
1. مقدمة
Spanner هي خدمة قواعد بيانات موزّعة عالميًا وقابلة للتوسّع أفقيًا ومُدارة بالكامل، وهي مناسبة لمهام العمل التشغيلية العلائقية وغير العلائقية.
تتضمّن Spanner إمكانية البحث المتّجه المضمّنة، ما يتيح لك إجراء بحث عن التشابه أو البحث الدلالي وتنفيذ التوليد المعزّز بالاسترجاع في تطبيقات الذكاء الاصطناعي التوليدي على نطاق واسع، وذلك باستخدام ميزات البحث عن أقرب جار K (KNN) أو البحث عن أقرب جار تقريبي (ANN).
تعرض طلبات البحث عن تطابق الأوصاف في Spanner بيانات جديدة في الوقت الفعلي فور إتمام المعاملات، تمامًا مثل أي طلب بحث آخر عن بيانات التشغيل.
في هذا التمرين العملي، ستتعرّف على كيفية إعداد الميزات الأساسية اللازمة للاستفادة من Spanner في إجراء البحث عن المتّجهات، والوصول إلى نماذج التضمين ونماذج اللغات الكبيرة من "حديقة النماذج" في Vertex AI باستخدام SQL.
سيبدو التصميم على النحو التالي:
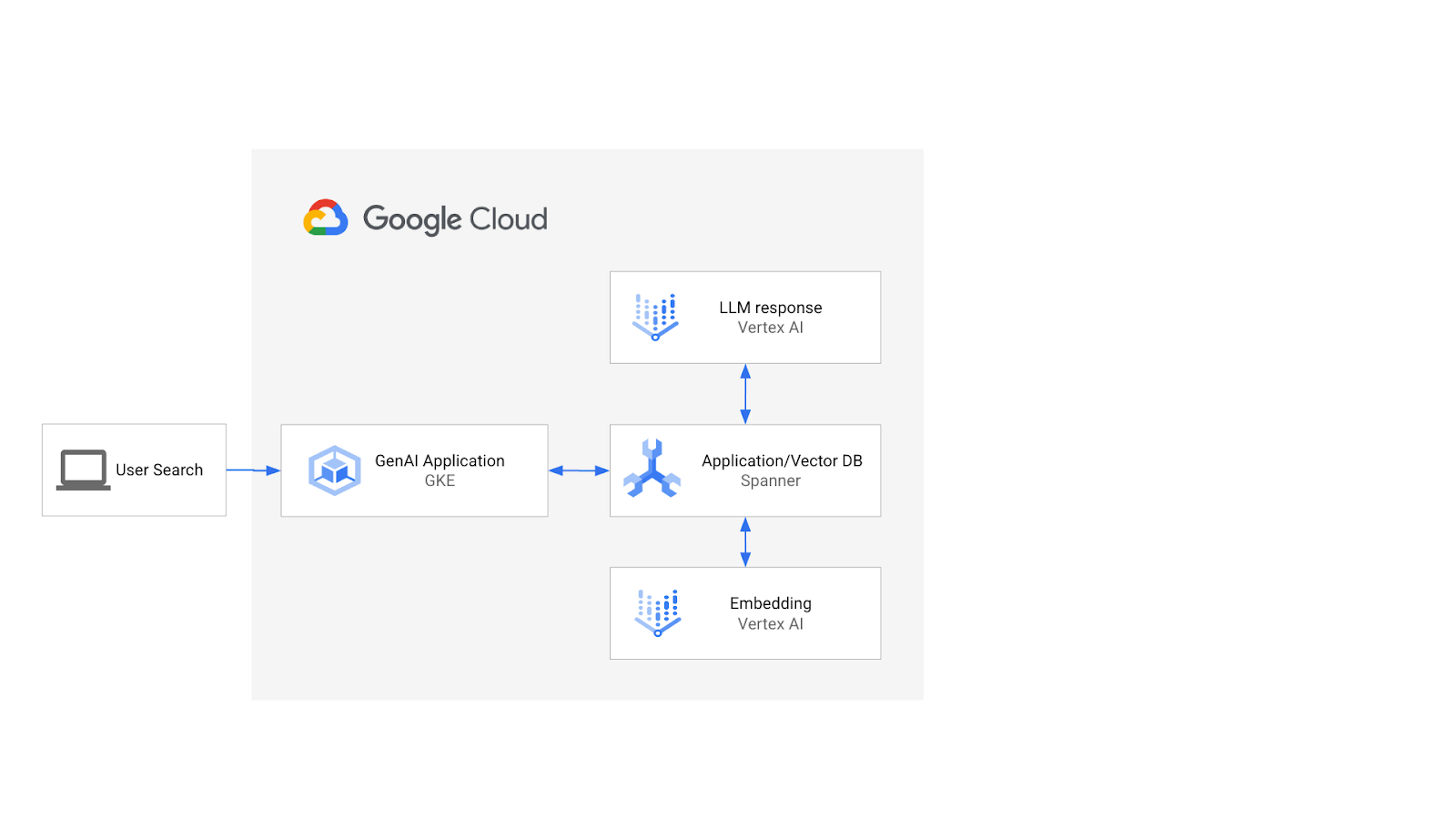
وباستخدام هذه الأساسيات، ستتعرّف على كيفية إنشاء فهرس متّجه يستند إلى خوارزمية ScaNN، وكيفية استخدام دوال المسافة APPROX عندما تحتاج أحمال العمل الدلالية إلى التوسّع.
ما ستنشئه
في هذا الدرس التطبيقي، ستنفّذ ما يلي:
- إنشاء مثيل Spanner
- إعداد مخطط قاعدة بيانات Spanner للتكامل مع نماذج التضمين والنماذج اللغوية الكبيرة في Vertex AI
- تحميل مجموعة بيانات خاصة ببائع تجزئة
- إصدار طلبات بحث عن التشابه في المشاكل مقابل مجموعة البيانات
- توفير سياق لنموذج LLM من أجل إنشاء اقتراحات خاصة بالمنتجات
- عدِّل المخطط وأنشئ فهرسًا متّجهيًا.
- غيِّر طلبات البحث للاستفادة من فهرس المتجهات الذي تم إنشاؤه حديثًا.
أهداف الدورة التعليمية
- كيفية إعداد مثيل Spanner
- كيفية الدمج مع VertexAI
- كيفية استخدام Spanner لإجراء بحث مستند إلى المتجهات للعثور على عناصر مشابهة في مجموعة بيانات خاصة بالبيع بالتجزئة
- كيفية إعداد قاعدة البيانات لتوسيع نطاق أحمال عمل البحث المتّجه باستخدام البحث التقريبي عن أقرب جيران
المتطلبات
2. الإعداد والمتطلبات
إنشاء مشروع
إذا لم يكن لديك حساب Google (Gmail أو Google Apps)، عليك إنشاء حساب. سجِّل الدخول إلى "وحدة تحكّم Google Cloud Platform" (console.cloud.google.com) وأنشِئ مشروعًا جديدًا.
إذا كان لديك مشروع، انقر على القائمة المنسدلة لاختيار المشروع في أعلى يمين وحدة التحكّم:

وانقر على الزر "مشروع جديد" في مربّع الحوار الناتج لإنشاء مشروع جديد:
إذا لم يكن لديك مشروع، من المفترض أن يظهر لك مربّع حوار مشابه لما يلي لإنشاء مشروعك الأول:
يتيح لك مربّع حوار إنشاء المشروع اللاحق إدخال تفاصيل مشروعك الجديد:
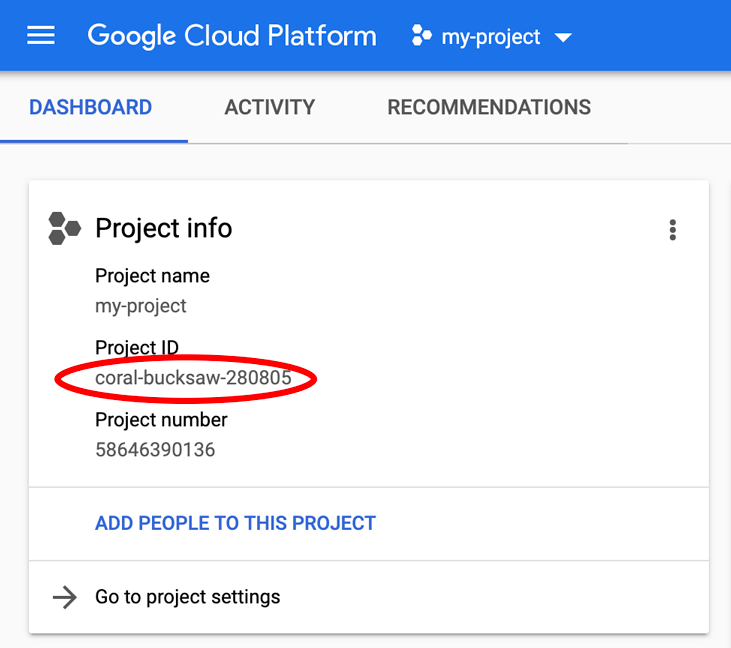
تذكَّر رقم تعريف المشروع، وهو اسم فريد في جميع مشاريع Google Cloud (الاسم أعلاه مستخدَم حاليًا ولن يكون متاحًا لك، نأسف لذلك). سيُشار إليه لاحقًا في هذا الدرس التطبيقي حول الترميز باسم PROJECT_ID.
بعد ذلك، إذا لم يسبق لك إجراء ذلك، عليك تفعيل الفوترة في Developers Console من أجل استخدام موارد Google Cloud وتفعيل Spanner API.
لن تكلفك تجربة هذا الدرس التطبيقي حول الترميز أكثر من بضعة دولارات، ولكن قد تكون التكلفة أعلى إذا قررت استخدام المزيد من الموارد أو إذا تركتها قيد التشغيل (راجِع قسم "التنظيف" في نهاية هذا المستند). يمكنك الاطّلاع على مستندات أسعار Google Cloud Spanner هنا.
يمكن لمستخدمي Google Cloud Platform الجدد الاستفادة من فترة تجريبية مجانية بقيمة 300 دولار أمريكي، ما يجعل هذا الدرس التطبيقي حول الترميز مجانيًا تمامًا.
إعداد Google Cloud Shell
على الرغم من إمكانية تشغيل Google Cloud وSpanner عن بُعد من الكمبيوتر المحمول، سنستخدم في هذا الدرس التطبيقي حول الترميز Google Cloud Shell، وهي بيئة سطر أوامر تعمل في السحابة الإلكترونية.
يتم تحميل هذا الجهاز الافتراضي المستند إلى Debian بجميع أدوات التطوير التي تحتاج إليها. توفّر هذه الخدمة دليلًا رئيسيًا دائمًا بسعة 5 غيغابايت وتعمل في Google Cloud، ما يؤدي إلى تحسين أداء الشبكة والمصادقة بشكل كبير. يعني ذلك أنّ كل ما تحتاج إليه لهذا الدرس التطبيقي حول الترميز هو متصفّح (نعم، يمكن استخدامه على جهاز Chromebook).
- لتفعيل Cloud Shell من Cloud Console، ما عليك سوى النقر على "تفعيل Cloud Shell"
 (يستغرق توفير البيئة والاتصال بها بضع لحظات فقط).
(يستغرق توفير البيئة والاتصال بها بضع لحظات فقط).
بعد الاتصال بـ Cloud Shell، من المفترض أن تلاحظ أنّه تم إثبات هويتك وأنّ المشروع تم ضبطه على PROJECT_ID.
gcloud auth list
ناتج الأمر
Credentialed accounts:
- <myaccount>@<mydomain>.com (active)
gcloud config list project
ناتج الأمر
[core]
project = <PROJECT_ID>
إذا لم يتم ضبط المشروع لسبب ما، ما عليك سوى تنفيذ الأمر التالي:
gcloud config set project <PROJECT_ID>
هل تبحث عن PROJECT_ID؟ يمكنك الاطّلاع على المعرّف الذي استخدمته في خطوات الإعداد أو البحث عنه في لوحة بيانات Cloud Console:
يضبط Cloud Shell أيضًا بعض متغيرات البيئة تلقائيًا، ما قد يكون مفيدًا عند تنفيذ الأوامر المستقبلية.
echo $GOOGLE_CLOUD_PROJECT
ناتج الأمر
<PROJECT_ID>
تفعيل واجهات برمجة التطبيقات Spanner API وVertexAI API
gcloud services enable spanner.googleapis.com
gcloud services enable aiplatform.googleapis.com
التحقّق من سياسة "إدارة الهوية وإمكانية الوصول":
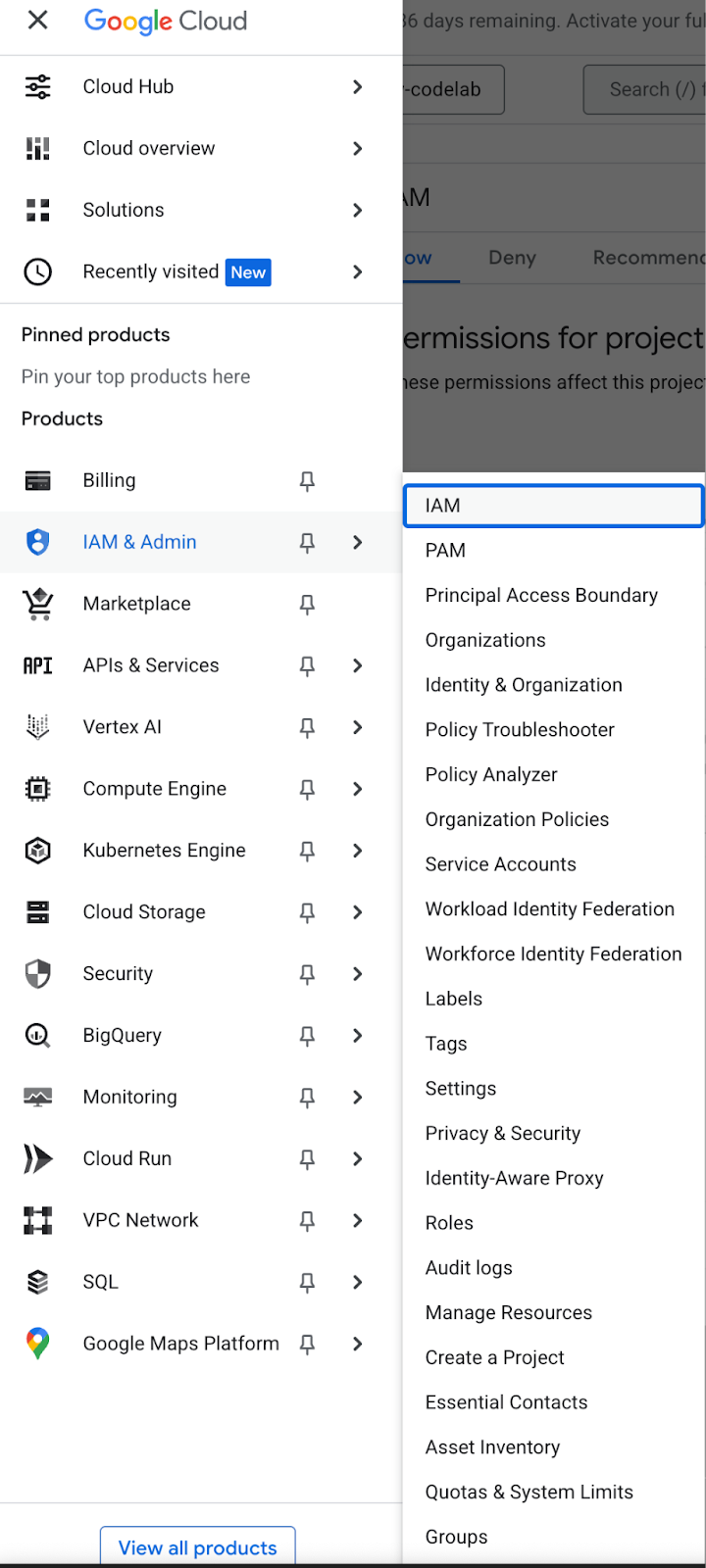
الشيء الوحيد المطلوب في سياسة "إدارة الهوية وإمكانية الوصول" لجعل البحث المتّجه يعمل في مثيل Spanner هو منح service-<PROJECT_NUMBER>@gcp-sa-spanner.iam.gserviceaccount.com دور وكيل خدمة Cloud Spanner API. انقر على رمز الأشرطة الثلاثة في أعلى يمين الصفحة كما هو موضح أدناه:
ستظهر لك سياسة إدارة الهوية وإمكانية الوصول على النحو التالي:
يمكنك التحقّق من إعداد "إدارة الهوية وإمكانية الوصول" ضمن "الإذن" كما هو موضّح أدناه.
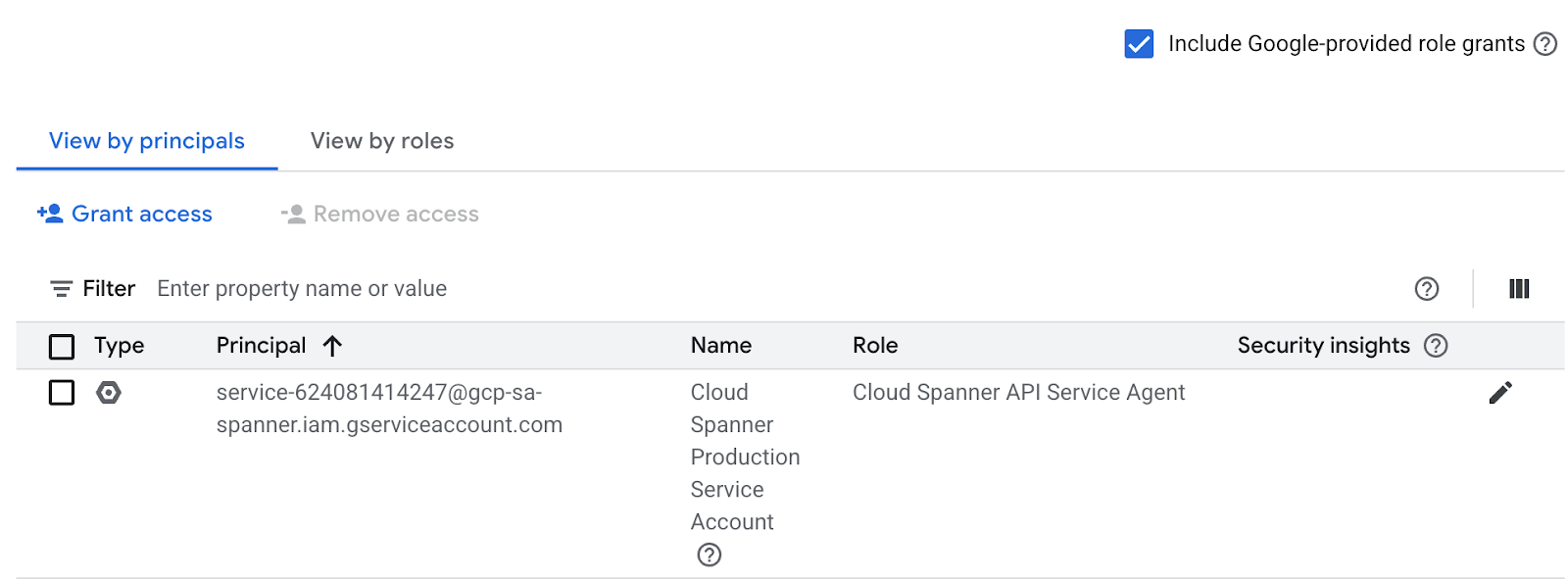
إذا لم يكن Cloud Spanner API Service Agent متوفّرًا، استخدِم الأمر أدناه لمنحه. يمكنك الاطّلاع على المزيد من التعليمات هنا.
$ gcloud beta services identity create --service=spanner.googleapis.com --project=<PROJECT_ID>
$ gcloud projects add-iam-policy-binding <PROJECT_NUMBER> --member=serviceAccount:service-<PROJECT_NUMBER>@gcp-sa-spanner.iam.gserviceaccount.com --role=roles/spanner.serviceAgent --condition=None
ملخّص
في هذه الخطوة، عليك إعداد مشروعك إذا لم يكن لديك مشروع حالي، وتفعيل Cloud Shell، وتفعيل واجهات برمجة التطبيقات المطلوبة.
التالي
بعد ذلك، ستُعدّ مثيل Spanner وقاعدة البيانات.
3- إنشاء مثيل وقاعدة بيانات Spanner
إنشاء مثيل Spanner
في هذه الخطوة، سنعدّ مثيل Spanner للدرس التطبيقي حول الترميز. لإجراء ذلك، افتح Cloud Shell ونفِّذ الأمر التالي:
export SPANNER_INSTANCE_ID=retail-demo
gcloud spanner instances create $SPANNER_INSTANCE_ID \
--edition=ENTERPRISE \
--config=regional-us-central1 \
--description="spanner AI retail demo" \
--nodes=1
يجب أن يكون الإصدار الأدنى ENTERPRISE. لا يتضمّن إصدار STANDARD ميزة البحث المتّجهي.
ناتج الأمر:
$ Creating instance...done.
إنشاء قاعدة البيانات
بعد تشغيل مثيلك، يمكنك إنشاء قاعدة البيانات. تسمح خدمة Spanner بإنشاء قواعد بيانات متعددة على مثيل واحد.
قاعدة البيانات هي المكان الذي تحدّد فيه المخطط. يمكنك أيضًا التحكّم في المستخدمين الذين يمكنهم الوصول إلى قاعدة البيانات، وإعداد تشفير مخصّص، وضبط أداة التحسين، وتحديد فترة التخزين.
لإنشاء قاعدة البيانات، استخدِم أداة سطر الأوامر gcloud مرة أخرى:
export SPANNER_DATABASE=cymbal-bikes
gcloud spanner databases create $SPANNER_DATABASE \
--instance=$SPANNER_INSTANCE_ID
ناتج الأمر:
$ Creating database...done.
ملخّص
في هذه الخطوة، أنشأت مثيل Spanner وقاعدة البيانات.
التالي
بعد ذلك، ستُعدّ مخطط Spanner والبيانات.
4. تحميل مخطّط Cymbal والبيانات
إنشاء مخطط Cymbal
لإعداد المخطّط، انتقِل إلى Spanner Studio:
يتضمّن المخطط جزأين. أولاً، عليك إضافة جدول products. انسخ هذه العبارة والصقها في علامة التبويب الفارغة.
بالنسبة إلى المخطط، انسخ DDL هذا والصقه في المربّع:
CREATE TABLE products(
categoryId INT64 NOT NULL,
productId INT64 NOT NULL,
productName STRING(MAX) NOT NULL,
productDescription STRING(MAX) NOT NULL,
productDescriptionEmbedding ARRAY<FLOAT32>,
createTime TIMESTAMP NOT NULL
OPTIONS (
allow_commit_timestamp = TRUE),
inventoryCount INT64 NOT NULL,
priceInCents INT64,)
PRIMARY KEY(categoryId, productId);
بعد ذلك، انقر على الزر run وانتظِر بضع ثوانٍ إلى أن يتم إنشاء المخطط.
بعد ذلك، ستنشئ النموذجين وتضبطهما على نقاط نهاية نماذج Vertex AI.
النموذج الأول هو نموذج تضمين يُستخدَم لإنشاء عمليات تضمين من النص، والنموذج الثاني هو نموذج لغوي كبير يُستخدَم لإنشاء ردود استنادًا إلى البيانات في Spanner.
ألصِق المخطط التالي في علامة تبويب جديدة في Spanner Studio:
CREATE OR REPLACE MODEL EmbeddingsModel
INPUT(content STRING(MAX)) OUTPUT(embeddings STRUCT<values ARRAY<FLOAT32>>) REMOTE
OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/<PROJECT_ID>/locations/us-central1/publishers/google/models/text-embedding-004');
CREATE OR REPLACE MODEL LLMModel
INPUT(prompt STRING(MAX)) OUTPUT(content STRING(MAX)) REMOTE
OPTIONS (
endpoint = '//aiplatform.googleapis.com/projects/<PROJECT_ID>/locations/us-central1/publishers/google/models/gemini-2.0-flash-001',
default_batch_size = 1);
بعد ذلك، انقر على الزر run وانتظِر بضع ثوانٍ إلى أن يتم إنشاء النماذج.
في اللوحة اليمنى من Spanner Studio، من المفترض أن تظهر لك الجداول والنماذج التالية:
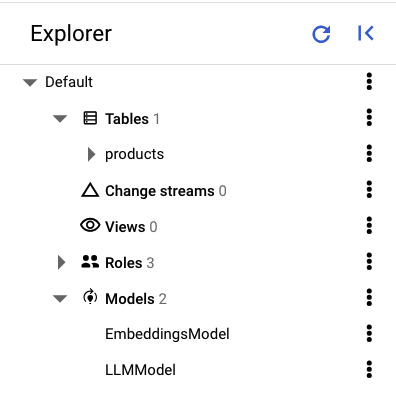
تحميل البيانات
الآن، عليك إدراج بعض المنتجات في قاعدة البيانات. افتح علامة تبويب جديدة في Spanner Studio، ثم انسخ عبارات الإدراج التالية والصِقها:
INSERT INTO products (categoryId, productId, productName, productDescription, createTime, inventoryCount, priceInCents)
VALUES (1, 1, "Cymbal Helios Helmet", "Safety meets style with the Cymbal children's bike helmet. Its lightweight design, superior ventilation, and adjustable fit ensure comfort and protection on every ride. Stay bright and keep your child safe under the sun with Cymbal Helios!", PENDING_COMMIT_TIMESTAMP(), 100, 10999),
(1, 2, "Cymbal Sprout", "Let their cycling journey begin with the Cymbal Sprout, the ideal balance bike for beginning riders ages 2-4 years. Its lightweight frame, low seat height, and puncture-proof tires promote stability and confidence as little ones learn to balance and steer. Watch them sprout into cycling enthusiasts with Cymbal Sprout!", PENDING_COMMIT_TIMESTAMP(), 10, 13999),
(1, 3, "Cymbal Spark Jr.", "Light, vibrant, and ready for adventure, the Spark Jr. is the perfect first bike for young riders (ages 5-8). Its sturdy frame, easy-to-use brakes, and puncture-resistant tires inspire confidence and endless playtime. Let the spark of cycling ignite with Cymbal!", PENDING_COMMIT_TIMESTAMP(), 34, 13900),
(1, 4, "Cymbal Summit", "Conquering trails is a breeze with the Summit mountain bike. Its lightweight aluminum frame, responsive suspension, and powerful disc brakes provide exceptional control and comfort for experienced bikers navigating rocky climbs or shredding downhill. Reach new heights with Cymbal Summit!", PENDING_COMMIT_TIMESTAMP(), 0, 79999),
(1, 5, "Cymbal Breeze", "Cruise in style and embrace effortless pedaling with the Breeze electric bike. Its whisper-quiet motor and long-lasting battery let you conquer hills and distances with ease. Enjoy scenic rides, commutes, or errands with a boost of confidence from Cymbal Breeze!", PENDING_COMMIT_TIMESTAMP(), 72, 129999),
(1, 6, "Cymbal Trailblazer Backpack", "Carry all your essentials in style with the Trailblazer backpack. Its water-resistant material, multiple compartments, and comfortable straps keep your gear organized and accessible, allowing you to focus on the adventure. Blaze new trails with Cymbal Trailblazer!", PENDING_COMMIT_TIMESTAMP(), 24, 7999),
(1, 7, "Cymbal Phoenix Lights", "See and be seen with the Phoenix bike lights. Powerful LEDs and multiple light modes ensure superior visibility, enhancing your safety and enjoyment during day or night rides. Light up your journey with Cymbal Phoenix!", PENDING_COMMIT_TIMESTAMP(), 87, 3999),
(1, 8, "Cymbal Windstar Pump", "Flat tires are no match for the Windstar pump. Its compact design, lightweight construction, and high-pressure capacity make inflating tires quick and effortless. Get back on the road in no time with Cymbal Windstar!", PENDING_COMMIT_TIMESTAMP(), 36, 24999),
(1, 9,"Cymbal Odyssey Multi-Tool","Be prepared for anything with the Odyssey multi-tool. This handy gadget features essential tools like screwdrivers, hex wrenches, and tire levers, keeping you ready for minor repairs and adjustments on the go. Conquer your journey with Cymbal Odyssey!", PENDING_COMMIT_TIMESTAMP(), 52, 999),
(1, 10,"Cymbal Nomad Water Bottle","Stay hydrated on every ride with the Nomad water bottle. Its sleek design, BPA-free construction, and secure lock lid make it the perfect companion for staying refreshed and motivated throughout your adventures. Hydrate and explore with Cymbal Nomad!", PENDING_COMMIT_TIMESTAMP(), 42, 1299);
انقر على الزر run لإدراج البيانات.
ملخّص
في هذه الخطوة، أنشأت المخطط وحمّلت بعض البيانات الأساسية في قاعدة بيانات cymbal-bikes.
التالي
بعد ذلك، ستدمج نموذج Embedding لإنشاء عمليات تضمين لأوصاف المنتجات، بالإضافة إلى تحويل طلب بحث نصي إلى عملية تضمين للبحث عن المنتجات ذات الصلة.
5- العمل باستخدام التضمينات
إنشاء تضمينات متّجهة لأوصاف المنتجات
لكي تعمل ميزة البحث المشابه على المنتجات، عليك إنشاء تضمينات لأوصاف المنتجات.
باستخدام EmbeddingsModel الذي تم إنشاؤه في المخطط، تصبح هذه UPDATE جملة DML بسيطة.
UPDATE products p1
SET
productDescriptionEmbedding = (
SELECT embeddings.values
FROM
ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT productDescription AS content))
)
WHERE categoryId = 1;
انقر على الزر run لتعديل أوصاف المنتجات.
في حال مواجهة أي خطأ، حاوِل تنفيذ أمر SQL في الوحدة الطرفية باستخدام أمر gcloud للحصول على رسالة خطأ أكثر تفصيلاً، على سبيل المثال:
gcloud spanner databases execute-sql <YOUR_DATA_BASE> --instance=<YOUR_INSTANCE> --sql 'UPDATE products p1
SET
productDescriptionEmbedding = (
SELECT embeddings.values
FROM
ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT productDescription AS content FROM products p2 WHERE p2.productId = p1.productId))
)
WHERE categoryId = 1;'
استخدام ميزة "البحث عن المتّجهات"
في هذا المثال، ستوفّر طلب بحث بلغة طبيعية من خلال طلب بحث SQL. سيحوّل طلب البحث هذا طلب البحث إلى تضمين، ثم سيبحث عن نتائج مشابهة استنادًا إلى عمليات التضمين المخزّنة لأوصاف المنتجات التي تم إنشاؤها في الخطوة السابقة.
-- Use Spanner's vector search, and integration with embedding and LLM models to
-- return items that are semantically relevant and available in inventory based on
-- real-time data.
SELECT
productName,
productDescription,
inventoryCount,
COSINE_DISTANCE(
productDescriptionEmbedding,
(
SELECT embeddings.values
FROM
ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a starter bike for my 3 year old child" AS content))
)) AS distance
FROM products
WHERE inventoryCount > 0
ORDER BY distance
LIMIT 5;
انقر على الزر run للعثور على المنتجات المشابهة. يجب أن تبدو النتائج على النحو التالي:
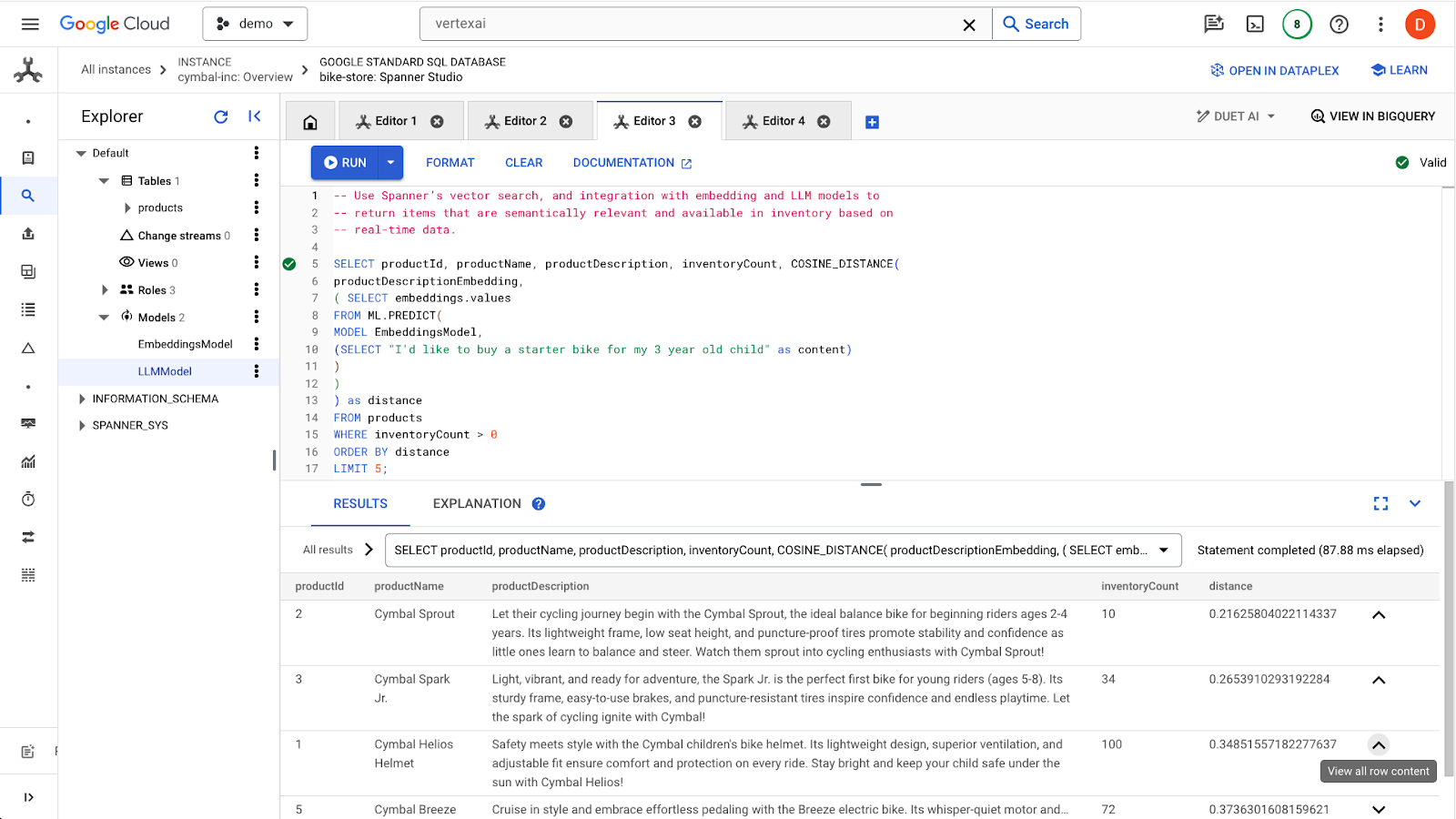
لاحظ أنّه يتم استخدام فلاتر إضافية في طلب البحث، مثل الاهتمام فقط بالمنتجات المتوفرة في المستودع (inventoryCount > 0).
ملخّص
في هذه الخطوة، أنشأت عمليات تضمين لأوصاف المنتجات وعملية تضمين لطلب البحث باستخدام SQL، مستفيدًا من تكامل Spanner مع النماذج في Vertex AI. أجريت أيضًا بحثًا مستندًا إلى المتجهات للعثور على منتجات مشابهة تتطابق مع طلب البحث.
الخطوات التالية
بعد ذلك، لنستخدم نتائج البحث لتزويد نموذج لغوي كبير بالمعلومات من أجل إنشاء ردّ مخصّص لكل منتج.
6. العمل مع نموذج لغوي كبير
يسهّل Spanner عملية التكامل مع نماذج اللغات الكبيرة (LLM) التي يتم عرضها من Vertex AI. يتيح ذلك للمطوّرين استخدام SQL للتفاعل مع النماذج اللغوية الكبيرة مباشرةً، بدلاً من مطالبة التطبيق بتنفيذ المنطق.
على سبيل المثال، لدينا النتائج من طلب بحث SQL السابق من المستخدم "I'd like to buy a starter bike for my 3 year old child".
يريد المطوّر تقديم ردّ لكل نتيجة يوضّح ما إذا كان المنتج مناسبًا للمستخدم، وذلك باستخدام الطلب التالي:
"Answer with ‘Yes' or ‘No' and explain why: Is this a good fit for me? I'd like to buy a starter bike for my 3 year old child"
إليك طلب البحث الذي يمكنك استخدامه:
-- Use an LLM to analyze this list and provide a recommendation on whether each
-- product is a good fit for the user. We use the vector search and real time
-- inventory data to first filter the products to reduce the size of the prompt to
-- the LLM.
SELECT productName, productDescription, inventoryCount, content AS LLMResponse
FROM
ML.PREDICT(
MODEL LLMModel,
(
SELECT
FORMAT(
"""Answer with Yes or No and explain why: Is this a good fit for me?
I would like to buy a starter bike for my 3 year old child \n Product Name: %s\nProduct Description: %s""", productName,productDescription) AS prompt,
-- Pass through columns.
inventoryCount,
productName,
productDescription,
FROM products
WHERE inventoryCount > 0
ORDER BY
COSINE_DISTANCE(
productDescriptionEmbedding,
(
SELECT embeddings.values
FROM
ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a starter bike for my 3 year old child" AS content))
))
LIMIT 5
));
انقر على الزر run لإصدار طلب البحث. يجب أن تبدو النتائج على النحو التالي:

المنتج الأول مناسب لطفل يبلغ من العمر 3 سنوات بسبب الفئة العمرية المذكورة في وصف المنتج (من سنتين إلى 4 سنوات). أما المنتجات الأخرى، فهي غير مناسبة.
ملخّص
في هذه الخطوة، عملت مع نموذج لغوي كبير لإنشاء ردود أساسية على طلبات من مستخدم.
الخطوات التالية
بعد ذلك، سنتعرّف على كيفية استخدام شبكة ANN لتوسيع نطاق البحث المتّجه.
7. التنفيذ على نطاق واسع للبحث عن المتّجهات
استخدمت أمثلة البحث المتّجه السابقة البحث المتّجه الدقيق المستند إلى أقرب جار k. يكون ذلك مفيدًا عندما تتمكّن من طلب البحث عن مجموعات فرعية محدّدة جدًا من بيانات Spanner. ويُقال إنّ هذه الأنواع من طلبات البحث قابلة للتقسيم بدرجة كبيرة.
إذا لم تكن لديك أحمال عمل قابلة للتقسيم بشكل كبير وكان لديك كمية كبيرة من البيانات، ننصحك باستخدام ميزة "البحث عن المتجهات باستخدام التقريب الأقرب جارًا" (ANN) التي تستفيد من خوارزمية ScaNN لزيادة أداء البحث.
لإجراء ذلك في Spanner، عليك تنفيذ ما يلي:
- إنشاء فهرس متجهات
- عدِّل طلب البحث للاستفادة من دوال المسافة APPROX.
إنشاء فهرس المتجهات
لإنشاء فهرس متجهات على مجموعة البيانات هذه، علينا أولاً تعديل العمود productDescriptionEmbeddings لتحديد طول كل متجه. لإضافة طول المتّجه إلى عمود، يجب إسقاط العمود الأصلي وإعادة إنشائه.
ALTER TABLE products DROP COLUMN productDescriptionEmbedding;
ALTER TABLE products
ADD COLUMN productDescriptionEmbedding ARRAY<FLOAT32>(vector_length => 768);
بعد ذلك، أعِد إنشاء عمليات التضمين من الخطوة Generate Vector embedding التي نفّذتها سابقًا.
UPDATE products p1
SET
productDescriptionEmbedding = (
SELECT embeddings.values
FROM
ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT productDescription AS content FROM products p2 WHERE p2.productId = p1.productId))
)
WHERE categoryId = 1;
بعد إنشاء العمود، أنشئ الفهرس:
CREATE VECTOR INDEX ProductDescriptionEmbeddingIndex
ON products(productDescriptionEmbedding)
WHERE productDescriptionEmbedding IS NOT NULL
OPTIONS (
distance_type = 'COSINE'
);
يمكنك الاطّلاع على PDML على https://cloud.google.com/spanner/docs/backfill-embeddings إذا كنت مهتمًا بذلك. عبارة DML واحدة هي معاملة تخضع لحدود 80 ألف عملية تغيير، لذا لا يمكنك تعديل عدد كبير جدًا من الصفوف في آنٍ واحد. تتعامل PDML مع تقسيمها إلى دفعات أصغر بكفاءة.
استخدام الفهرس الجديد
لاستخدام فهرس المتجهات الجديد، عليك تعديل طلب البحث السابق الخاص بالتضمين بشكل طفيف.
إليك طلب البحث الأصلي:
SELECT
productName,
productDescription,
inventoryCount,
COSINE_DISTANCE(
productDescriptionEmbedding,
(
SELECT embeddings.values
FROM
ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a starter bike for my 3 year old child" AS content))
)) AS distance
FROM products
WHERE inventoryCount > 0
ORDER BY distance
LIMIT 5;
عليك إجراء التغييرات التالية:
- استخدِم تلميح فهرس لفهرس المتجهات الجديد:
@{force_index=ProductDescriptionEmbeddingIndex} - غيِّر استدعاء الدالة
COSINE_DISTANCEإلىAPPROX_COSINE_DISTANCE. يُرجى العِلم أنّ خيارات JSON في طلب البحث النهائي أدناه مطلوبة أيضًا. - إنشاء التضمينات من الدالة ML.PREDICT بشكل منفصل
- انسخ نتائج التضمينات في طلب البحث النهائي.
إنشاء عمليات التضمين واستخدامها:
-- Generate the prompt embeddings
SELECT embeddings.values
FROM ML.PREDICT(
MODEL EmbeddingsModel,
(SELECT "I'd like to buy a starter bike for my 3 year old child" as content)
);
ميِّز النتائج من طلب البحث وانسخها.
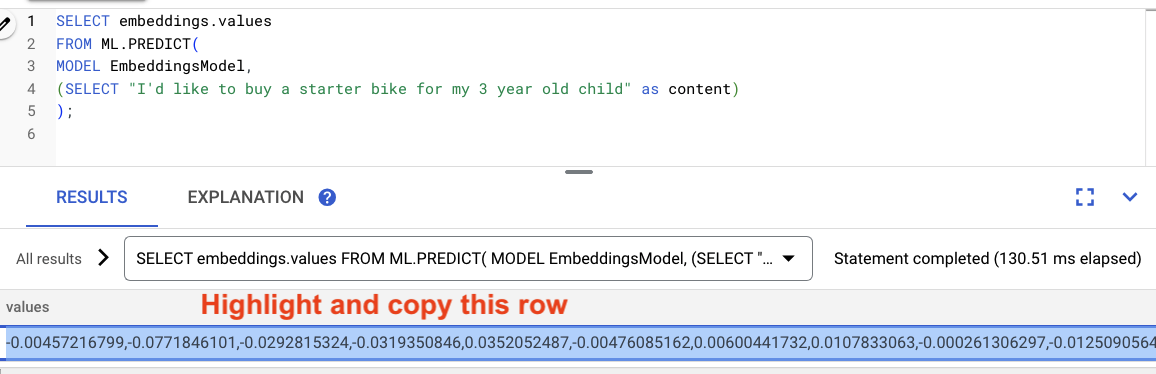
بعد ذلك، استبدِل <VECTOR> في طلب البحث التالي عن طريق لصق عمليات التضمين التي نسختها.
-- Generate the embeddings and query them using the vector index
SELECT
productName,
productDescription,
inventoryCount,
APPROX_COSINE_DISTANCE(
productDescriptionEmbedding,
array<float32>[@VECTOR],
options => JSON '{\"num_leaves_to_search\": 10}') AS distance
FROM products @{force_index = ProductDescriptionEmbeddingIndex}
WHERE productDescriptionEmbedding IS NOT NULL AND inventoryCount > 0
ORDER BY distance
LIMIT 5;
من المفترض أن تظهر بشكلٍ مشابه لما يلي:
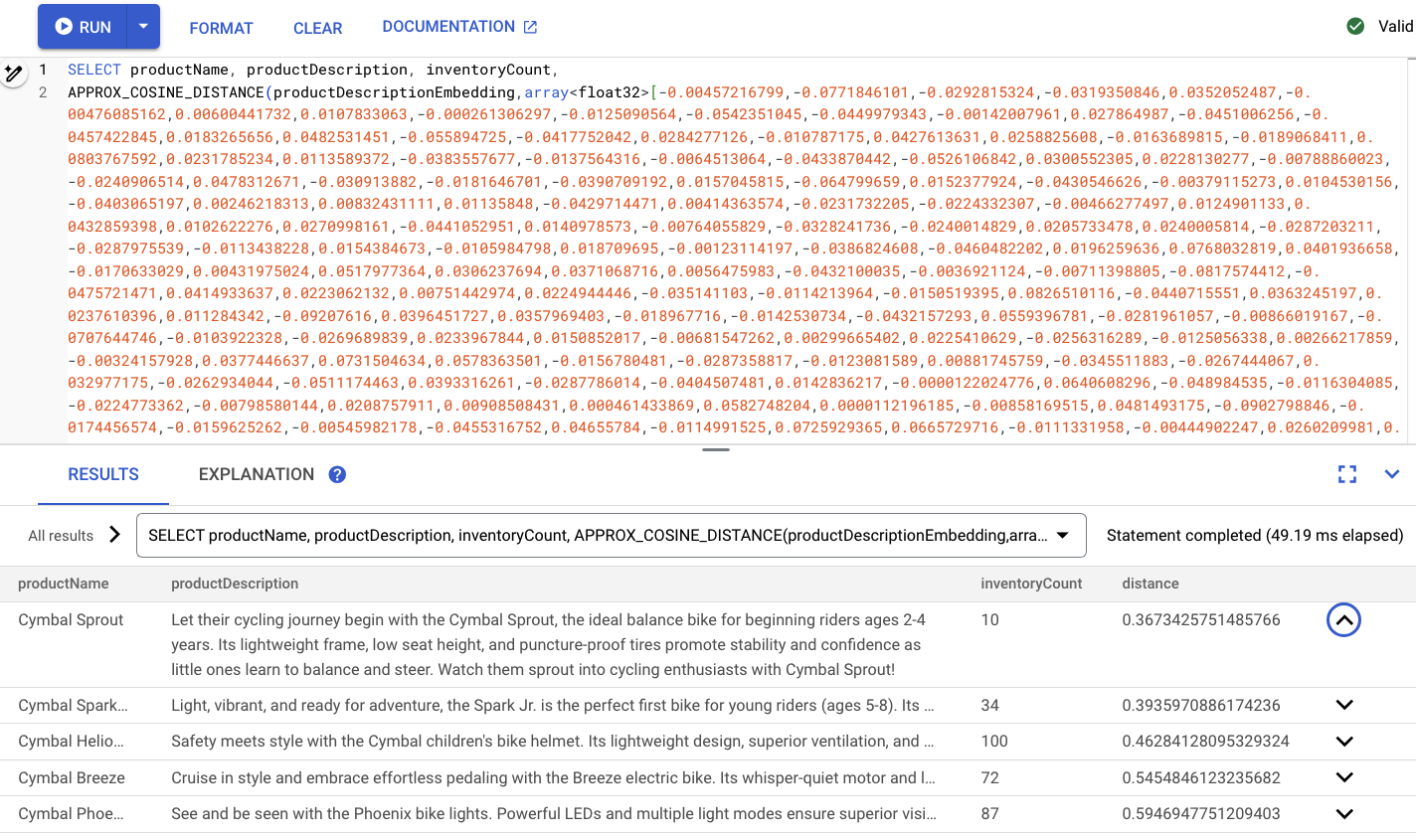
ملخّص
في هذه الخطوة، حوّلت المخطط لإنشاء فهرس متّجه. بعد ذلك، أعدت كتابة طلب البحث عن التضمين لإجراء بحث تقريبي عن أقرب جيران باستخدام فهرس المتجهات. هذه خطوة مهمة مع زيادة حجم بياناتك لتوسيع نطاق أحمال عمل البحث المتّجه.
الخطوات التالية
بعد ذلك، حان وقت إخلاء مساحة.
8. التنظيف (اختياري)
لإجراء ذلك، ما عليك سوى حذف مثيل 'retail-demo' الذي أنشأناه في الدرس العملي.
9- تهانينا!
تهانينا، لقد أجريت عملية بحث عن التشابهات بنجاح باستخدام ميزة "البحث المستند إلى المتجهات" المضمّنة في Spanner. بالإضافة إلى ذلك، رأيت مدى سهولة استخدام نماذج التضمين ونماذج اللغات الكبيرة لتوفير وظائف الذكاء الاصطناعي التوليدي مباشرةً باستخدام SQL.
أخيرًا، تعرّفت على عملية إجراء بحث تقريبي عن أقرب جار (ANN) باستخدام خوارزمية ScaNN لتوسيع نطاق أحمال عمل البحث المتّجه.
ما هي الخطوات التالية؟
يمكنك الاطّلاع على مزيد من المعلومات حول ميزة "البحث عن أقرب جيران" (بحث متّجهي عن أقرب جيران) في Spanner هنا: https://cloud.google.com/spanner/docs/find-k-nearest-neighbors
يمكنك الاطّلاع على مزيد من المعلومات حول ميزة "البحث عن أقرب جيران تقريبيين" (ANN vector search) في Spanner على الرابط: https://cloud.google.com/spanner/docs/find-approximate-nearest-neighbors
يمكنك أيضًا الاطّلاع على مزيد من المعلومات حول كيفية إجراء توقّعات على الإنترنت باستخدام لغة الاستعلامات البنيوية (SQL) من خلال دمج VertexAI في Spanner هنا: https://cloud.google.com/spanner/docs/ml