
1. לפני שמתחילים
ב-Codelab הזה נסביר איך להעביר מסד נתונים של MySQL מקומי עם פיצול (sharding) למסד נתונים של Cloud Spanner עם ניב GoogleSQL. תשתמשו בשירותי Google Cloud, כולל Spanner Migration Tool (SMT), Dataflow, Datastream, PubSub ו-Google Cloud Storage.
מה תלמדו:
- מהי סביבה עם שרדינג ואיך מגדירים אותה.
- איך משתמשים בממשק האינטרנט של Spanner Migration Tool (SMT) כדי להמיר סכימת MySQL לסכימה שתואמת ל-Spanner ולבצע שינויים מתקדמים בסכימה.
- איך לבצע העברת נתונים בכמות גדולה ממופע MySQL עם שרדינג ל-Cloud Spanner באמצעות Dataflow.
- איך מגדירים שכפול רציף (CDC) ממופע MySQL עם חלוקה לשברים ל-Cloud Spanner באמצעות Datastream ו-Dataflow.
- איך מגדירים שכפול הפוך מ-Spanner בחזרה למופעי MySQL עם שיתוף נתונים.
- איך משתמשים בהמרות בהתאמה אישית כדי לאכלס עמודות נוספות במהלך העברות בכמות גדולה, העברות בזמן אמת והעברות הפוכות.
- איך מגדירים טרנספורמציות של חלוקה באמצעות מפתחות ראשיים.
הנושאים שלא נכללים ב-Codelab הזה:
- רשתות מתקדמות בהתאמה אישית.
- יצירת תבניות Dataflow בהתאמה אישית מאפס.
- כוונון הביצועים של ההעברה.
- העברת אפליקציות: ה-Codelab הזה מתמקד בשכבת מסד הנתונים (סכימה ונתונים). היא לא כוללת את תהליך ההפעלה של פריסה מחדש או העברה של שירותי האפליקציה.
הדרישות
- פרויקט ב-Google Cloud שהחיוב בו מופעל.
- הרשאות IAM מספיקות להפעלת ממשקי API וליצירה ולניהול של משאבי Spanner, Dataflow, Datastream ו-GCS. תפקיד
Ownerבפרויקט הוא הפשוט ביותר לשימוש ב-codelab, אבל תפקידים ספציפיים יותר יוסברו בקטע 'הגדרת הסביבה'. - במהלך שלב ההגדרה, נקצה מכונה וירטואלית קטנה ב-Compute Engine כדי לדמות את השרת המקומי שלנו. מוודאים שהמכסה של הפרויקט מאפשרת ליצור מכונות וירטואליות.
- דפדפן אינטרנט, כמו Google Chrome.
- היכרות בסיסית עם מסוף Google Cloud ועם כלי שורת הפקודה כמו
gcloud. - גישה לסביבת מעטפת. מומלץ להשתמש ב-Cloud Shell כי הוא כולל את
gcloud.
פרטים נוספים על ההגדרה שלמעלה מופיעים בקטע הגדרת הסביבה.
2. הסבר על תהליך ההעברה
העברה של מסד נתונים עם שרדינג כוללת איחוד של כמה מופעים פיזיים ולוגיים של MySQL למסד נתונים יחיד של Spanner שאפשר להרחיב אותו אופקית. בקטע הזה מפורטים הארכיטקטורה והכלים העיקריים שבהם נעשה שימוש בהעברה.
ארכיטקטורה של תהליך המיגרציה
תהליך ההעברה כולל את השלבים הבאים:
1. המרת סכימה:
- מטרה: המרת סכימת מסד הנתונים של המקור לסכימה תואמת של Cloud Spanner.
- כלי: הכלי להעברת נתונים ל-Spanner (SMT)
- תהליך: SMT מנתח את סכימת מסד הנתונים של המקור ומפיק את שפת הגדרת הנתונים (DDL) המקבילה של Spanner. במופע היעד של Spanner, נוצר מסד נתונים וה-DDL מוחל באופן אוטומטי.
2. העברת נתונים בכמות גדולה:
- מטרה: ביצוע טעינה ראשונית ומלאה של נתונים קיימים ממסד הנתונים של המקור לטבלאות Spanner שהוקצו.
- כלי: Dataflow, באמצעות התבנית
Sourcedb to Spannerש-Google מספקת. - תהליך: משימת Dataflow הזו קוראת את כל הנתונים מטבלאות המקור שצוינו וכותבת אותם בטבלאות Spanner התואמות. הפעולה הזו מתבצעת אחרי שסכמת Spanner נוצרת.
3. מיגרציה פעילה (CDC):
- מטרה: לתעד ולהחיל שינויים שוטפים ממסד הנתונים של המקור על Cloud Spanner כמעט בזמן אמת, כדי למזער את זמן ההשבתה במהלך ההעברה.
- כלים:
- Datastream: מתעד שינויים (הוספות, עדכונים ומחיקות) ממסד הנתונים של המקור וכותב אותם ל-Cloud Storage (GCS).
- Dataflow: משתמש בתבנית
Datastream to Spannerכדי לקרוא את אירועי השינוי מ-GCS ולהחיל אותם על Cloud Spanner.
4. שכפול הפוך:
- מטרה: לשכפל שינויים בנתונים מ-Cloud Spanner בחזרה למסד הנתונים של המקור. האפשרות הזו יכולה להיות שימושית לאסטרטגיות גיבוי, להעברות מדורגות או לשמירה של העתק במקור לתרחישי שימוש ספציפיים.
- כלי: Dataflow, באמצעות התבנית
Spanner to SourceDb. - תהליך: העבודה הזו משתמשת בסנכרון שינויים בזרמי נתונים של Spanner כדי לתעד שינויים ב-Spanner ולכתוב אותם בחזרה למופע של מסד הנתונים של המקור.
הדיאגרמה הבאה ממחישה את הרכיבים ואת זרימת הנתונים:

הסברים על המונחים:
- רסיס פיזי: השרת הבסיסי או מופע החישוב שמארח את מסד הנתונים (במקרה שלנו, מכונה וירטואלית של GCE מקומית מדומה).
- רסיס לוגי: סכימת מסד הנתונים הספציפית בתוך שרת פיזי.
- מכונה וירטואלית (VM) של Compute Engine (GCE): מכונה וירטואלית שמתארחת בתשתית ענן של Google Cloud. ב-Codelab הזה אנחנו משתמשים במכונה וירטואלית ב-GCE כדי לדמות שרת bare-metal עצמאי, 'במקום', שמארח את מסד הנתונים של MySQL.
- Spanner Migration Tool (SMT): כלי שמשמש להערכת סכימות של MySQL, להצעת סכימות מקבילות של Spanner וליצירת Data Definition Language (DDL) של Spanner.
- שפת הגדרת נתונים (DDL): הצהרות שמשמשות להגדרה ולשינוי של מבנה מסד הנתונים, כמו הצהרות
CREATE TABLE. SMT יוצר DDL של Spanner על סמך הסכימה של Cloud SQL. - Dataflow: שירות מנוהל במלואו לעיבוד נתונים ללא שרתים (serverless). ב-codelab הזה, משתמשים בו כדי להריץ תבניות שסופקו על ידי Google להעברת נתונים בכמות גדולה, להחלת שינויים ב-Datastream ולשכפול הפוך.
- Datastream: שירות ללא שרת (serverless) לסימון נתונים שהשתנו (CDC) וליצירת רפליקות. ב-codelab הזה, משתמשים בו כדי להזרים שינויים ממופע MySQL שמארחים באופן מקומי אל Cloud Storage.
- Spanner Change Streams: תכונה של Spanner שמאפשרת להזרים שינויים בנתונים (הוספות, עדכונים, מחיקות) בזמן אמת, ומשמשת כמקור לשכפול הפוך.
- Pub/Sub: שירות העברת הודעות שמשמש להפרדה בין שירותים שמפיקים אירועים לבין שירותים שמעבדים אותם. בשיעור Codelab הזה, המערכת מפעילה את Dataflow כדי לעבד עדכונים בכל פעם ש-Datastream מעלה קבצים חדשים של שינויים ל-Cloud Storage.
3. הגדרת הסביבה
לפני שמתחילים במיגרציה, צריך להגדיר את הפרויקט בענן ב-Google Cloud ולהפעיל את השירותים הנדרשים.
1. בחירה או יצירה של פרויקט ב-Google Cloud
כדי להשתמש בשירותים ב-Codelab הזה, צריך פרויקט בענן ב-Google Cloud שמופעל בו חיוב.
- במסוף Google Cloud, עוברים לדף לבחירת הפרויקט: מעבר לדף לבחירת הפרויקט
- בוחרים פרויקט קיים או יוצרים פרויקט חדש ב-Google Cloud.
- מוודאים שהחיוב מופעל בפרויקט. איך מוודאים שהחיוב מופעל בפרויקט
2. פתיחת Cloud Shell
Cloud Shell היא סביבת שורת פקודה שפועלת ב-Google Cloud, וכוללת מראש את gcloud CLI וכלים אחרים שאתם צריכים.
- לוחצים על הלחצן Activate Cloud Shell (הפעלת Cloud Shell) בפינה הימנית העליונה של מסוף Google Cloud.
- בחלק התחתון של המסוף ייפתח סשן של Cloud Shell בתוך מסגרת חדשה ותופיע הודעה של שורת הפקודה.

3. הגדרת משתני פרויקט ומשתני סביבה
ב-Cloud Shell, מגדירים כמה משתני סביבה למזהה הפרויקט ולאזור שבו תשתמשו.
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1" # Or your preferred region
export ZONE="us-central1-a" # Or a zone within your selected region
gcloud config set project $PROJECT_ID
gcloud config set compute/region $REGION
gcloud config set compute/zone $ZONE
echo "Project ID: $PROJECT_ID"
echo "Region: $REGION"
echo "Zone: $ZONE"
4. הפעלה של ממשקי Google Cloud API הנדרשים
מפעילים את ממשקי ה-API שנדרשים ל-Cloud Spanner, ל-Dataflow, ל-Datastream ולשירותים קשורים אחרים.
gcloud services enable \
spanner.googleapis.com \
dataflow.googleapis.com \
datastream.googleapis.com \
pubsub.googleapis.com \
storage.googleapis.com \
compute.googleapis.com \
sqladmin.googleapis.com \
servicenetworking.googleapis.com \
cloudresourcemanager.googleapis.com
יכול להיות שיחלפו כמה דקות עד שהפקודה הזו תושלם.
4. הגדרת מסד הנתונים של MySQL כמקור
בקטע הזה נדמה ארכיטקטורת MySQL עם שרדינג מקומית על ידי הקצאת שתי מכונות וירטואליות ב-Compute Engine (שני השרדים הפיזיים שלנו). לאחר מכן נתקין את MySQL בשתי המכונות וניצור שני מסדי נתונים (ה'שברים הלוגיים' שלנו) בכל מכונה וירטואלית.
1. יצירת מכונות וירטואליות ב-Compute Engine (רסיסי נתונים פיזיים)
מריצים את הפקודות הבאות ב-Cloud Shell כדי ליצור שתי מכונות וירטואליות עם Ubuntu. בהמשך נשייך להם תגי רשת כדי לאפשר תנועה נכנסת של MySQL.
# Create Physical Shard 1
gcloud compute instances create mysql-physical-1 \
--zone=$ZONE \
--machine-type=e2-small \
--image-family=ubuntu-2204-lts \
--image-project=ubuntu-os-cloud \
--tags=mysql-server
# Create Physical Shard 2
gcloud compute instances create mysql-physical-2 \
--zone=$ZONE \
--machine-type=e2-small \
--image-family=ubuntu-2204-lts \
--image-project=ubuntu-os-cloud \
--tags=mysql-server
2. הגדרת כללים לחומת האש
כדי לאפשר גישת SSH מאובטחת בלי חשיפה ציבורית וכדי להפעיל את הקישוריות של Datastream:
יצירת כלל של חומת אש ל-SSH דרך IAP:
הכלל הזה מאפשר לשרת proxy לאימות זהויות (IAP) להגיע למכונות הווירטואליות שלכם ביציאת ה-SSH (מספר 22).
gcloud compute firewall-rules create allow-ssh-iap \
--direction=INGRESS \
--priority=1000 \
--network=default \
--action=ALLOW \
--rules=tcp:22 \
--source-ranges=35.235.240.0/20 \
--target-tags=mysql-server
יצירת כלל לחומת האש עבור Datastream (יציאת MySQL):
ל-Datastream צריכה להיות אפשרות להגיע למכונות הווירטואליות האלה דרך יציאת MySQL הרגילה (3306).
gcloud compute firewall-rules create allow-mysql-datastream \
--direction=INGRESS \
--priority=1000 \
--network=default \
--action=ALLOW \
--rules=tcp:3306 \
--source-ranges=0.0.0.0/0 \
--target-tags=mysql-server
3. התקנה והגדרה של MySQL ב-Physical Shard 1
מתחברים באמצעות SSH למכונה הווירטואלית הראשונה כדי להתקין את MySQL ולהגדיר רישום בינארי (שנדרש על ידי Datastream לשכפול בזמן אמת).
- מתחברים למכונה הווירטואלית הראשונה באמצעות SSH:
gcloud compute ssh mysql-physical-1 --zone=$ZONE --tunnel-through-iap
- מתקינים את MySQL:
sudo apt-get update
sudo apt-get install mysql-server-8.0 -y
# Verify the installation and version
sudo mysql --version
- מגדירים את הקובץ
mysqld.cnfכדי להפעיל רישום בינארי ולאפשר חיבורים חיצוניים:
sudo sed -i 's/bind-address.*/bind-address = 0.0.0.0/' /etc/mysql/mysql.conf.d/mysqld.cnf
echo -e "[mysqld]\nserver-id=1\nlog_bin=/var/log/mysql/mysql-bin.log\nbinlog_format=ROW" | sudo tee -a /etc/mysql/mysql.conf.d/mysqld.cnf
- מפעילים מחדש את MySQL כדי להחיל את השינויים:
sudo systemctl restart mysql
4. יצירת שברים לוגיים, הוספת נתונים ויצירת משתמש של מקור נתונים (שבר 1)
כשעדיין מחוברים ל-mysql-physical-1 באמצעות SSH, מתחברים להנחיית הפעולה של MySQL:
sudo mysql
מריצים את פקודות ה-SQL הבאות. הסקריפט הזה יוצר שני רסיסים לוגיים נפרדים (shard0_db ו-shard1_db), מגדיר את הסכימה הזהה בשניהם, מוסיף לכל אחד מהם נתונים שניתן לזיהוי מובהק (כדי להדגים את הפיצול) ויוצר את משתמש השכפול עבור Datastream.
מריצים את פקודות ה-SQL הבאות כדי ליצור את שני הרסיסים הלוגיים הראשונים, טבלה ומשתמש השכפול של Datastream:
CREATE DATABASE shard0_db;
CREATE DATABASE shard1_db;
USE shard0_db;
CREATE TABLE Customers (
CustomerId INT NOT NULL,
CustomerName VARCHAR(255),
CreditLimit DECIMAL(10, 2) NOT NULL,
LegacyRegion VARCHAR(50), -- Renamed to LoyaltyTier in Spanner
PRIMARY KEY (CustomerId),
CONSTRAINT CHK_CreditLimit CHECK (CreditLimit > 1000) -- Relaxed in Spanner to > 0
);
CREATE TABLE Orders (
CustomerId INT NOT NULL, -- Logically references Customers.CustomerId in Spanner
OrderId INT NOT NULL,
OrderValue DECIMAL(10, 2),
LegacyOrderSystem VARCHAR(50), -- Extra column in Source, to be dropped in Spanner
PRIMARY KEY (CustomerId, OrderId) -- Spanner PK will have one additional column in PK
);
INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LegacyRegion) VALUES
(4, 'David E.', 2000.00, 'EAST'),
(8, 'Eleanor F.', 8100.00, 'WEST'),
(12, 'Frank G.', 12000.00, 'NORTH'),
(16, 'Grace H.', 6500.00, 'SOUTH');
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem) VALUES
(4, 101, 150.00, 'WebStore_v1'),
(4, 102, 25.50, 'InStore_POS'),
(8, 103, 75.00, 'MobileApp_Legacy'),
(12, 104, 3000.00, 'WebStore_v1'),
(16, 105, 120.00, 'Partner_API');
USE shard1_db;
CREATE TABLE Customers (
CustomerId INT NOT NULL,
CustomerName VARCHAR(255),
CreditLimit DECIMAL(10, 2) NOT NULL,
LegacyRegion VARCHAR(50), -- Renamed to LoyaltyTier in Spanner
PRIMARY KEY (CustomerId),
CONSTRAINT CHK_CreditLimit CHECK (CreditLimit > 1000) -- Relaxed in Spanner to > 0
);
CREATE TABLE Orders (
CustomerId INT NOT NULL, -- Logically references Customers.CustomerId in Spanner
OrderId INT NOT NULL,
OrderValue DECIMAL(10, 2),
LegacyOrderSystem VARCHAR(50), -- Extra column in Source, to be dropped in Spanner
PRIMARY KEY (CustomerId, OrderId) -- Spanner PK will have one additional column in PK
);
INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LegacyRegion) VALUES
(1, 'Agnes N.', 5100.00, 'NORTHEAST'),(5, 'Alice I.', 15000.00, 'EAST'),
(9, 'Bob J.', 7500.00, 'WEST'),
(13, 'Charlie K.', 2200.00, 'CENTRAL');
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem) VALUES
(1, 201, 50.00, 'MobileApp_Legacy'),
(5, 202, 1250.00, 'WebStore_v1'),
(5, 203, 80.00, 'Partner_API'),
(9, 204, 600.00, 'InStore_POS'),
(13, 205, 199.99, 'WebStore_v1');
-- Create Datastream Replication User
CREATE USER 'datastream_user'@'%' IDENTIFIED BY 'complex_password_123';
GRANT REPLICATION SLAVE, REPLICATION CLIENT, SELECT, INSERT, UPDATE, DELETE ON *.* TO 'datastream_user'@'%';
FLUSH PRIVILEGES;
כאן אפשר למצוא את קובץ ה-dump של הסכימה שלמעלה. חשוב ליצור את המשתמש לשכפול של מקור הנתונים בנפרד, כי הוא לא נכלל בקובץ ה-dump.
5. אימות נתונים
כדי לבדוק במהירות שהנתונים קיימים:
SELECT 'Customers shard0_db' AS tbl, COUNT(*) FROM shard0_db.Customers
UNION ALL
SELECT 'Orders shard0_db', COUNT(*) FROM shard0_db.Orders
UNION ALL
SELECT 'Customers shard1_db', COUNT(*) FROM shard1_db.Customers
UNION ALL
SELECT 'Orders shard1_db', COUNT(*) FROM shard1_db.Orders;
EXIT;
הפלט הצפוי:
+---------------------+----------+ | tbl | COUNT(*) | +---------------------+----------+ | Customers shard0_db | 4 | | Orders shard0_db | 5 | | Customers shard1_db | 4 | | Orders shard1_db | 5 | +---------------------+----------+
מזינים exit כדי לצאת מהחיבור ל-VM של שארד פיזי 1.
6. חוזרים על הפעולה עבור Physical Shard 2
עכשיו חוזרים על אותו תהליך בדיוק עבור המכונה הווירטואלית השנייה, אבל יוצרים את shard2_db ואת shard3_db, ומשנים את server-id.
- מתחברים באמצעות SSH למכונה הווירטואלית השנייה:
gcloud compute ssh mysql-physical-2 --zone=$ZONE --tunnel-through-iap
- מתקינים את MySQL:
sudo apt-get update
sudo apt-get install mysql-server-8.0 -y
- מגדירים את הקובץ
mysqld.cnfכדי להפעיל רישום ביומן בינארי ולאפשר חיבורים חיצוניים [הערה: הערך של server-id חייב להיות שונה (למשל, 2)]
sudo sed -i 's/bind-address.*/bind-address = 0.0.0.0/' /etc/mysql/mysql.conf.d/mysqld.cnf
echo -e "[mysqld]\nserver-id=2\nlog_bin=/var/log/mysql/mysql-bin.log\nbinlog_format=ROW" | sudo tee -a /etc/mysql/mysql.conf.d/mysqld.cnf
- מפעילים מחדש את MySQL כדי להחיל את השינויים:
sudo systemctl restart mysql
- מזינים MySQL (
sudo mysql) ומריצים גרסה עם שינויים קלים של ה-SQL משלב 4:
CREATE DATABASE shard2_db;
CREATE DATABASE shard3_db;
USE shard2_db;
CREATE TABLE Customers (
CustomerId INT NOT NULL,
CustomerName VARCHAR(255),
CreditLimit DECIMAL(10, 2) NOT NULL,
LegacyRegion VARCHAR(50), -- Renamed to LoyaltyTier in Spanner
PRIMARY KEY (CustomerId),
CONSTRAINT CHK_CreditLimit CHECK (CreditLimit > 1000) -- Relaxed in Spanner to > 0
);
CREATE TABLE Orders (
CustomerId INT NOT NULL, -- Logically references Customers.CustomerId in Spanner
OrderId INT NOT NULL,
OrderValue DECIMAL(10, 2),
LegacyOrderSystem VARCHAR(50), -- Extra column in Source, to be dropped in Spanner
PRIMARY KEY (CustomerId, OrderId) -- Spanner PK will have one additional column in PK
);
INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LegacyRegion) VALUES
(2, 'Brian K.', 2500.00, 'SOUTHWEST'),
(6, 'Diana L.', 1999.00, 'NORTH'),
(10, 'Edward M.', 11000.00, 'EAST'),
(14, 'Fiona N.', 3000.00, 'WEST');
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem) VALUES
(2, 301, 100.00, 'CallCenter_System'),
(6, 302, 99.00, 'MobileApp_Legacy'),
(10, 303, 1000.00, 'WebStore_v1'),
(10, 304, 2500.00, 'InStore_POS'),
(14, 305, 130.00, 'MobileApp_Legacy');
USE shard3_db;
CREATE TABLE Customers (
CustomerId INT NOT NULL,
CustomerName VARCHAR(255),
CreditLimit DECIMAL(10, 2) NOT NULL,
LegacyRegion VARCHAR(50), -- Renamed to LoyaltyTier in Spanner
PRIMARY KEY (CustomerId),
CONSTRAINT CHK_CreditLimit CHECK (CreditLimit > 1000) -- Relaxed in Spanner to > 0
);
CREATE TABLE Orders (
CustomerId INT NOT NULL, -- Logically references Customers.CustomerId in Spanner
OrderId INT NOT NULL,
OrderValue DECIMAL(10, 2),
LegacyOrderSystem VARCHAR(50), -- Extra column in Source, to be dropped in Spanner
PRIMARY KEY (CustomerId, OrderId) -- Spanner PK will have one additional column in PK
);
INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LegacyRegion) VALUES
(3, 'Cathy Z.', 6000.00, 'CENTRAL'),
(7, 'George O.', 18000.00, 'SOUTH'),
(11, 'Helen P.', 4000.00, 'NORTHEAST'),
(15, 'Ivy Q.', 9500.00, 'SOUTHWEST');
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem) VALUES
(3, 401, 600.00, 'InStore_POS'),
(7, 402, 1200.00, 'CallCenter_System'),
(11, 403, 350.00, 'MobileApp_Legacy'),
(15, 404, 800.00, 'WebStore_v1'),
(99, 999, 25.00, 'CallCenter_System'); -- Failure row during Bulk Migration due to violation of interleaving
-- Create Datastream Replication User
CREATE USER 'datastream_user'@'%' IDENTIFIED BY 'complex_password_123';
GRANT REPLICATION SLAVE, REPLICATION CLIENT, SELECT, INSERT, UPDATE, DELETE ON *.* TO 'datastream_user'@'%';
FLUSH PRIVILEGES;
-- Verify Data
SELECT 'Customers shard2_db' AS tbl, COUNT(*) FROM shard2_db.Customers
UNION ALL
SELECT 'Orders shard2_db', COUNT(*) FROM shard2_db.Orders
UNION ALL
SELECT 'Customers shard3_db', COUNT(*) FROM shard3_db.Customers
UNION ALL
SELECT 'Orders shard3_db', COUNT(*) FROM shard3_db.Orders;
EXIT;
הפלט הצפוי:
+---------------------+----------+ | tbl | COUNT(*) | +---------------------+----------+ | Customers shard2_db | 4 | | Orders shard2_db | 5 | | Customers shard3_db | 4 | | Orders shard3_db | 5 | +---------------------+----------+
כאן אפשר למצוא את קובץ ה-dump של הסכימה שלמעלה. חשוב ליצור את המשתמש לשכפול של מקור הנתונים בנפרד, כי הוא לא נכלל בקובץ ה-dump.
מזינים exit כדי לצאת מהחיבור ל-VM.
5. הגדרה של Cloud Spanner
עכשיו מגדירים את מכונת היעד של Cloud Spanner שאליה יועברו הנתונים.
1. יצירת מכונה של Cloud Spanner
כדי לצמצם את זמן האחזור, כדאי ליצור מופע של Cloud Spanner באותו אזור שבו נמצאות המכונות הווירטואליות ב-Compute Engine. הפקודה הזו יוצרת מכונה קטנה שמתאימה ל-Codelab הזה, באמצעות 100 יחידות עיבוד.
export SPANNER_INSTANCE_NAME="target-spanner-instance"
export SPANNER_DATABASE_NAME="sharded-target-db"
export SPANNER_CONFIG="regional-${REGION}"
gcloud spanner instances create $SPANNER_INSTANCE_NAME \
--config=$SPANNER_CONFIG \
--description="Target Spanner Instance" \
--processing-units=100
יצירת המכונה עשויה להימשך דקה או שתיים.
6. המרת הסכימה באמצעות הכלי להעברה ל-Spanner (SMT)
משתמשים בממשק המשתמש האינטרנטי של Spanner Migration Tool (SMT) כדי להתחבר לאחד מהשארדים הלוגיים שלנו (shard0_db), לנתח את הסכימה שלו ולהחיל כמה שינויים מתקדמים לפני שממירים אותו ל-Cloud Spanner.
1. התקנת SMT
נריץ את ממשק המשתמש של SMT Web ישירות מ-Cloud Shell. בטרמינל של Cloud Shell, מורידים ומחלצים את הגרסה האחרונה של SMT:
sudo apt-get update && sudo apt-get install google-cloud-cli-spanner-migration-tool
# Verify installation
gcloud alpha spanner migrate web --help
2. התחברות למסד הנתונים של המקור
- אימות הסשן
# Authenticate your Google Cloud account
gcloud auth login
# Set up Application Default Credentials (ADC) for SMT
gcloud auth application-default login
# Ensure your current project is set correctly
gcloud config set project $PROJECT_ID
(הערה: כשמוצגת בקשה, לוחצים על כתובת ה-URL שמופיעה כדי לאשר את החשבון ומדביקים את קוד האימות בחזרה במסוף).
- קודם צריך להריץ את הפקודה הבאה בכרטיסייה חדשה ב-Cloud Shell כדי למצוא את כתובת ה-IP החיצונית של הרסיס הפיזי הראשון:
gcloud compute instances describe mysql-physical-1 --zone=$ZONE --format='get(networkInterfaces[0].accessConfigs[0].natIP)'
- הדפסת פרטי יעד של מופע Spanner לשימוש במהלך הגדרת SMT.
echo "Project ID: $PROJECT_ID"
echo "Instance ID: $SPANNER_INSTANCE_NAME"
echo "Database Name: $SPANNER_DATABASE_NAME"
- מפעילים את ממשק האינטרנט:
gcloud alpha spanner migrate web --port=8080
- בפינה השמאלית העליונה של חלון Cloud Shell, לוחצים על סמל תצוגה מקדימה באינטרנט (שנראה כמו עין) ובוחרים באפשרות תצוגה מקדימה ביציאה 8080. ממשק המשתמש של SMT ייפתח בכרטיסייה חדשה בדפדפן.
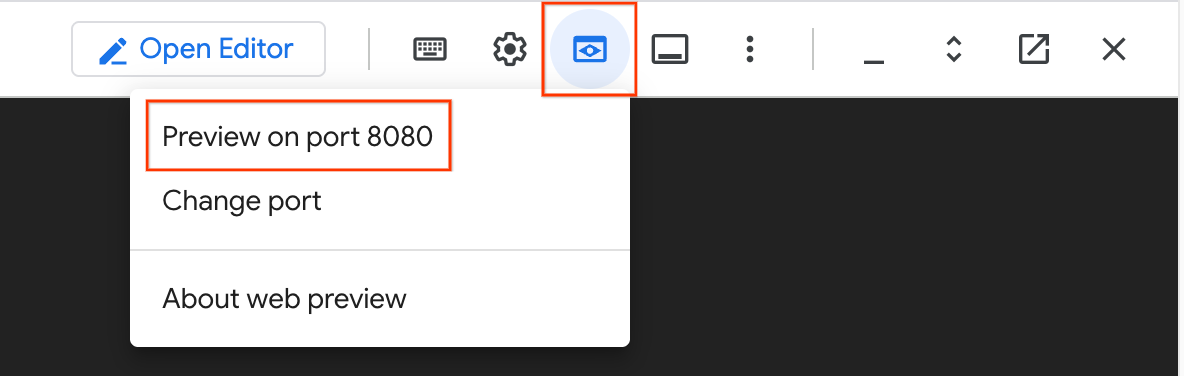
- בממשק האינטרנט של SMT, בוחרים באפשרות Connect to database (חיבור למסד נתונים).
- ממלאים את פרטי החיבור:
- סוג מסד הנתונים: MySQL
- מארח: (מדביקים את כתובת ה-IP משלב 2)
- יציאה: 3306
- משתמש:
datastream_user - סיסמה:
complex_password_123 - שם מסד הנתונים:
shard0_db
- לוחצים על לחצן העריכה בפינה השמאלית העליונה כדי להגדיר את מסד הנתונים של Spanner.
- מזינים את פרטי Spanner של היעד:
- מזהה פרויקט: (מדביקים את מזהה הפרויקט משלב 3)
- מכונת Spanner: (הדבקת מזהה המכונה משלב 3)
- לוחצים על בדיקת החיבור.
- אחרי שהבדיקה מסתיימת בהצלחה, לוחצים על Connect (קישור). הכלי SMT ינתח את מסד הנתונים של המקור ויציג סכמת Spanner בסיסית.

3. החלת שינויים בסכימה
עכשיו נשנה את הצורה של הסכימה כדי שתתאים לתרחישי ההעברה המורכבים שלנו.
בכלי לעריכת סכימות בממשק המשתמש של SMT, מבצעים את הפעולות הבאות:
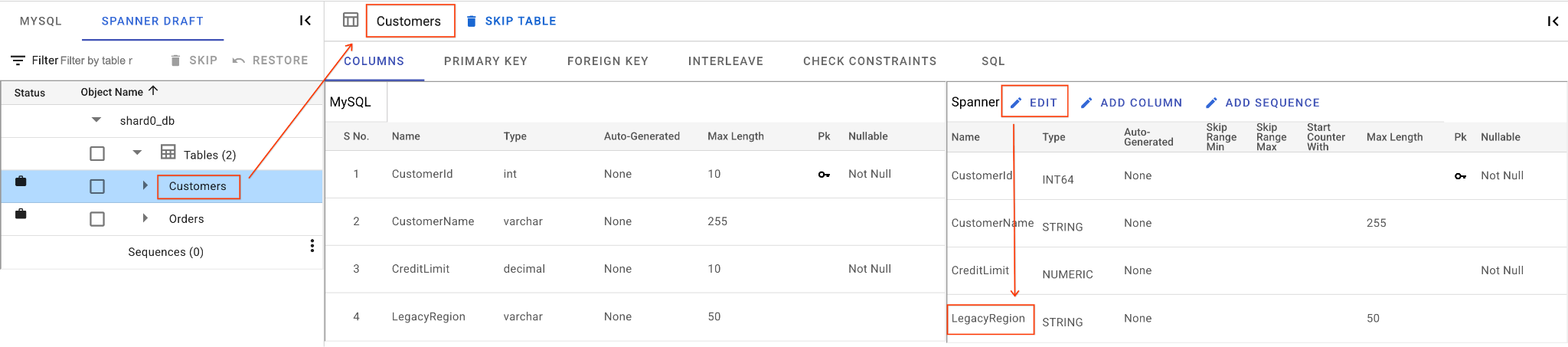
א. משנים את השם של העמודה LegacyRegion:
- לוחצים על הטבלה
Customersבחלונית הניווט הימנית. הכרטיסייה עמודות תיפתח כברירת מחדל. - לוחצים על הלחצן 'עריכה' בקטע Spanner.
- מחפשים את העמודה
LegacyRegionבתצוגת הסכימה של Spanner. - משנים את שם העמודה ב-Spanner ל-
LoyaltyTierעל ידי הקלדה בתיבת הדו-שיח של שם העמודה. - לוחצים על שמירה והמרה.

ב. הסרת ההגבלה של אילוץ הבדיקה:
- עדיין בטבלה
Customers, עוברים לכרטיסייה Check Constraints. - מחפשים את האילוץ
CHK_CreditLimit. לוחצים על סמל העריכה (עיפרון). - משנים את התנאי מ-
CreditLimit > 1000ל-CreditLimit > 0. (הפעולה הזו תגרום בכוונה לכך שההעברה ההפוכה של שורות עם מגבלות אשראי נמוכות יותר תיכשל והן יועברו ל-DLQ).

ג. מחיקת העמודה LegacyOrderSystem:
- לוחצים על הטבלה
Orders. הכרטיסייה עמודות תיפתח כברירת מחדל. - לוחצים על הלחצן 'עריכה' בקטע Spanner.
- מחפשים את העמודה
LegacyOrderSystemבתצוגת הסכימה של Spanner. - לוחצים על סמל האפשרויות הנוספות (3 נקודות) שלצד העמודה ובוחרים באפשרות הסרת העמודה.
- לוחצים על שמירה והמרה.

ד. מוסיפים את העמודה OrderSource והופכים אותה למפתח ראשי:
- עדיין בטבלה
Orders, לוחצים על הוספת עמודה. נותנים לו את השםOrderSourceומגדירים את הסוג ל-STRINGעם אורך של50, ללא יצירה אוטומטית, ומגדירים אתIsNullableל-No. - עוברים לכרטיסייה מפתח ראשי.
- לוחצים על עריכה ובוחרים באפשרות
OrderSourceמהתפריט הנפתח 'שם העמודה'. - לוחצים על הוספת עמודה ואז על שמירה והמרה.


ה. שילוב של טבלת ההזמנות:
- עדיין בטבלה
Orders, בתצוגת הטבלה הראשית, מאתרים את הכרטיסייה Interleave. - מגדירים את טבלת ההורה לערך
Customers. - בוחרים באפשרות
IN PARENTInterleave type (סוג השילוב) ובאפשרותNO ACTIONOn Delete Action (פעולה במקרה של מחיקה). - לוחצים על שמירה.

4. הורדת קובץ שינויים והחלת סכימה
- בפינה השמאלית העליונה של ממשק המשתמש של SMT, מאתרים את הלחצן Download Artifacts (הורדת ארטיפקטים). בוחרים באפשרות הורדת קובץ ההגדרות. שומרים את הקובץ במחשב המקומי. הקובץ הזה מכיל את כל השינויים במיפוי הסכימה שביצענו עכשיו, והוא ישמש את צינורות עיבוד הנתונים שלנו ב-Dataflow.
- לוחצים על הכנת ההעברה.

- בתפריט הנפתח, בוחרים באפשרות מצב העברה בתור
Schema. - מזינים את מסד הנתונים של Spanner שרוצים להעביר אליו את הנתונים:
sharded-target-db

- לוחצים על העברה.
- הכלי SMT יחיל את ה-DDL וייצור את מסד הנתונים ב-Spanner. אחרי שהתהליך מסתיים, אפשר להפסיק אותו ב-Cloud Shell (
Ctrl+C).
5. אימות הסכימה ב-Cloud Spanner
בודקים שהטבלאות נוצרו במסד הנתונים של Spanner.
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT table_name FROM information_schema.tables WHERE table_schema = '' ORDER BY table_name"
הפלט הבא אמור להתקבל:
table_name: Customers table_name: Orders
אופציונלי: אם רוצים לבדוק את ה-DDL בפועל של Spanner כדי לוודא שהוחלו אילוצי הבדיקה, השילוב והעמודות הנוספות, מריצים את הפקודה הבאה:
gcloud spanner databases ddl describe $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME
הפלט הצפוי:
CREATE TABLE Customers ( CustomerId INT64 NOT NULL, CustomerName STRING(255), CreditLimit NUMERIC NOT NULL, LoyaltyTier STRING(50), CONSTRAINT CHK_CreditLimit CHECK(`CreditLimit` > 0), ) PRIMARY KEY(CustomerId); CREATE TABLE Orders ( CustomerId INT64 NOT NULL, OrderId INT64 NOT NULL, OrderValue NUMERIC, OrderSource STRING(50) NOT NULL, ) PRIMARY KEY(CustomerId, OrderId, OrderSource), INTERLEAVE IN PARENT Customers ON DELETE NO ACTION;
7. הפעלה של סימון נתונים שהשתנו (CDC)
בקטע הזה מגדירים את הכלי 'הקלטה' להעברה. אם תגדירו את Datastream ואת Pub/Sub לפני שתתחילו בטעינת הנתונים בכמות גדולה, תוכלו לוודא שכל שינוי שמתבצע במסדי הנתונים של המקור מתועד ומוכנס לתור, וכך למנוע אובדן נתונים במהלך המעבר. ההגדרה הזו נדרשת להעברה הפעילה.
הארכיטקטורה שלנו כוללת שני שרתים פיזיים, ולכן אנחנו צריכים ליצור שני פרופילים נפרדים של מקור ב-Datastream ושני מקורות נתונים ב-Datastream. שני הזרמים ייכתבו לקטגוריה אחת של Google Cloud Storage (GCS), שתשמש כמקור מאוחד לצינור Dataflow שלנו.
1. יצירת קטגוריה של Cloud Storage
מקור הנתונים צריך יעד לאחסון אירועי השינוי שתועדו. ניצור קטגוריית GCS.
export BUCKET_NAME="migration-${PROJECT_ID}-bucket"
gcloud storage buckets create gs://${BUCKET_NAME} --location=$REGION
2. יצירת פרופילים של חיבורי Datastream
צריך שני פרופילים נפרדים של חיבור למקור MySQL (אחד לכל שארד פיזי) ופרופיל אחד של חיבור ליעד ב-Cloud Storage.
קבלת כתובות ה-IP של המקור
קודם כל, מאחזרים את כתובות ה-IP החיצוניות של שתי המכונות הווירטואליות ב-Compute Engine ושומרים אותן כמשתני סביבה:
export MYSQL_IP_1=$(gcloud compute instances describe mysql-physical-1 --zone=$ZONE --format='get(networkInterfaces[0].accessConfigs[0].natIP)')
export MYSQL_IP_2=$(gcloud compute instances describe mysql-physical-2 --zone=$ZONE --format='get(networkInterfaces[0].accessConfigs[0].natIP)')
יצירת פרופילים של חיבור למקור (MySQL ב-Compute Engine)
יוצרים את פרופילי החיבור של Datastream באמצעות datastream_user שנוצר קודם.
# Create Source Profile for Physical Shard 1
export SQL_CP_NAME_1="mysql-src-cp-1"
gcloud datastream connection-profiles create $SQL_CP_NAME_1 \
--location=$REGION \
--type=mysql \
--mysql-hostname=$MYSQL_IP_1 \
--mysql-port=3306 \
--mysql-username=datastream_user \
--mysql-password=complex_password_123 \
--display-name="MySQL Source 1 (Physical Shard 1)"
# Create Source Profile for Physical Shard 2
export SQL_CP_NAME_2="mysql-src-cp-2"
gcloud datastream connection-profiles create $SQL_CP_NAME_2 \
--location=$REGION \
--type=mysql \
--mysql-hostname=$MYSQL_IP_2 \
--mysql-port=3306 \
--mysql-username=datastream_user \
--mysql-password=complex_password_123 \
--display-name="MySQL Source 2 (Physical Shard 2)"
הערה: Datastream מתחבר למכונות הווירטואליות האלה באמצעות כתובות ה-IP הציבוריות שלהן, וזה מותר כי הוספנו את 0.0.0.0/0 לכללי חומת האש שלנו קודם לכן. בסביבת ייצור, צריך להוסיף לרשימת ההיתרים רק את טווחי כתובות ה-IP הציבוריות הספציפיות של Datastream.
יצירת פרופיל חיבור ליעד (Cloud Storage):
הוא מצביע על שורש הקטגוריה החדשה שנוצרה.
export GCS_CP_NAME="gcs-dest-cp"
gcloud datastream connection-profiles create $GCS_CP_NAME \
--location=$REGION \
--type=google-cloud-storage \
--bucket=$BUCKET_NAME \
--root-path=/ \
--display-name="GCS Destination" --force
3. יצירת מקורות נתונים ב-Datastream
עכשיו ניצור שני זרמי CDC. בשידור 1 יצולמו shard0_db ו-shard1_db. בשידור 2 יוצגו shard2_db ו-shard3_db. שני הסטרימים כותבים לאותו באקט GCS בפורמט Avro.
# Stream for Physical Shard 1
export STREAM_NAME_1="mysql-to-spanner-stream-1"
export GCS_STREAM_PATH_1="data/${STREAM_NAME_1}"
gcloud datastream streams create $STREAM_NAME_1 \
--location=$REGION \
--display-name="MySQL Source 1 CDC Stream" \
--source=$SQL_CP_NAME_1 \
--destination=$GCS_CP_NAME \
--mysql-source-config=<(echo "includeObjects:
mysqlDatabases:
- database: 'shard0_db'
- database: 'shard1_db'") \
--gcs-destination-config=<(echo "path: ${GCS_STREAM_PATH_1}/
fileRotationMb: 5
fileRotationInterval: 15s
avroFileFormat: {}") \
--backfill-none
# Stream for Physical Shard 2
export STREAM_NAME_2="mysql-to-spanner-stream-2"
export GCS_STREAM_PATH_2="data/${STREAM_NAME_2}"
gcloud datastream streams create $STREAM_NAME_2 \
--location=$REGION \
--display-name="MySQL Source 2 CDC Stream" \
--source=$SQL_CP_NAME_2 \
--destination=$GCS_CP_NAME \
--mysql-source-config=<(echo "includeObjects:
mysqlDatabases:
- database: 'shard2_db'
- database: 'shard3_db'") \
--gcs-destination-config=<(echo "path: ${GCS_STREAM_PATH_2}/
fileRotationMb: 5
fileRotationInterval: 15s
avroFileFormat: {}") \
--backfill-none
שימוש בהגדרות קטנות יותר של רוטציה של קבצים (5MB או 15 שניות) עוזר לנו לראות שינויים משוכפלים מהר יותר במהלך ה-codelab.
יכול להיות שיעבור קצת זמן עד להשלמת הפקודה. בדיקת הסטטוס: gcloud datastream streams describe $STREAM_NAME_1 --location=$REGION.
4. הפעלת השידורים של Datastream
מפעילים את שני הפידים כדי שהם יתחילו להקליט שינויים.
gcloud datastream streams update $STREAM_NAME_1 \
--location=$REGION \
--state=RUNNING
gcloud datastream streams update $STREAM_NAME_2 \
--location=$REGION \
--state=RUNNING
בדיקת הסטטוס: אפשר להריץ את הפקודה gcloud datastream streams describe $STREAM_NAME_1 --location=$REGION. הסטטוס יהיה בהתחלה STARTING וישתנה ל-RUNNING אחרי כמה רגעים. צריך לחכות עד ששניהם יפעלו באופן מלא לפני שמתחילים את ההעברה הפעילה.
5. הגדרת Pub/Sub להתראות GCS
צריך להודיע ל-Dataflow באופן מיידי כשזרם Datastream כותב קובץ חדש לדלי GCS. אנחנו נגדיר את GCS לשליחת התראות לנושא Pub/Sub יחיד.
יצירת נושא Pub/Sub:
export PUBSUB_TOPIC="datastream-gcs-updates"
gcloud pubsub topics create $PUBSUB_TOPIC
יצירת התראה ב-GCS
הודעה על הנושא בכל יצירת אובייקט עם הקידומת data/ (שכוללת את שני הזרמים שלנו).
gcloud storage buckets notifications create gs://${BUCKET_NAME} --topic=projects/$PROJECT_ID/topics/$PUBSUB_TOPIC --payload-format=json --object-prefix=data/
יצירת מינוי ל-Pub/Sub
יוצרים את המינוי עם מועד מומלץ לאישור ב-Dataflow.
export PUBSUB_SUBSCRIPTION="datastream-gcs-sub"
gcloud pubsub subscriptions create $PUBSUB_SUBSCRIPTION \
--topic=$PUBSUB_TOPIC \
--ack-deadline=600
8. שינוי בהתאמה אישית
מכיוון שהסכימה של Spanner שונה מהסכימה של MySQL (בגלל העמודות שהוספנו והסרנו דרך ממשק האינטרנט של SMT), ההעברה של Dataflow שמוכנה לשימוש תיכשל. ל-Dataflow דרושות הוראות למיפוי ההבדלים האלה במהלך צינורות העיבוד קדימה (מ-MySQL ל-Spanner) ואחורה (מ-Spanner ל-MySQL).
בנוסף, מכיוון שאנחנו מבצעים העברה הפוכה עם חלוקה למקטעים, ל-Dataflow נדרש מנגנון ניתוב כדי לדעת לאיזה מקטע לוגי (shard0_db, shard1_db וכו') שורה מעודכנת ב-Spanner שייכת במהלך השכפול ההפוך.
כדי לעשות את זה, נכתוב JAR של טרנספורמציה בהתאמה אישית באמצעות תבנית השבר בהתאמה אישית של Spanner שסופקה על ידי Google.
1. הורדת תבנית מותאמת אישית של שארד
ב-Cloud Shell, מורידים את מאגר התבניות של Google Cloud Dataflow ועוברים לתיקיית הרסיסים המותאמים אישית:
git clone https://github.com/GoogleCloudPlatform/DataflowTemplates.git
cd DataflowTemplates/v2/spanner-custom-shard
2. הגדרת הלוגיקה של טרנספורמציית הנתונים
צריך לערוך את הקובץ CustomTransformationFetcher.java.
- העברה קדימה (
toSpannerRow): מאכלסת את העמודהOrderSourceשנוספה באמצעות העמודהLegacyOrderSystemמ-MySQL. - העברה הפוכה (
toSourceRow): מאכלסת מחדש את העמודהLegacyOrderSystemשהוסרה ונדרשת על ידי MySQL, על ידי גזירה שלה מ-OrderSourceשל Spanner.
עורכים את הקובץ CustomTransformationFetcher.java. במקום לפתוח ידנית כלי לעריכת טקסט, מריצים את הפקודה הבאה כדי להחליף אוטומטית את קובץ התבנית בלוגיקה המותאמת אישית שלנו:
cat << 'EOF' > src/main/java/com/custom/CustomTransformationFetcher.java
package com.custom;
import com.google.cloud.teleport.v2.spanner.exceptions.InvalidTransformationException;
import com.google.cloud.teleport.v2.spanner.utils.ISpannerMigrationTransformer;
import com.google.cloud.teleport.v2.spanner.utils.MigrationTransformationRequest;
import com.google.cloud.teleport.v2.spanner.utils.MigrationTransformationResponse;
import java.util.HashMap;
import java.util.Map;
public class CustomTransformationFetcher implements ISpannerMigrationTransformer {
@Override
public void init(String customParameters) {}
@Override
public MigrationTransformationResponse toSpannerRow(MigrationTransformationRequest request)
throws InvalidTransformationException {
if (request.getTableName().equals("Orders")) {
Map<String, Object> requestRow = request.getRequestRow();
Map<String, Object> responseRow = new HashMap<>();
Object legacySysObj = requestRow.get("LegacyOrderSystem");
String legacySys = (legacySysObj != null) ? (String) legacySysObj : "UNKNOWN_SYSTEM";
// Transform: Trim the string to remove everything after the first underscore
String orderSource = legacySys;
if (legacySys.contains("_")) {
orderSource = legacySys.substring(0, legacySys.indexOf('_'));
}
// Populate the new Spanner column (e.g., "WebStore_v1" becomes "WebStore")
responseRow.put("OrderSource", orderSource);
return new MigrationTransformationResponse(responseRow, false);
}
return new MigrationTransformationResponse(new HashMap<>(), false);
}
@Override
public MigrationTransformationResponse toSourceRow(MigrationTransformationRequest request)
throws InvalidTransformationException {
if (request.getTableName().equals("Orders")) {
Map<String, Object> requestRow = request.getRequestRow();
Map<String, Object> responseRow = new HashMap<>();
// Safely fetch the Spanner OrderSource
Object sourceObj = requestRow.get("OrderSource");
String source = (sourceObj != null) ? (String) sourceObj : "UNKNOWN_SYSTEM";
String legacySys = "'" + source + "_v1'";
// Transform: Append a suffix to visibly prove the reverse transformation worked
// e.g., "WebStore" becomes "WebStore_v1"
responseRow.put("LegacyOrderSystem", legacySys);
return new MigrationTransformationResponse(responseRow, false);
}
return new MigrationTransformationResponse(new HashMap<>(), false);
}
@Override
public MigrationTransformationResponse transformFailedSpannerMutation(
MigrationTransformationRequest request) throws InvalidTransformationException {
return new MigrationTransformationResponse(new HashMap<>(), false);
}
}
EOF
3. הגדרת לוגיקת הפיצול ההפוך
Dataflow משתמש ב-CustomShardIdFetcher.java במהלך שכפול הפוך כדי לקבוע לאן צריך לנתב מוטציה של Spanner. אנחנו נשתמש במפתח הראשי CustomerId ובלוגיקה של מודולו (%4) כדי להפנות רשומות באופן דינמי בחזרה לשבר הלוגי הנכון שלהן.
עורכים את הקובץ CustomShardIdFetcher.java באמצעות cat ומחליפים את התוכן שלו לגמרי בקוד הבא:
cat << 'EOF' > src/main/java/com/custom/CustomShardIdFetcher.java
package com.custom;
import com.google.cloud.teleport.v2.spanner.utils.IShardIdFetcher;
import com.google.cloud.teleport.v2.spanner.utils.ShardIdRequest;
import com.google.cloud.teleport.v2.spanner.utils.ShardIdResponse;
import java.util.Map;
public class CustomShardIdFetcher implements IShardIdFetcher {
@Override
public void init(String parameters) {}
@Override
public ShardIdResponse getShardId(ShardIdRequest shardIdRequest) {
Map<String, Object> keys = shardIdRequest.getSpannerRecord
();
// Use the Primary Key to identify the correct logical shard
if (keys != null && keys.containsKey("CustomerId")) {
long customerId = Long.parseLong(keys.get("CustomerId").toString());
long shardIdx = customerId % 4;
ShardIdResponse response = new ShardIdResponse();
response.setLogicalShardId("shard" + shardIdx + "_db");
return response;
}
return new ShardIdResponse();
}
}
EOF
4. בנייה והעלאה של קובץ JAR
אחרי שכותבים את הלוגיקה המותאמת אישית ב-Java, צריך לקמפל אותה לקובץ JAR ולהעלות אותו לקטגוריה של Cloud Storage ב-Google Cloud Storage שיצרנו קודם, כדי ש-Dataflow יוכל לגשת אליו.
מריצים את הפקודות הבאות ב-Cloud Shell:
# Return to DataflowTemplates directory
cd ../..
# Build the JAR using Maven
mvn clean install -DskipTests -Dcheckstyle.skip -Dspotless.check.skip=true -Djib.skip -pl v2/spanner-custom-shard -am
# Upload the JAR to GCS
export CUSTOM_JAR_PATH="gs://${BUCKET_NAME}/custom-logic/spanner-custom-shard-1.0.jar"
gcloud storage cp v2/spanner-custom-shard/target/spanner-custom-shard-1.0-SNAPSHOT.jar $CUSTOM_JAR_PATH
# Return to home directory
cd ~
9. העברת נתונים בכמות גדולה מ-MySQL ל-Spanner
אחרי שיצרנו את סכימת Spanner ובנינו את קובץ ה-JAR של ההמרה בהתאמה אישית, אפשר להעתיק את הנתונים הקיימים ממסד הנתונים של MySQL אל Cloud Spanner. תשתמשו בSourcedb to Spanner תבנית Flex של Dataflow, שנועדה להעתקת נתונים בכמות גדולה ממסדי נתונים שאפשר לגשת אליהם באמצעות JDBC אל Spanner.
1. העלאת קובץ של שינויים בסכימה
בקטע 6, הורדתם את קובץ ה-JSON של Spanner Overrides באמצעות ממשק המשתמש האינטרנטי של SMT. אנחנו צריכים להעלות את הקובץ הזה לקטגוריית GCS שלנו כדי ש-Dataflow יוכל להשתמש בו למיפוי ההבדלים בסכימה (למשל, עמודות ששמן שונה).
- ב-Cloud Shell, לוחצים על תפריט שלוש הנקודות (עוד) ובוחרים באפשרות העלאה.

- בוחרים את קובץ ה-JSON של השינויים מברירת המחדל שהורדתם קודם (למשל,
spanner_overrides.json). - מעבירים אותו אל דלי GCS:
export OVERRIDES_FILE="spanner_overrides.json" # Change this if your downloaded file has a different name
export GCS_OVERRIDES_PATH="gs://${BUCKET_NAME}/config/${OVERRIDES_FILE}"
gcloud storage cp ~/${OVERRIDES_FILE} $GCS_OVERRIDES_PATH
2. יצירה והעלאה של קובץ הגדרות הפיצול
ל-Dataflow צריך להיות מידע על אופן ההתחברות לכל ארבעת הרסיסים הלוגיים בשני המכונות הווירטואליות הפיזיות. ניצור קובץ sharding.json בשביל זה.
מריצים את הפקודה הבאה ב-Cloud Shell כדי ליצור את התצורה ולהעלות אותה:
cat <<EOF > sharding.json
{
"configType": "dataflow",
"shardConfigurationBulk": {
"schemaSource": {
"dataShardId": "mysql-physical-1",
"host": "${MYSQL_IP_1}",
"user": "datastream_user",
"password": "complex_password_123",
"port": "3306",
"dbName": "shard0_db"
},
"dataShards": [
{
"dataShardId": "mysql-physical-1",
"host": "${MYSQL_IP_1}",
"user": "datastream_user",
"password": "complex_password_123",
"port": "3306",
"dbName": "",
"namespace": "namespace-mysql-1",
"databases": [
{
"dbName": "shard0_db",
"databaseId": "shard0_db",
"refDataShardId": "mysql-physical-1"
},
{
"dbName": "shard1_db",
"databaseId": "shard1_db",
"refDataShardId": "mysql-physical-1"
}
]
},
{
"dataShardId": "mysql-physical-2",
"host": "${MYSQL_IP_2}",
"user": "datastream_user",
"password": "complex_password_123",
"port": "3306",
"dbName": "",
"namespace": "namespace-mysql-2",
"databases": [
{
"dbName": "shard2_db",
"databaseId": "shard2_db",
"refDataShardId": "mysql-physical-2"
},
{
"dbName": "shard3_db",
"databaseId": "shard3_db",
"refDataShardId": "mysql-physical-2"
}
]
}
]
}
}
EOF
export GCS_SHARDING_PATH="gs://${BUCKET_NAME}/config/sharding.json"
gcloud storage cp sharding.json $GCS_SHARDING_PATH
3. הפעלת משימת Dataflow להעברת נתונים בכמות גדולה
נשתמש בתבנית Flex Sourcedb to Spanner. מכיוון שמדובר בהעברה עם חלוקה למקטעים ועם טרנספורמציות בהתאמה אישית, אנחנו מעבירים את קובץ ה-Overrides, את הגדרות החלוקה למקטעים ואת קובץ ה-JAR של Java בהתאמה אישית.
export JOB_NAME="mysql-sharded-bulk-to-spanner-$(date +%Y%m%d-%H%M%S)"
export OUTPUT_DIR="gs://${BUCKET_NAME}/bulk-migration"
gcloud dataflow flex-template run $JOB_NAME \
--project=$PROJECT_ID \
--region=$REGION \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Sourcedb_to_Spanner_Flex" \
--max-workers=2 \
--num-workers=1 \
--worker-machine-type=n2-highmem-8 \
--parameters \
sourceConfigURL=$GCS_SHARDING_PATH,\
instanceId=$SPANNER_INSTANCE_NAME,\
databaseId=$SPANNER_DATABASE_NAME,\
projectId=$PROJECT_ID,\
outputDirectory=$OUTPUT_DIR,\
username=datastream_user,\
password=complex_password_123,\
schemaOverridesFilePath=$GCS_OVERRIDES_PATH,\
transformationJarPath=$CUSTOM_JAR_PATH,\
transformationClassName=com.custom.CustomTransformationFetcher
הסבר על הפרמטרים העיקריים:
-
sourceConfigURL: הנתיב לקובץsharding.jsonשיצרנו. ההגדרה הזו מציינת ל-Dataflow איך להתחבר לכל ארבעת הרסיסים הלוגיים של MySQL בשני המכונות הווירטואליות הפיזיות. -
schemaOverridesFilePath: הנתיב לקובץ ה-JSON שהורד מממשק האינטרנט של SMT. ההוראה הזו מנחה את Dataflow איך לטפל בשינויים בסכימה שביצענו (כמו העמודהLegacyRegionשהוסרה ואילוץ הבדיקה שהוחמר). -
transformationJarPath: הנתיב ב-GCS לקובץ ה-JAR של Java שקומפל, שיצרנו בקטע הקודם. הקובץ הזה מכיל את הקוד בפועל להפעלת ההמרות המותאמות אישית. -
transformationClassName: השם מוגדר במלואו של מחלקת Java בתוך קובץ ה-JAR שלנו שמטמיעה את הלוגיקה של העברה קדימה (com.custom.CustomTransformationFetcher). -
outputDirectory: המיקום ב-GCS שבו Dataflow יכתוב את הקבצים הזמניים שלו, וחשוב מכך, את הקבצים של תור ההודעות המתות (DLQ). -
maxWorkers, numWorkers: קובעים את קנה המידה של עבודת Dataflow. הערך נשאר נמוך בגלל שמערך הנתונים קטן. -
instanceId,databaseId,projectId: מציינים את מסד הנתונים ואת מכונת היעד של Cloud Spanner.
הערה לגבי הרשת: העבודה הזו מתחברת למופע Cloud SQL דרך כתובת ה-IP הציבורית שלו. האפשרות הזו קיימת כי הוספתם בעבר את 0.0.0.0/0 לרשתות המורשות של המופע. כך מכונות וירטואליות של Dataflow Worker עם כתובות IP חיצוניות יכולות להגיע למסד הנתונים.
4. מעקב אחרי משימת Dataflow
אפשר לעקוב אחרי התקדמות העבודה במסוף Google Cloud:
- עוברים לדף 'משימות ב-Dataflow': לדף 'משימות ב-Dataflow'
- מאתרים את המשרה בשם
mysql-sharded-bulk-to-spanner-...ולוחצים עליה. - בודקים את תרשים המשימה ואת המדדים. מחכים שסטטוס העבודה ישתנה להצלחה. התהליך יימשך כ-5 עד 15 דקות.
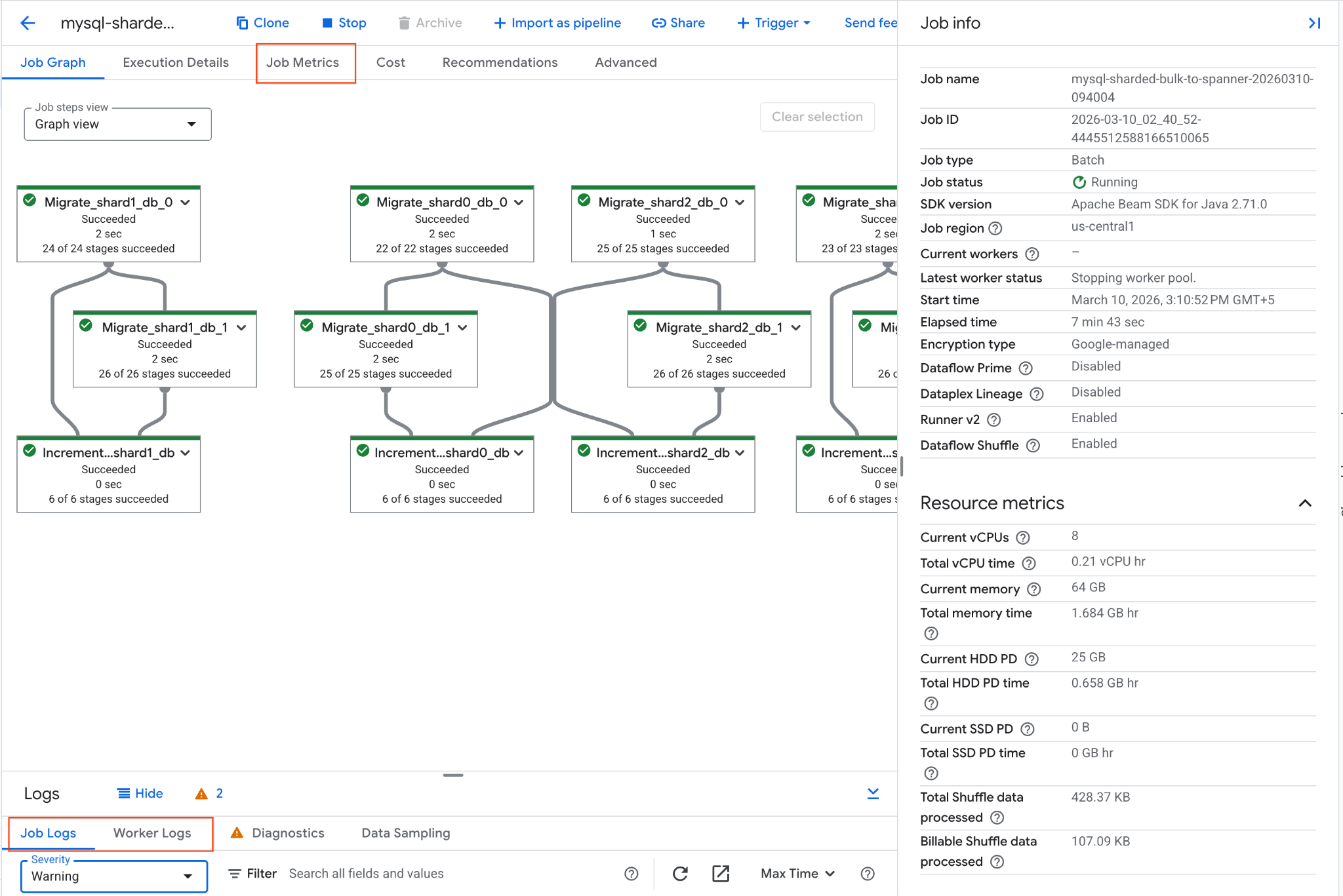
- אם נתקלים בבעיות בעבודה, אפשר לעיין בכרטיסייה Logs (יומנים) בדף הפרטים של עבודת Dataflow כדי למצוא הודעות שגיאה.
- מדדי עבודה מספקים מידע נוסף על התקדמות העבודה ועל צריכת המשאבים, כמו קצב העברת הנתונים וניצול המעבד.
5. אימות הנתונים ב-Cloud Spanner ובדיקת תור ההודעות שלא ניתן למסור (DLQ)
אחרי שהג'וב של Dataflow מסתיים בהצלחה, צריך לוודא שהנתונים הגיעו בבטחה ולבדוק את הרשומות שגרמנו להן להיכשל בכוונה.
א. אימות המצב הכללי של הנתונים שהועברו:
אפשר להשתמש ב-gcloud CLI כדי להריץ כמה בדיקות תקינות מהירות במסד הנתונים המאוחד של Spanner, כדי לוודא שהרשומות התקינות הועברו בצורה נכונה ושה-JAR המותאם אישית שלנו מילא את העמודה הנוספת.
# 1. Verify total Customer count
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT COUNT(*) as TotalCustomers FROM Customers"
# 2. Verify total Orders count (Total minus the orphan record)
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT COUNT(*) as TotalOrders FROM Orders"
# 3. Verify the Custom Transformation on OrderSource worked
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT CustomerId, OrderId, OrderSource FROM Orders LIMIT 3"
# 4. Verify that renamed column LoyaltyTier has the correct data
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT CustomerId, CustomerName, LoyaltyTier FROM Customers LIMIT 3"
הפלט הצפוי:
TotalCustomers: 16 TotalOrders: 19 CustomerId: 1 OrderId: 201 OrderSource: MobileApp CustomerId: 2 OrderId: 301 OrderSource: CallCenter CustomerId: 3 OrderId: 401 OrderSource: InStore CustomerId: 1 CustomerName: Agnes N. LoyaltyTier: NORTHEAST CustomerId: 2 CustomerName: Brian K. LoyaltyTier: SOUTHWEST CustomerId: 3 CustomerName: Cathy Z. LoyaltyTier: CENTRAL
- כל השורות בטבלת הלקוחות הועברו בהצלחה.
- אנחנו רואים שורה אחת שנכשלה בטבלה
OrdersבגללINTERLEAVE IN PARENTב-Spanner –CustomerId 99הוא צאצא יתום כי אין שורה תואמת בטבלהCustomers.
ב. בודקים את הכשלים המכוונים בתור להודעות שלא ניתן למסור:
הכשל שצוין למעלה מתועד בתיקיית תור ההודעות המתות (DLQ) שנוצרה על ידי צינור ההעברה בכמות גדולה.
- עוברים אל Cloud Storage במסוף Google Cloud.
- עוברים אל ה-bucket ופותחים את התיקייה
bulk-migration/dlq/severe. - בודקים את קובצי ה-JSON שבתוך התיקייה. תופיע השורה
Ordersעם היתוםCustomerId. - אפשר לנסות שוב לתקן שגיאות ב-DLQ של העברה בכמות גדולה לפי השלבים שמפורטים כאן.
הטעינה הראשונית של נתונים מ-Cloud SQL ל-Cloud Spanner הסתיימה. השלב הבא הוא להגדיר שכפול בזמן אמת כדי לתעד שינויים שמתבצעים באופן שוטף.
10. התחלת העברה פעילה (CDC)
אחרי שטעינת הנתונים בכמות גדולה מסתיימת, מפעילים משימת סטרימינג רציפה של Dataflow. העבודה הזו תקרא את אירועי Change Data Capture (CDC) ש-Datastream כותב לקטגוריית GCS שלכם ותחיל את השינויים האלה על Cloud Spanner כמעט בזמן אמת.
נבדוק גם את צינור עיבוד הנתונים הזה על ידי הזרקת נתונים תקינים ונתונים לא תקינים בכוונה, כדי לראות איך Dataflow מטפל בשכפול בזמן אמת ומנתב כשלים לתור ההודעות המתות (DLQ).
1. יצירת קובץ התצורה של שיתוף נתונים בהעברה חיה
בניגוד להעברה בכמות גדולה (שבה נעשה שימוש במחרוזות חיבור JDBC), פייפליין המיגרציה הפעילה קורא אירועים מ-Datastream מ-GCS. היא צריכה הגדרת JSON שונה לגמרי שממפה את שמות הזרמים ומסדי הנתונים של Datastream לשברי הנתונים הלוגיים של Spanner.
מריצים את הפקודה הבאה ב-Cloud Shell כדי ליצור ולהעלות את הגדרות הפיצול של השידור החי:
cat <<EOF > live-sharding.json
{
"StreamToDbAndShardMap": {
"${STREAM_NAME_1}": {
"shard0_db": "shard0_db",
"shard1_db": "shard1_db"
},
"${STREAM_NAME_2}": {
"shard2_db": "shard2_db",
"shard3_db": "shard3_db"
}
}
}
EOF
export GCS_LIVE_SHARDING_PATH="gs://${BUCKET_NAME}/config/live-sharding.json"
gcloud storage cp live-sharding.json $GCS_LIVE_SHARDING_PATH
2. הפעלת משימת Dataflow של העברה פעילה
מפעילים את משימת הסטרימינג של Dataflow כדי לקרוא מ-GCS ולכתוב ל-Spanner. התבנית הזו תשתמש בהתראות של GCS Pub/Sub כדי לעבד קבצים חדשים באופן מיידי.
export JOB_NAME_CDC="mysql-sharded-cdc-to-spanner-$(date +%Y%m%d-%H%M%S)"
export DLQ_DIR_CDC="gs://${BUCKET_NAME}/live-migration"
gcloud dataflow flex-template run $JOB_NAME_CDC \
--project=$PROJECT_ID \
--region=$REGION \
--worker-machine-type=n2-highmem-8 \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Cloud_Datastream_to_Spanner" \
--parameters \
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
projectId="$PROJECT_ID",\
inputFileFormat="avro",\
gcsPubSubSubscription="projects/${PROJECT_ID}/subscriptions/${PUBSUB_SUBSCRIPTION}",\
shardingContextFilePath=$GCS_LIVE_SHARDING_PATH,\
deadLetterQueueDirectory="$DLQ_DIR_CDC",\
transformationJarPath=$CUSTOM_JAR_PATH,\
transformationClassName="com.custom.CustomTransformationFetcher",\
schemaOverridesFilePath=$GCS_OVERRIDES_PATH,\
datastreamSourceType="mysql",\
dlqRetryMinutes=1,\
dlqMaxRetryCount=2
פרמטרים מרכזיים
-
gcsPubSubSubscription: מינוי Pub/Sub שמקבל התראות על קבצים חדשים מ-GCS. כך העבודה יכולה לעבד שינויים באופן מיידי בזמן ש-Datastream כותב אותם. -
inputFileFormat="avro": מציין ל-Dataflow לצפות לקובצי Avro מ-Datastream. הערך הזה צריך להיות זהה להגדרת ה'יעד' במקור הנתונים (לדוגמה,avroFileFormatלעומתjsonFileFormat). -
shardingContextFilePath: קובץ JSON שממפה את הזרמים של Datastream לרסיסים לוגיים. dlqRetryMinutes: מספר הדקות בין ניסיונות חוזרים של תור הודעות שלא ניתן למסור. ברירת המחדל היא10.-
dlqMaxRetryCount: המספר המקסימלי של ניסיונות חוזרים לשגיאות זמניות דרך תור DLQ. ברירת המחדל היא500.
עוקבים אחרי הפעלת המשימה ב-Dataflow Jobs Console.
3. הזרקת נתונים בזמן אמת והפעלת כשלים מכוונים
בזמן שמשימת הסטרימינג של Dataflow מתחילה (התהליך הזה יכול להימשך 3-5 דקות), נתחבר באמצעות SSH למכונה הווירטואלית הפיזית הראשונה של MySQL ונוסיף כמה רשומות חדשות. אנחנו נוסיף רשומה תקינה אחת ורשומה לא תקינה אחת.
מתחברים באמצעות SSH אל הרסיס הפיזי הראשון:
gcloud compute ssh mysql-physical-1 --zone=$ZONE
מתחברים ל-MySQL:
sudo mysql
מריצים את ההוספות הבאות ב-shard1_db:
USE shard1_db;
-- 1. Valid Insert: 'MobileApp_v2' will be trimmed to 'MobileApp'
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem)
VALUES (4, 501, 99.99, 'MobileApp_v2');
-- 2. Invalid Insert (DLQ Test): This violates Interleave constraint as CustomerId 99999 doesn't exist in Customers table.
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem)
VALUES (99999, 502, 50.00, 'WebStore_v1');
-- 3. Valid Update
UPDATE Orders SET OrderValue = '1500' WHERE CustomerId = 5 AND OrderId = 202;
-- 4. Valid Delete
DELETE FROM Orders WHERE CustomerId = 5 AND OrderId = 203;
EXIT;
מקלידים exit שוב כדי לחזור להנחיה של Cloud Shell.
4. אימות נתונים של העברה פעילה ובדיקה של תור ההודעות המתות של CDC
אחרי שהזנו את הנתונים, Datastream יתעד את אירועי ה-CDC, ו-Dataflow ינסה להחיל אותם על Spanner.
א. אימות השינויים התקפים ב-DML ב-Spanner
מריצים את השאילתות הבאות כדי לוודא שהאירועים INSERT, UPDATE ו-DELETE הגיעו ל-Spanner בהצלחה, ושההמרה המותאמת אישית הופעלה גם בהוספה וגם בעדכון.
# 1. Verify INSERT: Should return the new row with transformed OrderSource
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT CustomerId, OrderId, OrderValue, OrderSource FROM Orders WHERE CustomerId = 4 AND OrderId = 501"
# 2. Verify UPDATE: Should show OrderValue changed to 1500
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT CustomerId, OrderId, OrderValue, OrderSource FROM Orders WHERE CustomerId = 5 AND OrderId = 202"
# 3. Verify DELETE: Should return 0, confirming the order was deleted
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT COUNT(*) FROM Orders WHERE CustomerId = 5 AND OrderId = 203"
# 4. Verify DLQ Failure: Should return 0, confirming the row migration failed
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT COUNT(*) FROM Orders WHERE CustomerId = 99999 AND OrderId = 502"
הפלט הצפוי:
CustomerId: 4 OrderId: 501 OrderValue: 99.99 OrderSource: MobileApp CustomerId: 5 OrderId: 202 OrderValue: 1500 OrderSource: WebStore 0 0
הערה: אם שאילתה מסוימת לא מציגה את התוצאה הצפויה, כדאי להמתין דקה ולנסות שוב, כי יכול להיות שעובדי הסטרימינג עדיין מעבדים את התור.
ב. בודקים את הכישלון המכוון בתור להודעות שלא ניתן למסור (DLQ):
מכיוון של-CustomerId = 99999 אין הורה בטבלה Customers, המערכת הייתה אמורה לדחות אותו ב-Spanner ולהעביר אותו בבטחה לתור ההודעות המתות באמצעות Dataflow.
- עוברים אל Cloud Storage במסוף Google Cloud.
- עוברים אל ה-bucket ופותחים את התיקייה
live-migration/dlq/severe/. - יוצגו קובצי JSON חדשים שנוצרו. לוחצים עליהם כדי לבדוק את התוכן. יוצגו הפרטים של
CustomerId = 99999והודעת השגיאה הספציפית של Spanner:NOT_FOUND: Parent row for row [99999,502,WebStore] in table Orders is missing. Row cannot be written." - אפשר לנסות שוב לתקן שגיאות ב-DLQ של העברה פעילה על ידי הפעלת תבנית Dataflow עם ההגדרה
runMode=retryDLQ.
5. טיפול בשגיאות ב-DLQ
צריך לטפל ידנית בשגיאות בספרייה severe/. בואו נתקן את הבעיה בנתונים וננסה לעבד מחדש את האירוע שנכשל.
א. תיקון הנתונים במקור
השגיאה התרחשה כי רשומת הלקוח של ההורה CustomerId = 99999 חסרה. עכשיו נכניס אותו למסד הנתונים של MySQL.
מתחברים שוב ל-MySQL באמצעות SSH:
gcloud compute ssh mysql-physical-1 --zone=$ZONE
מתחברים ל-MySQL באמצעות sudo mysql ומזינים את שורת ההורה החסרה לתוך shard1_db:
USE shard1_db;
INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LegacyRegion) VALUES
(99999, 'DLQ Parent Holder', 5000.00, 'NORTH_AMERICA');
EXIT;
מקלידים exit כדי לחזור ל-Cloud Shell.
ב. הרצת משימת Dataflow של retryDLQ
כדי לעבד מחדש אירועים מ-severe/ DLQ, מפעילים את אותה תבנית Dataflow אבל במצב retryDLQ. במצב הזה, המערכת קוראת נתונים ספציפיים מהנתיב deadLetterQueueDirectory/severe, מריצה אותם מחדש דרך ההמרות המותאמות אישית ומחילת אותם על Spanner.
מפעילים את העבודה במצב retryDLQ:
export JOB_NAME_RETRY="mysql-sharded-cdc-retry-$(date +%Y%m%d-%H%M%S)"
gcloud dataflow flex-template run $JOB_NAME_RETRY \
--project=$PROJECT_ID \
--region=$REGION \
--worker-machine-type=n2-highmem-8 \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Cloud_Datastream_to_Spanner" \
--parameters \
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
projectId="$PROJECT_ID",\
runMode="retryDLQ",\
deadLetterQueueDirectory="$DLQ_DIR_CDC",\
datastreamSourceType="mysql",\
transformationJarPath=$CUSTOM_JAR_PATH,\
transformationClassName="com.custom.CustomTransformationFetcher",\
schemaOverridesFilePath=$GCS_OVERRIDES_PATH,\
shardingContextFilePath=$GCS_LIVE_SHARDING_PATH
שינויים מרכזיים בפרמטרים של ניסיון חוזר
-
runMode="retryDLQ": מציין לתבנית לקרוא מהספרייהsevereDLQ. - הוסר
gcsPubSubSubscription: לא נדרש כי אנחנו לא קוראים מקטגוריית GCS של Datastream בזמן אמת.
מעקב אחרי תהליך הניסיון החוזר:
בדומה לצינור ה-CDC הראשי, retryDLQ הוא צינור סטרימינג שיימשך RUNNING עד לביטול ידני.
- עוברים לדף Dataflow Job עבור
$JOB_NAME_RETRY. - בחלונית מדדים, מחפשים את שני המונים האלה:
-
elementsReconsumedFromDeadLetterQueue: הערכה מתבצעת כשהקבצים עם השגיאות מאוחזרים. -
Successful events: הערך גדל כשהרשומה נכתבת ב-Spanner. - בודקים אם יש כשלים חוזרים בספרייה
severe/. - אחרי שהערך של 'אירועים מוצלחים' גדל במספר הפריטים שרציתם לנסות לשלוח שוב (1 במקרה הבדיקה שלנו), עוברים לשלב האימות הבא.
ג. אימות הנתונים שנשלחו מחדש
אחרי שהמערכת תנסה שוב לייבא את הרשומה שנכשלה (יכול להיות שיעבור זמן עד שהפעולה תצליח), בודקים ב-Spanner אם שורת הצאצא הועברה בהצלחה:
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT CustomerId, OrderId, OrderValue, OrderSource FROM Orders WHERE CustomerId = 99999 AND OrderId = 502"
עכשיו השורה אמורה להופיע:
CustomerId: 99999 OrderId: 502 OrderValue: 50 OrderSource: WebStore
כדאי גם לבדוק את התיקייה $DLQ_DIR_CDC/severe/ ב-GCS. הקבצים שעברו עיבוד היו אמורים לעבור או להימחק, מה שמצביע על עיבוד מחדש מוצלח.
11. הגדרת שכפול הפוך (Spanner ל-MySQL)
כדי לטפל בתרחישים שבהם יכול להיות שתצטרכו לבצע החזרה לאחור או לשמור על סנכרון של מסד הנתונים המקורי של MySQL עם Spanner לתקופת מעבר, אתם יכולים להגדיר שכפול הפוך.
בצינור הזה נעשה שימוש ב-Spanner Change Streams כדי לתעד שינויים בזמן אמת ב-Spanner. לאחר מכן, הוא משתמש ב-JAR של Custom Transformation כדי לבצע מיפוי הפוך של ההבדלים בסכימה, וב-JAR של Custom Sharding כדי לחשב בדיוק לאיזו מכונה וירטואלית פיזית של MySQL ולשבר לוגי צריך לכתוב את העדכון בחזרה.
1. יצירת שינוי בשידור חי ב-Spanner
קודם כול, צריך ליצור מקור לשינויים במסד הנתונים של Spanner כדי לעקוב אחרי שינויים בטבלאות Customers ו-Orders.
export CHANGE_STREAM_NAME="CustomersOrdersChangeStream"
gcloud spanner databases ddl update $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--ddl="CREATE CHANGE STREAM $CHANGE_STREAM_NAME FOR Customers, Orders"
מעכשיו, בזרם השינויים הזה יתועדו כל שינויי הנתונים בטבלאות שצוינו.
2. יצירת מסד נתונים של Spanner למטא-נתונים של Dataflow
Spanner to SourceDB תבנית Dataflow דורשת מסד נתונים נפרד של Spanner לאחסון מטא-נתונים לניהול הצריכה של זרם השינויים.
export SPANNER_METADATA_DB_NAME="migration-metadata-db"
gcloud spanner databases create $SPANNER_METADATA_DB_NAME \
--instance=$SPANNER_INSTANCE_NAME
3. הכנת הגדרת חיבור Cloud SQL ל-Dataflow
תבנית Dataflow צריכה קובץ JSON ב-Cloud Storage שמכיל את פרטי החיבור למסד הנתונים של Cloud SQL.
יוצרים קובץ מקומי בשם shard_config.json:
cat <<EOF > reverse-sharding.json
[
{
"logicalShardId": "shard0_db",
"host": "${MYSQL_IP_1}",
"port": "3306",
"user": "datastream_user",
"password": "complex_password_123",
"dbName": "shard0_db"
},
{
"logicalShardId": "shard1_db",
"host": "${MYSQL_IP_1}",
"port": "3306",
"user": "datastream_user",
"password": "complex_password_123",
"dbName": "shard1_db"
},
{
"logicalShardId": "shard2_db",
"host": "${MYSQL_IP_2}",
"port": "3306",
"user": "datastream_user",
"password": "complex_password_123",
"dbName": "shard2_db"
},
{
"logicalShardId": "shard3_db",
"host": "${MYSQL_IP_2}",
"port": "3306",
"user": "datastream_user",
"password": "complex_password_123",
"dbName": "shard3_db"
}
]
EOF
מעלים את הקובץ הזה לקטגוריה של GCS:
export GCS_REVERSE_SHARDING_PATH="gs://${BUCKET_NAME}/config/reverse-sharding.json"
gcloud storage cp reverse-sharding.json $GCS_REVERSE_SHARDING_PATH
4. הפעלת משימת Dataflow של שכפול הפוך
מפעילים את משימת Dataflow באמצעות Spanner_to_SourceDb תבנית Flex.
export JOB_NAME_REVERSE="spanner-sharded-reverse-to-mysql-$(date +%Y%m%d-%H%M%S)"
export DLQ_DIR_REVERSE="gs://${BUCKET_NAME}/reverse-replication"
gcloud dataflow flex-template run $JOB_NAME_REVERSE \
--project=$PROJECT_ID \
--region=$REGION \
--worker-machine-type=n2-highmem-8 \
--max-workers=2 \
--num-workers=1 \
--additional-experiments=use_runner_v2 \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Spanner_to_SourceDb" \
--parameters \
changeStreamName="$CHANGE_STREAM_NAME",\
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
spannerProjectId="$PROJECT_ID",\
metadataInstance="$SPANNER_INSTANCE_NAME",\
metadataDatabase="$SPANNER_METADATA_DB_NAME",\
sourceShardsFilePath="$GCS_REVERSE_SHARDING_PATH",\
transformationJarPath=$CUSTOM_JAR_PATH,\
transformationClassName="com.custom.CustomTransformationFetcher",\
shardingCustomJarPath=$CUSTOM_JAR_PATH,\
shardingCustomClassName="com.custom.CustomShardIdFetcher",\
schemaOverridesFilePath=$GCS_OVERRIDES_PATH,\
deadLetterQueueDirectory=$DLQ_DIR_REVERSE
פרמטרים מרכזיים
-
changeStreamName: השם של זרם השינויים ב-Spanner שממנו רוצים לקרוא. -
metadataInstance, metadataDatabase: מופע או מסד נתונים של Spanner לאחסון המטא-נתונים שמשמשים את המחבר לשליטה בצריכת הנתונים של Change Stream API. -
sourceShardsFilePath: הנתיב ב-GCS אלshard_config.json. -
filtrationMode: מציין איך להשמיט רשומות מסוימות על סמך קריטריון. ברירת המחדל היאforward_migration(סינון רשומות שנכתבו באמצעות צינור ההעברה קדימה) -
shardingCustomJarPath: הנתיב ב-GCS לקובץ ה-JAR של Java שקומפל שיצרנו קודם. -
shardingCustomClassName: שם המחלקה המוגדר במלואו (com.custom.CustomShardIdFetcher) שמבצעת את המתמטיקה המודולרית המותאמת אישית%4כדי לקבוע באופן דינמי לאיזה רסיס לוגי צריך להעביר את הרשומה.
הערה לגבי הרשת: העובדים של Dataflow יתחברו למופע Cloud SQL באמצעות כתובת ה-IP הציבורית שצוינה ב-shard_config.json. החיבור הזה מותר בגלל הרשומה 0.0.0.0/0 ברשתות המורשות של מופע Cloud SQL.
עוקבים אחרי הפעלת המשימה ב-Dataflow Jobs Console.
5. הוספת נתוני Spanner והפעלת כשלים מכוונים
מחכים שמשימת Dataflow תעבור למצב Running (התהליך הזה יכול להימשך כ-5 דקות). לאחר מכן, נריץ חבילה מלאה של שאילתות (INSERT, UPDATE, DELETE) ישירות ב-Spanner, יחד עם כשל מכוון כדי לבדוק את תור ה-DLQ ההפוך.
מריצים את הפקודה הבאה ב-Cloud Shell:
# All these operations are done on rows mapping to shard0_db for convenience
# Valid INSERT: Insert parent row in Customers
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LoyaltyTier) VALUES (88, 'Reverse Tester', 5000, 'GOLD_TIER')"
# 1. Valid INSERT (Orders): 'WebStore' transformed to 'WebStore_v1'
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="INSERT INTO Orders (CustomerId, OrderId, OrderValue, OrderSource) VALUES (88, 9001, 150.00, 'WebStore')"
# 2. Valid UPDATE (Orders)
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="UPDATE Orders SET OrderValue = 200.00 WHERE CustomerId = 16 AND OrderId = 105 AND OrderSource = 'Partner'"
# 3. Valid DELETE (Orders)
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="DELETE FROM Orders WHERE CustomerId = 12 AND OrderId = 104 AND OrderSource = 'WebStore'"
# 4. INVALID Insert- DLQ Test: CreditLimit=500 will fail check constraint of >1000 at source
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LoyaltyTier) VALUES (44, 'DLQ Test Customer', 500, 'GOLD_TIER')"
6. אימות נתונים של שכפול הפוך ובדיקת תור ההודעות המתות
נבדוק שקובץ ה-JAR של הפיצול המותאם אישית העביר בהצלחה את CustomerId 88 אל shard0_db במכונה הווירטואלית הפיזית הראשונה, ושהקובץ JAR של ההמרה המותאמת אישית הסיר בהצלחה את "_TIER" מהאזור.
א. בודקים את הרשומה התקינה ב-MySQL:
מתחברים באמצעות SSH אל הרסיס הפיזי הראשון:
gcloud compute ssh mysql-physical-1 --zone=$ZONE
מתחברים ל-MySQL ומריצים את השאילתה shard0_db:
sudo mysql
USE shard0_db;
-- 1. Verify INSERT: Row migrated with transformed LegacyOrderSystem
SELECT CustomerId, OrderId, OrderValue, LegacyOrderSystem
FROM Orders
WHERE CustomerId = 88 AND OrderId = 9001;
-- 2. Verify UPDATE: The OrderValue should now be updated to 200.00.
SELECT CustomerId, OrderId, OrderValue, LegacyOrderSystem
FROM Orders
WHERE CustomerId = 16 AND OrderId = 105;
-- 3. Verify DELETE: Returns 0 rows, confirming the order was successfully deleted from MySQL.
SELECT CustomerId, OrderId
FROM Orders
WHERE CustomerId = 12 AND OrderId = 104;
-- 4. Verify failed replication - this should be in DLQ as CreditLimit < 1000 and will fail stricter check constraint at source
SELECT CustomerId, CustomerName, CreditLimit, LegacyRegion
FROM Customers
WHERE CustomerId = 44;
EXIT;
הפלט הצפוי ב-Cloud SQL צריך לשקף את השינויים שבוצעו ב-Spanner.
+------------+---------+------------+-------------------+ | CustomerId | OrderId | OrderValue | LegacyOrderSystem | +------------+---------+------------+-------------------+ | 88 | 9001 | 150.00 | Webstore_v1 | +------------+---------+------------+-------------------+ +------------+---------+------------+-------------------+ | CustomerId | OrderId | OrderValue | LegacyOrderSystem | +------------+---------+------------+-------------------+ | 16 | 105 | 200.00 | Partner_v1 | +------------+---------+------------+-------------------+ Empty set (0.00 sec) Empty set (0.00 sec)
סוג
exit
כדי לחזור ל-Cloud Shell.
הפעולה הזו מאשרת שצינור עיבוד הנתונים של השכפול ההפוך פועל ומסנכרן שינויים מ-Spanner בחזרה ל-Cloud SQL.
ב. בדיקת הכשל המכוון בתור להודעות שלא ניתן למסור (DLQ)
מכיוון שלרשומה החדשה Customers יש CreditLimit של 500 (שמפר את אילוץ הבדיקה הקפדני > 1000 שהגדרנו במסד הנתונים של MySQL), Dataflow זיהה את השגיאה בצורה בטוחה.
- עוברים אל Cloud Storage במסוף Google Cloud.
- עוברים אל ה-bucket ופותחים את התיקייה
dlq/severe/. - פותחים את קובץ ה-JSON כדי לראות את רשומת
Customersשנדחתה ואת השגיאה המדויקת של הפרת אילוץ הבדיקה. - אפשר לנסות שוב לתקן שגיאות ב-DLQ של שכפול הפוך על ידי הפעלת תבנית Dataflow עם ההגדרה
runMode=retryDLQ.
12. מחיקת משאבי הבדיקה
כדי להימנע מחיובים נוספים בחשבון Google Cloud, מוחקים את המשאבים שנוצרו במהלך ה-codelab הזה.
הגדרת משתני סביבה (אם צריך)
אם הסשן שלכם ב-Cloud Shell הסתיים בגלל חוסר פעילות או שפתחתם טרמינל חדש, תצטרכו לייצא מחדש את משתני הסביבה לפני שתריצו את פקודות הניקוי.
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1" # Or your preferred region
export ZONE="us-central1-a" # Or a zone within your selected region
export SPANNER_INSTANCE_NAME="target-spanner-instance"
export SPANNER_DATABASE_NAME="sharded-target-db"
export SPANNER_CONFIG="regional-${REGION}"
export BUCKET_NAME="migration-${PROJECT_ID}-bucket"
export MYSQL_IP_1=$(gcloud compute instances describe mysql-physical-1 --zone=$ZONE --format='get(networkInterfaces[0].accessConfigs[0].natIP)')
export MYSQL_IP_2=$(gcloud compute instances describe mysql-physical-2 --zone=$ZONE --format='get(networkInterfaces[0].accessConfigs[0].natIP)')
export SQL_CP_NAME_1="mysql-src-cp-1"
export SQL_CP_NAME_2="mysql-src-cp-2"
export GCS_CP_NAME="gcs-dest-cp"
export STREAM_NAME_1="mysql-to-spanner-stream-1"
export GCS_STREAM_PATH_1="data/${STREAM_NAME_1}"
export STREAM_NAME_2="mysql-to-spanner-stream-2"
export GCS_STREAM_PATH_2="data/${STREAM_NAME_2}"
export PUBSUB_TOPIC="datastream-gcs-updates"
export PUBSUB_SUBSCRIPTION="datastream-gcs-sub"
export CUSTOM_JAR_PATH="gs://${BUCKET_NAME}/custom-logic/spanner-custom-shard-1.0.jar"
export OVERRIDES_FILE="spanner_overrides.json"
export GCS_OVERRIDES_PATH="gs://${BUCKET_NAME}/config/${OVERRIDES_FILE}"
export GCS_SHARDING_PATH="gs://${BUCKET_NAME}/config/sharding.json"
export OUTPUT_DIR="gs://${BUCKET_NAME}/bulk-migration"
export GCS_LIVE_SHARDING_PATH="gs://${BUCKET_NAME}/config/live-sharding.json"
export DLQ_DIR_CDC="gs://${BUCKET_NAME}/live-migration"
export CHANGE_STREAM_NAME="CustomersOrdersChangeStream"
export SPANNER_METADATA_DB_NAME="migration-metadata-db"
export GCS_REVERSE_SHARDING_PATH="gs://${BUCKET_NAME}/config/reverse-sharding.json"
export DLQ_DIR_REVERSE="gs://${BUCKET_NAME}/reverse-replication"
הפסקת משימות סטרימינג של Dataflow
מציגים את רשימת המשימות כדי למצוא את מזהי המשימות של משימות ה-Dataflow שפועלות. מייצאים את JOB_ID_CDC ואת JOB_ID_REVERSE בהתאם.
gcloud dataflow jobs list --region=$REGION --filter="state=Running"
export JOB_ID_CDC=<PASTE_JOB_ID_HERE>
export JOB_ID_CDC_RETRY=<PASTE_JOB_ID_HERE>
export JOB_ID_REVERSE=<PASTE_JOB_ID_HERE>
מבטלים את המשימה Datastream to Spanner (העברה פעילה) ואת המשימה של הניסיון החוזר:
gcloud dataflow jobs cancel $JOB_ID_CDC --region=$REGION --project=$PROJECT_ID
gcloud dataflow jobs cancel $JOB_ID_CDC_RETRY --region=$REGION --project=$PROJECT_ID
מבטלים את המשימה Spanner to Cloud SQL (שכפול הפוך):
gcloud dataflow jobs cancel $JOB_ID_REVERSE --region=$REGION --project=$PROJECT_ID
מחיקה של משאבים ב-Datastream
עצירה ומחיקה של השידור:
gcloud datastream streams update $STREAM_NAME_1 \
--location=$REGION --state=PAUSED --project=$PROJECT_ID
# Wait a moment for the stream to pause
gcloud datastream streams delete $STREAM_NAME_1 \
--location=$REGION --project=$PROJECT_ID --quiet
gcloud datastream streams update $STREAM_NAME_2 \
--location=$REGION --state=PAUSED --project=$PROJECT_ID
# Wait a moment for the stream to pause
gcloud datastream streams delete $STREAM_NAME_2 \
--location=$REGION --project=$PROJECT_ID --quiet
# Delete Connection Profiles
gcloud datastream connection-profiles delete $SQL_CP_NAME_1 \
--location=$REGION --project=$PROJECT_ID --quiet
gcloud datastream connection-profiles delete $SQL_CP_NAME_2 \
--location=$REGION --project=$PROJECT_ID --quiet
gcloud datastream connection-profiles delete $GCS_CP_NAME \
--location=$REGION --project=$PROJECT_ID --quiet
מחיקת המכונות הווירטואליות של MySQL (מקור) (Compute Engine)
מוחקים את שתי המכונות ב-Compute Engine שדימו את הרסיסים הפיזיים של MySQL בשרת המקומי.
gcloud compute instances delete mysql-physical-1 mysql-physical-2 --zone=$ZONE --quiet
מחיקת כללים של חומת אש
מסירים את כללי חומת האש ברשת שנוצרו כדי לאפשר גישת SSH וקישוריות של Datastream למכונות הווירטואליות. (הערה: אם השתמשתם בשמות שונים לכללי חומת האש בשלב מוקדם יותר ב-codelab, צריך לשנות אותם כאן).
gcloud compute firewall-rules delete allow-ssh-iap --quiet
gcloud compute firewall-rules delete allow-mysql-datastream --quiet
מחיקת משאבי Pub/Sub
מחיקת מינוי:
gcloud pubsub subscriptions delete $PUBSUB_SUBSCRIPTION \
--project=$PROJECT_ID --quiet
מחיקת נושא:
gcloud pubsub topics delete $PUBSUB_TOPIC \
--project=$PROJECT_ID --quiet
מחיקה של מופע Cloud Spanner
מוחקים את מופע Cloud Spanner (פעולה זו מוחקת אוטומטית גם את מסד הנתונים sharded-target-db וגם את מסד הנתונים migration-metadata-db בתוכו).
gcloud spanner instances delete $SPANNER_INSTANCE_NAME \
--project=$PROJECT_ID --quiet
מחיקה של קטגוריית GCS ותוכן
לבסוף, מוחקים את הקטגוריה של Cloud Storage שכוללת את קובצי Datastream, את ההגדרות של Dataflow ואת תורי ההודעות המתות. הפקודה rm -r מוחקת באופן רקורסיבי את הקטגוריה ואת כל התוכן שלה.
gcloud storage rm --recursive gs://${BUCKET_NAME}
מחיקת קבצים מקומיים ב-Cloud Shell
כדי למחוק את הקבצים והספריות המקומיים שנוצרו ב-Cloud Shell במהלך שיעור ה-Codelab הזה, מריצים את הפקודות הבאות:
# Remove the JSON configuration files
rm -f sharding.json live-sharding.json reverse-sharding.json spanner_overrides.json
# Remove the cloned Google Cloud DataflowTemplates repository
rm -rf DataflowTemplates