
۱. قبل از شروع
این آزمایشگاه کد شما را در انتقال یک پایگاه داده MySQL تکه تکه شده به یک پایگاه داده Cloud Spanner با گویش GoogleSQL راهنمایی میکند. شما از سرویسهای Google Cloud شامل ابزار مهاجرت Spanner (SMT)، Dataflow، Datastream، PubSub و Google Cloud Storage استفاده خواهید کرد.
آنچه یاد خواهید گرفت:
- محیط شارد شده چیست و چگونه میتوان آن را راهاندازی کرد؟
- نحوه استفاده از رابط کاربری وب ابزار مهاجرت Spanner (SMT) برای تبدیل یک طرحواره MySQL به یک طرحواره سازگار با Spanner و انجام اصلاحات پیشرفته طرحواره.
- نحوه انجام مهاجرت حجم زیادی از دادههای حجیم از نمونه MySQL خرد شده به Cloud Spanner با استفاده از Dataflow.
- نحوه تنظیم تکثیر مداوم (CDC) از نمونه MySQL خرد شده به Cloud Spanner با استفاده از Datastream و Dataflow.
- نحوه پیکربندی Reverse Replication از Spanner برای بازگشت به نمونههای MySQL تکه تکه شده.
- نحوه استفاده از تبدیلهای سفارشی برای پر کردن ستونهای اضافی در طول مهاجرتهای گروهی، زنده و معکوس.
- نحوه پیکربندی تبدیلهای شاردینگ با استفاده از کلیدهای اصلی.
آنچه این آزمایشگاه کد پوشش نمیدهد:
- شبکهسازی سفارشی پیشرفته
- ساخت قالبهای سفارشی Dataflow از ابتدا
- تنظیم عملکرد مهاجرت.
- مهاجرت برنامه: این آزمایشگاه کد بر لایه پایگاه داده (طرحواره و داده) تمرکز دارد. این آزمایشگاه فرآیند عملیاتی استقرار مجدد یا مهاجرت سرویسهای برنامه شما را پوشش نمیدهد.
آنچه نیاز دارید
- یک پروژه گوگل کلود با قابلیت پرداخت.
- مجوزهای کافی IAM برای فعال کردن APIها و ایجاد/مدیریت منابع Spanner، Dataflow، Datastream و GCS. در حالی که نقش
Ownerپروژه برای یک آزمایشگاه کد سادهترین نقش است، نقشهای خاصتر در «تنظیمات محیط» پوشش داده خواهند شد. - ما در طول مرحله راهاندازی، یک ماشین مجازی کوچک Compute Engine برای شبیهسازی سرور داخلی خود فراهم خواهیم کرد. اطمینان حاصل کنید که سهمیه پروژه شما امکان ایجاد ماشین مجازی را فراهم میکند.
- یک مرورگر وب، مانند گوگل کروم.
- آشنایی اولیه با کنسول گوگل کلود و ابزارهای خط فرمان مانند
gcloud. - دسترسی به محیط shell. استفاده از Cloud Shell توصیه میشود زیرا شامل
gcloudمیشود.
جزئیات بیشتر در مورد تنظیمات فوق در بخش تنظیمات محیط پوشش داده شده است.
۲. درک فرآیند مهاجرت
مهاجرت یک پایگاه داده sharded شامل تجمیع چندین نمونه فیزیکی و منطقی MySQL در یک پایگاه داده Spanner واحد و مقیاسپذیر افقی است. این بخش معماری و ابزارهای کلیدی مورد استفاده در این مهاجرت را شرح میدهد.
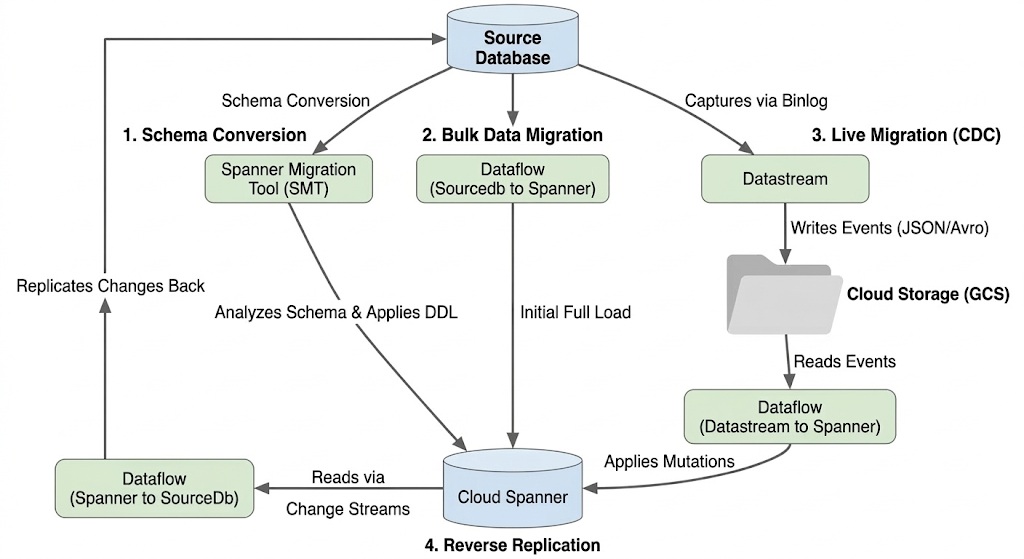
معماری جریان مهاجرت
روند مهاجرت شامل این مراحل است:
۱. تبدیل طرحواره:
- هدف: تبدیل طرحواره پایگاه داده منبع به یک طرحواره سازگار با Cloud Spanner.
- ابزار: ابزار مهاجرت Spanner (SMT)
- فرآیند: SMT طرحواره پایگاه داده منبع را تجزیه و تحلیل میکند و معادل آن را تولید میکند. زبان تعریف داده Spanner (DDL). در نمونه Spanner هدف، یک پایگاه داده ایجاد میشود و سپس DDL به طور خودکار اعمال میشود.
۲. مهاجرت دادههای حجیم:
- هدف: انجام بارگذاری اولیه و کامل دادههای موجود از پایگاه داده منبع به جداول Spanner فراهم شده.
- ابزار: Dataflow، با استفاده از الگوی
Sourcedb to Spannerارائه شده توسط گوگل. - فرآیند: این کار Dataflow تمام دادهها را از جداول منبع مشخص شده میخواند و آنها را در جداول Spanner مربوطه مینویسد. این کار پس از ایجاد طرحواره Spanner انجام میشود.
۳. مهاجرت زنده (CDC):
- هدف: ثبت و اعمال تغییرات مداوم از پایگاه داده منبع به Cloud Spanner تقریباً به صورت بلادرنگ، و به حداقل رساندن زمان از کارافتادگی در طول مهاجرت.
- ابزارها:
- جریان داده: تغییرات (درج، بهروزرسانی، حذف) را از پایگاه داده منبع ثبت کرده و آنها را در فضای ذخیرهسازی ابری (GCS) مینویسد.
- جریان داده: از الگوی
Datastream to Spannerبرای خواندن رویدادهای تغییر از GCS و اعمال آنها به Cloud Spanner استفاده میکند.
۴. همانندسازی معکوس:
- هدف: تکرار تغییرات دادهها از Cloud Spanner به پایگاه داده منبع. این میتواند برای استراتژیهای بازگشت به نسخه قبلی، مهاجرتهای مرحلهای یا حفظ یک نسخه مشابه در منبع برای موارد استفاده خاص مفید باشد.
- ابزار: Dataflow، با استفاده از الگوی
Spanner to SourceDb. - فرآیند: این کار از جریانهای تغییر Spanner برای ثبت تغییرات در Spanner و نوشتن مجدد آنها در نمونه پایگاه داده منبع استفاده میکند.
نمودار زیر اجزا و جریان داده را نشان میدهد:
اصطلاحات کلیدی:
- Shard فیزیکی: سرور یا نمونه محاسباتی اصلی که پایگاه داده را میزبانی میکند (در مورد ما، ماشین مجازی GCE شبیهسازی شده در محل).
- تکه منطقی: طرحواره پایگاه داده منفرد درون یک سرور فیزیکی.
- ماشین مجازی موتور محاسباتی (GCE) : یک ماشین مجازی که بر روی زیرساخت ابری گوگل میزبانی میشود. در این آزمایشگاه کد، ما از یک ماشین مجازی GCE برای شبیهسازی یک سرور مستقل و "در محل" که میزبان پایگاه داده MySQL منبع ما است، استفاده میکنیم.
- ابزار مهاجرت Spanner (SMT) : ابزاری که برای ارزیابی طرحوارههای MySQL، پیشنهاد معادلهای طرحواره Spanner و تولید زبان تعریف داده Spanner (DDL) استفاده میشود.
- زبان تعریف داده (DDL): دستوراتی که برای تعریف و تغییر ساختار پایگاه داده استفاده میشوند، مانند دستورات
CREATE TABLE. SMT دستورات DDL مربوط به Spanner را بر اساس طرح Cloud SQL تولید میکند. - Dataflow : یک سرویس پردازش داده کاملاً مدیریتشده و بدون سرور. در این آزمایشگاه کد، از آن برای اجرای قالبهای ارائه شده توسط گوگل برای انتقال دادههای انبوه، اعمال تغییرات Datastream و تکثیر معکوس استفاده میشود.
- Datastream : یک سرویس ضبط و تکثیر تغییرات (CDC) بدون سرور. در این آزمایشگاه کد، از آن برای انتقال تغییرات از نمونه MySQL میزبانی شده محلی به فضای ذخیرهسازی ابری استفاده میشود.
- Spanner Change Streams : یک ویژگی Spanner که امکان ارسال تغییرات در دادهها (درج، بهروزرسانی، حذف) را به صورت بلادرنگ فراهم میکند و به عنوان منبعی برای تکثیر معکوس استفاده میشود.
- Pub/Sub : یک سرویس پیامرسانی است که برای جدا کردن سرویسهایی که رویدادها را تولید میکنند از سرویسهایی که آنها را پردازش میکنند، استفاده میشود. در این آزمایشگاه کد، این سرویس، Dataflow را برای پردازش بهروزرسانیها، هر زمان که Datastream فایلهای تغییر جدید را در Cloud Storage آپلود میکند، فعال میکند.
۳. تنظیمات محیطی
قبل از شروع مهاجرت، باید پروژه Google Cloud خود را راهاندازی کرده و سرویسهای لازم را فعال کنید.
۱. یک پروژه گوگل کلود انتخاب یا ایجاد کنید
برای استفاده از خدمات این آزمایشگاه کد، به یک پروژه Google Cloud با قابلیت پرداخت صورتحساب نیاز دارید.
- در کنسول گوگل کلود، به صفحه انتخاب پروژه بروید: به انتخاب پروژه بروید
- یک پروژه Google Cloud انتخاب یا ایجاد کنید.
- مطمئن شوید که صورتحساب برای پروژه شما فعال است. یاد بگیرید که چگونه تأیید کنید که صورتحساب برای پروژه شما فعال است .
۲. پوسته ابری را باز کنید
Cloud Shell یک محیط خط فرمان است که در Google Cloud اجرا میشود و از قبل با رابط خط فرمان gcloud و سایر ابزارهای مورد نیاز شما بارگذاری شده است.
- روی دکمهی «فعالسازی پوستهی ابری» در سمت راست بالای کنسول ابری گوگل کلیک کنید.
- یک جلسه Cloud Shell درون یک قاب جدید در پایین کنسول باز میشود و یک اعلان خط فرمان را نمایش میدهد.

۳. تنظیم متغیرهای پروژه و محیط
در Cloud Shell، برخی از متغیرهای محیطی را برای شناسه پروژه و منطقهای که استفاده خواهید کرد، تنظیم کنید.
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1" # Or your preferred region
export ZONE="us-central1-a" # Or a zone within your selected region
gcloud config set project $PROJECT_ID
gcloud config set compute/region $REGION
gcloud config set compute/zone $ZONE
echo "Project ID: $PROJECT_ID"
echo "Region: $REGION"
echo "Zone: $ZONE"
۴. فعال کردن APIهای مورد نیاز گوگل کلود
APIهای لازم برای Cloud Spanner، Dataflow، Datastream و سایر سرویسهای مرتبط را فعال کنید.
gcloud services enable \
spanner.googleapis.com \
dataflow.googleapis.com \
datastream.googleapis.com \
pubsub.googleapis.com \
storage.googleapis.com \
compute.googleapis.com \
sqladmin.googleapis.com \
servicenetworking.googleapis.com \
cloudresourcemanager.googleapis.com
اجرای این دستور ممکن است چند دقیقه طول بکشد.
۴. پایگاه داده MySQL منبع را تنظیم کنید
در این بخش، ما با تهیه دو ماشین مجازی Compute Engine (دو "شارد فیزیکی" ما) یک معماری MySQL شارد شده در محل را شبیهسازی خواهیم کرد. سپس MySQL را روی هر دو نصب کرده و دو پایگاه داده ("شاردهای منطقی" ما) روی هر ماشین مجازی ایجاد خواهیم کرد.
۱. ایجاد ماشینهای مجازی موتور محاسباتی (Physical Shards)
دستورات زیر را در Cloud Shell اجرا کنید تا دو ماشین مجازی با اوبونتو ایجاد شود. ما بعداً به آنها برچسبهای شبکه اختصاص خواهیم داد تا ترافیک ورودی MySQL را مجاز کنیم.
# Create Physical Shard 1
gcloud compute instances create mysql-physical-1 \
--zone=$ZONE \
--machine-type=e2-small \
--image-family=ubuntu-2204-lts \
--image-project=ubuntu-os-cloud \
--tags=mysql-server
# Create Physical Shard 2
gcloud compute instances create mysql-physical-2 \
--zone=$ZONE \
--machine-type=e2-small \
--image-family=ubuntu-2204-lts \
--image-project=ubuntu-os-cloud \
--tags=mysql-server
۲. پیکربندی قوانین فایروال
برای دسترسی امن به SSH بدون نمایش عمومی و فعال کردن اتصال Datastream:
ایجاد قانون فایروال برای SSH از طریق IAP:
این قانون به Identity-Aware Proxy اجازه میدهد تا به ماشینهای مجازی شما روی پورت SSH (22) دسترسی پیدا کند.
gcloud compute firewall-rules create allow-ssh-iap \
--direction=INGRESS \
--priority=1000 \
--network=default \
--action=ALLOW \
--rules=tcp:22 \
--source-ranges=35.235.240.0/20 \
--target-tags=mysql-server
ایجاد قانون فایروال برای جریان داده (پورت MySQL):
جریان داده باید بتواند از طریق پورت استاندارد MySQL (3306) به این ماشینهای مجازی دسترسی پیدا کند.
gcloud compute firewall-rules create allow-mysql-datastream \
--direction=INGRESS \
--priority=1000 \
--network=default \
--action=ALLOW \
--rules=tcp:3306 \
--source-ranges=0.0.0.0/0 \
--target-tags=mysql-server
۳. نصب و پیکربندی MySQL روی Physical Shard 1
برای نصب MySQL و پیکربندی ثبت وقایع دودویی (که Datastream برای تکثیر زنده به آن نیاز دارد) به اولین ماشین مجازی خود SSH بزنید.
- به اولین ماشین مجازی SSH بزنید:
gcloud compute ssh mysql-physical-1 --zone=$ZONE --tunnel-through-iap
- نصب MySQL:
sudo apt-get update
sudo apt-get install mysql-server-8.0 -y
# Verify the installation and version
sudo mysql --version
- فایل
mysqld.cnfرا طوری پیکربندی کنید که ثبت وقایع باینری و اتصالات خارجی را فعال کند:
sudo sed -i 's/bind-address.*/bind-address = 0.0.0.0/' /etc/mysql/mysql.conf.d/mysqld.cnf
echo -e "[mysqld]\nserver-id=1\nlog_bin=/var/log/mysql/mysql-bin.log\nbinlog_format=ROW" | sudo tee -a /etc/mysql/mysql.conf.d/mysqld.cnf
- برای اعمال تغییرات، MySQL را مجدداً راهاندازی کنید:
sudo systemctl restart mysql
۴. ایجاد Shardهای منطقی، درج داده و ایجاد کاربر Datastream (Shard 1)
در حالی که هنوز به mysql-physical-1 از طریق SSH متصل هستید، وارد خط فرمان MySQL شوید:
sudo mysql
دستورات SQL زیر را اجرا کنید. این اسکریپت دو شارد منطقی مجزا ( shard0_db و shard1_db ) ایجاد میکند، طرحواره یکسانی را در هر دو تنظیم میکند، دادههای منحصر به فرد قابل شناسایی را در هر کدام وارد میکند (برای نمایش شاردینگ)، و کاربر تکثیر را برای Datastream ایجاد میکند.
دستورات SQL زیر را برای ایجاد دو Shard منطقی اول، یک جدول و کاربر تکثیر برای Datastream اجرا کنید:
CREATE DATABASE shard0_db;
CREATE DATABASE shard1_db;
USE shard0_db;
CREATE TABLE Customers (
CustomerId INT NOT NULL,
CustomerName VARCHAR(255),
CreditLimit DECIMAL(10, 2) NOT NULL,
LegacyRegion VARCHAR(50), -- Renamed to LoyaltyTier in Spanner
PRIMARY KEY (CustomerId),
CONSTRAINT CHK_CreditLimit CHECK (CreditLimit > 1000) -- Relaxed in Spanner to > 0
);
CREATE TABLE Orders (
CustomerId INT NOT NULL, -- Logically references Customers.CustomerId in Spanner
OrderId INT NOT NULL,
OrderValue DECIMAL(10, 2),
LegacyOrderSystem VARCHAR(50), -- Extra column in Source, to be dropped in Spanner
PRIMARY KEY (CustomerId, OrderId) -- Spanner PK will have one additional column in PK
);
INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LegacyRegion) VALUES
(4, 'David E.', 2000.00, 'EAST'),
(8, 'Eleanor F.', 8100.00, 'WEST'),
(12, 'Frank G.', 12000.00, 'NORTH'),
(16, 'Grace H.', 6500.00, 'SOUTH');
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem) VALUES
(4, 101, 150.00, 'WebStore_v1'),
(4, 102, 25.50, 'InStore_POS'),
(8, 103, 75.00, 'MobileApp_Legacy'),
(12, 104, 3000.00, 'WebStore_v1'),
(16, 105, 120.00, 'Partner_API');
USE shard1_db;
CREATE TABLE Customers (
CustomerId INT NOT NULL,
CustomerName VARCHAR(255),
CreditLimit DECIMAL(10, 2) NOT NULL,
LegacyRegion VARCHAR(50), -- Renamed to LoyaltyTier in Spanner
PRIMARY KEY (CustomerId),
CONSTRAINT CHK_CreditLimit CHECK (CreditLimit > 1000) -- Relaxed in Spanner to > 0
);
CREATE TABLE Orders (
CustomerId INT NOT NULL, -- Logically references Customers.CustomerId in Spanner
OrderId INT NOT NULL,
OrderValue DECIMAL(10, 2),
LegacyOrderSystem VARCHAR(50), -- Extra column in Source, to be dropped in Spanner
PRIMARY KEY (CustomerId, OrderId) -- Spanner PK will have one additional column in PK
);
INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LegacyRegion) VALUES
(1, 'Agnes N.', 5100.00, 'NORTHEAST'),(5, 'Alice I.', 15000.00, 'EAST'),
(9, 'Bob J.', 7500.00, 'WEST'),
(13, 'Charlie K.', 2200.00, 'CENTRAL');
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem) VALUES
(1, 201, 50.00, 'MobileApp_Legacy'),
(5, 202, 1250.00, 'WebStore_v1'),
(5, 203, 80.00, 'Partner_API'),
(9, 204, 600.00, 'InStore_POS'),
(13, 205, 199.99, 'WebStore_v1');
-- Create Datastream Replication User
CREATE USER 'datastream_user'@'%' IDENTIFIED BY 'complex_password_123';
GRANT REPLICATION SLAVE, REPLICATION CLIENT, SELECT, INSERT, UPDATE, DELETE ON *.* TO 'datastream_user'@'%';
FLUSH PRIVILEGES;
فایل dump مربوط به طرحواره فوق را میتوانید اینجا پیدا کنید. ایجاد کاربر تکثیر جریان داده (datastream replication user) به صورت جداگانه مهم است زیرا در فایل dump وجود ندارد.
۵. دادهها را تأیید کنید
به سرعت بررسی کنید که دادهها موجود هستند:
SELECT 'Customers shard0_db' AS tbl, COUNT(*) FROM shard0_db.Customers
UNION ALL
SELECT 'Orders shard0_db', COUNT(*) FROM shard0_db.Orders
UNION ALL
SELECT 'Customers shard1_db', COUNT(*) FROM shard1_db.Customers
UNION ALL
SELECT 'Orders shard1_db', COUNT(*) FROM shard1_db.Orders;
EXIT;
خروجی مورد انتظار:
+---------------------+----------+ | tbl | COUNT(*) | +---------------------+----------+ | Customers shard0_db | 4 | | Orders shard0_db | 5 | | Customers shard1_db | 4 | | Orders shard1_db | 5 | +---------------------+----------+
برای خروج از اتصال به ماشین مجازی شارد فیزیکی ۱، exit را وارد کنید.
۶. برای Physical Shard 2 تکرار کنید
اکنون دقیقاً همین فرآیند را برای ماشین مجازی دوم تکرار خواهید کرد، اما shard2_db و shard3_db ایجاد کرده و server-id تغییر خواهید داد.
- با SSH به ماشین مجازی دوم متصل شوید:
gcloud compute ssh mysql-physical-2 --zone=$ZONE --tunnel-through-iap
- نصب MySQL:
sudo apt-get update
sudo apt-get install mysql-server-8.0 -y
- فایل
mysqld.cnfرا طوری پیکربندی کنید که ثبت وقایع باینری را فعال کند و به اتصالات خارجی اجازه اتصال دهد [توجه داشته باشید که شناسه سرور باید متفاوت باشد (مثلاً ۲)]
sudo sed -i 's/bind-address.*/bind-address = 0.0.0.0/' /etc/mysql/mysql.conf.d/mysqld.cnf
echo -e "[mysqld]\nserver-id=2\nlog_bin=/var/log/mysql/mysql-bin.log\nbinlog_format=ROW" | sudo tee -a /etc/mysql/mysql.conf.d/mysqld.cnf
- برای اعمال تغییرات، MySQL را مجدداً راهاندازی کنید:
sudo systemctl restart mysql
- وارد MySQL شوید (
sudo mysql) و نسخه کمی اصلاحشده SQL از مرحله ۴ را اجرا کنید:
CREATE DATABASE shard2_db;
CREATE DATABASE shard3_db;
USE shard2_db;
CREATE TABLE Customers (
CustomerId INT NOT NULL,
CustomerName VARCHAR(255),
CreditLimit DECIMAL(10, 2) NOT NULL,
LegacyRegion VARCHAR(50), -- Renamed to LoyaltyTier in Spanner
PRIMARY KEY (CustomerId),
CONSTRAINT CHK_CreditLimit CHECK (CreditLimit > 1000) -- Relaxed in Spanner to > 0
);
CREATE TABLE Orders (
CustomerId INT NOT NULL, -- Logically references Customers.CustomerId in Spanner
OrderId INT NOT NULL,
OrderValue DECIMAL(10, 2),
LegacyOrderSystem VARCHAR(50), -- Extra column in Source, to be dropped in Spanner
PRIMARY KEY (CustomerId, OrderId) -- Spanner PK will have one additional column in PK
);
INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LegacyRegion) VALUES
(2, 'Brian K.', 2500.00, 'SOUTHWEST'),
(6, 'Diana L.', 1999.00, 'NORTH'),
(10, 'Edward M.', 11000.00, 'EAST'),
(14, 'Fiona N.', 3000.00, 'WEST');
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem) VALUES
(2, 301, 100.00, 'CallCenter_System'),
(6, 302, 99.00, 'MobileApp_Legacy'),
(10, 303, 1000.00, 'WebStore_v1'),
(10, 304, 2500.00, 'InStore_POS'),
(14, 305, 130.00, 'MobileApp_Legacy');
USE shard3_db;
CREATE TABLE Customers (
CustomerId INT NOT NULL,
CustomerName VARCHAR(255),
CreditLimit DECIMAL(10, 2) NOT NULL,
LegacyRegion VARCHAR(50), -- Renamed to LoyaltyTier in Spanner
PRIMARY KEY (CustomerId),
CONSTRAINT CHK_CreditLimit CHECK (CreditLimit > 1000) -- Relaxed in Spanner to > 0
);
CREATE TABLE Orders (
CustomerId INT NOT NULL, -- Logically references Customers.CustomerId in Spanner
OrderId INT NOT NULL,
OrderValue DECIMAL(10, 2),
LegacyOrderSystem VARCHAR(50), -- Extra column in Source, to be dropped in Spanner
PRIMARY KEY (CustomerId, OrderId) -- Spanner PK will have one additional column in PK
);
INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LegacyRegion) VALUES
(3, 'Cathy Z.', 6000.00, 'CENTRAL'),
(7, 'George O.', 18000.00, 'SOUTH'),
(11, 'Helen P.', 4000.00, 'NORTHEAST'),
(15, 'Ivy Q.', 9500.00, 'SOUTHWEST');
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem) VALUES
(3, 401, 600.00, 'InStore_POS'),
(7, 402, 1200.00, 'CallCenter_System'),
(11, 403, 350.00, 'MobileApp_Legacy'),
(15, 404, 800.00, 'WebStore_v1'),
(99, 999, 25.00, 'CallCenter_System'); -- Failure row during Bulk Migration due to violation of interleaving
-- Create Datastream Replication User
CREATE USER 'datastream_user'@'%' IDENTIFIED BY 'complex_password_123';
GRANT REPLICATION SLAVE, REPLICATION CLIENT, SELECT, INSERT, UPDATE, DELETE ON *.* TO 'datastream_user'@'%';
FLUSH PRIVILEGES;
-- Verify Data
SELECT 'Customers shard2_db' AS tbl, COUNT(*) FROM shard2_db.Customers
UNION ALL
SELECT 'Orders shard2_db', COUNT(*) FROM shard2_db.Orders
UNION ALL
SELECT 'Customers shard3_db', COUNT(*) FROM shard3_db.Customers
UNION ALL
SELECT 'Orders shard3_db', COUNT(*) FROM shard3_db.Orders;
EXIT;
خروجی مورد انتظار:
+---------------------+----------+ | tbl | COUNT(*) | +---------------------+----------+ | Customers shard2_db | 4 | | Orders shard2_db | 5 | | Customers shard3_db | 4 | | Orders shard3_db | 5 | +---------------------+----------+
فایل dump مربوط به طرحواره فوق را میتوانید اینجا پیدا کنید. ایجاد کاربر تکثیر جریان داده (datastream replication user) به صورت جداگانه مهم است زیرا در فایل dump وجود ندارد.
برای خروج از اتصال به ماشین مجازی، exit را وارد کنید.
۵. تنظیم اسپنر ابری
اکنون، نمونهی هدف Cloud Spanner را که دادهها به آن منتقل خواهند شد، تنظیم خواهید کرد.
۱. یک نمونهی Cloud Spanner ایجاد کنید
برای به حداقل رساندن تأخیر، یک نمونه Cloud Spanner در همان منطقهای که ماشینهای مجازی Compute Engine شما قرار دارند، ایجاد کنید. این دستور با استفاده از ۱۰۰ واحد پردازشی، یک نمونه کوچک مناسب برای این آزمایشگاه کد ایجاد میکند.
export SPANNER_INSTANCE_NAME="target-spanner-instance"
export SPANNER_DATABASE_NAME="sharded-target-db"
export SPANNER_CONFIG="regional-${REGION}"
gcloud spanner instances create $SPANNER_INSTANCE_NAME \
--config=$SPANNER_CONFIG \
--description="Target Spanner Instance" \
--processing-units=100
ایجاد نمونه ممکن است یک یا دو دقیقه طول بکشد.
۶. تبدیل طرحواره با استفاده از ابزار مهاجرت Spanner (SMT)
از رابط کاربری وب ابزار مهاجرت Spanner (SMT) برای اتصال به یکی از Shardهای منطقی ما ( shard0_db ) استفاده کنید، طرحواره آن را تجزیه و تحلیل کنید و قبل از تبدیل آن به Cloud Spanner، چندین اصلاح پیشرفته اعمال کنید.
۱. نصب SMT
ما رابط کاربری وب SMT را مستقیماً از Cloud Shell اجرا خواهیم کرد. در ترمینال Cloud Shell خود، آخرین نسخه SMT را دانلود و استخراج کنید:
sudo apt-get update && sudo apt-get install google-cloud-cli-spanner-migration-tool
# Verify installation
gcloud alpha spanner migrate web --help
۲. اتصال به پایگاه داده منبع
- جلسه خود را تأیید کنید
# Authenticate your Google Cloud account
gcloud auth login
# Set up Application Default Credentials (ADC) for SMT
gcloud auth application-default login
# Ensure your current project is set correctly
gcloud config set project $PROJECT_ID
(توجه: وقتی از شما خواسته شد، URL ارائه شده را برای تأیید حساب خود دنبال کنید و کد تأیید را دوباره در ترمینال وارد کنید.)
- ابتدا، با اجرای دستور زیر در یک تب جدید Cloud Shell، IP خارجی اولین Shard فیزیکی خود را پیدا کنید:
gcloud compute instances describe mysql-physical-1 --zone=$ZONE --format='get(networkInterfaces[0].accessConfigs[0].natIP)'
- جزئیات نمونهی آچار هدف را که هنگام پیکربندی SMT استفاده میشود، چاپ کنید.
echo "Project ID: $PROJECT_ID"
echo "Instance ID: $SPANNER_INSTANCE_NAME"
echo "Database Name: $SPANNER_DATABASE_NAME"
- رابط کاربری وب را اجرا کنید:
gcloud alpha spanner migrate web --port=8080
- در سمت راست بالای پنجره Cloud Shell خود، روی نماد پیشنمایش وب (که شبیه چشم است) کلیک کنید و پیشنمایش را روی پورت ۸۰۸۰ انتخاب کنید. این کار رابط کاربری SMT را در یک برگه مرورگر جدید باز میکند.

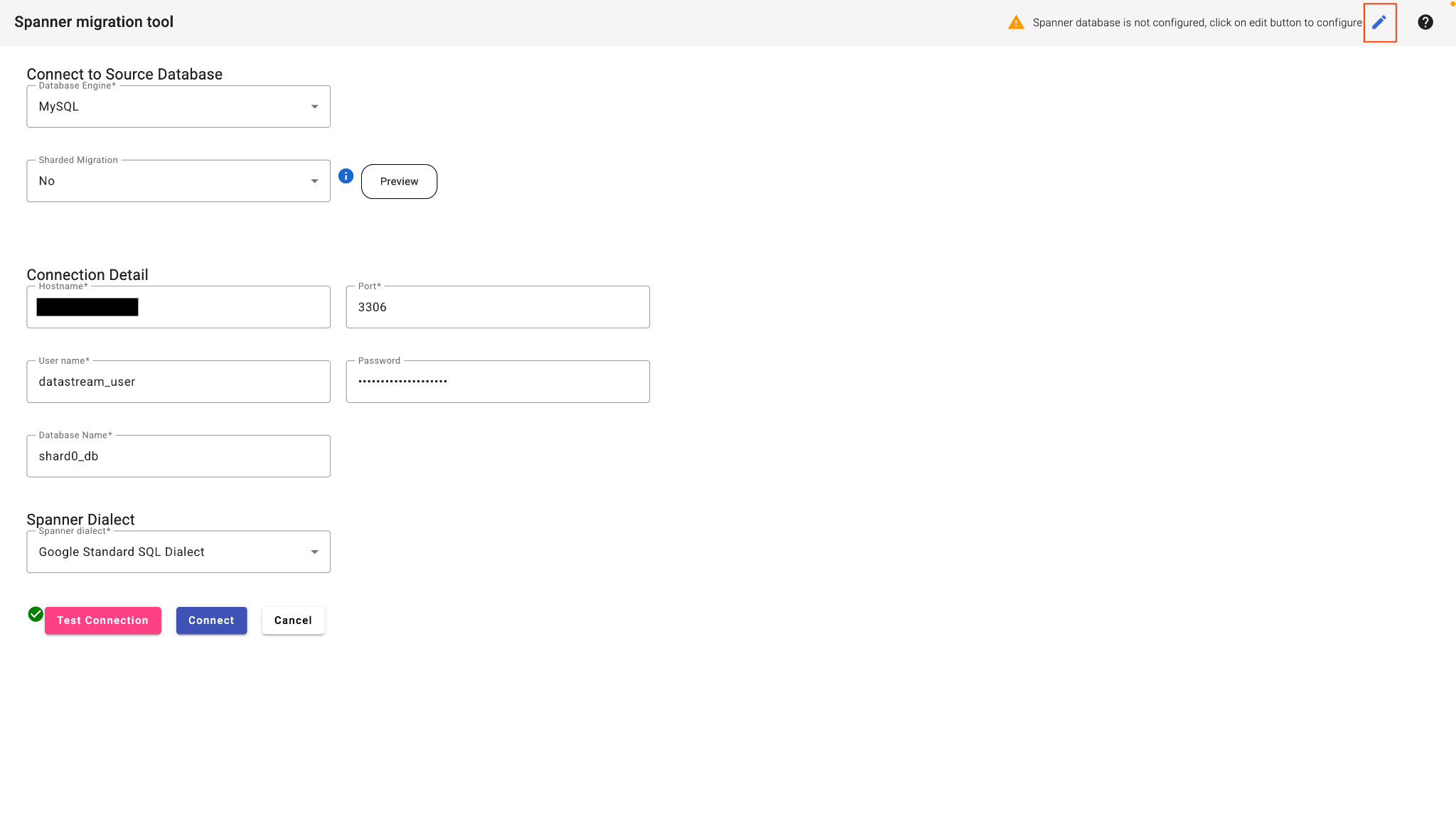
- در رابط کاربری وب SMT، گزینه اتصال به پایگاه داده را انتخاب کنید.
- جزئیات اتصال را پر کنید:
- نوع پایگاه داده: MySQL
- میزبان: (آدرس IP را از مرحله ۲ وارد کنید)
- بندر: ۳۳۰۶
- کاربر:
datastream_user - رمز عبور:
complex_password_123 - نام پایگاه داده:
shard0_db
- برای پیکربندی پایگاه داده Spanner، روی دکمه ویرایش در گوشه بالا سمت راست کلیک کنید.
- جزئیات Target Spanner خود را وارد کنید:
- شناسه پروژه: (شناسه پروژه را از مرحله ۳ وارد کنید)
- نمونهی آچار: (شناسهی نمونه را از مرحلهی ۳ جایگذاری کنید)
- روی تست اتصال کلیک کنید.
- پس از طی شدن این مرحله، روی «اتصال» کلیک کنید. SMT پایگاه داده منبع را تجزیه و تحلیل کرده و یک طرحواره پایه Spanner ارائه میدهد.
۳. اعمال تغییرات طرحواره
اکنون طرحواره را تغییر شکل میدهیم تا سناریوهای پیچیده مهاجرت خود را پوشش دهد.
در ویرایشگر طرحواره رابط کاربری SMT، اقدامات زیر را انجام دهید:
الف. ستون LegacyRegion را تغییر نام دهید:
- روی جدول
Customersدر پنل ناوبری سمت چپ کلیک کنید. این کار به طور پیشفرض تب ستونها را باز میکند. - روی دکمه ویرایش در بخش آچار کلیک کنید.
- ستون
LegacyRegionرا در نمای طرحواره Spanner پیدا کنید. - با تایپ کردن در کادر محاورهای نام ستون، نام ستون Spanner را به
LoyaltyTierتغییر دهید. - روی ذخیره و تبدیل کلیک کنید.


ب. محدودیت بررسی را کاهش دهید:
- همچنان که در جدول
Customersهستید، به تب Check Constraints بروید. - محدودیت
CHK_CreditLimitرا پیدا کنید. روی نماد ویرایش (مداد) کلیک کنید. - شرط را از
CreditLimit > 1000بهCreditLimit > 0تغییر دهید. (این کار عمداً باعث میشود ردیفهایی که محدودیت اعتبار پایینتری دارند، مهاجرت معکوس را با شکست مواجه کرده و به DLQ منتقل شوند.)

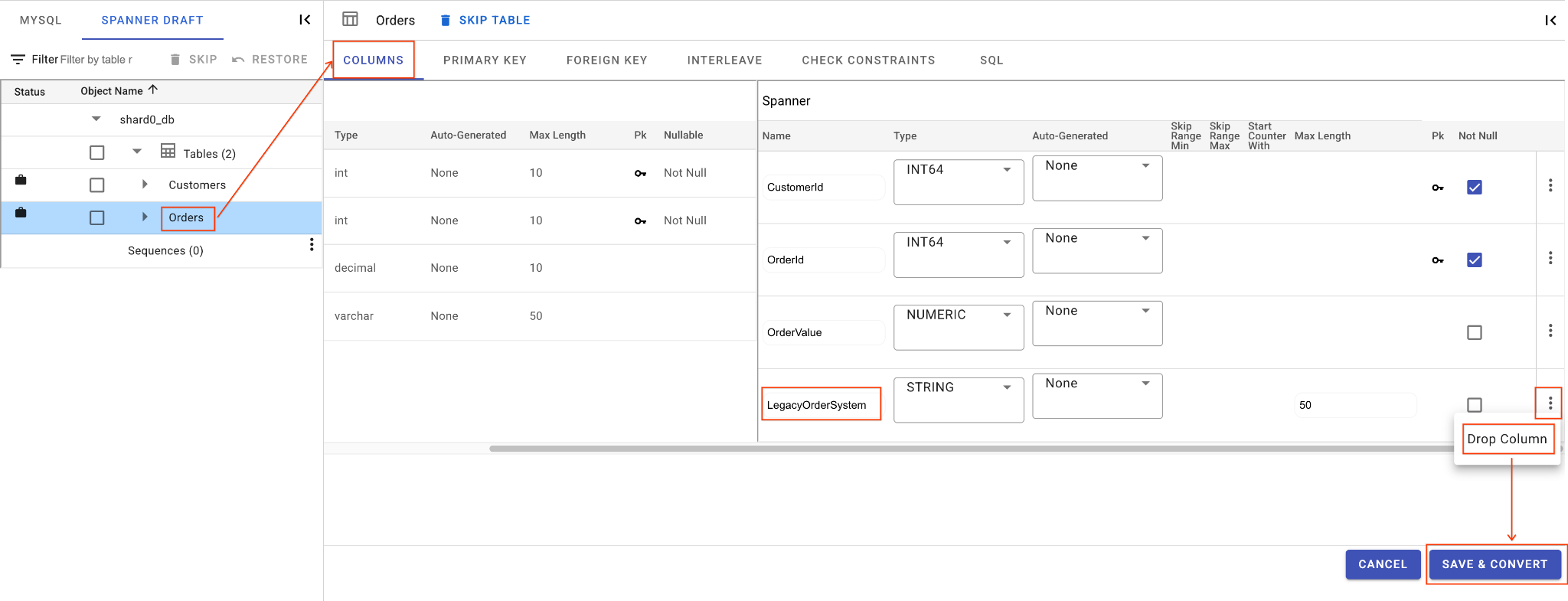
ج. ستون LegacyOrderSystem را حذف کنید:
- روی جدول
Ordersکلیک کنید، به طور پیشفرض تب Columns باز میشود. - روی دکمه ویرایش در بخش آچار کلیک کنید.
- ستون
LegacyOrderSystemرا در نمای طرحواره Spanner پیدا کنید. - روی نماد منوی سهنقطهای کنار آن کلیک کنید و گزینهی «رها کردن ستون» را انتخاب کنید.
- روی ذخیره و تبدیل کلیک کنید.
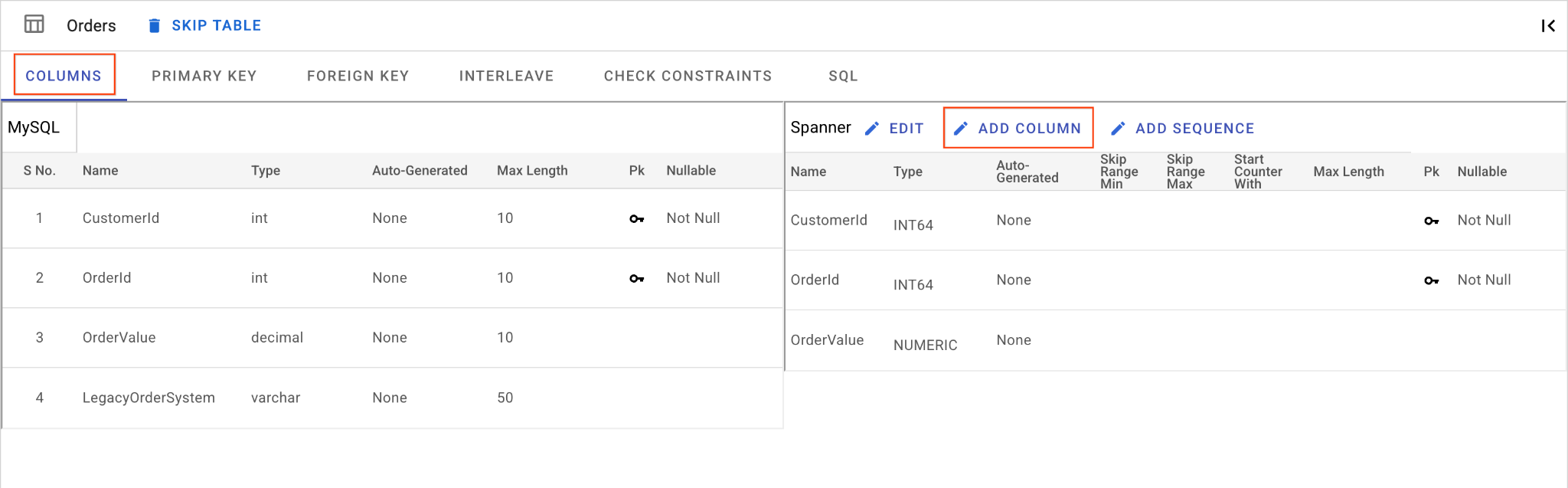
د. ستون OrderSource را اضافه کنید و آن را به عنوان کلید اصلی (Primary Key) قرار دهید:
- همچنان که در جدول
Orders، روی Add Column کلیک کنید. نام آن راOrderSourceبگذارید و نوع آن را رویSTRINGبا طول50، بدون تولید خودکار وIsNullableرا رویNoتنظیم کنید. - به برگه کلید اصلی بروید.
- روی ویرایش کلیک کنید و از منوی کشویی نام ستون،
OrderSourceرا انتخاب کنید. - روی افزودن ستون کلیک کنید و سپس ذخیره و تبدیل را انجام دهید .

ه. جدول سفارشات را در جای مناسب قرار دهید:
- همچنان که در جدول
Ordersهستید، در نمای جدول اصلی، تب Interleave را پیدا کنید. - جدول والد را روی
Customersتنظیم کنید. - نوع Interleave را
IN PARENTو در مورد Delete ActionNO ACTIONانتخاب کنید. - روی ذخیره کلیک کنید.

۴. دانلود فایل Overrides و اعمال Schema
- در گوشه سمت راست بالای رابط کاربری SMT، دکمه Download Artifacts را پیدا کنید. گزینه Download Overrides File را انتخاب کنید. این فایل را در دستگاه محلی خود ذخیره کنید. این فایل شامل تمام تغییرات نگاشت طرحواره است که ما ایجاد کردهایم و توسط خطوط لوله Dataflow ما استفاده خواهد شد.
- روی آمادهسازی مهاجرت کلیک کنید.
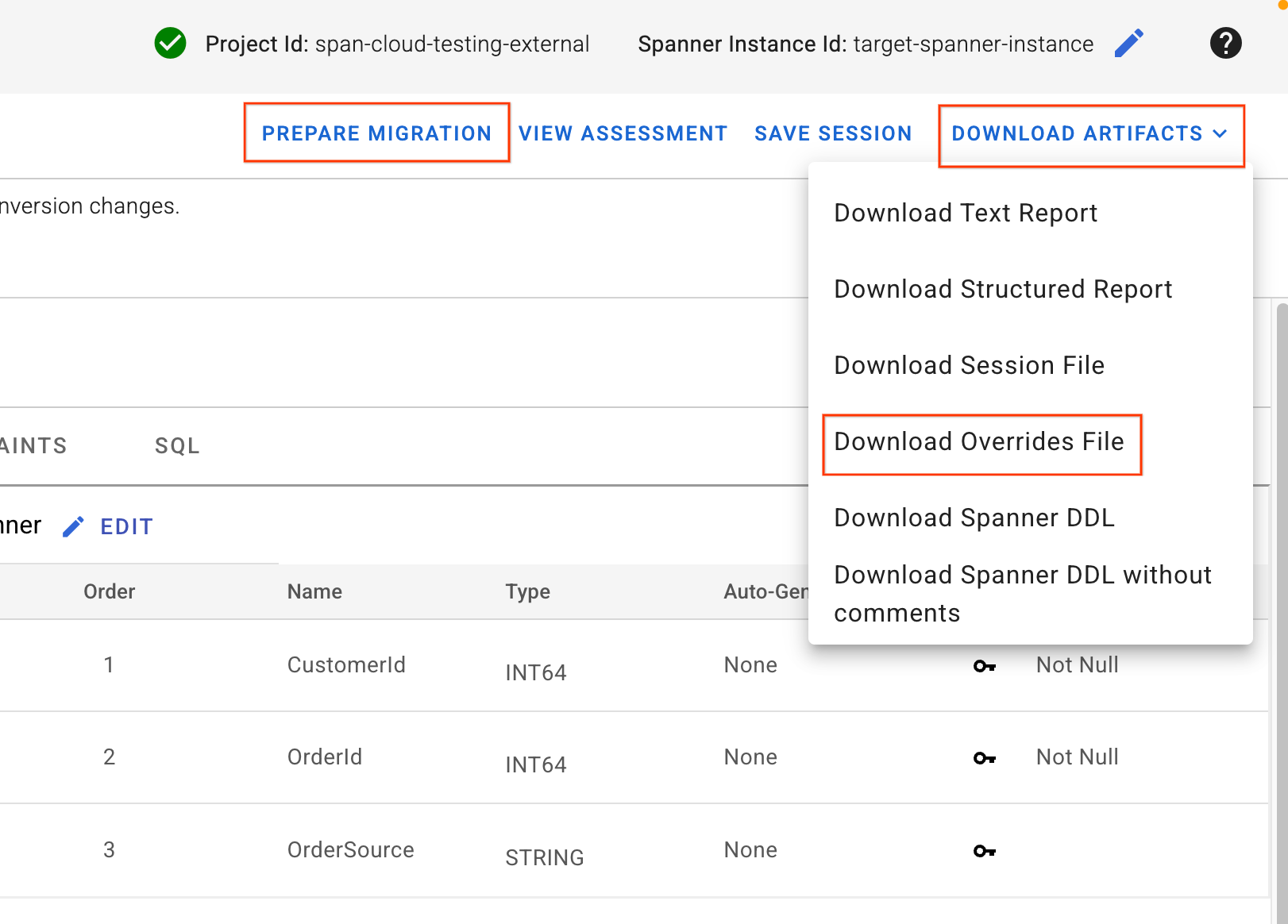
- از منوی کشویی، حالت مهاجرت (Migration Mode) را به عنوان
Schemaانتخاب کنید. - پایگاه داده Target Spanner خود را وارد کنید:
sharded-target-db

- روی مهاجرت کلیک کنید.
- SMT DDL را اعمال کرده و پایگاه داده Spanner را ایجاد میکند. میتوانید پس از اتمام فرآیند SMT در Cloud Shell (
Ctrl+C) با خیال راحت آن را متوقف کنید.
۵. تأیید طرحواره در Cloud Spanner
بررسی کنید که جداول در پایگاه داده Spanner ایجاد شده باشند.
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT table_name FROM information_schema.tables WHERE table_schema = '' ORDER BY table_name"
شما باید خروجی زیر را ببینید:
table_name: Customers table_name: Orders
اختیاری: اگر میخواهید Spanner DDL واقعی را بررسی کنید تا تأیید کنید که محدودیتهای بررسی، جایگذاری و ستونهای اضافی اعمال شدهاند، دستور زیر را اجرا کنید:
gcloud spanner databases ddl describe $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME
خروجی مورد انتظار:
CREATE TABLE Customers ( CustomerId INT64 NOT NULL, CustomerName STRING(255), CreditLimit NUMERIC NOT NULL, LoyaltyTier STRING(50), CONSTRAINT CHK_CreditLimit CHECK(`CreditLimit` > 0), ) PRIMARY KEY(CustomerId); CREATE TABLE Orders ( CustomerId INT64 NOT NULL, OrderId INT64 NOT NULL, OrderValue NUMERIC, OrderSource STRING(50) NOT NULL, ) PRIMARY KEY(CustomerId, OrderId, OrderSource), INTERLEAVE IN PARENT Customers ON DELETE NO ACTION;
۷. مقداردهی اولیهی ثبت دادههای تغییر (CDC)
در این بخش، شما "ضبطکننده" را برای مهاجرت خود تنظیم خواهید کرد. با پیکربندی Datastream و Pub/Sub قبل از شروع بارگذاری دادههای حجیم، اطمینان حاصل میکنید که هر تغییری که در پایگاههای داده منبع ایجاد میشود، ثبت و در صف قرار میگیرد و از هرگونه از دست رفتن دادهها در طول انتقال جلوگیری میشود. این تنظیمات برای مهاجرت زنده مورد نیاز است.
از آنجا که معماری ما شامل دو سرور فیزیکی است، باید دو پروفایل منبع Datastream جداگانه و دو جریان Datastream ایجاد کنیم. هر دو جریان در یک سطل Google Cloud Storage (GCS) واحد نوشته میشوند که به عنوان منبع یکپارچه برای خط لوله Dataflow ما عمل خواهد کرد.
۱. یک سطل ذخیرهسازی ابری ایجاد کنید
جریان داده به یک مقصد برای ذخیره رویدادهای تغییر ثبتشده نیاز دارد. بیایید یک سطل GCS ایجاد کنیم.
export BUCKET_NAME="migration-${PROJECT_ID}-bucket"
gcloud storage buckets create gs://${BUCKET_NAME} --location=$REGION
۲. ایجاد پروفایلهای اتصال جریان داده
ما به دو پروفایل اتصال منبع MySQL مجزا (یکی برای هر شارد فیزیکی) و یک پروفایل اتصال هدف برای Cloud Storage نیاز داریم.
دریافت آدرسهای IP مبدا
ابتدا، آدرسهای IP خارجی دو ماشین مجازی Compute Engine خود را دریافت کرده و آنها را به عنوان متغیرهای محیطی ذخیره کنید:
export MYSQL_IP_1=$(gcloud compute instances describe mysql-physical-1 --zone=$ZONE --format='get(networkInterfaces[0].accessConfigs[0].natIP)')
export MYSQL_IP_2=$(gcloud compute instances describe mysql-physical-2 --zone=$ZONE --format='get(networkInterfaces[0].accessConfigs[0].natIP)')
ایجاد پروفایلهای اتصال منبع (MySQL روی Compute Engine)
با استفاده از datastream_user که قبلاً ایجاد شده است، پروفایلهای اتصال Datastream را ایجاد کنید.
# Create Source Profile for Physical Shard 1
export SQL_CP_NAME_1="mysql-src-cp-1"
gcloud datastream connection-profiles create $SQL_CP_NAME_1 \
--location=$REGION \
--type=mysql \
--mysql-hostname=$MYSQL_IP_1 \
--mysql-port=3306 \
--mysql-username=datastream_user \
--mysql-password=complex_password_123 \
--display-name="MySQL Source 1 (Physical Shard 1)"
# Create Source Profile for Physical Shard 2
export SQL_CP_NAME_2="mysql-src-cp-2"
gcloud datastream connection-profiles create $SQL_CP_NAME_2 \
--location=$REGION \
--type=mysql \
--mysql-hostname=$MYSQL_IP_2 \
--mysql-port=3306 \
--mysql-username=datastream_user \
--mysql-password=complex_password_123 \
--display-name="MySQL Source 2 (Physical Shard 2)"
توجه: Datastream از طریق IP های عمومی آنها به این ماشینهای مجازی متصل میشود، که به دلیل اضافه کردن 0.0.0.0/0 به قوانین فایروال ما قبلاً مجاز است. در یک محیط عملیاتی، شما باید به شدت محدوده IP های عمومی خاص Datastream را در لیست خود قرار دهید.
ایجاد پروفایل اتصال مقصد (فضای ابری):
این به ریشه سطل تازه ایجاد شده شما اشاره دارد.
export GCS_CP_NAME="gcs-dest-cp"
gcloud datastream connection-profiles create $GCS_CP_NAME \
--location=$REGION \
--type=google-cloud-storage \
--bucket=$BUCKET_NAME \
--root-path=/ \
--display-name="GCS Destination" --force
۳. ایجاد جریانهای داده
اکنون دو جریان CDC ایجاد خواهیم کرد. جریان ۱ shard0_db و shard1_db را ضبط خواهد کرد. جریان ۲ shard2_db و shard3_db را ضبط خواهد کرد. هر دو جریان در یک سطل GCS با فرمت Avro مینویسند.
# Stream for Physical Shard 1
export STREAM_NAME_1="mysql-to-spanner-stream-1"
export GCS_STREAM_PATH_1="data/${STREAM_NAME_1}"
gcloud datastream streams create $STREAM_NAME_1 \
--location=$REGION \
--display-name="MySQL Source 1 CDC Stream" \
--source=$SQL_CP_NAME_1 \
--destination=$GCS_CP_NAME \
--mysql-source-config=<(echo "includeObjects:
mysqlDatabases:
- database: 'shard0_db'
- database: 'shard1_db'") \
--gcs-destination-config=<(echo "path: ${GCS_STREAM_PATH_1}/
fileRotationMb: 5
fileRotationInterval: 15s
avroFileFormat: {}") \
--backfill-none
# Stream for Physical Shard 2
export STREAM_NAME_2="mysql-to-spanner-stream-2"
export GCS_STREAM_PATH_2="data/${STREAM_NAME_2}"
gcloud datastream streams create $STREAM_NAME_2 \
--location=$REGION \
--display-name="MySQL Source 2 CDC Stream" \
--source=$SQL_CP_NAME_2 \
--destination=$GCS_CP_NAME \
--mysql-source-config=<(echo "includeObjects:
mysqlDatabases:
- database: 'shard2_db'
- database: 'shard3_db'") \
--gcs-destination-config=<(echo "path: ${GCS_STREAM_PATH_2}/
fileRotationMb: 5
fileRotationInterval: 15s
avroFileFormat: {}") \
--backfill-none
استفاده از تنظیمات چرخش فایل کوچکتر (۵ مگابایت یا ۱۵ ثانیه) به ما کمک میکند تا تغییرات تکرار شده را در طول آزمایش کد سریعتر ببینیم.
تکمیل این دستور ممکن است کمی طول بکشد. وضعیت را بررسی کنید: gcloud datastream streams describe $STREAM_NAME_1 --location=$REGION .
۴. شروع جریانهای داده
هر دو جریان را فعال کنید تا شروع به ضبط تغییرات کنند.
gcloud datastream streams update $STREAM_NAME_1 \
--location=$REGION \
--state=RUNNING
gcloud datastream streams update $STREAM_NAME_2 \
--location=$REGION \
--state=RUNNING
بررسی وضعیت: میتوانید gcloud datastream streams describe $STREAM_NAME_1 --location=$REGION اجرا کنید. وضعیت در ابتدا STARTING خواهد بود و پس از چند لحظه به RUNNING تغییر میکند. قبل از شروع مهاجرت زنده، صبر کنید تا هر دو به طور کامل اجرا شوند.
۵. تنظیمات Pub/Sub را برای اعلانهای GCS انجام دهید
جریان داده باید بلافاصله مطلع شود که هر یک از جریانهای داده، فایل جدیدی را در سطل GCS مینویسد. ما GCS را طوری پیکربندی خواهیم کرد که اعلانها را به یک موضوع Pub/Sub واحد ارسال کند.
ایجاد یک موضوع عمومی/زیرموضوع:
export PUBSUB_TOPIC="datastream-gcs-updates"
gcloud pubsub topics create $PUBSUB_TOPIC
ایجاد اعلان GCS
در صورت ایجاد هرگونه شیء تحت پیشوند data/ (که هر دو جریان ما را پوشش میدهد) به تاپیک اطلاع دهید.
gcloud storage buckets notifications create gs://${BUCKET_NAME} --topic=projects/$PROJECT_ID/topics/$PUBSUB_TOPIC --payload-format=json --object-prefix=data/
ایجاد یک اشتراک در Pub/Sub
اشتراک را با یک مهلت تأیید توصیهشده برای Dataflow ایجاد کنید.
export PUBSUB_SUBSCRIPTION="datastream-gcs-sub"
gcloud pubsub subscriptions create $PUBSUB_SUBSCRIPTION \
--topic=$PUBSUB_TOPIC \
--ack-deadline=600
۸. تبدیل سفارشی
از آنجایی که طرحواره Spanner ما با طرحواره MySQL ما متفاوت است (به دلیل ستونهایی که از طریق رابط کاربری وب SMT اضافه و حذف کردهایم)، مهاجرت Dataflow از ابتدا با شکست مواجه خواهد شد. Dataflow به دستورالعملهایی در مورد نحوه نگاشت این تفاوتها در طول خطوط لوله رو به جلو (MySQL به Spanner) و معکوس (Spanner به MySQL) نیاز دارد.
علاوه بر این، از آنجا که ما در حال انجام یک مهاجرت معکوس خرد شده هستیم، Dataflow به یک مکانیزم مسیریابی نیاز دارد تا بداند یک ردیف Spanner بهروزرسانی شده در طول همانندسازی معکوس به کدام خرد منطقی ( shard0_db ، shard1_db و غیره) تعلق دارد.
ما با نوشتن یک فایل JAR تبدیل سفارشی با استفاده از الگوی Spanner Custom Shard ارائه شده توسط گوگل، به این هدف دست خواهیم یافت.
۱. قالب سفارشی Shard را دانلود کنید
در Cloud Shell خود، مخزن Google Cloud Dataflow Templates را دانلود کنید و به پوشهی custom shard بروید:
git clone https://github.com/GoogleCloudPlatform/DataflowTemplates.git
cd DataflowTemplates/v2/spanner-custom-shard
۲. پیکربندی منطق تبدیل داده
ما باید فایل CustomTransformationFetcher.java را ویرایش کنیم.
- مهاجرت رو به جلو (
toSpannerRow): ستونOrderSourceکه به تازگی اضافه شده است را با استفاده از ستونLegacyOrderSystemاز MySQL پر میکند. - مهاجرت معکوس (
toSourceRow): ستونLegacyOrderSystemحذف شده که MySQL به آن نیاز دارد را دوباره پر میکند و آن را ازOrderSourceمربوط به Spanner استخراج میکند.
فایل CustomTransformationFetcher.java را ویرایش کنید. به جای باز کردن دستی ویرایشگر متن، دستور زیر را اجرا کنید تا فایل الگو به طور خودکار با منطق سفارشی ما بازنویسی شود:
cat << 'EOF' > src/main/java/com/custom/CustomTransformationFetcher.java
package com.custom;
import com.google.cloud.teleport.v2.spanner.exceptions.InvalidTransformationException;
import com.google.cloud.teleport.v2.spanner.utils.ISpannerMigrationTransformer;
import com.google.cloud.teleport.v2.spanner.utils.MigrationTransformationRequest;
import com.google.cloud.teleport.v2.spanner.utils.MigrationTransformationResponse;
import java.util.HashMap;
import java.util.Map;
public class CustomTransformationFetcher implements ISpannerMigrationTransformer {
@Override
public void init(String customParameters) {}
@Override
public MigrationTransformationResponse toSpannerRow(MigrationTransformationRequest request)
throws InvalidTransformationException {
if (request.getTableName().equals("Orders")) {
Map<String, Object> requestRow = request.getRequestRow();
Map<String, Object> responseRow = new HashMap<>();
Object legacySysObj = requestRow.get("LegacyOrderSystem");
String legacySys = (legacySysObj != null) ? (String) legacySysObj : "UNKNOWN_SYSTEM";
// Transform: Trim the string to remove everything after the first underscore
String orderSource = legacySys;
if (legacySys.contains("_")) {
orderSource = legacySys.substring(0, legacySys.indexOf('_'));
}
// Populate the new Spanner column (e.g., "WebStore_v1" becomes "WebStore")
responseRow.put("OrderSource", orderSource);
return new MigrationTransformationResponse(responseRow, false);
}
return new MigrationTransformationResponse(new HashMap<>(), false);
}
@Override
public MigrationTransformationResponse toSourceRow(MigrationTransformationRequest request)
throws InvalidTransformationException {
if (request.getTableName().equals("Orders")) {
Map<String, Object> requestRow = request.getRequestRow();
Map<String, Object> responseRow = new HashMap<>();
// Safely fetch the Spanner OrderSource
Object sourceObj = requestRow.get("OrderSource");
String source = (sourceObj != null) ? (String) sourceObj : "UNKNOWN_SYSTEM";
String legacySys = "'" + source + "_v1'";
// Transform: Append a suffix to visibly prove the reverse transformation worked
// e.g., "WebStore" becomes "WebStore_v1"
responseRow.put("LegacyOrderSystem", legacySys);
return new MigrationTransformationResponse(responseRow, false);
}
return new MigrationTransformationResponse(new HashMap<>(), false);
}
@Override
public MigrationTransformationResponse transformFailedSpannerMutation(
MigrationTransformationRequest request) throws InvalidTransformationException {
return new MigrationTransformationResponse(new HashMap<>(), false);
}
}
EOF
۳. منطق شاردینگ معکوس را پیکربندی کنید
Dataflow در طول همانندسازی معکوس از CustomShardIdFetcher.java برای تعیین محل مسیریابی جهش Spanner استفاده میکند. ما از کلید اصلی CustomerId و منطق modulo ( %4 ) برای مسیریابی پویای رکوردها به shard منطقی صحیح آنها استفاده خواهیم کرد.
فایل CustomShardIdFetcher.java را با استفاده از cat ویرایش کنید و محتویات آن را به طور کامل با کد زیر جایگزین کنید:
cat << 'EOF' > src/main/java/com/custom/CustomShardIdFetcher.java
package com.custom;
import com.google.cloud.teleport.v2.spanner.utils.IShardIdFetcher;
import com.google.cloud.teleport.v2.spanner.utils.ShardIdRequest;
import com.google.cloud.teleport.v2.spanner.utils.ShardIdResponse;
import java.util.Map;
public class CustomShardIdFetcher implements IShardIdFetcher {
@Override
public void init(String parameters) {}
@Override
public ShardIdResponse getShardId(ShardIdRequest shardIdRequest) {
Map<String, Object> keys = shardIdRequest.getSpannerRecord
();
// Use the Primary Key to identify the correct logical shard
if (keys != null && keys.containsKey("CustomerId")) {
long customerId = Long.parseLong(keys.get("CustomerId").toString());
long shardIdx = customerId % 4;
ShardIdResponse response = new ShardIdResponse();
response.setLogicalShardId("shard" + shardIdx + "_db");
return response;
}
return new ShardIdResponse();
}
}
EOF
۴. ساخت و آپلود فایل JAR
حالا که منطق جاوای سفارشی ما نوشته شده است، باید آن را در یک فایل JAR کامپایل کنیم و در مخزن ذخیرهسازی ابری گوگل که قبلاً ایجاد کردیم آپلود کنیم تا Dataflow بتواند به آن دسترسی داشته باشد.
دستورات زیر را در Cloud Shell اجرا کنید:
# Return to DataflowTemplates directory
cd ../..
# Build the JAR using Maven
mvn clean install -DskipTests -Dcheckstyle.skip -Dspotless.check.skip=true -Djib.skip -pl v2/spanner-custom-shard -am
# Upload the JAR to GCS
export CUSTOM_JAR_PATH="gs://${BUCKET_NAME}/custom-logic/spanner-custom-shard-1.0.jar"
gcloud storage cp v2/spanner-custom-shard/target/spanner-custom-shard-1.0-SNAPSHOT.jar $CUSTOM_JAR_PATH
# Return to home directory
cd ~
۹. انتقال انبوه دادهها از MySQL به Spanner
با قرار دادن طرحواره Spanner و ساخت فایل JAR تبدیل سفارشی، اکنون میتوانیم دادههای موجود را از پایگاه داده MySQL شما به Cloud Spanner کپی کنیم. شما از الگوی Sourcedb to Spanner Dataflow Flex استفاده خواهید کرد که برای کپی کردن انبوه دادهها از پایگاههای داده قابل دسترسی با JDBC به Spanner طراحی شده است.
۱. فایل Schema Overrides را آپلود کنید
در بخش ۶، شما فایل JSON مربوط به Spanner Overrides را با استفاده از رابط کاربری وب SMT دانلود کردید. ما باید این فایل را در مخزن GCS خود آپلود کنیم تا Dataflow بتواند از آن برای نگاشت تفاوتهای طرحواره (مانند تغییر نام ستونها) استفاده کند.
- در Cloud Shell خود، روی منوی سه نقطه (More) کلیک کنید و Upload را انتخاب کنید.

- فایل Overrides JSON که قبلاً دانلود کردهاید (مثلاً
spanner_overrides.json) را انتخاب کنید. - آن را به سطل GCS خود منتقل کنید:
export OVERRIDES_FILE="spanner_overrides.json" # Change this if your downloaded file has a different name
export GCS_OVERRIDES_PATH="gs://${BUCKET_NAME}/config/${OVERRIDES_FILE}"
gcloud storage cp ~/${OVERRIDES_FILE} $GCS_OVERRIDES_PATH
۲. فایل پیکربندی Sharding را ایجاد و آپلود کنید
Dataflow باید بداند که چگونه به هر چهار بخش منطقی در دو ماشین مجازی فیزیکی شما متصل شود. برای این کار یک فایل sharding.json ایجاد خواهیم کرد.
برای تولید و آپلود پیکربندی، دستور زیر را در Cloud Shell اجرا کنید:
cat <<EOF > sharding.json
{
"configType": "dataflow",
"shardConfigurationBulk": {
"schemaSource": {
"dataShardId": "mysql-physical-1",
"host": "${MYSQL_IP_1}",
"user": "datastream_user",
"password": "complex_password_123",
"port": "3306",
"dbName": "shard0_db"
},
"dataShards": [
{
"dataShardId": "mysql-physical-1",
"host": "${MYSQL_IP_1}",
"user": "datastream_user",
"password": "complex_password_123",
"port": "3306",
"dbName": "",
"namespace": "namespace-mysql-1",
"databases": [
{
"dbName": "shard0_db",
"databaseId": "shard0_db",
"refDataShardId": "mysql-physical-1"
},
{
"dbName": "shard1_db",
"databaseId": "shard1_db",
"refDataShardId": "mysql-physical-1"
}
]
},
{
"dataShardId": "mysql-physical-2",
"host": "${MYSQL_IP_2}",
"user": "datastream_user",
"password": "complex_password_123",
"port": "3306",
"dbName": "",
"namespace": "namespace-mysql-2",
"databases": [
{
"dbName": "shard2_db",
"databaseId": "shard2_db",
"refDataShardId": "mysql-physical-2"
},
{
"dbName": "shard3_db",
"databaseId": "shard3_db",
"refDataShardId": "mysql-physical-2"
}
]
}
]
}
}
EOF
export GCS_SHARDING_PATH="gs://${BUCKET_NAME}/config/sharding.json"
gcloud storage cp sharding.json $GCS_SHARDING_PATH
۳. اجرای عملیات جریان دادهی مهاجرت انبوه
ما از الگوی Sourcedb to Spanner Flex استفاده خواهیم کرد. از آنجا که این یک مهاجرت sharded با تبدیلهای سفارشی است، فایل Overrides، پیکربندی Sharding و Java JAR سفارشی خود را ارسال میکنیم.
export JOB_NAME="mysql-sharded-bulk-to-spanner-$(date +%Y%m%d-%H%M%S)"
export OUTPUT_DIR="gs://${BUCKET_NAME}/bulk-migration"
gcloud dataflow flex-template run $JOB_NAME \
--project=$PROJECT_ID \
--region=$REGION \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Sourcedb_to_Spanner_Flex" \
--max-workers=2 \
--num-workers=1 \
--worker-machine-type=n2-highmem-8 \
--parameters \
sourceConfigURL=$GCS_SHARDING_PATH,\
instanceId=$SPANNER_INSTANCE_NAME,\
databaseId=$SPANNER_DATABASE_NAME,\
projectId=$PROJECT_ID,\
outputDirectory=$OUTPUT_DIR,\
username=datastream_user,\
password=complex_password_123,\
schemaOverridesFilePath=$GCS_OVERRIDES_PATH,\
transformationJarPath=$CUSTOM_JAR_PATH,\
transformationClassName=com.custom.CustomTransformationFetcher
پارامترهای کلیدی توضیح داده شده:
-
sourceConfigURL: مسیر فایلsharding.jsonکه ایجاد کردیم. این به Dataflow میگوید که چگونه به هر چهار shard منطقی MySQL ما در دو ماشین مجازی فیزیکی متصل شود. -
schemaOverridesFilePath: مسیر فایل JSON که از رابط کاربری وب SMT دانلود کردیم. این به Dataflow دستور میدهد که چگونه تغییرات طرحوارهای که ایجاد کردهایم (مانند حذف ستونLegacyRegionو محدودیت بررسی دقیقتر) را مدیریت کند. -
transformationJarPath: مسیر GCS به فایل JAR جاوای کامپایلشدهای که در بخش قبل ساختیم. این شامل کد واقعی برای اجرای تبدیلهای سفارشی ما است. -
transformationClassName: نام کامل کلاس جاوا درون JAR ما که منطق مهاجرت رو به جلو (com.custom.CustomTransformationFetcher) را پیادهسازی میکند. -
outputDirectory: محل GCS که Dataflow فایلهای موقت خود و از همه مهمتر، فایلهای Dead Letter Queue (DLQ) را در آن مینویسد. -
maxWorkersوnumWorkers: مقیاسبندی کار Dataflow را کنترل میکند. برای این مجموعه داده کوچک، مقدار آن پایین نگه داشته میشود. -
instanceId،databaseId،projectId: نمونه و پایگاه داده هدف Cloud Spanner را مشخص میکند.
نکته شبکه: این کار از طریق IP عمومی به نمونه Cloud SQL متصل میشود. این امر به این دلیل امکانپذیر است که شما قبلاً 0.0.0.0/0 به شبکههای مجاز نمونه اضافه کردهاید. این به ماشینهای مجازی Dataflow worker که دارای IPهای خارجی هستند، اجازه میدهد تا به پایگاه داده دسترسی پیدا کنند.
۴. نظارت بر کار جریان داده
میتوانید پیشرفت کار را در کنسول ابری گوگل پیگیری کنید:
- به صفحه مشاغل Dataflow بروید: به Dataflow Jobs بروید
- کاری با نام
mysql-sharded-bulk-to-spanner-...را پیدا کرده و روی آن کلیک کنید. - نمودار و معیارهای کار را مشاهده کنید. منتظر بمانید تا وضعیت کار به «موفق» تغییر کند. این کار تقریباً ۵ تا ۱۵ دقیقه طول میکشد.

- اگر کار با مشکلاتی مواجه شد، تب Logs را در صفحه جزئیات کار Dataflow برای پیامهای خطا بررسی کنید.
- معیارهای کار، اطلاعات بیشتری در مورد پیشرفت کار و میزان مصرف منابع مانند توان عملیاتی و میزان استفاده از CPU ارائه میدهد.
۵. دادهها را در Cloud Spanner تأیید کنید و صف نامههای مرده (DLQ) را بررسی کنید
زمانی که کار Dataflow با موفقیت انجام شد، باید تأیید کنیم که دادههای ما به سلامت رسیدهاند و رکوردهایی را که عمداً برای خرابی مهندسی کردهایم، بررسی کنیم.
الف. سلامت کلی دادههای منتقلشده را تأیید کنید:
از رابط خط فرمان gcloud برای اجرای چند بررسی سریع سلامت پایگاه داده تلفیقی Spanner خود استفاده کنید تا مطمئن شوید رکوردهای معتبر به درستی منتقل شدهاند و JAR سفارشی ما ستون اضافی را پر کرده است.
# 1. Verify total Customer count
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT COUNT(*) as TotalCustomers FROM Customers"
# 2. Verify total Orders count (Total minus the orphan record)
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT COUNT(*) as TotalOrders FROM Orders"
# 3. Verify the Custom Transformation on OrderSource worked
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT CustomerId, OrderId, OrderSource FROM Orders LIMIT 3"
# 4. Verify that renamed column LoyaltyTier has the correct data
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT CustomerId, CustomerName, LoyaltyTier FROM Customers LIMIT 3"
خروجی مورد انتظار:
TotalCustomers: 16 TotalOrders: 19 CustomerId: 1 OrderId: 201 OrderSource: MobileApp CustomerId: 2 OrderId: 301 OrderSource: CallCenter CustomerId: 3 OrderId: 401 OrderSource: InStore CustomerId: 1 CustomerName: Agnes N. LoyaltyTier: NORTHEAST CustomerId: 2 CustomerName: Brian K. LoyaltyTier: SOUTHWEST CustomerId: 3 CustomerName: Cathy Z. LoyaltyTier: CENTRAL
- تمام ردیفهای جدول مشتریان با موفقیت منتقل شدند.
- ما شاهد شکست ۱ ردیف در جدول
Ordersبه دلیلINTERLEAVE IN PARENTدر Spanner هستیم -CustomerId 99به دلیل عدم وجود ردیف مربوطه در جدولCustomersیک فرزند یتیم است.
ب. بررسی خطاهای عمدی در DLQ:
خرابی فوق در پوشه Dead Letter Queue (DLQ) که توسط خط لوله Bulk Migration ایجاد شده است، مستند شده است.
- در کنسول گوگل کلود به بخش فضای ذخیرهسازی ابری (Cloud Storage) بروید.
- به سطل خود بروید و پوشه
bulk-migration/dlq/severeرا باز کنید. - فایلهای JSON داخل را بررسی کنید. ردیف
Ordersرا باCustomerIdبدون نام پیدا خواهید کرد. - خطاهای DLQ مربوط به مهاجرت انبوه را میتوان با دنبال کردن مراحل ذکر شده در اینجا دوباره امتحان کرد.
بارگذاری اولیه حجم زیادی از دادهها از Cloud SQL به Cloud Spanner اکنون تکمیل شده است. گام بعدی، راهاندازی تکثیر زنده برای ثبت تغییرات مداوم است.
۱۰. شروع مهاجرت زنده (CDC)
اکنون که بارگذاری دادههای حجیم تکمیل شده است، یک کار استریمینگ مداوم Dataflow را راهاندازی خواهید کرد. این کار رویدادهای Change Data Capture (CDC) را که Datastream در حال نوشتن در سطل GCS شما است، میخواند و آن تغییرات را تقریباً به صورت بلادرنگ در Cloud Spanner اعمال میکند.
ما همچنین این خط لوله را با تزریق دادههای معتبر و دادههای عمداً نامعتبر آزمایش خواهیم کرد تا مشاهده کنیم که Dataflow چگونه تکثیر زنده را مدیریت میکند و خرابیها را به صف نامههای از دست رفته (DLQ) هدایت میکند.
۱. فایل پیکربندی شاردینگ مهاجرت زنده را ایجاد کنید
برخلاف مهاجرت انبوه (که از رشتههای اتصال JDBC استفاده میکند)، خط لوله مهاجرت زنده رویدادهای Datastream را از GCS میخواند. این خط لوله به یک پیکربندی JSON کاملاً متفاوت نیاز دارد که نامهای جریان Datastream و پایگاههای داده را به بخشهای منطقی Spanner شما نگاشت کند.
برای ایجاد و آپلود پیکربندی شاردینگ زنده، دستور زیر را در Cloud Shell اجرا کنید:
cat <<EOF > live-sharding.json
{
"StreamToDbAndShardMap": {
"${STREAM_NAME_1}": {
"shard0_db": "shard0_db",
"shard1_db": "shard1_db"
},
"${STREAM_NAME_2}": {
"shard2_db": "shard2_db",
"shard3_db": "shard3_db"
}
}
}
EOF
export GCS_LIVE_SHARDING_PATH="gs://${BUCKET_NAME}/config/live-sharding.json"
gcloud storage cp live-sharding.json $GCS_LIVE_SHARDING_PATH
۲. اجرای کار Live Migration Dataflow
کار Streaming Dataflow را برای خواندن از GCS و نوشتن در Spanner اجرا کنید. این الگو از اعلانهای GCS Pub/Sub برای پردازش فوری فایلهای جدید استفاده میکند.
export JOB_NAME_CDC="mysql-sharded-cdc-to-spanner-$(date +%Y%m%d-%H%M%S)"
export DLQ_DIR_CDC="gs://${BUCKET_NAME}/live-migration"
gcloud dataflow flex-template run $JOB_NAME_CDC \
--project=$PROJECT_ID \
--region=$REGION \
--worker-machine-type=n2-highmem-8 \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Cloud_Datastream_to_Spanner" \
--parameters \
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
projectId="$PROJECT_ID",\
inputFileFormat="avro",\
gcsPubSubSubscription="projects/${PROJECT_ID}/subscriptions/${PUBSUB_SUBSCRIPTION}",\
shardingContextFilePath=$GCS_LIVE_SHARDING_PATH,\
deadLetterQueueDirectory="$DLQ_DIR_CDC",\
transformationJarPath=$CUSTOM_JAR_PATH,\
transformationClassName="com.custom.CustomTransformationFetcher",\
schemaOverridesFilePath=$GCS_OVERRIDES_PATH,\
datastreamSourceType="mysql",\
dlqRetryMinutes=1,\
dlqMaxRetryCount=2
پارامترهای کلیدی
-
gcsPubSubSubscription: اشتراک Pub/Sub که به اعلانهای فایل جدید از GCS گوش میدهد. این به job اجازه میدهد تا تغییرات را فوراً همزمان با نوشتن آنها توسط Datastream پردازش کند. -
inputFileFormat="avro": به Dataflow میگوید که فایلهای Avro را از Datastream دریافت کند. این باید با پیکربندی "مقصد" Datastream شما مطابقت داشته باشد (مثلاًavroFileFormatدر مقابلjsonFileFormat). -
shardingContextFilePath: یک فایل JSON که جریانهای داده را به بخشهای منطقی نگاشت میکند. -
dlqRetryMinutes: تعداد دقایق بین تلاش مجدد برای ورود به صف نامههای مرده. مقدار پیشفرض10است. -
dlqMaxRetryCount: حداکثر تعداد دفعاتی که میتوان خطاهای موقت را از طریق DLQ دوباره بررسی کرد. مقدار پیشفرض500است.
شروع کار را در کنسول کارهای Dataflow نظارت کنید.
۳. تزریق دادههای زنده و ایجاد خطاهای عمدی
در حالی که کار استریمینگ Dataflow شروع میشود (این کار میتواند ۳ تا ۵ دقیقه طول بکشد)، بیایید از طریق SSH به اولین ماشین مجازی فیزیکی MySQL خود وارد شویم و چند رکورد جدید وارد کنیم. ما یک رکورد معتبر و یک رکورد نامعتبر وارد خواهیم کرد.
با استفاده از SSH به اولین شارد فیزیکی متصل شوید:
gcloud compute ssh mysql-physical-1 --zone=$ZONE
وارد MySQL شوید:
sudo mysql
دستورات زیر را در shard1_db اجرا کنید:
USE shard1_db;
-- 1. Valid Insert: 'MobileApp_v2' will be trimmed to 'MobileApp'
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem)
VALUES (4, 501, 99.99, 'MobileApp_v2');
-- 2. Invalid Insert (DLQ Test): This violates Interleave constraint as CustomerId 99999 doesn't exist in Customers table.
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem)
VALUES (99999, 502, 50.00, 'WebStore_v1');
-- 3. Valid Update
UPDATE Orders SET OrderValue = '1500' WHERE CustomerId = 5 AND OrderId = 202;
-- 4. Valid Delete
DELETE FROM Orders WHERE CustomerId = 5 AND OrderId = 203;
EXIT;
برای بازگشت به اعلان Cloud Shell، دوباره exit تایپ کنید.
۴. دادههای مهاجرت زنده را تأیید کنید و DLQ مربوط به CDC را بررسی کنید
حالا که دادهها را تزریق کردهایم، Datastream رویدادهای CDC را ثبت میکند و Dataflow تلاش میکند تا آنها را در Spanner اعمال کند.
الف. تغییرات معتبر DML در Spanner را تأیید کنید
برای تأیید اینکه رویدادهای INSERT ، UPDATE و DELETE با موفقیت به Spanner رسیدهاند و اینکه تبدیل سفارشی هم در مرحله درج و هم در مرحله بهروزرسانی اجرا شده است، کوئریهای زیر را اجرا کنید.
# 1. Verify INSERT: Should return the new row with transformed OrderSource
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT CustomerId, OrderId, OrderValue, OrderSource FROM Orders WHERE CustomerId = 4 AND OrderId = 501"
# 2. Verify UPDATE: Should show OrderValue changed to 1500
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT CustomerId, OrderId, OrderValue, OrderSource FROM Orders WHERE CustomerId = 5 AND OrderId = 202"
# 3. Verify DELETE: Should return 0, confirming the order was deleted
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT COUNT(*) FROM Orders WHERE CustomerId = 5 AND OrderId = 203"
# 4. Verify DLQ Failure: Should return 0, confirming the row migration failed
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT COUNT(*) FROM Orders WHERE CustomerId = 99999 AND OrderId = 502"
خروجی مورد انتظار:
CustomerId: 4 OrderId: 501 OrderValue: 99.99 OrderSource: MobileApp CustomerId: 5 OrderId: 202 OrderValue: 1500 OrderSource: WebStore 0 0
توجه: اگر هر پرسوجویی نتیجه مورد انتظار را نشان نداد، یک دقیقه صبر کنید و دوباره امتحان کنید، زیرا ممکن است کارگران جریانساز هنوز در حال پردازش صف باشند.
ب. بررسی خطای عمدی در DLQ:
از آنجا که CustomerId = 99999 هیچ والدی در جدول Customers ندارد، باید توسط Spanner رد شده و توسط Dataflow به طور ایمن به DLQ هدایت میشد.
- در کنسول گوگل کلود به بخش فضای ذخیرهسازی ابری (Cloud Storage) بروید.
- به سطل خود بروید و پوشهی
live-migration/dlq/severe/را باز کنید. - You should see newly generated JSON files. Click on them to inspect the contents. You will see the details of
CustomerId = 99999and the specific Spanner error message:NOT_FOUND: Parent row for row [99999,502,WebStore] in table Orders is missing. Row cannot be written." - Live Migration DLQ errors can be retried by running the dataflow template with
runMode=retryDLQset.
5. Handling DLQ Errors
Errors in the severe/ directory require manual intervention. Let's fix the data issue and reprocess the failed event.
A. Fix the Data in the Source
The error occurred because the parent customer record CustomerId = 99999 is missing. Let's insert it into the source MySQL database.
SSH into the MySQL instance again:
gcloud compute ssh mysql-physical-1 --zone=$ZONE
Log into MySQL using sudo mysql and insert the missing parent row into shard1_db :
USE shard1_db;
INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LegacyRegion) VALUES
(99999, 'DLQ Parent Holder', 5000.00, 'NORTH_AMERICA');
EXIT;
Type exit to return to Cloud Shell.
B. Run the retryDLQ Dataflow Job
To reprocess events from the severe/ DLQ, you launch the same Dataflow template but in retryDLQ mode. This mode specifically reads from the deadLetterQueueDirectory/severe path, re-runs them through your custom transformations, and applies them to Spanner.
Launch the job in retryDLQ mode:
export JOB_NAME_RETRY="mysql-sharded-cdc-retry-$(date +%Y%m%d-%H%M%S)"
gcloud dataflow flex-template run $JOB_NAME_RETRY \
--project=$PROJECT_ID \
--region=$REGION \
--worker-machine-type=n2-highmem-8 \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Cloud_Datastream_to_Spanner" \
--parameters \
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
projectId="$PROJECT_ID",\
runMode="retryDLQ",\
deadLetterQueueDirectory="$DLQ_DIR_CDC",\
datastreamSourceType="mysql",\
transformationJarPath=$CUSTOM_JAR_PATH,\
transformationClassName="com.custom.CustomTransformationFetcher",\
schemaOverridesFilePath=$GCS_OVERRIDES_PATH,\
shardingContextFilePath=$GCS_LIVE_SHARDING_PATH
Key Parameter Changes for Retry
-
runMode="retryDLQ": Tells the template to read from thesevereDLQ directory. - Removed
gcsPubSubSubscription: Not needed as we are not reading from the live Datastream GCS bucket.
Monitor the Retry Process:
Like the main CDC pipeline, retryDLQ is a streaming pipeline that will remain RUNNING till manually cancelled.
- Go to the Dataflow Job page for
$JOB_NAME_RETRY. - Under the Metrics pane, look for these two counters:
-
elementsReconsumedFromDeadLetterQueue: Evaluates when the error files are being fetched. -
Successful events: Increments when the record is written into Spanner. - Check the
severe/directory for recurring failures. - Once Successful events has incremented by the number of items you wanted to retry (1 in our test case), go to the next verification step.
C. Verify the Retried Data
After the failed record is retried (might take some time to succeed), check Spanner to see if the child row was migrated successfully:
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT CustomerId, OrderId, OrderValue, OrderSource FROM Orders WHERE CustomerId = 99999 AND OrderId = 502"
You should now see the row:
CustomerId: 99999 OrderId: 502 OrderValue: 50 OrderSource: WebStore
Also, check the $DLQ_DIR_CDC/severe/ folder in GCS. The processed files should have been moved or deleted, indicating successful reprocessing.
11. Set Up Reverse Replication (Spanner to MySQL)
To handle scenarios where you might need to rollback or keep the original MySQL database in sync with Spanner for a transitional period, you can set up reverse replication.
This pipeline uses Spanner Change Streams to capture live modifications in Spanner. It then uses our Custom Transformation JAR to reverse-map the schema differences, and our Custom Sharding JAR to calculate exactly which physical MySQL VM and logical shard the update should be written back to.
1. Create a Spanner Change Stream
First, you need to create a change stream in your Spanner database to track changes on the Customers and Orders tables.
export CHANGE_STREAM_NAME="CustomersOrdersChangeStream"
gcloud spanner databases ddl update $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--ddl="CREATE CHANGE STREAM $CHANGE_STREAM_NAME FOR Customers, Orders"
This change stream will now record all data modifications to the specified tables.
2. Create a Spanner Database for Dataflow Metadata
The Spanner to SourceDB Dataflow template requires a separate Spanner database to store metadata for managing the change stream consumption.
export SPANNER_METADATA_DB_NAME="migration-metadata-db"
gcloud spanner databases create $SPANNER_METADATA_DB_NAME \
--instance=$SPANNER_INSTANCE_NAME
3. Prepare Cloud SQL Connection Configuration for Dataflow
The Dataflow template needs a JSON file in Cloud Storage containing the connection details for the target Cloud SQL database.
Create a local file named shard_config.json :
cat <<EOF > reverse-sharding.json
[
{
"logicalShardId": "shard0_db",
"host": "${MYSQL_IP_1}",
"port": "3306",
"user": "datastream_user",
"password": "complex_password_123",
"dbName": "shard0_db"
},
{
"logicalShardId": "shard1_db",
"host": "${MYSQL_IP_1}",
"port": "3306",
"user": "datastream_user",
"password": "complex_password_123",
"dbName": "shard1_db"
},
{
"logicalShardId": "shard2_db",
"host": "${MYSQL_IP_2}",
"port": "3306",
"user": "datastream_user",
"password": "complex_password_123",
"dbName": "shard2_db"
},
{
"logicalShardId": "shard3_db",
"host": "${MYSQL_IP_2}",
"port": "3306",
"user": "datastream_user",
"password": "complex_password_123",
"dbName": "shard3_db"
}
]
EOF
Upload this file to your GCS bucket:
export GCS_REVERSE_SHARDING_PATH="gs://${BUCKET_NAME}/config/reverse-sharding.json"
gcloud storage cp reverse-sharding.json $GCS_REVERSE_SHARDING_PATH
4. Run the Reverse Replication Dataflow Job
Launch the Dataflow job using the Spanner_to_SourceDb Flex Template.
export JOB_NAME_REVERSE="spanner-sharded-reverse-to-mysql-$(date +%Y%m%d-%H%M%S)"
export DLQ_DIR_REVERSE="gs://${BUCKET_NAME}/reverse-replication"
gcloud dataflow flex-template run $JOB_NAME_REVERSE \
--project=$PROJECT_ID \
--region=$REGION \
--worker-machine-type=n2-highmem-8 \
--max-workers=2 \
--num-workers=1 \
--additional-experiments=use_runner_v2 \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Spanner_to_SourceDb" \
--parameters \
changeStreamName="$CHANGE_STREAM_NAME",\
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
spannerProjectId="$PROJECT_ID",\
metadataInstance="$SPANNER_INSTANCE_NAME",\
metadataDatabase="$SPANNER_METADATA_DB_NAME",\
sourceShardsFilePath="$GCS_REVERSE_SHARDING_PATH",\
transformationJarPath=$CUSTOM_JAR_PATH,\
transformationClassName="com.custom.CustomTransformationFetcher",\
shardingCustomJarPath=$CUSTOM_JAR_PATH,\
shardingCustomClassName="com.custom.CustomShardIdFetcher",\
schemaOverridesFilePath=$GCS_OVERRIDES_PATH,\
deadLetterQueueDirectory=$DLQ_DIR_REVERSE
Key Parameters
-
changeStreamName: The name of the Spanner change stream to read from. -
metadataInstance, metadataDatabase: The Spanner instance/database to store the metadata used by the connector to control the consumption of the change stream API data. -
sourceShardsFilePath: The GCS path to yourshard_config.json. -
filtrationMode: Specifies how to drop certain records based on a criteria. Defaults toforward_migration(filter records written using the forward migration pipeline) -
shardingCustomJarPath: The GCS path to the compiled Java JAR file we built earlier. -
shardingCustomClassName: The fully qualified class name (com.custom.CustomShardIdFetcher) that executes our custom%4modulo math to dynamically determine which logical shard should receive the record.
Network Note: The Dataflow workers will connect to the Cloud SQL instance using the Public IP specified in shard_config.json . This connection is permitted due to the 0.0.0.0/0 entry in the Cloud SQL instance's Authorized Networks.
Monitor the job startup in the Dataflow Jobs Console .
5. Inject Spanner Data and Trigger Intentional Failures
Wait for the Dataflow job to enter the Running state (this can take ~5 minutes). Then, let's execute a full suite of queries ( INSERT , UPDATE , DELETE ) directly into Spanner, along with an intentional failure to test the reverse DLQ.
Run the following in Cloud Shell:
# All these operations are done on rows mapping to shard0_db for convenience
# Valid INSERT: Insert parent row in Customers
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LoyaltyTier) VALUES (88, 'Reverse Tester', 5000, 'GOLD_TIER')"
# 1. Valid INSERT (Orders): 'WebStore' transformed to 'WebStore_v1'
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="INSERT INTO Orders (CustomerId, OrderId, OrderValue, OrderSource) VALUES (88, 9001, 150.00, 'WebStore')"
# 2. Valid UPDATE (Orders)
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="UPDATE Orders SET OrderValue = 200.00 WHERE CustomerId = 16 AND OrderId = 105 AND OrderSource = 'Partner'"
# 3. Valid DELETE (Orders)
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="DELETE FROM Orders WHERE CustomerId = 12 AND OrderId = 104 AND OrderSource = 'WebStore'"
# 4. INVALID Insert- DLQ Test: CreditLimit=500 will fail check constraint of >1000 at source
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LoyaltyTier) VALUES (44, 'DLQ Test Customer', 500, 'GOLD_TIER')"
6. Verify Reverse Replication Data and Inspect the DLQ
Let's confirm that our Custom Sharding JAR successfully routed CustomerId 88 to shard0_db on our first physical VM, and that the Custom Transformation JAR successfully stripped "_TIER" from the region.
A. Verify the Valid Record in MySQL:
SSH into the first physical shard:
gcloud compute ssh mysql-physical-1 --zone=$ZONE
Log into MySQL and query shard0_db :
sudo mysql
USE shard0_db;
-- 1. Verify INSERT: Row migrated with transformed LegacyOrderSystem
SELECT CustomerId, OrderId, OrderValue, LegacyOrderSystem
FROM Orders
WHERE CustomerId = 88 AND OrderId = 9001;
-- 2. Verify UPDATE: The OrderValue should now be updated to 200.00.
SELECT CustomerId, OrderId, OrderValue, LegacyOrderSystem
FROM Orders
WHERE CustomerId = 16 AND OrderId = 105;
-- 3. Verify DELETE: Returns 0 rows, confirming the order was successfully deleted from MySQL.
SELECT CustomerId, OrderId
FROM Orders
WHERE CustomerId = 12 AND OrderId = 104;
-- 4. Verify failed replication - this should be in DLQ as CreditLimit < 1000 and will fail stricter check constraint at source
SELECT CustomerId, CustomerName, CreditLimit, LegacyRegion
FROM Customers
WHERE CustomerId = 44;
EXIT;
Expected output in Cloud SQL should reflect the changes made in Spanner.
+------------+---------+------------+-------------------+ | CustomerId | OrderId | OrderValue | LegacyOrderSystem | +------------+---------+------------+-------------------+ | 88 | 9001 | 150.00 | Webstore_v1 | +------------+---------+------------+-------------------+ +------------+---------+------------+-------------------+ | CustomerId | OrderId | OrderValue | LegacyOrderSystem | +------------+---------+------------+-------------------+ | 16 | 105 | 200.00 | Partner_v1 | +------------+---------+------------+-------------------+ Empty set (0.00 sec) Empty set (0.00 sec)
نوع
exit
to return to Cloud Shell.
This confirms that the reverse replication pipeline is functioning, synchronizing changes from Spanner back to Cloud SQL.
B. Check the Intentional Failure in the DLQ
Because our new Customers record has a CreditLimit of 500 (which violates the strict > 1000 check constraint we defined in our source MySQL database), Dataflow safely caught the error.
- Navigate to Cloud Storage in the Google Cloud Console.
- Go to your bucket and open the
dlq/severe/folder. - Open the JSON file to see the rejected
Customersrecord and the exact check constraint violation error. - Reverse Replication DLQ errors can be retried by running the dataflow template with
runMode=retryDLQset.
12. Clean Up Resources
To avoid incurring further charges to your Google Cloud account, delete the resources created during this codelab.
Set Environment Variables (if needed)
If your Cloud Shell session timed out or you opened a new terminal, you will need to re-export your environment variables before running the cleanup commands.
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1" # Or your preferred region
export ZONE="us-central1-a" # Or a zone within your selected region
export SPANNER_INSTANCE_NAME="target-spanner-instance"
export SPANNER_DATABASE_NAME="sharded-target-db"
export SPANNER_CONFIG="regional-${REGION}"
export BUCKET_NAME="migration-${PROJECT_ID}-bucket"
export MYSQL_IP_1=$(gcloud compute instances describe mysql-physical-1 --zone=$ZONE --format='get(networkInterfaces[0].accessConfigs[0].natIP)')
export MYSQL_IP_2=$(gcloud compute instances describe mysql-physical-2 --zone=$ZONE --format='get(networkInterfaces[0].accessConfigs[0].natIP)')
export SQL_CP_NAME_1="mysql-src-cp-1"
export SQL_CP_NAME_2="mysql-src-cp-2"
export GCS_CP_NAME="gcs-dest-cp"
export STREAM_NAME_1="mysql-to-spanner-stream-1"
export GCS_STREAM_PATH_1="data/${STREAM_NAME_1}"
export STREAM_NAME_2="mysql-to-spanner-stream-2"
export GCS_STREAM_PATH_2="data/${STREAM_NAME_2}"
export PUBSUB_TOPIC="datastream-gcs-updates"
export PUBSUB_SUBSCRIPTION="datastream-gcs-sub"
export CUSTOM_JAR_PATH="gs://${BUCKET_NAME}/custom-logic/spanner-custom-shard-1.0.jar"
export OVERRIDES_FILE="spanner_overrides.json"
export GCS_OVERRIDES_PATH="gs://${BUCKET_NAME}/config/${OVERRIDES_FILE}"
export GCS_SHARDING_PATH="gs://${BUCKET_NAME}/config/sharding.json"
export OUTPUT_DIR="gs://${BUCKET_NAME}/bulk-migration"
export GCS_LIVE_SHARDING_PATH="gs://${BUCKET_NAME}/config/live-sharding.json"
export DLQ_DIR_CDC="gs://${BUCKET_NAME}/live-migration"
export CHANGE_STREAM_NAME="CustomersOrdersChangeStream"
export SPANNER_METADATA_DB_NAME="migration-metadata-db"
export GCS_REVERSE_SHARDING_PATH="gs://${BUCKET_NAME}/config/reverse-sharding.json"
export DLQ_DIR_REVERSE="gs://${BUCKET_NAME}/reverse-replication"
Stop Dataflow Streaming Jobs
List your jobs to find the Job IDs of the running dataflow jobs. Export JOB_ID_CDC and JOB_ID_REVERSE accordingly.
gcloud dataflow jobs list --region=$REGION --filter="state=Running"
export JOB_ID_CDC=<PASTE_JOB_ID_HERE>
export JOB_ID_CDC_RETRY=<PASTE_JOB_ID_HERE>
export JOB_ID_REVERSE=<PASTE_JOB_ID_HERE>
Cancel the Datastream to Spanner (Live Migration) job and its retry job:
gcloud dataflow jobs cancel $JOB_ID_CDC --region=$REGION --project=$PROJECT_ID
gcloud dataflow jobs cancel $JOB_ID_CDC_RETRY --region=$REGION --project=$PROJECT_ID
Cancel the Spanner to Cloud SQL (Reverse Replication) job:
gcloud dataflow jobs cancel $JOB_ID_REVERSE --region=$REGION --project=$PROJECT_ID
Delete Datastream Resources
Stop and Delete the Stream:
gcloud datastream streams update $STREAM_NAME_1 \
--location=$REGION --state=PAUSED --project=$PROJECT_ID
# Wait a moment for the stream to pause
gcloud datastream streams delete $STREAM_NAME_1 \
--location=$REGION --project=$PROJECT_ID --quiet
gcloud datastream streams update $STREAM_NAME_2 \
--location=$REGION --state=PAUSED --project=$PROJECT_ID
# Wait a moment for the stream to pause
gcloud datastream streams delete $STREAM_NAME_2 \
--location=$REGION --project=$PROJECT_ID --quiet
# Delete Connection Profiles
gcloud datastream connection-profiles delete $SQL_CP_NAME_1 \
--location=$REGION --project=$PROJECT_ID --quiet
gcloud datastream connection-profiles delete $SQL_CP_NAME_2 \
--location=$REGION --project=$PROJECT_ID --quiet
gcloud datastream connection-profiles delete $GCS_CP_NAME \
--location=$REGION --project=$PROJECT_ID --quiet
Delete the Source MySQL VMs (Compute Engine)
Delete the two Compute Engine instances that simulated the on-prem MySQL physical shards.
gcloud compute instances delete mysql-physical-1 mysql-physical-2 --zone=$ZONE --quiet
Delete Firewall Rules
Remove the network firewall rules created to allow SSH access and Datastream connectivity to your VMs. (Note: If you used different names for your firewall rules earlier in the codelab, adjust them here).
gcloud compute firewall-rules delete allow-ssh-iap --quiet
gcloud compute firewall-rules delete allow-mysql-datastream --quiet
Delete Pub/Sub Resources
Delete Subscription:
gcloud pubsub subscriptions delete $PUBSUB_SUBSCRIPTION \
--project=$PROJECT_ID --quiet
Delete Topic:
gcloud pubsub topics delete $PUBSUB_TOPIC \
--project=$PROJECT_ID --quiet
Delete Cloud Spanner Instance
Delete the Cloud Spanner instance (this automatically deletes both the sharded-target-db and the migration-metadata-db databases inside it).
gcloud spanner instances delete $SPANNER_INSTANCE_NAME \
--project=$PROJECT_ID --quiet
Delete GCS Bucket and Contents
Finally, delete the Cloud Storage bucket that holds the Datastream files, Dataflow configs, and Dead Letter Queues. The rm -r command recursively deletes the bucket and all its contents.
gcloud storage rm --recursive gs://${BUCKET_NAME}
Delete Local Cloud Shell Files
To clean up the local files and directories generated in your Cloud Shell during this codelab, run the following commands:
# Remove the JSON configuration files
rm -f sharding.json live-sharding.json reverse-sharding.json spanner_overrides.json
# Remove the cloned Google Cloud DataflowTemplates repository
rm -rf DataflowTemplates