
1. قبل البدء
يوضّح لك هذا الدرس التطبيقي حول الترميز كيفية نقل قاعدة بيانات MySQL مجزّأة محلية إلى قاعدة بيانات Cloud Spanner باستخدام لغة GoogleSQL. ستستخدم خدمات Google Cloud، بما في ذلك "أداة نقل البيانات إلى Spanner" (SMT) وDataflow وDatastream وPubSub وGoogle Cloud Storage.
ما ستتعرّف عليه:
- ما هي البيئة المقسّمة وكيفية إعدادها؟
- كيفية استخدام واجهة مستخدم الويب لأداة Spanner Migration Tool (SMT) لتحويل مخطط MySQL إلى مخطط متوافق مع Spanner وإجراء تعديلات متقدّمة على المخطط
- كيفية إجراء عملية نقل بيانات مجمّعة من مثيل MySQL مقسَّم إلى Cloud Spanner باستخدام Dataflow
- كيفية إعداد النسخ المتماثل المستمر (CDC) من مثيل MySQL مقسَّم إلى Cloud Spanner باستخدام Datastream وDataflow
- كيفية إعداد عملية النسخ المتماثل العكسي من Spanner إلى مثيلات MySQL المقسّمة
- كيفية استخدام "عمليات التحويل المخصّصة" لتعبئة أعمدة إضافية أثناء عمليات النقل المجمّعة والمباشرة والعكسية
- كيفية ضبط عمليات تحويل التقسيم باستخدام المفاتيح الأساسية
لا يتناول هذا الدرس التطبيقي حول الترميز ما يلي:
- إعدادات الشبكة المخصّصة المتقدّمة
- إنشاء نماذج Dataflow مخصّصة من البداية
- تحسين أداء عملية نقل البيانات
- نقل التطبيقات: يركّز هذا الدرس التطبيقي حول الترميز على طبقة قاعدة البيانات (المخطط والبيانات). لا يشمل ذلك عملية إعادة نشر خدمات التطبيق أو نقلها.
المتطلبات
- مشروع Google Cloud تم تفعيل الفوترة فيه
- أذونات IAM كافية لتفعيل واجهات برمجة التطبيقات وإنشاء موارد Spanner وDataflow وDatastream وGCS وإدارتها على الرغم من أنّ دور "المشروع"
Ownerهو الأبسط بالنسبة إلى درس تطبيقي حول الترميز، سيتم تناول أدوار أكثر تحديدًا في "إعداد البيئة". - سنوفّر جهازًا افتراضيًا صغيرًا على Compute Engine خلال مرحلة الإعداد لمحاكاة الخادم المحلي. تأكَّد من أنّ حصة مشروعك تسمح بإنشاء آلات افتراضية.
- متصفّح ويب، مثل Google Chrome
- معرفة أساسية بوحدة تحكّم Google Cloud وأدوات سطر الأوامر، مثل
gcloud - الوصول إلى بيئة shell ننصح باستخدام Cloud Shell لأنّه يتضمّن
gcloud.
يمكنك الاطّلاع على مزيد من التفاصيل حول عملية الإعداد المذكورة أعلاه في قسم إعداد البيئة.
2. فهم عملية نقل البيانات
تتضمّن عملية نقل قاعدة بيانات مقسّمة دمج عدة مثيلات فعلية ومنطقية من MySQL في قاعدة بيانات Spanner واحدة قابلة للتوسّع أفقيًا. يوضّح هذا القسم البنية الأساسية والأدوات الرئيسية المستخدَمة في عملية نقل البيانات.
بنية مسار نقل البيانات
تتضمّن عملية نقل البيانات المراحل التالية:
1. تحويل المخطط:
- الغرض: تحويل مخطط قاعدة البيانات المصدر إلى مخطط متوافق مع Cloud Spanner
- الأداة: أداة نقل البيانات إلى Spanner (SMT)
- العملية: يحلّل SMT مخطط قاعدة البيانات المصدر وينشئ لغة تعريف البيانات (DDL) المكافئة في Spanner. في مثيل Spanner المستهدف، يتم إنشاء قاعدة بيانات ثم يتم تطبيق DDL تلقائيًا.
2. نقل البيانات المجمّعة:
- الغرض: إجراء عملية تحميل كاملة وأولية للبيانات الحالية من قاعدة البيانات المصدر إلى جداول Spanner التي تم توفيرها
- الأداة: Dataflow، باستخدام نموذج
Sourcedb to Spannerالذي توفّره Google - العملية: تقرأ مهمة Dataflow هذه جميع البيانات من جداول المصدر المحدّدة وتكتبها في جداول Spanner المقابلة. يتم ذلك بعد إنشاء مخطط Spanner.
3- النقل المباشر (CDC):
- الغرض: تسجيل التغييرات المستمرة وتطبيقها من قاعدة البيانات المصدر إلى Cloud Spanner في الوقت الفعلي تقريبًا، ما يقلّل من وقت التوقف عن العمل أثناء عملية نقل البيانات
- الأدوات:
- Datastream: تسجّل التغييرات (عمليات الإدراج والتعديل والحذف) من قاعدة البيانات المصدر وتكتبها في Cloud Storage (GCS).
- Dataflow: تستخدِم نموذج
Datastream to Spannerلقراءة أحداث التغيير من GCS وتطبيقها على Cloud Spanner.
4. النسخ المتماثل العكسي:
- الغرض: تكرار تغييرات البيانات من Cloud Spanner إلى قاعدة البيانات المصدر. يمكن أن يكون ذلك مفيدًا لاستراتيجيات الاحتياط أو عمليات النقل المرحلية أو الاحتفاظ بنسخة طبق الأصل في المصدر لحالات استخدام معيّنة.
- الأداة: Dataflow، باستخدام النموذج
Spanner to SourceDb - المعالجة: تستخدم هذه المهمة "قنوات تغيير" Spanner لتسجيل التعديلات في Spanner وإعادة كتابتها إلى مثيل قاعدة البيانات المصدر.
يوضّح المخطّط التالي المكوّنات وتدفّق البيانات:

المصطلحات الرئيسية:
- الجزء الفعلي: هو الخادم الأساسي أو مثيل الحوسبة الفعلي الذي يستضيف قاعدة البيانات (في حالتنا، الجهاز الظاهري لمحاكي GCE على الجهاز).
- التقسيم المنطقي: هو مخطط قاعدة البيانات الفردي داخل خادم فعلي.
- الجهاز الافتراضي (VM) في Compute Engine (GCE): هو جهاز افتراضي مستضاف على البنية التحتية لـ Google Cloud. في هذا الدرس التطبيقي حول الترميز، نستخدم جهازًا افتراضيًا على Google Compute Engine لمحاكاة خادم مستقل "محلي" بدون نظام تشغيل يستضيف قاعدة بيانات MySQL المصدر.
- أداة نقل البيانات في Spanner (SMT): هي أداة تُستخدم لتقييم مخططات MySQL واقتراح مكافئات لمخططات Spanner وإنشاء لغة تعريف البيانات (DDL) في Spanner.
- لغة تعريف البيانات (DDL): عبارات تُستخدم لتحديد بنية قاعدة البيانات وتعديلها، مثل عبارات
CREATE TABLE. تنشئ أداة SMT لغة تعريف البيانات (DDL) في Spanner استنادًا إلى مخطط Cloud SQL. - Dataflow: هي خدمة مُدارة بالكامل لمعالجة البيانات بدون خادم. في هذا الدرس التطبيقي حول الترميز، يتم استخدامها لتشغيل النماذج التي توفّرها Google لنقل البيانات المجمّعة، وتطبيق تغييرات Datastream، وعكس عملية النسخ المتماثل.
- Datastream: هي خدمة حوسبة بدون خادم لعملية التقاط البيانات المتغيرة (CDC) وإنشاء النسخ المتماثلة. يتم استخدامها لبث التغييرات من مثيل MySQL المستضاف محليًا إلى Cloud Storage في هذا الدرس التطبيقي حول الترميز.
- Spanner Change Streams: هي إحدى ميزات Spanner التي تتيح بث التغييرات على البيانات (عمليات الإدراج والتعديل والحذف) في الوقت الفعلي، وتُستخدَم كمصدر للنسخ المتماثل العكسي.
- Pub/Sub: هي خدمة مراسلة تُستخدَم لفصل الخدمات التي تنشئ الأحداث عن الخدمات التي تعالجها. في هذا الدرس التطبيقي حول الترميز، يتم تشغيل Dataflow لمعالجة التعديلات كلما حمّل Datastream ملفات تغيير جديدة إلى Cloud Storage.
3- إعداد البيئة
قبل بدء عملية نقل البيانات، عليك إعداد مشروعك على Google Cloud وتفعيل الخدمات اللازمة.
1. اختيار مشروع Google Cloud أو إنشاؤه
يجب أن يكون لديك مشروع على السحابة الإلكترونية من Google Cloud مع تفعيل الفوترة لاستخدام الخدمات في هذا الدرس العملي.
- في Google Cloud Console، انتقِل إلى صفحة اختيار المشروع: الانتقال إلى أداة اختيار المشروع
- اختَر مشروعًا على Google Cloud أو أنشِئ مشروعًا.
- تأكَّد من تفعيل الفوترة لمشروعك. كيفية التأكّد من تفعيل الفوترة لمشروعك
2. فتح Cloud Shell
Cloud Shell هي بيئة سطر أوامر تعمل في Google Cloud ومحمَّلة مسبقًا بواجهة سطر الأوامر gcloud والأدوات الأخرى التي تحتاج إليها.
- انقر على الزر تفعيل Cloud Shell في أعلى يسار Google Cloud Console.
- يتم فتح جلسة Cloud Shell داخل إطار جديد في أسفل وحدة التحكّم ويتم عرض موجه سطر الأوامر.

3- ضبط متغيرات المشروع والبيئة
في Cloud Shell، اضبط بعض متغيرات البيئة لرقم تعريف مشروعك والمنطقة التي ستستخدمها.
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1" # Or your preferred region
export ZONE="us-central1-a" # Or a zone within your selected region
gcloud config set project $PROJECT_ID
gcloud config set compute/region $REGION
gcloud config set compute/zone $ZONE
echo "Project ID: $PROJECT_ID"
echo "Region: $REGION"
echo "Zone: $ZONE"
4. تفعيل واجهات Google Cloud APIs المطلوبة
فعِّل واجهات برمجة التطبيقات اللازمة لخدمات Cloud Spanner وDataflow وDatastream والخدمات الأخرى ذات الصلة.
gcloud services enable \
spanner.googleapis.com \
dataflow.googleapis.com \
datastream.googleapis.com \
pubsub.googleapis.com \
storage.googleapis.com \
compute.googleapis.com \
sqladmin.googleapis.com \
servicenetworking.googleapis.com \
cloudresourcemanager.googleapis.com
قد يستغرق إكمال هذا الأمر بضع دقائق.
4. إعداد قاعدة بيانات MySQL المصدر
في هذا القسم، سنحاكي بنية MySQL مجزّأة محلية من خلال توفير جهازَين افتراضيَين من Compute Engine (الجزءان "الماديان"). بعد ذلك، سنثبِّت MySQL على كليهما وننشئ قاعدتَي بيانات (التقسيم المنطقي) على كل آلة افتراضية.
1. إنشاء أجهزة Compute Engine الافتراضية (الأجزاء المادية)
نفِّذ الأوامر التالية في Cloud Shell لإنشاء آلتين افتراضيتَين تعملان بنظام التشغيل Ubuntu. سنخصّص لها علامات شبكة للسماح بحركة بيانات MySQL الواردة لاحقًا.
# Create Physical Shard 1
gcloud compute instances create mysql-physical-1 \
--zone=$ZONE \
--machine-type=e2-small \
--image-family=ubuntu-2204-lts \
--image-project=ubuntu-os-cloud \
--tags=mysql-server
# Create Physical Shard 2
gcloud compute instances create mysql-physical-2 \
--zone=$ZONE \
--machine-type=e2-small \
--image-family=ubuntu-2204-lts \
--image-project=ubuntu-os-cloud \
--tags=mysql-server
2. ضبط قواعد جدار الحماية
للسماح بالوصول الآمن إلى بروتوكول النقل الآمن بدون تعريض البيانات للجميع ولتفعيل إمكانية الاتصال بخدمة Datastream، اتّبِع الخطوات التالية:
إنشاء قاعدة جدار حماية لبروتوكول SSH من خلال IAP:
تسمح هذه القاعدة لخدمة Identity-Aware Proxy بالوصول إلى الأجهزة الافتراضية على منفذ SSH (22).
gcloud compute firewall-rules create allow-ssh-iap \
--direction=INGRESS \
--priority=1000 \
--network=default \
--action=ALLOW \
--rules=tcp:22 \
--source-ranges=35.235.240.0/20 \
--target-tags=mysql-server
إنشاء قاعدة جدار الحماية لخدمة Datastream (منفذ MySQL):
يجب أن يتمكّن Datastream من الوصول إلى هذه الأجهزة الافتراضية على منفذ MySQL العادي (3306).
gcloud compute firewall-rules create allow-mysql-datastream \
--direction=INGRESS \
--priority=1000 \
--network=default \
--action=ALLOW \
--rules=tcp:3306 \
--source-ranges=0.0.0.0/0 \
--target-tags=mysql-server
3- تثبيت MySQL وضبطه على الجزء 1 من قاعدة البيانات
يمكنك استخدام SSH للوصول إلى جهازك الافتراضي الأول من أجل تثبيت MySQL وإعداد تسجيل البيانات الثنائية (الذي تتطلّبه خدمة Datastream لإجراء عملية النسخ المتماثل المباشر).
- استخدِم بروتوكول النقل الآمن (SSH) للوصول إلى الجهاز الظاهري الأول:
gcloud compute ssh mysql-physical-1 --zone=$ZONE --tunnel-through-iap
- ثبِّت MySQL:
sudo apt-get update
sudo apt-get install mysql-server-8.0 -y
# Verify the installation and version
sudo mysql --version
- اضبط ملف
mysqld.cnfلتفعيل تسجيل البيانات الثنائية والسماح بالاتصالات الخارجية:
sudo sed -i 's/bind-address.*/bind-address = 0.0.0.0/' /etc/mysql/mysql.conf.d/mysqld.cnf
echo -e "[mysqld]\nserver-id=1\nlog_bin=/var/log/mysql/mysql-bin.log\nbinlog_format=ROW" | sudo tee -a /etc/mysql/mysql.conf.d/mysqld.cnf
- أعِد تشغيل MySQL لتطبيق التغييرات:
sudo systemctl restart mysql
4. إنشاء أقسام منطقية وإدراج البيانات وإنشاء مستخدم لتدفق البيانات (القسم 1)
أثناء تسجيل الدخول إلى mysql-physical-1 باستخدام بروتوكول SSH، سجِّل الدخول إلى موجه MySQL:
sudo mysql
نفِّذ أوامر SQL التالية. ينشئ هذا النص البرمجي جزأين منطقيين منفصلين (shard0_db وshard1_db)، ويضبط المخطط المتطابق في كليهما، ويدرج بيانات يمكن التعرّف عليها بدقة في كل جزء (لتوضيح التقسيم)، وينشئ مستخدم النسخ المتماثل لخدمة Datastream.
نفِّذ أوامر SQL التالية لإنشاء أول شريحتَين منطقيتَين وجدول ومستخدم النسخ المتماثل لخدمة Datastream:
CREATE DATABASE shard0_db;
CREATE DATABASE shard1_db;
USE shard0_db;
CREATE TABLE Customers (
CustomerId INT NOT NULL,
CustomerName VARCHAR(255),
CreditLimit DECIMAL(10, 2) NOT NULL,
LegacyRegion VARCHAR(50), -- Renamed to LoyaltyTier in Spanner
PRIMARY KEY (CustomerId),
CONSTRAINT CHK_CreditLimit CHECK (CreditLimit > 1000) -- Relaxed in Spanner to > 0
);
CREATE TABLE Orders (
CustomerId INT NOT NULL, -- Logically references Customers.CustomerId in Spanner
OrderId INT NOT NULL,
OrderValue DECIMAL(10, 2),
LegacyOrderSystem VARCHAR(50), -- Extra column in Source, to be dropped in Spanner
PRIMARY KEY (CustomerId, OrderId) -- Spanner PK will have one additional column in PK
);
INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LegacyRegion) VALUES
(4, 'David E.', 2000.00, 'EAST'),
(8, 'Eleanor F.', 8100.00, 'WEST'),
(12, 'Frank G.', 12000.00, 'NORTH'),
(16, 'Grace H.', 6500.00, 'SOUTH');
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem) VALUES
(4, 101, 150.00, 'WebStore_v1'),
(4, 102, 25.50, 'InStore_POS'),
(8, 103, 75.00, 'MobileApp_Legacy'),
(12, 104, 3000.00, 'WebStore_v1'),
(16, 105, 120.00, 'Partner_API');
USE shard1_db;
CREATE TABLE Customers (
CustomerId INT NOT NULL,
CustomerName VARCHAR(255),
CreditLimit DECIMAL(10, 2) NOT NULL,
LegacyRegion VARCHAR(50), -- Renamed to LoyaltyTier in Spanner
PRIMARY KEY (CustomerId),
CONSTRAINT CHK_CreditLimit CHECK (CreditLimit > 1000) -- Relaxed in Spanner to > 0
);
CREATE TABLE Orders (
CustomerId INT NOT NULL, -- Logically references Customers.CustomerId in Spanner
OrderId INT NOT NULL,
OrderValue DECIMAL(10, 2),
LegacyOrderSystem VARCHAR(50), -- Extra column in Source, to be dropped in Spanner
PRIMARY KEY (CustomerId, OrderId) -- Spanner PK will have one additional column in PK
);
INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LegacyRegion) VALUES
(1, 'Agnes N.', 5100.00, 'NORTHEAST'),(5, 'Alice I.', 15000.00, 'EAST'),
(9, 'Bob J.', 7500.00, 'WEST'),
(13, 'Charlie K.', 2200.00, 'CENTRAL');
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem) VALUES
(1, 201, 50.00, 'MobileApp_Legacy'),
(5, 202, 1250.00, 'WebStore_v1'),
(5, 203, 80.00, 'Partner_API'),
(9, 204, 600.00, 'InStore_POS'),
(13, 205, 199.99, 'WebStore_v1');
-- Create Datastream Replication User
CREATE USER 'datastream_user'@'%' IDENTIFIED BY 'complex_password_123';
GRANT REPLICATION SLAVE, REPLICATION CLIENT, SELECT, INSERT, UPDATE, DELETE ON *.* TO 'datastream_user'@'%';
FLUSH PRIVILEGES;
يمكن العثور على ملف التفريغ الخاص بالمخطط أعلاه هنا. من المهم إنشاء مستخدم لنسخ البيانات من مصدرها بشكل منفصل لأنّ ذلك غير مضمّن في ملف التفريغ.
5- التحقّق من البيانات
للتحقّق بسرعة من توفّر البيانات، اتّبِع الخطوات التالية:
SELECT 'Customers shard0_db' AS tbl, COUNT(*) FROM shard0_db.Customers
UNION ALL
SELECT 'Orders shard0_db', COUNT(*) FROM shard0_db.Orders
UNION ALL
SELECT 'Customers shard1_db', COUNT(*) FROM shard1_db.Customers
UNION ALL
SELECT 'Orders shard1_db', COUNT(*) FROM shard1_db.Orders;
EXIT;
الناتج المتوقّع:
+---------------------+----------+ | tbl | COUNT(*) | +---------------------+----------+ | Customers shard0_db | 4 | | Orders shard0_db | 5 | | Customers shard1_db | 4 | | Orders shard1_db | 5 | +---------------------+----------+
أدخِل exit للخروج من الاتصال بالجهاز الظاهري 1.
6. كرِّر الخطوات نفسها لتقسيم Physical Shard 2
عليك الآن تكرار العملية نفسها تمامًا للجهاز الظاهري الثاني، ولكن ستنشئ shard2_db وshard3_db، وتغيّر server-id.
- استخدِم بروتوكول النقل الآمن (SSH) للوصول إلى الجهاز الظاهري الثاني:
gcloud compute ssh mysql-physical-2 --zone=$ZONE --tunnel-through-iap
- ثبِّت MySQL:
sudo apt-get update
sudo apt-get install mysql-server-8.0 -y
- اضبط ملف
mysqld.cnfلتفعيل تسجيل البيانات الثنائية والسماح بالاتصالات الخارجية [يجب أن يكون رقم تعريف الخادم مختلفًا (على سبيل المثال، 2)]
sudo sed -i 's/bind-address.*/bind-address = 0.0.0.0/' /etc/mysql/mysql.conf.d/mysqld.cnf
echo -e "[mysqld]\nserver-id=2\nlog_bin=/var/log/mysql/mysql-bin.log\nbinlog_format=ROW" | sudo tee -a /etc/mysql/mysql.conf.d/mysqld.cnf
- أعِد تشغيل MySQL لتطبيق التغييرات:
sudo systemctl restart mysql
- أدخِل MySQL (
sudo mysql) ونفِّذ نسخة معدَّلة قليلاً من SQL من الخطوة 4:
CREATE DATABASE shard2_db;
CREATE DATABASE shard3_db;
USE shard2_db;
CREATE TABLE Customers (
CustomerId INT NOT NULL,
CustomerName VARCHAR(255),
CreditLimit DECIMAL(10, 2) NOT NULL,
LegacyRegion VARCHAR(50), -- Renamed to LoyaltyTier in Spanner
PRIMARY KEY (CustomerId),
CONSTRAINT CHK_CreditLimit CHECK (CreditLimit > 1000) -- Relaxed in Spanner to > 0
);
CREATE TABLE Orders (
CustomerId INT NOT NULL, -- Logically references Customers.CustomerId in Spanner
OrderId INT NOT NULL,
OrderValue DECIMAL(10, 2),
LegacyOrderSystem VARCHAR(50), -- Extra column in Source, to be dropped in Spanner
PRIMARY KEY (CustomerId, OrderId) -- Spanner PK will have one additional column in PK
);
INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LegacyRegion) VALUES
(2, 'Brian K.', 2500.00, 'SOUTHWEST'),
(6, 'Diana L.', 1999.00, 'NORTH'),
(10, 'Edward M.', 11000.00, 'EAST'),
(14, 'Fiona N.', 3000.00, 'WEST');
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem) VALUES
(2, 301, 100.00, 'CallCenter_System'),
(6, 302, 99.00, 'MobileApp_Legacy'),
(10, 303, 1000.00, 'WebStore_v1'),
(10, 304, 2500.00, 'InStore_POS'),
(14, 305, 130.00, 'MobileApp_Legacy');
USE shard3_db;
CREATE TABLE Customers (
CustomerId INT NOT NULL,
CustomerName VARCHAR(255),
CreditLimit DECIMAL(10, 2) NOT NULL,
LegacyRegion VARCHAR(50), -- Renamed to LoyaltyTier in Spanner
PRIMARY KEY (CustomerId),
CONSTRAINT CHK_CreditLimit CHECK (CreditLimit > 1000) -- Relaxed in Spanner to > 0
);
CREATE TABLE Orders (
CustomerId INT NOT NULL, -- Logically references Customers.CustomerId in Spanner
OrderId INT NOT NULL,
OrderValue DECIMAL(10, 2),
LegacyOrderSystem VARCHAR(50), -- Extra column in Source, to be dropped in Spanner
PRIMARY KEY (CustomerId, OrderId) -- Spanner PK will have one additional column in PK
);
INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LegacyRegion) VALUES
(3, 'Cathy Z.', 6000.00, 'CENTRAL'),
(7, 'George O.', 18000.00, 'SOUTH'),
(11, 'Helen P.', 4000.00, 'NORTHEAST'),
(15, 'Ivy Q.', 9500.00, 'SOUTHWEST');
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem) VALUES
(3, 401, 600.00, 'InStore_POS'),
(7, 402, 1200.00, 'CallCenter_System'),
(11, 403, 350.00, 'MobileApp_Legacy'),
(15, 404, 800.00, 'WebStore_v1'),
(99, 999, 25.00, 'CallCenter_System'); -- Failure row during Bulk Migration due to violation of interleaving
-- Create Datastream Replication User
CREATE USER 'datastream_user'@'%' IDENTIFIED BY 'complex_password_123';
GRANT REPLICATION SLAVE, REPLICATION CLIENT, SELECT, INSERT, UPDATE, DELETE ON *.* TO 'datastream_user'@'%';
FLUSH PRIVILEGES;
-- Verify Data
SELECT 'Customers shard2_db' AS tbl, COUNT(*) FROM shard2_db.Customers
UNION ALL
SELECT 'Orders shard2_db', COUNT(*) FROM shard2_db.Orders
UNION ALL
SELECT 'Customers shard3_db', COUNT(*) FROM shard3_db.Customers
UNION ALL
SELECT 'Orders shard3_db', COUNT(*) FROM shard3_db.Orders;
EXIT;
الناتج المتوقّع:
+---------------------+----------+ | tbl | COUNT(*) | +---------------------+----------+ | Customers shard2_db | 4 | | Orders shard2_db | 5 | | Customers shard3_db | 4 | | Orders shard3_db | 5 | +---------------------+----------+
يمكن العثور على ملف التفريغ الخاص بالمخطط أعلاه هنا. من المهم إنشاء مستخدم لنسخ البيانات من مصدرها بشكل منفصل لأنّ ذلك غير مضمّن في ملف التفريغ.
أدخِل exit للخروج من الاتصال بالجهاز الظاهري.
5- إعداد Cloud Spanner
الآن، عليك إعداد مثيل Cloud Spanner المستهدف الذي سيتم نقل البيانات إليه.
1. إنشاء مثيل Cloud Spanner
أنشئ مثيلاً من Cloud Spanner في المنطقة نفسها التي تتضمّن أجهزة Compute Engine الافتراضية لتقليل وقت الاستجابة. ينشئ هذا الأمر مثيلاً صغيرًا مناسبًا لهذا الدرس التطبيقي حول الترميز، باستخدام 100 وحدة معالجة.
export SPANNER_INSTANCE_NAME="target-spanner-instance"
export SPANNER_DATABASE_NAME="sharded-target-db"
export SPANNER_CONFIG="regional-${REGION}"
gcloud spanner instances create $SPANNER_INSTANCE_NAME \
--config=$SPANNER_CONFIG \
--description="Target Spanner Instance" \
--processing-units=100
قد يستغرق إنشاء الجهاز الافتراضي دقيقة أو دقيقتَين.
6. تحويل المخطط باستخدام "أداة نقل البيانات في Spanner" (SMT)
استخدِم واجهة مستخدم الويب لأداة نقل البيانات إلى Spanner (SMT) للاتصال بأحد الأجزاء المنطقية (shard0_db)، وتحليل المخطط الخاص به، وتطبيق العديد من التعديلات المتقدّمة قبل تحويله إلى Cloud Spanner.
1. تثبيت أداة SMT
سنشغّل واجهة مستخدم الويب الخاصة بأداة SMT مباشرةً من Cloud Shell. في نافذة Cloud Shell، نزِّل أحدث إصدار من "أداة نقل البيانات الذكية" واستخرِجه:
sudo apt-get update && sudo apt-get install google-cloud-cli-spanner-migration-tool
# Verify installation
gcloud alpha spanner migrate web --help
2. الربط بقاعدة البيانات المصدر
- مصادقة جلستك
# Authenticate your Google Cloud account
gcloud auth login
# Set up Application Default Credentials (ADC) for SMT
gcloud auth application-default login
# Ensure your current project is set correctly
gcloud config set project $PROJECT_ID
(ملاحظة: عند مطالبتك بذلك، اتّبِع عنوان URL المقدَّم لتفويض حسابك وأعِد لصق رمز التحقّق في نافذة الأوامر.)
- أولاً، ابحث عن عنوان IP الخارجي للشريحة المادية الأولى من خلال تنفيذ ما يلي في علامة تبويب جديدة في Cloud Shell:
gcloud compute instances describe mysql-physical-1 --zone=$ZONE --format='get(networkInterfaces[0].accessConfigs[0].natIP)'
- اطبع تفاصيل مثيل Spanner المستهدف لاستخدامها أثناء ضبط SMT.
echo "Project ID: $PROJECT_ID"
echo "Instance ID: $SPANNER_INSTANCE_NAME"
echo "Database Name: $SPANNER_DATABASE_NAME"
- تشغيل واجهة المستخدم على الويب:
gcloud alpha spanner migrate web --port=8080
- في أعلى يسار نافذة Cloud Shell، انقر على رمز المعاينة على الويب (يبدو كعين) واختَر المعاينة على المنفذ 8080. سيؤدي ذلك إلى فتح واجهة مستخدم "أداة نقل البيانات من Google" في علامة تبويب متصفّح جديدة.

- في واجهة مستخدم الويب الخاصة بأداة SMT، انقر على الربط بقاعدة البيانات.
- أدخِل تفاصيل الربط:
- نوع قاعدة البيانات: MySQL
- المضيف: (ألصِق عنوان IP من الخطوة 2)
- المنفذ: 3306
- المستخدم:
datastream_user - كلمة المرور:
complex_password_123 - اسم قاعدة البيانات:
shard0_db
- انقر على زر التعديل في أعلى يسار الصفحة لإعداد قاعدة بيانات Spanner.
- أدخِل تفاصيل Target Spanner:
- رقم تعريف المشروع: (ألصِق رقم تعريف المشروع من الخطوة 3)
- مثيل Spanner: (ألصِق رقم تعريف المثيل من الخطوة 3)
- انقر على اختبار الاتصال.
- بعد اجتياز هذا الاختبار، انقر على ربط (Connect). ستحلّل "أداة نقل المخطط" قاعدة البيانات المصدر وستعرض مخططًا أساسيًا في Spanner.

3- تطبيق تعديلات المخطط
سنعيد الآن تشكيل المخطط لتغطية سيناريوهات النقل المعقّدة.
في "محرّر المخطط" بواجهة مستخدم SMT، نفِّذ الإجراءات التالية:
أ. أعِد تسمية عمود LegacyRegion:
- انقر على جدول
Customersفي لوحة التنقّل اليمنى. سيتم فتح علامة التبويب الأعمدة تلقائيًا. - انقر على الزر "تعديل" في قسم Spanner.
- ابحث عن العمود
LegacyRegionفي طريقة عرض مخطط Spanner. - غيِّر اسم عمود Spanner إلى
LoyaltyTierعن طريق الكتابة في مربّع حوار اسم العمود. - انقر على حفظ وتحويل.


ب. تخفيف قيد التحقّق:
- في جدول
Customers، انتقِل إلى علامة التبويب قيود التحقّق. - ابحث عن القيد
CHK_CreditLimit. انقر على رمز التعديل (القلم الرصاص). - غيِّر الشرط من
CreditLimit > 1000إلىCreditLimit > 0. (سيؤدي ذلك عمدًا إلى تعذُّر نقل الصفوف التي تتضمّن حدودًا أدنى للرصيد إلى الإصدار السابق وإدراجها في قائمة انتظار الرسائل غير المعالَجة).

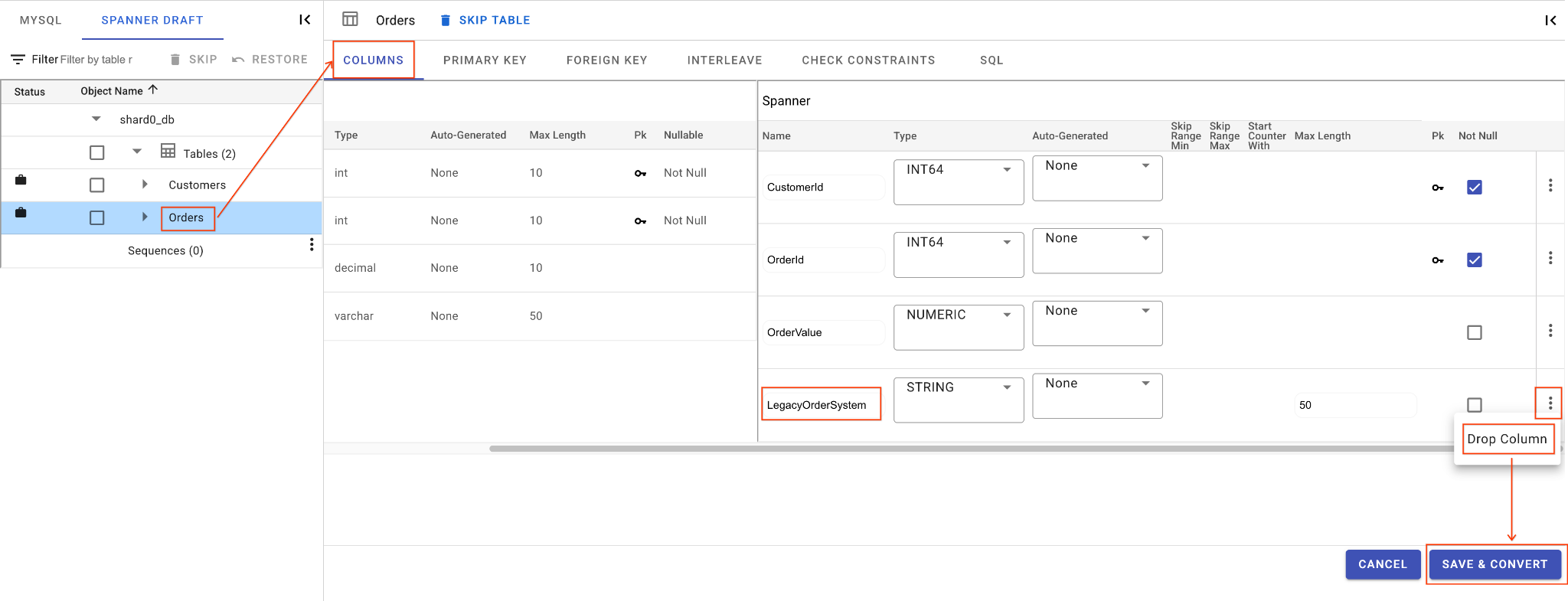
ج. إزالة عمود LegacyOrderSystem:
- انقر على جدول
Orders، وسيتم فتح علامة التبويب الأعمدة تلقائيًا. - انقر على الزر "تعديل" في قسم Spanner.
- ابحث عن العمود
LegacyOrderSystemفي طريقة عرض مخطط Spanner. - انقر على رمز قائمة النقاط الثلاث بجانبه واختَر إزالة العمود.
- انقر على حفظ وتحويل.
د. إضافة عمود OrderSource وجعله مفتاحًا أساسيًا:
- في جدول
Orders، انقر على إضافة عمود. أطلِق عليها الاسمOrderSourceواضبط النوع علىSTRINGمع تحديد الطول50، بدون إنشاء تلقائي، واضبطIsNullableعلىNo. - انتقِل إلى علامة التبويب المفتاح الأساسي.
- انقر على تعديل واختَر
OrderSourceمن القائمة المنسدلة "اسم العمود". - انقر على إضافة عمود، ثمّ على حفظ وتحويل.


E. دمج جدول الطلبات:
- في جدول
Orders، ابحث عن علامة التبويب الدمج في عرض الجدول الرئيسي. - اضبط الجدول الرئيسي على
Customers. - اختَر
IN PARENTنوع الدمج وNO ACTIONالإجراء عند الحذف. - انقر على حفظ.

4. تنزيل ملفات عمليات الإلغاء وتطبيق المخطط
- في أعلى يسار واجهة مستخدم SMT، ابحث عن الزر تنزيل العناصر. انقر على الخيار تنزيل ملف عمليات الإلغاء. احفظ هذا الملف على جهازك. يحتوي هذا الملف على جميع التغييرات التي أجريناها للتو على ربط المخطط وسيتم استخدامه من خلال عمليات Dataflow.
- انقر على إعداد عملية نقل البيانات.

- اختَر وضع النقل كـ
Schemaمن القائمة المنسدلة. - أدخِل قاعدة بيانات Target Spanner:
sharded-target-db

- انقر على نقل البيانات.
- ستطبّق أداة SMT تعريف البيانات (DDL) وتنشئ قاعدة بيانات Spanner. يمكنك إيقاف عملية SMT بأمان في Cloud Shell (
Ctrl+C) بعد اكتمالها.
5- التحقّق من صحة المخطط في Cloud Spanner
تأكَّد من إنشاء الجداول في قاعدة بيانات Spanner.
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT table_name FROM information_schema.tables WHERE table_schema = '' ORDER BY table_name"
من المفترض أن يظهر لك الناتج التالي:
table_name: Customers table_name: Orders
اختياري: إذا أردت التحقّق من صحة قيود التحقّق والتقسيم والتداخل والأعمدة الإضافية التي تم تطبيقها، شغِّل الأمر التالي:
gcloud spanner databases ddl describe $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME
الناتج المتوقّع:
CREATE TABLE Customers ( CustomerId INT64 NOT NULL, CustomerName STRING(255), CreditLimit NUMERIC NOT NULL, LoyaltyTier STRING(50), CONSTRAINT CHK_CreditLimit CHECK(`CreditLimit` > 0), ) PRIMARY KEY(CustomerId); CREATE TABLE Orders ( CustomerId INT64 NOT NULL, OrderId INT64 NOT NULL, OrderValue NUMERIC, OrderSource STRING(50) NOT NULL, ) PRIMARY KEY(CustomerId, OrderId, OrderSource), INTERLEAVE IN PARENT Customers ON DELETE NO ACTION;
7. بدء عملية "تسجيل البيانات المتغيرة" (CDC)
في هذا القسم، عليك إعداد "أداة التسجيل" لعملية نقل البيانات. من خلال إعداد Datastream وPub/Sub قبل بدء تحميل البيانات المجمّعة، يمكنك التأكّد من تسجيل كل تغيير يتم إجراؤه على قواعد البيانات المصدر وإضافته إلى قائمة الانتظار، ما يمنع فقدان أي بيانات أثناء عملية النقل. يجب إكمال عملية الإعداد هذه لاستخدام ميزة "نقل البيانات المباشر".
بما أنّ بنيتنا الأساسية تتضمّن خادمَين فعليَين، يجب إنشاء ملفَين منفصلَين لمصدر بيانات Datastream ومصدرَين لبيانات Datastream. سيتم تسجيل كلا المصدرَين في حزمة واحدة من Google Cloud Storage (GCS)، والتي ستكون بمثابة المصدر الموحّد لبرنامج Dataflow.
1. إنشاء حزمة في Cloud Storage
يتطلّب مصدر البيانات وجهة لتخزين أحداث التغيير التي تمّت مراقبتها. لننشئ حزمة GCS.
export BUCKET_NAME="migration-${PROJECT_ID}-bucket"
gcloud storage buckets create gs://${BUCKET_NAME} --location=$REGION
2. إنشاء ملفات شخصية لعمليات ربط مصادر البيانات
نحتاج إلى ملفَي تعريف مختلفَين لاتصال مصدر MySQL (واحد لكل جزء فعلي) وملف تعريف واحد لاتصال الوجهة في Cloud Storage.
الحصول على عناوين IP المصدر
أولاً، احصل على عناوين IP الخارجية لجهازَي Compute Engine الظاهريَين وخزِّنها كمتغيرات بيئية:
export MYSQL_IP_1=$(gcloud compute instances describe mysql-physical-1 --zone=$ZONE --format='get(networkInterfaces[0].accessConfigs[0].natIP)')
export MYSQL_IP_2=$(gcloud compute instances describe mysql-physical-2 --zone=$ZONE --format='get(networkInterfaces[0].accessConfigs[0].natIP)')
إنشاء ملفات تعريف لعمليات الربط بمصدر البيانات (MySQL على Compute Engine)
أنشئ ملفات تعريف ربط Datastream باستخدام datastream_user الذي تم إنشاؤه سابقًا.
# Create Source Profile for Physical Shard 1
export SQL_CP_NAME_1="mysql-src-cp-1"
gcloud datastream connection-profiles create $SQL_CP_NAME_1 \
--location=$REGION \
--type=mysql \
--mysql-hostname=$MYSQL_IP_1 \
--mysql-port=3306 \
--mysql-username=datastream_user \
--mysql-password=complex_password_123 \
--display-name="MySQL Source 1 (Physical Shard 1)"
# Create Source Profile for Physical Shard 2
export SQL_CP_NAME_2="mysql-src-cp-2"
gcloud datastream connection-profiles create $SQL_CP_NAME_2 \
--location=$REGION \
--type=mysql \
--mysql-hostname=$MYSQL_IP_2 \
--mysql-port=3306 \
--mysql-username=datastream_user \
--mysql-password=complex_password_123 \
--display-name="MySQL Source 2 (Physical Shard 2)"
ملاحظة: تتصل خدمة Datastream بهذه الأجهزة الافتراضية من خلال عناوين IP العامة الخاصة بها، وهو أمر مسموح به لأنّنا أضفنا 0.0.0.0/0 إلى قواعد جدار الحماية في وقت سابق. في بيئة الإنتاج، عليك إدراج نطاقات عناوين IP العامة المحدّدة في Datastream في القائمة المسموح بها.
إنشاء ملف تعريف لربط الوجهة (Cloud Storage):
يشير ذلك إلى جذر الحِزمة التي تم إنشاؤها حديثًا.
export GCS_CP_NAME="gcs-dest-cp"
gcloud datastream connection-profiles create $GCS_CP_NAME \
--location=$REGION \
--type=google-cloud-storage \
--bucket=$BUCKET_NAME \
--root-path=/ \
--display-name="GCS Destination" --force
3- إنشاء مصادر بيانات
سننشئ الآن مصدرَين لبيانات "التقاط تغيير البيانات". سيلتقط البث 1 shard0_db وshard1_db. سيلتقط البث 2 shard2_db وshard3_db. تتم كتابة كلا المصدرَين في حزمة GCS نفسها بتنسيق Avro.
# Stream for Physical Shard 1
export STREAM_NAME_1="mysql-to-spanner-stream-1"
export GCS_STREAM_PATH_1="data/${STREAM_NAME_1}"
gcloud datastream streams create $STREAM_NAME_1 \
--location=$REGION \
--display-name="MySQL Source 1 CDC Stream" \
--source=$SQL_CP_NAME_1 \
--destination=$GCS_CP_NAME \
--mysql-source-config=<(echo "includeObjects:
mysqlDatabases:
- database: 'shard0_db'
- database: 'shard1_db'") \
--gcs-destination-config=<(echo "path: ${GCS_STREAM_PATH_1}/
fileRotationMb: 5
fileRotationInterval: 15s
avroFileFormat: {}") \
--backfill-none
# Stream for Physical Shard 2
export STREAM_NAME_2="mysql-to-spanner-stream-2"
export GCS_STREAM_PATH_2="data/${STREAM_NAME_2}"
gcloud datastream streams create $STREAM_NAME_2 \
--location=$REGION \
--display-name="MySQL Source 2 CDC Stream" \
--source=$SQL_CP_NAME_2 \
--destination=$GCS_CP_NAME \
--mysql-source-config=<(echo "includeObjects:
mysqlDatabases:
- database: 'shard2_db'
- database: 'shard3_db'") \
--gcs-destination-config=<(echo "path: ${GCS_STREAM_PATH_2}/
fileRotationMb: 5
fileRotationInterval: 15s
avroFileFormat: {}") \
--backfill-none
يساعدنا استخدام إعدادات أصغر لتدوير الملفات (5 ميغابايت أو 15 ثانية) في رصد التغييرات المنسوخة بشكل أسرع أثناء درس تطبيقي حول الترميز.
قد يستغرق إكمال هذا الأمر بعض الوقت. التحقّق من الحالة: gcloud datastream streams describe $STREAM_NAME_1 --location=$REGION
4. بدء عمليات بث Datastream
فعِّل كلا المصدرَين لبدء تسجيل التغييرات.
gcloud datastream streams update $STREAM_NAME_1 \
--location=$REGION \
--state=RUNNING
gcloud datastream streams update $STREAM_NAME_2 \
--location=$REGION \
--state=RUNNING
التحقّق من الحالة: يمكنك تنفيذ gcloud datastream streams describe $STREAM_NAME_1 --location=$REGION. ستكون الحالة في البداية STARTING وستتغيّر إلى RUNNING بعد بضع لحظات. انتظِر إلى أن يتم تشغيلهما بالكامل قبل بدء عملية النقل المباشر.
5- إعداد Pub/Sub لإشعارات GCS
يجب إعلام Dataflow على الفور عندما يكتب أي من مصادر Datastream ملفًا جديدًا في حزمة GCS. سنضبط GCS لإرسال الإشعارات إلى موضوع واحد في Pub/Sub.
إنشاء موضوع Pub/Sub:
export PUBSUB_TOPIC="datastream-gcs-updates"
gcloud pubsub topics create $PUBSUB_TOPIC
إنشاء إشعار GCS
إرسال إشعار إلى الموضوع عند إنشاء أي عنصر ضمن البادئة data/ (التي تغطي كلا المصدرين)
gcloud storage buckets notifications create gs://${BUCKET_NAME} --topic=projects/$PROJECT_ID/topics/$PUBSUB_TOPIC --payload-format=json --object-prefix=data/
إنشاء اشتراك في Pub/Sub
أنشئ الاشتراك مع تحديد الموعد النهائي المقترَح للإقرار باستلام البيانات في Dataflow.
export PUBSUB_SUBSCRIPTION="datastream-gcs-sub"
gcloud pubsub subscriptions create $PUBSUB_SUBSCRIPTION \
--topic=$PUBSUB_TOPIC \
--ack-deadline=600
8. التحويل المخصّص
بما أنّ مخطط Spanner يختلف عن مخطط MySQL (بسبب الأعمدة التي أضفناها وأزلناها من خلال واجهة مستخدم الويب الخاصة بأداة SMT)، ستفشل عملية نقل البيانات الجاهزة في Dataflow. تحتاج Dataflow إلى تعليمات حول كيفية ربط هذه الاختلافات أثناء خطوط النقل الأمامية (من MySQL إلى Spanner) والعكسية (من Spanner إلى MySQL).
بالإضافة إلى ذلك، بما أنّنا نُجري عملية نقل عكسي مجزّأ، تحتاج Dataflow إلى آلية توجيه لمعرفة الجزء المنطقي (shard0_db أو shard1_db أو غير ذلك) الذي ينتمي إليه صف Spanner المعدَّل أثناء عملية النسخ المتماثل العكسي.
سنحقّق ذلك من خلال كتابة ملف Custom Transformation JAR باستخدام نموذج Spanner Custom Shard الذي توفّره Google.
1. تنزيل نموذج التقسيم المخصّص
في Cloud Shell، نزِّل مستودع نماذج Google Cloud Dataflow وانتقِل إلى مجلد الأجزاء المخصّصة:
git clone https://github.com/GoogleCloudPlatform/DataflowTemplates.git
cd DataflowTemplates/v2/spanner-custom-shard
2. ضبط منطق تحويل البيانات
علينا تعديل ملف CustomTransformationFetcher.java.
- نقل البيانات إلى الأمام (
toSpannerRow): يتم ملء العمودOrderSourceالذي تمت إضافته حديثًا باستخدام العمودLegacyOrderSystemمن MySQL. - عملية النقل العكسي (
toSourceRow): تعيد ملء العمودLegacyOrderSystemالذي تم إسقاطه والذي يتطلبه MySQL، وذلك من خلال استخراجه منOrderSourceفي Spanner.
عدِّل الملف CustomTransformationFetcher.java. بدلاً من فتح محرّر نصوص يدويًا، نفِّذ الأمر التالي للكتابة تلقائيًا فوق ملف النموذج باستخدام منطقنا المخصّص:
cat << 'EOF' > src/main/java/com/custom/CustomTransformationFetcher.java
package com.custom;
import com.google.cloud.teleport.v2.spanner.exceptions.InvalidTransformationException;
import com.google.cloud.teleport.v2.spanner.utils.ISpannerMigrationTransformer;
import com.google.cloud.teleport.v2.spanner.utils.MigrationTransformationRequest;
import com.google.cloud.teleport.v2.spanner.utils.MigrationTransformationResponse;
import java.util.HashMap;
import java.util.Map;
public class CustomTransformationFetcher implements ISpannerMigrationTransformer {
@Override
public void init(String customParameters) {}
@Override
public MigrationTransformationResponse toSpannerRow(MigrationTransformationRequest request)
throws InvalidTransformationException {
if (request.getTableName().equals("Orders")) {
Map<String, Object> requestRow = request.getRequestRow();
Map<String, Object> responseRow = new HashMap<>();
Object legacySysObj = requestRow.get("LegacyOrderSystem");
String legacySys = (legacySysObj != null) ? (String) legacySysObj : "UNKNOWN_SYSTEM";
// Transform: Trim the string to remove everything after the first underscore
String orderSource = legacySys;
if (legacySys.contains("_")) {
orderSource = legacySys.substring(0, legacySys.indexOf('_'));
}
// Populate the new Spanner column (e.g., "WebStore_v1" becomes "WebStore")
responseRow.put("OrderSource", orderSource);
return new MigrationTransformationResponse(responseRow, false);
}
return new MigrationTransformationResponse(new HashMap<>(), false);
}
@Override
public MigrationTransformationResponse toSourceRow(MigrationTransformationRequest request)
throws InvalidTransformationException {
if (request.getTableName().equals("Orders")) {
Map<String, Object> requestRow = request.getRequestRow();
Map<String, Object> responseRow = new HashMap<>();
// Safely fetch the Spanner OrderSource
Object sourceObj = requestRow.get("OrderSource");
String source = (sourceObj != null) ? (String) sourceObj : "UNKNOWN_SYSTEM";
String legacySys = "'" + source + "_v1'";
// Transform: Append a suffix to visibly prove the reverse transformation worked
// e.g., "WebStore" becomes "WebStore_v1"
responseRow.put("LegacyOrderSystem", legacySys);
return new MigrationTransformationResponse(responseRow, false);
}
return new MigrationTransformationResponse(new HashMap<>(), false);
}
@Override
public MigrationTransformationResponse transformFailedSpannerMutation(
MigrationTransformationRequest request) throws InvalidTransformationException {
return new MigrationTransformationResponse(new HashMap<>(), false);
}
}
EOF
3- ضبط منطق التقسيم العكسي
تستخدِم Dataflow CustomShardIdFetcher.java أثناء النسخ المتماثل العكسي لتحديد المكان الذي يجب توجيه تغيير Spanner إليه. سنستخدم المفتاح الأساسي CustomerId ومنطق modulo (%4) لإعادة توجيه السجلات ديناميكيًا إلى الجزء المنطقي الصحيح.
عدِّل الملف CustomShardIdFetcher.java باستخدام cat واستبدِل محتواه بالكامل بالرمز التالي:
cat << 'EOF' > src/main/java/com/custom/CustomShardIdFetcher.java
package com.custom;
import com.google.cloud.teleport.v2.spanner.utils.IShardIdFetcher;
import com.google.cloud.teleport.v2.spanner.utils.ShardIdRequest;
import com.google.cloud.teleport.v2.spanner.utils.ShardIdResponse;
import java.util.Map;
public class CustomShardIdFetcher implements IShardIdFetcher {
@Override
public void init(String parameters) {}
@Override
public ShardIdResponse getShardId(ShardIdRequest shardIdRequest) {
Map<String, Object> keys = shardIdRequest.getSpannerRecord
();
// Use the Primary Key to identify the correct logical shard
if (keys != null && keys.containsKey("CustomerId")) {
long customerId = Long.parseLong(keys.get("CustomerId").toString());
long shardIdx = customerId % 4;
ShardIdResponse response = new ShardIdResponse();
response.setLogicalShardId("shard" + shardIdx + "_db");
return response;
}
return new ShardIdResponse();
}
}
EOF
4. إنشاء ملف JAR وتحميله
بعد كتابة منطق Java المخصّص، علينا تجميعه في ملف JAR وتحميله إلى حزمة Google Cloud Storage التي أنشأناها سابقًا ليتمكّن Dataflow من الوصول إليه.
نفِّذ الأوامر التالية في Cloud Shell:
# Return to DataflowTemplates directory
cd ../..
# Build the JAR using Maven
mvn clean install -DskipTests -Dcheckstyle.skip -Dspotless.check.skip=true -Djib.skip -pl v2/spanner-custom-shard -am
# Upload the JAR to GCS
export CUSTOM_JAR_PATH="gs://${BUCKET_NAME}/custom-logic/spanner-custom-shard-1.0.jar"
gcloud storage cp v2/spanner-custom-shard/target/spanner-custom-shard-1.0-SNAPSHOT.jar $CUSTOM_JAR_PATH
# Return to home directory
cd ~
9- نقل البيانات بشكل مجمّع من MySQL إلى Spanner
بعد إعداد مخطط Spanner وإنشاء ملف Custom Transformation JAR، يمكننا الآن نسخ البيانات الحالية من قاعدة بيانات MySQL إلى Cloud Spanner. ستستخدم Sourcedb to Spanner Dataflow Flex Template، وهو مصمّم لنسخ البيانات بشكل مجمّع من قواعد البيانات التي يمكن الوصول إليها من خلال JDBC إلى Spanner.
1. تحميل ملف عمليات إلغاء المخطط
في القسم 6، نزّلت ملف JSON الخاص بتجاوزات Spanner باستخدام واجهة مستخدم SMT على الويب. علينا تحميل هذا الملف إلى حزمة GCS لكي تتمكّن خدمة Dataflow من استخدامه لربط اختلافات المخطط (مثل الأعمدة التي تمت إعادة تسميتها).
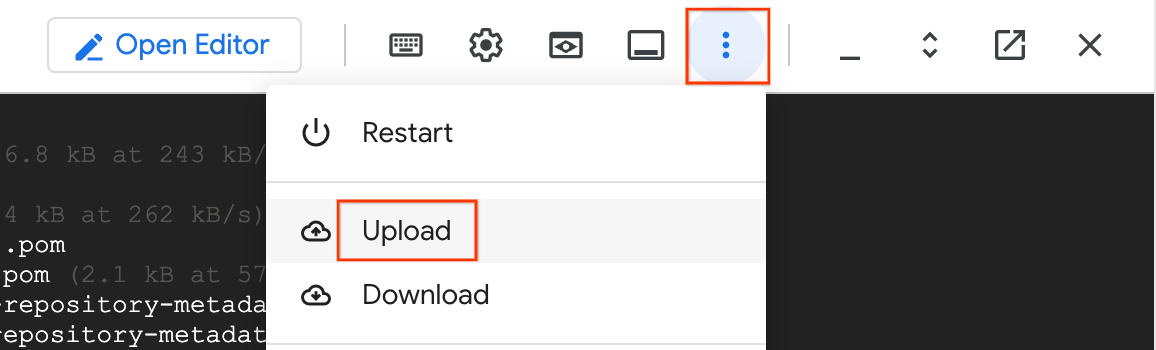
- في Cloud Shell، انقر على قائمة الخيارات الإضافية (المزيد) واختَر تحميل.
- اختَر ملف JSON الخاص بعمليات الإلغاء الذي نزّلته سابقًا (على سبيل المثال،
spanner_overrides.json). - انقل الملف إلى حزمة GCS باتّباع الخطوات التالية:
export OVERRIDES_FILE="spanner_overrides.json" # Change this if your downloaded file has a different name
export GCS_OVERRIDES_PATH="gs://${BUCKET_NAME}/config/${OVERRIDES_FILE}"
gcloud storage cp ~/${OVERRIDES_FILE} $GCS_OVERRIDES_PATH
2. إنشاء ملف إعداد التقسيم وتحميله
يجب أن تعرف خدمة Dataflow كيفية الاتصال بجميع الأقسام المنطقية الأربعة على مستوى الآلتين الافتراضيتين الفعليتين. سننشئ ملف sharding.json لهذا الغرض.
نفِّذ ما يلي في Cloud Shell لإنشاء الإعدادات وتحميلها:
cat <<EOF > sharding.json
{
"configType": "dataflow",
"shardConfigurationBulk": {
"schemaSource": {
"dataShardId": "mysql-physical-1",
"host": "${MYSQL_IP_1}",
"user": "datastream_user",
"password": "complex_password_123",
"port": "3306",
"dbName": "shard0_db"
},
"dataShards": [
{
"dataShardId": "mysql-physical-1",
"host": "${MYSQL_IP_1}",
"user": "datastream_user",
"password": "complex_password_123",
"port": "3306",
"dbName": "",
"namespace": "namespace-mysql-1",
"databases": [
{
"dbName": "shard0_db",
"databaseId": "shard0_db",
"refDataShardId": "mysql-physical-1"
},
{
"dbName": "shard1_db",
"databaseId": "shard1_db",
"refDataShardId": "mysql-physical-1"
}
]
},
{
"dataShardId": "mysql-physical-2",
"host": "${MYSQL_IP_2}",
"user": "datastream_user",
"password": "complex_password_123",
"port": "3306",
"dbName": "",
"namespace": "namespace-mysql-2",
"databases": [
{
"dbName": "shard2_db",
"databaseId": "shard2_db",
"refDataShardId": "mysql-physical-2"
},
{
"dbName": "shard3_db",
"databaseId": "shard3_db",
"refDataShardId": "mysql-physical-2"
}
]
}
]
}
}
EOF
export GCS_SHARDING_PATH="gs://${BUCKET_NAME}/config/sharding.json"
gcloud storage cp sharding.json $GCS_SHARDING_PATH
3- تشغيل مهمة Bulk Migration Dataflow
سنستخدم نموذج Sourcedb إلى Spanner المرن. بما أنّ عملية النقل هذه مجزّأة وتتضمّن عمليات تحويل مخصّصة، فإنّنا نمرّر ملف Overrides وملف Sharding config وملف Java JAR المخصّص.
export JOB_NAME="mysql-sharded-bulk-to-spanner-$(date +%Y%m%d-%H%M%S)"
export OUTPUT_DIR="gs://${BUCKET_NAME}/bulk-migration"
gcloud dataflow flex-template run $JOB_NAME \
--project=$PROJECT_ID \
--region=$REGION \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Sourcedb_to_Spanner_Flex" \
--max-workers=2 \
--num-workers=1 \
--worker-machine-type=n2-highmem-8 \
--parameters \
sourceConfigURL=$GCS_SHARDING_PATH,\
instanceId=$SPANNER_INSTANCE_NAME,\
databaseId=$SPANNER_DATABASE_NAME,\
projectId=$PROJECT_ID,\
outputDirectory=$OUTPUT_DIR,\
username=datastream_user,\
password=complex_password_123,\
schemaOverridesFilePath=$GCS_OVERRIDES_PATH,\
transformationJarPath=$CUSTOM_JAR_PATH,\
transformationClassName=com.custom.CustomTransformationFetcher
شرح المَعلمات الرئيسية:
sourceConfigURL: مسار ملفsharding.jsonالذي أنشأناه يخبر هذا الإعداد Dataflow بكيفية الاتصال بجميع أقسام MySQL المنطقية الأربعة على مستوى الآلتين الافتراضيتين الماديتين.schemaOverridesFilePath: مسار ملف JSON الذي نزّلناه من واجهة مستخدم الويب الخاصة بأداة SMT يُعلِم هذا الأمر خدمة Dataflow بكيفية التعامل مع تعديلات المخطط التي أجريناها (مثل عمودLegacyRegionالذي تم إسقاطه وقيود التحقّق الأكثر صرامة).-
transformationJarPath: مسار GCS إلى ملف Java JAR المجمَّع الذي أنشأناه في القسم السابق. يحتوي هذا الملف على الرمز البرمجي الفعلي لتنفيذ عمليات التحويل المخصّصة. -
transformationClassName: الاسم المؤهَّل بالكامل لفئة Java داخل ملف JAR الذي ينفّذ منطق النقل إلى الإصدار الأحدث (com.custom.CustomTransformationFetcher). outputDirectory: موقع GCS الذي ستكتب فيه خدمة Dataflow ملفاتها المؤقتة، والأهم من ذلك، ملفات قائمة الرسائل غير الصالحة (DLQ).maxWorkers،numWorkers: تتحكّم في توسيع نطاق مهمة Dataflow. تم إبقاء القيمة منخفضة لمجموعة البيانات الصغيرة هذه.- استبدِل
instanceIdوdatabaseIdوprojectIdبمثيل وقاعدة بيانات Cloud Spanner المستهدَفين.
ملاحظة بشأن الشبكة: ترتبط هذه المهمة بمثيل Cloud SQL عبر عنوان IP العلني. يمكن إجراء ذلك لأنّك أضفت 0.0.0.0/0 سابقًا إلى "الشبكات المسموح بها" في الجهاز الظاهري. يسمح ذلك لأجهزة VM العاملة في Dataflow، والتي تتضمّن عناوين IP خارجية، بالوصول إلى قاعدة البيانات.
4. مراقبة مهمة Dataflow
يمكنك تتبُّع مدى تقدّم المهمة في Google Cloud Console:
- انتقِل إلى صفحة "مهام Dataflow": الانتقال إلى "مهام Dataflow"
- ابحث عن الوظيفة المسماة
mysql-sharded-bulk-to-spanner-...وانقر عليها. - مراقبة الرسم البياني للوظائف والمقاييس انتظِر إلى أن تتغيّر حالة المهمة إلى تم بنجاح. من المفترض أن يستغرق ذلك مدة تتراوح بين 5 و15 دقيقة تقريبًا.

- إذا واجهت المهمة مشاكل، راجِع علامة التبويب السجلات ضِمن صفحة تفاصيل مهمة Dataflow بحثًا عن رسائل الخطأ.
- تقدّم مقاييس المهام المزيد من المعلومات حول تقدّم المهمة واستهلاك الموارد، مثل سرعة معالجة البيانات واستخدام وحدة المعالجة المركزية.
5- التحقّق من البيانات في Cloud Spanner وفحص قائمة انتظار الرسائل غير الصالحة (DLQ)
بعد اكتمال مهمة Dataflow بنجاح، علينا التأكّد من وصول بياناتنا بأمان وفحص السجلات التي صمّمناها عمدًا لتفشل.
أ. التحقّق من الصحة العامة للبيانات التي تم نقلها:
استخدِم واجهة سطر الأوامر gcloud لتنفيذ بعض عمليات التحقّق السريعة من سلامة قاعدة بيانات Spanner الموحّدة للتأكّد من نقل السجلات الصالحة بشكلٍ صحيح وملء ملف JAR المخصّص للعمود الإضافي.
# 1. Verify total Customer count
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT COUNT(*) as TotalCustomers FROM Customers"
# 2. Verify total Orders count (Total minus the orphan record)
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT COUNT(*) as TotalOrders FROM Orders"
# 3. Verify the Custom Transformation on OrderSource worked
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT CustomerId, OrderId, OrderSource FROM Orders LIMIT 3"
# 4. Verify that renamed column LoyaltyTier has the correct data
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT CustomerId, CustomerName, LoyaltyTier FROM Customers LIMIT 3"
الناتج المتوقّع:
TotalCustomers: 16 TotalOrders: 19 CustomerId: 1 OrderId: 201 OrderSource: MobileApp CustomerId: 2 OrderId: 301 OrderSource: CallCenter CustomerId: 3 OrderId: 401 OrderSource: InStore CustomerId: 1 CustomerName: Agnes N. LoyaltyTier: NORTHEAST CustomerId: 2 CustomerName: Brian K. LoyaltyTier: SOUTHWEST CustomerId: 3 CustomerName: Cathy Z. LoyaltyTier: CENTRAL
- تم نقل جميع الصفوف في جدول "العملاء" بنجاح.
- نلاحظ تعذُّر إكمال صف واحد في جدول
OrdersبسببINTERLEAVE IN PARENTعلى Spanner.CustomerId 99هو عنصر فرعي غير مرتبط بسبب عدم توفّر صف مطابق في جدولCustomers.
ب. التحقّق من حالات الفشل المقصودة في قائمة انتظار الرسائل غير الصالحة:
تم توثيق الخطأ أعلاه في مجلد "قائمة الرسائل غير المرسَلة" (DLQ) الذي تم إنشاؤه بواسطة مسار النقل المجمّع.
- انتقِل إلى Cloud Storage في Google Cloud Console.
- انتقِل إلى الحزمة وافتح المجلد
bulk-migration/dlq/severe. - افحص ملفات JSON في الداخل. ستجد الصف
Ordersالذي يحتوي على العنصر اليتيمCustomerId. - يمكن إعادة محاولة إصلاح أخطاء قائمة انتظار الرسائل غير المعالَجة لعملية النقل المجمّع باتّباع الخطوات المذكورة هنا.
اكتملت الآن عملية التحميل المجمّع الأوّلي للبيانات من Cloud SQL إلى Cloud Spanner. الخطوة التالية هي إعداد عملية النسخ المتماثل المباشر لتسجيل التغييرات الجارية.
10. بدء عملية النقل المباشر (تغيير البيانات)
بعد اكتمال عملية تحميل البيانات المجمّعة، ستطلق مهمة بث مستمر في Dataflow. ستقرأ هذه المهمة أحداث "تسجيل بيانات التغيير" (CDC) التي يكتبها Datastream في حزمة GCS، وستطبّق هذه التغييرات على Cloud Spanner في الوقت الفعلي تقريبًا.
سنجرّب أيضًا مسار النقل هذا من خلال إدخال بيانات صالحة وغير صالحة عمدًا لمراقبة طريقة تعامل Dataflow مع النسخ المتماثل المباشر وتوجيه الأخطاء إلى قائمة الرسائل غير الصالحة (DLQ).
1. إنشاء ملف إعداد تقسيم البيانات في عملية النقل المباشر
على عكس عملية النقل المجمّع (التي تستخدم سلاسل اتصال JDBC)، يقرأ مسار النقل المباشر أحداث Datastream من GCS. يتطلّب ذلك إعداد JSON مختلفًا تمامًا يربط بين أسماء مصادر Datastream وقواعد البيانات وشرائح Spanner المنطقية.
نفِّذ ما يلي في Cloud Shell لإنشاء إعدادات التقسيم المباشر وتحميلها:
cat <<EOF > live-sharding.json
{
"StreamToDbAndShardMap": {
"${STREAM_NAME_1}": {
"shard0_db": "shard0_db",
"shard1_db": "shard1_db"
},
"${STREAM_NAME_2}": {
"shard2_db": "shard2_db",
"shard3_db": "shard3_db"
}
}
}
EOF
export GCS_LIVE_SHARDING_PATH="gs://${BUCKET_NAME}/config/live-sharding.json"
gcloud storage cp live-sharding.json $GCS_LIVE_SHARDING_PATH
2. تشغيل مهمة Dataflow لنقل البيانات المباشر
شغِّل مهمة Dataflow لبث البيانات من أجل القراءة من GCS والكتابة إلى Spanner. سيستخدم هذا النموذج إشعارات GCS Pub/Sub لمعالجة الملفات الجديدة على الفور.
export JOB_NAME_CDC="mysql-sharded-cdc-to-spanner-$(date +%Y%m%d-%H%M%S)"
export DLQ_DIR_CDC="gs://${BUCKET_NAME}/live-migration"
gcloud dataflow flex-template run $JOB_NAME_CDC \
--project=$PROJECT_ID \
--region=$REGION \
--worker-machine-type=n2-highmem-8 \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Cloud_Datastream_to_Spanner" \
--parameters \
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
projectId="$PROJECT_ID",\
inputFileFormat="avro",\
gcsPubSubSubscription="projects/${PROJECT_ID}/subscriptions/${PUBSUB_SUBSCRIPTION}",\
shardingContextFilePath=$GCS_LIVE_SHARDING_PATH,\
deadLetterQueueDirectory="$DLQ_DIR_CDC",\
transformationJarPath=$CUSTOM_JAR_PATH,\
transformationClassName="com.custom.CustomTransformationFetcher",\
schemaOverridesFilePath=$GCS_OVERRIDES_PATH,\
datastreamSourceType="mysql",\
dlqRetryMinutes=1,\
dlqMaxRetryCount=2
المَعلمات الرئيسية
gcsPubSubSubscription: اشتراك Pub/Sub الذي يستمع إلى إشعارات الملفات الجديدة من GCS. يتيح ذلك للمهمة معالجة التغييرات على الفور أثناء كتابة Datastream لها.inputFileFormat="avro": يطلب من Dataflow توقّع ملفات Avro من Datastream. يجب أن يتطابق هذا مع إعدادات "الوجهة" في مصدر البيانات (على سبيل المثال،avroFileFormatمقابلjsonFileFormat).shardingContextFilePath: ملف JSON يربط بين مصادر بيانات Datastream وأقسام منطقية.dlqRetryMinutes: عدد الدقائق بين محاولات إعادة الإرسال إلى قائمة انتظار الرسائل غير الصالحة. القيمة التلقائية هي10.-
dlqMaxRetryCount: الحد الأقصى لعدد المرات التي يمكن فيها إعادة محاولة الأخطاء المؤقتة من خلال قائمة انتظار الرسائل غير المعالَجة. القيمة التلقائية هي500.
يمكنك مراقبة بدء تشغيل الوظيفة في وحدة تحكّم وظائف Dataflow.
3- إدخال بيانات مباشرة وتفعيل حالات تعذُّر مقصودة
أثناء بدء تشغيل مهمة البث في Dataflow (قد يستغرق ذلك من 3 إلى 5 دقائق)، لننتقل إلى أول جهاز افتراضي فعلي يعمل بنظام MySQL عبر SSH ونُدرج بعض السجلات الجديدة. سندرج سجلاً صالحًا وسجلاً غير صالح.
استخدِم بروتوكول SSH للوصول إلى الجزء الأول من قاعدة البيانات:
gcloud compute ssh mysql-physical-1 --zone=$ZONE
سجِّل الدخول إلى MySQL:
sudo mysql
نفِّذ عمليات الإدراج التالية على shard1_db:
USE shard1_db;
-- 1. Valid Insert: 'MobileApp_v2' will be trimmed to 'MobileApp'
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem)
VALUES (4, 501, 99.99, 'MobileApp_v2');
-- 2. Invalid Insert (DLQ Test): This violates Interleave constraint as CustomerId 99999 doesn't exist in Customers table.
INSERT INTO Orders (CustomerId, OrderId, OrderValue, LegacyOrderSystem)
VALUES (99999, 502, 50.00, 'WebStore_v1');
-- 3. Valid Update
UPDATE Orders SET OrderValue = '1500' WHERE CustomerId = 5 AND OrderId = 202;
-- 4. Valid Delete
DELETE FROM Orders WHERE CustomerId = 5 AND OrderId = 203;
EXIT;
اكتب exit مرة أخرى للرجوع إلى طلب Cloud Shell.
4. التحقّق من بيانات نقل البيانات المباشرة وفحص قائمة انتظار الرسائل غير المعالَجة في CDC
بعد إدخال البيانات، سترصد خدمة Datastream أحداث التقاط البيانات المتغيرة (CDC)، وستحاول خدمة Dataflow تطبيقها على Spanner.
أ. التحقّق من صحة تغييرات لغة معالجة البيانات (DML) في Spanner
نفِّذ طلبات البحث التالية للتأكّد من أنّ الأحداث INSERT وUPDATE وDELETE قد وصلت بنجاح إلى Spanner، وأنّ عملية التحويل المخصّص تم تنفيذها عند كلّ من الإدراج والتعديل.
# 1. Verify INSERT: Should return the new row with transformed OrderSource
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT CustomerId, OrderId, OrderValue, OrderSource FROM Orders WHERE CustomerId = 4 AND OrderId = 501"
# 2. Verify UPDATE: Should show OrderValue changed to 1500
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT CustomerId, OrderId, OrderValue, OrderSource FROM Orders WHERE CustomerId = 5 AND OrderId = 202"
# 3. Verify DELETE: Should return 0, confirming the order was deleted
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT COUNT(*) FROM Orders WHERE CustomerId = 5 AND OrderId = 203"
# 4. Verify DLQ Failure: Should return 0, confirming the row migration failed
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT COUNT(*) FROM Orders WHERE CustomerId = 99999 AND OrderId = 502"
الناتج المتوقّع:
CustomerId: 4 OrderId: 501 OrderValue: 99.99 OrderSource: MobileApp CustomerId: 5 OrderId: 202 OrderValue: 1500 OrderSource: WebStore 0 0
ملاحظة: إذا لم يعرض أي طلب البحث النتيجة المتوقّعة، انتظِر دقيقة واحدة وحاوِل مجددًا، لأنّ العاملين في البث قد يكونون لا يزالون بصدد معالجة قائمة الانتظار.
ب. التحقّق من الخطأ المقصود في قائمة انتظار الرسائل غير الصالحة:
بما أنّ CustomerId = 99999 ليس لديه عنصر رئيسي في جدول Customers، كان من المفترض أن يرفضه Spanner وأن يتم توجيهه بأمان إلى قائمة انتظار الرسائل غير الصالحة من خلال Dataflow.
- انتقِل إلى Cloud Storage في Google Cloud Console.
- انتقِل إلى الحزمة وافتح المجلد
live-migration/dlq/severe/. - من المفترض أن تظهر لك ملفات JSON تم إنشاؤها حديثًا. انقر عليها لفحص المحتوى. ستظهر لك تفاصيل
CustomerId = 99999ورسالة خطأ Spanner المحدّدة:NOT_FOUND: Parent row for row [99999,502,WebStore] in table Orders is missing. Row cannot be written." - يمكن إعادة محاولة أخطاء قائمة انتظار الرسائل غير المعالَجة في عملية النقل المباشر من خلال تشغيل نموذج تدفق البيانات مع ضبط
runMode=retryDLQ.
5- معالجة أخطاء قائمة انتظار الرسائل غير الصالحة
تتطلّب الأخطاء في الدليل severe/ تدخّلاً يدويًا. لنحلّ مشكلة البيانات ونعيد معالجة الحدث الذي تعذّر تنفيذه.
أ. إصلاح البيانات في المصدر
حدث الخطأ لأنّ سجلّ العميل الرئيسي CustomerId = 99999 غير متوفّر. لنُدرِجها في قاعدة بيانات MySQL المصدر.
استخدِم بروتوكول SSH للدخول إلى مثيل MySQL مرة أخرى:
gcloud compute ssh mysql-physical-1 --zone=$ZONE
سجِّل الدخول إلى MySQL باستخدام sudo mysql وأدرِج صف العنصر الرئيسي الناقص في shard1_db:
USE shard1_db;
INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LegacyRegion) VALUES
(99999, 'DLQ Parent Holder', 5000.00, 'NORTH_AMERICA');
EXIT;
اكتب exit للرجوع إلى Cloud Shell.
ب. تنفيذ مهمة Dataflow الخاصة بإعادة المحاولة في قائمة انتظار الرسائل غير الصالحة
لإعادة معالجة الأحداث من severe/ قائمة انتظار الرسائل غير المعالَجة، عليك تشغيل نموذج Dataflow نفسه ولكن في وضع retryDLQ. يقرأ هذا الوضع تحديدًا من المسار deadLetterQueueDirectory/severe، ويعيد تشغيلها من خلال عمليات التحويل المخصّصة، ويطبّقها على Spanner.
ابدأ المهمة في وضع retryDLQ:
export JOB_NAME_RETRY="mysql-sharded-cdc-retry-$(date +%Y%m%d-%H%M%S)"
gcloud dataflow flex-template run $JOB_NAME_RETRY \
--project=$PROJECT_ID \
--region=$REGION \
--worker-machine-type=n2-highmem-8 \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Cloud_Datastream_to_Spanner" \
--parameters \
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
projectId="$PROJECT_ID",\
runMode="retryDLQ",\
deadLetterQueueDirectory="$DLQ_DIR_CDC",\
datastreamSourceType="mysql",\
transformationJarPath=$CUSTOM_JAR_PATH,\
transformationClassName="com.custom.CustomTransformationFetcher",\
schemaOverridesFilePath=$GCS_OVERRIDES_PATH,\
shardingContextFilePath=$GCS_LIVE_SHARDING_PATH
التغييرات الرئيسية على المَعلمات لإعادة المحاولة
-
runMode="retryDLQ": يطلب من النموذج القراءة من دليلsevereDLQ. - تمت إزالة
gcsPubSubSubscription: لا حاجة إليها لأنّنا لا نقرأ من حزمة GCS المباشرة في Datastream.
مراقبة عملية إعادة المحاولة:
مثل مسار نقل البيانات الرئيسي في CDC، فإنّ retryDLQ هو مسار نقل بيانات متدفّق سيظل RUNNING إلى أن يتم إلغاؤه يدويًا.
- انتقِل إلى صفحة "مهمة Dataflow" الخاصة بـ
$JOB_NAME_RETRY. - ضِمن لوحة المقاييس، ابحث عن العدادَين التاليَين:
-
elementsReconsumedFromDeadLetterQueue: يتم تقييمها عند جلب ملفات الخطأ. Successful events: يتم زيادته عند كتابة السجلّ في Spanner.- تحقَّق من الدليل
severe/بحثًا عن حالات تعذُّر متكرّرة. - بعد أن يزداد عدد أحداث "ناجح" بمقدار عدد العناصر التي أردت إعادة محاولة إرسالها (1 في حالة الاختبار)، انتقِل إلى خطوة التحقّق التالية.
ج. التحقّق من البيانات التي تمت إعادة محاولة إرسالها
بعد إعادة محاولة السجلّ الذي تعذّر نقله (قد يستغرق ذلك بعض الوقت)، تحقَّق من Spanner لمعرفة ما إذا تم نقل صف التابع بنجاح:
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT CustomerId, OrderId, OrderValue, OrderSource FROM Orders WHERE CustomerId = 99999 AND OrderId = 502"
من المفترض أن يظهر لك الصف الآن:
CustomerId: 99999 OrderId: 502 OrderValue: 50 OrderSource: WebStore
تحقَّق أيضًا من المجلد $DLQ_DIR_CDC/severe/ في GCS. من المفترض أن تكون الملفات التي تمت معالجتها قد تم نقلها أو حذفها، ما يشير إلى إعادة المعالجة بنجاح.
11. إعداد النسخ المتماثل العكسي (من Spanner إلى MySQL)
للتعامل مع السيناريوهات التي قد تحتاج فيها إلى العودة إلى الحالة السابقة أو إبقاء قاعدة بيانات MySQL الأصلية متزامنة مع Spanner لفترة انتقالية، يمكنك إعداد عملية النسخ المتماثل العكسي.
يستخدم مسار البيانات هذا ميزة "قنوات تغيير البيانات" في Spanner لتسجيل التعديلات المباشرة في Spanner. بعد ذلك، تستخدم هذه الخدمة ملف Custom Transformation JAR لعكس عملية ربط الاختلافات في المخطط، وملف Custom Sharding JAR لحساب آلة MySQL الافتراضية المادية والجزء المنطقي اللذين يجب إعادة كتابة التعديل فيهما.
1. إنشاء "بث تغييرات" في Spanner
عليك أولاً إنشاء مصدر بيانات لتغيير البث في قاعدة بيانات Spanner لتتبُّع التغييرات في الجدولَين Customers وOrders.
export CHANGE_STREAM_NAME="CustomersOrdersChangeStream"
gcloud spanner databases ddl update $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--ddl="CREATE CHANGE STREAM $CHANGE_STREAM_NAME FOR Customers, Orders"
سيسجّل مصدر تغيير البيانات هذا الآن جميع تعديلات البيانات في الجداول المحدّدة.
2. إنشاء قاعدة بيانات Spanner لبيانات Dataflow الوصفية
يتطلّب نموذج Spanner to SourceDB Dataflow قاعدة بيانات Spanner منفصلة لتخزين بيانات التعريف من أجل إدارة استخدام "دفق التغيير".
export SPANNER_METADATA_DB_NAME="migration-metadata-db"
gcloud spanner databases create $SPANNER_METADATA_DB_NAME \
--instance=$SPANNER_INSTANCE_NAME
3- إعداد إعدادات اتصال Cloud SQL لخدمة Dataflow
يحتاج نموذج Dataflow إلى ملف JSON في Cloud Storage يحتوي على تفاصيل الاتصال بقاعدة بيانات Cloud SQL المستهدَفة.
أنشئ ملفًا محليًا باسم shard_config.json:
cat <<EOF > reverse-sharding.json
[
{
"logicalShardId": "shard0_db",
"host": "${MYSQL_IP_1}",
"port": "3306",
"user": "datastream_user",
"password": "complex_password_123",
"dbName": "shard0_db"
},
{
"logicalShardId": "shard1_db",
"host": "${MYSQL_IP_1}",
"port": "3306",
"user": "datastream_user",
"password": "complex_password_123",
"dbName": "shard1_db"
},
{
"logicalShardId": "shard2_db",
"host": "${MYSQL_IP_2}",
"port": "3306",
"user": "datastream_user",
"password": "complex_password_123",
"dbName": "shard2_db"
},
{
"logicalShardId": "shard3_db",
"host": "${MYSQL_IP_2}",
"port": "3306",
"user": "datastream_user",
"password": "complex_password_123",
"dbName": "shard3_db"
}
]
EOF
حمِّل هذا الملف إلى حزمة GCS:
export GCS_REVERSE_SHARDING_PATH="gs://${BUCKET_NAME}/config/reverse-sharding.json"
gcloud storage cp reverse-sharding.json $GCS_REVERSE_SHARDING_PATH
4. تشغيل مهمة Dataflow الخاصة بالنسخ المتماثل العكسي
شغِّل مهمة Dataflow باستخدام Spanner_to_SourceDb Flex Template.
export JOB_NAME_REVERSE="spanner-sharded-reverse-to-mysql-$(date +%Y%m%d-%H%M%S)"
export DLQ_DIR_REVERSE="gs://${BUCKET_NAME}/reverse-replication"
gcloud dataflow flex-template run $JOB_NAME_REVERSE \
--project=$PROJECT_ID \
--region=$REGION \
--worker-machine-type=n2-highmem-8 \
--max-workers=2 \
--num-workers=1 \
--additional-experiments=use_runner_v2 \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Spanner_to_SourceDb" \
--parameters \
changeStreamName="$CHANGE_STREAM_NAME",\
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
spannerProjectId="$PROJECT_ID",\
metadataInstance="$SPANNER_INSTANCE_NAME",\
metadataDatabase="$SPANNER_METADATA_DB_NAME",\
sourceShardsFilePath="$GCS_REVERSE_SHARDING_PATH",\
transformationJarPath=$CUSTOM_JAR_PATH,\
transformationClassName="com.custom.CustomTransformationFetcher",\
shardingCustomJarPath=$CUSTOM_JAR_PATH,\
shardingCustomClassName="com.custom.CustomShardIdFetcher",\
schemaOverridesFilePath=$GCS_OVERRIDES_PATH,\
deadLetterQueueDirectory=$DLQ_DIR_REVERSE
المَعلمات الرئيسية
changeStreamName: اسم "دفق تغييرات" Spanner الذي سيتم القراءة منه.- استبدِل
metadataInstance, metadataDatabaseبمثيل Spanner أو قاعدة بياناته لتخزين البيانات الوصفية التي يستخدمها الموصل للتحكّم في استهلاك بيانات Change Stream API. sourceShardsFilePath: مسار GCS إلىshard_config.jsonfiltrationMode: تحدّد هذه السمة كيفية حذف سجلّات معيّنة استنادًا إلى معيار معيّن. القيمة التلقائية هيforward_migration(فلترة السجلات التي تمت كتابتها باستخدام مسار نقل البيانات إلى الإصدار الأحدث)-
shardingCustomJarPath: مسار GCS إلى ملف JAR المجمَّع في Java الذي أنشأناه سابقًا. shardingCustomClassName: اسم الفئة المؤهَّل بالكامل (com.custom.CustomShardIdFetcher) الذي ينفّذ عملية حسابية مخصّصة%4modulo لتحديد الجزء المنطقي الذي يجب أن يتلقّى السجلّ بشكلٍ ديناميكي.
ملاحظة بشأن الشبكة: ستربط العاملات في Dataflow بمثيل Cloud SQL باستخدام عنوان IP العلني المحدّد في shard_config.json. يُسمح بهذا الاتصال بسبب الإدخال 0.0.0.0/0 في "الشبكات المصرّح بها" الخاصة بمثيل Cloud SQL.
يمكنك مراقبة بدء تشغيل الوظيفة في وحدة تحكّم وظائف Dataflow.
5- إدخال بيانات Spanner وتفعيل حالات تعذُّر مقصودة
انتظِر إلى أن تنتقل مهمة Dataflow إلى الحالة Running (قد يستغرق ذلك حوالي 5 دقائق). بعد ذلك، لننفّذ مجموعة كاملة من طلبات البحث (INSERT وUPDATE وDELETE) مباشرةً في Spanner، بالإضافة إلى حدوث خطأ مقصود لاختبار قائمة انتظار الرسائل غير الصالحة العكسية.
نفِّذ ما يلي في Cloud Shell:
# All these operations are done on rows mapping to shard0_db for convenience
# Valid INSERT: Insert parent row in Customers
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LoyaltyTier) VALUES (88, 'Reverse Tester', 5000, 'GOLD_TIER')"
# 1. Valid INSERT (Orders): 'WebStore' transformed to 'WebStore_v1'
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="INSERT INTO Orders (CustomerId, OrderId, OrderValue, OrderSource) VALUES (88, 9001, 150.00, 'WebStore')"
# 2. Valid UPDATE (Orders)
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="UPDATE Orders SET OrderValue = 200.00 WHERE CustomerId = 16 AND OrderId = 105 AND OrderSource = 'Partner'"
# 3. Valid DELETE (Orders)
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="DELETE FROM Orders WHERE CustomerId = 12 AND OrderId = 104 AND OrderSource = 'WebStore'"
# 4. INVALID Insert- DLQ Test: CreditLimit=500 will fail check constraint of >1000 at source
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="INSERT INTO Customers (CustomerId, CustomerName, CreditLimit, LoyaltyTier) VALUES (44, 'DLQ Test Customer', 500, 'GOLD_TIER')"
6. التحقّق من بيانات النسخ المتماثل العكسي وفحص قائمة انتظار الرسائل غير الصالحة (DLQ)
لنؤكّد أنّ ملف Custom Sharding JAR قد وجّه CustomerId 88 بنجاح إلى shard0_db على أول جهاز افتراضي فعلي، وأنّ ملف Custom Transformation JAR قد أزال "_TIER" بنجاح من المنطقة.
أ. تحقَّق من السجلّ الصالح في MySQL:
استخدِم بروتوكول SSH للوصول إلى الجزء الأول من قاعدة البيانات:
gcloud compute ssh mysql-physical-1 --zone=$ZONE
سجِّل الدخول إلى MySQL واطلب البحث عن shard0_db:
sudo mysql
USE shard0_db;
-- 1. Verify INSERT: Row migrated with transformed LegacyOrderSystem
SELECT CustomerId, OrderId, OrderValue, LegacyOrderSystem
FROM Orders
WHERE CustomerId = 88 AND OrderId = 9001;
-- 2. Verify UPDATE: The OrderValue should now be updated to 200.00.
SELECT CustomerId, OrderId, OrderValue, LegacyOrderSystem
FROM Orders
WHERE CustomerId = 16 AND OrderId = 105;
-- 3. Verify DELETE: Returns 0 rows, confirming the order was successfully deleted from MySQL.
SELECT CustomerId, OrderId
FROM Orders
WHERE CustomerId = 12 AND OrderId = 104;
-- 4. Verify failed replication - this should be in DLQ as CreditLimit < 1000 and will fail stricter check constraint at source
SELECT CustomerId, CustomerName, CreditLimit, LegacyRegion
FROM Customers
WHERE CustomerId = 44;
EXIT;
يجب أن يعكس الناتج المتوقّع في Cloud SQL التغييرات التي تم إجراؤها في Spanner.
+------------+---------+------------+-------------------+ | CustomerId | OrderId | OrderValue | LegacyOrderSystem | +------------+---------+------------+-------------------+ | 88 | 9001 | 150.00 | Webstore_v1 | +------------+---------+------------+-------------------+ +------------+---------+------------+-------------------+ | CustomerId | OrderId | OrderValue | LegacyOrderSystem | +------------+---------+------------+-------------------+ | 16 | 105 | 200.00 | Partner_v1 | +------------+---------+------------+-------------------+ Empty set (0.00 sec) Empty set (0.00 sec)
النوع
exit
للرجوع إلى Cloud Shell
يؤكّد ذلك أنّ مسار النسخ المتماثل العكسي يعمل، حيث تتم مزامنة التغييرات من Spanner إلى Cloud SQL.
ب. التحقّق من الخطأ المقصود في قائمة انتظار الرسائل غير الصالحة
بما أنّ سجلّ Customers الجديد يتضمّن CreditLimit بقيمة 500 (ما يخالف قيود التحقّق الصارمة > 1000 التي حدّدناها في قاعدة بيانات MySQL المصدر)، رصدت خدمة Dataflow الخطأ بأمان.
- انتقِل إلى Cloud Storage في Google Cloud Console.
- انتقِل إلى الحزمة وافتح المجلد
dlq/severe/. - افتح ملف JSON للاطّلاع على السجلّ
Customersالمرفوض وخطأ انتهاك قيود التحقّق الدقيق. - يمكن إعادة محاولة إصلاح أخطاء قائمة انتظار الرسائل غير المعالَجة (DLQ) لعملية النسخ المتماثل العكسي من خلال تشغيل نموذج تدفق البيانات مع ضبط
runMode=retryDLQ.
12. تنظيف الموارد
لتجنُّب تكبُّد رسوم إضافية على حسابك على Google Cloud، احذف الموارد التي تم إنشاؤها أثناء استخدام هذا الدرس التطبيقي حول الترميز.
ضبط متغيرات البيئة (إذا لزم الأمر)
إذا انتهت مهلة جلسة Cloud Shell أو فتحت نافذة طرفية جديدة، عليك إعادة تصدير متغيرات البيئة قبل تنفيذ أوامر التنظيف.
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1" # Or your preferred region
export ZONE="us-central1-a" # Or a zone within your selected region
export SPANNER_INSTANCE_NAME="target-spanner-instance"
export SPANNER_DATABASE_NAME="sharded-target-db"
export SPANNER_CONFIG="regional-${REGION}"
export BUCKET_NAME="migration-${PROJECT_ID}-bucket"
export MYSQL_IP_1=$(gcloud compute instances describe mysql-physical-1 --zone=$ZONE --format='get(networkInterfaces[0].accessConfigs[0].natIP)')
export MYSQL_IP_2=$(gcloud compute instances describe mysql-physical-2 --zone=$ZONE --format='get(networkInterfaces[0].accessConfigs[0].natIP)')
export SQL_CP_NAME_1="mysql-src-cp-1"
export SQL_CP_NAME_2="mysql-src-cp-2"
export GCS_CP_NAME="gcs-dest-cp"
export STREAM_NAME_1="mysql-to-spanner-stream-1"
export GCS_STREAM_PATH_1="data/${STREAM_NAME_1}"
export STREAM_NAME_2="mysql-to-spanner-stream-2"
export GCS_STREAM_PATH_2="data/${STREAM_NAME_2}"
export PUBSUB_TOPIC="datastream-gcs-updates"
export PUBSUB_SUBSCRIPTION="datastream-gcs-sub"
export CUSTOM_JAR_PATH="gs://${BUCKET_NAME}/custom-logic/spanner-custom-shard-1.0.jar"
export OVERRIDES_FILE="spanner_overrides.json"
export GCS_OVERRIDES_PATH="gs://${BUCKET_NAME}/config/${OVERRIDES_FILE}"
export GCS_SHARDING_PATH="gs://${BUCKET_NAME}/config/sharding.json"
export OUTPUT_DIR="gs://${BUCKET_NAME}/bulk-migration"
export GCS_LIVE_SHARDING_PATH="gs://${BUCKET_NAME}/config/live-sharding.json"
export DLQ_DIR_CDC="gs://${BUCKET_NAME}/live-migration"
export CHANGE_STREAM_NAME="CustomersOrdersChangeStream"
export SPANNER_METADATA_DB_NAME="migration-metadata-db"
export GCS_REVERSE_SHARDING_PATH="gs://${BUCKET_NAME}/config/reverse-sharding.json"
export DLQ_DIR_REVERSE="gs://${BUCKET_NAME}/reverse-replication"
إيقاف مهام البث في Dataflow
أدرِج وظائفك للعثور على معرّفات الوظائف الخاصة بوظائف تدفق البيانات قيد التشغيل. صدِّر JOB_ID_CDC وJOB_ID_REVERSE وفقًا لذلك.
gcloud dataflow jobs list --region=$REGION --filter="state=Running"
export JOB_ID_CDC=<PASTE_JOB_ID_HERE>
export JOB_ID_CDC_RETRY=<PASTE_JOB_ID_HERE>
export JOB_ID_REVERSE=<PASTE_JOB_ID_HERE>
ألغِ مهمة Datastream to Spanner (النقل المباشر) ومهمة إعادة المحاولة:
gcloud dataflow jobs cancel $JOB_ID_CDC --region=$REGION --project=$PROJECT_ID
gcloud dataflow jobs cancel $JOB_ID_CDC_RETRY --region=$REGION --project=$PROJECT_ID
ألغِ مهمة Spanner to Cloud SQL (النسخ الاحتياطي العكسي) باتّباع الخطوات التالية:
gcloud dataflow jobs cancel $JOB_ID_REVERSE --region=$REGION --project=$PROJECT_ID
حذف موارد Datastream
إيقاف البث وحذفه:
gcloud datastream streams update $STREAM_NAME_1 \
--location=$REGION --state=PAUSED --project=$PROJECT_ID
# Wait a moment for the stream to pause
gcloud datastream streams delete $STREAM_NAME_1 \
--location=$REGION --project=$PROJECT_ID --quiet
gcloud datastream streams update $STREAM_NAME_2 \
--location=$REGION --state=PAUSED --project=$PROJECT_ID
# Wait a moment for the stream to pause
gcloud datastream streams delete $STREAM_NAME_2 \
--location=$REGION --project=$PROJECT_ID --quiet
# Delete Connection Profiles
gcloud datastream connection-profiles delete $SQL_CP_NAME_1 \
--location=$REGION --project=$PROJECT_ID --quiet
gcloud datastream connection-profiles delete $SQL_CP_NAME_2 \
--location=$REGION --project=$PROJECT_ID --quiet
gcloud datastream connection-profiles delete $GCS_CP_NAME \
--location=$REGION --project=$PROJECT_ID --quiet
حذف الأجهزة الافتراضية لمصدر MySQL (Compute Engine)
احذف آلتَي Compute Engine الافتراضيتَين اللتَين تحاكيان الأقسام المادية لـ MySQL المحلية.
gcloud compute instances delete mysql-physical-1 mysql-physical-2 --zone=$ZONE --quiet
حذف قواعد جدار الحماية
أزِل قواعد جدار الحماية بين الشبكات التي تم إنشاؤها للسماح بالوصول إلى بروتوكول النقل الآمن (SSH) وإمكانية الاتصال بخدمة Datastream على الأجهزة الافتراضية (VMs). (ملاحظة: إذا كنت قد استخدمت أسماء مختلفة لقواعد جدار الحماية في وقت سابق من الدرس التطبيقي حول الترميز، عدِّلها هنا).
gcloud compute firewall-rules delete allow-ssh-iap --quiet
gcloud compute firewall-rules delete allow-mysql-datastream --quiet
حذف موارد Pub/Sub
حذف الاشتراك:
gcloud pubsub subscriptions delete $PUBSUB_SUBSCRIPTION \
--project=$PROJECT_ID --quiet
حذف الموضوع:
gcloud pubsub topics delete $PUBSUB_TOPIC \
--project=$PROJECT_ID --quiet
حذف مثيل Cloud Spanner
احذف مثيل Cloud Spanner (يؤدي ذلك تلقائيًا إلى حذف كل من قاعدة بيانات sharded-target-db وقاعدة بيانات migration-metadata-db بداخله).
gcloud spanner instances delete $SPANNER_INSTANCE_NAME \
--project=$PROJECT_ID --quiet
حذف حزمة GCS ومحتواها
أخيرًا، احذف حزمة Cloud Storage التي تحتوي على ملفات Datastream وإعدادات Dataflow وقوائم Dead Letter Queues. يحذف الأمر rm -r الحزمة وجميع محتوياتها بشكل متكرر.
gcloud storage rm --recursive gs://${BUCKET_NAME}
حذف ملفات Cloud Shell المحلية
لتنظيف الملفات والأدلة المحلية التي تم إنشاؤها في Cloud Shell أثناء هذا الدرس التطبيقي حول الترميز، نفِّذ الأوامر التالية:
# Remove the JSON configuration files
rm -f sharding.json live-sharding.json reverse-sharding.json spanner_overrides.json
# Remove the cloned Google Cloud DataflowTemplates repository
rm -rf DataflowTemplates