
1. บทนำ
Spanner เป็นบริการฐานข้อมูลที่มีการจัดการครบวงจร ปรับขนาดในแนวนอนได้ และมีการกระจายทั่วโลก ซึ่งเหมาะสำหรับภาระงานด้านการดำเนินงานทั้งแบบเชิงสัมพันธ์และไม่ใช่เชิงสัมพันธ์
Spanner มีการรองรับการค้นหาเวกเตอร์ในตัว ซึ่งช่วยให้คุณทำการค้นหาความคล้ายคลึงหรือการค้นหาเชิงความหมาย และใช้การสร้างการดึงข้อมูลเสริม (RAG) ในแอปพลิเคชัน GenAI ได้ในวงกว้าง โดยใช้ฟีเจอร์K-Nearest Neighbor ที่แน่นอน (KNN) หรือฟีเจอร์Approximate Nearest Neighbor (ANN)
การค้นหาเวกเตอร์ของ Spanner จะแสดงข้อมูลแบบเรียลไทม์ล่าสุดทันทีที่มีการคอมมิตธุรกรรม เช่นเดียวกับการค้นหาอื่นๆ ในข้อมูลการดำเนินงาน
ใน Lab นี้ คุณจะได้ดูวิธีการตั้งค่าฟีเจอร์พื้นฐานที่จำเป็นต่อการใช้ประโยชน์จาก Spanner เพื่อทำการค้นหาเวกเตอร์ รวมถึงเข้าถึงโมเดลการฝังและโมเดล LLM จากโมเดลการ์เดนของ Vertex AI โดยใช้ SQL
สถาปัตยกรรมจะมีลักษณะดังนี้
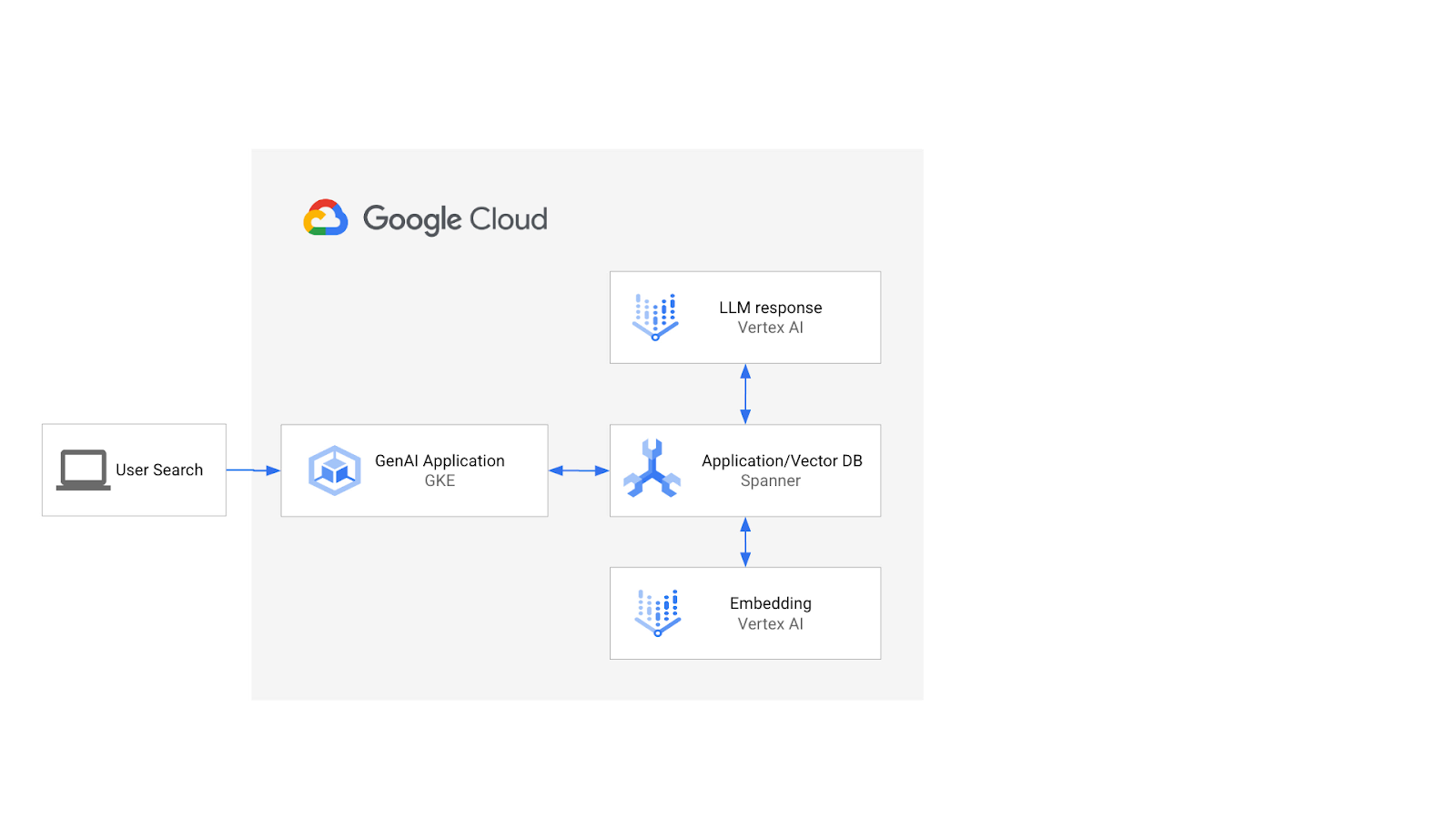
เมื่อมีพื้นฐานดังกล่าวแล้ว คุณจะได้เรียนรู้วิธีสร้างดัชนีเวกเตอร์ที่ขับเคลื่อนโดยอัลกอริทึม ScaNN และใช้ฟังก์ชันระยะทาง APPROX เมื่อปริมาณงานเชิงความหมายต้องปรับขนาด
สิ่งที่คุณจะสร้าง
ในห้องทดลองนี้ คุณจะทำสิ่งต่อไปนี้
- สร้างอินสแตนซ์ Spanner
- ตั้งค่าสคีมาฐานข้อมูลของ Spanner เพื่อผสานรวมกับโมเดลการฝังและโมเดล LLM ใน Vertex AI
- โหลดชุดข้อมูลการค้าปลีก
- ส่งคำค้นหาการค้นหาความคล้ายคลึงของปัญหาเทียบกับชุดข้อมูล
- ระบุบริบทให้กับโมเดล LLM เพื่อสร้างคำแนะนำที่เฉพาะเจาะจงสำหรับผลิตภัณฑ์
- แก้ไขสคีมาและสร้างดัชนีเวกเตอร์
- เปลี่ยนการค้นหาเพื่อใช้ประโยชน์จากดัชนีเวกเตอร์ที่สร้างขึ้นใหม่
สิ่งที่คุณจะได้เรียนรู้
- วิธีตั้งค่าอินสแตนซ์ Spanner
- วิธีผสานรวมกับ Vertex AI
- วิธีใช้ Spanner เพื่อทำการค้นหาเวกเตอร์เพื่อค้นหารายการที่คล้ายกันในชุดข้อมูลการค้าปลีก
- วิธีเตรียมฐานข้อมูลเพื่อปรับขนาดภาระงานการค้นหาเวกเตอร์โดยใช้การค้นหา ANN
สิ่งที่คุณต้องมี
2. การตั้งค่าและข้อกำหนด
สร้างโปรเจ็กต์
หากยังไม่มีบัญชี Google (Gmail หรือ Google Apps) คุณต้องสร้างบัญชี ลงชื่อเข้าใช้คอนโซล Google Cloud Platform ( console.cloud.google.com) แล้วสร้างโปรเจ็กต์ใหม่
หากมีโปรเจ็กต์อยู่แล้ว ให้คลิกเมนูแบบเลื่อนลงเพื่อเลือกโปรเจ็กต์ที่ด้านซ้ายบนของคอนโซล

แล้วคลิกปุ่ม "โปรเจ็กต์ใหม่" ในกล่องโต้ตอบที่ปรากฏขึ้นเพื่อสร้างโปรเจ็กต์ใหม่
หากยังไม่มีโปรเจ็กต์ คุณจะเห็นกล่องโต้ตอบแบบนี้เพื่อสร้างโปรเจ็กต์แรก
กล่องโต้ตอบการสร้างโปรเจ็กต์ในภายหลังจะช่วยให้คุณป้อนรายละเอียดของโปรเจ็กต์ใหม่ได้
โปรดจดจำรหัสโปรเจ็กต์ ซึ่งเป็นชื่อที่ไม่ซ้ำกันในโปรเจ็กต์ Google Cloud ทั้งหมด (ชื่อด้านบนมีผู้ใช้แล้วและจะใช้ไม่ได้ ขออภัย) ซึ่งจะเรียกว่า PROJECT_ID ในภายหลังใน Codelab นี้
จากนั้น หากยังไม่ได้ดำเนินการ คุณจะต้องเปิดใช้การเรียกเก็บเงินใน Developers Console เพื่อใช้ทรัพยากร Google Cloud และเปิดใช้ Spanner API
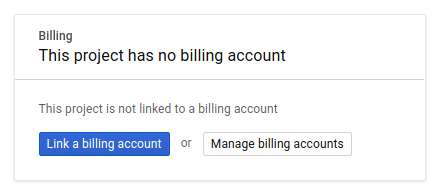
การทำตาม Codelab นี้ไม่ควรมีค่าใช้จ่ายเกิน 2-3 ดอลลาร์ แต่ก็อาจมีค่าใช้จ่ายมากกว่านี้หากคุณตัดสินใจใช้ทรัพยากรเพิ่มเติมหรือปล่อยให้ทรัพยากรทำงานต่อไป (ดูส่วน "การล้างข้อมูล" ที่ท้ายเอกสารนี้) ดูเอกสารประกอบเกี่ยวกับการกำหนดราคาของ Google Cloud Spanner ได้ที่นี่
ผู้ใช้ใหม่ของ Google Cloud Platform มีสิทธิ์รับช่วงทดลองใช้ฟรีมูลค่า$300 ซึ่งจะทำให้ Codelab นี้ไม่มีค่าใช้จ่ายใดๆ
การตั้งค่า Google Cloud Shell
แม้ว่าคุณจะใช้งาน Google Cloud และ Spanner จากระยะไกลในแล็ปท็อปได้ แต่ใน Codelab นี้เราจะใช้ Google Cloud Shell ซึ่งเป็นสภาพแวดล้อมบรรทัดคำสั่งที่ทำงานในระบบคลาวด์
เครื่องเสมือนที่ใช้ Debian นี้มาพร้อมเครื่องมือพัฒนาทั้งหมดที่คุณต้องการ โดยมีไดเรกทอรีหลักแบบถาวรขนาด 5 GB และทำงานใน Google Cloud ซึ่งช่วยเพิ่มประสิทธิภาพเครือข่ายและการตรวจสอบสิทธิ์ได้อย่างมาก ซึ่งหมายความว่าคุณจะต้องมีเพียงเบราว์เซอร์เท่านั้นสำหรับโค้ดแล็บนี้ (ใช่แล้ว ใช้ได้ใน Chromebook)
- หากต้องการเปิดใช้งาน Cloud Shell จาก Cloud Console เพียงคลิกเปิดใช้งาน Cloud Shell
 (ระบบจะจัดสรรและเชื่อมต่อกับสภาพแวดล้อมในเวลาไม่กี่นาที)
(ระบบจะจัดสรรและเชื่อมต่อกับสภาพแวดล้อมในเวลาไม่กี่นาที)
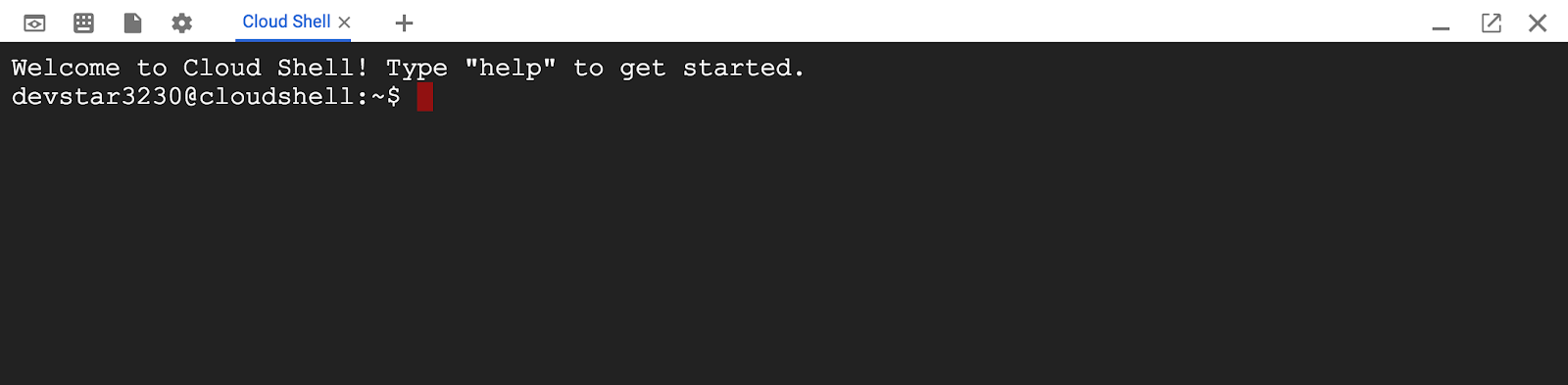
เมื่อเชื่อมต่อกับ Cloud Shell แล้ว คุณควรเห็นว่าคุณได้รับการตรวจสอบสิทธิ์แล้วและระบบได้ตั้งค่าโปรเจ็กต์เป็น PROJECT_ID ของคุณแล้ว
gcloud auth list
เอาต์พุตจากคำสั่ง
Credentialed accounts:
- <myaccount>@<mydomain>.com (active)
gcloud config list project
เอาต์พุตจากคำสั่ง
[core]
project = <PROJECT_ID>
หากไม่ได้ตั้งค่าโปรเจ็กต์ด้วยเหตุผลบางประการ ให้เรียกใช้คำสั่งต่อไปนี้
gcloud config set project <PROJECT_ID>
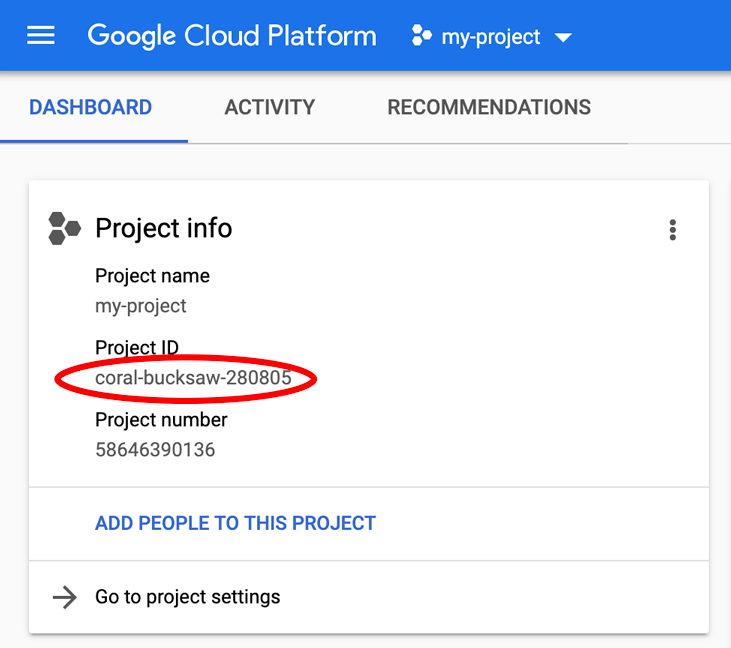
หากกำลังมองหา PROJECT_ID ตรวจสอบว่าคุณใช้รหัสใดในขั้นตอนการตั้งค่า หรือค้นหารหัสในแดชบอร์ด Cloud Console
นอกจากนี้ Cloud Shell ยังตั้งค่าตัวแปรสภาพแวดล้อมบางอย่างโดยค่าเริ่มต้น ซึ่งอาจมีประโยชน์เมื่อคุณเรียกใช้คำสั่งในอนาคต
echo $GOOGLE_CLOUD_PROJECT
เอาต์พุตจากคำสั่ง
<PROJECT_ID>
เปิดใช้ Spanner API และ VertexAI API
gcloud services enable spanner.googleapis.com
gcloud services enable aiplatform.googleapis.com
ตรวจสอบนโยบาย IAM
สิ่งเดียวที่ต้องมีในนโยบาย IAM เพื่อให้การค้นหาเวกเตอร์ทำงานในอินสแตนซ์ Spanner ได้คือการให้สิทธิ์ service-<PROJECT_NUMBER>@gcp-sa-spanner.iam.gserviceaccount.com เป็นตัวแทนบริการ Cloud Spanner API คลิกไอคอน 3 ขีดที่มุมซ้ายบนดังด้านล่าง
คุณจะเห็นนโยบาย IAM ที่นั่น
คุณตรวจสอบการตั้งค่า IAM ได้ในส่วนสิทธิ์ดังที่แสดงด้านล่าง
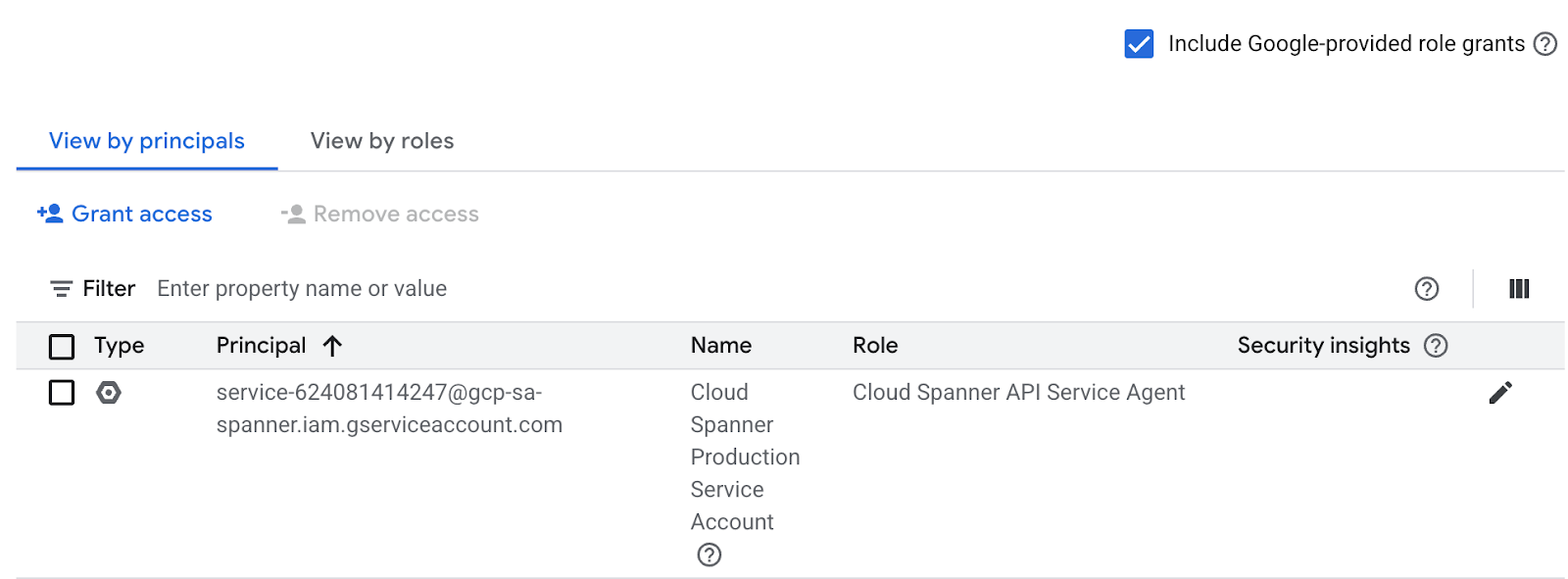
และหากไม่มี Cloud Spanner API Service Agent ให้ใช้คำสั่งด้านล่างเพื่อมอบสิทธิ์ ดูวิธีการเพิ่มเติมได้ที่นี่
$ gcloud beta services identity create --service=spanner.googleapis.com --project=<PROJECT_ID>
$ gcloud projects add-iam-policy-binding <PROJECT_NUMBER> --member=serviceAccount:service-<PROJECT_NUMBER>@gcp-sa-spanner.iam.gserviceaccount.com --role=roles/spanner.serviceAgent --condition=None
สรุป
ในขั้นตอนนี้ คุณได้ตั้งค่าโปรเจ็กต์หากยังไม่มี เปิดใช้งาน Cloud Shell และเปิดใช้ API ที่จำเป็น
ถัดไป
จากนั้นคุณจะตั้งค่าอินสแตนซ์และฐานข้อมูล Spanner
3. สร้างอินสแตนซ์และฐานข้อมูล Spanner
สร้างอินสแตนซ์ Spanner
ในขั้นตอนนี้ เราจะตั้งค่าอินสแตนซ์ Spanner สำหรับ Codelab โดยเปิด Cloud Shell แล้วเรียกใช้คำสั่งต่อไปนี้
export SPANNER_INSTANCE_ID=retail-demo
gcloud spanner instances create $SPANNER_INSTANCE_ID \
--edition=ENTERPRISE \
--config=regional-us-central1 \
--description="spanner AI retail demo" \
--nodes=1
รุ่นต่ำสุดควรเป็น ENTERPRISE STANDARD ไม่มีฟีเจอร์การค้นหาเวกเตอร์
เอาต์พุตจากคำสั่ง:
$ Creating instance...done.
สร้างฐานข้อมูล
เมื่ออินสแตนซ์ทำงานแล้ว คุณจะสร้างฐานข้อมูลได้ Spanner อนุญาตให้มีฐานข้อมูลหลายรายการในอินสแตนซ์เดียว
ฐานข้อมูลคือที่ที่คุณกำหนดสคีมา นอกจากนี้ คุณยังควบคุมผู้ที่มีสิทธิ์เข้าถึงฐานข้อมูล ตั้งค่าการเข้ารหัสที่กำหนดเอง กำหนดค่าเครื่องมือเพิ่มประสิทธิภาพ และตั้งค่าระยะเวลาเก็บรักษาได้ด้วย
หากต้องการสร้างฐานข้อมูล ให้ใช้เครื่องมือบรรทัดคำสั่ง gcloud อีกครั้ง
export SPANNER_DATABASE=cymbal-bikes
gcloud spanner databases create $SPANNER_DATABASE \
--instance=$SPANNER_INSTANCE_ID
เอาต์พุตจากคำสั่ง:
$ Creating database...done.
สรุป
ในขั้นตอนนี้ คุณได้สร้างอินสแตนซ์และฐานข้อมูล Spanner แล้ว
ถัดไป
จากนั้นคุณจะตั้งค่าสคีมาและข้อมูล Spanner
4. โหลดสคีมาและข้อมูล Cymbal
สร้างสคีมา Cymbal
หากต้องการตั้งค่าสคีมา ให้ไปที่ Spanner Studio โดยทำดังนี้
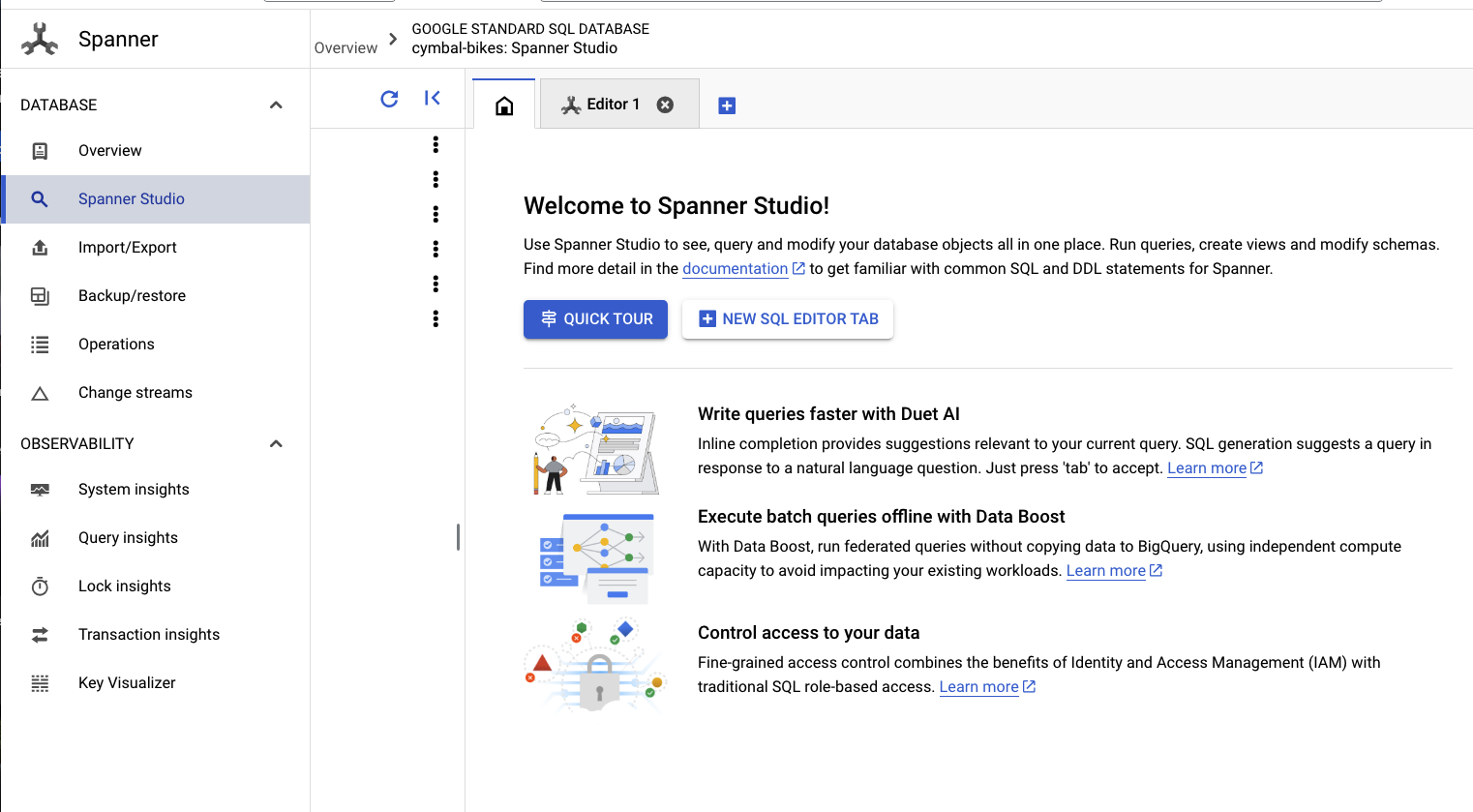
โดยสคีมามี 2 ส่วน ก่อนอื่น ให้เพิ่มproductsตาราง คัดลอกและวางคำสั่งนี้ในแท็บที่ว่างเปล่า
สำหรับสคีมา ให้คัดลอกและวาง DDL นี้ลงในช่อง
CREATE TABLE products(
categoryId INT64 NOT NULL,
productId INT64 NOT NULL,
productName STRING(MAX) NOT NULL,
productDescription STRING(MAX) NOT NULL,
productDescriptionEmbedding ARRAY<FLOAT32>,
createTime TIMESTAMP NOT NULL
OPTIONS (
allow_commit_timestamp = TRUE),
inventoryCount INT64 NOT NULL,
priceInCents INT64,)
PRIMARY KEY(categoryId, productId);
จากนั้นคลิกปุ่ม run แล้วรอสักครู่เพื่อให้ระบบสร้างสคีมา
จากนั้นคุณจะสร้างโมเดล 2 รายการและกำหนดค่าให้เป็นปลายทางโมเดล Vertex AI
โมเดลแรกคือโมเดลการฝังที่ใช้ในการสร้างการฝังจากข้อความ และโมเดลที่ 2 คือโมเดล LLM ที่ใช้ในการสร้างคำตอบตามข้อมูลใน Spanner
วางสคีมาต่อไปนี้ลงในแท็บใหม่ใน Spanner Studio
CREATE OR REPLACE MODEL EmbeddingsModel
INPUT(content STRING(MAX)) OUTPUT(embeddings STRUCT<values ARRAY<FLOAT32>>) REMOTE
OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/<PROJECT_ID>/locations/us-central1/publishers/google/models/text-embedding-004');
CREATE OR REPLACE MODEL LLMModel
INPUT(prompt STRING(MAX)) OUTPUT(content STRING(MAX)) REMOTE
OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/<PROJECT_ID>/locations/us-central1/publishers/google/models/gemini-2.0-flash-001',
default_batch_size = 1);
จากนั้นคลิกปุ่ม run แล้วรอ 2-3 วินาทีเพื่อให้ระบบสร้างโมเดล
ในแผงด้านซ้ายของ Spanner Studio คุณควรเห็นตารางและโมเดลต่อไปนี้
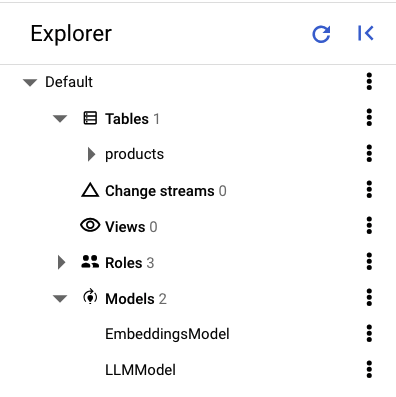
โหลดข้อมูล
ตอนนี้คุณคงต้องการแทรกผลิตภัณฑ์บางอย่างลงในฐานข้อมูล เปิดแท็บใหม่ใน Spanner Studio จากนั้นคัดลอกและวางคำสั่ง INSERT ต่อไปนี้
INSERT INTO products (categoryId, productId, productName, productDescription, createTime, inventoryCount, priceInCents)
VALUES (1, 1, "Cymbal Helios Helmet", "Safety meets style with the Cymbal children's bike helmet. Its lightweight design, superior ventilation, and adjustable fit ensure comfort and protection on every ride. Stay bright and keep your child safe under the sun with Cymbal Helios!", PENDING_COMMIT_TIMESTAMP(), 100, 10999),
(1, 2, "Cymbal Sprout", "Let their cycling journey begin with the Cymbal Sprout, the ideal balance bike for beginning riders ages 2-4 years. Its lightweight frame, low seat height, and puncture-proof tires promote stability and confidence as little ones learn to balance and steer. Watch them sprout into cycling enthusiasts with Cymbal Sprout!", PENDING_COMMIT_TIMESTAMP(), 10, 13999),
(1, 3, "Cymbal Spark Jr.", "Light, vibrant, and ready for adventure, the Spark Jr. is the perfect first bike for young riders (ages 5-8). Its sturdy frame, easy-to-use brakes, and puncture-resistant tires inspire confidence and endless playtime. Let the spark of cycling ignite with Cymbal!", PENDING_COMMIT_TIMESTAMP(), 34, 13900),
(1, 4, "Cymbal Summit", "Conquering trails is a breeze with the Summit mountain bike. Its lightweight aluminum frame, responsive suspension, and powerful disc brakes provide exceptional control and comfort for experienced bikers navigating rocky climbs or shredding downhill. Reach new heights with Cymbal Summit!", PENDING_COMMIT_TIMESTAMP(), 0, 79999),
(1, 5, "Cymbal Breeze", "Cruise in style and embrace effortless pedaling with the Breeze electric bike. Its whisper-quiet motor and long-lasting battery let you conquer hills and distances with ease. Enjoy scenic rides, commutes, or errands with a boost of confidence from Cymbal Breeze!", PENDING_COMMIT_TIMESTAMP(), 72, 129999),
(1, 6, "Cymbal Trailblazer Backpack", "Carry all your essentials in style with the Trailblazer backpack. Its water-resistant material, multiple compartments, and comfortable straps keep your gear organized and accessible, allowing you to focus on the adventure. Blaze new trails with Cymbal Trailblazer!", PENDING_COMMIT_TIMESTAMP(), 24, 7999),
(1, 7, "Cymbal Phoenix Lights", "See and be seen with the Phoenix bike lights. Powerful LEDs and multiple light modes ensure superior visibility, enhancing your safety and enjoyment during day or night rides. Light up your journey with Cymbal Phoenix!", PENDING_COMMIT_TIMESTAMP(), 87, 3999),
(1, 8, "Cymbal Windstar Pump", "Flat tires are no match for the Windstar pump. Its compact design, lightweight construction, and high-pressure capacity make inflating tires quick and effortless. Get back on the road in no time with Cymbal Windstar!", PENDING_COMMIT_TIMESTAMP(), 36, 24999),
(1, 9,"Cymbal Odyssey Multi-Tool","Be prepared for anything with the Odyssey multi-tool. This handy gadget features essential tools like screwdrivers, hex wrenches, and tire levers, keeping you ready for minor repairs and adjustments on the go. Conquer your journey with Cymbal Odyssey!", PENDING_COMMIT_TIMESTAMP(), 52, 999),
(1, 10,"Cymbal Nomad Water Bottle","Stay hydrated on every ride with the Nomad water bottle. Its sleek design, BPA-free construction, and secure lock lid make it the perfect companion for staying refreshed and motivated throughout your adventures. Hydrate and explore with Cymbal Nomad!", PENDING_COMMIT_TIMESTAMP(), 42, 1299);
คลิกปุ่ม run เพื่อแทรกข้อมูล
สรุป
ในขั้นตอนนี้ คุณได้สร้างสคีมาและโหลดข้อมูลพื้นฐานบางอย่างลงในฐานข้อมูล cymbal-bikes
ถัดไป
จากนั้นคุณจะผสานรวมกับโมเดลการฝังเพื่อสร้างการฝังสำหรับคำอธิบายผลิตภัณฑ์ รวมถึงแปลงคำขอค้นหาที่เป็นข้อความเป็นการฝังเพื่อค้นหาผลิตภัณฑ์ที่เกี่ยวข้อง
5. ใช้งานการฝัง
สร้างการฝังเวกเตอร์สำหรับรายละเอียดผลิตภัณฑ์
หากต้องการให้การค้นหาที่คล้ายกันทำงานกับผลิตภัณฑ์ คุณต้องสร้างการฝังสำหรับคำอธิบายผลิตภัณฑ์
เมื่อมี EmbeddingsModel ที่สร้างในสคีมาแล้ว นี่คือคำสั่ง DML ที่เรียบง่ายของ UPDATE
UPDATE products p1
SET
productDescriptionEmbedding = (
SELECT embeddings.values
FROM
ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT productDescription AS content))
)
WHERE categoryId = 1;
คลิกrunเพื่ออัปเดตคำอธิบายผลิตภัณฑ์
หากพบข้อผิดพลาด ให้ลองเรียกใช้คำสั่ง SQL ในเทอร์มินัลโดยใช้คำสั่ง gcloud เพื่อดูข้อความแสดงข้อผิดพลาดแบบละเอียดเพิ่มเติม เช่น
gcloud spanner databases execute-sql <YOUR_DATA_BASE> --instance=<YOUR_INSTANCE> --sql 'UPDATE products p1
SET
productDescriptionEmbedding = (
SELECT embeddings.values
FROM
ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT productDescription AS content FROM products p2 WHERE p2.productId = p1.productId))
)
WHERE categoryId = 1;'
การใช้การค้นหาเวกเตอร์
ในตัวอย่างนี้ คุณจะส่งคำขอค้นหาในภาษาธรรมชาติผ่านคำค้นหา SQL คำค้นหานี้จะเปลี่ยนคำขอค้นหาเป็นการฝัง จากนั้นค้นหาผลลัพธ์ที่คล้ายกันโดยอิงจากการฝังที่จัดเก็บไว้ของคำอธิบายผลิตภัณฑ์ที่สร้างขึ้นในขั้นตอนก่อนหน้า
-- Use Spanner's vector search, and integration with embedding and LLM models to
-- return items that are semantically relevant and available in inventory based on
-- real-time data.
SELECT
productName,
productDescription,
inventoryCount,
COSINE_DISTANCE(
productDescriptionEmbedding,
(
SELECT embeddings.values
FROM
ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a starter bike for my 3 year old child" AS content))
)) AS distance
FROM products
WHERE inventoryCount > 0
ORDER BY distance
LIMIT 5;
คลิกปุ่ม run เพื่อค้นหาผลิตภัณฑ์ที่คล้ายกัน ผลลัพธ์ควรมีลักษณะดังนี้
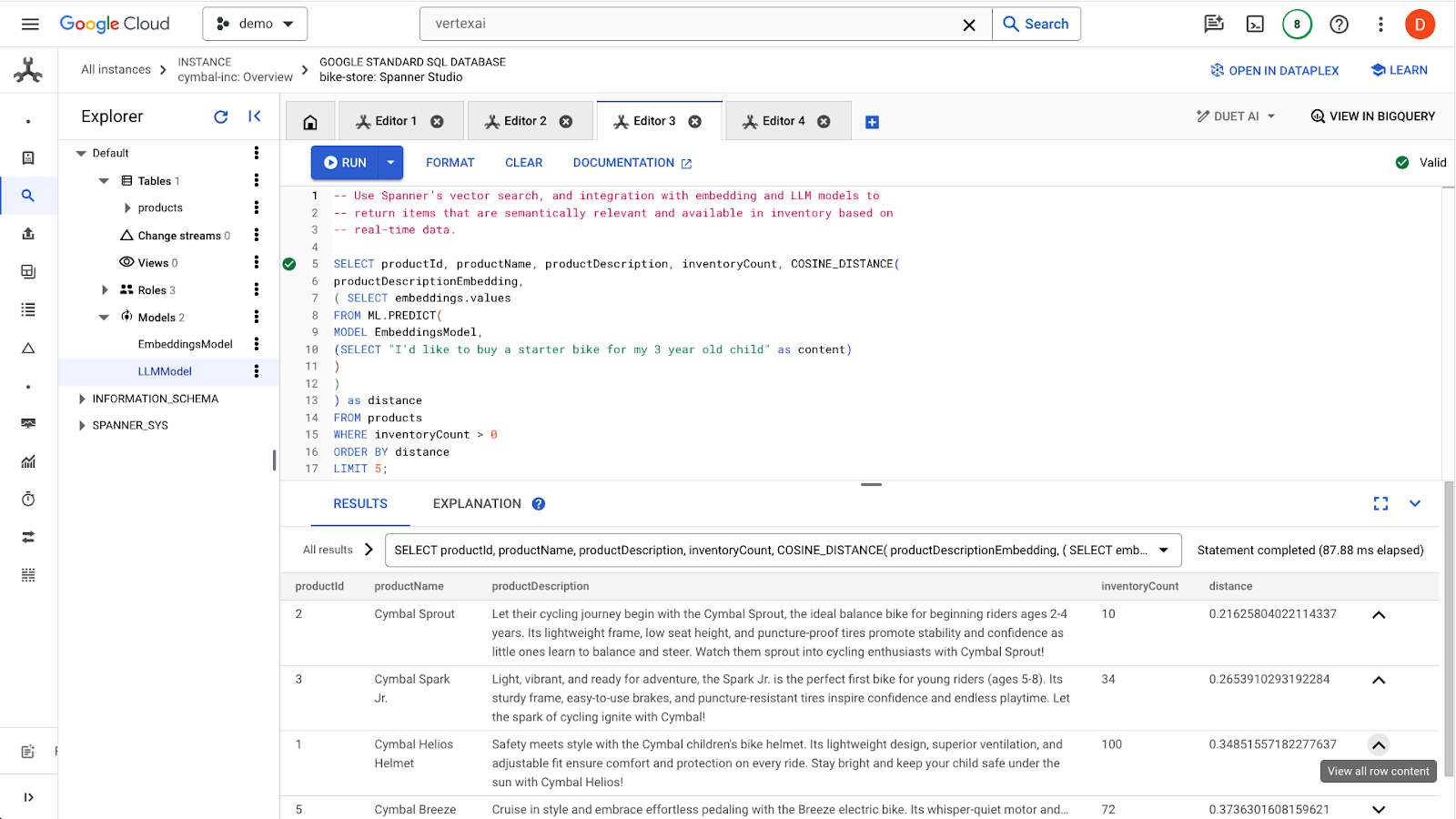
โปรดสังเกตว่ามีการใช้ตัวกรองเพิ่มเติมในคำค้นหา เช่น สนใจเฉพาะผลิตภัณฑ์ที่มีสินค้าพร้อมจำหน่าย (inventoryCount > 0)
สรุป
ในขั้นตอนนี้ คุณได้สร้างการฝังคำอธิบายผลิตภัณฑ์และการฝังคำขอค้นหาโดยใช้ SQL ซึ่งใช้ประโยชน์จากการผสานรวม Spanner กับโมเดลใน Vertex AI นอกจากนี้ คุณยังทำการค้นหาเวกเตอร์เพื่อค้นหาผลิตภัณฑ์ที่คล้ายกันซึ่งตรงกับคำขอค้นหา
ขั้นตอนถัดไป
จากนั้น เราจะใช้ผลการค้นหาเพื่อป้อนข้อมูลลงใน LLM เพื่อสร้างคำตอบที่กำหนดเองสำหรับแต่ละผลิตภัณฑ์
6. ทำงานด้วย LLM
Spanner ช่วยให้ผสานรวมกับโมเดล LLM ที่ให้บริการจาก Vertex AI ได้ง่าย ซึ่งช่วยให้นักพัฒนาซอฟต์แวร์ใช้ SQL เพื่อเชื่อมต่อกับ LLM ได้โดยตรง แทนที่จะกำหนดให้แอปพลิเคชันดำเนินการตามตรรกะ
ตัวอย่างเช่น เรามีผลลัพธ์จากการค้นหา SQL ก่อนหน้าจากผู้ใช้ "I'd like to buy a starter bike for my 3 year old child".
นักพัฒนาแอปต้องการให้คำตอบสำหรับผลลัพธ์แต่ละรายการว่าผลิตภัณฑ์เหมาะกับผู้ใช้หรือไม่ โดยใช้พรอมต์ต่อไปนี้
"Answer with ‘Yes' or ‘No' and explain why: Is this a good fit for me? I'd like to buy a starter bike for my 3 year old child"
คุณใช้การค้นหาต่อไปนี้ได้
-- Use an LLM to analyze this list and provide a recommendation on whether each
-- product is a good fit for the user. We use the vector search and real time
-- inventory data to first filter the products to reduce the size of the prompt to
-- the LLM.
SELECT productName, productDescription, inventoryCount, content AS LLMResponse
FROM
ML.PREDICT(
MODEL LLMModel,
(
SELECT
FORMAT(
"""Answer with Yes or No and explain why: Is this a good fit for me?
I would like to buy a starter bike for my 3 year old child \n Product Name: %s\nProduct Description: %s""", productName,productDescription) AS prompt,
-- Pass through columns.
inventoryCount,
productName,
productDescription,
FROM products
WHERE inventoryCount > 0
ORDER BY
COSINE_DISTANCE(
productDescriptionEmbedding,
(
SELECT embeddings.values
FROM
ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a starter bike for my 3 year old child" AS content))
))
LIMIT 5
));
คลิกปุ่ม run เพื่อออกคำค้นหา ผลลัพธ์ควรมีลักษณะดังนี้
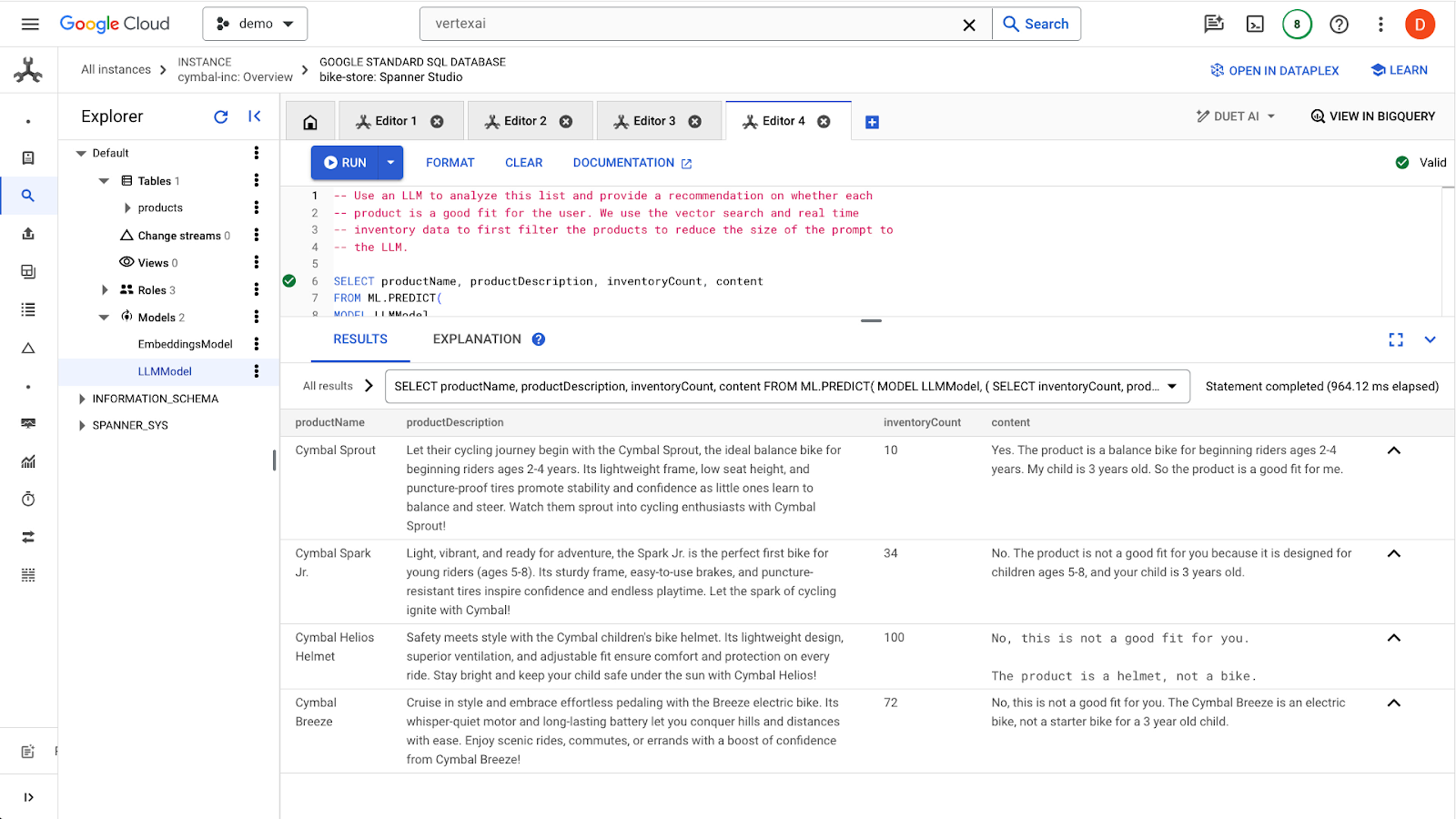
ผลิตภัณฑ์แรกเหมาะสำหรับเด็กอายุ 3 ขวบเนื่องจากช่วงอายุในคำอธิบายผลิตภัณฑ์ (อายุ 2-4 ขวบ) ผลิตภัณฑ์อื่นๆ ไม่เหมาะกับคุณ
สรุป
ในขั้นตอนนี้ คุณได้ทำงานร่วมกับ LLM เพื่อสร้างคำตอบพื้นฐานสำหรับพรอมต์จากผู้ใช้
ขั้นตอนถัดไป
ต่อไป เรามาดูวิธีใช้ ANN เพื่อปรับขนาดการค้นหาเวกเตอร์กัน
7. การปรับขนาดการค้นหาเวกเตอร์
ตัวอย่างการค้นหาเวกเตอร์ก่อนหน้านี้ใช้การค้นหาเวกเตอร์แบบ KNN ที่ตรงกันทุกประการ ซึ่งจะเป็นประโยชน์อย่างยิ่งเมื่อคุณค้นหาชุดข้อมูลย่อยที่เฉพาะเจาะจงมากของข้อมูล Spanner ได้ คำค้นหาประเภทดังกล่าวเรียกว่าแบ่งพาร์ติชันได้สูง
หากไม่มีภาระงานที่แบ่งพาร์ติชันได้สูงและมีข้อมูลจำนวนมาก คุณควรใช้การค้นหาเวกเตอร์ ANN โดยใช้อัลกอริทึม ScaNN เพื่อเพิ่มประสิทธิภาพการค้นหา
หากต้องการดำเนินการดังกล่าวใน Spanner คุณจะต้องทำ 2 อย่างต่อไปนี้
- สร้างดัชนีเวกเตอร์
- แก้ไขการค้นหาเพื่อใช้ฟังก์ชันระยะทาง APPROX
สร้างดัชนีเวกเตอร์
หากต้องการสร้างดัชนีเวกเตอร์ในชุดข้อมูลนี้ ก่อนอื่นเราจะต้องแก้ไขคอลัมน์ productDescriptionEmbeddings เพื่อกำหนดความยาวของแต่ละเวกเตอร์ หากต้องการเพิ่มความยาวเวกเตอร์ลงในคอลัมน์ คุณต้องวางคอลัมน์เดิมและสร้างใหม่
ALTER TABLE products DROP COLUMN productDescriptionEmbedding;
ALTER TABLE products
ADD COLUMN productDescriptionEmbedding ARRAY<FLOAT32>(vector_length => 768);
จากนั้นสร้างการฝังอีกครั้งจากGenerate Vector embeddingที่คุณเรียกใช้ก่อนหน้านี้
UPDATE products p1
SET
productDescriptionEmbedding = (
SELECT embeddings.values
FROM
ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT productDescription AS content FROM products p2 WHERE p2.productId = p1.productId))
)
WHERE categoryId = 1;
หลังจากสร้างคอลัมน์แล้ว ให้สร้างดัชนี
CREATE VECTOR INDEX ProductDescriptionEmbeddingIndex
ON products(productDescriptionEmbedding)
WHERE productDescriptionEmbedding IS NOT NULL
OPTIONS (
distance_type = 'COSINE'
);
ดู PDML ได้ที่ https://cloud.google.com/spanner/docs/backfill-embeddings หากสนใจ คำสั่ง DML เดียวคือธุรกรรมที่มีการจำกัดการเปลี่ยนแปลงสูงสุด 80,000 รายการ ดังนั้นคุณจึงอัปเดตหลายแถวพร้อมกันไม่ได้ PDML จะจัดการการแบ่งข้อมูลออกเป็นกลุ่มเล็กๆ ได้อย่างมีประสิทธิภาพ
ใช้ดัชนีใหม่
หากต้องการใช้ดัชนีเวกเตอร์ใหม่ คุณจะต้องแก้ไขการค้นหาการฝังก่อนหน้าเล็กน้อย
นี่คือคำค้นหาเดิม
SELECT
productName,
productDescription,
inventoryCount,
COSINE_DISTANCE(
productDescriptionEmbedding,
(
SELECT embeddings.values
FROM
ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a starter bike for my 3 year old child" AS content))
)) AS distance
FROM products
WHERE inventoryCount > 0
ORDER BY distance
LIMIT 5;
คุณจะต้องทำการเปลี่ยนแปลงต่อไปนี้
- ใช้คำใบ้ดัชนีสำหรับดัชนีเวกเตอร์ใหม่:
@{force_index=ProductDescriptionEmbeddingIndex} - เปลี่ยนการเรียกใช้ฟังก์ชัน
COSINE_DISTANCEเป็นAPPROX_COSINE_DISTANCEโปรดทราบว่าต้องใช้ตัวเลือก JSON ในการค้นหาสุดท้ายด้านล่างด้วย - สร้างการฝังจากฟังก์ชัน ML.PREDICT แยกกัน
- คัดลอกผลลัพธ์ของการฝังลงในการค้นหาสุดท้าย
สร้างและใช้การฝังโดยทำดังนี้
-- Generate the prompt embeddings
SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a starter bike for my 3 year old child" as content)
);
ไฮไลต์ผลลัพธ์จากการค้นหา แล้วคัดลอก
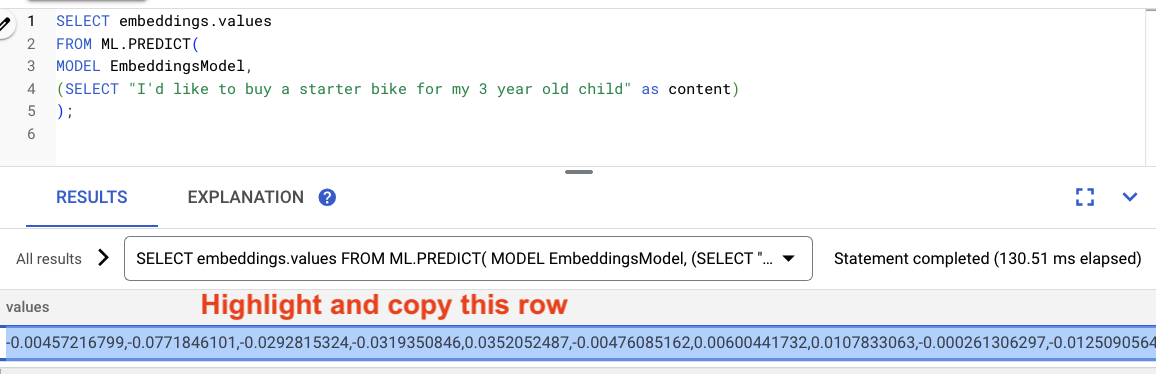
จากนั้นแทนที่ <VECTOR> ในการค้นหาต่อไปนี้โดยวางการฝังที่คัดลอกไว้
-- Generate the embeddings and query them using the vector index
SELECT
productName,
productDescription,
inventoryCount,
APPROX_COSINE_DISTANCE(
productDescriptionEmbedding,
array<float32>[@VECTOR],
options => JSON '{\"num_leaves_to_search\": 10}') AS distance
FROM products @{force_index = ProductDescriptionEmbeddingIndex}
WHERE productDescriptionEmbedding IS NOT NULL AND inventoryCount > 0
ORDER BY distance
LIMIT 5;
ซึ่งควรมีหน้าตาเช่นนี้
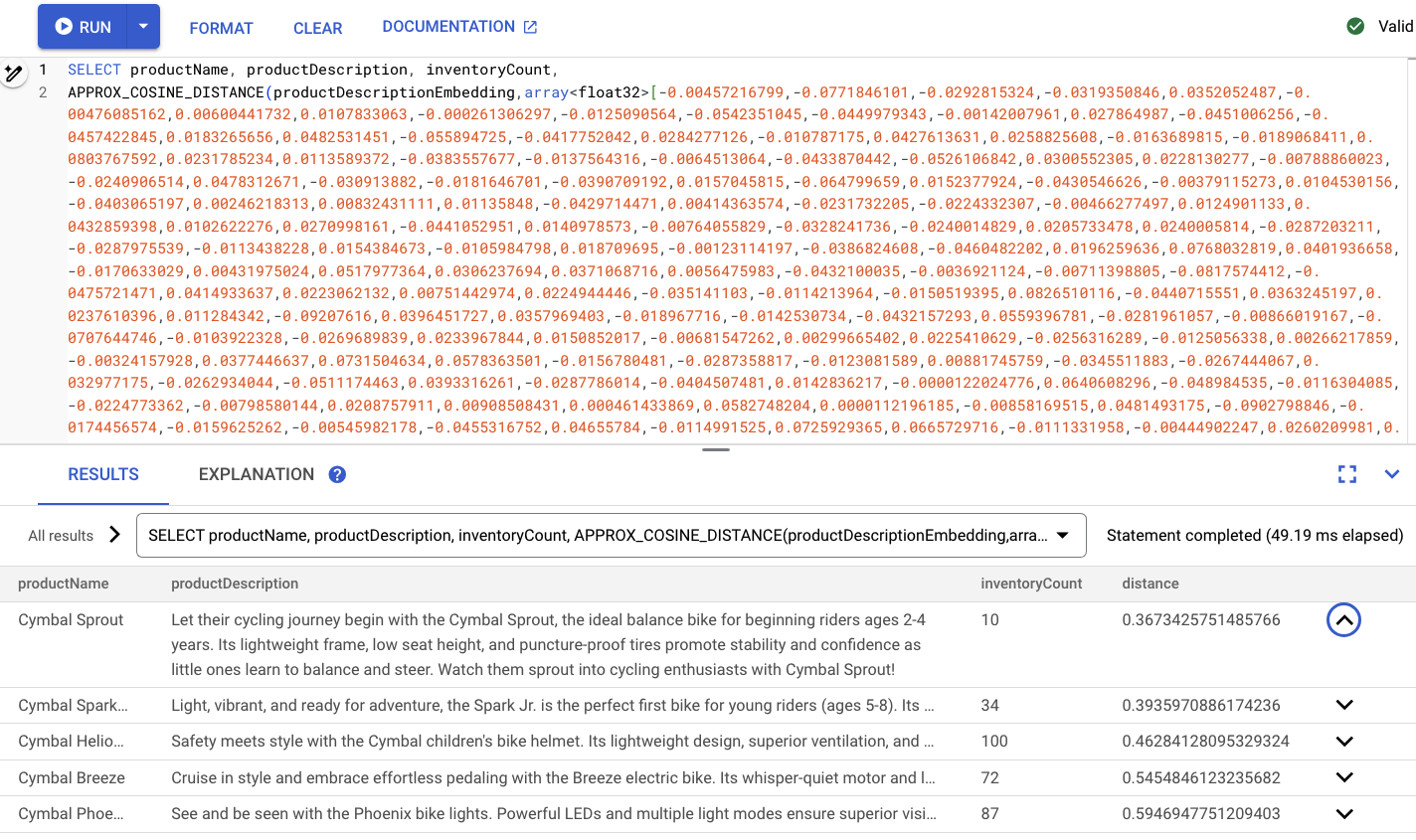
สรุป
ในขั้นตอนนี้ คุณได้แปลงสคีมาเพื่อสร้างดัชนีเวกเตอร์ จากนั้นคุณก็เขียนคำค้นหา Embedding ใหม่เพื่อทำการค้นหา ANN โดยใช้ดัชนีเวกเตอร์ ขั้นตอนนี้มีความสำคัญอย่างยิ่งเมื่อข้อมูลของคุณเพิ่มขึ้นเพื่อปรับขนาดภาระงานการค้นหาเวกเตอร์
ขั้นตอนถัดไป
จากนั้นก็ถึงเวลาทำความสะอาด
8. การล้างข้อมูล (ไม่บังคับ)
หากต้องการล้างข้อมูล เพียงลบอินสแตนซ์ 'retail-demo' ที่เราสร้างไว้ใน Codelab
9. ยินดีด้วย
ขอแสดงความยินดี คุณค้นหาความคล้ายคลึงโดยใช้ Vector Search ในตัวของ Spanner ได้สำเร็จ นอกจากนี้ คุณยังเห็นว่าการทำงานกับโมเดลการฝังและ LLM เพื่อให้ฟังก์ชัน Generative AI โดยตรงโดยใช้ SQL นั้นง่ายเพียงใด
สุดท้ายนี้ คุณได้เรียนรู้กระบวนการค้นหา ANN ที่ขับเคลื่อนโดยอัลกอริทึม ScaNN เพื่อปรับขนาดภาระงานการค้นหาเวกเตอร์
ขั้นตอนต่อไปคืออะไร
ดูข้อมูลเพิ่มเติมเกี่ยวกับฟีเจอร์การค้นหาเวกเตอร์ที่ใกล้ที่สุดแบบตรงกัน (KNN) ของ Spanner ได้ที่ https://cloud.google.com/spanner/docs/find-k-nearest-neighbors
ดูข้อมูลเพิ่มเติมเกี่ยวกับฟีเจอร์การค้นหาเวกเตอร์เพื่อนบ้านที่ใกล้ที่สุดโดยประมาณ (ANN) ของ Spanner ได้ที่ https://cloud.google.com/spanner/docs/find-approximate-nearest-neighbors
นอกจากนี้ คุณยังอ่านข้อมูลเพิ่มเติมเกี่ยวกับวิธีทำการคาดการณ์ออนไลน์ด้วย SQL โดยใช้การผสานรวม Vertex AI ของ Spanner ได้ที่ https://cloud.google.com/spanner/docs/ml