
1. Trước khi bắt đầu
Lớp học lập trình này được thiết kế để xây dựng dựa trên kết quả cuối cùng của lớp học lập trình trước trong loạt video này nhằm phát hiện bình luận không liên quan bằng TensorFlow.js.
Trong lớp học lập trình cuối cùng, bạn đã tạo một trang web hoạt động với đầy đủ chức năng cho blog video hư cấu. Bạn có thể lọc bình luận rác trước khi những bình luận đó được gửi đến máy chủ để lưu trữ hoặc đến các ứng dụng khác đã kết nối bằng cách sử dụng một mô hình phát hiện bình luận không liên quan do TensorFlow.js hỗ trợ trong trình duyệt.
Kết quả cuối cùng của lớp học lập trình đó sẽ như sau:

Mặc dù phương thức này hoạt động rất hiệu quả, nhưng vẫn có những trường hợp hiếm gặp cần phát hiện mà hệ thống không phát hiện được. Bạn có thể huấn luyện lại mô hình để dự phòng các tình huống mà mô hình không thể xử lý.
Lớp học lập trình này tập trung vào việc sử dụng xử lý ngôn ngữ tự nhiên (nghệ thuật hiểu ngôn ngữ của con người thông qua máy tính) và hướng dẫn bạn cách sửa đổi ứng dụng web hiện có mà bạn đã tạo (bạn nên tham gia các lớp học lập trình theo thứ tự), để giải quyết vấn đề thực tế của vấn đề spam nhận xét mà nhiều nhà phát triển web chắc chắn sẽ gặp phải khi họ xử lý một trong số các ứng dụng web phổ biến ngày càng tăng hiện nay.
Trong lớp học lập trình này, bạn sẽ tìm hiểu sâu hơn bằng cách huấn luyện lại mô hình ML để tính đến những thay đổi về nội dung tin nhắn rác và có thể phát triển theo thời gian, dựa trên các xu hướng hiện tại hoặc các chủ đề thảo luận phổ biến. Nhờ đó, bạn có thể cập nhật mô hình này và tính đến những thay đổi như vậy.
Điều kiện tiên quyết
- Đã hoàn thành lớp học lập trình đầu tiên trong loạt bài học này.
- Kiến thức cơ bản về các công nghệ web bao gồm HTML, CSS và JavaScript.
Sản phẩm bạn sẽ tạo ra
Bạn sẽ sử dụng lại trang web đã tạo trước đây cho một blog video ảo có phần bình luận theo thời gian thực. Sau đó, bạn sẽ nâng cấp trang web này để tải một phiên bản tuỳ chỉnh đã huấn luyện của mô hình phát hiện nội dung rác bằng TensorFlow.js. Nhờ đó, trang web này hoạt động hiệu quả hơn trong các trường hợp hiếm gặp mà trước đây lẽ ra sẽ không thành công. Tất nhiên, là nhà phát triển web và kỹ sư, bạn có thể thay đổi trải nghiệm người dùng giả định này để sử dụng lại trên bất kỳ trang web nào mà bạn có thể đang làm việc trong vai trò hằng ngày và điều chỉnh giải pháp cho phù hợp với mọi trường hợp sử dụng của khách hàng – có thể đó là blog, diễn đàn hoặc một dạng CMS nào đó, chẳng hạn như Drupal.
Hãy cùng tấn công...
Kiến thức bạn sẽ học được
Bạn sẽ:
- Xác định các trường hợp đặc biệt mà mô hình huấn luyện trước không thành công
- Huấn luyện lại Mô hình phân loại spam đã được tạo bằng Model Maker.
- Hãy xuất mô hình dựa trên Python này sang định dạng TensorFlow.js để sử dụng trong các trình duyệt.
- Cập nhật mô hình được lưu trữ và từ điển của mô hình đó bằng mô hình mới được huấn luyện rồi kiểm tra kết quả
Chúng tôi giả định rằng bạn đã quen thuộc với HTML5, CSS và JavaScript. Bạn cũng sẽ chạy một số mã Python qua một "co Labs" sổ tay để đào tạo lại mô hình đã được tạo bằng Model Maker mà không cần phải có kiến thức về Python để thực hiện việc này.
2. Thiết lập để viết mã
Một lần nữa, bạn sẽ sử dụng Glitch.com để lưu trữ và sửa đổi ứng dụng web. Nếu chưa hoàn thành lớp học lập trình tiên quyết, bạn có thể sao chép kết quả cuối cùng tại đây làm điểm xuất phát. Nếu có thắc mắc về cách hoạt động của mã nguồn, bạn nên hoàn tất lớp học lập trình trước về cách tạo ứng dụng web hoạt động này trước khi tiếp tục.
Trên Glitch, bạn chỉ cần nhấp vào nút remix this (phối lại nội dung này) để phát triển nhánh và tạo một nhóm tệp mới mà bạn có thể chỉnh sửa.
3. Khám phá các trường hợp hiếm gặp trong giải pháp trước
Nếu bạn mở trang web hoàn chỉnh mà bạn vừa sao chép và thử nhập một số bình luận, bạn sẽ nhận thấy rằng khoảng thời gian này sẽ hoạt động như dự kiến, chặn những bình luận có vẻ giống nội dung rác như mong đợi và cho phép thông qua các phản hồi hợp lệ.
Tuy nhiên, nếu bạn trở nên miệt thị và cố gắng diễn đạt những câu gây phá vỡ mô hình này, thì có thể bạn sẽ thành công vào một lúc nào đó. Sau khi thử và lỗi, bạn có thể tự tạo các ví dụ như dưới đây. Hãy thử dán các thông tin này vào ứng dụng web hiện có, kiểm tra bảng điều khiển và xem xác suất quay lại nếu nhận xét là spam:
Bình luận hợp pháp được đăng mà không có vấn đề (nội dung phủ định thực sự):
- "Chà, tôi thích video đó, thật tuyệt vời." Xác suất spam: 47,91854%
- "Hoàn toàn yêu thích các bản minh hoạ này! Bạn có muốn biết thêm thông tin không?" Xác suất spam: 47,15898%
- "Tôi có thể truy cập vào trang web nào để tìm hiểu thêm?" Xác suất spam: 15,32495%
Điều này thật tuyệt, xác suất cho tất cả các trường hợp trên là khá thấp và thực hiện thành công thông qua SPAM_THRESHOLD mặc định với xác suất tối thiểu là 75% trước khi hành động được thực hiện (được xác định trong mã script.js từ lớp học lập trình trước).
Bây giờ, hãy thử viết một số bình luận sắc sảo hơn nhưng bị đánh dấu là vi phạm, mặc dù những bình luận này không phải là...
Bình luận hợp lệ được đánh dấu là vi phạm (dương tính giả):
- "Ai đó có thể liên kết đến trang web về chiếc khẩu trang mà anh ấy đang đeo không?" Xác suất spam: 98,46466%
- "Tôi có thể mua bài hát này trên Spotify không? Hãy cho tôi biết nhé!" Xác suất spam: 94,40953%
- "Ai đó có thể liên hệ với tôi để cung cấp thông tin chi tiết về cách tải TensorFlow.js xuống không?" Xác suất spam: 83,20084%
Ối! Có vẻ như những bình luận hợp lệ này đang bị đánh dấu là vi phạm, nhưng lẽ ra phải được cho phép. Bạn có thể làm gì để khắc phục vấn đề này?
Một lựa chọn đơn giản là tăng SPAM_THRESHOLD để có độ tin cậy hơn 98,5%. Trong trường hợp đó, những nhận xét bị phân loại sai này sẽ được đăng. Do vậy, hãy tiếp tục với những kết quả khác có thể xảy ra dưới đây...
Bình luận rác bị đánh dấu là vi phạm (hoàn toàn dương tính):
- "Thật tuyệt, nhưng hãy thử xem các đường liên kết tải xuống tốt hơn trên trang web của tôi!" Xác suất spam: 99,77873%
- "Tôi biết một số người có thể mua cho bạn một số loại thuốc chỉ cần xem tệp pr0của tôi để biết chi tiết" Xác suất làm phiền: 98,46955%
- "Xem hồ sơ của tôi để tải thêm nhiều video thú vị và chất lượng hơn nữa! http://example.com" Xác suất spam: 96,26383%
Được rồi, điều này hoạt động như dự kiến với ngưỡng 75% ban đầu của chúng tôi, nhưng vì trong bước trước, bạn đã thay đổi SPAM_THRESHOLD thành hơn 98,5% tự tin, điều này có nghĩa là 2 ví dụ ở đây sẽ được cho qua, vì vậy có thể ngưỡng này quá cao. Có thể 96% là tốt hơn? Nhưng nếu bạn làm như vậy, thì một trong các bình luận trong phần trước (dương tính giả) sẽ bị đánh dấu là bình luận rác khi bình luận đó hợp lệ vì được đánh giá ở mức 98,46466%.
Trong trường hợp này, tốt nhất là bạn nên ghi lại tất cả những nhận xét vi phạm thực sự này và chỉ cần huấn luyện lại cho những lỗi nêu trên. Khi đặt ngưỡng thành 96%, tất cả dương tính thật vẫn được thu thập và bạn loại bỏ 2 trong số các kết quả dương tính giả ở trên. Không tệ nếu chỉ thay đổi một số.
Hãy tiếp tục...
Bình luận rác được phép đăng (âm tính giả):
- "Xem hồ sơ của tôi để tải thêm nhiều video tuyệt vời và hay hơn nữa!" Xác suất spam: 7,54926%
- "Nhận chiết khấu cho các lớp đào tạo phòng tập thể dục của chúng tôi, hãy xem pr0file!" Xác suất spam: 17,49849%
- "trời ơi, cổ phiếu GOOG vừa tăng mạnh! Hãy đến trước khi quá muộn!" Xác suất spam: 20,42894%
Đối với những nhận xét này, bạn không thể làm gì chỉ bằng cách thay đổi thêm giá trị SPAM_THRESHOLD. Việc giảm ngưỡng nội dung rác từ 96% xuống còn ~9% sẽ khiến những bình luận chân thật bị đánh dấu là bình luận rác – một trong số đó là bình luận hợp lệ nhưng vẫn có tỷ lệ bình luận là 58%. Cách duy nhất để xử lý các nhận xét như thế này là đào tạo lại mô hình với các trường hợp hiếm gặp như vậy trong dữ liệu huấn luyện để mô hình học được cách điều chỉnh góc nhìn thế giới đối với nội dung rác.
Mặc dù hiện tại chỉ còn lựa chọn duy nhất là huấn luyện lại mô hình, nhưng bạn cũng đã biết cách tinh chỉnh ngưỡng thời điểm quyết định gọi nội dung rác để cải thiện hiệu suất. Là con người, 75% có vẻ khá tự tin, nhưng đối với mô hình này, bạn cần tăng gần 81,5% hơn để hiệu quả hơn với dữ liệu đầu vào mẫu.
Không có giá trị kỳ diệu nào hoạt động hiệu quả trên các mô hình khác nhau, và ngưỡng giá trị này cần phải được đặt trên cơ sở từng mô hình sau khi thử nghiệm với dữ liệu thực tế để xem xét giá trị nào hoạt động hiệu quả.
Trong một số trường hợp, việc có kết quả dương tính giả (hoặc âm tính) có thể gây ra hậu quả nghiêm trọng (ví dụ như trong ngành y tế). Do đó, bạn có thể điều chỉnh ngưỡng của mình lên rất cao và yêu cầu xem xét thủ công hơn đối với những người không đáp ứng ngưỡng. Đây là lựa chọn của bạn với tư cách là nhà phát triển và cần một số thử nghiệm.
4. Huấn luyện lại mô hình phát hiện bình luận không liên quan
Trong phần trước, bạn đã xác định một số trường hợp đặc biệt không thành công đối với mô hình, trong đó lựa chọn duy nhất là huấn luyện lại mô hình để tính đến các tình huống này. Trong hệ thống sản xuất, bạn có thể tìm thấy những bình luận này theo thời gian khi người dùng gắn cờ một bình luận là bình luận rác theo cách thủ công (những bình luận này đã được cho qua) hoặc người kiểm duyệt sẽ xem xét bình luận bị gắn cờ để nhận ra rằng một số bình luận không thực sự là bình luận rác. Họ có thể đánh dấu những bình luận đó để huấn luyện lại. Giả sử bạn đã thu thập một loạt dữ liệu mới cho những trường hợp hiếm gặp này (để có kết quả tốt nhất, bạn nên có một số biến thể của những câu mới này nếu có thể), giờ đây chúng tôi sẽ tiếp tục hướng dẫn bạn cách huấn luyện lại mô hình với những trường hợp hiếm gặp đó.
Tóm tắt về mô hình tạo sẵn
Mô hình tạo sẵn mà bạn sử dụng là mô hình do bên thứ ba tạo ra thông qua Model Maker. Mô hình này sử dụng phương pháp "Nhúng từ trung bình" để mô hình hoạt động.
Vì mô hình được xây dựng bằng Model Maker, bạn sẽ cần chuyển nhanh sang Python để đào tạo lại mô hình, sau đó xuất mô hình đã tạo sang định dạng TensorFlow.js để bạn có thể sử dụng trong trình duyệt. Rất may là Model Maker giúp việc sử dụng các mô hình của họ cực kỳ đơn giản. Vì vậy, bạn có thể dễ dàng làm theo. Chúng tôi sẽ hướng dẫn bạn thực hiện quy trình này nên đừng lo nếu bạn chưa từng sử dụng Python!
Colab
Vì không quá quan tâm đến lớp học lập trình này nên bạn muốn thiết lập một máy chủ Linux chứa tất cả các tiện ích Python đã cài đặt, nên bạn chỉ cần thực thi mã thông qua trình duyệt web bằng cách sử dụng "Colab Notebook". Những sổ tay này có thể kết nối với một "máy chủ phụ trợ" - đơn giản là một máy chủ đã cài đặt sẵn một số nội dung, từ đó bạn có thể thực thi mã tuỳ ý trong trình duyệt web và xem kết quả. Điều này rất hữu ích để tạo nguyên mẫu nhanh hoặc sử dụng trong các hướng dẫn như thế này.
Chỉ cần truy cập vào colab.research.google.com là bạn sẽ thấy màn hình chào mừng như sau:
Bây giờ, hãy nhấp vào nút New Notebook (Sổ tay mới) ở dưới cùng bên phải của cửa sổ bật lên và bạn sẽ thấy một colab trống như sau:
Tuyệt vời! Bước tiếp theo là kết nối colab giao diện người dùng với một số máy chủ phụ trợ để bạn có thể thực thi đoạn mã Python mà bạn sẽ viết. Hãy thực hiện bằng cách nhấp vào Kết nối ở trên cùng bên phải rồi chọn Kết nối với môi trường thời gian chạy được lưu trữ.
Sau khi kết nối, bạn sẽ thấy biểu tượng RAM và Ổ đĩa xuất hiện ở vị trí tương ứng, như sau:
Tốt lắm! Bây giờ, bạn có thể bắt đầu lập trình bằng Python để đào tạo lại mô hình Model Maker. Chỉ cần thực hiện theo các bước bên dưới.
Bước 1
Trong ô đầu tiên hiện đang trống, hãy sao chép mã bên dưới. Thao tác này sẽ cài đặt Trình tạo mô hình TensorFlow Lite cho bạn bằng trình quản lý gói của Python có tên là "pip" (tương tự như npm mà hầu hết người đọc của lớp học lập trình này có thể quen thuộc hơn từ hệ sinh thái JS):
!apt-get install libasound-dev portaudio19-dev libportaudio2 libportaudiocpp0
!pip install -q tflite-model-maker
Tuy nhiên, việc dán mã vào ô sẽ không thực thi mã đó. Tiếp theo, di chuột qua ô màu xám mà bạn đã dán mã ở trên vào và nút "phát" nhỏ biểu tượng sẽ xuất hiện ở bên trái của ô như được đánh dấu dưới đây:
 Nhấp vào nút phát để thực thi đoạn mã vừa nhập vào ô.
Nhấp vào nút phát để thực thi đoạn mã vừa nhập vào ô.
Bây giờ, bạn sẽ thấy trình tạo mô hình đang được cài đặt:
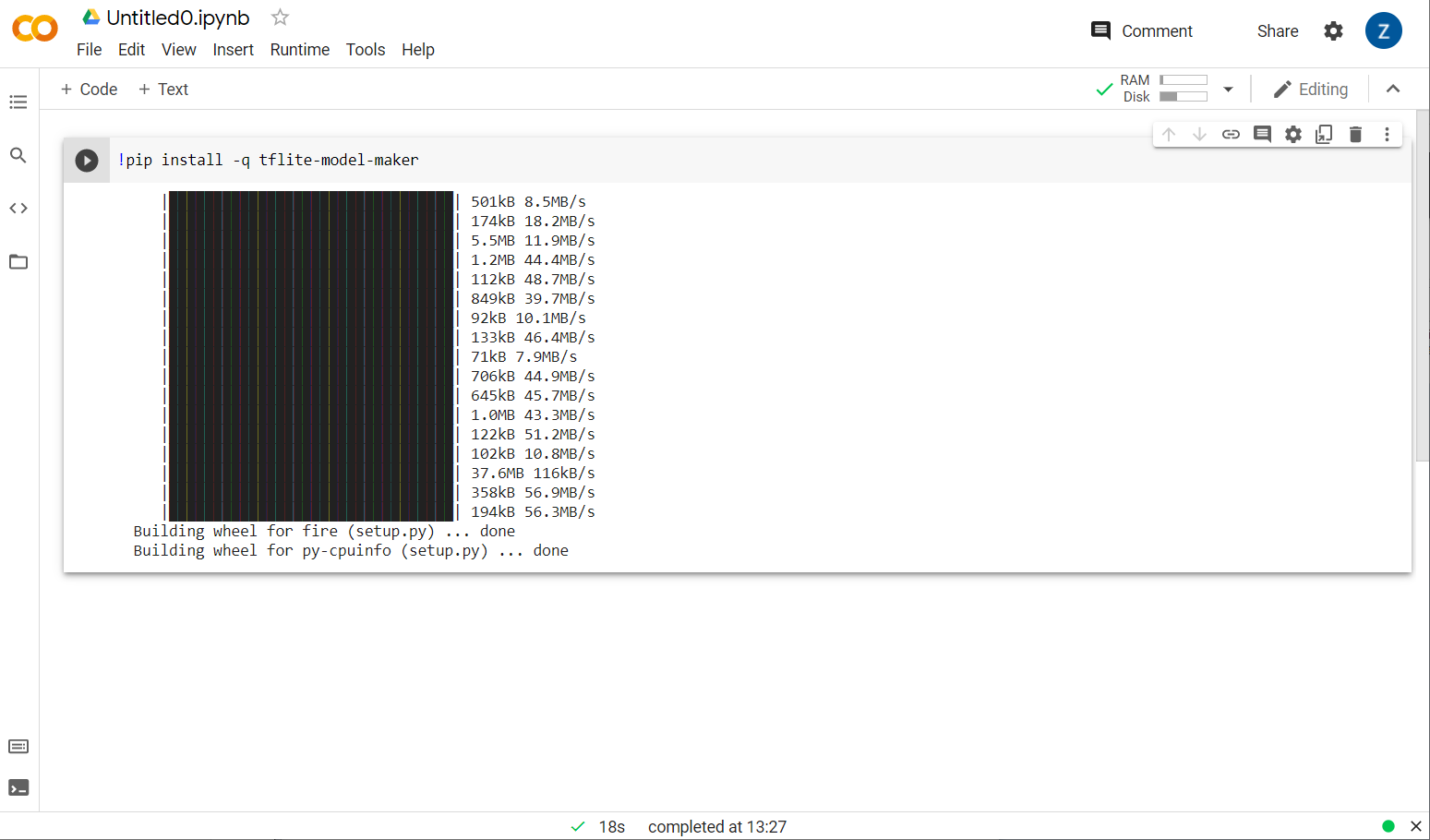
Sau khi quá trình thực thi ô này hoàn tất như minh hoạ, hãy chuyển sang bước tiếp theo ở bên dưới.
Bước 2
Tiếp theo, hãy thêm một ô chứa mã mới như minh hoạ để bạn có thể dán thêm mã sau ô đầu tiên và thực thi mã đó riêng biệt:
Ô tiếp theo được thực thi sẽ có một số lệnh nhập mà phần mã trong phần còn lại của sổ tay sẽ cần sử dụng. Sao chép và dán nội dung bên dưới vào ô mới được tạo:
import numpy as np
import os
from tflite_model_maker import configs
from tflite_model_maker import ExportFormat
from tflite_model_maker import model_spec
from tflite_model_maker import text_classifier
from tflite_model_maker.text_classifier import DataLoader
import tensorflow as tf
assert tf.__version__.startswith('2')
tf.get_logger().setLevel('ERROR')
Đây là nội dung khá chuẩn, ngay cả khi bạn không quen dùng Python. Bạn chỉ đang nhập một số tiện ích và các chức năng của Trình tạo mô hình cần thiết cho thuật toán phân loại spam. Bước này cũng sẽ kiểm tra xem bạn có đang chạy TensorFlow 2.x (yêu cầu để sử dụng Trình tạo mô hình) hay không.
Cuối cùng, cũng giống như trước đó, thực thi ô bằng cách nhấn phím "phát" biểu tượng khi bạn di chuột qua ô rồi thêm một ô chứa mã mới cho bước tiếp theo.
Bước 3
Tiếp theo, bạn sẽ tải dữ liệu từ một máy chủ từ xa xuống thiết bị của mình và đặt biến training_data thành đường dẫn của tệp cục bộ thu được được tải xuống:
data_file = tf.keras.utils.get_file(fname='comment-spam-extras.csv', origin='https://storage.googleapis.com/jmstore/TensorFlowJS/EdX/code/6.5/jm_blog_comments_extras.csv', extract=False)
Model Maker có thể đào tạo các mô hình từ các tệp CSV đơn giản như tệp đã tải xuống. Bạn chỉ cần chỉ định cột nào chứa văn bản và cột nào chứa nhãn. Bạn sẽ thấy cách thực hiện việc đó trong Bước 5. Bạn có thể tự tải trực tiếp tệp CSV xuống để xem nội dung trong tệp nếu muốn.
Bạn sẽ nhận thấy tên của tệp này là jm_blog_comments_extras.csv – tệp này chỉ đơn giản là dữ liệu huấn luyện ban đầu mà chúng tôi đã sử dụng để tạo mô hình spam nhận xét đầu tiên được kết hợp với dữ liệu trường hợp đặc biệt mới mà bạn phát hiện được nên tất cả đều nằm trong một tệp. Ngoài các câu mới mà bạn muốn học, bạn cũng cần có dữ liệu huấn luyện ban đầu dùng để huấn luyện mô hình.
Không bắt buộc: Nếu tải tệp CSV này xuống và kiểm tra vài dòng cuối, bạn sẽ thấy ví dụ về những trường hợp hiếm gặp, hoạt động không đúng cách trước đây. Các bài tập này vừa được thêm vào cuối dữ liệu huấn luyện hiện có mà mô hình tạo sẵn dùng để tự huấn luyện.
Thực thi ô này, sau khi thực thi xong, hãy thêm một ô mới rồi chuyển đến bước 4.
Bước 4
Khi sử dụng Model Maker, bạn không tạo mô hình từ đầu. Bạn thường sử dụng các mô hình hiện có mà sau đó bạn sẽ tuỳ chỉnh theo nhu cầu của mình.
Model Maker cung cấp một số tính năng nhúng cho mô hình học trước mà bạn có thể sử dụng, nhưng đơn giản và nhanh nhất để bắt đầu là average_word_vec, đây là phương thức bạn đã sử dụng trong lớp học lập trình trước đó để xây dựng trang web. Đây là mã:
spec = model_spec.get('average_word_vec')
spec.num_words = 2000
spec.seq_len = 20
spec.wordvec_dim = 7
Hãy tiếp tục và chạy mã đó sau khi bạn dán mã vào ô mới.
Hiểu rõ
num_words
tham số
Đây là số từ mà bạn muốn mô hình sử dụng. Có thể bạn cho rằng càng nhiều thì càng tốt, nhưng nhìn chung có một điểm hấp dẫn dựa trên tần suất mà mỗi từ được sử dụng. Nếu bạn sử dụng mọi từ trong toàn bộ tập sao lục, có thể mô hình sẽ cố gắng học và cân bằng trọng số của những từ chỉ được sử dụng một lần - điều này không thực sự hữu ích. Bạn sẽ thấy trong bất kỳ tập sao lục văn bản nào có nhiều từ chỉ được sử dụng một hoặc hai lần và thường không đáng để sử dụng những từ này trong mô hình của bạn vì chúng có ảnh hưởng không đáng kể đến cảm nhận tổng thể. Vì vậy, bạn có thể điều chỉnh mô hình dựa trên số lượng từ mong muốn bằng cách sử dụng tham số num_words. Số nhỏ hơn ở đây sẽ có mô hình nhỏ hơn và nhanh hơn, nhưng có thể kém chính xác hơn vì nhận dạng ít từ hơn. Số lượng lớn hơn trong trường hợp này sẽ có mô hình lớn hơn và có thể có tốc độ chậm hơn. Việc tìm ra giải pháp phù hợp là yếu tố quan trọng. Là một kỹ sư máy học, bạn có thể tự chọn ra giải pháp phù hợp nhất cho trường hợp sử dụng của mình.
Hiểu rõ
wordvec_dim
tham số
Tham số wordvec_dim là số chiều bạn muốn sử dụng cho vectơ của mỗi từ. Về cơ bản, các phương diện này là các đặc điểm khác nhau (do thuật toán học máy tạo ra khi huấn luyện) mà chương trình sẽ sử dụng bất kỳ từ nào để đo lường và liên kết hiệu quả nhất những từ tương tự nhau theo cách có ý nghĩa.
Ví dụ: nếu bạn có một phương diện về mức độ "y tế" một từ là, một từ như "thuốc" có thể đạt điểm cao ở đây trong thứ nguyên này và được liên kết với các từ có điểm cao khác như "xray", nhưng "mèo" sẽ đạt điểm thấp cho tham số này. Hoá ra "phương diện y tế" là hữu ích để xác định spam khi kết hợp với các thứ nguyên có thể có khác mà nó có thể quyết định sử dụng đáng kể.
Trong trường hợp những từ được xếp hạng cao theo "phương diện y khoa" có thể cho rằng một chiều thứ 2 tương quan các từ ngữ với cơ thể con người có thể hữu ích. Những từ như "chân", "cánh tay", "cổ" có thể đạt điểm cao ở khía cạnh y tế và cũng khá cao trong khía cạnh y tế.
Mô hình đó có thể sử dụng các phương diện này để phát hiện những từ có nhiều khả năng liên quan đến nội dung rác hơn. Có thể email rác thường có chứa những từ liên quan đến cả bộ phận y tế lẫn bộ phận cơ thể người.
Quy tắc chung được xác định từ nghiên cứu là căn bậc 4 của số từ phù hợp với tham số này. Vì vậy, nếu tôi đang sử dụng 2000 từ, một điểm khởi đầu tốt cho việc này là 7 chiều. Nếu thay đổi số từ được sử dụng, bạn cũng có thể thay đổi số lượng từ.
Hiểu rõ
seq_len
tham số
Các mô hình thường rất cứng nhắc khi chọn giá trị đầu vào. Đối với một mô hình ngôn ngữ, điều này có nghĩa là mô hình ngôn ngữ đó có thể phân loại các câu có độ dài cụ thể, tĩnh. Giá trị này được xác định bằng tham số seq_len, trong đó tham số này có nghĩa là "độ dài trình tự". Khi bạn chuyển đổi các từ thành số (hoặc mã thông báo), một câu sẽ trở thành một chuỗi các mã thông báo này. Vì vậy, mô hình của bạn sẽ được huấn luyện (trong trường hợp này) để phân loại và nhận dạng các câu có 20 mã thông báo. Nếu dài hơn 3 khoảng này, câu đó sẽ bị cắt bớt. Nếu video ngắn hơn thì sẽ có khoảng đệm – giống như trong lớp học lập trình đầu tiên của loạt bài này.
Bước 5 – tải dữ liệu huấn luyện
Trước đó, bạn đã tải tệp CSV xuống. Đã đến lúc sử dụng trình tải dữ liệu để biến dữ liệu này thành dữ liệu huấn luyện mà mô hình có thể nhận dạng.
data = DataLoader.from_csv(
filename=data_file,
text_column='commenttext',
label_column='spam',
model_spec=spec,
delimiter=',',
shuffle=True,
is_training=True)
train_data, test_data = data.split(0.9)
Nếu mở tệp CSV trong trình chỉnh sửa, bạn sẽ thấy mỗi dòng chỉ có hai giá trị và các giá trị này được mô tả bằng văn bản trong dòng đầu tiên của tệp. Thông thường, mỗi mục nhập được coi là một "cột". Bạn sẽ thấy nội dung mô tả cho cột đầu tiên là commenttext và mục đầu tiên trên mỗi dòng là văn bản của nhận xét.
Tương tự, mã mô tả cho cột thứ hai là spam và bạn sẽ thấy mục nhập thứ hai trên mỗi dòng là TRUE hoặc FALSE để cho biết liệu văn bản đó có bị coi là bình luận rác hay không. Các thuộc tính khác thiết lập thông số mô hình mà bạn đã tạo ở bước 4, cùng với một ký tự dấu phân cách, trong trường hợp này là dấu phẩy vì tệp được phân tách bằng dấu phẩy. Bạn cũng đặt một thông số xáo trộn để sắp xếp lại dữ liệu huấn luyện ngẫu nhiên sao cho những dữ liệu có thể đã tương tự hoặc được thu thập cùng nhau được trải ra ngẫu nhiên trong toàn bộ tập dữ liệu.
Sau đó, bạn sẽ sử dụng data.split() để chia dữ liệu thành dữ liệu huấn luyện và dữ liệu kiểm thử. Giá trị .9 cho biết 90% tập dữ liệu sẽ được dùng để huấn luyện, phần còn lại cho mục đích kiểm thử.
Bước 6 – Xây dựng mô hình
Thêm một ô khác mà chúng ta sẽ thêm mã để tạo mô hình:
model = text_classifier.create(train_data, model_spec=spec, epochs=50)
Thao tác này sẽ tạo một mô hình phân loại văn bản bằng Model Maker và bạn chỉ định dữ liệu huấn luyện bạn muốn sử dụng (được xác định ở bước 4), thông số kỹ thuật của mô hình (cũng được thiết lập ở bước 4) và một số thời gian bắt đầu của hệ thống, trong trường hợp này là 50.
Nguyên tắc cơ bản của công nghệ học máy là đây là cách khớp mẫu. Ban đầu, Google Analytics 4 sẽ tải trọng số đã huấn luyện trước cho các từ và nhóm các từ lại với nhau bằng tính năng "dự đoán" tệp nào khi được nhóm lại với nhau chỉ ra thư rác và tệp nào thì không. Ở lần đầu tiên, khoảng thời gian này có thể gần với 50:50, vì mô hình chỉ đang bắt đầu như hình dưới đây:

Sau đó, thuật toán sẽ đo lường kết quả của việc này và thay đổi trọng số của mô hình để tinh chỉnh dự đoán rồi thử lại. Đây là một thời gian bắt đầu của hệ thống. Vì vậy, bằng cách chỉ định epochs=50, mã sẽ đi qua "vòng lặp" đó 50 lần như minh hoạ:

Vì vậy, vào thời điểm bạn đạt đến thời gian bắt đầu của hệ thống thứ 50, mô hình sẽ báo cáo mức độ chính xác cao hơn nhiều. Trong trường hợp này là hiển thị 99,1%!
Bước 7 – Xuất Mô hình
Sau khi huấn luyện xong, bạn có thể xuất mô hình. TensorFlow đào tạo một mô hình theo định dạng riêng và bạn cần chuyển đổi mô hình này sang định dạng TensorFlow.js để sử dụng trên trang web. Chỉ cần dán nội dung sau đây vào một ô mới và thực thi:
model.export(export_dir="/js_export/", export_format=[ExportFormat.TFJS, ExportFormat.LABEL, ExportFormat.VOCAB])
!zip -r /js_export/ModelFiles.zip /js_export/
Sau khi thực thi mã này, nếu nhấp vào biểu tượng thư mục nhỏ ở bên trái Colab, bạn có thể chuyển đến thư mục mà bạn đã xuất ở trên (trong thư mục gốc – có thể bạn phải chuyển lên một cấp độ khác) và tìm gói zip của các tệp đã xuất có trong ModelFiles.zip.
Tải tệp zip này xuống máy tính của bạn ngay bây giờ vì bạn sẽ sử dụng các tệp đó giống như trong lớp học lập trình đầu tiên:
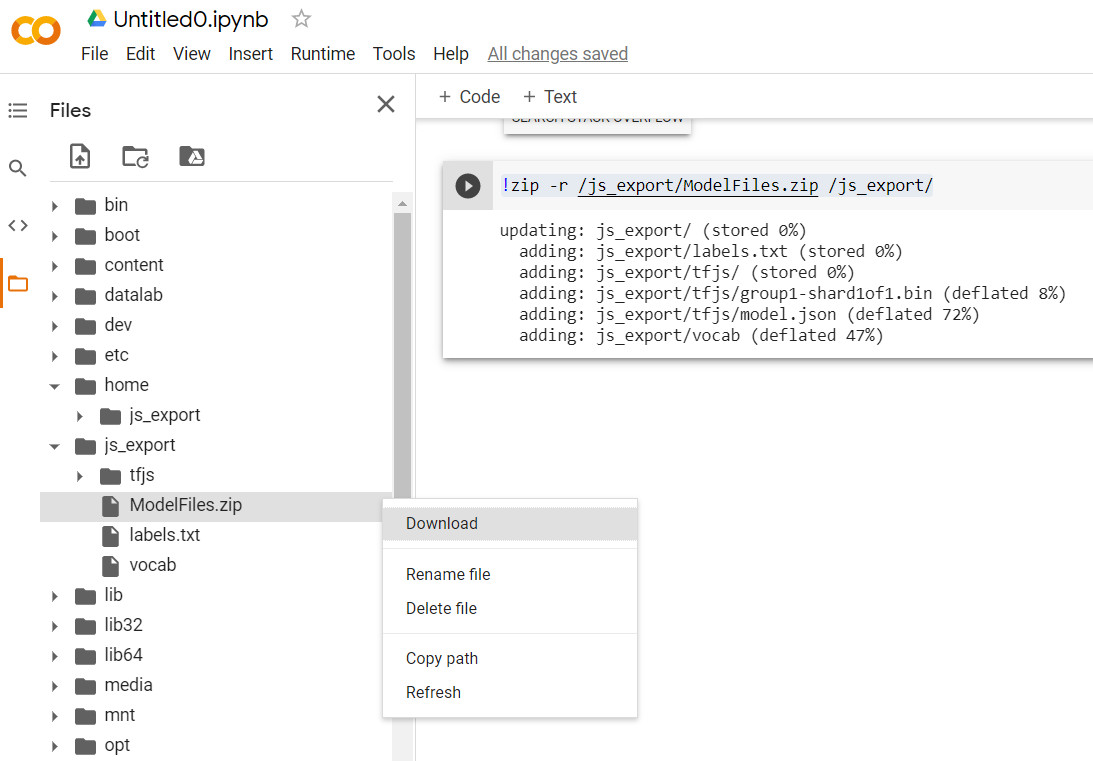
Tuyệt vời! Phần Python đã kết thúc, giờ đây bạn có thể quay lại mảnh đất JavaScript mà bạn biết và yêu thích. Chà!
5. Cung cấp mô hình học máy mới
Giờ thì bạn đã có thể tải mô hình. Tuy nhiên, trước đó bạn phải tải các tệp mô hình mới đã tải xuống ở lớp học lập trình này lên thì mới có thể lưu trữ và sử dụng được trong mã.
Trước tiên, nếu bạn chưa thực hiện thao tác này, hãy giải nén các tệp cho mô hình vừa tải xuống từ sổ tay Colab Model Maker mà bạn vừa chạy. Bạn sẽ thấy các tệp sau nằm trong các thư mục khác nhau của nó:
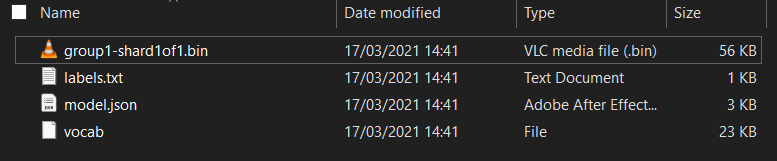
Ở đây bạn có gì?
model.json– Đây là một trong các tệp tạo nên mô hình TensorFlow.js đã được huấn luyện. Bạn sẽ tham chiếu tệp cụ thể này trong mã JS.group1-shard1of1.bin– Đây là một tệp nhị phân chứa nhiều dữ liệu đã lưu cho mô hình TensorFlow.js đã xuất và sẽ cần được lưu trữ ở đâu đó trên máy chủ của bạn để tải xuống trong cùng thư mục vớimodel.jsonở trên.vocab– Tệp lạ không có phần mở rộng này là một tệp từ Model Maker giúp chúng ta biết cách mã hoá các từ trong câu để mô hình hiểu cách sử dụng chúng. Bạn sẽ tìm hiểu kỹ hơn về phương pháp này trong phần tiếp theo.labels.txt– Mã này chỉ chứa tên lớp thu được mà mô hình sẽ dự đoán. Đối với mô hình này, nếu bạn mở tệp này trong trình chỉnh sửa văn bản, tệp chỉ có giá trị "false" và "true" được liệt kê cho biết "không phải spam" hoặc "thư rác" làm đầu ra dự đoán.
Lưu trữ các tệp mô hình TensorFlow.js
Trước tiên, hãy đặt các tệp model.json và *.bin được tạo trên máy chủ web để bạn có thể truy cập chúng qua trang web của mình.
Xoá tệp mô hình hiện có
Vì đang xây dựng dựa trên kết quả cuối cùng của lớp học lập trình đầu tiên trong chuỗi này, trước tiên, bạn phải xoá các tệp mô hình hiện có đã tải lên. Nếu đang sử dụng Glitch.com, bạn chỉ cần kiểm tra bảng điều khiển tệp ở bên trái cho model.json và group1-shard1of1.bin, nhấp vào trình đơn thả xuống có biểu tượng 3 dấu chấm cho từng tệp và chọn xoá như sau:
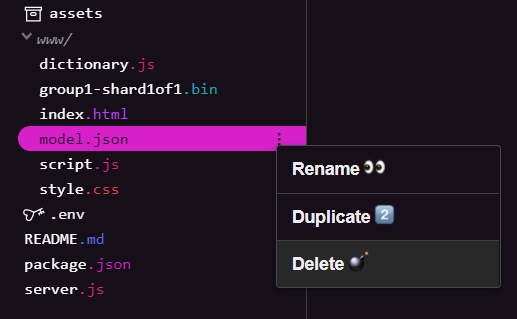
Tải tệp mới lên Glitch
Tuyệt vời! Bây giờ, hãy tải video mới lên:
- Mở thư mục Asset (tài sản) trong bảng điều khiển bên trái của dự án Glitch rồi xoá mọi thành phần cũ đã tải lên nếu chúng trùng tên.
- Nhấp vào tải thành phần lên rồi chọn
group1-shard1of1.binđể tải lên thư mục này. Sau khi tải lên, ứng dụng sẽ có dạng như sau:
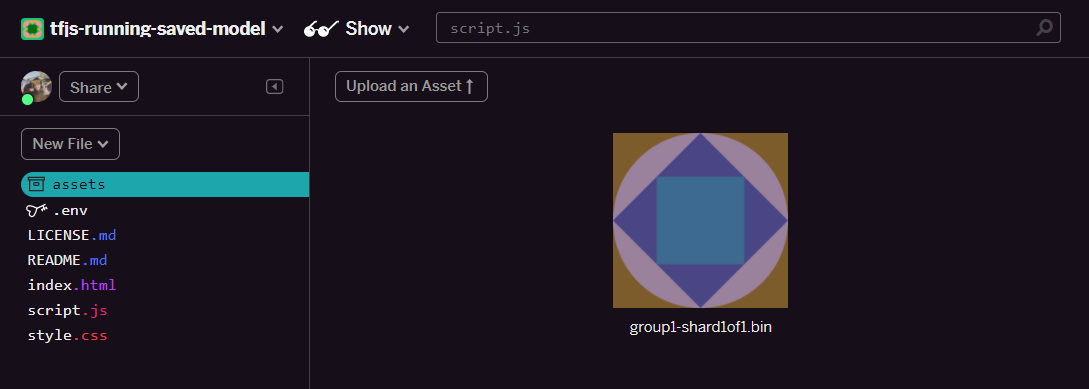
- Tuyệt vời! Bây giờ, bạn cũng có thể thực hiện tương tự với tệp model.json để 2 tệp sẽ nằm trong thư mục tài sản của bạn như sau:
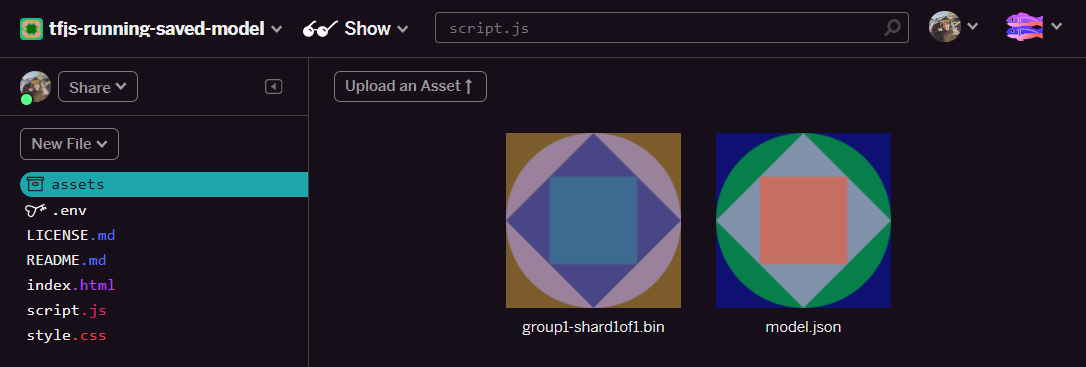
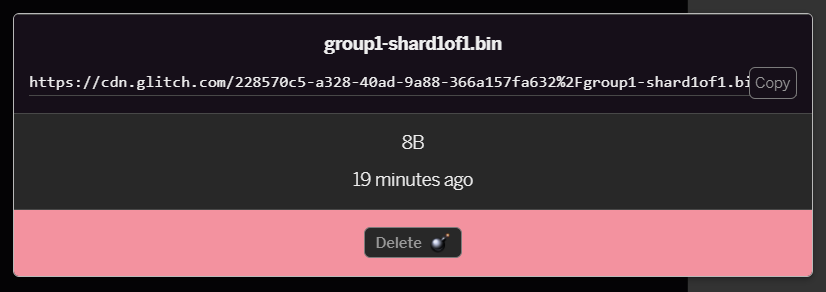
- Nếu nhấp vào tệp
group1-shard1of1.binbạn vừa tải lên, bạn có thể sao chép URL vào vị trí của tệp đó. Sao chép đường dẫn này ngay bây giờ như minh hoạ:
- Bây giờ, hãy nhấp vào Công cụ ở phía dưới cùng bên trái của màn hình > Terminal. Chờ cửa sổ dòng lệnh tải.
- Sau khi tải, hãy nhập nội dung sau đây rồi nhấn Enter để thay đổi thư mục thành thư mục
www:
điểm cuối:
cd www
- Tiếp theo, hãy sử dụng
wgetđể tải 2 tệp vừa tải lên xuống bằng cách thay thế URL bên dưới bằng các URL bạn đã tạo cho các tệp trong thư mục thành phần trên Glitch (kiểm tra thư mục thành phần để tìm URL tuỳ chỉnh của từng tệp).
Xin lưu ý rằng khoảng cách giữa hai URL và URL bạn cần sử dụng sẽ khác với những URL được hiển thị nhưng trông giống nhau:
thiết bị đầu cuối
wget https://cdn.glitch.com/1cb82939-a5dd-42a2-9db9-0c42cab7e407%2Fmodel.json?v=1616111344958 https://cdn.glitch.com/1cb82939-a5dd-42a2-9db9-0c42cab7e407%2Fgroup1-shard1of1.bin?v=1616017964562
Tuyệt vời! Giờ đây, bạn đã tạo bản sao của các tệp được tải lên thư mục www.
Tuy nhiên, ngay bây giờ, các ứng dụng này sẽ được tải xuống với những tên lạ. Nếu nhập ls vào cửa sổ dòng lệnh rồi nhấn phím Enter, bạn sẽ thấy nội dung có dạng như sau:

- Sử dụng lệnh
mvđể đổi tên các tệp. Nhập nội dung sau vào bảng điều khiển và nhấn Enter sau mỗi dòng:
điểm cuối:
mv *group1-shard1of1.bin* group1-shard1of1.bin
mv *model.json* model.json
- Cuối cùng, hãy làm mới dự án Glitch bằng cách nhập
refreshvào cửa sổ dòng lệnh rồi nhấn Enter:
điểm cuối:
refresh
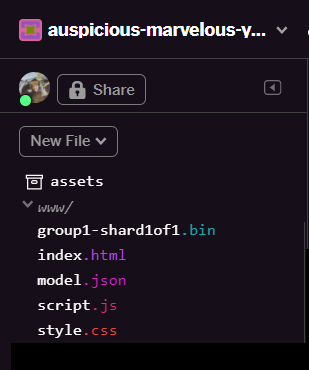
Sau khi làm mới, bạn sẽ thấy model.json và group1-shard1of1.bin trong thư mục www của giao diện người dùng:
Tuyệt vời! Bước cuối cùng là cập nhật tệp dictionary.js.
- Tự chuyển đổi tệp từ vựng mới tải xuống sang định dạng JS theo cách thủ công thông qua trình chỉnh sửa văn bản hoặc sử dụng công cụ này rồi lưu kết quả dưới dạng
dictionary.jstrong thư mụcwww. Nếu đã có tệpdictionary.js, bạn chỉ cần sao chép và dán nội dung mới lên tệp đó rồi lưu tệp.
Thật tuyệt vời! Bạn đã cập nhật thành công tất cả các tệp đã thay đổi. Nếu bây giờ bạn thử và sử dụng trang web, bạn sẽ thấy mô hình được đào tạo lại có thể tính đến các trường hợp hiếm gặp được phát hiện và rút kinh nghiệm như sau:
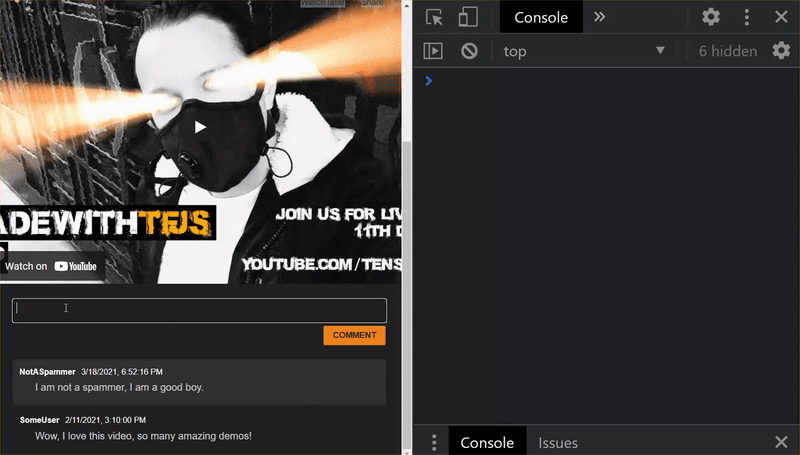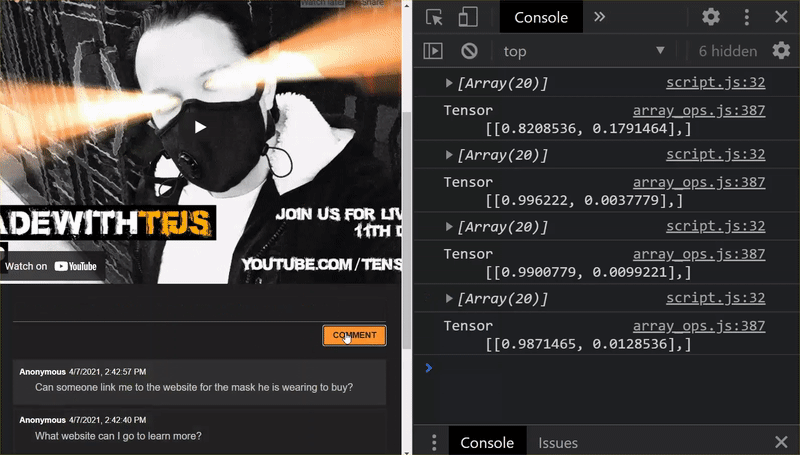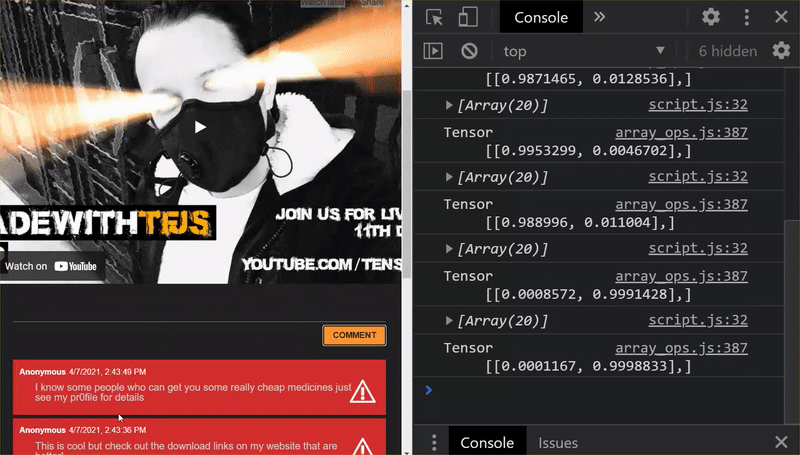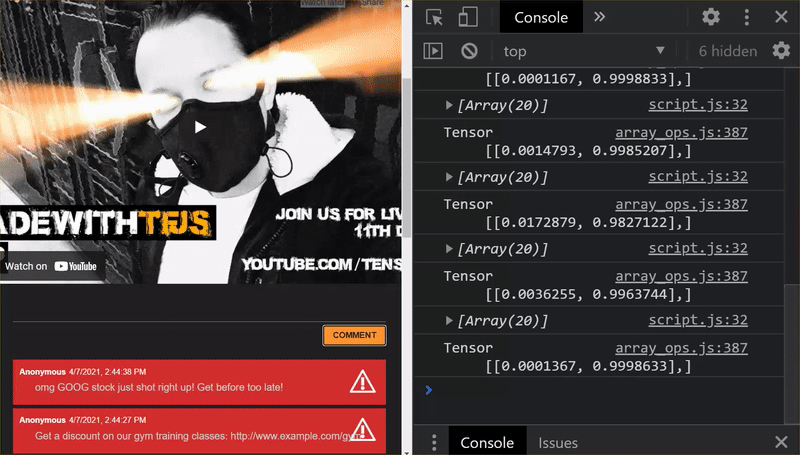
Như bạn có thể thấy, 6 lô đầu tiên hiện được phân loại chính xác là không phải thư rác và 6 lô thứ hai đều được xác định là thư rác. Tuyệt lắm!
Hãy thử một số biến thể để xem nó có được khái quát hoá tốt không. Ban đầu có một câu thất bại như:
"cổ phiếu GOOG vừa tăng vọt! Hãy đến trước khi quá muộn!"
Hiện tại, thư này đã được phân loại chính xác là nội dung rác, nhưng điều gì sẽ xảy ra nếu bạn thay đổi thành:
"Vì vậy, cổ phiếu XYZ vừa tăng giá trị! Hãy mua ngay trước khi quá muộn!"
Ở đây, bạn nhận được thông tin dự đoán có khả năng 98% là nội dung rác, điều này đúng ngay cả khi bạn đã thay đổi ký hiệu cổ phiếu và cách diễn đạt một chút.
Tất nhiên, nếu thực sự cố gắng phá vỡ mô hình mới này, bạn sẽ có thể và nó sẽ bắt đầu thu thập nhiều dữ liệu huấn luyện hơn nữa để có cơ hội tốt nhất trong việc ghi lại nhiều biến thể độc đáo hơn cho các tình huống phổ biến mà bạn có thể gặp phải trên mạng. Trong một lớp học lập trình sau này, chúng tôi sẽ hướng dẫn bạn cách liên tục cải thiện mô hình bằng dữ liệu trực tiếp khi mô hình được gắn cờ.
6. Xin chúc mừng!
Xin chúc mừng! Bạn đã huấn luyện lại một mô hình học máy hiện có để có thể tự cập nhật hoạt động cho các trường hợp hiếm gặp mà bạn phát hiện ra, đồng thời triển khai những thay đổi đó cho trình duyệt bằng TensorFlow.js cho ứng dụng thực tế.
Tóm tắt
Trong lớp học lập trình này, bạn đã:
- Phát hiện những trường hợp hiếm gặp không hoạt động khi sử dụng mô hình bình luận rác được tạo sẵn
- Đã đào tạo lại mô hình Model Maker để tính đến các trường hợp hiếm gặp mà bạn đã phát hiện
- Đã xuất mô hình huấn luyện mới sang định dạng TensorFlow.js
- Đã cập nhật ứng dụng web của bạn để sử dụng các tệp mới
Tiếp theo là gì?
Bản cập nhật này hoạt động rất hiệu quả, nhưng cũng giống như mọi ứng dụng web, thay đổi sẽ xảy ra theo thời gian. Sẽ tốt hơn rất nhiều nếu ứng dụng liên tục tự cải thiện theo thời gian thay vì chúng ta phải làm điều này theo cách thủ công mỗi lần. Bạn có thể nghĩ cách để tự động hoá các bước này để tự động huấn luyện lại một mô hình (chẳng hạn như khi có 100 bình luận mới bị đánh dấu là phân loại không chính xác) không? Hãy đội chiếc mũ kỹ thuật web thông thường của bạn lên và bạn có thể tìm ra cách tạo quy trình để thực hiện việc này một cách tự động. Nếu không thì đừng lo lắng, hãy tham khảo lớp học lập trình tiếp theo trong loạt video hướng dẫn cách làm.
Chia sẻ với chúng tôi về những video bạn làm ra
Bạn cũng có thể dễ dàng mở rộng những nội dung mình làm hôm nay cho các trường hợp sử dụng sáng tạo khác. Bạn cũng nên có tư duy sáng tạo và tiếp tục đột nhập.
Đừng quên gắn thẻ chúng tôi trên mạng xã hội bằng hashtag #MadeWithTFJS để có cơ hội xuất hiện nổi bật trên blog của TensorFlow hoặc thậm chí là các sự kiện trong tương lai. Chúng tôi rất muốn xem thành quả của bạn.
Các lớp học lập trình khác về TensorFlow.js để tìm hiểu sâu hơn
- Sử dụng dịch vụ lưu trữ Firebase để triển khai và lưu trữ mô hình TensorFlow.js trên quy mô lớn.
- Tạo một webcam thông minh bằng mô hình phát hiện đối tượng được tạo sẵn bằng TensorFlow.js
Trang web nên thanh toán
- Trang web chính thức của TensorFlow.js
- Mô hình tạo sẵn TensorFlow.js
- API TensorFlow.js
- Chương trình TensorFlow.js và Chia sẻ – tìm nguồn cảm hứng và xem những điều người khác đã làm.