
1. 📖 Pengantar

Pernahkah Anda merasa frustrasi dan terlalu malas untuk mengelola semua pengeluaran pribadi Anda? Saya juga! Oleh karena itu, dalam codelab ini, kita akan membuat asisten pengelola pengeluaran pribadi yang didukung oleh Gemini 2.5 untuk melakukan semua tugas untuk kita. Mulai dari mengelola tanda terima yang diupload hingga menganalisis apakah Anda sudah terlalu banyak mengeluarkan uang untuk membeli kopi.
Asisten ini akan dapat diakses melalui browser web dalam bentuk antarmuka web chat, tempat Anda dapat berkomunikasi dengannya, mengupload beberapa gambar tanda terima dan meminta asisten untuk menyimpannya, atau mungkin ingin menelusuri beberapa tanda terima untuk mendapatkan file dan melakukan analisis pengeluaran. Semua ini dibangun di atas framework Agent Development Kit Google
Aplikasi itu sendiri dibagi menjadi 2 layanan: frontend dan backend; memungkinkan Anda membuat prototipe cepat dan mencoba tampilannya, serta memahami tampilan kontrak API untuk mengintegrasikan keduanya.
Selama mengikuti codelab, Anda akan menggunakan pendekatan langkah demi langkah sebagai berikut:
- Siapkan project Google Cloud Anda dan Aktifkan semua API yang diperlukan di project tersebut
- Menyiapkan bucket di Google Cloud Storage dan database di Firestore
- Membuat Pengindeksan Firestore
- Menyiapkan ruang kerja untuk lingkungan coding Anda
- Menyusun kode sumber, alat, perintah, dll. agen ADK
- Menguji agen menggunakan UI Pengembangan Web lokal ADK
- Buat layanan frontend - antarmuka chat menggunakan library Gradio, untuk mengirim beberapa kueri dan mengupload gambar tanda terima
- Bangun layanan backend - server HTTP menggunakan FastAPI yang merupakan tempat kode agen ADK, SessionService, dan Artifact Service berada
- Mengelola variabel lingkungan dan menyiapkan file yang diperlukan untuk men-deploy aplikasi ke Cloud Run
- Men-deploy aplikasi ke Cloud Run
Ringkasan Arsitektur

Prasyarat
- Nyaman bekerja dengan Python
- Pemahaman tentang arsitektur full-stack dasar menggunakan layanan HTTP
Yang akan Anda pelajari
- Pembuatan prototipe web frontend dengan Gradio
- Pengembangan layanan backend dengan FastAPI dan Pydantic
- Merancang Agen ADK sambil memanfaatkan beberapa kemampuannya
- Penggunaan alat
- Pengelolaan Sesi dan Artefak
- Penggunaan callback untuk modifikasi input sebelum dikirim ke Gemini
- Memanfaatkan BuiltInPlanner untuk meningkatkan eksekusi tugas dengan melakukan perencanaan
- Proses debug cepat melalui antarmuka web lokal ADK
- Strategi untuk mengoptimalkan interaksi multimodal melalui parsing dan pengambilan informasi melalui teknik perintah dan modifikasi permintaan Gemini menggunakan callback ADK
- Agentic Retrieval Augmented Generation menggunakan Firestore sebagai Database Vektor
- Mengelola variabel lingkungan dalam file YAML dengan Pydantic-settings
- Men-deploy aplikasi ke Cloud Run menggunakan Dockerfile dan menyediakan variabel lingkungan dengan file YAML
Yang Anda butuhkan
- Browser web Chrome
- Akun Gmail
- Project Cloud dengan penagihan diaktifkan
Codelab ini, yang dirancang untuk developer dari semua tingkat keahlian (termasuk pemula), menggunakan Python dalam aplikasi contohnya. Namun, pengetahuan Python tidak diperlukan untuk memahami konsep yang disajikan.
2. 🚀 Sebelum memulai
Pilih Project Aktif di Konsol Cloud
Codelab ini mengasumsikan bahwa Anda sudah memiliki project Google Cloud dengan penagihan yang diaktifkan. Jika belum memilikinya, Anda dapat mengikuti petunjuk di bawah untuk memulai.
- Di Konsol Google Cloud, di halaman pemilih project, pilih atau buat project Google Cloud.
- Pastikan penagihan diaktifkan untuk project Cloud Anda. Pelajari cara memeriksa apakah penagihan telah diaktifkan pada suatu project.

Siapkan Database Firestore
Selanjutnya, kita juga perlu membuat Database Firestore. Firestore dalam mode Native adalah database dokumen NoSQL yang dibuat untuk penskalaan otomatis, performa tinggi, dan kemudahan pengembangan aplikasi. Selain itu, alat ini dapat berfungsi sebagai database vektor yang dapat mendukung teknik Retrieval Augmented Generation untuk lab kami.
- Telusuri "firestore" di kotak penelusuran, lalu klik produk Firestore

- Kemudian, klik tombol Create A Firestore Database
- Gunakan (default) sebagai nama ID database dan biarkan Standard Edition dipilih. Untuk demo lab ini, gunakan Firestore Native dengan aturan keamanan Terbuka.
- Anda juga akan melihat bahwa database ini sebenarnya memiliki Penggunaan Tingkat Gratis YEAY! Setelah itu, klik Create Database Button

Setelah melakukan langkah-langkah ini, Anda akan dialihkan ke Database Firestore yang baru saja Anda buat
Menyiapkan Project Cloud di Terminal Cloud Shell
- Anda akan menggunakan Cloud Shell, lingkungan command line yang berjalan di Google Cloud yang telah dilengkapi dengan bq. Klik Activate Cloud Shell di bagian atas konsol Google Cloud.

- Setelah terhubung ke Cloud Shell, Anda dapat memeriksa bahwa Anda sudah diautentikasi dan project sudah ditetapkan ke project ID Anda menggunakan perintah berikut:
gcloud auth list
- Jalankan perintah berikut di Cloud Shell untuk mengonfirmasi bahwa perintah gcloud mengetahui project Anda.
gcloud config list project
- Jika project Anda belum ditetapkan, gunakan perintah berikut untuk menetapkannya:
gcloud config set project <YOUR_PROJECT_ID>
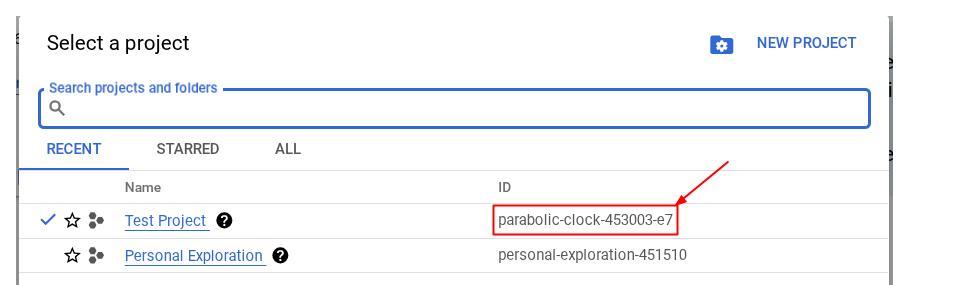
Atau, Anda juga dapat melihat ID PROJECT_ID di konsol
Klik project tersebut dan Anda akan melihat semua project dan project ID di sisi kanan
- Aktifkan API yang diperlukan melalui perintah yang ditampilkan di bawah. Proses ini mungkin memerlukan waktu beberapa menit, jadi harap bersabar.
gcloud services enable aiplatform.googleapis.com \
firestore.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
cloudresourcemanager.googleapis.com
Setelah perintah berhasil dieksekusi, Anda akan melihat pesan yang mirip dengan yang ditampilkan di bawah:
Operation "operations/..." finished successfully.
Alternatif untuk perintah gcloud adalah melalui konsol dengan menelusuri setiap produk atau menggunakan link ini.
Jika ada API yang terlewat, Anda dapat mengaktifkannya kapan saja selama pelaksanaan.
Baca dokumentasi untuk mempelajari perintah gcloud dan penggunaannya.
Siapkan Bucket Google Cloud Storage
Selanjutnya, dari terminal yang sama, kita perlu menyiapkan bucket GCS untuk menyimpan file yang diupload. Jalankan perintah berikut untuk membuat bucket. Nama bucket yang unik namun relevan dengan tanda terima asisten pengeluaran pribadi akan diperlukan, sehingga kita akan menggunakan nama bucket berikut yang dikombinasikan dengan project ID Anda
gsutil mb -l us-central1 gs://personal-expense-{your-project-id}
Outputnya akan menampilkan
Creating gs://personal-expense-{your-project-id}
Anda dapat memverifikasinya dengan membuka Navigation Menu di kiri atas browser dan memilih Cloud Storage -> Bucket

Membuat Indeks Firestore untuk Penelusuran
Firestore adalah database NoSQL secara native, yang menawarkan performa dan fleksibilitas yang unggul dalam model data, tetapi memiliki batasan dalam hal kueri yang kompleks. Karena kita berencana menggunakan beberapa kueri multi-kolom gabungan dan penelusuran vektor, kita harus membuat beberapa indeks terlebih dahulu. Anda dapat membaca detail selengkapnya di dokumentasi ini
- Jalankan perintah berikut untuk membuat indeks guna mendukung kueri gabungan
gcloud firestore indexes composite create \
--collection-group=personal-expense-assistant-receipts \
--field-config field-path=total_amount,order=ASCENDING \
--field-config field-path=transaction_time,order=ASCENDING \
--field-config field-path=__name__,order=ASCENDING \
--database="(default)"
- Dan jalankan yang ini untuk mendukung penelusuran vektor
gcloud firestore indexes composite create \
--collection-group="personal-expense-assistant-receipts" \
--query-scope=COLLECTION \
--field-config field-path="embedding",vector-config='{"dimension":"768", "flat": "{}"}' \
--database="(default)"
Anda dapat memeriksa indeks yang dibuat dengan membuka Firestore di konsol cloud, mengklik instance database (default), lalu memilih Indexes di menu navigasi

Buka Cloud Shell Editor dan Siapkan Direktori Kerja Aplikasi
Sekarang, kita dapat menyiapkan editor kode untuk melakukan beberapa hal terkait coding. Kita akan menggunakan Cloud Shell Editor untuk melakukannya
- Klik tombol Open Editor, yang akan membuka Cloud Shell Editor, kita dapat menulis kode di sini

- Selanjutnya, kita juga perlu memeriksa apakah shell sudah dikonfigurasi ke PROJECT ID yang benar yang Anda miliki. Jika Anda melihat ada nilai di dalam ( ) sebelum ikon $ di terminal ( pada screenshot di bawah, nilainya adalah "adk-multimodal-tool"), nilai ini menunjukkan project yang dikonfigurasi untuk sesi shell aktif Anda.

Jika nilai yang ditampilkan sudah benar, Anda dapat melewati perintah berikutnya. Namun, jika tidak benar atau tidak ada, jalankan perintah berikut
gcloud config set project <YOUR_PROJECT_ID>
- Selanjutnya, clone direktori kerja template untuk codelab ini dari GitHub dengan menjalankan perintah berikut. Tindakan ini akan membuat direktori kerja di direktori personal-expense-assistant
git clone https://github.com/alphinside/personal-expense-assistant-adk-codelab-starter.git personal-expense-assistant
- Setelah itu, buka bagian atas Cloud Shell Editor, klik File->Open Folder, temukan direktori username Anda, lalu temukan direktori personal-expense-assistant, lalu klik tombol OK. Tindakan ini akan menjadikan direktori yang dipilih sebagai direktori kerja utama. Dalam contoh ini, nama penggunanya adalah alvinprayuda, sehingga jalur direktori ditampilkan di bawah


Sekarang, Editor Cloud Shell Anda akan terlihat seperti ini

Penyiapan Lingkungan
Siapkan Lingkungan Virtual Python
Langkah selanjutnya adalah menyiapkan lingkungan pengembangan. Terminal aktif Anda saat ini harus berada di dalam direktori kerja personal-expense-assistant. Kita akan menggunakan Python 3.12 dalam codelab ini dan kita akan menggunakan pengelola project Python uv untuk menyederhanakan kebutuhan pembuatan dan pengelolaan versi Python serta lingkungan virtual
- Jika Anda belum membuka terminal, buka dengan mengklik Terminal -> New Terminal , atau gunakan Ctrl + Shift + C , yang akan membuka jendela terminal di bagian bawah browser

- Sekarang , mari kita lakukan inisialisasi lingkungan virtual menggunakan
uv. Jalankan perintah ini
cd ~/personal-expense-assistant
uv sync --frozen
Tindakan ini akan membuat direktori .venv dan menginstal dependensi. Pratinjau cepat di pyproject.toml akan memberi Anda informasi tentang dependensi yang ditampilkan seperti ini
dependencies = [
"datasets>=3.5.0",
"google-adk==1.18",
"google-cloud-firestore>=2.20.1",
"gradio>=5.23.1",
"pydantic>=2.10.6",
"pydantic-settings[yaml]>=2.8.1",
]
Menyiapkan File Konfigurasi
Sekarang kita perlu menyiapkan file konfigurasi untuk project ini. Kita menggunakan pydantic-settings untuk membaca konfigurasi dari file YAML.
Kita telah menyediakan template file di dalam settings.yaml.example , kita perlu menyalin file dan mengganti namanya menjadi settings.yaml. Jalankan perintah ini untuk membuat file
cp settings.yaml.example settings.yaml
Kemudian, salin nilai berikut ke dalam file
GCLOUD_LOCATION: "us-central1"
GCLOUD_PROJECT_ID: "your-project-id"
BACKEND_URL: "http://localhost:8081/chat"
STORAGE_BUCKET_NAME: "personal-expense-{your-project-id}"
DB_COLLECTION_NAME: "personal-expense-assistant-receipts"
Untuk codelab ini, kita akan menggunakan nilai yang telah dikonfigurasi sebelumnya untuk GCLOUD_LOCATION, BACKEND_URL, dan DB_COLLECTION_NAME .
Sekarang kita dapat melanjutkan ke langkah berikutnya, yaitu membuat agen dan kemudian layanan
3. 🚀 Bangun Agen menggunakan ADK Google dan Gemini 2.5
Pengantar Struktur Direktori ADK
Mari kita mulai dengan mempelajari apa yang ditawarkan ADK dan cara membuat agen. Dokumentasi lengkap ADK dapat diakses di URL ini . ADK menawarkan banyak utilitas dalam eksekusi perintah CLI-nya. Beberapa di antaranya adalah sebagai berikut :
- Menyiapkan struktur direktori agen
- Mencoba interaksi dengan cepat melalui input output CLI
- Menyiapkan antarmuka web UI pengembangan lokal dengan cepat
Sekarang, mari buat struktur direktori agen menggunakan perintah CLI. Jalankan perintah berikut.
uv run adk create expense_manager_agent
Saat diminta, pilih model gemini-2.5-flash dan backend Vertex AI. Kemudian, wizard akan meminta project ID dan lokasi. Anda dapat menerima opsi default dengan menekan enter, atau mengubahnya sesuai kebutuhan. Periksa kembali bahwa Anda menggunakan project ID yang benar yang dibuat sebelumnya di lab ini. Outputnya akan terlihat seperti ini:
Choose a model for the root agent: 1. gemini-2.5-flash 2. Other models (fill later) Choose model (1, 2): 1 1. Google AI 2. Vertex AI Choose a backend (1, 2): 2 You need an existing Google Cloud account and project, check out this link for details: https://google.github.io/adk-docs/get-started/quickstart/#gemini---google-cloud-vertex-ai Enter Google Cloud project ID [going-multimodal-lab]: Enter Google Cloud region [us-central1]: Agent created in /home/username/personal-expense-assistant/expense_manager_agent: - .env - __init__.py - agent.py
Tindakan ini akan membuat struktur direktori agen berikut
expense_manager_agent/ ├── __init__.py ├── .env ├── agent.py
Jika Anda memeriksa init.py dan agent.py, Anda akan melihat kode ini
# __init__.py
from . import agent
# agent.py
from google.adk.agents import Agent
root_agent = Agent(
model='gemini-2.5-flash',
name='root_agent',
description='A helpful assistant for user questions.',
instruction='Answer user questions to the best of your knowledge',
)
Sekarang Anda dapat mengujinya dengan menjalankan
uv run adk run expense_manager_agent
Setelah selesai menguji, Anda dapat keluar dari agen dengan mengetik exit atau menekan Ctrl+D.
Membangun Agen Pengelola Pengeluaran
Mari kita bangun agen pengelola pengeluaran. Buka file expense_manager_agent/agent.py dan salin kode di bawah yang akan berisi root_agent.
# expense_manager_agent/agent.py
from google.adk.agents import Agent
from expense_manager_agent.tools import (
store_receipt_data,
search_receipts_by_metadata_filter,
search_relevant_receipts_by_natural_language_query,
get_receipt_data_by_image_id,
)
from expense_manager_agent.callbacks import modify_image_data_in_history
import os
from settings import get_settings
from google.adk.planners import BuiltInPlanner
from google.genai import types
SETTINGS = get_settings()
os.environ["GOOGLE_CLOUD_PROJECT"] = SETTINGS.GCLOUD_PROJECT_ID
os.environ["GOOGLE_CLOUD_LOCATION"] = SETTINGS.GCLOUD_LOCATION
os.environ["GOOGLE_GENAI_USE_VERTEXAI"] = "TRUE"
# Get the code file directory path and read the task prompt file
current_dir = os.path.dirname(os.path.abspath(__file__))
prompt_path = os.path.join(current_dir, "task_prompt.md")
with open(prompt_path, "r") as file:
task_prompt = file.read()
root_agent = Agent(
name="expense_manager_agent",
model="gemini-2.5-flash",
description=(
"Personal expense agent to help user track expenses, analyze receipts, and manage their financial records"
),
instruction=task_prompt,
tools=[
store_receipt_data,
get_receipt_data_by_image_id,
search_receipts_by_metadata_filter,
search_relevant_receipts_by_natural_language_query,
],
planner=BuiltInPlanner(
thinking_config=types.ThinkingConfig(
thinking_budget=2048,
)
),
before_model_callback=modify_image_data_in_history,
)
Penjelasan Kode
Skrip ini berisi inisiasi agen tempat kita menginisialisasi hal-hal berikut:
- Menetapkan model yang akan digunakan menjadi
gemini-2.5-flash - Siapkan deskripsi dan petunjuk agen sebagai perintah sistem yang dibaca dari
task_prompt.md - Menyediakan alat yang diperlukan untuk mendukung fungsi agen
- Mengaktifkan perencanaan sebelum membuat respons atau eksekusi akhir menggunakan kemampuan penalaran Gemini 2.5 Flash
- Siapkan pencegatan callback sebelum mengirim permintaan ke Gemini untuk membatasi jumlah data gambar yang dikirim sebelum membuat prediksi
4. 🚀 Mengonfigurasi Alat Agen
Agen pengelola pengeluaran kami akan memiliki kemampuan berikut:
- Mengekstrak data dari gambar tanda terima dan menyimpan data serta file
- Penelusuran persis pada data pengeluaran
- Penelusuran kontekstual pada data pengeluaran
Oleh karena itu, kita memerlukan alat yang sesuai untuk mendukung fungsi ini. Buat file baru di direktori expense_manager_agent dan beri nama tools.py
touch expense_manager_agent/tools.py
Buka expense_manage_agent/tools.py, lalu salin kode di bawah
# expense_manager_agent/tools.py
import datetime
from typing import Dict, List, Any
from google.cloud import firestore
from google.cloud.firestore_v1.vector import Vector
from google.cloud.firestore_v1 import FieldFilter
from google.cloud.firestore_v1.base_query import And
from google.cloud.firestore_v1.base_vector_query import DistanceMeasure
from settings import get_settings
from google import genai
SETTINGS = get_settings()
DB_CLIENT = firestore.Client(
project=SETTINGS.GCLOUD_PROJECT_ID
) # Will use "(default)" database
COLLECTION = DB_CLIENT.collection(SETTINGS.DB_COLLECTION_NAME)
GENAI_CLIENT = genai.Client(
vertexai=True, location=SETTINGS.GCLOUD_LOCATION, project=SETTINGS.GCLOUD_PROJECT_ID
)
EMBEDDING_DIMENSION = 768
EMBEDDING_FIELD_NAME = "embedding"
INVALID_ITEMS_FORMAT_ERR = """
Invalid items format. Must be a list of dictionaries with 'name', 'price', and 'quantity' keys."""
RECEIPT_DESC_FORMAT = """
Store Name: {store_name}
Transaction Time: {transaction_time}
Total Amount: {total_amount}
Currency: {currency}
Purchased Items:
{purchased_items}
Receipt Image ID: {receipt_id}
"""
def sanitize_image_id(image_id: str) -> str:
"""Sanitize image ID by removing any leading/trailing whitespace."""
if image_id.startswith("[IMAGE-"):
image_id = image_id.split("ID ")[1].split("]")[0]
return image_id.strip()
def store_receipt_data(
image_id: str,
store_name: str,
transaction_time: str,
total_amount: float,
purchased_items: List[Dict[str, Any]],
currency: str = "IDR",
) -> str:
"""
Store receipt data in the database.
Args:
image_id (str): The unique identifier of the image. For example IMAGE-POSITION 0-ID 12345,
the ID of the image is 12345.
store_name (str): The name of the store.
transaction_time (str): The time of purchase, in ISO format ("YYYY-MM-DDTHH:MM:SS.ssssssZ").
total_amount (float): The total amount spent.
purchased_items (List[Dict[str, Any]]): A list of items purchased with their prices. Each item must have:
- name (str): The name of the item.
- price (float): The price of the item.
- quantity (int, optional): The quantity of the item. Defaults to 1 if not provided.
currency (str, optional): The currency of the transaction, can be derived from the store location.
If unsure, default is "IDR".
Returns:
str: A success message with the receipt ID.
Raises:
Exception: If the operation failed or input is invalid.
"""
try:
# In case of it provide full image placeholder, extract the id string
image_id = sanitize_image_id(image_id)
# Check if the receipt already exists
doc = get_receipt_data_by_image_id(image_id)
if doc:
return f"Receipt with ID {image_id} already exists"
# Validate transaction time
if not isinstance(transaction_time, str):
raise ValueError(
"Invalid transaction time: must be a string in ISO format 'YYYY-MM-DDTHH:MM:SS.ssssssZ'"
)
try:
datetime.datetime.fromisoformat(transaction_time.replace("Z", "+00:00"))
except ValueError:
raise ValueError(
"Invalid transaction time format. Must be in ISO format 'YYYY-MM-DDTHH:MM:SS.ssssssZ'"
)
# Validate items format
if not isinstance(purchased_items, list):
raise ValueError(INVALID_ITEMS_FORMAT_ERR)
for _item in purchased_items:
if (
not isinstance(_item, dict)
or "name" not in _item
or "price" not in _item
):
raise ValueError(INVALID_ITEMS_FORMAT_ERR)
if "quantity" not in _item:
_item["quantity"] = 1
# Create a combined text from all receipt information for better embedding
result = GENAI_CLIENT.models.embed_content(
model="text-embedding-004",
contents=RECEIPT_DESC_FORMAT.format(
store_name=store_name,
transaction_time=transaction_time,
total_amount=total_amount,
currency=currency,
purchased_items=purchased_items,
receipt_id=image_id,
),
)
embedding = result.embeddings[0].values
doc = {
"receipt_id": image_id,
"store_name": store_name,
"transaction_time": transaction_time,
"total_amount": total_amount,
"currency": currency,
"purchased_items": purchased_items,
EMBEDDING_FIELD_NAME: Vector(embedding),
}
COLLECTION.add(doc)
return f"Receipt stored successfully with ID: {image_id}"
except Exception as e:
raise Exception(f"Failed to store receipt: {str(e)}")
def search_receipts_by_metadata_filter(
start_time: str,
end_time: str,
min_total_amount: float = -1.0,
max_total_amount: float = -1.0,
) -> str:
"""
Filter receipts by metadata within a specific time range and optionally by amount.
Args:
start_time (str): The start datetime for the filter (in ISO format, e.g. 'YYYY-MM-DDTHH:MM:SS.ssssssZ').
end_time (str): The end datetime for the filter (in ISO format, e.g. 'YYYY-MM-DDTHH:MM:SS.ssssssZ').
min_total_amount (float): The minimum total amount for the filter (inclusive). Defaults to -1.
max_total_amount (float): The maximum total amount for the filter (inclusive). Defaults to -1.
Returns:
str: A string containing the list of receipt data matching all applied filters.
Raises:
Exception: If the search failed or input is invalid.
"""
try:
# Validate start and end times
if not isinstance(start_time, str) or not isinstance(end_time, str):
raise ValueError("start_time and end_time must be strings in ISO format")
try:
datetime.datetime.fromisoformat(start_time.replace("Z", "+00:00"))
datetime.datetime.fromisoformat(end_time.replace("Z", "+00:00"))
except ValueError:
raise ValueError("start_time and end_time must be strings in ISO format")
# Start with the base collection reference
query = COLLECTION
# Build the composite query by properly chaining conditions
# Notes that this demo assume 1 user only,
# need to refactor the query for multiple user
filters = [
FieldFilter("transaction_time", ">=", start_time),
FieldFilter("transaction_time", "<=", end_time),
]
# Add optional filters
if min_total_amount != -1:
filters.append(FieldFilter("total_amount", ">=", min_total_amount))
if max_total_amount != -1:
filters.append(FieldFilter("total_amount", "<=", max_total_amount))
# Apply the filters
composite_filter = And(filters=filters)
query = query.where(filter=composite_filter)
# Execute the query and collect results
search_result_description = "Search by Metadata Results:\n"
for doc in query.stream():
data = doc.to_dict()
data.pop(
EMBEDDING_FIELD_NAME, None
) # Remove embedding as it's not needed for display
search_result_description += f"\n{RECEIPT_DESC_FORMAT.format(**data)}"
return search_result_description
except Exception as e:
raise Exception(f"Error filtering receipts: {str(e)}")
def search_relevant_receipts_by_natural_language_query(
query_text: str, limit: int = 5
) -> str:
"""
Search for receipts with content most similar to the query using vector search.
This tool can be use for user query that is difficult to translate into metadata filters.
Such as store name or item name which sensitive to string matching.
Use this tool if you cannot utilize the search by metadata filter tool.
Args:
query_text (str): The search text (e.g., "coffee", "dinner", "groceries").
limit (int, optional): Maximum number of results to return (default: 5).
Returns:
str: A string containing the list of contextually relevant receipt data.
Raises:
Exception: If the search failed or input is invalid.
"""
try:
# Generate embedding for the query text
result = GENAI_CLIENT.models.embed_content(
model="text-embedding-004", contents=query_text
)
query_embedding = result.embeddings[0].values
# Notes that this demo assume 1 user only,
# need to refactor the query for multiple user
vector_query = COLLECTION.find_nearest(
vector_field=EMBEDDING_FIELD_NAME,
query_vector=Vector(query_embedding),
distance_measure=DistanceMeasure.EUCLIDEAN,
limit=limit,
)
# Execute the query and collect results
search_result_description = "Search by Contextual Relevance Results:\n"
for doc in vector_query.stream():
data = doc.to_dict()
data.pop(
EMBEDDING_FIELD_NAME, None
) # Remove embedding as it's not needed for display
search_result_description += f"\n{RECEIPT_DESC_FORMAT.format(**data)}"
return search_result_description
except Exception as e:
raise Exception(f"Error searching receipts: {str(e)}")
def get_receipt_data_by_image_id(image_id: str) -> Dict[str, Any]:
"""
Retrieve receipt data from the database using the image_id.
Args:
image_id (str): The unique identifier of the receipt image. For example, if the placeholder is
[IMAGE-ID 12345], the ID to use is 12345.
Returns:
Dict[str, Any]: A dictionary containing the receipt data with the following keys:
- receipt_id (str): The unique identifier of the receipt image.
- store_name (str): The name of the store.
- transaction_time (str): The time of purchase in UTC.
- total_amount (float): The total amount spent.
- currency (str): The currency of the transaction.
- purchased_items (List[Dict[str, Any]]): List of items purchased with their details.
Returns an empty dictionary if no receipt is found.
"""
# In case of it provide full image placeholder, extract the id string
image_id = sanitize_image_id(image_id)
# Query the receipts collection for documents with matching receipt_id (image_id)
# Notes that this demo assume 1 user only,
# need to refactor the query for multiple user
query = COLLECTION.where(filter=FieldFilter("receipt_id", "==", image_id)).limit(1)
docs = list(query.stream())
if not docs:
return {}
# Get the first matching document
doc_data = docs[0].to_dict()
doc_data.pop(EMBEDDING_FIELD_NAME, None)
return doc_data
Penjelasan Kode
Dalam penerapan fungsi alat ini, kami merancang alat berdasarkan 2 ide utama ini:
- Mem-parsing data tanda terima dan memetakan ke file asli menggunakan placeholder string ID Gambar
[IMAGE-ID <hash-of-image-1>] - Menyimpan dan mengambil data menggunakan database Firestore
Alat "store_receipt_data"

Alat ini adalah alat Pengenalan Karakter Optik, yang akan mengurai informasi yang diperlukan dari data gambar, bersama dengan mengenali string ID Gambar dan memetakannya bersama untuk disimpan dalam database Firestore.
Selain itu, alat ini juga mengonversi konten tanda terima menjadi embedding menggunakan text-embedding-004 sehingga semua metadata dan embedding disimpan serta diindeks bersama-sama. Memungkinkan fleksibilitas untuk diambil baik dengan kueri maupun penelusuran kontekstual.
Setelah berhasil menjalankan alat ini, Anda dapat melihat bahwa data tanda terima sudah diindeks dalam database Firestore seperti yang ditunjukkan di bawah

Alat "search_receipts_by_metadata_filter"

Alat ini mengonversi kueri pengguna menjadi filter kueri metadata yang mendukung penelusuran menurut rentang tanggal dan/atau total transaksi. API ini akan menampilkan semua data tanda terima yang cocok, yang dalam prosesnya kita akan menghapus kolom sematan karena tidak diperlukan oleh agen untuk pemahaman kontekstual
Alat "search_relevant_receipts_by_natural_language_query"

Ini adalah alat Retrieval-Augmented Generation (RAG) kami. Agen kami memiliki kemampuan untuk mendesain kuerinya sendiri guna mengambil tanda terima yang relevan dari database vektor dan juga dapat memilih kapan harus menggunakan alat ini. Gagasan untuk mengizinkan keputusan independen dari agen apakah akan menggunakan alat RAG ini atau tidak dan mendesain kuerinya sendiri adalah salah satu definisi pendekatan Agentic RAG.
Kami tidak hanya mengizinkannya membuat kuerinya sendiri, tetapi juga mengizinkannya memilih jumlah dokumen relevan yang ingin diambil. Dikombinasikan dengan rekayasa perintah yang tepat, misalnya
# Example prompt Always filter the result from tool search_relevant_receipts_by_natural_language_query as the returned result may contain irrelevant information
Hal ini akan menjadikan alat ini sebagai alat canggih yang dapat menelusuri hampir semua hal, meskipun mungkin tidak menampilkan semua hasil yang diharapkan karena sifat penelusuran tetangga terdekat yang tidak persis.
5. 🚀 Modifikasi Konteks Percakapan melalui Callback
ADK Google memungkinkan kita "mencegat" runtime agen di berbagai tingkat. Anda dapat membaca lebih lanjut kemampuan mendetail ini di dokumentasi ini . Dalam lab ini, kita menggunakan before_model_callback untuk mengubah permintaan sebelum dikirim ke LLM guna menghapus data gambar dalam konteks histori percakapan lama ( hanya menyertakan data gambar dalam 3 interaksi pengguna terakhir) agar lebih efisien
Namun, kami tetap ingin agen memiliki konteks data gambar jika diperlukan. Oleh karena itu, kami menambahkan mekanisme untuk menambahkan placeholder ID gambar string setelah setiap data byte gambar dalam percakapan. Hal ini akan membantu agen menautkan ID gambar ke data filenya yang sebenarnya, yang dapat digunakan baik pada saat penyimpanan atau pengambilan gambar. Strukturnya akan terlihat seperti ini
<image-byte-data-1> [IMAGE-ID <hash-of-image-1>] <image-byte-data-2> [IMAGE-ID <hash-of-image-2>] And so on..
Selain itu, saat data byte menjadi tidak berlaku dalam histori percakapan, ID string masih ada untuk tetap memungkinkan akses data dengan bantuan penggunaan alat. Contoh struktur histori setelah data gambar dihapus
[IMAGE-ID <hash-of-image-1>] [IMAGE-ID <hash-of-image-2>] And so on..
Ayo mulai! Buat file baru di direktori expense_manager_agent dan beri nama callbacks.py
touch expense_manager_agent/callbacks.py
Buka file expense_manager_agent/callbacks.py, lalu salin kode di bawah
# expense_manager_agent/callbacks.py
import hashlib
from google.genai import types
from google.adk.agents.callback_context import CallbackContext
from google.adk.models.llm_request import LlmRequest
def modify_image_data_in_history(
callback_context: CallbackContext, llm_request: LlmRequest
) -> None:
# The following code will modify the request sent to LLM
# We will only keep image data in the last 3 user messages using a reverse and counter approach
# Count how many user messages we've processed
user_message_count = 0
# Process the reversed list
for content in reversed(llm_request.contents):
# Only count for user manual query, not function call
if (content.role == "user") and (content.parts[0].function_response is None):
user_message_count += 1
modified_content_parts = []
# Check any missing image ID placeholder for any image data
# Then remove image data from conversation history if more than 3 user messages
for idx, part in enumerate(content.parts):
if part.inline_data is None:
modified_content_parts.append(part)
continue
if (
(idx + 1 >= len(content.parts))
or (content.parts[idx + 1].text is None)
or (not content.parts[idx + 1].text.startswith("[IMAGE-ID "))
):
# Generate hash ID for the image and add a placeholder
image_data = part.inline_data.data
hasher = hashlib.sha256(image_data)
image_hash_id = hasher.hexdigest()[:12]
placeholder = f"[IMAGE-ID {image_hash_id}]"
# Only keep image data in the last 3 user messages
if user_message_count <= 3:
modified_content_parts.append(part)
modified_content_parts.append(types.Part(text=placeholder))
else:
# Only keep image data in the last 3 user messages
if user_message_count <= 3:
modified_content_parts.append(part)
# This will modify the contents inside the llm_request
content.parts = modified_content_parts
6. 🚀 Perintah
Mendesain agen dengan interaksi dan kemampuan yang kompleks mengharuskan kita menemukan perintah yang cukup baik untuk memandu agen agar dapat berperilaku seperti yang kita inginkan.
Sebelumnya, kami memiliki mekanisme tentang cara menangani data gambar dalam histori percakapan, dan juga memiliki alat yang mungkin tidak mudah digunakan, seperti search_relevant_receipts_by_natural_language_query. Kami juga ingin agen dapat menelusuri dan mengambil gambar tanda terima yang benar kepada kami. Artinya, kita perlu menyampaikan semua informasi ini dengan benar dalam struktur perintah yang tepat
Kita akan meminta agen untuk menyusun output ke dalam format markdown berikut untuk mengurai proses berpikir, respons akhir, dan lampiran ( jika ada)
# THINKING PROCESS
Thinking process here
# FINAL RESPONSE
Response to the user here
Attachments put inside json block
{
"attachments": [
"[IMAGE-ID <hash-id-1>]",
"[IMAGE-ID <hash-id-2>]",
...
]
}
Mari kita mulai dengan perintah berikut untuk mencapai ekspektasi awal kita terhadap perilaku agen pengelola pengeluaran. File task_prompt.md seharusnya sudah ada di direktori kerja yang ada, tetapi kita perlu memindahkannya ke direktori expense_manager_agent. Jalankan perintah berikut untuk memindahkannya
mv task_prompt.md expense_manager_agent/task_prompt.md
7. 🚀 Menguji Agen
Sekarang, mari kita coba berkomunikasi dengan agen melalui CLI, jalankan perintah berikut
uv run adk run expense_manager_agent
Output yang ditampilkan akan seperti ini, tempat Anda dapat bergiliran melakukan chat dengan agen, tetapi Anda hanya dapat mengirim teks melalui antarmuka ini
Log setup complete: /tmp/agents_log/agent.xxxx_xxx.log To access latest log: tail -F /tmp/agents_log/agent.latest.log Running agent root_agent, type exit to exit. user: hello [root_agent]: Hello there! How can I help you today? user:
Selain interaksi CLI, ADK juga memungkinkan kita memiliki UI pengembangan untuk berinteraksi dan memeriksa apa yang terjadi selama interaksi. Jalankan perintah berikut untuk memulai server UI pengembangan lokal
uv run adk web --port 8080
Perintah ini akan menghasilkan output seperti contoh berikut, yang berarti kita sudah dapat mengakses antarmuka web
INFO: Started server process [xxxx] INFO: Waiting for application startup. +-----------------------------------------------------------------------------+ | ADK Web Server started | | | | For local testing, access at http://localhost:8080. | +-----------------------------------------------------------------------------+ INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)
Sekarang, untuk memeriksanya, klik tombol Web Preview di area atas Cloud Shell Editor Anda, lalu pilih Preview on port 8080

Anda akan melihat halaman web berikut tempat Anda dapat memilih agen yang tersedia di tombol drop-down kiri atas ( dalam kasus ini, agennya adalah expense_manager_agent) dan berinteraksi dengan bot. Anda akan melihat banyak informasi tentang detail log selama runtime agen di jendela kiri

Mari coba beberapa tindakan. Upload 2 contoh tanda terima ini ( sumber : set data Hugging Face mousserlane/id_receipt_dataset) . Klik kanan setiap gambar, lalu pilih Simpan Gambar sebagai.. ( tindakan ini akan mendownload gambar tanda terima), lalu upload file ke bot dengan mengklik ikon "klip" dan mengatakan bahwa Anda ingin menyimpan tanda terima ini


Setelah itu, coba kueri berikut untuk melakukan penelusuran atau pengambilan file
- "Berikan rincian biaya dan totalnya selama tahun 2023"
- "Give me receipt file from Indomaret" (Beri saya file tanda terima dari Indomaret)
Saat menggunakan beberapa alat, Anda dapat memeriksa apa yang terjadi di UI pengembangan

Lihat cara agen merespons Anda dan periksa apakah agen mematuhi semua aturan yang diberikan dalam perintah di dalam task_prompt.py. Selamat! Sekarang Anda memiliki agen pengembangan yang berfungsi lengkap.
Sekarang saatnya melengkapinya dengan UI dan kemampuan yang tepat dan bagus untuk mengupload dan mendownload file gambar.
8. 🚀 Membangun Layanan Frontend menggunakan Gradio
Kita akan membuat antarmuka web chat yang terlihat seperti ini
Aplikasi ini berisi antarmuka chat dengan kolom input bagi pengguna untuk mengirim teks dan mengupload file gambar tanda terima.
Kita akan membangun layanan frontend menggunakan Gradio.
Buat file baru dan beri nama frontend.py
touch frontend.py
lalu salin kode berikut dan simpan
import mimetypes
import gradio as gr
import requests
import base64
from typing import List, Dict, Any
from settings import get_settings
from PIL import Image
import io
from schema import ImageData, ChatRequest, ChatResponse
SETTINGS = get_settings()
def encode_image_to_base64_and_get_mime_type(image_path: str) -> ImageData:
"""Encode a file to base64 string and get MIME type.
Reads an image file and returns the base64-encoded image data and its MIME type.
Args:
image_path: Path to the image file to encode.
Returns:
ImageData object containing the base64 encoded image data and its MIME type.
"""
# Read the image file
with open(image_path, "rb") as file:
image_content = file.read()
# Get the mime type
mime_type = mimetypes.guess_type(image_path)[0]
# Base64 encode the image
base64_data = base64.b64encode(image_content).decode("utf-8")
# Return as ImageData object
return ImageData(serialized_image=base64_data, mime_type=mime_type)
def decode_base64_to_image(base64_data: str) -> Image.Image:
"""Decode a base64 string to PIL Image.
Converts a base64-encoded image string back to a PIL Image object
that can be displayed or processed further.
Args:
base64_data: Base64 encoded string of the image.
Returns:
PIL Image object of the decoded image.
"""
# Decode the base64 string and convert to PIL Image
image_data = base64.b64decode(base64_data)
image_buffer = io.BytesIO(image_data)
image = Image.open(image_buffer)
return image
def get_response_from_llm_backend(
message: Dict[str, Any],
history: List[Dict[str, Any]],
) -> List[str | gr.Image]:
"""Send the message and history to the backend and get a response.
Args:
message: Dictionary containing the current message with 'text' and optional 'files' keys.
history: List of previous message dictionaries in the conversation.
Returns:
List containing text response and any image attachments from the backend service.
"""
# Extract files and convert to base64
image_data = []
if uploaded_files := message.get("files", []):
for file_path in uploaded_files:
image_data.append(encode_image_to_base64_and_get_mime_type(file_path))
# Prepare the request payload
payload = ChatRequest(
text=message["text"],
files=image_data,
session_id="default_session",
user_id="default_user",
)
# Send request to backend
try:
response = requests.post(SETTINGS.BACKEND_URL, json=payload.model_dump())
response.raise_for_status() # Raise exception for HTTP errors
result = ChatResponse(**response.json())
if result.error:
return [f"Error: {result.error}"]
chat_responses = []
if result.thinking_process:
chat_responses.append(
gr.ChatMessage(
role="assistant",
content=result.thinking_process,
metadata={"title": "🧠 Thinking Process"},
)
)
chat_responses.append(gr.ChatMessage(role="assistant", content=result.response))
if result.attachments:
for attachment in result.attachments:
image_data = attachment.serialized_image
chat_responses.append(gr.Image(decode_base64_to_image(image_data)))
return chat_responses
except requests.exceptions.RequestException as e:
return [f"Error connecting to backend service: {str(e)}"]
if __name__ == "__main__":
demo = gr.ChatInterface(
get_response_from_llm_backend,
title="Personal Expense Assistant",
description="This assistant can help you to store receipts data, find receipts, and track your expenses during certain period.",
type="messages",
multimodal=True,
textbox=gr.MultimodalTextbox(file_count="multiple", file_types=["image"]),
)
demo.launch(
server_name="0.0.0.0",
server_port=8080,
)
Setelah itu, kita dapat mencoba menjalankan layanan frontend dengan perintah berikut. Jangan lupa mengganti nama file main.py menjadi frontend.py
uv run frontend.py
Anda akan melihat output yang mirip dengan ini di konsol cloud Anda
* Running on local URL: http://0.0.0.0:8080 To create a public link, set `share=True` in `launch()`.
Setelah itu, Anda dapat memeriksa antarmuka web saat Anda ctrl+klik link URL lokal. Atau, Anda juga dapat mengakses aplikasi frontend dengan mengklik tombol Web Preview di sisi kanan atas Cloud Editor, lalu memilih Preview on port 8080
Anda akan melihat antarmuka web, tetapi Anda akan mendapatkan error yang diharapkan saat mencoba mengirimkan chat karena layanan backend belum disiapkan

Sekarang, biarkan layanan berjalan dan jangan hentikan dulu. Kita akan menjalankan layanan backend di tab terminal lain
Penjelasan Kode
Dalam kode frontend ini, pertama-tama kita memungkinkan pengguna mengirim teks dan mengupload beberapa file. Gradio memungkinkan kita membuat fungsionalitas semacam ini dengan metode gr.ChatInterface yang dikombinasikan dengan gr.MultimodalTextbox
Sekarang, sebelum mengirim file dan teks ke backend, kita perlu mengetahui jenis MIME file karena diperlukan oleh backend. Kita juga perlu mengenkode byte file gambar ke base64 dan mengirimkannya bersama dengan mimetype.
class ImageData(BaseModel):
"""Model for image data with hash identifier.
Attributes:
serialized_image: Optional Base64 encoded string of the image content.
mime_type: MIME type of the image.
"""
serialized_image: str
mime_type: str
Skema yang digunakan untuk interaksi frontend - backend ditentukan dalam schema.py. Kita menggunakan Pydantic BaseModel untuk menerapkan validasi data dalam skema
Saat menerima respons, kami sudah memisahkan bagian mana yang merupakan proses berpikir, respons akhir, dan lampiran. Dengan demikian, kita dapat menggunakan komponen Gradio untuk menampilkan setiap komponen dengan komponen UI.
class ChatResponse(BaseModel):
"""Model for a chat response.
Attributes:
response: The text response from the model.
thinking_process: Optional thinking process of the model.
attachments: List of image data to be displayed to the user.
error: Optional error message if something went wrong.
"""
response: str
thinking_process: str = ""
attachments: List[ImageData] = []
error: Optional[str] = None
9. 🚀 Membangun Layanan Backend menggunakan FastAPI
Selanjutnya, kita perlu membuat backend yang dapat menginisialisasi Agen kita bersama dengan komponen lain agar dapat menjalankan runtime agen.
Buat file baru, dan beri nama backend.py
touch backend.py
Salin kode berikut
from expense_manager_agent.agent import root_agent as expense_manager_agent
from google.adk.sessions import InMemorySessionService
from google.adk.runners import Runner
from google.adk.events import Event
from fastapi import FastAPI, Body, Depends
from typing import AsyncIterator
from types import SimpleNamespace
import uvicorn
from contextlib import asynccontextmanager
from utils import (
extract_attachment_ids_and_sanitize_response,
download_image_from_gcs,
extract_thinking_process,
format_user_request_to_adk_content_and_store_artifacts,
)
from schema import ImageData, ChatRequest, ChatResponse
import logger
from google.adk.artifacts import GcsArtifactService
from settings import get_settings
SETTINGS = get_settings()
APP_NAME = "expense_manager_app"
# Application state to hold service contexts
class AppContexts(SimpleNamespace):
"""A class to hold application contexts with attribute access"""
session_service: InMemorySessionService = None
artifact_service: GcsArtifactService = None
expense_manager_agent_runner: Runner = None
# Initialize application state
app_contexts = AppContexts()
@asynccontextmanager
async def lifespan(app: FastAPI):
# Initialize service contexts during application startup
app_contexts.session_service = InMemorySessionService()
app_contexts.artifact_service = GcsArtifactService(
bucket_name=SETTINGS.STORAGE_BUCKET_NAME
)
app_contexts.expense_manager_agent_runner = Runner(
agent=expense_manager_agent, # The agent we want to run
app_name=APP_NAME, # Associates runs with our app
session_service=app_contexts.session_service, # Uses our session manager
artifact_service=app_contexts.artifact_service, # Uses our artifact manager
)
logger.info("Application started successfully")
yield
logger.info("Application shutting down")
# Perform cleanup during application shutdown if necessary
# Helper function to get application state as a dependency
async def get_app_contexts() -> AppContexts:
return app_contexts
# Create FastAPI app
app = FastAPI(title="Personal Expense Assistant API", lifespan=lifespan)
@app.post("/chat", response_model=ChatResponse)
async def chat(
request: ChatRequest = Body(...),
app_context: AppContexts = Depends(get_app_contexts),
) -> ChatResponse:
"""Process chat request and get response from the agent"""
# Prepare the user's message in ADK format and store image artifacts
content = await format_user_request_to_adk_content_and_store_artifacts(
request=request,
app_name=APP_NAME,
artifact_service=app_context.artifact_service,
)
final_response_text = "Agent did not produce a final response." # Default
# Use the session ID from the request or default if not provided
session_id = request.session_id
user_id = request.user_id
# Create session if it doesn't exist
if not await app_context.session_service.get_session(
app_name=APP_NAME, user_id=user_id, session_id=session_id
):
await app_context.session_service.create_session(
app_name=APP_NAME, user_id=user_id, session_id=session_id
)
try:
# Process the message with the agent
# Type annotation: runner.run_async returns an AsyncIterator[Event]
events_iterator: AsyncIterator[Event] = (
app_context.expense_manager_agent_runner.run_async(
user_id=user_id, session_id=session_id, new_message=content
)
)
async for event in events_iterator: # event has type Event
# Key Concept: is_final_response() marks the concluding message for the turn
if event.is_final_response():
if event.content and event.content.parts:
# Extract text from the first part
final_response_text = event.content.parts[0].text
elif event.actions and event.actions.escalate:
# Handle potential errors/escalations
final_response_text = f"Agent escalated: {event.error_message or 'No specific message.'}"
break # Stop processing events once the final response is found
logger.info(
"Received final response from agent", raw_final_response=final_response_text
)
# Extract and process any attachments and thinking process in the response
base64_attachments = []
sanitized_text, attachment_ids = extract_attachment_ids_and_sanitize_response(
final_response_text
)
sanitized_text, thinking_process = extract_thinking_process(sanitized_text)
# Download images from GCS and replace hash IDs with base64 data
for image_hash_id in attachment_ids:
# Download image data and get MIME type
result = await download_image_from_gcs(
artifact_service=app_context.artifact_service,
image_hash=image_hash_id,
app_name=APP_NAME,
user_id=user_id,
session_id=session_id,
)
if result:
base64_data, mime_type = result
base64_attachments.append(
ImageData(serialized_image=base64_data, mime_type=mime_type)
)
logger.info(
"Processed response with attachments",
sanitized_response=sanitized_text,
thinking_process=thinking_process,
attachment_ids=attachment_ids,
)
return ChatResponse(
response=sanitized_text,
thinking_process=thinking_process,
attachments=base64_attachments,
)
except Exception as e:
logger.error("Error processing chat request", error_message=str(e))
return ChatResponse(
response="", error=f"Error in generating response: {str(e)}"
)
# Only run the server if this file is executed directly
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8081)
Setelah itu, kita dapat mencoba menjalankan layanan backend. Ingatlah bahwa pada langkah sebelumnya kita menjalankan layanan frontend dengan benar, sekarang kita perlu membuka terminal baru dan mencoba menjalankan layanan backend ini
- Buat terminal baru. Buka terminal Anda di area bawah, lalu temukan tombol "+" untuk membuat terminal baru. Atau, Anda dapat menekan Ctrl + Shift + C untuk membuka terminal baru

- Setelah itu, pastikan Anda berada di direktori kerja personal-expense-assistant, lalu jalankan perintah berikut
uv run backend.py
- Jika berhasil, output akan ditampilkan seperti ini
INFO: Started server process [xxxxx] INFO: Waiting for application startup. INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8081 (Press CTRL+C to quit)
Penjelasan Kode
Menginisialisasi Agen ADK, SessionService, dan ArtifactService
Untuk menjalankan agen di layanan backend, kita perlu membuat Runner yang menggunakan SessionService dan agen kita. SessionService akan mengelola histori dan status percakapan, sehingga saat diintegrasikan dengan Runner, agen kita akan dapat menerima konteks percakapan yang sedang berlangsung.
Kami juga menggunakan ArtifactService untuk menangani file yang diupload. Anda dapat membaca detail selengkapnya tentang Sesi dan Artefak ADK di sini
...
@asynccontextmanager
async def lifespan(app: FastAPI):
# Initialize service contexts during application startup
app_contexts.session_service = InMemorySessionService()
app_contexts.artifact_service = GcsArtifactService(
bucket_name=SETTINGS.STORAGE_BUCKET_NAME
)
app_contexts.expense_manager_agent_runner = Runner(
agent=expense_manager_agent, # The agent we want to run
app_name=APP_NAME, # Associates runs with our app
session_service=app_contexts.session_service, # Uses our session manager
artifact_service=app_contexts.artifact_service, # Uses our artifact manager
)
logger.info("Application started successfully")
yield
logger.info("Application shutting down")
# Perform cleanup during application shutdown if necessary
...
Dalam demo ini, kita menggunakan InMemorySessionService dan GcsArtifactService untuk diintegrasikan dengan Runner agen kita. Karena histori percakapan disimpan dalam memori, histori akan hilang setelah layanan backend dihentikan atau dimulai ulang. Kita melakukan inisialisasi ini di dalam siklus proses aplikasi FastAPI untuk disuntikkan sebagai dependensi di rute /chat.
Mengupload dan Mendownload Gambar dengan GcsArtifactService
Semua gambar yang diupload akan disimpan sebagai artefak oleh GcsArtifactService, Anda dapat memeriksanya di dalam fungsi format_user_request_to_adk_content_and_store_artifacts di dalam utils.py
...
# Prepare the user's message in ADK format and store image artifacts
content = await asyncio.to_thread(
format_user_request_to_adk_content_and_store_artifacts,
request=request,
app_name=APP_NAME,
artifact_service=app_context.artifact_service,
)
...
Semua permintaan yang akan diproses oleh peluncur agen harus diformat ke dalam jenis types.Content. Di dalam fungsi, kita juga memproses setiap data gambar dan mengekstrak ID-nya untuk diganti dengan placeholder ID Gambar.
Mekanisme serupa digunakan untuk mendownload lampiran setelah mengekstrak ID gambar menggunakan regex:
...
sanitized_text, attachment_ids = extract_attachment_ids_and_sanitize_response(
final_response_text
)
sanitized_text, thinking_process = extract_thinking_process(sanitized_text)
# Download images from GCS and replace hash IDs with base64 data
for image_hash_id in attachment_ids:
# Download image data and get MIME type
result = await asyncio.to_thread(
download_image_from_gcs,
artifact_service=app_context.artifact_service,
image_hash=image_hash_id,
app_name=APP_NAME,
user_id=user_id,
session_id=session_id,
)
...
10. 🚀 Pengujian Integrasi
Sekarang, Anda akan menjalankan beberapa layanan di tab konsol cloud yang berbeda:
- Layanan frontend berjalan di port 8080
* Running on local URL: http://0.0.0.0:8080 To create a public link, set `share=True` in `launch()`.
- Layanan backend berjalan di port 8081
INFO: Started server process [xxxxx] INFO: Waiting for application startup. INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8081 (Press CTRL+C to quit)
Pada status saat ini, Anda dapat mengupload gambar tanda terima dan melakukan percakapan dengan lancar bersama asisten dari aplikasi web di port 8080.
Klik tombol Web Preview di area atas Cloud Shell Editor Anda, lalu pilih Preview on port 8080
Sekarang, mari kita berinteraksi dengan asisten.
Download tanda terima berikut. Rentang tanggal data tanda terima ini adalah antara tahun 2023-2024 dan minta asisten untuk menyimpan/menguploadnya
- Receipt Drive ( sumber set data Hugging Face
mousserlane/id_receipt_dataset)
Tanyakan berbagai hal
- "Berikan perincian pengeluaran bulanan saya selama tahun 2023-2024"
- "Show me receipt for coffee transaction" (Tampilkan tanda terima untuk transaksi kopi)
- "Give me receipt file from Yakiniku Like" (Beri saya file tanda terima dari Yakiniku Like)
- Dst.
Berikut beberapa cuplikan interaksi yang berhasil


11. 🚀 Men-deploy ke Cloud Run
Sekarang, tentu saja kita ingin mengakses aplikasi luar biasa ini dari mana saja. Untuk melakukannya, kita dapat mengemas aplikasi ini dan men-deploy-nya ke Cloud Run. Untuk demo ini, layanan ini akan diekspos sebagai layanan publik yang dapat diakses oleh orang lain. Namun, perlu diingat bahwa ini bukan praktik terbaik untuk jenis aplikasi ini karena lebih cocok untuk aplikasi pribadi
Dalam codelab ini, kita akan menempatkan layanan frontend dan backend dalam 1 container. Kita akan memerlukan bantuan supervisord untuk mengelola kedua layanan. Anda dapat memeriksa file supervisord.conf dan memeriksa Dockerfile yang menetapkan supervisord sebagai entrypoint.
Pada tahap ini, kita sudah memiliki semua file yang diperlukan untuk men-deploy aplikasi ke Cloud Run. Mari kita deploy. Buka Terminal Cloud Shell dan pastikan project saat ini dikonfigurasi ke project aktif Anda. Jika tidak, Anda harus menggunakan perintah gcloud configure untuk menyetel project ID:
gcloud config set project [PROJECT_ID]
Kemudian, jalankan perintah berikut untuk men-deploy-nya ke Cloud Run.
gcloud run deploy personal-expense-assistant \
--source . \
--port=8080 \
--allow-unauthenticated \
--env-vars-file=settings.yaml \
--memory 1024Mi \
--region us-central1
Jika Anda diminta untuk mengonfirmasi pembuatan registry artefak untuk repositori Docker, cukup jawab Y. Perhatikan bahwa kami mengizinkan akses tanpa autentikasi di sini karena ini adalah aplikasi demo. Sebaiknya gunakan autentikasi yang sesuai untuk aplikasi perusahaan dan produksi Anda.
Setelah deployment selesai, Anda akan mendapatkan link yang mirip dengan di bawah ini:
https://personal-expense-assistant-*******.us-central1.run.app
Lanjutkan dan gunakan aplikasi Anda dari jendela Samaran atau perangkat seluler Anda. Produk tersebut seharusnya sudah ditampilkan.
12. 🎯 Tantangan
Sekarang saatnya Anda bersinar dan mengasah keterampilan eksplorasi Anda. Apakah Anda memiliki kemampuan untuk mengubah kode sehingga backend dapat mengakomodasi beberapa pengguna? Komponen apa yang perlu diperbarui?
13. 🧹 Membersihkan
Agar tidak menimbulkan biaya pada akun Google Cloud Anda untuk resource yang digunakan dalam codelab ini, ikuti langkah-langkah berikut:
- Di konsol Google Cloud, buka halaman Manage resources.
- Dalam daftar project, pilih project yang ingin Anda hapus, lalu klik Delete.
- Pada dialog, ketik project ID, lalu klik Shut down untuk menghapus project.
- Atau, Anda dapat membuka Cloud Run di konsol, memilih layanan yang baru saja Anda deploy, lalu menghapusnya.