
১. শুরু করার আগে
এই কোডল্যাবটি আপনাকে একটি শার্ডেড অন-প্রেম MySQL ডেটাবেসকে GoogleSQL ডায়ালেক্টসহ একটি ক্লাউড স্প্যানার ডেটাবেসে মাইগ্রেট করার পদ্ধতি ধাপে ধাপে দেখাবে। আপনি স্প্যানার মাইগ্রেশন টুল (SMT), ডেটাফ্লো, ডেটাস্ট্রিম, পাবসাব এবং গুগল ক্লাউড স্টোরেজসহ গুগল ক্লাউডের বিভিন্ন পরিষেবা ব্যবহার করবেন।
আপনি যা শিখবেন:
- শার্ডেড এনভায়রনমেন্ট কী এবং কীভাবে এটি সেট আপ করতে হয়।
- কীভাবে স্প্যানার মাইগ্রেশন টুল (SMT) ওয়েব UI ব্যবহার করে একটি MySQL স্কিমাকে স্প্যানার-সামঞ্জস্যপূর্ণ স্কিমাতে রূপান্তর করা যায় এবং উন্নত স্কিমা পরিবর্তন সম্পাদন করা যায়।
- ডেটাফ্লো ব্যবহার করে কীভাবে শার্ডেড MySQL ইনস্ট্যান্স থেকে ক্লাউড স্প্যানারে বাল্ক ডেটা মাইগ্রেশন করা যায়।
- Datastream এবং Dataflow ব্যবহার করে শার্ডেড MySQL ইনস্ট্যান্স থেকে ক্লাউড স্প্যানারে কীভাবে কন্টিনিউয়াস রেপ্লিকেশন (CDC) সেট আপ করবেন।
- স্প্যানার থেকে শার্ডেড MySQL ইনস্ট্যান্সগুলোতে রিভার্স রেপ্লিকেশন কীভাবে কনফিগার করবেন।
- বাল্ক, লাইভ এবং রিভার্স মাইগ্রেশনের সময় অতিরিক্ত কলাম পূরণ করতে কাস্টম ট্রান্সফরমেশন কীভাবে ব্যবহার করবেন
- প্রাইমারি কী ব্যবহার করে শার্ডিং ট্রান্সফরমেশন কীভাবে কনফিগার করতে হয়।
এই কোডল্যাবে যা অন্তর্ভুক্ত নয়:
- উন্নত কাস্টম নেটওয়ার্কিং।
- প্রথম থেকে কাস্টম ডেটাফ্লো টেমপ্লেট তৈরি করা।
- মাইগ্রেশন পারফরম্যান্স টিউনিং।
- অ্যাপ্লিকেশন মাইগ্রেশন: এই কোডল্যাবটি ডাটাবেস লেয়ারের (স্কিমা এবং ডেটা) উপর আলোকপাত করে। এটি আপনার অ্যাপ্লিকেশন সার্ভিসগুলো রিডিপ্লয় বা মাইগ্রেট করার অপারেশনাল প্রক্রিয়া অন্তর্ভুক্ত করে না।
আপনার যা যা লাগবে
- বিলিং সক্ষম একটি গুগল ক্লাউড প্রজেক্ট।
- এপিআই সক্রিয় করতে এবং স্প্যানার, ডেটাফ্লো, ডেটাস্ট্রিম ও জিসিএস রিসোর্স তৈরি/পরিচালনা করার জন্য পর্যাপ্ত আইএএম অনুমতি । যদিও একটি কোডল্যাবের জন্য প্রজেক্ট
Ownerভূমিকাটি সবচেয়ে সহজ, আরও নির্দিষ্ট ভূমিকাগুলো 'এনভায়রনমেন্ট সেটআপ' অংশে আলোচনা করা হবে। - সেটআপ পর্ব চলাকালীন আমরা আমাদের অন-প্রিমিস সার্ভারকে অনুকরণ করার জন্য একটি ছোট Compute Engine VM প্রস্তুত করব। আপনার প্রজেক্ট কোটা VM তৈরির জন্য যথেষ্ট কিনা, তা নিশ্চিত করুন।
- একটি ওয়েব ব্রাউজার, যেমন গুগল ক্রোম।
- গুগল ক্লাউড কনসোল এবং
gcloudমতো কমান্ড-লাইন টুল সম্পর্কে প্রাথমিক ধারণা থাকা। - Access to a shell environment. Cloud Shell is recommended as it includes
gcloud.
More details on the above setup is covered in the Environment Setup section.
২. অভিবাসন প্রক্রিয়া বোঝা
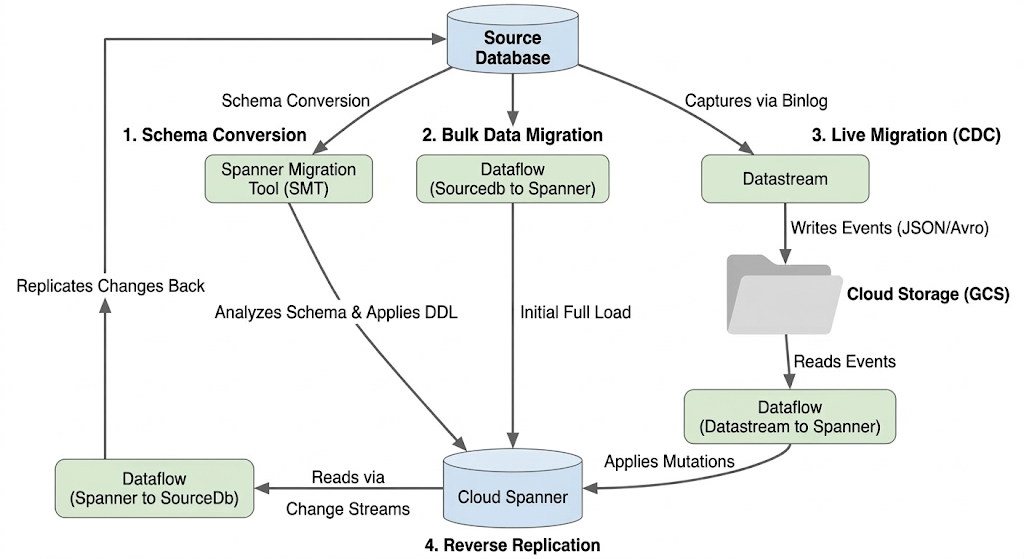
একটি শার্ডেড ডেটাবেস মাইগ্রেট করার অর্থ হলো একাধিক ফিজিক্যাল এবং লজিক্যাল MySQL ইনস্ট্যান্সকে একটি একক, হরাইজন্টালি স্কেলেবল স্প্যানার ডেটাবেসে একীভূত করা। এই বিভাগে মাইগ্রেশনে ব্যবহৃত আর্কিটেকচার এবং প্রধান টুলগুলোর রূপরেখা দেওয়া হয়েছে।
অভিবাসন প্রবাহ স্থাপত্য
স্থানান্তর প্রক্রিয়ার মধ্যে এই পর্যায়গুলো অন্তর্ভুক্ত:
১. স্কিমা রূপান্তর:
- উদ্দেশ্য: উৎস ডেটাবেস স্কিমাটিকে একটি সামঞ্জস্যপূর্ণ ক্লাউড স্প্যানার স্কিমাতে রূপান্তর করা।
- টুল: স্প্যানার মাইগ্রেশন টুল (SMT)
- প্রক্রিয়া: SMT উৎস ডেটাবেস স্কিমা বিশ্লেষণ করে এবং এর সমতুল্য স্প্যানার ডেটা ডেফিনিশন ল্যাঙ্গুয়েজ (DDL) তৈরি করে। টার্গেট স্প্যানার ইনস্ট্যান্সে একটি ডেটাবেস তৈরি করা হয় এবং তারপর DDL-টি স্বয়ংক্রিয়ভাবে প্রয়োগ করা হয়।
২. বৃহৎ ডেটা স্থানান্তর:
- উদ্দেশ্য: উৎস ডাটাবেস থেকে প্রোভিশন করা স্প্যানার টেবিলগুলিতে বিদ্যমান ডেটার একটি প্রাথমিক ও সম্পূর্ণ লোড সম্পাদন করা।
- টুল: ডেটাফ্লো, গুগল-প্রদত্ত
Sourcedb to Spannerটেমপ্লেট ব্যবহার করে। - প্রক্রিয়া: এই ডেটাফ্লো জবটি নির্দিষ্ট সোর্স টেবিলগুলো থেকে সমস্ত ডেটা পড়ে এবং সেগুলোকে সংশ্লিষ্ট স্প্যানার টেবিলগুলোতে লিখে দেয়। স্প্যানার স্কিমা তৈরি হওয়ার পর এই কাজটি করা হয়।
৩. জীবন্ত অভিবাসন (সিডিসি):
- উদ্দেশ্য: মাইগ্রেশন চলাকালীন ডাউনটাইম কমিয়ে, সোর্স ডাটাবেস থেকে ক্লাউড স্প্যানারে চলমান পরিবর্তনগুলো প্রায় রিয়েল-টাইমে গ্রহণ ও প্রয়োগ করা।
- সরঞ্জাম:
- ডেটাস্ট্রিম: উৎস ডেটাবেস থেকে পরিবর্তনসমূহ (সন্নিবেশ, হালনাগাদ, মুছে ফেলা) গ্রহণ করে এবং সেগুলোকে ক্লাউড স্টোরেজ (GCS)-এ লিখে রাখে।
- ডেটাফ্লো: GCS থেকে পরিবর্তনের ইভেন্টগুলো পড়তে এবং সেগুলোকে ক্লাউড স্প্যানারে প্রয়োগ করতে '
Datastream to Spannerটেমপ্লেট ব্যবহার করে।
৪. বিপরীত প্রতিলিপিকরণ:
- উদ্দেশ্য: ক্লাউড স্প্যানার থেকে ডেটার পরিবর্তনগুলো সোর্স ডেটাবেসে প্রতিলিপি করা। এটি ফলব্যাক কৌশল, পর্যায়ক্রমিক মাইগ্রেশন, অথবা নির্দিষ্ট ব্যবহারের ক্ষেত্রে সোর্সে একটি প্রতিলিপি রক্ষণাবেক্ষণের জন্য সহায়ক হতে পারে।
- টুল: ডেটাফ্লো,
Spanner to SourceDbটেমপ্লেট ব্যবহার করে। - প্রক্রিয়া: এই কাজটি স্প্যানারের পরিবর্তনগুলো ধারণ করতে এবং সেগুলোকে উৎস ডাটাবেস ইনস্ট্যান্সে পুনরায় লিখে দিতে স্প্যানার চেঞ্জ স্ট্রিম ব্যবহার করে।
নিম্নলিখিত ডায়াগ্রামটি উপাদান এবং ডেটা প্রবাহ চিত্রিত করে:
মূল পরিভাষা:
- ফিজিক্যাল শার্ড: প্রকৃত অন্তর্নিহিত সার্ভার বা কম্পিউট ইনস্ট্যান্স যা ডেটাবেস হোস্ট করে (আমাদের ক্ষেত্রে, সিমুলেটেড অন-প্রেম GCE VM)।
- লজিক্যাল শার্ড: একটি ফিজিক্যাল সার্ভারের অভ্যন্তরে অবস্থিত স্বতন্ত্র ডাটাবেস স্কিমা।
- কম্পিউট ইঞ্জিন (GCE) ভিএম : গুগল ক্লাউড পরিকাঠামোতে হোস্ট করা একটি ভার্চুয়াল মেশিন। এই কোডল্যাবে, আমরা আমাদের সোর্স MySQL ডেটাবেস হোস্টকারী একটি স্বতন্ত্র, "অন-প্রিমিস" বেয়ার-মেটাল সার্ভারকে সিমুলেট করতে একটি GCE ভিএম ব্যবহার করি।
- স্প্যানার মাইগ্রেশন টুল (SMT) : একটি টুল যা MySQL স্কিমা মূল্যায়ন করতে, স্প্যানার স্কিমার সমতুল্য বিকল্পের পরামর্শ দিতে এবং স্প্যানার ডেটা ডেফিনিশন ল্যাঙ্গুয়েজ (DDL) তৈরি করতে ব্যবহৃত হয়।
- ডেটা ডেফিনিশন ল্যাঙ্গুয়েজ (DDL): ডাটাবেসের কাঠামো নির্ধারণ ও পরিবর্তন করতে ব্যবহৃত স্টেটমেন্ট, যেমন
CREATE TABLEস্টেটমেন্ট। SMT, ক্লাউড SQL স্কিমার উপর ভিত্তি করে স্প্যানার DDL তৈরি করে। - ডেটাফ্লো : একটি সম্পূর্ণভাবে পরিচালিত, সার্ভারবিহীন ডেটা প্রসেসিং পরিষেবা। এই কোডল্যাবে, এটি গুগল-প্রদত্ত টেমপ্লেটগুলো চালানোর জন্য ব্যবহৃত হয়, যার মধ্যে রয়েছে বাল্ক ডেটা ট্রান্সফার, ডেটাস্ট্রিম পরিবর্তন প্রয়োগ এবং রিভার্স রেপ্লিকেশন।
- ডেটাস্ট্রিম : একটি সার্ভারবিহীন চেঞ্জ ডেটা ক্যাপচার (CDC) এবং রেপ্লিকেশন সার্ভিস। এই কোডল্যাবে, এটি স্থানীয়ভাবে হোস্ট করা MySQL ইনস্ট্যান্স থেকে ক্লাউড স্টোরেজে পরিবর্তনসমূহ স্ট্রিম করতে ব্যবহৃত হয়।
- স্প্যানার চেঞ্জ স্ট্রিমস : স্প্যানারের একটি ফিচার যা ডেটার পরিবর্তন (ইনসার্ট, আপডেট, ডিলিট) রিয়েল-টাইমে স্ট্রিম করার সুযোগ দেয় এবং এটি রিভার্স রেপ্লিকেশনের উৎস হিসেবে ব্যবহৃত হয়।
- Pub/Sub : A messaging service used to decouple services that produce events from services that process them. In this codelab, it triggers Dataflow to process updates whenever Datastream uploads new change files to Cloud Storage.
৩. পরিবেশ সেটআপ
মাইগ্রেশন শুরু করার আগে, আপনাকে আপনার গুগল ক্লাউড প্রজেক্ট সেট আপ করতে হবে এবং প্রয়োজনীয় সার্ভিসগুলো চালু করতে হবে।
১. একটি গুগল ক্লাউড প্রজেক্ট নির্বাচন করুন বা তৈরি করুন
এই কোডল্যাবের পরিষেবাগুলো ব্যবহার করার জন্য আপনার বিলিং চালু করা একটি গুগল ক্লাউড প্রজেক্ট প্রয়োজন।
- Google Cloud Console-এ, প্রজেক্ট সিলেক্টর পেজে যান: প্রজেক্ট সিলেক্টরে যান
- একটি গুগল ক্লাউড প্রজেক্ট নির্বাচন করুন বা তৈরি করুন।
- আপনার প্রোজেক্টের জন্য বিলিং চালু আছে কিনা তা নিশ্চিত করুন। আপনার প্রোজেক্টের জন্য বিলিং চালু আছে কিনা তা কীভাবে নিশ্চিত করবেন তা জানুন।
২. ক্লাউড শেল খুলুন
ক্লাউড শেল হলো গুগল ক্লাউডে চালিত একটি কমান্ড-লাইন পরিবেশ, যা gcloud CLI এবং আপনার প্রয়োজনীয় অন্যান্য টুলসহ আগে থেকেই লোড করা থাকে।
- গুগল ক্লাউড কনসোলের উপরের ডানদিকে থাকা ‘Activate Cloud Shell’ বোতামটিতে ক্লিক করুন।
- কনসোলের নীচে একটি নতুন ফ্রেমে একটি ক্লাউড শেল সেশন খোলে এবং একটি কমান্ড-লাইন প্রম্পট প্রদর্শন করে।

৩. প্রজেক্ট এবং এনভায়রনমেন্ট ভেরিয়েবল সেট করুন
ক্লাউড শেলে, আপনার প্রজেক্ট আইডি এবং ব্যবহৃত অঞ্চলের জন্য কিছু এনভায়রনমেন্ট ভেরিয়েবল সেট আপ করুন।
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1" # Or your preferred region
export ZONE="us-central1-a" # Or a zone within your selected region
gcloud config set project $PROJECT_ID
gcloud config set compute/region $REGION
gcloud config set compute/zone $ZONE
echo "Project ID: $PROJECT_ID"
echo "Region: $REGION"
echo "Zone: $ZONE"
৪. প্রয়োজনীয় গুগল ক্লাউড এপিআইগুলো সক্রিয় করুন
Cloud Spanner, Dataflow, Datastream এবং অন্যান্য সংশ্লিষ্ট পরিষেবাগুলির জন্য প্রয়োজনীয় API গুলি সক্রিয় করুন।
gcloud services enable \
spanner.googleapis.com \
dataflow.googleapis.com \
datastream.googleapis.com \
pubsub.googleapis.com \
storage.googleapis.com \
compute.googleapis.com \
sqladmin.googleapis.com \
servicenetworking.googleapis.com \
cloudresourcemanager.googleapis.com
এই কমান্ডটি সম্পন্ন হতে কয়েক মিনিট সময় লাগতে পারে।
৪. উৎস MySQL ডেটাবেস সেট আপ করুন
এই অংশে, আমরা দুটি Compute Engine ভার্চুয়াল মেশিন (আমাদের দুটি "ফিজিক্যাল শার্ড") প্রোভিশনিং করে একটি অন-প্রিমিস শার্ডেড MySQL আর্কিটেকচার সিমুলেট করব। এরপর আমরা উভয়টিতেই MySQL ইনস্টল করব এবং প্রতিটি VM-এ দুটি করে ডেটাবেস (আমাদের "লজিক্যাল শার্ড") তৈরি করব।
১. কম্পিউট ইঞ্জিন ভিএম (ফিজিক্যাল শার্ড) তৈরি করুন
উবুন্টু সহ দুটি ভিএম তৈরি করতে ক্লাউড শেলে নিম্নলিখিত কমান্ডগুলি চালান। পরবর্তীতে ইনবাউন্ড MySQL ট্র্যাফিকের অনুমতি দেওয়ার জন্য আমরা সেগুলিতে নেটওয়ার্ক ট্যাগ যুক্ত করব।
# Create Physical Shard 1
gcloud compute instances create mysql-physical-1 \
--zone=$ZONE \
--machine-type=e2-small \
--image-family=ubuntu-2204-lts \
--image-project=ubuntu-os-cloud \
--tags=mysql-server
# Create Physical Shard 2
gcloud compute instances create mysql-physical-2 \
--zone=$ZONE \
--machine-type=e2-small \
--image-family=ubuntu-2204-lts \
--image-project=ubuntu-os-cloud \
--tags=mysql-server
২. ফায়ারওয়াল নিয়মাবলী কনফিগার করুন
সর্বজনীন প্রকাশ ছাড়াই সুরক্ষিত SSH অ্যাক্সেস এবং ডেটাস্ট্রিম সংযোগ সক্ষম করতে:
IAP এর মাধ্যমে SSH এর জন্য ফায়ারওয়াল নিয়ম তৈরি করুন:
এই নিয়মটি আইডেন্টিটি-অ্যাওয়ার প্রক্সিকে SSH পোর্ট (22) এ আপনার VM গুলিতে পৌঁছানোর অনুমতি দেয়।
gcloud compute firewall-rules create allow-ssh-iap \
--direction=INGRESS \
--priority=1000 \
--network=default \
--action=ALLOW \
--rules=tcp:22 \
--source-ranges=35.235.240.0/20 \
--target-tags=mysql-server
ডেটাস্ট্রিমের (MySQL পোর্ট) জন্য ফায়ারওয়াল নিয়ম তৈরি করুন:
ডেটাস্ট্রিমকে স্ট্যান্ডার্ড MySQL পোর্ট (3306)-এর মাধ্যমে এই VM-গুলোতে পৌঁছাতে সক্ষম হতে হবে।
gcloud compute firewall-rules create allow-mysql-datastream \
--direction=INGRESS \
--priority=1000 \
--network=default \
--action=ALLOW \
--rules=tcp:3306 \
--source-ranges=0.0.0.0/0 \
--target-tags=mysql-server
৩. ফিজিক্যাল শার্ড ১-এ MySQL ইনস্টল এবং কনফিগার করুন
আপনার প্রথম ভিএম-এ SSH করে MySQL ইনস্টল করুন এবং বাইনারি লগিং কনফিগার করুন (যা ডেটাস্ট্রিমের লাইভ রেপ্লিকেশনের জন্য প্রয়োজন)।
- প্রথম ভিএম-এ SSH করুন:
gcloud compute ssh mysql-physical-1 --zone=$ZONE --tunnel-through-iap
- MySQL ইনস্টল করুন:
sudo apt-get update
sudo apt-get install mysql-server-8.0 -y
# Verify the installation and version
sudo mysql --version
- বাইনারি লগিং চালু করতে এবং বাহ্যিক সংযোগের অনুমতি দিতে
mysqld.cnfফাইলটি কনফিগার করুন:
sudo sed -i 's/bind-address.*/bind-address = 0.0.0.0/' /etc/mysql/mysql.conf.d/mysqld.cnf
echo -e "[mysqld]\nserver-id=1\nlog_bin=/var/log/mysql/mysql-bin.log\nbinlog_format=ROW" | sudo tee -a /etc/mysql/mysql.conf.d/mysqld.cnf
- পরিবর্তনগুলি প্রয়োগ করতে MySQL পুনরায় চালু করুন:
sudo systemctl restart mysql
৪. লজিক্যাল শার্ড তৈরি করুন, ডেটা সন্নিবেশ করুন এবং ডেটাস্ট্রিম ব্যবহারকারী তৈরি করুন (শার্ড ১)
mysql-physical-1 এ SSH সংযুক্ত থাকা অবস্থায়, MySQL প্রম্পটে লগ ইন করুন:
sudo mysql
নিম্নলিখিত SQL কমান্ডগুলো চালান। এই স্ক্রিপ্টটি দুটি স্বতন্ত্র লজিক্যাল শার্ড ( shard0_db এবং shard1_db ) তৈরি করে, উভয়টিতে অভিন্ন স্কিমা সেট আপ করে, প্রতিটিতে স্বতন্ত্রভাবে শনাক্তযোগ্য ডেটা সন্নিবেশ করে (শার্ডিং প্রদর্শনের জন্য), এবং ডেটাস্ট্রিমের জন্য রেপ্লিকেশন ইউজার তৈরি করে।
আপনার প্রথম দুটি লজিক্যাল শার্ড, একটি টেবিল এবং ডেটাস্ট্রিমের জন্য রেপ্লিকেশন ইউজার তৈরি করতে নিম্নলিখিত SQL কমান্ডগুলো চালান:
CREATE DATABASE shard0_db;
CREATE DATABASE shard1_db;
USE shard0_db;
CREATE TABLE Customers (
CustomerId INT NOT NULL,
CustomerName VARCHAR(255),
CreditLimit DECIMAL(10, 2) NOT NULL,
LegacyRegion VARCHAR(50), -- Renamed to LoyaltyTier in Spanner
PRIMARY KEY (CustomerId),
CONSTRAINT CHK_CreditLimit CHECK (CreditLimit > 1000) -- Relaxed in Spanner to > 0
);
CREATE TABLE Orders (
CustomerId INT NOT NULL, -- Logically references Customers.CustomerId in Spanner
OrderId INT NOT NULL,
OrderValue DECIMAL(10, 2),
LegacyOrderSystem VARCHAR(50), -- Extra column in Source, to be dropped in Spanner
PRIMARY KEY (CustomerId, OrderId) -- Spanner PK will have one additional column in PK
);
INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LegacyRegion) VALUES
(4, 'David E.', 2000.00, 'EAST'),
(8, 'Eleanor F.', 8100.00, 'WEST'),
(12, 'Frank G.', 12000.00, 'NORTH'),
(16, 'Grace H.', 6500.00, 'SOUTH');
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem) VALUES
(4, 101, 150.00, 'WebStore_v1'),
(4, 102, 25.50, 'InStore_POS'),
(8, 103, 75.00, 'MobileApp_Legacy'),
(12, 104, 3000.00, 'WebStore_v1'),
(16, 105, 120.00, 'Partner_API');
USE shard1_db;
CREATE TABLE Customers (
CustomerId INT NOT NULL,
CustomerName VARCHAR(255),
CreditLimit DECIMAL(10, 2) NOT NULL,
LegacyRegion VARCHAR(50), -- Renamed to LoyaltyTier in Spanner
PRIMARY KEY (CustomerId),
CONSTRAINT CHK_CreditLimit CHECK (CreditLimit > 1000) -- Relaxed in Spanner to > 0
);
CREATE TABLE Orders (
CustomerId INT NOT NULL, -- Logically references Customers.CustomerId in Spanner
OrderId INT NOT NULL,
OrderValue DECIMAL(10, 2),
LegacyOrderSystem VARCHAR(50), -- Extra column in Source, to be dropped in Spanner
PRIMARY KEY (CustomerId, OrderId) -- Spanner PK will have one additional column in PK
);
INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LegacyRegion) VALUES
(1, 'Agnes N.', 5100.00, 'NORTHEAST'),(5, 'Alice I.', 15000.00, 'EAST'),
(9, 'Bob J.', 7500.00, 'WEST'),
(13, 'Charlie K.', 2200.00, 'CENTRAL');
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem) VALUES
(1, 201, 50.00, 'MobileApp_Legacy'),
(5, 202, 1250.00, 'WebStore_v1'),
(5, 203, 80.00, 'Partner_API'),
(9, 204, 600.00, 'InStore_POS'),
(13, 205, 199.99, 'WebStore_v1');
-- Create Datastream Replication User
CREATE USER 'datastream_user'@'%' IDENTIFIED BY 'complex_password_123';
GRANT REPLICATION SLAVE, REPLICATION CLIENT, SELECT, INSERT, UPDATE, DELETE ON *.* TO 'datastream_user'@'%';
FLUSH PRIVILEGES;
উপরোক্ত স্কিমার ডাম্প ফাইলটি এখানে পাওয়া যাবে। ডেটাস্ট্রিম রেপ্লিকেশন ইউজারটি আলাদাভাবে তৈরি করা গুরুত্বপূর্ণ, কারণ এটি ডাম্প ফাইলে অন্তর্ভুক্ত থাকে না।
৫. ডেটা যাচাই করুন
ডেটা উপস্থিত আছে কিনা দ্রুত যাচাই করুন:
SELECT 'Customers shard0_db' AS tbl, COUNT(*) FROM shard0_db.Customers
UNION ALL
SELECT 'Orders shard0_db', COUNT(*) FROM shard0_db.Orders
UNION ALL
SELECT 'Customers shard1_db', COUNT(*) FROM shard1_db.Customers
UNION ALL
SELECT 'Orders shard1_db', COUNT(*) FROM shard1_db.Orders;
EXIT;
প্রত্যাশিত আউটপুট:
+---------------------+----------+ | tbl | COUNT(*) | +---------------------+----------+ | Customers shard0_db | 4 | | Orders shard0_db | 5 | | Customers shard1_db | 4 | | Orders shard1_db | 5 | +---------------------+----------+
ফিজিক্যাল শার্ড ১ ভিএম-এর সংযোগ বিচ্ছিন্ন করতে exit চাপুন।
৬. ফিজিক্যাল শার্ড ২-এর জন্য পুনরাবৃত্তি করুন।
এখন আপনি দ্বিতীয় ভিএম-এর জন্য হুবহু একই প্রক্রিয়াটি পুনরাবৃত্তি করবেন, তবে এক্ষেত্রে আপনি shard2_db ও shard3_db তৈরি করবেন এবং server-id পরিবর্তন করবেন।
- দ্বিতীয় ভিএম-এ SSH করুন:
gcloud compute ssh mysql-physical-2 --zone=$ZONE --tunnel-through-iap
- MySQL ইনস্টল করুন:
sudo apt-get update
sudo apt-get install mysql-server-8.0 -y
- বাইনারি লগিং চালু করতে এবং বাহ্যিক সংযোগের অনুমতি দিতে
mysqld.cnfফাইলটি কনফিগার করুন। [উল্লেখ্য যে, সার্ভার-আইডি অবশ্যই ভিন্ন হতে হবে (যেমন, ২)]
sudo sed -i 's/bind-address.*/bind-address = 0.0.0.0/' /etc/mysql/mysql.conf.d/mysqld.cnf
echo -e "[mysqld]\nserver-id=2\nlog_bin=/var/log/mysql/mysql-bin.log\nbinlog_format=ROW" | sudo tee -a /etc/mysql/mysql.conf.d/mysqld.cnf
- পরিবর্তনগুলি প্রয়োগ করতে MySQL পুনরায় চালু করুন:
sudo systemctl restart mysql
- MySQL-এ প্রবেশ করুন (
sudo mysql) এবং ধাপ ৪ থেকে পাওয়া SQL-টির সামান্য পরিবর্তিত সংস্করণটি চালান:
CREATE DATABASE shard2_db;
CREATE DATABASE shard3_db;
USE shard2_db;
CREATE TABLE Customers (
CustomerId INT NOT NULL,
CustomerName VARCHAR(255),
CreditLimit DECIMAL(10, 2) NOT NULL,
LegacyRegion VARCHAR(50), -- Renamed to LoyaltyTier in Spanner
PRIMARY KEY (CustomerId),
CONSTRAINT CHK_CreditLimit CHECK (CreditLimit > 1000) -- Relaxed in Spanner to > 0
);
CREATE TABLE Orders (
CustomerId INT NOT NULL, -- Logically references Customers.CustomerId in Spanner
OrderId INT NOT NULL,
OrderValue DECIMAL(10, 2),
LegacyOrderSystem VARCHAR(50), -- Extra column in Source, to be dropped in Spanner
PRIMARY KEY (CustomerId, OrderId) -- Spanner PK will have one additional column in PK
);
INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LegacyRegion) VALUES
(2, 'Brian K.', 2500.00, 'SOUTHWEST'),
(6, 'Diana L.', 1999.00, 'NORTH'),
(10, 'Edward M.', 11000.00, 'EAST'),
(14, 'Fiona N.', 3000.00, 'WEST');
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem) VALUES
(2, 301, 100.00, 'CallCenter_System'),
(6, 302, 99.00, 'MobileApp_Legacy'),
(10, 303, 1000.00, 'WebStore_v1'),
(10, 304, 2500.00, 'InStore_POS'),
(14, 305, 130.00, 'MobileApp_Legacy');
USE shard3_db;
CREATE TABLE Customers (
CustomerId INT NOT NULL,
CustomerName VARCHAR(255),
CreditLimit DECIMAL(10, 2) NOT NULL,
LegacyRegion VARCHAR(50), -- Renamed to LoyaltyTier in Spanner
PRIMARY KEY (CustomerId),
CONSTRAINT CHK_CreditLimit CHECK (CreditLimit > 1000) -- Relaxed in Spanner to > 0
);
CREATE TABLE Orders (
CustomerId INT NOT NULL, -- Logically references Customers.CustomerId in Spanner
OrderId INT NOT NULL,
OrderValue DECIMAL(10, 2),
LegacyOrderSystem VARCHAR(50), -- Extra column in Source, to be dropped in Spanner
PRIMARY KEY (CustomerId, OrderId) -- Spanner PK will have one additional column in PK
);
INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LegacyRegion) VALUES
(3, 'Cathy Z.', 6000.00, 'CENTRAL'),
(7, 'George O.', 18000.00, 'SOUTH'),
(11, 'Helen P.', 4000.00, 'NORTHEAST'),
(15, 'Ivy Q.', 9500.00, 'SOUTHWEST');
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem) VALUES
(3, 401, 600.00, 'InStore_POS'),
(7, 402, 1200.00, 'CallCenter_System'),
(11, 403, 350.00, 'MobileApp_Legacy'),
(15, 404, 800.00, 'WebStore_v1'),
(99, 999, 25.00, 'CallCenter_System'); -- Failure row during Bulk Migration due to violation of interleaving
-- Create Datastream Replication User
CREATE USER 'datastream_user'@'%' IDENTIFIED BY 'complex_password_123';
GRANT REPLICATION SLAVE, REPLICATION CLIENT, SELECT, INSERT, UPDATE, DELETE ON *.* TO 'datastream_user'@'%';
FLUSH PRIVILEGES;
-- Verify Data
SELECT 'Customers shard2_db' AS tbl, COUNT(*) FROM shard2_db.Customers
UNION ALL
SELECT 'Orders shard2_db', COUNT(*) FROM shard2_db.Orders
UNION ALL
SELECT 'Customers shard3_db', COUNT(*) FROM shard3_db.Customers
UNION ALL
SELECT 'Orders shard3_db', COUNT(*) FROM shard3_db.Orders;
EXIT;
প্রত্যাশিত আউটপুট:
+---------------------+----------+ | tbl | COUNT(*) | +---------------------+----------+ | Customers shard2_db | 4 | | Orders shard2_db | 5 | | Customers shard3_db | 4 | | Orders shard3_db | 5 | +---------------------+----------+
উপরোক্ত স্কিমার ডাম্প ফাইলটি এখানে পাওয়া যাবে। ডেটাস্ট্রিম রেপ্লিকেশন ইউজারটি আলাদাভাবে তৈরি করা গুরুত্বপূর্ণ, কারণ এটি ডাম্প ফাইলে অন্তর্ভুক্ত থাকে না।
ভিএম-এর সংযোগ বিচ্ছিন্ন করতে exit চাপুন।
৫. ক্লাউড স্প্যানার সেট আপ করুন
এখন, আপনি সেই টার্গেট ক্লাউড স্প্যানার ইনস্ট্যান্সটি সেট আপ করবেন যেখানে ডেটা মাইগ্রেট করা হবে।
১. একটি ক্লাউড স্প্যানার ইনস্ট্যান্স তৈরি করুন
লেটেন্সি কমাতে আপনার Compute Engine VM-গুলোর মতো একই অঞ্চলে একটি Cloud Spanner ইনস্ট্যান্স তৈরি করুন। এই কমান্ডটি ১০০টি প্রসেসিং ইউনিট ব্যবহার করে এই কোডল্যাবের জন্য উপযুক্ত একটি ছোট ইনস্ট্যান্স তৈরি করে।
export SPANNER_INSTANCE_NAME="target-spanner-instance"
export SPANNER_DATABASE_NAME="sharded-target-db"
export SPANNER_CONFIG="regional-${REGION}"
gcloud spanner instances create $SPANNER_INSTANCE_NAME \
--config=$SPANNER_CONFIG \
--description="Target Spanner Instance" \
--processing-units=100
ইনস্ট্যান্স তৈরি হতে এক বা দুই মিনিট সময় লাগতে পারে।
৬. স্প্যানার মাইগ্রেশন টুল (SMT) ব্যবহার করে স্কিমা রূপান্তর করুন।
ক্লাউড স্প্যানারে রূপান্তর করার আগে, স্প্যানার মাইগ্রেশন টুল (SMT) ওয়েব UI ব্যবহার করে আমাদের একটি লজিক্যাল শার্ডের ( shard0_db ) সাথে সংযোগ স্থাপন করুন, এর স্কিমা বিশ্লেষণ করুন এবং বেশ কিছু উন্নত পরিবর্তন প্রয়োগ করুন।
১. SMT ইনস্টল করুন
আমরা সরাসরি ক্লাউড শেল থেকে SMT ওয়েব UI চালাব। আপনার ক্লাউড শেল টার্মিনালে, সর্বশেষ SMT রিলিজটি ডাউনলোড এবং এক্সট্র্যাক্ট করুন:
sudo apt-get update && sudo apt-get install google-cloud-cli-spanner-migration-tool
# Verify installation
gcloud alpha spanner migrate web --help
২. উৎস ডাটাবেসের সাথে সংযোগ করুন
- আপনার সেশন প্রমাণীকরণ করুন
# Authenticate your Google Cloud account
gcloud auth login
# Set up Application Default Credentials (ADC) for SMT
gcloud auth application-default login
# Ensure your current project is set correctly
gcloud config set project $PROJECT_ID
(দ্রষ্টব্য: অনুরোধ করা হলে, আপনার অ্যাকাউন্ট অনুমোদন করার জন্য প্রদত্ত URL-টি অনুসরণ করুন এবং যাচাইকরণ কোডটি টার্মিনালে পেস্ট করুন।)
- প্রথমে, একটি নতুন ক্লাউড শেল ট্যাবে এটি চালিয়ে আপনার প্রথম ফিজিক্যাল শার্ডের এক্সটার্নাল আইপি খুঁজে বের করুন:
gcloud compute instances describe mysql-physical-1 --zone=$ZONE --format='get(networkInterfaces[0].accessConfigs[0].natIP)'
- SMT কনফিগার করার সময় ব্যবহার করার জন্য টার্গেট স্প্যানার ইনস্ট্যান্সের বিবরণ প্রিন্ট করুন।
echo "Project ID: $PROJECT_ID"
echo "Instance ID: $SPANNER_INSTANCE_NAME"
echo "Database Name: $SPANNER_DATABASE_NAME"
- ওয়েব UI চালু করুন:
gcloud alpha spanner migrate web --port=8080
- আপনার ক্লাউড শেল উইন্ডোর উপরের ডানদিকে, ওয়েব প্রিভিউ আইকনে (এটি দেখতে একটি চোখের মতো) ক্লিক করুন এবং পোর্ট ৮০৮০-তে প্রিভিউ নির্বাচন করুন। এটি একটি নতুন ব্রাউজার ট্যাবে SMT UI খুলবে।
- SMT ওয়েব UI-তে, ‘Connect to database’ নির্বাচন করুন।
- সংযোগের বিবরণ পূরণ করুন:
- ডাটাবেসের ধরণ: MySQL
- হোস্ট: (ধাপ ২ থেকে আইপি অ্যাড্রেসটি পেস্ট করুন)
- বন্দর: ৩৩০৬
- ব্যবহারকারী:
datastream_user - পাসওয়ার্ড:
complex_password_123 - ডাটাবেসের নাম:
shard0_db
- স্প্যানার ডাটাবেস কনফিগার করতে উপরের ডান কোণায় থাকা এডিট বাটনে ক্লিক করুন।
- আপনার টার্গেট স্প্যানারের বিবরণ লিখুন:
- প্রজেক্ট আইডি: (ধাপ ৩ থেকে প্রজেক্ট আইডি পেস্ট করুন)
- স্প্যানার ইনস্ট্যান্স: (ধাপ ৩ থেকে ইনস্ট্যান্স আইডি পেস্ট করুন)
- সংযোগ পরীক্ষা করতে ক্লিক করুন।
- এটি সম্পন্ন হলে, কানেক্ট (Connect) বাটনে ক্লিক করুন। SMT সোর্স ডাটাবেসটি বিশ্লেষণ করে একটি বেসলাইন স্প্যানার স্কিমা উপস্থাপন করবে।

৩. স্কিমা পরিবর্তন প্রয়োগ করুন
আমরা এখন আমাদের জটিল মাইগ্রেশন পরিস্থিতিগুলো অন্তর্ভুক্ত করার জন্য স্কিমাটি পুনর্গঠন করব।
SMT UI-এর স্কিমা এডিটরে, নিম্নলিখিত কাজগুলো সম্পাদন করুন:
A. LegacyRegion কলামটির নাম পরিবর্তন করুন:
- বাম দিকের নেভিগেশন প্যানেলে থাকা
Customersটেবিলে ক্লিক করুন। এটি ডিফল্টরূপে Columns ট্যাবটি খুলবে। - স্প্যানার সেকশনে থাকা এডিট বাটনে ক্লিক করুন।
- স্প্যানার স্কিমা ভিউতে
LegacyRegionকলামটি খুঁজুন। - কলামের নামের ডায়ালগ বক্সে টাইপ করে স্প্যানার কলামের নাম পরিবর্তন করে
LoyaltyTierকরুন। - সংরক্ষণ করুন ও রূপান্তর করুন -এ ক্লিক করুন।


খ. চেক সীমাবদ্ধতা শিথিল করুন:
-
Customersটেবিলে থাকা অবস্থায়, Check Constraints ট্যাবে যান। -
CHK_CreditLimitকনস্ট্রেইন্টটি খুঁজুন। এডিট (পেন্সিল) আইকনে ক্লিক করুন। - শর্তটি
CreditLimit > 1000থেকেCreditLimit > 0-তে পরিবর্তন করুন। (এর ফলে ইচ্ছাকৃতভাবে কম ক্রেডিট লিমিটযুক্ত সারিগুলো রিভার্স মাইগ্রেশনে ব্যর্থ হবে এবং DLQ-তে চলে যাবে)।

C. LegacyOrderSystem কলামটি ড্রপ করুন:
-
Ordersটেবিলে ক্লিক করলে ডিফল্টভাবে Columns ট্যাবটি খুলে যাবে। - স্প্যানার সেকশনে থাকা এডিট বাটনে ক্লিক করুন।
- স্প্যানার স্কিমা ভিউতে
LegacyOrderSystemকলামটি খুঁজুন। - এর পাশে থাকা ৩-ডট মেনু আইকনে ক্লিক করুন এবং ড্রপ কলাম নির্বাচন করুন।
- সংরক্ষণ করুন এবং রূপান্তর করুন -এ ক্লিক করুন।

D. OrderSource কলাম যোগ করুন এবং এটিকে প্রাইমারি কী করুন:
-
Ordersটেবিলে থাকা অবস্থায়, Add Column-এ ক্লিক করুন। এর নাম দিনOrderSourceএবং এর টাইপSTRINGও দৈর্ঘ্য50সেট করুন, কোনো অটো-জেনারেটেশন রাখবেন না এবংIsNullableNoসেট করুন। - প্রাইমারি কী ট্যাবে যান।
- এডিট-এ ক্লিক করুন এবং কলাম নেম ড্রপডাউন থেকে
OrderSourceনির্বাচন করুন। - অ্যাড কলাম -এ ক্লিক করুন এবং তারপরে সেভ অ্যান্ড কনভার্ট করুন ।


E. অর্ডার টেবিলটি পর্যায়ক্রমে সাজান:
- এখনও
Ordersটেবিলে, মূল টেবিল ভিউতে Interleave ট্যাবটি খুঁজুন। - প্যারেন্ট টেবিলটি
Customersএ সেট করুন। -
IN PARENTইন্টারলিভ টাইপ এবং ডিলিট অ্যাকশনেNO ACTIONনির্বাচন করুন। - সংরক্ষণ করুন- এ ক্লিক করুন।

৪. ওভাররাইড ফাইল ডাউনলোড করুন এবং স্কিমা প্রয়োগ করুন
- SMT UI-এর উপরের ডান কোণায়, 'Download Artifacts ' বাটনটি খুঁজুন। 'Download Overrides File' অপশনটি নির্বাচন করুন। এই ফাইলটি আপনার লোকাল মেশিনে সেভ করুন। এই ফাইলটিতে আমাদের করা সমস্ত স্কিমা ম্যাপিং পরিবর্তন রয়েছে এবং এটি আমাদের ডেটাফ্লো পাইপলাইন দ্বারা ব্যবহৃত হবে।
- মাইগ্রেশন প্রস্তুত করতে ক্লিক করুন।

- ড্রপডাউন থেকে মাইগ্রেশন মোড হিসেবে
Schemaনির্বাচন করুন। - আপনার টার্গেট স্প্যানার ডেটাবেস লিখুন:
sharded-target-db

- মাইগ্রেট-এ ক্লিক করুন।
- SMT ডিডিএল প্রয়োগ করবে এবং স্প্যানার ডাটাবেস তৈরি করবে। এটি সম্পন্ন হয়ে গেলে আপনি ক্লাউড শেল-এ (
Ctrl+C) নিরাপদে SMT প্রসেসটি বন্ধ করতে পারেন।
৫. ক্লাউড স্প্যানারে স্কিমা যাচাই করুন
স্প্যানার ডেটাবেসে টেবিলগুলো তৈরি হয়েছে কিনা তা যাচাই করুন।
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT table_name FROM information_schema.tables WHERE table_schema = '' ORDER BY table_name"
আপনি নিম্নলিখিত আউটপুট দেখতে পাবেন:
table_name: Customers table_name: Orders
ঐচ্ছিক: আপনার চেক কনস্ট্রেইন্ট, ইন্টারলিভিং এবং অতিরিক্ত কলামগুলো প্রয়োগ করা হয়েছে কিনা তা যাচাই করতে, প্রকৃত স্প্যানার ডিডিএল (Spanner DDL) পরীক্ষা করার জন্য নিম্নলিখিত কমান্ডটি চালান:
gcloud spanner databases ddl describe $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME
প্রত্যাশিত আউটপুট:
CREATE TABLE Customers ( CustomerId INT64 NOT NULL, CustomerName STRING(255), CreditLimit NUMERIC NOT NULL, LoyaltyTier STRING(50), CONSTRAINT CHK_CreditLimit CHECK(`CreditLimit` > 0), ) PRIMARY KEY(CustomerId); CREATE TABLE Orders ( CustomerId INT64 NOT NULL, OrderId INT64 NOT NULL, OrderValue NUMERIC, OrderSource STRING(50) NOT NULL, ) PRIMARY KEY(CustomerId, OrderId, OrderSource), INTERLEAVE IN PARENT Customers ON DELETE NO ACTION;
৭. চেঞ্জ ডেটা ক্যাপচার (CDC) চালু করুন
এই অংশে, আপনি আপনার মাইগ্রেশনের জন্য 'রেকর্ডার' সেট আপ করবেন। বাল্ক ডেটা লোড শুরু হওয়ার আগে ডেটাস্ট্রিম এবং পাব/সাব কনফিগার করার মাধ্যমে, আপনি নিশ্চিত করেন যে সোর্স ডেটাবেসগুলিতে করা প্রতিটি পরিবর্তন ক্যাপচার এবং কিউতে যুক্ত হয়, যা স্থানান্তরের সময় ডেটা হারানোর ঝুঁকি প্রতিরোধ করে। লাইভ মাইগ্রেশনের জন্য এই সেটআপটি আবশ্যক।
যেহেতু আমাদের আর্কিটেকচারে দুটি ফিজিক্যাল সার্ভার রয়েছে, তাই আমাদের দুটি পৃথক ডেটাস্ট্রিম সোর্স প্রোফাইল এবং দুটি ডেটাস্ট্রিম স্ট্রিম তৈরি করতে হবে। উভয় স্ট্রিমই একটিমাত্র গুগল ক্লাউড স্টোরেজ (GCS) বাকেটে ডেটা লিখবে, যা আমাদের ডেটাফ্লো পাইপলাইনের জন্য একীভূত উৎস হিসেবে কাজ করবে।
১. একটি ক্লাউড স্টোরেজ বাকেট তৈরি করুন
ক্যাপচার করা পরিবর্তন ইভেন্টগুলো সংরক্ষণ করার জন্য ডেটাস্ট্রিমের একটি গন্তব্য প্রয়োজন। চলুন একটি GCS বাকেট তৈরি করা যাক।
export BUCKET_NAME="migration-${PROJECT_ID}-bucket"
gcloud storage buckets create gs://${BUCKET_NAME} --location=$REGION
২. ডেটাস্ট্রিম সংযোগ প্রোফাইল তৈরি করুন
আমাদের দুটি স্বতন্ত্র MySQL সোর্স কানেকশন প্রোফাইল (প্রতিটি ফিজিক্যাল শার্ডের জন্য একটি) এবং ক্লাউড স্টোরেজের জন্য একটি টার্গেট কানেকশন প্রোফাইল প্রয়োজন।
উৎস আইপি ঠিকানাগুলি পান
প্রথমে, আমাদের দুটি Compute Engine VM-এর এক্সটার্নাল আইপি অ্যাড্রেসগুলো সংগ্রহ করুন এবং সেগুলোকে এনভায়রনমেন্ট ভেরিয়েবল হিসেবে সংরক্ষণ করুন:
export MYSQL_IP_1=$(gcloud compute instances describe mysql-physical-1 --zone=$ZONE --format='get(networkInterfaces[0].accessConfigs[0].natIP)')
export MYSQL_IP_2=$(gcloud compute instances describe mysql-physical-2 --zone=$ZONE --format='get(networkInterfaces[0].accessConfigs[0].natIP)')
সোর্স কানেকশন প্রোফাইল তৈরি করুন (কম্পিউট ইঞ্জিনে MySQL)
পূর্বে তৈরি করা datastream_user ব্যবহার করে ডেটাস্ট্রিম সংযোগ প্রোফাইলগুলি তৈরি করুন।
# Create Source Profile for Physical Shard 1
export SQL_CP_NAME_1="mysql-src-cp-1"
gcloud datastream connection-profiles create $SQL_CP_NAME_1 \
--location=$REGION \
--type=mysql \
--mysql-hostname=$MYSQL_IP_1 \
--mysql-port=3306 \
--mysql-username=datastream_user \
--mysql-password=complex_password_123 \
--display-name="MySQL Source 1 (Physical Shard 1)"
# Create Source Profile for Physical Shard 2
export SQL_CP_NAME_2="mysql-src-cp-2"
gcloud datastream connection-profiles create $SQL_CP_NAME_2 \
--location=$REGION \
--type=mysql \
--mysql-hostname=$MYSQL_IP_2 \
--mysql-port=3306 \
--mysql-username=datastream_user \
--mysql-password=complex_password_123 \
--display-name="MySQL Source 2 (Physical Shard 2)"
দ্রষ্টব্য: ডেটাস্ট্রিম এই ভিএমগুলোর সাথে তাদের পাবলিক আইপি-র মাধ্যমে সংযোগ স্থাপন করে, যা অনুমোদিত কারণ আমরা পূর্বে আমাদের ফায়ারওয়াল নিয়মে 0.0.0.0/0 যোগ করেছি। একটি প্রোডাকশন পরিবেশে, আপনাকে ডেটাস্ট্রিমের নির্দিষ্ট পাবলিক আইপি রেঞ্জগুলোকে কঠোরভাবে অনুমতি-তালিকাভুক্ত করতে হবে।
গন্তব্য সংযোগ প্রোফাইল তৈরি করুন (ক্লাউড স্টোরেজ):
এটি আপনার নতুন তৈরি করা বাকেটের রুটকে নির্দেশ করে।
export GCS_CP_NAME="gcs-dest-cp"
gcloud datastream connection-profiles create $GCS_CP_NAME \
--location=$REGION \
--type=google-cloud-storage \
--bucket=$BUCKET_NAME \
--root-path=/ \
--display-name="GCS Destination" --force
৩. ডেটাস্ট্রিম তৈরি করুন
আমরা এখন দুটি সিডিসি স্ট্রিম তৈরি করব। স্ট্রিম ১ shard0_db এবং shard1_db ক্যাপচার করবে। স্ট্রিম ২ shard2_db এবং shard3_db ক্যাপচার করবে। উভয় স্ট্রিমই অ্যাভ্রো ফরম্যাটে একই জিসিএস বাকেটে ডেটা লিখবে।
# Stream for Physical Shard 1
export STREAM_NAME_1="mysql-to-spanner-stream-1"
export GCS_STREAM_PATH_1="data/${STREAM_NAME_1}"
gcloud datastream streams create $STREAM_NAME_1 \
--location=$REGION \
--display-name="MySQL Source 1 CDC Stream" \
--source=$SQL_CP_NAME_1 \
--destination=$GCS_CP_NAME \
--mysql-source-config=<(echo "includeObjects:
mysqlDatabases:
- database: 'shard0_db'
- database: 'shard1_db'") \
--gcs-destination-config=<(echo "path: ${GCS_STREAM_PATH_1}/
fileRotationMb: 5
fileRotationInterval: 15s
avroFileFormat: {}") \
--backfill-none
# Stream for Physical Shard 2
export STREAM_NAME_2="mysql-to-spanner-stream-2"
export GCS_STREAM_PATH_2="data/${STREAM_NAME_2}"
gcloud datastream streams create $STREAM_NAME_2 \
--location=$REGION \
--display-name="MySQL Source 2 CDC Stream" \
--source=$SQL_CP_NAME_2 \
--destination=$GCS_CP_NAME \
--mysql-source-config=<(echo "includeObjects:
mysqlDatabases:
- database: 'shard2_db'
- database: 'shard3_db'") \
--gcs-destination-config=<(echo "path: ${GCS_STREAM_PATH_2}/
fileRotationMb: 5
fileRotationInterval: 15s
avroFileFormat: {}") \
--backfill-none
ছোট ফাইল রোটেশন সেটিংস (৫ এমবি বা ১৫ সেকেন্ড) ব্যবহার করলে কোডল্যাবের সময় পুনরাবৃত্ত পরিবর্তনগুলো আরও দ্রুত দেখা যায়।
এই কমান্ডটি সম্পন্ন হতে কিছুটা সময় লাগতে পারে। স্ট্যাটাস চেক করুন: gcloud datastream streams describe $STREAM_NAME_1 --location=$REGION .
৪. ডেটাস্ট্রিমগুলো চালু করুন
উভয় স্ট্রিম সক্রিয় করুন যাতে সেগুলি পরিবর্তনগুলি রেকর্ড করা শুরু করে।
gcloud datastream streams update $STREAM_NAME_1 \
--location=$REGION \
--state=RUNNING
gcloud datastream streams update $STREAM_NAME_2 \
--location=$REGION \
--state=RUNNING
স্ট্যাটাস চেক করুন: আপনি gcloud datastream streams describe $STREAM_NAME_1 --location=$REGION চালাতে পারেন। স্টেটটি প্রথমে STARTING থাকবে এবং কিছুক্ষণ পর RUNNING এ পরিবর্তিত হবে। লাইভ মাইগ্রেশন শুরু করার আগে উভয়ই সম্পূর্ণরূপে চালু হওয়া পর্যন্ত অপেক্ষা করুন।
৫. GCS নোটিফিকেশনের জন্য Pub/Sub সেট আপ করুন
যখনই কোনো ডেটাস্ট্রিম GCS বাকেটে একটি নতুন ফাইল লেখে, তখন ডেটাফ্লোকে অবিলম্বে অবহিত করতে হবে। আমরা GCS-কে একটিমাত্র পাব/সাব টপিকে নোটিফিকেশন পাঠানোর জন্য কনফিগার করব।
একটি পাব/সাব টপিক তৈরি করুন:
export PUBSUB_TOPIC="datastream-gcs-updates"
gcloud pubsub topics create $PUBSUB_TOPIC
GCS বিজ্ঞপ্তি তৈরি করুন
data/ প্রিফিক্সের অধীনে যেকোনো অবজেক্ট তৈরি হলে টপিকটিকে অবহিত করুন (যা আমাদের উভয় স্ট্রিমকেই অন্তর্ভুক্ত করে)।
gcloud storage buckets notifications create gs://${BUCKET_NAME} --topic=projects/$PROJECT_ID/topics/$PUBSUB_TOPIC --payload-format=json --object-prefix=data/
একটি পাব/সাব সাবস্ক্রিপশন তৈরি করুন
ডেটাফ্লো-এর জন্য একটি প্রস্তাবিত স্বীকৃতি প্রদানের শেষ তারিখসহ সাবস্ক্রিপশনটি তৈরি করুন।
export PUBSUB_SUBSCRIPTION="datastream-gcs-sub"
gcloud pubsub subscriptions create $PUBSUB_SUBSCRIPTION \
--topic=$PUBSUB_TOPIC \
--ack-deadline=600
৮. কাস্টম রূপান্তর
যেহেতু আমাদের স্প্যানার স্কিমা আমাদের MySQL স্কিমা থেকে ভিন্ন (SMT ওয়েব UI-এর মাধ্যমে কলাম যোগ এবং বাদ দেওয়ার কারণে), তাই ডেটাফ্লো-এর ডিফল্ট মাইগ্রেশন ব্যর্থ হবে। ফরোয়ার্ড (MySQL থেকে স্প্যানার) এবং রিভার্স (স্প্যানার থেকে MySQL) পাইপলাইন চলাকালীন এই পার্থক্যগুলো কীভাবে ম্যাপ করতে হবে, সে বিষয়ে ডেটাফ্লো-এর নির্দেশনা প্রয়োজন।
এছাড়াও, যেহেতু আমরা একটি শার্ডেড রিভার্স মাইগ্রেশন করছি, তাই রিভার্স রেপ্লিকেশনের সময় একটি আপডেট হওয়া স্প্যানার রো কোন লজিক্যাল শার্ডের ( shard0_db , shard1_db ইত্যাদি) অন্তর্গত, তা জানার জন্য ডেটাফ্লো-র একটি রাউটিং মেকানিজম প্রয়োজন।
আমরা গুগল-প্রদত্ত স্প্যানার কাস্টম শার্ড টেমপ্লেট ব্যবহার করে একটি কাস্টম ট্রান্সফরমেশন জার (JAR) লেখার মাধ্যমে এটি সম্পন্ন করব।
১. কাস্টম শার্ড টেমপ্লেটটি ডাউনলোড করুন
আপনার ক্লাউড শেলে, গুগল ক্লাউড ডেটাফ্লো টেমপ্লেটস রিপোজিটরিটি ডাউনলোড করুন এবং কাস্টম শার্ড ফোল্ডারে যান:
git clone https://github.com/GoogleCloudPlatform/DataflowTemplates.git
cd DataflowTemplates/v2/spanner-custom-shard
২. ডেটা রূপান্তর লজিক কনফিগার করুন
আমাদের CustomTransformationFetcher.java ফাইলটি সম্পাদনা করতে হবে।
- ফরওয়ার্ড মাইগ্রেশন (
toSpannerRow): MySQL-এরLegacyOrderSystemকলাম ব্যবহার করে নতুন যোগ করাOrderSourceকলামটি পূরণ করে। - রিভার্স মাইগ্রেশন (
toSourceRow): MySQL-এর প্রয়োজনীয় ড্রপ হয়ে যাওয়াLegacyOrderSystemকলামটিকে স্প্যানারেরOrderSourceথেকে ডিরাইভ করে পুনরায় পূরণ করে।
CustomTransformationFetcher.java ফাইলটি সম্পাদনা করুন। ম্যানুয়ালি টেক্সট এডিটর খোলার পরিবর্তে, আমাদের নিজস্ব লজিক দিয়ে টেমপ্লেট ফাইলটি স্বয়ংক্রিয়ভাবে ওভাররাইট করতে নিম্নলিখিত কমান্ডটি চালান:
cat << 'EOF' > src/main/java/com/custom/CustomTransformationFetcher.java
package com.custom;
import com.google.cloud.teleport.v2.spanner.exceptions.InvalidTransformationException;
import com.google.cloud.teleport.v2.spanner.utils.ISpannerMigrationTransformer;
import com.google.cloud.teleport.v2.spanner.utils.MigrationTransformationRequest;
import com.google.cloud.teleport.v2.spanner.utils.MigrationTransformationResponse;
import java.util.HashMap;
import java.util.Map;
public class CustomTransformationFetcher implements ISpannerMigrationTransformer {
@Override
public void init(String customParameters) {}
@Override
public MigrationTransformationResponse toSpannerRow(MigrationTransformationRequest request)
throws InvalidTransformationException {
if (request.getTableName().equals("Orders")) {
Map<String, Object> requestRow = request.getRequestRow();
Map<String, Object> responseRow = new HashMap<>();
Object legacySysObj = requestRow.get("LegacyOrderSystem");
String legacySys = (legacySysObj != null) ? (String) legacySysObj : "UNKNOWN_SYSTEM";
// Transform: Trim the string to remove everything after the first underscore
String orderSource = legacySys;
if (legacySys.contains("_")) {
orderSource = legacySys.substring(0, legacySys.indexOf('_'));
}
// Populate the new Spanner column (e.g., "WebStore_v1" becomes "WebStore")
responseRow.put("OrderSource", orderSource);
return new MigrationTransformationResponse(responseRow, false);
}
return new MigrationTransformationResponse(new HashMap<>(), false);
}
@Override
public MigrationTransformationResponse toSourceRow(MigrationTransformationRequest request)
throws InvalidTransformationException {
if (request.getTableName().equals("Orders")) {
Map<String, Object> requestRow = request.getRequestRow();
Map<String, Object> responseRow = new HashMap<>();
// Safely fetch the Spanner OrderSource
Object sourceObj = requestRow.get("OrderSource");
String source = (sourceObj != null) ? (String) sourceObj : "UNKNOWN_SYSTEM";
String legacySys = "'" + source + "_v1'";
// Transform: Append a suffix to visibly prove the reverse transformation worked
// e.g., "WebStore" becomes "WebStore_v1"
responseRow.put("LegacyOrderSystem", legacySys);
return new MigrationTransformationResponse(responseRow, false);
}
return new MigrationTransformationResponse(new HashMap<>(), false);
}
@Override
public MigrationTransformationResponse transformFailedSpannerMutation(
MigrationTransformationRequest request) throws InvalidTransformationException {
return new MigrationTransformationResponse(new HashMap<>(), false);
}
}
EOF
৩. রিভার্স শার্ডিং লজিক কনফিগার করুন
রিভার্স রেপ্লিকেশনের সময় একটি স্প্যানার মিউটেশন কোথায় রাউট করা উচিত তা নির্ধারণ করতে ডেটাফ্লো CustomShardIdFetcher.java ব্যবহার করে। আমরা CustomerId প্রাইমারি কী এবং মডুলো ( %4 ) লজিক ব্যবহার করে রেকর্ডগুলোকে ডায়নামিকভাবে তাদের সঠিক লজিক্যাল শার্ডে রাউট করব।
`cat` ব্যবহার করে CustomShardIdFetcher.java ফাইলটি সম্পাদনা করুন এবং এর ভেতরের সমস্ত লেখা নিচের কোড দিয়ে প্রতিস্থাপন করুন:
cat << 'EOF' > src/main/java/com/custom/CustomShardIdFetcher.java
package com.custom;
import com.google.cloud.teleport.v2.spanner.utils.IShardIdFetcher;
import com.google.cloud.teleport.v2.spanner.utils.ShardIdRequest;
import com.google.cloud.teleport.v2.spanner.utils.ShardIdResponse;
import java.util.Map;
public class CustomShardIdFetcher implements IShardIdFetcher {
@Override
public void init(String parameters) {}
@Override
public ShardIdResponse getShardId(ShardIdRequest shardIdRequest) {
Map<String, Object> keys = shardIdRequest.getSpannerRecord
();
// Use the Primary Key to identify the correct logical shard
if (keys != null && keys.containsKey("CustomerId")) {
long customerId = Long.parseLong(keys.get("CustomerId").toString());
long shardIdx = customerId % 4;
ShardIdResponse response = new ShardIdResponse();
response.setLogicalShardId("shard" + shardIdx + "_db");
return response;
}
return new ShardIdResponse();
}
}
EOF
৪. JAR ফাইলটি তৈরি করুন এবং আপলোড করুন
আমাদের নিজস্ব জাভা লজিক লেখা হয়ে গেলে, এটিকে একটি JAR ফাইলে কম্পাইল করে আমাদের আগে তৈরি করা গুগল ক্লাউড স্টোরেজ বাকেটে আপলোড করতে হবে, যাতে ডেটাফ্লো এটি অ্যাক্সেস করতে পারে।
ক্লাউড শেলে নিম্নলিখিত কমান্ডগুলি চালান:
# Return to DataflowTemplates directory
cd ../..
# Build the JAR using Maven
mvn clean install -DskipTests -Dcheckstyle.skip -Dspotless.check.skip=true -Djib.skip -pl v2/spanner-custom-shard -am
# Upload the JAR to GCS
export CUSTOM_JAR_PATH="gs://${BUCKET_NAME}/custom-logic/spanner-custom-shard-1.0.jar"
gcloud storage cp v2/spanner-custom-shard/target/spanner-custom-shard-1.0-SNAPSHOT.jar $CUSTOM_JAR_PATH
# Return to home directory
cd ~
৯. MySQL থেকে Spanner-এ ডেটা একযোগে স্থানান্তর করুন
স্প্যানার স্কিমা তৈরি হয়ে গেলে এবং আমাদের কাস্টম ট্রান্সফরমেশন JAR নির্মিত হলে, আমরা এখন আপনার MySQL ডাটাবেস থেকে বিদ্যমান ডেটা ক্লাউড স্প্যানারে কপি করতে পারি। এর জন্য আপনি Sourcedb to Spanner ডেটাফ্লো ফ্লেক্স টেমপ্লেট ব্যবহার করবেন, যা JDBC-অ্যাক্সেসযোগ্য ডাটাবেস থেকে স্প্যানারে একসাথে অনেক ডেটা কপি করার জন্য ডিজাইন করা হয়েছে।
১. স্কিমা ওভাররাইড ফাইলটি আপলোড করুন
সেকশন ৬-এ, আপনি SMT ওয়েব UI ব্যবহার করে স্প্যানার ওভাররাইডস JSON ফাইলটি ডাউনলোড করেছেন। আমাদের এটি GCS বাকেটে আপলোড করতে হবে, যাতে ডেটাফ্লো স্কিমার পার্থক্যগুলো (যেমন নাম পরিবর্তন করা কলাম) ম্যাপ করার জন্য এটি ব্যবহার করতে পারে।
- আপনার ক্লাউড শেলে, তিন-বিন্দু মেনুতে (More) ক্লিক করুন এবং আপলোড নির্বাচন করুন।

- আপনি আগে ডাউনলোড করা Overrides JSON ফাইলটি নির্বাচন করুন (যেমন,
spanner_overrides.json)। - এটিকে আপনার GCS বাকেটে সরান:
export OVERRIDES_FILE="spanner_overrides.json" # Change this if your downloaded file has a different name
export GCS_OVERRIDES_PATH="gs://${BUCKET_NAME}/config/${OVERRIDES_FILE}"
gcloud storage cp ~/${OVERRIDES_FILE} $GCS_OVERRIDES_PATH
২. শার্ডিং কনফিগারেশন ফাইল তৈরি এবং আপলোড করুন
আপনার দুটি ফিজিক্যাল ভিএম জুড়ে থাকা চারটি লজিক্যাল শার্ডের সাথেই কীভাবে সংযোগ স্থাপন করতে হয়, তা ডেটাফ্লোকে জানতে হবে। এর জন্য আমরা একটি sharding.json ফাইল তৈরি করব।
কনফিগারেশন তৈরি ও আপলোড করতে ক্লাউড শেলে নিম্নলিখিতটি চালান:
cat <<EOF > sharding.json
{
"configType": "dataflow",
"shardConfigurationBulk": {
"schemaSource": {
"dataShardId": "mysql-physical-1",
"host": "${MYSQL_IP_1}",
"user": "datastream_user",
"password": "complex_password_123",
"port": "3306",
"dbName": "shard0_db"
},
"dataShards": [
{
"dataShardId": "mysql-physical-1",
"host": "${MYSQL_IP_1}",
"user": "datastream_user",
"password": "complex_password_123",
"port": "3306",
"dbName": "",
"namespace": "namespace-mysql-1",
"databases": [
{
"dbName": "shard0_db",
"databaseId": "shard0_db",
"refDataShardId": "mysql-physical-1"
},
{
"dbName": "shard1_db",
"databaseId": "shard1_db",
"refDataShardId": "mysql-physical-1"
}
]
},
{
"dataShardId": "mysql-physical-2",
"host": "${MYSQL_IP_2}",
"user": "datastream_user",
"password": "complex_password_123",
"port": "3306",
"dbName": "",
"namespace": "namespace-mysql-2",
"databases": [
{
"dbName": "shard2_db",
"databaseId": "shard2_db",
"refDataShardId": "mysql-physical-2"
},
{
"dbName": "shard3_db",
"databaseId": "shard3_db",
"refDataShardId": "mysql-physical-2"
}
]
}
]
}
}
EOF
export GCS_SHARDING_PATH="gs://${BUCKET_NAME}/config/sharding.json"
gcloud storage cp sharding.json $GCS_SHARDING_PATH
৩. বাল্ক মাইগ্রেশন ডেটাফ্লো জবটি চালান
আমরা সোর্সডিবি টু স্প্যানার ফ্লেক্স টেমপ্লেট ব্যবহার করব। যেহেতু এটি কাস্টম ট্রান্সফরমেশন সহ একটি শার্ডেড মাইগ্রেশন, তাই আমরা ওভাররাইডস ফাইল, শার্ডিং কনফিগ এবং আমাদের কাস্টম জাভা জার (JAR) পাস করব।
export JOB_NAME="mysql-sharded-bulk-to-spanner-$(date +%Y%m%d-%H%M%S)"
export OUTPUT_DIR="gs://${BUCKET_NAME}/bulk-migration"
gcloud dataflow flex-template run $JOB_NAME \
--project=$PROJECT_ID \
--region=$REGION \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Sourcedb_to_Spanner_Flex" \
--max-workers=2 \
--num-workers=1 \
--worker-machine-type=n2-highmem-8 \
--parameters \
sourceConfigURL=$GCS_SHARDING_PATH,\
instanceId=$SPANNER_INSTANCE_NAME,\
databaseId=$SPANNER_DATABASE_NAME,\
projectId=$PROJECT_ID,\
outputDirectory=$OUTPUT_DIR,\
username=datastream_user,\
password=complex_password_123,\
schemaOverridesFilePath=$GCS_OVERRIDES_PATH,\
transformationJarPath=$CUSTOM_JAR_PATH,\
transformationClassName=com.custom.CustomTransformationFetcher
মূল প্যারামিটারগুলোর ব্যাখ্যা:
-
sourceConfigURL: আমাদের তৈরি করাsharding.jsonফাইলের পাথ। এটি ডেটাফ্লোকে বলে দেয় যে দুটি ফিজিক্যাল ভিএম জুড়ে থাকা আমাদের চারটি লজিক্যাল MySQL শার্ডের সাথে কীভাবে সংযোগ স্থাপন করতে হবে। -
schemaOverridesFilePath: এটি হলো সেই JSON ফাইলের পাথ যা আমরা SMT ওয়েব UI থেকে ডাউনলোড করেছি। আমাদের করা স্কিমা পরিবর্তনগুলো (যেমনLegacyRegionকলামটি বাদ দেওয়া এবং চেক কনস্ট্রেইন্ট আরও কঠোর করা) কীভাবে পরিচালনা করতে হবে, তা ডেটাফ্লোকে এই পাথ নির্দেশ দেয়। -
transformationJarPath: পূর্ববর্তী বিভাগে আমাদের তৈরি করা কম্পাইল করা জাভা JAR ফাইলের GCS পাথ। এতে আমাদের কাস্টম ট্রান্সফরমেশনগুলো কার্যকর করার মূল কোড রয়েছে। -
transformationClassName: আমাদের JAR-এর ভিতরে থাকা জাভা ক্লাসের পূর্ণাঙ্গ নাম, যা ফরওয়ার্ড মাইগ্রেশন লজিক (com.custom.CustomTransformationFetcher) বাস্তবায়ন করে। -
outputDirectory: GCS-এর সেই অবস্থান যেখানে ডেটাফ্লো তার অস্থায়ী ফাইল এবং সবচেয়ে গুরুত্বপূর্ণভাবে, ডেড লেটার কিউ (DLQ) ফাইলগুলো লিখবে। -
maxWorkers,numWorkers: ডেটাফ্লো জবের স্কেলিং নিয়ন্ত্রণ করে। এই ছোট ডেটাসেটের জন্য এর মান কম রাখা হয়েছে। -
instanceId,databaseId,projectId: লক্ষ্য ক্লাউড স্প্যানার ইনস্ট্যান্স এবং ডাটাবেস নির্দিষ্ট করে।
নেটওয়ার্ক নোট: এই জবটি ক্লাউড SQL ইনস্ট্যান্সের পাবলিক আইপি-র মাধ্যমে এর সাথে সংযোগ স্থাপন করে। এটি সম্ভব হয়েছে কারণ আপনি পূর্বে ইনস্ট্যান্সটির অনুমোদিত নেটওয়ার্কের তালিকায় 0.0.0.0/0 যোগ করেছেন। এর ফলে ডেটাফ্লো ওয়ার্কার ভিএমগুলো, যাদের এক্সটার্নাল আইপি রয়েছে, তারা ডাটাবেসে পৌঁছাতে পারে।
৪. ডেটাফ্লো জবটি মনিটর করুন
আপনি গুগল ক্লাউড কনসোলে কাজটি അവതരിക്കിക്കുന്ന
- ডেটাফ্লো জবস পৃষ্ঠায় যান: ডেটাফ্লো জবস-এ যান
-
mysql-sharded-bulk-to-spanner-...নামের জবটি খুঁজুন এবং সেটিতে ক্লিক করুন। - জব গ্রাফ এবং মেট্রিক্স পর্যবেক্ষণ করুন। জবের স্ট্যাটাস 'সফল' ( Succeeded) হওয়া পর্যন্ত অপেক্ষা করুন। এতে আনুমানিক ৫-১৫ মিনিট সময় লাগতে পারে।

- জবটিতে কোনো সমস্যা দেখা দিলে, ত্রুটির বার্তাগুলোর জন্য ডেটাফ্লো জব ডিটেইলস পেজের মধ্যে থাকা লগস ট্যাবটি পর্যালোচনা করুন।
- জব মেট্রিক্স কাজের অগ্রগতি এবং রিসোর্স ব্যবহার, যেমন থ্রুপুট ও সিপিইউ ইউটিলাইজেশন, সম্পর্কে আরও তথ্য প্রদান করে।
৫. ক্লাউড স্প্যানারে ডেটা যাচাই করুন এবং ডেড লেটার কিউ (DLQ) পরিদর্শন করুন।
ডেটাফ্লো জবটি সফলভাবে সম্পন্ন হয়ে গেলে, আমাদের ডেটা নিরাপদে পৌঁছেছে কিনা তা যাচাই করতে হবে এবং ইচ্ছাকৃতভাবে ত্রুটিপূর্ণ করে রাখা রেকর্ডগুলো পরীক্ষা করতে হবে।
ক. স্থানান্তরিত ডেটার সামগ্রিক অবস্থা যাচাই করুন:
আপনার একত্রিত স্প্যানার ডাটাবেসে বৈধ রেকর্ডগুলি সঠিকভাবে স্থানান্তরিত হয়েছে এবং আমাদের কাস্টম JAR অতিরিক্ত কলামটি পূরণ করেছে কিনা তা নিশ্চিত করতে, gcloud CLI ব্যবহার করে কয়েকটি দ্রুত স্বাস্থ্য পরীক্ষা চালান।
# 1. Verify total Customer count
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT COUNT(*) as TotalCustomers FROM Customers"
# 2. Verify total Orders count (Total minus the orphan record)
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT COUNT(*) as TotalOrders FROM Orders"
# 3. Verify the Custom Transformation on OrderSource worked
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT CustomerId, OrderId, OrderSource FROM Orders LIMIT 3"
# 4. Verify that renamed column LoyaltyTier has the correct data
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT CustomerId, CustomerName, LoyaltyTier FROM Customers LIMIT 3"
প্রত্যাশিত আউটপুট:
TotalCustomers: 16 TotalOrders: 19 CustomerId: 1 OrderId: 201 OrderSource: MobileApp CustomerId: 2 OrderId: 301 OrderSource: CallCenter CustomerId: 3 OrderId: 401 OrderSource: InStore CustomerId: 1 CustomerName: Agnes N. LoyaltyTier: NORTHEAST CustomerId: 2 CustomerName: Brian K. LoyaltyTier: SOUTHWEST CustomerId: 3 CustomerName: Cathy Z. LoyaltyTier: CENTRAL
- Customers টেবিলের সমস্ত সারি সফলভাবে স্থানান্তরিত হয়েছে।
- স্প্যানারে
INTERLEAVE IN PARENTত্রুটির কারণেOrdersটেবিলে একটি সারি ব্যর্থ হয়েছে -Customersটেবিলে কোনো সংশ্লিষ্ট সারি না থাকায়CustomerId 99একটি অনাথ চাইল্ড (orphan child) হিসেবে চিহ্নিত হয়েছে।
খ. ডিএলকিউ-তে ইচ্ছাকৃত ব্যর্থতাগুলো যাচাই করুন:
বাল্ক মাইগ্রেশন পাইপলাইন দ্বারা তৈরি ডেড লেটার কিউ (DLQ) ফোল্ডারে উপরোক্ত ব্যর্থতাটি নথিভুক্ত করা হয়।
- গুগল ক্লাউড কনসোলে ক্লাউড স্টোরেজে যান।
- আপনার বাকেটে যান এবং
bulk-migration/dlq/severeফোল্ডারটি খুলুন। - ভেতরের JSON ফাইলগুলো পরীক্ষা করুন। আপনি
Ordersসারিটি খুঁজে পাবেন যেখানেCustomerIdনামের একটি অনাথ আইডি রয়েছে। - এখানে উল্লিখিত ধাপগুলো অনুসরণ করে বাল্ক মাইগ্রেশন ডিএলকিউ (DLQ) ত্রুটিগুলো পুনরায় চেষ্টা করা যেতে পারে।
ক্লাউড এসকিউএল থেকে ক্লাউড স্প্যানারে ডেটার প্রাথমিক বাল্ক লোড এখন সম্পন্ন হয়েছে। পরবর্তী পদক্ষেপ হলো চলমান পরিবর্তনগুলো ক্যাপচার করার জন্য লাইভ রেপ্লিকেশন সেট আপ করা।
১০. লাইভ মাইগ্রেশন শুরু করুন (সিডিসি)
বাল্ক ডেটা লোড সম্পন্ন হলে, আপনি একটি নিরবচ্ছিন্ন ডেটাফ্লো স্ট্রিমিং জব চালু করবেন। এই জবটি ডেটাস্ট্রিম দ্বারা আপনার GCS বাকেটে লেখা চেঞ্জ ডেটা ক্যাপচার (CDC) ইভেন্টগুলো পড়বে এবং প্রায় রিয়েল-টাইমে সেই পরিবর্তনগুলো ক্লাউড স্প্যানারে প্রয়োগ করবে।
ডেটাফ্লো কীভাবে লাইভ রেপ্লিকেশন পরিচালনা করে এবং ব্যর্থ ডেটাগুলোকে ডেড লেটার কিউ (DLQ)-তে পাঠায়, তা পর্যবেক্ষণ করার জন্য আমরা বৈধ এবং ইচ্ছাকৃতভাবে অবৈধ উভয় প্রকার ডেটা প্রবেশ করিয়ে এই পাইপলাইনটি পরীক্ষা করব।
১. লাইভ মাইগ্রেশন শার্ডিং কনফিগারেশন ফাইল তৈরি করুন
বাল্ক মাইগ্রেশনের (যা JDBC কানেকশন স্ট্রিং ব্যবহার করে) বিপরীতে, লাইভ মাইগ্রেশন পাইপলাইন GCS থেকে ডেটাস্ট্রিম ইভেন্টগুলো পড়ে। এর জন্য সম্পূর্ণ ভিন্ন একটি JSON কনফিগারেশন প্রয়োজন, যা ডেটাস্ট্রিম স্ট্রিমের নাম এবং ডেটাবেসগুলোকে আপনার লজিক্যাল স্প্যানার শার্ডগুলোর সাথে ম্যাপ করে।
লাইভ শার্ডিং কনফিগারেশন তৈরি ও আপলোড করতে ক্লাউড শেলে নিম্নলিখিত কমান্ডটি চালান:
cat <<EOF > live-sharding.json
{
"StreamToDbAndShardMap": {
"${STREAM_NAME_1}": {
"shard0_db": "shard0_db",
"shard1_db": "shard1_db"
},
"${STREAM_NAME_2}": {
"shard2_db": "shard2_db",
"shard3_db": "shard3_db"
}
}
}
EOF
export GCS_LIVE_SHARDING_PATH="gs://${BUCKET_NAME}/config/live-sharding.json"
gcloud storage cp live-sharding.json $GCS_LIVE_SHARDING_PATH
২. লাইভ মাইগ্রেশন ডেটাফ্লো জবটি চালান
GCS থেকে ডেটা পড়তে এবং স্প্যানারে লিখতে স্ট্রিমিং ডেটাফ্লো জবটি চালু করুন। এই টেমপ্লেটটি নতুন ফাইলগুলোকে তাৎক্ষণিকভাবে প্রসেস করার জন্য GCS পাব/সাব নোটিফিকেশন ব্যবহার করবে।
export JOB_NAME_CDC="mysql-sharded-cdc-to-spanner-$(date +%Y%m%d-%H%M%S)"
export DLQ_DIR_CDC="gs://${BUCKET_NAME}/live-migration"
gcloud dataflow flex-template run $JOB_NAME_CDC \
--project=$PROJECT_ID \
--region=$REGION \
--worker-machine-type=n2-highmem-8 \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Cloud_Datastream_to_Spanner" \
--parameters \
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
projectId="$PROJECT_ID",\
inputFileFormat="avro",\
gcsPubSubSubscription="projects/${PROJECT_ID}/subscriptions/${PUBSUB_SUBSCRIPTION}",\
shardingContextFilePath=$GCS_LIVE_SHARDING_PATH,\
deadLetterQueueDirectory="$DLQ_DIR_CDC",\
transformationJarPath=$CUSTOM_JAR_PATH,\
transformationClassName="com.custom.CustomTransformationFetcher",\
schemaOverridesFilePath=$GCS_OVERRIDES_PATH,\
datastreamSourceType="mysql",\
dlqRetryMinutes=1,\
dlqMaxRetryCount=2
মূল পরামিতি
-
gcsPubSubSubscription: এটি সেই পাব/সাব সাবস্ক্রিপশন যা GCS থেকে নতুন ফাইলের নোটিফিকেশন শোনে। এর ফলে, ডেটাস্ট্রিম পরিবর্তনগুলো লেখার সাথে সাথেই জবটি তা তাৎক্ষণিকভাবে প্রসেস করতে পারে। -
inputFileFormat="avro": এটি Dataflow-কে জানায় যে Datastream থেকে Avro ফাইল আশা করতে হবে। এটি অবশ্যই আপনার Datastream-এর 'Destination' কনফিগারেশনের সাথে মিলতে হবে (যেমন,avroFileFormatবনামjsonFileFormat)। -
shardingContextFilePath: একটি JSON ফাইল যা ডেটাস্ট্রিম স্ট্রিমগুলোকে লজিক্যাল শার্ডের সাথে ম্যাপ করে। -
dlqRetryMinutes: ডেড লেটার কিউ পুনরায় চেষ্টা করার মধ্যবর্তী মিনিটের সংখ্যা। ডিফল্ট মান10। -
dlqMaxRetryCount: DLQ-এর মাধ্যমে অস্থায়ী ত্রুটিগুলো সর্বোচ্চ যতবার পুনরায় চেষ্টা করা যাবে। এর ডিফল্ট মান500।
ডেটাফ্লো জবস কনসোলে জবটির সূচনা পর্যবেক্ষণ করুন।
৩. লাইভ ডেটা প্রবেশ করান এবং ইচ্ছাকৃত ব্যর্থতা ঘটান
ডেটাফ্লো স্ট্রিমিং জবটি চালু হওয়ার সময়ে (এতে ৩-৫ মিনিট সময় লাগতে পারে), চলুন আমাদের প্রথম ফিজিক্যাল MySQL VM-এ SSH করে কিছু নতুন রেকর্ড ইনসার্ট করি। আমরা একটি বৈধ রেকর্ড এবং একটি অবৈধ রেকর্ড ইনসার্ট করব।
প্রথম ফিজিক্যাল শার্ডে SSH করুন:
gcloud compute ssh mysql-physical-1 --zone=$ZONE
MySQL-এ লগ ইন করুন:
sudo mysql
shard1_db তে নিম্নলিখিত ইনসার্টগুলো চালান:
USE shard1_db;
-- 1. Valid Insert: 'MobileApp_v2' will be trimmed to 'MobileApp'
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem)
VALUES (4, 501, 99.99, 'MobileApp_v2');
-- 2. Invalid Insert (DLQ Test): This violates Interleave constraint as CustomerId 99999 doesn't exist in Customers table.
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem)
VALUES (99999, 502, 50.00, 'WebStore_v1');
-- 3. Valid Update
UPDATE Orders SET OrderValue = '1500' WHERE CustomerId = 5 AND OrderId = 202;
-- 4. Valid Delete
DELETE FROM Orders WHERE CustomerId = 5 AND OrderId = 203;
EXIT;
আপনার ক্লাউড শেল প্রম্পটে ফিরে যেতে আবার exit টাইপ করুন।
৪. লাইভ মাইগ্রেশন ডেটা যাচাই করুন এবং সিডিসি ডিএলকিউ পরিদর্শন করুন।
এখন যেহেতু আমরা ডেটা ইনজেক্ট করেছি, ডেটাস্ট্রিম সিডিসি ইভেন্টগুলো ক্যাপচার করবে এবং ডেটাফ্লো সেগুলো স্প্যানারে প্রয়োগ করার চেষ্টা করবে।
A. স্প্যানারে বৈধ DML পরিবর্তনগুলি যাচাই করুন
INSERT , UPDATE , এবং DELETE ইভেন্টগুলো সফলভাবে স্প্যানারে পৌঁছেছে কিনা, এবং INSERT ও UPDATE উভয় ক্ষেত্রেই কাস্টম ট্রান্সফরমেশনটি কার্যকর হয়েছে কিনা, তা যাচাই করতে নিম্নলিখিত কোয়েরিগুলো চালান।
# 1. Verify INSERT: Should return the new row with transformed OrderSource
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT CustomerId, OrderId, OrderValue, OrderSource FROM Orders WHERE CustomerId = 4 AND OrderId = 501"
# 2. Verify UPDATE: Should show OrderValue changed to 1500
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT CustomerId, OrderId, OrderValue, OrderSource FROM Orders WHERE CustomerId = 5 AND OrderId = 202"
# 3. Verify DELETE: Should return 0, confirming the order was deleted
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT COUNT(*) FROM Orders WHERE CustomerId = 5 AND OrderId = 203"
# 4. Verify DLQ Failure: Should return 0, confirming the row migration failed
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT COUNT(*) FROM Orders WHERE CustomerId = 99999 AND OrderId = 502"
প্রত্যাশিত আউটপুট:
CustomerId: 4 OrderId: 501 OrderValue: 99.99 OrderSource: MobileApp CustomerId: 5 OrderId: 202 OrderValue: 1500 OrderSource: WebStore 0 0
দ্রষ্টব্য: যদি কোনো কোয়েরি প্রত্যাশিত ফলাফল না দেখায়, তবে এক মিনিট অপেক্ষা করে আবার চেষ্টা করুন, কারণ স্ট্রিমিং ওয়ার্কাররা তখনও কিউটি প্রসেস করতে পারে।
খ. DLQ-তে ইচ্ছাকৃত ব্যর্থতা যাচাই করুন:
যেহেতু Customers টেবিলে CustomerId = 99999 কোনো প্যারেন্ট নেই, তাই এটিকে স্প্যানার দ্বারা প্রত্যাখ্যাত হওয়া উচিত ছিল এবং ডেটাফ্লো দ্বারা নিরাপদে DLQ-তে পাঠানো উচিত ছিল।
- গুগল ক্লাউড কনসোলে ক্লাউড স্টোরেজে যান।
- আপনার বাকেটে যান এবং
live-migration/dlq/severe/ফোল্ডারটি খুলুন। - আপনি নতুন তৈরি হওয়া JSON ফাইলগুলো দেখতে পাবেন। সেগুলোর ভেতরের বিষয়বস্তু পরীক্ষা করার জন্য সেগুলোর উপর ক্লিক করুন। আপনি
CustomerId = 99999এর বিবরণ এবং নির্দিষ্ট স্প্যানার ত্রুটির বার্তাটি দেখতে পাবেন:NOT_FOUND: Parent row for row [99999,502,WebStore] in table Orders is missing. Row cannot be written." -
runMode=retryDLQসেট করে ডেটাফ্লো টেমপ্লেটটি রান করার মাধ্যমে লাইভ মাইগ্রেশন DLQ ত্রুটিগুলো পুনরায় চেষ্টা করা যেতে পারে।
৫. DLQ ত্রুটি পরিচালনা
severe/ ডিরেক্টরিতে থাকা ত্রুটিগুলোর জন্য ম্যানুয়াল হস্তক্ষেপ প্রয়োজন। চলুন ডেটা সমস্যাটি সমাধান করে ব্যর্থ হওয়া ইভেন্টটি পুনরায় প্রসেস করি।
ক. উৎসে ডেটা ঠিক করুন
The error occurred because the parent customer record CustomerId = 99999 is missing. Let's insert it into the source MySQL database.
SSH into the MySQL instance again:
gcloud compute ssh mysql-physical-1 --zone=$ZONE
Log into MySQL using sudo mysql and insert the missing parent row into shard1_db :
USE shard1_db;
INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LegacyRegion) VALUES
(99999, 'DLQ Parent Holder', 5000.00, 'NORTH_AMERICA');
EXIT;
Type exit to return to Cloud Shell.
B. Run the retryDLQ Dataflow Job
To reprocess events from the severe/ DLQ, you launch the same Dataflow template but in retryDLQ mode. This mode specifically reads from the deadLetterQueueDirectory/severe path, re-runs them through your custom transformations, and applies them to Spanner.
Launch the job in retryDLQ mode:
export JOB_NAME_RETRY="mysql-sharded-cdc-retry-$(date +%Y%m%d-%H%M%S)"
gcloud dataflow flex-template run $JOB_NAME_RETRY \
--project=$PROJECT_ID \
--region=$REGION \
--worker-machine-type=n2-highmem-8 \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Cloud_Datastream_to_Spanner" \
--parameters \
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
projectId="$PROJECT_ID",\
runMode="retryDLQ",\
deadLetterQueueDirectory="$DLQ_DIR_CDC",\
datastreamSourceType="mysql",\
transformationJarPath=$CUSTOM_JAR_PATH,\
transformationClassName="com.custom.CustomTransformationFetcher",\
schemaOverridesFilePath=$GCS_OVERRIDES_PATH,\
shardingContextFilePath=$GCS_LIVE_SHARDING_PATH
পুনরায় চেষ্টার জন্য মূল প্যারামিটার পরিবর্তন
-
runMode="retryDLQ": Tells the template to read from thesevereDLQ directory. - Removed
gcsPubSubSubscription: Not needed as we are not reading from the live Datastream GCS bucket.
Monitor the Retry Process:
Like the main CDC pipeline, retryDLQ is a streaming pipeline that will remain RUNNING till manually cancelled.
- Go to the Dataflow Job page for
$JOB_NAME_RETRY. - Under the Metrics pane, look for these two counters:
-
elementsReconsumedFromDeadLetterQueue: Evaluates when the error files are being fetched. -
Successful events: Increments when the record is written into Spanner. - Check the
severe/directory for recurring failures. - Once Successful events has incremented by the number of items you wanted to retry (1 in our test case), go to the next verification step.
C. Verify the Retried Data
After the failed record is retried (might take some time to succeed), check Spanner to see if the child row was migrated successfully:
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT CustomerId, OrderId, OrderValue, OrderSource FROM Orders WHERE CustomerId = 99999 AND OrderId = 502"
You should now see the row:
CustomerId: 99999 OrderId: 502 OrderValue: 50 OrderSource: WebStore
Also, check the $DLQ_DIR_CDC/severe/ folder in GCS. The processed files should have been moved or deleted, indicating successful reprocessing.
11. Set Up Reverse Replication (Spanner to MySQL)
To handle scenarios where you might need to rollback or keep the original MySQL database in sync with Spanner for a transitional period, you can set up reverse replication.
This pipeline uses Spanner Change Streams to capture live modifications in Spanner. It then uses our Custom Transformation JAR to reverse-map the schema differences, and our Custom Sharding JAR to calculate exactly which physical MySQL VM and logical shard the update should be written back to.
1. Create a Spanner Change Stream
First, you need to create a change stream in your Spanner database to track changes on the Customers and Orders tables.
export CHANGE_STREAM_NAME="CustomersOrdersChangeStream"
gcloud spanner databases ddl update $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--ddl="CREATE CHANGE STREAM $CHANGE_STREAM_NAME FOR Customers, Orders"
This change stream will now record all data modifications to the specified tables.
2. Create a Spanner Database for Dataflow Metadata
The Spanner to SourceDB Dataflow template requires a separate Spanner database to store metadata for managing the change stream consumption.
export SPANNER_METADATA_DB_NAME="migration-metadata-db"
gcloud spanner databases create $SPANNER_METADATA_DB_NAME \
--instance=$SPANNER_INSTANCE_NAME
3. Prepare Cloud SQL Connection Configuration for Dataflow
The Dataflow template needs a JSON file in Cloud Storage containing the connection details for the target Cloud SQL database.
Create a local file named shard_config.json :
cat <<EOF > reverse-sharding.json
[
{
"logicalShardId": "shard0_db",
"host": "${MYSQL_IP_1}",
"port": "3306",
"user": "datastream_user",
"password": "complex_password_123",
"dbName": "shard0_db"
},
{
"logicalShardId": "shard1_db",
"host": "${MYSQL_IP_1}",
"port": "3306",
"user": "datastream_user",
"password": "complex_password_123",
"dbName": "shard1_db"
},
{
"logicalShardId": "shard2_db",
"host": "${MYSQL_IP_2}",
"port": "3306",
"user": "datastream_user",
"password": "complex_password_123",
"dbName": "shard2_db"
},
{
"logicalShardId": "shard3_db",
"host": "${MYSQL_IP_2}",
"port": "3306",
"user": "datastream_user",
"password": "complex_password_123",
"dbName": "shard3_db"
}
]
EOF
Upload this file to your GCS bucket:
export GCS_REVERSE_SHARDING_PATH="gs://${BUCKET_NAME}/config/reverse-sharding.json"
gcloud storage cp reverse-sharding.json $GCS_REVERSE_SHARDING_PATH
4. Run the Reverse Replication Dataflow Job
Launch the Dataflow job using the Spanner_to_SourceDb Flex Template.
export JOB_NAME_REVERSE="spanner-sharded-reverse-to-mysql-$(date +%Y%m%d-%H%M%S)"
export DLQ_DIR_REVERSE="gs://${BUCKET_NAME}/reverse-replication"
gcloud dataflow flex-template run $JOB_NAME_REVERSE \
--project=$PROJECT_ID \
--region=$REGION \
--worker-machine-type=n2-highmem-8 \
--max-workers=2 \
--num-workers=1 \
--additional-experiments=use_runner_v2 \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Spanner_to_SourceDb" \
--parameters \
changeStreamName="$CHANGE_STREAM_NAME",\
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
spannerProjectId="$PROJECT_ID",\
metadataInstance="$SPANNER_INSTANCE_NAME",\
metadataDatabase="$SPANNER_METADATA_DB_NAME",\
sourceShardsFilePath="$GCS_REVERSE_SHARDING_PATH",\
transformationJarPath=$CUSTOM_JAR_PATH,\
transformationClassName="com.custom.CustomTransformationFetcher",\
shardingCustomJarPath=$CUSTOM_JAR_PATH,\
shardingCustomClassName="com.custom.CustomShardIdFetcher",\
schemaOverridesFilePath=$GCS_OVERRIDES_PATH,\
deadLetterQueueDirectory=$DLQ_DIR_REVERSE
Key Parameters
-
changeStreamName: The name of the Spanner change stream to read from. -
metadataInstance, metadataDatabase: The Spanner instance/database to store the metadata used by the connector to control the consumption of the change stream API data. -
sourceShardsFilePath: The GCS path to yourshard_config.json. -
filtrationMode: Specifies how to drop certain records based on a criteria. Defaults toforward_migration(filter records written using the forward migration pipeline) -
shardingCustomJarPath: The GCS path to the compiled Java JAR file we built earlier. -
shardingCustomClassName: The fully qualified class name (com.custom.CustomShardIdFetcher) that executes our custom%4modulo math to dynamically determine which logical shard should receive the record.
Network Note: The Dataflow workers will connect to the Cloud SQL instance using the Public IP specified in shard_config.json . This connection is permitted due to the 0.0.0.0/0 entry in the Cloud SQL instance's Authorized Networks.
Monitor the job startup in the Dataflow Jobs Console .
5. Inject Spanner Data and Trigger Intentional Failures
Wait for the Dataflow job to enter the Running state (this can take ~5 minutes). Then, let's execute a full suite of queries ( INSERT , UPDATE , DELETE ) directly into Spanner, along with an intentional failure to test the reverse DLQ.
Run the following in Cloud Shell:
# All these operations are done on rows mapping to shard0_db for convenience
# Valid INSERT: Insert parent row in Customers
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LoyaltyTier) VALUES (88, 'Reverse Tester', 5000, 'GOLD_TIER')"
# 1. Valid INSERT (Orders): 'WebStore' transformed to 'WebStore_v1'
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="INSERT INTO Orders (CustomerId, OrderId, OrderValue, OrderSource) VALUES (88, 9001, 150.00, 'WebStore')"
# 2. Valid UPDATE (Orders)
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="UPDATE Orders SET OrderValue = 200.00 WHERE CustomerId = 16 AND OrderId = 105 AND OrderSource = 'Partner'"
# 3. Valid DELETE (Orders)
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="DELETE FROM Orders WHERE CustomerId = 12 AND OrderId = 104 AND OrderSource = 'WebStore'"
# 4. INVALID Insert- DLQ Test: CreditLimit=500 will fail check constraint of >1000 at source
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LoyaltyTier) VALUES (44, 'DLQ Test Customer', 500, 'GOLD_TIER')"
6. Verify Reverse Replication Data and Inspect the DLQ
Let's confirm that our Custom Sharding JAR successfully routed CustomerId 88 to shard0_db on our first physical VM, and that the Custom Transformation JAR successfully stripped "_TIER" from the region.
A. Verify the Valid Record in MySQL:
SSH into the first physical shard:
gcloud compute ssh mysql-physical-1 --zone=$ZONE
Log into MySQL and query shard0_db :
sudo mysql
USE shard0_db;
-- 1. Verify INSERT: Row migrated with transformed LegacyOrderSystem
SELECT CustomerId, OrderId, OrderValue, LegacyOrderSystem
FROM Orders
WHERE CustomerId = 88 AND OrderId = 9001;
-- 2. Verify UPDATE: The OrderValue should now be updated to 200.00.
SELECT CustomerId, OrderId, OrderValue, LegacyOrderSystem
FROM Orders
WHERE CustomerId = 16 AND OrderId = 105;
-- 3. Verify DELETE: Returns 0 rows, confirming the order was successfully deleted from MySQL.
SELECT CustomerId, OrderId
FROM Orders
WHERE CustomerId = 12 AND OrderId = 104;
-- 4. Verify failed replication - this should be in DLQ as CreditLimit < 1000 and will fail stricter check constraint at source
SELECT CustomerId, CustomerName, CreditLimit, LegacyRegion
FROM Customers
WHERE CustomerId = 44;
EXIT;
Expected output in Cloud SQL should reflect the changes made in Spanner.
+------------+---------+------------+-------------------+ | CustomerId | OrderId | OrderValue | LegacyOrderSystem | +------------+---------+------------+-------------------+ | 88 | 9001 | 150.00 | Webstore_v1 | +------------+---------+------------+-------------------+ +------------+---------+------------+-------------------+ | CustomerId | OrderId | OrderValue | LegacyOrderSystem | +------------+---------+------------+-------------------+ | 16 | 105 | 200.00 | Partner_v1 | +------------+---------+------------+-------------------+ Empty set (0.00 sec) Empty set (0.00 sec)
প্রকার
exit
to return to Cloud Shell.
This confirms that the reverse replication pipeline is functioning, synchronizing changes from Spanner back to Cloud SQL.
খ. DLQ-তে ইচ্ছাকৃত ব্যর্থতা যাচাই করুন।
Because our new Customers record has a CreditLimit of 500 (which violates the strict > 1000 check constraint we defined in our source MySQL database), Dataflow safely caught the error.
- Navigate to Cloud Storage in the Google Cloud Console.
- Go to your bucket and open the
dlq/severe/folder. - Open the JSON file to see the rejected
Customersrecord and the exact check constraint violation error. - Reverse Replication DLQ errors can be retried by running the dataflow template with
runMode=retryDLQset.
12. Clean Up Resources
To avoid incurring further charges to your Google Cloud account, delete the resources created during this codelab.
Set Environment Variables (if needed)
If your Cloud Shell session timed out or you opened a new terminal, you will need to re-export your environment variables before running the cleanup commands.
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1" # Or your preferred region
export ZONE="us-central1-a" # Or a zone within your selected region
export SPANNER_INSTANCE_NAME="target-spanner-instance"
export SPANNER_DATABASE_NAME="sharded-target-db"
export SPANNER_CONFIG="regional-${REGION}"
export BUCKET_NAME="migration-${PROJECT_ID}-bucket"
export MYSQL_IP_1=$(gcloud compute instances describe mysql-physical-1 --zone=$ZONE --format='get(networkInterfaces[0].accessConfigs[0].natIP)')
export MYSQL_IP_2=$(gcloud compute instances describe mysql-physical-2 --zone=$ZONE --format='get(networkInterfaces[0].accessConfigs[0].natIP)')
export SQL_CP_NAME_1="mysql-src-cp-1"
export SQL_CP_NAME_2="mysql-src-cp-2"
export GCS_CP_NAME="gcs-dest-cp"
export STREAM_NAME_1="mysql-to-spanner-stream-1"
export GCS_STREAM_PATH_1="data/${STREAM_NAME_1}"
export STREAM_NAME_2="mysql-to-spanner-stream-2"
export GCS_STREAM_PATH_2="data/${STREAM_NAME_2}"
export PUBSUB_TOPIC="datastream-gcs-updates"
export PUBSUB_SUBSCRIPTION="datastream-gcs-sub"
export CUSTOM_JAR_PATH="gs://${BUCKET_NAME}/custom-logic/spanner-custom-shard-1.0.jar"
export OVERRIDES_FILE="spanner_overrides.json"
export GCS_OVERRIDES_PATH="gs://${BUCKET_NAME}/config/${OVERRIDES_FILE}"
export GCS_SHARDING_PATH="gs://${BUCKET_NAME}/config/sharding.json"
export OUTPUT_DIR="gs://${BUCKET_NAME}/bulk-migration"
export GCS_LIVE_SHARDING_PATH="gs://${BUCKET_NAME}/config/live-sharding.json"
export DLQ_DIR_CDC="gs://${BUCKET_NAME}/live-migration"
export CHANGE_STREAM_NAME="CustomersOrdersChangeStream"
export SPANNER_METADATA_DB_NAME="migration-metadata-db"
export GCS_REVERSE_SHARDING_PATH="gs://${BUCKET_NAME}/config/reverse-sharding.json"
export DLQ_DIR_REVERSE="gs://${BUCKET_NAME}/reverse-replication"
Stop Dataflow Streaming Jobs
List your jobs to find the Job IDs of the running dataflow jobs. Export JOB_ID_CDC and JOB_ID_REVERSE accordingly.
gcloud dataflow jobs list --region=$REGION --filter="state=Running"
export JOB_ID_CDC=<PASTE_JOB_ID_HERE>
export JOB_ID_CDC_RETRY=<PASTE_JOB_ID_HERE>
export JOB_ID_REVERSE=<PASTE_JOB_ID_HERE>
Cancel the Datastream to Spanner (Live Migration) job and its retry job:
gcloud dataflow jobs cancel $JOB_ID_CDC --region=$REGION --project=$PROJECT_ID
gcloud dataflow jobs cancel $JOB_ID_CDC_RETRY --region=$REGION --project=$PROJECT_ID
Cancel the Spanner to Cloud SQL (Reverse Replication) job:
gcloud dataflow jobs cancel $JOB_ID_REVERSE --region=$REGION --project=$PROJECT_ID
Delete Datastream Resources
Stop and Delete the Stream:
gcloud datastream streams update $STREAM_NAME_1 \
--location=$REGION --state=PAUSED --project=$PROJECT_ID
# Wait a moment for the stream to pause
gcloud datastream streams delete $STREAM_NAME_1 \
--location=$REGION --project=$PROJECT_ID --quiet
gcloud datastream streams update $STREAM_NAME_2 \
--location=$REGION --state=PAUSED --project=$PROJECT_ID
# Wait a moment for the stream to pause
gcloud datastream streams delete $STREAM_NAME_2 \
--location=$REGION --project=$PROJECT_ID --quiet
# Delete Connection Profiles
gcloud datastream connection-profiles delete $SQL_CP_NAME_1 \
--location=$REGION --project=$PROJECT_ID --quiet
gcloud datastream connection-profiles delete $SQL_CP_NAME_2 \
--location=$REGION --project=$PROJECT_ID --quiet
gcloud datastream connection-profiles delete $GCS_CP_NAME \
--location=$REGION --project=$PROJECT_ID --quiet
Delete the Source MySQL VMs (Compute Engine)
Delete the two Compute Engine instances that simulated the on-prem MySQL physical shards.
gcloud compute instances delete mysql-physical-1 mysql-physical-2 --zone=$ZONE --quiet
Delete Firewall Rules
Remove the network firewall rules created to allow SSH access and Datastream connectivity to your VMs. (Note: If you used different names for your firewall rules earlier in the codelab, adjust them here).
gcloud compute firewall-rules delete allow-ssh-iap --quiet
gcloud compute firewall-rules delete allow-mysql-datastream --quiet
Delete Pub/Sub Resources
Delete Subscription:
gcloud pubsub subscriptions delete $PUBSUB_SUBSCRIPTION \
--project=$PROJECT_ID --quiet
Delete Topic:
gcloud pubsub topics delete $PUBSUB_TOPIC \
--project=$PROJECT_ID --quiet
Delete Cloud Spanner Instance
Delete the Cloud Spanner instance (this automatically deletes both the sharded-target-db and the migration-metadata-db databases inside it).
gcloud spanner instances delete $SPANNER_INSTANCE_NAME \
--project=$PROJECT_ID --quiet
Delete GCS Bucket and Contents
Finally, delete the Cloud Storage bucket that holds the Datastream files, Dataflow configs, and Dead Letter Queues. The rm -r command recursively deletes the bucket and all its contents.
gcloud storage rm --recursive gs://${BUCKET_NAME}
Delete Local Cloud Shell Files
To clean up the local files and directories generated in your Cloud Shell during this codelab, run the following commands:
# Remove the JSON configuration files
rm -f sharding.json live-sharding.json reverse-sharding.json spanner_overrides.json
# Remove the cloned Google Cloud DataflowTemplates repository
rm -rf DataflowTemplates