
1. আপনি শুরু করার আগে
এই কোডল্যাবটি TensorFlow.js ব্যবহার করে মন্তব্য স্প্যাম সনাক্তকরণের জন্য এই সিরিজের পূর্ববর্তী কোডল্যাবের শেষ ফলাফলের উপর ভিত্তি করে তৈরি করা হয়েছে।
শেষ কোডল্যাবে আপনি একটি কাল্পনিক ভিডিও ব্লগের জন্য একটি সম্পূর্ণ কার্যকরী ওয়েবপৃষ্ঠা তৈরি করেছেন৷ ব্রাউজারে TensorFlow.js দ্বারা চালিত একটি প্রাক-প্রশিক্ষিত মন্তব্য স্প্যাম সনাক্তকরণ মডেল ব্যবহার করে স্টোরেজের জন্য সার্ভারে বা অন্য সংযুক্ত ক্লায়েন্টদের কাছে পাঠানোর আগে আপনি স্প্যামের জন্য মন্তব্যগুলি ফিল্টার করতে সক্ষম হয়েছিলেন৷
সেই কোডল্যাবের শেষ ফলাফল নীচে দেখানো হয়েছে:
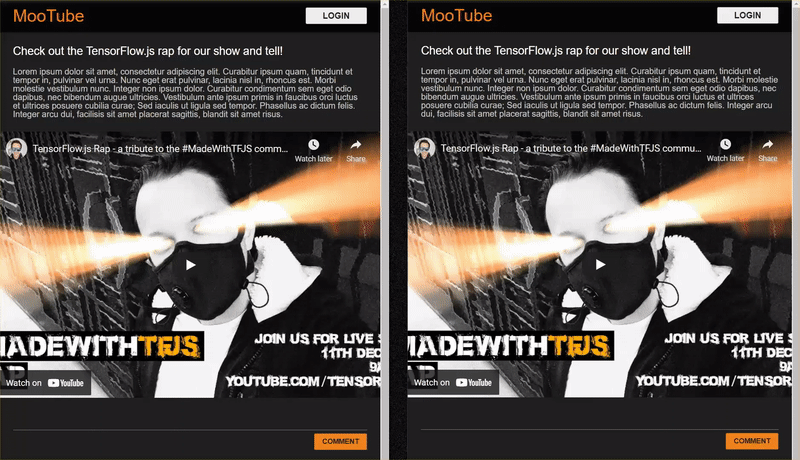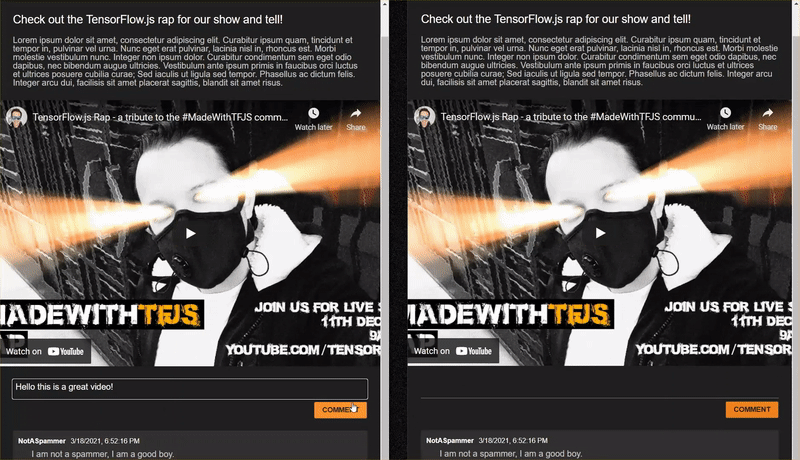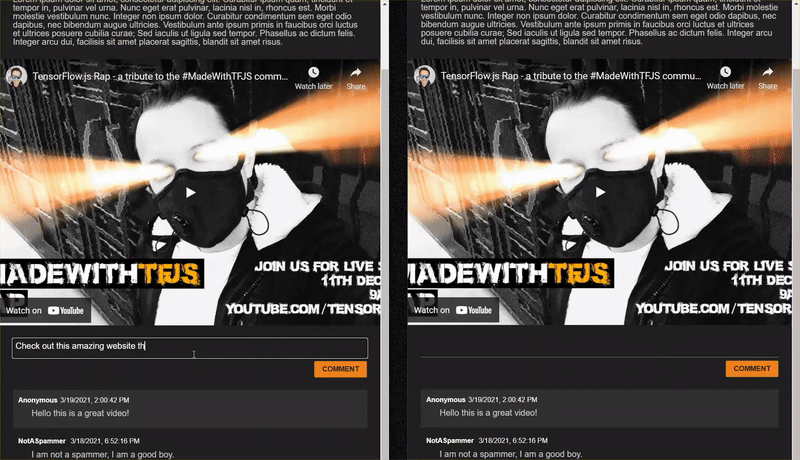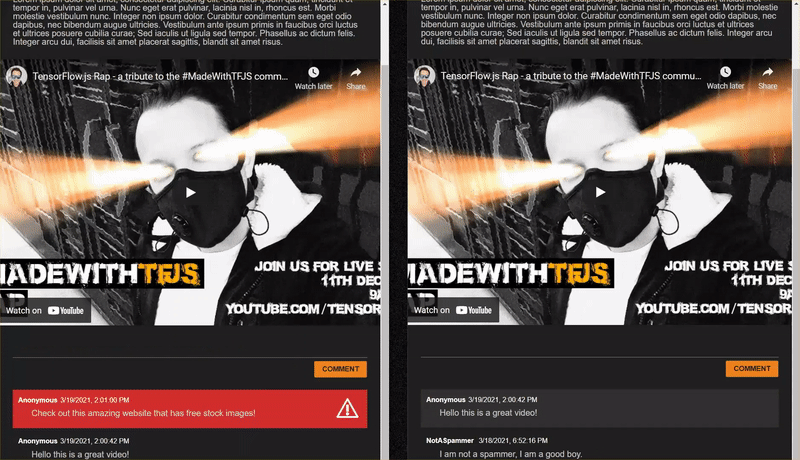
যদিও এটি খুব সুন্দরভাবে কাজ করেছে, সেখানে অন্বেষণ করার জন্য প্রান্তের কেস রয়েছে যে এটি সনাক্ত করতে অক্ষম। আপনি মডেলটিকে পুনরায় প্রশিক্ষণ দিতে পারেন যে পরিস্থিতিগুলি পরিচালনা করতে অক্ষম ছিল তার জন্য অ্যাকাউন্টে।
এই কোডল্যাবটি প্রাকৃতিক ভাষা প্রক্রিয়াকরণ (কম্পিউটার দিয়ে মানুষের ভাষা বোঝার শিল্প) ব্যবহার করার উপর ফোকাস করে এবং আপনাকে দেখায় কিভাবে আপনার তৈরি করা একটি বিদ্যমান ওয়েব অ্যাপ সংশোধন করতে হয় ( কোডল্যাবগুলিকে ক্রমানুসারে নেওয়ার জন্য এটি অত্যন্ত পরামর্শ দেওয়া হয়), কমেন্ট স্প্যামের আসল সমস্যা, যেটি অনেক ওয়েব ডেভেলপাররা অবশ্যই সম্মুখীন হবে যখন তারা বর্তমান সময়ে বিদ্যমান জনপ্রিয় ওয়েব অ্যাপের একটি ক্রমবর্ধমান সংখ্যায় কাজ করে।
এই কোডল্যাবে আপনি আপনার এমএল মডেলটিকে স্প্যাম বার্তা সামগ্রীতে পরিবর্তনের জন্য অ্যাকাউন্টে পুনরায় প্রশিক্ষণ দিয়ে আরও এক ধাপ এগিয়ে যাবেন যা সময়ের সাথে সাথে বিবর্তিত হতে পারে, বর্তমান প্রবণতা বা আলোচনার জনপ্রিয় বিষয়গুলির উপর ভিত্তি করে আপনাকে মডেলটিকে আপ টু ডেট রাখতে এবং অ্যাকাউন্টের জন্য অ্যাকাউন্ট করার অনুমতি দেয় যেমন পরিবর্তন।
পূর্বশর্ত
- এই সিরিজের প্রথম কোডল্যাব সম্পূর্ণ করেছে।
- HTML, CSS এবং JavaScript সহ ওয়েব প্রযুক্তির প্রাথমিক জ্ঞান।
আপনি কি নির্মাণ করবেন
আপনি একটি কাল্পনিক ভিডিও ব্লগের জন্য একটি রিয়েল টাইম মন্তব্য বিভাগ সহ পূর্বে নির্মিত ওয়েবসাইটটি পুনরায় ব্যবহার করবেন এবং TensorFlow.js ব্যবহার করে স্প্যাম সনাক্তকরণ মডেলের একটি কাস্টম প্রশিক্ষিত সংস্করণ লোড করতে এটিকে আপগ্রেড করবেন, তাই এটি এজ ক্ষেত্রে আরও ভাল পারফর্ম করে যেগুলি আগে এটি ব্যর্থ হত৷ . অবশ্যই ওয়েব ডেভেলপার এবং প্রকৌশলী হিসাবে আপনি এই কাল্পনিক UX যেকোন ওয়েবসাইটে পুনঃব্যবহারের জন্য পরিবর্তন করতে পারেন যা আপনি আপনার প্রতিদিনের ভূমিকায় কাজ করছেন এবং যেকোন ক্লায়েন্ট ব্যবহারের ক্ষেত্রে মানানসই সমাধানটি মানিয়ে নিতে পারেন - হতে পারে এটি একটি ব্লগ, ফোরাম বা কিছু CMS এর ফর্ম, যেমন ড্রুপাল।
আসুন হ্যাকিং করা যাক...
আপনি কি শিখবেন
আপনি করবেন:
- প্রাক-প্রশিক্ষিত মডেল ব্যর্থ হয়েছে প্রান্ত ক্ষেত্রে চিহ্নিত করুন
- মডেল মেকার ব্যবহার করে তৈরি করা স্প্যাম শ্রেণীবিভাগের মডেলটিকে পুনরায় প্রশিক্ষণ দিন।
- ব্রাউজারে ব্যবহারের জন্য এই পাইথন ভিত্তিক মডেলটি TensorFlow.js ফরম্যাটে রপ্তানি করুন।
- সদ্য প্রশিক্ষিত একজনের সাথে হোস্ট করা মডেল এবং এর অভিধান আপডেট করুন এবং ফলাফল পরীক্ষা করুন
HTML5, CSS, এবং JavaScript এর সাথে পরিচিতি এই ল্যাবের জন্য ধরে নেওয়া হয়। আপনি মডেল মেকার ব্যবহার করে তৈরি করা মডেলটিকে পুনরায় প্রশিক্ষণের জন্য একটি "কো ল্যাব" নোটবুকের মাধ্যমে কিছু পাইথন কোড চালাবেন, তবে এটি করার জন্য পাইথনের সাথে কোনও পরিচিতির প্রয়োজন নেই৷
2. কোড সেট আপ করুন
আবার আপনি ওয়েব অ্যাপ্লিকেশন হোস্ট এবং পরিবর্তন করতে Glitch.com ব্যবহার করবেন। যদি আপনি ইতিমধ্যেই পূর্বশর্ত কোডল্যাব সম্পূর্ণ না করে থাকেন, তাহলে আপনি শেষ ফলাফলটি এখানে আপনার শুরুর বিন্দু হিসেবে ক্লোন করতে পারেন। কোডটি কীভাবে কাজ করে সে সম্পর্কে আপনার যদি প্রশ্ন থাকে তবে এটি জোরদারভাবে উত্সাহিত করা হচ্ছে যে আপনি চালিয়ে যাওয়ার আগে এই কার্যকরী ওয়েব অ্যাপটি কীভাবে তৈরি করবেন তার পূর্বের কোডল্যাবটি সম্পূর্ণ করুন ৷
Glitch-এ, এটিকে কাঁটাচামচ করতে এবং আপনি সম্পাদনা করতে পারেন এমন ফাইলগুলির একটি নতুন সেট তৈরি করতে এই বোতামটি রিমিক্সে ক্লিক করুন।
3. পূর্ববর্তী সমাধানে প্রান্ত কেস আবিষ্কার করুন
আপনি যদি এইমাত্র ক্লোন করা সম্পূর্ণ ওয়েবসাইটটি খুলেন এবং কিছু মন্তব্য টাইপ করার চেষ্টা করেন তবে আপনি লক্ষ্য করবেন যে বেশিরভাগ সময় এটি উদ্দেশ্য হিসাবে কাজ করে, প্রত্যাশিত স্প্যামের মতো শোনায় এমন মন্তব্যগুলিকে ব্লক করে এবং বৈধ প্রতিক্রিয়াগুলির মাধ্যমে অনুমতি দেয়৷
যাইহোক, আপনি যদি কৌশলী হন এবং মডেলটি ভাঙতে চেষ্টা করেন এবং শব্দগুচ্ছ করেন তবে আপনি সম্ভবত কিছু সময়ে সফল হবেন। কিছুটা ট্রায়াল এবং ত্রুটির সাথে আপনি ম্যানুয়ালি নীচে দেখানো উদাহরণগুলি তৈরি করতে পারেন৷ বিদ্যমান ওয়েব অ্যাপে এগুলি পেস্ট করার চেষ্টা করুন, কনসোলটি পরীক্ষা করুন এবং মন্তব্যটি স্প্যাম হলে ফিরে আসার সম্ভাবনাগুলি দেখুন:
সমস্যা ছাড়াই পোস্ট করা বৈধ মন্তব্য (সত্য নেতিবাচক):
- "বাহ, আমি সেই ভিডিওটি পছন্দ করি, আশ্চর্যজনক কাজ।" স্প্যামের সম্ভাবনা: 47.91854%
- "পুরোপুরি এই ডেমো পছন্দ! আর কোন বিবরণ আছে?" সম্ভাব্যতা স্প্যাম: 47.15898%
- "আমি আরও জানতে কোন ওয়েবসাইটে যেতে পারি?" সম্ভাব্যতা স্প্যাম: 15.32495%
এটি দুর্দান্ত, উপরের সমস্তগুলির জন্য সম্ভাবনাগুলি বেশ কম এবং সফলভাবে এটিকে ডিফল্ট SPAM_THRESHOLD এর মাধ্যমে তৈরি করে একটি 75% ন্যূনতম সম্ভাব্যতার আগে পদক্ষেপ নেওয়ার আগে (আগের কোডল্যাব থেকে script.js কোডে সংজ্ঞায়িত)।
এখন আসুন চেষ্টা করি এবং আরও কিছু তীক্ষ্ণ মন্তব্য লিখি যা স্প্যাম হিসাবে চিহ্নিত হয় যদিও সেগুলি না হয়...
স্প্যাম হিসেবে চিহ্নিত বৈধ মন্তব্য (মিথ্যা ইতিবাচক):
- "কেউ কি তার পরা মুখোশের জন্য ওয়েবসাইট লিঙ্ক করতে পারে?" স্প্যামের সম্ভাবনা: 98.46466%
- "আমি কি স্পটিফাইতে এই গানটি কিনতে পারি? কেউ দয়া করে আমাকে জানান!" স্প্যামের সম্ভাবনা: 94.40953%
- "কেউ কি TensorFlow.js ডাউনলোড করার বিষয়ে বিস্তারিত জানতে আমার সাথে যোগাযোগ করতে পারেন?" সম্ভাব্যতা স্প্যাম: 83.20084%
আরে না! মনে হচ্ছে এই বৈধ মন্তব্যগুলিকে স্প্যাম হিসাবে চিহ্নিত করা হচ্ছে যখন তাদের অনুমতি দেওয়া উচিত৷ কিভাবে আপনি যে ঠিক করতে পারেন?
একটি সহজ বিকল্প হল SPAM_THRESHOLD বাড়িয়ে 98.5% আত্মবিশ্বাসী হওয়া। সেই ক্ষেত্রে এই ভুল শ্রেণিবদ্ধ মন্তব্যগুলি পোস্ট করা হবে। এটি মাথায় রেখে, আসুন নীচের অন্যান্য সম্ভাব্য ফলাফলগুলি চালিয়ে যাই...
স্প্যাম মন্তব্য স্প্যাম হিসাবে চিহ্নিত (সত্য ইতিবাচক):
- "এটি দুর্দান্ত তবে আমার ওয়েবসাইটে ডাউনলোড লিঙ্কগুলি দেখুন যা আরও ভাল!" সম্ভাব্যতা স্প্যাম: 99.77873%
- "আমি এমন কিছু লোককে জানি যারা আপনাকে কিছু ওষুধ পেতে পারে শুধু বিস্তারিত জানার জন্য আমার pr0file দেখুন" সম্ভাব্যতা স্প্যাম: 98.46955%
- "আরও ভালো ভিডিও ডাউনলোড করতে আমার প্রোফাইল দেখুন! http://example.com" সম্ভাব্যতা স্প্যাম: 96.26383%
ঠিক আছে, তাই এটি আমাদের মূল 75% থ্রেশহোল্ডের সাথে প্রত্যাশিতভাবে কাজ করছে, কিন্তু পূর্ববর্তী ধাপে আপনি SPAM_THRESHOLD 98.5% এর বেশি আত্মবিশ্বাসে পরিবর্তন করেছেন, এর অর্থ এখানে 2টি উদাহরণ দেওয়া হবে, তাই হয়ত থ্রেশহোল্ডটি খুব বেশি . হয়তো 96% ভাল? কিন্তু আপনি যদি তা করেন, তাহলে পূর্ববর্তী বিভাগের একটি মন্তব্য (মিথ্যা ইতিবাচক) স্প্যাম হিসাবে চিহ্নিত হবে যখন সেগুলি বৈধ ছিল কারণ এটি 98.46466% রেট করা হয়েছিল৷
এই ক্ষেত্রে সম্ভবত এই সমস্ত বাস্তব স্প্যাম মন্তব্যগুলি ক্যাপচার করা এবং উপরের ব্যর্থতার জন্য পুনরায় প্রশিক্ষণ দেওয়া সম্ভবত সেরা। থ্রেশহোল্ড 96% এ সেট করার মাধ্যমে সমস্ত সত্য ইতিবাচক এখনও ক্যাপচার করা হয় এবং আপনি উপরের 2টি মিথ্যা ইতিবাচক বাদ দেন। শুধুমাত্র একটি সংখ্যা পরিবর্তন করার জন্য খুব খারাপ নয়।
চলুন চালিয়ে যাই...
স্প্যাম মন্তব্য যা পোস্ট করার অনুমতি দেওয়া হয়েছিল (মিথ্যা নেতিবাচক):
- "আরও ভালো ভিডিও ডাউনলোড করতে আমার প্রোফাইল দেখুন!" স্প্যামের সম্ভাবনা: 7.54926%
- " আমাদের জিম প্রশিক্ষণ ক্লাসে ডিসকাউন্ট পান pr0file দেখুন! " সম্ভাব্যতা স্প্যাম: 17.49849%
- "ওএমজি GOOG স্টক ঠিক উপরে গুলি করা হয়েছে! খুব দেরি হওয়ার আগে পান!" স্প্যামের সম্ভাবনা: 20.42894%
এই মন্তব্যগুলির জন্য আপনি কেবল SPAM_THRESHOLD মান পরিবর্তন করে কিছুই করতে পারবেন না৷ স্প্যামের জন্য থ্রেশহোল্ড 96% থেকে ~9% কমিয়ে আসল মন্তব্যগুলিকে স্প্যাম হিসাবে চিহ্নিত করা হবে - তাদের মধ্যে একটির 58% রেটিং আছে যদিও এটি বৈধ। এই ধরনের মন্তব্যের সাথে মোকাবিলা করার একমাত্র উপায় হল প্রশিক্ষণের ডেটাতে অন্তর্ভুক্ত এই ধরনের এজ কেসগুলির সাথে মডেলটিকে পুনরায় প্রশিক্ষণ দেওয়া যাতে এটি স্প্যাম কি না তার জন্য বিশ্বের তার দৃষ্টিভঙ্গি সামঞ্জস্য করতে শিখে।
যদিও এখন একমাত্র বিকল্পটি হল মডেলটিকে পুনরায় প্রশিক্ষণ দেওয়া, আপনি এটিও দেখেছেন যে আপনি যখন কর্মক্ষমতা উন্নত করার জন্য কিছু স্প্যাম বলার সিদ্ধান্ত নেন তখন আপনি কীভাবে থ্রেশহোল্ডকে পরিমার্জন করতে পারেন৷ একজন মানুষ হিসাবে, 75% বেশ আত্মবিশ্বাসী বলে মনে হচ্ছে, কিন্তু এই মডেলের জন্য আপনাকে 81.5% এর কাছাকাছি বাড়াতে হবে উদাহরণ ইনপুটগুলির সাথে আরও কার্যকর হতে।
বিভিন্ন মডেল জুড়ে ভালোভাবে কাজ করে এমন কোনো একটি জাদুকরী মান নেই, এবং এই থ্রেশহোল্ড মানটি প্রতি মডেলের ভিত্তিতে সেট করা প্রয়োজন যা ভাল কাজ করে তার জন্য বাস্তব বিশ্বের ডেটা নিয়ে পরীক্ষা করার পরে।
এমন কিছু পরিস্থিতি থাকতে পারে যেখানে একটি মিথ্যা ইতিবাচক (বা নেতিবাচক) গুরুতর পরিণতি হতে পারে (যেমন চিকিৎসা শিল্পে) তাই আপনি আপনার থ্রেশহোল্ডকে খুব বেশি সামঞ্জস্য করতে পারেন এবং যে থ্রেশহোল্ড পূরণ করে না তাদের জন্য আরও ম্যানুয়াল পর্যালোচনার অনুরোধ করতে পারেন। এটি একজন বিকাশকারী হিসাবে আপনার পছন্দ এবং কিছু পরীক্ষা-নিরীক্ষার প্রয়োজন।
4. মন্তব্য স্প্যাম সনাক্তকরণ মডেল পুনরায় প্রশিক্ষণ
পূর্ববর্তী বিভাগে আপনি বেশ কয়েকটি প্রান্তের ক্ষেত্রে চিহ্নিত করেছেন যেগুলি মডেলের জন্য ব্যর্থ হয়েছিল যেখানে একমাত্র বিকল্প ছিল এই পরিস্থিতিগুলির জন্য মডেলটিকে পুনরায় প্রশিক্ষণ দেওয়া। একটি প্রোডাকশন সিস্টেমে আপনি সময়ের সাথে সাথে এইগুলি খুঁজে পেতে পারেন যখন লোকেরা একটি মন্তব্যকে স্প্যাম হিসাবে ম্যানুয়ালি ফ্ল্যাগ করে যাকে অনুমতি দেওয়া হয় বা পতাকাযুক্ত মন্তব্যগুলি পর্যালোচনা করে মডারেটররা বুঝতে পারেন যে কিছু আসলে স্প্যাম নয় এবং পুনরায় প্রশিক্ষণের জন্য এই জাতীয় মন্তব্যগুলি চিহ্নিত করতে পারে। ধরে নিচ্ছি আপনি এই এজ কেসগুলির জন্য একগুচ্ছ নতুন ডেটা সংগ্রহ করেছেন (সর্বোত্তম ফলাফলের জন্য যদি আপনি পারেন তবে এই নতুন বাক্যগুলির কিছু বৈচিত্র থাকা উচিত), আমরা এখন আপনাকে সেই প্রান্তের কেসগুলিকে মাথায় রেখে মডেলটিকে কীভাবে পুনরায় প্রশিক্ষণ দেওয়া যায় তা দেখানোর জন্য এগিয়ে যাব।
প্রি-মেড মডেল রিক্যাপ
আপনি যে পূর্ব-তৈরি মডেলটি ব্যবহার করেছেন সেটি একটি মডেল যা মডেল মেকারের মাধ্যমে তৃতীয় পক্ষের দ্বারা তৈরি করা হয়েছিল যা কাজ করার জন্য একটি "গড় শব্দ এম্বেডিং" মডেল ব্যবহার করে৷
যেহেতু মডেলটি Model Maker দিয়ে তৈরি করা হয়েছিল, আপনাকে মডেলটিকে পুনরায় প্রশিক্ষণের জন্য Python-এ সংক্ষেপে স্যুইচ করতে হবে এবং তারপর তৈরি করা মডেলটিকে TensorFlow.js ফরম্যাটে রপ্তানি করতে হবে যাতে আপনি এটি ব্রাউজারে ব্যবহার করতে পারেন। সৌভাগ্যক্রমে মডেল মেকার তাদের মডেলগুলি ব্যবহার করা খুব সহজ করে তোলে তাই এটি অনুসরণ করা বেশ সহজ হওয়া উচিত এবং আমরা আপনাকে প্রক্রিয়াটির মাধ্যমে গাইড করব তাই আপনি যদি আগে কখনও পাইথন ব্যবহার না করেন তবে চিন্তা করবেন না!
কোলাবস
যেহেতু আপনি এই কোডল্যাবে এতটা উদ্বিগ্ন নন যে সমস্ত পাইথন ইউটিলিটি ইনস্টল করা সহ একটি লিনাক্স সার্ভার সেট আপ করতে চান, আপনি "কোলাব নোটবুক" ব্যবহার করে ওয়েব ব্রাউজারের মাধ্যমে কোড চালাতে পারেন। এই নোটবুকগুলি একটি "ব্যাকএন্ড"-এর সাথে সংযোগ করতে পারে - যা কেবলমাত্র একটি সার্ভার যা কিছু জিনিস আগে থেকে ইনস্টল করা আছে, যেখান থেকে আপনি ওয়েব ব্রাউজারের মধ্যে নির্বিচারে কোড চালাতে পারেন এবং ফলাফলগুলি দেখতে পারেন৷ এটি দ্রুত প্রোটোটাইপ করার জন্য বা এই জাতীয় টিউটোরিয়ালগুলিতে ব্যবহারের জন্য খুব দরকারী।
শুধুমাত্র colab.research.google.com- এ যান এবং দেখানো হিসাবে আপনাকে একটি স্বাগত স্ক্রীন উপস্থাপন করা হবে:
এখন পপ আপ উইন্ডোর নীচে ডানদিকের নিউ নোটবুক বোতামে ক্লিক করুন এবং আপনি এইরকম একটি ফাঁকা কোলাব দেখতে পাবেন:
দারুণ! পরবর্তী ধাপ হল ফ্রন্টএন্ড কোল্যাবকে কিছু ব্যাকএন্ড সার্ভারের সাথে সংযুক্ত করা যাতে আপনি যে পাইথন কোডটি লিখবেন তা কার্যকর করতে পারেন। উপরের ডানদিকে সংযোগ ক্লিক করে এবং হোস্ট করা রানটাইমে সংযোগ নির্বাচন করে এটি করুন।
একবার সংযুক্ত হয়ে গেলে আপনি দেখতে পাবেন যে RAM এবং ডিস্ক আইকনগুলি এর জায়গায় উপস্থিত হবে, যেমন:
ভালো কাজ! আপনি এখন মডেল মেকার মডেলকে পুনরায় প্রশিক্ষণ দিতে পাইথনে কোডিং শুরু করতে পারেন। শুধু নিচের ধাপগুলো অনুসরণ করুন।
ধাপ 1
প্রথম ঘরে যেটি বর্তমানে খালি রয়েছে, নীচের কোডটি অনুলিপি করুন। এটি "পিপ" নামক পাইথনের প্যাকেজ ম্যানেজার ব্যবহার করে আপনার জন্য টেনসরফ্লো লাইট মডেল মেকার ইনস্টল করবে (এটি npm-এর মতো যা এই কোড ল্যাবের বেশিরভাগ পাঠক JS ইকোসিস্টেম থেকে আরও পরিচিত হতে পারে):
!apt-get install libasound-dev portaudio19-dev libportaudio2 libportaudiocpp0
!pip install -q tflite-model-maker
কক্ষে কোড আটকানো যদিও এটি কার্যকর করবে না। এরপরে, আপনি উপরের কোডটি যে ধূসর কক্ষে পেস্ট করেছেন তার উপরে আপনার মাউস ঘোরান, এবং নীচে হাইলাইট করা ঘরের বামদিকে একটি ছোট "প্লে" আইকন প্রদর্শিত হবে:
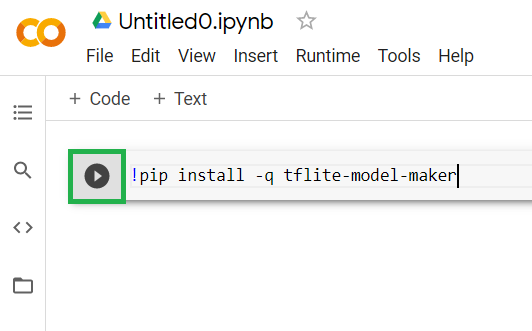 কক্ষে টাইপ করা কোডটি কার্যকর করতে প্লে বোতামে ক্লিক করুন।
কক্ষে টাইপ করা কোডটি কার্যকর করতে প্লে বোতামে ক্লিক করুন।
আপনি এখন মডেল মেকার ইনস্টল করা দেখতে পাবেন:
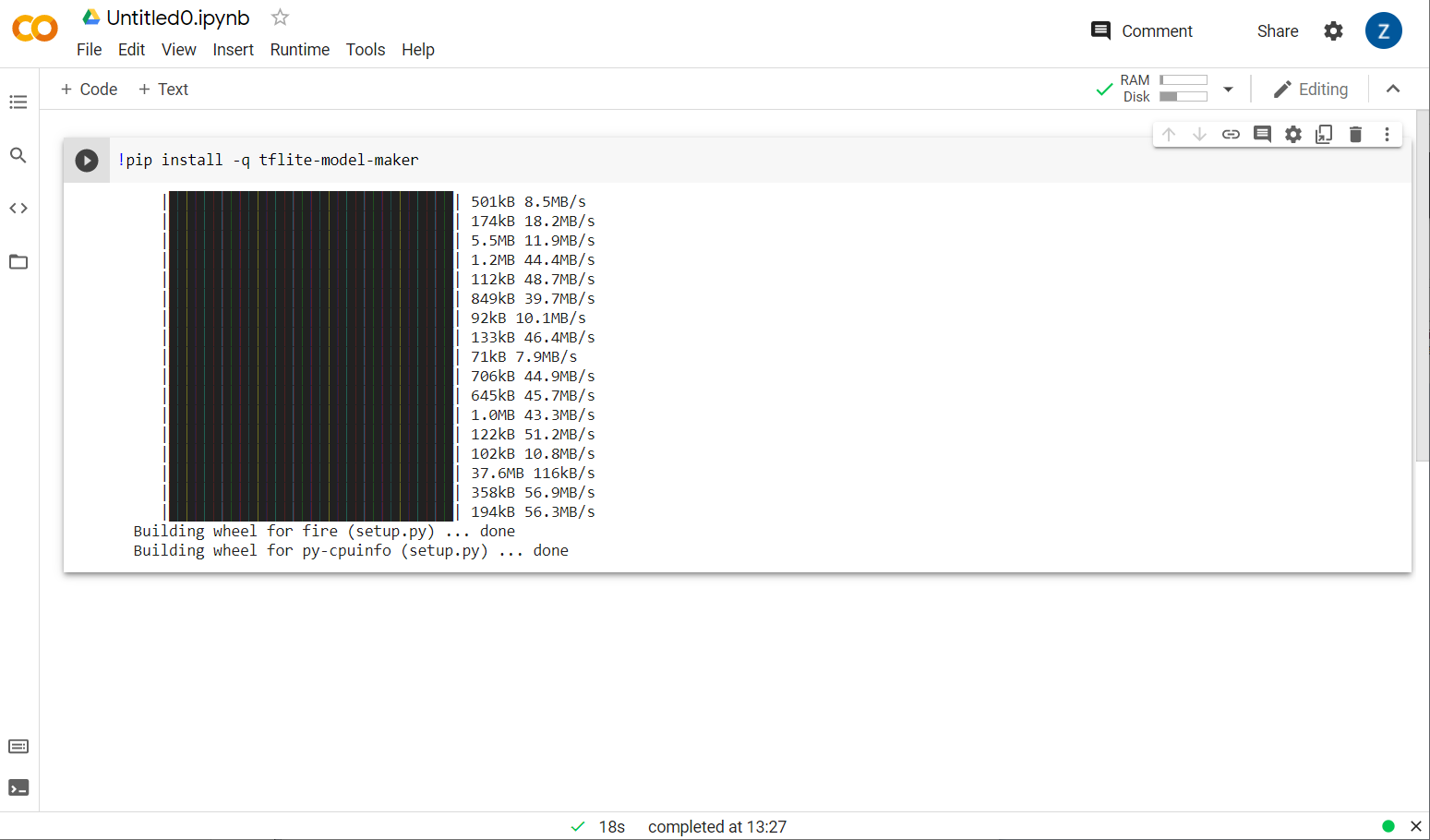
একবার দেখানো হিসাবে এই ঘরটির সম্পাদন সম্পূর্ণ হলে, নীচের পরবর্তী ধাপে যান।
ধাপ 2
এরপরে, দেখানো হিসাবে একটি নতুন কোড সেল যুক্ত করুন যাতে আপনি প্রথম ঘরের পরে আরও কিছু কোড পেস্ট করতে পারেন এবং এটি আলাদাভাবে চালাতে পারেন:
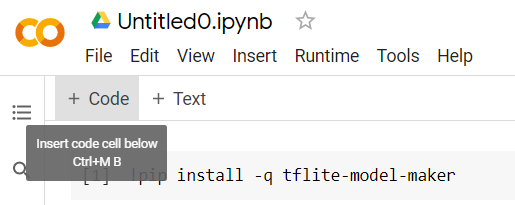
সম্পাদিত পরবর্তী সেলটিতে অনেকগুলি আমদানি থাকবে যা নোটবুকের বাকি কোডটি ব্যবহার করতে হবে৷ তৈরি করা নতুন ঘরে নীচেরটি অনুলিপি করুন এবং পেস্ট করুন:
import numpy as np
import os
from tflite_model_maker import configs
from tflite_model_maker import ExportFormat
from tflite_model_maker import model_spec
from tflite_model_maker import text_classifier
from tflite_model_maker.text_classifier import DataLoader
import tensorflow as tf
assert tf.__version__.startswith('2')
tf.get_logger().setLevel('ERROR')
আপনি পাইথনের সাথে পরিচিত না হলেও বেশ মানসম্মত জিনিস। আপনি শুধু কিছু ইউটিলিটি আমদানি করছেন এবং স্প্যাম শ্রেণীবিভাগের জন্য প্রয়োজনীয় মডেল মেকার ফাংশন। আপনি TensorFlow 2.x চালাচ্ছেন কিনা তা দেখতে এটিও পরীক্ষা করবে যা মডেল মেকার ব্যবহার করার জন্য প্রয়োজনীয়।
পরিশেষে, ঠিক আগের মতই, যখন আপনি সেলের উপরে হোভার করবেন তখন "প্লে" আইকন টিপে সেলটি এক্সিকিউট করুন এবং পরবর্তী ধাপের জন্য একটি নতুন কোড সেল যোগ করুন।
ধাপ 3
এরপরে আপনি আপনার ডিভাইসে একটি দূরবর্তী সার্ভার থেকে ডেটা ডাউনলোড করবেন এবং ডাউনলোড করা স্থানীয় ফাইলের পাথ হিসাবে training_data ভেরিয়েবল সেট করবেন:
data_file = tf.keras.utils.get_file(fname='comment-spam-extras.csv', origin='https://storage.googleapis.com/jmstore/TensorFlowJS/EdX/code/6.5/jm_blog_comments_extras.csv', extract=False)
মডেল মেকার ডাউনলোড করা সহজ CSV ফাইল থেকে মডেলদের প্রশিক্ষণ দিতে পারে। আপনাকে শুধু নির্দিষ্ট করতে হবে কোন কলামে টেক্সট থাকবে এবং কোনটি লেবেল ধরে থাকবে। আপনি ধাপ 5-এ এটি কীভাবে করবেন তা দেখতে পাবেন। আপনি চাইলে নির্দ্বিধায় CSV ফাইলটি সরাসরি ডাউনলোড করুন এতে কী রয়েছে তা দেখতে।
এই ফাইলটির নাম jm_blog_comments _extras .csv - এই ফাইলটি কেবলমাত্র মূল প্রশিক্ষণ ডেটা যা আমরা আপনার আবিষ্কৃত নতুন এজ কেস ডেটার সাথে মিলিত প্রথম মন্তব্য স্প্যাম মডেল তৈরি করতে ব্যবহার করেছি। ফাইল আপনি যে নতুন বাক্যগুলি থেকে শিখতে চান তার পাশাপাশি মডেলটিকে প্রশিক্ষণ দেওয়ার জন্য ব্যবহৃত মূল প্রশিক্ষণ ডেটার প্রয়োজন।
ঐচ্ছিক: আপনি যদি এই CSV ফাইলটি ডাউনলোড করেন এবং শেষ কয়েকটি লাইন চেক করেন তাহলে আপনি এজ কেসগুলির উদাহরণ দেখতে পাবেন যা আগে সঠিকভাবে কাজ করছিল না। এগুলি কেবলমাত্র বিদ্যমান প্রশিক্ষণ ডেটার শেষে যোগ করা হয়েছে যা পূর্ব-নির্মিত মডেলটি নিজেকে প্রশিক্ষণের জন্য ব্যবহৃত হয়।
এই সেলটি এক্সিকিউট করুন, তারপর এটি চালানো শেষ হলে, একটি নতুন সেল যোগ করুন এবং ধাপ 4 এ যান।
ধাপ 4
মডেল মেকার ব্যবহার করার সময়, আপনি স্ক্র্যাচ থেকে মডেল তৈরি করবেন না। আপনি সাধারণত বিদ্যমান মডেলগুলি ব্যবহার করেন যা আপনি আপনার প্রয়োজন অনুসারে কাস্টমাইজ করবেন।
মডেল মেকার আপনি ব্যবহার করতে পারেন এমন বেশ কয়েকটি প্রি-লার্ন মডেল এমবেডিং প্রদান করে, তবে সবচেয়ে সহজ এবং দ্রুত শুরু করা হল average_word_vec যা আপনি আপনার ওয়েবসাইট তৈরি করতে আগের কোডল্যাবে ব্যবহার করেছেন। এখানে কোড আছে:
spec = model_spec.get('average_word_vec')
spec.num_words = 2000
spec.seq_len = 20
spec.wordvec_dim = 7
আপনি নতুন কক্ষে এটি পেস্ট করার পরে এগিয়ে যান এবং চালান৷
বোঝা
num_words
প্যারামিটার
এই শব্দের সংখ্যা আপনি মডেল ব্যবহার করতে চান. আপনি ভাবতে পারেন যে যত বেশি তত ভাল, তবে সাধারণত প্রতিটি শব্দ ব্যবহার করা ফ্রিকোয়েন্সির উপর ভিত্তি করে একটি মিষ্টি জায়গা রয়েছে। আপনি যদি সম্পূর্ণ কর্পাসের প্রতিটি শব্দ ব্যবহার করেন, তাহলে আপনি মডেলটি শিখতে এবং শুধুমাত্র একবার ব্যবহৃত শব্দের ওজনের ভারসাম্য বজায় রাখার চেষ্টা করতে পারেন - এটি খুব দরকারী নয়। আপনি যেকোন টেক্সট কর্পাসে দেখতে পাবেন যে অনেক শব্দ শুধুমাত্র একবার বা দুইবার ব্যবহার করা হয়, এবং সাধারণত সেগুলি আপনার মডেলে ব্যবহার করা মূল্যবান নয় কারণ তাদের সামগ্রিক অনুভূতিতে নগণ্য প্রভাব রয়েছে। তাই আপনি num_words প্যারামিটার ব্যবহার করে আপনার পছন্দের শব্দের সংখ্যার উপর আপনার মডেল টিউন করতে পারেন। এখানে একটি ছোট সংখ্যার একটি ছোট এবং দ্রুত মডেল থাকবে, কিন্তু এটি কম সঠিক হতে পারে, কারণ এটি কম শব্দ চিনতে পারে। এখানে একটি বড় সংখ্যার একটি বড় এবং সম্ভাব্য ধীর মডেল থাকবে৷ আপনার ব্যবহারের ক্ষেত্রে কোনটি সবচেয়ে ভাল কাজ করে তা নির্ধারণ করার জন্য একটি মেশিন লার্নিং ইঞ্জিনিয়ার হিসাবে মিষ্টি স্পটটি খুঁজে পাওয়াটাই গুরুত্বপূর্ণ এবং এটি আপনার উপর নির্ভর করে।
বোঝা
wordvec_dim
প্যারামিটার
wordvec_dim প্যারামিটার হল প্রতিটি শব্দের ভেক্টরের জন্য আপনি যে মাত্রাগুলি ব্যবহার করতে চান তার সংখ্যা। এই মাত্রাগুলি মূলত বিভিন্ন বৈশিষ্ট্য (প্রশিক্ষণ দেওয়ার সময় মেশিন লার্নিং অ্যালগরিদম দ্বারা তৈরি) যে কোনও প্রদত্ত শব্দ পরিমাপ করা যেতে পারে যার মাধ্যমে প্রোগ্রামটি চেষ্টা করবে এবং সর্বোত্তমভাবে কিছু অর্থপূর্ণ উপায়ে অনুরূপ শব্দগুলিকে ব্যবহার করবে৷
উদাহরণস্বরূপ, একটি শব্দ কতটা "মেডিকেল" ছিল তার জন্য আপনার যদি একটি মাত্রা থাকে, তাহলে "পিলস" এর মতো একটি শব্দ এখানে এই মাত্রায় উচ্চ স্কোর করতে পারে এবং "xray" এর মতো অন্যান্য উচ্চ স্কোরিং শব্দের সাথে যুক্ত হতে পারে, কিন্তু "বিড়াল" স্কোর করবে এই মাত্রা কম. এটি চালু হতে পারে যে একটি "চিকিৎসা মাত্রা" স্প্যাম নির্ধারণের জন্য উপযোগী যখন অন্যান্য সম্ভাব্য মাত্রার সাথে এটি ব্যবহার করার সিদ্ধান্ত নিতে পারে যেগুলি তাৎপর্যপূর্ণ।
"মেডিকেল ডাইমেনশন"-এ উচ্চ স্কোর করে এমন শব্দের ক্ষেত্রে এটা মনে হতে পারে যে মানবদেহের সাথে শব্দের সম্পর্কযুক্ত একটি 2য় মাত্রা কার্যকর হতে পারে। "লেগ", "বাহু", "ঘাড়" এর মতো শব্দগুলি এখানে উচ্চ স্কোর করতে পারে এবং চিকিৎসা মাত্রায়ও মোটামুটি উচ্চ।
মডেলটি এই মাত্রাগুলি ব্যবহার করে তারপরে স্প্যামের সাথে যুক্ত শব্দগুলি সনাক্ত করতে সক্ষম করতে পারে৷ হতে পারে স্প্যাম ইমেলগুলিতে এমন শব্দ থাকার সম্ভাবনা বেশি থাকে যা মেডিকেল এবং মানবদেহের উভয় অঙ্গ।
গবেষনা থেকে স্থির করা নিয়ম হল যে শব্দ সংখ্যার চতুর্থ মূল এই প্যারামিটারের জন্য ভাল কাজ করে। তাই যদি আমি 2000 শব্দ ব্যবহার করি, তাহলে এর জন্য একটি ভাল সূচনা পয়েন্ট হল 7 মাত্রা। আপনি ব্যবহৃত শব্দের সংখ্যা পরিবর্তন করলে, আপনি এটিও পরিবর্তন করতে পারেন।
বোঝা
seq_len
প্যারামিটার
ইনপুট মানগুলির ক্ষেত্রে মডেলগুলি সাধারণত খুব কঠোর হয়৷ একটি ভাষা মডেলের জন্য, এর মানে হল যে ভাষা মডেল একটি নির্দিষ্ট, স্থির, দৈর্ঘ্যের বাক্যকে শ্রেণীবদ্ধ করতে পারে। এটি seq_len প্যারামিটার দ্বারা নির্ধারিত হয়, যেখানে এটি 'সিকোয়েন্স লেন্থ' এর জন্য দাঁড়ায়। আপনি যখন শব্দকে সংখ্যায় (বা টোকেন) রূপান্তর করেন, তখন একটি বাক্য এই টোকেনগুলির একটি ক্রম হয়ে যায়। সুতরাং আপনার মডেলকে (এই ক্ষেত্রে) 20টি টোকেন আছে এমন বাক্যগুলিকে শ্রেণিবদ্ধ করতে এবং সনাক্ত করতে প্রশিক্ষিত করা হবে। যদি বাক্যটি এর চেয়ে দীর্ঘ হয় তবে তা কেটে ফেলা হবে। যদি এটি ছোট হয় তবে এটি প্যাড করা হবে - ঠিক এই সিরিজের প্রথম কোডল্যাবের মতো।
ধাপ 5 - প্রশিক্ষণ ডেটা লোড করুন
আগে আপনি CSV ফাইল ডাউনলোড করেছেন। মডেলটি চিনতে পারে এমন প্রশিক্ষণ ডেটাতে পরিণত করার জন্য এখন একটি ডেটা লোডার ব্যবহার করার সময়।
data = DataLoader.from_csv(
filename=data_file,
text_column='commenttext',
label_column='spam',
model_spec=spec,
delimiter=',',
shuffle=True,
is_training=True)
train_data, test_data = data.split(0.9)
আপনি যদি একটি এডিটরে CSV ফাইলটি খোলেন, আপনি দেখতে পাবেন যে প্রতিটি লাইনে দুটি মান রয়েছে এবং ফাইলের প্রথম লাইনে পাঠ্য সহ বর্ণনা করা হয়েছে। সাধারণত প্রতিটি এন্ট্রিকে একটি 'কলাম' হিসেবে গণ্য করা হয়। আপনি দেখতে পাবেন যে প্রথম কলামের বর্ণনাকারী হল commenttext , এবং প্রতিটি লাইনের প্রথম এন্ট্রি হল মন্তব্যের পাঠ্য।
একইভাবে, দ্বিতীয় কলামের বর্ণনাকারী হল spam , এবং আপনি দেখতে পাবেন যে প্রতিটি লাইনের দ্বিতীয় এন্ট্রিটি সত্য বা মিথ্যা তা বোঝাতে যদি সেই পাঠ্যটিকে মন্তব্য স্প্যাম হিসাবে বিবেচনা করা হয় বা না হয়। অন্যান্য বৈশিষ্ট্যগুলি মডেল স্পেক সেট করে যা আপনি ধাপ 4 এ তৈরি করেছেন, একটি বিভাজক অক্ষর সহ, যা এই ক্ষেত্রে একটি কমা কারণ ফাইলটি কমা দ্বারা পৃথক করা হয়েছে। আপনি প্রশিক্ষণ ডেটাকে এলোমেলোভাবে পুনর্বিন্যাস করার জন্য একটি শাফেল প্যারামিটারও সেট করেছেন যাতে একই রকম বা একত্রে সংগৃহীত জিনিসগুলি এলোমেলোভাবে সমগ্র ডেটা সেট জুড়ে ছড়িয়ে পড়ে।
তারপর আপনি ডেটাকে প্রশিক্ষণ এবং পরীক্ষার ডেটাতে বিভক্ত করতে data.split() ব্যবহার করবেন। .9 নির্দেশ করে যে ডেটাসেটের 90% প্রশিক্ষণের জন্য ব্যবহার করা হবে, বাকিটা পরীক্ষার জন্য।
ধাপ 6 - মডেল তৈরি করুন
আরেকটি সেল যোগ করুন যেখানে আমরা মডেল তৈরি করতে কোড যোগ করব:
model = text_classifier.create(train_data, model_spec=spec, epochs=50)
এটি মডেল মেকারের সাথে একটি টেক্সট ক্লাসিফায়ার মডেল তৈরি করে, এবং আপনি যে প্রশিক্ষণ ডেটা ব্যবহার করতে চান তা নির্দিষ্ট করুন (যা ধাপ 4 এ সংজ্ঞায়িত করা হয়েছে), মডেল স্পেসিফিকেশন (যা ধাপ 4 এও সেট করা হয়েছিল), এবং বেশ কয়েকটি যুগ, এই ক্ষেত্রে 50.
মেশিন লার্নিং এর মূল নীতি হল এটি প্যাটার্ন ম্যাচিং এর একটি ফর্ম। প্রাথমিকভাবে, এটি শব্দগুলির জন্য প্রাক-প্রশিক্ষিত ওজনগুলি লোড করবে এবং তাদের একটি 'ভবিষ্যদ্বাণী' সহ একত্রিত করার চেষ্টা করবে কোনটি একসাথে গোষ্ঠীবদ্ধ হলে স্প্যাম নির্দেশ করে এবং কোনটি নয়৷ প্রথমবার, এটি সম্ভবত 50:50 এর কাছাকাছি হতে পারে, কারণ মডেলটি শুধুমাত্র নীচে দেখানো হিসাবে শুরু হচ্ছে:

তারপরে এটি এর ফলাফলগুলি পরিমাপ করবে এবং এর ভবিষ্যদ্বাণীকে পরিবর্তন করতে মডেলের ওজন পরিবর্তন করবে এবং এটি আবার চেষ্টা করবে। এটি একটি যুগ। সুতরাং, epochs=50 নির্দিষ্ট করে, এটি সেই 'লুপ'-এর মধ্য দিয়ে 50 বার যাবে যেমন দেখানো হয়েছে:

সুতরাং আপনি যখন 50 তম যুগে পৌঁছাবেন, মডেলটি অনেক উচ্চ স্তরের নির্ভুলতার রিপোর্ট করবে। এই ক্ষেত্রে 99.1% দেখাচ্ছে!
ধাপ 7 - মডেলটি রপ্তানি করুন
আপনার প্রশিক্ষণ শেষ হয়ে গেলে, আপনি মডেলটি রপ্তানি করতে পারেন। TensorFlow একটি মডেলকে তার নিজস্ব বিন্যাসে প্রশিক্ষণ দেয় এবং এটিকে একটি ওয়েব পৃষ্ঠায় ব্যবহারের জন্য TensorFlow.js বিন্যাসে রূপান্তর করতে হবে। শুধুমাত্র একটি নতুন কক্ষে নিম্নলিখিত পেস্ট করুন এবং এটি চালান:
model.export(export_dir="/js_export/", export_format=[ExportFormat.TFJS, ExportFormat.LABEL, ExportFormat.VOCAB])
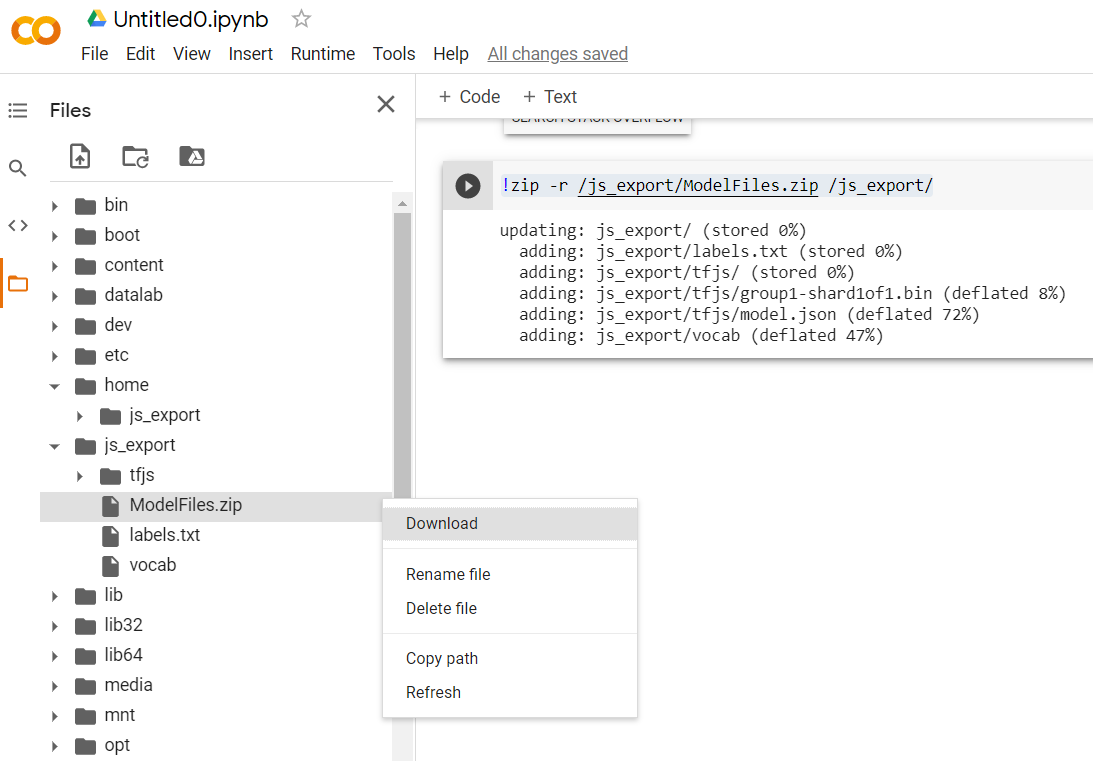
!zip -r /js_export/ModelFiles.zip /js_export/
এই কোডটি কার্যকর করার পরে, আপনি Colab-এর বাম দিকের ছোট ফোল্ডার আইকনে ক্লিক করলে আপনি উপরে যে ফোল্ডারে এক্সপোর্ট করেছেন সেখানে নেভিগেট করতে পারবেন (রুট ডিরেক্টরিতে - আপনাকে একটি লেভেল উপরে যেতে হতে পারে) এবং এর জিপ বান্ডেল খুঁজে পেতে পারেন। ModelFiles.zip এ থাকা ফাইল রপ্তানি করা হয়।
এই জিপ ফাইলটি এখন আপনার কম্পিউটারে ডাউনলোড করুন কারণ আপনি সেই ফাইলগুলিকে প্রথম কোডল্যাবের মতোই ব্যবহার করবেন:
দারুণ! পাইথন অংশ শেষ, আপনি এখন জাভাস্ক্রিপ্ট ল্যান্ডে ফিরে যেতে পারেন যা আপনি জানেন এবং ভালবাসেন। ফাউ!
5. নতুন মেশিন লার্নিং মডেল পরিবেশন করা
আপনি এখন মডেল লোড করার জন্য প্রায় প্রস্তুত. আপনি এটি করার আগে যদিও আপনাকে কোডল্যাবে আগে ডাউনলোড করা নতুন মডেল ফাইলগুলি আপলোড করতে হবে যাতে এটি আপনার কোডের মধ্যে হোস্ট করা এবং ব্যবহারযোগ্য।
প্রথমত, আপনি যদি ইতিমধ্যে এটি না করে থাকেন, আপনি এইমাত্র যে মডেল মেকার কোলাব নোটবুকটি চালান তা থেকে ডাউনলোড করা মডেলের ফাইলগুলি আনজিপ করুন৷ আপনার বিভিন্ন ফোল্ডারের মধ্যে থাকা নিম্নলিখিত ফাইলগুলি দেখতে হবে:
আপনার এখানে কি আছে?
-
model.json- এটি এমন একটি ফাইল যা প্রশিক্ষিত TensorFlow.js মডেল তৈরি করে। আপনি JS কোডে এই নির্দিষ্ট ফাইলটি উল্লেখ করবেন। -
group1-shard1of1.bin- এটি একটি বাইনারি ফাইল যাতে রপ্তানি করা TensorFlow.js মডেলের জন্য অনেক বেশি সংরক্ষিত ডেটা রয়েছে এবং উপরেরmodel.jsonএর মতো একই ডিরেক্টরিতে ডাউনলোড করার জন্য আপনার সার্ভারে কোথাও হোস্ট করা প্রয়োজন। -
vocab- কোন এক্সটেনশন ছাড়াই এই অদ্ভুত ফাইলটি Model Maker থেকে এমন কিছু যা আমাদের দেখায় কিভাবে বাক্যে শব্দগুলিকে এনকোড করতে হয় যাতে মডেল বুঝতে পারে সেগুলি কীভাবে ব্যবহার করতে হয়৷ আপনি পরবর্তী বিভাগে এই বিষয়ে আরও ডুব দেবেন। -
labels.txt- এটিতে কেবল ফলের ক্লাসনাম রয়েছে যা মডেলটি ভবিষ্যদ্বাণী করবে। এই মডেলের জন্য আপনি যদি এই ফাইলটি আপনার টেক্সট এডিটরে খোলেন তাহলে এটির ভবিষ্যদ্বাণী আউটপুট হিসাবে "স্প্যাম নয়" বা "স্প্যাম" নির্দেশ করে "মিথ্যা" এবং "সত্য" তালিকাভুক্ত করা হয়েছে।
TensorFlow.js মডেল ফাইল হোস্ট করুন
প্রথমে model.json এবং *.bin ফাইলগুলি রাখুন যা একটি ওয়েব সার্ভারে তৈরি হয়েছিল যাতে আপনি আপনার ওয়েব পৃষ্ঠার মাধ্যমে সেগুলি অ্যাক্সেস করতে পারেন।
বিদ্যমান মডেল ফাইল মুছুন
যেহেতু আপনি এই সিরিজের প্রথম কোডল্যাবের শেষ ফলাফল তৈরি করছেন, আপনাকে প্রথমে আপলোড করা বিদ্যমান মডেল ফাইলগুলি মুছে ফেলতে হবে। আপনি যদি Glitch.com ব্যবহার করেন, তাহলে model.json এবং group1-shard1of1.bin এর জন্য বাম দিকের ফাইল প্যানেলটি পরীক্ষা করুন, প্রতিটি ফাইলের জন্য 3 ডট মেনু ড্রপডাউনে ক্লিক করুন এবং দেখানো হিসাবে মুছুন নির্বাচন করুন:
গ্লিচে নতুন ফাইল আপলোড করা হচ্ছে
দারুণ! এখন নতুন আপলোড করুন:
- আপনার গ্লিচ প্রকল্পের বাম হাতের প্যানেলে সম্পদ ফোল্ডারটি খুলুন এবং আপলোড করা পুরানো সম্পদগুলি মুছুন যদি তাদের একই নাম থাকে।
- একটি সম্পদ আপলোড ক্লিক করুন এবং এই ফোল্ডারে আপলোড করতে
group1-shard1of1.binনির্বাচন করুন৷ একবার আপলোড করা হলে এটি এখন এইরকম হওয়া উচিত:
- দারুণ! এখন model.json ফাইলের জন্যও একই কাজ করুন যাতে 2টি ফাইল আপনার সম্পদ ফোল্ডারে এইভাবে থাকা উচিত:
- আপনি এইমাত্র আপলোড করা
group1-shard1of1.binফাইলটিতে ক্লিক করলে আপনি URLটিকে এর অবস্থানে অনুলিপি করতে সক্ষম হবেন। দেখানো হিসাবে এখন এই পথটি অনুলিপি করুন:
- এখন স্ক্রিনের নীচে বাম দিকে, Tools > Terminal এ ক্লিক করুন। টার্মিনাল উইন্ডো লোড হওয়ার জন্য অপেক্ষা করুন।
- একবার লোড হয়ে গেলে নিম্নলিখিতটি টাইপ করুন এবং তারপর
wwwফোল্ডারে ডিরেক্টরি পরিবর্তন করতে এন্টার টিপুন:
টার্মিনাল:
cd www
- এরপর, Glitch-এ সম্পদ ফোল্ডারে ফাইলগুলির জন্য তৈরি করা URLগুলির সাথে নীচের URLগুলি প্রতিস্থাপন করে মাত্র আপলোড করা 2টি ফাইল ডাউনলোড করতে
wgetব্যবহার করুন (প্রতিটি ফাইলের কাস্টম URL-এর জন্য সম্পদ ফোল্ডারটি পরীক্ষা করুন)৷
দুটি ইউআরএল-এর মধ্যবর্তী স্থান এবং আপনার যে ইউআরএলগুলি ব্যবহার করতে হবে সেগুলি দেখানোর থেকে আলাদা হবে কিন্তু দেখতে একই রকম হবে:
টার্মিনাল
wget https://cdn.glitch.com/1cb82939-a5dd-42a2-9db9-0c42cab7e407%2Fmodel.json?v=1616111344958 https://cdn.glitch.com/1cb82939-a5dd-42a2-9db9-0c42cab7e407%2Fgroup1-shard1of1.bin?v=1616017964562
সুপার! আপনি এখন www ফোল্ডারে আপলোড করা ফাইলগুলির একটি অনুলিপি তৈরি করেছেন৷
যাইহোক, এই মুহূর্তে তারা অদ্ভুত নাম দিয়ে ডাউনলোড করা হবে. আপনি টার্মিনালে ls লিখে এন্টার চাপলে এরকম কিছু দেখতে পাবেন:

-
mvকমান্ড ব্যবহার করে ফাইলগুলির নাম পরিবর্তন করুন। কনসোলে নিম্নলিখিতটি টাইপ করুন এবং প্রতিটি লাইনের পরে এন্টার টিপুন:
টার্মিনাল:
mv *group1-shard1of1.bin* group1-shard1of1.bin
mv *model.json* model.json
- অবশেষে, টার্মিনালে
refreshটাইপ করে গ্লিচ প্রজেক্ট রিফ্রেশ করুন এবং এন্টার টিপুন:
টার্মিনাল:
refresh
রিফ্রেশ করার পরে আপনি এখন ইউজার ইন্টারফেসের www ফোল্ডারে model.json এবং group1-shard1of1.bin দেখতে পাবেন:
দারুণ! শেষ ধাপ হল dictionary.js ফাইলটি আপডেট করা।
- আপনার নতুন ডাউনলোড করা vocab ফাইলটিকে সঠিক JS ফরম্যাটে রূপান্তর করুন ম্যানুয়ালি আপনার টেক্সট এডিটরের মাধ্যমে অথবা এই টুলটি ব্যবহার করে এবং ফলস্বরূপ আউটপুটটি আপনার
wwwফোল্ডারের মধ্যেdictionary.jsহিসাবে সংরক্ষণ করুন। আপনার যদি ইতিমধ্যে একটিdictionary.jsফাইল থাকে তবে আপনি কেবল এটিতে নতুন বিষয়বস্তু অনুলিপি এবং পেস্ট করতে পারেন এবং ফাইলটি সংরক্ষণ করতে পারেন।
উহু! আপনি সফলভাবে সমস্ত পরিবর্তিত ফাইল আপডেট করেছেন এবং আপনি যদি এখন ওয়েবসাইটটি ব্যবহার করার চেষ্টা করেন এবং ব্যবহার করেন তবে আপনি লক্ষ্য করবেন যে কীভাবে পুনরায় প্রশিক্ষিত মডেলটি আবিষ্কৃত এবং দেখানো এজ কেসগুলির জন্য হিসাব করতে সক্ষম হবে:
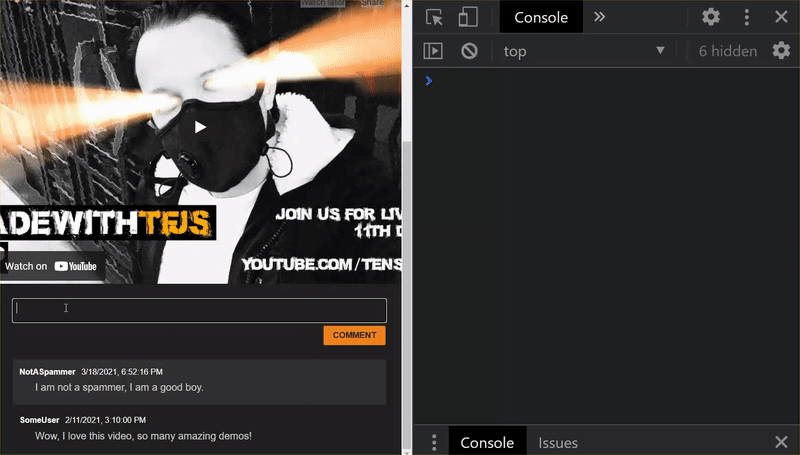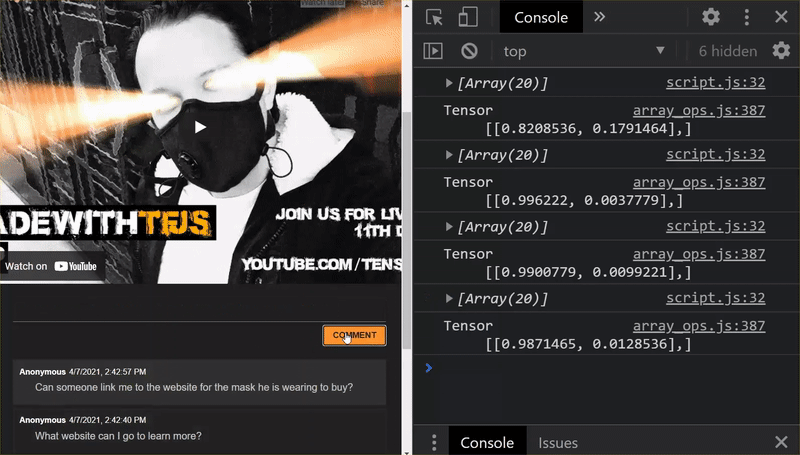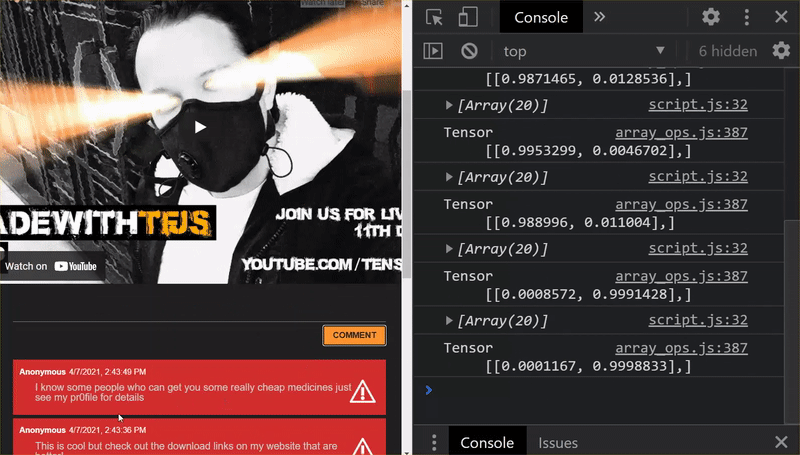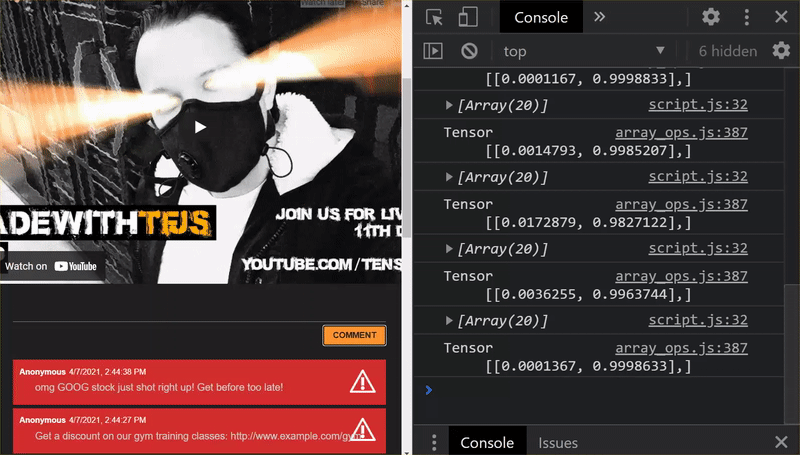
আপনি দেখতে পাচ্ছেন, প্রথম 6টি এখন সঠিকভাবে স্প্যাম নয় হিসাবে শ্রেণীবদ্ধ করা হয়েছে, এবং 6-এর 2য় ব্যাচকে স্প্যাম হিসাবে চিহ্নিত করা হয়েছে৷ নিখুঁত!
এটি ভালভাবে সাধারণ করা হয়েছে কিনা তা দেখতে কিছু বৈচিত্রও চেষ্টা করা যাক। মূলত একটি ব্যর্থ বাক্য ছিল যেমন:
" ওএমজি GOOG স্টক ঠিক উপরে গুলি করা হয়েছে! খুব দেরি হওয়ার আগে পান! "
এটি এখন সঠিকভাবে স্প্যাম হিসাবে শ্রেণীবদ্ধ করা হয়েছে, কিন্তু আপনি যদি এটিকে এতে পরিবর্তন করেন তবে কী হবে:
" তাই XYZ স্টকের মান বেড়েছে! খুব দেরি হওয়ার আগেই কিছু কিনুন! "
এখানে আপনি স্প্যাম হওয়ার সম্ভাবনা 98% এর একটি ভবিষ্যদ্বাণী পাবেন যা সঠিক যদিও আপনি স্টক প্রতীক এবং শব্দগুলি সামান্য পরিবর্তন করেছেন।
অবশ্যই আপনি যদি সত্যিই এই নতুন মডেলটি ভাঙ্গার চেষ্টা করেন, আপনি সক্ষম হবেন, এবং এটি আরও বেশি প্রশিক্ষণের ডেটা সংগ্রহ করতে নেমে আসবে যাতে আপনি অনলাইনে যে সাধারণ পরিস্থিতিগুলির মুখোমুখি হতে পারেন তার জন্য আরও অনন্য বৈচিত্রগুলি ক্যাপচার করার সর্বোত্তম সুযোগ রয়েছে৷ ভবিষ্যতের কোডল্যাবে আমরা আপনাকে দেখাব কিভাবে লাইভ ডেটা দিয়ে আপনার মডেলটিকে পতাকাঙ্কিত করার সাথে সাথে ক্রমাগত উন্নতি করতে হয়।
6. অভিনন্দন!
অভিনন্দন, আপনি বাস্তব বিশ্বের অ্যাপ্লিকেশনের জন্য TensorFlow.js-এর সাহায্যে ব্রাউজারে সেই পরিবর্তনগুলি খুঁজে পেয়েছেন এবং স্থাপন করেছেন এমন এজ কেসগুলির জন্য কাজ করার জন্য নিজেকে আপডেট করার জন্য আপনি একটি বিদ্যমান মেশিন লার্নিং মডেলকে পুনরায় প্রশিক্ষণ দিতে পেরেছেন৷
রিক্যাপ
এই কোডল্যাবে আপনি:
- আগে থেকে তৈরি মন্তব্য স্প্যাম মডেল ব্যবহার করার সময় কাজ করছে না যে প্রান্ত কেস আবিষ্কৃত
- আপনার আবিষ্কৃত এজ কেসগুলিকে বিবেচনায় নিতে মডেল মেকার মডেলটিকে পুনরায় প্রশিক্ষণ দেওয়া হয়েছে৷
- নতুন প্রশিক্ষিত মডেলটি TensorFlow.js ফর্ম্যাটে রপ্তানি করা হয়েছে
- নতুন ফাইল ব্যবহার করার জন্য আপনার ওয়েব অ্যাপ আপডেট করা হয়েছে
এরপর কি?
সুতরাং এই আপডেটটি দুর্দান্ত কাজ করে, তবে যে কোনও ওয়েব অ্যাপের মতো, সময়ের সাথে সাথে পরিবর্তন ঘটবে। আমাদের প্রতিবার ম্যানুয়ালি এটি করার পরিবর্তে অ্যাপটি সময়ের সাথে সাথে নিজেকে ক্রমাগত উন্নত করলে এটি আরও ভাল হবে। আপনি কি ভাবতে পারেন যে আপনি কীভাবে এই পদক্ষেপগুলিকে স্বয়ংক্রিয়ভাবে একটি মডেল পুনরায় প্রশিক্ষণ দেওয়ার জন্য স্বয়ংক্রিয়ভাবে করতে পারেন, উদাহরণস্বরূপ, 100টি নতুন মন্তব্য ভুলভাবে শ্রেণীবদ্ধ হিসাবে চিহ্নিত করা হয়েছে? আপনার নিয়মিত ওয়েব ইঞ্জিনিয়ারিং হ্যাটটি রাখুন এবং আপনি সম্ভবত এটি স্বয়ংক্রিয়ভাবে করার জন্য কীভাবে একটি পাইপলাইন তৈরি করবেন তা বের করতে পারেন। যদি না হয়, কোন উদ্বেগ নেই, সিরিজের পরবর্তী কোডল্যাবের জন্য সন্ধান করুন যা আপনাকে কীভাবে দেখাবে।
আপনি কি আমাদের সাথে শেয়ার করুন
অন্যান্য সৃজনশীল ব্যবহারের ক্ষেত্রেও আপনি আজ যা করেছেন তা আপনি সহজেই প্রসারিত করতে পারেন এবং আমরা আপনাকে বাক্সের বাইরে চিন্তা করতে এবং হ্যাকিং চালিয়ে যেতে উত্সাহিত করি।
আপনার প্রকল্পের TensorFlow ব্লগে বা এমনকি ভবিষ্যতের ইভেন্টগুলি দেখানোর সুযোগের জন্য #MadeWithTFJS হ্যাশট্যাগ ব্যবহার করে সোশ্যাল মিডিয়াতে আমাদের ট্যাগ করতে ভুলবেন না। আপনি কি বানাবেন তা আমরা দেখতে চাই।
আরও গভীরে যেতে আরও TensorFlow.js কোডল্যাব
- স্কেলে একটি TensorFlow.js মডেল স্থাপন এবং হোস্ট করতে Firebase হোস্টিং ব্যবহার করুন।
- TensorFlow.js এর সাথে একটি প্রি-মেড অবজেক্ট ডিটেকশন মডেল ব্যবহার করে একটি স্মার্ট ওয়েবক্যাম তৈরি করুন
চেক আউট ওয়েবসাইট
- TensorFlow.js অফিসিয়াল ওয়েবসাইট
- TensorFlow.js প্রি-মেড মডেল
- TensorFlow.js API
- TensorFlow.js দেখান এবং বলুন - অনুপ্রাণিত হন এবং দেখুন অন্যরা কী করেছে৷