
1. 始める前に
この Codelab は、TensorFlow.js を使用したコメントスパム検出について、このシリーズの前の Codelab の最終結果をベースに作成されています。
前回の Codelab では、架空の動画ブログ用に完全に機能するウェブページを作成しました。ブラウザで TensorFlow.js による事前トレーニング済みのコメントスパム検出モデルを使用することで、コメントがサーバーや接続された他のクライアントに送信される前に、スパムのフィルタをフィルタリングできました。
この Codelab の最終結果は次のとおりです。
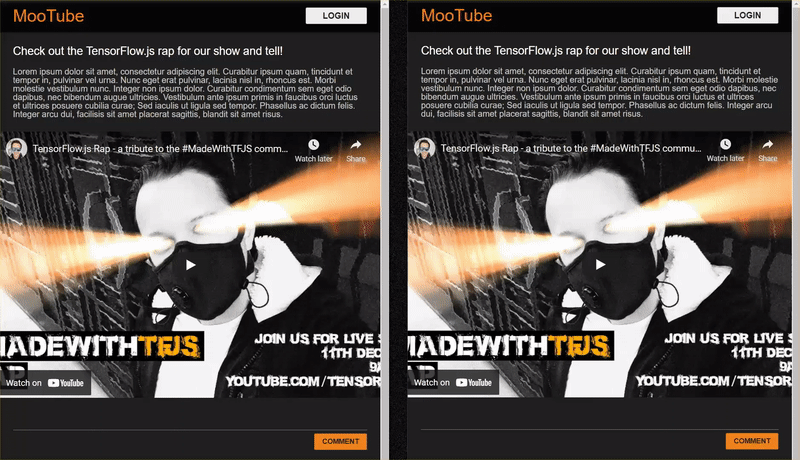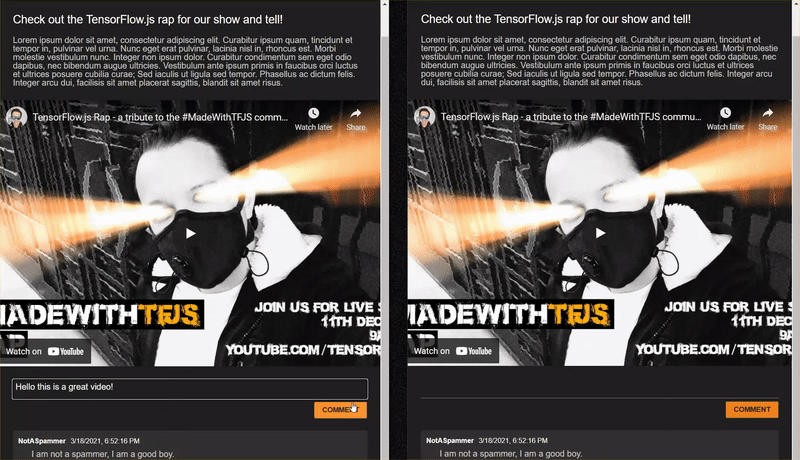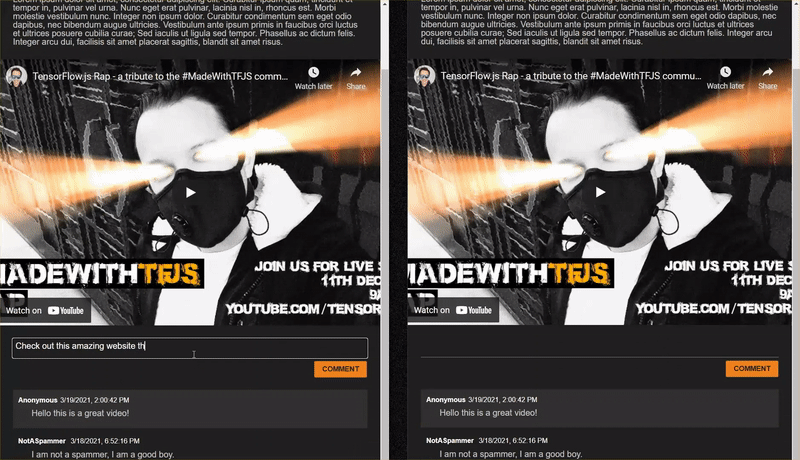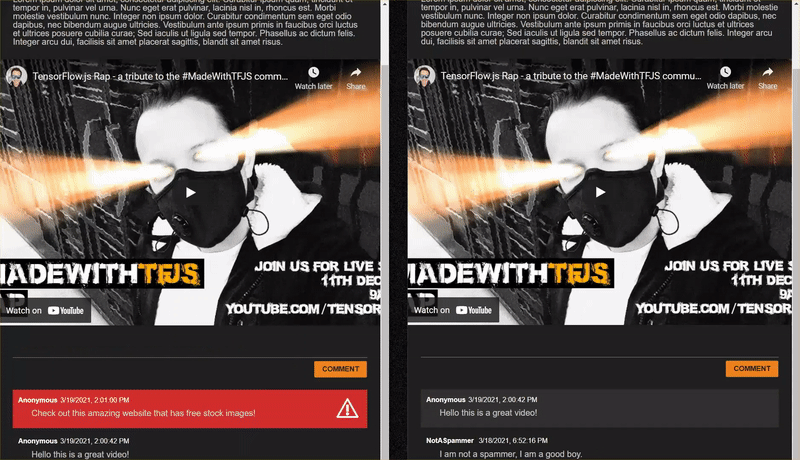
これは非常にうまくいきましたが、検出できなかったエッジケースがあります。処理できなかった状況を説明するために、モデルを再トレーニングできます。
この Codelab では、自然言語処理(コンピュータで人間の言語を理解する技術)の使用に重点を置き、作成した既存のウェブアプリを変更して(順番に Codelab を受講することを強くおすすめします)、コメントスパムという非常に現実的な問題に取り組む方法を紹介します。コメントスパムは、現在増加し続ける人気のウェブアプリの 1 つで作業を行うウェブ デベロッパーの多くが確実に直面する問題です。
この Codelab では、さらに一歩進めて、現在の傾向や話題のトピックに基づいて、時間の経過とともに変化する可能性のあるスパム メッセージ コンテンツの変化を考慮するように ML モデルを再トレーニングします。これにより、モデルを最新の状態に保ち、そのような変化に対応できます。
前提条件
- このシリーズの最初の Codelab を修了している。
- HTML、CSS、JavaScript などのウェブ技術に関する基本的な知識。
作成するアプリの概要
作成したウェブサイトを架空の動画ブログ用に再利用し、リアルタイムのコメント セクションを作成します。そして、TensorFlow.js を使用してスパム検出モデルのカスタム トレーニング バージョンを読み込むようにアップグレードします。これにより、以前はうまくいかなかったエッジケースでのパフォーマンスが向上します。もちろん、ウェブ デベロッパーやエンジニアは、この架空の UX を日常業務で担当するウェブサイトで再利用できるように変更し、お客様のユースケースに合わせてソリューションを調整できます。ブログ、フォーラム、Drupal などのなんらかの形式の CMS などが考えられます。
さあ、ハッキングをしよう...
学習内容
次のことを行います。
- 事前トレーニング済みモデルが失敗したエッジケースを特定する
- Model Maker を使用して作成した迷惑メール分類モデルを再トレーニングします。
- この Python ベースのモデルを、ブラウザで使用するために TensorFlow.js 形式にエクスポートします。
- ホストされているモデルとその辞書を新しくトレーニングされたモデルで更新し、結果を確認する
また、HTML5、CSS、JavaScript の知識があることが前提となります。ラボでは Python コードもいくつか実行し、ノートブックを使用して Model Maker で作成されたモデルを再トレーニングしますが、Python の知識は必要ありません。
2. コーディングの準備
ここでも、Glitch.com を使用してウェブ アプリケーションのホストと変更を行います。前提条件となる Codelab をまだ完了していない場合は、出発点としてここで最終的な結果のクローンを作成できます。コードの仕組みについて不明な点がある場合は、先に進む前に、このウェブアプリの動作を確認できる 前の Codelab を完了することを強くおすすめします。
Glitch で [remix this] ボタンをクリックするだけでフォークして、編集可能な新しいファイルセットを作成できます。
3. 前のソリューションのエッジケースを検出する
先ほどクローンを作成した完成版ウェブサイトを開いてコメントを入力しようとすると、たいていは意図したとおりに機能しており、スパムのように聞こえるコメントは想定どおりブロックされ、正当な応答が許容されていることがわかります。
しかし、モデルを壊すために巧妙な言葉遣いをするようになれば、いずれ成功するでしょう。次のような例は、少し試行錯誤すれば手動で作成できます。これを既存のウェブアプリに貼り付けて、コンソールで、コメントがスパムかどうかを判断して再度表示される可能性を確認します。
問題なく投稿された正当なコメント(真陰性):
- 「素晴らしい動画です、すばらしいですね。」確率スパム: 47.91854%
- 「このデモはとても気に入りました。詳細はございますか?」確率スパム: 47.15898%
- 「どのウェブサイトにアクセスして詳細を確認できますか?」確率スパム: 15.32495%
これは素晴らしいことです。これらすべての確率は非常に低く、アクションが行われる前にデフォルトの SPAM_THRESHOLD(最小確率 75%)を無事に通過できます(前の Codelab の script.js コードで定義された)。
では、実際はそうではないにもかかわらずスパムとマークされる、鋭いコメントを書いてみよう...
スパムとしてマークされた正当なコメント(誤検出):
- 「彼が着用しているマスクのウェブサイトへのリンクを貼ってもらえますか?」確率スパム: 98.46466%
- 「この曲を Spotify で購入できますか?よろしければお知らせください。」確率スパム: 94.40953%
- 「TensorFlow.js のダウンロード方法について、どなたか問い合わせてもらえますか?」確率スパム: 83.20084%
現在のところ、このような正当なコメントは、許可するべきときにスパムとしてマークされているようです。どうすれば解決できるでしょうか?
シンプルな選択肢の一つは、SPAM_THRESHOLD を信頼度 98.5% 以上に上げることです。不適切に分類されたコメントは投稿されることになります。この点を念頭に置いて、次に考えられる他の結果を見てみましょう...
スパムとして分類されたスパムコメント(真陽性):
- 「これは素晴らしいことですが、私のウェブサイトのダウンロード リンクを見てください。」確率スパム: 99.77873%
- 「薬を処方してくれる人もいます。詳しくは pr0file をご覧ください」 確率スパム: 98.46955%
- 「プロフィールを見て、もっとすてきな動画を一時保存しましょう。http://example.com" 確率スパム: 96.26383%
これは、元の 75% しきい値で想定どおり動作していますが、前のステップで SPAM_THRESHOLD の信頼性を 98.5% 以上に変更したため、ここでは 2 つの例が通過することになり、しきい値が高すぎる可能性があります。96% の方がよいかもしれません。ただし、これを行うと、前のセクションのコメントの 1 つ(誤検出)は正当であればスパムとしてマークされ、評価は 98.46466% になります。
そのような場合は、本物のスパムコメントをすべて捕捉し、上記のエラーに対して再度トレーニングを行うのが最善でしょう。しきい値を 96% に設定すると、すべての真陽性が取り込まれ、上記の 2 つの偽陽性が除外されます。1 つの数字を変更するだけでも十分です。
続けましょう...
投稿が許可されたスパムコメント(偽陰性):
- 「プロフィールを見て、さらに素晴らしい動画を一時保存できます。」確率スパム: 7.54926%
- 「ジムのトレーニング クラスが割引料金で受けられます。pr0file をご覧ください。」確率スパム: 17.49849%
- 「OK GOOG の株価がまちまちで、この間に合わない!」確率スパム: 20.42894%
このようなコメントについては、SPAM_THRESHOLD 値をさらに変更するだけでは対応できません。スパムのしきい値を 96% から最大 9% に引き下げると、正当なコメントはスパムとしてマークされることになります。そのうちの 1 つは、正当なコメントであっても 58% の評価を獲得しています。このようなコメントに対処する唯一の方法は、このようなエッジケースをトレーニング データに含めてモデルを再トレーニングし、スパムかどうかによって世界観を調整することを学習することです。
今左の選択肢はモデルの再トレーニングだけですが、スパムコールの判断基準を絞り込んでパフォーマンスを向上させる方法も確認しました。人間としては 75% という自信がかなりあるように見えますが、このモデルでは、サンプル入力の効果を高めるために 81.5% 近くまで値を増やす必要がありました。
さまざまなモデルで効果を発揮する魔法の価値は 1 つではありません。このしきい値は、実世界のデータで何がうまく機能するかテストした後に、モデルごとに設定する必要があります。
偽陽性(または偽陰性)が重大な結果(医療業界など)に及ぶ場合もあるため、しきい値を非常に高く設定し、しきい値を満たさない場合は手動による審査を増やすことをおすすめします。この方法はデベロッパーとして選択し、試行錯誤が必要です。
4. コメントスパム検出モデルを再トレーニングする
前のセクションでは、モデルで失敗する複数のエッジケースを特定しました。これらの状況に対応するためにモデルを再トレーニングするという選択肢しかありませんでした。本番環境システムでは、誰かが手動でコメントをスパムとして報告し、通過した場合や、報告されたコメントを確認するモデレーターが実際にはスパムではないことに気づき、再トレーニングのためにマークを付けて、こうしたコメントに気づくことがあります。これらのエッジケースに関する多数の新しいデータを収集したと仮定します(可能であれば、これらの新しい文のバリエーションを用意することをおすすめします)。ここでは、これらのエッジケースを念頭に置いてモデルを再トレーニングする方法を説明します。
事前構築済みモデルのまとめ
ここで使用した既製のモデルは、サードパーティが Model Maker で「平均的な単語のエンベディング」を使用して作成したモデルでした。必要があります。
モデルは Model Maker で構築しているため、Python に一時的に切り替えてモデルを再トレーニングする必要があります。その後、作成したモデルを TensorFlow.js 形式でエクスポートして、ブラウザで使用できるようにします。ありがたいことに Model Maker では、モデルを簡単に使用できます。使い方はとても簡単です。手順を案内しますので、Python を使ったことがない方でも心配はいりません。
Colab
この Codelab では、さまざまな Python ユーティリティをすべてインストールして Linux サーバーをセットアップすることにあまり関心がないので、「Colab ノートブック」を使用してウェブブラウザからコードを実行するだけです。これらのノートブックは「バックエンド」に接続できますは、いくつかの要素がプリインストールされた単純なサーバーです。そこからウェブブラウザ内で任意のコードを実行し、結果を確認できます。これは迅速なプロトタイピングやこのようなチュートリアルでの使用に非常に便利です。
colab.research.google.com にアクセスすると、次のようなウェルカム画面が表示されます。
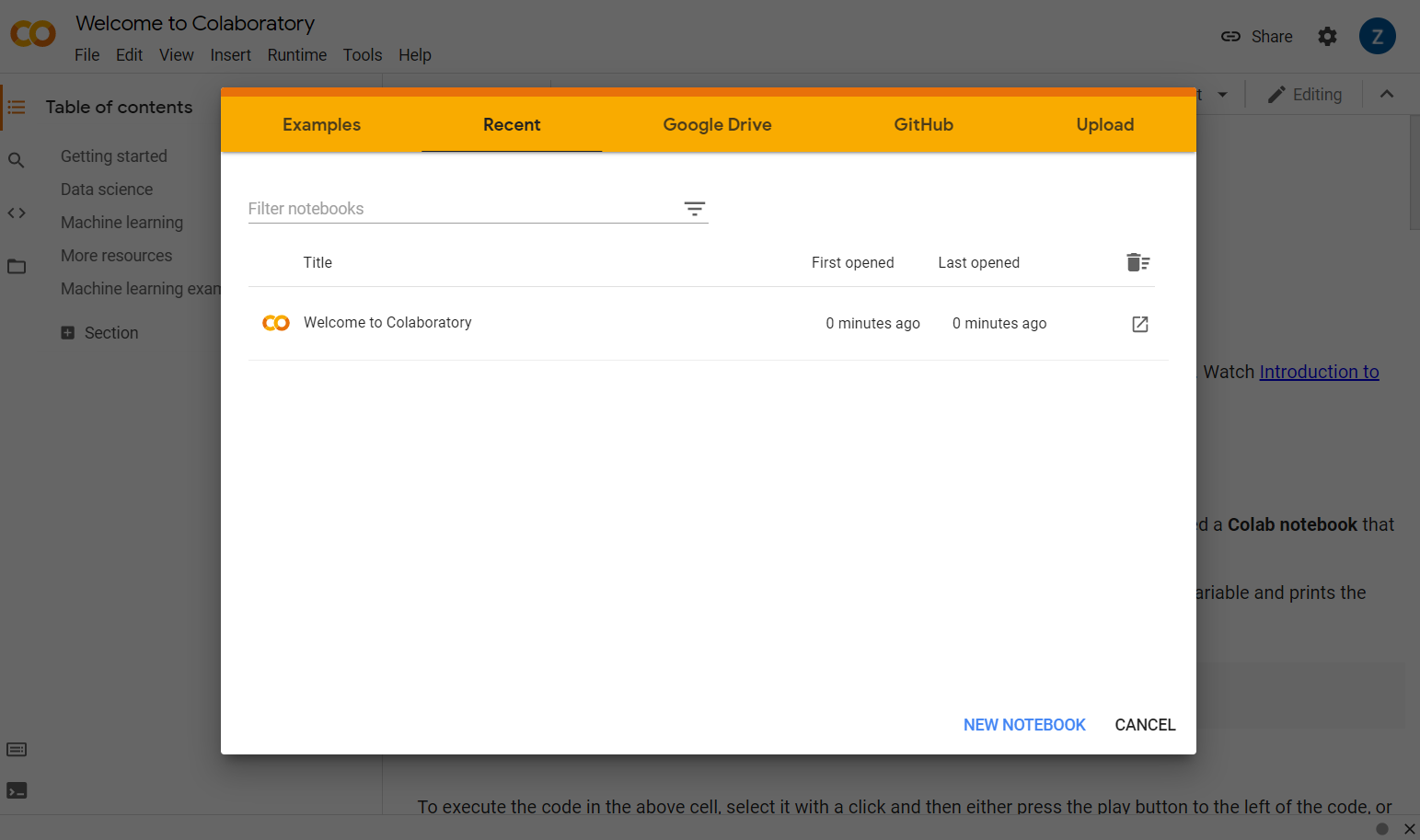
ポップアップ ウィンドウの右下にある [新しいノートブック] ボタンをクリックすると、次のような空の Colab が表示されます。
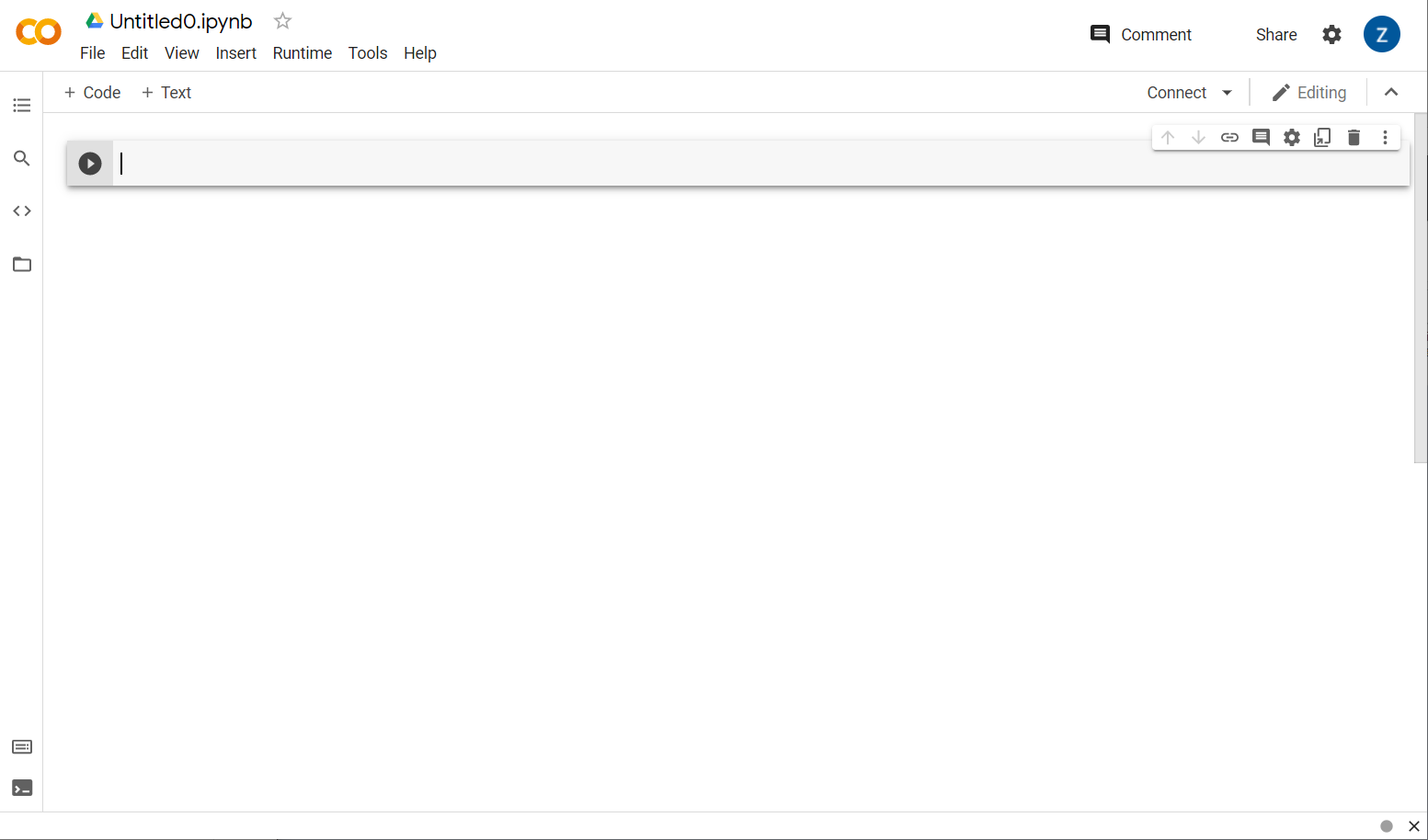
これで次のステップでは、フロントエンド Colab をバックエンド サーバーに接続し、作成する Python コードを実行できるようにします。これを行うには、右上の [接続] をクリックし、[ホスト型ランタイムに接続] を選択します。
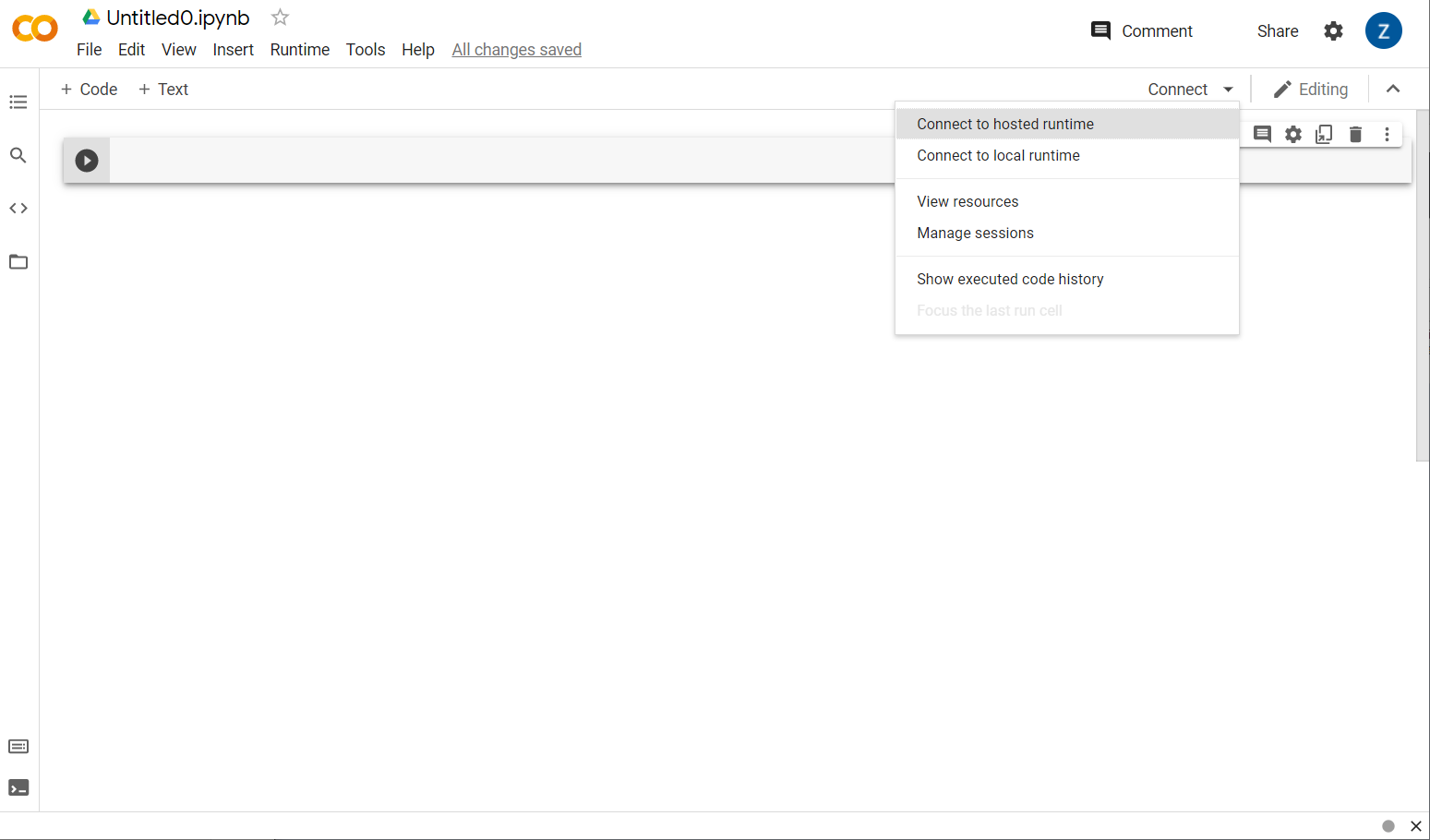
接続すると、次のように RAM とディスクのアイコンが表示されます。
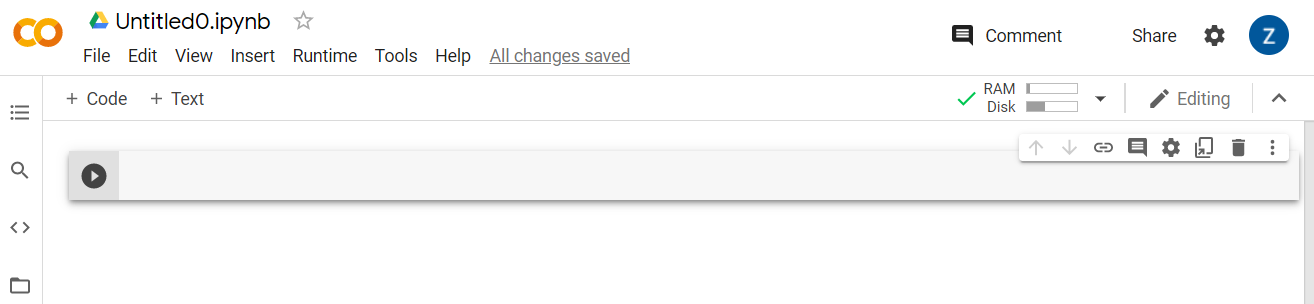
よくできました!Python でコーディングを開始して、Model Maker モデルを再トレーニングできるようになりました。手順は次のとおりです。
ステップ 1
現在空になっている最初のセルに、以下のコードをコピーします。「pip」という Python のパッケージ マネージャーを使用して TensorFlow Lite Model Maker がインストールされます(これは、このコードラボのほとんどの読者の方が JS エコシステムから見慣れている npm に似ています)。
!apt-get install libasound-dev portaudio19-dev libportaudio2 libportaudiocpp0
!pip install -q tflite-model-maker
セルにコードを貼り付けても実行されません。次に、上のコードを貼り付けた灰色のセルの上にカーソルを置き、小さな再生ボタンを表示します。アイコンがセルの左側に表示されます。
 再生ボタンをクリックすると、セルに入力したコードが実行されます。
再生ボタンをクリックすると、セルに入力したコードが実行されます。
モデルメーカーがインストールされています。
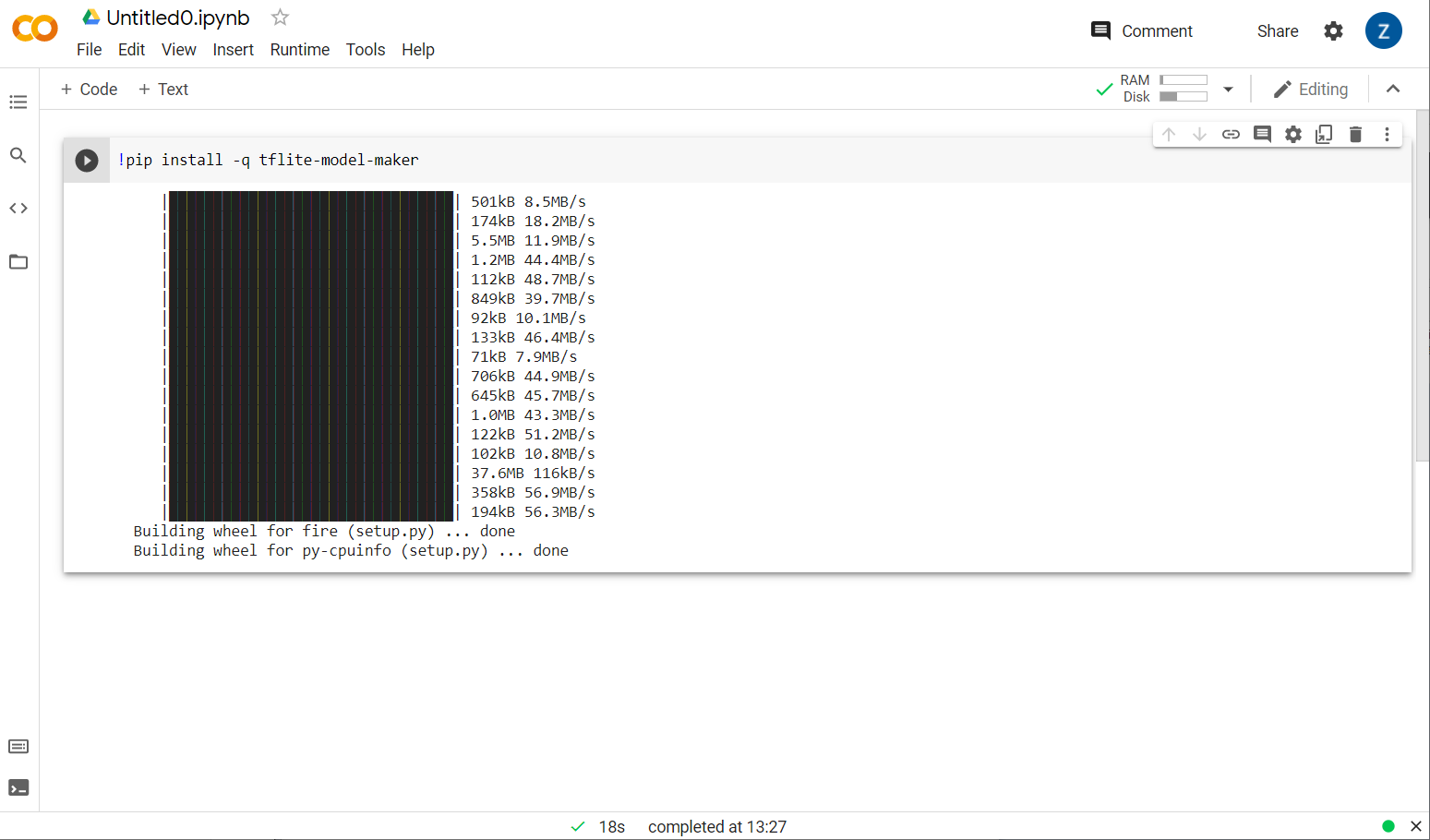
図のようにこのセルの実行が完了したら、次のステップに進みます。
ステップ 2
次に、次に示す新しいコードセルを追加します。これにより、最初のセルの後にコードをさらに貼り付けて、個別に実行できます。
次に実行されるセルには、ノートブックの残りの部分のコードで使用する必要があるインポートがいくつか含まれています。作成した新しいセルに、次のコードをコピーして貼り付けます。
import numpy as np
import os
from tflite_model_maker import configs
from tflite_model_maker import ExportFormat
from tflite_model_maker import model_spec
from tflite_model_maker import text_classifier
from tflite_model_maker.text_classifier import DataLoader
import tensorflow as tf
assert tf.__version__.startswith('2')
tf.get_logger().setLevel('ERROR')
Python に詳しくなくても、かなり標準的な内容です。スパム分類器に必要なユーティリティと Model Maker 関数をインポートしているだけです。また、Model Maker の使用要件である TensorFlow 2.x を実行しているかどうかも確認します。
最後に、先ほどと同様に、再生ボタンを押してセルを実行します。アイコン にカーソルを合わせ、次のステップで新しいコードセルを追加します。
ステップ 3
次に、リモート サーバーからデバイスにデータをダウンロードし、ダウンロードしたローカル ファイルのパスを training_data 変数に設定します。
data_file = tf.keras.utils.get_file(fname='comment-spam-extras.csv', origin='https://storage.googleapis.com/jmstore/TensorFlowJS/EdX/code/6.5/jm_blog_comments_extras.csv', extract=False)
Model Maker では、ダウンロードしたファイルなどのシンプルな CSV ファイルからモデルをトレーニングできます。テキストを格納する列とラベルを保持する列を指定するだけで済みます。その方法はステップ 5 で説明します。必要に応じて、CSV ファイルを直接ダウンロードして、その内容を確認できます。
このファイルの名前は jm_blog_comments_extras.csv です。このファイルは、最初のコメントスパムモデルを生成する際に使用した元のトレーニング データと、お客様が発見した新しいエッジケース データと組み合わせたため、すべて 1 つのファイルになっています。学習に使用する新しい文に加えて、モデルのトレーニングに使用した元のトレーニング データも必要です。
省略可: この CSV ファイルをダウンロードして最後の数行を確認すると、以前は正しく動作しなかったエッジケースの例を確認できます。既製のモデルが自己トレーニングに使用した既存のトレーニング データの最後に追加されただけです。
このセルを実行し、実行が完了したら新しいセルを追加して、手順 4 に進みます。
ステップ 4
Model Maker を使用する場合、モデルをゼロから作成する必要はありません。通常は既存のモデルを使用し、その後、ニーズに合わせてカスタマイズします。
Model Maker には、事前に学習したモデル エンベディングがいくつか用意されていますが、前の Codelab でウェブサイトを構築するために使用した average_word_vec が最も簡単で、すぐに使えます。以下にコードを示します。
spec = model_spec.get('average_word_vec')
spec.num_words = 2000
spec.seq_len = 20
spec.wordvec_dim = 7
新しいセルに貼り付けたら、それを実行します。
ユーザーの
num_words
parameter
これは、モデルで使用する単語の数です。「多ければ多いほど良い」と思うかもしれませんが、一般的に、各単語が使用される頻度に基づいて最適解が存在します。コーパス全体のすべての単語を使用すると、モデルが一度だけ使用される単語の重みを学習し、バランスを取ろうとします。これはあまり有用ではありません。どのテキスト コーパスでも、多くの単語が 1 回か 2 回しか使用されていないことがわかります。また、全体的な感情にはほとんど影響しないため、通常はそれらの単語をモデルで使用する価値はありません。そのため、num_words パラメータを使用して、必要な単語数でモデルを調整できます。数値が小さいほどモデルは小さく、高速になりますが、認識する単語が少なくなるため、精度が低くなる可能性があります。数値が大きいほど、モデルは大きくなり、処理速度が低下する可能性があります。スイート スポットを見つけることが重要であり、ML エンジニアは自分のユースケースに最適なものを見つける必要があります。
ユーザーの
wordvec_dim
parameter
wordvec_dim パラメータは、各単語のベクトルに使用する次元数です。これらの次元は基本的に、任意の単語を測定できるさまざまな特性(トレーニング時に ML アルゴリズムによって作成される)であり、プログラムはこの特性に基づいて、類似する単語を有意義な方法で関連付けようとします。
たとえば、「医療」というディメンションが「pills」のような単語を他の高スコアの単語(例: 「xray」でも「cat」でも)と関連付けられる場合があります。このディメンションのスコアは低くなります「医学的次元」は、は、重要であると判断する可能性のある他のディメンションと組み合わされた場合に、スパムを判断するのに有用です。
「医学的次元」のスコアが高い単語の場合単語と人体を関連付ける第 2 次元が有用であると判断する場合があります。「脚」、「腕」、「首」などの単語医療の面でもかなり高いスコアを出します。
モデルはこれらのディメンションを使用して、スパムに関連付けられている可能性が高い単語を検出できるようになります。たとえば、迷惑メールには医療部位と人体部位の両方の単語が含まれる可能性が高くなります。
研究から判断された経験則では、このパラメータには単語数の 4 乗根がうまく機能します。したがって、2, 000 単語を使用する場合は、出発点として 7 次元から始めることをおすすめします。使用する単語数も変更できます。
ユーザーの
seq_len
parameter
一般に、入力値に対してモデルは非常に厳格です。言語モデルの場合は、特定の静的長さの文を分類できることを意味します。これは seq_len パラメータによって決まります。このパラメータは、「シーケンスの長さ」を表します。単語を数字(またはトークン)に変換すると、文はこれらのトークンのシーケンスになります。そのため、モデルは(この場合は)20 個のトークンを含む文を分類して認識するようにトレーニングされます。文がこれより長い場合は切り捨てられます。短い場合は、このシリーズの最初の Codelab と同様に、パディングされます。
ステップ 5 - トレーニング データを読み込む
先ほど CSV ファイルをダウンロードしました。次に、データローダを使用して、モデルが認識できるトレーニング データに変換します。
data = DataLoader.from_csv(
filename=data_file,
text_column='commenttext',
label_column='spam',
model_spec=spec,
delimiter=',',
shuffle=True,
is_training=True)
train_data, test_data = data.split(0.9)
この CSV ファイルをエディタで開くと、各行には 2 つの値のみが表示され、その説明がファイルの先頭行に記述されています。通常、各エントリは「列」とみなされます。最初の列の記述子は commenttext で、各行の最初のエントリはコメントのテキストです。
同様に、2 番目の列の記述子は spam で、各行の 2 番目のエントリは、そのテキストがコメントスパムとみなされるかどうかを示す TRUE または FALSE です。他のプロパティは、手順 4 で作成したモデル仕様を、区切り文字(この場合はカンマで区切られているため)とともに設定します。また、シャッフル パラメータを設定して、トレーニング データをランダムに再配置し、類似したデータや収集されたデータがデータセット全体でランダムに分散されるようにします。
次に、data.split() を使用して、データをトレーニング データとテストデータに分割します。0.9 は、データセットの 90% がトレーニングに使用され、残りがテストに使用されることを示します。
ステップ 6 - モデルを構築する
モデルを構築するためのコードを追加する別のセルを追加します。
model = text_classifier.create(train_data, model_spec=spec, epochs=50)
これにより、Model Maker でテキスト分類モデルが作成され、使用するトレーニング データ(ステップ 4 で定義)、モデルの仕様(ステップ 4 でも設定したもの)、エポック数(この場合は 50)を指定します。
ML の基本原則は、一種のパターン マッチングであるということです。最初に、トレーニング済みの単語の重みを読み込み、「予測」によってそれらの重みをグループ化することを試みます。グループ化した場合、スパムを示しているものとそうでないものを区別できます。最初は、以下に示すようにモデルは始まったばかりなので、50:50 近くになる可能性が高くなります。

その結果が測定され、モデルの重みを変更して予測が微調整され、再試行されます。これがエポックです。epochs=50 と指定すると、この「ループ」が発生します。50 回繰り返します。

そのため、50 エポックに達する頃には、モデルは精度が非常に高いレベルを報告することになります。この例では 99.1% となっています。
手順 7 - モデルをエクスポートする
トレーニングが完了したら、モデルをエクスポートできます。TensorFlow は独自の形式でモデルをトレーニングします。ウェブページで使用するには、TensorFlow.js 形式に変換する必要があります。新しいセルに次のコードを貼り付けて実行するだけです。
model.export(export_dir="/js_export/", export_format=[ExportFormat.TFJS, ExportFormat.LABEL, ExportFormat.VOCAB])
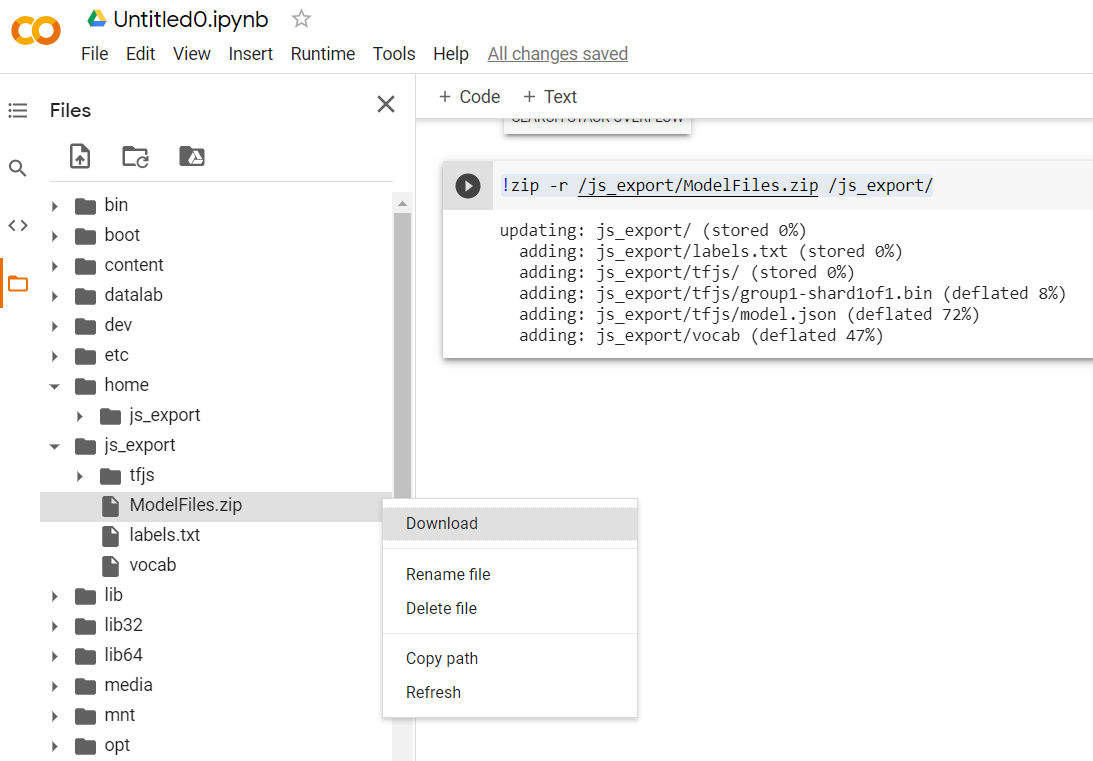
!zip -r /js_export/ModelFiles.zip /js_export/
このコードを実行した後、Colab の左側にある小さなフォルダ アイコンをクリックすると、上記でエクスポートしたフォルダ(ルート ディレクトリにあるフォルダに移動するか、場合によっては 1 階層上)に移動し、ModelFiles.zip に含まれているエクスポートされたファイルの zip バンドルを見つけることができます。
最初の Codelab と同様に、この zip ファイルをパソコンにダウンロードします。
これでPython のパートは終了です。使い慣れた JavaScript 環境に戻ることができます。さて、
5. 新しい ML モデルのサービング
これで、モデルを読み込む準備がほぼ整いました。ただし、その前に、Codelab の前半でダウンロードした新しいモデルファイルをアップロードし、ホストしてコード内で使用できるようにする必要があります。
まず、実行した Model Maker Colab ノートブックからダウンロードしたモデルのファイルをまだ解凍していない場合は、解凍します。さまざまなフォルダ内に次のファイルが含まれています。
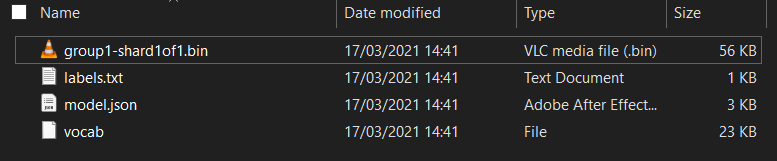
この製品には何がありますか?
model.json- トレーニング済みの TensorFlow.js モデルを構成するファイルの一つです。JS コードでこの特定のファイルを参照します。group1-shard1of1.bin- エクスポートされた TensorFlow.js モデル用に保存されているデータの多くを含むバイナリ ファイルです。上記のmodel.jsonと同じディレクトリにダウンロードするには、サーバー上のどこかにホストする必要があります。vocab- 拡張子のないこの奇妙なファイルは Model Maker によるもので、文中の単語をエンコードしてモデルがその使用方法を理解できるようにする方法が示されています。これについては、次のセクションで詳しく説明します。labels.txt- モデルが予測する結果のクラス名のみが含まれます。このモデルでは、ファイルをテキスト エディタで開くと、"false" になります。かつ「true」である「迷惑メールではない」と表示されるまたは「スパム」使用します。
TensorFlow.js モデルファイルをホストする
まず、生成された model.json ファイルと *.bin ファイルをウェブサーバーに配置して、ウェブページからアクセスできるようにします。
既存のモデルファイルを削除する
このシリーズの最初の Codelab の最終的な結果を基に構築するため、まず、アップロードした既存のモデルファイルを削除する必要があります。Glitch.com を使用している場合は、左側のファイルパネルで model.json と group1-shard1of1.bin を確認し、各ファイルのその他メニューのプルダウンをクリックして、次に示すように [削除] を選択します。
Glitch に新しいファイルをアップロードする
これで新しいものをアップロードします。
- Glitch プロジェクトの左側のパネルにある assets フォルダを開き、同じ名前の古いアセットがすべてアップロードされている場合は削除します。
- [アセットをアップロード] をクリックして
group1-shard1of1.binを選択し、このフォルダにアップロードします。アップロードが完了すると、次のようになります。
- これでmodel.json ファイルについても同様に、次のように、アセット フォルダに 2 つのファイルを配置します。
- 先ほどアップロードした
group1-shard1of1.binファイルをクリックすると、URL をその場所にコピーできます。次に示すように、このパスをコピーします。
- 画面左下の [ツール] >ターミナル:ターミナル ウィンドウが読み込まれるまで待ちます。
- 読み込まれたら、次のコマンドを入力して Enter キーを押して、ディレクトリを
wwwフォルダに変更します。
terminal:
cd www
- 次に、
wgetを使用して、アップロードした 2 つのファイルをダウンロードします。以下の URL を、Glitch のアセット フォルダにファイル用に生成した URL に置き換えます(各ファイルのカスタム URL のアセット フォルダを確認してください)。
2 つの URL の間のスペースに注意してください。実際の URL は、ここに示されているものとは異なりますが、よく似ています。
ターミナル
wget https://cdn.glitch.com/1cb82939-a5dd-42a2-9db9-0c42cab7e407%2Fmodel.json?v=1616111344958 https://cdn.glitch.com/1cb82939-a5dd-42a2-9db9-0c42cab7e407%2Fgroup1-shard1of1.bin?v=1616017964562
すばらしい!これで、www フォルダにアップロードされたファイルのコピーが作成されました。
しかし今のところ、おかしな名前でダウンロードされます。ターミナルに「ls」と入力して Enter キーを押すと、次のように表示されます。

mvコマンドを使用して、ファイルの名前を変更します。コンソールに次のように入力し、各行の後に Enter キーを押します。
terminal:
mv *group1-shard1of1.bin* group1-shard1of1.bin
mv *model.json* model.json
- 最後に、ターミナルで「
refresh」と入力し、Enter キーを押して Glitch プロジェクトを更新します。
terminal:
refresh
更新すると、ユーザー インターフェースの www フォルダに model.json と group1-shard1of1.bin が表示されます。
これで最後のステップとして、dictionary.js ファイルを更新します。
- テキスト エディタで手動で、またはこちらのツールを使用して、ダウンロードした新しい語彙ファイルを正しい JS 形式に変換し、生成された出力を
dictionary.jsとしてwwwフォルダに保存します。すでにdictionary.jsファイルがある場合は、新しい内容をコピーして保存するだけです。
おめでとうございます!変更したすべてのファイルが正常に更新されました。ここでウェブサイトを使用してみると、再トレーニングされたモデルが、以下のように検出および学習したエッジケースを説明できることがわかります。
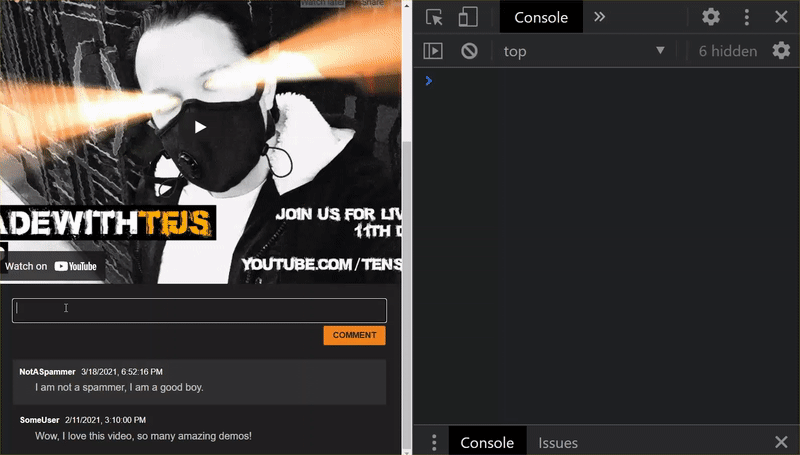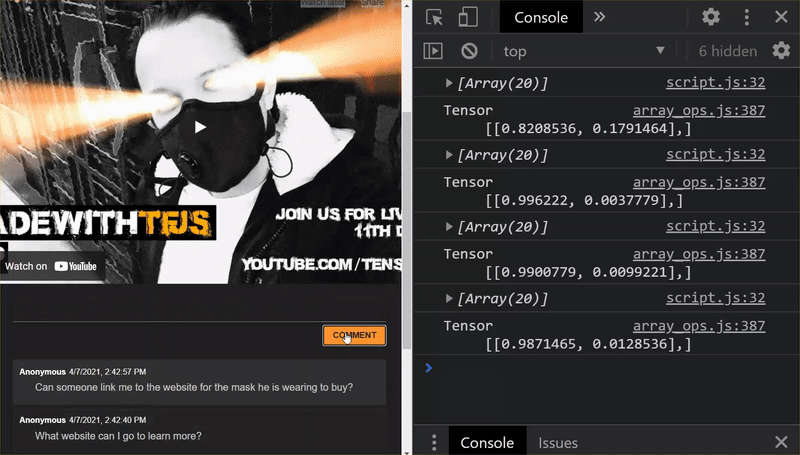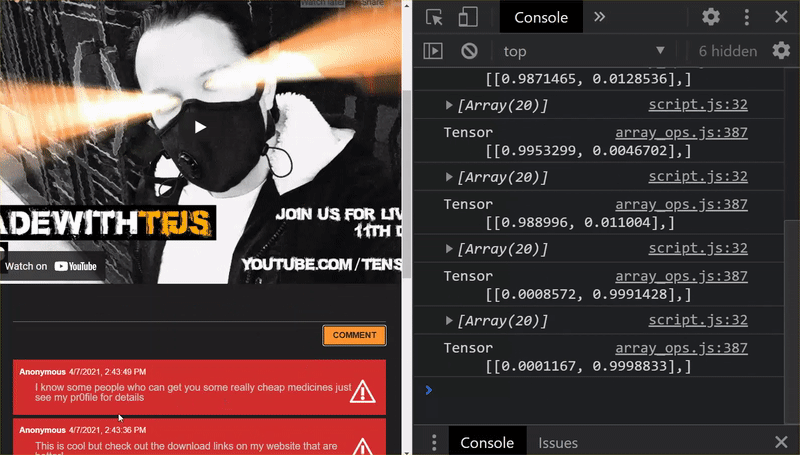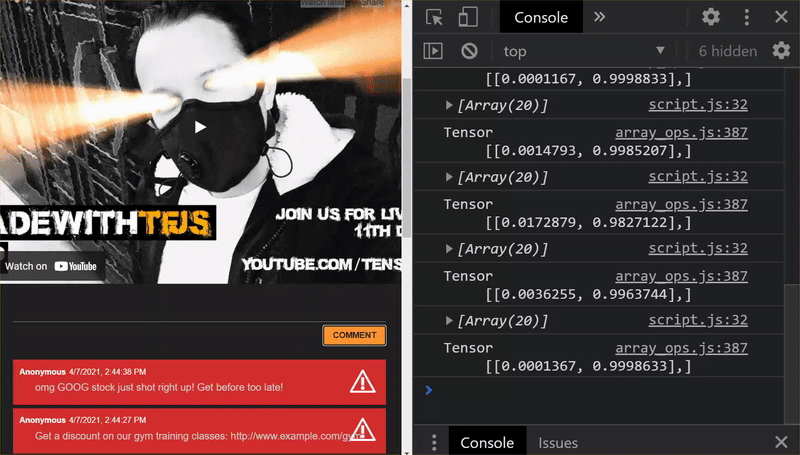
ご覧のように、最初の 6 件が正しく迷惑メールではないと分類され、2 番目のバッチ 6 件はすべて迷惑メールとして識別されるようになりました。正解です。
いくつかのバリエーションも試して、一般化されているかどうかを確認してみましょう。当初、次のような文章が失敗していました。
「ああ、もういいのに。この前に到着しましょう。」
現在は正常に迷惑メールとして分類されていますが、次のように変更した場合はどうなるでしょうか。
「つまり、XYZ の株価が上昇したということです。手遅れになる前に、ぜひお買い求めください。」
ここでは、銘柄記号と表現を少し変更しても、スパムである確率が 98% で正しいと予測されます。
もちろん、この新しいモデルを本格的に破ろうとするならば可能です。最終的には、オンラインで遭遇する可能性が高い一般的な状況で、より独自性のあるバリエーションをキャプチャする可能性を最大限に引き出すため、さらに多くのトレーニング データを収集することになります。今後の Codelab で、フラグが立てられたライブデータを使用してモデルを継続的に改善する方法を紹介します。
6. 完了
お疲れさまでした。これで、既存の ML モデルを再トレーニングして、見つけたエッジケースで動作するように更新し、実際のアプリケーション用に TensorFlow.js を使用して変更をブラウザにデプロイできました。
内容のまとめ
この Codelab では次のことを学びました。
- 既製のコメントスパムモデルを使用した場合に機能しなかったエッジケースを発見
- 発見したエッジケースを考慮するように Model Maker モデルを再トレーニングする
- 新しいトレーニング済みモデルを TensorFlow.js 形式にエクスポートした
- 新しいファイルを使用するようにウェブアプリを更新しました
次のステップ
この更新は正常に機能しますが、他のウェブアプリと同様に、今後とも変更が加えられます。アプリが時間の経過とともに継続的に改善されれば、毎回手動で行う必要がなくなり、はるかに改善されます。たとえば、誤って分類された新しいコメントが 100 件あった場合に、これらのステップを自動化してモデルを自動的に再トレーニングする方法を考えてみましょう。普段のウェブ エンジニアリングの仕事をこなすだけで、これを自動的に行うパイプラインを作成できそうです。まだの場合は、シリーズの次の Codelab でその方法をご紹介する予定ですので、ぜひご期待ください。
成功事例を共有する
今作成したものは、他のクリエイティブなユースケースにも簡単に拡張できます。既成概念にとらわれず、ハッキングを続けることをおすすめします。
ソーシャル メディアで #MadeWithTFJS のハッシュタグを付けて、プロジェクトが TensorFlow ブログや今後のイベントで紹介されるチャンスをお見逃しなく。皆さんが作るものを楽しみにしています。
TensorFlow.js のその他の Codelab: 理解を深める
- Firebase Hosting を使用して TensorFlow.js モデルを大規模にデプロイし、ホストします。
- TensorFlow.js で既製のオブジェクト検出モデルを使用してスマート ウェブカメラを作成する
おすすめのウェブサイト
- TensorFlow.js 公式ウェブサイト
- TensorFlow.js の既製モデル
- TensorFlow.js API
- TensorFlow.js のショーと伝える - インスピレーションを得て、他の人が作成したものを見る。