
1. Zanim zaczniesz
To ćwiczenie prowadzi użytkowników przez proces migracji rozproszonej bazy danych MySQL z lokalnego serwera do bazy danych Cloud Spanner z dialektem GoogleSQL. Będziesz korzystać z usług Google Cloud, w tym z narzędzia do migracji Spanner (SMT), Dataflow, Datastream, PubSub i Google Cloud Storage.
Czego się dowiesz:
- Czym jest środowisko podzielone na partycje i jak je skonfigurować.
- Jak za pomocą interfejsu internetowego narzędzia do migracji usługi Spanner (SMT) przekonwertować schemat MySQL na schemat zgodny z usługą Spanner i wprowadzić zaawansowane modyfikacje schematu.
- Jak przeprowadzić migrację zbiorczą danych z podzielonej na partycje instancji MySQL do Cloud Spanner za pomocą Dataflow.
- Jak skonfigurować ciągłą replikację (CDC) z rozproszonej instancji MySQL do Cloud Spanner za pomocą Datastream i Dataflow.
- Jak skonfigurować replikację zwrotną ze Spannera z powrotem do instancji MySQL z podziałem na fragmenty.
- Jak używać niestandardowych przekształceń do wypełniania dodatkowych kolumn podczas migracji zbiorczych, na żywo i odwrotnych.
- Jak skonfigurować przekształcenia dzielenia na partycje za pomocą kluczy podstawowych.
Czego nie obejmuje to ćwiczenie:
- Zaawansowane sieci niestandardowe.
- tworzenie niestandardowych szablonów Dataflow od podstaw;
- Dostrajanie wydajności migracji.
- Migracja aplikacji: ten przewodnik skupia się na warstwie bazy danych (schemat i dane). Nie obejmuje to procesu operacyjnego ponownego wdrażania ani migracji usług aplikacji.
Czego potrzebujesz
- Projekt Google Cloud z włączonymi płatnościami.
- Wystarczające uprawnienia IAM do włączania interfejsów API oraz tworzenia zasobów Spanner, Dataflow, Datastream i GCS oraz zarządzania nimi. Rola Projekt
Ownerjest najprostsza w przypadku laboratorium, ale bardziej szczegółowe role zostaną omówione w sekcji „Konfiguracja środowiska”. - W fazie konfiguracji udostępnimy małą maszynę wirtualną Compute Engine, aby zasymulować serwer lokalny. Sprawdź, czy limit projektu umożliwia utworzenie maszyny wirtualnej.
- przeglądarkę, np. Google Chrome;
- Podstawowa znajomość konsoli Google Cloud i narzędzi wiersza poleceń, takich jak
gcloud. - Dostęp do środowiska powłoki. Zalecamy korzystanie z Cloud Shell, ponieważ zawiera ona
gcloud.
Więcej informacji o powyższej konfiguracji znajdziesz w sekcji Konfigurowanie środowiska.
2. Omówienie procesu migracji
Migracja bazy danych z podziałem na fragmenty polega na skonsolidowaniu wielu fizycznych i logicznych instancji MySQL w jedną, skalowalną w poziomie bazę danych Spanner. W tej sekcji opisujemy architekturę i najważniejsze narzędzia używane podczas migracji.
Architektura procesu migracji
Proces migracji obejmuje te etapy:
1. Konwersja schematu:
- Cel: przekonwertowanie schematu źródłowej bazy danych na zgodny schemat Cloud Spanner.
- Narzędzie: narzędzie do migracji usługi Spanner (SMT)
- Proces: SMT analizuje schemat źródłowej bazy danych i generuje odpowiedni język definiowania danych (DDL) w Spannerze. W docelowej instancji Spanner zostanie utworzona baza danych, a następnie automatycznie zastosowany DDL.
2. Migracja danych zbiorczych:
- Cel: przeprowadzenie wstępnego, pełnego wczytania istniejących danych ze źródłowej bazy danych do udostępnionych tabel Spanner.
- Narzędzie: Dataflow z użyciem dostarczonego przez Google
Sourcedb to Spannerszablonu. - Proces: to zadanie Dataflow odczytuje wszystkie dane z określonych tabel źródłowych i zapisuje je w odpowiednich tabelach Spannera. Odbywa się to po utworzeniu schematu Spanner.
3. Migracja na żywo (CDC):
- Cel: rejestrowanie i stosowanie bieżących zmian z bazy danych źródłowej w Cloud Spanner w czasie zbliżonym do rzeczywistego, co minimalizuje czas przestoju podczas migracji.
- Narzędzia:
- Datastream: przechwytuje zmiany (wstawienia, aktualizacje, usunięcia) ze źródłowej bazy danych i zapisuje je w Cloud Storage (GCS).
- Dataflow: Używa szablonu
Datastream to Spannerdo odczytywania zdarzeń zmiany z GCS i stosowania ich w Cloud Spanner.
4. Replikacja odwrotna:
- Cel: replikowanie zmian danych z Cloud Spanner z powrotem do źródłowej bazy danych. Może to być przydatne w przypadku strategii rezerwowych, migracji etapowych lub utrzymywania repliki w źródle w określonych przypadkach użycia.
- Narzędzie: Dataflow, przy użyciu
Spanner to SourceDbszablonu. - Proces: to zadanie wykorzystuje strumienie zmian w usłudze Spanner do rejestrowania modyfikacji w usłudze Spanner i zapisywania ich z powrotem w instancji źródłowej bazy danych.
Ten diagram przedstawia komponenty i przepływ danych:

Kluczowe terminy:
- Fizyczny fragment: rzeczywisty serwer lub instancja obliczeniowa hostująca bazę danych (w naszym przypadku symulowana lokalna maszyna wirtualna GCE).
- Partycja logiczna: pojedynczy schemat bazy danych na serwerze fizycznym.
- Maszyna wirtualna Compute Engine (GCE): maszyna wirtualna hostowana w infrastrukturze w chmurze Google Cloud. W tym ćwiczeniu używamy maszyny wirtualnej GCE do symulowania samodzielnego serwera typu bare metal „on-premise”, na którym znajduje się źródłowa baza danych MySQL.
- Narzędzie do migracji Spanner (SMT): narzędzie służące do oceny schematów MySQL, sugerowania odpowiedników schematów Spanner i generowania języka definiowania danych (DDL) Spanner.
- Język definiowania danych (DDL): instrukcje używane do definiowania i modyfikowania struktury bazy danych, np. instrukcje
CREATE TABLE. SMT generuje kod DDL Spanner na podstawie schematu Cloud SQL. - Dataflow: w pełni zarządzana, bezserwerowa usługa przetwarzania danych. W tym ćwiczeniu jest on używany do uruchamiania udostępnionych przez Google szablonów do przenoszenia danych zbiorczych, stosowania zmian w Datastream i replikacji zwrotnej.
- Datastream: bezserwerowa usługa do replikacji i przechwytywania zmian danych (CDC). W tym ćwiczeniu służy do przesyłania strumieniowego zmian z lokalnie hostowanej instancji MySQL do Cloud Storage.
- Strumienie zmian w usłudze Spanner: funkcja Spannera, która umożliwia strumieniowe przesyłanie zmian danych (wstawień, aktualizacji i usunięć) w czasie rzeczywistym. Jest używana jako źródło replikacji zwrotnej.
- Pub/Sub: usługa do przesyłania wiadomości, która służy do oddzielania usług generujących zdarzenia od usług, które je przetwarzają. W tym laboratorium kodowym wywołuje Dataflow do przetwarzania aktualizacji za każdym razem, gdy Datastream przesyła nowe pliki zmian do Cloud Storage.
3. Konfiguracja środowiska
Zanim rozpoczniesz migrację, musisz skonfigurować projekt Google Cloud i włączyć niezbędne usługi.
1. Wybieranie lub tworzenie projektu Google Cloud
Aby korzystać z usług w tym ćwiczeniu, musisz mieć projekt Google Cloud z włączonym rozliczeniem.
- W konsoli Google Cloud otwórz stronę selektora projektów: Otwórz selektor projektów
- Wybierz lub utwórz projekt w chmurze Google.
- Sprawdź, czy w projekcie włączone są płatności. Dowiedz się, jak sprawdzić, czy w projekcie włączone są płatności.
2. Otwieranie Cloud Shell
Cloud Shell to środowisko wiersza poleceń działające w Google Cloud, które zawiera zainstalowany interfejs gcloud i inne potrzebne narzędzia.
- W prawym górnym rogu konsoli Google Cloud kliknij przycisk Aktywuj Cloud Shell.
- Sesja Cloud Shell otworzy się w nowej ramce u dołu konsoli. Zostanie również wyświetlony monit wiersza poleceń.

3. Ustawianie zmiennych projektu i środowiska
W Cloud Shell skonfiguruj zmienne środowiskowe dla identyfikatora projektu i regionu, którego będziesz używać.
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1" # Or your preferred region
export ZONE="us-central1-a" # Or a zone within your selected region
gcloud config set project $PROJECT_ID
gcloud config set compute/region $REGION
gcloud config set compute/zone $ZONE
echo "Project ID: $PROJECT_ID"
echo "Region: $REGION"
echo "Zone: $ZONE"
4. Włączanie wymaganych interfejsów Google Cloud API
Włącz interfejsy API niezbędne do korzystania z Cloud Spanner, Dataflow, Datastream i innych powiązanych usług.
gcloud services enable \
spanner.googleapis.com \
dataflow.googleapis.com \
datastream.googleapis.com \
pubsub.googleapis.com \
storage.googleapis.com \
compute.googleapis.com \
sqladmin.googleapis.com \
servicenetworking.googleapis.com \
cloudresourcemanager.googleapis.com
Wykonanie tego polecenia może potrwać kilka minut.
4. Konfigurowanie źródłowej bazy danych MySQL
W tej sekcji zasymulujemy lokalną architekturę MySQL z podziałem na fragmenty, udostępniając 2 maszyny wirtualne Compute Engine (nasze 2 „fizyczne fragmenty”). Następnie zainstalujemy na obu maszynach wirtualnych MySQL i utworzymy na każdej z nich 2 bazy danych (nasze „fragmenty logiczne”).
1. Tworzenie maszyn wirtualnych Compute Engine (fragmentów fizycznych)
Aby utworzyć 2 maszyny wirtualne z Ubuntu, uruchom w Cloud Shell te polecenia: Przypiszemy im tagi sieciowe, aby później zezwolić na ruch przychodzący MySQL.
# Create Physical Shard 1
gcloud compute instances create mysql-physical-1 \
--zone=$ZONE \
--machine-type=e2-small \
--image-family=ubuntu-2204-lts \
--image-project=ubuntu-os-cloud \
--tags=mysql-server
# Create Physical Shard 2
gcloud compute instances create mysql-physical-2 \
--zone=$ZONE \
--machine-type=e2-small \
--image-family=ubuntu-2204-lts \
--image-project=ubuntu-os-cloud \
--tags=mysql-server
2. Konfigurowanie reguł zapory sieciowej
Aby umożliwić bezpieczny dostęp przez SSH bez narażania się na zagrożenia publiczne i włączyć łączność Datastream:
Utwórz regułę zapory sieciowej dla SSH przez IAP:
Ta reguła umożliwia Identity-Aware Proxy dostęp do maszyn wirtualnych na porcie SSH (22).
gcloud compute firewall-rules create allow-ssh-iap \
--direction=INGRESS \
--priority=1000 \
--network=default \
--action=ALLOW \
--rules=tcp:22 \
--source-ranges=35.235.240.0/20 \
--target-tags=mysql-server
Utwórz regułę zapory sieciowej dla Datastream (port MySQL):
Datastream musi mieć możliwość uzyskania dostępu do tych maszyn wirtualnych na standardowym porcie MySQL (3306).
gcloud compute firewall-rules create allow-mysql-datastream \
--direction=INGRESS \
--priority=1000 \
--network=default \
--action=ALLOW \
--rules=tcp:3306 \
--source-ranges=0.0.0.0/0 \
--target-tags=mysql-server
3. Instalowanie i konfigurowanie MySQL na fizycznym fragmencie 1
Połącz się przez SSH z pierwszą maszyną wirtualną, aby zainstalować MySQL i skonfigurować logowanie binarne (które jest wymagane przez Datastream do replikacji na żywo).
- Połącz się z pierwszą maszyną wirtualną przez SSH:
gcloud compute ssh mysql-physical-1 --zone=$ZONE --tunnel-through-iap
- Zainstaluj MySQL:
sudo apt-get update
sudo apt-get install mysql-server-8.0 -y
# Verify the installation and version
sudo mysql --version
- Skonfiguruj plik
mysqld.cnf, aby włączyć logowanie binarne i zezwolić na połączenia zewnętrzne:
sudo sed -i 's/bind-address.*/bind-address = 0.0.0.0/' /etc/mysql/mysql.conf.d/mysqld.cnf
echo -e "[mysqld]\nserver-id=1\nlog_bin=/var/log/mysql/mysql-bin.log\nbinlog_format=ROW" | sudo tee -a /etc/mysql/mysql.conf.d/mysqld.cnf
- Ponownie uruchom MySQL, aby zastosować zmiany:
sudo systemctl restart mysql
4. Tworzenie fragmentów logicznych, wstawianie danych i tworzenie użytkownika Datastream (fragment 1)
Połącz się przez SSH z mysql-physical-1 i zaloguj się w wierszu poleceń MySQL:
sudo mysql
Uruchom te polecenia SQL. Ten skrypt tworzy 2 osobne logiczne fragmenty (shard0_db i shard1_db), konfiguruje w nich identyczny schemat, wstawia do każdego z nich jednoznacznie identyfikowalne dane (aby zademonstrować fragmentację) i tworzy użytkownika replikacji dla Datastream.
Aby utworzyć pierwsze 2 fragmenty logiczne, tabelę i użytkownika replikacji dla Datastream, uruchom te polecenia SQL:
CREATE DATABASE shard0_db;
CREATE DATABASE shard1_db;
USE shard0_db;
CREATE TABLE Customers (
CustomerId INT NOT NULL,
CustomerName VARCHAR(255),
CreditLimit DECIMAL(10, 2) NOT NULL,
LegacyRegion VARCHAR(50), -- Renamed to LoyaltyTier in Spanner
PRIMARY KEY (CustomerId),
CONSTRAINT CHK_CreditLimit CHECK (CreditLimit > 1000) -- Relaxed in Spanner to > 0
);
CREATE TABLE Orders (
CustomerId INT NOT NULL, -- Logically references Customers.CustomerId in Spanner
OrderId INT NOT NULL,
OrderValue DECIMAL(10, 2),
LegacyOrderSystem VARCHAR(50), -- Extra column in Source, to be dropped in Spanner
PRIMARY KEY (CustomerId, OrderId) -- Spanner PK will have one additional column in PK
);
INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LegacyRegion) VALUES
(4, 'David E.', 2000.00, 'EAST'),
(8, 'Eleanor F.', 8100.00, 'WEST'),
(12, 'Frank G.', 12000.00, 'NORTH'),
(16, 'Grace H.', 6500.00, 'SOUTH');
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem) VALUES
(4, 101, 150.00, 'WebStore_v1'),
(4, 102, 25.50, 'InStore_POS'),
(8, 103, 75.00, 'MobileApp_Legacy'),
(12, 104, 3000.00, 'WebStore_v1'),
(16, 105, 120.00, 'Partner_API');
USE shard1_db;
CREATE TABLE Customers (
CustomerId INT NOT NULL,
CustomerName VARCHAR(255),
CreditLimit DECIMAL(10, 2) NOT NULL,
LegacyRegion VARCHAR(50), -- Renamed to LoyaltyTier in Spanner
PRIMARY KEY (CustomerId),
CONSTRAINT CHK_CreditLimit CHECK (CreditLimit > 1000) -- Relaxed in Spanner to > 0
);
CREATE TABLE Orders (
CustomerId INT NOT NULL, -- Logically references Customers.CustomerId in Spanner
OrderId INT NOT NULL,
OrderValue DECIMAL(10, 2),
LegacyOrderSystem VARCHAR(50), -- Extra column in Source, to be dropped in Spanner
PRIMARY KEY (CustomerId, OrderId) -- Spanner PK will have one additional column in PK
);
INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LegacyRegion) VALUES
(1, 'Agnes N.', 5100.00, 'NORTHEAST'),(5, 'Alice I.', 15000.00, 'EAST'),
(9, 'Bob J.', 7500.00, 'WEST'),
(13, 'Charlie K.', 2200.00, 'CENTRAL');
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem) VALUES
(1, 201, 50.00, 'MobileApp_Legacy'),
(5, 202, 1250.00, 'WebStore_v1'),
(5, 203, 80.00, 'Partner_API'),
(9, 204, 600.00, 'InStore_POS'),
(13, 205, 199.99, 'WebStore_v1');
-- Create Datastream Replication User
CREATE USER 'datastream_user'@'%' IDENTIFIED BY 'complex_password_123';
GRANT REPLICATION SLAVE, REPLICATION CLIENT, SELECT, INSERT, UPDATE, DELETE ON *.* TO 'datastream_user'@'%';
FLUSH PRIVILEGES;
Plik zrzutu dla powyższego schematu znajdziesz tutaj. Ważne jest, aby osobno utworzyć użytkownika replikacji strumienia danych, ponieważ nie jest on uwzględniony w pliku zrzutu.
5. Weryfikacja danych
Szybko sprawdź, czy dane są dostępne:
SELECT 'Customers shard0_db' AS tbl, COUNT(*) FROM shard0_db.Customers
UNION ALL
SELECT 'Orders shard0_db', COUNT(*) FROM shard0_db.Orders
UNION ALL
SELECT 'Customers shard1_db', COUNT(*) FROM shard1_db.Customers
UNION ALL
SELECT 'Orders shard1_db', COUNT(*) FROM shard1_db.Orders;
EXIT;
Oczekiwane dane wyjściowe:
+---------------------+----------+ | tbl | COUNT(*) | +---------------------+----------+ | Customers shard0_db | 4 | | Orders shard0_db | 5 | | Customers shard1_db | 4 | | Orders shard1_db | 5 | +---------------------+----------+
Wpisz exit, aby zakończyć połączenie z maszyną wirtualną fizycznego fragmentu 1.
6. Powtórz te czynności w przypadku Physical Shard 2.
Teraz powtórz dokładnie ten sam proces w przypadku drugiej maszyny wirtualnej, ale utwórz shard2_db i shard3_db oraz zmień server-id.
- Połącz się z drugą maszyną wirtualną przez SSH:
gcloud compute ssh mysql-physical-2 --zone=$ZONE --tunnel-through-iap
- Zainstaluj MySQL:
sudo apt-get update
sudo apt-get install mysql-server-8.0 -y
- Skonfiguruj plik
mysqld.cnf, aby włączyć logowanie binarne i zezwolić na połączenia zewnętrzne [pamiętaj, że identyfikator serwera musi być inny (np.2)].
sudo sed -i 's/bind-address.*/bind-address = 0.0.0.0/' /etc/mysql/mysql.conf.d/mysqld.cnf
echo -e "[mysqld]\nserver-id=2\nlog_bin=/var/log/mysql/mysql-bin.log\nbinlog_format=ROW" | sudo tee -a /etc/mysql/mysql.conf.d/mysqld.cnf
- Ponownie uruchom MySQL, aby zastosować zmiany:
sudo systemctl restart mysql
- Wpisz MySQL (
sudo mysql) i uruchom nieco zmodyfikowaną wersję kodu SQL z kroku 4:
CREATE DATABASE shard2_db;
CREATE DATABASE shard3_db;
USE shard2_db;
CREATE TABLE Customers (
CustomerId INT NOT NULL,
CustomerName VARCHAR(255),
CreditLimit DECIMAL(10, 2) NOT NULL,
LegacyRegion VARCHAR(50), -- Renamed to LoyaltyTier in Spanner
PRIMARY KEY (CustomerId),
CONSTRAINT CHK_CreditLimit CHECK (CreditLimit > 1000) -- Relaxed in Spanner to > 0
);
CREATE TABLE Orders (
CustomerId INT NOT NULL, -- Logically references Customers.CustomerId in Spanner
OrderId INT NOT NULL,
OrderValue DECIMAL(10, 2),
LegacyOrderSystem VARCHAR(50), -- Extra column in Source, to be dropped in Spanner
PRIMARY KEY (CustomerId, OrderId) -- Spanner PK will have one additional column in PK
);
INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LegacyRegion) VALUES
(2, 'Brian K.', 2500.00, 'SOUTHWEST'),
(6, 'Diana L.', 1999.00, 'NORTH'),
(10, 'Edward M.', 11000.00, 'EAST'),
(14, 'Fiona N.', 3000.00, 'WEST');
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem) VALUES
(2, 301, 100.00, 'CallCenter_System'),
(6, 302, 99.00, 'MobileApp_Legacy'),
(10, 303, 1000.00, 'WebStore_v1'),
(10, 304, 2500.00, 'InStore_POS'),
(14, 305, 130.00, 'MobileApp_Legacy');
USE shard3_db;
CREATE TABLE Customers (
CustomerId INT NOT NULL,
CustomerName VARCHAR(255),
CreditLimit DECIMAL(10, 2) NOT NULL,
LegacyRegion VARCHAR(50), -- Renamed to LoyaltyTier in Spanner
PRIMARY KEY (CustomerId),
CONSTRAINT CHK_CreditLimit CHECK (CreditLimit > 1000) -- Relaxed in Spanner to > 0
);
CREATE TABLE Orders (
CustomerId INT NOT NULL, -- Logically references Customers.CustomerId in Spanner
OrderId INT NOT NULL,
OrderValue DECIMAL(10, 2),
LegacyOrderSystem VARCHAR(50), -- Extra column in Source, to be dropped in Spanner
PRIMARY KEY (CustomerId, OrderId) -- Spanner PK will have one additional column in PK
);
INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LegacyRegion) VALUES
(3, 'Cathy Z.', 6000.00, 'CENTRAL'),
(7, 'George O.', 18000.00, 'SOUTH'),
(11, 'Helen P.', 4000.00, 'NORTHEAST'),
(15, 'Ivy Q.', 9500.00, 'SOUTHWEST');
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem) VALUES
(3, 401, 600.00, 'InStore_POS'),
(7, 402, 1200.00, 'CallCenter_System'),
(11, 403, 350.00, 'MobileApp_Legacy'),
(15, 404, 800.00, 'WebStore_v1'),
(99, 999, 25.00, 'CallCenter_System'); -- Failure row during Bulk Migration due to violation of interleaving
-- Create Datastream Replication User
CREATE USER 'datastream_user'@'%' IDENTIFIED BY 'complex_password_123';
GRANT REPLICATION SLAVE, REPLICATION CLIENT, SELECT, INSERT, UPDATE, DELETE ON *.* TO 'datastream_user'@'%';
FLUSH PRIVILEGES;
-- Verify Data
SELECT 'Customers shard2_db' AS tbl, COUNT(*) FROM shard2_db.Customers
UNION ALL
SELECT 'Orders shard2_db', COUNT(*) FROM shard2_db.Orders
UNION ALL
SELECT 'Customers shard3_db', COUNT(*) FROM shard3_db.Customers
UNION ALL
SELECT 'Orders shard3_db', COUNT(*) FROM shard3_db.Orders;
EXIT;
Oczekiwane dane wyjściowe:
+---------------------+----------+ | tbl | COUNT(*) | +---------------------+----------+ | Customers shard2_db | 4 | | Orders shard2_db | 5 | | Customers shard3_db | 4 | | Orders shard3_db | 5 | +---------------------+----------+
Plik zrzutu dla powyższego schematu znajdziesz tutaj. Ważne jest, aby osobno utworzyć użytkownika replikacji strumienia danych, ponieważ nie jest on uwzględniony w pliku zrzutu.
Wpisz exit, aby zakończyć połączenie z maszyną wirtualną.
5. Konfigurowanie Cloud Spanner
Teraz skonfigurujesz docelową instancję Cloud Spanner, do której zostaną przeniesione dane.
1. Tworzenie instancji Cloud Spanner
Utwórz instancję Cloud Spanner w tym samym regionie co maszyny wirtualne Compute Engine, aby zminimalizować opóźnienie. To polecenie tworzy małą instancję odpowiednią do tego ćwiczenia, która wykorzystuje 100 jednostek przetwarzania.
export SPANNER_INSTANCE_NAME="target-spanner-instance"
export SPANNER_DATABASE_NAME="sharded-target-db"
export SPANNER_CONFIG="regional-${REGION}"
gcloud spanner instances create $SPANNER_INSTANCE_NAME \
--config=$SPANNER_CONFIG \
--description="Target Spanner Instance" \
--processing-units=100
Tworzenie instancji może potrwać minutę lub dwie.
6. Konwertowanie schematu za pomocą narzędzia Spanner Migration Tool (SMT)
Użyj interfejsu internetowego narzędzia Spanner Migration Tool (SMT), aby połączyć się z jednym z naszych logicznych fragmentów (shard0_db), przeanalizować jego schemat i zastosować kilka zaawansowanych modyfikacji przed przekonwertowaniem go na Cloud Spanner.
1. Instalowanie SMT
Uruchomimy interfejs SMT Web UI bezpośrednio z Cloud Shell. W terminalu Cloud Shell pobierz i wyodrębnij najnowszą wersję SMT:
sudo apt-get update && sudo apt-get install google-cloud-cli-spanner-migration-tool
# Verify installation
gcloud alpha spanner migrate web --help
2. Połącz się ze źródłową bazą danych
- Uwierzytelnianie sesji
# Authenticate your Google Cloud account
gcloud auth login
# Set up Application Default Credentials (ADC) for SMT
gcloud auth application-default login
# Ensure your current project is set correctly
gcloud config set project $PROJECT_ID
(Uwaga: gdy pojawi się odpowiedni komunikat, otwórz podany adres URL, aby autoryzować konto, a następnie wklej kod weryfikacyjny z powrotem do terminala).
- Najpierw znajdź zewnętrzny adres IP pierwszego fizycznego fragmentu, uruchamiając to polecenie w nowej karcie Cloud Shell:
gcloud compute instances describe mysql-physical-1 --zone=$ZONE --format='get(networkInterfaces[0].accessConfigs[0].natIP)'
- Wydrukuj szczegóły docelowej instancji Spanner, które będą używane podczas konfigurowania SMT.
echo "Project ID: $PROJECT_ID"
echo "Instance ID: $SPANNER_INSTANCE_NAME"
echo "Database Name: $SPANNER_DATABASE_NAME"
- Uruchom interfejs internetowy:
gcloud alpha spanner migrate web --port=8080
- W prawym górnym rogu okna Cloud Shell kliknij ikonę podglądu w przeglądarce (wygląda jak oko) i wybierz Podejrzyj na porcie 8080. Spowoduje to otwarcie interfejsu SMT w nowej karcie przeglądarki.

- W interfejsie SMT wybierz Connect to database (Połącz z bazą danych).
- Wypełnij szczegóły połączenia:
- Typ bazy danych: MySQL
- Host: (wklej adres IP z kroku 2)
- Port: 3306
- Użytkownik:
datastream_user - Hasło:
complex_password_123 - Nazwa bazy danych:
shard0_db
- Aby skonfigurować bazę danych Spanner, w prawym górnym rogu kliknij przycisk edycji.
- Wpisz szczegóły docelowego Spannera:
- Identyfikator projektu: (wklej identyfikator projektu z kroku 3)
- Instancja Spannera: (wklej identyfikator instancji z kroku 3)
- Kliknij Testuj połączenie.
- Gdy to się uda, kliknij Połącz. SMT przeanalizuje źródłową bazę danych i przedstawi podstawowy schemat Spanner.

3. Zastosuj modyfikacje schematu
Teraz przekształcimy schemat, aby uwzględnić złożone scenariusze migracji.
W edytorze schematu interfejsu SMT wykonaj te czynności:
A. Zmień nazwę kolumny LegacyRegion:
- W panelu nawigacyjnym po lewej stronie kliknij tabelę
Customers. Domyślnie otworzy się karta Kolumny. - W sekcji Spanner kliknij przycisk Edytuj.
- W widoku schematu Spanner odszukaj kolumnę
LegacyRegion. - Zmień nazwę kolumny Spanner na
LoyaltyTier, wpisując ją w odpowiednim oknie. - Kliknij Zapisz i przekonwertuj.


B. Złagodzenie ograniczenia sprawdzania:
- W tabeli
Customersotwórz kartę Check Constraints (Ograniczenia sprawdzania). - Znajdź ograniczenie
CHK_CreditLimit. Kliknij ikonę Edytuj (ołówek). - Zmień warunek z
CreditLimit > 1000naCreditLimit > 0. (Spowoduje to celowe niepowodzenie migracji zwrotnej wierszy z niższymi limitami kredytowymi i przeniesienie ich do kolejki DLQ).

C. Usuń kolumnę LegacyOrderSystem:
- Kliknij tabelę
Orders. Domyślnie otworzy się karta Kolumny. - W sekcji Spanner kliknij przycisk Edytuj.
- W widoku schematu Spanner odszukaj kolumnę
LegacyOrderSystem. - Kliknij ikonę menu z 3 kropkami obok niej i wybierz Usuń kolumnę.
- Kliknij Zapisz i skonwertuj.

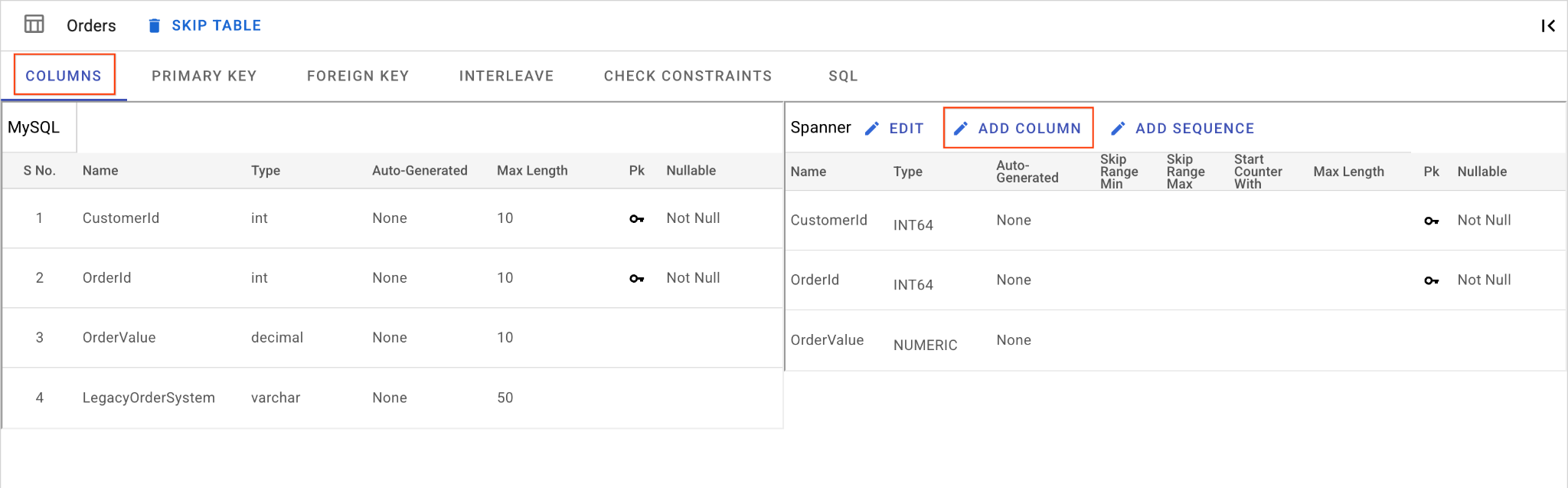
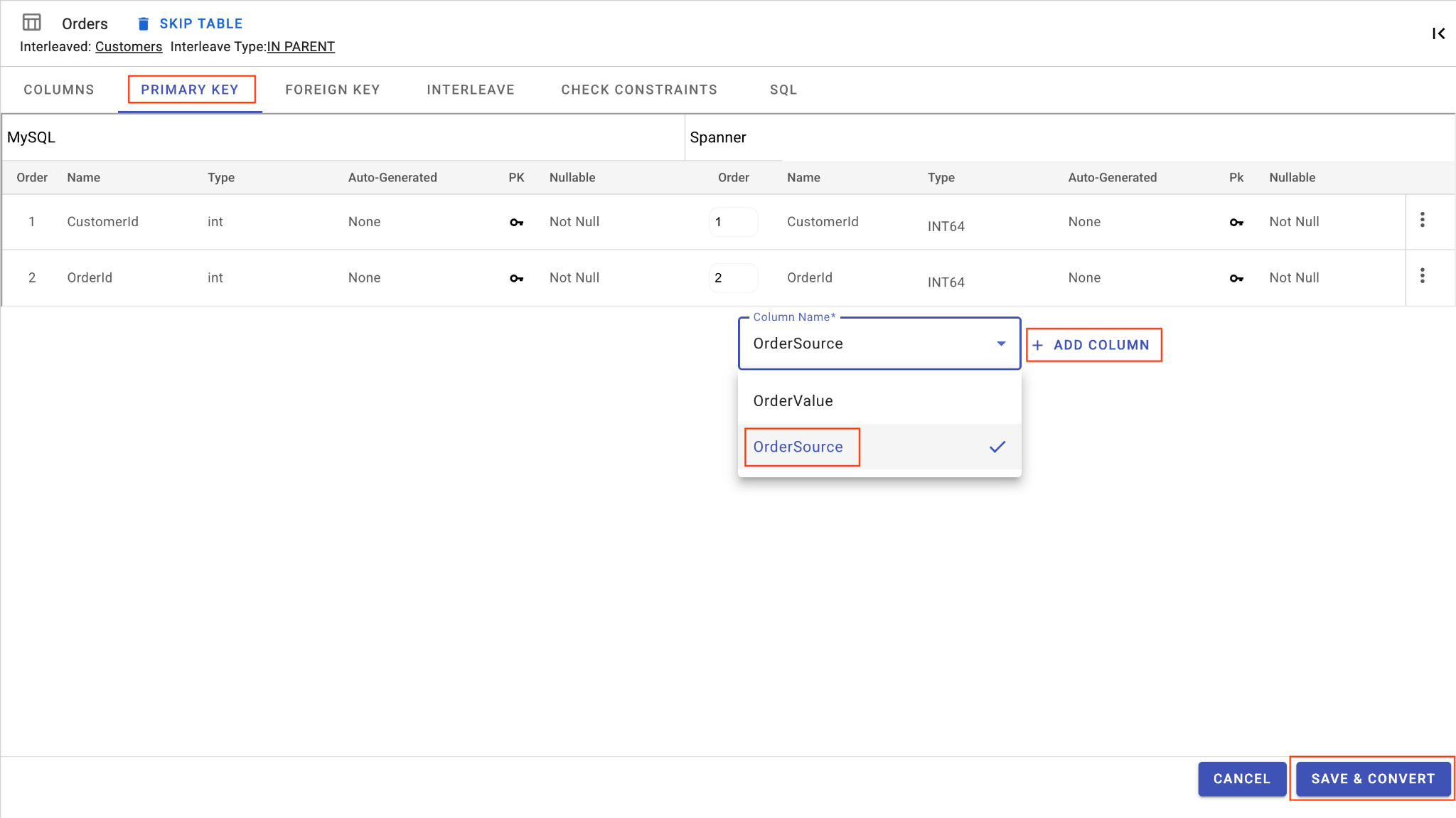
D. Dodaj kolumnę OrderSource i ustaw ją jako klucz podstawowy:
- W tabeli
Orderskliknij Dodaj kolumnę. Nadaj mu nazwęOrderSourcei ustaw typ naSTRINGo długości50, bez automatycznego generowania, a wartośćIsNullableustaw naNo. - Otwórz kartę Klucz podstawowy.
- Kliknij Edytuj i w menu Nazwa kolumny wybierz
OrderSource. - Kliknij kolejno Dodaj kolumnę i Zapisz i przekonwertuj.
E. Przeplataj tabelę zamówień:
- W tabeli
Ordersw głównym widoku tabeli znajdź kartę Przeplatanie. - Ustaw tabelę nadrzędną na
Customers. - Wybierz
IN PARENTInterleave type (Typ przeplatania) iNO ACTIONOn Delete Action (Działanie po usunięciu). - Kliknij Zapisz.

4. Pobieranie pliku zastąpień i stosowanie schematu
- W prawym górnym rogu interfejsu SMT znajdź przycisk Pobierz artefakty. Kliknij Pobierz plik zastąpień. Zapisz ten plik na komputerze lokalnym. Ten plik zawiera wszystkie zmiany mapowania schematu, które właśnie wprowadziliśmy, i będzie używany przez nasze potoki Dataflow.
- Kliknij Przygotuj migrację.

- W menu wybierz Tryb migracji jako
Schema. - Wpisz docelową bazę danych Spanner:
sharded-target-db

- Kliknij Przenieś.
- SMT zastosuje DDL i utworzy bazę danych Spanner. Po zakończeniu procesu SMT możesz bezpiecznie go zatrzymać w Cloud Shell (
Ctrl+C).
5. Weryfikowanie schematu w Cloud Spanner
Sprawdź, czy tabele zostały utworzone w bazie danych Spanner.
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT table_name FROM information_schema.tables WHERE table_schema = '' ORDER BY table_name"
Powinny się wyświetlić te dane wyjściowe:
table_name: Customers table_name: Orders
Opcjonalnie: jeśli chcesz sprawdzić rzeczywisty kod DDL Spanner, aby upewnić się, że zastosowano ograniczenia sprawdzania, przeplatanie i dodatkowe kolumny, uruchom to polecenie:
gcloud spanner databases ddl describe $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME
Oczekiwane dane wyjściowe:
CREATE TABLE Customers ( CustomerId INT64 NOT NULL, CustomerName STRING(255), CreditLimit NUMERIC NOT NULL, LoyaltyTier STRING(50), CONSTRAINT CHK_CreditLimit CHECK(`CreditLimit` > 0), ) PRIMARY KEY(CustomerId); CREATE TABLE Orders ( CustomerId INT64 NOT NULL, OrderId INT64 NOT NULL, OrderValue NUMERIC, OrderSource STRING(50) NOT NULL, ) PRIMARY KEY(CustomerId, OrderId, OrderSource), INTERLEAVE IN PARENT Customers ON DELETE NO ACTION;
7. Inicjowanie przechwytywania zmian danych
W tej sekcji skonfigurujesz „rejestrator” migracji. Skonfigurowanie Datastream i Pub/Sub przed rozpoczęciem wczytywania zbiorczego danych zapewnia przechwytywanie i kolejkowanie wszystkich zmian wprowadzanych w źródłowych bazach danych, co zapobiega utracie danych podczas przejścia. Ta konfiguracja jest wymagana w przypadku migracji na żywo.
Nasza architektura obejmuje 2 serwery fizyczne, dlatego musimy utworzyć 2 osobne profile źródła Datastream i 2 strumienie Datastream. Oba strumienie będą zapisywać dane w jednym zasobniku Google Cloud Storage (GCS), który będzie stanowić ujednolicone źródło dla naszego potoku Dataflow.
1. Tworzenie zasobnika Cloud Storage
Datastream wymaga miejsca docelowego do przechowywania przechwyconych zdarzeń zmian. Utwórzmy zasobnik GCS.
export BUCKET_NAME="migration-${PROJECT_ID}-bucket"
gcloud storage buckets create gs://${BUCKET_NAME} --location=$REGION
2. Tworzenie profili połączeń Datastream
Potrzebujemy 2 różnych profili połączeń źródłowych MySQL (po jednym dla każdego fragmentu fizycznego) i 1 profilu połączenia docelowego dla Cloud Storage.
Pobieranie źródłowych adresów IP
Najpierw pobierz zewnętrzne adresy IP naszych 2 maszyn wirtualnych Compute Engine i zapisz je jako zmienne środowiskowe:
export MYSQL_IP_1=$(gcloud compute instances describe mysql-physical-1 --zone=$ZONE --format='get(networkInterfaces[0].accessConfigs[0].natIP)')
export MYSQL_IP_2=$(gcloud compute instances describe mysql-physical-2 --zone=$ZONE --format='get(networkInterfaces[0].accessConfigs[0].natIP)')
Tworzenie profili połączeń ze źródłem (MySQL w Compute Engine)
Utwórz profile połączeń Datastream, używając utworzonego wcześniej datastream_user.
# Create Source Profile for Physical Shard 1
export SQL_CP_NAME_1="mysql-src-cp-1"
gcloud datastream connection-profiles create $SQL_CP_NAME_1 \
--location=$REGION \
--type=mysql \
--mysql-hostname=$MYSQL_IP_1 \
--mysql-port=3306 \
--mysql-username=datastream_user \
--mysql-password=complex_password_123 \
--display-name="MySQL Source 1 (Physical Shard 1)"
# Create Source Profile for Physical Shard 2
export SQL_CP_NAME_2="mysql-src-cp-2"
gcloud datastream connection-profiles create $SQL_CP_NAME_2 \
--location=$REGION \
--type=mysql \
--mysql-hostname=$MYSQL_IP_2 \
--mysql-port=3306 \
--mysql-username=datastream_user \
--mysql-password=complex_password_123 \
--display-name="MySQL Source 2 (Physical Shard 2)"
Uwaga: Datastream łączy się z tymi maszynami wirtualnymi za pomocą ich publicznych adresów IP, co jest dozwolone, ponieważ wcześniej dodaliśmy 0.0.0.0/0 do naszych reguł zapory sieciowej. W środowisku produkcyjnym należy ściśle zezwalać na określone publiczne zakresy adresów IP Datastream.
Tworzenie profilu połączenia docelowego (Cloud Storage):
Wskazuje to katalog główny nowo utworzonego zasobnika.
export GCS_CP_NAME="gcs-dest-cp"
gcloud datastream connection-profiles create $GCS_CP_NAME \
--location=$REGION \
--type=google-cloud-storage \
--bucket=$BUCKET_NAME \
--root-path=/ \
--display-name="GCS Destination" --force
3. Tworzenie strumieni Datastream
Teraz utworzymy 2 strumienie CDC. Strumień 1 będzie rejestrować shard0_db i shard1_db. Strumień 2 będzie rejestrować shard2_db i shard3_db. Oba strumienie zapisują dane w tym samym zasobniku GCS w formacie Avro.
# Stream for Physical Shard 1
export STREAM_NAME_1="mysql-to-spanner-stream-1"
export GCS_STREAM_PATH_1="data/${STREAM_NAME_1}"
gcloud datastream streams create $STREAM_NAME_1 \
--location=$REGION \
--display-name="MySQL Source 1 CDC Stream" \
--source=$SQL_CP_NAME_1 \
--destination=$GCS_CP_NAME \
--mysql-source-config=<(echo "includeObjects:
mysqlDatabases:
- database: 'shard0_db'
- database: 'shard1_db'") \
--gcs-destination-config=<(echo "path: ${GCS_STREAM_PATH_1}/
fileRotationMb: 5
fileRotationInterval: 15s
avroFileFormat: {}") \
--backfill-none
# Stream for Physical Shard 2
export STREAM_NAME_2="mysql-to-spanner-stream-2"
export GCS_STREAM_PATH_2="data/${STREAM_NAME_2}"
gcloud datastream streams create $STREAM_NAME_2 \
--location=$REGION \
--display-name="MySQL Source 2 CDC Stream" \
--source=$SQL_CP_NAME_2 \
--destination=$GCS_CP_NAME \
--mysql-source-config=<(echo "includeObjects:
mysqlDatabases:
- database: 'shard2_db'
- database: 'shard3_db'") \
--gcs-destination-config=<(echo "path: ${GCS_STREAM_PATH_2}/
fileRotationMb: 5
fileRotationInterval: 15s
avroFileFormat: {}") \
--backfill-none
Używanie mniejszych ustawień rotacji plików (5 MB lub 15 sekund) pomaga nam szybciej zauważyć powielone zmiany podczas ćwiczeń.
Wykonanie tego polecenia może trochę potrwać. Sprawdź stan: gcloud datastream streams describe $STREAM_NAME_1 --location=$REGION.
4. Uruchamianie strumieni Datastream
Aktywuj oba strumienie, aby rozpocząć rejestrowanie zmian.
gcloud datastream streams update $STREAM_NAME_1 \
--location=$REGION \
--state=RUNNING
gcloud datastream streams update $STREAM_NAME_2 \
--location=$REGION \
--state=RUNNING
Sprawdź stan: możesz uruchomić gcloud datastream streams describe $STREAM_NAME_1 --location=$REGION. Początkowo stan będzie oznaczony jako STARTING, a po chwili zmieni się na RUNNING. Zanim rozpoczniesz migrację na żywo, poczekaj, aż oba będą w pełni uruchomione.
5. Konfigurowanie Pub/Sub na potrzeby powiadomień GCS
Dataflow musi być natychmiast powiadamiany, gdy strumień Datastream zapisuje nowy plik w zasobniku GCS. Skonfigurujemy GCS tak, aby wysyłał powiadomienia do jednego tematu Pub/Sub.
Utwórz temat Pub/Sub:
export PUBSUB_TOPIC="datastream-gcs-updates"
gcloud pubsub topics create $PUBSUB_TOPIC
Tworzenie powiadomienia GCS
Powiadamiaj temat o każdym utworzeniu obiektu z prefiksem data/ (obejmuje to oba nasze strumienie).
gcloud storage buckets notifications create gs://${BUCKET_NAME} --topic=projects/$PROJECT_ID/topics/$PUBSUB_TOPIC --payload-format=json --object-prefix=data/
Tworzenie subskrypcji Pub/Sub
Utwórz subskrypcję z zalecanym terminem potwierdzenia dla Dataflow.
export PUBSUB_SUBSCRIPTION="datastream-gcs-sub"
gcloud pubsub subscriptions create $PUBSUB_SUBSCRIPTION \
--topic=$PUBSUB_TOPIC \
--ack-deadline=600
8. Transformacja niestandardowa
Ponieważ schemat Spanner różni się od schematu MySQL (ze względu na kolumny, które zostały dodane i usunięte za pomocą interfejsu SMT), gotowa migracja Dataflow zakończy się niepowodzeniem. Dataflow potrzebuje instrukcji, jak mapować te różnice w potokach w kierunku do przodu (z MySQL do Spannera) i w kierunku do tyłu (ze Spannera do MySQL).
Dodatkowo, ponieważ przeprowadzamy migrację zwrotną z podziałem na fragmenty, Dataflow potrzebuje mechanizmu routingu, aby podczas replikacji zwrotnej wiedzieć, do którego fragmentu logicznego (shard0_db, shard1_db itp.) należy zaktualizowany wiersz Spannera.
Osiągniemy to, pisząc niestandardowy plik JAR transformacji za pomocą udostępnionego przez Google szablonu niestandardowego podziału Spanner.
1. Pobierz szablon niestandardowego podziału
W Cloud Shell pobierz repozytorium szablonów Google Cloud Dataflow i przejdź do folderu niestandardowego fragmentu:
git clone https://github.com/GoogleCloudPlatform/DataflowTemplates.git
cd DataflowTemplates/v2/spanner-custom-shard
2. Konfigurowanie logiki przekształcania danych
Musimy edytować plik CustomTransformationFetcher.java.
- Migracja do przodu (
toSpannerRow): wypełnia nowo dodaną kolumnęOrderSourcedanymi z kolumnyLegacyOrderSystemw MySQL. - Migracja odwrotna (
toSourceRow): ponownie wypełnia usuniętą kolumnęLegacyOrderSystem, której wymaga MySQL, na podstawie kolumnyOrderSourcew Spannerze.
Edytuj plik CustomTransformationFetcher.java. Zamiast ręcznie otwierać edytor tekstu, uruchom to polecenie, aby automatycznie zastąpić plik szablonu naszą niestandardową logiką:
cat << 'EOF' > src/main/java/com/custom/CustomTransformationFetcher.java
package com.custom;
import com.google.cloud.teleport.v2.spanner.exceptions.InvalidTransformationException;
import com.google.cloud.teleport.v2.spanner.utils.ISpannerMigrationTransformer;
import com.google.cloud.teleport.v2.spanner.utils.MigrationTransformationRequest;
import com.google.cloud.teleport.v2.spanner.utils.MigrationTransformationResponse;
import java.util.HashMap;
import java.util.Map;
public class CustomTransformationFetcher implements ISpannerMigrationTransformer {
@Override
public void init(String customParameters) {}
@Override
public MigrationTransformationResponse toSpannerRow(MigrationTransformationRequest request)
throws InvalidTransformationException {
if (request.getTableName().equals("Orders")) {
Map<String, Object> requestRow = request.getRequestRow();
Map<String, Object> responseRow = new HashMap<>();
Object legacySysObj = requestRow.get("LegacyOrderSystem");
String legacySys = (legacySysObj != null) ? (String) legacySysObj : "UNKNOWN_SYSTEM";
// Transform: Trim the string to remove everything after the first underscore
String orderSource = legacySys;
if (legacySys.contains("_")) {
orderSource = legacySys.substring(0, legacySys.indexOf('_'));
}
// Populate the new Spanner column (e.g., "WebStore_v1" becomes "WebStore")
responseRow.put("OrderSource", orderSource);
return new MigrationTransformationResponse(responseRow, false);
}
return new MigrationTransformationResponse(new HashMap<>(), false);
}
@Override
public MigrationTransformationResponse toSourceRow(MigrationTransformationRequest request)
throws InvalidTransformationException {
if (request.getTableName().equals("Orders")) {
Map<String, Object> requestRow = request.getRequestRow();
Map<String, Object> responseRow = new HashMap<>();
// Safely fetch the Spanner OrderSource
Object sourceObj = requestRow.get("OrderSource");
String source = (sourceObj != null) ? (String) sourceObj : "UNKNOWN_SYSTEM";
String legacySys = "'" + source + "_v1'";
// Transform: Append a suffix to visibly prove the reverse transformation worked
// e.g., "WebStore" becomes "WebStore_v1"
responseRow.put("LegacyOrderSystem", legacySys);
return new MigrationTransformationResponse(responseRow, false);
}
return new MigrationTransformationResponse(new HashMap<>(), false);
}
@Override
public MigrationTransformationResponse transformFailedSpannerMutation(
MigrationTransformationRequest request) throws InvalidTransformationException {
return new MigrationTransformationResponse(new HashMap<>(), false);
}
}
EOF
3. Konfigurowanie logiki odwrotnego dzielenia na partycje
Dataflow używa CustomShardIdFetcher.java podczas replikacji zwrotnej, aby określić, gdzie powinna być kierowana mutacja Spanner. Użyjemy CustomerIdklucza podstawowego i logiki modulo (%4), aby dynamicznie kierować rekordy z powrotem do odpowiedniego logicznego fragmentu.
Edytuj plik CustomShardIdFetcher.java za pomocą polecenia cat i całkowicie zastąp jego zawartość tym kodem:
cat << 'EOF' > src/main/java/com/custom/CustomShardIdFetcher.java
package com.custom;
import com.google.cloud.teleport.v2.spanner.utils.IShardIdFetcher;
import com.google.cloud.teleport.v2.spanner.utils.ShardIdRequest;
import com.google.cloud.teleport.v2.spanner.utils.ShardIdResponse;
import java.util.Map;
public class CustomShardIdFetcher implements IShardIdFetcher {
@Override
public void init(String parameters) {}
@Override
public ShardIdResponse getShardId(ShardIdRequest shardIdRequest) {
Map<String, Object> keys = shardIdRequest.getSpannerRecord
();
// Use the Primary Key to identify the correct logical shard
if (keys != null && keys.containsKey("CustomerId")) {
long customerId = Long.parseLong(keys.get("CustomerId").toString());
long shardIdx = customerId % 4;
ShardIdResponse response = new ShardIdResponse();
response.setLogicalShardId("shard" + shardIdx + "_db");
return response;
}
return new ShardIdResponse();
}
}
EOF
4. Tworzenie i przesyłanie pliku JAR
Teraz, gdy mamy już napisaną niestandardową logikę w języku Java, musimy skompilować ją do pliku JAR i przesłać do utworzonego wcześniej zasobnika Cloud Storage, aby Dataflow mógł uzyskać do niej dostęp.
Uruchom w Cloud Shell te polecenia:
# Return to DataflowTemplates directory
cd ../..
# Build the JAR using Maven
mvn clean install -DskipTests -Dcheckstyle.skip -Dspotless.check.skip=true -Djib.skip -pl v2/spanner-custom-shard -am
# Upload the JAR to GCS
export CUSTOM_JAR_PATH="gs://${BUCKET_NAME}/custom-logic/spanner-custom-shard-1.0.jar"
gcloud storage cp v2/spanner-custom-shard/target/spanner-custom-shard-1.0-SNAPSHOT.jar $CUSTOM_JAR_PATH
# Return to home directory
cd ~
9. Zbiorcza migracja danych z MySQL do Spannera
Po utworzeniu schematu Spanner i zbudowaniu pliku JAR niestandardowej transformacji możemy teraz skopiować istniejące dane z bazy danych MySQL do Cloud Spanner. Użyjesz Sourcedb to Spanner elastycznego szablonu Dataflow, który jest przeznaczony do kopiowania zbiorczego danych z baz danych dostępnych przez JDBC do Spanner.
1. Prześlij plik zastąpień schematu
W sekcji 6 pobrano plik JSON z zastąpieniami Spanner za pomocą interfejsu SMT. Musimy przesłać ten plik do zasobnika GCS, aby Dataflow mógł go używać do mapowania różnic w schemacie (np. zmienionych nazw kolumn).
- W Cloud Shell kliknij menu z 3 kropkami (Więcej) i wybierz Prześlij.

- Wybierz pobrany wcześniej plik JSON z zastąpieniami (np.
spanner_overrides.json). - Przenieś go do zasobnika GCS:
export OVERRIDES_FILE="spanner_overrides.json" # Change this if your downloaded file has a different name
export GCS_OVERRIDES_PATH="gs://${BUCKET_NAME}/config/${OVERRIDES_FILE}"
gcloud storage cp ~/${OVERRIDES_FILE} $GCS_OVERRIDES_PATH
2. Tworzenie i przesyłanie pliku konfiguracyjnego podziału
Dataflow musi wiedzieć, jak połączyć się ze wszystkimi 4 logicznymi fragmentami na 2 fizycznych maszynach wirtualnych. Utworzymy w tym celu plik sharding.json.
Aby wygenerować i przesłać konfigurację, uruchom w Cloud Shell to polecenie:
cat <<EOF > sharding.json
{
"configType": "dataflow",
"shardConfigurationBulk": {
"schemaSource": {
"dataShardId": "mysql-physical-1",
"host": "${MYSQL_IP_1}",
"user": "datastream_user",
"password": "complex_password_123",
"port": "3306",
"dbName": "shard0_db"
},
"dataShards": [
{
"dataShardId": "mysql-physical-1",
"host": "${MYSQL_IP_1}",
"user": "datastream_user",
"password": "complex_password_123",
"port": "3306",
"dbName": "",
"namespace": "namespace-mysql-1",
"databases": [
{
"dbName": "shard0_db",
"databaseId": "shard0_db",
"refDataShardId": "mysql-physical-1"
},
{
"dbName": "shard1_db",
"databaseId": "shard1_db",
"refDataShardId": "mysql-physical-1"
}
]
},
{
"dataShardId": "mysql-physical-2",
"host": "${MYSQL_IP_2}",
"user": "datastream_user",
"password": "complex_password_123",
"port": "3306",
"dbName": "",
"namespace": "namespace-mysql-2",
"databases": [
{
"dbName": "shard2_db",
"databaseId": "shard2_db",
"refDataShardId": "mysql-physical-2"
},
{
"dbName": "shard3_db",
"databaseId": "shard3_db",
"refDataShardId": "mysql-physical-2"
}
]
}
]
}
}
EOF
export GCS_SHARDING_PATH="gs://${BUCKET_NAME}/config/sharding.json"
gcloud storage cp sharding.json $GCS_SHARDING_PATH
3. Uruchamianie zadania Dataflow migracji zbiorczej
Użyjemy szablonu Flex Sourcedb to Spanner. Jest to migracja z podziałem na fragmenty i niestandardowymi przekształceniami, dlatego przekazujemy plik zastąpień, konfigurację podziału na fragmenty i nasz niestandardowy plik JAR w języku Java.
export JOB_NAME="mysql-sharded-bulk-to-spanner-$(date +%Y%m%d-%H%M%S)"
export OUTPUT_DIR="gs://${BUCKET_NAME}/bulk-migration"
gcloud dataflow flex-template run $JOB_NAME \
--project=$PROJECT_ID \
--region=$REGION \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Sourcedb_to_Spanner_Flex" \
--max-workers=2 \
--num-workers=1 \
--worker-machine-type=n2-highmem-8 \
--parameters \
sourceConfigURL=$GCS_SHARDING_PATH,\
instanceId=$SPANNER_INSTANCE_NAME,\
databaseId=$SPANNER_DATABASE_NAME,\
projectId=$PROJECT_ID,\
outputDirectory=$OUTPUT_DIR,\
username=datastream_user,\
password=complex_password_123,\
schemaOverridesFilePath=$GCS_OVERRIDES_PATH,\
transformationJarPath=$CUSTOM_JAR_PATH,\
transformationClassName=com.custom.CustomTransformationFetcher
Wyjaśnienie kluczowych parametrów:
sourceConfigURL: ścieżka do utworzonego przez nas plikusharding.json. Informuje to Dataflow, jak połączyć się ze wszystkimi 4 logicznymi fragmentami MySQL na 2 fizycznych maszynach wirtualnych.schemaOverridesFilePath: ścieżka do pliku JSON pobranego z interfejsu SMT. Dzięki temu Dataflow wie, jak obsługiwać wprowadzone przez nas zmiany w schemacie (np. usuniętą kolumnęLegacyRegioni bardziej rygorystyczne ograniczenie sprawdzania).transformationJarPath: ścieżka GCS do skompilowanego pliku JAR w języku Java, który został utworzony w poprzedniej sekcji. Zawiera on rzeczywisty kod do wykonania naszych niestandardowych przekształceń.transformationClassName: Pełna i jednoznaczna nazwa klasy Java w naszym pliku JAR, która implementuje logikę migracji do przodu (com.custom.CustomTransformationFetcher).outputDirectory: lokalizacja GCS, w której Dataflow będzie zapisywać pliki tymczasowe, a przede wszystkim pliki kolejki DLQ.maxWorkers,numWorkers: steruje skalowaniem zadania Dataflow. W przypadku tego małego zbioru danych jest ona niska.instanceId,databaseId,projectId: określa docelową instancję i bazę danych Cloud Spanner.
Uwaga dotycząca sieci: to zadanie łączy się z instancją Cloud SQL za pomocą publicznego adresu IP. Jest to możliwe, ponieważ wcześniej dodano 0.0.0.0/0 do autoryzowanych sieci instancji. Umożliwia to maszynom wirtualnym Dataflow, które mają zewnętrzne adresy IP, dostęp do bazy danych.
4. Monitorowanie zadania Dataflow
Postęp zadania możesz śledzić w konsoli Google Cloud:
- Otwórz stronę Zadania Dataflow: Otwórz stronę Zadania Dataflow
- Znajdź zadanie o nazwie
mysql-sharded-bulk-to-spanner-...i kliknij je. - Przyjrzyj się wykresowi zadania i jego danym. Poczekaj, aż stan zadania zmieni się na Ukończono. Powinno to zająć około 5–15 minut.

- Jeśli zadanie napotka problemy, na karcie Logi na stronie szczegółów zadania Dataflow sprawdź komunikaty o błędach.
- Dane zadania zawierają więcej informacji o postępach zadania i zużyciu zasobów, takich jak przepustowość i wykorzystanie procesora.
5. Sprawdzanie danych w Cloud Spanner i sprawdzanie kolejki DLQ
Gdy zadanie Dataflow zostanie ukończone, musimy sprawdzić, czy dane zostały przesłane prawidłowo, i zbadać rekordy, które celowo zaprojektowaliśmy tak, aby nie przeszły weryfikacji.
A. Sprawdź ogólny stan przeniesionych danych:
Użyj gcloud interfejsu CLI, aby przeprowadzić kilka szybkich testów stanu skonsolidowanej bazy danych Spanner i upewnić się, że prawidłowe rekordy zostały prawidłowo przeniesione, a nasz niestandardowy plik JAR wypełnił dodatkową kolumnę.
# 1. Verify total Customer count
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT COUNT(*) as TotalCustomers FROM Customers"
# 2. Verify total Orders count (Total minus the orphan record)
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT COUNT(*) as TotalOrders FROM Orders"
# 3. Verify the Custom Transformation on OrderSource worked
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT CustomerId, OrderId, OrderSource FROM Orders LIMIT 3"
# 4. Verify that renamed column LoyaltyTier has the correct data
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT CustomerId, CustomerName, LoyaltyTier FROM Customers LIMIT 3"
Oczekiwane dane wyjściowe:
TotalCustomers: 16 TotalOrders: 19 CustomerId: 1 OrderId: 201 OrderSource: MobileApp CustomerId: 2 OrderId: 301 OrderSource: CallCenter CustomerId: 3 OrderId: 401 OrderSource: InStore CustomerId: 1 CustomerName: Agnes N. LoyaltyTier: NORTHEAST CustomerId: 2 CustomerName: Brian K. LoyaltyTier: SOUTHWEST CustomerId: 3 CustomerName: Cathy Z. LoyaltyTier: CENTRAL
- Wszystkie wiersze w tabeli Klienci zostały przeniesione.
- W tabeli
Orderswystąpił błąd w 1 wierszu z powoduINTERLEAVE IN PARENTw usłudze Spanner –CustomerId 99jest osieroconym elementem podrzędnym, ponieważ w tabeliCustomersnie ma odpowiadającego mu wiersza.
B. Sprawdź celowe błędy w DLQ:
Powyższy błąd jest udokumentowany w folderze kolejki DLQ utworzonym przez potok migracji zbiorczej.
- W konsoli Google Cloud otwórz Cloud Storage.
- Otwórz kosz i przejdź do folderu
bulk-migration/dlq/severe. - Sprawdź pliki JSON w środku. Znajdziesz wiersz
Ordersz osieroconym elementemCustomerId. - Błędy DLQ migracji zbiorczej można ponowić, wykonując czynności opisane tutaj.
Początkowe wczytywanie zbiorcze danych z Cloud SQL do Cloud Spanner zostało zakończone. Następnym krokiem jest skonfigurowanie replikacji na żywo, aby rejestrować bieżące zmiany.
10. Rozpocznij migrację na żywo (CDC)
Po zakończeniu wsadowego wczytywania danych uruchomisz ciągłe zadanie strumieniowego przesyłania Dataflow. To zadanie będzie odczytywać zdarzenia przechwytywania zmian danych (CDC), które Datastream zapisuje w zasobniku GCS, i stosować te zmiany w Cloud Spanner w czasie zbliżonym do rzeczywistego.
Przetestujemy też ten potok, wstrzykując do niego prawidłowe i celowo nieprawidłowe dane, aby sprawdzić, jak Dataflow radzi sobie z replikacją na żywo i kieruje błędy do kolejki DLQ.
1. Tworzenie pliku konfiguracyjnego dzielenia migracji na żywo
W przeciwieństwie do migracji głównej (która używa ciągów połączenia JDBC) potok migracji na żywo odczytuje zdarzenia Datastream z GCS. Wymaga to zupełnie innej konfiguracji JSON, która mapuje nazwy strumieni Datastream i bazy danych na logiczne fragmenty Spanner.
Aby utworzyć i przesłać konfigurację dynamicznego podziału na fragmenty, uruchom w Cloud Shell to polecenie:
cat <<EOF > live-sharding.json
{
"StreamToDbAndShardMap": {
"${STREAM_NAME_1}": {
"shard0_db": "shard0_db",
"shard1_db": "shard1_db"
},
"${STREAM_NAME_2}": {
"shard2_db": "shard2_db",
"shard3_db": "shard3_db"
}
}
}
EOF
export GCS_LIVE_SHARDING_PATH="gs://${BUCKET_NAME}/config/live-sharding.json"
gcloud storage cp live-sharding.json $GCS_LIVE_SHARDING_PATH
2. Uruchamianie zadania Dataflow migracji na żywo
Uruchom strumieniowe zadanie Dataflow, aby odczytywać dane z GCS i zapisywać je w Spannerze. Ten szablon będzie używać powiadomień GCS Pub/Sub do natychmiastowego przetwarzania nowych plików.
export JOB_NAME_CDC="mysql-sharded-cdc-to-spanner-$(date +%Y%m%d-%H%M%S)"
export DLQ_DIR_CDC="gs://${BUCKET_NAME}/live-migration"
gcloud dataflow flex-template run $JOB_NAME_CDC \
--project=$PROJECT_ID \
--region=$REGION \
--worker-machine-type=n2-highmem-8 \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Cloud_Datastream_to_Spanner" \
--parameters \
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
projectId="$PROJECT_ID",\
inputFileFormat="avro",\
gcsPubSubSubscription="projects/${PROJECT_ID}/subscriptions/${PUBSUB_SUBSCRIPTION}",\
shardingContextFilePath=$GCS_LIVE_SHARDING_PATH,\
deadLetterQueueDirectory="$DLQ_DIR_CDC",\
transformationJarPath=$CUSTOM_JAR_PATH,\
transformationClassName="com.custom.CustomTransformationFetcher",\
schemaOverridesFilePath=$GCS_OVERRIDES_PATH,\
datastreamSourceType="mysql",\
dlqRetryMinutes=1,\
dlqMaxRetryCount=2
Kluczowe parametry
gcsPubSubSubscription: subskrypcja Pub/Sub, która nasłuchuje powiadomień o nowych plikach z GCS. Dzięki temu zadanie może przetwarzać zmiany natychmiast po ich zapisaniu przez Datastream.inputFileFormat="avro": informuje Dataflow, że ma oczekiwać plików Avro z Datastream. Musi to być zgodne z konfiguracją „Miejsca docelowego” w Datastream (np.avroFileFormatvs.jsonFileFormat).shardingContextFilePath: plik JSON, który mapuje strumienie Datastream na logiczne fragmenty.dlqRetryMinutes: liczba minut między ponownymi próbami wysłania wiadomości do kolejki niedostarczonych wiadomości. Domyślna wartość to10.dlqMaxRetryCount: maksymalna liczba prób ponowienia błędów tymczasowych za pomocą kolejki DLQ. Domyślna wartość to500.
Monitoruj uruchamianie zadania w konsoli zadań Dataflow.
3. Wstrzykiwanie danych na żywo i wywoływanie celowych błędów
Podczas uruchamiania zadania przesyłania strumieniowego Dataflow (może to potrwać 3–5 minut) połączmy się przez SSH z pierwszą fizyczną maszyną wirtualną MySQL i wstawmy kilka nowych rekordów. Wstawimy 1 prawidłowy i 1 nieprawidłowy rekord.
Połącz się przez SSH z pierwszym fizycznym fragmentem:
gcloud compute ssh mysql-physical-1 --zone=$ZONE
Zaloguj się w MySQL:
sudo mysql
Uruchom te wstawki w shard1_db:
USE shard1_db;
-- 1. Valid Insert: 'MobileApp_v2' will be trimmed to 'MobileApp'
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem)
VALUES (4, 501, 99.99, 'MobileApp_v2');
-- 2. Invalid Insert (DLQ Test): This violates Interleave constraint as CustomerId 99999 doesn't exist in Customers table.
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem)
VALUES (99999, 502, 50.00, 'WebStore_v1');
-- 3. Valid Update
UPDATE Orders SET OrderValue = '1500' WHERE CustomerId = 5 AND OrderId = 202;
-- 4. Valid Delete
DELETE FROM Orders WHERE CustomerId = 5 AND OrderId = 203;
EXIT;
Wpisz ponownie exit, aby wrócić do wiersza poleceń Cloud Shell.
4. Weryfikowanie danych migracji na żywo i sprawdzanie kolejki DLQ CDC
Po wstrzyknięciu danych usługa Datastream przechwyci zdarzenia CDC, a Dataflow spróbuje zastosować je w Spannerze.
A. Weryfikowanie prawidłowych zmian DML w Spannerze
Uruchom te zapytania, aby sprawdzić, czy zdarzenia INSERT, UPDATE i DELETE zostały prawidłowo przesłane do Spannera oraz czy niestandardowa transformacja została uruchomiona zarówno w przypadku wstawienia, jak i aktualizacji.
# 1. Verify INSERT: Should return the new row with transformed OrderSource
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT CustomerId, OrderId, OrderValue, OrderSource FROM Orders WHERE CustomerId = 4 AND OrderId = 501"
# 2. Verify UPDATE: Should show OrderValue changed to 1500
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT CustomerId, OrderId, OrderValue, OrderSource FROM Orders WHERE CustomerId = 5 AND OrderId = 202"
# 3. Verify DELETE: Should return 0, confirming the order was deleted
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT COUNT(*) FROM Orders WHERE CustomerId = 5 AND OrderId = 203"
# 4. Verify DLQ Failure: Should return 0, confirming the row migration failed
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT COUNT(*) FROM Orders WHERE CustomerId = 99999 AND OrderId = 502"
Oczekiwane dane wyjściowe:
CustomerId: 4 OrderId: 501 OrderValue: 99.99 OrderSource: MobileApp CustomerId: 5 OrderId: 202 OrderValue: 1500 OrderSource: WebStore 0 0
Uwaga: jeśli któreś zapytanie nie zwróci oczekiwanego wyniku, poczekaj minutę i spróbuj ponownie, ponieważ pracownicy strumieniowania mogą wciąż przetwarzać kolejkę.
B. Sprawdź celowe niepowodzenie w DLQ:
Ponieważ element CustomerId = 99999 nie ma elementu nadrzędnego w tabeli Customers, powinien zostać odrzucony przez Spanner i bezpiecznie przekierowany do kolejki DLQ przez Dataflow.
- W konsoli Google Cloud otwórz Cloud Storage.
- Otwórz kosz i przejdź do folderu
live-migration/dlq/severe/. - Powinny pojawić się nowo wygenerowane pliki JSON. Kliknij je, aby sprawdzić zawartość. Zobaczysz szczegóły
CustomerId = 99999i konkretny komunikat o błędzie Spanner:NOT_FOUND: Parent row for row [99999,502,WebStore] in table Orders is missing. Row cannot be written." - Błędy DLQ migracji na żywo można ponowić, uruchamiając szablon przepływu danych z ustawioną wartością
runMode=retryDLQ.
5. Obsługa błędów DLQ
Błędy w katalogu severe/ wymagają ręcznej interwencji. Rozwiążmy problem z danymi i ponownie przetwórzmy nieudane zdarzenie.
A. Popraw dane w źródle
Błąd wystąpił, ponieważ brakuje rekordu klienta nadrzędnego CustomerId = 99999. Wstawmy go do źródłowej bazy danych MySQL.
Ponownie połącz się z instancją MySQL przez SSH:
gcloud compute ssh mysql-physical-1 --zone=$ZONE
Zaloguj się w MySQL za pomocą sudo mysql i wstaw brakujący wiersz nadrzędny do shard1_db:
USE shard1_db;
INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LegacyRegion) VALUES
(99999, 'DLQ Parent Holder', 5000.00, 'NORTH_AMERICA');
EXIT;
Wpisz exit, aby wrócić do Cloud Shell.
B. Uruchamianie zadania Dataflow retryDLQ
Aby ponownie przetworzyć zdarzenia z kolejki DLQ severe/, uruchom ten sam szablon Dataflow, ale w trybie retryDLQ. W tym trybie dane są odczytywane ze ścieżki deadLetterQueueDirectory/severe, ponownie przetwarzane za pomocą niestandardowych przekształceń i stosowane w Spannerze.
Uruchom zadanie w trybie retryDLQ:
export JOB_NAME_RETRY="mysql-sharded-cdc-retry-$(date +%Y%m%d-%H%M%S)"
gcloud dataflow flex-template run $JOB_NAME_RETRY \
--project=$PROJECT_ID \
--region=$REGION \
--worker-machine-type=n2-highmem-8 \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Cloud_Datastream_to_Spanner" \
--parameters \
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
projectId="$PROJECT_ID",\
runMode="retryDLQ",\
deadLetterQueueDirectory="$DLQ_DIR_CDC",\
datastreamSourceType="mysql",\
transformationJarPath=$CUSTOM_JAR_PATH,\
transformationClassName="com.custom.CustomTransformationFetcher",\
schemaOverridesFilePath=$GCS_OVERRIDES_PATH,\
shardingContextFilePath=$GCS_LIVE_SHARDING_PATH
Zmiany kluczowych parametrów ponawiania
runMode="retryDLQ": informuje szablon, że ma odczytywać dane z katalogusevereDLQ.- Usunięto
gcsPubSubSubscription: nie jest potrzebne, ponieważ nie odczytujemy danych z zasobnika GCS Datastream na żywo.
Monitorowanie procesu ponawiania:
Podobnie jak główny potok CDC, retryDLQ to potok przesyłania strumieniowego, który pozostanie RUNNING do momentu ręcznego anulowania.
- Otwórz stronę zadania Dataflow dla
$JOB_NAME_RETRY. - W panelu Dane znajdź te 2 liczniki:
elementsReconsumedFromDeadLetterQueue: ocenia, kiedy pobierane są pliki błędów.Successful events: zwiększa się, gdy rekord jest zapisywany w usłudze Spanner.- Sprawdź, czy w katalogu
severe/nie występują powtarzające się błędy. - Gdy liczba w sekcji „Udało się” zwiększy się o liczbę elementów, które chcesz ponownie przesłać (w naszym przypadku o 1), przejdź do następnego kroku weryfikacji.
C. Weryfikowanie ponowionych danych
Po ponowieniu próby przetworzenia nieudanego rekordu (może to trochę potrwać) sprawdź w Spannerze, czy wiersz podrzędny został prawidłowo przeniesiony:
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT CustomerId, OrderId, OrderValue, OrderSource FROM Orders WHERE CustomerId = 99999 AND OrderId = 502"
Powinien pojawić się wiersz:
CustomerId: 99999 OrderId: 502 OrderValue: 50 OrderSource: WebStore
Sprawdź też folder $DLQ_DIR_CDC/severe/ w GCS. Przetworzone pliki powinny zostać przeniesione lub usunięte, co oznacza, że ponowne przetwarzanie się powiodło.
11. Konfigurowanie replikacji zwrotnej (Spanner do MySQL)
Aby obsługiwać scenariusze, w których może być konieczne wycofanie zmian lub utrzymanie synchronizacji oryginalnej bazy danych MySQL z bazą danych Spanner w okresie przejściowym, możesz skonfigurować replikację zwrotną.
Ta ścieżka potoku korzysta ze strumieni zmian w Spannerze, aby rejestrować na żywo modyfikacje w Spannerze. Następnie używa naszego niestandardowego pliku JAR transformacji do odwrotnego mapowania różnic w schemacie oraz naszego niestandardowego pliku JAR dzielenia na partycje do obliczania, na której fizycznej maszynie wirtualnej MySQL i logicznej partycji należy zapisać aktualizację.
1. Tworzenie strumienia zmian w Spannerze
Najpierw musisz utworzyć strumień zmian w bazie danych Spanner, aby śledzić zmiany w tabelach Customers i Orders.
export CHANGE_STREAM_NAME="CustomersOrdersChangeStream"
gcloud spanner databases ddl update $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--ddl="CREATE CHANGE STREAM $CHANGE_STREAM_NAME FOR Customers, Orders"
Ten strumień zmian będzie teraz rejestrować wszystkie modyfikacje danych w określonych tabelach.
2. Tworzenie bazy danych Spanner na potrzeby metadanych Dataflow
Spanner to SourceDB Szablon Dataflow wymaga osobnej bazy danych Spanner do przechowywania metadanych na potrzeby zarządzania wykorzystaniem strumienia zmian.
export SPANNER_METADATA_DB_NAME="migration-metadata-db"
gcloud spanner databases create $SPANNER_METADATA_DB_NAME \
--instance=$SPANNER_INSTANCE_NAME
3. Przygotowywanie konfiguracji połączenia z Cloud SQL na potrzeby Dataflow
Szablon Dataflow wymaga pliku JSON w Cloud Storage zawierającego szczegóły połączenia z docelową bazą danych Cloud SQL.
Utwórz plik lokalny o nazwie shard_config.json:
cat <<EOF > reverse-sharding.json
[
{
"logicalShardId": "shard0_db",
"host": "${MYSQL_IP_1}",
"port": "3306",
"user": "datastream_user",
"password": "complex_password_123",
"dbName": "shard0_db"
},
{
"logicalShardId": "shard1_db",
"host": "${MYSQL_IP_1}",
"port": "3306",
"user": "datastream_user",
"password": "complex_password_123",
"dbName": "shard1_db"
},
{
"logicalShardId": "shard2_db",
"host": "${MYSQL_IP_2}",
"port": "3306",
"user": "datastream_user",
"password": "complex_password_123",
"dbName": "shard2_db"
},
{
"logicalShardId": "shard3_db",
"host": "${MYSQL_IP_2}",
"port": "3306",
"user": "datastream_user",
"password": "complex_password_123",
"dbName": "shard3_db"
}
]
EOF
Prześlij ten plik do zasobnika GCS:
export GCS_REVERSE_SHARDING_PATH="gs://${BUCKET_NAME}/config/reverse-sharding.json"
gcloud storage cp reverse-sharding.json $GCS_REVERSE_SHARDING_PATH
4. Uruchamianie zadania Dataflow replikacji zwrotnej
Uruchom zadanie Dataflow za pomocą szablonu Flex Spanner_to_SourceDb.
export JOB_NAME_REVERSE="spanner-sharded-reverse-to-mysql-$(date +%Y%m%d-%H%M%S)"
export DLQ_DIR_REVERSE="gs://${BUCKET_NAME}/reverse-replication"
gcloud dataflow flex-template run $JOB_NAME_REVERSE \
--project=$PROJECT_ID \
--region=$REGION \
--worker-machine-type=n2-highmem-8 \
--max-workers=2 \
--num-workers=1 \
--additional-experiments=use_runner_v2 \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Spanner_to_SourceDb" \
--parameters \
changeStreamName="$CHANGE_STREAM_NAME",\
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
spannerProjectId="$PROJECT_ID",\
metadataInstance="$SPANNER_INSTANCE_NAME",\
metadataDatabase="$SPANNER_METADATA_DB_NAME",\
sourceShardsFilePath="$GCS_REVERSE_SHARDING_PATH",\
transformationJarPath=$CUSTOM_JAR_PATH,\
transformationClassName="com.custom.CustomTransformationFetcher",\
shardingCustomJarPath=$CUSTOM_JAR_PATH,\
shardingCustomClassName="com.custom.CustomShardIdFetcher",\
schemaOverridesFilePath=$GCS_OVERRIDES_PATH,\
deadLetterQueueDirectory=$DLQ_DIR_REVERSE
Kluczowe parametry
changeStreamName: nazwa strumienia zmian w Spannerze, z którego mają być odczytywane dane.metadataInstance, metadataDatabase: instancja lub baza danych Spanner do przechowywania metadanych używanych przez łącznik do kontrolowania wykorzystania danych interfejsu Change Stream API.sourceShardsFilePath: ścieżka GCS do Twojegoshard_config.json.filtrationMode: określa, jak usuwać określone rekordy na podstawie kryteriów. Domyślnieforward_migration(filtruje rekordy zapisane za pomocą potoku migracji do przodu)shardingCustomJarPath: ścieżka GCS do skompilowanego pliku JAR w języku Java, który został utworzony wcześniej.shardingCustomClassName: pełna i jednoznaczna nazwa klasy (com.custom.CustomShardIdFetcher), która wykonuje nasze niestandardowe działanie matematyczne%4modulo, aby dynamicznie określić, który logiczny fragment powinien otrzymać rekord.
Uwaga dotycząca sieci: instancje robocze Dataflow będą łączyć się z instancją Cloud SQL przy użyciu publicznego adresu IP określonego w shard_config.json. To połączenie jest dozwolone ze względu na wpis 0.0.0.0/0 w sekcji Autoryzowane sieci instancji Cloud SQL.
Monitoruj uruchamianie zadania w konsoli zadań Dataflow.
5. Wstrzykiwanie danych Spannera i wywoływanie celowych błędów
Poczekaj, aż zadanie Dataflow przejdzie w stan Running (może to potrwać około 5 minut). Następnie wykonaj pełny pakiet zapytań (INSERT, UPDATE, DELETE) bezpośrednio w usłudze Spanner, a także celowo wywołaj błąd, aby przetestować odwrotną kolejkę DLQ.
Uruchom to polecenie w Cloud Shell:
# All these operations are done on rows mapping to shard0_db for convenience
# Valid INSERT: Insert parent row in Customers
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LoyaltyTier) VALUES (88, 'Reverse Tester', 5000, 'GOLD_TIER')"
# 1. Valid INSERT (Orders): 'WebStore' transformed to 'WebStore_v1'
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="INSERT INTO Orders (CustomerId, OrderId, OrderValue, OrderSource) VALUES (88, 9001, 150.00, 'WebStore')"
# 2. Valid UPDATE (Orders)
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="UPDATE Orders SET OrderValue = 200.00 WHERE CustomerId = 16 AND OrderId = 105 AND OrderSource = 'Partner'"
# 3. Valid DELETE (Orders)
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="DELETE FROM Orders WHERE CustomerId = 12 AND OrderId = 104 AND OrderSource = 'WebStore'"
# 4. INVALID Insert- DLQ Test: CreditLimit=500 will fail check constraint of >1000 at source
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LoyaltyTier) VALUES (44, 'DLQ Test Customer', 500, 'GOLD_TIER')"
6. Weryfikowanie danych replikacji zwrotnej i sprawdzanie kolejki DLQ
Sprawdźmy, czy nasz plik JAR niestandardowego dzielenia na partycje prawidłowo przekierował CustomerId 88 do shard0_db na naszej pierwszej fizycznej maszynie wirtualnej oraz czy plik JAR niestandardowej transformacji prawidłowo usunął "_TIER" z regionu.
A. Sprawdź prawidłowy rekord w MySQL:
Połącz się przez SSH z pierwszym fizycznym fragmentem:
gcloud compute ssh mysql-physical-1 --zone=$ZONE
Zaloguj się w MySQL i wyślij zapytanie shard0_db:
sudo mysql
USE shard0_db;
-- 1. Verify INSERT: Row migrated with transformed LegacyOrderSystem
SELECT CustomerId, OrderId, OrderValue, LegacyOrderSystem
FROM Orders
WHERE CustomerId = 88 AND OrderId = 9001;
-- 2. Verify UPDATE: The OrderValue should now be updated to 200.00.
SELECT CustomerId, OrderId, OrderValue, LegacyOrderSystem
FROM Orders
WHERE CustomerId = 16 AND OrderId = 105;
-- 3. Verify DELETE: Returns 0 rows, confirming the order was successfully deleted from MySQL.
SELECT CustomerId, OrderId
FROM Orders
WHERE CustomerId = 12 AND OrderId = 104;
-- 4. Verify failed replication - this should be in DLQ as CreditLimit < 1000 and will fail stricter check constraint at source
SELECT CustomerId, CustomerName, CreditLimit, LegacyRegion
FROM Customers
WHERE CustomerId = 44;
EXIT;
Oczekiwane dane wyjściowe w Cloud SQL powinny odzwierciedlać zmiany wprowadzone w Spannerze.
+------------+---------+------------+-------------------+ | CustomerId | OrderId | OrderValue | LegacyOrderSystem | +------------+---------+------------+-------------------+ | 88 | 9001 | 150.00 | Webstore_v1 | +------------+---------+------------+-------------------+ +------------+---------+------------+-------------------+ | CustomerId | OrderId | OrderValue | LegacyOrderSystem | +------------+---------+------------+-------------------+ | 16 | 105 | 200.00 | Partner_v1 | +------------+---------+------------+-------------------+ Empty set (0.00 sec) Empty set (0.00 sec)
Typ
exit
aby wrócić do Cloud Shell.
Potwierdza to, że potok replikacji zwrotnej działa i synchronizuje zmiany z Spanner z powrotem do Cloud SQL.
B. Sprawdź celowe niepowodzenie w DLQ
Nowy rekord Customers ma wartość CreditLimit 500 (co narusza ścisłe ograniczenie > 1000 zdefiniowane w źródłowej bazie danych MySQL), więc Dataflow bezpiecznie wykrył ten błąd.
- W konsoli Google Cloud otwórz Cloud Storage.
- Otwórz kosz i przejdź do folderu
dlq/severe/. - Otwórz plik JSON, aby zobaczyć odrzucony rekord
Customersi dokładny błąd naruszenia ograniczenia sprawdzania. - Błędy DLQ replikacji zwrotnej można ponowić, uruchamiając szablon Dataflow z ustawioną wartością
runMode=retryDLQ.
12. Czyszczenie zasobów
Aby uniknąć dalszych opłat na koncie Google Cloud, usuń zasoby utworzone podczas tego ćwiczenia.
Ustawianie zmiennych środowiskowych (w razie potrzeby)
Jeśli przekroczysz limit czasu sesji Cloud Shell lub otworzysz nowy terminal, przed uruchomieniem poleceń czyszczenia musisz ponownie wyeksportować zmienne środowiskowe.
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1" # Or your preferred region
export ZONE="us-central1-a" # Or a zone within your selected region
export SPANNER_INSTANCE_NAME="target-spanner-instance"
export SPANNER_DATABASE_NAME="sharded-target-db"
export SPANNER_CONFIG="regional-${REGION}"
export BUCKET_NAME="migration-${PROJECT_ID}-bucket"
export MYSQL_IP_1=$(gcloud compute instances describe mysql-physical-1 --zone=$ZONE --format='get(networkInterfaces[0].accessConfigs[0].natIP)')
export MYSQL_IP_2=$(gcloud compute instances describe mysql-physical-2 --zone=$ZONE --format='get(networkInterfaces[0].accessConfigs[0].natIP)')
export SQL_CP_NAME_1="mysql-src-cp-1"
export SQL_CP_NAME_2="mysql-src-cp-2"
export GCS_CP_NAME="gcs-dest-cp"
export STREAM_NAME_1="mysql-to-spanner-stream-1"
export GCS_STREAM_PATH_1="data/${STREAM_NAME_1}"
export STREAM_NAME_2="mysql-to-spanner-stream-2"
export GCS_STREAM_PATH_2="data/${STREAM_NAME_2}"
export PUBSUB_TOPIC="datastream-gcs-updates"
export PUBSUB_SUBSCRIPTION="datastream-gcs-sub"
export CUSTOM_JAR_PATH="gs://${BUCKET_NAME}/custom-logic/spanner-custom-shard-1.0.jar"
export OVERRIDES_FILE="spanner_overrides.json"
export GCS_OVERRIDES_PATH="gs://${BUCKET_NAME}/config/${OVERRIDES_FILE}"
export GCS_SHARDING_PATH="gs://${BUCKET_NAME}/config/sharding.json"
export OUTPUT_DIR="gs://${BUCKET_NAME}/bulk-migration"
export GCS_LIVE_SHARDING_PATH="gs://${BUCKET_NAME}/config/live-sharding.json"
export DLQ_DIR_CDC="gs://${BUCKET_NAME}/live-migration"
export CHANGE_STREAM_NAME="CustomersOrdersChangeStream"
export SPANNER_METADATA_DB_NAME="migration-metadata-db"
export GCS_REVERSE_SHARDING_PATH="gs://${BUCKET_NAME}/config/reverse-sharding.json"
export DLQ_DIR_REVERSE="gs://${BUCKET_NAME}/reverse-replication"
Zatrzymywanie zadań strumieniowych Dataflow
Wyświetl listę zadań, aby znaleźć identyfikatory uruchomionych zadań Dataflow. Wyeksportuj odpowiednio JOB_ID_CDC i JOB_ID_REVERSE.
gcloud dataflow jobs list --region=$REGION --filter="state=Running"
export JOB_ID_CDC=<PASTE_JOB_ID_HERE>
export JOB_ID_CDC_RETRY=<PASTE_JOB_ID_HERE>
export JOB_ID_REVERSE=<PASTE_JOB_ID_HERE>
Anuluj zadanie Datastream to Spanner (migracja na żywo) i jego ponowne wykonanie:
gcloud dataflow jobs cancel $JOB_ID_CDC --region=$REGION --project=$PROJECT_ID
gcloud dataflow jobs cancel $JOB_ID_CDC_RETRY --region=$REGION --project=$PROJECT_ID
Anuluj zadanie Spanner to Cloud SQL (replikacja zwrotna):
gcloud dataflow jobs cancel $JOB_ID_REVERSE --region=$REGION --project=$PROJECT_ID
Usuwanie zasobów strumienia danych
Zatrzymaj i usuń strumień:
gcloud datastream streams update $STREAM_NAME_1 \
--location=$REGION --state=PAUSED --project=$PROJECT_ID
# Wait a moment for the stream to pause
gcloud datastream streams delete $STREAM_NAME_1 \
--location=$REGION --project=$PROJECT_ID --quiet
gcloud datastream streams update $STREAM_NAME_2 \
--location=$REGION --state=PAUSED --project=$PROJECT_ID
# Wait a moment for the stream to pause
gcloud datastream streams delete $STREAM_NAME_2 \
--location=$REGION --project=$PROJECT_ID --quiet
# Delete Connection Profiles
gcloud datastream connection-profiles delete $SQL_CP_NAME_1 \
--location=$REGION --project=$PROJECT_ID --quiet
gcloud datastream connection-profiles delete $SQL_CP_NAME_2 \
--location=$REGION --project=$PROJECT_ID --quiet
gcloud datastream connection-profiles delete $GCS_CP_NAME \
--location=$REGION --project=$PROJECT_ID --quiet
Usuwanie źródłowych maszyn wirtualnych MySQL (Compute Engine)
Usuń 2 instancje Compute Engine, które symulowały fizyczne fragmenty lokalnej bazy danych MySQL.
gcloud compute instances delete mysql-physical-1 mysql-physical-2 --zone=$ZONE --quiet
Usuwanie reguł zapory sieciowej
Usuń reguły zapory sieciowej utworzone w celu zezwolenia na dostęp SSH i łączność Datastream z maszynami wirtualnymi. (Uwaga: jeśli w poprzednich krokach tego laboratorium użyto innych nazw reguł zapory sieciowej, dostosuj je tutaj).
gcloud compute firewall-rules delete allow-ssh-iap --quiet
gcloud compute firewall-rules delete allow-mysql-datastream --quiet
Usuwanie zasobów Pub/Sub
Usuń subskrypcję:
gcloud pubsub subscriptions delete $PUBSUB_SUBSCRIPTION \
--project=$PROJECT_ID --quiet
Usuń temat:
gcloud pubsub topics delete $PUBSUB_TOPIC \
--project=$PROJECT_ID --quiet
Usuwanie instancji Cloud Spanner
Usuń instancję Cloud Spanner (spowoduje to automatyczne usunięcie baz danych sharded-target-db i migration-metadata-db).
gcloud spanner instances delete $SPANNER_INSTANCE_NAME \
--project=$PROJECT_ID --quiet
Usuwanie zasobnika GCS i jego zawartości
Na koniec usuń zasobnik Cloud Storage, w którym znajdują się pliki Datastream, konfiguracje Dataflow i kolejki wiadomości niedostarczonych. Polecenie rm -r rekursywnie usuwa zasobnik i całą jego zawartość.
gcloud storage rm --recursive gs://${BUCKET_NAME}
Usuwanie lokalnych plików Cloud Shell
Aby zwolnić miejsce na lokalnych plikach i katalogach wygenerowanych w Cloud Shell podczas tego ćwiczenia, uruchom te polecenia:
# Remove the JSON configuration files
rm -f sharding.json live-sharding.json reverse-sharding.json spanner_overrides.json
# Remove the cloned Google Cloud DataflowTemplates repository
rm -rf DataflowTemplates