
1. Başlamadan önce
Bu codelab, parçalanmış bir şirket içi MySQL veritabanını GoogleSQL lehçesiyle Cloud Spanner veritabanına taşıma konusunda size yol gösterir. Spanner Migration Tool (SMT), Dataflow, Datastream, Pub/Sub ve Google Cloud Storage dahil olmak üzere Google Cloud hizmetlerini kullanacaksınız.
Öğrenecekleriniz:
- Parçalanmış ortam nedir ve nasıl ayarlanır?
- MySQL şemasını Spanner ile uyumlu bir şemaya dönüştürmek ve gelişmiş şema değişiklikleri yapmak için Spanner Migration Tool (SMT) Web kullanıcı arayüzünü kullanma.
- Dataflow kullanarak parçalanmış MySQL örneğinden Cloud Spanner'a toplu veri taşıma işlemini gerçekleştirme.
- Datastream ve Dataflow kullanarak parçalanmış MySQL örneğinden Cloud Spanner'a sürekli çoğaltma (CDC) ayarlama.
- Spanner'dan parçalanmış MySQL örneklerine tersine replikasyonun nasıl yapılandırılacağı.
- Toplu, canlı ve tersine taşıma işlemleri sırasında ek sütunları doldurmak için özel dönüşümleri kullanma
- Birincil anahtarları kullanarak parçalama dönüşümlerini yapılandırma
Bu codelab'de ele alınmayan konular:
- Gelişmiş özel ağ iletişimi.
- Sıfırdan özel Dataflow şablonları oluşturma
- Taşıma performansını ayarlama
- Uygulama Taşıma: Bu codelab, veritabanı katmanına (şema ve veriler) odaklanır. Uygulama hizmetlerinizin yeniden dağıtılması veya taşınmasıyla ilgili operasyonel süreçleri kapsamaz.
İhtiyacınız olanlar
- Faturalandırmanın etkin olduğu bir Google Cloud projesi.
- API'leri etkinleştirmek ve Spanner, Dataflow, Datastream ile GCS kaynaklarını oluşturup yönetmek için yeterli IAM izinleri. Proje
Ownerrolü, bir codelab için en basit rol olsa da "Ortam Kurulumu" bölümünde daha spesifik roller ele alınacaktır. - Kurulum aşamasında şirket içi sunucumuzu simüle etmek için küçük bir Compute Engine sanal makinesi sağlayacağız. Proje kotanızın sanal makine oluşturmaya izin verdiğinden emin olun.
- Google Chrome gibi bir web tarayıcısı
- Google Cloud Console ve
gcloudgibi komut satırı araçları hakkında temel düzeyde bilgi sahibi olmak. - Kabuk ortamına erişim.
gcloudiçerdiğinden Cloud Shell önerilir.
Yukarıdaki kurulumla ilgili daha fazla ayrıntı Ortam Kurulumu bölümünde açıklanmaktadır.
2. Taşıma Sürecini Anlama
Parçalanmış bir veritabanını taşıma işlemi, birden fazla fiziksel ve mantıksal MySQL örneğini tek bir yatay olarak ölçeklenebilir Spanner veritabanında birleştirmeyi içerir. Bu bölümde, mimari ve taşıma işleminde kullanılan temel araçlar açıklanmaktadır.
Taşıma Akışı Mimarisi
Taşıma işlemi şu aşamaları içerir:
1. Şema Dönüşümü:
- Amaç: Kaynak veritabanı şemasını uyumlu bir Cloud Spanner şemasına dönüştürmek.
- Araç: Spanner Taşıma Aracı (SMT)
- Süreç: SMT, kaynak veritabanı şemasını analiz eder ve eşdeğer Spanner Veri Tanımlama Dili'ni (DDL) oluşturur. Hedef Spanner örneğinde bir veritabanı oluşturulur ve DDL otomatik olarak uygulanır.
2. Toplu Veri Taşıma:
- Amaç: Kaynak veritabanındaki mevcut verilerin, sağlanan Spanner tablolarına ilk ve tam yüklemesini gerçekleştirmek.
- Araç: Google tarafından sağlanan
Sourcedb to Spannerşablonunu kullanan Dataflow. - Süreç: Bu Dataflow işi, belirtilen kaynak tablolardaki tüm verileri okur ve karşılık gelen Spanner tablolarına yazar. Bu işlem, Spanner şeması oluşturulduktan sonra yapılır.
3. Canlı geçiş (CDC):
- Amaç: Kaynak veritabanındaki devam eden değişiklikleri neredeyse gerçek zamanlı olarak yakalayıp Cloud Spanner'a uygulamak ve taşıma sırasında kapalı kalma süresini en aza indirmek.
- Araçlar:
- Datastream: Kaynak veritabanındaki değişiklikleri (eklemeler, güncellemeler, silmeler) yakalar ve bunları Cloud Storage'a (GCS) yazar.
- Dataflow: GCS'deki değişiklik etkinliklerini okumak ve bunları Cloud Spanner'a uygulamak için
Datastream to Spannerşablonunu kullanır.
4. Tersine Çoğaltma:
- Amaç: Cloud Spanner'daki veri değişikliklerini kaynak veritabanına geri kopyalamak. Bu özellik, yedek stratejileri, aşamalı geçişler veya belirli kullanım alanları için kaynakta bir kopya tutmak için yararlı olabilir.
- Araç:
Spanner to SourceDbşablonunu kullanan Dataflow. - İşlem: Bu iş, Spanner'daki değişiklikleri yakalamak ve bunları kaynak veritabanı örneğine geri yazmak için Spanner değişiklik akışlarını kullanır.
Aşağıdaki şemada bileşenler ve veri akışı gösterilmektedir:

Temel Terminoloji:
- Fiziksel Parça: Veritabanını barındıran gerçek temel sunucu veya işlem örneği (bizim durumumuzda, şirket içi GCE VM'nin simülasyonu).
- Mantıksal Parça: Fiziksel bir sunucudaki bağımsız veritabanı şeması.
- Compute Engine (GCE) VM: Google Cloud altyapısında barındırılan sanal makine. Bu codelab'de, kaynak MySQL veritabanımızı barındıran bağımsız bir "şirket içi" çıplak metal sunucuyu simüle etmek için bir GCE VM kullanıyoruz.
- Spanner Taşıma Aracı (SMT): MySQL şemalarını değerlendirmek, Spanner şema eşdeğerlerini önermek ve Spanner Veri Tanımlama Dili (DDL)'ni oluşturmak için kullanılan bir araçtır.
- Veri Tanımlama Dili (DDL): Veritabanı yapısını tanımlamak ve değiştirmek için kullanılan ifadelerdir (ör.
CREATE TABLEifadeleri). SMT, Cloud SQL şemasına göre Spanner DDL'si oluşturur. - Dataflow: Tümüyle yönetilen, sunucusuz bir veri işleme hizmeti. Bu codelab'de, toplu veri aktarımı, Datastream değişikliklerini uygulama ve ters çoğaltma için Google tarafından sağlanan şablonları çalıştırmak üzere kullanılır.
- Datastream: Sunucusuz bir Değişiklik Veri Yakalama (CDC) ve replikasyon hizmetidir. Bu codelab'de, yerel olarak barındırılan MySQL örneğindeki değişiklikleri Cloud Storage'e aktarmak için kullanılır.
- Spanner Değişiklik Akışları: Verilerdeki değişikliklerin (eklemeler, güncellemeler, silmeler) gerçek zamanlı olarak aktarılmasına olanak tanıyan bir Spanner özelliği. Ters çoğaltma için kaynak olarak kullanılır.
- Pub/Sub: Etkinlik üreten hizmetleri bunları işleyen hizmetlerden ayırmak için kullanılan bir mesajlaşma hizmeti. Bu codelab'de, Datastream Cloud Storage'a yeni değişiklik dosyaları yüklediğinde Dataflow'un güncellemeleri işlemesi tetiklenir.
3. Ortam Kurulumu
Taşıma işlemine başlamadan önce Google Cloud projenizi ayarlamanız ve gerekli hizmetleri etkinleştirmeniz gerekir.
1. Google Cloud projesi seçme veya oluşturma
Bu codelab'deki hizmetleri kullanmak için faturalandırmanın etkinleştirildiği bir Google Cloud projesine ihtiyacınız var.
- Google Cloud Console'da proje seçici sayfasına gidin: Proje Seçici'ye git
- Bir Google Cloud projesi seçin veya oluşturun.
- Projeniz için faturalandırmanın etkinleştirildiğinden emin olun. Projeniz için faturalandırmanın etkinleştirildiğini nasıl onaylayacağınızı öğrenin.
2. Cloud Shell'i açın
Cloud Shell, Google Cloud'da çalışan ve gcloud KSA'sı ile ihtiyaç duyduğunuz diğer araçlar önceden yüklenmiş olarak gelen bir komut satırı ortamıdır.
- Google Cloud Console'un sağ üst kısmındaki Cloud Shell'i Etkinleştir düğmesini tıklayın.
- Konsolun altındaki yeni bir çerçevede Cloud Shell oturumu açılır ve komut satırı istemi görüntülenir.

3. Proje ve Ortam Değişkenlerini Ayarlama
Cloud Shell'de proje kimliğiniz ve kullanacağınız bölge için bazı ortam değişkenleri ayarlayın.
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1" # Or your preferred region
export ZONE="us-central1-a" # Or a zone within your selected region
gcloud config set project $PROJECT_ID
gcloud config set compute/region $REGION
gcloud config set compute/zone $ZONE
echo "Project ID: $PROJECT_ID"
echo "Region: $REGION"
echo "Zone: $ZONE"
4. Gerekli Google Cloud API'lerini etkinleştirme
Cloud Spanner, Dataflow, Datastream ve diğer ilgili hizmetler için gerekli API'leri etkinleştirin.
gcloud services enable \
spanner.googleapis.com \
dataflow.googleapis.com \
datastream.googleapis.com \
pubsub.googleapis.com \
storage.googleapis.com \
compute.googleapis.com \
sqladmin.googleapis.com \
servicenetworking.googleapis.com \
cloudresourcemanager.googleapis.com
Bu komutun tamamlanması birkaç dakika sürebilir.
4. Kaynak MySQL Veritabanını Ayarlama
Bu bölümde, iki Compute Engine sanal makinesi (2 "fiziksel parçamız") sağlayarak şirket içi parçalanmış bir MySQL mimarisini simüle edeceğiz. Ardından, her ikisine de MySQL'i yükleyip her sanal makinede iki veritabanı (mantıksal parçalarımız) oluşturacağız.
1. Compute Engine sanal makinelerini (fiziksel parçalar) oluşturma
Ubuntu ile iki sanal makine oluşturmak için Cloud Shell'de aşağıdaki komutları çalıştırın. Daha sonra gelen MySQL trafiğine izin vermek için bunlara ağ etiketleri atayacağız.
# Create Physical Shard 1
gcloud compute instances create mysql-physical-1 \
--zone=$ZONE \
--machine-type=e2-small \
--image-family=ubuntu-2204-lts \
--image-project=ubuntu-os-cloud \
--tags=mysql-server
# Create Physical Shard 2
gcloud compute instances create mysql-physical-2 \
--zone=$ZONE \
--machine-type=e2-small \
--image-family=ubuntu-2204-lts \
--image-project=ubuntu-os-cloud \
--tags=mysql-server
2. Güvenlik Duvarı Kurallarını Yapılandırma
Herkese açık erişim olmadan güvenli SSH erişimine izin vermek ve Datastream bağlantısını etkinleştirmek için:
IAP üzerinden SSH için güvenlik duvarı kuralı oluşturma:
Bu kural, Identity-Aware Proxy'nin SSH bağlantı noktası (22) üzerinden sanal makinelerinize ulaşmasına olanak tanır.
gcloud compute firewall-rules create allow-ssh-iap \
--direction=INGRESS \
--priority=1000 \
--network=default \
--action=ALLOW \
--rules=tcp:22 \
--source-ranges=35.235.240.0/20 \
--target-tags=mysql-server
Datastream (MySQL bağlantı noktası) için güvenlik duvarı kuralı oluşturma:
DataStream'in, standart MySQL bağlantı noktası (3306) üzerinden bu sanal makinelere ulaşabilmesi gerekir.
gcloud compute firewall-rules create allow-mysql-datastream \
--direction=INGRESS \
--priority=1000 \
--network=default \
--action=ALLOW \
--rules=tcp:3306 \
--source-ranges=0.0.0.0/0 \
--target-tags=mysql-server
3. MySQL'i fiziksel parça 1'e yükleme ve yapılandırma
MySQL'i yüklemek ve ikili günlük kaydını yapılandırmak için ilk sanal makinenize SSH ile bağlanın (bu, Datastream'in canlı çoğaltma için gereklidir).
- İlk sanal makineye SSH uygulayın:
gcloud compute ssh mysql-physical-1 --zone=$ZONE --tunnel-through-iap
- MySQL'i yükleyin:
sudo apt-get update
sudo apt-get install mysql-server-8.0 -y
# Verify the installation and version
sudo mysql --version
- İkili program günlük kaydını etkinleştirmek ve harici bağlantılara izin vermek için
mysqld.cnfdosyasını yapılandırın:
sudo sed -i 's/bind-address.*/bind-address = 0.0.0.0/' /etc/mysql/mysql.conf.d/mysqld.cnf
echo -e "[mysqld]\nserver-id=1\nlog_bin=/var/log/mysql/mysql-bin.log\nbinlog_format=ROW" | sudo tee -a /etc/mysql/mysql.conf.d/mysqld.cnf
- Değişiklikleri uygulamak için MySQL'i yeniden başlatın:
sudo systemctl restart mysql
4. Mantıksal Parçalar Oluşturma, Veri Ekleme ve Veri Akışı Kullanıcısı Oluşturma (1. Parça)
Hâlâ mysql-physical-1 için SSH bağlantısı açıkken MySQL istemine giriş yapın:
sudo mysql
Aşağıdaki SQL komutlarını çalıştırın. Bu komut dosyası iki ayrı mantıksal parça (shard0_db ve shard1_db) oluşturur, her ikisinde de aynı şemayı ayarlar, her birine kimliği net bir şekilde tespit edilebilir veriler ekler (parçalama işlemini göstermek için) ve Datastream için replikasyon kullanıcısını oluşturur.
İlk iki mantıksal parçanızı, bir tabloyu ve Datastream için replikasyon kullanıcısını oluşturmak üzere aşağıdaki SQL komutlarını çalıştırın:
CREATE DATABASE shard0_db;
CREATE DATABASE shard1_db;
USE shard0_db;
CREATE TABLE Customers (
CustomerId INT NOT NULL,
CustomerName VARCHAR(255),
CreditLimit DECIMAL(10, 2) NOT NULL,
LegacyRegion VARCHAR(50), -- Renamed to LoyaltyTier in Spanner
PRIMARY KEY (CustomerId),
CONSTRAINT CHK_CreditLimit CHECK (CreditLimit > 1000) -- Relaxed in Spanner to > 0
);
CREATE TABLE Orders (
CustomerId INT NOT NULL, -- Logically references Customers.CustomerId in Spanner
OrderId INT NOT NULL,
OrderValue DECIMAL(10, 2),
LegacyOrderSystem VARCHAR(50), -- Extra column in Source, to be dropped in Spanner
PRIMARY KEY (CustomerId, OrderId) -- Spanner PK will have one additional column in PK
);
INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LegacyRegion) VALUES
(4, 'David E.', 2000.00, 'EAST'),
(8, 'Eleanor F.', 8100.00, 'WEST'),
(12, 'Frank G.', 12000.00, 'NORTH'),
(16, 'Grace H.', 6500.00, 'SOUTH');
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem) VALUES
(4, 101, 150.00, 'WebStore_v1'),
(4, 102, 25.50, 'InStore_POS'),
(8, 103, 75.00, 'MobileApp_Legacy'),
(12, 104, 3000.00, 'WebStore_v1'),
(16, 105, 120.00, 'Partner_API');
USE shard1_db;
CREATE TABLE Customers (
CustomerId INT NOT NULL,
CustomerName VARCHAR(255),
CreditLimit DECIMAL(10, 2) NOT NULL,
LegacyRegion VARCHAR(50), -- Renamed to LoyaltyTier in Spanner
PRIMARY KEY (CustomerId),
CONSTRAINT CHK_CreditLimit CHECK (CreditLimit > 1000) -- Relaxed in Spanner to > 0
);
CREATE TABLE Orders (
CustomerId INT NOT NULL, -- Logically references Customers.CustomerId in Spanner
OrderId INT NOT NULL,
OrderValue DECIMAL(10, 2),
LegacyOrderSystem VARCHAR(50), -- Extra column in Source, to be dropped in Spanner
PRIMARY KEY (CustomerId, OrderId) -- Spanner PK will have one additional column in PK
);
INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LegacyRegion) VALUES
(1, 'Agnes N.', 5100.00, 'NORTHEAST'),(5, 'Alice I.', 15000.00, 'EAST'),
(9, 'Bob J.', 7500.00, 'WEST'),
(13, 'Charlie K.', 2200.00, 'CENTRAL');
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem) VALUES
(1, 201, 50.00, 'MobileApp_Legacy'),
(5, 202, 1250.00, 'WebStore_v1'),
(5, 203, 80.00, 'Partner_API'),
(9, 204, 600.00, 'InStore_POS'),
(13, 205, 199.99, 'WebStore_v1');
-- Create Datastream Replication User
CREATE USER 'datastream_user'@'%' IDENTIFIED BY 'complex_password_123';
GRANT REPLICATION SLAVE, REPLICATION CLIENT, SELECT, INSERT, UPDATE, DELETE ON *.* TO 'datastream_user'@'%';
FLUSH PRIVILEGES;
Yukarıdaki şemaya ait döküm dosyasını burada bulabilirsiniz. Döküm dosyasına dahil edilmediği için veri akışı replikasyon kullanıcısını ayrı olarak oluşturmanız önemlidir.
5. Verileri doğrulama
Verilerin mevcut olup olmadığını hızlıca kontrol edin:
SELECT 'Customers shard0_db' AS tbl, COUNT(*) FROM shard0_db.Customers
UNION ALL
SELECT 'Orders shard0_db', COUNT(*) FROM shard0_db.Orders
UNION ALL
SELECT 'Customers shard1_db', COUNT(*) FROM shard1_db.Customers
UNION ALL
SELECT 'Orders shard1_db', COUNT(*) FROM shard1_db.Orders;
EXIT;
Beklenen çıkış:
+---------------------+----------+ | tbl | COUNT(*) | +---------------------+----------+ | Customers shard0_db | 4 | | Orders shard0_db | 5 | | Customers shard1_db | 4 | | Orders shard1_db | 5 | +---------------------+----------+
Fiziksel parça 1 sanal makinesiyle bağlantıdan çıkmak için exit girin.
6. Fiziksel Parça 2 için tekrarlayın.
Şimdi ikinci sanal makine için de aynı işlemi tekrarlayacaksınız ancak shard2_db ve shard3_db oluşturup server-id değerini değiştireceksiniz.
- İkinci sanal makineye SSH uygulayın:
gcloud compute ssh mysql-physical-2 --zone=$ZONE --tunnel-through-iap
- MySQL'i yükleyin:
sudo apt-get update
sudo apt-get install mysql-server-8.0 -y
- İkili günlük kaydını etkinleştirmek ve harici bağlantılara izin vermek için
mysqld.cnfdosyasını yapılandırın [Sunucu kimliğinin farklı olması gerektiğini unutmayın (ör. 2)]
sudo sed -i 's/bind-address.*/bind-address = 0.0.0.0/' /etc/mysql/mysql.conf.d/mysqld.cnf
echo -e "[mysqld]\nserver-id=2\nlog_bin=/var/log/mysql/mysql-bin.log\nbinlog_format=ROW" | sudo tee -a /etc/mysql/mysql.conf.d/mysqld.cnf
- Değişiklikleri uygulamak için MySQL'i yeniden başlatın:
sudo systemctl restart mysql
- MySQL'i (
sudo mysql) girin ve 4. adımda yer alan SQL'in biraz değiştirilmiş bir sürümünü çalıştırın:
CREATE DATABASE shard2_db;
CREATE DATABASE shard3_db;
USE shard2_db;
CREATE TABLE Customers (
CustomerId INT NOT NULL,
CustomerName VARCHAR(255),
CreditLimit DECIMAL(10, 2) NOT NULL,
LegacyRegion VARCHAR(50), -- Renamed to LoyaltyTier in Spanner
PRIMARY KEY (CustomerId),
CONSTRAINT CHK_CreditLimit CHECK (CreditLimit > 1000) -- Relaxed in Spanner to > 0
);
CREATE TABLE Orders (
CustomerId INT NOT NULL, -- Logically references Customers.CustomerId in Spanner
OrderId INT NOT NULL,
OrderValue DECIMAL(10, 2),
LegacyOrderSystem VARCHAR(50), -- Extra column in Source, to be dropped in Spanner
PRIMARY KEY (CustomerId, OrderId) -- Spanner PK will have one additional column in PK
);
INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LegacyRegion) VALUES
(2, 'Brian K.', 2500.00, 'SOUTHWEST'),
(6, 'Diana L.', 1999.00, 'NORTH'),
(10, 'Edward M.', 11000.00, 'EAST'),
(14, 'Fiona N.', 3000.00, 'WEST');
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem) VALUES
(2, 301, 100.00, 'CallCenter_System'),
(6, 302, 99.00, 'MobileApp_Legacy'),
(10, 303, 1000.00, 'WebStore_v1'),
(10, 304, 2500.00, 'InStore_POS'),
(14, 305, 130.00, 'MobileApp_Legacy');
USE shard3_db;
CREATE TABLE Customers (
CustomerId INT NOT NULL,
CustomerName VARCHAR(255),
CreditLimit DECIMAL(10, 2) NOT NULL,
LegacyRegion VARCHAR(50), -- Renamed to LoyaltyTier in Spanner
PRIMARY KEY (CustomerId),
CONSTRAINT CHK_CreditLimit CHECK (CreditLimit > 1000) -- Relaxed in Spanner to > 0
);
CREATE TABLE Orders (
CustomerId INT NOT NULL, -- Logically references Customers.CustomerId in Spanner
OrderId INT NOT NULL,
OrderValue DECIMAL(10, 2),
LegacyOrderSystem VARCHAR(50), -- Extra column in Source, to be dropped in Spanner
PRIMARY KEY (CustomerId, OrderId) -- Spanner PK will have one additional column in PK
);
INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LegacyRegion) VALUES
(3, 'Cathy Z.', 6000.00, 'CENTRAL'),
(7, 'George O.', 18000.00, 'SOUTH'),
(11, 'Helen P.', 4000.00, 'NORTHEAST'),
(15, 'Ivy Q.', 9500.00, 'SOUTHWEST');
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem) VALUES
(3, 401, 600.00, 'InStore_POS'),
(7, 402, 1200.00, 'CallCenter_System'),
(11, 403, 350.00, 'MobileApp_Legacy'),
(15, 404, 800.00, 'WebStore_v1'),
(99, 999, 25.00, 'CallCenter_System'); -- Failure row during Bulk Migration due to violation of interleaving
-- Create Datastream Replication User
CREATE USER 'datastream_user'@'%' IDENTIFIED BY 'complex_password_123';
GRANT REPLICATION SLAVE, REPLICATION CLIENT, SELECT, INSERT, UPDATE, DELETE ON *.* TO 'datastream_user'@'%';
FLUSH PRIVILEGES;
-- Verify Data
SELECT 'Customers shard2_db' AS tbl, COUNT(*) FROM shard2_db.Customers
UNION ALL
SELECT 'Orders shard2_db', COUNT(*) FROM shard2_db.Orders
UNION ALL
SELECT 'Customers shard3_db', COUNT(*) FROM shard3_db.Customers
UNION ALL
SELECT 'Orders shard3_db', COUNT(*) FROM shard3_db.Orders;
EXIT;
Beklenen çıkış:
+---------------------+----------+ | tbl | COUNT(*) | +---------------------+----------+ | Customers shard2_db | 4 | | Orders shard2_db | 5 | | Customers shard3_db | 4 | | Orders shard3_db | 5 | +---------------------+----------+
Yukarıdaki şemaya ait döküm dosyasını burada bulabilirsiniz. Döküm dosyasına dahil edilmediği için veri akışı replikasyon kullanıcısını ayrı olarak oluşturmanız önemlidir.
Sanal makineyle bağlantıdan çıkmak için exit girin.
5. Cloud Spanner'ı ayarlama
Şimdi, verilerin taşınacağı hedef Cloud Spanner örneğini ayarlayacaksınız.
1. Cloud Spanner örneği oluşturma
Gecikmeyi en aza indirmek için Compute Engine sanal makinelerinizle aynı bölgede bir Cloud Spanner örneği oluşturun. Bu komut, 100 işleme birimi kullanarak bu codelab için uygun küçük bir örnek oluşturur.
export SPANNER_INSTANCE_NAME="target-spanner-instance"
export SPANNER_DATABASE_NAME="sharded-target-db"
export SPANNER_CONFIG="regional-${REGION}"
gcloud spanner instances create $SPANNER_INSTANCE_NAME \
--config=$SPANNER_CONFIG \
--description="Target Spanner Instance" \
--processing-units=100
Örnek oluşturma işlemi bir veya iki dakika sürebilir.
6. Spanner Taşıma Aracı'nı (SMT) kullanarak şemayı dönüştürme
Mantıksal parçalarımızdan birine (shard0_db) bağlanmak, şemasını analiz etmek ve Cloud Spanner'a dönüştürmeden önce çeşitli gelişmiş değişiklikler uygulamak için Spanner Migration Tool (SMT) Web kullanıcı arayüzünü kullanın.
1. SMT'yi yükleme
SMT Web kullanıcı arayüzünü doğrudan Cloud Shell'den çalıştıracağız. Cloud Shell terminalinizde en son SMT sürümünü indirip ayıklayın:
sudo apt-get update && sudo apt-get install google-cloud-cli-spanner-migration-tool
# Verify installation
gcloud alpha spanner migrate web --help
2. Kaynak veritabanına bağlanma
- Oturumunuzun kimliğini doğrulama
# Authenticate your Google Cloud account
gcloud auth login
# Set up Application Default Credentials (ADC) for SMT
gcloud auth application-default login
# Ensure your current project is set correctly
gcloud config set project $PROJECT_ID
(Not: İstendiğinde, hesabınızı yetkilendirmek için sağlanan URL'yi takip edin ve doğrulama kodunu tekrar terminale yapıştırın.)
- Öncelikle, yeni bir Cloud Shell sekmesinde aşağıdaki komutu çalıştırarak ilk fiziksel parçanızın harici IP'sini bulun:
gcloud compute instances describe mysql-physical-1 --zone=$ZONE --format='get(networkInterfaces[0].accessConfigs[0].natIP)'
- SMT yapılandırılırken kullanılacak hedef anahtar örneği ayrıntılarını yazdırın.
echo "Project ID: $PROJECT_ID"
echo "Instance ID: $SPANNER_INSTANCE_NAME"
echo "Database Name: $SPANNER_DATABASE_NAME"
- Web kullanıcı arayüzünü başlatın:
gcloud alpha spanner migrate web --port=8080
- Cloud Shell pencerenizin sağ üst kısmında Web önizlemesi simgesini (göz gibi görünür) tıklayın ve 8080 bağlantı noktasında önizle'yi seçin. Bu işlem, SMT kullanıcı arayüzünü yeni bir tarayıcı sekmesinde açar.

- SMT web kullanıcı arayüzünde Veritabanına bağlan'ı seçin.
- Bağlantı ayrıntılarını girin:
- Veritabanı Türü: MySQL
- Ana makine: (2. adımdaki IP adresini yapıştırın)
- Bağlantı noktası: 3306
- Kullanıcı:
datastream_user - Şifre:
complex_password_123 - Veritabanı Adı:
shard0_db
- Spanner veritabanını yapılandırmak için sağ üst köşedeki düzenle düğmesini tıklayın.
- Hedef Spanner ayrıntılarınızı girin:
- Proje kimliği: (3. adımdaki proje kimliğini yapıştırın)
- Spanner örneği: (3. adımdaki örnek kimliğini yapıştırın)
- Bağlantıyı Test Et'i tıklayın.
- Bu işlem tamamlandıktan sonra Bağlan'ı tıklayın. SMT, kaynak veritabanını analiz eder ve temel bir Spanner şeması sunar.

3. Şema Değişikliklerini Uygulama
Şimdi şemayı, karmaşık taşıma senaryolarımızı kapsayacak şekilde yeniden şekillendireceğiz.
SMT kullanıcı arayüzünün şema düzenleyicisinde aşağıdaki işlemleri yapın:
C. LegacyRegion sütununu yeniden adlandırın:
- Soldaki gezinme bölmesinde
Customerstablosunu tıklayın. Varsayılan olarak Sütunlar sekmesi açılır. - Anahtar bölümünde Düzenle düğmesini tıklayın.
- Spanner şema görünümünde
LegacyRegionsütununu bulun. - Sütun adı iletişim kutusuna yazarak Spanner sütun adını
LoyaltyTierolarak değiştirin. - Kaydet ve Dönüştür'ü tıklayın.


B. Check kısıtlamasını gevşetin:
Customerstablosunda kalmaya devam ederek Check Constraints (Kısıtlamaları Kontrol Et) sekmesine gidin.CHK_CreditLimitkısıtlamasını bulun. Düzenle (kalem) simgesini tıklayın.- Koşulu
CreditLimit > 1000yerineCreditLimit > 0olarak değiştirin. (Bu işlem, daha düşük kredi limitlerine sahip satırların ters taşıma işleminin başarısız olmasına ve DLQ'ya düşmesine neden olur.)

C. LegacyOrderSystem sütununu bırakın:
Orderstablosunu tıkladığınızda varsayılan olarak Sütunlar sekmesi açılır.- Anahtar bölümünde Düzenle düğmesini tıklayın.
- Spanner şema görünümünde
LegacyOrderSystemsütununu bulun. - Yanındaki 3 noktalı menü simgesini tıklayın ve Sütunu Bırak'ı seçin.
- Kaydet ve Dönüştür'ü tıklayın.

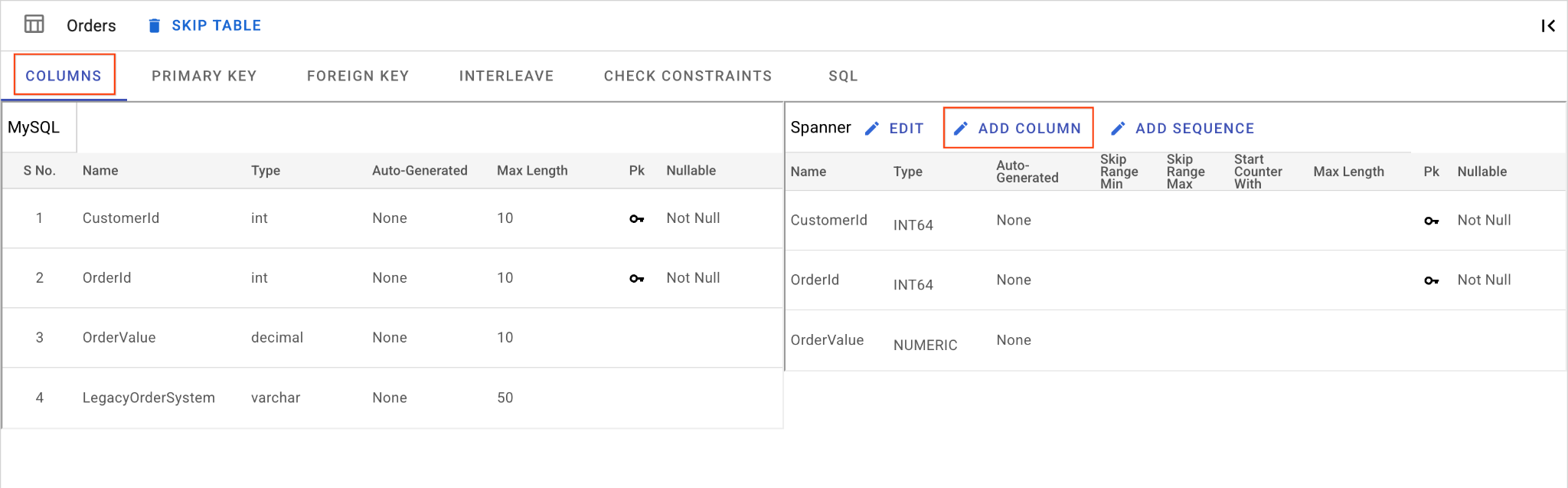
D. OrderSource sütununu ekleyin ve birincil anahtar yapın:
Orderstablosundayken Sütun Ekle'yi tıklayın.OrderSourceolarak adlandırın ve türü50uzunluğunda, otomatik oluşturma olmadanSTRINGolarak ayarlayın.IsNullabledeğeriniNoolarak ayarlayın.- Birincil Anahtar sekmesine gidin.
- Düzenle'yi tıklayın ve Sütun Adı açılır listesinden
OrderSourcesimgesini seçin. - Sütun Ekle'yi ve ardından Kaydet ve Dönüştür'ü tıklayın.

E. Siparişler tablosunu araya ekleyin:
- Hâlâ
Orderstablosundayken ana tablo görünümünde Interleave (Araya Ekleme) sekmesini bulun. - Üst tabloyu
Customersolarak ayarlayın. IN PARENTAralama türü veNO ACTIONSilme işleminde seçeneğini belirleyin.- Kaydet'i tıklayın.

4. Geçersiz kılma dosyasını indirme ve şemayı uygulama
- SMT kullanıcı arayüzünün sağ üst köşesinde Download Artifacts (Öğeleri İndir) düğmesini bulun. Geçersiz Kılma Dosyasını İndir seçeneğini belirleyin. Bu dosyayı yerel makinenize kaydedin. Bu dosya, az önce yaptığımız tüm şema eşleme değişikliklerini içerir ve Dataflow ardışık düzenlerimiz tarafından kullanılır.
- Taşıma İşlemini Hazırla'yı tıklayın.

- Açılır listeden
Schemaolarak Taşıma Modu'nu seçin. - Hedef Spanner veritabanınızı girin:
sharded-target-db

- Taşı'yı tıklayın.
- SMT, DDL'yi uygular ve Spanner veritabanını oluşturur. Tamamlandıktan sonra Cloud Shell'de (
Ctrl+C) SMT sürecini güvenli bir şekilde durdurabilirsiniz.
5. Cloud Spanner'da Şemayı Doğrulama
Tabloların Spanner veritabanında oluşturulduğunu kontrol edin.
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT table_name FROM information_schema.tables WHERE table_schema = '' ORDER BY table_name"
Aşağıdaki çıkışı göreceksiniz:
table_name: Customers table_name: Orders
İsteğe bağlı: Kontrol kısıtlamalarınızın, araya yerleştirme işleminizin ve ek sütunlarınızın uygulandığını doğrulamak için gerçek Spanner DDL'yi kontrol etmek istiyorsanız aşağıdaki komutu çalıştırın:
gcloud spanner databases ddl describe $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME
Beklenen çıkış:
CREATE TABLE Customers ( CustomerId INT64 NOT NULL, CustomerName STRING(255), CreditLimit NUMERIC NOT NULL, LoyaltyTier STRING(50), CONSTRAINT CHK_CreditLimit CHECK(`CreditLimit` > 0), ) PRIMARY KEY(CustomerId); CREATE TABLE Orders ( CustomerId INT64 NOT NULL, OrderId INT64 NOT NULL, OrderValue NUMERIC, OrderSource STRING(50) NOT NULL, ) PRIMARY KEY(CustomerId, OrderId, OrderSource), INTERLEAVE IN PARENT Customers ON DELETE NO ACTION;
7. Değişiklik Verisi Yakalama'yı (CDC) başlatma
Bu bölümde, taşıma işleminiz için "kaydedici"yi ayarlayacaksınız. Toplu veri yükleme işlemi başlamadan önce Datastream ve Pub/Sub'ı yapılandırarak kaynak veritabanlarında yapılan her değişikliğin yakalanıp sıraya alınmasını sağlarsınız. Böylece geçiş sırasında veri kaybı yaşanmaz. Bu kurulum, canlı taşıma için gereklidir.
Mimari yapımızda iki fiziksel sunucu bulunduğundan iki ayrı DataStream kaynak profili ve iki DataStream akışı oluşturmamız gerekir. Her iki akış da Dataflow ardışık düzenimiz için birleştirilmiş kaynak görevi görecek tek bir Google Cloud Storage (GCS) paketine yazılır.
1. Cloud Storage paketi oluşturma
Veri akışı, yakalanan değişiklik etkinliklerini depolamak için bir hedef gerektirir. GCS paketi oluşturalım.
export BUCKET_NAME="migration-${PROJECT_ID}-bucket"
gcloud storage buckets create gs://${BUCKET_NAME} --location=$REGION
2. Veri akışı bağlantı profilleri oluşturma
İki farklı MySQL kaynak bağlantı profiline (her fiziksel parça için bir tane) ve Cloud Storage için bir hedef bağlantı profiline ihtiyacımız var.
Kaynak IP adreslerini alma
İlk olarak, iki Compute Engine sanal makinemizin harici IP adreslerini getirin ve bunları ortam değişkenleri olarak saklayın:
export MYSQL_IP_1=$(gcloud compute instances describe mysql-physical-1 --zone=$ZONE --format='get(networkInterfaces[0].accessConfigs[0].natIP)')
export MYSQL_IP_2=$(gcloud compute instances describe mysql-physical-2 --zone=$ZONE --format='get(networkInterfaces[0].accessConfigs[0].natIP)')
Kaynak bağlantı profilleri oluşturma (Compute Engine'de MySQL)
Daha önce oluşturulan datastream_user kullanılarak Datastream bağlantı profilleri oluşturulur.
# Create Source Profile for Physical Shard 1
export SQL_CP_NAME_1="mysql-src-cp-1"
gcloud datastream connection-profiles create $SQL_CP_NAME_1 \
--location=$REGION \
--type=mysql \
--mysql-hostname=$MYSQL_IP_1 \
--mysql-port=3306 \
--mysql-username=datastream_user \
--mysql-password=complex_password_123 \
--display-name="MySQL Source 1 (Physical Shard 1)"
# Create Source Profile for Physical Shard 2
export SQL_CP_NAME_2="mysql-src-cp-2"
gcloud datastream connection-profiles create $SQL_CP_NAME_2 \
--location=$REGION \
--type=mysql \
--mysql-hostname=$MYSQL_IP_2 \
--mysql-port=3306 \
--mysql-username=datastream_user \
--mysql-password=complex_password_123 \
--display-name="MySQL Source 2 (Physical Shard 2)"
Not: Datastream, bu VM'lere herkese açık IP'leri üzerinden bağlanır. Daha önce güvenlik duvarı kurallarımıza 0.0.0.0/0 eklediğimiz için bu bağlantıya izin verilir. Üretim ortamında, Datastream'in belirli herkese açık IP aralıklarını kesinlikle izin verilenler listesine eklemeniz gerekir.
Hedef bağlantı profili oluşturma (Cloud Storage):
Bu, yeni oluşturduğunuz paketin kökünü gösterir.
export GCS_CP_NAME="gcs-dest-cp"
gcloud datastream connection-profiles create $GCS_CP_NAME \
--location=$REGION \
--type=google-cloud-storage \
--bucket=$BUCKET_NAME \
--root-path=/ \
--display-name="GCS Destination" --force
3. Veri akışı oluşturma
Şimdi iki CDC akışı oluşturacağız. 1. akışta shard0_db ve shard1_db kaydedilir. 2. yayın, shard2_db ve shard3_db'ı yakalayacak. Her iki akış da Avro biçiminde aynı GCS paketine yazar.
# Stream for Physical Shard 1
export STREAM_NAME_1="mysql-to-spanner-stream-1"
export GCS_STREAM_PATH_1="data/${STREAM_NAME_1}"
gcloud datastream streams create $STREAM_NAME_1 \
--location=$REGION \
--display-name="MySQL Source 1 CDC Stream" \
--source=$SQL_CP_NAME_1 \
--destination=$GCS_CP_NAME \
--mysql-source-config=<(echo "includeObjects:
mysqlDatabases:
- database: 'shard0_db'
- database: 'shard1_db'") \
--gcs-destination-config=<(echo "path: ${GCS_STREAM_PATH_1}/
fileRotationMb: 5
fileRotationInterval: 15s
avroFileFormat: {}") \
--backfill-none
# Stream for Physical Shard 2
export STREAM_NAME_2="mysql-to-spanner-stream-2"
export GCS_STREAM_PATH_2="data/${STREAM_NAME_2}"
gcloud datastream streams create $STREAM_NAME_2 \
--location=$REGION \
--display-name="MySQL Source 2 CDC Stream" \
--source=$SQL_CP_NAME_2 \
--destination=$GCS_CP_NAME \
--mysql-source-config=<(echo "includeObjects:
mysqlDatabases:
- database: 'shard2_db'
- database: 'shard3_db'") \
--gcs-destination-config=<(echo "path: ${GCS_STREAM_PATH_2}/
fileRotationMb: 5
fileRotationInterval: 15s
avroFileFormat: {}") \
--backfill-none
Daha küçük dosya döndürme ayarlarını (5 MB veya 15 saniye) kullanmak, codelab sırasında çoğaltılan değişiklikleri daha hızlı görmemize yardımcı olur.
Bu komutun tamamlanması biraz zaman alabilir. Çek durumu: gcloud datastream streams describe $STREAM_NAME_1 --location=$REGION.
4. Datastream akışlarını başlatma
Değişiklikleri kaydetmeye başlamaları için her iki akışı da etkinleştirin.
gcloud datastream streams update $STREAM_NAME_1 \
--location=$REGION \
--state=RUNNING
gcloud datastream streams update $STREAM_NAME_2 \
--location=$REGION \
--state=RUNNING
Durumu kontrol etme: gcloud datastream streams describe $STREAM_NAME_1 --location=$REGION komutunu çalıştırabilirsiniz. Durum başlangıçta STARTING olur ve birkaç dakika sonra RUNNING olarak değişir. Canlı taşıma işlemini başlatmadan önce her ikisinin de tam olarak çalışmasını bekleyin.
5. GCS bildirimleri için Pub/Sub'ı ayarlama
Dataflow, Datastream akışı GCS paketine yeni bir dosya yazdığında hemen bilgilendirilmelidir. GCS'yi, tek bir Pub/Sub konusuna bildirim gönderecek şekilde yapılandıracağız.
Pub/Sub konusu oluşturma:
export PUBSUB_TOPIC="datastream-gcs-updates"
gcloud pubsub topics create $PUBSUB_TOPIC
GCS bildirimi oluşturma
data/ öneki altındaki herhangi bir nesne oluşturma işleminde konuyu bilgilendirin (bu, her iki yayınımızı da kapsar).
gcloud storage buckets notifications create gs://${BUCKET_NAME} --topic=projects/$PROJECT_ID/topics/$PUBSUB_TOPIC --payload-format=json --object-prefix=data/
Pub/Sub aboneliği oluşturma
Dataflow için önerilen onay son tarihiyle abonelik oluşturun.
export PUBSUB_SUBSCRIPTION="datastream-gcs-sub"
gcloud pubsub subscriptions create $PUBSUB_SUBSCRIPTION \
--topic=$PUBSUB_TOPIC \
--ack-deadline=600
8. Özel Dönüşüm
Spanner şemamız, SMT web kullanıcı arayüzü üzerinden eklediğimiz ve bıraktığımız sütunlar nedeniyle MySQL şemamızdan farklı olduğundan, kullanıma hazır Dataflow taşıma işlemi başarısız olur. Dataflow'un, ileri (MySQL'den Spanner'a) ve geri (Spanner'dan MySQL'e) işlem hatları sırasında bu farklılıkları nasıl eşleyeceğine dair talimatlara ihtiyacı vardır.
Ayrıca, parçalanmış ters taşıma işlemi yaptığımız için Dataflow'un, ters çoğaltma sırasında güncellenen bir Spanner satırının hangi mantıksal parçaya (shard0_db, shard1_db vb.) ait olduğunu bilmesi için bir yönlendirme mekanizmasına ihtiyacı vardır.
Bu işlemi, Google tarafından sağlanan Spanner Özel Parçalama şablonunu kullanarak bir Özel Dönüşüm JAR'ı yazarak gerçekleştireceğiz.
1. Özel Parçalama Şablonunu İndirme
Cloud Shell'inizde Google Cloud Dataflow Templates deposunu indirin ve özel parça klasörüne gidin:
git clone https://github.com/GoogleCloudPlatform/DataflowTemplates.git
cd DataflowTemplates/v2/spanner-custom-shard
2. Veri Dönüştürme Mantığını Yapılandırma
CustomTransformationFetcher.java dosyasını düzenlememiz gerekiyor.
- İleriye dönük taşıma (
toSpannerRow): Yeni eklenenOrderSourcesütununu MySQL'dekiLegacyOrderSystemsütununu kullanarak doldurur. - Tersine Taşıma (
toSourceRow): MySQL'in gerektirdiği bırakılanLegacyOrderSystemsütununu Spanner'ınOrderSourcesütunundan türeterek yeniden doldurur.
CustomTransformationFetcher.java dosyasını düzenleyin. Bir metin düzenleyiciyi manuel olarak açmak yerine, şablon dosyasının özel mantığımızla otomatik olarak üzerine yazmak için aşağıdaki komutu çalıştırın:
cat << 'EOF' > src/main/java/com/custom/CustomTransformationFetcher.java
package com.custom;
import com.google.cloud.teleport.v2.spanner.exceptions.InvalidTransformationException;
import com.google.cloud.teleport.v2.spanner.utils.ISpannerMigrationTransformer;
import com.google.cloud.teleport.v2.spanner.utils.MigrationTransformationRequest;
import com.google.cloud.teleport.v2.spanner.utils.MigrationTransformationResponse;
import java.util.HashMap;
import java.util.Map;
public class CustomTransformationFetcher implements ISpannerMigrationTransformer {
@Override
public void init(String customParameters) {}
@Override
public MigrationTransformationResponse toSpannerRow(MigrationTransformationRequest request)
throws InvalidTransformationException {
if (request.getTableName().equals("Orders")) {
Map<String, Object> requestRow = request.getRequestRow();
Map<String, Object> responseRow = new HashMap<>();
Object legacySysObj = requestRow.get("LegacyOrderSystem");
String legacySys = (legacySysObj != null) ? (String) legacySysObj : "UNKNOWN_SYSTEM";
// Transform: Trim the string to remove everything after the first underscore
String orderSource = legacySys;
if (legacySys.contains("_")) {
orderSource = legacySys.substring(0, legacySys.indexOf('_'));
}
// Populate the new Spanner column (e.g., "WebStore_v1" becomes "WebStore")
responseRow.put("OrderSource", orderSource);
return new MigrationTransformationResponse(responseRow, false);
}
return new MigrationTransformationResponse(new HashMap<>(), false);
}
@Override
public MigrationTransformationResponse toSourceRow(MigrationTransformationRequest request)
throws InvalidTransformationException {
if (request.getTableName().equals("Orders")) {
Map<String, Object> requestRow = request.getRequestRow();
Map<String, Object> responseRow = new HashMap<>();
// Safely fetch the Spanner OrderSource
Object sourceObj = requestRow.get("OrderSource");
String source = (sourceObj != null) ? (String) sourceObj : "UNKNOWN_SYSTEM";
String legacySys = "'" + source + "_v1'";
// Transform: Append a suffix to visibly prove the reverse transformation worked
// e.g., "WebStore" becomes "WebStore_v1"
responseRow.put("LegacyOrderSystem", legacySys);
return new MigrationTransformationResponse(responseRow, false);
}
return new MigrationTransformationResponse(new HashMap<>(), false);
}
@Override
public MigrationTransformationResponse transformFailedSpannerMutation(
MigrationTransformationRequest request) throws InvalidTransformationException {
return new MigrationTransformationResponse(new HashMap<>(), false);
}
}
EOF
3. Ters parçalama mantığını yapılandırma
Dataflow, ters çoğaltma sırasında bir Spanner mutasyonunun nereye yönlendirilmesi gerektiğini belirlemek için CustomShardIdFetcher.java kullanır. Kayıtları dinamik olarak doğru mantıksal parçalarına geri yönlendirmek için CustomerId birincil anahtarını ve modulo (%4) mantığını kullanırız.
CustomShardIdFetcher.java dosyasını cat komutunu kullanarak düzenleyin ve içeriğini tamamen aşağıdaki kodla değiştirin:
cat << 'EOF' > src/main/java/com/custom/CustomShardIdFetcher.java
package com.custom;
import com.google.cloud.teleport.v2.spanner.utils.IShardIdFetcher;
import com.google.cloud.teleport.v2.spanner.utils.ShardIdRequest;
import com.google.cloud.teleport.v2.spanner.utils.ShardIdResponse;
import java.util.Map;
public class CustomShardIdFetcher implements IShardIdFetcher {
@Override
public void init(String parameters) {}
@Override
public ShardIdResponse getShardId(ShardIdRequest shardIdRequest) {
Map<String, Object> keys = shardIdRequest.getSpannerRecord
();
// Use the Primary Key to identify the correct logical shard
if (keys != null && keys.containsKey("CustomerId")) {
long customerId = Long.parseLong(keys.get("CustomerId").toString());
long shardIdx = customerId % 4;
ShardIdResponse response = new ShardIdResponse();
response.setLogicalShardId("shard" + shardIdx + "_db");
return response;
}
return new ShardIdResponse();
}
}
EOF
4. JAR'ı oluşturma ve yükleme
Özel Java mantığımız yazıldığına göre, Dataflow'un erişebilmesi için bunu bir JAR dosyası olarak derlememiz ve daha önce oluşturduğumuz Google Cloud Storage paketine yüklememiz gerekiyor.
Cloud Shell'de aşağıdaki komutları çalıştırın:
# Return to DataflowTemplates directory
cd ../..
# Build the JAR using Maven
mvn clean install -DskipTests -Dcheckstyle.skip -Dspotless.check.skip=true -Djib.skip -pl v2/spanner-custom-shard -am
# Upload the JAR to GCS
export CUSTOM_JAR_PATH="gs://${BUCKET_NAME}/custom-logic/spanner-custom-shard-1.0.jar"
gcloud storage cp v2/spanner-custom-shard/target/spanner-custom-shard-1.0-SNAPSHOT.jar $CUSTOM_JAR_PATH
# Return to home directory
cd ~
9. MySQL'den Spanner'a Verileri Toplu Taşıma
Spanner şeması yerinde ve özel dönüşüm JAR'ımız oluşturulduğuna göre artık MySQL veritabanınızdaki mevcut verileri Cloud Spanner'a kopyalayabiliriz. JDBC ile erişilebilen veritabanlarından Spanner'a toplu olarak veri kopyalamak için tasarlanmış Sourcedb to Spanner Dataflow Flex şablonunu kullanacaksınız.
1. Şema geçersiz kılma dosyasını yükleyin
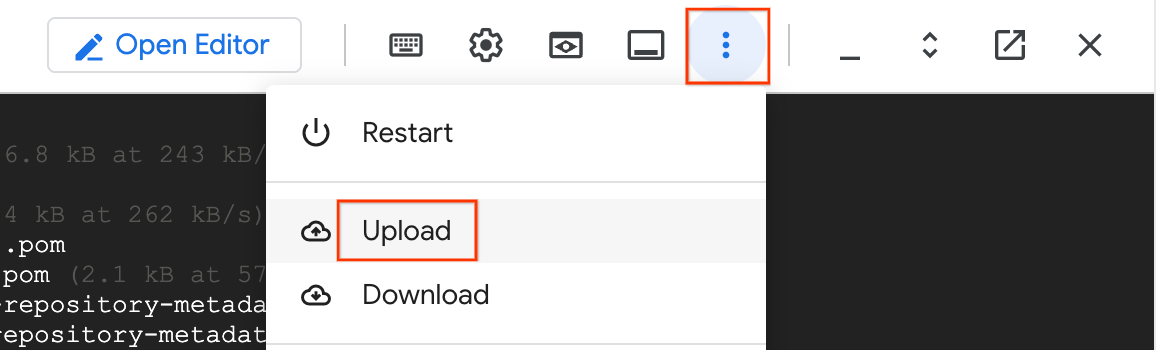
6. bölümde, SMT web kullanıcı arayüzünü kullanarak Spanner Geçersiz Kılmaları JSON dosyasını indirdiniz. Dataflow'un şema farklılıklarını (ör. yeniden adlandırılan sütunlar) eşlemek için kullanabilmesi amacıyla bu dosyayı GCS paketimize yüklememiz gerekir.
- Cloud Shell'inizde üç nokta menüsünü (Diğer) tıklayın ve Yükle'yi seçin.
- Daha önce indirdiğiniz Geçersiz Kılmalar JSON dosyasını (ör.
spanner_overrides.json) seçin. - Dosyayı GCS paketinize taşıyın:
export OVERRIDES_FILE="spanner_overrides.json" # Change this if your downloaded file has a different name
export GCS_OVERRIDES_PATH="gs://${BUCKET_NAME}/config/${OVERRIDES_FILE}"
gcloud storage cp ~/${OVERRIDES_FILE} $GCS_OVERRIDES_PATH
2. Parçalama Yapılandırma Dosyasını Oluşturma ve Yükleme
Dataflow'un, iki fiziksel VM'nizdeki dört mantıksal parçanın tümüne nasıl bağlanacağını bilmesi gerekir. Bunun için bir sharding.json dosyası oluşturacağız.
Yapılandırmayı oluşturup yüklemek için Cloud Shell'de aşağıdaki komutu çalıştırın:
cat <<EOF > sharding.json
{
"configType": "dataflow",
"shardConfigurationBulk": {
"schemaSource": {
"dataShardId": "mysql-physical-1",
"host": "${MYSQL_IP_1}",
"user": "datastream_user",
"password": "complex_password_123",
"port": "3306",
"dbName": "shard0_db"
},
"dataShards": [
{
"dataShardId": "mysql-physical-1",
"host": "${MYSQL_IP_1}",
"user": "datastream_user",
"password": "complex_password_123",
"port": "3306",
"dbName": "",
"namespace": "namespace-mysql-1",
"databases": [
{
"dbName": "shard0_db",
"databaseId": "shard0_db",
"refDataShardId": "mysql-physical-1"
},
{
"dbName": "shard1_db",
"databaseId": "shard1_db",
"refDataShardId": "mysql-physical-1"
}
]
},
{
"dataShardId": "mysql-physical-2",
"host": "${MYSQL_IP_2}",
"user": "datastream_user",
"password": "complex_password_123",
"port": "3306",
"dbName": "",
"namespace": "namespace-mysql-2",
"databases": [
{
"dbName": "shard2_db",
"databaseId": "shard2_db",
"refDataShardId": "mysql-physical-2"
},
{
"dbName": "shard3_db",
"databaseId": "shard3_db",
"refDataShardId": "mysql-physical-2"
}
]
}
]
}
}
EOF
export GCS_SHARDING_PATH="gs://${BUCKET_NAME}/config/sharding.json"
gcloud storage cp sharding.json $GCS_SHARDING_PATH
3. Toplu taşıma Dataflow işini çalıştırma
Sourcedb to Spanner Flex Şablonu'nu kullanacağız. Bu, özel dönüşümler içeren parçalanmış bir taşıma işlemi olduğundan geçersiz kılma dosyası, parçalama yapılandırması ve özel Java JAR'ımızı iletiyoruz.
export JOB_NAME="mysql-sharded-bulk-to-spanner-$(date +%Y%m%d-%H%M%S)"
export OUTPUT_DIR="gs://${BUCKET_NAME}/bulk-migration"
gcloud dataflow flex-template run $JOB_NAME \
--project=$PROJECT_ID \
--region=$REGION \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Sourcedb_to_Spanner_Flex" \
--max-workers=2 \
--num-workers=1 \
--worker-machine-type=n2-highmem-8 \
--parameters \
sourceConfigURL=$GCS_SHARDING_PATH,\
instanceId=$SPANNER_INSTANCE_NAME,\
databaseId=$SPANNER_DATABASE_NAME,\
projectId=$PROJECT_ID,\
outputDirectory=$OUTPUT_DIR,\
username=datastream_user,\
password=complex_password_123,\
schemaOverridesFilePath=$GCS_OVERRIDES_PATH,\
transformationJarPath=$CUSTOM_JAR_PATH,\
transformationClassName=com.custom.CustomTransformationFetcher
Temel Parametreler Açıklaması:
sourceConfigURL: Oluşturduğumuzsharding.jsondosyasının yolu. Bu, Dataflow'a iki fiziksel VM'deki dört mantıksal MySQL parçamızın tümüne nasıl bağlanacağını söyler.schemaOverridesFilePath: SMT web kullanıcı arayüzünden indirdiğimiz JSON dosyasının yolu. Bu, Dataflow'a yaptığımız şema değişikliklerinin (ör. bırakılanLegacyRegionsütunu ve sıkılaştırılan kontrol kısıtlaması) nasıl işleneceği konusunda talimat verir.transformationJarPath: Önceki bölümde oluşturduğumuz derlenmiş Java JAR dosyasının GCS yolu. Bu, özel dönüşümlerimizi yürütmek için gereken gerçek kodu içerir.transformationClassName: İleriye dönük taşıma mantığını (com.custom.CustomTransformationFetcher) uygulayan JAR'ımızdaki Java sınıfının tam nitelikli adı.outputDirectory: Dataflow'un geçici dosyalarını ve en önemlisi de işlenemeyen ileti kuyruğu (DLQ) dosyalarını yazacağı GCS konumu.maxWorkers,numWorkers: Dataflow işinin ölçeklendirmesini kontrol eder. Bu küçük veri kümesi için düşük tutulur.instanceId,databaseId,projectId: Hedef Cloud Spanner örneğini ve veritabanını belirtir.
Ağ Notu: Bu iş, Cloud SQL örneğine genel IP'si üzerinden bağlanır. Bunun nedeni, daha önce 0.0.0.0/0 adresini örneğin Yetkili Ağları'na eklemiş olmanızdır. Bu sayede, harici IP'lere sahip Dataflow çalışan VM'leri veritabanına ulaşabilir.
4. Dataflow işini izleme
İşin ilerleme durumunu Google Cloud Console'da takip edebilirsiniz:
- Dataflow işleri sayfasına gidin: Dataflow işlerine git
mysql-sharded-bulk-to-spanner-...adlı işi bulup tıklayın.- İş grafiğini ve metrikleri inceleyin. İş durumunun Başarılı olarak değişmesini bekleyin. Bu işlem yaklaşık 5-15 dakika sürer.

- İşte sorunlarla karşılaşılırsa hata mesajları için Dataflow işi ayrıntıları sayfasındaki Günlükler sekmesini inceleyin.
- İş Metrikleri, işin ilerleme durumu ve kaynak tüketimi (ör. işleme hızı ve CPU kullanımı) hakkında daha fazla bilgi verir.
5. Cloud Spanner'daki verileri doğrulama ve işlenemeyen ileti kuyruğunu (DLQ) inceleme
Dataflow işi başarıyla tamamlandıktan sonra verilerimizin güvenli bir şekilde geldiğini doğrulamamız ve başarısız olacak şekilde tasarladığımız kayıtları incelememiz gerekir.
C. Taşınan Verilerin Genel Durumunu Doğrulama:
Geçerli kayıtların doğru şekilde taşındığından ve özel JAR'ımızın ek sütunu doldurduğundan emin olmak için birleştirilmiş Spanner veritabanınızda birkaç hızlı durum kontrolü çalıştırmak üzere gcloud CLI'yı kullanın.
# 1. Verify total Customer count
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT COUNT(*) as TotalCustomers FROM Customers"
# 2. Verify total Orders count (Total minus the orphan record)
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT COUNT(*) as TotalOrders FROM Orders"
# 3. Verify the Custom Transformation on OrderSource worked
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT CustomerId, OrderId, OrderSource FROM Orders LIMIT 3"
# 4. Verify that renamed column LoyaltyTier has the correct data
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT CustomerId, CustomerName, LoyaltyTier FROM Customers LIMIT 3"
Beklenen çıkış:
TotalCustomers: 16 TotalOrders: 19 CustomerId: 1 OrderId: 201 OrderSource: MobileApp CustomerId: 2 OrderId: 301 OrderSource: CallCenter CustomerId: 3 OrderId: 401 OrderSource: InStore CustomerId: 1 CustomerName: Agnes N. LoyaltyTier: NORTHEAST CustomerId: 2 CustomerName: Brian K. LoyaltyTier: SOUTHWEST CustomerId: 3 CustomerName: Cathy Z. LoyaltyTier: CENTRAL
- Customers tablosundaki tüm satırlar başarıyla taşındı.
- Spanner'daki
INTERLEAVE IN PARENTnedeniyleOrderstablosunda 1 satır hatası görüyoruz.CustomerId 99,Customerstablosunda karşılık gelen satır olmadığı için bağımsız bir alt öğe.
B. DLQ'daki Amaçlı Hataları Kontrol Edin:
Yukarıdaki hata, toplu taşıma ardışık düzeni tarafından oluşturulan Dead Letter Queue (DLQ) klasöründe belgelenir.
- Google Cloud Console'da Cloud Storage'a gidin.
- Paketinize gidip
bulk-migration/dlq/severeklasörünü açın. - İçindeki JSON dosyalarını inceleyin. Üst öğesi olmayan
CustomerIdileOrderssatırını görürsünüz. - Toplu taşıma DLQ hataları, burada belirtilen adımlar uygulanarak yeniden denenebilir.
Cloud SQL'den Cloud Spanner'a ilk toplu veri yükleme işlemi tamamlandı. Bir sonraki adım, devam eden değişiklikleri yakalamak için canlı replikasyonu ayarlamaktır.
10. Canlı geçişi (CDC) başlatma
Toplu veri yükleme işlemi tamamlandığına göre artık sürekli bir Dataflow akış işi başlatabilirsiniz. Bu iş, Datastream'in GCS paketlerinize yazdığı Değişiklik Verilerini Yakalama (CDC) etkinliklerini okur ve bu değişiklikleri Cloud Spanner'a neredeyse gerçek zamanlı olarak uygular.
Ayrıca, Dataflow'un canlı replikasyonu nasıl işlediğini ve hataları nasıl Dead Letter Queue'ya (DLQ) yönlendirdiğini gözlemlemek için bu ardışık düzeni hem geçerli hem de kasıtlı olarak geçersiz veriler ekleyerek test edeceğiz.
1. Canlı Taşıma Parçalama Yapılandırma Dosyası'nı oluşturma
Toplu geçiş işleminden (JDBC bağlantı dizelerini kullanır) farklı olarak, canlı geçiş ardışık düzeni GCS'den Datastream etkinliklerini okur. Datastream akış adlarını ve veritabanlarını mantıksal Spanner parçalarınıza eşleyen tamamen farklı bir JSON yapılandırması gerekir.
Canlı parçalama yapılandırmasını oluşturup yüklemek için Cloud Shell'de aşağıdaki komutu çalıştırın:
cat <<EOF > live-sharding.json
{
"StreamToDbAndShardMap": {
"${STREAM_NAME_1}": {
"shard0_db": "shard0_db",
"shard1_db": "shard1_db"
},
"${STREAM_NAME_2}": {
"shard2_db": "shard2_db",
"shard3_db": "shard3_db"
}
}
}
EOF
export GCS_LIVE_SHARDING_PATH="gs://${BUCKET_NAME}/config/live-sharding.json"
gcloud storage cp live-sharding.json $GCS_LIVE_SHARDING_PATH
2. Canlı geçiş Dataflow işini çalıştırma
GCS'den okuma yapmak ve Spanner'a yazmak için akış Dataflow işini başlatın. Bu şablon, yeni dosyaları anında işlemek için GCS Pub/Sub bildirimlerini kullanır.
export JOB_NAME_CDC="mysql-sharded-cdc-to-spanner-$(date +%Y%m%d-%H%M%S)"
export DLQ_DIR_CDC="gs://${BUCKET_NAME}/live-migration"
gcloud dataflow flex-template run $JOB_NAME_CDC \
--project=$PROJECT_ID \
--region=$REGION \
--worker-machine-type=n2-highmem-8 \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Cloud_Datastream_to_Spanner" \
--parameters \
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
projectId="$PROJECT_ID",\
inputFileFormat="avro",\
gcsPubSubSubscription="projects/${PROJECT_ID}/subscriptions/${PUBSUB_SUBSCRIPTION}",\
shardingContextFilePath=$GCS_LIVE_SHARDING_PATH,\
deadLetterQueueDirectory="$DLQ_DIR_CDC",\
transformationJarPath=$CUSTOM_JAR_PATH,\
transformationClassName="com.custom.CustomTransformationFetcher",\
schemaOverridesFilePath=$GCS_OVERRIDES_PATH,\
datastreamSourceType="mysql",\
dlqRetryMinutes=1,\
dlqMaxRetryCount=2
Temel Parametreler
gcsPubSubSubscription: GCS'den gelen yeni dosya bildirimlerini dinleyen Pub/Sub aboneliği. Bu sayede, Datastream değişiklikleri yazdıkça işleme alınır.inputFileFormat="avro": Dataflow'a Datastream'den Avro dosyaları beklemesini söyler. Bu, veri akışınızın "Hedef" yapılandırmasıyla eşleşmelidir (ör.avroFileFormatvejsonFileFormat).shardingContextFilePath: Datastream akışlarını mantıksal parçalara eşleyen bir JSON dosyası.dlqRetryMinutes: İşlenemeyen ileti kuyruğu yeniden denemeleri arasındaki süre (dakika). Varsayılan olarak10değerine ayarlanır.dlqMaxRetryCount: Geçici hataların DLQ üzerinden yeniden denenme sayısı üst sınırı. Varsayılan olarak500değerine ayarlanır.
İşin başlatılmasını Dataflow İşleri Konsolu'nda izleyin.
3. Canlı Veri Ekleme ve Amaçlı Hataları Tetikleme
Dataflow akış işi başlatılırken (bu işlem 3-5 dakika sürebilir) ilk fiziksel MySQL VM'mize SSH ile bağlanıp bazı yeni kayıtlar ekleyelim. Bir geçerli kayıt ve bir geçersiz kayıt ekleyeceğiz.
İlk fiziksel parçaya SSH uygulama:
gcloud compute ssh mysql-physical-1 --zone=$ZONE
MySQL'e giriş yapın:
sudo mysql
shard1_db üzerinde aşağıdaki eklemeleri çalıştırın:
USE shard1_db;
-- 1. Valid Insert: 'MobileApp_v2' will be trimmed to 'MobileApp'
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem)
VALUES (4, 501, 99.99, 'MobileApp_v2');
-- 2. Invalid Insert (DLQ Test): This violates Interleave constraint as CustomerId 99999 doesn't exist in Customers table.
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem)
VALUES (99999, 502, 50.00, 'WebStore_v1');
-- 3. Valid Update
UPDATE Orders SET OrderValue = '1500' WHERE CustomerId = 5 AND OrderId = 202;
-- 4. Valid Delete
DELETE FROM Orders WHERE CustomerId = 5 AND OrderId = 203;
EXIT;
Cloud Shell isteminize dönmek için exit tuşuna tekrar basın.
4. Canlı Taşıma Verilerini Doğrulama ve CDC DLQ'yu İnceleme
Veriler eklendikten sonra Datastream, CDC etkinliklerini yakalar ve Dataflow bunları Spanner'a uygulamaya çalışır.
C. Spanner'da Geçerli DML Değişikliklerini Doğrulama
INSERT, UPDATE ve DELETE etkinliklerinin Spanner'a başarıyla ulaştığını ve özel dönüşümün hem ekleme hem de güncelleme işleminde tetiklendiğini doğrulamak için aşağıdaki sorguları çalıştırın.
# 1. Verify INSERT: Should return the new row with transformed OrderSource
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT CustomerId, OrderId, OrderValue, OrderSource FROM Orders WHERE CustomerId = 4 AND OrderId = 501"
# 2. Verify UPDATE: Should show OrderValue changed to 1500
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT CustomerId, OrderId, OrderValue, OrderSource FROM Orders WHERE CustomerId = 5 AND OrderId = 202"
# 3. Verify DELETE: Should return 0, confirming the order was deleted
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT COUNT(*) FROM Orders WHERE CustomerId = 5 AND OrderId = 203"
# 4. Verify DLQ Failure: Should return 0, confirming the row migration failed
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT COUNT(*) FROM Orders WHERE CustomerId = 99999 AND OrderId = 502"
Beklenen çıkış:
CustomerId: 4 OrderId: 501 OrderValue: 99.99 OrderSource: MobileApp CustomerId: 5 OrderId: 202 OrderValue: 1500 OrderSource: WebStore 0 0
Not: Herhangi bir sorgu beklenen sonucu göstermiyorsa akış çalışanları kuyruğu işlemeye devam ediyor olabilir. Bu nedenle, bir dakika bekleyip tekrar deneyin.
B. DLQ'da Amaçlı Hata olup olmadığını kontrol edin:
CustomerId = 99999, Customers tablosunda üst öğeye sahip olmadığından Spanner tarafından reddedilmeli ve Dataflow tarafından DLQ'ya güvenli bir şekilde yönlendirilmelidir.
- Google Cloud Console'da Cloud Storage'a gidin.
- Paketinize gidip
live-migration/dlq/severe/klasörünü açın. - Yeni oluşturulan JSON dosyalarını görürsünüz. İçerikleri incelemek için bunları tıklayın.
CustomerId = 99999ile ilgili ayrıntıları ve belirli Spanner hata mesajını görürsünüz:NOT_FOUND: Parent row for row [99999,502,WebStore] in table Orders is missing. Row cannot be written." - Veri akışı şablonu
runMode=retryDLQayarıyla çalıştırılarak canlı taşıma DLQ hataları yeniden denenebilir.
5. DLQ hatalarını işleme
severe/ dizinindeki hatalar için manuel müdahale gerekir. Veri sorununu düzeltip başarısız olan etkinliği yeniden işleyelim.
C. Kaynakta Verileri Düzeltme
Hata, üst müşteri kaydı CustomerId = 99999 eksik olduğundan oluştu. Şimdi bunu kaynak MySQL veritabanına ekleyelim.
MySQL örneğine tekrar SSH uygulayın:
gcloud compute ssh mysql-physical-1 --zone=$ZONE
sudo mysql kullanarak MySQL'e giriş yapın ve eksik üst satırı shard1_db içine ekleyin:
USE shard1_db;
INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LegacyRegion) VALUES
(99999, 'DLQ Parent Holder', 5000.00, 'NORTH_AMERICA');
EXIT;
Cloud Shell'e dönmek için exit yazın.
B. retryDLQ Dataflow işini çalıştırma
severe/ DLQ'daki etkinlikleri yeniden işlemek için aynı Dataflow şablonunu başlatırsınız ancak bu kez retryDLQ modunda. Bu mod, özellikle deadLetterQueueDirectory/severe yolundan okur, bunları özel dönüşümlerinizden yeniden geçirir ve Spanner'a uygular.
İşi retryDLQ modunda başlatın:
export JOB_NAME_RETRY="mysql-sharded-cdc-retry-$(date +%Y%m%d-%H%M%S)"
gcloud dataflow flex-template run $JOB_NAME_RETRY \
--project=$PROJECT_ID \
--region=$REGION \
--worker-machine-type=n2-highmem-8 \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Cloud_Datastream_to_Spanner" \
--parameters \
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
projectId="$PROJECT_ID",\
runMode="retryDLQ",\
deadLetterQueueDirectory="$DLQ_DIR_CDC",\
datastreamSourceType="mysql",\
transformationJarPath=$CUSTOM_JAR_PATH,\
transformationClassName="com.custom.CustomTransformationFetcher",\
schemaOverridesFilePath=$GCS_OVERRIDES_PATH,\
shardingContextFilePath=$GCS_LIVE_SHARDING_PATH
Yeniden deneme için temel parametre değişiklikleri
runMode="retryDLQ": ŞablonunsevereDLQ dizininden okumasını sağlar.- Kaldırıldı
gcsPubSubSubscription: Canlı Datastream GCS paketinden okuma yapmadığımız için gerekli değil.
Yeniden deneme sürecini izleyin:
Ana CDC ardışık düzeni gibi retryDLQ da manuel olarak iptal edilene kadar RUNNING kalacak bir akış ardışık düzenidir.
$JOB_NAME_RETRYiçin Dataflow işi sayfasına gidin.- Metrikler bölmesinde şu iki sayacı bulun:
elementsReconsumedFromDeadLetterQueue: Hata dosyaları getirilirken değerlendirilir.Successful events: Kayıt Spanner'a yazıldığında artar.- Yinelenen hatalar için
severe/dizinini kontrol edin. - Başarılı etkinlik sayısı, yeniden denemek istediğiniz öğe sayısı kadar arttığında (test durumumuzda 1) bir sonraki doğrulama adımına geçin.
C. Yeniden Denenen Verileri Doğrulama
Başarısız kayıt yeniden denendikten sonra (başarılı olması biraz zaman alabilir) alt satırın başarıyla taşınıp taşınmadığını görmek için Spanner'ı kontrol edin:
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT CustomerId, OrderId, OrderValue, OrderSource FROM Orders WHERE CustomerId = 99999 AND OrderId = 502"
Şimdi satırı görmeniz gerekir:
CustomerId: 99999 OrderId: 502 OrderValue: 50 OrderSource: WebStore
Ayrıca, GCS'deki $DLQ_DIR_CDC/severe/ klasörünü de kontrol edin. İşlenen dosyalar taşınmış veya silinmiş olmalıdır. Bu, yeniden işlemenin başarılı olduğunu gösterir.
11. Tersine Çoğaltmayı Ayarlama (Spanner'dan MySQL'e)
Geri alma veya geçiş dönemi boyunca orijinal MySQL veritabanını Spanner ile senkronize tutma gibi senaryoları ele almak için ters çoğaltma ayarlayabilirsiniz.
Bu ardışık düzen, Spanner'daki canlı değişiklikleri yakalamak için Spanner Değişiklik Akışlarını kullanır. Ardından, şema farklılıklarını tersine eşlemek için Özel Dönüşüm JAR'ımızı, güncellemenin tam olarak hangi fiziksel MySQL VM'sine ve mantıksal parçasına geri yazılması gerektiğini hesaplamak için de Özel Parçalama JAR'ımızı kullanır.
1. Spanner değişiklik akışı oluşturma
Öncelikle, Customers ve Orders tablolarındaki değişiklikleri izlemek için Spanner veritabanınızda bir değişiklik akışı oluşturmanız gerekir.
export CHANGE_STREAM_NAME="CustomersOrdersChangeStream"
gcloud spanner databases ddl update $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--ddl="CREATE CHANGE STREAM $CHANGE_STREAM_NAME FOR Customers, Orders"
Bu değişiklik akışı artık belirtilen tablolarda yapılan tüm veri değişikliklerini kaydeder.
2. Dataflow meta verileri için Spanner veritabanı oluşturma
Spanner to SourceDB Dataflow şablonu, değişiklik akışı tüketimini yönetmek için meta verileri depolamak üzere ayrı bir Spanner veritabanı gerektirir.
export SPANNER_METADATA_DB_NAME="migration-metadata-db"
gcloud spanner databases create $SPANNER_METADATA_DB_NAME \
--instance=$SPANNER_INSTANCE_NAME
3. Dataflow için Cloud SQL bağlantı yapılandırmasını hazırlama
Dataflow şablonu, hedef Cloud SQL veritabanının bağlantı ayrıntılarını içeren bir Cloud Storage JSON dosyasına ihtiyaç duyar.
shard_config.json adlı bir yerel dosya oluşturun:
cat <<EOF > reverse-sharding.json
[
{
"logicalShardId": "shard0_db",
"host": "${MYSQL_IP_1}",
"port": "3306",
"user": "datastream_user",
"password": "complex_password_123",
"dbName": "shard0_db"
},
{
"logicalShardId": "shard1_db",
"host": "${MYSQL_IP_1}",
"port": "3306",
"user": "datastream_user",
"password": "complex_password_123",
"dbName": "shard1_db"
},
{
"logicalShardId": "shard2_db",
"host": "${MYSQL_IP_2}",
"port": "3306",
"user": "datastream_user",
"password": "complex_password_123",
"dbName": "shard2_db"
},
{
"logicalShardId": "shard3_db",
"host": "${MYSQL_IP_2}",
"port": "3306",
"user": "datastream_user",
"password": "complex_password_123",
"dbName": "shard3_db"
}
]
EOF
Bu dosyayı GCS paketinize yükleyin:
export GCS_REVERSE_SHARDING_PATH="gs://${BUCKET_NAME}/config/reverse-sharding.json"
gcloud storage cp reverse-sharding.json $GCS_REVERSE_SHARDING_PATH
4. Ters Çoğaltma Dataflow İşini Çalıştırma
Spanner_to_SourceDb Flex şablonunu kullanarak Dataflow işini başlatın.
export JOB_NAME_REVERSE="spanner-sharded-reverse-to-mysql-$(date +%Y%m%d-%H%M%S)"
export DLQ_DIR_REVERSE="gs://${BUCKET_NAME}/reverse-replication"
gcloud dataflow flex-template run $JOB_NAME_REVERSE \
--project=$PROJECT_ID \
--region=$REGION \
--worker-machine-type=n2-highmem-8 \
--max-workers=2 \
--num-workers=1 \
--additional-experiments=use_runner_v2 \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Spanner_to_SourceDb" \
--parameters \
changeStreamName="$CHANGE_STREAM_NAME",\
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
spannerProjectId="$PROJECT_ID",\
metadataInstance="$SPANNER_INSTANCE_NAME",\
metadataDatabase="$SPANNER_METADATA_DB_NAME",\
sourceShardsFilePath="$GCS_REVERSE_SHARDING_PATH",\
transformationJarPath=$CUSTOM_JAR_PATH,\
transformationClassName="com.custom.CustomTransformationFetcher",\
shardingCustomJarPath=$CUSTOM_JAR_PATH,\
shardingCustomClassName="com.custom.CustomShardIdFetcher",\
schemaOverridesFilePath=$GCS_OVERRIDES_PATH,\
deadLetterQueueDirectory=$DLQ_DIR_REVERSE
Temel Parametreler
changeStreamName: Okunacak Spanner değişiklik akışının adı.metadataInstance, metadataDatabase: Bağlayıcı tarafından değişiklik akışı API verilerinin kullanımını kontrol etmek için kullanılan meta verileri depolayan Spanner örneği/veritabanı.sourceShardsFilePath:shard_config.jsondosyanızın GCS yolu.filtrationMode: Belirli kayıtların bir ölçüte göre nasıl bırakılacağını belirtir. Varsayılan olarakforward_migration(ileri taşıma ardışık düzeni kullanılarak yazılan kayıtları filtrele)shardingCustomJarPath: Daha önce oluşturduğumuz derlenmiş Java JAR dosyasının GCS yolu.shardingCustomClassName: Kaydı hangi mantıksal parçanın alacağını dinamik olarak belirlemek için özel%4modulo matematik işlemini yürüten tam nitelikli sınıf adı (com.custom.CustomShardIdFetcher).
Ağ Notu: Dataflow çalışanları, shard_config.json içinde belirtilen herkese açık IP'yi kullanarak Cloud SQL örneğine bağlanır. Bu bağlantıya, Cloud SQL örneğinin Yetkili Ağlar bölümündeki 0.0.0.0/0 girişi nedeniyle izin verilir.
İşin başlatılmasını Dataflow İşleri Konsolu'nda izleyin.
5. Spanner verileri ekleme ve kasıtlı hataları tetikleme
Dataflow işinin Running durumuna geçmesini bekleyin (bu işlem yaklaşık 5 dakika sürebilir). Ardından, ters DLQ'yu test etmek için kasıtlı bir hata ile birlikte doğrudan Spanner'da tam bir sorgu paketi (INSERT, UPDATE, DELETE) yürütelim.
Cloud Shell'de aşağıdaki komut satırını çalıştırın:
# All these operations are done on rows mapping to shard0_db for convenience
# Valid INSERT: Insert parent row in Customers
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LoyaltyTier) VALUES (88, 'Reverse Tester', 5000, 'GOLD_TIER')"
# 1. Valid INSERT (Orders): 'WebStore' transformed to 'WebStore_v1'
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="INSERT INTO Orders (CustomerId, OrderId, OrderValue, OrderSource) VALUES (88, 9001, 150.00, 'WebStore')"
# 2. Valid UPDATE (Orders)
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="UPDATE Orders SET OrderValue = 200.00 WHERE CustomerId = 16 AND OrderId = 105 AND OrderSource = 'Partner'"
# 3. Valid DELETE (Orders)
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="DELETE FROM Orders WHERE CustomerId = 12 AND OrderId = 104 AND OrderSource = 'WebStore'"
# 4. INVALID Insert- DLQ Test: CreditLimit=500 will fail check constraint of >1000 at source
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LoyaltyTier) VALUES (44, 'DLQ Test Customer', 500, 'GOLD_TIER')"
6. Ters Çoğaltma Verilerini Doğrulama ve DLQ'yu İnceleme
İlk fiziksel sanal makinemizde Custom Sharding JAR'ımızın CustomerId 88 öğesini shard0_db öğesine başarıyla yönlendirdiğini ve Custom Transformation JAR'ımızın "_TIER" öğesini bölgeden başarıyla kaldırdığını doğrulayalım.
C. MySQL'de Geçerli Kaydı Doğrulama:
İlk fiziksel parçaya SSH uygulama:
gcloud compute ssh mysql-physical-1 --zone=$ZONE
MySQL'e giriş yapın ve shard0_db sorgusunu çalıştırın:
sudo mysql
USE shard0_db;
-- 1. Verify INSERT: Row migrated with transformed LegacyOrderSystem
SELECT CustomerId, OrderId, OrderValue, LegacyOrderSystem
FROM Orders
WHERE CustomerId = 88 AND OrderId = 9001;
-- 2. Verify UPDATE: The OrderValue should now be updated to 200.00.
SELECT CustomerId, OrderId, OrderValue, LegacyOrderSystem
FROM Orders
WHERE CustomerId = 16 AND OrderId = 105;
-- 3. Verify DELETE: Returns 0 rows, confirming the order was successfully deleted from MySQL.
SELECT CustomerId, OrderId
FROM Orders
WHERE CustomerId = 12 AND OrderId = 104;
-- 4. Verify failed replication - this should be in DLQ as CreditLimit < 1000 and will fail stricter check constraint at source
SELECT CustomerId, CustomerName, CreditLimit, LegacyRegion
FROM Customers
WHERE CustomerId = 44;
EXIT;
Cloud SQL'deki beklenen çıkış, Spanner'da yapılan değişiklikleri yansıtmalıdır.
+------------+---------+------------+-------------------+ | CustomerId | OrderId | OrderValue | LegacyOrderSystem | +------------+---------+------------+-------------------+ | 88 | 9001 | 150.00 | Webstore_v1 | +------------+---------+------------+-------------------+ +------------+---------+------------+-------------------+ | CustomerId | OrderId | OrderValue | LegacyOrderSystem | +------------+---------+------------+-------------------+ | 16 | 105 | 200.00 | Partner_v1 | +------------+---------+------------+-------------------+ Empty set (0.00 sec) Empty set (0.00 sec)
Tür
exit
Cloud Shell'e dönmek için.
Bu, ters replika ardışık düzeninin çalıştığını ve Spanner'daki değişiklikleri Cloud SQL'e geri senkronize ettiğini doğrular.
B. DLQ'da Amaçlı Hata Olup Olmadığını Kontrol Etme
Yeni Customers kaydımızın 500 CreditLimit değeri (kaynak MySQL veritabanımızda tanımladığımız katı > 1000 kontrol kısıtlamasını ihlal ediyor) olduğundan Dataflow hatayı güvenli bir şekilde yakaladı.
- Google Cloud Console'da Cloud Storage'a gidin.
- Paketinize gidip
dlq/severe/klasörünü açın. - Reddedilen
Customerskaydını ve tam olarak hangi kontrol kısıtlaması ihlali hatasının oluştuğunu görmek için JSON dosyasını açın. - Ters çoğaltma DLQ hataları,
runMode=retryDLQayarlanmış veri akışı şablonu çalıştırılarak yeniden denenebilir.
12. Kaynakları Temizleme
Google Cloud hesabınızın daha fazla ücretlendirilmesini önlemek için bu codelab sırasında oluşturulan kaynakları silin.
Ortam değişkenlerini ayarlama (gerekirse)
Cloud Shell oturumunuzun zaman aşımına uğraması veya yeni bir terminal açmanız durumunda, temizleme komutlarını çalıştırmadan önce ortam değişkenlerinizi yeniden dışa aktarmanız gerekir.
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1" # Or your preferred region
export ZONE="us-central1-a" # Or a zone within your selected region
export SPANNER_INSTANCE_NAME="target-spanner-instance"
export SPANNER_DATABASE_NAME="sharded-target-db"
export SPANNER_CONFIG="regional-${REGION}"
export BUCKET_NAME="migration-${PROJECT_ID}-bucket"
export MYSQL_IP_1=$(gcloud compute instances describe mysql-physical-1 --zone=$ZONE --format='get(networkInterfaces[0].accessConfigs[0].natIP)')
export MYSQL_IP_2=$(gcloud compute instances describe mysql-physical-2 --zone=$ZONE --format='get(networkInterfaces[0].accessConfigs[0].natIP)')
export SQL_CP_NAME_1="mysql-src-cp-1"
export SQL_CP_NAME_2="mysql-src-cp-2"
export GCS_CP_NAME="gcs-dest-cp"
export STREAM_NAME_1="mysql-to-spanner-stream-1"
export GCS_STREAM_PATH_1="data/${STREAM_NAME_1}"
export STREAM_NAME_2="mysql-to-spanner-stream-2"
export GCS_STREAM_PATH_2="data/${STREAM_NAME_2}"
export PUBSUB_TOPIC="datastream-gcs-updates"
export PUBSUB_SUBSCRIPTION="datastream-gcs-sub"
export CUSTOM_JAR_PATH="gs://${BUCKET_NAME}/custom-logic/spanner-custom-shard-1.0.jar"
export OVERRIDES_FILE="spanner_overrides.json"
export GCS_OVERRIDES_PATH="gs://${BUCKET_NAME}/config/${OVERRIDES_FILE}"
export GCS_SHARDING_PATH="gs://${BUCKET_NAME}/config/sharding.json"
export OUTPUT_DIR="gs://${BUCKET_NAME}/bulk-migration"
export GCS_LIVE_SHARDING_PATH="gs://${BUCKET_NAME}/config/live-sharding.json"
export DLQ_DIR_CDC="gs://${BUCKET_NAME}/live-migration"
export CHANGE_STREAM_NAME="CustomersOrdersChangeStream"
export SPANNER_METADATA_DB_NAME="migration-metadata-db"
export GCS_REVERSE_SHARDING_PATH="gs://${BUCKET_NAME}/config/reverse-sharding.json"
export DLQ_DIR_REVERSE="gs://${BUCKET_NAME}/reverse-replication"
Dataflow akış işlerini durdurma
Çalışan Dataflow işlerinin iş kimliklerini bulmak için işlerinizi listeleyin. JOB_ID_CDC ve JOB_ID_REVERSE öğelerini buna göre dışa aktarın.
gcloud dataflow jobs list --region=$REGION --filter="state=Running"
export JOB_ID_CDC=<PASTE_JOB_ID_HERE>
export JOB_ID_CDC_RETRY=<PASTE_JOB_ID_HERE>
export JOB_ID_REVERSE=<PASTE_JOB_ID_HERE>
Datastream to Spanner (Canlı Taşıma) işini ve yeniden deneme işini iptal edin:
gcloud dataflow jobs cancel $JOB_ID_CDC --region=$REGION --project=$PROJECT_ID
gcloud dataflow jobs cancel $JOB_ID_CDC_RETRY --region=$REGION --project=$PROJECT_ID
Spanner to Cloud SQL (Ters Çoğaltma) işini iptal etme:
gcloud dataflow jobs cancel $JOB_ID_REVERSE --region=$REGION --project=$PROJECT_ID
Veri akışı kaynaklarını silme
Akışı durdurup silme:
gcloud datastream streams update $STREAM_NAME_1 \
--location=$REGION --state=PAUSED --project=$PROJECT_ID
# Wait a moment for the stream to pause
gcloud datastream streams delete $STREAM_NAME_1 \
--location=$REGION --project=$PROJECT_ID --quiet
gcloud datastream streams update $STREAM_NAME_2 \
--location=$REGION --state=PAUSED --project=$PROJECT_ID
# Wait a moment for the stream to pause
gcloud datastream streams delete $STREAM_NAME_2 \
--location=$REGION --project=$PROJECT_ID --quiet
# Delete Connection Profiles
gcloud datastream connection-profiles delete $SQL_CP_NAME_1 \
--location=$REGION --project=$PROJECT_ID --quiet
gcloud datastream connection-profiles delete $SQL_CP_NAME_2 \
--location=$REGION --project=$PROJECT_ID --quiet
gcloud datastream connection-profiles delete $GCS_CP_NAME \
--location=$REGION --project=$PROJECT_ID --quiet
Kaynak MySQL sanal makinelerini (Compute Engine) silin.
Şirket içi MySQL fiziksel parçalarını simüle eden iki Compute Engine örneğini silin.
gcloud compute instances delete mysql-physical-1 mysql-physical-2 --zone=$ZONE --quiet
Güvenlik duvarı kurallarını silme
Sanal makinelerinize SSH erişimine ve DataStream bağlantısına izin vermek için oluşturulan ağ güvenlik duvarı kurallarını kaldırın. (Not: Codelab'in önceki bölümlerinde güvenlik duvarı kurallarınız için farklı adlar kullandıysanız bunları burada ayarlayın.)
gcloud compute firewall-rules delete allow-ssh-iap --quiet
gcloud compute firewall-rules delete allow-mysql-datastream --quiet
Pub/Sub kaynaklarını silme
Aboneliği silme:
gcloud pubsub subscriptions delete $PUBSUB_SUBSCRIPTION \
--project=$PROJECT_ID --quiet
Konuyu silme:
gcloud pubsub topics delete $PUBSUB_TOPIC \
--project=$PROJECT_ID --quiet
Cloud Spanner örneğini silme
Cloud Spanner örneğini silin (bu işlem, içindeki hem sharded-target-db hem de migration-metadata-db veritabanlarını otomatik olarak siler).
gcloud spanner instances delete $SPANNER_INSTANCE_NAME \
--project=$PROJECT_ID --quiet
GCS Paketi ve İçeriğini Silme
Son olarak, DataStream dosyalarını, Dataflow yapılandırmalarını ve işlenemeyen ileti kuyruklarını içeren Cloud Storage paketini silin. rm -r komutu, paketi ve tüm içeriklerini yinelemeli olarak siler.
gcloud storage rm --recursive gs://${BUCKET_NAME}
Yerel Cloud Shell Dosyalarını Silme
Bu codelab sırasında Cloud Shell'inizde oluşturulan yerel dosya ve dizinleri temizlemek için aşağıdaki komutları çalıştırın:
# Remove the JSON configuration files
rm -f sharding.json live-sharding.json reverse-sharding.json spanner_overrides.json
# Remove the cloned Google Cloud DataflowTemplates repository
rm -rf DataflowTemplates