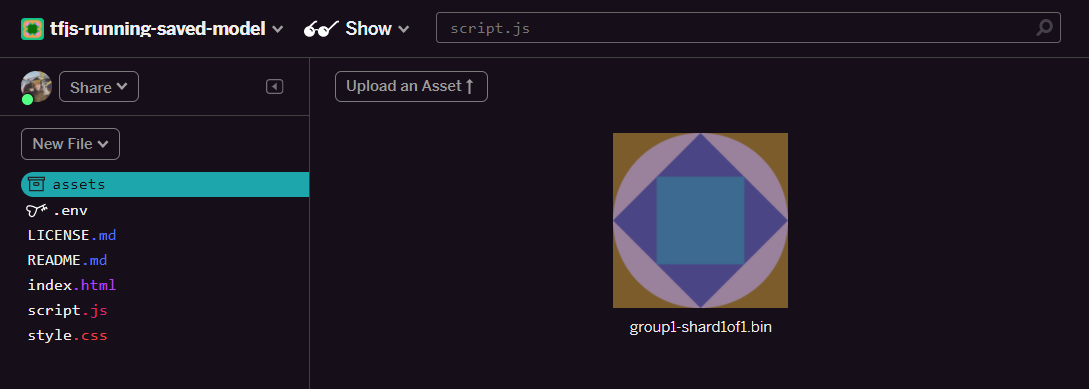
- คลิกอัปโหลดเนื้อหา แล้วเลือก
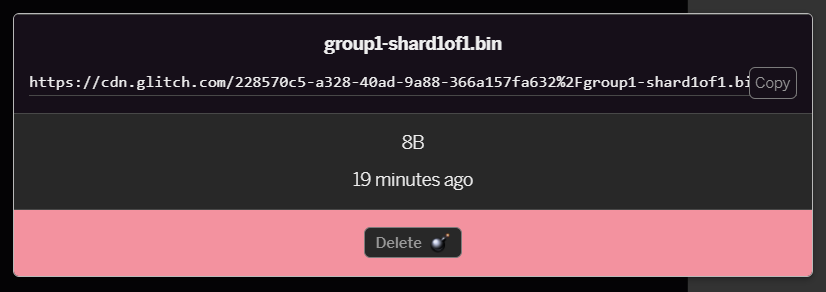
group1-shard1of1.binเพื่ออัปโหลดลงในโฟลเดอร์นี้ เมื่ออัปโหลดแล้วควรมีลักษณะดังนี้
- เยี่ยม! ให้ทำแบบเดียวกันนี้กับไฟล์ model.json ด้วย โดยไฟล์ 2 ไฟล์ควรอยู่ในโฟลเดอร์เนื้อหาดังนี้
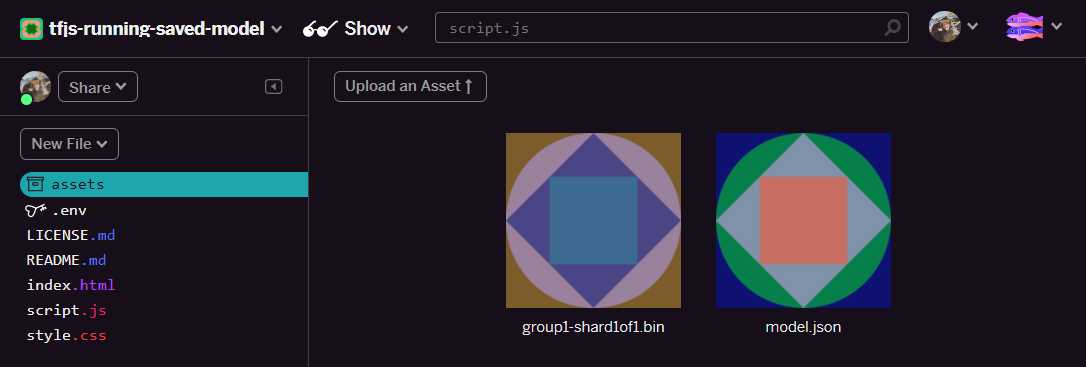
- หากคลิกไฟล์
group1-shard1of1.binที่เพิ่งอัปโหลด คุณจะคัดลอก URL ไปยังตำแหน่งนั้นได้ คัดลอกเส้นทางนี้ตามที่ปรากฏทันที
- ที่ด้านซ้ายล่างของหน้าจอ ให้คลิกเครื่องมือ > Terminal รอให้หน้าต่างเทอร์มินัลโหลดขึ้นมา
- เมื่อโหลดแล้วให้พิมพ์คำสั่งต่อไปนี้ แล้วกด Enter เพื่อเปลี่ยนไดเรกทอรีไปยังโฟลเดอร์
www
เทอร์มินัล:
cd www
- จากนั้น ใช้
wgetเพื่อดาวน์โหลดไฟล์ 2 ไฟล์ที่เพิ่งอัปโหลดโดยแทนที่ URL ด้านล่างด้วย URL ที่คุณสร้างสำหรับไฟล์ในโฟลเดอร์เนื้อหาบน Glitch (ตรวจสอบโฟลเดอร์เนื้อหาสำหรับ URL ที่กำหนดเองของแต่ละไฟล์)
โปรดทราบว่าช่องว่างระหว่าง URL ทั้งสองและ URL ที่คุณจะต้องใช้จะต่างจาก URL ที่แสดง แต่จะมีลักษณะคล้ายคลึงกัน
เทอร์มินัล
wget https://cdn.glitch.com/1cb82939-a5dd-42a2-9db9-0c42cab7e407%2Fmodel.json?v=1616111344958 https://cdn.glitch.com/1cb82939-a5dd-42a2-9db9-0c42cab7e407%2Fgroup1-shard1of1.bin?v=1616017964562
ยอดเยี่ยม! ตอนนี้คุณได้ทำสำเนาไฟล์ที่อัปโหลดไปยังโฟลเดอร์ www แล้ว
แต่ในตอนนี้จะมีการดาวน์โหลดที่มีชื่อแปลกๆ หากคุณพิมพ์ ls ในเทอร์มินัลแล้วกด Enter คุณจะเห็นข้อมูลดังนี้

- ใช้คำสั่ง
mvเพื่อเปลี่ยนชื่อไฟล์ พิมพ์ข้อความต่อไปนี้ลงในคอนโซล แล้วกด Enter หลังจากแต่ละบรรทัด
เทอร์มินัล:
mv *group1-shard1of1.bin* group1-shard1of1.bin
mv *model.json* model.json
- สุดท้าย รีเฟรชโปรเจ็กต์ Glitch โดยพิมพ์
refreshในเทอร์มินัลและกด Enter:
เทอร์มินัล:
refresh
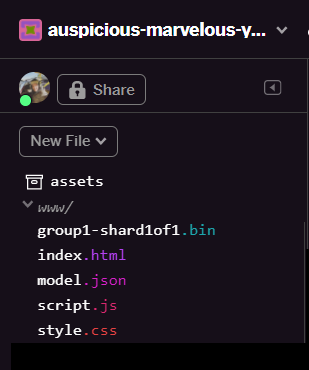
เมื่อรีเฟรชแล้ว คุณจะเห็น model.json และ group1-shard1of1.bin ในโฟลเดอร์ www ของอินเทอร์เฟซผู้ใช้
เยี่ยม! ขั้นตอนสุดท้ายคือการอัปเดตไฟล์ dictionary.js
- แปลงไฟล์ vocab ที่ดาวน์โหลดมาใหม่เป็นรูปแบบ JS ที่ถูกต้องด้วยตนเองผ่านเครื่องมือแก้ไขข้อความหรือใช้เครื่องมือนี้ แล้วบันทึกผลลัพธ์เป็น
dictionary.jsในโฟลเดอร์wwwของคุณ หากมีไฟล์dictionary.jsอยู่แล้ว ก็เพียงคัดลอกและวางเนื้อหาใหม่ทับไฟล์เหล่านั้น แล้วบันทึกไฟล์
ไชโย คุณอัปเดตไฟล์ที่มีการเปลี่ยนแปลงทั้งหมดเรียบร้อยแล้ว และหากคุณลองใช้เว็บไซต์ในตอนนี้ คุณจะสังเกตเห็นว่าโมเดลที่ฝึกใช้นั้นควรสามารถอธิบายกรณีปัญหาหลักที่พบและเรียนรู้จากกรณีใด ดังที่แสดงด้านล่างนี้
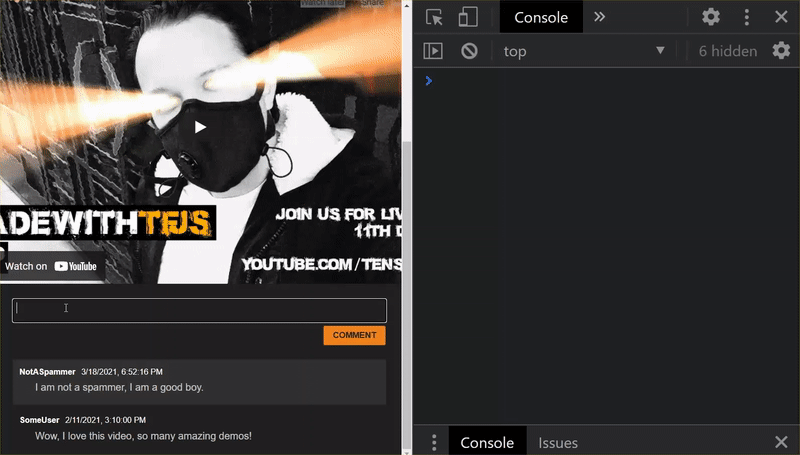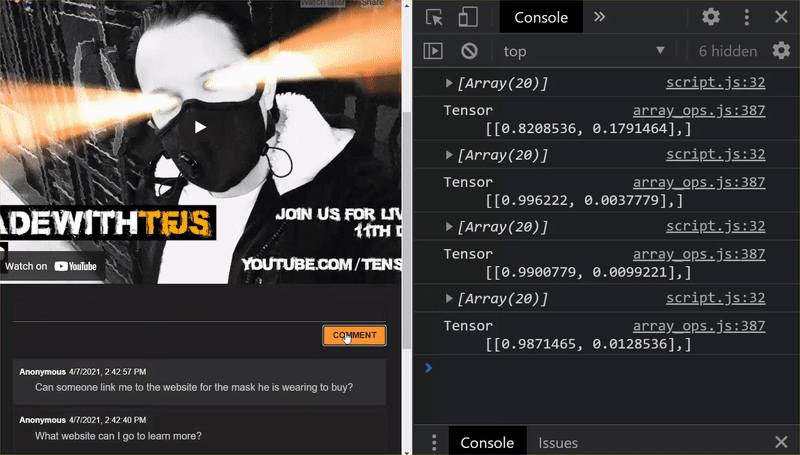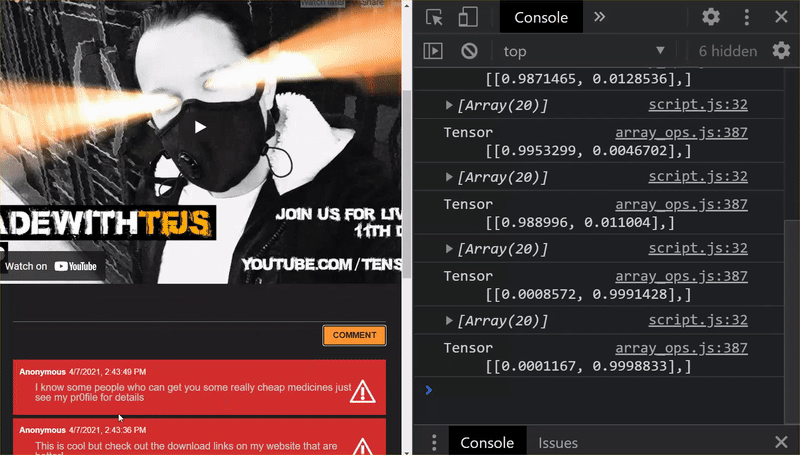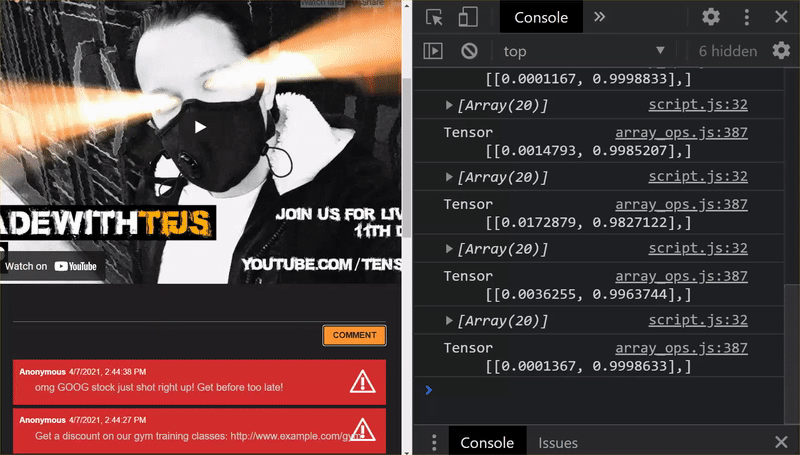
คุณจะเห็นได้ว่า 6 รายการแรกจัดประเภทว่าเป็นสแปมอย่างถูกต้องแล้ว และ 6 กลุ่มแรกถูกระบุว่าเป็นสแปมทั้งหมด งั้นก็แจ๋วเลย
ลองใช้รูปแบบอื่นๆ ด้วยเพื่อดูว่าเป็นแบบทั่วไปดีหรือไม่ เดิมมีประโยคล้มเหลว เช่น
"โอ้ หุ้น GOOG เพิ่งพุ่งตัวไป รีบไปก่อน!"
ข้อความนี้มีการจัดประเภทว่าเป็นสแปมอย่างถูกต้อง แต่จะเกิดอะไรขึ้นหากคุณเปลี่ยนเป็นข้อความต่อไปนี้
"หุ้น XYZ มีมูลค่าเพิ่มขึ้น รีบซื้อของก่อนจะสายเกินไป"
นี่คือการคาดคะเนว่ามีแนวโน้มที่จะเป็นสแปม 98% ซึ่งถูกต้อง แม้ว่าคุณจะเปลี่ยนสัญลักษณ์หุ้นและข้อความเล็กน้อยก็ตาม
แน่นอนว่าถ้าคุณพยายามแยกรูปแบบใหม่นี้จริงๆ คุณก็สามารถทำได้ และนี่จะเป็นการรวบรวมข้อมูลการฝึกเพิ่มมากขึ้น เพื่อให้มีโอกาสมากที่สุดในการเก็บข้อมูลรูปแบบต่างๆ ที่ไม่ซ้ำกับสถานการณ์ทั่วไปที่คุณน่าจะพบเจอในโลกออนไลน์ ใน Codelab ในอนาคต เราจะแสดงวิธีปรับปรุงโมเดลอย่างต่อเนื่องด้วยข้อมูลที่เผยแพร่อยู่ตามที่มีการแจ้งว่าไม่เหมาะสม
6. ยินดีด้วย
ยินดีด้วย คุณได้ฝึกโมเดลแมชชีนเลิร์นนิงที่มีอยู่อีกครั้งเพื่อให้อัปเดตตัวเองให้ทำงานได้สำหรับ Edge Case ที่คุณพบ และปรับใช้การเปลี่ยนแปลงเหล่านั้นในเบราว์เซอร์ด้วย TensorFlow.js สำหรับแอปพลิเคชันในโลกแห่งความเป็นจริงแล้ว
สรุป
ใน Codelab นี้ คุณจะทำสิ่งต่อไปนี้ได้
- พบกรณีที่เป็นปัญหาที่สุดที่ใช้งานไม่ได้เมื่อใช้โมเดลสแปมความคิดเห็นที่ทำไว้ล่วงหน้า
- ฝึกโมเดลเครื่องสร้างแบบจำลองเพื่อพิจารณาถึงกรณีขอบที่อาจพบได้
- ส่งออกโมเดลใหม่ที่ฝึกแล้วเป็นรูปแบบ TensorFlow.js
- อัปเดตเว็บแอปเพื่อใช้ไฟล์ใหม่แล้ว
สิ่งที่ต้องทำต่อไป
การอัปเดตนี้ทำงานได้ดี แต่การเปลี่ยนแปลงจะเกิดขึ้นเมื่อเวลาผ่านไป เช่นเดียวกับเว็บแอปอื่นๆ คงจะดีกว่ามากหากแอปมีการปรับปรุงตัวเองอย่างต่อเนื่องเมื่อเวลาผ่านไป แทนที่จะที่เราจะต้องปรับปรุงแอปด้วยตนเองทุกครั้ง ลองนึกดูว่าคุณสามารถทำให้ขั้นตอนเหล่านี้ทำงานโดยอัตโนมัติเพื่อฝึกโมเดลโดยอัตโนมัติอีกครั้งได้อย่างไรหลังจากได้ เช่น ความคิดเห็นใหม่ 100 รายการที่มีการทำเครื่องหมายว่าจัดประเภทไม่ถูกต้อง สวมบทบาทเป็นวิศวกรเว็บตามปกติของคุณ คุณน่าจะหาวิธีสร้างไปป์ไลน์เพื่อทำงานนี้โดยอัตโนมัติได้ หากไม่ใช่ ก็ไม่ต้องกังวลไป พบกับ Codelab ถัดไปในชุดนี้ซึ่งจะแสดงวิธีการให้คุณทราบ
แชร์สิ่งที่คุณทำกับเรา
คุณสามารถต่อยอดสิ่งที่คุณทำในวันนี้ไปยังกรณีการใช้งานที่สร้างสรรค์อื่นๆ ได้ง่ายๆ เช่นกัน และเราขอแนะนำให้คุณคิดนอกกรอบและแฮ็กไปเรื่อยๆ
อย่าลืมติดแท็กเราบนโซเชียลมีเดียโดยใช้แฮชแท็ก #MadeWithTFJS เพื่อลุ้นโอกาสให้โปรเจ็กต์ของคุณปรากฏบนบล็อก TensorFlow หรือแม้แต่กิจกรรมในอนาคต เราอยากเห็นสิ่งที่คุณสร้าง
Codelab ของ TensorFlow.js เพิ่มเติมที่ช่วยให้ข้อมูลเจาะลึกยิ่งขึ้น
- ใช้โฮสติ้งของ Firebase เพื่อทำให้ใช้งานได้และโฮสต์โมเดล TensorFlow.js จำนวนมาก
- สร้างเว็บแคมอัจฉริยะโดยใช้โมเดลตรวจจับวัตถุสำเร็จรูปด้วย TensorFlow.js
เว็บไซต์ที่น่าสนใจ
- เว็บไซต์อย่างเป็นทางการของ TensorFlow.js
- โมเดลสำเร็จรูปของ TensorFlow.js
- API ของ TensorFlow.js
- การแสดงของ TensorFlow.js และ บอกเล่า - ได้รับแรงบันดาลใจและดูว่าคนอื่นๆ สร้างอะไรไว้