
1. Avant de commencer
Cet atelier de programmation vous guide dans la migration d'une base de données MySQL fragmentée sur site vers une base de données Cloud Spanner avec le dialecte GoogleSQL. Vous utiliserez les services Google Cloud, y compris Spanner Migration Tool (SMT), Dataflow, Datastream, Pub/Sub et Google Cloud Storage.
Vous y découvrirez :
- Qu'est-ce qu'un environnement partitionné et comment le configurer ?
- Découvrez comment utiliser l'interface utilisateur Web de l'outil de migration Spanner (SMT) pour convertir un schéma MySQL en un schéma compatible avec Spanner et effectuer des modifications avancées du schéma.
- Découvrez comment effectuer la migration de données en masse d'une instance MySQL partitionnée vers Cloud Spanner à l'aide de Dataflow.
- Découvrez comment configurer la réplication continue (CDC) d'une instance MySQL partitionnée vers Cloud Spanner à l'aide de Datastream et Dataflow.
- Configurer la réplication inversée de Spanner vers les instances MySQL segmentées
- Découvrez comment utiliser les transformations personnalisées pour remplir des colonnes supplémentaires lors des migrations groupées, à chaud et inversées.
- Configurer les transformations de partitionnement à l'aide de clés primaires
Ce que cet atelier de programmation ne couvre PAS :
- Mise en réseau personnalisée avancée.
- Créer des modèles Dataflow personnalisés de toutes pièces
- Réglage des performances de la migration.
- Migration d'application : cet atelier de programmation se concentre sur la couche de base de données (schéma et données). Il ne couvre pas le processus opérationnel de redéploiement ou de migration de vos services d'application.
Prérequis
- Un projet Google Cloud avec facturation activée.
- Des autorisations IAM suffisantes pour activer les API et créer/gérer les ressources Spanner, Dataflow, Datastream et GCS. Bien que le rôle
Ownerdu projet soit le plus simple pour un atelier de programmation, des rôles plus spécifiques seront abordés dans la section "Configuration de l'environnement". - Nous allons provisionner une petite VM Compute Engine lors de la phase de configuration pour simuler notre serveur sur site. Assurez-vous que le quota de votre projet permet la création de VM.
- Un navigateur Web, tel que Google Chrome.
- Connaissances de base de la console Google Cloud et des outils de ligne de commande tels que
gcloud. - Accès à un environnement shell. Nous vous recommandons d'utiliser Cloud Shell, car il inclut
gcloud.
Pour en savoir plus sur la configuration ci-dessus, consultez la section Configuration de l'environnement.
2. Comprendre le processus de migration
La migration d'une base de données partitionnée implique de regrouper plusieurs instances MySQL physiques et logiques dans une seule base de données Spanner à scaling horizontal. Cette section décrit l'architecture et les principaux outils utilisés pour la migration.
Architecture du flux de migration
Le processus de migration comporte les étapes suivantes :
1. Conversion de schéma :
- Objectif : convertir le schéma de la base de données source en un schéma Cloud Spanner compatible.
- Outil : outil de migration Spanner (SMT, Spanner Migration Tool)
- Processus : SMT analyse le schéma de la base de données source et génère le langage de définition de données (DDL) Spanner équivalent. Dans l'instance Spanner cible, une base de données est créée et le DDL est ensuite appliqué automatiquement.
2. Migration groupée des données :
- Objectif : effectuer un chargement complet initial des données existantes de la base de données source vers les tables Spanner provisionnées.
- Outil : Dataflow, à l'aide du modèle
Sourcedb to Spannerfourni par Google. - Processus : ce job Dataflow lit toutes les données des tables sources spécifiées et les écrit dans les tables Spanner correspondantes. Cette opération est effectuée après la création du schéma Spanner.
3. Migration à chaud (CDC) :
- Objectif : capturer et appliquer les modifications en cours de la base de données source à Cloud Spanner en temps quasi réel, en minimisant les temps d'arrêt pendant la migration.
- Outils :
- Datastream : capture les modifications (insertions, mises à jour, suppressions) de la base de données source et les écrit dans Cloud Storage (GCS).
- Dataflow : utilise le modèle
Datastream to Spannerpour lire les événements de modification depuis GCS et les appliquer à Cloud Spanner.
4. Réplication inverse :
- Objectif : répliquer les modifications de données de Cloud Spanner vers la base de données source. Cela peut être utile pour les stratégies de secours, les migrations par étapes ou le maintien d'une réplique dans la source pour des cas d'utilisation spécifiques.
- Outil : Dataflow, à l'aide du modèle
Spanner to SourceDb. - Processus : cette tâche utilise les flux de modification Spanner pour capturer les modifications apportées à Spanner et les réécrire dans l'instance de base de données source.
Le schéma suivant illustre les composants et le flux de données :

Terminologie clé :
- Partition physique : serveur ou instance de calcul sous-jacents hébergeant la base de données (dans notre cas, la VM GCE sur site simulée).
- Partition logique : schéma de base de données individuel au sein d'un serveur physique.
- VM Compute Engine (GCE) : machine virtuelle hébergée sur l'infrastructure Google Cloud. Dans cet atelier de programmation, nous utilisons une VM GCE pour simuler un serveur bare metal autonome "sur site" hébergeant notre base de données MySQL source.
- Outil de migration Spanner (SMT) : outil utilisé pour évaluer les schémas MySQL, suggérer des schémas Spanner équivalents et générer le langage de définition de données (LDD) Spanner.
- Langage de définition de données (LDD) : instructions utilisées pour définir et modifier la structure de la base de données, telles que les instructions
CREATE TABLE. SMT génère le LDD Spanner en fonction du schéma Cloud SQL. - Dataflow : service de traitement de données sans serveur et entièrement géré. Dans cet atelier de programmation, il est utilisé pour exécuter des modèles fournis par Google pour le transfert de données en masse, l'application des modifications Datastream et la réplication inversée.
- Datastream : service de capture et de réplication de données modifiées (CDC) sans serveur. Dans cet atelier de programmation, il est utilisé pour diffuser les modifications de l'instance MySQL hébergée localement dans Cloud Storage.
- Flux de modifications Spanner : fonctionnalité Spanner qui permet de diffuser en temps réel les modifications apportées aux données (insertions, mises à jour, suppressions). Elle est utilisée comme source pour la réplication inversée.
- Pub/Sub : service de messagerie utilisé pour dissocier les services qui produisent des événements de ceux qui les traitent. Dans cet atelier de programmation, il déclenche Dataflow pour traiter les mises à jour chaque fois que Datastream importe de nouveaux fichiers de modifications dans Cloud Storage.
3. Configuration de l'environnement
Avant de pouvoir commencer la migration, vous devez configurer votre projet Google Cloud et activer les services nécessaires.
1. Sélectionner ou créer un projet Google Cloud
Pour utiliser les services de cet atelier de programmation, vous devez disposer d'un projet Google Cloud pour lequel la facturation est activée.
- Dans la console Google Cloud, accédez à la page de sélection du projet : Accéder au sélecteur de projet
- Sélectionnez ou créez un projet Google Cloud.
- Assurez-vous que la facturation est activée pour votre projet. Découvrez comment vérifier que la facturation est activée pour votre projet.
2. Ouvrir Cloud Shell
Cloud Shell est un environnement de ligne de commande exécuté dans Google Cloud. Il est préchargé avec la CLI gcloud et d'autres outils dont vous avez besoin.
- Cliquez sur le bouton Activer Cloud Shell en haut à droite de la console Google Cloud.
- Une session Cloud Shell s'ouvre dans un nouveau cadre en bas de la console et affiche une invite de ligne de commande.

3. Définir les variables de projet et d'environnement
Dans Cloud Shell, configurez des variables d'environnement pour l'ID de votre projet et la région que vous utiliserez.
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1" # Or your preferred region
export ZONE="us-central1-a" # Or a zone within your selected region
gcloud config set project $PROJECT_ID
gcloud config set compute/region $REGION
gcloud config set compute/zone $ZONE
echo "Project ID: $PROJECT_ID"
echo "Region: $REGION"
echo "Zone: $ZONE"
4. Activer les API Google Cloud requises
Activez les API nécessaires pour Cloud Spanner, Dataflow, Datastream et d'autres services associés.
gcloud services enable \
spanner.googleapis.com \
dataflow.googleapis.com \
datastream.googleapis.com \
pubsub.googleapis.com \
storage.googleapis.com \
compute.googleapis.com \
sqladmin.googleapis.com \
servicenetworking.googleapis.com \
cloudresourcemanager.googleapis.com
L'exécution de cette commande peut prendre quelques minutes.
4. Configurer la base de données MySQL source
Dans cette section, nous allons simuler une architecture MySQL fragmentée sur site en provisionnant deux machines virtuelles Compute Engine (nos deux "fragments physiques"). Nous allons ensuite installer MySQL sur les deux et créer deux bases de données (nos "shards logiques") sur chaque VM.
1. Créer les VM Compute Engine (partitions physiques)
Exécutez les commandes suivantes dans Cloud Shell pour créer deux VM avec Ubuntu. Nous leur attribuerons des tags réseau pour autoriser le trafic MySQL entrant ultérieurement.
# Create Physical Shard 1
gcloud compute instances create mysql-physical-1 \
--zone=$ZONE \
--machine-type=e2-small \
--image-family=ubuntu-2204-lts \
--image-project=ubuntu-os-cloud \
--tags=mysql-server
# Create Physical Shard 2
gcloud compute instances create mysql-physical-2 \
--zone=$ZONE \
--machine-type=e2-small \
--image-family=ubuntu-2204-lts \
--image-project=ubuntu-os-cloud \
--tags=mysql-server
2. Configurer les règles de pare-feu
Pour autoriser un accès SSH sécurisé sans exposition publique et activer la connectivité Datastream :
Créez une règle de pare-feu pour SSH via IAP :
Cette règle permet à Identity-Aware Proxy d'accéder à vos VM sur le port SSH (22).
gcloud compute firewall-rules create allow-ssh-iap \
--direction=INGRESS \
--priority=1000 \
--network=default \
--action=ALLOW \
--rules=tcp:22 \
--source-ranges=35.235.240.0/20 \
--target-tags=mysql-server
Créez une règle de pare-feu pour Datastream (port MySQL) :
Datastream doit pouvoir accéder à ces VM sur le port MySQL standard (3306).
gcloud compute firewall-rules create allow-mysql-datastream \
--direction=INGRESS \
--priority=1000 \
--network=default \
--action=ALLOW \
--rules=tcp:3306 \
--source-ranges=0.0.0.0/0 \
--target-tags=mysql-server
3. Installer et configurer MySQL sur le shard physique 1
Connectez-vous en SSH à votre première VM pour installer MySQL et configurer la journalisation binaire (requise par Datastream pour la réplication en direct).
- Connectez-vous en SSH à la première VM :
gcloud compute ssh mysql-physical-1 --zone=$ZONE --tunnel-through-iap
- Installez MySQL :
sudo apt-get update
sudo apt-get install mysql-server-8.0 -y
# Verify the installation and version
sudo mysql --version
- Configurez le fichier
mysqld.cnfpour activer la journalisation binaire et autoriser les connexions externes :
sudo sed -i 's/bind-address.*/bind-address = 0.0.0.0/' /etc/mysql/mysql.conf.d/mysqld.cnf
echo -e "[mysqld]\nserver-id=1\nlog_bin=/var/log/mysql/mysql-bin.log\nbinlog_format=ROW" | sudo tee -a /etc/mysql/mysql.conf.d/mysqld.cnf
- Redémarrez MySQL pour appliquer les modifications :
sudo systemctl restart mysql
4. Créer des partitions logiques, insérer des données et créer un utilisateur Datastream (partition 1)
Toujours connecté en SSH à mysql-physical-1, connectez-vous à l'invite MySQL :
sudo mysql
Exécutez les commandes SQL suivantes. Ce script crée deux fragments logiques distincts (shard0_db et shard1_db), configure le même schéma dans les deux, insère des données identifiables de manière unique dans chacun (pour illustrer le partitionnement) et crée l'utilisateur de réplication pour Datastream.
Exécutez les commandes SQL suivantes pour créer vos deux premiers shards logiques, une table et l'utilisateur de réplication pour Datastream :
CREATE DATABASE shard0_db;
CREATE DATABASE shard1_db;
USE shard0_db;
CREATE TABLE Customers (
CustomerId INT NOT NULL,
CustomerName VARCHAR(255),
CreditLimit DECIMAL(10, 2) NOT NULL,
LegacyRegion VARCHAR(50), -- Renamed to LoyaltyTier in Spanner
PRIMARY KEY (CustomerId),
CONSTRAINT CHK_CreditLimit CHECK (CreditLimit > 1000) -- Relaxed in Spanner to > 0
);
CREATE TABLE Orders (
CustomerId INT NOT NULL, -- Logically references Customers.CustomerId in Spanner
OrderId INT NOT NULL,
OrderValue DECIMAL(10, 2),
LegacyOrderSystem VARCHAR(50), -- Extra column in Source, to be dropped in Spanner
PRIMARY KEY (CustomerId, OrderId) -- Spanner PK will have one additional column in PK
);
INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LegacyRegion) VALUES
(4, 'David E.', 2000.00, 'EAST'),
(8, 'Eleanor F.', 8100.00, 'WEST'),
(12, 'Frank G.', 12000.00, 'NORTH'),
(16, 'Grace H.', 6500.00, 'SOUTH');
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem) VALUES
(4, 101, 150.00, 'WebStore_v1'),
(4, 102, 25.50, 'InStore_POS'),
(8, 103, 75.00, 'MobileApp_Legacy'),
(12, 104, 3000.00, 'WebStore_v1'),
(16, 105, 120.00, 'Partner_API');
USE shard1_db;
CREATE TABLE Customers (
CustomerId INT NOT NULL,
CustomerName VARCHAR(255),
CreditLimit DECIMAL(10, 2) NOT NULL,
LegacyRegion VARCHAR(50), -- Renamed to LoyaltyTier in Spanner
PRIMARY KEY (CustomerId),
CONSTRAINT CHK_CreditLimit CHECK (CreditLimit > 1000) -- Relaxed in Spanner to > 0
);
CREATE TABLE Orders (
CustomerId INT NOT NULL, -- Logically references Customers.CustomerId in Spanner
OrderId INT NOT NULL,
OrderValue DECIMAL(10, 2),
LegacyOrderSystem VARCHAR(50), -- Extra column in Source, to be dropped in Spanner
PRIMARY KEY (CustomerId, OrderId) -- Spanner PK will have one additional column in PK
);
INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LegacyRegion) VALUES
(1, 'Agnes N.', 5100.00, 'NORTHEAST'),(5, 'Alice I.', 15000.00, 'EAST'),
(9, 'Bob J.', 7500.00, 'WEST'),
(13, 'Charlie K.', 2200.00, 'CENTRAL');
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem) VALUES
(1, 201, 50.00, 'MobileApp_Legacy'),
(5, 202, 1250.00, 'WebStore_v1'),
(5, 203, 80.00, 'Partner_API'),
(9, 204, 600.00, 'InStore_POS'),
(13, 205, 199.99, 'WebStore_v1');
-- Create Datastream Replication User
CREATE USER 'datastream_user'@'%' IDENTIFIED BY 'complex_password_123';
GRANT REPLICATION SLAVE, REPLICATION CLIENT, SELECT, INSERT, UPDATE, DELETE ON *.* TO 'datastream_user'@'%';
FLUSH PRIVILEGES;
Le fichier de vidage pour le schéma ci-dessus est disponible sur cette page. Il est important de créer l'utilisateur de réplication du flux de données séparément, car il n'est pas inclus dans le fichier de vidage.
5. Vérifier les données
Vérifiez rapidement que les données sont présentes :
SELECT 'Customers shard0_db' AS tbl, COUNT(*) FROM shard0_db.Customers
UNION ALL
SELECT 'Orders shard0_db', COUNT(*) FROM shard0_db.Orders
UNION ALL
SELECT 'Customers shard1_db', COUNT(*) FROM shard1_db.Customers
UNION ALL
SELECT 'Orders shard1_db', COUNT(*) FROM shard1_db.Orders;
EXIT;
Résultat attendu :
+---------------------+----------+ | tbl | COUNT(*) | +---------------------+----------+ | Customers shard0_db | 4 | | Orders shard0_db | 5 | | Customers shard1_db | 4 | | Orders shard1_db | 5 | +---------------------+----------+
Saisissez exit pour quitter la connexion à la VM du shard physique 1.
6. Répétez l'opération pour le fragment physique 2.
Répétez la procédure pour la deuxième VM, mais créez shard2_db et shard3_db, et modifiez server-id.
- Connectez-vous en SSH à la deuxième VM :
gcloud compute ssh mysql-physical-2 --zone=$ZONE --tunnel-through-iap
- Installez MySQL :
sudo apt-get update
sudo apt-get install mysql-server-8.0 -y
- Configurez le fichier
mysqld.cnfpour activer la journalisation binaire et autoriser les connexions externes [notez que l'ID du serveur doit être différent (par exemple, 2)].
sudo sed -i 's/bind-address.*/bind-address = 0.0.0.0/' /etc/mysql/mysql.conf.d/mysqld.cnf
echo -e "[mysqld]\nserver-id=2\nlog_bin=/var/log/mysql/mysql-bin.log\nbinlog_format=ROW" | sudo tee -a /etc/mysql/mysql.conf.d/mysqld.cnf
- Redémarrez MySQL pour appliquer les modifications :
sudo systemctl restart mysql
- Saisissez MySQL (
sudo mysql), puis exécutez une version légèrement modifiée du code SQL de l'étape 4 :
CREATE DATABASE shard2_db;
CREATE DATABASE shard3_db;
USE shard2_db;
CREATE TABLE Customers (
CustomerId INT NOT NULL,
CustomerName VARCHAR(255),
CreditLimit DECIMAL(10, 2) NOT NULL,
LegacyRegion VARCHAR(50), -- Renamed to LoyaltyTier in Spanner
PRIMARY KEY (CustomerId),
CONSTRAINT CHK_CreditLimit CHECK (CreditLimit > 1000) -- Relaxed in Spanner to > 0
);
CREATE TABLE Orders (
CustomerId INT NOT NULL, -- Logically references Customers.CustomerId in Spanner
OrderId INT NOT NULL,
OrderValue DECIMAL(10, 2),
LegacyOrderSystem VARCHAR(50), -- Extra column in Source, to be dropped in Spanner
PRIMARY KEY (CustomerId, OrderId) -- Spanner PK will have one additional column in PK
);
INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LegacyRegion) VALUES
(2, 'Brian K.', 2500.00, 'SOUTHWEST'),
(6, 'Diana L.', 1999.00, 'NORTH'),
(10, 'Edward M.', 11000.00, 'EAST'),
(14, 'Fiona N.', 3000.00, 'WEST');
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem) VALUES
(2, 301, 100.00, 'CallCenter_System'),
(6, 302, 99.00, 'MobileApp_Legacy'),
(10, 303, 1000.00, 'WebStore_v1'),
(10, 304, 2500.00, 'InStore_POS'),
(14, 305, 130.00, 'MobileApp_Legacy');
USE shard3_db;
CREATE TABLE Customers (
CustomerId INT NOT NULL,
CustomerName VARCHAR(255),
CreditLimit DECIMAL(10, 2) NOT NULL,
LegacyRegion VARCHAR(50), -- Renamed to LoyaltyTier in Spanner
PRIMARY KEY (CustomerId),
CONSTRAINT CHK_CreditLimit CHECK (CreditLimit > 1000) -- Relaxed in Spanner to > 0
);
CREATE TABLE Orders (
CustomerId INT NOT NULL, -- Logically references Customers.CustomerId in Spanner
OrderId INT NOT NULL,
OrderValue DECIMAL(10, 2),
LegacyOrderSystem VARCHAR(50), -- Extra column in Source, to be dropped in Spanner
PRIMARY KEY (CustomerId, OrderId) -- Spanner PK will have one additional column in PK
);
INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LegacyRegion) VALUES
(3, 'Cathy Z.', 6000.00, 'CENTRAL'),
(7, 'George O.', 18000.00, 'SOUTH'),
(11, 'Helen P.', 4000.00, 'NORTHEAST'),
(15, 'Ivy Q.', 9500.00, 'SOUTHWEST');
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem) VALUES
(3, 401, 600.00, 'InStore_POS'),
(7, 402, 1200.00, 'CallCenter_System'),
(11, 403, 350.00, 'MobileApp_Legacy'),
(15, 404, 800.00, 'WebStore_v1'),
(99, 999, 25.00, 'CallCenter_System'); -- Failure row during Bulk Migration due to violation of interleaving
-- Create Datastream Replication User
CREATE USER 'datastream_user'@'%' IDENTIFIED BY 'complex_password_123';
GRANT REPLICATION SLAVE, REPLICATION CLIENT, SELECT, INSERT, UPDATE, DELETE ON *.* TO 'datastream_user'@'%';
FLUSH PRIVILEGES;
-- Verify Data
SELECT 'Customers shard2_db' AS tbl, COUNT(*) FROM shard2_db.Customers
UNION ALL
SELECT 'Orders shard2_db', COUNT(*) FROM shard2_db.Orders
UNION ALL
SELECT 'Customers shard3_db', COUNT(*) FROM shard3_db.Customers
UNION ALL
SELECT 'Orders shard3_db', COUNT(*) FROM shard3_db.Orders;
EXIT;
Résultat attendu :
+---------------------+----------+ | tbl | COUNT(*) | +---------------------+----------+ | Customers shard2_db | 4 | | Orders shard2_db | 5 | | Customers shard3_db | 4 | | Orders shard3_db | 5 | +---------------------+----------+
Le fichier de vidage pour le schéma ci-dessus est disponible sur cette page. Il est important de créer l'utilisateur de réplication du flux de données séparément, car il n'est pas inclus dans le fichier de vidage.
Saisissez exit pour quitter la connexion à la VM.
5. Configurer Cloud Spanner
Vous allez maintenant configurer l'instance Cloud Spanner cible vers laquelle les données seront migrées.
1. Créer une instance Cloud Spanner
Créez une instance Cloud Spanner dans la même région que vos VM Compute Engine pour minimiser la latence. Cette commande crée une petite instance adaptée à cet atelier de programmation, en utilisant 100 unités de traitement.
export SPANNER_INSTANCE_NAME="target-spanner-instance"
export SPANNER_DATABASE_NAME="sharded-target-db"
export SPANNER_CONFIG="regional-${REGION}"
gcloud spanner instances create $SPANNER_INSTANCE_NAME \
--config=$SPANNER_CONFIG \
--description="Target Spanner Instance" \
--processing-units=100
La création d'une instance peut prendre une ou deux minutes.
6. Convertir le schéma à l'aide de l'outil de migration Spanner (SMT)
Utilisez l'interface utilisateur Web de l'outil de migration Spanner (SMT) pour vous connecter à l'un de nos fragments logiques (shard0_db), analyser son schéma et appliquer plusieurs modifications avancées avant de le convertir en Cloud Spanner.
1. Installer SMT
Nous allons exécuter l'interface utilisateur Web SMT directement à partir de Cloud Shell. Dans votre terminal Cloud Shell, téléchargez et extrayez la dernière version de SMT :
sudo apt-get update && sudo apt-get install google-cloud-cli-spanner-migration-tool
# Verify installation
gcloud alpha spanner migrate web --help
2. Se connecter à la base de données source
- Authentifier votre session
# Authenticate your Google Cloud account
gcloud auth login
# Set up Application Default Credentials (ADC) for SMT
gcloud auth application-default login
# Ensure your current project is set correctly
gcloud config set project $PROJECT_ID
(Remarque : Lorsque vous y êtes invité, suivez l'URL fournie pour autoriser votre compte et collez le code de validation dans le terminal.)
- Commencez par trouver l'adresse IP externe de votre premier shard physique en exécutant la commande suivante dans un nouvel onglet Cloud Shell :
gcloud compute instances describe mysql-physical-1 --zone=$ZONE --format='get(networkInterfaces[0].accessConfigs[0].natIP)'
- Imprimez les détails de l'instance Spanner cible à utiliser lors de la configuration de SMT.
echo "Project ID: $PROJECT_ID"
echo "Instance ID: $SPANNER_INSTANCE_NAME"
echo "Database Name: $SPANNER_DATABASE_NAME"
- Lancez l'UI Web :
gcloud alpha spanner migrate web --port=8080
- En haut à droite de la fenêtre Cloud Shell, cliquez sur l'icône Aperçu sur le Web (en forme d'œil), puis sélectionnez Prévisualiser sur le port 8080. L'interface utilisateur SMT s'ouvre dans un nouvel onglet du navigateur.

- Dans l'UI Web SMT, sélectionnez Connect to database (Se connecter à la base de données).
- Saisissez les informations de connexion :
- Type de base de données : MySQL
- Hôte : (collez l'adresse IP de l'étape 2)
- Port : 3306
- Utilisateur :
datastream_user - Mot de passe :
complex_password_123 - Nom de la base de données :
shard0_db
- Cliquez sur le bouton "Modifier" en haut à droite pour configurer la base de données Spanner.
- Saisissez les informations de votre instance Spanner cible :
- ID du projet : (collez l'ID du projet de l'étape 3)
- Instance Spanner : (collez l'ID d'instance de l'étape 3)
- Cliquez sur Test Connection (Tester la connexion).
- Une fois la vérification réussie, cliquez sur Connect (Connecter). SMT analysera la base de données source et présentera un schéma Spanner de référence.

3. Appliquer les modifications du schéma
Nous allons maintenant remodeler le schéma pour couvrir nos scénarios de migration complexes.
Dans l'éditeur de schéma de l'interface utilisateur SMT, effectuez les actions suivantes :
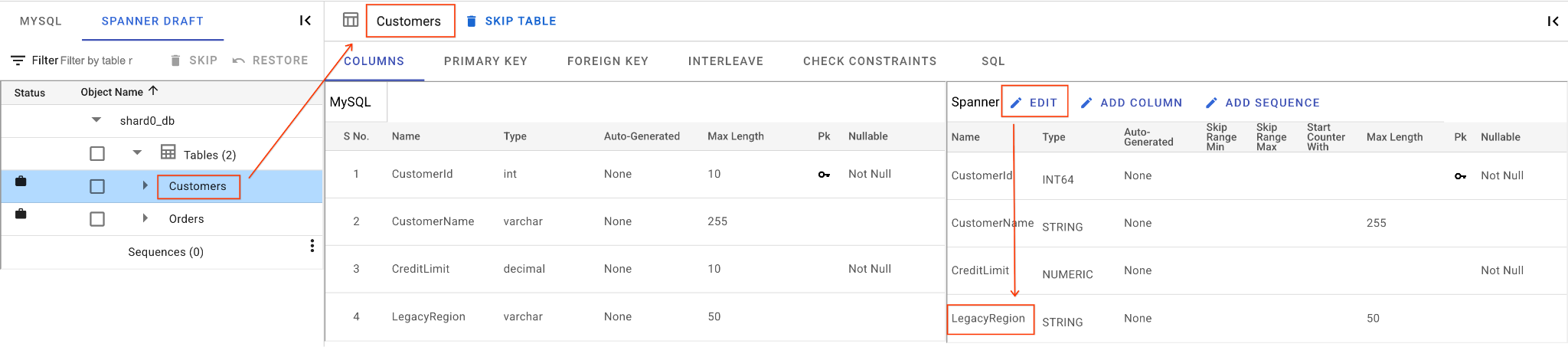
A. Renommez la colonne "LegacyRegion" :
- Cliquez sur le tableau
Customersdans le volet de navigation de gauche. L'onglet Colonnes s'ouvre par défaut. - Cliquez sur le bouton "Modifier" dans la section Spanner.
- Localisez la colonne
LegacyRegiondans la vue du schéma Spanner. - Modifiez le nom de la colonne Spanner en
LoyaltyTierdans la boîte de dialogue du nom de la colonne. - Cliquez sur Enregistrer et convertir.
B. Assouplissez la contrainte de vérification :
- Toujours dans le tableau
Customers, accédez à l'onglet Check Constraints (Contraintes de vérification). - Recherchez la contrainte
CHK_CreditLimit. Cliquez sur l'icône Modifier (en forme de crayon). - Remplacez la condition
CreditLimit > 1000parCreditLimit > 0. (Cela entraînera intentionnellement l'échec de la migration inverse des lignes avec des limites de crédit inférieures et leur placement dans la DLQ.)

C. Supprimez la colonne "LegacyOrderSystem" :
- Cliquez sur le tableau
Orders. L'onglet Colonnes s'ouvre par défaut. - Cliquez sur le bouton "Modifier" dans la section Spanner.
- Localisez la colonne
LegacyOrderSystemdans la vue du schéma Spanner. - Cliquez sur l'icône du menu à trois points à côté, puis sélectionnez Supprimer la colonne.
- Cliquez sur Enregistrer et convertir.

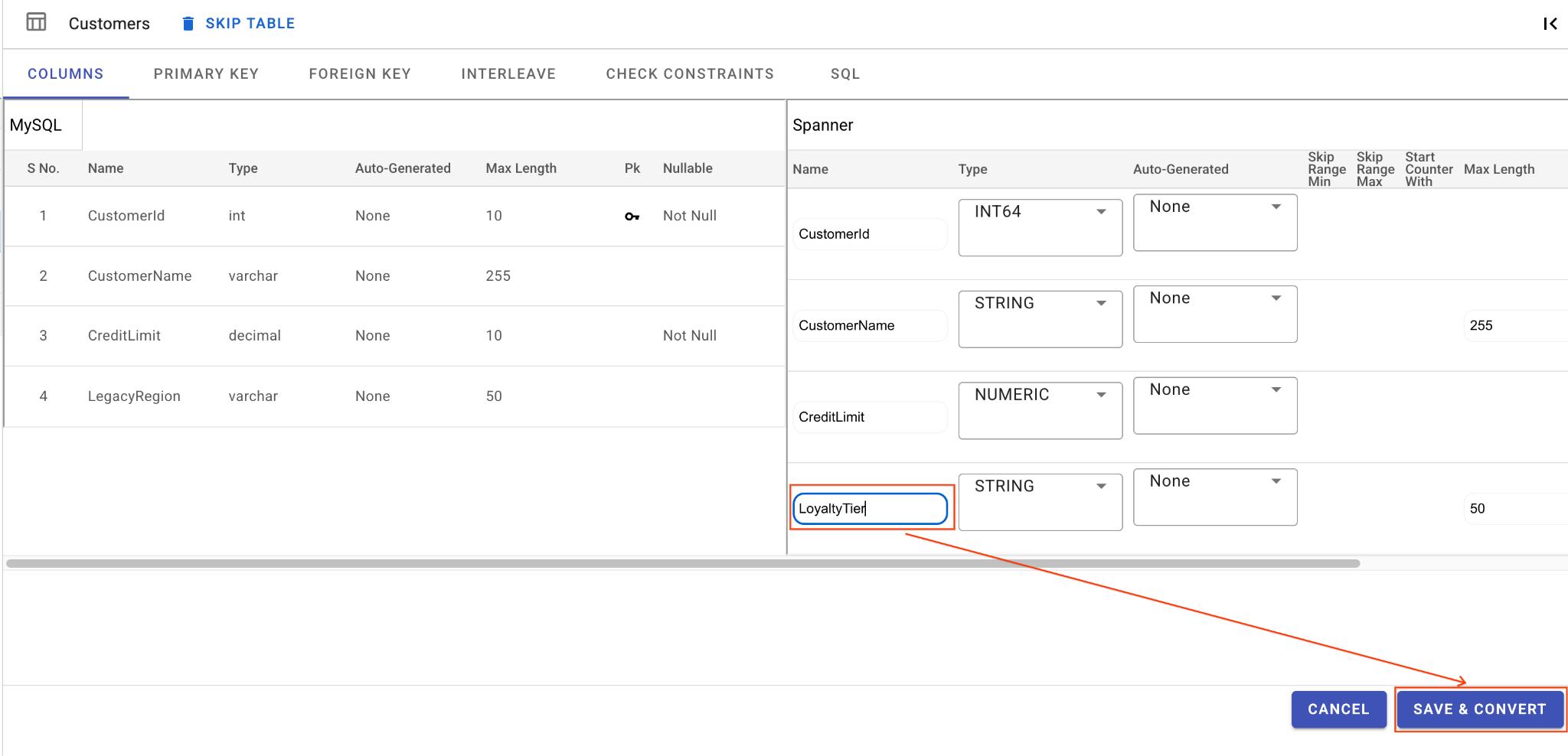
D. Ajoutez la colonne "OrderSource" et définissez-la comme clé primaire :
- Toujours dans le tableau
Orders, cliquez sur Ajouter une colonne. Nommez-leOrderSourceet définissez le type surSTRINGavec une longueur de50, sans génération automatique, et définissezIsNullablesurNo. - Accédez à l'onglet Clé primaire.
- Cliquez sur Modifier, puis sélectionnez
OrderSourcedans le menu déroulant "Nom de la colonne". - Cliquez sur Ajouter une colonne, puis sur Enregistrer et convertir.

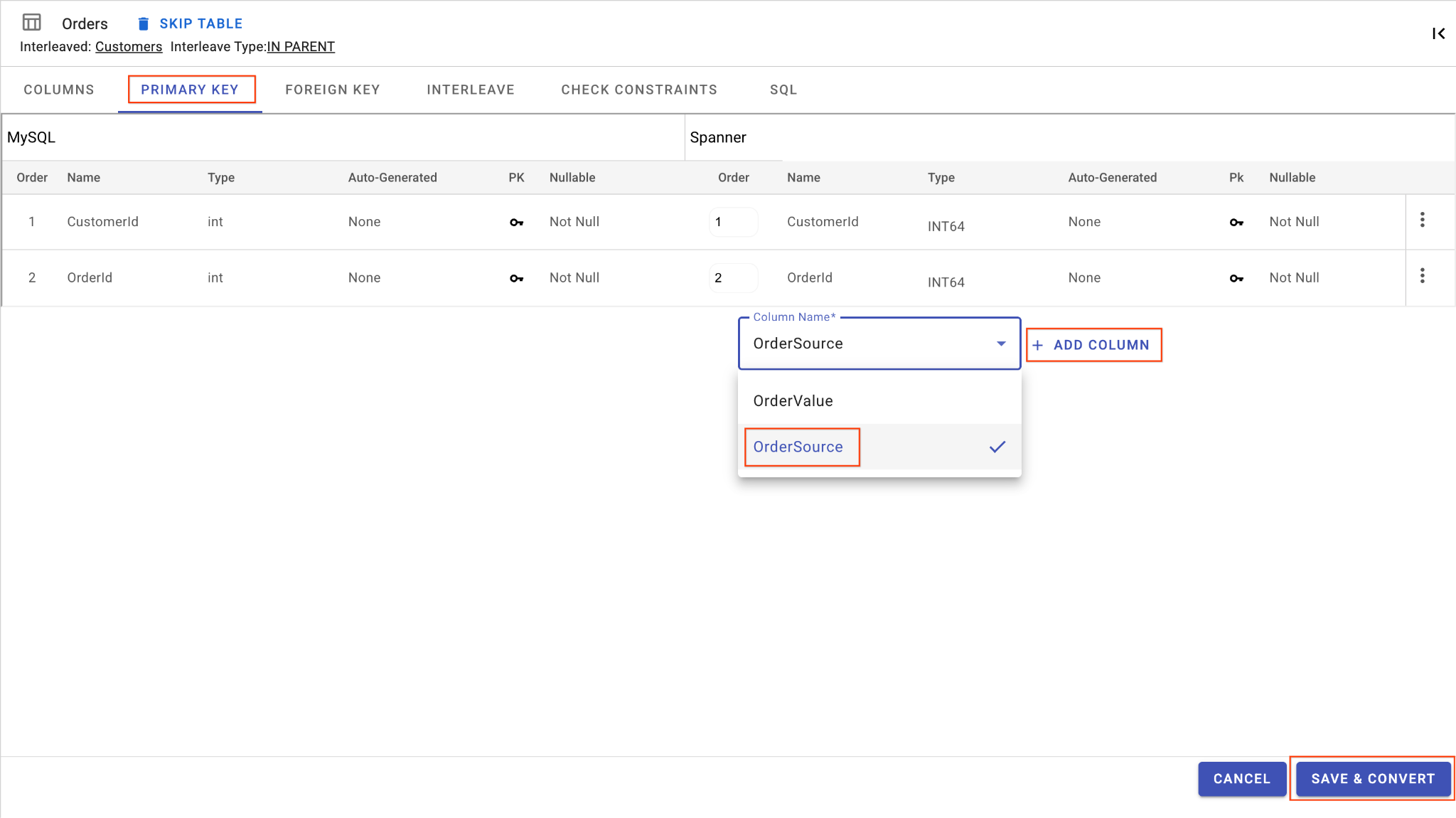
E. Entrelacez la table "Orders" :
- Toujours dans le tableau
Orders, dans la vue Tableau principal, recherchez l'onglet Entrelacer. - Définissez la table parente sur
Customers. - Choisissez le type d'entrelacement
IN PARENTet l'action à effectuer en cas de suppressionNO ACTION. - Cliquez sur Enregistrer.

4. Télécharger le fichier de remplacement et appliquer le schéma
- En haut à droite de l'interface utilisateur SMT, recherchez le bouton Download Artifacts (Télécharger les artefacts). Sélectionnez l'option Télécharger le fichier de remplacement. Enregistrez ce fichier sur votre ordinateur local. Ce fichier contient toutes les modifications de mappage de schéma que nous venons d'effectuer et sera utilisé par nos pipelines Dataflow.
- Cliquez sur Préparer la migration.

- Dans le menu déroulant, sélectionnez Mode Migration comme
Schema. - Saisissez votre base de données Spanner cible :
sharded-target-db

- Cliquez sur Migrer.
- SMT appliquera le DDL et créera la base de données Spanner. Une fois le processus SMT terminé, vous pouvez l'arrêter dans Cloud Shell (
Ctrl+C) sans risque.
5. Vérifier le schéma dans Cloud Spanner
Vérifiez que les tables ont été créées dans la base de données Spanner.
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT table_name FROM information_schema.tables WHERE table_schema = '' ORDER BY table_name"
Vous devriez obtenir le résultat suivant :
table_name: Customers table_name: Orders
Facultatif : Si vous souhaitez vérifier le DDL Spanner réel pour vous assurer que vos contraintes de vérification, votre entrelacement et vos colonnes supplémentaires ont été appliqués, exécutez la commande suivante :
gcloud spanner databases ddl describe $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME
Résultat attendu :
CREATE TABLE Customers ( CustomerId INT64 NOT NULL, CustomerName STRING(255), CreditLimit NUMERIC NOT NULL, LoyaltyTier STRING(50), CONSTRAINT CHK_CreditLimit CHECK(`CreditLimit` > 0), ) PRIMARY KEY(CustomerId); CREATE TABLE Orders ( CustomerId INT64 NOT NULL, OrderId INT64 NOT NULL, OrderValue NUMERIC, OrderSource STRING(50) NOT NULL, ) PRIMARY KEY(CustomerId, OrderId, OrderSource), INTERLEAVE IN PARENT Customers ON DELETE NO ACTION;
7. Initialiser la capture de données modifiées (CDC)
Dans cette section, vous allez configurer l'enregistreur pour votre migration. En configurant Datastream et Pub/Sub avant le début du chargement groupé des données, vous vous assurez que chaque modification apportée aux bases de données sources est capturée et mise en file d'attente, ce qui évite toute perte de données pendant la transition. Cette configuration est requise pour la migration en direct.
Comme notre architecture implique deux serveurs physiques, nous devons créer deux profils sources Datastream et deux flux Datastream distincts. Les deux flux écriront dans un seul bucket Google Cloud Storage (GCS), qui servira de source unifiée pour notre pipeline Dataflow.
1. Créer un bucket Cloud Storage
Datastream nécessite une destination pour stocker les événements de modification capturés. Commençons par créer un bucket GCS.
export BUCKET_NAME="migration-${PROJECT_ID}-bucket"
gcloud storage buckets create gs://${BUCKET_NAME} --location=$REGION
2. Créer des profils de connexion Datastream
Nous avons besoin de deux profils de connexion source MySQL distincts (un pour chaque partition physique) et d'un profil de connexion cible pour Cloud Storage.
Obtenir les adresses IP sources
Commencez par récupérer les adresses IP externes de nos deux VM Compute Engine et stockez-les en tant que variables d'environnement :
export MYSQL_IP_1=$(gcloud compute instances describe mysql-physical-1 --zone=$ZONE --format='get(networkInterfaces[0].accessConfigs[0].natIP)')
export MYSQL_IP_2=$(gcloud compute instances describe mysql-physical-2 --zone=$ZONE --format='get(networkInterfaces[0].accessConfigs[0].natIP)')
Créer des profils de connexion source (MySQL sur Compute Engine)
Créez les profils de connexion Datastream à l'aide de l'datastream_user créé précédemment.
# Create Source Profile for Physical Shard 1
export SQL_CP_NAME_1="mysql-src-cp-1"
gcloud datastream connection-profiles create $SQL_CP_NAME_1 \
--location=$REGION \
--type=mysql \
--mysql-hostname=$MYSQL_IP_1 \
--mysql-port=3306 \
--mysql-username=datastream_user \
--mysql-password=complex_password_123 \
--display-name="MySQL Source 1 (Physical Shard 1)"
# Create Source Profile for Physical Shard 2
export SQL_CP_NAME_2="mysql-src-cp-2"
gcloud datastream connection-profiles create $SQL_CP_NAME_2 \
--location=$REGION \
--type=mysql \
--mysql-hostname=$MYSQL_IP_2 \
--mysql-port=3306 \
--mysql-username=datastream_user \
--mysql-password=complex_password_123 \
--display-name="MySQL Source 2 (Physical Shard 2)"
Remarque : Datastream se connecte à ces VM via leurs adresses IP publiques, ce qui est autorisé, car nous avons ajouté 0.0.0.0/0 à nos règles de pare-feu précédemment. Dans un environnement de production, vous devez autoriser strictement les plages d'adresses IP publiques spécifiques de Datastream.
Créez un profil de connexion de destination (Cloud Storage) :
Il s'agit de la racine du bucket que vous venez de créer.
export GCS_CP_NAME="gcs-dest-cp"
gcloud datastream connection-profiles create $GCS_CP_NAME \
--location=$REGION \
--type=google-cloud-storage \
--bucket=$BUCKET_NAME \
--root-path=/ \
--display-name="GCS Destination" --force
3. Créer des flux Datastream
Nous allons maintenant créer deux flux CDC. Le flux 1 capture shard0_db et shard1_db. Le flux 2 capture shard2_db et shard3_db. Les deux flux écrivent dans le même bucket GCS au format Avro.
# Stream for Physical Shard 1
export STREAM_NAME_1="mysql-to-spanner-stream-1"
export GCS_STREAM_PATH_1="data/${STREAM_NAME_1}"
gcloud datastream streams create $STREAM_NAME_1 \
--location=$REGION \
--display-name="MySQL Source 1 CDC Stream" \
--source=$SQL_CP_NAME_1 \
--destination=$GCS_CP_NAME \
--mysql-source-config=<(echo "includeObjects:
mysqlDatabases:
- database: 'shard0_db'
- database: 'shard1_db'") \
--gcs-destination-config=<(echo "path: ${GCS_STREAM_PATH_1}/
fileRotationMb: 5
fileRotationInterval: 15s
avroFileFormat: {}") \
--backfill-none
# Stream for Physical Shard 2
export STREAM_NAME_2="mysql-to-spanner-stream-2"
export GCS_STREAM_PATH_2="data/${STREAM_NAME_2}"
gcloud datastream streams create $STREAM_NAME_2 \
--location=$REGION \
--display-name="MySQL Source 2 CDC Stream" \
--source=$SQL_CP_NAME_2 \
--destination=$GCS_CP_NAME \
--mysql-source-config=<(echo "includeObjects:
mysqlDatabases:
- database: 'shard2_db'
- database: 'shard3_db'") \
--gcs-destination-config=<(echo "path: ${GCS_STREAM_PATH_2}/
fileRotationMb: 5
fileRotationInterval: 15s
avroFileFormat: {}") \
--backfill-none
L'utilisation de paramètres de rotation de fichiers plus petits (5 Mo ou 15 secondes) nous permet de voir les modifications répliquées plus rapidement pendant l'atelier de programmation.
L'exécution de cette commande peut prendre un certain temps. Vérifiez l'état : gcloud datastream streams describe $STREAM_NAME_1 --location=$REGION.
4. Démarrer les flux Datastream
Activez les deux flux pour qu'ils commencent à enregistrer les modifications.
gcloud datastream streams update $STREAM_NAME_1 \
--location=$REGION \
--state=RUNNING
gcloud datastream streams update $STREAM_NAME_2 \
--location=$REGION \
--state=RUNNING
Vérifier l'état : vous pouvez exécuter gcloud datastream streams describe $STREAM_NAME_1 --location=$REGION. L'état est initialement STARTING, puis passe à RUNNING au bout de quelques instants. Attendez que les deux soient entièrement en cours d'exécution avant de lancer la migration en direct.
5. Configurer Pub/Sub pour les notifications GCS
Dataflow doit être averti immédiatement lorsqu'un flux Datastream écrit un nouveau fichier dans le bucket GCS. Nous allons configurer GCS pour qu'il envoie des notifications à un seul sujet Pub/Sub.
Créez un sujet Pub/Sub :
export PUBSUB_TOPIC="datastream-gcs-updates"
gcloud pubsub topics create $PUBSUB_TOPIC
Créer une notification GCS
Envoyez une notification au thème lors de la création d'un objet sous le préfixe data/ (qui couvre nos deux flux).
gcloud storage buckets notifications create gs://${BUCKET_NAME} --topic=projects/$PROJECT_ID/topics/$PUBSUB_TOPIC --payload-format=json --object-prefix=data/
Créer un abonnement Pub/Sub
Créez l'abonnement avec un délai d'accusé de réception recommandé pour Dataflow.
export PUBSUB_SUBSCRIPTION="datastream-gcs-sub"
gcloud pubsub subscriptions create $PUBSUB_SUBSCRIPTION \
--topic=$PUBSUB_TOPIC \
--ack-deadline=600
8. Transformation personnalisée
Étant donné que notre schéma Spanner diffère de notre schéma MySQL (en raison des colonnes que nous avons ajoutées et supprimées via l'interface utilisateur Web SMT), la migration Dataflow prête à l'emploi échouera. Dataflow a besoin d'instructions sur la façon de mapper ces différences lors des pipelines avant (MySQL vers Spanner) et inverse (Spanner vers MySQL).
De plus, comme nous effectuons une migration inverse fragmentée, Dataflow a besoin d'un mécanisme de routage pour savoir à quel fragment logique (shard0_db, shard1_db, etc.) appartient une ligne Spanner mise à jour lors de la réplication inverse.
Pour ce faire, nous allons écrire un fichier JAR de transformation personnalisée à l'aide du modèle de partitionnement personnalisé Spanner fourni par Google.
1. Télécharger le modèle de partition personnalisée
Dans votre Cloud Shell, téléchargez le dépôt de modèles Google Cloud Dataflow et accédez au dossier de partition personnalisée :
git clone https://github.com/GoogleCloudPlatform/DataflowTemplates.git
cd DataflowTemplates/v2/spanner-custom-shard
2. Configurer la logique de transformation des données
Nous devons modifier le fichier CustomTransformationFetcher.java.
- Migration avant (
toSpannerRow) : remplit la colonneOrderSourcenouvellement ajoutée à l'aide de la colonneLegacyOrderSystemde MySQL. - Migration inverse (
toSourceRow) : repopule la colonneLegacyOrderSystemsupprimée requise par MySQL, en la dérivant deOrderSourcede Spanner.
Modifiez le fichier CustomTransformationFetcher.java. Au lieu d'ouvrir manuellement un éditeur de texte, exécutez la commande suivante pour remplacer automatiquement le fichier de modèle par notre logique personnalisée :
cat << 'EOF' > src/main/java/com/custom/CustomTransformationFetcher.java
package com.custom;
import com.google.cloud.teleport.v2.spanner.exceptions.InvalidTransformationException;
import com.google.cloud.teleport.v2.spanner.utils.ISpannerMigrationTransformer;
import com.google.cloud.teleport.v2.spanner.utils.MigrationTransformationRequest;
import com.google.cloud.teleport.v2.spanner.utils.MigrationTransformationResponse;
import java.util.HashMap;
import java.util.Map;
public class CustomTransformationFetcher implements ISpannerMigrationTransformer {
@Override
public void init(String customParameters) {}
@Override
public MigrationTransformationResponse toSpannerRow(MigrationTransformationRequest request)
throws InvalidTransformationException {
if (request.getTableName().equals("Orders")) {
Map<String, Object> requestRow = request.getRequestRow();
Map<String, Object> responseRow = new HashMap<>();
Object legacySysObj = requestRow.get("LegacyOrderSystem");
String legacySys = (legacySysObj != null) ? (String) legacySysObj : "UNKNOWN_SYSTEM";
// Transform: Trim the string to remove everything after the first underscore
String orderSource = legacySys;
if (legacySys.contains("_")) {
orderSource = legacySys.substring(0, legacySys.indexOf('_'));
}
// Populate the new Spanner column (e.g., "WebStore_v1" becomes "WebStore")
responseRow.put("OrderSource", orderSource);
return new MigrationTransformationResponse(responseRow, false);
}
return new MigrationTransformationResponse(new HashMap<>(), false);
}
@Override
public MigrationTransformationResponse toSourceRow(MigrationTransformationRequest request)
throws InvalidTransformationException {
if (request.getTableName().equals("Orders")) {
Map<String, Object> requestRow = request.getRequestRow();
Map<String, Object> responseRow = new HashMap<>();
// Safely fetch the Spanner OrderSource
Object sourceObj = requestRow.get("OrderSource");
String source = (sourceObj != null) ? (String) sourceObj : "UNKNOWN_SYSTEM";
String legacySys = "'" + source + "_v1'";
// Transform: Append a suffix to visibly prove the reverse transformation worked
// e.g., "WebStore" becomes "WebStore_v1"
responseRow.put("LegacyOrderSystem", legacySys);
return new MigrationTransformationResponse(responseRow, false);
}
return new MigrationTransformationResponse(new HashMap<>(), false);
}
@Override
public MigrationTransformationResponse transformFailedSpannerMutation(
MigrationTransformationRequest request) throws InvalidTransformationException {
return new MigrationTransformationResponse(new HashMap<>(), false);
}
}
EOF
3. Configurer la logique de sharding inversé
Dataflow utilise CustomShardIdFetcher.java lors de la réplication inversée pour déterminer où une mutation Spanner doit être routée. Nous utiliserons la clé primaire CustomerId et la logique modulo (%4) pour rediriger dynamiquement les enregistrements vers leur partition logique appropriée.
Modifiez le fichier CustomShardIdFetcher.java à l'aide de cat et remplacez entièrement son contenu par le code suivant :
cat << 'EOF' > src/main/java/com/custom/CustomShardIdFetcher.java
package com.custom;
import com.google.cloud.teleport.v2.spanner.utils.IShardIdFetcher;
import com.google.cloud.teleport.v2.spanner.utils.ShardIdRequest;
import com.google.cloud.teleport.v2.spanner.utils.ShardIdResponse;
import java.util.Map;
public class CustomShardIdFetcher implements IShardIdFetcher {
@Override
public void init(String parameters) {}
@Override
public ShardIdResponse getShardId(ShardIdRequest shardIdRequest) {
Map<String, Object> keys = shardIdRequest.getSpannerRecord
();
// Use the Primary Key to identify the correct logical shard
if (keys != null && keys.containsKey("CustomerId")) {
long customerId = Long.parseLong(keys.get("CustomerId").toString());
long shardIdx = customerId % 4;
ShardIdResponse response = new ShardIdResponse();
response.setLogicalShardId("shard" + shardIdx + "_db");
return response;
}
return new ShardIdResponse();
}
}
EOF
4. Compiler et importer le fichier JAR
Maintenant que notre logique Java personnalisée est écrite, nous devons la compiler dans un fichier JAR et l'importer dans le bucket Google Cloud Storage que nous avons créé précédemment afin que Dataflow puisse y accéder.
Exécutez les commandes suivantes dans Cloud Shell :
# Return to DataflowTemplates directory
cd ../..
# Build the JAR using Maven
mvn clean install -DskipTests -Dcheckstyle.skip -Dspotless.check.skip=true -Djib.skip -pl v2/spanner-custom-shard -am
# Upload the JAR to GCS
export CUSTOM_JAR_PATH="gs://${BUCKET_NAME}/custom-logic/spanner-custom-shard-1.0.jar"
gcloud storage cp v2/spanner-custom-shard/target/spanner-custom-shard-1.0-SNAPSHOT.jar $CUSTOM_JAR_PATH
# Return to home directory
cd ~
9. Migrer des données de MySQL vers Spanner en masse
Maintenant que le schéma Spanner est en place et que notre fichier JAR de transformation personnalisée est créé, nous pouvons copier les données existantes de votre base de données MySQL vers Cloud Spanner. Vous allez utiliser le modèle Flex Dataflow Sourcedb to Spanner, conçu pour copier des données en masse depuis des bases de données accessibles via JDBC vers Spanner.
1. Importer le fichier de remplacement du schéma
Dans la section 6, vous avez téléchargé le fichier JSON des remplacements Spanner à l'aide de l'interface utilisateur Web SMT. Nous devons l'importer dans notre bucket GCS afin que Dataflow puisse l'utiliser pour mapper les différences de schéma (comme les colonnes renommées).
- Dans Cloud Shell, cliquez sur le menu à trois points (Plus), puis sélectionnez Importer.
- Sélectionnez le fichier JSON des remplacements que vous avez téléchargé précédemment (par exemple,
spanner_overrides.json). - Déplacez-le vers votre bucket GCS :
export OVERRIDES_FILE="spanner_overrides.json" # Change this if your downloaded file has a different name
export GCS_OVERRIDES_PATH="gs://${BUCKET_NAME}/config/${OVERRIDES_FILE}"
gcloud storage cp ~/${OVERRIDES_FILE} $GCS_OVERRIDES_PATH
2. Créer et importer le fichier de configuration du partitionnement
Dataflow doit savoir comment se connecter aux quatre partitions logiques sur vos deux VM physiques. Pour cela, nous allons créer un fichier sharding.json.
Exécutez la commande suivante dans Cloud Shell pour générer et importer la configuration :
cat <<EOF > sharding.json
{
"configType": "dataflow",
"shardConfigurationBulk": {
"schemaSource": {
"dataShardId": "mysql-physical-1",
"host": "${MYSQL_IP_1}",
"user": "datastream_user",
"password": "complex_password_123",
"port": "3306",
"dbName": "shard0_db"
},
"dataShards": [
{
"dataShardId": "mysql-physical-1",
"host": "${MYSQL_IP_1}",
"user": "datastream_user",
"password": "complex_password_123",
"port": "3306",
"dbName": "",
"namespace": "namespace-mysql-1",
"databases": [
{
"dbName": "shard0_db",
"databaseId": "shard0_db",
"refDataShardId": "mysql-physical-1"
},
{
"dbName": "shard1_db",
"databaseId": "shard1_db",
"refDataShardId": "mysql-physical-1"
}
]
},
{
"dataShardId": "mysql-physical-2",
"host": "${MYSQL_IP_2}",
"user": "datastream_user",
"password": "complex_password_123",
"port": "3306",
"dbName": "",
"namespace": "namespace-mysql-2",
"databases": [
{
"dbName": "shard2_db",
"databaseId": "shard2_db",
"refDataShardId": "mysql-physical-2"
},
{
"dbName": "shard3_db",
"databaseId": "shard3_db",
"refDataShardId": "mysql-physical-2"
}
]
}
]
}
}
EOF
export GCS_SHARDING_PATH="gs://${BUCKET_NAME}/config/sharding.json"
gcloud storage cp sharding.json $GCS_SHARDING_PATH
3. Exécuter le job Dataflow de migration groupée
Nous allons utiliser le modèle Flex Sourcedb vers Spanner. Comme il s'agit d'une migration partitionnée avec des transformations personnalisées, nous transmettons le fichier de remplacement, la configuration de partitionnement et notre fichier JAR Java personnalisé.
export JOB_NAME="mysql-sharded-bulk-to-spanner-$(date +%Y%m%d-%H%M%S)"
export OUTPUT_DIR="gs://${BUCKET_NAME}/bulk-migration"
gcloud dataflow flex-template run $JOB_NAME \
--project=$PROJECT_ID \
--region=$REGION \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Sourcedb_to_Spanner_Flex" \
--max-workers=2 \
--num-workers=1 \
--worker-machine-type=n2-highmem-8 \
--parameters \
sourceConfigURL=$GCS_SHARDING_PATH,\
instanceId=$SPANNER_INSTANCE_NAME,\
databaseId=$SPANNER_DATABASE_NAME,\
projectId=$PROJECT_ID,\
outputDirectory=$OUTPUT_DIR,\
username=datastream_user,\
password=complex_password_123,\
schemaOverridesFilePath=$GCS_OVERRIDES_PATH,\
transformationJarPath=$CUSTOM_JAR_PATH,\
transformationClassName=com.custom.CustomTransformationFetcher
Explication des paramètres clés :
sourceConfigURL: chemin d'accès au fichiersharding.jsonque nous avons créé. Cela indique à Dataflow comment se connecter aux quatre partitions logiques MySQL sur les deux VM physiques.schemaOverridesFilePath: chemin d'accès au fichier JSON que nous avons téléchargé depuis l'interface utilisateur Web SMT. Cela indique à Dataflow comment gérer les modifications de schéma que nous avons apportées (comme la colonneLegacyRegionsupprimée et la contrainte de vérification renforcée).transformationJarPath: chemin d'accès GCS au fichier JAR Java compilé que nous avons créé dans la section précédente. Il contient le code permettant d'exécuter nos transformations personnalisées.transformationClassName: nom complet de la classe Java dans notre fichier JAR qui implémente la logique de migration vers l'avant (com.custom.CustomTransformationFetcher).outputDirectory: emplacement GCS où Dataflow écrira ses fichiers temporaires et, surtout, les fichiers de la file d'attente de lettres mortes.maxWorkers,numWorkers: contrôle la mise à l'échelle du job Dataflow. Faible pour ce petit ensemble de données.instanceId,databaseId,projectId: spécifie l'instance et la base de données Cloud Spanner cibles.
Remarque sur le réseau : Ce job se connecte à l'instance Cloud SQL via son adresse IP publique. Cela est possible, car vous avez précédemment ajouté 0.0.0.0/0 aux réseaux autorisés de l'instance. Cela permet aux VM de nœud de calcul Dataflow, qui disposent d'adresses IP externes, d'accéder à la base de données.
4. Surveiller le job Dataflow
Vous pouvez suivre la progression du job dans la console Google Cloud :
- Accédez à la page "Jobs Dataflow" : Accéder à la page "Jobs Dataflow"
- Localisez le job nommé
mysql-sharded-bulk-to-spanner-...et cliquez dessus. - Observez le graphique et les métriques du job. Attendez que l'état du job passe à Réussi. Cette opération devrait prendre environ 5 à 15 minutes.

- Si le job rencontre des problèmes, consultez l'onglet Journaux sur la page des détails du job Dataflow pour obtenir des messages d'erreur.
- Les métriques de job fournissent plus d'informations sur la progression du job et la consommation de ressources, comme le débit et l'utilisation du processeur.
5. Vérifier les données dans Cloud Spanner et inspecter la file d'attente de lettres mortes (DLQ)
Une fois le job Dataflow terminé, nous devons vérifier que nos données sont bien arrivées et inspecter les enregistrements que nous avons intentionnellement conçus pour échouer.
A. Vérifiez l'état général des données migrées :
Utilisez l'interface de ligne de commande gcloud pour effectuer quelques vérifications rapides de l'état de votre base de données Spanner consolidée. Vous pourrez ainsi vous assurer que les enregistrements valides ont été correctement migrés et que notre fichier JAR personnalisé a rempli la colonne supplémentaire.
# 1. Verify total Customer count
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT COUNT(*) as TotalCustomers FROM Customers"
# 2. Verify total Orders count (Total minus the orphan record)
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT COUNT(*) as TotalOrders FROM Orders"
# 3. Verify the Custom Transformation on OrderSource worked
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT CustomerId, OrderId, OrderSource FROM Orders LIMIT 3"
# 4. Verify that renamed column LoyaltyTier has the correct data
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT CustomerId, CustomerName, LoyaltyTier FROM Customers LIMIT 3"
Résultat attendu :
TotalCustomers: 16 TotalOrders: 19 CustomerId: 1 OrderId: 201 OrderSource: MobileApp CustomerId: 2 OrderId: 301 OrderSource: CallCenter CustomerId: 3 OrderId: 401 OrderSource: InStore CustomerId: 1 CustomerName: Agnes N. LoyaltyTier: NORTHEAST CustomerId: 2 CustomerName: Brian K. LoyaltyTier: SOUTHWEST CustomerId: 3 CustomerName: Cathy Z. LoyaltyTier: CENTRAL
- Toutes les lignes de la table "Customers" ont été migrées.
- Nous constatons 1 échec de ligne dans la table
Ordersen raison deINTERLEAVE IN PARENTsur Spanner :CustomerId 99est un enfant orphelin, car il n'y a pas de ligne correspondante dans la tableCustomers.
B. Vérifiez les échecs intentionnels dans la DLQ :
L'échec ci-dessus est consigné dans le dossier de file d'attente de lettres mortes (DLQ) créé par le pipeline de migration groupée.
- Accédez à Cloud Storage dans la console Google Cloud.
- Accédez à votre bucket et ouvrez le dossier
bulk-migration/dlq/severe. - Inspectez les fichiers JSON à l'intérieur. Vous trouverez la ligne
Ordersavec l'élément orphelinCustomerId. - Vous pouvez réessayer de corriger les erreurs de file d'attente de lettres mortes liées à la migration groupée en suivant ces étapes.
Le chargement groupé initial des données de Cloud SQL vers Cloud Spanner est maintenant terminé. L'étape suivante consiste à configurer la réplication en direct pour capturer les modifications en cours.
10. Démarrer la migration à chaud (CDC)
Maintenant que le chargement groupé des données est terminé, vous allez lancer un job de streaming Dataflow continu. Cette tâche lira les événements de capture des données modifiées (CDC) que Datastream écrit dans votre bucket GCS et appliquera ces modifications à Cloud Spanner en temps quasi réel.
Nous allons également tester ce pipeline en injectant des données valides et volontairement non valides pour observer comment Dataflow gère la réplication en direct et achemine les échecs vers la file d'attente de lettres mortes (DLQ).
1. Créer le fichier de configuration du partitionnement de la migration en direct
Contrairement à la migration groupée (qui utilise des chaînes de connexion JDBC), le pipeline de migration en direct lit les événements Datastream à partir de GCS. Il nécessite une configuration JSON complètement différente qui mappe les noms de flux et les bases de données Datastream à vos partitions Spanner logiques.
Exécutez la commande suivante dans Cloud Shell pour créer et importer la configuration du partitionnement en direct :
cat <<EOF > live-sharding.json
{
"StreamToDbAndShardMap": {
"${STREAM_NAME_1}": {
"shard0_db": "shard0_db",
"shard1_db": "shard1_db"
},
"${STREAM_NAME_2}": {
"shard2_db": "shard2_db",
"shard3_db": "shard3_db"
}
}
}
EOF
export GCS_LIVE_SHARDING_PATH="gs://${BUCKET_NAME}/config/live-sharding.json"
gcloud storage cp live-sharding.json $GCS_LIVE_SHARDING_PATH
2. Exécuter le job Dataflow de migration à chaud
Lancez le job Dataflow de streaming pour lire les données depuis GCS et les écrire dans Spanner. Ce modèle utilise les notifications GCS Pub/Sub pour traiter instantanément les nouveaux fichiers.
export JOB_NAME_CDC="mysql-sharded-cdc-to-spanner-$(date +%Y%m%d-%H%M%S)"
export DLQ_DIR_CDC="gs://${BUCKET_NAME}/live-migration"
gcloud dataflow flex-template run $JOB_NAME_CDC \
--project=$PROJECT_ID \
--region=$REGION \
--worker-machine-type=n2-highmem-8 \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Cloud_Datastream_to_Spanner" \
--parameters \
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
projectId="$PROJECT_ID",\
inputFileFormat="avro",\
gcsPubSubSubscription="projects/${PROJECT_ID}/subscriptions/${PUBSUB_SUBSCRIPTION}",\
shardingContextFilePath=$GCS_LIVE_SHARDING_PATH,\
deadLetterQueueDirectory="$DLQ_DIR_CDC",\
transformationJarPath=$CUSTOM_JAR_PATH,\
transformationClassName="com.custom.CustomTransformationFetcher",\
schemaOverridesFilePath=$GCS_OVERRIDES_PATH,\
datastreamSourceType="mysql",\
dlqRetryMinutes=1,\
dlqMaxRetryCount=2
Paramètres clés
gcsPubSubSubscription: abonnement Pub/Sub qui écoute les notifications de nouveaux fichiers provenant de GCS. Cela permet au job de traiter les modifications instantanément à mesure que Datastream les écrit.inputFileFormat="avro": indique à Dataflow qu'il doit s'attendre à recevoir des fichiers Avro de Datastream. Elle doit correspondre à la configuration de la destination Datastream (par exemple,avroFileFormatoujsonFileFormat).shardingContextFilePath: fichier JSON mappant les flux Datastream aux partitions logiques.dlqRetryMinutes: nombre de minutes entre les tentatives d'exécution de la file d'attente de lettres mortes. La valeur par défaut est10.dlqMaxRetryCount: nombre maximal de nouvelles tentatives en raison d'erreurs temporaires via la file d'attente de lettres mortes. La valeur par défaut est500.
Surveillez le démarrage du job dans la console des jobs Dataflow.
3. Injecter des données en direct et déclencher des échecs intentionnels
Pendant le démarrage de la tâche de streaming Dataflow (qui peut prendre trois à cinq minutes), connectons-nous en SSH à notre première VM MySQL physique et insérons de nouveaux enregistrements. Nous allons insérer un enregistrement valide et un enregistrement non valide.
Connectez-vous en SSH au premier fragment physique :
gcloud compute ssh mysql-physical-1 --zone=$ZONE
Connectez-vous à MySQL :
sudo mysql
Exécutez les insertions suivantes sur shard1_db :
USE shard1_db;
-- 1. Valid Insert: 'MobileApp_v2' will be trimmed to 'MobileApp'
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem)
VALUES (4, 501, 99.99, 'MobileApp_v2');
-- 2. Invalid Insert (DLQ Test): This violates Interleave constraint as CustomerId 99999 doesn't exist in Customers table.
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem)
VALUES (99999, 502, 50.00, 'WebStore_v1');
-- 3. Valid Update
UPDATE Orders SET OrderValue = '1500' WHERE CustomerId = 5 AND OrderId = 202;
-- 4. Valid Delete
DELETE FROM Orders WHERE CustomerId = 5 AND OrderId = 203;
EXIT;
Saisissez à nouveau exit pour revenir à votre invite Cloud Shell.
4. Vérifier les données de la migration à chaud et inspecter la DLQ CDC
Maintenant que nous avons injecté les données, Datastream capture les événements CDC et Dataflow tente de les appliquer à Spanner.
A. Vérifier les modifications LMD valides dans Spanner
Exécutez les requêtes suivantes pour vérifier que les événements INSERT, UPDATE et DELETE ont bien été envoyés à Spanner, et que la transformation personnalisée a été déclenchée à la fois lors de l'insertion et de la mise à jour.
# 1. Verify INSERT: Should return the new row with transformed OrderSource
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT CustomerId, OrderId, OrderValue, OrderSource FROM Orders WHERE CustomerId = 4 AND OrderId = 501"
# 2. Verify UPDATE: Should show OrderValue changed to 1500
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT CustomerId, OrderId, OrderValue, OrderSource FROM Orders WHERE CustomerId = 5 AND OrderId = 202"
# 3. Verify DELETE: Should return 0, confirming the order was deleted
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT COUNT(*) FROM Orders WHERE CustomerId = 5 AND OrderId = 203"
# 4. Verify DLQ Failure: Should return 0, confirming the row migration failed
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT COUNT(*) FROM Orders WHERE CustomerId = 99999 AND OrderId = 502"
Résultat attendu :
CustomerId: 4 OrderId: 501 OrderValue: 99.99 OrderSource: MobileApp CustomerId: 5 OrderId: 202 OrderValue: 1500 OrderSource: WebStore 0 0
Remarque : Si une requête ne donne pas le résultat attendu, patientez une minute et réessayez, car les workers de streaming sont peut-être encore en train de traiter la file d'attente.
B. Vérifiez l'échec intentionnel dans la DLQ :
Étant donné que CustomerId = 99999 n'a pas de parent dans la table Customers, il aurait dû être rejeté par Spanner et routé de manière sécurisée vers la DLQ par Dataflow.
- Accédez à Cloud Storage dans la console Google Cloud.
- Accédez à votre bucket et ouvrez le dossier
live-migration/dlq/severe/. - Vous devriez voir les fichiers JSON nouvellement générés. Cliquez dessus pour inspecter le contenu. Les détails de
CustomerId = 99999et le message d'erreur Spanner spécifique s'affichent :NOT_FOUND: Parent row for row [99999,502,WebStore] in table Orders is missing. Row cannot be written." - Vous pouvez réessayer les erreurs de file d'attente de lettres mortes de la migration en direct en exécutant le modèle Dataflow avec
runMode=retryDLQdéfini.
5. Gérer les erreurs de la file d'attente de lettres mortes
Les erreurs dans le répertoire severe/ nécessitent une intervention manuelle. Corrigeons le problème de données et retraitons l'événement ayant échoué.
A. Corriger les données dans la source
Cette erreur s'est produite, car l'enregistrement client parent CustomerId = 99999 est manquant. Insérons-le dans la base de données MySQL source.
Connectez-vous à nouveau en SSH à l'instance MySQL :
gcloud compute ssh mysql-physical-1 --zone=$ZONE
Connectez-vous à MySQL à l'aide de sudo mysql et insérez la ligne parente manquante dans shard1_db :
USE shard1_db;
INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LegacyRegion) VALUES
(99999, 'DLQ Parent Holder', 5000.00, 'NORTH_AMERICA');
EXIT;
Saisissez exit pour revenir à Cloud Shell.
B. Exécuter le job Dataflow retryDLQ
Pour retraiter les événements de la DLQ severe/, vous lancez le même modèle Dataflow, mais en mode retryDLQ. Ce mode lit spécifiquement le chemin d'accès deadLetterQueueDirectory/severe, réexécute les transformations personnalisées et les applique à Spanner.
Lancez le job en mode retryDLQ :
export JOB_NAME_RETRY="mysql-sharded-cdc-retry-$(date +%Y%m%d-%H%M%S)"
gcloud dataflow flex-template run $JOB_NAME_RETRY \
--project=$PROJECT_ID \
--region=$REGION \
--worker-machine-type=n2-highmem-8 \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Cloud_Datastream_to_Spanner" \
--parameters \
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
projectId="$PROJECT_ID",\
runMode="retryDLQ",\
deadLetterQueueDirectory="$DLQ_DIR_CDC",\
datastreamSourceType="mysql",\
transformationJarPath=$CUSTOM_JAR_PATH,\
transformationClassName="com.custom.CustomTransformationFetcher",\
schemaOverridesFilePath=$GCS_OVERRIDES_PATH,\
shardingContextFilePath=$GCS_LIVE_SHARDING_PATH
Modifications clés des paramètres pour les nouvelles tentatives
runMode="retryDLQ": indique au modèle de lire à partir du répertoire de la file d'attente de lettres mortessevere.- Suppression de
gcsPubSubSubscription: inutile, car nous ne lisons pas le bucket GCS Datastream en direct.
Surveillez le processus de nouvelle tentative :
Comme le pipeline CDC principal, retryDLQ est un pipeline de flux de données qui restera RUNNING jusqu'à son annulation manuelle.
- Accédez à la page "Job Dataflow" pour
$JOB_NAME_RETRY. - Dans le volet Métriques, recherchez les deux compteurs suivants :
elementsReconsumedFromDeadLetterQueue: évalue le moment où les fichiers d'erreur sont récupérés.Successful events: incrémenté lorsque l'enregistrement est écrit dans Spanner.- Consultez le répertoire
severe/pour détecter les échecs récurrents. - Une fois que le nombre d'événements "Réussite" a augmenté du nombre d'éléments que vous souhaitez réessayer (1 dans notre cas de test), passez à l'étape de validation suivante.
C. Vérifier les données réessayées
Une fois que l'enregistrement ayant échoué a été retenté (cela peut prendre un certain temps), vérifiez dans Spanner si la ligne enfant a bien été migrée :
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT CustomerId, OrderId, OrderValue, OrderSource FROM Orders WHERE CustomerId = 99999 AND OrderId = 502"
La ligne devrait maintenant s'afficher :
CustomerId: 99999 OrderId: 502 OrderValue: 50 OrderSource: WebStore
Vérifiez également le dossier $DLQ_DIR_CDC/severe/ dans GCS. Les fichiers traités auraient dû être déplacés ou supprimés, ce qui indique que le retraitement a réussi.
11. Configurer la réplication inversée (Spanner vers MySQL)
Pour gérer les scénarios dans lesquels vous pourriez avoir besoin de rétablir ou de synchroniser la base de données MySQL d'origine avec Spanner pendant une période de transition, vous pouvez configurer la réplication inversée.
Ce pipeline utilise les flux de modifications Spanner pour capturer les modifications en direct dans Spanner. Il utilise ensuite notre fichier JAR de transformation personnalisée pour inverser le mappage des différences de schéma, et notre fichier JAR de partitionnement personnalisé pour calculer exactement la VM MySQL physique et le partitionnement logique dans lesquels la mise à jour doit être réécrite.
1. Créer un flux de modifications Spanner
Tout d'abord, vous devez créer un flux de modifications dans votre base de données Spanner pour suivre les modifications apportées aux tables Customers et Orders.
export CHANGE_STREAM_NAME="CustomersOrdersChangeStream"
gcloud spanner databases ddl update $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--ddl="CREATE CHANGE STREAM $CHANGE_STREAM_NAME FOR Customers, Orders"
Ce flux de modifications enregistre désormais toutes les modifications apportées aux données des tables spécifiées.
2. Créer une base de données Spanner pour les métadonnées Dataflow
Le modèle Dataflow Spanner to SourceDB nécessite une base de données Spanner distincte pour stocker les métadonnées permettant de gérer la consommation du flux de modification.
export SPANNER_METADATA_DB_NAME="migration-metadata-db"
gcloud spanner databases create $SPANNER_METADATA_DB_NAME \
--instance=$SPANNER_INSTANCE_NAME
3. Préparer la configuration de la connexion Cloud SQL pour Dataflow
Le modèle Dataflow a besoin d'un fichier JSON dans Cloud Storage contenant les informations de connexion à la base de données Cloud SQL cible.
Créez un fichier local nommé shard_config.json :
cat <<EOF > reverse-sharding.json
[
{
"logicalShardId": "shard0_db",
"host": "${MYSQL_IP_1}",
"port": "3306",
"user": "datastream_user",
"password": "complex_password_123",
"dbName": "shard0_db"
},
{
"logicalShardId": "shard1_db",
"host": "${MYSQL_IP_1}",
"port": "3306",
"user": "datastream_user",
"password": "complex_password_123",
"dbName": "shard1_db"
},
{
"logicalShardId": "shard2_db",
"host": "${MYSQL_IP_2}",
"port": "3306",
"user": "datastream_user",
"password": "complex_password_123",
"dbName": "shard2_db"
},
{
"logicalShardId": "shard3_db",
"host": "${MYSQL_IP_2}",
"port": "3306",
"user": "datastream_user",
"password": "complex_password_123",
"dbName": "shard3_db"
}
]
EOF
Importez ce fichier dans votre bucket GCS :
export GCS_REVERSE_SHARDING_PATH="gs://${BUCKET_NAME}/config/reverse-sharding.json"
gcloud storage cp reverse-sharding.json $GCS_REVERSE_SHARDING_PATH
4. Exécuter le job Dataflow de réplication inversée
Lancez le job Dataflow à l'aide du modèle Flex Spanner_to_SourceDb.
export JOB_NAME_REVERSE="spanner-sharded-reverse-to-mysql-$(date +%Y%m%d-%H%M%S)"
export DLQ_DIR_REVERSE="gs://${BUCKET_NAME}/reverse-replication"
gcloud dataflow flex-template run $JOB_NAME_REVERSE \
--project=$PROJECT_ID \
--region=$REGION \
--worker-machine-type=n2-highmem-8 \
--max-workers=2 \
--num-workers=1 \
--additional-experiments=use_runner_v2 \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Spanner_to_SourceDb" \
--parameters \
changeStreamName="$CHANGE_STREAM_NAME",\
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
spannerProjectId="$PROJECT_ID",\
metadataInstance="$SPANNER_INSTANCE_NAME",\
metadataDatabase="$SPANNER_METADATA_DB_NAME",\
sourceShardsFilePath="$GCS_REVERSE_SHARDING_PATH",\
transformationJarPath=$CUSTOM_JAR_PATH,\
transformationClassName="com.custom.CustomTransformationFetcher",\
shardingCustomJarPath=$CUSTOM_JAR_PATH,\
shardingCustomClassName="com.custom.CustomShardIdFetcher",\
schemaOverridesFilePath=$GCS_OVERRIDES_PATH,\
deadLetterQueueDirectory=$DLQ_DIR_REVERSE
Paramètres clés
changeStreamName: nom du flux de modifications Spanner à lire.metadataInstance, metadataDatabase: instance/base de données Spanner permettant de stocker les métadonnées utilisées par le connecteur pour contrôler la consommation des données de l'API Change Streams.sourceShardsFilePath: chemin d'accès GCS à votreshard_config.json.filtrationMode: spécifie comment supprimer certains enregistrements en fonction d'un critère. La valeur par défaut estforward_migration(filtrer les enregistrements écrits à l'aide du pipeline de migration directe).shardingCustomJarPath: chemin d'accès GCS au fichier JAR Java compilé que nous avons créé précédemment.shardingCustomClassName: nom de classe complet (com.custom.CustomShardIdFetcher) qui exécute notre mathématique modulo%4personnalisée pour déterminer de manière dynamique le shard logique qui doit recevoir l'enregistrement.
Remarque sur le réseau : Les nœuds de calcul Dataflow se connecteront à l'instance Cloud SQL à l'aide de l'adresse IP publique spécifiée dans shard_config.json. Cette connexion est autorisée en raison de l'entrée 0.0.0.0/0 dans les réseaux autorisés de l'instance Cloud SQL.
Surveillez le démarrage du job dans la console des jobs Dataflow.
5. Injecter des données Spanner et déclencher des échecs intentionnels
Attendez que le job Dataflow passe à l'état Running (cela peut prendre environ cinq minutes). Ensuite, exécutons une suite complète de requêtes (INSERT, UPDATE, DELETE) directement dans Spanner, ainsi qu'un échec intentionnel pour tester la file d'attente de lettres mortes inversée.
Exécutez la commande suivante dans Cloud Shell :
# All these operations are done on rows mapping to shard0_db for convenience
# Valid INSERT: Insert parent row in Customers
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LoyaltyTier) VALUES (88, 'Reverse Tester', 5000, 'GOLD_TIER')"
# 1. Valid INSERT (Orders): 'WebStore' transformed to 'WebStore_v1'
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="INSERT INTO Orders (CustomerId, OrderId, OrderValue, OrderSource) VALUES (88, 9001, 150.00, 'WebStore')"
# 2. Valid UPDATE (Orders)
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="UPDATE Orders SET OrderValue = 200.00 WHERE CustomerId = 16 AND OrderId = 105 AND OrderSource = 'Partner'"
# 3. Valid DELETE (Orders)
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="DELETE FROM Orders WHERE CustomerId = 12 AND OrderId = 104 AND OrderSource = 'WebStore'"
# 4. INVALID Insert- DLQ Test: CreditLimit=500 will fail check constraint of >1000 at source
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LoyaltyTier) VALUES (44, 'DLQ Test Customer', 500, 'GOLD_TIER')"
6. Vérifier les données de réplication inversée et inspecter la DLQ
Vérifions que notre fichier JAR de sharding personnalisé a bien routé CustomerId 88 vers shard0_db sur notre première VM physique et que le fichier JAR de transformation personnalisée a bien supprimé "_TIER" de la région.
A. Vérifiez l'enregistrement valide dans MySQL :
Connectez-vous en SSH au premier fragment physique :
gcloud compute ssh mysql-physical-1 --zone=$ZONE
Connectez-vous à MySQL et interrogez shard0_db :
sudo mysql
USE shard0_db;
-- 1. Verify INSERT: Row migrated with transformed LegacyOrderSystem
SELECT CustomerId, OrderId, OrderValue, LegacyOrderSystem
FROM Orders
WHERE CustomerId = 88 AND OrderId = 9001;
-- 2. Verify UPDATE: The OrderValue should now be updated to 200.00.
SELECT CustomerId, OrderId, OrderValue, LegacyOrderSystem
FROM Orders
WHERE CustomerId = 16 AND OrderId = 105;
-- 3. Verify DELETE: Returns 0 rows, confirming the order was successfully deleted from MySQL.
SELECT CustomerId, OrderId
FROM Orders
WHERE CustomerId = 12 AND OrderId = 104;
-- 4. Verify failed replication - this should be in DLQ as CreditLimit < 1000 and will fail stricter check constraint at source
SELECT CustomerId, CustomerName, CreditLimit, LegacyRegion
FROM Customers
WHERE CustomerId = 44;
EXIT;
La sortie attendue dans Cloud SQL doit refléter les modifications apportées dans Spanner.
+------------+---------+------------+-------------------+ | CustomerId | OrderId | OrderValue | LegacyOrderSystem | +------------+---------+------------+-------------------+ | 88 | 9001 | 150.00 | Webstore_v1 | +------------+---------+------------+-------------------+ +------------+---------+------------+-------------------+ | CustomerId | OrderId | OrderValue | LegacyOrderSystem | +------------+---------+------------+-------------------+ | 16 | 105 | 200.00 | Partner_v1 | +------------+---------+------------+-------------------+ Empty set (0.00 sec) Empty set (0.00 sec)
Type
exit
pour revenir à Cloud Shell.
Cela confirme que le pipeline de réplication inversée fonctionne et synchronise les modifications de Spanner vers Cloud SQL.
B. Vérifier l'échec intentionnel dans la DLQ
Étant donné que notre nouvel enregistrement Customers a une valeur CreditLimit de 500 (ce qui ne respecte pas la contrainte de vérification stricte > 1000 que nous avons définie dans notre base de données MySQL source), Dataflow a détecté l'erreur de manière sécurisée.
- Accédez à Cloud Storage dans la console Google Cloud.
- Accédez à votre bucket et ouvrez le dossier
dlq/severe/. - Ouvrez le fichier JSON pour afficher l'enregistrement
Customersrefusé et l'erreur exacte de non-respect de la contrainte de vérification. - Vous pouvez réessayer les erreurs de file d'attente de lettres mortes de réplication inverse en exécutant le modèle Dataflow avec
runMode=retryDLQdéfini.
12. Nettoyer les ressources
Pour éviter que des frais supplémentaires ne soient facturés sur votre compte Google Cloud, supprimez les ressources créées lors de cet atelier de programmation.
Définir des variables d'environnement (si nécessaire)
Si votre session Cloud Shell a expiré ou si vous avez ouvert un nouveau terminal, vous devrez réexporter vos variables d'environnement avant d'exécuter les commandes de nettoyage.
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1" # Or your preferred region
export ZONE="us-central1-a" # Or a zone within your selected region
export SPANNER_INSTANCE_NAME="target-spanner-instance"
export SPANNER_DATABASE_NAME="sharded-target-db"
export SPANNER_CONFIG="regional-${REGION}"
export BUCKET_NAME="migration-${PROJECT_ID}-bucket"
export MYSQL_IP_1=$(gcloud compute instances describe mysql-physical-1 --zone=$ZONE --format='get(networkInterfaces[0].accessConfigs[0].natIP)')
export MYSQL_IP_2=$(gcloud compute instances describe mysql-physical-2 --zone=$ZONE --format='get(networkInterfaces[0].accessConfigs[0].natIP)')
export SQL_CP_NAME_1="mysql-src-cp-1"
export SQL_CP_NAME_2="mysql-src-cp-2"
export GCS_CP_NAME="gcs-dest-cp"
export STREAM_NAME_1="mysql-to-spanner-stream-1"
export GCS_STREAM_PATH_1="data/${STREAM_NAME_1}"
export STREAM_NAME_2="mysql-to-spanner-stream-2"
export GCS_STREAM_PATH_2="data/${STREAM_NAME_2}"
export PUBSUB_TOPIC="datastream-gcs-updates"
export PUBSUB_SUBSCRIPTION="datastream-gcs-sub"
export CUSTOM_JAR_PATH="gs://${BUCKET_NAME}/custom-logic/spanner-custom-shard-1.0.jar"
export OVERRIDES_FILE="spanner_overrides.json"
export GCS_OVERRIDES_PATH="gs://${BUCKET_NAME}/config/${OVERRIDES_FILE}"
export GCS_SHARDING_PATH="gs://${BUCKET_NAME}/config/sharding.json"
export OUTPUT_DIR="gs://${BUCKET_NAME}/bulk-migration"
export GCS_LIVE_SHARDING_PATH="gs://${BUCKET_NAME}/config/live-sharding.json"
export DLQ_DIR_CDC="gs://${BUCKET_NAME}/live-migration"
export CHANGE_STREAM_NAME="CustomersOrdersChangeStream"
export SPANNER_METADATA_DB_NAME="migration-metadata-db"
export GCS_REVERSE_SHARDING_PATH="gs://${BUCKET_NAME}/config/reverse-sharding.json"
export DLQ_DIR_REVERSE="gs://${BUCKET_NAME}/reverse-replication"
Arrêter les tâches de traitement par flux Dataflow
Listez vos jobs pour trouver les ID des jobs Dataflow en cours d'exécution. Exportez JOB_ID_CDC et JOB_ID_REVERSE en conséquence.
gcloud dataflow jobs list --region=$REGION --filter="state=Running"
export JOB_ID_CDC=<PASTE_JOB_ID_HERE>
export JOB_ID_CDC_RETRY=<PASTE_JOB_ID_HERE>
export JOB_ID_REVERSE=<PASTE_JOB_ID_HERE>
Annulez le job Datastream to Spanner (migration à chaud) et sa tâche de nouvelle tentative :
gcloud dataflow jobs cancel $JOB_ID_CDC --region=$REGION --project=$PROJECT_ID
gcloud dataflow jobs cancel $JOB_ID_CDC_RETRY --region=$REGION --project=$PROJECT_ID
Annulez le job Spanner to Cloud SQL (réplication inversée) :
gcloud dataflow jobs cancel $JOB_ID_REVERSE --region=$REGION --project=$PROJECT_ID
Supprimer les ressources Datastream
Arrêter et supprimer le flux :
gcloud datastream streams update $STREAM_NAME_1 \
--location=$REGION --state=PAUSED --project=$PROJECT_ID
# Wait a moment for the stream to pause
gcloud datastream streams delete $STREAM_NAME_1 \
--location=$REGION --project=$PROJECT_ID --quiet
gcloud datastream streams update $STREAM_NAME_2 \
--location=$REGION --state=PAUSED --project=$PROJECT_ID
# Wait a moment for the stream to pause
gcloud datastream streams delete $STREAM_NAME_2 \
--location=$REGION --project=$PROJECT_ID --quiet
# Delete Connection Profiles
gcloud datastream connection-profiles delete $SQL_CP_NAME_1 \
--location=$REGION --project=$PROJECT_ID --quiet
gcloud datastream connection-profiles delete $SQL_CP_NAME_2 \
--location=$REGION --project=$PROJECT_ID --quiet
gcloud datastream connection-profiles delete $GCS_CP_NAME \
--location=$REGION --project=$PROJECT_ID --quiet
Supprimer les VM MySQL sources (Compute Engine)
Supprimez les deux instances Compute Engine qui simulaient les partitions physiques MySQL sur site.
gcloud compute instances delete mysql-physical-1 mysql-physical-2 --zone=$ZONE --quiet
Supprimer des règles de pare-feu
Supprimez les règles de pare-feu réseau créées pour autoriser l'accès SSH et la connectivité Datastream à vos VM. (Remarque : Si vous avez utilisé des noms différents pour vos règles de pare-feu plus tôt dans l'atelier de programmation, ajustez-les ici.)
gcloud compute firewall-rules delete allow-ssh-iap --quiet
gcloud compute firewall-rules delete allow-mysql-datastream --quiet
Supprimer les ressources Pub/Sub
Supprimer un abonnement :
gcloud pubsub subscriptions delete $PUBSUB_SUBSCRIPTION \
--project=$PROJECT_ID --quiet
Supprimer un thème :
gcloud pubsub topics delete $PUBSUB_TOPIC \
--project=$PROJECT_ID --quiet
Supprimer une instance Cloud Spanner
Supprimez l'instance Cloud Spanner (cela supprime automatiquement les bases de données sharded-target-db et migration-metadata-db qu'elle contient).
gcloud spanner instances delete $SPANNER_INSTANCE_NAME \
--project=$PROJECT_ID --quiet
Supprimer le bucket GCS et son contenu
Enfin, supprimez le bucket Cloud Storage contenant les fichiers Datastream, les configurations Dataflow et les files d'attente de messages non distribués. La commande rm -r supprime de manière récursive le bucket et tout son contenu.
gcloud storage rm --recursive gs://${BUCKET_NAME}
Supprimer les fichiers Cloud Shell locaux
Pour nettoyer les fichiers et répertoires locaux générés dans Cloud Shell pendant cet atelier de programmation, exécutez les commandes suivantes :
# Remove the JSON configuration files
rm -f sharding.json live-sharding.json reverse-sharding.json spanner_overrides.json
# Remove the cloned Google Cloud DataflowTemplates repository
rm -rf DataflowTemplates