
1. शुरू करने से पहले
इस कोडलैब में, आपको GoogleSQL डायलेक्ट का इस्तेमाल करके, किसी शार्ड किए गए ऑन-प्रिमाइसेस MySQL डेटाबेस को Cloud Spanner डेटाबेस में माइग्रेट करने का तरीका बताया गया है. आपको Google Cloud की सेवाओं का इस्तेमाल करना होगा. इनमें Spanner Migration Tool (SMT), Dataflow, Datastream, PubSub, और Google Cloud Storage शामिल हैं.
आपको यह जानकारी मिलेगी:
- शार्ड किया गया एनवायरमेंट क्या है और इसे कैसे सेट अप किया जाता है.
- MySQL स्कीमा को Spanner के साथ काम करने वाले स्कीमा में बदलने और स्कीमा में बेहतर बदलाव करने के लिए, Spanner Migration Tool (SMT) के वेब यूज़र इंटरफ़ेस (यूआई) का इस्तेमाल करने का तरीका.
- Dataflow का इस्तेमाल करके, शार्ड किए गए MySQL इंस्टेंस से Cloud Spanner में डेटा को एक साथ कैसे माइग्रेट करें.
- Datastream और Dataflow का इस्तेमाल करके, शार्ड किए गए MySQL इंस्टेंस से Cloud Spanner में लगातार रेप्लिकेशन (सीडीसी) कैसे सेट अप करें.
- Spanner से शार्ड किए गए MySQL इंस्टेंस में रिवर्स रेप्लिकेशन को कॉन्फ़िगर करने का तरीका.
- एक साथ कई, लाइव, और रिवर्स माइग्रेशन के दौरान अतिरिक्त कॉलम में डेटा भरने के लिए, कस्टम ट्रांसफ़ॉर्मेशन का इस्तेमाल कैसे करें.
- प्राइमरी बटन का इस्तेमाल करके, शार्डिंग ट्रांसफ़ॉर्मेशन को कॉन्फ़िगर करने का तरीका.
इस कोडलैब में यह जानकारी शामिल नहीं है:
- बेहतर कस्टम नेटवर्किंग.
- शुरुआत से कस्टम डेटाफ़्लो टेंप्लेट बनाना.
- माइग्रेशन की परफ़ॉर्मेंस को बेहतर बनाना.
- ऐप्लिकेशन माइग्रेशन: यह कोडलैब, डेटाबेस लेयर (स्कीमा और डेटा) पर फ़ोकस करता है. इसमें, ऐप्लिकेशन सेवाओं को फिर से डिप्लॉय करने या माइग्रेट करने की प्रोसेस शामिल नहीं है.
आपको किन चीज़ों की ज़रूरत होगी
- बिलिंग की सुविधा वाला Google Cloud प्रोजेक्ट.
- एपीआई चालू करने और Spanner, Dataflow, Datastream, और GCS संसाधन बनाने/मैनेज करने के लिए, IAM की ज़रूरी अनुमतियां. प्रोजेक्ट
Ownerकी भूमिका, कोडलैब के लिए सबसे आसान है. हालांकि, "एनवायरमेंट सेटअप" में ज़्यादा खास भूमिकाओं के बारे में बताया जाएगा. - हम सेटअप के दौरान, Compute Engine का एक छोटा वीएम उपलब्ध कराएंगे, ताकि हम अपने ऑन-प्रिमाइसेस सर्वर को सिम्युलेट कर सकें. पक्का करें कि आपके प्रोजेक्ट के कोटा के हिसाब से, वीएम बनाया जा सकता हो.
- कोई वेब ब्राउज़र, जैसे कि Google Chrome.
- Google Cloud Console और
gcloudजैसे कमांड-लाइन टूल के बारे में बुनियादी जानकारी होनी चाहिए. - शेल एनवायरमेंट का ऐक्सेस. हमारा सुझाव है कि आप Cloud Shell का इस्तेमाल करें, क्योंकि इसमें
gcloudशामिल है.
ऊपर दिए गए सेटअप के बारे में ज़्यादा जानकारी, एनवायरमेंट सेटअप सेक्शन में दी गई है.
2. माइग्रेशन की प्रोसेस के बारे में जानकारी
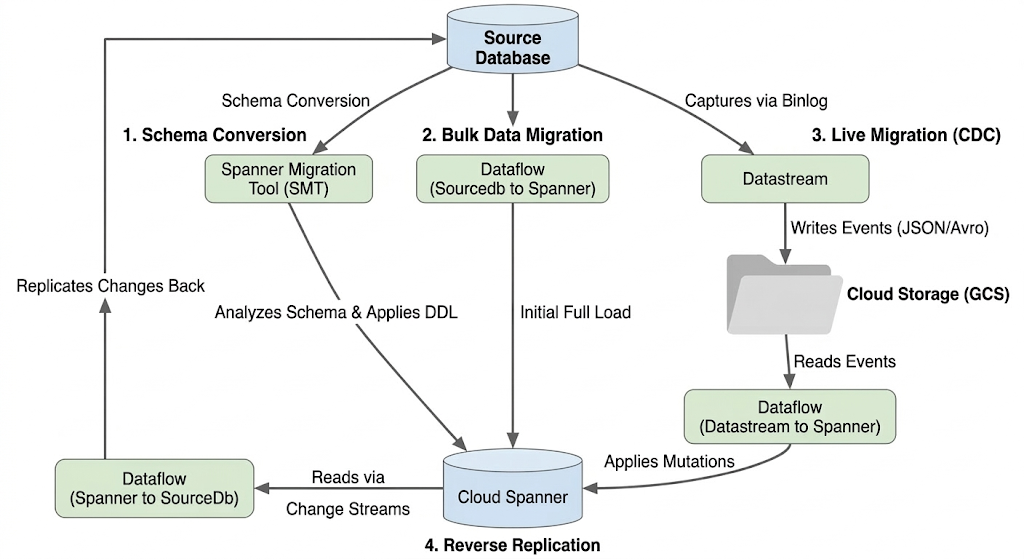
शार्ड किए गए डेटाबेस को माइग्रेट करने का मतलब है कि कई फ़िज़िकल और लॉजिकल MySQL इंस्टेंस को एक ही हॉरिज़ॉन्टली स्केल किए जा सकने वाले Spanner डेटाबेस में कंसोलिडेट करना. इस सेक्शन में, माइग्रेशन में इस्तेमाल किए गए आर्किटेक्चर और मुख्य टूल के बारे में बताया गया है.
माइग्रेशन फ़्लो का आर्किटेक्चर
माइग्रेशन की प्रोसेस में ये चरण शामिल होते हैं:
1. स्कीमा कन्वर्ज़न:
- मकसद: सोर्स डेटाबेस के स्कीमा को Cloud Spanner के साथ काम करने वाले स्कीमा में बदलना.
- टूल: Spanner Migration Tool (SMT)
- प्रोसेस: SMT, सोर्स डेटाबेस के स्कीमा का विश्लेषण करता है और उसके बराबर Spanner डेटा डेफ़िनिशन लैंग्वेज (डीडीएल) जनरेट करता है. टारगेट Spanner इंस्टेंस में, एक डेटाबेस बनाया जाता है. इसके बाद, DDL अपने-आप लागू हो जाता है.
2. बल्क डेटा माइग्रेशन:
- मकसद: सोर्स डेटाबेस से, उपलब्ध कराई गई Spanner टेबल में मौजूदा डेटा का शुरुआती और पूरा लोड ट्रांसफ़र करना.
- टूल: Google की ओर से उपलब्ध कराए गए
Sourcedb to Spannerटेंप्लेट का इस्तेमाल करके, Dataflow. - प्रोसेस: यह Dataflow जॉब, बताई गई सोर्स टेबल से सारा डेटा पढ़ती है और उसे Spanner की मिलती-जुलती टेबल में लिखती है. यह काम, Spanner स्कीमा बनाने के बाद किया जाता है.
3. लाइव माइग्रेशन (सीडीसी):
- मकसद: सोर्स डेटाबेस में हो रहे बदलावों को रीयल टाइम में कैप्चर करना और उन्हें Cloud Spanner पर लागू करना. इससे माइग्रेशन के दौरान डाउनटाइम कम होता है.
- टूल:
- Datastream: यह सोर्स डेटाबेस में हुए बदलावों (डेटा डालना, अपडेट करना, मिटाना) को कैप्चर करता है और उन्हें Cloud Storage (GCS) में लिखता है.
- डेटाफ़्लो: यह GCS से बदलाव वाले इवेंट को पढ़ने और उन्हें Cloud Spanner पर लागू करने के लिए,
Datastream to Spannerटेंप्लेट का इस्तेमाल करता है.
4. उलटा दोहराव:
- मकसद: Cloud Spanner से डेटा में हुए बदलावों को सोर्स डेटाबेस में वापस लाना. यह फ़ेलबैक रणनीतियों, चरणों में माइग्रेशन या इस्तेमाल के कुछ खास मामलों के लिए सोर्स में रेप्लिका बनाए रखने के लिए फ़ायदेमंद हो सकता है.
- टूल:
Spanner to SourceDbटेंप्लेट का इस्तेमाल करके डेटाफ़्लो. - प्रोसेस: यह जॉब, Spanner में किए गए बदलावों को कैप्चर करने के लिए Spanner की चेंज स्ट्रीम का इस्तेमाल करती है. साथ ही, इन बदलावों को सोर्स डेटाबेस इंस्टेंस में वापस लिखती है.
इस डायग्राम में कॉम्पोनेंट और डेटा फ़्लो दिखाया गया है:
मुख्य शब्दावली:
- फ़िज़िकल शार्ड: यह डेटाबेस को होस्ट करने वाला असल सर्वर या कंप्यूट इंस्टेंस होता है. हमारे मामले में, यह ऑन-प्रिमाइसेस GCE वीएम होता है.
- लॉजिकल शार्ड: किसी फ़िज़िकल सर्वर में मौजूद अलग-अलग डेटाबेस स्कीमा.
- Compute Engine (GCE) VM: Google Cloud के इन्फ़्रास्ट्रक्चर पर होस्ट की गई वर्चुअल मशीन. इस कोडलैब में, हम GCE वीएम का इस्तेमाल करके, स्टैंडअलोन "ऑन-प्रिमाइसेस" बेयर-मेटल सर्वर को सिम्युलेट करते हैं. यह सर्वर, हमारे सोर्स MySQL डेटाबेस को होस्ट करता है.
- Spanner Migration Tool (SMT): इस टूल का इस्तेमाल MySQL स्कीमा का आकलन करने, Spanner के मिलते-जुलते स्कीमा के सुझाव देने, और Spanner डेटा डेफ़िनिशन लैंग्वेज (डीडीएल) जनरेट करने के लिए किया जाता है.
- डेटा परिभाषा की भाषा (डीडीएल): डेटाबेस के स्ट्रक्चर को तय करने और उसमें बदलाव करने के लिए इस्तेमाल किए जाने वाले स्टेटमेंट, जैसे कि
CREATE TABLEस्टेटमेंट. SMT, Cloud SQL स्कीमा के आधार पर Spanner DDL जनरेट करता है. - Dataflow: यह पूरी तरह से मैनेज की जाने वाली, बिना सर्वर वाली डेटा प्रोसेसिंग सेवा है. इस कोडलैब में, इसका इस्तेमाल एक साथ कई फ़ाइलों को ट्रांसफ़र करने, डेटा स्ट्रीम में बदलाव करने, और रिवर्स रेप्लिकेशन के लिए Google के उपलब्ध कराए गए टेंप्लेट को चलाने के लिए किया जाता है.
- Datastream: यह सर्वरलेस चेंज डेटा कैप्चर (सीडीसी) और रेप्लिकेशन सेवा है. इस कोड लैब में, इसका इस्तेमाल स्थानीय तौर पर होस्ट किए गए MySQL इंस्टेंस से Cloud Storage में बदलावों को स्ट्रीम करने के लिए किया जाता है.
- Spanner की बदलाव स्ट्रीम: यह Spanner की एक सुविधा है. इसकी मदद से, डेटा में हुए बदलावों (डेटा डालना, अपडेट करना, मिटाना) को रीयल-टाइम में स्ट्रीम किया जा सकता है. इसका इस्तेमाल रिवर्स रेप्लिकेशन के सोर्स के तौर पर किया जाता है.
- Pub/Sub: यह एक मैसेज सेवा है. इसका इस्तेमाल, इवेंट जनरेट करने वाली सेवाओं को इवेंट प्रोसेस करने वाली सेवाओं से अलग करने के लिए किया जाता है. इस कोडलैब में, जब भी Datastream, Cloud Storage में बदलाव की नई फ़ाइलें अपलोड करता है, तब यह Dataflow को अपडेट प्रोसेस करने के लिए ट्रिगर करता है.
3. एनवायरमेंट सेटअप करना
माइग्रेशन शुरू करने से पहले, आपको अपना Google Cloud प्रोजेक्ट सेट अप करना होगा. साथ ही, ज़रूरी सेवाएं चालू करनी होंगी.
1. Google Cloud प्रोजेक्ट चुनें या बनाएं
इस कोडलैब में दी गई सेवाओं का इस्तेमाल करने के लिए, आपके पास ऐसा Google Cloud प्रोजेक्ट होना चाहिए जिसमें बिलिंग की सुविधा चालू हो.
- Google Cloud Console में, प्रोजेक्ट चुनने वाले पेज पर जाएं: प्रोजेक्ट चुनने वाले पेज पर जाएं
- कोई Google Cloud प्रोजेक्ट चुनें या बनाएं.
- पक्का करें कि आपके प्रोजेक्ट के लिए बिलिंग चालू हो. यह पुष्टि करने का तरीका जानें कि आपके प्रोजेक्ट के लिए बिलिंग चालू है या नहीं.
2. Cloud Shell खोलें
Cloud Shell, Google Cloud में चलने वाला कमांड-लाइन एनवायरमेंट है. इसमें gcloud CLI और अन्य ज़रूरी टूल पहले से लोड होते हैं.
- Google Cloud Console में सबसे ऊपर दाईं ओर मौजूद, Cloud Shell चालू करें बटन पर क्लिक करें.
- Cloud Shell सेशन, कंसोल में सबसे नीचे मौजूद नए फ़्रेम में खुलता है. इसमें कमांड-लाइन प्रॉम्प्ट दिखता है.

3. प्रोजेक्ट और एनवायरमेंट वैरिएबल सेट करना
Cloud Shell में, अपने प्रोजेक्ट आईडी और इस्तेमाल किए जाने वाले क्षेत्र के लिए कुछ एनवायरमेंट वैरिएबल सेट अप करें.
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1" # Or your preferred region
export ZONE="us-central1-a" # Or a zone within your selected region
gcloud config set project $PROJECT_ID
gcloud config set compute/region $REGION
gcloud config set compute/zone $ZONE
echo "Project ID: $PROJECT_ID"
echo "Region: $REGION"
echo "Zone: $ZONE"
4. ज़रूरी Google Cloud API चालू करना
Cloud Spanner, Dataflow, Datastream, और इनसे जुड़ी अन्य सेवाओं के लिए ज़रूरी एपीआई चालू करें.
gcloud services enable \
spanner.googleapis.com \
dataflow.googleapis.com \
datastream.googleapis.com \
pubsub.googleapis.com \
storage.googleapis.com \
compute.googleapis.com \
sqladmin.googleapis.com \
servicenetworking.googleapis.com \
cloudresourcemanager.googleapis.com
इस कमांड को पूरा होने में कुछ मिनट लग सकते हैं.
4. सोर्स MySQL डेटाबेस सेट अप करना
इस सेक्शन में, हम दो Compute Engine वर्चुअल मशीनें (हमारे दो "फ़िज़िकल शार्ड") उपलब्ध कराकर, ऑन-प्रिमाइसेस शार्ड किए गए MySQL आर्किटेक्चर का सिम्युलेशन करेंगे. इसके बाद, हम दोनों पर MySQL इंस्टॉल करेंगे और हर वीएम पर दो डेटाबेस (हमारे "लॉजिकल शार्ड") बनाएंगे.
1. Compute Engine वीएम (फ़िज़िकल शार्ड) बनाना
Ubuntu के साथ दो वीएम बनाने के लिए, Cloud Shell में ये कमांड चलाएं. हम उन्हें नेटवर्क टैग असाइन करेंगे, ताकि बाद में इनबाउंड MySQL ट्रैफ़िक की अनुमति दी जा सके.
# Create Physical Shard 1
gcloud compute instances create mysql-physical-1 \
--zone=$ZONE \
--machine-type=e2-small \
--image-family=ubuntu-2204-lts \
--image-project=ubuntu-os-cloud \
--tags=mysql-server
# Create Physical Shard 2
gcloud compute instances create mysql-physical-2 \
--zone=$ZONE \
--machine-type=e2-small \
--image-family=ubuntu-2204-lts \
--image-project=ubuntu-os-cloud \
--tags=mysql-server
2. फ़ायरवॉल के नियमों को कॉन्फ़िगर करना
सार्वजनिक तौर पर उपलब्ध कराए बिना सुरक्षित एसएसएच ऐक्सेस की अनुमति देने और डेटास्ट्रीम कनेक्टिविटी चालू करने के लिए:
IAP के ज़रिए एसएसएच के लिए फ़ायरवॉल नियम बनाएं:
इस नियम की मदद से, Identity-Aware Proxy को एसएसएच पोर्ट (22) पर आपके वीएम तक पहुंचने की अनुमति मिलती है.
gcloud compute firewall-rules create allow-ssh-iap \
--direction=INGRESS \
--priority=1000 \
--network=default \
--action=ALLOW \
--rules=tcp:22 \
--source-ranges=35.235.240.0/20 \
--target-tags=mysql-server
Datastream (MySQL पोर्ट) के लिए फ़ायरवॉल का नियम बनाएं:
डेटास्ट्रीम को स्टैंडर्ड MySQL पोर्ट (3306) पर इन वीएम तक पहुंचने की अनुमति होनी चाहिए.
gcloud compute firewall-rules create allow-mysql-datastream \
--direction=INGRESS \
--priority=1000 \
--network=default \
--action=ALLOW \
--rules=tcp:3306 \
--source-ranges=0.0.0.0/0 \
--target-tags=mysql-server
3. फ़िज़िकल शार्ड 1 पर MySQL को इंस्टॉल और कॉन्फ़िगर करना
MySQL इंस्टॉल करने के लिए, अपनी पहली वीएम में SSH करें. साथ ही, बाइनरी लॉगिंग को कॉन्फ़िगर करें. लाइव रेप्लिकेशन के लिए, Datastream को इसकी ज़रूरत होती है.
- पहले वीएम में एसएसएच करें:
gcloud compute ssh mysql-physical-1 --zone=$ZONE --tunnel-through-iap
- MySQL इंस्टॉल करें:
sudo apt-get update
sudo apt-get install mysql-server-8.0 -y
# Verify the installation and version
sudo mysql --version
- बाइनरी लॉगिंग चालू करने और बाहरी कनेक्शन की अनुमति देने के लिए,
mysqld.cnfफ़ाइल को कॉन्फ़िगर करें:
sudo sed -i 's/bind-address.*/bind-address = 0.0.0.0/' /etc/mysql/mysql.conf.d/mysqld.cnf
echo -e "[mysqld]\nserver-id=1\nlog_bin=/var/log/mysql/mysql-bin.log\nbinlog_format=ROW" | sudo tee -a /etc/mysql/mysql.conf.d/mysqld.cnf
- बदलाव लागू करने के लिए, MySQL को रीस्टार्ट करें:
sudo systemctl restart mysql
4. लॉजिकल शार्ड बनाना, डेटा डालना, और डेटास्ट्रीम उपयोगकर्ता (शार्ड 1) बनाना
mysql-physical-1 में SSH का इस्तेमाल करते समय, MySQL प्रॉम्प्ट में लॉग इन करें:
sudo mysql
यहां दिए गए एसक्यूएल कमांड चलाएं. यह स्क्रिप्ट, दो अलग-अलग लॉजिकल शार्ड (shard0_db और shard1_db) बनाती है. साथ ही, दोनों में एक जैसा स्कीमा सेट अप करती है. इसके अलावा, हर शार्ड में यूनीक आइडेंटिफ़ायर वाला डेटा डालती है, ताकि शार्डिंग को दिखाया जा सके. साथ ही, Datastream के लिए रेप्लिकेशन उपयोगकर्ता बनाती है.
अपने पहले दो लॉजिकल शार्ड, टेबल, और Datastream के लिए रेप्लिकेशन उपयोगकर्ता बनाने के लिए, यहां दी गई SQL कमांड चलाएं:
CREATE DATABASE shard0_db;
CREATE DATABASE shard1_db;
USE shard0_db;
CREATE TABLE Customers (
CustomerId INT NOT NULL,
CustomerName VARCHAR(255),
CreditLimit DECIMAL(10, 2) NOT NULL,
LegacyRegion VARCHAR(50), -- Renamed to LoyaltyTier in Spanner
PRIMARY KEY (CustomerId),
CONSTRAINT CHK_CreditLimit CHECK (CreditLimit > 1000) -- Relaxed in Spanner to > 0
);
CREATE TABLE Orders (
CustomerId INT NOT NULL, -- Logically references Customers.CustomerId in Spanner
OrderId INT NOT NULL,
OrderValue DECIMAL(10, 2),
LegacyOrderSystem VARCHAR(50), -- Extra column in Source, to be dropped in Spanner
PRIMARY KEY (CustomerId, OrderId) -- Spanner PK will have one additional column in PK
);
INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LegacyRegion) VALUES
(4, 'David E.', 2000.00, 'EAST'),
(8, 'Eleanor F.', 8100.00, 'WEST'),
(12, 'Frank G.', 12000.00, 'NORTH'),
(16, 'Grace H.', 6500.00, 'SOUTH');
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem) VALUES
(4, 101, 150.00, 'WebStore_v1'),
(4, 102, 25.50, 'InStore_POS'),
(8, 103, 75.00, 'MobileApp_Legacy'),
(12, 104, 3000.00, 'WebStore_v1'),
(16, 105, 120.00, 'Partner_API');
USE shard1_db;
CREATE TABLE Customers (
CustomerId INT NOT NULL,
CustomerName VARCHAR(255),
CreditLimit DECIMAL(10, 2) NOT NULL,
LegacyRegion VARCHAR(50), -- Renamed to LoyaltyTier in Spanner
PRIMARY KEY (CustomerId),
CONSTRAINT CHK_CreditLimit CHECK (CreditLimit > 1000) -- Relaxed in Spanner to > 0
);
CREATE TABLE Orders (
CustomerId INT NOT NULL, -- Logically references Customers.CustomerId in Spanner
OrderId INT NOT NULL,
OrderValue DECIMAL(10, 2),
LegacyOrderSystem VARCHAR(50), -- Extra column in Source, to be dropped in Spanner
PRIMARY KEY (CustomerId, OrderId) -- Spanner PK will have one additional column in PK
);
INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LegacyRegion) VALUES
(1, 'Agnes N.', 5100.00, 'NORTHEAST'),(5, 'Alice I.', 15000.00, 'EAST'),
(9, 'Bob J.', 7500.00, 'WEST'),
(13, 'Charlie K.', 2200.00, 'CENTRAL');
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem) VALUES
(1, 201, 50.00, 'MobileApp_Legacy'),
(5, 202, 1250.00, 'WebStore_v1'),
(5, 203, 80.00, 'Partner_API'),
(9, 204, 600.00, 'InStore_POS'),
(13, 205, 199.99, 'WebStore_v1');
-- Create Datastream Replication User
CREATE USER 'datastream_user'@'%' IDENTIFIED BY 'complex_password_123';
GRANT REPLICATION SLAVE, REPLICATION CLIENT, SELECT, INSERT, UPDATE, DELETE ON *.* TO 'datastream_user'@'%';
FLUSH PRIVILEGES;
ऊपर दिए गए स्कीमा के लिए डंप फ़ाइल यहां देखी जा सकती है. डेटास्ट्रीम रेप्लिकेशन उपयोगकर्ता को अलग से बनाना ज़रूरी है, क्योंकि यह डंप फ़ाइल में शामिल नहीं होता.
5. डेटा की पुष्टि करना
जल्दी से यह जांचें कि डेटा मौजूद है या नहीं:
SELECT 'Customers shard0_db' AS tbl, COUNT(*) FROM shard0_db.Customers
UNION ALL
SELECT 'Orders shard0_db', COUNT(*) FROM shard0_db.Orders
UNION ALL
SELECT 'Customers shard1_db', COUNT(*) FROM shard1_db.Customers
UNION ALL
SELECT 'Orders shard1_db', COUNT(*) FROM shard1_db.Orders;
EXIT;
अनुमानित आउटपुट:
+---------------------+----------+ | tbl | COUNT(*) | +---------------------+----------+ | Customers shard0_db | 4 | | Orders shard0_db | 5 | | Customers shard1_db | 4 | | Orders shard1_db | 5 | +---------------------+----------+
फ़िज़िकल शार्ड 1 वीएम से कनेक्शन बंद करने के लिए, exit डालें.
6. फ़िजिकल शार्ड 2 के लिए भी यही तरीका दोहराएं
अब आपको दूसरे वीएम के लिए भी यही प्रोसेस दोहरानी होगी. हालांकि, आपको shard2_db और shard3_db बनाना होगा. साथ ही, server-id में बदलाव करना होगा.
- दूसरे वीएम में एसएसएच करें:
gcloud compute ssh mysql-physical-2 --zone=$ZONE --tunnel-through-iap
- MySQL इंस्टॉल करें:
sudo apt-get update
sudo apt-get install mysql-server-8.0 -y
- बाइनरी लॉगिंग चालू करने और बाहरी कनेक्शन की अनुमति देने के लिए,
mysqld.cnfफ़ाइल को कॉन्फ़िगर करें [ध्यान दें कि server-id अलग होना चाहिए (उदाहरण के लिए, 2)]
sudo sed -i 's/bind-address.*/bind-address = 0.0.0.0/' /etc/mysql/mysql.conf.d/mysqld.cnf
echo -e "[mysqld]\nserver-id=2\nlog_bin=/var/log/mysql/mysql-bin.log\nbinlog_format=ROW" | sudo tee -a /etc/mysql/mysql.conf.d/mysqld.cnf
- बदलाव लागू करने के लिए, MySQL को रीस्टार्ट करें:
sudo systemctl restart mysql
- MySQL (
sudo mysql) डालें और चौथे चरण में दी गई एसक्यूएल क्वेरी का थोड़ा बदला हुआ वर्शन चलाएं:
CREATE DATABASE shard2_db;
CREATE DATABASE shard3_db;
USE shard2_db;
CREATE TABLE Customers (
CustomerId INT NOT NULL,
CustomerName VARCHAR(255),
CreditLimit DECIMAL(10, 2) NOT NULL,
LegacyRegion VARCHAR(50), -- Renamed to LoyaltyTier in Spanner
PRIMARY KEY (CustomerId),
CONSTRAINT CHK_CreditLimit CHECK (CreditLimit > 1000) -- Relaxed in Spanner to > 0
);
CREATE TABLE Orders (
CustomerId INT NOT NULL, -- Logically references Customers.CustomerId in Spanner
OrderId INT NOT NULL,
OrderValue DECIMAL(10, 2),
LegacyOrderSystem VARCHAR(50), -- Extra column in Source, to be dropped in Spanner
PRIMARY KEY (CustomerId, OrderId) -- Spanner PK will have one additional column in PK
);
INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LegacyRegion) VALUES
(2, 'Brian K.', 2500.00, 'SOUTHWEST'),
(6, 'Diana L.', 1999.00, 'NORTH'),
(10, 'Edward M.', 11000.00, 'EAST'),
(14, 'Fiona N.', 3000.00, 'WEST');
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem) VALUES
(2, 301, 100.00, 'CallCenter_System'),
(6, 302, 99.00, 'MobileApp_Legacy'),
(10, 303, 1000.00, 'WebStore_v1'),
(10, 304, 2500.00, 'InStore_POS'),
(14, 305, 130.00, 'MobileApp_Legacy');
USE shard3_db;
CREATE TABLE Customers (
CustomerId INT NOT NULL,
CustomerName VARCHAR(255),
CreditLimit DECIMAL(10, 2) NOT NULL,
LegacyRegion VARCHAR(50), -- Renamed to LoyaltyTier in Spanner
PRIMARY KEY (CustomerId),
CONSTRAINT CHK_CreditLimit CHECK (CreditLimit > 1000) -- Relaxed in Spanner to > 0
);
CREATE TABLE Orders (
CustomerId INT NOT NULL, -- Logically references Customers.CustomerId in Spanner
OrderId INT NOT NULL,
OrderValue DECIMAL(10, 2),
LegacyOrderSystem VARCHAR(50), -- Extra column in Source, to be dropped in Spanner
PRIMARY KEY (CustomerId, OrderId) -- Spanner PK will have one additional column in PK
);
INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LegacyRegion) VALUES
(3, 'Cathy Z.', 6000.00, 'CENTRAL'),
(7, 'George O.', 18000.00, 'SOUTH'),
(11, 'Helen P.', 4000.00, 'NORTHEAST'),
(15, 'Ivy Q.', 9500.00, 'SOUTHWEST');
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem) VALUES
(3, 401, 600.00, 'InStore_POS'),
(7, 402, 1200.00, 'CallCenter_System'),
(11, 403, 350.00, 'MobileApp_Legacy'),
(15, 404, 800.00, 'WebStore_v1'),
(99, 999, 25.00, 'CallCenter_System'); -- Failure row during Bulk Migration due to violation of interleaving
-- Create Datastream Replication User
CREATE USER 'datastream_user'@'%' IDENTIFIED BY 'complex_password_123';
GRANT REPLICATION SLAVE, REPLICATION CLIENT, SELECT, INSERT, UPDATE, DELETE ON *.* TO 'datastream_user'@'%';
FLUSH PRIVILEGES;
-- Verify Data
SELECT 'Customers shard2_db' AS tbl, COUNT(*) FROM shard2_db.Customers
UNION ALL
SELECT 'Orders shard2_db', COUNT(*) FROM shard2_db.Orders
UNION ALL
SELECT 'Customers shard3_db', COUNT(*) FROM shard3_db.Customers
UNION ALL
SELECT 'Orders shard3_db', COUNT(*) FROM shard3_db.Orders;
EXIT;
अनुमानित आउटपुट:
+---------------------+----------+ | tbl | COUNT(*) | +---------------------+----------+ | Customers shard2_db | 4 | | Orders shard2_db | 5 | | Customers shard3_db | 4 | | Orders shard3_db | 5 | +---------------------+----------+
ऊपर दिए गए स्कीमा के लिए डंप फ़ाइल यहां देखी जा सकती है. डेटास्ट्रीम रेप्लिकेशन उपयोगकर्ता को अलग से बनाना ज़रूरी है, क्योंकि यह डंप फ़ाइल में शामिल नहीं होता.
वर्चुअल मशीन (वीएम) से कनेक्शन बंद करने के लिए, exit डालें.
5. Cloud Spanner सेट अप करना
अब आपको टारगेट Cloud Spanner इंस्टेंस सेट अप करना होगा. डेटा को इसी इंस्टेंस में माइग्रेट किया जाएगा.
1. Cloud Spanner इंस्टेंस बनाना
लेटेंसी कम करने के लिए, Cloud Spanner इंस्टेंस को उसी क्षेत्र में बनाएं जहां आपके Compute Engine वीएम मौजूद हैं. इस निर्देश से, इस कोडलैब के लिए एक छोटा इंस्टेंस बनाया जाता है. इसमें 100 प्रोसेसिंग यूनिट का इस्तेमाल किया जाता है.
export SPANNER_INSTANCE_NAME="target-spanner-instance"
export SPANNER_DATABASE_NAME="sharded-target-db"
export SPANNER_CONFIG="regional-${REGION}"
gcloud spanner instances create $SPANNER_INSTANCE_NAME \
--config=$SPANNER_CONFIG \
--description="Target Spanner Instance" \
--processing-units=100
इंस्टेंस बनने में एक या दो मिनट लग सकते हैं.
6. Spanner Migration Tool (SMT) का इस्तेमाल करके, स्कीमा को बदलें
Spanner Migration Tool (SMT) के वेब यूज़र इंटरफ़ेस (यूआई) का इस्तेमाल करके, हमारे लॉजिकल शार्ड (shard0_db) में से किसी एक से कनेक्ट करें. इसके बाद, इसके स्कीमा का विश्लेषण करें और इसे Cloud Spanner में बदलने से पहले, इसमें कई अडवांस बदलाव करें.
1. SMT इंस्टॉल करना
हम SMT Web UI को सीधे Cloud Shell से चलाएंगे. अपने Cloud Shell टर्मिनल में, SMT की सबसे नई रिलीज़ डाउनलोड करें और उसे एक्सट्रैक्ट करें:
sudo apt-get update && sudo apt-get install google-cloud-cli-spanner-migration-tool
# Verify installation
gcloud alpha spanner migrate web --help
2. सोर्स डेटाबेस से कनेक्ट करना
- अपने सेशन की पुष्टि करना
# Authenticate your Google Cloud account
gcloud auth login
# Set up Application Default Credentials (ADC) for SMT
gcloud auth application-default login
# Ensure your current project is set correctly
gcloud config set project $PROJECT_ID
(ध्यान दें: प्रॉम्प्ट मिलने पर, अपने खाते को अनुमति देने के लिए दिए गए यूआरएल पर जाएं. इसके बाद, पुष्टि करने वाले कोड को वापस टर्मिनल में चिपकाएं.)
- सबसे पहले, अपने पहले फ़िज़िकल शार्ड का बाहरी आईपी पता ढूंढें. इसके लिए, Cloud Shell के नए टैब में यह कमांड चलाएं:
gcloud compute instances describe mysql-physical-1 --zone=$ZONE --format='get(networkInterfaces[0].accessConfigs[0].natIP)'
- SMT को कॉन्फ़िगर करते समय इस्तेमाल की जाने वाली, टारगेट स्पैनर इंस्टेंस की जानकारी प्रिंट करें.
echo "Project ID: $PROJECT_ID"
echo "Instance ID: $SPANNER_INSTANCE_NAME"
echo "Database Name: $SPANNER_DATABASE_NAME"
- वेब यूज़र इंटरफ़ेस (यूआई) लॉन्च करें:
gcloud alpha spanner migrate web --port=8080
- Cloud Shell विंडो में सबसे ऊपर दाईं ओर, वेब झलक आइकॉन (यह आंख जैसा दिखता है) पर क्लिक करें. इसके बाद, पोर्ट 8080 पर झलक देखें को चुनें. इससे, SMT का यूज़र इंटरफ़ेस (यूआई) एक नए ब्राउज़र टैब में खुलेगा.

- SMT के वेब यूज़र इंटरफ़ेस (यूआई) में, डेटाबेस से कनेक्ट करें को चुनें.
- कनेक्शन की जानकारी डालें:
- डेटाबेस टाइप: MySQL
- होस्ट: (दूसरे चरण से आईपी पता चिपकाएं)
- पोर्ट: 3306
- उपयोगकर्ता:
datastream_user - पासवर्ड:
complex_password_123 - डेटाबेस का नाम:
shard0_db
- Spanner डेटाबेस को कॉन्फ़िगर करने के लिए, सबसे ऊपर दाएं कोने में मौजूद 'बदलाव करें' बटन पर क्लिक करें.
- Target Spanner की जानकारी डालें:
- प्रोजेक्ट आईडी: (तीसरे चरण से प्रोजेक्ट आईडी चिपकाएं)
- Spanner इंस्टेंस: (तीसरे चरण से इंस्टेंस आईडी चिपकाएं)
- कनेक्शन की जांच करें पर क्लिक करें.
- पुष्टि हो जाने के बाद, कनेक्ट करें पर क्लिक करें. SMT, सोर्स डेटाबेस का विश्लेषण करेगा और Spanner का एक बेसलाइन स्कीमा दिखाएगा.

3. स्कीमा में किए गए बदलाव लागू करना
अब हम स्कीमा को फिर से तैयार करेंगे, ताकि माइग्रेशन के मुश्किल मामलों को कवर किया जा सके.
SMT के यूज़र इंटरफ़ेस (यूआई) के स्कीमा एडिटर में, ये कार्रवाइयां करें:
A. LegacyRegion कॉलम का नाम बदलें:
- बाईं ओर मौजूद नेविगेशन पैनल में,
Customersटेबल पर क्लिक करें. इससे कॉलम टैब डिफ़ॉल्ट रूप से खुल जाएगा. - स्पैनर सेक्शन में मौजूद, बदलाव करें बटन पर क्लिक करें.
- स्पैनर स्कीमा व्यू में,
LegacyRegionकॉलम ढूंढें. - कॉलम का नाम बदलने वाले डायलॉग में, Spanner कॉलम का नाम बदलकर
LoyaltyTierकरें. - सेव करें और बदलें पर क्लिक करें.


B. चेक कंस्ट्रेंट को हटाना:
- अब भी
Customersटेबल पर, Check Constraints टैब पर जाएं. CHK_CreditLimitकंस्ट्रेंट ढूंढें. बदलाव करें (पेंसिल) आइकॉन पर क्लिक करें.- शर्त को
CreditLimit > 1000से बदलकरCreditLimit > 0करें. (इससे कम क्रेडिट लिमिट वाली पंक्तियों को जान-बूझकर रिवर्स माइग्रेशन में शामिल नहीं किया जाएगा और उन्हें डीएलक्यू में डाल दिया जाएगा).

C. LegacyOrderSystem कॉलम हटाएं:
Ordersटेबल पर क्लिक करें. इससे कॉलम टैब डिफ़ॉल्ट रूप से खुल जाएगा.- स्पैनर सेक्शन में मौजूद, बदलाव करें बटन पर क्लिक करें.
- स्पैनर स्कीमा व्यू में,
LegacyOrderSystemकॉलम ढूंढें. - इसके बगल में मौजूद, तीन बिंदु वाले मेन्यू आइकॉन पर क्लिक करें. इसके बाद, कॉलम हटाएं को चुनें.
- सेव करें और बदलें पर क्लिक करें.

डी॰ OrderSource कॉलम जोड़ें और इसे प्राइमरी कुंजी बनाएं:
- अब भी
Ordersटेबल में, कॉलम जोड़ें पर क्लिक करें. इसेOrderSourceनाम दें और टाइप कोSTRINGपर सेट करें. इसकी लंबाई50होनी चाहिए. इसे अपने-आप जनरेट नहीं होना चाहिए. साथ ही,IsNullableकोNoपर सेट करें. - प्राइमरी पासकोड टैब पर जाएं.
- बदलाव करें पर क्लिक करें और कॉलम के नाम वाले ड्रॉपडाउन से
OrderSourceचुनें. - कॉलम जोड़ें पर क्लिक करें. इसके बाद, सेव करें और बदलें पर क्लिक करें.
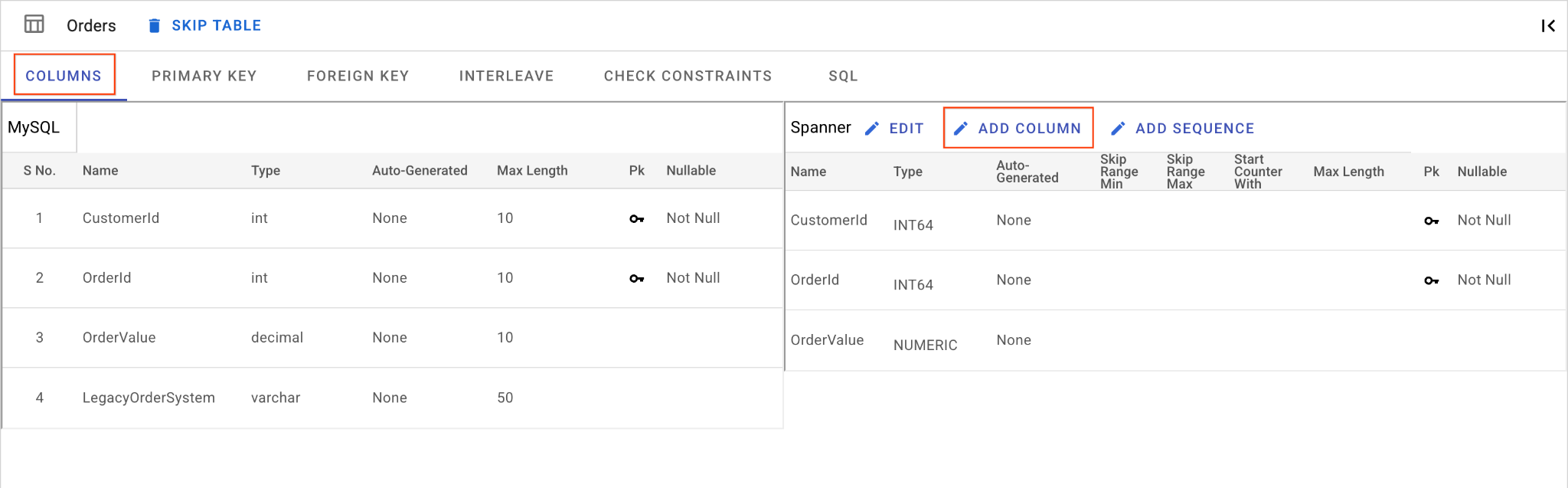

ई॰ ऑर्डर की टेबल को इंटरलीव करें:
- अब भी
Ordersटेबल में, मुख्य टेबल व्यू में इंटरलीव टैब ढूंढें. - पैरंट टेबल को
Customersपर सेट करें. IN PARENTइंटरलीव टाइप औरNO ACTIONमिटाने पर की जाने वाली कार्रवाई चुनें.- सेव करें पर क्लिक करें.

4. बदलाव की जानकारी वाली फ़ाइल डाउनलोड करना और स्कीमा लागू करना
- एसएमटी के यूज़र इंटरफ़ेस (यूआई) में सबसे ऊपर दाएं कोने में, आर्टफ़ैक्ट डाउनलोड करें बटन ढूंढें. बदलाव की जानकारी वाली फ़ाइल डाउनलोड करें विकल्प चुनें. इस फ़ाइल को अपने कंप्यूटर पर सेव करें. इस फ़ाइल में, स्कीमा मैपिंग में किए गए सभी बदलाव शामिल हैं. इसका इस्तेमाल हमारी Dataflow पाइपलाइन करेंगी.
- माइग्रेशन की तैयारी करें पर क्लिक करें.

- ड्रॉपडाउन से,
Schemaके तौर पर माइग्रेशन मोड चुनें. - अपना टारगेट स्पैनर डेटाबेस डालें:
sharded-target-db

- माइग्रेट करें पर क्लिक करें.
- एसएमटी, डीडीएल लागू करेगा और Spanner डेटाबेस बनाएगा. एसएमटी प्रोसेस पूरी होने के बाद, Cloud Shell (
Ctrl+C) में इसे सुरक्षित तरीके से रोका जा सकता है.
5. Cloud Spanner में स्कीमा की पुष्टि करना
देखें कि Spanner डेटाबेस में टेबल बनाई गई हैं या नहीं.
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT table_name FROM information_schema.tables WHERE table_schema = '' ORDER BY table_name"
आपको यह आउटपुट दिखेगा:
table_name: Customers table_name: Orders
ज़रूरी नहीं: अगर आपको यह पुष्टि करनी है कि चेक कंस्ट्रेंट, इंटरलीविंग, और अतिरिक्त कॉलम लागू किए गए हैं, तो Spanner DDL की जांच करें. इसके लिए, यह कमांड चलाएं:
gcloud spanner databases ddl describe $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME
अनुमानित आउटपुट:
CREATE TABLE Customers ( CustomerId INT64 NOT NULL, CustomerName STRING(255), CreditLimit NUMERIC NOT NULL, LoyaltyTier STRING(50), CONSTRAINT CHK_CreditLimit CHECK(`CreditLimit` > 0), ) PRIMARY KEY(CustomerId); CREATE TABLE Orders ( CustomerId INT64 NOT NULL, OrderId INT64 NOT NULL, OrderValue NUMERIC, OrderSource STRING(50) NOT NULL, ) PRIMARY KEY(CustomerId, OrderId, OrderSource), INTERLEAVE IN PARENT Customers ON DELETE NO ACTION;
7. बदले गए डेटा को कैप्चर करने की सुविधा (सीडीसी) शुरू करना
इस सेक्शन में, आपको माइग्रेशन के लिए "रिकॉर्डर" सेट अप करना होगा. डेटा को एक साथ लोड करने की प्रोसेस शुरू होने से पहले, Datastream और Pub/Sub को कॉन्फ़िगर करके यह पक्का किया जाता है कि सोर्स डेटाबेस में किए गए हर बदलाव को कैप्चर और क्यू किया जाए. इससे ट्रांज़िशन के दौरान डेटा का नुकसान नहीं होता. लाइव माइग्रेशन के लिए, यह सेटअप ज़रूरी है.
हमारे आर्किटेक्चर में दो फ़िज़िकल सर्वर शामिल हैं. इसलिए, हमें दो अलग-अलग Datastream सोर्स प्रोफ़ाइलें और दो Datastream स्ट्रीम बनानी होंगी. दोनों स्ट्रीम, एक ही Google Cloud Storage (GCS) बकेट में डेटा लिखेंगी. यह बकेट, हमारी Dataflow पाइपलाइन के लिए एक ही सोर्स के तौर पर काम करेगी.
1. Cloud Storage बकेट बनाना
डेटा स्ट्रीम को कैप्चर किए गए बदलावों से जुड़े इवेंट को सेव करने के लिए, डेस्टिनेशन की ज़रूरत होती है. आइए, एक GCS बकेट बनाएं.
export BUCKET_NAME="migration-${PROJECT_ID}-bucket"
gcloud storage buckets create gs://${BUCKET_NAME} --location=$REGION
2. डेटास्ट्रीम कनेक्शन प्रोफ़ाइलें बनाना
हमें दो अलग-अलग MySQL सोर्स कनेक्शन प्रोफ़ाइल (हर फ़िज़िकल शार्ड के लिए एक) और Cloud Storage के लिए एक टारगेट कनेक्शन प्रोफ़ाइल की ज़रूरत होती है.
सोर्स आईपी पते पाना
सबसे पहले, हमारे दो Compute Engine वीएम के बाहरी आईपी पते फ़ेच करें और उन्हें एनवायरमेंट वैरिएबल के तौर पर सेव करें:
export MYSQL_IP_1=$(gcloud compute instances describe mysql-physical-1 --zone=$ZONE --format='get(networkInterfaces[0].accessConfigs[0].natIP)')
export MYSQL_IP_2=$(gcloud compute instances describe mysql-physical-2 --zone=$ZONE --format='get(networkInterfaces[0].accessConfigs[0].natIP)')
सोर्स कनेक्शन प्रोफ़ाइलें बनाना (Compute Engine पर MySQL)
पहले बनाए गए datastream_user का इस्तेमाल करके, Datastream कनेक्शन प्रोफ़ाइलें बनाएं.
# Create Source Profile for Physical Shard 1
export SQL_CP_NAME_1="mysql-src-cp-1"
gcloud datastream connection-profiles create $SQL_CP_NAME_1 \
--location=$REGION \
--type=mysql \
--mysql-hostname=$MYSQL_IP_1 \
--mysql-port=3306 \
--mysql-username=datastream_user \
--mysql-password=complex_password_123 \
--display-name="MySQL Source 1 (Physical Shard 1)"
# Create Source Profile for Physical Shard 2
export SQL_CP_NAME_2="mysql-src-cp-2"
gcloud datastream connection-profiles create $SQL_CP_NAME_2 \
--location=$REGION \
--type=mysql \
--mysql-hostname=$MYSQL_IP_2 \
--mysql-port=3306 \
--mysql-username=datastream_user \
--mysql-password=complex_password_123 \
--display-name="MySQL Source 2 (Physical Shard 2)"
ध्यान दें: Datastream, इन वीएम से उनके सार्वजनिक आईपी पतों के ज़रिए कनेक्ट होता है. इसकी अनुमति इसलिए है, क्योंकि हमने फ़ायरवॉल के नियमों में 0.0.0.0/0 को पहले ही जोड़ दिया था. प्रोडक्शन एनवायरमेंट में, Datastream की खास सार्वजनिक आईपी रेंज को सिर्फ़ अनुमति दी जाती है.
डेस्टिनेशन कनेक्शन प्रोफ़ाइल (Cloud Storage) बनाएं:
यह आपकी नई बकेट के रूट की ओर ले जाता है.
export GCS_CP_NAME="gcs-dest-cp"
gcloud datastream connection-profiles create $GCS_CP_NAME \
--location=$REGION \
--type=google-cloud-storage \
--bucket=$BUCKET_NAME \
--root-path=/ \
--display-name="GCS Destination" --force
3. डेटा स्ट्रीम बनाना
अब हम दो सीडीसी स्ट्रीम बनाएंगे. स्ट्रीम 1, shard0_db और shard1_db को कैप्चर करेगी. दूसरी स्ट्रीम में shard2_db और shard3_db को कैप्चर किया जाएगा. दोनों स्ट्रीम, Avro फ़ॉर्मैट में एक ही GCS बकेट में डेटा लिखती हैं.
# Stream for Physical Shard 1
export STREAM_NAME_1="mysql-to-spanner-stream-1"
export GCS_STREAM_PATH_1="data/${STREAM_NAME_1}"
gcloud datastream streams create $STREAM_NAME_1 \
--location=$REGION \
--display-name="MySQL Source 1 CDC Stream" \
--source=$SQL_CP_NAME_1 \
--destination=$GCS_CP_NAME \
--mysql-source-config=<(echo "includeObjects:
mysqlDatabases:
- database: 'shard0_db'
- database: 'shard1_db'") \
--gcs-destination-config=<(echo "path: ${GCS_STREAM_PATH_1}/
fileRotationMb: 5
fileRotationInterval: 15s
avroFileFormat: {}") \
--backfill-none
# Stream for Physical Shard 2
export STREAM_NAME_2="mysql-to-spanner-stream-2"
export GCS_STREAM_PATH_2="data/${STREAM_NAME_2}"
gcloud datastream streams create $STREAM_NAME_2 \
--location=$REGION \
--display-name="MySQL Source 2 CDC Stream" \
--source=$SQL_CP_NAME_2 \
--destination=$GCS_CP_NAME \
--mysql-source-config=<(echo "includeObjects:
mysqlDatabases:
- database: 'shard2_db'
- database: 'shard3_db'") \
--gcs-destination-config=<(echo "path: ${GCS_STREAM_PATH_2}/
fileRotationMb: 5
fileRotationInterval: 15s
avroFileFormat: {}") \
--backfill-none
फ़ाइल रोटेशन की छोटी सेटिंग (5 एमबी या 15 सेकंड) का इस्तेमाल करने से, हमें कोडलैब के दौरान डुप्लीकेट किए गए बदलावों को तेज़ी से देखने में मदद मिलती है.
इस कमांड को पूरा होने में कुछ समय लग सकता है. स्टेटस देखें: gcloud datastream streams describe $STREAM_NAME_1 --location=$REGION.
4. Datastream Streams शुरू करना
दोनों स्ट्रीम चालू करें, ताकि वे बदलावों को रिकॉर्ड करना शुरू कर सकें.
gcloud datastream streams update $STREAM_NAME_1 \
--location=$REGION \
--state=RUNNING
gcloud datastream streams update $STREAM_NAME_2 \
--location=$REGION \
--state=RUNNING
स्थिति देखें: gcloud datastream streams describe $STREAM_NAME_1 --location=$REGION को चलाया जा सकता है. शुरुआत में स्थिति STARTING होगी और कुछ देर बाद यह RUNNING में बदल जाएगी. लाइव माइग्रेशन शुरू करने से पहले, दोनों के पूरी तरह से चालू होने का इंतज़ार करें.
5. GCS सूचनाओं के लिए Pub/Sub सेट अप करना
जब Datastream स्ट्रीम, GCS बकेट में कोई नई फ़ाइल लिखती है, तो Dataflow को इसकी सूचना तुरंत मिलनी चाहिए. हम GCS को कॉन्फ़िगर करेंगे, ताकि वह एक Pub/Sub विषय पर सूचनाएं भेज सके.
Pub/Sub विषय बनाएं:
export PUBSUB_TOPIC="datastream-gcs-updates"
gcloud pubsub topics create $PUBSUB_TOPIC
GCS सूचना बनाएं
data/ प्रीफ़िक्स के तहत कोई भी ऑब्जेक्ट बनाने पर, विषय को सूचना दें. इसमें हमारी दोनों स्ट्रीम शामिल हैं.
gcloud storage buckets notifications create gs://${BUCKET_NAME} --topic=projects/$PROJECT_ID/topics/$PUBSUB_TOPIC --payload-format=json --object-prefix=data/
Pub/Sub की सदस्यता बनाना
Dataflow के लिए, सूचना पाने की सुझाई गई समयसीमा के साथ सदस्यता बनाएं.
export PUBSUB_SUBSCRIPTION="datastream-gcs-sub"
gcloud pubsub subscriptions create $PUBSUB_SUBSCRIPTION \
--topic=$PUBSUB_TOPIC \
--ack-deadline=600
8. कस्टम ट्रांसफ़ॉर्मेशन
हमारे Spanner स्कीमा और MySQL स्कीमा में अंतर है. इसकी वजह यह है कि हमने SMT के वेब यूज़र इंटरफ़ेस (यूआई) के ज़रिए कुछ कॉलम जोड़े और हटाए हैं. इसलिए, Dataflow माइग्रेशन की डिफ़ॉल्ट सुविधा काम नहीं करेगी. Dataflow को यह निर्देश देने होंगे कि फ़ॉरवर्ड (MySQL से Spanner) और रिवर्स (Spanner से MySQL) पाइपलाइन के दौरान, इन अंतरों को कैसे मैप किया जाए.
इसके अलावा, हम शार्ड की गई रिवर्स माइग्रेशन की प्रोसेस कर रहे हैं. इसलिए, Dataflow को एक राउटिंग मेकेनिज़्म की ज़रूरत होती है. इससे यह पता चलता है कि रिवर्स रेप्लिकेशन के दौरान, अपडेट की गई Spanner लाइन किस लॉजिकल शार्ड (shard0_db, shard1_db वगैरह) से जुड़ी है.
हम Google के दिए गए Spanner Custom Shard टेंप्लेट का इस्तेमाल करके, कस्टम ट्रांसफ़ॉर्मेशन JAR लिखेंगे.
1. कस्टम शार्ड टेंप्लेट डाउनलोड करें
Cloud Shell में, Google Cloud Dataflow Templates रिपॉज़िटरी डाउनलोड करें और कस्टम शार्ड फ़ोल्डर पर जाएं:
git clone https://github.com/GoogleCloudPlatform/DataflowTemplates.git
cd DataflowTemplates/v2/spanner-custom-shard
2. डेटा ट्रांसफ़ॉर्मेशन लॉजिक कॉन्फ़िगर करना
हमें CustomTransformationFetcher.java फ़ाइल में बदलाव करना है.
- फ़ॉरवर्ड माइग्रेशन (
toSpannerRow): यह MySQL केLegacyOrderSystemकॉलम का इस्तेमाल करके, नए जोड़े गएOrderSourceकॉलम में डेटा भरता है. - रिवर्स माइग्रेशन (
toSourceRow): यह ड्रॉप किए गएLegacyOrderSystemकॉलम को फिर से भरता है. यह कॉलम MySQL के लिए ज़रूरी होता है. यह Spanner केOrderSourceसे लिया जाता है.
CustomTransformationFetcher.java फ़ाइल में बदलाव करें. टेक्स्ट एडिटर को मैन्युअल तरीके से खोलने के बजाय, यहां दी गई कमांड चलाएं. इससे टेंप्लेट फ़ाइल में मौजूद कॉन्टेंट, हमारे कस्टम लॉजिक से अपने-आप बदल जाएगा:
cat << 'EOF' > src/main/java/com/custom/CustomTransformationFetcher.java
package com.custom;
import com.google.cloud.teleport.v2.spanner.exceptions.InvalidTransformationException;
import com.google.cloud.teleport.v2.spanner.utils.ISpannerMigrationTransformer;
import com.google.cloud.teleport.v2.spanner.utils.MigrationTransformationRequest;
import com.google.cloud.teleport.v2.spanner.utils.MigrationTransformationResponse;
import java.util.HashMap;
import java.util.Map;
public class CustomTransformationFetcher implements ISpannerMigrationTransformer {
@Override
public void init(String customParameters) {}
@Override
public MigrationTransformationResponse toSpannerRow(MigrationTransformationRequest request)
throws InvalidTransformationException {
if (request.getTableName().equals("Orders")) {
Map<String, Object> requestRow = request.getRequestRow();
Map<String, Object> responseRow = new HashMap<>();
Object legacySysObj = requestRow.get("LegacyOrderSystem");
String legacySys = (legacySysObj != null) ? (String) legacySysObj : "UNKNOWN_SYSTEM";
// Transform: Trim the string to remove everything after the first underscore
String orderSource = legacySys;
if (legacySys.contains("_")) {
orderSource = legacySys.substring(0, legacySys.indexOf('_'));
}
// Populate the new Spanner column (e.g., "WebStore_v1" becomes "WebStore")
responseRow.put("OrderSource", orderSource);
return new MigrationTransformationResponse(responseRow, false);
}
return new MigrationTransformationResponse(new HashMap<>(), false);
}
@Override
public MigrationTransformationResponse toSourceRow(MigrationTransformationRequest request)
throws InvalidTransformationException {
if (request.getTableName().equals("Orders")) {
Map<String, Object> requestRow = request.getRequestRow();
Map<String, Object> responseRow = new HashMap<>();
// Safely fetch the Spanner OrderSource
Object sourceObj = requestRow.get("OrderSource");
String source = (sourceObj != null) ? (String) sourceObj : "UNKNOWN_SYSTEM";
String legacySys = "'" + source + "_v1'";
// Transform: Append a suffix to visibly prove the reverse transformation worked
// e.g., "WebStore" becomes "WebStore_v1"
responseRow.put("LegacyOrderSystem", legacySys);
return new MigrationTransformationResponse(responseRow, false);
}
return new MigrationTransformationResponse(new HashMap<>(), false);
}
@Override
public MigrationTransformationResponse transformFailedSpannerMutation(
MigrationTransformationRequest request) throws InvalidTransformationException {
return new MigrationTransformationResponse(new HashMap<>(), false);
}
}
EOF
3. रिवर्स शार्डिंग लॉजिक कॉन्फ़िगर करना
डेटाफ़्लो, रिवर्स रेप्लिकेशन के दौरान CustomShardIdFetcher.java का इस्तेमाल करता है. इससे यह तय किया जाता है कि Spanner म्यूटेशन को कहां रूट किया जाना चाहिए. हम CustomerId प्राइमरी कुंजी और मॉडुलस (%4) लॉजिक का इस्तेमाल करके, रिकॉर्ड को डाइनैमिक तरीके से उनके सही लॉजिकल शार्ड पर वापस भेजेंगे.
cat का इस्तेमाल करके CustomShardIdFetcher.java फ़ाइल में बदलाव करें और इसके पूरे कॉन्टेंट को इस कोड से बदलें:
cat << 'EOF' > src/main/java/com/custom/CustomShardIdFetcher.java
package com.custom;
import com.google.cloud.teleport.v2.spanner.utils.IShardIdFetcher;
import com.google.cloud.teleport.v2.spanner.utils.ShardIdRequest;
import com.google.cloud.teleport.v2.spanner.utils.ShardIdResponse;
import java.util.Map;
public class CustomShardIdFetcher implements IShardIdFetcher {
@Override
public void init(String parameters) {}
@Override
public ShardIdResponse getShardId(ShardIdRequest shardIdRequest) {
Map<String, Object> keys = shardIdRequest.getSpannerRecord
();
// Use the Primary Key to identify the correct logical shard
if (keys != null && keys.containsKey("CustomerId")) {
long customerId = Long.parseLong(keys.get("CustomerId").toString());
long shardIdx = customerId % 4;
ShardIdResponse response = new ShardIdResponse();
response.setLogicalShardId("shard" + shardIdx + "_db");
return response;
}
return new ShardIdResponse();
}
}
EOF
4. JAR बनाना और अपलोड करना
अब हमारा कस्टम Java लॉजिक लिखा जा चुका है. इसलिए, हमें इसे JAR फ़ाइल में कंपाइल करना होगा. इसके बाद, इसे उस Google Cloud Storage बकेट में अपलोड करना होगा जिसे हमने पहले बनाया था, ताकि Dataflow इसे ऐक्सेस कर सके.
Cloud Shell में ये कमांड चलाएं:
# Return to DataflowTemplates directory
cd ../..
# Build the JAR using Maven
mvn clean install -DskipTests -Dcheckstyle.skip -Dspotless.check.skip=true -Djib.skip -pl v2/spanner-custom-shard -am
# Upload the JAR to GCS
export CUSTOM_JAR_PATH="gs://${BUCKET_NAME}/custom-logic/spanner-custom-shard-1.0.jar"
gcloud storage cp v2/spanner-custom-shard/target/spanner-custom-shard-1.0-SNAPSHOT.jar $CUSTOM_JAR_PATH
# Return to home directory
cd ~
9. MySQL से Spanner में एक साथ कई डेटाबेस माइग्रेट करना
Spanner स्कीमा और कस्टम ट्रांसफ़ॉर्मेशन JAR के बन जाने के बाद, अब हम आपके MySQL डेटाबेस से मौजूदा डेटा को Cloud Spanner में कॉपी कर सकते हैं. आपको Sourcedb to Spanner डेटाफ़्लो फ़्लेक्स टेंप्लेट का इस्तेमाल करना होगा. इसे JDBC से ऐक्सेस किए जा सकने वाले डेटाबेस से Spanner में डेटा कॉपी करने के लिए डिज़ाइन किया गया है.
1. स्कीमा ओवरराइड फ़ाइल अपलोड करना
छठे सेक्शन में, आपने SMT के वेब यूज़र इंटरफ़ेस (यूआई) का इस्तेमाल करके, Spanner Overrides JSON फ़ाइल डाउनलोड की थी. हमें इसे अपने GCS बकेट में अपलोड करना होगा, ताकि Dataflow इसका इस्तेमाल स्कीमा में हुए बदलावों (जैसे कि कॉलम के नाम बदले जाना) को मैप करने के लिए कर सके.
- Cloud Shell में, तीन बिंदु वाले मेन्यू (ज़्यादा) पर क्लिक करें. इसके बाद, अपलोड करें को चुनें.

- बदलावों की जानकारी वाली उस JSON फ़ाइल को चुनें जिसे आपने पहले डाउनलोड किया था. उदाहरण के लिए,
spanner_overrides.json. - इसे अपने GCS बकेट में ले जाएं:
export OVERRIDES_FILE="spanner_overrides.json" # Change this if your downloaded file has a different name
export GCS_OVERRIDES_PATH="gs://${BUCKET_NAME}/config/${OVERRIDES_FILE}"
gcloud storage cp ~/${OVERRIDES_FILE} $GCS_OVERRIDES_PATH
2. शार्डिंग कॉन्फ़िगरेशन फ़ाइल बनाना और अपलोड करना
Dataflow को यह पता होना चाहिए कि आपके दो फ़िज़िकल वीएम में मौजूद सभी चार लॉजिकल शार्ड से कैसे कनेक्ट किया जाए. हम इसके लिए एक sharding.json फ़ाइल बनाएंगे.
कॉन्फ़िगरेशन जनरेट करने और उसे अपलोड करने के लिए, Cloud Shell में यह कमांड चलाएं:
cat <<EOF > sharding.json
{
"configType": "dataflow",
"shardConfigurationBulk": {
"schemaSource": {
"dataShardId": "mysql-physical-1",
"host": "${MYSQL_IP_1}",
"user": "datastream_user",
"password": "complex_password_123",
"port": "3306",
"dbName": "shard0_db"
},
"dataShards": [
{
"dataShardId": "mysql-physical-1",
"host": "${MYSQL_IP_1}",
"user": "datastream_user",
"password": "complex_password_123",
"port": "3306",
"dbName": "",
"namespace": "namespace-mysql-1",
"databases": [
{
"dbName": "shard0_db",
"databaseId": "shard0_db",
"refDataShardId": "mysql-physical-1"
},
{
"dbName": "shard1_db",
"databaseId": "shard1_db",
"refDataShardId": "mysql-physical-1"
}
]
},
{
"dataShardId": "mysql-physical-2",
"host": "${MYSQL_IP_2}",
"user": "datastream_user",
"password": "complex_password_123",
"port": "3306",
"dbName": "",
"namespace": "namespace-mysql-2",
"databases": [
{
"dbName": "shard2_db",
"databaseId": "shard2_db",
"refDataShardId": "mysql-physical-2"
},
{
"dbName": "shard3_db",
"databaseId": "shard3_db",
"refDataShardId": "mysql-physical-2"
}
]
}
]
}
}
EOF
export GCS_SHARDING_PATH="gs://${BUCKET_NAME}/config/sharding.json"
gcloud storage cp sharding.json $GCS_SHARDING_PATH
3. बल्क माइग्रेशन डेटाफ़्लो जॉब चलाएं
हम Sourcedb to Spanner फ़्लेक्स टेंप्लेट का इस्तेमाल करेंगे. यह कस्टम ट्रांसफ़ॉर्मेशन के साथ शार्ड किया गया माइग्रेशन है. इसलिए, हम Overrides फ़ाइल, Sharding config, और कस्टम Java JAR पास करते हैं.
export JOB_NAME="mysql-sharded-bulk-to-spanner-$(date +%Y%m%d-%H%M%S)"
export OUTPUT_DIR="gs://${BUCKET_NAME}/bulk-migration"
gcloud dataflow flex-template run $JOB_NAME \
--project=$PROJECT_ID \
--region=$REGION \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Sourcedb_to_Spanner_Flex" \
--max-workers=2 \
--num-workers=1 \
--worker-machine-type=n2-highmem-8 \
--parameters \
sourceConfigURL=$GCS_SHARDING_PATH,\
instanceId=$SPANNER_INSTANCE_NAME,\
databaseId=$SPANNER_DATABASE_NAME,\
projectId=$PROJECT_ID,\
outputDirectory=$OUTPUT_DIR,\
username=datastream_user,\
password=complex_password_123,\
schemaOverridesFilePath=$GCS_OVERRIDES_PATH,\
transformationJarPath=$CUSTOM_JAR_PATH,\
transformationClassName=com.custom.CustomTransformationFetcher
मुख्य पैरामीटर के बारे में जानकारी:
sourceConfigURL: हमने जोsharding.jsonफ़ाइल बनाई है उसका पाथ. इससे Dataflow को यह पता चलता है कि दो फ़िज़िकल वीएम में मौजूद हमारे सभी चार लॉजिकल MySQL शार्ड से कैसे कनेक्ट करना है.schemaOverridesFilePath: यह SMT Web UI से डाउनलोड की गई JSON फ़ाइल का पाथ है. इससे Dataflow को यह निर्देश मिलता है कि हमने स्कीमा में जो बदलाव किए हैं उन्हें कैसे हैंडल करना है. जैसे, हटा दिया गयाLegacyRegionकॉलम और चेक की गई शर्त को और ज़्यादा सख्त करना.transformationJarPath: कंपाइल की गई Java JAR फ़ाइल का GCS पाथ, जिसे हमने पिछले सेक्शन में बनाया था. इसमें कस्टम ट्रांसफ़ॉर्मेशन को लागू करने के लिए, असल कोड होता है.transformationClassName: हमारे JAR में मौजूद Java क्लास का पूरी तरह क्वालिफ़ाइड नाम. यह क्लास, फ़ॉरवर्ड माइग्रेशन लॉजिक (com.custom.CustomTransformationFetcher) को लागू करती है.outputDirectory: यह GCS की वह जगह है जहां Dataflow अपनी अस्थायी फ़ाइलें लिखेगा. साथ ही, सबसे ज़रूरी बात यह है कि यह वह जगह है जहां Dead Letter Queue (DLQ) फ़ाइलें लिखी जाएंगी.maxWorkers,numWorkers: इससे Dataflow जॉब की स्केलिंग को कंट्रोल किया जाता है. इस छोटे डेटासेट के लिए, इसे कम रखा गया है.instanceId,databaseId,projectId: इससे टारगेट Cloud Spanner इंस्टेंस और डेटाबेस के बारे में पता चलता है.
नेटवर्क से जुड़ी जानकारी: यह जॉब, Cloud SQL इंस्टेंस से उसके पब्लिक आईपी के ज़रिए कनेक्ट होती है. ऐसा इसलिए हो सका, क्योंकि आपने पहले इंस्टेंस के लिए, 0.0.0.0/0 को अनुमति वाले नेटवर्क में जोड़ा था. इससे डेटाफ़्लो वर्कर वीएम को डेटाबेस तक पहुंचने की अनुमति मिलती है. इन वीएम के पास बाहरी आईपी होते हैं.
4. Dataflow जॉब की निगरानी करना
Google Cloud Console में जाकर, जॉब की प्रोग्रेस को ट्रैक किया जा सकता है:
- Dataflow Jobs पेज पर जाएं: Dataflow Jobs पर जाएं
mysql-sharded-bulk-to-spanner-...नाम की नौकरी ढूंढें और उस पर क्लिक करें.- जॉब ग्राफ़ और मेट्रिक देखें. जॉब का स्टेटस Succeeded में बदलने तक इंतज़ार करें. इसमें करीब 5 से 15 मिनट लगेंगे.

- अगर नौकरी में समस्याएं आती हैं, तो गड़बड़ी के मैसेज देखने के लिए, डेटाफ़्लो जॉब की ज़्यादा जानकारी वाले पेज में मौजूद लॉग टैब देखें.
- जॉब मेट्रिक से, जॉब की प्रोग्रेस और संसाधन के इस्तेमाल के बारे में ज़्यादा जानकारी मिलती है. जैसे, थ्रूपुट और सीपीयू का इस्तेमाल.
5. Cloud Spanner में डेटा की पुष्टि करना और डेड लेटर क्यू (डीएलक्यू) की जांच करना
Dataflow जॉब के पूरा होने के बाद, हमें यह पुष्टि करनी होगी कि हमारा डेटा सुरक्षित तरीके से पहुंच गया है. साथ ही, हमें उन रिकॉर्ड की जांच करनी होगी जिन्हें हमने जान-बूझकर फ़ेल होने के लिए तैयार किया था.
A. माइग्रेट किए गए डेटा की पूरी सेहत की पुष्टि करें:
gcloud CLI का इस्तेमाल करके, अपने स्पैनर डेटाबेस की कुछ बुनियादी जांचें करें. इससे यह पक्का किया जा सकेगा कि मान्य रिकॉर्ड सही तरीके से माइग्रेट हुए हैं और हमारे कस्टम JAR ने अतिरिक्त कॉलम में डेटा भरा है.
# 1. Verify total Customer count
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT COUNT(*) as TotalCustomers FROM Customers"
# 2. Verify total Orders count (Total minus the orphan record)
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT COUNT(*) as TotalOrders FROM Orders"
# 3. Verify the Custom Transformation on OrderSource worked
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT CustomerId, OrderId, OrderSource FROM Orders LIMIT 3"
# 4. Verify that renamed column LoyaltyTier has the correct data
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT CustomerId, CustomerName, LoyaltyTier FROM Customers LIMIT 3"
अनुमानित आउटपुट:
TotalCustomers: 16 TotalOrders: 19 CustomerId: 1 OrderId: 201 OrderSource: MobileApp CustomerId: 2 OrderId: 301 OrderSource: CallCenter CustomerId: 3 OrderId: 401 OrderSource: InStore CustomerId: 1 CustomerName: Agnes N. LoyaltyTier: NORTHEAST CustomerId: 2 CustomerName: Brian K. LoyaltyTier: SOUTHWEST CustomerId: 3 CustomerName: Cathy Z. LoyaltyTier: CENTRAL
- Customers टेबल की सभी पंक्तियों को माइग्रेट कर दिया गया है.
- हमें Spanner पर
INTERLEAVE IN PARENTकी वजह से,Ordersटेबल में एक लाइन में गड़बड़ी दिख रही है.Customersटेबल में कोई भी लाइन मौजूद न होने की वजह से,CustomerId 99एक अनाथ चाइल्ड है.
B. डीएलएक्यू में जान-बूझकर की गई गड़बड़ियों की जांच करें:
ऊपर दी गई गड़बड़ी की जानकारी, बल्क माइग्रेशन पाइपलाइन से बनाए गए डेड लेटर क्यू (डीएलक्यू) फ़ोल्डर में सेव की जाती है.
- Google Cloud Console में Cloud Storage पर जाएं.
- अपने बकेट पर जाएं और
bulk-migration/dlq/severeफ़ोल्डर खोलें. - इसके अंदर मौजूद JSON फ़ाइलों की जांच करें. आपको अनाथ
CustomerIdके साथOrdersलाइन दिखेगी. - एक साथ कई ईमेल पतों को माइग्रेट करने के दौरान DLQ से जुड़ी गड़बड़ियों को ठीक करने के लिए, यहां दिया गया तरीका अपनाएं.
Cloud SQL से Cloud Spanner में डेटा को एक साथ लोड करने की शुरुआती प्रोसेस अब पूरी हो गई है. अगला चरण, लाइव रेप्लिकेशन सेट अप करना है, ताकि मौजूदा बदलावों को कैप्चर किया जा सके.
10. लाइव माइग्रेशन (सीडीसी) शुरू करें
बल्क डेटा लोड होने के बाद, आपको डेटाफ़्लो की लगातार स्ट्रीमिंग करने वाला जॉब लॉन्च करना होगा. यह जॉब, Change Data Capture (सीडीसी) इवेंट को पढ़ेगी. इन इवेंट को Datastream, आपके GCS बकेट में लिख रहा है. साथ ही, इन बदलावों को Cloud Spanner में रीयल-टाइम के आस-पास लागू करेगी.
हम इस पाइपलाइन की जांच भी करेंगे. इसके लिए, हम जान-बूझकर अमान्य डेटा और मान्य डेटा, दोनों को इंजेक्ट करेंगे. इससे हमें यह पता चलेगा कि Dataflow, लाइव रेप्लिकेशन को कैसे मैनेज करता है और गड़बड़ियों को डेड लेटर क्यू (डीएलक्यू) में कैसे भेजता है.
1. लाइव माइग्रेशन शार्डिंग कॉन्फ़िगरेशन फ़ाइल बनाना
बल्क माइग्रेशन (जो JDBC कनेक्शन स्ट्रिंग का इस्तेमाल करता है) के उलट, लाइव माइग्रेशन पाइपलाइन, GCS से Datastream इवेंट पढ़ती है. इसके लिए, एक बिलकुल अलग JSON कॉन्फ़िगरेशन की ज़रूरत होती है. यह Datastream स्ट्रीम के नामों और डेटाबेस को आपके लॉजिकल Spanner शार्ड से मैप करता है.
लाइव शार्डिंग कॉन्फ़िगरेशन बनाने और उसे अपलोड करने के लिए, Cloud Shell में यह कमांड चलाएँ:
cat <<EOF > live-sharding.json
{
"StreamToDbAndShardMap": {
"${STREAM_NAME_1}": {
"shard0_db": "shard0_db",
"shard1_db": "shard1_db"
},
"${STREAM_NAME_2}": {
"shard2_db": "shard2_db",
"shard3_db": "shard3_db"
}
}
}
EOF
export GCS_LIVE_SHARDING_PATH="gs://${BUCKET_NAME}/config/live-sharding.json"
gcloud storage cp live-sharding.json $GCS_LIVE_SHARDING_PATH
2. लाइव माइग्रेशन डेटाफ़्लो जॉब चलाना
GCS से डेटा पढ़ने और Spanner में डेटा लिखने के लिए, स्ट्रीमिंग Dataflow जॉब लॉन्च करें. यह टेंप्लेट, नई फ़ाइलों को तुरंत प्रोसेस करने के लिए GCS Pub/Sub सूचनाओं का इस्तेमाल करेगा.
export JOB_NAME_CDC="mysql-sharded-cdc-to-spanner-$(date +%Y%m%d-%H%M%S)"
export DLQ_DIR_CDC="gs://${BUCKET_NAME}/live-migration"
gcloud dataflow flex-template run $JOB_NAME_CDC \
--project=$PROJECT_ID \
--region=$REGION \
--worker-machine-type=n2-highmem-8 \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Cloud_Datastream_to_Spanner" \
--parameters \
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
projectId="$PROJECT_ID",\
inputFileFormat="avro",\
gcsPubSubSubscription="projects/${PROJECT_ID}/subscriptions/${PUBSUB_SUBSCRIPTION}",\
shardingContextFilePath=$GCS_LIVE_SHARDING_PATH,\
deadLetterQueueDirectory="$DLQ_DIR_CDC",\
transformationJarPath=$CUSTOM_JAR_PATH,\
transformationClassName="com.custom.CustomTransformationFetcher",\
schemaOverridesFilePath=$GCS_OVERRIDES_PATH,\
datastreamSourceType="mysql",\
dlqRetryMinutes=1,\
dlqMaxRetryCount=2
मुख्य पैरामीटर
gcsPubSubSubscription: यह Pub/Sub सदस्यता, GCS से नई फ़ाइल की सूचनाएं पाने के लिए होती है. इससे, Datastream के डेटा लिखने के साथ ही, जॉब में बदलावों को तुरंत प्रोसेस किया जा सकता है.inputFileFormat="avro": इससे Dataflow को यह पता चलता है कि Datastream से Avro फ़ाइलें मिलेंगी. यह आपके डेटास्ट्रीम के "डेस्टिनेशन" कॉन्फ़िगरेशन से मेल खाना चाहिए. उदाहरण के लिए,avroFileFormatबनामjsonFileFormat.shardingContextFilePath: यह एक JSON फ़ाइल है. इसमें डेटा स्ट्रीम को लॉजिकल शार्ड से मैप किया जाता है.dlqRetryMinutes: यह डेड लेटर क्यू में फिर से कोशिश करने के बीच का समय (मिनटों में) होता है. यह डिफ़ॉल्ट रूप से10पर सेट होता है.dlqMaxRetryCount: डीएलक्यू के ज़रिए, कुछ समय के लिए होने वाली गड़बड़ियों को ज़्यादा से ज़्यादा कितनी बार फिर से आज़माया जा सकता है. यह डिफ़ॉल्ट रूप से500पर सेट होता है.
Dataflow Jobs Console में जाकर, नौकरी के शुरू होने की प्रोसेस पर नज़र रखें.
3. लाइव डेटा इंजेक्ट करना और जान-बूझकर गड़बड़ियां ट्रिगर करना
Dataflow स्ट्रीमिंग जॉब शुरू होने में 3 से 5 मिनट लग सकते हैं. इस दौरान, हम अपनी पहली फ़िज़िकल MySQL वीएम में SSH करते हैं और कुछ नए रिकॉर्ड डालते हैं. हम एक मान्य रिकॉर्ड और एक अमान्य रिकॉर्ड डालेंगे.
पहले फ़िज़िकल शार्ड में एसएसएच करें:
gcloud compute ssh mysql-physical-1 --zone=$ZONE
MySQL में लॉग इन करें:
sudo mysql
shard1_db पर ये इंसर्ट चलाएं:
USE shard1_db;
-- 1. Valid Insert: 'MobileApp_v2' will be trimmed to 'MobileApp'
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem)
VALUES (4, 501, 99.99, 'MobileApp_v2');
-- 2. Invalid Insert (DLQ Test): This violates Interleave constraint as CustomerId 99999 doesn't exist in Customers table.
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem)
VALUES (99999, 502, 50.00, 'WebStore_v1');
-- 3. Valid Update
UPDATE Orders SET OrderValue = '1500' WHERE CustomerId = 5 AND OrderId = 202;
-- 4. Valid Delete
DELETE FROM Orders WHERE CustomerId = 5 AND OrderId = 203;
EXIT;
Cloud Shell प्रॉम्प्ट पर वापस जाने के लिए, exit फिर से टाइप करें.
4. लाइव माइग्रेशन डेटा की पुष्टि करना और सीडीसी डीएलक्यू की जांच करना
डेटा इंजेक्ट करने के बाद, Datastream, सीडीसी इवेंट कैप्चर करेगा. साथ ही, Dataflow उन्हें Spanner पर लागू करने की कोशिश करेगा.
A. Spanner में मान्य DML बदलावों की पुष्टि करना
यह पुष्टि करने के लिए कि INSERT, UPDATE, और DELETE इवेंट, Spanner तक पहुंच गए हैं और कस्टम ट्रांसफ़ॉर्मेशन, इंसर्ट और अपडेट, दोनों पर ट्रिगर हुआ है, यहां दी गई क्वेरी चलाएं.
# 1. Verify INSERT: Should return the new row with transformed OrderSource
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT CustomerId, OrderId, OrderValue, OrderSource FROM Orders WHERE CustomerId = 4 AND OrderId = 501"
# 2. Verify UPDATE: Should show OrderValue changed to 1500
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT CustomerId, OrderId, OrderValue, OrderSource FROM Orders WHERE CustomerId = 5 AND OrderId = 202"
# 3. Verify DELETE: Should return 0, confirming the order was deleted
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT COUNT(*) FROM Orders WHERE CustomerId = 5 AND OrderId = 203"
# 4. Verify DLQ Failure: Should return 0, confirming the row migration failed
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT COUNT(*) FROM Orders WHERE CustomerId = 99999 AND OrderId = 502"
अनुमानित आउटपुट:
CustomerId: 4 OrderId: 501 OrderValue: 99.99 OrderSource: MobileApp CustomerId: 5 OrderId: 202 OrderValue: 1500 OrderSource: WebStore 0 0
ध्यान दें: अगर किसी क्वेरी का नतीजा उम्मीद के मुताबिक नहीं दिखता है, तो एक मिनट इंतज़ार करें और फिर से कोशिश करें. ऐसा इसलिए, क्योंकि स्ट्रीमिंग वर्कर अब भी कतार में मौजूद क्वेरी को प्रोसेस कर रहे हो सकते हैं.
B. डीएलएक्यू में जान-बूझकर की गई गड़बड़ी की जांच करें:
CustomerId = 99999 का पैरंट, Customers टेबल में मौजूद नहीं है. इसलिए, इसे Spanner ने अस्वीकार कर दिया और Dataflow ने इसे DLQ में सुरक्षित तरीके से भेज दिया.
- Google Cloud Console में Cloud Storage पर जाएं.
- अपने बकेट पर जाएं और
live-migration/dlq/severe/फ़ोल्डर खोलें. - आपको नई जनरेट की गई JSON फ़ाइलें दिखेंगी. कॉन्टेंट की जांच करने के लिए, उन पर क्लिक करें. आपको
CustomerId = 99999की जानकारी और Spanner से जुड़ी गड़बड़ी का मैसेज दिखेगा:NOT_FOUND: Parent row for row [99999,502,WebStore] in table Orders is missing. Row cannot be written." - लाइव माइग्रेशन DLQ से जुड़ी गड़बड़ियों को ठीक करने के लिए,
runMode=retryDLQसेट करके डेटाफ़्लो टेंप्लेट को फिर से चलाया जा सकता है.
5. DLQ से जुड़ी गड़बड़ियों को ठीक करना
severe/ डायरेक्ट्री में मौजूद गड़बड़ियों को मैन्युअल तरीके से ठीक करना होता है. आइए, डेटा से जुड़ी समस्या को ठीक करें और इवेंट को फिर से प्रोसेस करें.
A. सोर्स में मौजूद डेटा को ठीक करना
यह गड़बड़ी इसलिए हुई है, क्योंकि पैरंट ग्राहक का रिकॉर्ड CustomerId = 99999 मौजूद नहीं है. आइए, इसे सोर्स MySQL डेटाबेस में डालें.
MySQL इंस्टेंस में फिर से एसएसएच करें:
gcloud compute ssh mysql-physical-1 --zone=$ZONE
sudo mysql का इस्तेमाल करके MySQL में लॉग इन करें और shard1_db में छूटी हुई पैरंट लाइन डालें:
USE shard1_db;
INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LegacyRegion) VALUES
(99999, 'DLQ Parent Holder', 5000.00, 'NORTH_AMERICA');
EXIT;
Cloud Shell पर वापस जाने के लिए, exit टाइप करें.
B. retryDLQ Dataflow जॉब को चलाएं
severe/ डीएलक्यू से इवेंट को फिर से प्रोसेस करने के लिए, उसी Dataflow टेंप्लेट को retryDLQ मोड में लॉन्च करें. यह मोड, खास तौर पर deadLetterQueueDirectory/severe पाथ से डेटा को पढ़ता है. इसके बाद, उसे आपके कस्टम ट्रांसफ़ॉर्मेशन के ज़रिए फिर से प्रोसेस करता है और Spanner पर लागू करता है.
retryDLQ मोड में जॉब लॉन्च करें:
export JOB_NAME_RETRY="mysql-sharded-cdc-retry-$(date +%Y%m%d-%H%M%S)"
gcloud dataflow flex-template run $JOB_NAME_RETRY \
--project=$PROJECT_ID \
--region=$REGION \
--worker-machine-type=n2-highmem-8 \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Cloud_Datastream_to_Spanner" \
--parameters \
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
projectId="$PROJECT_ID",\
runMode="retryDLQ",\
deadLetterQueueDirectory="$DLQ_DIR_CDC",\
datastreamSourceType="mysql",\
transformationJarPath=$CUSTOM_JAR_PATH,\
transformationClassName="com.custom.CustomTransformationFetcher",\
schemaOverridesFilePath=$GCS_OVERRIDES_PATH,\
shardingContextFilePath=$GCS_LIVE_SHARDING_PATH
फिर से कोशिश करने के लिए मुख्य पैरामीटर में बदलाव
runMode="retryDLQ": यह टेंप्लेट कोsevereDLQ डायरेक्ट्री से पढ़ने के लिए कहता है.gcsPubSubSubscriptionको हटाया गया: इसकी ज़रूरत नहीं है, क्योंकि हम लाइव डेटास्ट्रीम के GCS बकेट से डेटा नहीं पढ़ रहे हैं.
फिर से कोशिश करने की प्रोसेस पर नज़र रखें:
मुख्य सीडीसी पाइपलाइन की तरह, retryDLQ एक स्ट्रीमिंग पाइपलाइन है. यह तब तक RUNNING रहेगी, जब तक इसे मैन्युअल तरीके से रद्द नहीं किया जाता.
$JOB_NAME_RETRYके लिए, Dataflow जॉब पेज पर जाएं.- मेट्रिक पैनल में जाकर, इन दो काउंटर को देखें:
elementsReconsumedFromDeadLetterQueue: इसका आकलन तब किया जाता है, जब गड़बड़ी वाली फ़ाइलें फ़ेच की जा रही हों.Successful events: जब रिकॉर्ड को Spanner में लिखा जाता है, तब यह बढ़ता है.- बार-बार होने वाली गड़बड़ियों के लिए,
severe/डायरेक्ट्री देखें. - जब 'सफल इवेंट' की संख्या, उन आइटम की संख्या से बढ़ जाए जिनके लिए आपको फिर से कोशिश करनी है (हमारे टेस्ट केस में 1), तो पुष्टि करने के अगले चरण पर जाएं.
C. फिर से कोशिश किए गए डेटा की पुष्टि करना
रिकॉर्ड को फिर से प्रोसेस करने की कोशिश की जाती है. इसमें कुछ समय लग सकता है. इसके बाद, Spanner में जाकर देखें कि चाइल्ड रो को माइग्रेट किया गया है या नहीं:
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT CustomerId, OrderId, OrderValue, OrderSource FROM Orders WHERE CustomerId = 99999 AND OrderId = 502"
अब आपको यह लाइन दिखेगी:
CustomerId: 99999 OrderId: 502 OrderValue: 50 OrderSource: WebStore
इसके अलावा, GCS में $DLQ_DIR_CDC/severe/ फ़ोल्डर भी देखें. प्रोसेस की गई फ़ाइलों को दूसरी जगह ले जाया गया हो या मिटा दिया गया हो. इससे पता चलता है कि फ़ाइलों को फिर से प्रोसेस किया गया है.
11. रिवर्स रेप्लिकेशन (Spanner से MySQL) सेट अप करना
ऐसे मामलों में जहां आपको कुछ समय के लिए, MySQL डेटाबेस को Spanner के साथ सिंक करना हो या रोलबैक करना हो, तो रिवर्स रेप्लिकेशन सेट अप किया जा सकता है.
यह पाइपलाइन, Spanner में लाइव बदलावों को कैप्चर करने के लिए Spanner Change Streams का इस्तेमाल करती है. इसके बाद, यह हमारे कस्टम ट्रांसफ़ॉर्मेशन JAR का इस्तेमाल करके, स्कीमा के अंतर को रिवर्स-मैप करता है. साथ ही, हमारे कस्टम शार्डिंग JAR का इस्तेमाल करके यह पता लगाता है कि अपडेट को किस फ़िज़िकल MySQL VM और लॉजिकल शार्ड में वापस लिखा जाना चाहिए.
1. Spanner की बदलाव वाली स्ट्रीम बनाना
सबसे पहले, आपको अपने Spanner डेटाबेस में बदलाव की स्ट्रीम बनानी होगी, ताकि Customers और Orders टेबल में हुए बदलावों को ट्रैक किया जा सके.
export CHANGE_STREAM_NAME="CustomersOrdersChangeStream"
gcloud spanner databases ddl update $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--ddl="CREATE CHANGE STREAM $CHANGE_STREAM_NAME FOR Customers, Orders"
यह बदलाव स्ट्रीम, अब चुनी गई टेबल में किए गए सभी बदलावों को रिकॉर्ड करेगी.
2. Dataflow के मेटाडेटा के लिए Spanner डेटाबेस बनाना
Spanner to SourceDB Dataflow टेंप्लेट को एक अलग Spanner डेटाबेस की ज़रूरत होती है. इससे बदलाव के स्ट्रीम के इस्तेमाल से जुड़े मेटाडेटा को सेव किया जा सकता है.
export SPANNER_METADATA_DB_NAME="migration-metadata-db"
gcloud spanner databases create $SPANNER_METADATA_DB_NAME \
--instance=$SPANNER_INSTANCE_NAME
3. Dataflow के लिए Cloud SQL कनेक्शन कॉन्फ़िगरेशन तैयार करना
Dataflow टेंप्लेट को Cloud Storage में मौजूद एक JSON फ़ाइल की ज़रूरत होती है. इसमें टारगेट Cloud SQL डेटाबेस के कनेक्शन की जानकारी होती है.
shard_config.json नाम की लोकल फ़ाइल बनाएं:
cat <<EOF > reverse-sharding.json
[
{
"logicalShardId": "shard0_db",
"host": "${MYSQL_IP_1}",
"port": "3306",
"user": "datastream_user",
"password": "complex_password_123",
"dbName": "shard0_db"
},
{
"logicalShardId": "shard1_db",
"host": "${MYSQL_IP_1}",
"port": "3306",
"user": "datastream_user",
"password": "complex_password_123",
"dbName": "shard1_db"
},
{
"logicalShardId": "shard2_db",
"host": "${MYSQL_IP_2}",
"port": "3306",
"user": "datastream_user",
"password": "complex_password_123",
"dbName": "shard2_db"
},
{
"logicalShardId": "shard3_db",
"host": "${MYSQL_IP_2}",
"port": "3306",
"user": "datastream_user",
"password": "complex_password_123",
"dbName": "shard3_db"
}
]
EOF
इस फ़ाइल को अपने GCS बकेट में अपलोड करें:
export GCS_REVERSE_SHARDING_PATH="gs://${BUCKET_NAME}/config/reverse-sharding.json"
gcloud storage cp reverse-sharding.json $GCS_REVERSE_SHARDING_PATH
4. रिवर्स रेप्लिकेशन डेटाफ़्लो जॉब चलाना
Spanner_to_SourceDb फ़्लेक्स टेंप्लेट का इस्तेमाल करके, डेटाफ़्लो जॉब लॉन्च करें.
export JOB_NAME_REVERSE="spanner-sharded-reverse-to-mysql-$(date +%Y%m%d-%H%M%S)"
export DLQ_DIR_REVERSE="gs://${BUCKET_NAME}/reverse-replication"
gcloud dataflow flex-template run $JOB_NAME_REVERSE \
--project=$PROJECT_ID \
--region=$REGION \
--worker-machine-type=n2-highmem-8 \
--max-workers=2 \
--num-workers=1 \
--additional-experiments=use_runner_v2 \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Spanner_to_SourceDb" \
--parameters \
changeStreamName="$CHANGE_STREAM_NAME",\
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
spannerProjectId="$PROJECT_ID",\
metadataInstance="$SPANNER_INSTANCE_NAME",\
metadataDatabase="$SPANNER_METADATA_DB_NAME",\
sourceShardsFilePath="$GCS_REVERSE_SHARDING_PATH",\
transformationJarPath=$CUSTOM_JAR_PATH,\
transformationClassName="com.custom.CustomTransformationFetcher",\
shardingCustomJarPath=$CUSTOM_JAR_PATH,\
shardingCustomClassName="com.custom.CustomShardIdFetcher",\
schemaOverridesFilePath=$GCS_OVERRIDES_PATH,\
deadLetterQueueDirectory=$DLQ_DIR_REVERSE
मुख्य पैरामीटर
changeStreamName: Spanner की उस बदलाव स्ट्रीम का नाम जिससे डेटा पढ़ना है.metadataInstance, metadataDatabase: यह Spanner इंस्टेंस/डेटाबेस है. इसमें कनेक्टर इस्तेमाल किया गया मेटाडेटा सेव किया जाता है. इससे, बदलाव के स्ट्रीम एपीआई डेटा के इस्तेमाल को कंट्रोल किया जा सकता है.sourceShardsFilePath: आपकेshard_config.jsonका GCS पाथ.filtrationMode: इससे यह तय होता है कि किसी शर्त के आधार पर कुछ रिकॉर्ड कैसे हटाए जाएं. डिफ़ॉल्ट रूप से, यहforward_migrationपर सेट होता है. इसका मतलब है कि फ़ॉरवर्ड माइग्रेशन पाइपलाइन का इस्तेमाल करके लिखे गए रिकॉर्ड को फ़िल्टर किया जाता हैshardingCustomJarPath: कंपाइल की गई Java JAR फ़ाइल का GCS पाथ, जिसे हमने पहले बनाया था.shardingCustomClassName: पूरी तरह क्वालिफ़ाइड क्लास का नाम (com.custom.CustomShardIdFetcher). यह हमारे कस्टम%4मॉड्युलो मैथ को लागू करता है, ताकि डाइनैमिक तौर पर यह तय किया जा सके कि कौनसा लॉजिकल शार्ड रिकॉर्ड को स्वीकार करेगा.
नेटवर्क से जुड़ी जानकारी: Dataflow वर्कर, shard_config.json में दिए गए सार्वजनिक आईपी का इस्तेमाल करके Cloud SQL इंस्टेंस से कनेक्ट होंगे. Cloud SQL इंस्टेंस के अनुमति वाले नेटवर्क में 0.0.0.0/0 एंट्री की वजह से, इस कनेक्शन को अनुमति दी गई है.
Dataflow Jobs Console में जाकर, नौकरी के शुरू होने की प्रोसेस पर नज़र रखें.
5. Spanner डेटा इंजेक्ट करना और जान-बूझकर गड़बड़ियां ट्रिगर करना
Dataflow जॉब के Running स्थिति में आने का इंतज़ार करें. इसमें ~5 मिनट लग सकते हैं. इसके बाद, हम क्वेरी के पूरे सुइट (INSERT, UPDATE, DELETE) को सीधे तौर पर Spanner में एक्ज़ीक्यूट करेंगे. साथ ही, रिवर्स डीएलक्यू की जांच करने के लिए, जान-बूझकर एक क्वेरी को फ़ेल करेंगे.
Cloud Shell में यह कमांड चलाएं:
# All these operations are done on rows mapping to shard0_db for convenience
# Valid INSERT: Insert parent row in Customers
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LoyaltyTier) VALUES (88, 'Reverse Tester', 5000, 'GOLD_TIER')"
# 1. Valid INSERT (Orders): 'WebStore' transformed to 'WebStore_v1'
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="INSERT INTO Orders (CustomerId, OrderId, OrderValue, OrderSource) VALUES (88, 9001, 150.00, 'WebStore')"
# 2. Valid UPDATE (Orders)
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="UPDATE Orders SET OrderValue = 200.00 WHERE CustomerId = 16 AND OrderId = 105 AND OrderSource = 'Partner'"
# 3. Valid DELETE (Orders)
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="DELETE FROM Orders WHERE CustomerId = 12 AND OrderId = 104 AND OrderSource = 'WebStore'"
# 4. INVALID Insert- DLQ Test: CreditLimit=500 will fail check constraint of >1000 at source
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LoyaltyTier) VALUES (44, 'DLQ Test Customer', 500, 'GOLD_TIER')"
6. डेटा के रिवर्स रेप्लिकेशन की पुष्टि करना और डीएलक्यू की जांच करना
आइए, पुष्टि करें कि हमारे कस्टम शार्डिंग JAR ने हमारे पहले फ़िज़िकल वीएम पर CustomerId 88 को shard0_db पर सफलतापूर्वक रूट किया है. साथ ही, कस्टम ट्रांसफ़ॉर्मेशन JAR ने क्षेत्र से "_TIER" को सफलतापूर्वक हटा दिया है.
A. MySQL में मान्य रिकॉर्ड की पुष्टि करें:
पहले फ़िज़िकल शार्ड में एसएसएच करें:
gcloud compute ssh mysql-physical-1 --zone=$ZONE
MySQL में लॉग इन करें और shard0_db क्वेरी करें:
sudo mysql
USE shard0_db;
-- 1. Verify INSERT: Row migrated with transformed LegacyOrderSystem
SELECT CustomerId, OrderId, OrderValue, LegacyOrderSystem
FROM Orders
WHERE CustomerId = 88 AND OrderId = 9001;
-- 2. Verify UPDATE: The OrderValue should now be updated to 200.00.
SELECT CustomerId, OrderId, OrderValue, LegacyOrderSystem
FROM Orders
WHERE CustomerId = 16 AND OrderId = 105;
-- 3. Verify DELETE: Returns 0 rows, confirming the order was successfully deleted from MySQL.
SELECT CustomerId, OrderId
FROM Orders
WHERE CustomerId = 12 AND OrderId = 104;
-- 4. Verify failed replication - this should be in DLQ as CreditLimit < 1000 and will fail stricter check constraint at source
SELECT CustomerId, CustomerName, CreditLimit, LegacyRegion
FROM Customers
WHERE CustomerId = 44;
EXIT;
Cloud SQL में दिखने वाला आउटपुट, Spanner में किए गए बदलावों के मुताबिक होना चाहिए.
+------------+---------+------------+-------------------+ | CustomerId | OrderId | OrderValue | LegacyOrderSystem | +------------+---------+------------+-------------------+ | 88 | 9001 | 150.00 | Webstore_v1 | +------------+---------+------------+-------------------+ +------------+---------+------------+-------------------+ | CustomerId | OrderId | OrderValue | LegacyOrderSystem | +------------+---------+------------+-------------------+ | 16 | 105 | 200.00 | Partner_v1 | +------------+---------+------------+-------------------+ Empty set (0.00 sec) Empty set (0.00 sec)
टाइप
exit
Cloud Shell पर वापस जाने के लिए.
इससे पुष्टि होती है कि रिवर्स रेप्लिकेशन पाइपलाइन काम कर रही है और Spanner से Cloud SQL में बदलावों को सिंक कर रही है.
B. DLQ में जान-बूझकर की गई गड़बड़ी की जांच करना
हमारे नए Customers रिकॉर्ड में CreditLimit की वैल्यू 500 है. यह वैल्यू, सोर्स MySQL डेटाबेस में तय की गई > 1000 चेक कंस्ट्रेंट का उल्लंघन करती है. इसलिए, Dataflow ने इस गड़बड़ी का पता लगा लिया.
- Google Cloud Console में Cloud Storage पर जाएं.
- अपने बकेट पर जाएं और
dlq/severe/फ़ोल्डर खोलें. - अस्वीकार किए गए
Customersरिकॉर्ड और चेक कंस्ट्रेंट के उल्लंघन की गड़बड़ी देखने के लिए, JSON फ़ाइल खोलें. - रिवर्स रेप्लिकेशन डीएलक्यू की गड़बड़ियों को ठीक करने के लिए,
runMode=retryDLQको सेट करके डेटाफ़्लो टेंप्लेट को फिर से चलाया जा सकता है.
12. संसाधन मिटाएं
अपने Google Cloud खाते पर ज़्यादा शुल्क लगने से बचने के लिए, इस कोडलैब के दौरान बनाई गई संसाधनों को मिटा दें.
ज़रूरत पड़ने पर, एनवायरमेंट वैरिएबल सेट करें
अगर आपका Cloud Shell सेशन खत्म हो गया है या आपने नया टर्मिनल खोला है, तो आपको क्लीनअप कमांड चलाने से पहले, एनवायरमेंट वैरिएबल को फिर से एक्सपोर्ट करना होगा.
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1" # Or your preferred region
export ZONE="us-central1-a" # Or a zone within your selected region
export SPANNER_INSTANCE_NAME="target-spanner-instance"
export SPANNER_DATABASE_NAME="sharded-target-db"
export SPANNER_CONFIG="regional-${REGION}"
export BUCKET_NAME="migration-${PROJECT_ID}-bucket"
export MYSQL_IP_1=$(gcloud compute instances describe mysql-physical-1 --zone=$ZONE --format='get(networkInterfaces[0].accessConfigs[0].natIP)')
export MYSQL_IP_2=$(gcloud compute instances describe mysql-physical-2 --zone=$ZONE --format='get(networkInterfaces[0].accessConfigs[0].natIP)')
export SQL_CP_NAME_1="mysql-src-cp-1"
export SQL_CP_NAME_2="mysql-src-cp-2"
export GCS_CP_NAME="gcs-dest-cp"
export STREAM_NAME_1="mysql-to-spanner-stream-1"
export GCS_STREAM_PATH_1="data/${STREAM_NAME_1}"
export STREAM_NAME_2="mysql-to-spanner-stream-2"
export GCS_STREAM_PATH_2="data/${STREAM_NAME_2}"
export PUBSUB_TOPIC="datastream-gcs-updates"
export PUBSUB_SUBSCRIPTION="datastream-gcs-sub"
export CUSTOM_JAR_PATH="gs://${BUCKET_NAME}/custom-logic/spanner-custom-shard-1.0.jar"
export OVERRIDES_FILE="spanner_overrides.json"
export GCS_OVERRIDES_PATH="gs://${BUCKET_NAME}/config/${OVERRIDES_FILE}"
export GCS_SHARDING_PATH="gs://${BUCKET_NAME}/config/sharding.json"
export OUTPUT_DIR="gs://${BUCKET_NAME}/bulk-migration"
export GCS_LIVE_SHARDING_PATH="gs://${BUCKET_NAME}/config/live-sharding.json"
export DLQ_DIR_CDC="gs://${BUCKET_NAME}/live-migration"
export CHANGE_STREAM_NAME="CustomersOrdersChangeStream"
export SPANNER_METADATA_DB_NAME="migration-metadata-db"
export GCS_REVERSE_SHARDING_PATH="gs://${BUCKET_NAME}/config/reverse-sharding.json"
export DLQ_DIR_REVERSE="gs://${BUCKET_NAME}/reverse-replication"
डेटाफ़्लो स्ट्रीमिंग जॉब बंद करना
डेटाफ़्लो की चालू नौकरियों के जॉब आईडी ढूंढने के लिए, अपनी नौकरियां लिस्ट करें. इसके बाद, JOB_ID_CDC और JOB_ID_REVERSE को एक्सपोर्ट करें.
gcloud dataflow jobs list --region=$REGION --filter="state=Running"
export JOB_ID_CDC=<PASTE_JOB_ID_HERE>
export JOB_ID_CDC_RETRY=<PASTE_JOB_ID_HERE>
export JOB_ID_REVERSE=<PASTE_JOB_ID_HERE>
Datastream to Spanner (लाइव माइग्रेशन) जॉब और फिर से कोशिश करने वाली जॉब को रद्द करें:
gcloud dataflow jobs cancel $JOB_ID_CDC --region=$REGION --project=$PROJECT_ID
gcloud dataflow jobs cancel $JOB_ID_CDC_RETRY --region=$REGION --project=$PROJECT_ID
Spanner to Cloud SQL (रिवर्स रेप्लिकेशन) जॉब रद्द करें:
gcloud dataflow jobs cancel $JOB_ID_REVERSE --region=$REGION --project=$PROJECT_ID
Datastream संसाधन मिटाना
स्ट्रीम बंद करना और मिटाना:
gcloud datastream streams update $STREAM_NAME_1 \
--location=$REGION --state=PAUSED --project=$PROJECT_ID
# Wait a moment for the stream to pause
gcloud datastream streams delete $STREAM_NAME_1 \
--location=$REGION --project=$PROJECT_ID --quiet
gcloud datastream streams update $STREAM_NAME_2 \
--location=$REGION --state=PAUSED --project=$PROJECT_ID
# Wait a moment for the stream to pause
gcloud datastream streams delete $STREAM_NAME_2 \
--location=$REGION --project=$PROJECT_ID --quiet
# Delete Connection Profiles
gcloud datastream connection-profiles delete $SQL_CP_NAME_1 \
--location=$REGION --project=$PROJECT_ID --quiet
gcloud datastream connection-profiles delete $SQL_CP_NAME_2 \
--location=$REGION --project=$PROJECT_ID --quiet
gcloud datastream connection-profiles delete $GCS_CP_NAME \
--location=$REGION --project=$PROJECT_ID --quiet
सोर्स MySQL वीएम (Compute Engine) मिटाना
उन दो Compute Engine इंस्टेंस को मिटाएं जिन्होंने ऑन-प्रेम MySQL फ़िज़िकल शार्ड का सिम्युलेशन किया था.
gcloud compute instances delete mysql-physical-1 mysql-physical-2 --zone=$ZONE --quiet
फ़ायरवॉल के नियम मिटाना
एसएसएच ऐक्सेस और अपने वीएम से Datastream कनेक्ट करने की अनुमति देने के लिए बनाई गई नेटवर्क फ़ायरवॉल की सेटिंग हटाएं. (ध्यान दें: अगर आपने कोडलैब में पहले फ़ायरवॉल के नियमों के लिए अलग-अलग नामों का इस्तेमाल किया है, तो उन्हें यहां अडजस्ट करें).
gcloud compute firewall-rules delete allow-ssh-iap --quiet
gcloud compute firewall-rules delete allow-mysql-datastream --quiet
Pub/Sub संसाधन मिटाना
सदस्यता मिटाना:
gcloud pubsub subscriptions delete $PUBSUB_SUBSCRIPTION \
--project=$PROJECT_ID --quiet
विषय मिटाएं:
gcloud pubsub topics delete $PUBSUB_TOPIC \
--project=$PROJECT_ID --quiet
Cloud Spanner इंस्टेंस मिटाना
Cloud Spanner इंस्टेंस मिटाएं. इससे, इसके अंदर मौजूद sharded-target-db और migration-metadata-db, दोनों डेटाबेस अपने-आप मिट जाते हैं.
gcloud spanner instances delete $SPANNER_INSTANCE_NAME \
--project=$PROJECT_ID --quiet
GCS बकेट और कॉन्टेंट मिटाना
आखिर में, उस Cloud Storage बकेट को मिटा दें जिसमें Datastream फ़ाइलें, Dataflow कॉन्फ़िगरेशन, और डेड लेटर क्यू मौजूद हैं. rm -r कमांड, बकेट और उसके सभी कॉन्टेंट को बार-बार मिटाती है.
gcloud storage rm --recursive gs://${BUCKET_NAME}
लोकल Cloud Shell की फ़ाइलें मिटाना
इस कोडलैब के दौरान Cloud Shell में जनरेट हुई लोकल फ़ाइलों और डायरेक्ट्री को हटाने के लिए, ये कमांड चलाएं:
# Remove the JSON configuration files
rm -f sharding.json live-sharding.json reverse-sharding.json spanner_overrides.json
# Remove the cloned Google Cloud DataflowTemplates repository
rm -rf DataflowTemplates