
১. সংক্ষিপ্ত বিবরণ
স্প্যানার একটি সম্পূর্ণভাবে পরিচালিত, হরাইজন্টালি স্কেলেবল এবং বিশ্বব্যাপী বিতরণযোগ্য ডাটাবেস পরিষেবা, যা রিলেশনাল এবং নন-রিলেশনাল উভয় ধরনের অপারেশনাল ওয়ার্কলোডের জন্য চমৎকার। এর মূল সক্ষমতার বাইরেও, স্প্যানার শক্তিশালী উন্নত বৈশিষ্ট্য প্রদান করে যা ইন্টেলিজেন্ট এবং ডেটা-চালিত অ্যাপ্লিকেশন তৈরি করতে সক্ষম করে।
এই কোডল্যাবটি স্প্যানার (Spanner) সম্পর্কিত মৌলিক ধারণার উপর ভিত্তি করে তৈরি এবং একটি অনলাইন ব্যাংকিং অ্যাপ্লিকেশনকে ভিত্তি হিসেবে ব্যবহার করে, আপনার ডেটা প্রসেসিং ও বিশ্লেষণ ক্ষমতা বাড়ানোর জন্য এর উন্নত ইন্টিগ্রেশনগুলো কাজে লাগানোর বিষয়ে বিস্তারিত আলোচনা করে।
আমরা তিনটি প্রধান উন্নত বৈশিষ্ট্যের উপর আলোকপাত করব:
- ভার্টেক্স এআই ইন্টিগ্রেশন : গুগল ক্লাউডের এআই প্ল্যাটফর্ম, ভার্টেক্স এআই-এর সাথে স্প্যানারকে কীভাবে নির্বিঘ্নে ইন্টিগ্রেট করা যায় তা জানুন। আপনি শিখবেন কীভাবে স্প্যানার SQL কোয়েরির ভেতর থেকে সরাসরি ভার্টেক্স এআই মডেলগুলোকে কল করতে হয়, যা ডেটাবেসের মধ্যেই শক্তিশালী ট্রান্সফরমেশন এবং প্রেডিকশন সক্ষম করে। এর ফলে আমাদের ব্যাংকিং অ্যাপ্লিকেশনটি বাজেট ট্র্যাকিং এবং অ্যানোমালি ডিটেকশনের মতো ব্যবহারের জন্য ট্রানজ্যাকশনগুলোকে স্বয়ংক্রিয়ভাবে ক্যাটাগরাইজ করতে পারে।
- পূর্ণ-পাঠ্য অনুসন্ধান : স্প্যানারের মধ্যে কীভাবে পূর্ণ-পাঠ্য অনুসন্ধান কার্যকারিতা প্রয়োগ করতে হয় তা শিখুন। আপনি টেক্সট ডেটা ইন্ডেক্সিং এবং আপনার অপারেশনাল ডেটার মধ্যে কীওয়ার্ড-ভিত্তিক অনুসন্ধান করার জন্য কার্যকর কোয়েরি লেখা সম্পর্কে জানবেন, যা শক্তিশালী ডেটা ডিসকভারি সক্ষম করে, যেমন আমাদের ব্যাংকিং সিস্টেমের মধ্যে ইমেল ঠিকানা দ্বারা গ্রাহকদের দক্ষতার সাথে খুঁজে বের করা।
- BigQuery ফেডারেটেড কোয়েরি : BigQuery-তে থাকা ডেটা সরাসরি কোয়েরি করার জন্য কীভাবে স্প্যানারের ফেডারেটেড কোয়েরি সক্ষমতা ব্যবহার করা যায়, তা জানুন। এটি আপনাকে ডেটা ডুপ্লিকেশন বা জটিল ETL প্রক্রিয়া ছাড়াই ব্যাপক অন্তর্দৃষ্টি এবং রিপোর্টিংয়ের জন্য স্প্যানারের রিয়েল-টাইম অপারেশনাল ডেটার সাথে BigQuery-এর অ্যানালিটিক্যাল ডেটাসেট একত্রিত করার সুযোগ দেয়। এটি BigQuery থেকে প্রাপ্ত রিয়েল-টাইম গ্রাহক ডেটার সাথে বিস্তৃত ঐতিহাসিক ট্রেন্ডগুলোকে একত্রিত করে আমাদের ব্যাংকিং অ্যাপ্লিকেশনের বিভিন্ন ক্ষেত্রে, যেমন টার্গেটেড মার্কেটিং ক্যাম্পেইনে, শক্তি জোগায়।
আপনি যা শিখবেন
- কীভাবে একটি স্প্যানার ইনস্ট্যান্স সেটআপ করবেন।
- কিভাবে ডাটাবেস এবং টেবিল তৈরি করতে হয়।
- আপনার স্প্যানার ডাটাবেস টেবিলগুলিতে কীভাবে ডেটা লোড করবেন।
- স্প্যানার থেকে ভার্টেক্স এআই মডেলগুলিকে কীভাবে কল করবেন
- ফাজি সার্চ এবং ফুল-টেক্সট সার্চ ব্যবহার করে কীভাবে আপনার স্প্যানার ডাটাবেসে কোয়েরি করবেন।
- BigQuery থেকে Spanner-এর বিরুদ্ধে কীভাবে ফেডারেটেড কোয়েরি চালানো যায়
- আপনার স্প্যানার ইনস্ট্যান্সটি কীভাবে ডিলিট করবেন।
আপনার যা যা লাগবে
- একটি গুগল ক্লাউড প্রজেক্ট যা একটি বিলিং অ্যাকাউন্টের সাথে সংযুক্ত।
- একটি ওয়েব ব্রাউজার, যেমন ক্রোম বা ফায়ারফক্স ।
২. সেটআপ এবং প্রয়োজনীয়তা
একটি প্রকল্প তৈরি করুন
আপনার যদি আগে থেকেই বিলিং চালু করা কোনো গুগল ক্লাউড প্রজেক্ট থাকে, তাহলে কনসোলের উপরের বাম দিকে থাকা প্রজেক্ট সিলেকশন পুল-ডাউন মেনুতে ক্লিক করুন:

প্রজেক্টটি নির্বাচন করা হয়ে গেলে, প্রয়োজনীয় API-গুলো সক্রিয় করার ধাপে চলে যান।
আপনার যদি আগে থেকে কোনো গুগল অ্যাকাউন্ট (জিমেইল বা গুগল অ্যাপস) না থাকে, তবে আপনাকে অবশ্যই একটি তৈরি করতে হবে। গুগল ক্লাউড প্ল্যাটফর্ম কনসোলে ( console.cloud.google.com ) সাইন-ইন করুন এবং একটি নতুন প্রজেক্ট তৈরি করুন।
নতুন প্রজেক্ট তৈরি করতে, প্রদর্শিত ডায়ালগ বক্সে থাকা 'NEW PROJECT' বাটনে ক্লিক করুন:

আপনার যদি আগে থেকে কোনো প্রজেক্ট না থাকে, তাহলে আপনার প্রথম প্রজেক্টটি তৈরি করার জন্য এইরকম একটি ডায়ালগ বক্স দেখতে পাবেন:

পরবর্তী প্রজেক্ট তৈরির ডায়ালগ বক্সে আপনি আপনার নতুন প্রজেক্টের বিবরণ লিখতে পারবেন।
প্রজেক্ট আইডিটি মনে রাখবেন, যা সমস্ত গুগল ক্লাউড প্রজেক্ট জুড়ে একটি অনন্য নাম। এই কোডল্যাবে এটিকে পরবর্তীতে PROJECT_ID হিসাবে উল্লেখ করা হবে।

এরপরে, যদি আপনি আগে থেকে তা না করে থাকেন, তাহলে Google Cloud রিসোর্স ব্যবহার করার জন্য এবং Spanner API , Vertex AI API , BigQuery API , ও BigQuery Connection API সক্রিয় করার জন্য আপনাকে ডেভেলপার কনসোলে বিলিং চালু করতে হবে।

স্প্যানারের মূল্য এখানে নথিভুক্ত করা হয়েছে। অন্যান্য সরঞ্জামের সাথে সম্পর্কিত অন্যান্য খরচ তাদের নির্দিষ্ট মূল্য নির্ধারণের পৃষ্ঠাগুলিতে নথিভুক্ত করা হবে।
গুগল ক্লাউড প্ল্যাটফর্মের নতুন ব্যবহারকারীরা ৩০০ ডলারের একটি বিনামূল্যে ট্রায়ালের জন্য যোগ্য।
গুগল ক্লাউড শেল সেটআপ
এই কোডল্যাবে আমরা গুগল ক্লাউড শেল ব্যবহার করব, যা ক্লাউডে চালিত একটি কমান্ড লাইন পরিবেশ।
এই ডেবিয়ান-ভিত্তিক ভার্চুয়াল মেশিনটিতে আপনার প্রয়োজনীয় সমস্ত ডেভেলপমেন্ট টুলস লোড করা আছে। এটি একটি স্থায়ী ৫ জিবি হোম ডিরেক্টরি প্রদান করে এবং গুগল ক্লাউডে চলে, যা নেটওয়ার্ক পারফরম্যান্স ও অথেনটিকেশনকে ব্যাপকভাবে উন্নত করে। এর মানে হলো, এই কোডল্যাবের জন্য আপনার শুধু একটি ব্রাউজার প্রয়োজন হবে।
ক্লাউড কনসোল থেকে ক্লাউড শেল সক্রিয় করতে, কেবল 'Activate Cloud Shell'-এ ক্লিক করুন। ![]() (পরিবেশের জন্য ব্যবস্থা করতে এবং সংযোগ স্থাপন করতে মাত্র কয়েক মুহূর্ত সময় লাগা উচিত)।
(পরিবেশের জন্য ব্যবস্থা করতে এবং সংযোগ স্থাপন করতে মাত্র কয়েক মুহূর্ত সময় লাগা উচিত)।

ক্লাউড শেলে সংযুক্ত হওয়ার পর, আপনি দেখতে পাবেন যে আপনাকে ইতিমধ্যেই প্রমাণীকৃত করা হয়েছে এবং প্রজেক্টটি আপনার PROJECT_ID তে সেট করা আছে।
gcloud auth list
প্রত্যাশিত আউটপুট:
Credentialed Accounts ACTIVE: * ACCOUNT: <myaccount>@<mydomain>.com
gcloud config list project
প্রত্যাশিত আউটপুট:
[core] project = <PROJECT_ID>
যদি কোনো কারণে প্রজেক্টটি সেট করা না থাকে, তাহলে নিম্নলিখিত কমান্ডটি দিন:
gcloud config set project <PROJECT_ID>
আপনার PROJECT_ID খুঁজছেন? সেটআপের ধাপগুলিতে আপনি কোন আইডি ব্যবহার করেছিলেন তা দেখে নিন অথবা ক্লাউড কনসোল ড্যাশবোর্ডে এটি খুঁজে দেখুন:

ক্লাউড শেল ডিফল্টরূপে কিছু এনভায়রনমেন্ট ভেরিয়েবলও সেট করে, যা ভবিষ্যতে কমান্ড চালানোর সময় কাজে লাগতে পারে।
echo $GOOGLE_CLOUD_PROJECT
প্রত্যাশিত আউটপুট:
<PROJECT_ID>
প্রয়োজনীয় API গুলি সক্রিয় করুন
আপনার প্রোজেক্টের জন্য স্প্যানার, ভার্টেক্স এআই, এবং বিগকোয়েরি এপিআই সক্রিয় করুন:
gcloud services enable spanner.googleapis.com
gcloud services enable aiplatform.googleapis.com
gcloud services enable bigquery.googleapis.com
gcloud services enable bigqueryconnection.googleapis.com
সারসংক্ষেপ
এই ধাপে, আপনার যদি আগে থেকে কোনো প্রজেক্ট না থাকে তবে তা সেট আপ করেছেন, ক্লাউড শেল সক্রিয় করেছেন এবং প্রয়োজনীয় এপিআইগুলো চালু করেছেন।
এরপরে
এরপরে, আপনি স্প্যানার ইনস্ট্যান্সটি সেট আপ করবেন।
৩. একটি স্প্যানার ইনস্ট্যান্স সেটআপ করুন
স্প্যানার ইনস্ট্যান্স তৈরি করুন
এই ধাপে, আপনি কোডল্যাবের জন্য একটি স্প্যানার ইনস্ট্যান্স সেট আপ করবেন। এটি করার জন্য, ক্লাউড শেল খুলুন এবং এই কমান্ডটি চালান:
export SPANNER_INSTANCE=cloudspanner-onlinebanking
gcloud spanner instances create $SPANNER_INSTANCE \
--config=regional-us-central1 \
--description="Spanner Online Banking" \
--nodes=1 \
--edition=ENTERPRISE \
--default-backup-schedule-type=NONE
প্রত্যাশিত আউটপুট:
Creating instance...done.
সারসংক্ষেপ
এই ধাপে, আপনি স্প্যানার ইনস্ট্যান্সটি তৈরি করেছেন।
এরপরে
এরপরে, আপনি প্রাথমিক অ্যাপ্লিকেশনটি প্রস্তুত করবেন এবং ডেটাবেস ও স্কিমা তৈরি করবেন।
৪. একটি ডাটাবেস এবং স্কিমা তৈরি করুন
প্রাথমিক আবেদনপত্র প্রস্তুত করুন।
এই ধাপে আপনি কোডের মাধ্যমে ডাটাবেস এবং স্কিমা তৈরি করবেন।
প্রথমে, Maven ব্যবহার করে onlinebanking নামের একটি জাভা অ্যাপ্লিকেশন তৈরি করুন:
mvn -B archetype:generate \
-DarchetypeGroupId=org.apache.maven.archetypes \
-DgroupId=com.google.codelabs \
-DartifactId=onlinebanking \
-DjavaCompilerVersion=1.8 \
-DjunitVersion=4.13.2 \
-DarchetypeVersion=1.5
যে ডেটা ফাইলগুলো আমরা ডাটাবেসে যোগ করব, সেগুলো চেকআউট করে কপি করুন (কোড রিপোজিটরির জন্য এখানে দেখুন):
git clone https://github.com/GoogleCloudPlatform/cloud-spanner-samples.git
cp -r ./cloud-spanner-samples/banking/data ./onlinebanking
অ্যাপ্লিকেশন ফোল্ডারে যান:
cd onlinebanking
Maven pom.xml ফাইলটি খুলুন। Google Cloud লাইব্রেরিগুলির ভার্সন ম্যানেজ করার জন্য Maven BOM ব্যবহার করতে ডিপেন্ডেন্সি ম্যানেজমেন্ট সেকশনটি যোগ করুন:
<dependencyManagement>
<dependencies>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>libraries-bom</artifactId>
<version>26.56.0</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
এডিটর এবং ফাইলটি দেখতে এইরকম হবে: 
নিশ্চিত করুন যে dependencies বিভাগে অ্যাপ্লিকেশনটি যে লাইব্রেরিগুলো ব্যবহার করবে সেগুলো অন্তর্ভুক্ত আছে:
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13.2</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-nop</artifactId>
<version>2.0.9</version>
</dependency>
<dependency>
<groupId>com.opencsv</groupId>
<artifactId>opencsv</artifactId>
<version>5.10</version>
</dependency>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-spanner</artifactId>
</dependency>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-bigquery</artifactId>
</dependency>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-bigqueryconnection</artifactId>
</dependency>
</dependencies>
অবশেষে, বিল্ড প্লাগইনগুলি প্রতিস্থাপন করুন যাতে অ্যাপ্লিকেশনটি একটি রানযোগ্য JAR-এ প্যাকেজ করা হয়:
<build>
<plugins>
<plugin>
<artifactId>maven-resources-plugin</artifactId>
<version>3.3.1</version>
<executions>
<execution>
<id>copy-resources</id>
<phase>process-resources</phase>
<goals>
<goal>copy-resources</goal>
</goals>
<configuration>
<outputDirectory>${project.build.directory}/${project.artifactId}-resources</outputDirectory>
<resources>
<resource>
<directory>resources</directory>
<filtering>true</filtering>
</resource>
</resources>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-dependency-plugin</artifactId>
<version>3.8.1</version>
<executions>
<execution>
<id>copy-dependencies</id>
<phase>prepare-package</phase>
<goals>
<goal>copy-dependencies</goal>
</goals>
<configuration>
<outputDirectory>${project.build.directory}/${project.artifactId}-resources/lib</outputDirectory>
<overWriteReleases>false</overWriteReleases>
<overWriteSnapshots>false</overWriteSnapshots>
<overWriteIfNewer>true</overWriteIfNewer>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<version>3.4.2</version>
<configuration>
<finalName>${project.artifactId}</finalName>
<outputDirectory>${project.build.directory}</outputDirectory>
<archive>
<index>false</index>
<manifest>
<mainClass>com.google.codelabs.App</mainClass>
<addClasspath>true</addClasspath>
<classpathPrefix>${project.artifactId}-resources/lib/</classpathPrefix>
</manifest>
</archive>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-failsafe-plugin</artifactId>
<version>3.2.5</version>
<executions>
<execution>
<goals>
<goal>integration-test</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>3.2.5</version>
<configuration>
<useSystemClassLoader>false</useSystemClassLoader>
</configuration>
</plugin>
</plugins>
</build>
Cloud Shell Editor-এর 'File' মেনুর অধীনে 'Save' নির্বাচন করে অথবা Ctrl+S চেপে pom.xml ফাইলে আপনার করা পরিবর্তনগুলি সংরক্ষণ করুন।
এখন যেহেতু ডিপেন্ডেন্সিগুলো প্রস্তুত, আপনি অ্যাপটিতে একটি স্কিমা, কিছু ইনডেক্স (সার্চ সহ) এবং একটি রিমোট এন্ডপয়েন্টের সাথে সংযুক্ত একটি এআই মডেল তৈরি করার জন্য কোড যোগ করবেন। এই কোডল্যাব জুড়ে আপনি এই আর্টিফ্যাক্টগুলোর উপর ভিত্তি করে ক্লাসটিতে আরও মেথড যুক্ত করবেন।
onlinebanking/src/main/java/com/google/codelabs এর অধীনে থাকা App.java খুলুন এবং এর ভেতরের লেখাগুলো নিচের কোড দিয়ে প্রতিস্থাপন করুন:
package com.google.codelabs;
import java.util.Arrays;
import java.util.List;
import java.util.concurrent.ExecutionException;
import com.google.api.gax.longrunning.OperationFuture;
import com.google.cloud.bigquery.BigQuery;
import com.google.cloud.bigquery.BigQueryOptions;
import com.google.cloud.spanner.Database;
import com.google.cloud.spanner.DatabaseAdminClient;
import com.google.cloud.spanner.DatabaseClient;
import com.google.cloud.spanner.DatabaseId;
import com.google.cloud.spanner.Spanner;
import com.google.cloud.spanner.SpannerException;
import com.google.cloud.spanner.SpannerExceptionFactory;
import com.google.cloud.spanner.SpannerOptions;
import com.google.spanner.admin.database.v1.CreateDatabaseMetadata;
public class App {
// Create the Spanner database and schema
public static void create(DatabaseAdminClient dbAdminClient, DatabaseId db,
String location, String model) {
System.out.println("Creating Spanner database...");
List<String> statements = Arrays.asList(
"CREATE TABLE Customers (\n"
+ " CustomerId INT64 NOT NULL,\n"
+ " FirstName STRING(256) NOT NULL,\n"
+ " LastName STRING(256) NOT NULL,\n"
+ " FullName STRING(512) AS (FirstName || ' ' || LastName) STORED,\n"
+ " Email STRING(512) NOT NULL,\n"
+ " EmailTokens TOKENLIST AS\n"
+ " (TOKENIZE_SUBSTRING(Email, ngram_size_min=>2, ngram_size_max=>3,\n"
+ " relative_search_types=>[\"all\"])) HIDDEN,\n"
+ " Address STRING(MAX)\n"
+ ") PRIMARY KEY (CustomerId)",
"CREATE INDEX CustomersByEmail\n"
+ "ON Customers(Email)",
"CREATE SEARCH INDEX CustomersFuzzyEmail\n"
+ "ON Customers(EmailTokens)",
"CREATE TABLE Accounts (\n"
+ " AccountId INT64 NOT NULL,\n"
+ " CustomerId INT64 NOT NULL,\n"
+ " AccountType STRING(256) NOT NULL,\n"
+ " Balance NUMERIC NOT NULL,\n"
+ " OpenDate TIMESTAMP NOT NULL\n"
+ ") PRIMARY KEY (AccountId)",
"CREATE INDEX AccountsByCustomer\n"
+ "ON Accounts (CustomerId)",
"CREATE TABLE TransactionLedger (\n"
+ " TransactionId INT64 NOT NULL,\n"
+ " AccountId INT64 NOT NULL,\n"
+ " TransactionType STRING(256) NOT NULL,\n"
+ " Amount NUMERIC NOT NULL,\n"
+ " Timestamp TIMESTAMP NOT NULL"
+ " OPTIONS(allow_commit_timestamp=true),\n"
+ " Category STRING(256),\n"
+ " Description STRING(MAX),\n"
+ " CategoryTokens TOKENLIST AS (TOKENIZE_FULLTEXT(Category)) HIDDEN,\n"
+ " DescriptionTokens TOKENLIST AS (TOKENIZE_FULLTEXT(Description)) HIDDEN\n"
+ ") PRIMARY KEY (AccountId, TransactionId),\n"
+ "INTERLEAVE IN PARENT Accounts ON DELETE CASCADE",
"CREATE INDEX TransactionLedgerByAccountType\n"
+ "ON TransactionLedger(AccountId, TransactionType)",
"CREATE INDEX TransactionLedgerByCategory\n"
+ "ON TransactionLedger(AccountId, Category)",
"CREATE SEARCH INDEX TransactionLedgerTextSearch\n"
+ "ON TransactionLedger(CategoryTokens, DescriptionTokens)",
"CREATE MODEL TransactionCategoryModel\n"
+ "INPUT (prompt STRING(MAX))\n"
+ "OUTPUT (content STRING(MAX))\n"
+ "REMOTE OPTIONS (\n"
+ " endpoint = '//aiplatform.googleapis.com/projects/" + db.getInstanceId().getProject()
+ "/locations/" + location + "/publishers/google/models/" + model + "',\n"
+ " default_batch_size = 1\n"
+ ")");
OperationFuture<Database, CreateDatabaseMetadata> op = dbAdminClient.createDatabase(
db.getInstanceId().getInstance(),
db.getDatabase(),
statements);
try {
Database dbOperation = op.get();
System.out.println("Created Spanner database [" + dbOperation.getId() + "]");
} catch (ExecutionException e) {
throw (SpannerException) e.getCause();
} catch (InterruptedException e) {
throw SpannerExceptionFactory.propagateInterrupt(e);
}
}
static void printUsageAndExit() {
System.out.println("Online Online Banking Application 1.0.0");
System.out.println("Usage:");
System.out.println(" java -jar target/onlinebanking.jar <command> [command_option(s)]");
System.out.println("");
System.out.println("Examples:");
System.out.println(" java -jar target/onlinebanking.jar create");
System.out.println(" - Create a sample Spanner database and schema in your "
+ "project.\n");
System.exit(1);
}
public static void main(String[] args) {
if (args.length < 1) {
printUsageAndExit();
}
String instanceId = System.getProperty("SPANNER_INSTANCE", System.getenv("SPANNER_INSTANCE"));
String databaseId = System.getProperty("SPANNER_DATABASE", System.getenv("SPANNER_DATABASE"));
String location = System.getenv().getOrDefault("SPANNER_LOCATION", "us-central1");
String model = System.getenv().getOrDefault("SPANNER_MODEL", "gemini-2.0-flash-lite");
if (instanceId == null || databaseId == null) {
System.err.println("Missing one or more required environment variables: SPANNER_INSTANCE or "
+ "SPANNER_DATABASE");
System.exit(1);
}
BigQueryOptions bigqueryOptions = BigQueryOptions.newBuilder().build();
BigQuery bigquery = bigqueryOptions.getService();
SpannerOptions spannerOptions = SpannerOptions.newBuilder().build();
try (Spanner spanner = spannerOptions.getService()) {
String command = args[0];
DatabaseId db = DatabaseId.of(spannerOptions.getProjectId(), instanceId, databaseId);
DatabaseClient dbClient = spanner.getDatabaseClient(db);
DatabaseAdminClient dbAdminClient = spanner.getDatabaseAdminClient();
switch (command) {
case "create":
create(dbAdminClient, db, location, model);
break;
default:
printUsageAndExit();
}
}
}
}
App.java তে পরিবর্তনগুলো সংরক্ষণ করুন।
আপনার কোড যে বিভিন্ন সত্তাগুলো তৈরি করছে তা দেখুন এবং অ্যাপ্লিকেশন JAR-টি বিল্ড করুন:
mvn package
প্রত্যাশিত আউটপুট:
[INFO] Building jar: /home/your_user/onlinebanking/target/onlinebanking.jar [INFO] ------------------------------------------------------------------------ [INFO] BUILD SUCCESS
ব্যবহারের তথ্য দেখতে অ্যাপ্লিকেশনটি চালান:
java -jar target/onlinebanking.jar
প্রত্যাশিত আউটপুট:
Online Banking Application 1.0.0
Usage:
java -jar target/onlinebanking.jar <command> [command_option(s)]
Examples:
java -jar target/onlinebanking.jar create
- Create a sample Spanner database and schema in your project.
ডাটাবেস এবং স্কিমা তৈরি করুন
প্রয়োজনীয় অ্যাপ্লিকেশন এনভায়রনমেন্ট ভেরিয়েবলগুলো সেট করুন:
export SPANNER_INSTANCE=cloudspanner-onlinebanking
export SPANNER_DATABASE=onlinebanking
create কমান্ডটি চালিয়ে ডাটাবেস এবং স্কিমা তৈরি করুন:
java -jar target/onlinebanking.jar create
প্রত্যাশিত আউটপুট:
Creating Spanner database... Created Spanner database [<DATABASE_RESOURCE_NAME>]
স্প্যানারে স্কিমাটি পরীক্ষা করুন
স্প্যানার কনসোলে , আপনার সদ্য তৈরি করা ইনস্ট্যান্স এবং ডেটাবেসে যান।
আপনাকে Accounts , Customers এবং TransactionLedger - এই তিনটি টেবিলই দেখতে হবে।

এই পদক্ষেপটি ডাটাবেস স্কিমা তৈরি করে, যার মধ্যে Accounts , Customers , এবং TransactionLedger টেবিলগুলো অন্তর্ভুক্ত থাকে। এর সাথে অপ্টিমাইজ করা ডেটা পুনরুদ্ধারের জন্য সেকেন্ডারি ইনডেক্স এবং একটি Vertex AI মডেল রেফারেন্সও যুক্ত থাকে।

উন্নত ডেটা লোকালিটির মাধ্যমে অ্যাকাউন্ট-নির্দিষ্ট ট্রানজ্যাকশনের জন্য কোয়েরির পারফরম্যান্স বাড়াতে TransactionLedger টেবিলটিকে অ্যাকাউন্টস টেবিলের মধ্যে অন্তর্ভুক্ত করা হয়েছে।
এই কোডল্যাবে ব্যবহৃত সাধারণ ডেটা অ্যাক্সেস প্যাটার্ন, যেমন—সঠিক ও TransactionLedgerByAccountType ইমেলের মাধ্যমে গ্রাহক খোঁজা, গ্রাহক অনুযায়ী অ্যাকাউন্ট পুনরুদ্ধার করা এবং দক্ষতার সাথে লেনদেনের ডেটা কোয়েরি ও অনুসন্ধান করা—অপ্টিমাইজ করার জন্য সেকেন্ডারি ইনডেক্সগুলো ( CustomersByEmail , CustomersFuzzyEmail , AccountsByCustomer AccountsByCustomer TransactionLedgerByCategory , TransactionLedgerByCategory, TransactionLedgerTextSearch ) প্রয়োগ করা হয়েছে।
TransactionCategoryModel Vertex AI ব্যবহার করে একটি LLM-এ সরাসরি SQL কল করার সুবিধা দেয়, যা এই কোডল্যাবে ডাইনামিক ট্রানজ্যাকশন ক্যাটাগরাইজেশনের জন্য ব্যবহৃত হয়।
সারসংক্ষেপ
এই ধাপে, আপনি স্প্যানার ডাটাবেস এবং স্কিমা তৈরি করেছেন।
এরপরে
এরপরে, আপনি নমুনা অ্যাপ্লিকেশন ডেটা লোড করবেন।
৫. ডেটা লোড করুন
এখন, আপনি CSV ফাইল থেকে ডেটাবেসে নমুনা ডেটা লোড করার কার্যকারিতা যোগ করবেন।
App.java খুলুন এবং ইম্পোর্টগুলো প্রতিস্থাপন করে শুরু করুন:
package com.google.codelabs;
import java.io.FileReader;
import java.math.BigDecimal;
import java.time.Duration;
import java.time.Instant;
import java.time.temporal.ChronoUnit;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Random;
import java.util.concurrent.ExecutionException;
import com.google.api.gax.longrunning.OperationFuture;
import com.google.cloud.Timestamp;
import com.google.cloud.bigquery.BigQuery;
import com.google.cloud.bigquery.BigQueryOptions;
import com.google.cloud.spanner.Database;
import com.google.cloud.spanner.DatabaseAdminClient;
import com.google.cloud.spanner.DatabaseClient;
import com.google.cloud.spanner.DatabaseId;
import com.google.cloud.spanner.Key;
import com.google.cloud.spanner.Spanner;
import com.google.cloud.spanner.SpannerException;
import com.google.cloud.spanner.SpannerExceptionFactory;
import com.google.cloud.spanner.SpannerOptions;
import com.google.cloud.spanner.Statement;
import com.google.cloud.spanner.Struct;
import com.google.spanner.admin.database.v1.CreateDatabaseMetadata;
import com.opencsv.CSVReader;
তারপর App ক্লাসে insert মেথডগুলো যোগ করুন:
// Insert customers from CSV
public static void insertCustomers(DatabaseClient dbClient) {
System.out.println("Inserting customers...");
dbClient
.readWriteTransaction()
.run(transaction -> {
int count = 0;
List<Statement> statements = new ArrayList<>();
try (CSVReader reader = new CSVReader(new FileReader("data/customers.csv"))) {
reader.skip(1);
String[] line;
while ((line = reader.readNext()) != null) {
Statement statement = Statement.newBuilder(
"INSERT INTO Customers (CustomerId, FirstName, LastName, Email, Address) "
+ "VALUES (@customerId, @firstName, @lastName, @email, @address)")
.bind("customerId").to(Long.parseLong(line[0]))
.bind("firstName").to(line[1])
.bind("lastName").to(line[2])
.bind("email").to(line[3])
.bind("address").to(line[4])
.build();
statements.add(statement);
count++;
}
transaction.batchUpdate(statements);
System.out.println("Inserted " + count + " customers");
return null;
}
});
}
// Insert accounts from CSV
public static void insertAccounts(DatabaseClient dbClient) {
System.out.println("Inserting accounts...");
dbClient
.readWriteTransaction()
.run(transaction -> {
int count = 0;
List<Statement> statements = new ArrayList<>();
try (CSVReader reader = new CSVReader(new FileReader("data/accounts.csv"))) {
reader.skip(1);
String[] line;
while ((line = reader.readNext()) != null) {
Statement statement = Statement.newBuilder(
"INSERT INTO Accounts (AccountId, CustomerId, AccountType, Balance, OpenDate) "
+ "VALUES (@accountId, @customerId, @accountType, @balance, @openDate)")
.bind("accountId").to(Long.parseLong(line[0]))
.bind("customerId").to(Long.parseLong(line[1]))
.bind("accountType").to(line[2])
.bind("balance").to(new BigDecimal(line[3]))
.bind("openDate").to(line[4])
.build();
statements.add(statement);
count++;
}
transaction.batchUpdate(statements);
System.out.println("Inserted " + count + " accounts");
return null;
}
});
}
// Insert transactions from CSV
public static void insertTransactions(DatabaseClient dbClient) {
System.out.println("Inserting transactions...");
dbClient
.readWriteTransaction()
.run(transaction -> {
int count = 0;
List<Statement> statements = new ArrayList<>();
try (CSVReader reader = new CSVReader(new FileReader("data/transactions.csv"))) {
reader.skip(1);
String[] line;
// Specify timestamps that are within last 30 days
Random random = new Random();
Instant startTime = Instant.now().minus(15, ChronoUnit.DAYS);
Instant currentTimestamp = startTime;
Map<Long, BigDecimal> balanceChanges = new HashMap<>();
while ((line = reader.readNext()) != null) {
long accountId = Long.parseLong(line[1]);
String transactionType = line[2];
BigDecimal amount = new BigDecimal(line[3]);
int randomMinutes = random.nextInt(60) + 1;
currentTimestamp = currentTimestamp.plus(Duration.ofMinutes(randomMinutes));
Timestamp timestamp = Timestamp.ofTimeSecondsAndNanos(
currentTimestamp.getEpochSecond(), currentTimestamp.getNano());
Statement statement = Statement.newBuilder(
"INSERT INTO TransactionLedger (TransactionId, AccountId, TransactionType, Amount,"
+ "Timestamp, Category, Description) "
+ "VALUES (@transactionId, @accountId, @transactionType, @amount, @timestamp,"
+ "@category, @description)")
.bind("transactionId").to(Long.parseLong(line[0]))
.bind("accountId").to(accountId)
.bind("transactionType").to(transactionType)
.bind("amount").to(amount)
.bind("timestamp").to(timestamp)
.bind("category").to(line[5])
.bind("description").to(line[6])
.build();
statements.add(statement);
// Track balance changes per account
BigDecimal balanceChange = balanceChanges.getOrDefault(accountId,
BigDecimal.ZERO);
if ("Credit".equalsIgnoreCase(transactionType)) {
balanceChanges.put(accountId, balanceChange.add(amount));
} else if ("Debit".equalsIgnoreCase(transactionType)) {
balanceChanges.put(accountId, balanceChange.subtract(amount));
} else {
System.err.println("Unsupported transaction type: " + transactionType);
continue;
}
count++;
}
// Apply final balance updates
for (Map.Entry<Long, BigDecimal> entry : balanceChanges.entrySet()) {
long accountId = entry.getKey();
BigDecimal balanceChange = entry.getValue();
Struct row = transaction.readRow(
"Accounts",
Key.of(accountId),
List.of("Balance"));
if (row != null) {
BigDecimal currentBalance = row.getBigDecimal("Balance");
BigDecimal updatedBalance = currentBalance.add(balanceChange);
Statement statement = Statement.newBuilder(
"UPDATE Accounts SET Balance = @balance WHERE AccountId = @accountId")
.bind("accountId").to(accountId)
.bind("balance").to(updatedBalance)
.build();
statements.add(statement);
}
}
transaction.batchUpdate(statements);
System.out.println("Inserted " + count + " transactions");
}
return null;
});
}
switch (command) -এর মধ্যে insert করার জন্য main মেথডে আরেকটি case স্টেটমেন্ট যোগ করুন:
case "insert":
String insertType = (args.length >= 2) ? args[1] : "";
if (insertType.equals("customers")) {
insertCustomers(dbClient);
} else if (insertType.equals("accounts")) {
insertAccounts(dbClient);
} else if (insertType.equals("transactions")) {
insertTransactions(dbClient);
} else {
insertCustomers(dbClient);
insertAccounts(dbClient);
insertTransactions(dbClient);
}
break;
অবশেষে, printUsageAndExit মেথডে insert ব্যবহারের পদ্ধতিটি সংযুক্ত করুন:
System.out.println(" java -jar target/onlinebanking.jar insert");
System.out.println(" - Insert sample Customers, Accounts, and Transactions into the "
+ "database.\n");
App.java তে আপনার করা পরিবর্তনগুলো সংরক্ষণ করুন।
অ্যাপ্লিকেশনটি পুনর্নির্মাণ করুন:
mvn package
insert কমান্ডটি চালিয়ে নমুনা ডেটা সন্নিবেশ করুন:
java -jar target/onlinebanking.jar insert
প্রত্যাশিত আউটপুট:
Inserting customers... Inserted 100 customers Inserting accounts... Inserted 125 accounts Inserting transactions... Inserted 200 transactions
স্প্যানার কনসোলে , আপনার ইনস্ট্যান্স এবং ডাটাবেসের জন্য স্প্যানার স্টুডিওতে ফিরে যান। তারপর TransactionLedger টেবিলটি নির্বাচন করুন এবং ডেটা লোড হয়েছে কিনা তা যাচাই করতে সাইডবারে "ডেটা" (Data) বোতামে ক্লিক করুন। টেবিলটিতে ২০০টি সারি থাকার কথা।

সারসংক্ষেপ
এই ধাপে, আপনি ডেটাবেসে নমুনা ডেটা সন্নিবেশ করেছেন।
এরপরে
এরপরে, আপনি সরাসরি স্প্যানার এসকিউএল (Spanner SQL)-এর মধ্যেই ব্যাংকিং লেনদেনগুলোকে স্বয়ংক্রিয়ভাবে শ্রেণিবদ্ধ করতে ভার্টেক্স এআই (Vertex AI) ইন্টিগ্রেশন ব্যবহার করবেন।
৬. ভার্টেক্স এআই দিয়ে ডেটা শ্রেণীবদ্ধ করুন
এই ধাপে, আপনি স্প্যানার এসকিউএল (Spanner SQL)-এর মধ্যেই সরাসরি আপনার আর্থিক লেনদেনগুলোকে স্বয়ংক্রিয়ভাবে শ্রেণিবদ্ধ করতে ভার্টেক্স এআই (Vertex AI)-এর শক্তিকে কাজে লাগাবেন। ভার্টেক্স এআই-এর সাহায্যে আপনি আগে থেকে প্রশিক্ষিত কোনো মডেল বেছে নিতে পারেন অথবা আপনার নিজের মডেলকে প্রশিক্ষণ দিয়ে স্থাপন করতে পারেন। ভার্টেক্স এআই মডেল গার্ডেন (Vertex AI Model Garden) -এ উপলব্ধ মডেলগুলো দেখুন।
এই কোডল্যাবের জন্য আমরা জেমিনি মডেলগুলোর মধ্যে একটি, Gemini Flash Lite ব্যবহার করব। জেমিনির এই সংস্করণটি সাশ্রয়ী, অথচ এটি দৈনন্দিন বেশিরভাগ কাজই সামলাতে পারে।
বর্তমানে, আমাদের বেশ কিছু আর্থিক লেনদেন রয়েছে যেগুলোকে আমরা বিবরণের উপর ভিত্তি করে শ্রেণিবদ্ধ করতে চাই ( groceries , transportation ইত্যাদি)। আমরা স্প্যানারে একটি মডেল রেজিস্টার করে এবং তারপর এআই মডেলটিকে কল করার জন্য ML.PREDICT ব্যবহার করে এটি করতে পারি।
আমাদের ব্যাংকিং অ্যাপ্লিকেশনে, গ্রাহকের আচরণ সম্পর্কে আরও গভীর ধারণা পাওয়ার জন্য আমরা লেনদেনগুলোকে বিভিন্ন শ্রেণিতে ভাগ করতে চাইতে পারি। এর ফলে আমরা পরিষেবাগুলোকে ব্যক্তিগতকৃত করতে, অস্বাভাবিকতা আরও কার্যকরভাবে শনাক্ত করতে, অথবা গ্রাহককে মাস-ভিত্তিক তার বাজেট ট্র্যাক করার সুযোগ দিতে পারি।
প্রথম ধাপটি ইতিমধ্যেই সম্পন্ন হয়ে গিয়েছিল যখন আমরা ডাটাবেস এবং স্কিমা তৈরি করেছিলাম, যা এইরকম একটি মডেল তৈরি করেছিল:
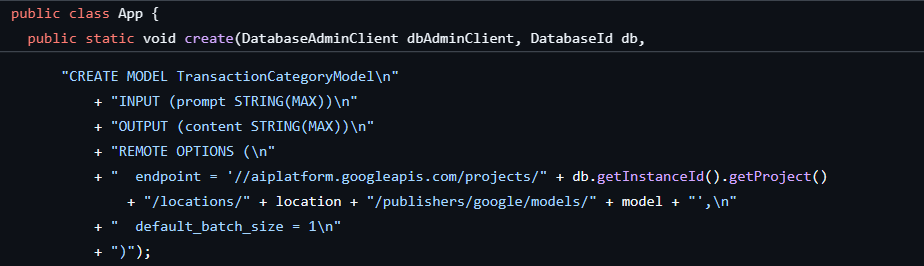
এরপরে, আমরা অ্যাপ্লিকেশনটিতে ML.PREDICT কল করার জন্য একটি মেথড যোগ করব।
App.java খুলুন এবং categorize মেথডটি যোগ করুন:
// Use Vertex AI to set the category of transactions
public static void categorize(DatabaseClient dbClient) {
System.out.println("Categorizing transactions...");
try {
// Create a prompt to instruct the LLM how to categorize the transactions
String categories = String.join(", ", Arrays.asList("Entertainment", "Gifts", "Groceries",
"Investment", "Medical", "Movies", "Online Shopping", "Other", "Purchases", "Refund",
"Restaurants", "Salary", "Transfer", "Transportation", "Utilities"));
String prompt = "Categorize the following financial activity into one of these "
+ "categories: " + categories + ". Return Other if the description cannot be mapped to "
+ "one of these categories. Only return the exact category string, no other text or "
+ "punctuation or reasoning. Description: ";
String sql = "UPDATE TransactionLedger SET Category = (\n"
+ " SELECT content FROM ML.PREDICT(MODEL `TransactionCategoryModel`, (\n"
+ " SELECT CONCAT('" + prompt + "', CASE WHEN TRIM(Description) = ''\n"
+ " THEN 'Other' ELSE Description END) AS prompt\n"
+ " ))\n"
+ ") WHERE TRUE";
// Use partitioned update to batch update a large number of rows
dbClient.executePartitionedUpdate(Statement.of(sql));
System.out.println("Completed categorizing transactions");
} catch (SpannerException e) {
throw e;
}
}
শ্রেণীভুক্ত করার জন্য main মেথডে আরেকটি কেস স্টেটমেন্ট যোগ করুন:
case "categorize":
categorize(dbClient);
break;
অবশেষে, printUsageAndExit মেথডে `categorize` ব্যবহারের নিয়মটি যুক্ত করুন:
System.out.println(" java -jar target/onlinebanking.jar categorize");
System.out.println(" - Use AI to categorize transactions in the database.\n");
App.java তে আপনার করা পরিবর্তনগুলো সংরক্ষণ করুন।
অ্যাপ্লিকেশনটি পুনর্নির্মাণ করুন:
mvn package
categorize কমান্ডটি চালিয়ে ডাটাবেসের লেনদেনগুলোকে শ্রেণিবদ্ধ করুন:
java -jar target/onlinebanking.jar categorize
প্রত্যাশিত আউটপুট:
Categorizing transactions... Completed categorizing transactions
স্প্যানার স্টুডিওতে, TransactionLedger টেবিলের জন্য Preview Data স্টেটমেন্টটি চালান। এখন সব সারির জন্য Category কলামটি পূরণ হয়ে যাবে।

এখন যেহেতু আমরা লেনদেনগুলোকে শ্রেণিবদ্ধ করেছি, আমরা এই তথ্য অভ্যন্তরীণ বা গ্রাহক-সম্পর্কিত জিজ্ঞাসার জন্য ব্যবহার করতে পারি। পরবর্তী ধাপে আমরা দেখব, কীভাবে খুঁজে বের করা যায় যে একজন নির্দিষ্ট গ্রাহক মাসজুড়ে একটি নির্দিষ্ট বিভাগে কত খরচ করছেন।
সারসংক্ষেপ
এই ধাপে, আপনি আপনার ডেটার এআই-চালিত শ্রেণিবিন্যাস করার জন্য একটি পূর্ব-প্রশিক্ষিত মডেল ব্যবহার করেছেন।
এরপরে
এরপরে, আপনি ফাজি এবং ফুল-টেক্সট সার্চ করার জন্য টোকেনাইজেশন ব্যবহার করবেন।
৭. পূর্ণ-পাঠ্য অনুসন্ধান ব্যবহার করে কোয়েরি করুন
কোয়েরি কোড যোগ করুন
স্প্যানার অনেকগুলো পূর্ণ-পাঠ্য অনুসন্ধানের বিকল্প প্রদান করে। এই ধাপে আপনি একটি যথার্থ-সদৃশ অনুসন্ধান, তারপর একটি অস্পষ্ট অনুসন্ধান এবং একটি পূর্ণ-পাঠ্য অনুসন্ধান করবেন।
App.java খুলুন এবং ইম্পোর্টগুলো প্রতিস্থাপন করে শুরু করুন:
package com.google.codelabs;
import java.io.FileReader;
import java.math.BigDecimal;
import java.time.Duration;
import java.time.Instant;
import java.time.temporal.ChronoUnit;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Random;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.TimeUnit;
import com.google.api.gax.longrunning.OperationFuture;
import com.google.cloud.Timestamp;
import com.google.cloud.bigquery.BigQuery;
import com.google.cloud.bigquery.BigQueryOptions;
import com.google.cloud.spanner.Database;
import com.google.cloud.spanner.DatabaseAdminClient;
import com.google.cloud.spanner.DatabaseClient;
import com.google.cloud.spanner.DatabaseId;
import com.google.cloud.spanner.Key;
import com.google.cloud.spanner.ReadOnlyTransaction;
import com.google.cloud.spanner.ResultSet;
import com.google.cloud.spanner.Spanner;
import com.google.cloud.spanner.SpannerException;
import com.google.cloud.spanner.SpannerExceptionFactory;
import com.google.cloud.spanner.SpannerOptions;
import com.google.cloud.spanner.Statement;
import com.google.cloud.spanner.Struct;
import com.google.cloud.spanner.TimestampBound;
import com.google.spanner.admin.database.v1.CreateDatabaseMetadata;
import com.opencsv.CSVReader;
তারপর কোয়েরি মেথডগুলো যোগ করুন:
// Get current account balance(s) by customer
public static void getBalance(DatabaseClient dbClient, long customerId) {
String query = "SELECT AccountId, Balance\n"
+ "FROM Accounts\n"
+ "WHERE CustomerId = @customerId";
Statement statement = Statement.newBuilder(query)
.bind("customerId").to(customerId)
.build();
// Ignore ongoing transactions, use stale reads as seconds-old data is sufficient
TimestampBound stalenessBound = TimestampBound.ofMaxStaleness(5, TimeUnit.SECONDS);
try (ReadOnlyTransaction transaction = dbClient.singleUseReadOnlyTransaction(stalenessBound);
ResultSet resultSet = transaction.executeQuery(statement);) {
System.out.println("Account balances for customer " + customerId + ":");
while (resultSet.next()) {
System.out.println(" Account " + resultSet.getLong("AccountId") + ": "
+ resultSet.getBigDecimal("Balance"));
}
}
}
// Find customers by email
public static void findCustomers(DatabaseClient dbClient, String email) {
// Query using fuzzy search (ngrams) to allow for spelling mistakes
String query = "SELECT CustomerId, Email\n"
+ "FROM Customers\n"
+ "WHERE SEARCH_NGRAMS(EmailTokens, @email)\n"
+ "ORDER BY SCORE_NGRAMS(EmailTokens, @email) DESC\n"
+ "LIMIT 10";
Statement statement = Statement.newBuilder(query)
.bind("email").to(email)
.build();
try (ReadOnlyTransaction transaction = dbClient.singleUseReadOnlyTransaction();
ResultSet resultSet = transaction.executeQuery(statement)) {
System.out.println("Customer emails matching " + email + " (top 10 matches):");
while (resultSet.next()) {
System.out.println(" Customer " + resultSet.getLong("CustomerId") + ": "
+ resultSet.getString("Email"));
}
}
}
// Get total monthly spending for a customer by category
public static void getSpending(DatabaseClient dbClient, long customerId, String category) {
// Query category using full-text search
String query = "SELECT SUM(Amount) as TotalSpending\n"
+ "FROM TransactionLedger t\n"
+ "JOIN Accounts a\n"
+ " ON t.AccountId = a.AccountId\n"
+ "WHERE t.TransactionType = 'Debit'\n"
+ " AND a.CustomerId = @customerId\n"
+ " AND t.Timestamp >= TIMESTAMP_ADD(CURRENT_TIMESTAMP(), INTERVAL -30 DAY)\n"
+ " AND (SEARCH(t.CategoryTokens, @category) OR SEARCH(t.DescriptionTokens, @category))";
Statement statement = Statement.newBuilder(query)
.bind("customerId").to(customerId)
.bind("category").to(category)
.build();
try (ReadOnlyTransaction transaction = dbClient.singleUseReadOnlyTransaction();
ResultSet resultSet = transaction.executeQuery(statement);) {
System.out.println("Total spending for customer " + customerId + " under category "
+ category + ":");
while (resultSet.next()) {
BigDecimal totalSpending = BigDecimal.ZERO;
if (!resultSet.isNull("TotalSpending")) {
totalSpending = resultSet.getBigDecimal("TotalSpending");
}
System.out.println(" " + totalSpending);
}
}
}
কোয়েরির জন্য main মেথডে আরেকটি case স্টেটমেন্ট যোগ করুন:
case "query":
String queryType = (args.length >= 2) ? args[1] : "";
if (queryType.equals("balance")) {
long customerId = (args.length >= 3) ? Long.parseLong(args[2]) : 1L;
getBalance(dbClient, customerId);
} else if (queryType.equals("email")) {
String email = (args.length >= 3) ? args[2] : "";
findCustomers(dbClient, email);
} else if (queryType.equals("spending")) {
long customerId = (args.length >= 3) ? Long.parseLong(args[2]) : 1L;
String category = (args.length >= 4) ? args[3] : "";
getSpending(dbClient, customerId, category);
} else {
printUsageAndExit();
}
break;
অবশেষে, printUsageAndExit মেথডটিতে কোয়েরি কমান্ডগুলো কীভাবে ব্যবহার করতে হয় তা সংযুক্ত করুন:
System.out.println(" java -jar target/onlinebanking.jar query balance 1");
System.out.println(" - Query customer account balance(s) by customer id.\n");
System.out.println(" java -jar target/onlinebanking.jar query email madi");
System.out.println(" - Find customers by email using fuzzy search.\n");
System.out.println(" java -jar target/onlinebanking.jar query spending 1 groceries");
System.out.println(" - Query customer spending by customer id and category using "
+ "full-text search.\n");
App.java তে আপনার করা পরিবর্তনগুলো সংরক্ষণ করুন।
অ্যাপ্লিকেশনটি পুনর্নির্মাণ করুন:
mvn package
গ্রাহকের অ্যাকাউন্ট ব্যালেন্সের জন্য একটি সঠিক-মিল অনুসন্ধান চালান।
একটি এক্সাক্ট-ম্যাচ কোয়েরি এমন সারিগুলো খুঁজে বের করে যা কোনো একটি টার্মের সাথে হুবহু মিলে যায়।
পারফরম্যান্স উন্নত করার জন্য আপনি যখন ডেটাবেস এবং স্কিমা তৈরি করেছিলেন, তখনই একটি ইনডেক্স যোগ করা হয়েছিল:
"CREATE INDEX AccountsByCustomer\n"
+ "ON Accounts (CustomerId)",
getBalance মেথডটি প্রদত্ত customerId-এর সাথে মেলে এমন গ্রাহকদের খুঁজে বের করার জন্য পরোক্ষভাবে এই ইনডেক্সটি ব্যবহার করে এবং সেই গ্রাহকের অন্তর্গত অ্যাকাউন্টগুলোর সাথেও যুক্ত হয়।
স্প্যানার স্টুডিওতে সরাসরি এক্সিকিউট করলে কোয়েরিটি দেখতে এইরকম হয়: 
এই কমান্ডটি চালিয়ে গ্রাহক 1 -এর অ্যাকাউন্টের ব্যালেন্স(গুলি) দেখুন:
java -jar target/onlinebanking.jar query balance 1
প্রত্যাশিত আউটপুট:
Account balances for customer 1: Account 1: 9875.25 Account 7: 9900 Account 110: 38200
এখানে ১০০ জন গ্রাহক আছেন, তাই আপনি ভিন্ন গ্রাহক আইডি উল্লেখ করে অন্য যেকোনো গ্রাহকের অ্যাকাউন্টের ব্যালেন্সও জানতে পারেন:
java -jar target/onlinebanking.jar query balance 5
java -jar target/onlinebanking.jar query balance 10
java -jar target/onlinebanking.jar query balance 99
গ্রাহকের ইমেলগুলির বিরুদ্ধে একটি অস্পষ্ট অনুসন্ধান চালান
ফাজি সার্চের মাধ্যমে সার্চ টার্মের আনুমানিক মিল খুঁজে পাওয়া যায়, যার মধ্যে বানানের ভিন্নতা এবং টাইপের ভুলও অন্তর্ভুক্ত থাকে।
আপনি যখন ডাটাবেস এবং স্কিমা তৈরি করেছিলেন, তখনই একটি এন-গ্রাম ইনডেক্স যোগ করা হয়েছিল:
CREATE TABLE Customers (
...
EmailTokens TOKENLIST AS (TOKENIZE_SUBSTRING(Email,
ngram_size_min=>2,
ngram_size_max=>3,
relative_search_types=>["all"])) HIDDEN,
) PRIMARY KEY(CustomerId);
CREATE SEARCH INDEX CustomersFuzzyEmail ON Customers(EmailTokens);
findCustomers মেথডটি ইমেইলের মাধ্যমে গ্রাহকদের খুঁজে বের করার জন্য এই ইনডেক্সে কোয়েরি করতে SEARCH_NGRAMS এবং SCORE_NGRAMS ব্যবহার করে। যেহেতু `email` কলামটি এন-গ্রাম টোকেনাইজ করা হয়েছে, তাই এই কোয়েরিতে বানান ভুল থাকলেও সঠিক উত্তর পাওয়া যেতে পারে। ফলাফলগুলো সেরা মিলের ভিত্তিতে সাজানো হয়।
madi ধারণকারী মিলে যাওয়া গ্রাহকের ইমেল ঠিকানাগুলি খুঁজে বের করতে নিম্নলিখিত কমান্ডটি চালান:
java -jar target/onlinebanking.jar query email madi
প্রত্যাশিত আউটপুট:
Customer emails matching madi (top 10 matches): Customer 39: madison.perez@example.com Customer 64: mason.gray@example.com Customer 91: mabel.alexander@example.com
এই প্রতিক্রিয়াটি madi বা অনুরূপ কোনো স্ট্রিং অন্তর্ভুক্ত থাকা নিকটতম মিলগুলোকে ক্রমানুসারে দেখায়।
স্প্যানার স্টুডিওতে সরাসরি এক্সিকিউট করলে কোয়েরিটি দেখতে এইরকম হয়: 
ফাজি সার্চ emily -এর মতো নামের বানান ভুলের ক্ষেত্রেও সাহায্য করতে পারে।
java -jar target/onlinebanking.jar query email emily
java -jar target/onlinebanking.jar query email emliy
java -jar target/onlinebanking.jar query email emilee
প্রত্যাশিত আউটপুট:
Customer emails matching emliy (top 10 matches): Customer 31: emily.lopez@example.com
প্রতিটি ক্ষেত্রেই প্রত্যাশিত গ্রাহক ইমেলটি শীর্ষ ফলাফল হিসেবে প্রদর্শিত হয়।
পূর্ণ-পাঠ্য অনুসন্ধানের মাধ্যমে লেনদেন অনুসন্ধান করুন
স্প্যানারের ফুল-টেক্সট সার্চ ফিচারটি কীওয়ার্ড বা বাক্যাংশের উপর ভিত্তি করে রেকর্ড খুঁজে বের করতে ব্যবহৃত হয়। এটি বানান ভুল সংশোধন করতে বা সমার্থক শব্দ খুঁজতে সক্ষম।
আপনি যখন ডেটাবেস এবং স্কিমা তৈরি করেছিলেন, তখনই একটি পূর্ণ-পাঠ্য অনুসন্ধান সূচক যোগ করা হয়েছিল:
CREATE TABLE TransactionLedger ( ... CategoryTokens TOKENLIST AS (TOKENIZE_FULLTEXT(Category)) HIDDEN, DescriptionTokens TOKENLIST AS (TOKENIZE_FULLTEXT(Description)) HIDDEN, ) PRIMARY KEY(AccountId, TransactionId), INTERLEAVE IN PARENT Accounts ON DELETE CASCADE; CREATE SEARCH INDEX TransactionLedgerTextSearch ON TransactionLedger(CategoryTokens, DescriptionTokens);
getSpending মেথডটি সেই ইনডেক্সের সাথে মেলানোর জন্য SEARCH ফুল-টেক্সট সার্চ ফাংশন ব্যবহার করে। এটি প্রদত্ত কাস্টমার আইডির জন্য গত ৩০ দিনের সমস্ত খরচ (ডেবিট) খুঁজে বের করে।
এই কমান্ডটি চালিয়ে গ্রাহক 1 এর গত এক মাসের groceries বিভাগের মোট খরচ জানুন:
java -jar target/onlinebanking.jar query spending 1 groceries
প্রত্যাশিত আউটপুট:
Total spending for customer 1 under category groceries: 50
আপনি অন্যান্য বিভাগ জুড়েও (যা আমরা আগের ধাপে শ্রেণীবদ্ধ করেছি) খরচ খুঁজে পেতে পারেন, অথবা একটি ভিন্ন গ্রাহক আইডি ব্যবহার করতে পারেন:
java -jar target/onlinebanking.jar query spending 1 transportation
java -jar target/onlinebanking.jar query spending 1 restaurants
java -jar target/onlinebanking.jar query spending 12 entertainment
সারসংক্ষেপ
এই ধাপে, আপনি এক্সাক্ট-ম্যাচ কোয়েরির পাশাপাশি ফাজি এবং ফুল-টেক্সট সার্চও করেছেন।
এরপরে
এরপরে, আপনি ফেডারেটেড কোয়েরি চালানোর জন্য স্প্যানারকে গুগল বিগকোয়েরির সাথে ইন্টিগ্রেট করবেন, যা আপনাকে আপনার রিয়েল-টাইম স্প্যানার ডেটার সাথে বিগকোয়েরি ডেটা একত্রিত করার সুযোগ দেবে।
৮. BigQuery দিয়ে ফেডারেটেড কোয়েরি চালান।
BigQuery ডেটাসেট তৈরি করুন
এই ধাপে, আপনি ফেডারেটেড কোয়েরি ব্যবহারের মাধ্যমে BigQuery এবং Spanner-এর ডেটা একত্রিত করবেন।
এটি করার জন্য, ক্লাউড শেল কমান্ড লাইনে, প্রথমে একটি MarketingCampaigns ডেটাসেট তৈরি করুন:
bq mk --location=us-central1 MarketingCampaigns
প্রত্যাশিত আউটপুট:
Dataset '<PROJECT_ID>:MarketingCampaigns' successfully created.
এবং ডেটাসেটে একটি CustomerSegments টেবিল:
bq mk --table MarketingCampaigns.CustomerSegments CampaignId:STRING,CampaignName:STRING,CustomerId:INT64
প্রত্যাশিত আউটপুট:
Table '<PROJECT_ID>:MarketingCampaigns.CustomerSegments' successfully created.
এরপর, BigQuery থেকে Spanner-এ একটি সংযোগ স্থাপন করুন:
bq mk --connection \
--connection_type=CLOUD_SPANNER \
--properties="{\"database\": \"projects/$GOOGLE_CLOUD_PROJECT/instances/cloudspanner-onlinebanking/databases/onlinebanking\", \"useParallelism\": true, \"useDataBoost\": true}" \
--location=us-central1 \
spanner-connection
প্রত্যাশিত আউটপুট:
Connection <PROJECT_NUMBER>.us-central1.spanner-connection successfully created
অবশেষে, BigQuery টেবিলে কিছু গ্রাহক যোগ করুন যাদেরকে আমাদের Spanner ডেটার সাথে যুক্ত করা যাবে:
bq query --use_legacy_sql=false '
INSERT INTO MarketingCampaigns.CustomerSegments (CampaignId, CampaignName, CustomerId)
VALUES
("campaign1", "Spring Promotion", 1),
("campaign1", "Spring Promotion", 3),
("campaign1", "Spring Promotion", 5),
("campaign1", "Spring Promotion", 7),
("campaign1", "Spring Promotion", 9),
("campaign1", "Spring Promotion", 11)'
প্রত্যাশিত আউটপুট:
Waiting on bqjob_r76a7ce76c5ec948f_0000019644bda052_1 ... (0s) Current status: DONE Number of affected rows: 6
BigQuery-তে কোয়েরি করে আপনি ডেটা উপলব্ধ আছে কিনা তা যাচাই করতে পারেন:
bq query --use_legacy_sql=false "SELECT * FROM MarketingCampaigns.CustomerSegments"
প্রত্যাশিত আউটপুট:
+------------+------------------+------------+ | CampaignId | CampaignName | CustomerId | +------------+------------------+------------+ | campaign1 | Spring Promotion | 1 | | campaign1 | Spring Promotion | 5 | | campaign1 | Spring Promotion | 7 | | campaign1 | Spring Promotion | 9 | | campaign1 | Spring Promotion | 11 | | campaign1 | Spring Promotion | 3 | +------------+------------------+------------+
BigQuery-তে থাকা এই ডেটা বিভিন্ন ব্যাংক ওয়ার্কফ্লোর মাধ্যমে যুক্ত হওয়া তথ্যকে প্রতিনিধিত্ব করে। উদাহরণস্বরূপ, এটি হতে পারে সেইসব গ্রাহকদের তালিকা যারা সম্প্রতি অ্যাকাউন্ট খুলেছেন বা কোনো মার্কেটিং প্রমোশনের জন্য সাইন আপ করেছেন। আমাদের মার্কেটিং ক্যাম্পেইনে যে গ্রাহকদের লক্ষ্য করতে চাই, তাদের তালিকা নির্ধারণ করার জন্য আমাদের BigQuery-তে থাকা এই ডেটা এবং Spanner-এ থাকা রিয়েল-টাইম ডেটা উভয়কেই কোয়েরি করতে হবে, এবং একটি ফেডারেটেড কোয়েরি আমাদেরকে একটিমাত্র কোয়েরির মাধ্যমেই এই কাজটি করার সুযোগ দেয়।
BigQuery দিয়ে একটি ফেডারেটেড কোয়েরি চালান
এরপরে, ফেডারেটেড কোয়েরিটি সম্পাদন করার জন্য আমরা অ্যাপ্লিকেশনটিতে EXTERNAL_QUERY কল করার একটি মেথড যুক্ত করব। এর ফলে BigQuery এবং Spanner জুড়ে গ্রাহকের ডেটা জয়েন ও বিশ্লেষণ করা যাবে, যেমন—গ্রাহকদের সাম্প্রতিক খরচের উপর ভিত্তি করে আমাদের মার্কেটিং ক্যাম্পেইনের জন্য কোন গ্রাহকরা শর্ত পূরণ করে তা শনাক্ত করা।
App.java খুলুন এবং ইম্পোর্টগুলো প্রতিস্থাপন করে শুরু করুন:
package com.google.codelabs;
import java.io.FileReader;
import java.math.BigDecimal;
import java.time.Duration;
import java.time.Instant;
import java.time.temporal.ChronoUnit;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Random;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.TimeUnit;
import com.google.api.gax.longrunning.OperationFuture;
import com.google.cloud.Timestamp;
import com.google.cloud.bigquery.BigQuery;
import com.google.cloud.bigquery.BigQueryException;
import com.google.cloud.bigquery.BigQueryOptions;
import com.google.cloud.bigquery.connection.v1.ConnectionName;
import com.google.cloud.bigquery.JobException;
import com.google.cloud.bigquery.QueryJobConfiguration;
import com.google.cloud.bigquery.TableResult;
import com.google.cloud.spanner.Database;
import com.google.cloud.spanner.DatabaseAdminClient;
import com.google.cloud.spanner.DatabaseClient;
import com.google.cloud.spanner.DatabaseId;
import com.google.cloud.spanner.Key;
import com.google.cloud.spanner.ReadOnlyTransaction;
import com.google.cloud.spanner.ResultSet;
import com.google.cloud.spanner.Spanner;
import com.google.cloud.spanner.SpannerException;
import com.google.cloud.spanner.SpannerExceptionFactory;
import com.google.cloud.spanner.SpannerOptions;
import com.google.cloud.spanner.Statement;
import com.google.cloud.spanner.Struct;
import com.google.cloud.spanner.TimestampBound;
import com.google.spanner.admin.database.v1.CreateDatabaseMetadata;
import com.opencsv.CSVReader;
তারপর campaign পদ্ধতি যোগ করুন:
// Get customers for quarterly marketing campaign in BigQuery using Spanner data
public static void campaign(BigQuery bq, DatabaseId db, String location, String campaignId,
int threshold) {
// The BigQuery dataset, table, and Spanner connection must already exist for this to succeed
ConnectionName connection = ConnectionName.of(db.getInstanceId().getProject(), location,
"spanner-connection");
// Use a federated query to bring Spanner data into BigQuery
String bqQuery = "SELECT cs.CampaignName, c.CustomerId, c.FullName, t.TotalSpending\n"
+ "FROM MarketingCampaigns.CustomerSegments cs\n"
+ "JOIN EXTERNAL_QUERY('" + connection.toString() + "',\n"
+ " \"SELECT t.AccountId, SUM(t.Amount) AS TotalSpending"
+ " FROM TransactionLedger t"
+ " WHERE t.Timestamp >= TIMESTAMP_ADD(CURRENT_TIMESTAMP(), INTERVAL -90 DAY)"
+ " GROUP BY t.AccountId"
+ " HAVING SUM(t.Amount) > " + threshold + "\"\n"
+ ") t ON cs.CustomerId = t.AccountId\n"
+ "JOIN EXTERNAL_QUERY('" + connection.toString() + "',\n"
+ " \"SELECT CustomerId, FullName"
+ " FROM Customers\"\n"
+ ") c ON c.CustomerId = cs.CustomerId\n"
+ "WHERE cs.CampaignId = '" + campaignId + "'";
try {
QueryJobConfiguration queryConfig = QueryJobConfiguration.newBuilder(bqQuery).build();
TableResult results = bq.query(queryConfig);
System.out.println("Customers for campaign (" + campaignId + "):");
results.iterateAll().forEach(row -> {
System.out.println(" " + row.get("FullName").getStringValue()
+ " (" + row.get("CustomerId").getStringValue() + ")");
});
} catch (JobException e) {
throw (BigQueryException) e.getCause();
} catch (InterruptedException e) {
throw SpannerExceptionFactory.propagateInterrupt(e);
}
}
ক্যাম্পেইনের জন্য main মেথডে আরেকটি কেস স্টেটমেন্ট যোগ করুন:
case "campaign":
String campaignId = (args.length >= 2) ? args[1] : "";
int threshold = (args.length >= 3) ? Integer.parseInt(args[2]) : 5000;
campaign(bigquery, db, location, campaignId, threshold);
break;
অবশেষে, printUsageAndExit মেথডটিতে ক্যাম্পেইন ব্যবহারের নিয়মাবলী যুক্ত করুন:
System.out.println(" java -jar target/onlinebanking.jar campaign campaign1 5000");
System.out.println(" - Use Federated Queries (BigQuery) to find customers that match a "
+ "marketing campaign by name based on a recent spending threshold.\n");
App.java তে আপনার করা পরিবর্তনগুলো সংরক্ষণ করুন।
অ্যাপ্লিকেশনটি পুনর্নির্মাণ করুন:
mvn package
campaign কমান্ডটি চালিয়ে একটি ফেডারেটেড কোয়েরির মাধ্যমে সেইসব গ্রাহকদের চিহ্নিত করুন, যাদেরকে মার্কেটিং ক্যাম্পেইন ( campaign1 )-এ অন্তর্ভুক্ত করা উচিত, যদি তারা গত ৩ মাসে কমপক্ষে $5000 খরচ করে থাকেন।
java -jar target/onlinebanking.jar campaign campaign1 5000
প্রত্যাশিত আউটপুট:
Customers for campaign (campaign1): Alice Smith (1) Eve Davis (5) Kelly Thomas (11)
আমরা এখন এই গ্রাহকদের বিশেষ অফার বা পুরস্কারের মাধ্যমে আকৃষ্ট করতে পারি।
অথবা আমরা এমন আরও বেশি সংখ্যক গ্রাহকদের সন্ধান করতে পারি, যারা গত ৩ মাসে একটি অপেক্ষাকৃত কম ব্যয়ের সীমা অর্জন করেছেন:
java -jar target/onlinebanking.jar campaign campaign1 2500
প্রত্যাশিত আউটপুট:
Customers for campaign (campaign1): Alice Smith (1) Charlie Williams (3) Eve Davis (5) Ivy Taylor (9) Kelly Thomas (11)
সারসংক্ষেপ
এই ধাপে, আপনি BigQuery থেকে ফেডারেটেড কোয়েরিগুলো সফলভাবে সম্পাদন করেছেন, যা রিয়েল-টাইম স্প্যানার ডেটা নিয়ে এসেছে।
এরপরে
এরপরে, চার্জ এড়ানোর জন্য আপনি এই কোডল্যাবের জন্য তৈরি করা রিসোর্সগুলো পরিষ্কার করতে পারেন।
৯. পরিষ্করণ (ঐচ্ছিক)
এই ধাপটি ঐচ্ছিক। আপনি যদি আপনার স্প্যানার ইনস্ট্যান্স নিয়ে পরীক্ষা-নিরীক্ষা চালিয়ে যেতে চান, তবে এই মুহূর্তে এটি পরিষ্কার করার প্রয়োজন নেই। তবে, আপনি যে প্রজেক্টটি ব্যবহার করছেন, সেটির জন্য ইনস্ট্যান্সটির চার্জ অব্যাহত থাকবে। যদি আপনার এই ইনস্ট্যান্সটির আর কোনো প্রয়োজন না থাকে, তবে এই চার্জগুলো এড়াতে আপনার এখনই এটি ডিলিট করে দেওয়া উচিত। স্প্যানার ইনস্ট্যান্স ছাড়াও, এই কোডল্যাবটি একটি BigQuery ডেটাসেট এবং কানেকশনও তৈরি করেছে, যেগুলোর আর প্রয়োজন না থাকলে সেগুলো পরিষ্কার করে ফেলা উচিত।
স্প্যানার ইনস্ট্যান্সটি মুছে ফেলুন:
gcloud spanner instances delete cloudspanner-onlinebanking
আপনি চালিয়ে যেতে চান কিনা তা নিশ্চিত করুন ( Y টাইপ করুন):
Delete instance [cloudspanner-onlinebanking]. Are you sure? Do you want to continue (Y/n)?
BigQuery সংযোগ এবং ডেটাসেট মুছে ফেলুন:
bq rm --connection --location=us-central1 spanner-connection
bq rm -r MarketingCampaigns
BigQuery ডেটাসেটটি মুছে ফেলার বিষয়টি নিশ্চিত করুন ( Y টাইপ করুন):
rm: remove dataset '<PROJECT_ID>:MarketingCampaigns'? (y/N)
১০. অভিনন্দন
🚀 আপনি একটি নতুন ক্লাউড স্প্যানার ইনস্ট্যান্স তৈরি করেছেন, একটি খালি ডেটাবেস তৈরি করেছেন, নমুনা ডেটা লোড করেছেন, উন্নত অপারেশন ও কোয়েরি সম্পাদন করেছেন এবং (ঐচ্ছিকভাবে) ক্লাউড স্প্যানার ইনস্ট্যান্সটি মুছে ফেলেছেন।
আমরা যা আলোচনা করেছি
- কীভাবে একটি স্প্যানার ইনস্ট্যান্স সেটআপ করবেন।
- কিভাবে ডাটাবেস এবং টেবিল তৈরি করতে হয়।
- আপনার স্প্যানার ডাটাবেস টেবিলগুলিতে কীভাবে ডেটা লোড করবেন।
- স্প্যানার থেকে ভার্টেক্স এআই মডেলগুলিকে কীভাবে কল করবেন
- ফাজি সার্চ এবং ফুল-টেক্সট সার্চ ব্যবহার করে কীভাবে আপনার স্প্যানার ডাটাবেসে কোয়েরি করবেন।
- BigQuery থেকে Spanner-এর বিরুদ্ধে কীভাবে ফেডারেটেড কোয়েরি চালানো যায়
- আপনার স্প্যানার ইনস্ট্যান্সটি কীভাবে ডিলিট করবেন।
এরপর কী?
- স্প্যানারের উন্নত বৈশিষ্ট্যগুলো সম্পর্কে আরও জানুন, যার মধ্যে রয়েছে:
- উপলব্ধ স্প্যানার ক্লায়েন্ট লাইব্রেরিগুলো দেখুন।