
1. Prima di iniziare
Questo codelab ti guida nella migrazione di un database MySQL on-premise partizionato a un database Cloud Spanner con il dialetto GoogleSQL. Utilizzerai i servizi Google Cloud, tra cui Spanner Migration Tool (SMT), Dataflow, Datastream, Pub/Sub e Google Cloud Storage.
Cosa imparerai:
- Che cos'è un ambiente partizionato e come configurarlo.
- Come utilizzare la UI web dello strumento di migrazione di Spanner (SMT) per convertire uno schema MySQL in uno schema compatibile con Spanner ed eseguire modifiche avanzate dello schema.
- Come eseguire la migrazione collettiva dei dati dall'istanza MySQL partizionata a Cloud Spanner utilizzando Dataflow.
- Come configurare la replica continua (CDC) dall'istanza MySQL partizionata a Cloud Spanner utilizzando Datastream e Dataflow.
- Come configurare la replica inversa da Spanner alle istanze MySQL con sharding.
- Come utilizzare le trasformazioni personalizzate per compilare colonne aggiuntive durante le migrazioni collettive, live e inverse.
- Come configurare le trasformazioni di partizionamento utilizzando le chiavi primarie.
Cosa NON copre questo codelab:
- Networking personalizzato avanzato.
- Creazione di modelli Dataflow personalizzati da zero.
- Ottimizzazione del rendimento della migrazione.
- Migrazione delle applicazioni:questo codelab si concentra sul livello del database (schema e dati). Non copre il processo operativo di ripristino o migrazione dei servizi applicativi.
Che cosa ti serve
- Un progetto Google Cloud con la fatturazione abilitata.
- Autorizzazioni IAM sufficienti per attivare le API e creare/gestire risorse Spanner, Dataflow, Datastream e GCS. Sebbene il ruolo Progetto
Ownersia il più semplice per un codelab, i ruoli più specifici verranno trattati nella sezione "Configurazione dell'ambiente". - Durante la fase di configurazione, verrà eseguito il provisioning di una piccola VM di Compute Engine per simulare il nostro server on-premise. Assicurati che la quota del progetto consenta la creazione di VM.
- Un browser web, ad esempio Google Chrome.
- Familiarità di base con la console Google Cloud e gli strumenti a riga di comando come
gcloud. - Accesso a un ambiente shell. Cloud Shell è consigliato perché include
gcloud.
Ulteriori dettagli sulla configurazione precedente sono disponibili nella sezione Configurazione dell'ambiente.
2. Informazioni sul processo di migrazione
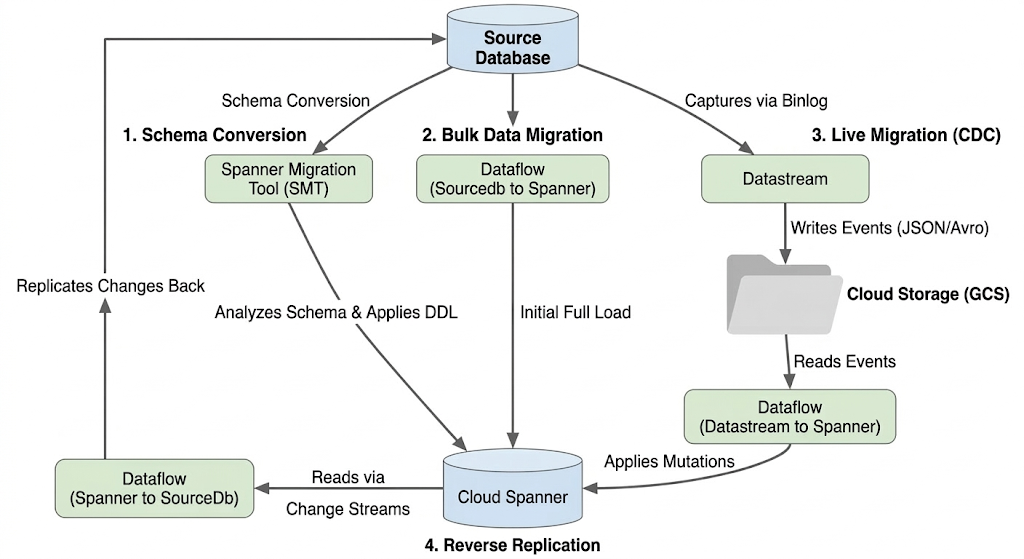
La migrazione di un database partizionato comporta il consolidamento di più istanze MySQL fisiche e logiche in un unico database Spanner scalabile orizzontalmente. Questa sezione descrive l'architettura e gli strumenti chiave utilizzati nella migrazione.
Architettura del flusso di migrazione
Il processo di migrazione prevede le seguenti fasi:
1. Conversione dello schema:
- Scopo:convertire lo schema del database di origine in uno schema Cloud Spanner compatibile.
- Strumento: Strumento di migrazione di Spanner (SMT)
- Procedura:SMT analizza lo schema del database di origine e genera il Data Definition Language (DDL) di Spanner equivalente. Nell'istanza Spanner di destinazione viene creato un database e la DDL viene applicata automaticamente.
2. Migrazione dei dati in blocco:
- Scopo:eseguire un caricamento completo iniziale dei dati esistenti dal database di origine alle tabelle Spanner di cui è stato eseguito il provisioning.
- Strumento:Dataflow, utilizzando il modello
Sourcedb to Spannerfornito da Google. - Processo:questo job Dataflow legge tutti i dati dalle tabelle di origine specificate e li scrive nelle tabelle Spanner corrispondenti. Questa operazione viene eseguita dopo la creazione dello schema Spanner.
3. Migrazione live (CDC):
- Scopo:acquisire e applicare le modifiche in corso dal database di origine a Cloud Spanner quasi in tempo reale, riducendo al minimo i tempi di inattività durante la migrazione.
- Strumenti:
- Datastream:acquisisce le modifiche (inserimenti, aggiornamenti, eliminazioni) dal database di origine e le scrive in Cloud Storage (GCS).
- Dataflow:utilizza il modello
Datastream to Spannerper leggere gli eventi di modifica da GCS e applicarli a Cloud Spanner.
4. Replica inversa:
- Scopo:replicare le modifiche ai dati da Cloud Spanner al database di origine. Ciò può essere utile per le strategie di fallback, le migrazioni in fasi o per mantenere una replica nell'origine per casi d'uso specifici.
- Strumento:Dataflow, utilizzando il modello
Spanner to SourceDb. - Processo:questo job utilizza i flussi di modifiche in tempo reale di Spanner per acquisire le modifiche in Spanner e riscriverle nell'istanza del database di origine.
Il seguente diagramma illustra i componenti e il flusso di dati:
Terminologia chiave:
- Shard fisico:il server o l'istanza di computing sottostante effettivo che ospita il database (nel nostro caso, la VM GCE on-premise simulata).
- Shard logico:lo schema di database individuale all'interno di un server fisico.
- VM Compute Engine (GCE): una macchina virtuale ospitata sull'infrastruttura cloud di Google. In questo codelab utilizziamo una VM GCE per simulare un server bare metal autonomo "on-premise" che ospita il nostro database MySQL di origine.
- Strumento di migrazione Spanner (SMT): uno strumento utilizzato per valutare gli schemi MySQL, suggerire equivalenti dello schema Spanner e generare il Data Definition Language (DDL) di Spanner.
- Data Definition Language (DDL): istruzioni utilizzate per definire e modificare la struttura del database, ad esempio le istruzioni
CREATE TABLE. SMT genera il linguaggio DDL di Spanner in base allo schema Cloud SQL. - Dataflow: un servizio di elaborazione dei dati serverless completamente gestito. In questo codelab, viene utilizzato per eseguire i modelli forniti da Google per il trasferimento collettivo dei dati, l'applicazione delle modifiche di Datastream e la replica inversa.
- Datastream: un servizio di replica e Change Data Capture (CDC) serverless. In questo codelab viene utilizzato per trasmettere in streaming le modifiche dall'istanza MySQL ospitata localmente a Cloud Storage.
- Flussi di modifiche di Spanner: una funzionalità di Spanner che consente di trasmettere in streaming le modifiche ai dati (inserimenti, aggiornamenti, eliminazioni) in tempo reale, utilizzata come origine per la replica inversa.
- Pub/Sub: un servizio di messaggistica utilizzato per disaccoppiare i servizi che producono eventi da quelli che li elaborano. In questo codelab, attiva Dataflow per elaborare gli aggiornamenti ogni volta che Datastream carica nuovi file di modifiche in Cloud Storage.
3. Configurazione dell'ambiente
Prima di poter iniziare la migrazione, devi configurare il progetto Google Cloud e abilitare i servizi necessari.
1. Selezionare o creare un progetto Google Cloud
Per utilizzare i servizi in questo codelab, devi disporre di un progetto Google Cloud con la fatturazione abilitata.
- Nella console Google Cloud, vai alla pagina del selettore dei progetti: Vai al selettore dei progetti
- Seleziona o crea un progetto Google Cloud.
- Verifica che la fatturazione sia attivata per il tuo progetto. Scopri come verificare che la fatturazione sia abilitata per il tuo progetto.
2. Apri Cloud Shell
Cloud Shell è un ambiente a riga di comando in esecuzione in Google Cloud che viene precaricato con l'interfaccia a riga di comando gcloud e altri strumenti necessari.
- Fai clic sul pulsante Attiva Cloud Shell in alto a destra nella console Google Cloud.
- All'interno di un nuovo frame nella parte inferiore della console si apre una sessione di Cloud Shell e viene visualizzato un prompt della riga di comando.

3. Imposta le variabili di progetto e di ambiente
In Cloud Shell, configura alcune variabili di ambiente per l'ID progetto e la regione che utilizzerai.
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1" # Or your preferred region
export ZONE="us-central1-a" # Or a zone within your selected region
gcloud config set project $PROJECT_ID
gcloud config set compute/region $REGION
gcloud config set compute/zone $ZONE
echo "Project ID: $PROJECT_ID"
echo "Region: $REGION"
echo "Zone: $ZONE"
4. Abilita le API Cloud richieste
Abilita le API necessarie per Cloud Spanner, Dataflow, Datastream e altri servizi correlati.
gcloud services enable \
spanner.googleapis.com \
dataflow.googleapis.com \
datastream.googleapis.com \
pubsub.googleapis.com \
storage.googleapis.com \
compute.googleapis.com \
sqladmin.googleapis.com \
servicenetworking.googleapis.com \
cloudresourcemanager.googleapis.com
Il completamento di questo comando potrebbe richiedere alcuni minuti.
4. Configura il database MySQL di origine
In questa sezione simuleremo un'architettura MySQL con partizionamento on-premise eseguendo il provisioning di due macchine virtuali Compute Engine (i nostri due "shard fisici"). Poi installeremo MySQL su entrambe e creeremo due database (i nostri "shard logici") su ogni VM.
1. Crea le VM Compute Engine (shard fisici)
Esegui questi comandi in Cloud Shell per creare due VM con Ubuntu. Assegneremo loro tag di rete per consentire il traffico MySQL in entrata in un secondo momento.
# Create Physical Shard 1
gcloud compute instances create mysql-physical-1 \
--zone=$ZONE \
--machine-type=e2-small \
--image-family=ubuntu-2204-lts \
--image-project=ubuntu-os-cloud \
--tags=mysql-server
# Create Physical Shard 2
gcloud compute instances create mysql-physical-2 \
--zone=$ZONE \
--machine-type=e2-small \
--image-family=ubuntu-2204-lts \
--image-project=ubuntu-os-cloud \
--tags=mysql-server
2. Configura le regole firewall
Per consentire l'accesso SSH sicuro senza esposizione pubblica e per abilitare la connettività Datastream:
Crea una regola firewall per SSH tramite IAP:
Questa regola consente a Identity-Aware Proxy di raggiungere le tue VM sulla porta SSH (22).
gcloud compute firewall-rules create allow-ssh-iap \
--direction=INGRESS \
--priority=1000 \
--network=default \
--action=ALLOW \
--rules=tcp:22 \
--source-ranges=35.235.240.0/20 \
--target-tags=mysql-server
Crea una regola firewall per Datastream (porta MySQL):
Datastream deve essere in grado di raggiungere queste VM sulla porta MySQL standard (3306).
gcloud compute firewall-rules create allow-mysql-datastream \
--direction=INGRESS \
--priority=1000 \
--network=default \
--action=ALLOW \
--rules=tcp:3306 \
--source-ranges=0.0.0.0/0 \
--target-tags=mysql-server
3. Installa e configura MySQL su Physical Shard 1
Accedi tramite SSH alla prima VM per installare MySQL e configurare il logging binario (richiesto da Datastream per la replica in tempo reale).
- Accedi tramite SSH alla prima VM:
gcloud compute ssh mysql-physical-1 --zone=$ZONE --tunnel-through-iap
- Installa MySQL:
sudo apt-get update
sudo apt-get install mysql-server-8.0 -y
# Verify the installation and version
sudo mysql --version
- Configura il file
mysqld.cnfper abilitare il logging binario e consentire le connessioni esterne:
sudo sed -i 's/bind-address.*/bind-address = 0.0.0.0/' /etc/mysql/mysql.conf.d/mysqld.cnf
echo -e "[mysqld]\nserver-id=1\nlog_bin=/var/log/mysql/mysql-bin.log\nbinlog_format=ROW" | sudo tee -a /etc/mysql/mysql.conf.d/mysqld.cnf
- Riavvia MySQL per applicare le modifiche:
sudo systemctl restart mysql
4. Crea shard logici, inserisci dati e crea utente Datastream (shard 1)
Mentre la connessione SSH a mysql-physical-1 è ancora attiva, accedi al prompt MySQL:
sudo mysql
Esegui i seguenti comandi SQL. Questo script crea due shard logici distinti (shard0_db e shard1_db), configura lo stesso schema in entrambi, inserisce dati identificabili in modo univoco in ciascuno (per dimostrare lo sharding) e crea l'utente di replica per Datastream.
Esegui i seguenti comandi SQL per creare i primi due shard logici, una tabella e l'utente di replica per Datastream:
CREATE DATABASE shard0_db;
CREATE DATABASE shard1_db;
USE shard0_db;
CREATE TABLE Customers (
CustomerId INT NOT NULL,
CustomerName VARCHAR(255),
CreditLimit DECIMAL(10, 2) NOT NULL,
LegacyRegion VARCHAR(50), -- Renamed to LoyaltyTier in Spanner
PRIMARY KEY (CustomerId),
CONSTRAINT CHK_CreditLimit CHECK (CreditLimit > 1000) -- Relaxed in Spanner to > 0
);
CREATE TABLE Orders (
CustomerId INT NOT NULL, -- Logically references Customers.CustomerId in Spanner
OrderId INT NOT NULL,
OrderValue DECIMAL(10, 2),
LegacyOrderSystem VARCHAR(50), -- Extra column in Source, to be dropped in Spanner
PRIMARY KEY (CustomerId, OrderId) -- Spanner PK will have one additional column in PK
);
INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LegacyRegion) VALUES
(4, 'David E.', 2000.00, 'EAST'),
(8, 'Eleanor F.', 8100.00, 'WEST'),
(12, 'Frank G.', 12000.00, 'NORTH'),
(16, 'Grace H.', 6500.00, 'SOUTH');
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem) VALUES
(4, 101, 150.00, 'WebStore_v1'),
(4, 102, 25.50, 'InStore_POS'),
(8, 103, 75.00, 'MobileApp_Legacy'),
(12, 104, 3000.00, 'WebStore_v1'),
(16, 105, 120.00, 'Partner_API');
USE shard1_db;
CREATE TABLE Customers (
CustomerId INT NOT NULL,
CustomerName VARCHAR(255),
CreditLimit DECIMAL(10, 2) NOT NULL,
LegacyRegion VARCHAR(50), -- Renamed to LoyaltyTier in Spanner
PRIMARY KEY (CustomerId),
CONSTRAINT CHK_CreditLimit CHECK (CreditLimit > 1000) -- Relaxed in Spanner to > 0
);
CREATE TABLE Orders (
CustomerId INT NOT NULL, -- Logically references Customers.CustomerId in Spanner
OrderId INT NOT NULL,
OrderValue DECIMAL(10, 2),
LegacyOrderSystem VARCHAR(50), -- Extra column in Source, to be dropped in Spanner
PRIMARY KEY (CustomerId, OrderId) -- Spanner PK will have one additional column in PK
);
INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LegacyRegion) VALUES
(1, 'Agnes N.', 5100.00, 'NORTHEAST'),(5, 'Alice I.', 15000.00, 'EAST'),
(9, 'Bob J.', 7500.00, 'WEST'),
(13, 'Charlie K.', 2200.00, 'CENTRAL');
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem) VALUES
(1, 201, 50.00, 'MobileApp_Legacy'),
(5, 202, 1250.00, 'WebStore_v1'),
(5, 203, 80.00, 'Partner_API'),
(9, 204, 600.00, 'InStore_POS'),
(13, 205, 199.99, 'WebStore_v1');
-- Create Datastream Replication User
CREATE USER 'datastream_user'@'%' IDENTIFIED BY 'complex_password_123';
GRANT REPLICATION SLAVE, REPLICATION CLIENT, SELECT, INSERT, UPDATE, DELETE ON *.* TO 'datastream_user'@'%';
FLUSH PRIVILEGES;
Il file di dump per lo schema riportato sopra è disponibile qui. È importante creare separatamente l'utente di replica del flusso di dati, poiché non è incluso nel file di dump.
5. Verifica dei dati
Verifica rapidamente che i dati siano presenti:
SELECT 'Customers shard0_db' AS tbl, COUNT(*) FROM shard0_db.Customers
UNION ALL
SELECT 'Orders shard0_db', COUNT(*) FROM shard0_db.Orders
UNION ALL
SELECT 'Customers shard1_db', COUNT(*) FROM shard1_db.Customers
UNION ALL
SELECT 'Orders shard1_db', COUNT(*) FROM shard1_db.Orders;
EXIT;
Output previsto:
+---------------------+----------+ | tbl | COUNT(*) | +---------------------+----------+ | Customers shard0_db | 4 | | Orders shard0_db | 5 | | Customers shard1_db | 4 | | Orders shard1_db | 5 | +---------------------+----------+
Inserisci exit per uscire dalla connessione alla VM shard fisico 1.
6. Ripeti per lo shard fisico 2
Ora ripeterai esattamente la stessa procedura per la seconda VM, ma creerai shard2_db e shard3_db e modificherai server-id.
- Accedi tramite SSH alla seconda VM:
gcloud compute ssh mysql-physical-2 --zone=$ZONE --tunnel-through-iap
- Installa MySQL:
sudo apt-get update
sudo apt-get install mysql-server-8.0 -y
- Configura il file
mysqld.cnfper attivare la registrazione binaria e consentire le connessioni esterne [tieni presente che server-id deve essere diverso (ad es. 2)]
sudo sed -i 's/bind-address.*/bind-address = 0.0.0.0/' /etc/mysql/mysql.conf.d/mysqld.cnf
echo -e "[mysqld]\nserver-id=2\nlog_bin=/var/log/mysql/mysql-bin.log\nbinlog_format=ROW" | sudo tee -a /etc/mysql/mysql.conf.d/mysqld.cnf
- Riavvia MySQL per applicare le modifiche:
sudo systemctl restart mysql
- Inserisci MySQL (
sudo mysql) ed esegui una versione leggermente modificata dell'SQL del passaggio 4:
CREATE DATABASE shard2_db;
CREATE DATABASE shard3_db;
USE shard2_db;
CREATE TABLE Customers (
CustomerId INT NOT NULL,
CustomerName VARCHAR(255),
CreditLimit DECIMAL(10, 2) NOT NULL,
LegacyRegion VARCHAR(50), -- Renamed to LoyaltyTier in Spanner
PRIMARY KEY (CustomerId),
CONSTRAINT CHK_CreditLimit CHECK (CreditLimit > 1000) -- Relaxed in Spanner to > 0
);
CREATE TABLE Orders (
CustomerId INT NOT NULL, -- Logically references Customers.CustomerId in Spanner
OrderId INT NOT NULL,
OrderValue DECIMAL(10, 2),
LegacyOrderSystem VARCHAR(50), -- Extra column in Source, to be dropped in Spanner
PRIMARY KEY (CustomerId, OrderId) -- Spanner PK will have one additional column in PK
);
INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LegacyRegion) VALUES
(2, 'Brian K.', 2500.00, 'SOUTHWEST'),
(6, 'Diana L.', 1999.00, 'NORTH'),
(10, 'Edward M.', 11000.00, 'EAST'),
(14, 'Fiona N.', 3000.00, 'WEST');
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem) VALUES
(2, 301, 100.00, 'CallCenter_System'),
(6, 302, 99.00, 'MobileApp_Legacy'),
(10, 303, 1000.00, 'WebStore_v1'),
(10, 304, 2500.00, 'InStore_POS'),
(14, 305, 130.00, 'MobileApp_Legacy');
USE shard3_db;
CREATE TABLE Customers (
CustomerId INT NOT NULL,
CustomerName VARCHAR(255),
CreditLimit DECIMAL(10, 2) NOT NULL,
LegacyRegion VARCHAR(50), -- Renamed to LoyaltyTier in Spanner
PRIMARY KEY (CustomerId),
CONSTRAINT CHK_CreditLimit CHECK (CreditLimit > 1000) -- Relaxed in Spanner to > 0
);
CREATE TABLE Orders (
CustomerId INT NOT NULL, -- Logically references Customers.CustomerId in Spanner
OrderId INT NOT NULL,
OrderValue DECIMAL(10, 2),
LegacyOrderSystem VARCHAR(50), -- Extra column in Source, to be dropped in Spanner
PRIMARY KEY (CustomerId, OrderId) -- Spanner PK will have one additional column in PK
);
INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LegacyRegion) VALUES
(3, 'Cathy Z.', 6000.00, 'CENTRAL'),
(7, 'George O.', 18000.00, 'SOUTH'),
(11, 'Helen P.', 4000.00, 'NORTHEAST'),
(15, 'Ivy Q.', 9500.00, 'SOUTHWEST');
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem) VALUES
(3, 401, 600.00, 'InStore_POS'),
(7, 402, 1200.00, 'CallCenter_System'),
(11, 403, 350.00, 'MobileApp_Legacy'),
(15, 404, 800.00, 'WebStore_v1'),
(99, 999, 25.00, 'CallCenter_System'); -- Failure row during Bulk Migration due to violation of interleaving
-- Create Datastream Replication User
CREATE USER 'datastream_user'@'%' IDENTIFIED BY 'complex_password_123';
GRANT REPLICATION SLAVE, REPLICATION CLIENT, SELECT, INSERT, UPDATE, DELETE ON *.* TO 'datastream_user'@'%';
FLUSH PRIVILEGES;
-- Verify Data
SELECT 'Customers shard2_db' AS tbl, COUNT(*) FROM shard2_db.Customers
UNION ALL
SELECT 'Orders shard2_db', COUNT(*) FROM shard2_db.Orders
UNION ALL
SELECT 'Customers shard3_db', COUNT(*) FROM shard3_db.Customers
UNION ALL
SELECT 'Orders shard3_db', COUNT(*) FROM shard3_db.Orders;
EXIT;
Output previsto:
+---------------------+----------+ | tbl | COUNT(*) | +---------------------+----------+ | Customers shard2_db | 4 | | Orders shard2_db | 5 | | Customers shard3_db | 4 | | Orders shard3_db | 5 | +---------------------+----------+
Il file di dump per lo schema riportato sopra è disponibile qui. È importante creare separatamente l'utente di replica del flusso di dati, poiché non è incluso nel file di dump.
Inserisci exit per uscire dalla connessione alla VM.
5. Configura Cloud Spanner
Ora configurerai l'istanza Cloud Spanner di destinazione in cui verranno migrati i dati.
1. Crea un'istanza Cloud Spanner
Crea un'istanza Cloud Spanner nella stessa regione delle tue VM Compute Engine per ridurre al minimo la latenza. Questo comando crea un'istanza piccola adatta a questo codelab, utilizzando 100 unità di elaborazione.
export SPANNER_INSTANCE_NAME="target-spanner-instance"
export SPANNER_DATABASE_NAME="sharded-target-db"
export SPANNER_CONFIG="regional-${REGION}"
gcloud spanner instances create $SPANNER_INSTANCE_NAME \
--config=$SPANNER_CONFIG \
--description="Target Spanner Instance" \
--processing-units=100
La creazione dell'istanza potrebbe richiedere un paio di minuti.
6. Converti lo schema utilizzando lo strumento di migrazione di Spanner (SMT)
Utilizza la GUI web di Spanner Migration Tool (SMT) per connetterti a uno dei nostri shard logici (shard0_db), analizzarne lo schema e applicare diverse modifiche avanzate prima di convertirlo in Cloud Spanner.
1. Installare SMT
Eseguiamo la GUI web SMT direttamente da Cloud Shell. Nel terminale Cloud Shell, scarica ed estrai l'ultima release di SMT:
sudo apt-get update && sudo apt-get install google-cloud-cli-spanner-migration-tool
# Verify installation
gcloud alpha spanner migrate web --help
2. Connettiti al database di origine
- Autenticare la sessione
# Authenticate your Google Cloud account
gcloud auth login
# Set up Application Default Credentials (ADC) for SMT
gcloud auth application-default login
# Ensure your current project is set correctly
gcloud config set project $PROJECT_ID
(Nota: quando richiesto, segui l'URL fornito per autorizzare il tuo account e incolla il codice di verifica nel terminale.)
- Innanzitutto, trova l'IP esterno del primo shard fisico eseguendo questo comando in una nuova scheda di Cloud Shell:
gcloud compute instances describe mysql-physical-1 --zone=$ZONE --format='get(networkInterfaces[0].accessConfigs[0].natIP)'
- Stampa i dettagli dell'istanza Spanner di destinazione da utilizzare durante la configurazione di SMT.
echo "Project ID: $PROJECT_ID"
echo "Instance ID: $SPANNER_INSTANCE_NAME"
echo "Database Name: $SPANNER_DATABASE_NAME"
- Avvia l'interfaccia utente web:
gcloud alpha spanner migrate web --port=8080
- In alto a destra nella finestra di Cloud Shell, fai clic sull'icona Anteprima web (a forma di occhio) e seleziona Anteprima sulla porta 8080. L'interfaccia utente di SMT si aprirà in una nuova scheda del browser.

- Nell'interfaccia utente web di SMT, seleziona Connetti al database.
- Compila i dettagli della connessione:
- Tipo di database: MySQL
- Host: (incolla l'indirizzo IP del passaggio 2)
- Porta: 3306
- Utente:
datastream_user - Password:
complex_password_123 - Nome database:
shard0_db
- Fai clic sul pulsante di modifica nell'angolo in alto a destra per configurare il database Spanner.
- Inserisci i dettagli di Target Spanner:
- ID progetto: (incolla l'ID progetto del passaggio 3)
- Istanza Spanner: (incolla l'ID istanza del passaggio 3)
- Fai clic su Prova connessione.
- Una volta superato il test, fai clic su Connetti. SMT analizzerà il database di origine e presenterà uno schema Spanner di base.

3. Applica modifiche allo schema
Ora rimodelleremo lo schema per coprire i nostri complessi scenari di migrazione.
Nell'editor di schema della UI di SMT, esegui le seguenti azioni:
A. Rinomina la colonna LegacyRegion:
- Fai clic sulla tabella
Customersnel riquadro di navigazione a sinistra. Per impostazione predefinita, viene aperta la scheda Colonne. - Fai clic sul pulsante Modifica nella sezione Chiave.
- Individua la colonna
LegacyRegionnella visualizzazione dello schema Spanner. - Modifica il nome della colonna Spanner in
LoyaltyTierdigitandolo nella finestra di dialogo del nome della colonna. - Fai clic su Salva e converti.


B. Rilassa il vincolo di controllo:
- Sempre nella tabella
Customers, vai alla scheda Vincoli di controllo. - Trova il vincolo
CHK_CreditLimit. Fai clic sull'icona Modifica (a forma di matita). - Modifica la condizione da
CreditLimit > 1000aCreditLimit > 0. (In questo modo, le righe con limiti di credito inferiori non verranno migrate e verranno inserite nella DLQ).

C. Elimina la colonna LegacyOrderSystem:
- Fai clic sulla tabella
Ordersper aprire la scheda Colonne per impostazione predefinita. - Fai clic sul pulsante Modifica nella sezione Chiave.
- Individua la colonna
LegacyOrderSystemnella visualizzazione dello schema Spanner. - Fai clic sull'icona del menu con tre puntini accanto e seleziona Elimina colonna.
- Fai clic su Salva e converti.

D. Aggiungi la colonna OrderSource e impostala come chiave primaria:
- Sempre nella tabella
Orders, fai clic su Aggiungi colonna. Assegna il nomeOrderSourcee imposta il tipo suSTRINGcon lunghezza50, nessuna generazione automatica e impostaIsNullablesuNo. - Vai alla scheda Chiave primaria.
- Fai clic su Modifica e scegli
OrderSourcedal menu a discesa Nome colonna. - Fai clic su Aggiungi colonna e poi su Salva e converti.


E. Alterna la tabella degli ordini:
- Sempre nella tabella
Orders, nella visualizzazione principale della tabella individua la scheda Interleave. - Imposta la tabella principale su
Customers. - Scegli
IN PARENTTipo di interleaving eNO ACTIONAzione di eliminazione. - Fai clic su Salva.

4. Scaricare il file di override e applicare lo schema
- Nell'angolo in alto a destra della UI di SMT, individua il pulsante Scarica artefatti. Seleziona l'opzione Scarica file di override. Salva questo file sul tuo computer locale. Questo file contiene tutte le modifiche al mapping dello schema appena apportate e verrà utilizzato dalle nostre pipeline Dataflow.
- Fai clic su Prepara migrazione.

- Scegli Modalità di migrazione come
Schemadal menu a discesa. - Inserisci il database Spanner di destinazione:
sharded-target-db

- Fai clic su Esegui la migrazione.
- SMT applicherà il DDL e creerà il database Spanner. Puoi interrompere in sicurezza il processo SMT in Cloud Shell (
Ctrl+C) al termine.
5. Verifica lo schema in Cloud Spanner
Verifica che le tabelle siano state create nel database Spanner.
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT table_name FROM information_schema.tables WHERE table_schema = '' ORDER BY table_name"
Dovresti vedere l'output seguente:
table_name: Customers table_name: Orders
(Facoltativo) Se vuoi controllare il DDL Spanner effettivo per verificare che i vincoli di controllo, l'interleaving e le colonne aggiuntive siano stati applicati, esegui questo comando:
gcloud spanner databases ddl describe $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME
Output previsto:
CREATE TABLE Customers ( CustomerId INT64 NOT NULL, CustomerName STRING(255), CreditLimit NUMERIC NOT NULL, LoyaltyTier STRING(50), CONSTRAINT CHK_CreditLimit CHECK(`CreditLimit` > 0), ) PRIMARY KEY(CustomerId); CREATE TABLE Orders ( CustomerId INT64 NOT NULL, OrderId INT64 NOT NULL, OrderValue NUMERIC, OrderSource STRING(50) NOT NULL, ) PRIMARY KEY(CustomerId, OrderId, OrderSource), INTERLEAVE IN PARENT Customers ON DELETE NO ACTION;
7. Inizializza Change Data Capture (CDC)
In questa sezione configurerai il "registratore" per la migrazione. Configurando Datastream e Pub/Sub prima dell'inizio del caricamento collettivo dei dati, ti assicuri che ogni modifica apportata ai database di origine venga acquisita e messa in coda, evitando qualsiasi perdita di dati durante la transizione. Questa configurazione è necessaria per la migrazione live.
Poiché la nostra architettura prevede due server fisici, dobbiamo creare due profili di origine Datastream separati e due stream Datastream. Entrambi i flussi scriveranno in un unico bucket Google Cloud Storage (GCS), che fungerà da origine unificata per la pipeline Dataflow.
1. Crea un bucket Cloud Storage
Datastream richiede una destinazione per archiviare gli eventi di modifica acquisiti. Creiamo un bucket GCS.
export BUCKET_NAME="migration-${PROJECT_ID}-bucket"
gcloud storage buckets create gs://${BUCKET_NAME} --location=$REGION
2. Crea profili di connessione Datastream
Abbiamo bisogno di due profili di connessione di origine MySQL distinti (uno per ogni shard fisico) e di un profilo di connessione di destinazione per Cloud Storage.
Ottieni gli indirizzi IP di origine
Per prima cosa, recupera gli indirizzi IP esterni delle due VM Compute Engine e archiviali come variabili di ambiente:
export MYSQL_IP_1=$(gcloud compute instances describe mysql-physical-1 --zone=$ZONE --format='get(networkInterfaces[0].accessConfigs[0].natIP)')
export MYSQL_IP_2=$(gcloud compute instances describe mysql-physical-2 --zone=$ZONE --format='get(networkInterfaces[0].accessConfigs[0].natIP)')
Crea profili di connessione di origine (MySQL su Compute Engine)
Crea i profili di connessione Datastream utilizzando datastream_user creato in precedenza.
# Create Source Profile for Physical Shard 1
export SQL_CP_NAME_1="mysql-src-cp-1"
gcloud datastream connection-profiles create $SQL_CP_NAME_1 \
--location=$REGION \
--type=mysql \
--mysql-hostname=$MYSQL_IP_1 \
--mysql-port=3306 \
--mysql-username=datastream_user \
--mysql-password=complex_password_123 \
--display-name="MySQL Source 1 (Physical Shard 1)"
# Create Source Profile for Physical Shard 2
export SQL_CP_NAME_2="mysql-src-cp-2"
gcloud datastream connection-profiles create $SQL_CP_NAME_2 \
--location=$REGION \
--type=mysql \
--mysql-hostname=$MYSQL_IP_2 \
--mysql-port=3306 \
--mysql-username=datastream_user \
--mysql-password=complex_password_123 \
--display-name="MySQL Source 2 (Physical Shard 2)"
Nota:Datastream si connette a queste VM tramite i relativi IP pubblici, il che è consentito perché in precedenza abbiamo aggiunto 0.0.0.0/0 alle nostre regole firewall. In un ambiente di produzione, dovresti inserire rigorosamente nella lista consentita gli intervalli IP pubblici specifici di Datastream.
Crea il profilo di connessione di destinazione (Cloud Storage):
Questo percorso punta alla radice del bucket appena creato.
export GCS_CP_NAME="gcs-dest-cp"
gcloud datastream connection-profiles create $GCS_CP_NAME \
--location=$REGION \
--type=google-cloud-storage \
--bucket=$BUCKET_NAME \
--root-path=/ \
--display-name="GCS Destination" --force
3. Crea stream Datastream
Ora creeremo due flussi CDC. Lo stream 1 acquisirà shard0_db e shard1_db. Lo stream 2 acquisirà shard2_db e shard3_db. Entrambi i flussi scrivono nello stesso bucket GCS in formato Avro.
# Stream for Physical Shard 1
export STREAM_NAME_1="mysql-to-spanner-stream-1"
export GCS_STREAM_PATH_1="data/${STREAM_NAME_1}"
gcloud datastream streams create $STREAM_NAME_1 \
--location=$REGION \
--display-name="MySQL Source 1 CDC Stream" \
--source=$SQL_CP_NAME_1 \
--destination=$GCS_CP_NAME \
--mysql-source-config=<(echo "includeObjects:
mysqlDatabases:
- database: 'shard0_db'
- database: 'shard1_db'") \
--gcs-destination-config=<(echo "path: ${GCS_STREAM_PATH_1}/
fileRotationMb: 5
fileRotationInterval: 15s
avroFileFormat: {}") \
--backfill-none
# Stream for Physical Shard 2
export STREAM_NAME_2="mysql-to-spanner-stream-2"
export GCS_STREAM_PATH_2="data/${STREAM_NAME_2}"
gcloud datastream streams create $STREAM_NAME_2 \
--location=$REGION \
--display-name="MySQL Source 2 CDC Stream" \
--source=$SQL_CP_NAME_2 \
--destination=$GCS_CP_NAME \
--mysql-source-config=<(echo "includeObjects:
mysqlDatabases:
- database: 'shard2_db'
- database: 'shard3_db'") \
--gcs-destination-config=<(echo "path: ${GCS_STREAM_PATH_2}/
fileRotationMb: 5
fileRotationInterval: 15s
avroFileFormat: {}") \
--backfill-none
L'utilizzo di impostazioni di rotazione dei file più piccole (5 MB o 15 secondi) ci aiuta a visualizzare più rapidamente le modifiche replicate durante il codelab.
Il completamento di questo comando potrebbe richiedere un po' di tempo. Controlla lo stato: gcloud datastream streams describe $STREAM_NAME_1 --location=$REGION.
4. Avvia gli stream Datastream
Attiva entrambi i flussi in modo che inizino a registrare le modifiche.
gcloud datastream streams update $STREAM_NAME_1 \
--location=$REGION \
--state=RUNNING
gcloud datastream streams update $STREAM_NAME_2 \
--location=$REGION \
--state=RUNNING
Controlla lo stato: puoi eseguire gcloud datastream streams describe $STREAM_NAME_1 --location=$REGION. Inizialmente lo stato sarà STARTING e dopo qualche istante diventerà RUNNING. Attendi che entrambi siano in esecuzione prima di avviare la migrazione live.
5. Configura Pub/Sub per le notifiche GCS
Dataflow deve ricevere una notifica immediata quando lo stream Datastream scrive un nuovo file nel bucket GCS. Configureremo GCS per inviare notifiche a un singolo argomento Pub/Sub.
Crea un argomento Pub/Sub:
export PUBSUB_TOPIC="datastream-gcs-updates"
gcloud pubsub topics create $PUBSUB_TOPIC
Crea notifica GCS
Invia una notifica per l'argomento in caso di creazione di oggetti con il prefisso data/ (che copre entrambi i nostri stream).
gcloud storage buckets notifications create gs://${BUCKET_NAME} --topic=projects/$PROJECT_ID/topics/$PUBSUB_TOPIC --payload-format=json --object-prefix=data/
Crea una sottoscrizione Pub/Sub
Crea la sottoscrizione con una scadenza di riconoscimento consigliata per Dataflow.
export PUBSUB_SUBSCRIPTION="datastream-gcs-sub"
gcloud pubsub subscriptions create $PUBSUB_SUBSCRIPTION \
--topic=$PUBSUB_TOPIC \
--ack-deadline=600
8. Trasformazione personalizzata
Poiché lo schema Spanner è diverso dallo schema MySQL (a causa delle colonne aggiunte ed eliminate tramite la UI web di SMT), la migrazione Dataflow predefinita non andrà a buon fine. Dataflow ha bisogno di istruzioni su come mappare queste differenze durante le pipeline di avanzamento (da MySQL a Spanner) e inversione (da Spanner a MySQL).
Inoltre, poiché eseguiamo una migrazione inversa suddivisa in shard, Dataflow ha bisogno di un meccanismo di routing per sapere a quale shard logico (shard0_db, shard1_db e così via) appartiene una riga Spanner aggiornata durante la replica inversa.
A questo scopo, scriveremo un file JAR di trasformazione personalizzata utilizzando il modello di partizione personalizzata Spanner fornito da Google.
1. Scaricare il modello di shard personalizzato
In Cloud Shell, scarica il repository dei modelli Google Cloud Dataflow e vai alla cartella degli shard personalizzati:
git clone https://github.com/GoogleCloudPlatform/DataflowTemplates.git
cd DataflowTemplates/v2/spanner-custom-shard
2. Configurare la logica di trasformazione dei dati
Dobbiamo modificare il file CustomTransformationFetcher.java.
- Migrazione in avanti (
toSpannerRow): compila la colonnaOrderSourceappena aggiunta utilizzando la colonnaLegacyOrderSystemdi MySQL. - Migrazione inversa (
toSourceRow): ripopola la colonnaLegacyOrderSystemeliminata richiesta da MySQL, derivandola daOrderSourcedi Spanner.
Modifica il file CustomTransformationFetcher.java. Anziché aprire manualmente un editor di testo, esegui questo comando per sovrascrivere automaticamente il file modello con la nostra logica personalizzata:
cat << 'EOF' > src/main/java/com/custom/CustomTransformationFetcher.java
package com.custom;
import com.google.cloud.teleport.v2.spanner.exceptions.InvalidTransformationException;
import com.google.cloud.teleport.v2.spanner.utils.ISpannerMigrationTransformer;
import com.google.cloud.teleport.v2.spanner.utils.MigrationTransformationRequest;
import com.google.cloud.teleport.v2.spanner.utils.MigrationTransformationResponse;
import java.util.HashMap;
import java.util.Map;
public class CustomTransformationFetcher implements ISpannerMigrationTransformer {
@Override
public void init(String customParameters) {}
@Override
public MigrationTransformationResponse toSpannerRow(MigrationTransformationRequest request)
throws InvalidTransformationException {
if (request.getTableName().equals("Orders")) {
Map<String, Object> requestRow = request.getRequestRow();
Map<String, Object> responseRow = new HashMap<>();
Object legacySysObj = requestRow.get("LegacyOrderSystem");
String legacySys = (legacySysObj != null) ? (String) legacySysObj : "UNKNOWN_SYSTEM";
// Transform: Trim the string to remove everything after the first underscore
String orderSource = legacySys;
if (legacySys.contains("_")) {
orderSource = legacySys.substring(0, legacySys.indexOf('_'));
}
// Populate the new Spanner column (e.g., "WebStore_v1" becomes "WebStore")
responseRow.put("OrderSource", orderSource);
return new MigrationTransformationResponse(responseRow, false);
}
return new MigrationTransformationResponse(new HashMap<>(), false);
}
@Override
public MigrationTransformationResponse toSourceRow(MigrationTransformationRequest request)
throws InvalidTransformationException {
if (request.getTableName().equals("Orders")) {
Map<String, Object> requestRow = request.getRequestRow();
Map<String, Object> responseRow = new HashMap<>();
// Safely fetch the Spanner OrderSource
Object sourceObj = requestRow.get("OrderSource");
String source = (sourceObj != null) ? (String) sourceObj : "UNKNOWN_SYSTEM";
String legacySys = "'" + source + "_v1'";
// Transform: Append a suffix to visibly prove the reverse transformation worked
// e.g., "WebStore" becomes "WebStore_v1"
responseRow.put("LegacyOrderSystem", legacySys);
return new MigrationTransformationResponse(responseRow, false);
}
return new MigrationTransformationResponse(new HashMap<>(), false);
}
@Override
public MigrationTransformationResponse transformFailedSpannerMutation(
MigrationTransformationRequest request) throws InvalidTransformationException {
return new MigrationTransformationResponse(new HashMap<>(), false);
}
}
EOF
3. Configura la logica di reverse sharding
Dataflow utilizza CustomShardIdFetcher.java durante la replica inversa per determinare dove deve essere indirizzata una mutazione Spanner. Utilizzeremo la chiave primaria CustomerId e la logica modulo (%4) per reindirizzare dinamicamente i record al loro shard logico corretto.
Modifica il file CustomShardIdFetcher.java utilizzando cat e sostituisci completamente i suoi contenuti con il seguente codice:
cat << 'EOF' > src/main/java/com/custom/CustomShardIdFetcher.java
package com.custom;
import com.google.cloud.teleport.v2.spanner.utils.IShardIdFetcher;
import com.google.cloud.teleport.v2.spanner.utils.ShardIdRequest;
import com.google.cloud.teleport.v2.spanner.utils.ShardIdResponse;
import java.util.Map;
public class CustomShardIdFetcher implements IShardIdFetcher {
@Override
public void init(String parameters) {}
@Override
public ShardIdResponse getShardId(ShardIdRequest shardIdRequest) {
Map<String, Object> keys = shardIdRequest.getSpannerRecord
();
// Use the Primary Key to identify the correct logical shard
if (keys != null && keys.containsKey("CustomerId")) {
long customerId = Long.parseLong(keys.get("CustomerId").toString());
long shardIdx = customerId % 4;
ShardIdResponse response = new ShardIdResponse();
response.setLogicalShardId("shard" + shardIdx + "_db");
return response;
}
return new ShardIdResponse();
}
}
EOF
4. Crea e carica il file JAR
Ora che la nostra logica Java personalizzata è stata scritta, dobbiamo compilarla in un file JAR e caricarla nel bucket Cloud Storage che abbiamo creato in precedenza, in modo che Dataflow possa accedervi.
Esegui questi comandi in Cloud Shell:
# Return to DataflowTemplates directory
cd ../..
# Build the JAR using Maven
mvn clean install -DskipTests -Dcheckstyle.skip -Dspotless.check.skip=true -Djib.skip -pl v2/spanner-custom-shard -am
# Upload the JAR to GCS
export CUSTOM_JAR_PATH="gs://${BUCKET_NAME}/custom-logic/spanner-custom-shard-1.0.jar"
gcloud storage cp v2/spanner-custom-shard/target/spanner-custom-shard-1.0-SNAPSHOT.jar $CUSTOM_JAR_PATH
# Return to home directory
cd ~
9. Esegui la migrazione collettiva dei dati da MySQL a Spanner
Con lo schema Spanner in posizione e il JAR di trasformazione personalizzata creato, ora possiamo copiare i dati esistenti dal database MySQL a Cloud Spanner. Utilizzerai il modello flessibile Dataflow Sourcedb to Spanner, progettato per copiare in blocco i dati dai database accessibili tramite JDBC a Spanner.
1. Carica il file di override dello schema
Nella sezione 6, hai scaricato il file JSON Spanner Overrides utilizzando la GUI web di SMT. Dobbiamo caricarlo nel nostro bucket GCS in modo che Dataflow possa utilizzarlo per mappare le differenze dello schema (ad esempio le colonne rinominate).
- In Cloud Shell, fai clic sul menu con tre puntini (Altro) e seleziona Carica.
- Seleziona il file JSON degli override che hai scaricato in precedenza (ad es.
spanner_overrides.json). - Spostalo nel bucket GCS:
export OVERRIDES_FILE="spanner_overrides.json" # Change this if your downloaded file has a different name
export GCS_OVERRIDES_PATH="gs://${BUCKET_NAME}/config/${OVERRIDES_FILE}"
gcloud storage cp ~/${OVERRIDES_FILE} $GCS_OVERRIDES_PATH
2. Crea e carica il file di configurazione dello sharding
Dataflow deve sapere come connettersi a tutti e quattro gli shard logici nelle due VM fisiche. A questo scopo, creeremo un file sharding.json.
Esegui questo comando in Cloud Shell per generare e caricare la configurazione:
cat <<EOF > sharding.json
{
"configType": "dataflow",
"shardConfigurationBulk": {
"schemaSource": {
"dataShardId": "mysql-physical-1",
"host": "${MYSQL_IP_1}",
"user": "datastream_user",
"password": "complex_password_123",
"port": "3306",
"dbName": "shard0_db"
},
"dataShards": [
{
"dataShardId": "mysql-physical-1",
"host": "${MYSQL_IP_1}",
"user": "datastream_user",
"password": "complex_password_123",
"port": "3306",
"dbName": "",
"namespace": "namespace-mysql-1",
"databases": [
{
"dbName": "shard0_db",
"databaseId": "shard0_db",
"refDataShardId": "mysql-physical-1"
},
{
"dbName": "shard1_db",
"databaseId": "shard1_db",
"refDataShardId": "mysql-physical-1"
}
]
},
{
"dataShardId": "mysql-physical-2",
"host": "${MYSQL_IP_2}",
"user": "datastream_user",
"password": "complex_password_123",
"port": "3306",
"dbName": "",
"namespace": "namespace-mysql-2",
"databases": [
{
"dbName": "shard2_db",
"databaseId": "shard2_db",
"refDataShardId": "mysql-physical-2"
},
{
"dbName": "shard3_db",
"databaseId": "shard3_db",
"refDataShardId": "mysql-physical-2"
}
]
}
]
}
}
EOF
export GCS_SHARDING_PATH="gs://${BUCKET_NAME}/config/sharding.json"
gcloud storage cp sharding.json $GCS_SHARDING_PATH
3. Esegui il job Dataflow di migrazione collettiva
Utilizzeremo il modello flessibile Sourcedb to Spanner. Poiché si tratta di una migrazione con partizionamento con trasformazioni personalizzate, passiamo il file Overrides, la configurazione di partizionamento e il nostro JAR Java personalizzato.
export JOB_NAME="mysql-sharded-bulk-to-spanner-$(date +%Y%m%d-%H%M%S)"
export OUTPUT_DIR="gs://${BUCKET_NAME}/bulk-migration"
gcloud dataflow flex-template run $JOB_NAME \
--project=$PROJECT_ID \
--region=$REGION \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Sourcedb_to_Spanner_Flex" \
--max-workers=2 \
--num-workers=1 \
--worker-machine-type=n2-highmem-8 \
--parameters \
sourceConfigURL=$GCS_SHARDING_PATH,\
instanceId=$SPANNER_INSTANCE_NAME,\
databaseId=$SPANNER_DATABASE_NAME,\
projectId=$PROJECT_ID,\
outputDirectory=$OUTPUT_DIR,\
username=datastream_user,\
password=complex_password_123,\
schemaOverridesFilePath=$GCS_OVERRIDES_PATH,\
transformationJarPath=$CUSTOM_JAR_PATH,\
transformationClassName=com.custom.CustomTransformationFetcher
Spiegazione dei parametri chiave:
sourceConfigURL: il percorso del filesharding.jsonche abbiamo creato. Indica a Dataflow come connettersi a tutti e quattro i nostri shard MySQL logici nelle due VM fisiche.schemaOverridesFilePath: il percorso del file JSON scaricato dalla UI web di SMT. In questo modo, Dataflow sa come gestire le modifiche allo schema che abbiamo apportato (come la colonnaLegacyRegioneliminata e il vincolo di controllo più restrittivo).transformationJarPath: il percorso GCS del file JAR Java compilato che abbiamo creato nella sezione precedente. Contiene il codice effettivo per eseguire le nostre trasformazioni personalizzate.transformationClassName: il nome completo della classe Java all'interno del nostro file JAR che implementa la logica di migrazione in avanti (com.custom.CustomTransformationFetcher).outputDirectory: la posizione GCS in cui Dataflow scriverà i file temporanei e, soprattutto, i file della coda di messaggi non recapitabili (DLQ).maxWorkers,numWorkers: controlla lo scaling del job Dataflow. Mantenuto basso per questo piccolo set di dati.instanceId,databaseId,projectId: specifica l'istanza e il database Cloud Spanner di destinazione.
Nota di rete: questo job si connette all'istanza Cloud SQL tramite il relativo IP pubblico. Ciò è possibile perché in precedenza hai aggiunto 0.0.0.0/0 alle reti autorizzate dell'istanza. In questo modo, le VM worker Dataflow, che hanno IP esterni, possono raggiungere il database.
4. Monitora il job Dataflow
Puoi monitorare l'avanzamento del job nella console Google Cloud:
- Vai alla pagina Job Dataflow: Vai a Job Dataflow
- Individua il job denominato
mysql-sharded-bulk-to-spanner-...e fai clic su di esso. - Osserva il grafico del job e le metriche. Attendi che lo stato del job cambi in Riuscito. L'operazione dovrebbe richiedere circa 5-15 minuti.

- Se il job riscontra problemi, esamina la scheda Log nella pagina dei dettagli del job Dataflow per i messaggi di errore.
- Metriche del job fornisce maggiori informazioni sullo stato di avanzamento del job e sul consumo di risorse come velocità effettiva e utilizzo della CPU.
5. Verifica i dati in Cloud Spanner e ispeziona la coda di messaggi non recapitabili (DLQ)
Una volta completato correttamente il job Dataflow, dobbiamo verificare che i nostri dati siano arrivati in modo sicuro e ispezionare i record che abbiamo progettato intenzionalmente per non riuscire.
A. Verifica l'integrità complessiva dei dati di cui è stata eseguita la migrazione:
Utilizza la CLI gcloud per eseguire alcuni controlli di integrità rapidi sul database Spanner consolidato per assicurarti che i record validi siano stati migrati correttamente e che il nostro JAR personalizzato abbia compilato la colonna aggiuntiva.
# 1. Verify total Customer count
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT COUNT(*) as TotalCustomers FROM Customers"
# 2. Verify total Orders count (Total minus the orphan record)
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT COUNT(*) as TotalOrders FROM Orders"
# 3. Verify the Custom Transformation on OrderSource worked
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT CustomerId, OrderId, OrderSource FROM Orders LIMIT 3"
# 4. Verify that renamed column LoyaltyTier has the correct data
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT CustomerId, CustomerName, LoyaltyTier FROM Customers LIMIT 3"
Output previsto:
TotalCustomers: 16 TotalOrders: 19 CustomerId: 1 OrderId: 201 OrderSource: MobileApp CustomerId: 2 OrderId: 301 OrderSource: CallCenter CustomerId: 3 OrderId: 401 OrderSource: InStore CustomerId: 1 CustomerName: Agnes N. LoyaltyTier: NORTHEAST CustomerId: 2 CustomerName: Brian K. LoyaltyTier: SOUTHWEST CustomerId: 3 CustomerName: Cathy Z. LoyaltyTier: CENTRAL
- Tutte le righe della tabella Customers sono state migrate correttamente.
- Vediamo 1 riga non riuscita nella tabella
Ordersa causa diINTERLEAVE IN PARENTsu Spanner.CustomerId 99è un elemento secondario orfano perché non esiste una riga corrispondente nella tabellaCustomers.
B. Controlla gli errori intenzionali nella DLQ:
L'errore sopra riportato è documentato nella cartella Coda dei messaggi non recapitabili (DLQ) creata dalla pipeline di migrazione collettiva.
- Vai a Cloud Storage nella console Google Cloud.
- Vai al bucket e apri la cartella
bulk-migration/dlq/severe. - Ispeziona i file JSON all'interno. Troverai la riga
Orderscon l'elemento orfanoCustomerId. - È possibile riprovare a eseguire la migrazione collettiva degli errori DLQ seguendo i passaggi descritti qui.
Il caricamento collettivo iniziale dei dati da Cloud SQL a Cloud Spanner è ora completato. Il passaggio successivo consiste nel configurare la replica in tempo reale per acquisire le modifiche in corso.
10. Avvia migrazione live (CDC)
Ora che il caricamento collettivo dei dati è completato, avvierai un job di streaming Dataflow continuo. Questo job leggerà gli eventi Change Data Capture (CDC) che Datastream sta scrivendo nel tuo bucket GCS e applicherà queste modifiche a Cloud Spanner quasi in tempo reale.
Testeremo anche questa pipeline inserendo dati validi e intenzionalmente non validi per osservare come Dataflow gestisce la replica in tempo reale e indirizza gli errori alla coda di messaggi non recapitabili (DLQ).
1. Crea il file di configurazione dello sharding della migrazione live
A differenza della migrazione collettiva (che utilizza le stringhe di connessione JDBC), la pipeline di migrazione live legge gli eventi Datastream da GCS. Richiede una configurazione JSON completamente diversa che mappa i nomi degli stream e i database Datastream agli shard Spanner logici.
Esegui questo comando in Cloud Shell per creare e caricare la configurazione di partizionamento live:
cat <<EOF > live-sharding.json
{
"StreamToDbAndShardMap": {
"${STREAM_NAME_1}": {
"shard0_db": "shard0_db",
"shard1_db": "shard1_db"
},
"${STREAM_NAME_2}": {
"shard2_db": "shard2_db",
"shard3_db": "shard3_db"
}
}
}
EOF
export GCS_LIVE_SHARDING_PATH="gs://${BUCKET_NAME}/config/live-sharding.json"
gcloud storage cp live-sharding.json $GCS_LIVE_SHARDING_PATH
2. Esegui il job Dataflow di migrazione live
Avvia il job Dataflow di streaming per leggere da GCS e scrivere in Spanner. Questo modello utilizzerà le notifiche GCS Pub/Sub per elaborare immediatamente i nuovi file.
export JOB_NAME_CDC="mysql-sharded-cdc-to-spanner-$(date +%Y%m%d-%H%M%S)"
export DLQ_DIR_CDC="gs://${BUCKET_NAME}/live-migration"
gcloud dataflow flex-template run $JOB_NAME_CDC \
--project=$PROJECT_ID \
--region=$REGION \
--worker-machine-type=n2-highmem-8 \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Cloud_Datastream_to_Spanner" \
--parameters \
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
projectId="$PROJECT_ID",\
inputFileFormat="avro",\
gcsPubSubSubscription="projects/${PROJECT_ID}/subscriptions/${PUBSUB_SUBSCRIPTION}",\
shardingContextFilePath=$GCS_LIVE_SHARDING_PATH,\
deadLetterQueueDirectory="$DLQ_DIR_CDC",\
transformationJarPath=$CUSTOM_JAR_PATH,\
transformationClassName="com.custom.CustomTransformationFetcher",\
schemaOverridesFilePath=$GCS_OVERRIDES_PATH,\
datastreamSourceType="mysql",\
dlqRetryMinutes=1,\
dlqMaxRetryCount=2
Parametri chiave
gcsPubSubSubscription: l'abbonamento Pub/Sub che ascolta le notifiche di nuovi file da GCS. In questo modo, il job può elaborare le modifiche istantaneamente man mano che Datastream le scrive.inputFileFormat="avro": indica a Dataflow di prevedere file Avro da Datastream. Questo valore deve corrispondere alla configurazione della "Destinazione" di Datastream (ad es.avroFileFormatanzichéjsonFileFormat).shardingContextFilePath: un file JSON che mappa i flussi Datastream agli shard logici.dlqRetryMinutes: il numero di minuti tra i tentativi di ripetizione della coda dei messaggi non recapitabili. Il valore predefinito è10.dlqMaxRetryCount: Il numero massimo di tentativi per gli errori temporanei tramite DLQ. Il valore predefinito è500.
Monitora l'avvio del job nella console Dataflow Jobs.
3. Inserire dati in tempo reale e attivare errori intenzionali
Mentre il job di streaming Dataflow è in fase di avvio (l'operazione può richiedere 3-5 minuti), eseguiamo SSH nella prima VM MySQL fisica e inseriamo alcuni nuovi record. Inseriremo un record valido e uno non valido.
Accedi tramite SSH al primo shard fisico:
gcloud compute ssh mysql-physical-1 --zone=$ZONE
Accedi a MySQL:
sudo mysql
Esegui i seguenti inserimenti su shard1_db:
USE shard1_db;
-- 1. Valid Insert: 'MobileApp_v2' will be trimmed to 'MobileApp'
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem)
VALUES (4, 501, 99.99, 'MobileApp_v2');
-- 2. Invalid Insert (DLQ Test): This violates Interleave constraint as CustomerId 99999 doesn't exist in Customers table.
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem)
VALUES (99999, 502, 50.00, 'WebStore_v1');
-- 3. Valid Update
UPDATE Orders SET OrderValue = '1500' WHERE CustomerId = 5 AND OrderId = 202;
-- 4. Valid Delete
DELETE FROM Orders WHERE CustomerId = 5 AND OrderId = 203;
EXIT;
Digita di nuovo exit per tornare al prompt di Cloud Shell.
4. Verifica i dati della migrazione live e ispeziona la DLQ CDC
Ora che abbiamo inserito i dati, Datastream acquisisce gli eventi CDC e Dataflow tenta di applicarli a Spanner.
A. Verifica le modifiche DML valide in Spanner
Esegui le seguenti query per verificare che gli eventi INSERT, UPDATE e DELETE abbiano raggiunto correttamente Spanner e che la trasformazione personalizzata sia stata attivata sia per l'inserimento che per l'aggiornamento.
# 1. Verify INSERT: Should return the new row with transformed OrderSource
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT CustomerId, OrderId, OrderValue, OrderSource FROM Orders WHERE CustomerId = 4 AND OrderId = 501"
# 2. Verify UPDATE: Should show OrderValue changed to 1500
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT CustomerId, OrderId, OrderValue, OrderSource FROM Orders WHERE CustomerId = 5 AND OrderId = 202"
# 3. Verify DELETE: Should return 0, confirming the order was deleted
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT COUNT(*) FROM Orders WHERE CustomerId = 5 AND OrderId = 203"
# 4. Verify DLQ Failure: Should return 0, confirming the row migration failed
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT COUNT(*) FROM Orders WHERE CustomerId = 99999 AND OrderId = 502"
Output previsto:
CustomerId: 4 OrderId: 501 OrderValue: 99.99 OrderSource: MobileApp CustomerId: 5 OrderId: 202 OrderValue: 1500 OrderSource: WebStore 0 0
Nota: se una query non mostra il risultato previsto, attendi un minuto e riprova, poiché i worker di streaming potrebbero essere ancora in fase di elaborazione della coda.
B. Controlla l'errore intenzionale nella DLQ:
Poiché CustomerId = 99999 non ha un elemento principale nella tabella Customers, avrebbe dovuto essere rifiutato da Spanner e indirizzato in modo sicuro alla DLQ da Dataflow.
- Vai a Cloud Storage nella console Google Cloud.
- Vai al bucket e apri la cartella
live-migration/dlq/severe/. - Dovresti visualizzare i file JSON appena generati. Fai clic per ispezionare i contenuti. Vedrai i dettagli di
CustomerId = 99999e il messaggio di errore specifico di Spanner:NOT_FOUND: Parent row for row [99999,502,WebStore] in table Orders is missing. Row cannot be written." - È possibile riprovare a eseguire gli errori DLQ di Live Migration eseguendo il modello Dataflow con
runMode=retryDLQimpostato.
5. Gestione degli errori DLQ
Gli errori nella directory severe/ richiedono un intervento manuale. Risolviamo il problema relativo ai dati ed elaboriamo nuovamente l'evento non riuscito.
A. Correggere i dati nell'origine
L'errore si è verificato perché manca il record del cliente principale CustomerId = 99999. Inseriamolo nel database MySQL di origine.
Accedi di nuovo all'istanza MySQL:
gcloud compute ssh mysql-physical-1 --zone=$ZONE
Accedi a MySQL utilizzando sudo mysql e inserisci la riga padre mancante in shard1_db:
USE shard1_db;
INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LegacyRegion) VALUES
(99999, 'DLQ Parent Holder', 5000.00, 'NORTH_AMERICA');
EXIT;
Digita exit per tornare a Cloud Shell.
B. Esegui il job Dataflow retryDLQ
Per rielaborare gli eventi dalla DLQ severe/, avvia lo stesso modello Dataflow, ma in modalità retryDLQ. Questa modalità legge in modo specifico dal percorso deadLetterQueueDirectory/severe, li esegue nuovamente tramite le trasformazioni personalizzate e li applica a Spanner.
Avvia il job in modalità retryDLQ:
export JOB_NAME_RETRY="mysql-sharded-cdc-retry-$(date +%Y%m%d-%H%M%S)"
gcloud dataflow flex-template run $JOB_NAME_RETRY \
--project=$PROJECT_ID \
--region=$REGION \
--worker-machine-type=n2-highmem-8 \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Cloud_Datastream_to_Spanner" \
--parameters \
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
projectId="$PROJECT_ID",\
runMode="retryDLQ",\
deadLetterQueueDirectory="$DLQ_DIR_CDC",\
datastreamSourceType="mysql",\
transformationJarPath=$CUSTOM_JAR_PATH,\
transformationClassName="com.custom.CustomTransformationFetcher",\
schemaOverridesFilePath=$GCS_OVERRIDES_PATH,\
shardingContextFilePath=$GCS_LIVE_SHARDING_PATH
Modifiche ai parametri chiave per i nuovi tentativi
runMode="retryDLQ": indica al modello di leggere dalla directory DLQsevere.- Rimozione di
gcsPubSubSubscription: non necessario perché non leggiamo dal bucket GCS Datastream live.
Monitorare il processo di ripetizione:
Come la pipeline CDC principale, retryDLQ è una pipeline di streaming che rimarrà RUNNING fino all'annullamento manuale.
- Vai alla pagina Job Dataflow per
$JOB_NAME_RETRY. - Nel riquadro Metriche, cerca questi due contatori:
elementsReconsumedFromDeadLetterQueue: valuta quando vengono recuperati i file di errore.Successful events: incrementa quando il record viene scritto in Spanner.- Controlla la directory
severe/per errori ricorrenti. - Una volta che gli eventi riusciti sono aumentati del numero di elementi che volevi riprovare (1 nel nostro test case), vai al passaggio di verifica successivo.
C. Verificare i dati riprovati
Dopo che il record non riuscito è stato ritentato (potrebbe essere necessario un po' di tempo prima che l'operazione vada a buon fine), controlla Spanner per verificare se la riga secondaria è stata migrata correttamente:
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT CustomerId, OrderId, OrderValue, OrderSource FROM Orders WHERE CustomerId = 99999 AND OrderId = 502"
Ora dovresti vedere la riga:
CustomerId: 99999 OrderId: 502 OrderValue: 50 OrderSource: WebStore
Controlla anche la cartella $DLQ_DIR_CDC/severe/ in GCS. I file elaborati devono essere stati spostati o eliminati, a indicare che la rielaborazione è andata a buon fine.
11. Configura la replica inversa (da Spanner a MySQL)
Per gestire scenari in cui potresti dover eseguire il rollback o mantenere sincronizzato il database MySQL originale con Spanner per un periodo di transizione, puoi configurare la replica inversa.
Questa pipeline utilizza le modifiche in tempo reale di Spanner per acquisire le modifiche live in Spanner. Quindi, utilizza il nostro JAR di trasformazione personalizzata per eseguire il mapping inverso delle differenze dello schema e il nostro JAR di partizionamento personalizzato per calcolare esattamente a quale VM MySQL fisica e a quale shard logico deve essere riscritto l'aggiornamento.
1. Crea un flusso di modifiche Spanner
Innanzitutto, devi creare un flusso di modifiche nel database Spanner per monitorare le modifiche nelle tabelle Customers e Orders.
export CHANGE_STREAM_NAME="CustomersOrdersChangeStream"
gcloud spanner databases ddl update $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--ddl="CREATE CHANGE STREAM $CHANGE_STREAM_NAME FOR Customers, Orders"
Questo flusso di modifiche ora registrerà tutte le modifiche ai dati apportate alle tabelle specificate.
2. Crea un database Spanner per i metadati Dataflow
Il modello Dataflow Spanner to SourceDB richiede un database Spanner separato per archiviare i metadati per la gestione del consumo dello stream di modifiche.
export SPANNER_METADATA_DB_NAME="migration-metadata-db"
gcloud spanner databases create $SPANNER_METADATA_DB_NAME \
--instance=$SPANNER_INSTANCE_NAME
3. Prepara la configurazione della connessione Cloud SQL per Dataflow
Il modello Dataflow richiede un file JSON in Cloud Storage contenente i dettagli di connessione per il database Cloud SQL di destinazione.
Crea un file locale denominato shard_config.json:
cat <<EOF > reverse-sharding.json
[
{
"logicalShardId": "shard0_db",
"host": "${MYSQL_IP_1}",
"port": "3306",
"user": "datastream_user",
"password": "complex_password_123",
"dbName": "shard0_db"
},
{
"logicalShardId": "shard1_db",
"host": "${MYSQL_IP_1}",
"port": "3306",
"user": "datastream_user",
"password": "complex_password_123",
"dbName": "shard1_db"
},
{
"logicalShardId": "shard2_db",
"host": "${MYSQL_IP_2}",
"port": "3306",
"user": "datastream_user",
"password": "complex_password_123",
"dbName": "shard2_db"
},
{
"logicalShardId": "shard3_db",
"host": "${MYSQL_IP_2}",
"port": "3306",
"user": "datastream_user",
"password": "complex_password_123",
"dbName": "shard3_db"
}
]
EOF
Carica questo file nel tuo bucket GCS:
export GCS_REVERSE_SHARDING_PATH="gs://${BUCKET_NAME}/config/reverse-sharding.json"
gcloud storage cp reverse-sharding.json $GCS_REVERSE_SHARDING_PATH
4. Esegui il job Dataflow di replica inversa
Avvia il job Dataflow utilizzando il Spanner_to_SourceDb modello flessibile.
export JOB_NAME_REVERSE="spanner-sharded-reverse-to-mysql-$(date +%Y%m%d-%H%M%S)"
export DLQ_DIR_REVERSE="gs://${BUCKET_NAME}/reverse-replication"
gcloud dataflow flex-template run $JOB_NAME_REVERSE \
--project=$PROJECT_ID \
--region=$REGION \
--worker-machine-type=n2-highmem-8 \
--max-workers=2 \
--num-workers=1 \
--additional-experiments=use_runner_v2 \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Spanner_to_SourceDb" \
--parameters \
changeStreamName="$CHANGE_STREAM_NAME",\
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
spannerProjectId="$PROJECT_ID",\
metadataInstance="$SPANNER_INSTANCE_NAME",\
metadataDatabase="$SPANNER_METADATA_DB_NAME",\
sourceShardsFilePath="$GCS_REVERSE_SHARDING_PATH",\
transformationJarPath=$CUSTOM_JAR_PATH,\
transformationClassName="com.custom.CustomTransformationFetcher",\
shardingCustomJarPath=$CUSTOM_JAR_PATH,\
shardingCustomClassName="com.custom.CustomShardIdFetcher",\
schemaOverridesFilePath=$GCS_OVERRIDES_PATH,\
deadLetterQueueDirectory=$DLQ_DIR_REVERSE
Parametri chiave
changeStreamName: il nome dello stream di modifiche di Spanner da cui leggere.metadataInstance, metadataDatabase: l'istanza/il database Spanner in cui archiviare i metadati utilizzati dal connettore per controllare l'utilizzo dei dati dell'API change stream.sourceShardsFilePath: il percorso GCS del tuoshard_config.json.filtrationMode: specifica come eliminare determinati record in base a un criterio. Il valore predefinito èforward_migration(filtra i record scritti utilizzando la pipeline di migrazione in avanti)shardingCustomJarPath: il percorso GCS del file JAR Java compilato che abbiamo creato in precedenza.shardingCustomClassName: il nome della classe completo (com.custom.CustomShardIdFetcher) che esegue la nostra matematica modulo%4personalizzata per determinare dinamicamente quale shard logico deve ricevere il record.
Nota di rete:i worker Dataflow si connetteranno all'istanza Cloud SQL utilizzando l'IP pubblico specificato in shard_config.json. Questa connessione è consentita grazie alla voce 0.0.0.0/0 nelle reti autorizzate dell'istanza Cloud SQL.
Monitora l'avvio del job nella console Dataflow Jobs.
5. Inserire dati Spanner e attivare errori intenzionali
Attendi che il job Dataflow entri nello stato Running (l'operazione può richiedere circa 5 minuti). Poi, eseguiamo una suite completa di query (INSERT, UPDATE, DELETE) direttamente in Spanner, insieme a un errore intenzionale per testare la DLQ inversa.
Esegui il comando riportato di seguito in Cloud Shell:
# All these operations are done on rows mapping to shard0_db for convenience
# Valid INSERT: Insert parent row in Customers
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LoyaltyTier) VALUES (88, 'Reverse Tester', 5000, 'GOLD_TIER')"
# 1. Valid INSERT (Orders): 'WebStore' transformed to 'WebStore_v1'
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="INSERT INTO Orders (CustomerId, OrderId, OrderValue, OrderSource) VALUES (88, 9001, 150.00, 'WebStore')"
# 2. Valid UPDATE (Orders)
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="UPDATE Orders SET OrderValue = 200.00 WHERE CustomerId = 16 AND OrderId = 105 AND OrderSource = 'Partner'"
# 3. Valid DELETE (Orders)
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="DELETE FROM Orders WHERE CustomerId = 12 AND OrderId = 104 AND OrderSource = 'WebStore'"
# 4. INVALID Insert- DLQ Test: CreditLimit=500 will fail check constraint of >1000 at source
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LoyaltyTier) VALUES (44, 'DLQ Test Customer', 500, 'GOLD_TIER')"
6. Verificare i dati di replica inversa e ispezionare la DLQ
Verifichiamo che il nostro JAR di Custom Sharding abbia indirizzato correttamente CustomerId 88 a shard0_db nella nostra prima VM fisica e che il JAR di Custom Transformation abbia rimosso correttamente "_TIER" dalla regione.
A. Verifica il record valido in MySQL:
Accedi tramite SSH al primo shard fisico:
gcloud compute ssh mysql-physical-1 --zone=$ZONE
Accedi a MySQL ed esegui una query su shard0_db:
sudo mysql
USE shard0_db;
-- 1. Verify INSERT: Row migrated with transformed LegacyOrderSystem
SELECT CustomerId, OrderId, OrderValue, LegacyOrderSystem
FROM Orders
WHERE CustomerId = 88 AND OrderId = 9001;
-- 2. Verify UPDATE: The OrderValue should now be updated to 200.00.
SELECT CustomerId, OrderId, OrderValue, LegacyOrderSystem
FROM Orders
WHERE CustomerId = 16 AND OrderId = 105;
-- 3. Verify DELETE: Returns 0 rows, confirming the order was successfully deleted from MySQL.
SELECT CustomerId, OrderId
FROM Orders
WHERE CustomerId = 12 AND OrderId = 104;
-- 4. Verify failed replication - this should be in DLQ as CreditLimit < 1000 and will fail stricter check constraint at source
SELECT CustomerId, CustomerName, CreditLimit, LegacyRegion
FROM Customers
WHERE CustomerId = 44;
EXIT;
L'output previsto in Cloud SQL deve riflettere le modifiche apportate in Spanner.
+------------+---------+------------+-------------------+ | CustomerId | OrderId | OrderValue | LegacyOrderSystem | +------------+---------+------------+-------------------+ | 88 | 9001 | 150.00 | Webstore_v1 | +------------+---------+------------+-------------------+ +------------+---------+------------+-------------------+ | CustomerId | OrderId | OrderValue | LegacyOrderSystem | +------------+---------+------------+-------------------+ | 16 | 105 | 200.00 | Partner_v1 | +------------+---------+------------+-------------------+ Empty set (0.00 sec) Empty set (0.00 sec)
Tipo
exit
per tornare a Cloud Shell.
Ciò conferma che la pipeline di replica inversa funziona, sincronizzando le modifiche da Spanner a Cloud SQL.
B. Controlla l'errore intenzionale nella DLQ
Poiché il nostro nuovo record Customers ha un CreditLimit di 500 (che viola il vincolo di controllo > 1000 rigoroso che abbiamo definito nel nostro database MySQL di origine), Dataflow ha rilevato l'errore in modo sicuro.
- Vai a Cloud Storage nella console Google Cloud.
- Vai al bucket e apri la cartella
dlq/severe/. - Apri il file JSON per visualizzare il record
Customersrifiutato e l'errore esatto di violazione del vincolo di controllo. - È possibile riprovare a eseguire i tentativi di errore DLQ di replica inversa eseguendo il modello Dataflow con
runMode=retryDLQimpostato.
12. Esegui la pulizia delle risorse
Per evitare ulteriori addebiti al tuo account Google Cloud, elimina le risorse create durante questo codelab.
Imposta le variabili di ambiente (se necessario)
Se la sessione di Cloud Shell è scaduta o hai aperto un nuovo terminale, devi esportare nuovamente le variabili di ambiente prima di eseguire i comandi di pulizia.
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1" # Or your preferred region
export ZONE="us-central1-a" # Or a zone within your selected region
export SPANNER_INSTANCE_NAME="target-spanner-instance"
export SPANNER_DATABASE_NAME="sharded-target-db"
export SPANNER_CONFIG="regional-${REGION}"
export BUCKET_NAME="migration-${PROJECT_ID}-bucket"
export MYSQL_IP_1=$(gcloud compute instances describe mysql-physical-1 --zone=$ZONE --format='get(networkInterfaces[0].accessConfigs[0].natIP)')
export MYSQL_IP_2=$(gcloud compute instances describe mysql-physical-2 --zone=$ZONE --format='get(networkInterfaces[0].accessConfigs[0].natIP)')
export SQL_CP_NAME_1="mysql-src-cp-1"
export SQL_CP_NAME_2="mysql-src-cp-2"
export GCS_CP_NAME="gcs-dest-cp"
export STREAM_NAME_1="mysql-to-spanner-stream-1"
export GCS_STREAM_PATH_1="data/${STREAM_NAME_1}"
export STREAM_NAME_2="mysql-to-spanner-stream-2"
export GCS_STREAM_PATH_2="data/${STREAM_NAME_2}"
export PUBSUB_TOPIC="datastream-gcs-updates"
export PUBSUB_SUBSCRIPTION="datastream-gcs-sub"
export CUSTOM_JAR_PATH="gs://${BUCKET_NAME}/custom-logic/spanner-custom-shard-1.0.jar"
export OVERRIDES_FILE="spanner_overrides.json"
export GCS_OVERRIDES_PATH="gs://${BUCKET_NAME}/config/${OVERRIDES_FILE}"
export GCS_SHARDING_PATH="gs://${BUCKET_NAME}/config/sharding.json"
export OUTPUT_DIR="gs://${BUCKET_NAME}/bulk-migration"
export GCS_LIVE_SHARDING_PATH="gs://${BUCKET_NAME}/config/live-sharding.json"
export DLQ_DIR_CDC="gs://${BUCKET_NAME}/live-migration"
export CHANGE_STREAM_NAME="CustomersOrdersChangeStream"
export SPANNER_METADATA_DB_NAME="migration-metadata-db"
export GCS_REVERSE_SHARDING_PATH="gs://${BUCKET_NAME}/config/reverse-sharding.json"
export DLQ_DIR_REVERSE="gs://${BUCKET_NAME}/reverse-replication"
Arresta i job Dataflow Streaming
Elenca i tuoi job per trovare gli ID job dei job Dataflow in esecuzione. Esporta JOB_ID_CDC e JOB_ID_REVERSE di conseguenza.
gcloud dataflow jobs list --region=$REGION --filter="state=Running"
export JOB_ID_CDC=<PASTE_JOB_ID_HERE>
export JOB_ID_CDC_RETRY=<PASTE_JOB_ID_HERE>
export JOB_ID_REVERSE=<PASTE_JOB_ID_HERE>
Annulla il job Datastream to Spanner (migrazione live) e il relativo job di ripetizione:
gcloud dataflow jobs cancel $JOB_ID_CDC --region=$REGION --project=$PROJECT_ID
gcloud dataflow jobs cancel $JOB_ID_CDC_RETRY --region=$REGION --project=$PROJECT_ID
Annulla il job Spanner to Cloud SQL (replica inversa):
gcloud dataflow jobs cancel $JOB_ID_REVERSE --region=$REGION --project=$PROJECT_ID
Elimina risorse Datastream
Interrompi ed elimina lo stream:
gcloud datastream streams update $STREAM_NAME_1 \
--location=$REGION --state=PAUSED --project=$PROJECT_ID
# Wait a moment for the stream to pause
gcloud datastream streams delete $STREAM_NAME_1 \
--location=$REGION --project=$PROJECT_ID --quiet
gcloud datastream streams update $STREAM_NAME_2 \
--location=$REGION --state=PAUSED --project=$PROJECT_ID
# Wait a moment for the stream to pause
gcloud datastream streams delete $STREAM_NAME_2 \
--location=$REGION --project=$PROJECT_ID --quiet
# Delete Connection Profiles
gcloud datastream connection-profiles delete $SQL_CP_NAME_1 \
--location=$REGION --project=$PROJECT_ID --quiet
gcloud datastream connection-profiles delete $SQL_CP_NAME_2 \
--location=$REGION --project=$PROJECT_ID --quiet
gcloud datastream connection-profiles delete $GCS_CP_NAME \
--location=$REGION --project=$PROJECT_ID --quiet
Elimina le VM MySQL di origine (Compute Engine)
Elimina le due istanze Compute Engine che simulavano gli shard fisici MySQL on-premise.
gcloud compute instances delete mysql-physical-1 mysql-physical-2 --zone=$ZONE --quiet
Elimina regole firewall
Rimuovi le regole firewall di rete create per consentire l'accesso SSH e la connettività Datastream alle tue VM. (Nota: se hai utilizzato nomi diversi per le regole firewall in precedenza nel codelab, modificali qui).
gcloud compute firewall-rules delete allow-ssh-iap --quiet
gcloud compute firewall-rules delete allow-mysql-datastream --quiet
Elimina risorse Pub/Sub
Elimina abbonamento:
gcloud pubsub subscriptions delete $PUBSUB_SUBSCRIPTION \
--project=$PROJECT_ID --quiet
Elimina argomento:
gcloud pubsub topics delete $PUBSUB_TOPIC \
--project=$PROJECT_ID --quiet
Elimina istanza Cloud Spanner
Elimina l'istanza Cloud Spanner (in questo modo vengono eliminati automaticamente sia il database sharded-target-db che quello migration-metadata-db al suo interno).
gcloud spanner instances delete $SPANNER_INSTANCE_NAME \
--project=$PROJECT_ID --quiet
Eliminazione del bucket GCS e dei relativi contenuti
Infine, elimina il bucket Cloud Storage che contiene i file Datastream, le configurazioni Dataflow e le code di messaggi non recapitabili. Il comando rm -r elimina in modo ricorsivo il bucket e tutti i relativi contenuti.
gcloud storage rm --recursive gs://${BUCKET_NAME}
Elimina i file locali di Cloud Shell
Per liberare spazio nei file e nelle directory locali generati in Cloud Shell durante questo codelab, esegui i seguenti comandi:
# Remove the JSON configuration files
rm -f sharding.json live-sharding.json reverse-sharding.json spanner_overrides.json
# Remove the cloned Google Cloud DataflowTemplates repository
rm -rf DataflowTemplates