
1. Hinweis
In diesem Codelab wird beschrieben, wie Sie eine shardierte lokale MySQL-Datenbank zu einer Cloud Spanner-Datenbank mit dem GoogleSQL-Dialekt migrieren. Sie verwenden Google Cloud-Dienste wie das Spanner Migration Tool (SMT), Dataflow, Datastream, PubSub und Google Cloud Storage.
Die Themen:
- Was ist eine Shard-Umgebung und wie wird sie eingerichtet?
- So verwenden Sie die Web-UI des Cloud Spanner-Migrationstools (SMT), um ein MySQL-Schema in ein Cloud Spanner-kompatibles Schema zu konvertieren und erweiterte Schemaänderungen vorzunehmen.
- Hier wird beschrieben, wie Sie mit Dataflow eine Bulk-Datenmigration von einer shardierten MySQL-Instanz zu Cloud Spanner durchführen.
- Hier wird beschrieben, wie Sie die kontinuierliche Replikation (CDC) von einer shardierten MySQL-Instanz zu Cloud Spanner mit Datastream und Dataflow einrichten.
- So konfigurieren Sie die Reverse-Replikation von Spanner zurück zu den shardierten MySQL-Instanzen.
- Benutzerdefinierte Transformationen verwenden, um zusätzliche Spalten bei Bulk-, Live- und Rückmigrationen zu füllen
- Sharding-Transformationen mit Primärschlüsseln konfigurieren
Was in diesem Codelab NICHT behandelt wird:
- Erweiterte benutzerdefinierte Netzwerke.
- Benutzerdefinierte Dataflow-Vorlagen von Grund auf neu erstellen.
- Leistungsoptimierung der Migration.
- Anwendungsmigration:In diesem Codelab geht es um die Datenbankebene (Schema und Daten). Der operative Prozess der erneuten Bereitstellung oder Migration Ihrer Anwendungsdienste wird nicht behandelt.
Voraussetzungen
- Google Cloud-Projekt mit aktivierter Abrechnungsfunktion.
- Ausreichende IAM-Berechtigungen zum Aktivieren von APIs und zum Erstellen/Verwalten von Spanner-, Dataflow-, Datastream- und GCS-Ressourcen. Die Rolle „Projekt
Owner“ ist für ein Codelab am einfachsten. Spezifischere Rollen werden unter „Umgebung einrichten“ behandelt. - Wir stellen während der Einrichtungsphase eine kleine Compute Engine-VM bereit, um unseren lokalen Server zu simulieren. Prüfen Sie, ob Ihr Projektkontingent das Erstellen von VMs zulässt.
- Ein Webbrowser wie Google Chrome.
- Grundlegende Vertrautheit mit der Google Cloud Console und Befehlszeilentools wie
gcloud. - Zugriff auf eine Shell-Umgebung. Wir empfehlen Cloud Shell, da
gclouddarin enthalten ist.
Weitere Informationen zur Einrichtung finden Sie im Abschnitt Umgebung einrichten.
2. Migrationsprozess
Bei der Migration einer shardierten Datenbank werden mehrere physische und logische MySQL-Instanzen in einer einzelnen, horizontal skalierbaren Spanner-Datenbank konsolidiert. In diesem Abschnitt werden die Architektur und die wichtigsten Tools beschrieben, die bei der Migration verwendet werden.
Architektur des Migrationsablaufs
Der Migrationsprozess umfasst die folgenden Phasen:
1. Schemakonvertierung:
- Zweck:Das Quelldatenbankschema in ein kompatibles Cloud Spanner-Schema konvertieren.
- Tool:Spanner-Migrationstool (SMT)
- Prozess:SMT analysiert das Quelldatenbankschema und generiert die entsprechende Spanner-Datendefinitionssprache (DDL). In der Ziel-Spanner-Instanz wird eine Datenbank erstellt und die DDL wird dann automatisch angewendet.
2. Bulk-Datenmigration:
- Zweck:Führen Sie einen anfänglichen, vollständigen Ladevorgang für vorhandene Daten aus der Quelldatenbank in die bereitgestellten Spanner-Tabellen aus.
- Tool:Dataflow mit der von Google bereitgestellten Vorlage
Sourcedb to Spanner. - Prozess:Dieser Dataflow-Job liest alle Daten aus den angegebenen Quelltabellen und schreibt sie in die entsprechenden Spanner-Tabellen. Dies erfolgt nach der Erstellung des Spanner-Schemas.
3. Live-Migration (CDC):
- Zweck:Fortlaufende Änderungen aus der Quelldatenbank nahezu in Echtzeit in Cloud Spanner erfassen und anwenden, um Ausfallzeiten während der Migration zu minimieren.
- Optionen:
- Datastream:Erfasst Änderungen (Einfügungen, Aktualisierungen, Löschungen) aus der Quelldatenbank und schreibt sie in Cloud Storage (GCS).
- Dataflow:Verwendet die Vorlage
Datastream to Spanner, um die Änderungsereignisse aus GCS zu lesen und auf Cloud Spanner anzuwenden.
4. Rückwärtsreplikation:
- Zweck:Datenänderungen aus Cloud Spanner in die Quelldatenbank replizieren. Das kann für Fallback-Strategien, schrittweise Migrationen oder die Aufrechterhaltung eines Replikats in der Quelle für bestimmte Anwendungsfälle nützlich sein.
- Tool:Dataflow mit der Vorlage
Spanner to SourceDb. - Verarbeiten:Bei diesem Job werden Spanner-Änderungsstreams verwendet, um Änderungen in Spanner zu erfassen und in die Quelldatenbankinstanz zurückzuschreiben.
Das folgende Diagramm veranschaulicht die Komponenten und den Datenfluss:

Wichtige Begriffe:
- Physischer Shard:Der tatsächliche zugrunde liegende Server oder die Compute-Instanz, auf der die Datenbank gehostet wird (in unserem Fall die simulierte lokale GCE-VM).
- Logischer Shard:Das einzelne Datenbankschema auf einem physischen Server.
- Compute Engine-VM (GCE-VM):Eine virtuelle Maschine, die in der Google Cloud-Infrastruktur gehostet wird. In diesem Codelab verwenden wir eine GCE-VM, um einen eigenständigen Bare-Metal-Server zu simulieren, der unsere MySQL-Quelldatenbank hostet.
- Cloud Spanner-Migrationstool (SMT):Ein Tool, mit dem MySQL-Schemas bewertet, entsprechende Cloud Spanner-Schemas vorgeschlagen und die Cloud Spanner-Datendefinitionssprache (DDL) generiert werden.
- Datendefinitionssprache (Data Definition Language, DDL): Anweisungen zum Definieren und Ändern der Datenbankstruktur, z. B.
CREATE TABLE-Anweisungen. SMT generiert Spanner-DDL basierend auf dem Cloud SQL-Schema. - Dataflow:Ein vollständig verwalteter, serverloser Dienst zur Datenverarbeitung. In diesem Codelab wird es verwendet, um von Google bereitgestellte Vorlagen für die Bulk-Datenübertragung, die Anwendung von Datastream-Änderungen und die Rückwärtsreplikation auszuführen.
- Datastream:Ein serverloser Dienst für Change Data Capture (CDC) und Replikation. In diesem Codelab wird sie verwendet, um Änderungen aus der lokal gehosteten MySQL-Instanz in Cloud Storage zu streamen.
- Spanner-Änderungsstreams:Eine Spanner-Funktion, mit der Änderungen an Daten (Einfügungen, Aktualisierungen, Löschungen) in Echtzeit gestreamt werden können. Sie wird als Quelle für die Reverse-Replikation verwendet.
- Pub/Sub:Ein Messaging-Dienst, der verwendet wird, um Dienste, die Ereignisse erzeugen, von Diensten zu entkoppeln, die sie verarbeiten. In diesem Codelab wird Dataflow ausgelöst, um Aktualisierungen zu verarbeiten, sobald Datastream neue Änderungsdateien in Cloud Storage hochlädt.
3. Umgebung einrichten
Bevor Sie mit der Migration beginnen können, müssen Sie Ihr Google Cloud-Projekt einrichten und die erforderlichen Dienste aktivieren.
1. Google Cloud-Projekt auswählen oder erstellen
Sie benötigen ein Google Cloud-Projekt mit aktivierter Abrechnung, um die Dienste in diesem Codelab verwenden zu können.
- Rufen Sie in der Google Cloud Console die Seite für die Projektauswahl auf: Zur Projektauswahl
- Wählen Sie ein Google Cloud-Projekt aus oder erstellen Sie eines.
- Die Abrechnung für Ihr Projekt muss aktiviert sein. So prüfen Sie, ob die Abrechnung für Ihr Projekt aktiviert ist.
2. Cloud Shell öffnen
Cloud Shell ist eine Befehlszeilenumgebung, die in Google Cloud ausgeführt wird und in der die gcloud CLI und andere benötigte Tools vorinstalliert sind.
- Klicken Sie rechts oben in der Google Cloud Console auf die Schaltfläche Cloud Shell aktivieren.
- Im unteren Bereich der Konsole wird ein neuer Frame für die Cloud Shell-Sitzung geöffnet, in dem eine Befehlszeilen-Eingabeaufforderung angezeigt wird.

3. Projekt- und Umgebungsvariablen festlegen
Richten Sie in Cloud Shell einige Umgebungsvariablen für Ihre Projekt-ID und die Region ein, die Sie verwenden möchten.
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1" # Or your preferred region
export ZONE="us-central1-a" # Or a zone within your selected region
gcloud config set project $PROJECT_ID
gcloud config set compute/region $REGION
gcloud config set compute/zone $ZONE
echo "Project ID: $PROJECT_ID"
echo "Region: $REGION"
echo "Zone: $ZONE"
4. Erforderliche Google Cloud APIs aktivieren
Aktivieren Sie die APIs, die für Cloud Spanner, Dataflow, Datastream und andere zugehörige Dienste erforderlich sind.
gcloud services enable \
spanner.googleapis.com \
dataflow.googleapis.com \
datastream.googleapis.com \
pubsub.googleapis.com \
storage.googleapis.com \
compute.googleapis.com \
sqladmin.googleapis.com \
servicenetworking.googleapis.com \
cloudresourcemanager.googleapis.com
Die Verarbeitung dieses Befehls kann einige Minuten dauern.
4. MySQL-Quelldatenbank einrichten
In diesem Abschnitt simulieren wir eine lokale, shardbasierte MySQL-Architektur, indem wir zwei Compute Engine-VMs (unsere zwei „physischen Shards“) bereitstellen. Anschließend installieren wir MySQL auf beiden VMs und erstellen auf jeder VM zwei Datenbanken (unsere „logischen Shards“).
1. Compute Engine-VMs (physische Shards) erstellen
Führen Sie die folgenden Befehle in Cloud Shell aus, um zwei VMs mit Ubuntu zu erstellen. Wir weisen ihnen Netzwerk-Tags zu, um später eingehenden MySQL-Traffic zuzulassen.
# Create Physical Shard 1
gcloud compute instances create mysql-physical-1 \
--zone=$ZONE \
--machine-type=e2-small \
--image-family=ubuntu-2204-lts \
--image-project=ubuntu-os-cloud \
--tags=mysql-server
# Create Physical Shard 2
gcloud compute instances create mysql-physical-2 \
--zone=$ZONE \
--machine-type=e2-small \
--image-family=ubuntu-2204-lts \
--image-project=ubuntu-os-cloud \
--tags=mysql-server
2. Firewallregeln konfigurieren
So ermöglichen Sie sicheren SSH-Zugriff ohne öffentliche Offenlegung und aktivieren die Datastream-Verbindung:
Firewallregel für SSH über IAP erstellen:
Diese Regel ermöglicht es Identity-Aware Proxy, Ihre VMs über den SSH-Port (22) zu erreichen.
gcloud compute firewall-rules create allow-ssh-iap \
--direction=INGRESS \
--priority=1000 \
--network=default \
--action=ALLOW \
--rules=tcp:22 \
--source-ranges=35.235.240.0/20 \
--target-tags=mysql-server
Firewallregel für Datastream (MySQL-Port) erstellen:
Datastream muss diese VMs über den Standard-MySQL-Port (3306) erreichen können.
gcloud compute firewall-rules create allow-mysql-datastream \
--direction=INGRESS \
--priority=1000 \
--network=default \
--action=ALLOW \
--rules=tcp:3306 \
--source-ranges=0.0.0.0/0 \
--target-tags=mysql-server
3. MySQL auf dem physischen Shard 1 installieren und konfigurieren
Stellen Sie eine SSH-Verbindung zu Ihrer ersten VM her, um MySQL zu installieren und das binäre Logging zu konfigurieren, das für die Live-Replikation von Datastream erforderlich ist.
- Stellen Sie eine SSH-Verbindung zur ersten VM her:
gcloud compute ssh mysql-physical-1 --zone=$ZONE --tunnel-through-iap
- Installieren Sie MySQL:
sudo apt-get update
sudo apt-get install mysql-server-8.0 -y
# Verify the installation and version
sudo mysql --version
- Konfigurieren Sie die Datei
mysqld.cnf, um das binäre Logging zu aktivieren und externe Verbindungen zuzulassen:
sudo sed -i 's/bind-address.*/bind-address = 0.0.0.0/' /etc/mysql/mysql.conf.d/mysqld.cnf
echo -e "[mysqld]\nserver-id=1\nlog_bin=/var/log/mysql/mysql-bin.log\nbinlog_format=ROW" | sudo tee -a /etc/mysql/mysql.conf.d/mysqld.cnf
- Starten Sie MySQL neu, damit die Änderungen wirksam werden:
sudo systemctl restart mysql
4. Logische Shards erstellen, Daten einfügen und Datastream-Nutzer erstellen (Shard 1)
Melden Sie sich über die SSH-Verbindung zu mysql-physical-1 bei der MySQL-Eingabeaufforderung an:
sudo mysql
Führen Sie die folgenden SQL-Befehle aus. Mit diesem Skript werden zwei separate logische Shards (shard0_db und shard1_db) erstellt, in beiden wird das identische Schema eingerichtet, in jeden werden eindeutig identifizierbare Daten eingefügt (um Sharding zu demonstrieren) und der Replikationsnutzer für Datastream wird erstellt.
Führen Sie die folgenden SQL-Befehle aus, um die ersten beiden logischen Shards, eine Tabelle und den Replikationsnutzer für Datastream zu erstellen:
CREATE DATABASE shard0_db;
CREATE DATABASE shard1_db;
USE shard0_db;
CREATE TABLE Customers (
CustomerId INT NOT NULL,
CustomerName VARCHAR(255),
CreditLimit DECIMAL(10, 2) NOT NULL,
LegacyRegion VARCHAR(50), -- Renamed to LoyaltyTier in Spanner
PRIMARY KEY (CustomerId),
CONSTRAINT CHK_CreditLimit CHECK (CreditLimit > 1000) -- Relaxed in Spanner to > 0
);
CREATE TABLE Orders (
CustomerId INT NOT NULL, -- Logically references Customers.CustomerId in Spanner
OrderId INT NOT NULL,
OrderValue DECIMAL(10, 2),
LegacyOrderSystem VARCHAR(50), -- Extra column in Source, to be dropped in Spanner
PRIMARY KEY (CustomerId, OrderId) -- Spanner PK will have one additional column in PK
);
INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LegacyRegion) VALUES
(4, 'David E.', 2000.00, 'EAST'),
(8, 'Eleanor F.', 8100.00, 'WEST'),
(12, 'Frank G.', 12000.00, 'NORTH'),
(16, 'Grace H.', 6500.00, 'SOUTH');
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem) VALUES
(4, 101, 150.00, 'WebStore_v1'),
(4, 102, 25.50, 'InStore_POS'),
(8, 103, 75.00, 'MobileApp_Legacy'),
(12, 104, 3000.00, 'WebStore_v1'),
(16, 105, 120.00, 'Partner_API');
USE shard1_db;
CREATE TABLE Customers (
CustomerId INT NOT NULL,
CustomerName VARCHAR(255),
CreditLimit DECIMAL(10, 2) NOT NULL,
LegacyRegion VARCHAR(50), -- Renamed to LoyaltyTier in Spanner
PRIMARY KEY (CustomerId),
CONSTRAINT CHK_CreditLimit CHECK (CreditLimit > 1000) -- Relaxed in Spanner to > 0
);
CREATE TABLE Orders (
CustomerId INT NOT NULL, -- Logically references Customers.CustomerId in Spanner
OrderId INT NOT NULL,
OrderValue DECIMAL(10, 2),
LegacyOrderSystem VARCHAR(50), -- Extra column in Source, to be dropped in Spanner
PRIMARY KEY (CustomerId, OrderId) -- Spanner PK will have one additional column in PK
);
INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LegacyRegion) VALUES
(1, 'Agnes N.', 5100.00, 'NORTHEAST'),(5, 'Alice I.', 15000.00, 'EAST'),
(9, 'Bob J.', 7500.00, 'WEST'),
(13, 'Charlie K.', 2200.00, 'CENTRAL');
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem) VALUES
(1, 201, 50.00, 'MobileApp_Legacy'),
(5, 202, 1250.00, 'WebStore_v1'),
(5, 203, 80.00, 'Partner_API'),
(9, 204, 600.00, 'InStore_POS'),
(13, 205, 199.99, 'WebStore_v1');
-- Create Datastream Replication User
CREATE USER 'datastream_user'@'%' IDENTIFIED BY 'complex_password_123';
GRANT REPLICATION SLAVE, REPLICATION CLIENT, SELECT, INSERT, UPDATE, DELETE ON *.* TO 'datastream_user'@'%';
FLUSH PRIVILEGES;
Die Dump-Datei für das obige Schema finden Sie hier. Es ist wichtig, dass Sie den Nutzer für die Datenstromreplikation separat erstellen, da er nicht in der Dumpdatei enthalten ist.
5. Daten prüfen
Prüfen Sie schnell, ob die Daten vorhanden sind:
SELECT 'Customers shard0_db' AS tbl, COUNT(*) FROM shard0_db.Customers
UNION ALL
SELECT 'Orders shard0_db', COUNT(*) FROM shard0_db.Orders
UNION ALL
SELECT 'Customers shard1_db', COUNT(*) FROM shard1_db.Customers
UNION ALL
SELECT 'Orders shard1_db', COUNT(*) FROM shard1_db.Orders;
EXIT;
Erwartete Ausgabe:
+---------------------+----------+ | tbl | COUNT(*) | +---------------------+----------+ | Customers shard0_db | 4 | | Orders shard0_db | 5 | | Customers shard1_db | 4 | | Orders shard1_db | 5 | +---------------------+----------+
Geben Sie exit ein, um die Verbindung zur VM des physischen Shards 1 zu beenden.
6. Wiederholen Sie den Vorgang für den zweiten physischen Shard.
Wiederholen Sie nun genau denselben Vorgang für die zweite VM. Erstellen Sie dabei shard2_db und shard3_db und ändern Sie server-id.
- Stellen Sie eine SSH-Verbindung zur zweiten VM her:
gcloud compute ssh mysql-physical-2 --zone=$ZONE --tunnel-through-iap
- Installieren Sie MySQL:
sudo apt-get update
sudo apt-get install mysql-server-8.0 -y
- Konfigurieren Sie die Datei
mysqld.cnf, um das Binär-Logging zu aktivieren und externe Verbindungen zuzulassen. Die server-id muss sich unterscheiden (z. B. 2).
sudo sed -i 's/bind-address.*/bind-address = 0.0.0.0/' /etc/mysql/mysql.conf.d/mysqld.cnf
echo -e "[mysqld]\nserver-id=2\nlog_bin=/var/log/mysql/mysql-bin.log\nbinlog_format=ROW" | sudo tee -a /etc/mysql/mysql.conf.d/mysqld.cnf
- Starten Sie MySQL neu, damit die Änderungen wirksam werden:
sudo systemctl restart mysql
- Geben Sie MySQL (
sudo mysql) ein und führen Sie eine leicht modifizierte Version des SQL-Befehls aus Schritt 4 aus:
CREATE DATABASE shard2_db;
CREATE DATABASE shard3_db;
USE shard2_db;
CREATE TABLE Customers (
CustomerId INT NOT NULL,
CustomerName VARCHAR(255),
CreditLimit DECIMAL(10, 2) NOT NULL,
LegacyRegion VARCHAR(50), -- Renamed to LoyaltyTier in Spanner
PRIMARY KEY (CustomerId),
CONSTRAINT CHK_CreditLimit CHECK (CreditLimit > 1000) -- Relaxed in Spanner to > 0
);
CREATE TABLE Orders (
CustomerId INT NOT NULL, -- Logically references Customers.CustomerId in Spanner
OrderId INT NOT NULL,
OrderValue DECIMAL(10, 2),
LegacyOrderSystem VARCHAR(50), -- Extra column in Source, to be dropped in Spanner
PRIMARY KEY (CustomerId, OrderId) -- Spanner PK will have one additional column in PK
);
INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LegacyRegion) VALUES
(2, 'Brian K.', 2500.00, 'SOUTHWEST'),
(6, 'Diana L.', 1999.00, 'NORTH'),
(10, 'Edward M.', 11000.00, 'EAST'),
(14, 'Fiona N.', 3000.00, 'WEST');
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem) VALUES
(2, 301, 100.00, 'CallCenter_System'),
(6, 302, 99.00, 'MobileApp_Legacy'),
(10, 303, 1000.00, 'WebStore_v1'),
(10, 304, 2500.00, 'InStore_POS'),
(14, 305, 130.00, 'MobileApp_Legacy');
USE shard3_db;
CREATE TABLE Customers (
CustomerId INT NOT NULL,
CustomerName VARCHAR(255),
CreditLimit DECIMAL(10, 2) NOT NULL,
LegacyRegion VARCHAR(50), -- Renamed to LoyaltyTier in Spanner
PRIMARY KEY (CustomerId),
CONSTRAINT CHK_CreditLimit CHECK (CreditLimit > 1000) -- Relaxed in Spanner to > 0
);
CREATE TABLE Orders (
CustomerId INT NOT NULL, -- Logically references Customers.CustomerId in Spanner
OrderId INT NOT NULL,
OrderValue DECIMAL(10, 2),
LegacyOrderSystem VARCHAR(50), -- Extra column in Source, to be dropped in Spanner
PRIMARY KEY (CustomerId, OrderId) -- Spanner PK will have one additional column in PK
);
INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LegacyRegion) VALUES
(3, 'Cathy Z.', 6000.00, 'CENTRAL'),
(7, 'George O.', 18000.00, 'SOUTH'),
(11, 'Helen P.', 4000.00, 'NORTHEAST'),
(15, 'Ivy Q.', 9500.00, 'SOUTHWEST');
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem) VALUES
(3, 401, 600.00, 'InStore_POS'),
(7, 402, 1200.00, 'CallCenter_System'),
(11, 403, 350.00, 'MobileApp_Legacy'),
(15, 404, 800.00, 'WebStore_v1'),
(99, 999, 25.00, 'CallCenter_System'); -- Failure row during Bulk Migration due to violation of interleaving
-- Create Datastream Replication User
CREATE USER 'datastream_user'@'%' IDENTIFIED BY 'complex_password_123';
GRANT REPLICATION SLAVE, REPLICATION CLIENT, SELECT, INSERT, UPDATE, DELETE ON *.* TO 'datastream_user'@'%';
FLUSH PRIVILEGES;
-- Verify Data
SELECT 'Customers shard2_db' AS tbl, COUNT(*) FROM shard2_db.Customers
UNION ALL
SELECT 'Orders shard2_db', COUNT(*) FROM shard2_db.Orders
UNION ALL
SELECT 'Customers shard3_db', COUNT(*) FROM shard3_db.Customers
UNION ALL
SELECT 'Orders shard3_db', COUNT(*) FROM shard3_db.Orders;
EXIT;
Erwartete Ausgabe:
+---------------------+----------+ | tbl | COUNT(*) | +---------------------+----------+ | Customers shard2_db | 4 | | Orders shard2_db | 5 | | Customers shard3_db | 4 | | Orders shard3_db | 5 | +---------------------+----------+
Die Dump-Datei für das obige Schema finden Sie hier. Es ist wichtig, dass Sie den Nutzer für die Datenstromreplikation separat erstellen, da er nicht in der Dumpdatei enthalten ist.
Geben Sie exit ein, um die Verbindung zur VM zu beenden.
5. Cloud Spanner einrichten
Als Nächstes richten Sie die Cloud Spanner-Zielinstanz ein, in die die Daten migriert werden.
1. Cloud Spanner-Instanz erstellen
Erstellen Sie eine Cloud Spanner-Instanz in derselben Region wie Ihre Compute Engine-VMs, um die Latenz zu minimieren. Mit diesem Befehl wird eine kleine Instanz mit 100 Verarbeitungseinheiten erstellt, die für dieses Codelab geeignet ist.
export SPANNER_INSTANCE_NAME="target-spanner-instance"
export SPANNER_DATABASE_NAME="sharded-target-db"
export SPANNER_CONFIG="regional-${REGION}"
gcloud spanner instances create $SPANNER_INSTANCE_NAME \
--config=$SPANNER_CONFIG \
--description="Target Spanner Instance" \
--processing-units=100
Das Erstellen der Instanz kann ein oder zwei Minuten dauern.
6. Schema mit dem Cloud Spanner-Migrationstool (SMT) konvertieren
Verwenden Sie die Web-UI des Spanner Migration Tool (SMT), um eine Verbindung zu einem unserer logischen Shards (shard0_db) herzustellen, das Schema zu analysieren und mehrere erweiterte Änderungen vorzunehmen, bevor Sie es in Cloud Spanner konvertieren.
1. SMT installieren
Wir führen die SMT-Web-UI direkt über Cloud Shell aus. Laden Sie im Cloud Shell-Terminal den neuesten SMT-Release herunter und extrahieren Sie ihn:
sudo apt-get update && sudo apt-get install google-cloud-cli-spanner-migration-tool
# Verify installation
gcloud alpha spanner migrate web --help
2. Verbindung zur Quelldatenbank herstellen
- Sitzung authentifizieren
# Authenticate your Google Cloud account
gcloud auth login
# Set up Application Default Credentials (ADC) for SMT
gcloud auth application-default login
# Ensure your current project is set correctly
gcloud config set project $PROJECT_ID
Hinweis: Folgen Sie bei Aufforderung der angegebenen URL, um Ihr Konto zu autorisieren, und fügen Sie den Bestätigungscode wieder in das Terminal ein.
- Ermitteln Sie zuerst die externe IP-Adresse Ihres ersten physischen Shards, indem Sie diesen Befehl auf einem neuen Cloud Shell-Tab ausführen:
gcloud compute instances describe mysql-physical-1 --zone=$ZONE --format='get(networkInterfaces[0].accessConfigs[0].natIP)'
- Gibt die Details der Ziel-Spanner-Instanz aus, die beim Konfigurieren von SMT verwendet werden sollen.
echo "Project ID: $PROJECT_ID"
echo "Instance ID: $SPANNER_INSTANCE_NAME"
echo "Database Name: $SPANNER_DATABASE_NAME"
- Web-UI starten:
gcloud alpha spanner migrate web --port=8080
- Klicken Sie in Cloud Shell oben rechts auf das Symbol Webvorschau (sieht aus wie ein Auge) und wählen Sie Vorschau auf Port 8080 aus. Daraufhin wird die SMT-Benutzeroberfläche in einem neuen Browsertab geöffnet.

- Wählen Sie in der SMT-Web-UI Mit Datenbank verbinden aus.
- Geben Sie die Verbindungsdetails ein:
- Database Type (Datenbanktyp): MySQL
- Host : (IP-Adresse aus Schritt 2 einfügen)
- Port:3306
- Nutzer:
datastream_user - Passwort :
complex_password_123 - Datenbankname :
shard0_db
- Klicken Sie oben rechts auf die Schaltfläche „Bearbeiten“, um die Spanner-Datenbank zu konfigurieren.
- Geben Sie die Details für Target Spanner ein:
- Projekt-ID : (Projekt-ID aus Schritt 3 einfügen)
- Spanner-Instanz : (Instanz-ID aus Schritt 3 einfügen)
- Klicken Sie auf Test Connection.
- Wenn die Prüfung bestanden ist, klicken Sie auf Verbinden. SMT analysiert die Quelldatenbank und stellt ein Spanner-Basisschema bereit.

3. Schemaänderungen anwenden
Wir passen das Schema jetzt an, um unsere komplexen Migrationsszenarien abzudecken.
Führen Sie im Schemaeditor der SMT-Benutzeroberfläche die folgenden Aktionen aus:
A. Spalte „LegacyRegion“ umbenennen:
- Klicken Sie im linken Navigationsbereich auf die Tabelle
Customers. Standardmäßig wird der Tab Spalten geöffnet. - Klicken Sie im Bereich „Spanner“ auf die Schaltfläche „Bearbeiten“.
- Suchen Sie in der Spanner-Schemaansicht nach der Spalte
LegacyRegion. - Ändern Sie den Spanner-Spaltennamen in
LoyaltyTier, indem Sie den Spaltennamen in das Dialogfeld eingeben. - Klicken Sie auf Speichern und konvertieren.


B. Prüfbeschränkung lockern:
- Bleiben Sie in der Tabelle
Customersund rufen Sie den Tab Prüfbeschränkungen auf. - Suchen Sie die Einschränkung
CHK_CreditLimit. Klicken Sie auf das Symbol Bearbeiten (Bleistift). - Ändern Sie die Bedingung von
CreditLimit > 1000inCreditLimit > 0. Dadurch wird absichtlich bewirkt, dass Zeilen mit niedrigeren Kreditlimits bei der Rückmigration fehlschlagen und in die DLQ verschoben werden.

C. Spalte „LegacyOrderSystem“ löschen:
- Klicken Sie auf die Tabelle
Orders. Standardmäßig wird der Tab Spalten geöffnet. - Klicken Sie im Bereich „Spanner“ auf die Schaltfläche „Bearbeiten“.
- Suchen Sie in der Spanner-Schemaansicht nach der Spalte
LegacyOrderSystem. - Klicken Sie daneben auf das Dreipunkt-Menü und wählen Sie Spalte entfernen aus.
- Klicken Sie auf Speichern und konvertieren.
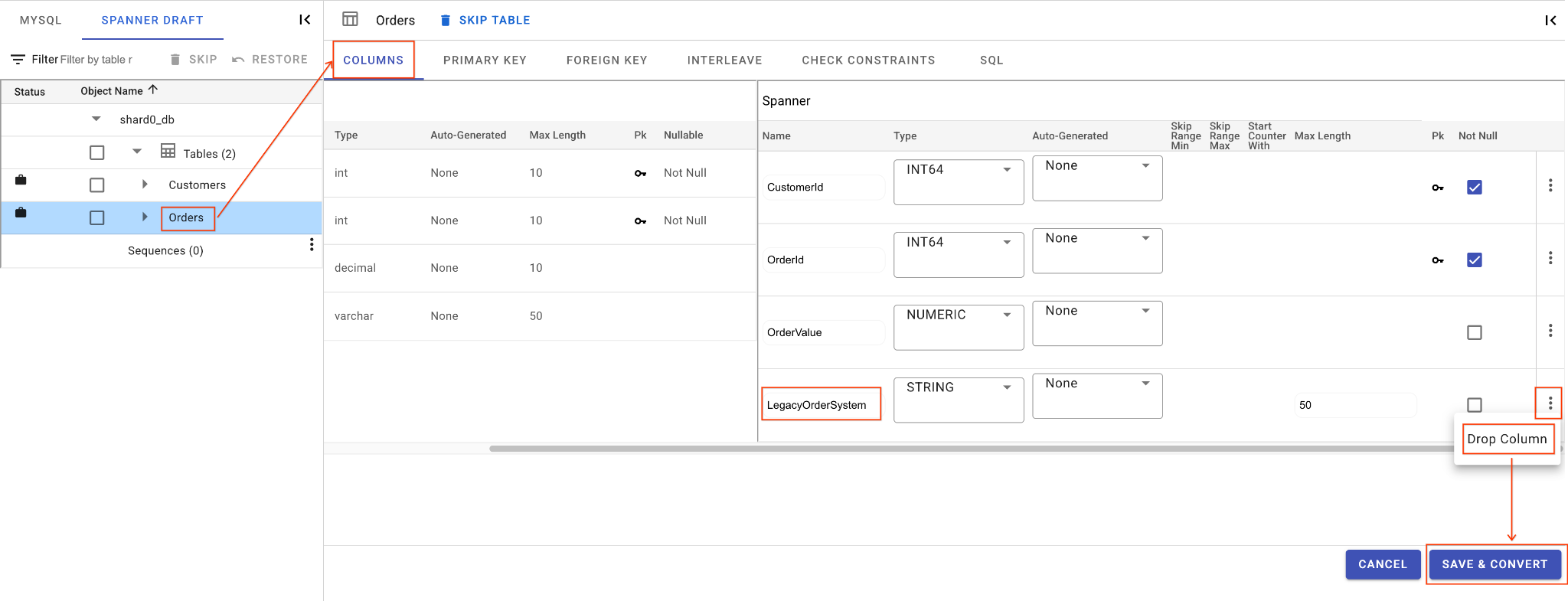
D. „OrderSource“-Spalte hinzufügen und als Primärschlüssel festlegen:
- Klicken Sie weiterhin in der Tabelle
Ordersauf Spalte hinzufügen. Geben Sie ihr den NamenOrderSourceund legen Sie den Typ aufSTRINGmit der Länge50fest. Aktivieren Sie die automatische Generierung nicht und setzen SieIsNullableaufNo. - Rufen Sie den Tab Primärschlüssel auf.
- Klicken Sie auf Bearbeiten und wählen Sie im Drop-down-Menü „Spaltenname“ die Option
OrderSourceaus. - Klicken Sie auf Spalte hinzufügen und dann auf Speichern und konvertieren.


E. Tabelle „Bestellungen“ verschachteln:
- Suchen Sie in der Haupttabellenansicht der Tabelle
Ordersnach dem Tab Verschachteln. - Legen Sie die übergeordnete Tabelle auf
Customersfest. - Wählen Sie
IN PARENTInterleave type (Verschachtelungstyp) undNO ACTIONOn Delete Action (Aktion beim Löschen) aus. - Klicken Sie auf Speichern.

4. Überschreibungsdatei herunterladen und Schema anwenden
- Suchen Sie rechts oben in der SMT-Benutzeroberfläche nach der Schaltfläche Artefakte herunterladen. Wählen Sie die Option Datei mit Überschreibungen herunterladen aus. Speichern Sie diese Datei auf Ihrem lokalen Computer. Diese Datei enthält alle Schemazuordnungsänderungen, die wir gerade vorgenommen haben, und wird von unseren Dataflow-Pipelines verwendet.
- Klicken Sie auf Migration vorbereiten.

- Wählen Sie im Drop-down-Menü Migrationsmodus als
Schemaaus. - Geben Sie die Ziel-Spanner-Datenbank ein:
sharded-target-db

- Klicken Sie auf Migrieren.
- SMT wendet die DDL an und erstellt die Spanner-Datenbank. Sie können den SMT-Prozess in Cloud Shell (
Ctrl+C) nach Abschluss sicher beenden.
5. Schema in Cloud Spanner überprüfen
Prüfen Sie, ob die Tabellen in der Spanner-Datenbank erstellt wurden.
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT table_name FROM information_schema.tables WHERE table_schema = '' ORDER BY table_name"
Es sollte folgende Ausgabe angezeigt werden:
table_name: Customers table_name: Orders
Optional:Wenn Sie die tatsächliche Spanner-DDL prüfen möchten, um zu sehen, ob Ihre Prüfeinschränkungen, das Interleaving und die zusätzlichen Spalten angewendet wurden, führen Sie den folgenden Befehl aus:
gcloud spanner databases ddl describe $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME
Erwartete Ausgabe:
CREATE TABLE Customers ( CustomerId INT64 NOT NULL, CustomerName STRING(255), CreditLimit NUMERIC NOT NULL, LoyaltyTier STRING(50), CONSTRAINT CHK_CreditLimit CHECK(`CreditLimit` > 0), ) PRIMARY KEY(CustomerId); CREATE TABLE Orders ( CustomerId INT64 NOT NULL, OrderId INT64 NOT NULL, OrderValue NUMERIC, OrderSource STRING(50) NOT NULL, ) PRIMARY KEY(CustomerId, OrderId, OrderSource), INTERLEAVE IN PARENT Customers ON DELETE NO ACTION;
7. Change Data Capture (CDC) initialisieren
In diesem Abschnitt richten Sie den „Recorder“ für die Migration ein. Wenn Sie Datastream und Pub/Sub vor dem Start des Bulk-Datenladevorgangs konfigurieren, wird jede Änderung an den Quelldatenbanken erfasst und in die Warteschlange gestellt. So wird ein Datenverlust während der Umstellung verhindert. Diese Einrichtung ist für die Live-Migration erforderlich.
Da unsere Architektur zwei physische Server umfasst, müssen wir zwei separate Datastream-Quellprofile und zwei Datastream-Streams erstellen. Beide Streams schreiben in einen einzelnen Google Cloud Storage-Bucket (GCS), der als einheitliche Quelle für unsere Dataflow-Pipeline dient.
1. Cloud Storage-Bucket erstellen
Datastream benötigt ein Ziel, in dem die erfassten Änderungsereignisse gespeichert werden. Erstellen wir einen GCS-Bucket.
export BUCKET_NAME="migration-${PROJECT_ID}-bucket"
gcloud storage buckets create gs://${BUCKET_NAME} --location=$REGION
2. Datastream-Verbindungsprofile erstellen
Wir benötigen zwei separate MySQL-Quellverbindungsprofile (eines für jeden physischen Shard) und ein Zielverbindungsprofil für Cloud Storage.
Quell-IP-Adressen abrufen
Rufen Sie zuerst die externen IP-Adressen unserer beiden Compute Engine-VMs ab und speichern Sie sie als Umgebungsvariablen:
export MYSQL_IP_1=$(gcloud compute instances describe mysql-physical-1 --zone=$ZONE --format='get(networkInterfaces[0].accessConfigs[0].natIP)')
export MYSQL_IP_2=$(gcloud compute instances describe mysql-physical-2 --zone=$ZONE --format='get(networkInterfaces[0].accessConfigs[0].natIP)')
Quellverbindungsprofile erstellen (MySQL in Compute Engine)
Erstellen Sie die Datastream-Verbindungsprofile mit dem zuvor erstellten datastream_user.
# Create Source Profile for Physical Shard 1
export SQL_CP_NAME_1="mysql-src-cp-1"
gcloud datastream connection-profiles create $SQL_CP_NAME_1 \
--location=$REGION \
--type=mysql \
--mysql-hostname=$MYSQL_IP_1 \
--mysql-port=3306 \
--mysql-username=datastream_user \
--mysql-password=complex_password_123 \
--display-name="MySQL Source 1 (Physical Shard 1)"
# Create Source Profile for Physical Shard 2
export SQL_CP_NAME_2="mysql-src-cp-2"
gcloud datastream connection-profiles create $SQL_CP_NAME_2 \
--location=$REGION \
--type=mysql \
--mysql-hostname=$MYSQL_IP_2 \
--mysql-port=3306 \
--mysql-username=datastream_user \
--mysql-password=complex_password_123 \
--display-name="MySQL Source 2 (Physical Shard 2)"
Hinweis:Datastream stellt über die öffentlichen IP-Adressen eine Verbindung zu diesen VMs her. Das ist zulässig, da wir 0.0.0.0/0 zuvor unseren Firewallregeln hinzugefügt haben. In einer Produktionsumgebung würden Sie die spezifischen öffentlichen IP-Bereiche von Datastream auf die Zulassungsliste setzen.
Zielverbindungsprofil erstellen (Cloud Storage):
Dies verweist auf den Stamm des neu erstellten Buckets.
export GCS_CP_NAME="gcs-dest-cp"
gcloud datastream connection-profiles create $GCS_CP_NAME \
--location=$REGION \
--type=google-cloud-storage \
--bucket=$BUCKET_NAME \
--root-path=/ \
--display-name="GCS Destination" --force
3. Datastream-Streams erstellen
Wir erstellen jetzt zwei CDC-Streams. In Stream 1 werden shard0_db und shard1_db erfasst. In Stream 2 werden shard2_db und shard3_db erfasst. Beide Streams schreiben im Avro-Format in denselben GCS-Bucket.
# Stream for Physical Shard 1
export STREAM_NAME_1="mysql-to-spanner-stream-1"
export GCS_STREAM_PATH_1="data/${STREAM_NAME_1}"
gcloud datastream streams create $STREAM_NAME_1 \
--location=$REGION \
--display-name="MySQL Source 1 CDC Stream" \
--source=$SQL_CP_NAME_1 \
--destination=$GCS_CP_NAME \
--mysql-source-config=<(echo "includeObjects:
mysqlDatabases:
- database: 'shard0_db'
- database: 'shard1_db'") \
--gcs-destination-config=<(echo "path: ${GCS_STREAM_PATH_1}/
fileRotationMb: 5
fileRotationInterval: 15s
avroFileFormat: {}") \
--backfill-none
# Stream for Physical Shard 2
export STREAM_NAME_2="mysql-to-spanner-stream-2"
export GCS_STREAM_PATH_2="data/${STREAM_NAME_2}"
gcloud datastream streams create $STREAM_NAME_2 \
--location=$REGION \
--display-name="MySQL Source 2 CDC Stream" \
--source=$SQL_CP_NAME_2 \
--destination=$GCS_CP_NAME \
--mysql-source-config=<(echo "includeObjects:
mysqlDatabases:
- database: 'shard2_db'
- database: 'shard3_db'") \
--gcs-destination-config=<(echo "path: ${GCS_STREAM_PATH_2}/
fileRotationMb: 5
fileRotationInterval: 15s
avroFileFormat: {}") \
--backfill-none
Wenn Sie kleinere Einstellungen für die Dateirotation (5 MB oder 15 Sekunden) verwenden, können wir replizierte Änderungen während des Codelabs schneller sehen.
Die Ausführung dieses Befehls kann einige Zeit in Anspruch nehmen. Status prüfen: gcloud datastream streams describe $STREAM_NAME_1 --location=$REGION.
4. Datastream-Streams starten
Aktivieren Sie beide Streams, damit Änderungen aufgezeichnet werden.
gcloud datastream streams update $STREAM_NAME_1 \
--location=$REGION \
--state=RUNNING
gcloud datastream streams update $STREAM_NAME_2 \
--location=$REGION \
--state=RUNNING
Status prüfen: Sie können gcloud datastream streams describe $STREAM_NAME_1 --location=$REGION ausführen. Der Status ist anfangs STARTING und ändert sich nach einigen Augenblicken in RUNNING. Warten Sie, bis beide vollständig ausgeführt werden, bevor Sie die Live-Migration starten.
5. Pub/Sub für GCS-Benachrichtigungen einrichten
Dataflow muss sofort benachrichtigt werden, wenn ein Datastream-Stream eine neue Datei in den GCS-Bucket schreibt. Wir konfigurieren GCS so, dass Benachrichtigungen an ein einzelnes Pub/Sub-Thema gesendet werden.
Pub/Sub-Thema erstellen:
export PUBSUB_TOPIC="datastream-gcs-updates"
gcloud pubsub topics create $PUBSUB_TOPIC
GCS-Benachrichtigung erstellen
Benachrichtige das Thema bei jeder Objekterstellung unter dem Präfix data/ (das beide Streams abdeckt).
gcloud storage buckets notifications create gs://${BUCKET_NAME} --topic=projects/$PROJECT_ID/topics/$PUBSUB_TOPIC --payload-format=json --object-prefix=data/
Pub/Sub-Abo erstellen
Erstellen Sie das Abo mit einer empfohlenen Bestätigungsfrist für Dataflow.
export PUBSUB_SUBSCRIPTION="datastream-gcs-sub"
gcloud pubsub subscriptions create $PUBSUB_SUBSCRIPTION \
--topic=$PUBSUB_TOPIC \
--ack-deadline=600
8. Benutzerdefinierte Transformation
Da sich unser Spanner-Schema von unserem MySQL-Schema unterscheidet (aufgrund der Spalten, die wir über die SMT-Web-UI hinzugefügt und entfernt haben), schlägt die Dataflow-Migration fehl. Dataflow benötigt Anweisungen, wie diese Unterschiede während der Forward-Pipeline (MySQL zu Spanner) und der Reverse-Pipeline (Spanner zu MySQL) zugeordnet werden sollen.
Da wir außerdem eine shardbasierte Rückmigration durchführen, benötigt Dataflow einen Routing-Mechanismus, um zu wissen, zu welchem logischen Shard (shard0_db, shard1_db usw.) eine aktualisierte Spanner-Zeile während der Rückreplikation gehört.
Dazu schreiben wir ein benutzerdefiniertes Transformations-JAR mit der von Google bereitgestellten benutzerdefinierten Spanner-Shard-Vorlage.
1. Benutzerdefinierte Shard-Vorlage herunterladen
Laden Sie in Cloud Shell das Google Cloud Dataflow-Vorlagen-Repository herunter und wechseln Sie zum benutzerdefinierten Shard-Ordner:
git clone https://github.com/GoogleCloudPlatform/DataflowTemplates.git
cd DataflowTemplates/v2/spanner-custom-shard
2. Datentransformationslogik konfigurieren
Wir müssen die Datei CustomTransformationFetcher.java bearbeiten.
- Vorwärtsmigration (
toSpannerRow): Die neu hinzugefügte SpalteOrderSourcewird mit der SpalteLegacyOrderSystemaus MySQL gefüllt. - Rückmigration (
toSourceRow): Füllt die gelöschte SpalteLegacyOrderSystem, die von MySQL benötigt wird, neu auf. Sie wird ausOrderSourcevon Spanner abgeleitet.
Bearbeiten Sie die Datei CustomTransformationFetcher.java. Anstatt einen Texteditor manuell zu öffnen, können Sie die Vorlagendatei mit dem folgenden Befehl automatisch mit Ihrer benutzerdefinierten Logik überschreiben:
cat << 'EOF' > src/main/java/com/custom/CustomTransformationFetcher.java
package com.custom;
import com.google.cloud.teleport.v2.spanner.exceptions.InvalidTransformationException;
import com.google.cloud.teleport.v2.spanner.utils.ISpannerMigrationTransformer;
import com.google.cloud.teleport.v2.spanner.utils.MigrationTransformationRequest;
import com.google.cloud.teleport.v2.spanner.utils.MigrationTransformationResponse;
import java.util.HashMap;
import java.util.Map;
public class CustomTransformationFetcher implements ISpannerMigrationTransformer {
@Override
public void init(String customParameters) {}
@Override
public MigrationTransformationResponse toSpannerRow(MigrationTransformationRequest request)
throws InvalidTransformationException {
if (request.getTableName().equals("Orders")) {
Map<String, Object> requestRow = request.getRequestRow();
Map<String, Object> responseRow = new HashMap<>();
Object legacySysObj = requestRow.get("LegacyOrderSystem");
String legacySys = (legacySysObj != null) ? (String) legacySysObj : "UNKNOWN_SYSTEM";
// Transform: Trim the string to remove everything after the first underscore
String orderSource = legacySys;
if (legacySys.contains("_")) {
orderSource = legacySys.substring(0, legacySys.indexOf('_'));
}
// Populate the new Spanner column (e.g., "WebStore_v1" becomes "WebStore")
responseRow.put("OrderSource", orderSource);
return new MigrationTransformationResponse(responseRow, false);
}
return new MigrationTransformationResponse(new HashMap<>(), false);
}
@Override
public MigrationTransformationResponse toSourceRow(MigrationTransformationRequest request)
throws InvalidTransformationException {
if (request.getTableName().equals("Orders")) {
Map<String, Object> requestRow = request.getRequestRow();
Map<String, Object> responseRow = new HashMap<>();
// Safely fetch the Spanner OrderSource
Object sourceObj = requestRow.get("OrderSource");
String source = (sourceObj != null) ? (String) sourceObj : "UNKNOWN_SYSTEM";
String legacySys = "'" + source + "_v1'";
// Transform: Append a suffix to visibly prove the reverse transformation worked
// e.g., "WebStore" becomes "WebStore_v1"
responseRow.put("LegacyOrderSystem", legacySys);
return new MigrationTransformationResponse(responseRow, false);
}
return new MigrationTransformationResponse(new HashMap<>(), false);
}
@Override
public MigrationTransformationResponse transformFailedSpannerMutation(
MigrationTransformationRequest request) throws InvalidTransformationException {
return new MigrationTransformationResponse(new HashMap<>(), false);
}
}
EOF
3. Logik für das Reverse Sharding konfigurieren
Dataflow verwendet CustomShardIdFetcher.java bei der umgekehrten Replikation, um zu bestimmen, wohin eine Spanner-Mutation weitergeleitet werden soll. Wir verwenden den Primärschlüssel CustomerId und die Modulo-Logik (%4), um Datensätze dynamisch an den richtigen logischen Shard weiterzuleiten.
Bearbeiten Sie die Datei CustomShardIdFetcher.java mit „cat“ und ersetzen Sie den gesamten Inhalt durch den folgenden Code:
cat << 'EOF' > src/main/java/com/custom/CustomShardIdFetcher.java
package com.custom;
import com.google.cloud.teleport.v2.spanner.utils.IShardIdFetcher;
import com.google.cloud.teleport.v2.spanner.utils.ShardIdRequest;
import com.google.cloud.teleport.v2.spanner.utils.ShardIdResponse;
import java.util.Map;
public class CustomShardIdFetcher implements IShardIdFetcher {
@Override
public void init(String parameters) {}
@Override
public ShardIdResponse getShardId(ShardIdRequest shardIdRequest) {
Map<String, Object> keys = shardIdRequest.getSpannerRecord
();
// Use the Primary Key to identify the correct logical shard
if (keys != null && keys.containsKey("CustomerId")) {
long customerId = Long.parseLong(keys.get("CustomerId").toString());
long shardIdx = customerId % 4;
ShardIdResponse response = new ShardIdResponse();
response.setLogicalShardId("shard" + shardIdx + "_db");
return response;
}
return new ShardIdResponse();
}
}
EOF
4. JAR-Datei erstellen und hochladen
Nachdem wir unsere benutzerdefinierte Java-Logik geschrieben haben, müssen wir sie in eine JAR-Datei kompilieren und in den Google Cloud Storage-Bucket hochladen, den wir zuvor erstellt haben, damit Dataflow darauf zugreifen kann.
Führen Sie die folgenden Befehle in Cloud Shell aus:
# Return to DataflowTemplates directory
cd ../..
# Build the JAR using Maven
mvn clean install -DskipTests -Dcheckstyle.skip -Dspotless.check.skip=true -Djib.skip -pl v2/spanner-custom-shard -am
# Upload the JAR to GCS
export CUSTOM_JAR_PATH="gs://${BUCKET_NAME}/custom-logic/spanner-custom-shard-1.0.jar"
gcloud storage cp v2/spanner-custom-shard/target/spanner-custom-shard-1.0-SNAPSHOT.jar $CUSTOM_JAR_PATH
# Return to home directory
cd ~
9. Daten im Bulk von MySQL zu Spanner migrieren
Nachdem das Spanner-Schema vorhanden und das benutzerdefinierte Transformations-JAR erstellt wurde, können wir die vorhandenen Daten aus Ihrer MySQL-Datenbank in Cloud Spanner kopieren. Sie verwenden die flexible Dataflow-Vorlage Sourcedb to Spanner, die für das Bulk-Kopieren von Daten aus JDBC-zugänglichen Datenbanken nach Spanner entwickelt wurde.
1. Überschreibungsdatei für Schema hochladen
In Abschnitt 6 haben Sie die JSON-Datei mit den Spanner-Überschreibungen über die SMT-Web-UI heruntergeladen. Wir müssen diese Datei in unseren GCS-Bucket hochladen, damit Dataflow sie verwenden kann, um die Schemaunterschiede (z. B. umbenannte Spalten) zuzuordnen.
- Klicken Sie in Cloud Shell auf das Dreipunkt-Menü (Mehr) und wählen Sie Hochladen aus.

- Wählen Sie die JSON-Datei mit den Überschreibungen aus, die Sie zuvor heruntergeladen haben (z.B.
spanner_overrides.json). - Verschieben Sie sie in Ihren GCS-Bucket:
export OVERRIDES_FILE="spanner_overrides.json" # Change this if your downloaded file has a different name
export GCS_OVERRIDES_PATH="gs://${BUCKET_NAME}/config/${OVERRIDES_FILE}"
gcloud storage cp ~/${OVERRIDES_FILE} $GCS_OVERRIDES_PATH
2. Sharding-Konfigurationsdatei erstellen und hochladen
Dataflow muss wissen, wie eine Verbindung zu allen vier logischen Shards auf Ihren beiden physischen VMs hergestellt wird. Dazu erstellen wir eine sharding.json-Datei.
Führen Sie in Cloud Shell den folgenden Befehl aus, um die Konfiguration zu generieren und hochzuladen:
cat <<EOF > sharding.json
{
"configType": "dataflow",
"shardConfigurationBulk": {
"schemaSource": {
"dataShardId": "mysql-physical-1",
"host": "${MYSQL_IP_1}",
"user": "datastream_user",
"password": "complex_password_123",
"port": "3306",
"dbName": "shard0_db"
},
"dataShards": [
{
"dataShardId": "mysql-physical-1",
"host": "${MYSQL_IP_1}",
"user": "datastream_user",
"password": "complex_password_123",
"port": "3306",
"dbName": "",
"namespace": "namespace-mysql-1",
"databases": [
{
"dbName": "shard0_db",
"databaseId": "shard0_db",
"refDataShardId": "mysql-physical-1"
},
{
"dbName": "shard1_db",
"databaseId": "shard1_db",
"refDataShardId": "mysql-physical-1"
}
]
},
{
"dataShardId": "mysql-physical-2",
"host": "${MYSQL_IP_2}",
"user": "datastream_user",
"password": "complex_password_123",
"port": "3306",
"dbName": "",
"namespace": "namespace-mysql-2",
"databases": [
{
"dbName": "shard2_db",
"databaseId": "shard2_db",
"refDataShardId": "mysql-physical-2"
},
{
"dbName": "shard3_db",
"databaseId": "shard3_db",
"refDataShardId": "mysql-physical-2"
}
]
}
]
}
}
EOF
export GCS_SHARDING_PATH="gs://${BUCKET_NAME}/config/sharding.json"
gcloud storage cp sharding.json $GCS_SHARDING_PATH
3. Dataflow-Job für die Bulk-Migration ausführen
Wir verwenden die flexible Vorlage Sourcedb zu Spanner. Da es sich um eine Migration mit Sharding und benutzerdefinierten Transformationen handelt, übergeben wir die Überschreibungen-Datei, die Sharding-Konfiguration und unsere benutzerdefinierte Java-JAR-Datei.
export JOB_NAME="mysql-sharded-bulk-to-spanner-$(date +%Y%m%d-%H%M%S)"
export OUTPUT_DIR="gs://${BUCKET_NAME}/bulk-migration"
gcloud dataflow flex-template run $JOB_NAME \
--project=$PROJECT_ID \
--region=$REGION \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Sourcedb_to_Spanner_Flex" \
--max-workers=2 \
--num-workers=1 \
--worker-machine-type=n2-highmem-8 \
--parameters \
sourceConfigURL=$GCS_SHARDING_PATH,\
instanceId=$SPANNER_INSTANCE_NAME,\
databaseId=$SPANNER_DATABASE_NAME,\
projectId=$PROJECT_ID,\
outputDirectory=$OUTPUT_DIR,\
username=datastream_user,\
password=complex_password_123,\
schemaOverridesFilePath=$GCS_OVERRIDES_PATH,\
transformationJarPath=$CUSTOM_JAR_PATH,\
transformationClassName=com.custom.CustomTransformationFetcher
Erklärung der wichtigsten Parameter:
sourceConfigURL: Der Pfad zur von uns erstellten Dateisharding.json. Dadurch wird Dataflow mitgeteilt, wie eine Verbindung zu allen vier logischen MySQL-Shards auf den beiden physischen VMs hergestellt werden soll.schemaOverridesFilePath: Der Pfad zur JSON-Datei, die wir über die SMT-Web-UI heruntergeladen haben. Damit wird Dataflow angewiesen, wie die von uns vorgenommenen Schemaänderungen zu verarbeiten sind, z. B. die gelöschte SpalteLegacyRegionund die strengere Prüfeinschränkung.transformationJarPath: Der GCS-Pfad zur kompilierten Java-JAR-Datei, die wir im vorherigen Abschnitt erstellt haben. Dieser enthält den eigentlichen Code zum Ausführen unserer benutzerdefinierten Transformationen.transformationClassName: Der vollständig qualifizierte Name der Java-Klasse in unserem JAR, die die Logik für die Vorwärtsmigration implementiert (com.custom.CustomTransformationFetcher).outputDirectory: Der GCS-Speicherort, an dem Dataflow seine temporären Dateien und vor allem die Dateien der Dead-Letter-Warteschlange (DLQ) schreibt.maxWorkers,numWorkers: Steuert die Skalierung des Dataflow-Jobs. Für dieses kleine Dataset wurde er niedrig gehalten.instanceId,databaseId,projectId: Gibt die Cloud Spanner-Zielinstanz und -Datenbank an.
Hinweis zum Netzwerk:Dieser Job stellt über die öffentliche IP-Adresse eine Verbindung zur Cloud SQL-Instanz her. Das ist möglich, weil Sie 0.0.0.0/0 zuvor den autorisierten Netzwerken der Instanz hinzugefügt haben. So können die Dataflow-Worker-VMs, die externe IPs haben, auf die Datenbank zugreifen.
4. Dataflow-Job überwachen
Sie können den Fortschritt des Jobs in der Google Cloud Console verfolgen:
- Rufen Sie die Seite „Dataflow-Jobs“ auf: Zur Seite „Dataflow-Jobs“
- Suchen Sie den Job mit dem Namen
mysql-sharded-bulk-to-spanner-...und klicken Sie darauf. - Jobgrafik und Messwerte ansehen Warten Sie, bis sich der Jobstatus in Erfolgreich ändert. Dies dauert etwa 5–15 Minuten.

- Wenn beim Job Probleme auftreten, sehen Sie sich auf der Seite mit den Dataflow-Jobdetails den Tab Logs an, um Fehlermeldungen zu finden.
- Unter Job-Messwerte finden Sie weitere Informationen zum Fortschritt des Jobs und zum Ressourcenverbrauch, z. B. Durchsatz und CPU-Auslastung.
5. Daten in Cloud Spanner prüfen und Dead-Letter-Warteschlange (DLQ) untersuchen
Nachdem der Dataflow-Job erfolgreich abgeschlossen wurde, müssen wir prüfen, ob unsere Daten sicher angekommen sind, und die Datensätze untersuchen, die wir absichtlich so konfiguriert haben, dass sie fehlschlagen.
A. Gesamtzustand der migrierten Daten prüfen:
Verwenden Sie die gcloud-Befehlszeile, um einige schnelle Systemdiagnosen für Ihre konsolidierte Spanner-Datenbank auszuführen. So können Sie prüfen, ob die gültigen Datensätze richtig migriert wurden und ob in der zusätzlichen Spalte Daten aus unserem benutzerdefinierten JAR eingefügt wurden.
# 1. Verify total Customer count
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT COUNT(*) as TotalCustomers FROM Customers"
# 2. Verify total Orders count (Total minus the orphan record)
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT COUNT(*) as TotalOrders FROM Orders"
# 3. Verify the Custom Transformation on OrderSource worked
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT CustomerId, OrderId, OrderSource FROM Orders LIMIT 3"
# 4. Verify that renamed column LoyaltyTier has the correct data
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT CustomerId, CustomerName, LoyaltyTier FROM Customers LIMIT 3"
Erwartete Ausgabe:
TotalCustomers: 16 TotalOrders: 19 CustomerId: 1 OrderId: 201 OrderSource: MobileApp CustomerId: 2 OrderId: 301 OrderSource: CallCenter CustomerId: 3 OrderId: 401 OrderSource: InStore CustomerId: 1 CustomerName: Agnes N. LoyaltyTier: NORTHEAST CustomerId: 2 CustomerName: Brian K. LoyaltyTier: SOUTHWEST CustomerId: 3 CustomerName: Cathy Z. LoyaltyTier: CENTRAL
- Alle Zeilen in der Tabelle „Customers“ wurden erfolgreich migriert.
- In der Tabelle
Orderssehen wir 1 Zeilenfehler aufgrund vonINTERLEAVE IN PARENTin Spanner –CustomerId 99ist ein untergeordnetes Element ohne zugehörige übergeordnete Zeile, da es keine entsprechende Zeile in der TabelleCustomersgibt.
B. Prüfen Sie die DLQ auf beabsichtigte Fehler:
Der oben genannte Fehler wird im Ordner „Dead-Letter-Warteschlange“ (DLQ) dokumentiert, der von der Bulk-Migrationspipeline erstellt wurde.
- Rufen Sie in der Google Cloud Console Cloud Storage auf.
- Rufen Sie Ihren Bucket auf und öffnen Sie den Ordner
bulk-migration/dlq/severe. - Sehen Sie sich die JSON-Dateien darin an. Sie finden die Zeile
Ordersmit dem verwaistenCustomerId. - DLQ-Fehler bei der Bulk-Migration können wiederholt werden. Folgen Sie dazu der Anleitung.
Der erste Bulk-Upload von Daten aus Cloud SQL in Cloud Spanner ist jetzt abgeschlossen. Im nächsten Schritt richten Sie die Live-Replikation ein, um laufende Änderungen zu erfassen.
10. Live-Migration (CDC) starten
Nachdem der Bulk-Datenladevorgang abgeschlossen ist, starten Sie einen kontinuierlichen Dataflow-Streamingjob. Mit diesem Job werden die CDC-Ereignisse (Change Data Capture) gelesen, die von Datastream in Ihren GCS-Bucket geschrieben werden, und diese Änderungen werden nahezu in Echtzeit auf Cloud Spanner angewendet.
Wir testen diese Pipeline auch, indem wir sowohl gültige als auch absichtlich ungültige Daten einfügen, um zu beobachten, wie Dataflow die Live-Replikation verarbeitet und Fehler an die Dead-Letter-Warteschlange weiterleitet.
1. Konfigurationsdatei für die Live-Migration von Shards erstellen
Im Gegensatz zur Bulk-Migration, bei der JDBC-Verbindungsstrings verwendet werden, werden bei der Live-Migrationspipeline Datastream-Ereignisse aus GCS gelesen. Dazu ist eine völlig andere JSON-Konfiguration erforderlich, in der Datastream-Streamnamen und ‑Datenbanken Ihren logischen Spanner-Shards zugeordnet werden.
Führen Sie den folgenden Befehl in Cloud Shell aus, um die Live-Sharding-Konfiguration zu erstellen und hochzuladen:
cat <<EOF > live-sharding.json
{
"StreamToDbAndShardMap": {
"${STREAM_NAME_1}": {
"shard0_db": "shard0_db",
"shard1_db": "shard1_db"
},
"${STREAM_NAME_2}": {
"shard2_db": "shard2_db",
"shard3_db": "shard3_db"
}
}
}
EOF
export GCS_LIVE_SHARDING_PATH="gs://${BUCKET_NAME}/config/live-sharding.json"
gcloud storage cp live-sharding.json $GCS_LIVE_SHARDING_PATH
2. Dataflow-Job für die Live-Migration ausführen
Starten Sie den Streaming-Dataflow-Job, um Daten aus GCS zu lesen und in Spanner zu schreiben. Bei dieser Vorlage werden GCS Pub/Sub-Benachrichtigungen verwendet, um neue Dateien sofort zu verarbeiten.
export JOB_NAME_CDC="mysql-sharded-cdc-to-spanner-$(date +%Y%m%d-%H%M%S)"
export DLQ_DIR_CDC="gs://${BUCKET_NAME}/live-migration"
gcloud dataflow flex-template run $JOB_NAME_CDC \
--project=$PROJECT_ID \
--region=$REGION \
--worker-machine-type=n2-highmem-8 \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Cloud_Datastream_to_Spanner" \
--parameters \
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
projectId="$PROJECT_ID",\
inputFileFormat="avro",\
gcsPubSubSubscription="projects/${PROJECT_ID}/subscriptions/${PUBSUB_SUBSCRIPTION}",\
shardingContextFilePath=$GCS_LIVE_SHARDING_PATH,\
deadLetterQueueDirectory="$DLQ_DIR_CDC",\
transformationJarPath=$CUSTOM_JAR_PATH,\
transformationClassName="com.custom.CustomTransformationFetcher",\
schemaOverridesFilePath=$GCS_OVERRIDES_PATH,\
datastreamSourceType="mysql",\
dlqRetryMinutes=1,\
dlqMaxRetryCount=2
Wichtige Parameter
gcsPubSubSubscription: Das Pub/Sub-Abo, das auf Benachrichtigungen zu neuen Dateien von GCS wartet. So kann der Job Änderungen sofort verarbeiten, wenn Datastream sie schreibt.inputFileFormat="avro": Gibt an, dass Dataflow Avro-Dateien von Datastream erwartet. Dies muss mit der Konfiguration des Datastreams für das Ziel übereinstimmen (z. B.avroFileFormatim Vergleich zujsonFileFormat).shardingContextFilePath: Eine JSON-Datei, in der Datastream-Streams logischen Shards zugeordnet werden.dlqRetryMinutes: Die Anzahl der Minuten zwischen DLQ-Wiederholungen (Dead Letter Queue). Die Standardeinstellung ist10.dlqMaxRetryCount: Die maximale Anzahl der Wiederholungsversuche über die DLQ bei vorübergehenden Fehlern. Die Standardeinstellung ist500.
Überwachen Sie den Jobstart in der Dataflow-Jobs-Konsole.
3. Livedaten einfügen und absichtliche Fehler auslösen
Während der Dataflow-Streamingjob gestartet wird (das kann 3 bis 5 Minuten dauern), stellen wir eine SSH-Verbindung zur ersten physischen MySQL-VM her und fügen einige neue Datensätze ein. Wir fügen einen gültigen und einen ungültigen Datensatz ein.
Stellen Sie eine SSH-Verbindung zum ersten physischen Shard her:
gcloud compute ssh mysql-physical-1 --zone=$ZONE
Melden Sie sich bei MySQL an:
sudo mysql
Führen Sie die folgenden Einfügungen für shard1_db aus:
USE shard1_db;
-- 1. Valid Insert: 'MobileApp_v2' will be trimmed to 'MobileApp'
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem)
VALUES (4, 501, 99.99, 'MobileApp_v2');
-- 2. Invalid Insert (DLQ Test): This violates Interleave constraint as CustomerId 99999 doesn't exist in Customers table.
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem)
VALUES (99999, 502, 50.00, 'WebStore_v1');
-- 3. Valid Update
UPDATE Orders SET OrderValue = '1500' WHERE CustomerId = 5 AND OrderId = 202;
-- 4. Valid Delete
DELETE FROM Orders WHERE CustomerId = 5 AND OrderId = 203;
EXIT;
Geben Sie noch einmal exit ein, um zur Cloud Shell-Eingabeaufforderung zurückzukehren.
4. Live-Migrationsdaten prüfen und CDC-DLQ untersuchen
Nachdem wir die Daten eingefügt haben, erfasst Datastream die CDC-Ereignisse und Dataflow versucht, sie auf Spanner anzuwenden.
A. Gültige DML-Änderungen in Cloud Spanner prüfen
Führen Sie die folgenden Abfragen aus, um zu prüfen, ob die Ereignisse INSERT, UPDATE und DELETE erfolgreich in Spanner eingegangen sind und ob die benutzerdefinierte Transformation sowohl beim Einfügen als auch beim Aktualisieren ausgelöst wurde.
# 1. Verify INSERT: Should return the new row with transformed OrderSource
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT CustomerId, OrderId, OrderValue, OrderSource FROM Orders WHERE CustomerId = 4 AND OrderId = 501"
# 2. Verify UPDATE: Should show OrderValue changed to 1500
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT CustomerId, OrderId, OrderValue, OrderSource FROM Orders WHERE CustomerId = 5 AND OrderId = 202"
# 3. Verify DELETE: Should return 0, confirming the order was deleted
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT COUNT(*) FROM Orders WHERE CustomerId = 5 AND OrderId = 203"
# 4. Verify DLQ Failure: Should return 0, confirming the row migration failed
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT COUNT(*) FROM Orders WHERE CustomerId = 99999 AND OrderId = 502"
Erwartete Ausgabe:
CustomerId: 4 OrderId: 501 OrderValue: 99.99 OrderSource: MobileApp CustomerId: 5 OrderId: 202 OrderValue: 1500 OrderSource: WebStore 0 0
Hinweis: Wenn bei einer Anfrage nicht das erwartete Ergebnis angezeigt wird, warten Sie eine Minute und versuchen Sie es noch einmal. Die Streaming-Worker verarbeiten die Warteschlange möglicherweise noch.
B. Prüfen Sie den absichtlichen Fehler in der DLQ:
Da CustomerId = 99999 kein übergeordnetes Element in der Tabelle Customers hat, sollte es von Spanner abgelehnt und von Dataflow sicher in die Warteschlange für unzustellbare Nachrichten weitergeleitet worden sein.
- Rufen Sie in der Google Cloud Console Cloud Storage auf.
- Rufen Sie Ihren Bucket auf und öffnen Sie den Ordner
live-migration/dlq/severe/. - Sie sollten neu generierte JSON-Dateien sehen. Klicken Sie darauf, um sich den Inhalt anzusehen. Sie sehen die Details von
CustomerId = 99999und die spezifische Spanner-Fehlermeldung:NOT_FOUND: Parent row for row [99999,502,WebStore] in table Orders is missing. Row cannot be written.". - Fehler in der DLQ für die Live-Migration können durch Ausführen der Dataflow-Vorlage mit
runMode=retryDLQbehoben werden.
5. DLQ-Fehler beheben
Fehler im Verzeichnis severe/ erfordern einen manuellen Eingriff. Wir beheben das Datenproblem und verarbeiten das fehlgeschlagene Ereignis noch einmal.
A. Daten in der Quelle korrigieren
Der Fehler ist aufgetreten, weil der übergeordnete Kundendatensatz CustomerId = 99999 fehlt. Fügen wir sie in die MySQL-Quelldatenbank ein.
Stellen Sie noch einmal eine SSH-Verbindung zur MySQL-Instanz her:
gcloud compute ssh mysql-physical-1 --zone=$ZONE
Melden Sie sich mit sudo mysql bei MySQL an und fügen Sie die fehlende übergeordnete Zeile in shard1_db ein:
USE shard1_db;
INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LegacyRegion) VALUES
(99999, 'DLQ Parent Holder', 5000.00, 'NORTH_AMERICA');
EXIT;
Geben Sie exit ein, um zu Cloud Shell zurückzukehren.
B. Dataflow-Job „retryDLQ“ ausführen
Wenn Sie Ereignisse aus der severe/-DLQ noch einmal verarbeiten möchten, starten Sie dieselbe Dataflow-Vorlage, aber im retryDLQ-Modus. In diesem Modus werden Daten speziell aus dem Pfad deadLetterQueueDirectory/severe gelesen, noch einmal durch Ihre benutzerdefinierten Transformationen geleitet und auf Spanner angewendet.
Starten Sie den Job im retryDLQ-Modus:
export JOB_NAME_RETRY="mysql-sharded-cdc-retry-$(date +%Y%m%d-%H%M%S)"
gcloud dataflow flex-template run $JOB_NAME_RETRY \
--project=$PROJECT_ID \
--region=$REGION \
--worker-machine-type=n2-highmem-8 \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Cloud_Datastream_to_Spanner" \
--parameters \
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
projectId="$PROJECT_ID",\
runMode="retryDLQ",\
deadLetterQueueDirectory="$DLQ_DIR_CDC",\
datastreamSourceType="mysql",\
transformationJarPath=$CUSTOM_JAR_PATH,\
transformationClassName="com.custom.CustomTransformationFetcher",\
schemaOverridesFilePath=$GCS_OVERRIDES_PATH,\
shardingContextFilePath=$GCS_LIVE_SHARDING_PATH
Wichtige Parameteränderungen für Wiederholungen
runMode="retryDLQ": Weist die Vorlage an, aus dem DLQ-Verzeichnisseverezu lesen.- Entfernt
gcsPubSubSubscription: Nicht erforderlich, da wir nicht aus dem GCS-Bucket des Live-Datastreams lesen.
Wiederholungsversuch beobachten:
Wie die Haupt-CDC-Pipeline ist retryDLQ eine Streamingpipeline, die so lange RUNNING bleibt, bis sie manuell abgebrochen wird.
- Rufen Sie die Dataflow-Jobseite für
$JOB_NAME_RETRYauf. - Suchen Sie im Bereich Messwerte nach diesen beiden Zählern:
elementsReconsumedFromDeadLetterQueue: Wird ausgewertet, wenn die Fehlerdateien abgerufen werden.Successful events: Wird erhöht, wenn der Datensatz in Spanner geschrieben wird.- Prüfen Sie das Verzeichnis
severe/auf wiederkehrende Fehler. - Wenn die Anzahl der erfolgreichen Ereignisse um die Anzahl der Elemente erhöht wurde, die Sie noch einmal versuchen wollten (in unserem Testlauf 1), fahren Sie mit dem nächsten Bestätigungsschritt fort.
C. Wiederholte Daten prüfen
Nachdem der fehlgeschlagene Datensatz noch einmal versucht wurde (es kann einige Zeit dauern, bis der Vorgang erfolgreich ist), prüfen Sie in Spanner, ob die untergeordnete Zeile erfolgreich migriert wurde:
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT CustomerId, OrderId, OrderValue, OrderSource FROM Orders WHERE CustomerId = 99999 AND OrderId = 502"
Jetzt sollte die Zeile angezeigt werden:
CustomerId: 99999 OrderId: 502 OrderValue: 50 OrderSource: WebStore
Prüfen Sie auch den Ordner $DLQ_DIR_CDC/severe/ in GCS. Die verarbeiteten Dateien sollten verschoben oder gelöscht worden sein. Das ist ein Zeichen dafür, dass die Verarbeitung erfolgreich war.
11. Reverse Replication einrichten (Spanner zu MySQL)
Für Szenarien, in denen Sie möglicherweise ein Rollback durchführen oder die ursprüngliche MySQL-Datenbank für einen Übergangszeitraum mit Spanner synchronisieren müssen, können Sie die umgekehrte Replikation einrichten.
In dieser Pipeline werden Spanner-Änderungsstreams verwendet, um Live-Änderungen in Spanner zu erfassen. Anschließend wird unser benutzerdefiniertes Transformations-JAR verwendet, um die Schemaunterschiede rückgängig zu machen, und unser benutzerdefiniertes Sharding-JAR, um genau zu berechnen, auf welche physische MySQL-VM und welchen logischen Shard das Update zurückgeschrieben werden soll.
1. Spanner-Änderungsstream erstellen
Zuerst müssen Sie einen Änderungsstream in Ihrer Spanner-Datenbank erstellen, um Änderungen an den Tabellen Customers und Orders zu verfolgen.
export CHANGE_STREAM_NAME="CustomersOrdersChangeStream"
gcloud spanner databases ddl update $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--ddl="CREATE CHANGE STREAM $CHANGE_STREAM_NAME FOR Customers, Orders"
In diesem Änderungsstream werden jetzt alle Datenänderungen an den angegebenen Tabellen aufgezeichnet.
2. Spanner-Datenbank für Dataflow-Metadaten erstellen
Für die Dataflow-Vorlage Spanner to SourceDB ist eine separate Spanner-Datenbank erforderlich, in der Metadaten zum Verwalten der Änderungsstream-Nutzung gespeichert werden.
export SPANNER_METADATA_DB_NAME="migration-metadata-db"
gcloud spanner databases create $SPANNER_METADATA_DB_NAME \
--instance=$SPANNER_INSTANCE_NAME
3. Cloud SQL-Verbindungskonfiguration für Dataflow vorbereiten
Für die Dataflow-Vorlage ist eine JSON-Datei in Cloud Storage erforderlich, die die Verbindungsdetails für die Cloud SQL-Zieldatenbank enthält.
Erstellen Sie eine lokale Datei mit dem Namen shard_config.json:
cat <<EOF > reverse-sharding.json
[
{
"logicalShardId": "shard0_db",
"host": "${MYSQL_IP_1}",
"port": "3306",
"user": "datastream_user",
"password": "complex_password_123",
"dbName": "shard0_db"
},
{
"logicalShardId": "shard1_db",
"host": "${MYSQL_IP_1}",
"port": "3306",
"user": "datastream_user",
"password": "complex_password_123",
"dbName": "shard1_db"
},
{
"logicalShardId": "shard2_db",
"host": "${MYSQL_IP_2}",
"port": "3306",
"user": "datastream_user",
"password": "complex_password_123",
"dbName": "shard2_db"
},
{
"logicalShardId": "shard3_db",
"host": "${MYSQL_IP_2}",
"port": "3306",
"user": "datastream_user",
"password": "complex_password_123",
"dbName": "shard3_db"
}
]
EOF
Laden Sie diese Datei in Ihren GCS-Bucket hoch:
export GCS_REVERSE_SHARDING_PATH="gs://${BUCKET_NAME}/config/reverse-sharding.json"
gcloud storage cp reverse-sharding.json $GCS_REVERSE_SHARDING_PATH
4. Dataflow-Job für die Rückwärtsreplikation ausführen
Starten Sie den Dataflow-Job mit der Spanner_to_SourceDb-Flex-Vorlage.
export JOB_NAME_REVERSE="spanner-sharded-reverse-to-mysql-$(date +%Y%m%d-%H%M%S)"
export DLQ_DIR_REVERSE="gs://${BUCKET_NAME}/reverse-replication"
gcloud dataflow flex-template run $JOB_NAME_REVERSE \
--project=$PROJECT_ID \
--region=$REGION \
--worker-machine-type=n2-highmem-8 \
--max-workers=2 \
--num-workers=1 \
--additional-experiments=use_runner_v2 \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Spanner_to_SourceDb" \
--parameters \
changeStreamName="$CHANGE_STREAM_NAME",\
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
spannerProjectId="$PROJECT_ID",\
metadataInstance="$SPANNER_INSTANCE_NAME",\
metadataDatabase="$SPANNER_METADATA_DB_NAME",\
sourceShardsFilePath="$GCS_REVERSE_SHARDING_PATH",\
transformationJarPath=$CUSTOM_JAR_PATH,\
transformationClassName="com.custom.CustomTransformationFetcher",\
shardingCustomJarPath=$CUSTOM_JAR_PATH,\
shardingCustomClassName="com.custom.CustomShardIdFetcher",\
schemaOverridesFilePath=$GCS_OVERRIDES_PATH,\
deadLetterQueueDirectory=$DLQ_DIR_REVERSE
Wichtige Parameter
changeStreamName: Der Name des Spanner-Änderungsstreams, aus dem gelesen werden soll.metadataInstance, metadataDatabase: Die Spanner-Instanz bzw. -Datenbank zum Speichern der Metadaten, die vom Connector verwendet werden, um die Nutzung der Änderungsstream-API-Daten zu steuern.sourceShardsFilePath: Der GCS-Pfad zu Ihremshard_config.json.filtrationMode: Gibt an, wie bestimmte Datensätze anhand eines Kriteriums gelöscht werden sollen. Standardmäßig wirdforward_migrationverwendet (Datensätze filtern, die mit der Forward-Migrationspipeline geschrieben wurden).shardingCustomJarPath: Der GCS-Pfad zur kompilierten Java-JAR-Datei, die wir zuvor erstellt haben.shardingCustomClassName: Der vollständig qualifizierte Klassenname (com.custom.CustomShardIdFetcher), der unsere benutzerdefinierte%4-Modulorechnung ausführt, um dynamisch zu bestimmen, welcher logische Shard den Datensatz empfangen soll.
Hinweis zum Netzwerk:Die Dataflow-Worker stellen über die in shard_config.json angegebene öffentliche IP-Adresse eine Verbindung zur Cloud SQL-Instanz her. Diese Verbindung ist aufgrund des 0.0.0.0/0-Eintrags in den autorisierten Netzwerken der Cloud SQL-Instanz zulässig.
Überwachen Sie den Jobstart in der Dataflow-Jobs-Konsole.
5. Spanner-Daten einfügen und absichtliche Fehler auslösen
Warten Sie, bis der Dataflow-Job den Status Running erreicht hat. Das kann etwa fünf Minuten dauern. Führen Sie dann eine vollständige Reihe von Abfragen (INSERT, UPDATE, DELETE) direkt in Spanner aus. Außerdem wird ein absichtlicher Fehler ausgelöst, um die Reverse-DLQ zu testen.
Führen Sie in Cloud Shell den folgenden Befehl aus:
# All these operations are done on rows mapping to shard0_db for convenience
# Valid INSERT: Insert parent row in Customers
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LoyaltyTier) VALUES (88, 'Reverse Tester', 5000, 'GOLD_TIER')"
# 1. Valid INSERT (Orders): 'WebStore' transformed to 'WebStore_v1'
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="INSERT INTO Orders (CustomerId, OrderId, OrderValue, OrderSource) VALUES (88, 9001, 150.00, 'WebStore')"
# 2. Valid UPDATE (Orders)
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="UPDATE Orders SET OrderValue = 200.00 WHERE CustomerId = 16 AND OrderId = 105 AND OrderSource = 'Partner'"
# 3. Valid DELETE (Orders)
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="DELETE FROM Orders WHERE CustomerId = 12 AND OrderId = 104 AND OrderSource = 'WebStore'"
# 4. INVALID Insert- DLQ Test: CreditLimit=500 will fail check constraint of >1000 at source
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LoyaltyTier) VALUES (44, 'DLQ Test Customer', 500, 'GOLD_TIER')"
6. Daten der umgekehrten Replikation prüfen und DLQ untersuchen
Wir prüfen, ob unser benutzerdefiniertes Sharding-JAR CustomerId 88 auf unserer ersten physischen VM erfolgreich an shard0_db weitergeleitet und das benutzerdefinierte Transformations-JAR "_TIER" erfolgreich aus der Region entfernt wurde.
A. Gültigen Datensatz in MySQL prüfen:
Stellen Sie eine SSH-Verbindung zum ersten physischen Shard her:
gcloud compute ssh mysql-physical-1 --zone=$ZONE
Melden Sie sich bei MySQL an und führen Sie die folgende Abfrage aus:shard0_db
sudo mysql
USE shard0_db;
-- 1. Verify INSERT: Row migrated with transformed LegacyOrderSystem
SELECT CustomerId, OrderId, OrderValue, LegacyOrderSystem
FROM Orders
WHERE CustomerId = 88 AND OrderId = 9001;
-- 2. Verify UPDATE: The OrderValue should now be updated to 200.00.
SELECT CustomerId, OrderId, OrderValue, LegacyOrderSystem
FROM Orders
WHERE CustomerId = 16 AND OrderId = 105;
-- 3. Verify DELETE: Returns 0 rows, confirming the order was successfully deleted from MySQL.
SELECT CustomerId, OrderId
FROM Orders
WHERE CustomerId = 12 AND OrderId = 104;
-- 4. Verify failed replication - this should be in DLQ as CreditLimit < 1000 and will fail stricter check constraint at source
SELECT CustomerId, CustomerName, CreditLimit, LegacyRegion
FROM Customers
WHERE CustomerId = 44;
EXIT;
Die erwartete Ausgabe in Cloud SQL sollte die in Spanner vorgenommenen Änderungen widerspiegeln.
+------------+---------+------------+-------------------+ | CustomerId | OrderId | OrderValue | LegacyOrderSystem | +------------+---------+------------+-------------------+ | 88 | 9001 | 150.00 | Webstore_v1 | +------------+---------+------------+-------------------+ +------------+---------+------------+-------------------+ | CustomerId | OrderId | OrderValue | LegacyOrderSystem | +------------+---------+------------+-------------------+ | 16 | 105 | 200.00 | Partner_v1 | +------------+---------+------------+-------------------+ Empty set (0.00 sec) Empty set (0.00 sec)
Typ
exit
um zu Cloud Shell zurückzukehren.
So können Sie bestätigen, dass die Pipeline für die umgekehrte Replikation funktioniert und Änderungen von Spanner zurück zu Cloud SQL synchronisiert werden.
B. Intentional Failure in der DLQ prüfen
Da unser neuer Customers-Datensatz einen CreditLimit-Wert von 500 hat (was gegen die strenge > 1000-Prüfeinschränkung verstößt, die wir in unserer MySQL-Quelldatenbank definiert haben), hat Dataflow den Fehler sicher abgefangen.
- Rufen Sie in der Google Cloud Console Cloud Storage auf.
- Rufen Sie Ihren Bucket auf und öffnen Sie den Ordner
dlq/severe/. - Öffnen Sie die JSON-Datei, um den abgelehnten
Customers-Eintrag und den genauen Fehler aufgrund der Verletzung der Prüfeinschränkung zu sehen. - Fehler in der DLQ für die umgekehrte Replikation können wiederholt werden, indem die Dataflow-Vorlage mit
runMode=retryDLQausgeführt wird.
12. Ressourcen bereinigen
Löschen Sie die in diesem Codelab erstellten Ressourcen, um zu vermeiden, dass Ihrem Google Cloud-Konto weitere Kosten in Rechnung gestellt werden.
Umgebungsvariablen festlegen (falls erforderlich)
Wenn das Zeitlimit für Ihre Cloud Shell-Sitzung überschritten wurde oder Sie ein neues Terminal geöffnet haben, müssen Sie die Umgebungsvariablen noch einmal exportieren, bevor Sie die Bereinigungsbefehle ausführen.
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1" # Or your preferred region
export ZONE="us-central1-a" # Or a zone within your selected region
export SPANNER_INSTANCE_NAME="target-spanner-instance"
export SPANNER_DATABASE_NAME="sharded-target-db"
export SPANNER_CONFIG="regional-${REGION}"
export BUCKET_NAME="migration-${PROJECT_ID}-bucket"
export MYSQL_IP_1=$(gcloud compute instances describe mysql-physical-1 --zone=$ZONE --format='get(networkInterfaces[0].accessConfigs[0].natIP)')
export MYSQL_IP_2=$(gcloud compute instances describe mysql-physical-2 --zone=$ZONE --format='get(networkInterfaces[0].accessConfigs[0].natIP)')
export SQL_CP_NAME_1="mysql-src-cp-1"
export SQL_CP_NAME_2="mysql-src-cp-2"
export GCS_CP_NAME="gcs-dest-cp"
export STREAM_NAME_1="mysql-to-spanner-stream-1"
export GCS_STREAM_PATH_1="data/${STREAM_NAME_1}"
export STREAM_NAME_2="mysql-to-spanner-stream-2"
export GCS_STREAM_PATH_2="data/${STREAM_NAME_2}"
export PUBSUB_TOPIC="datastream-gcs-updates"
export PUBSUB_SUBSCRIPTION="datastream-gcs-sub"
export CUSTOM_JAR_PATH="gs://${BUCKET_NAME}/custom-logic/spanner-custom-shard-1.0.jar"
export OVERRIDES_FILE="spanner_overrides.json"
export GCS_OVERRIDES_PATH="gs://${BUCKET_NAME}/config/${OVERRIDES_FILE}"
export GCS_SHARDING_PATH="gs://${BUCKET_NAME}/config/sharding.json"
export OUTPUT_DIR="gs://${BUCKET_NAME}/bulk-migration"
export GCS_LIVE_SHARDING_PATH="gs://${BUCKET_NAME}/config/live-sharding.json"
export DLQ_DIR_CDC="gs://${BUCKET_NAME}/live-migration"
export CHANGE_STREAM_NAME="CustomersOrdersChangeStream"
export SPANNER_METADATA_DB_NAME="migration-metadata-db"
export GCS_REVERSE_SHARDING_PATH="gs://${BUCKET_NAME}/config/reverse-sharding.json"
export DLQ_DIR_REVERSE="gs://${BUCKET_NAME}/reverse-replication"
Dataflow-Streamingjobs beenden
Listen Sie Ihre Jobs auf, um die Job-IDs der laufenden Dataflow-Jobs zu finden. Exportieren Sie JOB_ID_CDC und JOB_ID_REVERSE entsprechend.
gcloud dataflow jobs list --region=$REGION --filter="state=Running"
export JOB_ID_CDC=<PASTE_JOB_ID_HERE>
export JOB_ID_CDC_RETRY=<PASTE_JOB_ID_HERE>
export JOB_ID_REVERSE=<PASTE_JOB_ID_HERE>
Brechen Sie den Job Datastream to Spanner (Live-Migration) und den zugehörigen Wiederholungsjob ab:
gcloud dataflow jobs cancel $JOB_ID_CDC --region=$REGION --project=$PROJECT_ID
gcloud dataflow jobs cancel $JOB_ID_CDC_RETRY --region=$REGION --project=$PROJECT_ID
Brechen Sie den Job Spanner to Cloud SQL (Reverse Replication) ab:
gcloud dataflow jobs cancel $JOB_ID_REVERSE --region=$REGION --project=$PROJECT_ID
Datastream-Ressourcen löschen
Stream beenden und löschen:
gcloud datastream streams update $STREAM_NAME_1 \
--location=$REGION --state=PAUSED --project=$PROJECT_ID
# Wait a moment for the stream to pause
gcloud datastream streams delete $STREAM_NAME_1 \
--location=$REGION --project=$PROJECT_ID --quiet
gcloud datastream streams update $STREAM_NAME_2 \
--location=$REGION --state=PAUSED --project=$PROJECT_ID
# Wait a moment for the stream to pause
gcloud datastream streams delete $STREAM_NAME_2 \
--location=$REGION --project=$PROJECT_ID --quiet
# Delete Connection Profiles
gcloud datastream connection-profiles delete $SQL_CP_NAME_1 \
--location=$REGION --project=$PROJECT_ID --quiet
gcloud datastream connection-profiles delete $SQL_CP_NAME_2 \
--location=$REGION --project=$PROJECT_ID --quiet
gcloud datastream connection-profiles delete $GCS_CP_NAME \
--location=$REGION --project=$PROJECT_ID --quiet
MySQL-Quell-VMs (Compute Engine) löschen
Löschen Sie die beiden Compute Engine-Instanzen, die die physischen MySQL-Shards vor Ort simuliert haben.
gcloud compute instances delete mysql-physical-1 mysql-physical-2 --zone=$ZONE --quiet
Firewallregeln löschen
Entfernen Sie die Netzwerk-Firewallregeln, die erstellt wurden, um SSH-Zugriff und Datastream-Verbindungen zu Ihren VMs zu ermöglichen. Hinweis: Wenn Sie zuvor im Codelab andere Namen für Ihre Firewallregeln verwendet haben, passen Sie sie hier an.
gcloud compute firewall-rules delete allow-ssh-iap --quiet
gcloud compute firewall-rules delete allow-mysql-datastream --quiet
Pub/Sub-Ressourcen löschen
Abo löschen:
gcloud pubsub subscriptions delete $PUBSUB_SUBSCRIPTION \
--project=$PROJECT_ID --quiet
Thema löschen:
gcloud pubsub topics delete $PUBSUB_TOPIC \
--project=$PROJECT_ID --quiet
Cloud Spanner-Instanz löschen
Löschen Sie die Cloud Spanner-Instanz. Dadurch werden automatisch sowohl die Datenbank sharded-target-db als auch die Datenbank migration-metadata-db darin gelöscht.
gcloud spanner instances delete $SPANNER_INSTANCE_NAME \
--project=$PROJECT_ID --quiet
GCS-Bucket und ‑Inhalte löschen
Löschen Sie schließlich den Cloud Storage-Bucket, der die Datastream-Dateien, Dataflow-Konfigurationen und Dead-Letter-Queues enthält. Mit dem Befehl rm -r werden der Bucket und alle seine Inhalte rekursiv gelöscht.
gcloud storage rm --recursive gs://${BUCKET_NAME}
Lokale Cloud Shell-Dateien löschen
Führen Sie die folgenden Befehle aus, um die lokalen Dateien und Verzeichnisse zu bereinigen, die während dieses Codelabs in Ihrer Cloud Shell generiert wurden:
# Remove the JSON configuration files
rm -f sharding.json live-sharding.json reverse-sharding.json spanner_overrides.json
# Remove the cloned Google Cloud DataflowTemplates repository
rm -rf DataflowTemplates