
۱. مقدمه
این آزمایشگاه کد، یک طرح فنی برای متخصصان داده ارائه میدهد. این آزمایشگاه، رویکردی «کدمحور» را برای مدیریت دادهها ترسیم میکند و نحوهی گنجاندن مدیریت قوی کیفیت و فراداده را مستقیماً در چرخهی حیات توسعه نشان میدهد. در هستهی خود، کاتالوگ جهانی دیتاپلکس به عنوان یک ساختار دادهی هوشمند عمل میکند و سازمانها را قادر میسازد تا دادهها را در کل دارایی خود - از دریاچههای داده گرفته تا انبارها - به صورت مرکزی مدیریت، نظارت و مدیریت کنند.
این codelab نحوهی استفاده از Dataplex، BigQuery و Gemini CLI را برای مسطحسازی دادههای پیچیده، پروفایلبندی برنامهنویسیشدهی آنها، تولید پیشنهادهای هوشمند برای قوانین کیفیت داده و پیادهسازی اسکنهای کیفیت خودکار نشان میدهد. هدف اصلی، فراتر رفتن از فرآیندهای دستی و مبتنی بر رابط کاربری - که مستعد خطا و دشوار برای مقیاسپذیری هستند - و در عوض، ایجاد یک چارچوب "سیاست به عنوان کد" قوی و قابل کنترل از نظر نسخه است.
پیشنیازها
- درک اولیه از کنسول ابری گوگل
- مهارتهای پایه در رابط خط فرمان و پوسته ابری گوگل
آنچه یاد خواهید گرفت
- چگونه دادههای تو در تو در BigQuery را با استفاده از Materialized Views مسطح کنیم تا امکان پروفایلسازی جامع فراهم شود.
- نحوهی راهاندازی و مدیریت اسکن پروفایل Dataplex به صورت برنامهنویسی با استفاده از کتابخانهی کلاینت پایتون Dataplex.
- نحوه استخراج دادههای پروفایل و ساختاردهی آن به عنوان ورودی برای یک مدل هوش مصنوعی مولد.
- چگونه میتوان یک اعلان برای Gemini CLI طراحی کرد تا دادههای پروفایل را تجزیه و تحلیل کند و یک فایل قانون YAML سازگار با Dataplex تولید کند.
- اهمیت یک فرآیند تعاملی و انسان در حلقه (HITL) برای اعتبارسنجی پیکربندیهای تولید شده توسط هوش مصنوعی.
- نحوهی استقرار قوانین تولید شده به عنوان یک اسکن خودکار کیفیت داده.
آنچه نیاز دارید
- یک حساب کاربری گوگل کلود و پروژه گوگل کلود
- یک مرورگر وب مانند کروم
مفاهیم کلیدی: ارکان کیفیت دادههای دیتاپلکس
درک اجزای اصلی Dataplex برای ایجاد یک استراتژی موثر کیفیت داده ضروری است.
- اسکن پروفایل دادهها: یک کار Dataplex که دادهها را تجزیه و تحلیل میکند و فرادادههای آماری، از جمله درصدهای تهی، تعداد مقادیر متمایز و توزیع مقادیر را تولید میکند. این به عنوان مرحله "کشف" برنامهریزی شده ما عمل میکند.
- قوانین کیفیت داده: عبارات اعلانی که شرایطی را که دادههای شما باید برآورده کنند تعریف میکنند (مثلاً
NonNullExpectation،SetExpectation،RangeExpectation). - هوش مصنوعی مولد برای پیشنهاد قانون: استفاده از یک مدل زبانی بزرگ (مانند Gemini) برای تجزیه و تحلیل پروفایل دادهها و پیشنهاد قوانین مربوط به کیفیت داده. این امر فرآیند تعریف یک چارچوب کیفیت پایه را تسریع میکند.
- اسکن کیفیت دادهها: یک کار Dataplex که دادهها را در برابر مجموعهای از قوانین از پیش تعریف شده یا سفارشی اعتبارسنجی میکند.
- مدیریت برنامهریزیشده: موضوع اصلی مدیریت کنترلهای مدیریتی (مانند قوانین کیفیت) به صورت کد (مثلاً در فایلهای YAML و اسکریپتهای پایتون). این امر امکان اتوماسیون، نسخهبندی و ادغام در خطوط لوله CI/CD را فراهم میکند.
- انسان در حلقه (HITL): نقطه کنترل حیاتی ادغام تخصص و نظارت انسانی در یک گردش کار خودکار. برای پیکربندیهای تولید شده توسط هوش مصنوعی، HITL برای اعتبارسنجی صحت، مرتبط بودن با کسبوکار و ایمنی پیشنهادات قبل از استقرار ضروری است.
۲. تنظیمات و الزامات
شروع پوسته ابری
اگرچه میتوان از راه دور و از طریق لپتاپ، گوگل کلود را مدیریت کرد، اما در این آزمایشگاه کد، از گوگل کلود شل ، یک محیط خط فرمان که در فضای ابری اجرا میشود، استفاده خواهید کرد.
از کنسول گوگل کلود ، روی آیکون Cloud Shell در نوار ابزار بالا سمت راست کلیک کنید:
آمادهسازی و اتصال به محیط فقط چند لحظه طول میکشد. وقتی تمام شد، باید چیزی شبیه به این را ببینید:

این ماشین مجازی با تمام ابزارهای توسعهای که نیاز دارید، مجهز شده است. این ماشین مجازی یک دایرکتوری خانگی پایدار ۵ گیگابایتی ارائه میدهد و روی فضای ابری گوگل اجرا میشود که عملکرد شبکه و احراز هویت را تا حد زیادی بهبود میبخشد. تمام کارهای شما در این آزمایشگاه کد را میتوان در یک مرورگر انجام داد. نیازی به نصب چیزی ندارید.
فعال کردن API های مورد نیاز و پیکربندی محیط
در داخل Cloud Shell، مطمئن شوید که شناسه پروژه شما تنظیم شده است:
export PROJECT_ID=$(gcloud config get-value project)
gcloud config set project $PROJECT_ID
export LOCATION="us-central1"
export BQ_LOCATION="us"
export DATASET_ID="dataplex_dq_codelab"
export TABLE_ID="ga4_transactions"
gcloud services enable dataplex.googleapis.com \
bigquery.googleapis.com \
serviceusage.googleapis.com
در این مثال، ما us (multi-region) به عنوان مکان استفاده میکنیم، زیرا دادههای نمونه عمومی که استفاده خواهیم کرد نیز در us (multi-region) قرار دارند. BigQuery ایجاب میکند که دادههای منبع و جدول مقصد برای یک پرسوجو در یک مکان قرار داشته باشند.
ایجاد یک مجموعه داده اختصاصی BigQuery
یک مجموعه داده جدید BigQuery ایجاد کنید تا دادهها و نتایج نمونه ما را در خود جای دهد.
bq --location=us mk --dataset $PROJECT_ID:$DATASET_ID
آمادهسازی دادههای نمونه
برای این codelab، شما از یک مجموعه داده عمومی حاوی دادههای تجارت الکترونیک مبهمسازی شده از فروشگاه کالاهای گوگل استفاده خواهید کرد. از آنجایی که مجموعه دادههای عمومی فقط خواندنی هستند، باید یک کپی قابل تغییر در مجموعه داده خود ایجاد کنید. دستور bq زیر یک جدول جدید به نام ga4_transactions در مجموعه داده dataplex_dq_codelab شما ایجاد میکند. این دستور دادهها را از یک روز (2021-01-31) کپی میکند تا اطمینان حاصل شود که اسکنها به سرعت اجرا میشوند.
bq query \
--use_legacy_sql=false \
--destination_table=$PROJECT_ID:$DATASET_ID.$TABLE_ID \
--replace=true \
'SELECT * FROM `bigquery-public-data.ga4_obfuscated_sample_ecommerce.events_20210131`'
راه اندازی دایرکتوری نسخه ی نمایشی
برای شروع، یک مخزن GitHub را که شامل ساختار پوشههای لازم و فایلهای پشتیبانی برای این codelab است، کلون خواهید کرد.
git clone https://github.com/GoogleCloudPlatform/devrel-demos
cd devrel-demos/data-analytics/programmatic-dq
این دایرکتوری اکنون محل کار فعال شماست. تمام فایلهای بعدی در اینجا ایجاد خواهند شد.
۳. کشف خودکار دادهها با پروفایلسازی Dataplex
پروفایلسازی دادههای Dataplex ابزاری قدرتمند برای کشف خودکار اطلاعات آماری در مورد دادههای شما، مانند درصدهای تهی، منحصر به فرد بودن و توزیع مقادیر است. این فرآیند برای درک ساختار و کیفیت دادههای شما ضروری است. با این حال، یک محدودیت شناخته شده در پروفایلسازی Dataplex، عدم توانایی آن در بررسی کامل فیلدهای تو در تو یا تکراری (مثلاً انواع RECORD یا ARRAY ) در یک جدول است. این پروفایلسازی میتواند تشخیص دهد که یک ستون از نوع پیچیده است، اما نمیتواند فیلدهای منفرد را در آن ساختار تو در تو پروفایلسازی کند.
برای غلبه بر این مشکل، دادهها را به نماهای مادیسازیشدهی هدفمند تبدیل خواهیم کرد. این استراتژی هر فیلد را به یک ستون سطح بالا تبدیل میکند و Dataplex را قادر میسازد تا هر یک را به صورت جداگانه نمایه کند.
درک طرحواره تو در تو
ابتدا، بیایید طرح جدول منبع خود را بررسی کنیم. مجموعه داده Google Analytics 4 (GA4) شامل چندین ستون تو در تو و تکراری است. برای بازیابی کامل طرح، شامل تمام ساختارهای تو در تو، میتوانید از دستور bq show استفاده کنید و خروجی را به عنوان یک فایل JSON ذخیره کنید.
bq show --schema --format=json $PROJECT_ID:$DATASET_ID.$TABLE_ID > bq_schema.json
بررسی فایل bq_schema.json ساختارهای پیچیدهای مانند دستگاه، موقعیت جغرافیایی، تجارت الکترونیک و موارد رکورد تکراری را آشکار میکند. اینها ساختارهایی هستند که برای پروفایلبندی مؤثر نیاز به مسطحسازی دارند.
مسطحسازی دادهها با Materialized Views
ایجاد نماهای مادی (MV) موثرترین و کاربردیترین راه حل برای این چالش دادههای تو در تو است. MVها با محاسبه اولیه نتایج مسطح شده، مزایای قابل توجهی در عملکرد و هزینه پرس و جو ارائه میدهند، در حالی که ساختاری سادهتر و رابطهایتر را برای تحلیلگران و ابزارهای پروفایلینگ فراهم میکنند.
اولین فکری که به طور طبیعی به ذهن میرسد این است که همه چیز را در یک نمای واحد و غولپیکر خلاصه کنیم. با این حال، این رویکرد شهودی، دام خطرناکی را پنهان میکند که میتواند منجر به تخریب شدید دادهها شود. بیایید بررسی کنیم که چرا این یک اشتباه مهم است.
-
mv_ga4_user_session_flat.sql
CREATE OR REPLACE MATERIALIZED VIEW `$PROJECT_ID.$DATASET_ID.mv_ga4_user_session_flat`
OPTIONS (
enable_refresh = true,
refresh_interval_minutes = 30
) AS
SELECT
event_date, event_timestamp, event_name, user_pseudo_id, user_id, stream_id, platform,
device.category AS device_category,
device.operating_system AS device_os,
device.operating_system_version AS device_os_version,
device.language AS device_language,
device.web_info.browser AS device_browser,
geo.continent AS geo_continent,
geo.country AS geo_country,
geo.region AS geo_region,
geo.city AS geo_city,
traffic_source.name AS traffic_source_name,
traffic_source.medium AS traffic_source_medium,
traffic_source.source AS traffic_source_source
FROM
`$PROJECT_ID.$DATASET_ID.ga4_transactions`;
-
mv_ga4_ecommerce_transactions.sql
CREATE OR REPLACE MATERIALIZED VIEW `$PROJECT_ID.$DATASET_ID.mv_ga4_ecommerce_transactions`
OPTIONS (
enable_refresh = true,
refresh_interval_minutes = 30
) AS
SELECT
event_date, event_timestamp, user_pseudo_id, ecommerce.transaction_id,
ecommerce.total_item_quantity,
ecommerce.purchase_revenue_in_usd,
ecommerce.purchase_revenue,
ecommerce.refund_value_in_usd,
ecommerce.refund_value,
ecommerce.shipping_value_in_usd,
ecommerce.shipping_value,
ecommerce.tax_value_in_usd,
ecommerce.tax_value,
ecommerce.unique_items
FROM
`$PROJECT_ID.$DATASET_ID.ga4_transactions`
WHERE
ecommerce.transaction_id IS NOT NULL;
-
mv_ga4_ecommerce_items.sql
CREATE OR REPLACE MATERIALIZED VIEW `$PROJECT_ID.$DATASET_ID.mv_ga4_ecommerce_items`
OPTIONS (
enable_refresh = true,
refresh_interval_minutes = 30
) AS
SELECT
event_date, event_timestamp, event_name, user_pseudo_id, ecommerce.transaction_id,
item.item_id,
item.item_name,
item.item_brand,
item.item_variant,
item.item_category,
item.item_category2,
item.item_category3,
item.item_category4,
item.item_category5,
item.price_in_usd,
item.price,
item.quantity,
item.item_revenue_in_usd,
item.item_revenue,
item.coupon,
item.affiliation,
item.item_list_name,
item.promotion_name
FROM
`$PROJECT_ID.$DATASET_ID.ga4_transactions`,
UNNEST(items) AS item
WHERE
ecommerce.transaction_id IS NOT NULL;
حالا، این قالبها را با استفاده از ابزار خط فرمان bq اجرا کنید. دستور envsubst هر فایل را میخواند، متغیرهایی مانند $PROJECT_ID و $DATASET_ID را با مقادیر آنها از محیط shell شما جایگزین میکند و SQL معتبر و نهایی را به دستور bq query ارسال میکند.
envsubst < mv_ga4_user_session_flat.sql | bq query --use_legacy_sql=false
envsubst < mv_ga4_ecommerce_transactions.sql | bq query --use_legacy_sql=false
envsubst < mv_ga4_ecommerce_items.sql | bq query --use_legacy_sql=false
اسکنهای پروفایل را از طریق کلاینت پایتون اجرا کنید
اکنون که نماهای مسطح و قابل نمایهسازی خود را داریم، میتوانیم اسکنهای نمایه داده Dataplex را برای هر یک از آنها به صورت برنامهنویسی ایجاد و اجرا کنیم. اسکریپت پایتون زیر از کتابخانه کلاینت google-cloud-dataplex برای خودکارسازی این فرآیند استفاده میکند.
قبل از اجرای اسکریپت، ایجاد یک محیط پایتون ایزوله در دایرکتوری پروژه شما، یک اقدام بسیار مهم و ضروری است. این کار تضمین میکند که وابستگیهای پروژه به طور جداگانه مدیریت میشوند و از تداخل با سایر بستهها در محیط Cloud Shell شما جلوگیری میشود.
# Create the virtual environment
python3 -m venv dq_venv
# Activate the environment
source dq_venv/bin/activate
اکنون، کتابخانه کلاینت Dataplex را در محیط تازه فعال شده نصب کنید.
# Install the Dataplex client library
pip install google-cloud-dataplex
با راهاندازی محیط و نصب کتابخانه، آمادهی ایجاد اسکریپت ارکستراسیون هستید.
در نوار ابزار Cloud Shell، روی Open Editor کلیک کنید. یک فایل جدید با نام 1_run_dataplex_scans.py ایجاد کنید و کد پایتون زیر را در آن قرار دهید. اگر مخزن GitHub را کلون کنید، این فایل از قبل در پوشه شما وجود دارد.
این اسکریپت برای هر نمای مادی (Materialized View) یک اسکن ایجاد میکند (اگر از قبل وجود نداشته باشد)، اسکن را اجرا میکند و سپس تا زمانی که تمام کارهای اسکن کامل شود، نظرسنجی انجام میدهد.
import os
import sys
import time
from google.cloud import dataplex_v1
from google.api_core.exceptions import AlreadyExists
def create_and_run_scan(
client: dataplex_v1.DataScanServiceClient,
project_id: str,
location: str,
data_scan_id: str,
target_resource: str,
) -> dataplex_v1.DataScanJob | None:
"""
Creates and runs a single data profile scan.
Returns the executed Job object without waiting for completion.
"""
parent = client.data_scan_path(project_id, location, data_scan_id).rsplit('/', 2)[0]
scan_path = client.data_scan_path(project_id, location, data_scan_id)
# 1. Create Data Scan (skips if it already exists)
try:
data_scan = dataplex_v1.DataScan()
data_scan.data.resource = target_resource
data_scan.data_profile_spec = dataplex_v1.DataProfileSpec()
print(f"[INFO] Creating data scan '{data_scan_id}'...")
client.create_data_scan(
parent=parent,
data_scan=data_scan,
data_scan_id=data_scan_id
).result() # Wait for creation to complete
print(f"[SUCCESS] Data scan '{data_scan_id}' created.")
except AlreadyExists:
print(f"[INFO] Data scan '{data_scan_id}' already exists. Skipping creation.")
except Exception as e:
print(f"[ERROR] Error creating data scan '{data_scan_id}': {e}")
return None
# 2. Run Data Scan
try:
print(f"[INFO] Running data scan '{data_scan_id}'...")
run_response = client.run_data_scan(name=scan_path)
print(f"[SUCCESS] Job started for '{data_scan_id}'. Job ID: {run_response.job.name.split('/')[-1]}")
return run_response.job
except Exception as e:
print(f"[ERROR] Error running data scan '{data_scan_id}': {e}")
return None
def main():
"""Main execution function"""
# --- Load configuration from environment variables ---
PROJECT_ID = os.environ.get("PROJECT_ID")
LOCATION = os.environ.get("LOCATION")
DATASET_ID = os.environ.get("DATASET_ID")
if not all([PROJECT_ID, LOCATION, DATASET_ID]):
print("[ERROR] One or more required environment variables are not set.")
print("Please ensure PROJECT_ID, LOCATION, and DATASET_ID are exported in your shell.")
sys.exit(1)
print(f"[INFO] Using Project: {PROJECT_ID}, Location: {LOCATION}, Dataset: {DATASET_ID}")
# List of Materialized Views to profile
TARGET_VIEWS = [
"mv_ga4_user_session_flat",
"mv_ga4_ecommerce_transactions",
"mv_ga4_ecommerce_items"
]
# ----------------------------------------------------
client = dataplex_v1.DataScanServiceClient()
running_jobs = []
# 1. Create and run jobs for all target views
print("\n--- Starting Data Profiling Job Creation and Execution ---")
for view_name in TARGET_VIEWS:
data_scan_id = f"profile-scan-{view_name.replace('_', '-')}"
target_resource = f"//bigquery.googleapis.com/projects/{PROJECT_ID}/datasets/{DATASET_ID}/tables/{view_name}"
job = create_and_run_scan(client, PROJECT_ID, LOCATION, data_scan_id, target_resource)
if job:
running_jobs.append(job)
print("-------------------------------------------------------\n")
if not running_jobs:
print("[ERROR] No jobs were started. Exiting.")
return
# 2. Poll for all jobs to complete
print("--- Monitoring job completion status (checking every 30 seconds) ---")
completed_jobs = {}
while running_jobs:
jobs_to_poll_next = []
print(f"\n[STATUS] Checking status for {len(running_jobs)} running jobs...")
for job in running_jobs:
job_id_short = job.name.split('/')[-1][:13]
try:
updated_job = client.get_data_scan_job(name=job.name)
state = updated_job.state
if state in (dataplex_v1.DataScanJob.State.RUNNING, dataplex_v1.DataScanJob.State.PENDING, dataplex_v1.DataScanJob.State.CANCELING):
print(f" - Job {job_id_short}... Status: {state.name}")
jobs_to_poll_next.append(updated_job)
else:
print(f" - Job {job_id_short}... Status: {state.name} (Complete)")
completed_jobs[job.name] = updated_job
except Exception as e:
print(f"[ERROR] Could not check status for job {job_id_short}: {e}")
running_jobs = jobs_to_poll_next
if running_jobs:
time.sleep(30)
# 3. Print final results
print("\n--------------------------------------------------")
print("[SUCCESS] All data profiling jobs have completed.")
print("\nFinal Job Status Summary:")
for job_name, job in completed_jobs.items():
job_id_short = job_name.split('/')[-1][:13]
print(f" - Job {job_id_short}: {job.state.name}")
if job.state == dataplex_v1.DataScanJob.State.FAILED:
print(f" - Failure Message: {job.message}")
print("\nNext step: Analyze the profile results and generate quality rules.")
if __name__ == "__main__":
main()
حالا، اسکریپت را از ترمینال Cloud Shell خود اجرا کنید.
python 1_run_dataplex_scans.py
این اسکریپت اکنون پروفایلبندی سه نمای مادیشده شما را هماهنگ میکند و بهروزرسانیهای وضعیت را بهصورت بلادرنگ ارائه میدهد. پس از تکمیل، یک پروفایل آماری غنی و قابل خواندن توسط ماشین برای هر نما خواهید داشت که برای مرحله بعدی گردش کار ما آماده است: تولید قانون کیفیت داده مبتنی بر هوش مصنوعی.
میتوانید اسکنهای تکمیلشدهی پروفایل را در کنسول ابری گوگل مشاهده کنید.
- در منوی ناوبری، در بخش Govern به کاتالوگ و پروفایل Dataplex Universal بروید.
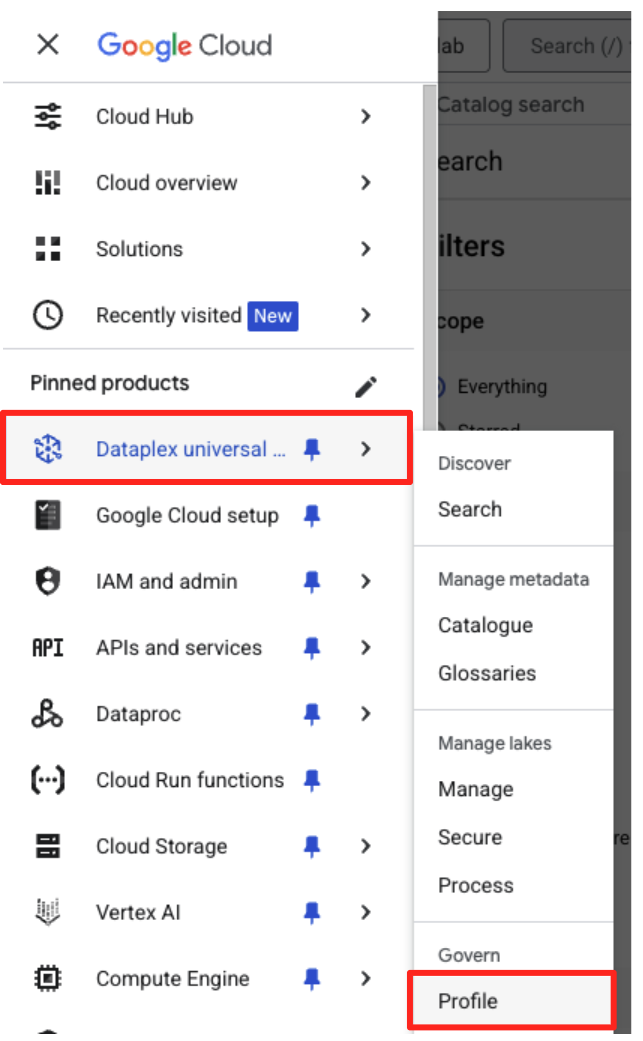
- شما باید سه اسکن پروفایل خود را به همراه آخرین وضعیت شغلی آنها مشاهده کنید. برای مشاهده نتایج دقیق، میتوانید روی هر اسکن کلیک کنید.

از پروفایل BigQuery تا ورودی آماده برای هوش مصنوعی
اسکنهای پروفایل Dataplex با موفقیت اجرا شدهاند. اگرچه نتایج در API Dataplex موجود است، اما برای استفاده از آنها به عنوان ورودی برای یک مدل هوش مصنوعی مولد، باید آنها را در یک فایل محلی ساختاریافته استخراج کنیم.
اسکریپت پایتون زیر، 2_dq_profile_save.py ، به صورت برنامهنویسیشده آخرین کار اسکن پروفایل موفق را برای نمای mv_ga4_user_session_flat ما پیدا میکند. سپس نتیجه کامل و دقیق پروفایل را بازیابی کرده و آن را به عنوان یک فایل JSON محلی با نام dq_profile_results.json ذخیره میکند. این فایل به عنوان ورودی مستقیم برای تحلیل هوش مصنوعی ما در مرحله بعدی عمل خواهد کرد.
در ویرایشگر Cloud Shell خود، یک فایل جدید با نام 2_dq_profile_save.py ایجاد کنید و کد زیر را در آن قرار دهید. مانند مرحله قبل، اگر مخزن را کلون کردهاید، میتوانید از ایجاد فایل صرف نظر کنید.
import os
import sys
import json
from google.cloud import dataplex_v1
from google.api_core.exceptions import NotFound
from google.protobuf.json_format import MessageToDict
# --- Configuration ---
# The Materialized View to analyze is fixed for this step.
TARGET_VIEW = "mv_ga4_user_session_flat"
OUTPUT_FILENAME = "dq_profile_results.json"
def save_to_json_file(content: dict, filename: str):
"""Saves the given dictionary content to a JSON file."""
try:
with open(filename, "w", encoding="utf-8") as f:
# Use indent=2 for a readable, "pretty-printed" JSON file.
json.dump(content, f, indent=2, ensure_ascii=False)
print(f"\n[SUCCESS] Profile results were saved to '{filename}'.")
except (IOError, TypeError) as e:
print(f"[ERROR] An error occurred while saving the file: {e}")
def get_latest_successful_job(
client: dataplex_v1.DataScanServiceClient,
project_id: str,
location: str,
data_scan_id: str
) -> dataplex_v1.DataScanJob | None:
"""Finds and returns the most recently succeeded job for a given data scan."""
scan_path = client.data_scan_path(project_id, location, data_scan_id)
print(f"\n[INFO] Looking for the latest successful job for scan '{data_scan_id}'...")
try:
# List all jobs for the specified scan, which are ordered most-recent first.
jobs_pager = client.list_data_scan_jobs(parent=scan_path)
# Iterate through jobs to find the first one that succeeded.
for job in jobs_pager:
if job.state == dataplex_v1.DataScanJob.State.SUCCEEDED:
return job
# If no successful job is found after checking all pages.
return None
except NotFound:
print(f"[WARN] No scan history found for '{data_scan_id}'.")
return None
def main():
"""Main execution function."""
# --- Load configuration from environment variables ---
PROJECT_ID = os.environ.get("PROJECT_ID")
LOCATION = os.environ.get("LOCATION")
if not all([PROJECT_ID, LOCATION]):
print("[ERROR] Required environment variables PROJECT_ID or LOCATION are not set.")
sys.exit(1)
print(f"[INFO] Using Project: {PROJECT_ID}, Location: {LOCATION}")
print(f"--- Starting Profile Retrieval for: {TARGET_VIEW} ---")
# Construct the data_scan_id based on the target view name.
data_scan_id = f"profile-scan-{TARGET_VIEW.replace('_', '-')}"
# 1. Initialize Dataplex client and get the latest successful job.
client = dataplex_v1.DataScanServiceClient()
latest_job = get_latest_successful_job(client, PROJECT_ID, LOCATION, data_scan_id)
if not latest_job:
print(f"\n[ERROR] No successful job record was found for '{data_scan_id}'.")
print("Please ensure the 'run_dataplex_scans.py' script has completed successfully.")
return
job_id_short = latest_job.name.split('/')[-1]
print(f"[SUCCESS] Found the latest successful job: '{job_id_short}'.")
# 2. Fetch the full, detailed profile result for the job.
print(f"[INFO] Retrieving detailed profile results for job '{job_id_short}'...")
try:
request = dataplex_v1.GetDataScanJobRequest(
name=latest_job.name,
view=dataplex_v1.GetDataScanJobRequest.DataScanJobView.FULL,
)
job_with_full_results = client.get_data_scan_job(request=request)
except Exception as e:
print(f"[ERROR] Failed to retrieve detailed job results: {e}")
return
# 3. Convert the profile result to a dictionary and save it to a JSON file.
if job_with_full_results.data_profile_result:
profile_dict = MessageToDict(job_with_full_results.data_profile_result._pb)
save_to_json_file(profile_dict, OUTPUT_FILENAME)
else:
print("[WARN] The job completed, but no data profile result was found within it.")
print("\n[INFO] Script finished successfully.")
if __name__ == "__main__":
main()
حالا، اسکریپت را از ترمینال خود اجرا کنید:
python 2_dq_profile_save.py
پس از اتمام موفقیتآمیز، فایل جدیدی با نام dq_profile_results.json در دایرکتوری خود خواهید داشت. این فایل حاوی فرادادههای آماری غنی و دقیقی است که ما برای تولید قوانین کیفیت داده از آنها استفاده خواهیم کرد. اگر میخواهید محتوای dq_profile_results.json را بررسی کنید، دستور زیر را اجرا کنید:
cat dq_profile_results.json
۴. تولید قوانین کیفیت داده با رابط خط فرمان Gemini
نصب و پیکربندی رابط خط فرمان Gemini
اگرچه میتوانید API مربوط به Gemini را به صورت برنامهنویسی فراخوانی کنید، اما استفاده از ابزاری مانند Gemini CLI روشی قدرتمند و تعاملی برای ادغام مستقیم هوش مصنوعی مولد در گردشهای کاری ترمینال شما ارائه میدهد. Gemini CLI فقط یک چتبات نیست؛ بلکه یک ابزار گردش کار خط فرمان است که میتواند فایلهای محلی شما را بخواند، کد شما را بفهمد و با سایر ابزارهای سیستمی مانند gcloud تعامل داشته باشد تا وظایف پیچیده را خودکار کند. این ویژگی، آن را برای مورد استفاده ما ایدهآل میکند.
پیشنیاز
ابتدا، مطمئن شوید که پیشنیازهای لازم را دارید: Node.js نسخه 20 یا بالاتر باید در محیط Cloud Shell شما نصب شده باشد. میتوانید نسخه خود را با اجرای node -v بررسی کنید.
نصب
دو روش برای استفاده از رابط خط فرمان Gemini وجود دارد: نصب موقت یا نصب دائمی. ما در اینجا هر دو روش را پوشش خواهیم داد.
شما میتوانید رابط خط فرمان Gemini را مستقیماً برای یک جلسه و بدون هیچ گونه نصب دائمی اجرا کنید. این تمیزترین و سریعترین راه برای "امتحان کردن" آن است، زیرا محیط شما را کاملاً بدون تغییر نگه میدارد.
در ترمینال Cloud Shell خود، دستور زیر را اجرا کنید:
npx https://github.com/google-gemini/gemini-cli
این دستور بسته CLI را به طور موقت دانلود و اجرا میکند.
برای هر پروژه واقعی، بهترین روش توصیه شده، نصب CLI به صورت محلی در دایرکتوری پروژه شما است. این رویکرد چندین مزیت کلیدی دارد:
- جداسازی وابستگی: تضمین میکند که پروژه شما نسخه CLI مخصوص به خود را دارد و از تداخل نسخهها با سایر پروژهها جلوگیری میکند.
- قابلیت تکثیر: هر کسی که پروژه شما را کپی کند، میتواند دقیقاً همان وابستگیها را نصب کند و این باعث میشود که تنظیمات شما قابل اعتماد و قابل حمل باشد.
- بهترین شیوهی همترازی: از مدل استاندارد مدیریت وابستگیهای پروژهی Node.js پیروی میکند و از مشکلات نصب سراسری (-g) اجتناب میکند.
برای نصب CLI به صورت محلی، دستور زیر را از پوشه پروژه خود ( programmatic-dq ) اجرا کنید:
npm install @google/gemini-cli
این یک پوشه node_modules درون programmatic-dq ایجاد میکند. برای اجرای نسخهای که نصب کردهاید، از دستور npx استفاده کنید.
npx gemini
راهاندازی برای اولین بار
هر روشی را که انتخاب کنید، اولین باری که CLI را اجرا میکنید، یک فرآیند راهاندازی یکباره را طی خواهد کرد.

از شما خواسته میشود که یک تم رنگی انتخاب کنید و سپس احراز هویت کنید. سادهترین روش این است که در صورت درخواست، با حساب گوگل خود وارد شوید. سطح رایگان ارائه شده برای این codelab کافی است.
اکنون که CLI نصب و پیکربندی شده است، آمادهاید تا به تولید قوانین بپردازید. CLI از فایلهای موجود در دایرکتوری فعلی خود آگاه است، که برای مرحله بعدی بسیار مهم است.
ایجاد قوانین کیفیت داده
اگرچه میتوان از یک LLM خواست که یک فایل پیکربندی را در یک مرحله تولید کند، اما ماهیت غیرقطعی مدلهای مولد به این معنی است که خروجی ممکن است همیشه کاملاً با طرحواره سختگیرانه مورد نیاز ابزارهایی مانند gcloud مطابقت نداشته باشد. یک روش قابل اعتمادتر، یک فرآیند تعاملی و چند مرحلهای است که در آن ابتدا از هوش مصنوعی به عنوان یک تحلیلگر برای پیشنهاد یک طرح استفاده میکنید، شما (متخصص انسانی) آن طرح را بررسی و تأیید میکنید و تنها پس از آن، هوش مصنوعی کد نهایی را بر اساس دستورالعملهای تأیید شده شما تولید میکند.
این رویکرد، فرآیند را از یک دستور ساده به یک جلسه مشارکتی تبدیل میکند و تضمین میکند که خروجی نهایی دقیق، معتبر و آماده برای استقرار است.
ابتدا، از Gemini میخواهیم که پروفایل آماری را تجزیه و تحلیل کند و به عنوان یک مهندس داده متخصص عمل کند و یک برنامه عملی پیشنهاد دهد. ما به صراحت به آن میگوییم که هنوز فایل YAML را ننویسد. این کار توجه آن را بر تجزیه و تحلیل و توجیه متمرکز میکند.
در جلسه تعاملی Gemini CLI خود، دستور زیر را وارد کنید:
You are an expert Google Cloud Dataplex engineer.
Your first task is to create a plan. I have a file in the current directory named ./dq_profile_results.json.
Based on the statistical data within that file, propose a step-by-step plan to create a Dataplex data quality rules file.
Your plan should identify which specific columns are good candidates for rules like nonNullExpectation, setExpectation, or rangeExpectation, and explain why based on the metrics (e.g., "Plan to create a nonNullExpectation for column X because its null percentage is 0%").
Do not write the YAML file yet. Just provide the plan.
جمینی فایل JSON را تجزیه و تحلیل میکند و باید یک طرح ساختاریافته مشابه این را برگرداند:
Plan to create Dataplex data quality rules
1. Create a row count rule:
- Analysis: The profile shows a total of 26,489 rows.
- Proposed Rule: I will implement a rowCount rule to ensure the table's row count remains within a healthy range (e.g., 20,000 to 30,000). This is a fundamental check to guard against major data loading failures or unexpected deletions.
2. Implement non-null expectation rules:
- Analysis: The profiling results show that many columns have no null values. For example, event_date, event_timestamp, event_name, user_pseudo_id, stream_id, and platform all appear to be fully populated.
- Proposed Rules: I will create nonNullExpectation rules for columns where the nullRatio is 0 or not present, indicating they are always expected to contain a value:
- event_date
- event_timestamp
- event_name
- user_pseudo_id
- stream_id
- platform
- device_category
- device_os
3. Implement set expectation rules:
- Analysis: Several columns contain a small, finite set of values, making them ideal for set validation.
- Proposed Rules: I will create setExpectation rules for these columns:
- platform: It only contains the value "WEB".
- device_category: It contains only "desktop", "mobile", and "tablet".
- geo_continent: It has a well-defined list of continents.
traffic_source_medium: It has a small list of valid mediums like "organic", "(none)", and "referral".
4. Implement range expectation rules:
- Analysis: The profile provides minimum and maximum values for numeric and string length fields.
- Proposed Rules: I will create rangeExpectation rules for the following:
- event_timestamp: The profile shows a clear min and max. I will use these values to create a range check.
- event_date (String Length): The profile indicates that the minLength and maxLength are both 8, which is perfect for enforcing a YYYYMMDD format.
این مهمترین مرحله در کل گردش کار است: بررسی انسان در حلقه (HITL). طرح تولید شده توسط Gemini صرفاً بر اساس الگوهای آماری در دادهها است. این طرح هیچ درکی از زمینه کسب و کار شما، تغییرات دادههای آینده یا هدف خاص پشت دادههای شما ندارد. نقش شما به عنوان متخصص انسانی، اعتبارسنجی، تصحیح و تأیید این طرح قبل از تبدیل آن به کد است.
طرحی را که جوزا ارائه داده است با دقت بررسی کنید.
- آیا منطقی است؟
- آیا با دانش تجاری شما همسو است؟
- آیا قوانینی وجود دارند که از نظر آماری درست باشند اما عملاً بیفایده باشند؟
خروجی که از Gemini دریافت میکنید ممکن است متفاوت باشد. هدف شما اصلاح آن است.
برای مثال، تصور کنید که طرح، قانون rowCount را پیشنهاد میدهد، زیرا جدول تعداد ثابتی ردیف در دادههای نمونه دارد. به عنوان یک متخصص انسانی، ممکن است بدانید که انتظار میرود اندازه این جدول روزانه افزایش یابد، و این امر، یک قانون سختگیرانه برای شمارش ردیف را غیرعملی میکند و احتمالاً باعث هشدارهای کاذب میشود. این یک نمونه عالی از بهکارگیری زمینه تجاری است که هوش مصنوعی فاقد آن است.
اکنون، شما بازخورد خود را به Gemini ارائه میدهید و دستور نهایی را برای تولید کد به آن میدهید. شما باید دستورالعمل زیر را بر اساس طرحی که واقعاً دریافت کردهاید و اصلاحاتی که میخواهید انجام دهید، تطبیق دهید.
دستور زیر یک الگو است. خط اول جایی است که شما اصلاحات خاص خود را ارائه میدهید. اگر طرحی که Gemini به شما داده کامل است و نیازی به تغییر ندارد، میتوانید آن خط را به سادگی حذف کنید.
در همان جلسه Gemini، نسخه اقتباسشده خود از دستورالعمل زیر را وارد کنید:
[YOUR CORRECTIONS AND APPROVAL GO HERE. Examples:
- "The plan looks good. Please proceed."
- "The rowCount rule is not necessary, as the table size changes daily. The rest of the plan is approved. Please proceed."
- "For the setExpectation on the geo_continent column, please also include 'Antarctica'."]
Once you have incorporated my feedback, please generate the `dq_rules.yaml` file.
You must adhere to the following strict requirements:
- Schema Compliance: The YAML structure must strictly conform to the DataQualityRule specification. For a definitive source of truth, you must refer to the sample_rule.yaml file in the current directory and the DataQualityRule class definition in the local virtual environment path: ./dq_venv/.../google/cloud/dataplex_v1/types/data_quality.py.
- Data-Driven Values: All rule parameters, such as thresholds or expected values, must be derived directly from the statistical metrics in dq_profile_results.json.
- Rule Justification: For each rule, add a comment (#) on the line above explaining the justification, as you outlined in your plan.
- Output Purity: The final output must only be the raw YAML code block, perfectly formatted and ready for immediate deployment.
اکنون Gemini محتوای YAML را بر اساس دستورالعملهای دقیق و تأیید شده توسط انسان تولید میکند. پس از اتمام، فایل جدیدی با نام dq_rules.yaml در دایرکتوری کاری خود خواهید یافت.
اسکن کیفیت داده را ایجاد و اجرا کنید
اکنون که یک فایل dq_rules.yaml تولید شده توسط هوش مصنوعی و معتبر شده توسط انسان دارید، میتوانید با اطمینان آن را مستقر کنید.
با تایپ کردن /quit یا دو بار فشردن Ctrl+C از محیط خط فرمان Gemini خارج شوید.
دستور gcloud زیر یک منبع اسکن داده جدید Dataplex ایجاد میکند. این دستور هنوز اسکن را اجرا نمیکند؛ بلکه صرفاً تعریف و پیکربندی اسکن (فایل YAML ما) را در Dataplex ثبت میکند.
این دستور را در ترمینال خود اجرا کنید:
export DQ_SCAN="dq-scan"
gcloud dataplex datascans create data-quality $DQ_SCAN \
--project=$PROJECT_ID \
--location=$LOCATION \
--data-quality-spec-file=dq_rules.yaml \
--data-source-resource="//bigquery.googleapis.com/projects/$PROJECT_ID/datasets/$DATASET_ID/tables/mv_ga4_user_session_flat"
با تعریف اسکن، میتوانید یک کار (job) را برای اجرای آن آغاز کنید.
gcloud dataplex datascans run $DQ_SCAN --location=$LOCATION --project=$PROJECT_ID
این دستور یک شناسهی کار (job ID) را نمایش میدهد. میتوانید وضعیت این کار را در بخش Dataplex کنسول Google Cloud مشاهده کنید. پس از تکمیل، نتایج برای تجزیه و تحلیل در یک جدول BigQuery نوشته میشوند.
۵. نقش حیاتی نیروی انسانی در حلقه (HITL)
اگرچه استفاده از Gemini برای تسریع تولید قانون فوقالعاده قدرتمند است، اما بسیار مهم است که با هوش مصنوعی به عنوان یک کمک خلبان بسیار ماهر رفتار شود، نه یک خلبان کاملاً خودکار. فرآیند انسان در حلقه (HITL) یک پیشنهاد اختیاری نیست؛ بلکه یک گام اساسی و غیرقابل مذاکره در هر گردش کار قوی و قابل اعتماد برای مدیریت دادهها است. صرفاً به کارگیری مصنوعات تولید شده توسط هوش مصنوعی بدون نظارت دقیق انسانی، دستورالعملی برای شکست است.
dq_rules.yaml تولید شده توسط هوش مصنوعی را به عنوان یک درخواست pull که توسط یک توسعهدهنده هوش مصنوعی بسیار سریع اما بیتجربه ارسال شده است، در نظر بگیرید. این درخواست قبل از ادغام در "شاخه اصلی" سیاست حاکمیتی شما و استقرار آن، نیاز به بررسی کامل توسط یک متخصص ارشد انسانی - شما - دارد. این بررسی برای کاهش نقاط ضعف ذاتی مدلهای زبان بزرگ ضروری است.
در اینجا به تفصیل توضیح داده شده است که چرا این بررسی انسانی ضروری است و شما باید به طور خاص به دنبال چه چیزی باشید:
۱. اعتبارسنجی زمینهای: هوش مصنوعی فاقد آگاهی تجاری است
- نقطه ضعف LLM : یک LLM استاد الگوها و آمار است، اما هیچ درکی از زمینه کسب و کار شما ندارد. برای مثال، اگر ستون
new_campaign_idدارای نسبت تهی ۹۸٪ باشد، یک LLM ممکن است به دلایل آماری این ستون را نادیده بگیرد. - نقش حیاتی نیروی انسانی: شما، به عنوان متخصص انسانی، میدانید که فیلد
new_campaign_idدیروز برای عرضه یک محصول بزرگ در هفته آینده اضافه شده است. میدانید که نسبت صفر آن باید در حال حاضر بالا باشد، اما انتظار میرود که به طور قابل توجهی کاهش یابد. همچنین میدانید که پس از پر شدن، باید از یک قالب خاص پیروی کند. هوش مصنوعی نمیتواند این دانش تجاری خارجی را استنباط کند. نقش شما این است که این زمینه تجاری را در پیشنهادات آماری هوش مصنوعی اعمال کنید و در صورت لزوم آنها را نادیده بگیرید یا تقویت کنید.
۲. صحت و دقت: محافظت در برابر توهم و خطاهای ظریف
- نقطه ضعف LLM: LLMها میتوانند «با اطمینان اشتباه کنند». آنها میتوانند «توهم» کنند یا کدی تولید کنند که به طور نامحسوسی نادرست باشد. برای مثال، ممکن است یک فایل YAML با یک قانون با نام صحیح اما یک پارامتر نامعتبر تولید کند، یا ممکن است یک نوع قانون را اشتباه بنویسد (مثلاً به جای
setExpectationصحیح،setExpectationsبنویسد). این خطاهای نامحسوس باعث میشوند که استقرار با شکست مواجه شود، اما تشخیص آنها میتواند دشوار باشد. - نقش حیاتی انسان: وظیفه شما این است که به عنوان اعتبارسنج نهایی خطکش و طرحواره عمل کنید. شما باید YAML تولید شده را با دقت با مشخصات رسمی Dataplex
DataQualityRuleبررسی کنید. شما فقط بررسی نمیکنید که آیا "درست به نظر میرسد" یا خیر؛ بلکه صحت نحوی و معنایی آن را نیز اعتبارسنجی میکنید تا مطمئن شوید که ۱۰۰٪ با API هدف مطابقت دارد. به همین دلیل است که codelab از Gemini میخواهد که به فایلهای طرحواره ارجاع دهد - تا احتمال خطا را کاهش دهد - اما تأیید نهایی بر عهده شماست.
۳. ایمنی و کاهش ریسک: جلوگیری از پیامدهای پاییندستی
- نقطه ضعف LLM: یک قانون کیفیت داده ناقص که در محیط عملیاتی به کار گرفته شود، میتواند عواقب شدیدی داشته باشد. اگر هوش مصنوعی،
rangeExpectationبرای مبلغ تراکنش مالی را بسیار گسترده پیشنهاد دهد، ممکن است در تشخیص فعالیتهای کلاهبرداری ناموفق باشد. برعکس، اگر قانونی را پیشنهاد کند که بر اساس یک نمونه داده کوچک، بسیار سختگیرانه باشد، میتواند تیم آماده به کار شما را با هزاران هشدار مثبت کاذب مواجه کند که منجر به خستگی ناشی از هشدار و از دست رفتن مسائل واقعی میشود. - نقش حیاتی انسان: شما مهندس ایمنی هستید. شما باید تأثیر بالقوهی هر قانون پیشنهادی هوش مصنوعی را در پاییندست ارزیابی کنید. از خود بپرسید: «اگر این قانون شکست بخورد چه اتفاقی میافتد؟ آیا هشدار قابل اجرا است؟ اگر این قانون به اشتباه تأیید شود، چه خطری وجود دارد؟» این ارزیابی ریسک، یک قابلیت منحصر به فرد انسانی است که هزینهی شکست را در مقابل سود حاصل از بررسی میسنجد.
۴. حکمرانی به عنوان یک فرآیند مستمر: گنجاندن دانش آیندهنگر
- نقطه ضعف LLM: دانش هوش مصنوعی مبتنی بر یک تصویر لحظهای ایستا از دادهها است - این پروفایل از یک نقطه زمانی خاص حاصل میشود. هیچ دانشی از رویدادهای آینده ندارد.
- نقش حیاتی انسان: استراتژی مدیریتی شما باید آیندهنگر باشد. شما میدانید که قرار است ماه آینده یک منبع داده منتقل شود که این امر stream_id را تغییر میدهد. شما میدانید که یک کشور جدید به لیست
geo_countryاضافه میشود. فرآیند HITL جایی است که شما این دانش مربوط به وضعیت آینده را تزریق میکنید، قوانین را بهروزرسانی یا موقتاً غیرفعال میکنید تا از بروز نقص در طول تحولات تجاری یا فنی برنامهریزیشده جلوگیری کنید. کیفیت دادهها یک تنظیم یکباره نیست؛ بلکه یک فرآیند زنده است که باید تکامل یابد و فقط یک انسان میتواند این تکامل را هدایت کند.
به طور خلاصه، HITL مکانیزم تضمین کیفیت و ایمنی ضروری است که حکمرانی مبتنی بر هوش مصنوعی را از یک ایده بدیع اما پرخطر به یک رویه مسئولانه، مقیاسپذیر و در سطح سازمانی تبدیل میکند. این مکانیزم تضمین میکند که سیاستهای نهایی اعمال شده نه تنها توسط هوش مصنوعی شتابدهی شدهاند، بلکه توسط انسان نیز اعتبارسنجی شدهاند و سرعت ماشینها را با خرد و دانش متخصصان انسانی ترکیب میکنند.
با این حال، این تأکید بر نظارت انسانی از ارزش هوش مصنوعی نمیکاهد. برعکس، هوش مصنوعی مولد نقش مهمی در تسریع فرآیند HITL ایفا میکند.
بدون هوش مصنوعی، یک مهندس داده باید:
- به صورت دستی کوئریهای پیچیده SQL برای پروفایل کردن دادهها بنویسید (مثلاً
COUNT DISTINCT،AVG،MIN،MAXبرای هر ستون). - با دقت و وسواس، نتایج را به صورت صفحه گسترده و جداگانه تجزیه و تحلیل کنید.
- نوشتن تک تک خطوط فایل قوانین YAML از ابتدا، کاری خستهکننده و مستعد خطا.
هوش مصنوعی این مراحل طاقتفرسا و زمانبر را خودکار میکند. این هوش مصنوعی مانند یک تحلیلگر خستگیناپذیر عمل میکند که فوراً مشخصات آماری را پردازش میکند و یک «پیشنویس اولیه» خوشساخت و ۸۰٪ کامل از سیاست ارائه میدهد.
این اساساً ماهیت کار انسان را تغییر میدهد. به جای صرف ساعتها وقت برای پردازش دستی دادهها و کدنویسی تکراری، متخصص انسانی میتواند بلافاصله روی ارزشمندترین وظایف تمرکز کند:
- اعمال شرایط بحرانی کسب و کار.
- اعتبارسنجی درستی منطق هوش مصنوعی.
- تصمیمگیریهای استراتژیک در مورد اینکه کدام قوانین واقعاً مهم هستند.
در این همکاری، هوش مصنوعی «چه چیزی» (الگوهای آماری چیستند؟) را مدیریت میکند و انسان را آزاد میگذارد تا روی «چرا» (چرا این الگو برای کسبوکار ما مهم است؟) و «خب که چی» (پس سیاست ما باید چه باشد؟) تمرکز کند. بنابراین، هوش مصنوعی جایگزین حلقه نمیشود؛ بلکه هر چرخه را در طول حلقه سریعتر، هوشمندانهتر و تأثیرگذارتر میکند.
۶. تمیز کردن محیط زیست
برای جلوگیری از هزینههای بعدی برای حساب Google Cloud خود برای منابع استفاده شده در این codelab، باید پروژهای که شامل منابع است را حذف کنید. با این حال، اگر میخواهید پروژه را نگه دارید، میتوانید منابع جداگانهای را که ایجاد کردهاید حذف کنید.
اسکنهای Dataplex را حذف کنید
ابتدا، اسکنهای پروفایل و کیفیتی که ایجاد کردهاید را حذف کنید. برای جلوگیری از حذف تصادفی منابع مهم، این دستورات از نامهای خاص اسکنهای ایجاد شده در این codelab استفاده میکنند.
# Delete the Data Quality Scan
gcloud dataplex datascans delete dq-scan \
--location=us-central1 \
--project=$PROJECT_ID --quiet
# Delete the Data Profile Scans
gcloud dataplex datascans delete profile-scan-mv-ga4-user-session-flat \
--location=us-central1 \
--project=$PROJECT_ID --quiet
gcloud dataplex datascans delete profile-scan-mv-ga4-ecommerce-transactions \
--location=us-central1 \
--project=$PROJECT_ID --quiet
gcloud dataplex datascans delete profile-scan-mv-ga4-ecommerce-items \
--location=us-central1 \
--project=$PROJECT_ID --quiet
مجموعه داده BigQuery را حذف کنید
در مرحله بعد، مجموعه داده BigQuery را حذف کنید. این دستور برگشتناپذیر است و از پرچم -f (force) برای حذف مجموعه داده و تمام جداول آن بدون تأیید استفاده میکند.
# Manually type this command to confirm you are deleting the correct dataset
bq rm -r -f --dataset $PROJECT_ID:dataplex_dq_codelab
۷. تبریک میگویم!
شما با موفقیت آزمایشگاه کد را به پایان رساندید!
شما یک گردش کار مدیریت دادهی برنامهای و سرتاسری ایجاد کردهاید. شما با استفاده از Materialized Views برای مسطحسازی دادههای پیچیدهی BigQuery شروع کردید و آن را برای تجزیه و تحلیل مناسب ساختید. سپس به صورت برنامهنویسیشده، اسکنهای پروفایل Dataplex را برای تولید فرادادههای آماری اجرا کردید. مهمتر از همه، از رابط خط فرمان Gemini برای تجزیه و تحلیل خروجی پروفایل و تولید هوشمندانهی یک مصنوع "سیاست به عنوان کد" ( dq_rules.yaml ) استفاده کردید. سپس از رابط خط فرمان برای استقرار این پیکربندی به عنوان یک اسکن خودکار کیفیت داده استفاده کردید و حلقهی یک استراتژی مدیریت مدرن و مقیاسپذیر را بستید.
اکنون شما به الگوی اساسی برای ساخت سیستمهای کیفیت داده قابل اعتماد، مبتنی بر هوش مصنوعی و معتبر شده توسط انسان در Google Cloud مجهز شدهاید.
قدم بعدی چیست؟
- ادغام با CI/CD: فایل dq_rules.yaml را بردارید و آن را در یک مخزن Git ذخیره کنید. یک خط لوله CI/CD (مثلاً با استفاده از Cloud Build یا GitHub Actions) ایجاد کنید که هر زمان فایل قانون بهروزرسانی میشود، اسکن Dataplex را بهطور خودکار اجرا کند.
- کاوش در قوانین SQL سفارشی: فراتر از انواع قوانین استاندارد. دیتاپلکس از قوانین SQL سفارشی برای اجرای منطق پیچیدهتر و خاص کسب و کار که نمیتوان با بررسیهای از پیش تعریف شده بیان کرد، پشتیبانی میکند. این یک ویژگی قدرتمند برای تطبیق اعتبارسنجی با نیازهای منحصر به فرد شماست.
- بهینهسازی اسکنها برای افزایش کارایی و کاهش هزینه: برای جداول بسیار بزرگ، میتوانید با عدم نیاز به اسکن مداوم کل مجموعه دادهها، عملکرد را بهبود بخشیده و هزینهها را کاهش دهید. با استفاده از فیلترها، اسکن را به بازههای زمانی خاص یا بخشهای داده محدود کنید، یا اسکنهای نمونهبرداری شده را برای بررسی درصد مشخصی از دادههای خود پیکربندی کنید.
- نتایج را تجسم کنید: خروجی هر اسکن کیفیت داده Dataplex در یک جدول BigQuery نوشته میشود. این جدول را به Looker Studio متصل کنید تا داشبوردهایی بسازید که نمرات کیفیت داده شما را در طول زمان، بر اساس ابعادی که تعریف کردهاید (مثلاً کامل بودن، اعتبار) جمعآوری میکنند. این امر نظارت را پیشگیرانه و قابل مشاهده برای همه ذینفعان میکند.
- به اشتراک گذاری بهترین شیوهها: به اشتراک گذاری دانش در سازمان خود را تشویق کنید تا از تجربه جمعی بهره برده و استراتژی کیفیت دادههای خود را بهبود بخشید. پرورش فرهنگ اعتماد به دادهها، کلید موفقیت تلاشهای مدیریتی شماست.
- مستندات را مطالعه کنید: