
1. ภาพรวม
การค้นหาตามบริบทเป็นฟังก์ชันการทํางานที่สําคัญซึ่งถือเป็นหัวใจสําคัญของแอปพลิเคชันในอุตสาหกรรมต่างๆ การสร้างข้อความที่เพิ่มประสิทธิภาพการดึงข้อมูลเป็นปัจจัยขับเคลื่อนที่สำคัญของวิวัฒนาการเทคโนโลยีที่สำคัญนี้มาอย่างยาวนานด้วยกลไกการดึงข้อมูลซึ่งทำงานด้วยระบบ Generative AI โมเดล Generative ที่มีกรอบเวลาบริบทขนาดใหญ่และคุณภาพเอาต์พุตที่น่าประทับใจกำลังเปลี่ยนแปลง AI RAG มีวิธีการที่ระบบระเบียบในการแทรกบริบทลงในแอปพลิเคชันและเอเจนต์ AI โดยอิงตามฐานข้อมูลที่จัดโครงสร้างหรือข้อมูลจากสื่อต่างๆ ข้อมูลตามบริบทนี้มีความสําคัญอย่างยิ่งต่อความชัดเจนของความจริงและความแม่นยําของเอาต์พุต แต่ผลลัพธ์เหล่านั้นมีความแม่นยำเพียงใด ธุรกิจของคุณอาศัยความแม่นยำของการจับคู่ตามบริบทและความเกี่ยวข้องเหล่านี้เป็นอย่างมากหรือไม่ โปรเจ็กต์นี้น่าจะเหมาะกับคุณ
เคล็ดลับในการค้นหาเวกเตอร์ไม่ใช่แค่การสร้างเวกเตอร์เท่านั้น แต่คือการรู้ว่าการจับคู่เวกเตอร์ของคุณมีประสิทธิภาพดีจริงหรือไม่ เราทุกคนเคยอยู่ในสถานการณ์ที่มองหน้าผลการค้นหาอย่างไร้จุดหมายและสงสัยว่า "นี่มันใช้งานได้ไหม" มาเจาะลึกวิธีประเมินคุณภาพของรายการที่ตรงกันของเวกเตอร์กัน คุณอาจสงสัยว่า "มีอะไรเปลี่ยนแปลงใน RAG บ้าง" ทุกอย่าง เป็นเวลาหลายปีที่การสร้างข้อความที่เพิ่มประสิทธิภาพการดึงข้อมูล (RAG) ดูเหมือนจะเป็นเป้าหมายที่เป็นไปได้แต่จับต้องได้ยาก ตอนนี้เราจึงมีเครื่องมือในการสร้างแอปพลิเคชัน RAG ที่มีประสิทธิภาพและความเสถียรที่จำเป็นสำหรับงานที่มีภารกิจสำคัญ
ตอนนี้เรามีความเข้าใจพื้นฐานเกี่ยวกับ 3 สิ่งต่อไปนี้แล้ว
- ความหมายของการค้นหาตามบริบทสำหรับตัวแทนและวิธีดำเนินการโดยใช้การค้นหาเวกเตอร์
- นอกจากนี้ เรายังเจาะลึกการค้นหาเวกเตอร์ภายในขอบเขตของข้อมูลที่อยู่ในฐานข้อมูลของคุณด้วย (ฐานข้อมูล Google Cloud ทั้งหมดรองรับฟีเจอร์นี้หากคุณยังไม่ทราบ)
- เราก้าวไปอีกขั้นกว่าประเทศอื่นๆ ในการบอกวิธีใช้ความสามารถ RAG ของ Vector Search แบบเบาที่มีประสิทธิภาพและคุณภาพสูงด้วยความสามารถของ AlloyDB Vector Search ที่ขับเคลื่อนโดยดัชนี ScaNN
หากคุณยังไม่ได้ทําการทดสอบ RAG ระดับพื้นฐาน ระดับกลาง และระดับขั้นสูงเล็กน้อย เราขอแนะนําให้อ่านบทความทั้ง 3 บทความที่นี่ ที่นี่ และที่นี่ตามลําดับที่ระบุ
การค้นหาสิทธิบัตรช่วยให้ผู้ใช้ค้นหาสิทธิบัตรที่เกี่ยวข้องกับบริบทของข้อความค้นหาได้ และเราได้สร้างเวอร์ชันนี้ไว้แล้วในอดีต ตอนนี้เราจะสร้างแอปพลิเคชันด้วยฟีเจอร์ RAG ใหม่และขั้นสูงที่ช่วยให้สามารถค้นหาตามบริบทที่ควบคุมคุณภาพสําหรับแอปพลิเคชันนั้นได้ มาเริ่มกันเลย
รูปภาพด้านล่างแสดงขั้นตอนโดยรวมของสิ่งที่เกิดขึ้นในแอปพลิเคชันนี้~ 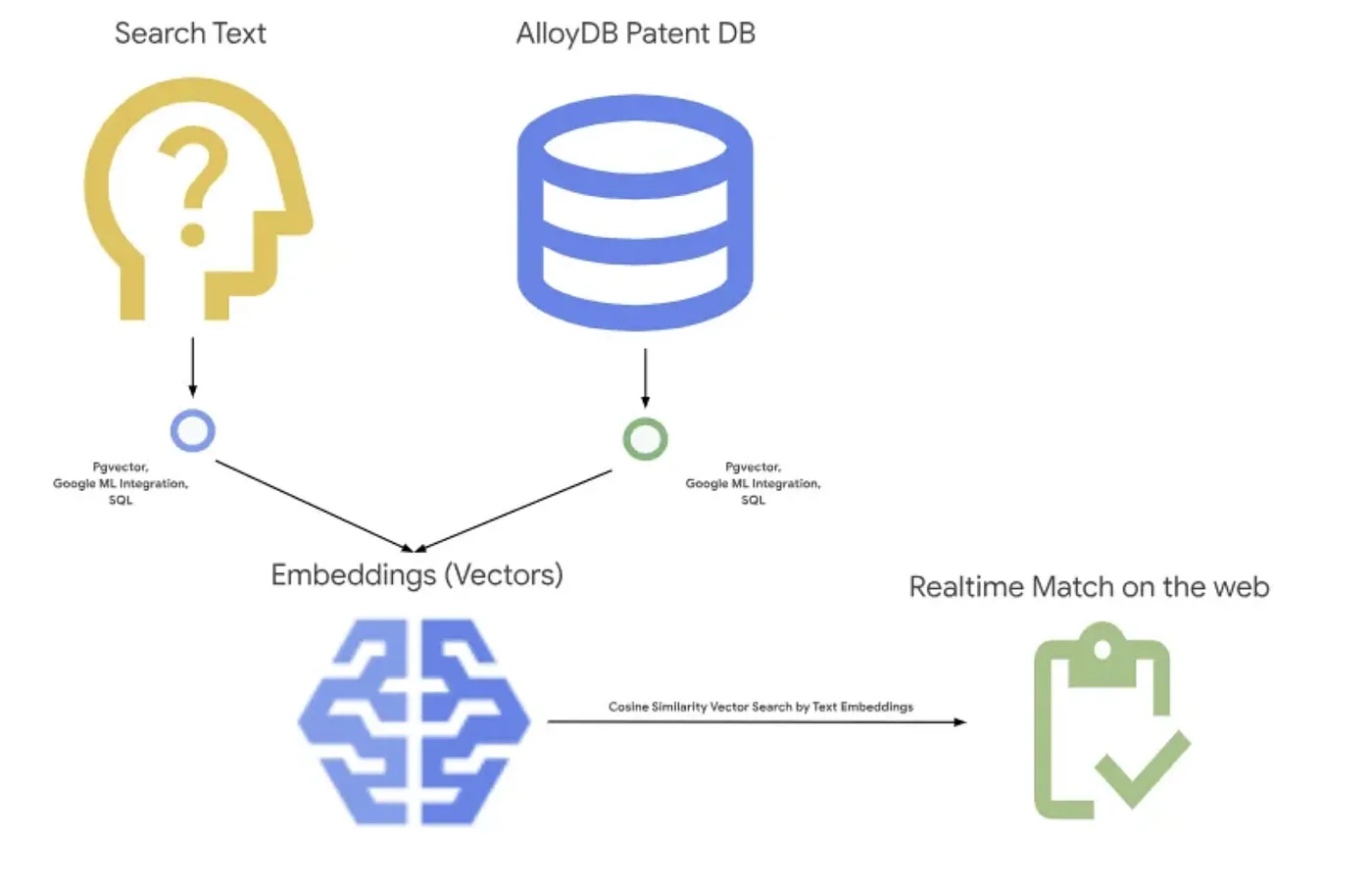
วัตถุประสงค์
อนุญาตให้ผู้ใช้ค้นหาสิทธิบัตรตามคำอธิบายที่เป็นข้อความที่มีประสิทธิภาพและคุณภาพดีขึ้น พร้อมทั้งประเมินคุณภาพของรายการที่ตรงกันซึ่งสร้างขึ้นโดยใช้ฟีเจอร์ RAG เวอร์ชันล่าสุดของ AlloyDB
สิ่งที่คุณจะสร้าง
ในส่วนนี้ คุณจะได้ทําสิ่งต่อไปนี้
- สร้างอินสแตนซ์ AlloyDB และโหลดชุดข้อมูลสาธารณะของสิทธิบัตร
- สร้างดัชนีข้อมูลเมตาและดัชนี ScaNN
- ใช้การค้นหาเวกเตอร์ขั้นสูงใน AlloyDB โดยใช้วิธีการกรองในบรรทัดของ ScaNN
- ใช้ฟีเจอร์การประเมินการเรียกคืน
- ประเมินคำตอบของคำค้นหา
ข้อกำหนด
2. ก่อนเริ่มต้น
สร้างโปรเจ็กต์
- ในคอนโซล Google Cloud ให้เลือกหรือสร้างโปรเจ็กต์ Google Cloud ในหน้าตัวเลือกโปรเจ็กต์
- ตรวจสอบว่าเปิดใช้การเรียกเก็บเงินสำหรับโปรเจ็กต์ Cloud แล้ว ดูวิธีตรวจสอบว่าเปิดใช้การเรียกเก็บเงินในโปรเจ็กต์หรือไม่
- คุณจะใช้ Cloud Shell ซึ่งเป็นสภาพแวดล้อมบรรทัดคำสั่งที่ทำงานใน Google Cloud คลิก "เปิดใช้งาน Cloud Shell" ที่ด้านบนของคอนโซล Google Cloud

- เมื่อเชื่อมต่อกับ Cloud Shell แล้ว ให้ตรวจสอบว่าคุณได้รับการตรวจสอบสิทธิ์แล้วและโปรเจ็กต์ได้รับการตั้งค่าเป็นรหัสโปรเจ็กต์ของคุณโดยใช้คําสั่งต่อไปนี้
gcloud auth list
- เรียกใช้คำสั่งต่อไปนี้ใน Cloud Shell เพื่อยืนยันว่าคำสั่ง gcloud รู้จักโปรเจ็กต์ของคุณ
gcloud config list project
- หากยังไม่ได้ตั้งค่าโปรเจ็กต์ ให้ใช้คําสั่งต่อไปนี้เพื่อตั้งค่า
gcloud config set project <YOUR_PROJECT_ID>
- เปิดใช้ API ที่จำเป็น คุณสามารถใช้คำสั่ง gcloud ในเทอร์มินัล Cloud Shell ได้โดยทำดังนี้
gcloud services enable alloydb.googleapis.com compute.googleapis.com cloudresourcemanager.googleapis.com servicenetworking.googleapis.com run.googleapis.com cloudbuild.googleapis.com cloudfunctions.googleapis.com aiplatform.googleapis.com
อีกทางเลือกหนึ่งสำหรับคำสั่ง gcloud คือผ่านคอนโซลโดยค้นหาผลิตภัณฑ์แต่ละรายการหรือใช้ลิงก์นี้
โปรดดูคำสั่งและการใช้งาน gcloud ในเอกสารประกอบ
3. การตั้งค่าฐานข้อมูล
ในชั้นนี้ เราจะใช้ AlloyDB เป็นฐานข้อมูลสําหรับข้อมูลสิทธิบัตร โดยจะใช้คลัสเตอร์เพื่อเก็บทรัพยากรทั้งหมด เช่น ฐานข้อมูลและบันทึก แต่ละคลัสเตอร์มีอินสแตนซ์หลักที่เป็นแหล่งเข้าถึงข้อมูล ตารางจะเก็บข้อมูลจริง
มาสร้างคลัสเตอร์ อินสแตนซ์ และตาราง AlloyDB ที่ระบบจะโหลดชุดข้อมูลสิทธิบัตรกัน
สร้างคลัสเตอร์และอินสแตนซ์
- ไปยังหน้า AlloyDB ใน Cloud Console วิธีที่ง่ายในการค้นหาหน้าส่วนใหญ่ใน Cloud Console คือค้นหาโดยใช้แถบค้นหาของคอนโซล
- เลือกสร้างคลัสเตอร์จากหน้านั้น

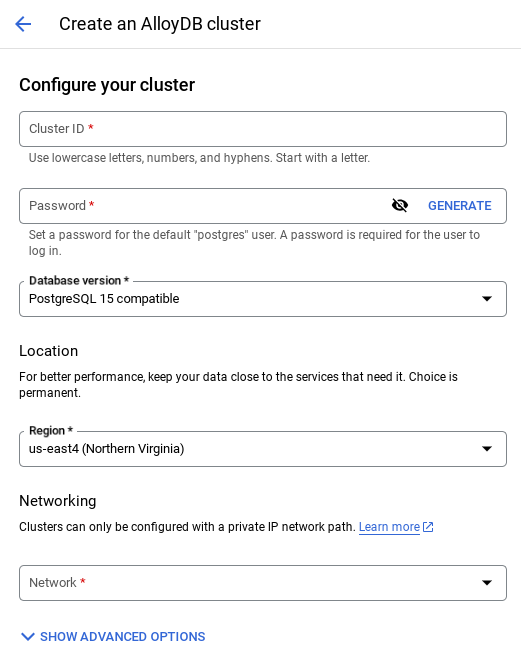
- คุณจะเห็นหน้าจอดังภาพด้านล่าง สร้างคลัสเตอร์และอินสแตนซ์ด้วยค่าต่อไปนี้ (ตรวจสอบว่าค่าตรงกันในกรณีที่คุณทำโคลนโค้ดแอปพลิเคชันจากรีโป)
- cluster id: "
vector-cluster" - password: "
alloydb" - PostgreSQL 15 / เวอร์ชันล่าสุดที่แนะนำ
- ภูมิภาค: "
us-central1" - เครือข่าย: "
default"
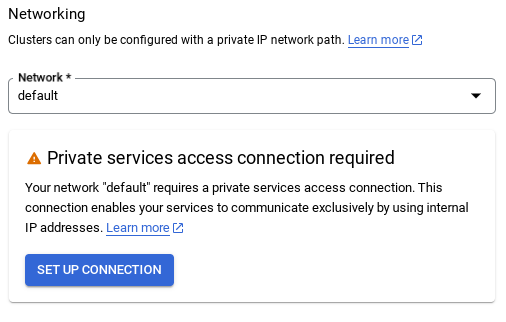
- เมื่อเลือกเครือข่ายเริ่มต้น คุณจะเห็นหน้าจอดังภาพด้านล่าง
เลือกตั้งค่าการเชื่อมต่อ
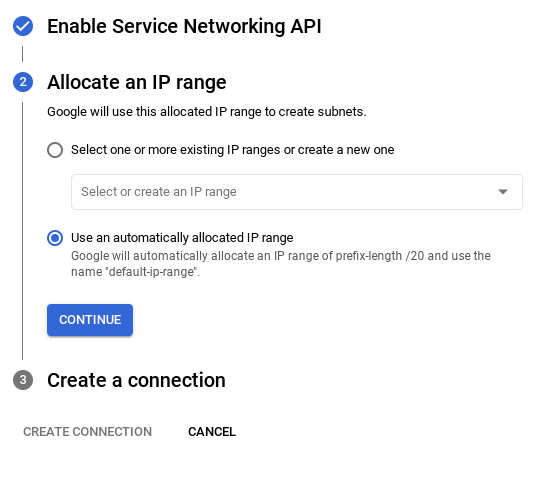
- จากนั้นเลือก "ใช้ช่วง IP ที่มีการจัดสรรโดยอัตโนมัติ" แล้วดำเนินการต่อ หลังจากตรวจสอบข้อมูลแล้ว ให้เลือกสร้างการเชื่อมต่อ
- เมื่อตั้งค่าเครือข่ายแล้ว คุณก็สร้างคลัสเตอร์ต่อได้ คลิกสร้างคลัสเตอร์เพื่อตั้งค่าคลัสเตอร์ให้เสร็จสมบูรณ์ตามที่แสดงด้านล่าง
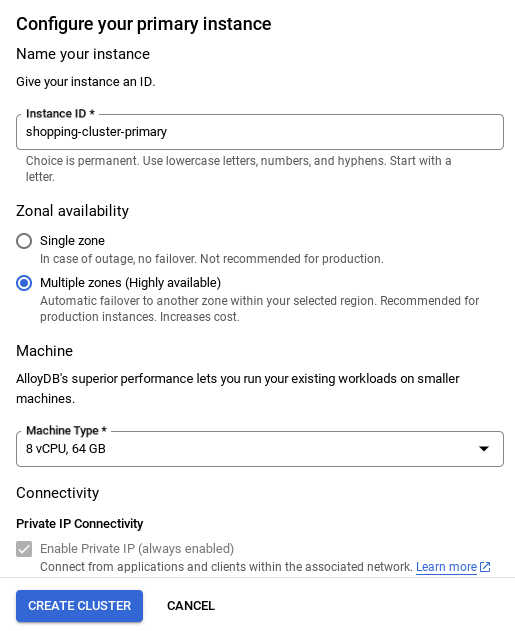
อย่าลืมเปลี่ยนรหัสอินสแตนซ์ (ซึ่งคุณจะเห็นเมื่อกำหนดค่าคลัสเตอร์ / อินสแตนซ์) เป็น
vector-instance หากเปลี่ยนไม่ได้ โปรดอย่าลืมใช้รหัสอินสแตนซ์ในการอ้างอิงทั้งหมดที่จะเกิดขึ้น
โปรดทราบว่าการสร้างคลัสเตอร์จะใช้เวลาประมาณ 10 นาที เมื่อดำเนินการเสร็จเรียบร้อยแล้ว คุณควรเห็นหน้าจอที่แสดงภาพรวมของคลัสเตอร์ที่คุณเพิ่งสร้างขึ้น
4. การนำเข้าข้อมูล
ตอนนี้ถึงเวลาเพิ่มตารางที่มีข้อมูลเกี่ยวกับร้านค้า ไปที่ AlloyDB เลือกคลัสเตอร์หลัก แล้วเลือก AlloyDB Studio
คุณอาจต้องรอให้อินสแตนซ์สร้างเสร็จ เมื่อสร้างแล้ว ให้ลงชื่อเข้าใช้ AlloyDB โดยใช้ข้อมูลเข้าสู่ระบบที่คุณสร้างขึ้นเมื่อสร้างคลัสเตอร์ ใช้ข้อมูลต่อไปนี้เพื่อตรวจสอบสิทธิ์ใน PostgreSQL
- ชื่อผู้ใช้ : "
postgres" - ฐานข้อมูล : "
postgres" - รหัสผ่าน : "
alloydb"
เมื่อตรวจสอบสิทธิ์เข้าสู่ AlloyDB Studio เรียบร้อยแล้ว ให้ป้อนคำสั่ง SQL ในเครื่องมือแก้ไข คุณสามารถเพิ่มหน้าต่างเครื่องมือแก้ไขได้หลายหน้าต่างโดยใช้เครื่องหมายบวกทางด้านขวาของหน้าต่างสุดท้าย
คุณจะป้อนคำสั่งสำหรับ AlloyDB ในหน้าต่างเครื่องมือแก้ไขโดยใช้ตัวเลือกเรียกใช้ รูปแบบ และล้างตามความจำเป็น
เปิดใช้ส่วนขยาย
เราจะใช้ส่วนขยาย pgvector และ google_ml_integration ในการสร้างแอปนี้ ส่วนขยาย pgvector ช่วยให้คุณจัดเก็บและค้นหาการฝังเวกเตอร์ได้ ส่วนขยาย google_ml_integration มีฟังก์ชันที่คุณใช้เข้าถึงปลายทางการคาดการณ์ Vertex AI เพื่อรับการคาดการณ์ใน SQL เปิดใช้ส่วนขยายเหล่านี้โดยเรียกใช้ DDL ต่อไปนี้
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
หากต้องการตรวจสอบส่วนขยายที่เปิดใช้ในฐานข้อมูล ให้เรียกใช้คําสั่ง SQL นี้
select extname, extversion from pg_extension;
สร้างตาราง
คุณสามารถสร้างตารางโดยใช้คำสั่ง DDL ด้านล่างใน AlloyDB Studio
CREATE TABLE patents_data ( id VARCHAR(25), type VARCHAR(25), number VARCHAR(20), country VARCHAR(2), date VARCHAR(20), abstract VARCHAR(300000), title VARCHAR(100000), kind VARCHAR(5), num_claims BIGINT, filename VARCHAR(100), withdrawn BIGINT, abstract_embeddings vector(768)) ;
คอลัมน์ abstract_embeddings จะอนุญาตให้จัดเก็บค่าเวกเตอร์ของข้อความ
ให้สิทธิ์
เรียกใช้คำสั่งด้านล่างเพื่ออนุญาตให้ดำเนินการกับฟังก์ชัน "embedding"
GRANT EXECUTE ON FUNCTION embedding TO postgres;
มอบบทบาทผู้ใช้ Vertex AI ให้กับบัญชีบริการ AlloyDB
จากคอนโซล IAM ของ Google Cloud ให้มอบสิทธิ์เข้าถึงบทบาท "ผู้ใช้ Vertex AI" ให้กับบัญชีบริการ AlloyDB (ซึ่งมีลักษณะดังนี้ service-<<PROJECT_NUMBER >>@gcp-sa-alloydb.iam.gserviceaccount.com) PROJECT_NUMBER จะมีหมายเลขโปรเจ็กต์ของคุณ
หรือจะเรียกใช้คําสั่งด้านล่างจากเทอร์มินัล Cloud Shell ก็ได้
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
โหลดข้อมูลสิทธิบัตรลงในฐานข้อมูล
เราจะใช้ชุดข้อมูลสาธารณะของ Google Patents ใน BigQuery เป็นชุดข้อมูล เราจะใช้ AlloyDB Studio เพื่อเรียกใช้การค้นหา ข้อมูลจะมาจากไฟล์ insert_scripts.sql นี้ และเราจะเรียกใช้ไฟล์นี้เพื่อโหลดข้อมูลสิทธิบัตร
- เปิดหน้า AlloyDB ในคอนโซล Google Cloud
- เลือกคลัสเตอร์ที่สร้างขึ้นใหม่ แล้วคลิกอินสแตนซ์
- ในเมนูการนำทางของ AlloyDB ให้คลิก AlloyDB Studio ลงชื่อเข้าใช้ด้วยข้อมูลเข้าสู่ระบบ
- เปิดแท็บใหม่โดยคลิกไอคอนแท็บใหม่ทางด้านขวา
- คัดลอกคำสั่งการค้นหา
insertจากสคริปต์insert_scripts.sqlที่กล่าวถึงข้างต้นไปยังเครื่องมือแก้ไข คุณคัดลอกคำสั่งแทรก 10-50 รายการเพื่อสาธิตกรณีการใช้งานนี้อย่างรวดเร็วได้ - คลิกเรียกใช้ ผลการค้นหาจะปรากฏในตารางผลลัพธ์
หมายเหตุ: คุณอาจเห็นว่าสคริปต์แทรกมีข้อมูลจำนวนมาก เนื่องจากเราได้รวมการฝังไว้ในสคริปต์การแทรก คลิก "ดูไฟล์ข้อมูล RAW" ในกรณีที่คุณพบปัญหาในการโหลดไฟล์ใน GitHub การดำเนินการนี้จะช่วยคุณประหยัดเวลา (ในขั้นตอนถัดไป) ในการสร้างการฝังมากกว่า 2-3 รายการ (สูงสุด 20-25 รายการ) ในกรณีที่คุณใช้บัญชีการเรียกเก็บเงินเครดิตช่วงทดลองใช้สำหรับ Google Cloud
5. สร้างการฝังสําหรับข้อมูลสิทธิบัตร
ก่อนอื่นมาทดสอบฟังก์ชันการฝังโดยเรียกใช้การค้นหาตัวอย่างต่อไปนี้
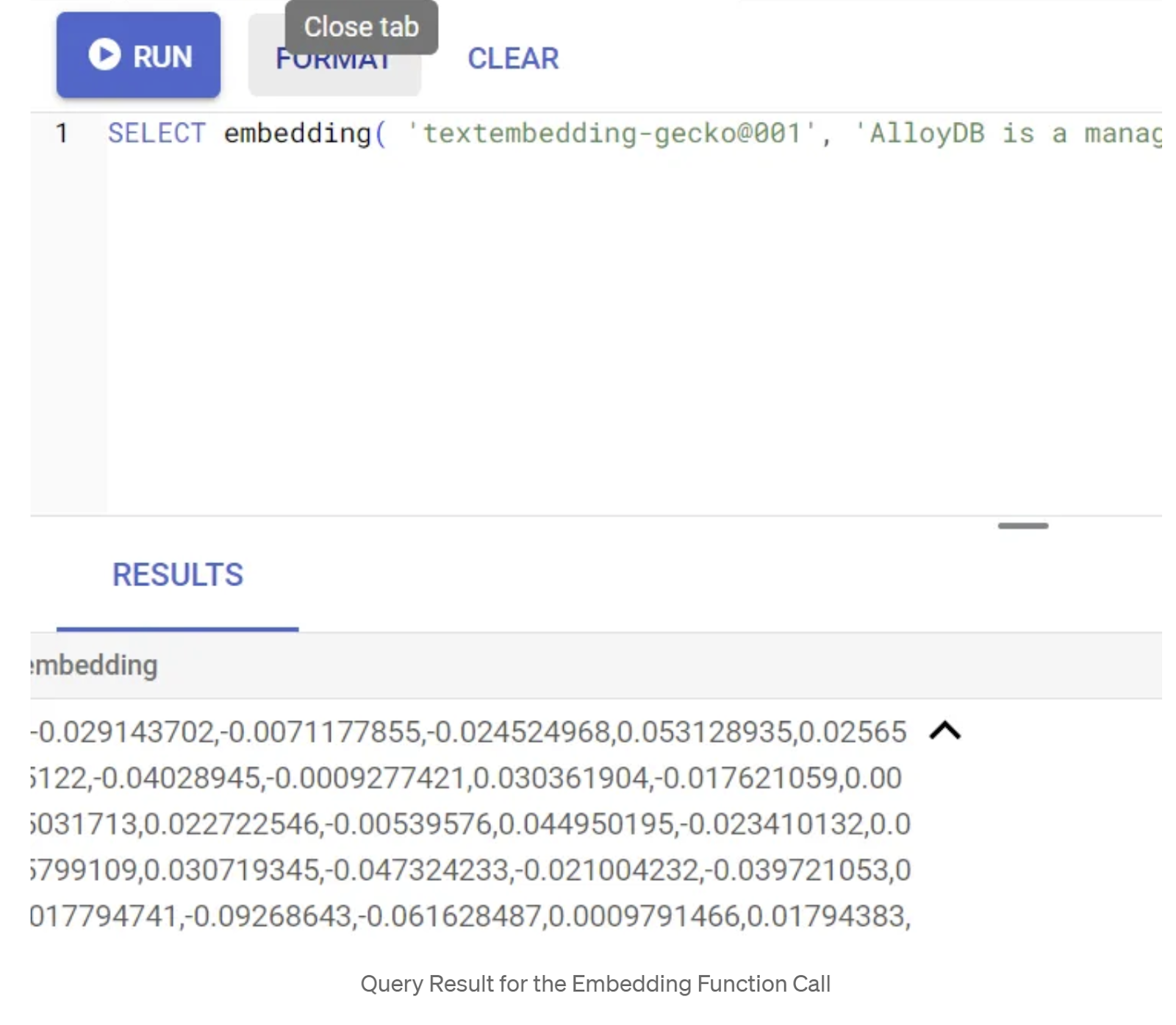
SELECT embedding('text-embedding-005', 'AlloyDB is a managed, cloud-hosted SQL database service.');
ซึ่งจะแสดงผลเวกเตอร์การฝังที่ดูเหมือนอาร์เรย์ของตัวเลขทศนิยมสำหรับข้อความตัวอย่างในการค้นหา มีลักษณะดังนี้
อัปเดตฟิลด์เวกเตอร์ abstract_embeddings
เรียกใช้ DML ด้านล่างเพื่ออัปเดตข้อมูลสรุปของสิทธิบัตรในตารางด้วยข้อมูลการฝังที่เกี่ยวข้องเฉพาะในกรณีที่คุณไม่ได้แทรกข้อมูล abstract_embeddings เป็นส่วนหนึ่งของสคริปต์การแทรก
UPDATE patents_data set abstract_embeddings = embedding( 'text-embedding-005', abstract);
คุณอาจพบปัญหาในการสร้างการฝังมากกว่า 2-3 รายการ (สูงสุด 20-25 รายการ) หากใช้บัญชีการเรียกเก็บเงินเครดิตช่วงทดลองใช้สำหรับ Google Cloud ด้วยเหตุนี้ เราจึงรวมการฝังไว้ในสคริปต์การแทรกแล้ว และคุณควรโหลดข้อมูลไว้ในตารางแล้วหากทำตามขั้นตอน "โหลดข้อมูลสิทธิบัตรลงในฐานข้อมูล" เสร็จแล้ว
6. ดำเนินการ RAG ขั้นสูงด้วยฟีเจอร์ใหม่ของ AlloyDB
เมื่อตาราง ข้อมูล และการฝังพร้อมแล้ว ให้ทําการค้นหาเวกเตอร์แบบเรียลไทม์สําหรับข้อความค้นหาของผู้ใช้ คุณสามารถทดสอบได้โดยเรียกใช้การค้นหาด้านล่าง
SELECT id || ' - ' || title as title FROM patents_data ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
ในข้อความค้นหานี้
- ข้อความที่ผู้ใช้ค้นหาคือ "การวิเคราะห์ความรู้สึก"
- เรากําลังแปลงเป็นองค์ประกอบในเมธอด embedding() โดยใช้โมเดล text-embedding-005
- "<=>" แสดงถึงการใช้วิธีการวัดระยะทางแบบ COSINE SIMILARITY
- เรากําลังแปลงผลลัพธ์ของวิธีการฝังเป็นประเภทเวกเตอร์เพื่อให้เข้ากันได้กับเวกเตอร์ที่จัดเก็บไว้ในฐานข้อมูล
- LIMIT 10 แสดงว่าเรากำลังเลือกข้อความค้นหาที่ตรงกันมากที่สุด 10 รายการ
AlloyDB ยกระดับ RAG ของ Vector Search ไปอีกขั้น ดังนี้
มีสิ่งใหม่ๆ มากมายที่เปิดตัว 2 รายการที่มุ่งเน้นนักพัฒนาแอป ได้แก่
- การกรองในบรรทัด
- ผู้ประเมินการเรียกคืน
การกรองในบรรทัด
ก่อนหน้านี้ในฐานะนักพัฒนาแอป คุณจะต้องดำเนินการค้นหาด้วยเวกเตอร์และจัดการกับการกรองและการเรียกข้อมูล ตัวเพิ่มประสิทธิภาพการค้นหาของ AlloyDB จะเลือกวิธีดำเนินการค้นหาด้วยตัวกรอง การกรองในบรรทัดเป็นเทคนิคใหม่ในการเพิ่มประสิทธิภาพการค้นหาที่ช่วยให้เครื่องมือเพิ่มประสิทธิภาพการค้นหา AlloyDB ประเมินทั้งเงื่อนไขการกรองข้อมูลเมตาและการค้นหาเวกเตอร์ควบคู่กัน โดยใช้ทั้งดัชนีเวกเตอร์และดัชนีในคอลัมน์ข้อมูลเมตา ซึ่งทำให้ประสิทธิภาพการเรียกคืนเพิ่มขึ้น และช่วยให้นักพัฒนาแอปใช้ประโยชน์จากสิ่งที่ AlloyDB มีให้ได้เลย
การกรองในบรรทัดเหมาะสําหรับกรณีที่มีความเฉพาะเจาะจงปานกลาง เมื่อ AlloyDB ค้นหาผ่านดัชนีเวกเตอร์ ระบบจะคํานวณเฉพาะระยะทางของเวกเตอร์ที่ตรงกับเงื่อนไขการกรองข้อมูลเมตา (ตัวกรองฟังก์ชันในการค้นหามักจะจัดการในประโยค WHERE) ซึ่งจะปรับปรุงประสิทธิภาพการค้นหาเหล่านี้ได้อย่างมาก นอกเหนือจากข้อดีของการกรองหลังการค้นหาหรือการกรองล่วงหน้า
- ติดตั้งหรืออัปเดตส่วนขยาย pgvector
CREATE EXTENSION IF NOT EXISTS vector WITH VERSION '0.8.0.google-3';
หากติดตั้งส่วนขยาย pgvector ไว้แล้ว ให้อัปเกรดส่วนขยายเวกเตอร์เป็นเวอร์ชัน 0.8.0.google-3 ขึ้นไปเพื่อรับความสามารถของเครื่องมือประเมินการจํา
ALTER EXTENSION vector UPDATE TO '0.8.0.google-3';
ขั้นตอนนี้ต้องดำเนินการเฉพาะในกรณีที่ส่วนขยายเวกเตอร์เป็น <0.8.0.google-3>
หมายเหตุสำคัญ: หากจํานวนแถวน้อยกว่า 100 รายการ คุณไม่จําเป็นต้องสร้างดัชนี ScaNN ตั้งแต่แรก เนื่องจากดัชนีนี้จะใช้กับแถวที่มีจํานวนน้อยกว่าไม่ได้ ในกรณีนี้ โปรดข้ามขั้นตอนต่อไปนี้
- หากต้องการสร้างดัชนี ScaNN ให้ติดตั้งส่วนขยาย alloydb_scann
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
- ก่อนอื่น ให้เรียกใช้คำค้นหาเวกเตอร์โดยไม่ใช้ดัชนีและโดยไม่เปิดใช้ตัวกรองในบรรทัด
SELECT id || ' - ' || title as title FROM patents_data
WHERE num_claims >= 15
ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
ผลลัพธ์ควรคล้ายกับตัวอย่างต่อไปนี้
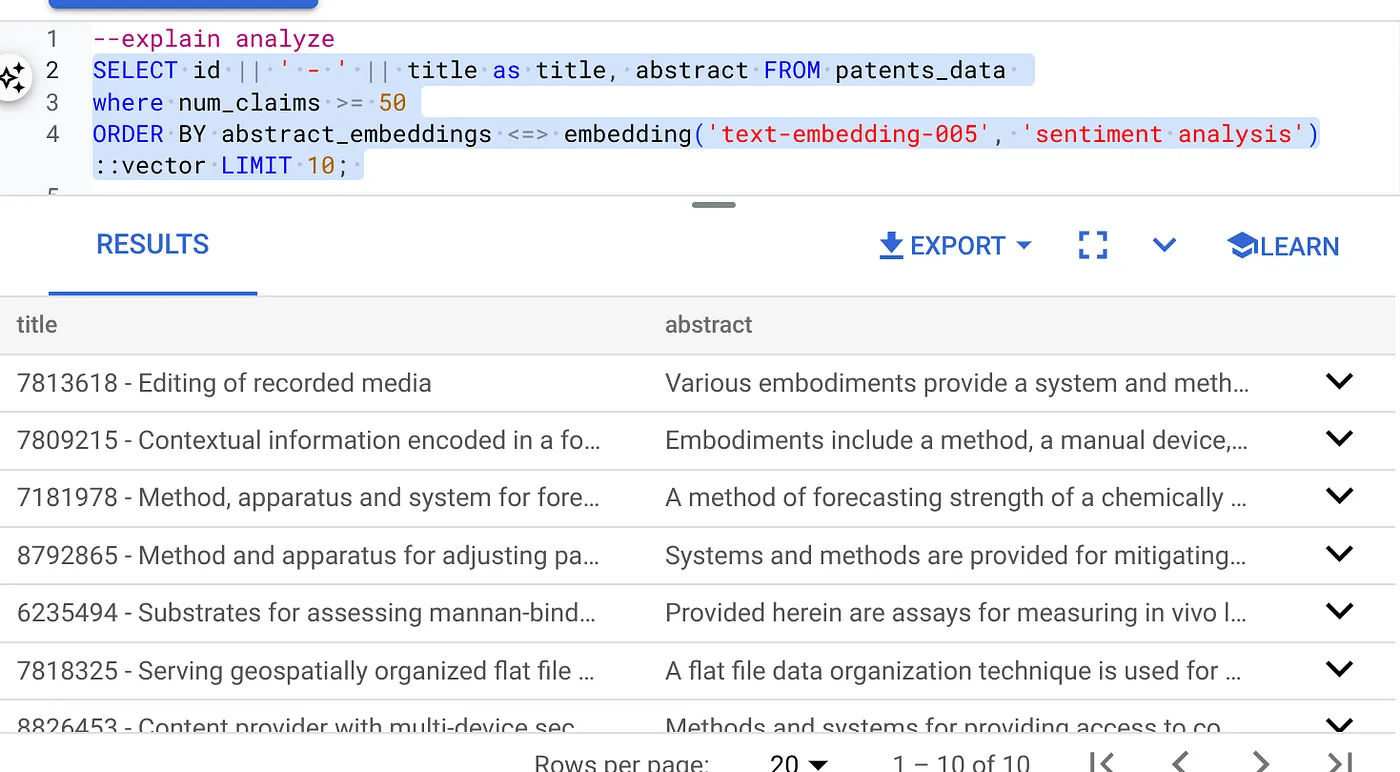
- เรียกใช้ Explain Analyze กับ URL ดังกล่าว (ไม่มีดัชนีหรือการกรองในบรรทัด)
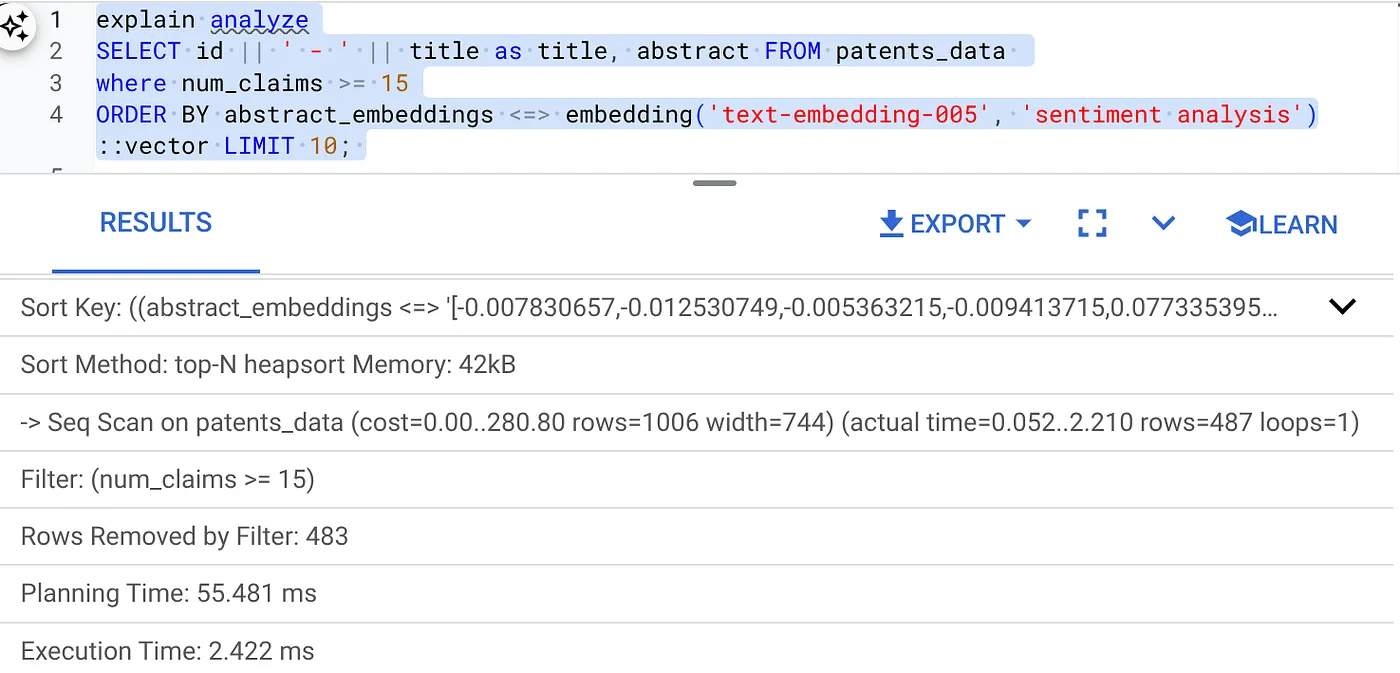
เวลาดำเนินการคือ 2.4 มิลลิวินาที
- มาสร้างดัชนีปกติในช่อง num_claims เพื่อให้เรากรองตามดัชนีนั้นได้
CREATE INDEX idx_patents_data_num_claims ON patents_data (num_claims);
- มาสร้างดัชนี SCANN สําหรับแอปพลิเคชันการค้นหาสิทธิบัตรกัน เรียกใช้คำสั่งต่อไปนี้จาก AlloyDB Studio
CREATE INDEX patent_index ON patents_data
USING scann (abstract_embeddings cosine)
WITH (num_leaves=32);
หมายเหตุสำคัญ: (num_leaves=32) มีผลกับชุดข้อมูลทั้งหมดที่มีแถวมากกว่า 1,000 แถว หากจํานวนแถวน้อยกว่า 100 รายการ คุณไม่จําเป็นต้องสร้างดัชนีตั้งแต่แรก เนื่องจากดัชนีจะไม่มีผลกับแถวที่มีจํานวนน้อยกว่า
- ตั้งค่าการกรองในบรรทัดเปิดใช้ในดัชนี ScaNN โดยทำดังนี้
SET scann.enable_inline_filtering = on
- ตอนนี้มาเรียกใช้ข้อความค้นหาเดียวกันที่มีตัวกรองและการค้นหาเวกเตอร์กัน
SELECT id || ' - ' || title as title FROM patents_data
WHERE num_claims >= 15
ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
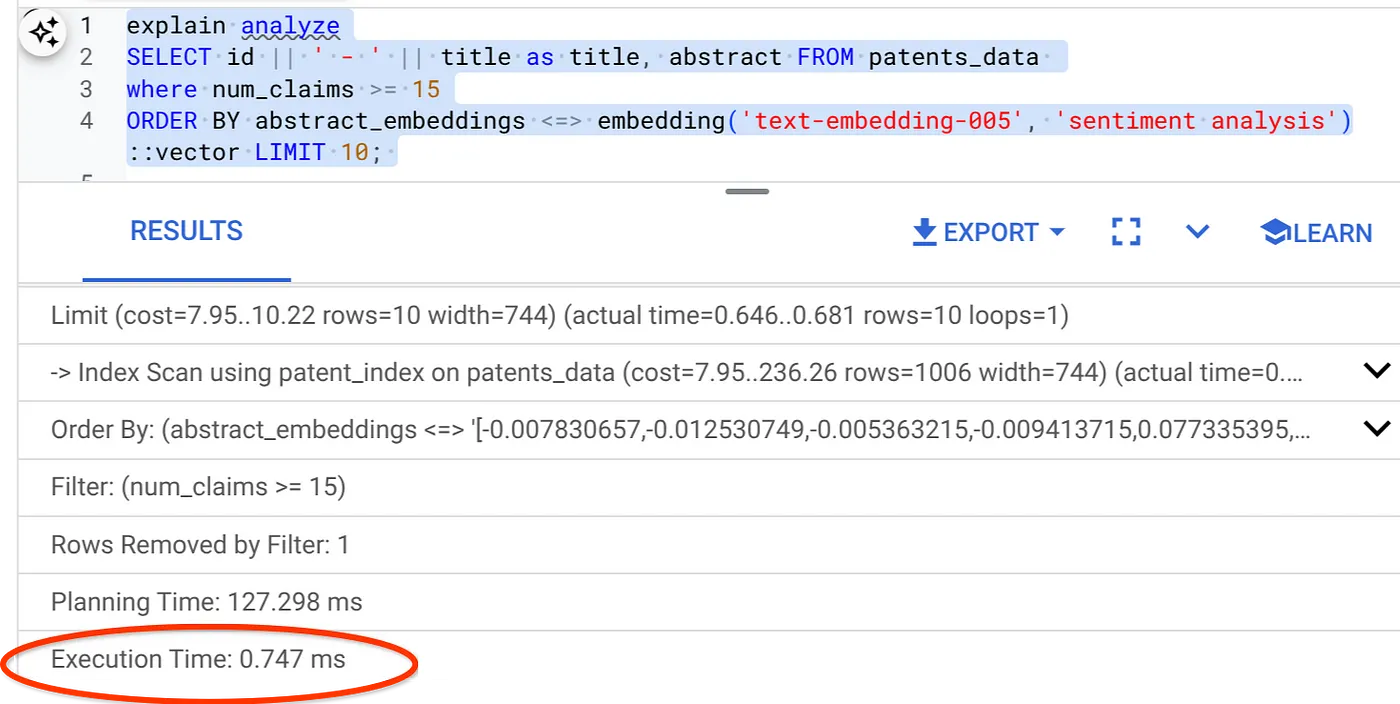
ดังที่คุณเห็น เวลาที่ใช้ในการดำเนินการลดลงอย่างมากสำหรับการค้นหาเวกเตอร์เดียวกัน การกรองในบรรทัดที่มีดัชนี ScaNN ใน Vector Search ทําให้เป็นไปได้
ต่อไปมาประเมินการเรียกคืนของ Vector Search ที่เปิดใช้ ScaNN นี้กัน
ผู้ประเมินการเรียกคืน
การเรียกคืนในการค้นหาแบบคล้ายกันคือเปอร์เซ็นต์ของอินสแตนซ์ที่เกี่ยวข้องซึ่งดึงมาจากการค้นหา เช่น จํานวนผลบวกจริง เมตริกนี้เป็นเมตริกที่ใช้กันมากที่สุดในการวัดคุณภาพการค้นหา แหล่งที่มาของอัตราความจำที่เสียไปอย่างหนึ่งมาจากความแตกต่างระหว่างการค้นหาเพื่อนบ้านที่ใกล้ที่สุดแบบใกล้เคียงหรือ aNN กับการค้นหาเพื่อนบ้านที่ใกล้ที่สุดแบบ k (ตรงทั้งหมด) หรือ kNN ดัชนีเวกเตอร์อย่าง ScaNN ของ AlloyDB ใช้อัลกอริทึม aNN ซึ่งช่วยให้คุณค้นหาเวกเตอร์ในชุดข้อมูลขนาดใหญ่ได้เร็วขึ้น แต่ประสิทธิภาพการเรียกคืนจะลดลงเล็กน้อย ตอนนี้ AlloyDB ช่วยให้คุณวัดการแลกเปลี่ยนนี้ในฐานข้อมูลได้โดยตรงสําหรับการค้นหาแต่ละรายการ และช่วยให้มั่นใจว่าข้อมูลจะเสถียรเมื่อเวลาผ่านไป คุณสามารถอัปเดตพารามิเตอร์การค้นหาและดัชนีตามข้อมูลนี้เพื่อให้ได้ผลลัพธ์และประสิทธิภาพที่ดียิ่งขึ้น
ตรรกะเบื้องหลังการเรียกคืนผลการค้นหาคืออะไร
ในบริบทของการค้นหาเวกเตอร์ การเรียกคืนหมายถึงเปอร์เซ็นต์ของเวกเตอร์ที่ดัชนีแสดงผลซึ่งเป็นจุดข้อมูลข้างเคียงที่อยู่ใกล้กันที่สุด เช่น หากการค้นหาเพื่อนบ้านที่อยู่ใกล้ที่สุดสำหรับเพื่อนบ้านที่อยู่ใกล้ที่สุด 20 รายแสดงผลเพื่อนบ้านที่อยู่ใกล้ที่สุดตามความเป็นจริง 19 ราย ค่าการเรียกคืนคือ 19/20x100 = 95% การเรียกคืนคือเมตริกที่ใช้วัดคุณภาพการค้นหา และหมายถึงเปอร์เซ็นต์ของผลลัพธ์ที่แสดงซึ่งใกล้เคียงกับเวกเตอร์การค้นหามากที่สุดอย่างเป็นกลาง
คุณสามารถดูการเรียกคืนสําหรับการค้นหาเวกเตอร์ในดัชนีเวกเตอร์สําหรับการกําหนดค่าหนึ่งๆ โดยใช้ฟังก์ชัน evaluate_query_recall ฟังก์ชันนี้ช่วยให้คุณปรับแต่งพารามิเตอร์เพื่อให้ได้ผลลัพธ์การเรียกข้อมูลคำค้นหาเวกเตอร์ที่ต้องการ
หมายเหตุสำคัญ:
หากคุณพบข้อผิดพลาด "สิทธิ์ถูกปฏิเสธ" ในดัชนี HNSW ในขั้นตอนต่อไปนี้ ให้ข้ามส่วนการประเมินการเรียกคืนทั้งหมดนี้ไปก่อน ปัญหานี้อาจเกี่ยวข้องกับข้อจํากัดการเข้าถึงในตอนนี้ เนื่องจากเพิ่งเปิดตัวเมื่อมีการบันทึกโค้ดแล็บนี้
- ตั้งค่า Flag เปิดใช้การสแกนดัชนีในดัชนี ScaNN และดัชนี HNSW
SET scann.enable_indexscan = on
SET hnsw.enable_index_scan = on
- เรียกใช้การค้นหาต่อไปนี้ใน AlloyDB Studio
SELECT
*
FROM
evaluate_query_recall($$
SELECT
id || ' - ' || title AS title,
abstract
FROM
patents_data
where num_claims >= 15
ORDER BY
abstract_embeddings <=> embedding('text-embedding-005',
'sentiment analysis')::vector
LIMIT 25 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
ฟังก์ชัน evaluate_query_recall จะรับการค้นหาเป็นพารามิเตอร์และแสดงผลความจํา ฉันใช้ข้อความค้นหาเดียวกับที่ใช้ตรวจสอบประสิทธิภาพเป็นข้อความค้นหาอินพุตของฟังก์ชัน เราได้เพิ่ม SCaNN เป็นวิธีการจัดทำดัชนีแล้ว ดูตัวเลือกพารามิเตอร์เพิ่มเติมได้ในเอกสารประกอบ
การเรียกคืนสำหรับคำค้นหาด้วยเวกเตอร์ที่เราใช้อยู่
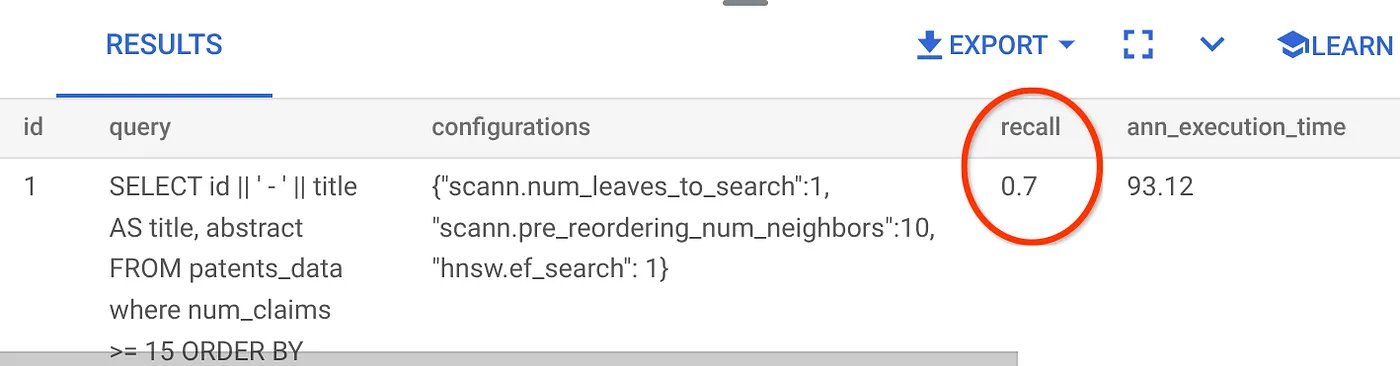
เราเห็นว่าการเรียกคืนคือ 70% ตอนนี้ฉันใช้ข้อมูลนี้เพื่อเปลี่ยนพารามิเตอร์ดัชนี วิธีการ พารามิเตอร์การค้นหา และปรับปรุงการเรียกคืนสำหรับ Vector Search นี้ได้
7. ทดสอบด้วยพารามิเตอร์การค้นหาและดัชนีที่แก้ไขแล้ว
ตอนนี้มาทดสอบการค้นหาโดยแก้ไขพารามิเตอร์การค้นหาตามการเรียกคืนที่ได้รับ
- เราได้แก้ไขจำนวนแถวในชุดผลลัพธ์เป็น 7 (จากเดิม 25) และพบว่าการเรียกคืนดีขึ้นเป็น 86%
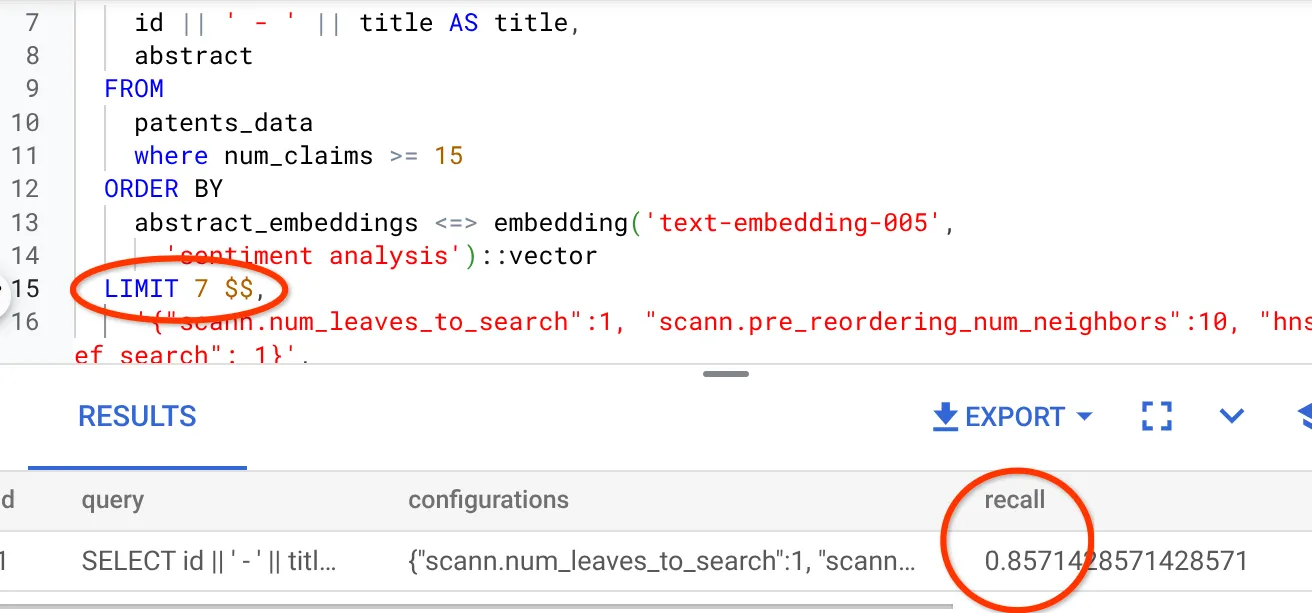
ซึ่งหมายความว่าฉันสามารถปรับเปลี่ยนจำนวนรายการที่ตรงกันซึ่งผู้ใช้จะเห็นได้แบบเรียลไทม์เพื่อปรับปรุงความเกี่ยวข้องของรายการที่ตรงกันให้สอดคล้องกับบริบทการค้นหาของผู้ใช้
- ลองอีกครั้งโดยแก้ไขพารามิเตอร์ดัชนี ดังนี้
ในการทดสอบนี้ เราจะใช้ฟังก์ชันระยะทางความคล้ายคลึง "L2 Distance" แทนฟังก์ชันระยะทางความคล้ายคลึง "Cosine" นอกจากนี้ เราจะเปลี่ยนขีดจํากัดของคําค้นหาเป็น 10 เพื่อแสดงให้เห็นว่าคุณภาพของผลการค้นหาดีขึ้นหรือไม่ แม้ว่าจะมีจํานวนชุดผลการค้นหาเพิ่มขึ้น
[ก่อน] การค้นหาที่ใช้ฟังก์ชันระยะทางความคล้ายคลึงของ Cosine
SELECT
*
FROM
evaluate_query_recall($$
SELECT
id || ' - ' || title AS title,
abstract
FROM
patents_data
where num_claims >= 15
ORDER BY
abstract_embeddings <=> embedding('text-embedding-005',
'sentiment analysis')::vector
LIMIT 10 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
หมายเหตุสำคัญมาก: คุณอาจสงสัยว่า "เราจะรู้ได้อย่างไรว่าคำค้นหานี้ใช้ความคล้ายคลึงแบบ COSINE" คุณระบุฟังก์ชันระยะทางได้โดยใช้ "<=>" เพื่อแสดงระยะทาง Cosine
ลิงก์เอกสารสำหรับฟังก์ชันระยะทางของ Vector Search
ผลการค้นหาข้างต้นคือ
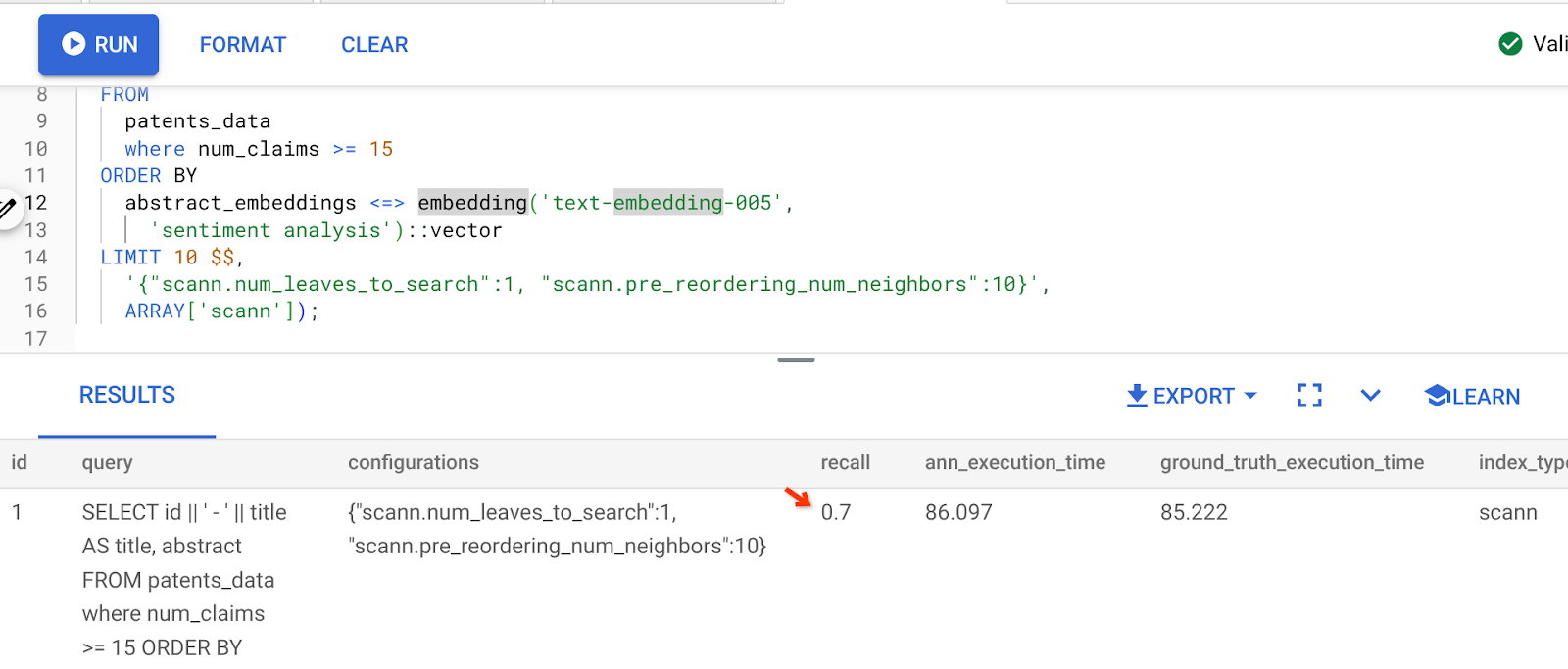
ดังที่คุณเห็น การเรียกคืนคือ 70% โดยไม่มีการเปลี่ยนแปลงตรรกะดัชนี จำดัชนี ScaNN ที่เราสร้างไว้ในขั้นตอนที่ 6 ของส่วนการกรองในบรรทัด "patent_index " ได้ไหม ดัชนีเดียวกันนี้ยังคงมีผลอยู่ขณะที่เราเรียกใช้การค้นหาข้างต้น
ตอนนี้มาสร้างดัชนีที่มีการค้นหาฟังก์ชันระยะทางแบบอื่นกัน ระยะทาง L2: <->
drop index patent_index;
CREATE INDEX patent_index_L2 ON patents_data
USING scann (abstract_embeddings L2)
WITH (num_leaves=32);
คำสั่ง DROP INDEX มีไว้เพื่อตรวจสอบว่าไม่มีดัชนีที่ไม่จำเป็นในตาราง
ตอนนี้ฉันสามารถเรียกใช้การค้นหาต่อไปนี้เพื่อประเมินการเรียกคืนหลังจากเปลี่ยนฟังก์ชันระยะทางของฟังก์ชันการค้นหาเวกเตอร์
[หลังจาก] การค้นหาที่ใช้ฟังก์ชันระยะทางความคล้ายคลึงของ Cosine
SELECT
*
FROM
evaluate_query_recall($$
SELECT
id || ' - ' || title AS title,
abstract
FROM
patents_data
where num_claims >= 15
ORDER BY
abstract_embeddings <-> embedding('text-embedding-005',
'sentiment analysis')::vector
LIMIT 10 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
ผลการค้นหาข้างต้นคือ
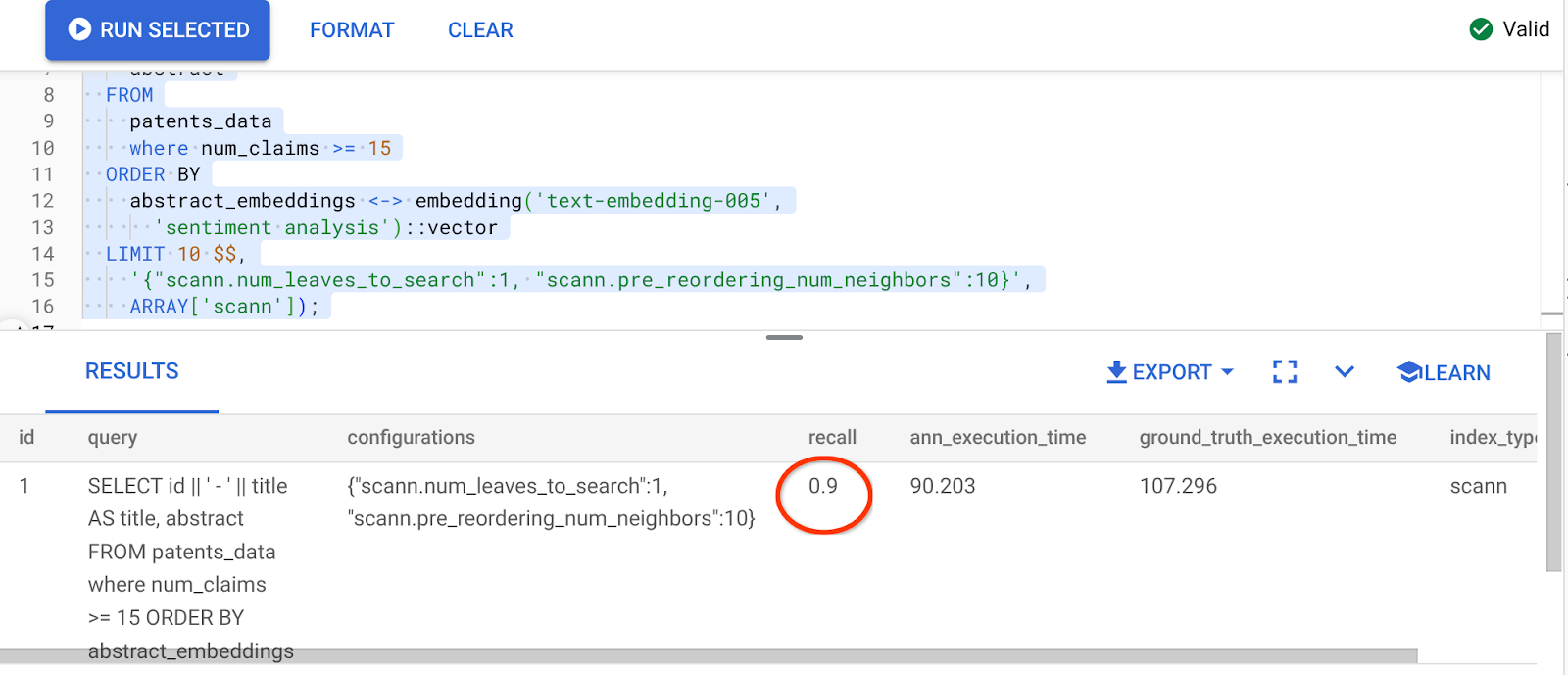
ค่าการจดจําเพิ่มขึ้นถึง 90% เลย
คุณเปลี่ยนพารามิเตอร์อื่นๆ ในดัชนีได้ เช่น num_leaves เป็นต้น โดยอิงตามค่าการเรียกคืนที่ต้องการและชุดข้อมูลที่แอปพลิเคชันใช้
8. ล้างข้อมูล
โปรดทำตามขั้นตอนต่อไปนี้เพื่อเลี่ยงไม่ให้เกิดการเรียกเก็บเงินกับบัญชี Google Cloud สำหรับทรัพยากรที่ใช้ในโพสต์นี้
- ในคอนโซล Google Cloud ให้ไปที่หน้าเครื่องมือจัดการทรัพยากร
- ในรายการโปรเจ็กต์ ให้เลือกโปรเจ็กต์ที่ต้องการลบ แล้วคลิกลบ
- ในกล่องโต้ตอบ ให้พิมพ์รหัสโปรเจ็กต์ แล้วคลิกปิดเพื่อลบโปรเจ็กต์
- หรือจะลบคลัสเตอร์ AlloyDB (เปลี่ยนตำแหน่งในไฮเปอร์ลิงก์นี้หากคุณไม่ได้เลือก us-central1 สำหรับคลัสเตอร์ ณ เวลาที่กําหนดค่า) ที่เราเพิ่งสร้างขึ้นสําหรับโปรเจ็กต์นี้โดยคลิกปุ่ม "ลบคลัสเตอร์" ก็ได้
9. ขอแสดงความยินดี
ยินดีด้วย คุณสร้างคำค้นหาเกี่ยวกับสิทธิบัตรตามบริบทด้วยเครื่องมือค้นหาเวกเตอร์ขั้นสูงของ AlloyDB เรียบร้อยแล้วเพื่อให้มีประสิทธิภาพสูงและเพื่อให้คำค้นหาทำงานตามความหมายอย่างแท้จริง เราได้รวบรวมแอปพลิเคชันเอนทิตีหลายเครื่องมือที่ควบคุมคุณภาพซึ่งใช้ ADK และ AlloyDB ทั้งหมดที่เราได้พูดคุยกันที่นี่เพื่อสร้างเอเจนต์การค้นหาและวิเคราะห์เวกเตอร์สิทธิบัตรที่มีประสิทธิภาพและมีคุณภาพสูง ซึ่งคุณสามารถดูได้ที่นี่ https://youtu.be/Y9fvVY0yZTY
หากต้องการดูวิธีสร้างตัวแทนดังกล่าว โปรดดูcodelab นี้