
1. खास जानकारी
अलग-अलग इंडस्ट्री में, कॉन्टेक्स्ट के हिसाब से खोज करने की सुविधा एक अहम फ़ंक्शन है. यह उनके ऐप्लिकेशन का मुख्य हिस्सा है. Retrieval Augmented Generation (RAG) का इस्तेमाल, इस ज़रूरी टेक्नोलॉजी को बेहतर बनाने के लिए काफ़ी समय से किया जा रहा है. इसमें जनरेटिव एआई की मदद से जानकारी पाने के तरीके शामिल हैं. जनरेटिव मॉडल, एआई की दुनिया में बदलाव ला रहे हैं. इनकी कॉन्टेक्स्ट विंडो बड़ी होती है और ये अच्छी क्वालिटी का आउटपुट देते हैं. आरएजी, एआई ऐप्लिकेशन और एजेंट में कॉन्टेक्स्ट जोड़ने का एक व्यवस्थित तरीका है. इससे उन्हें स्ट्रक्चर्ड डेटाबेस या अलग-अलग मीडिया से मिली जानकारी के आधार पर काम करने में मदद मिलती है. संदर्भ के हिसाब से मिले इस डेटा से, जवाब के सही होने और सटीक होने के बारे में पता चलता है. हालांकि, ये नतीजे कितने सटीक होते हैं? क्या आपका कारोबार, कॉन्टेक्स्ट के हिसाब से मिलते-जुलते कीवर्ड और उनकी प्रासंगिकता के सटीक होने पर निर्भर करता है? अगर हां, तो यह प्रोजेक्ट आपके लिए है!
वेक्टर सर्च की सबसे बड़ी समस्या यह नहीं है कि इसे कैसे बनाया जाए, बल्कि यह है कि यह कैसे पता लगाया जाए कि आपके वेक्टर मैच सही हैं या नहीं. हम सभी के साथ ऐसा कभी न कभी हुआ है, जब हमने नतीजों की सूची को बिना किसी मतलब के देखा हो और सोचा हो कि ‘क्या यह सुविधा काम भी कर रही है?!' आइए, जानते हैं कि वेक्टर मैच की क्वालिटी का आकलन कैसे किया जाता है. "तो RAG में क्या बदलाव हुआ?", आपने पूछा? सब कुछ! कई सालों से, रीट्रिवल ऑगमेंटेड जनरेशन (आरएजी) एक ऐसा लक्ष्य रहा है जिसे हासिल करना मुश्किल है, लेकिन यह काफ़ी फ़ायदेमंद है. अब हमारे पास, आरएजी ऐप्लिकेशन बनाने के लिए ज़रूरी टूल उपलब्ध हैं. इनकी मदद से, मिशन-क्रिटिकल टास्क के लिए ज़रूरी परफ़ॉर्मेंस और भरोसेमंद तरीके से काम करने वाले ऐप्लिकेशन बनाए जा सकते हैं.
अब हमें तीन चीज़ों के बारे में बुनियादी जानकारी मिल चुकी है:
- कॉन्टेक्स्ट के हिसाब से खोज करने की सुविधा का आपके एजेंट के लिए क्या मतलब है और Vector Search का इस्तेमाल करके इसे कैसे पूरा किया जा सकता है.
- हमने आपके डेटा के दायरे में वेक्टर सर्च की सुविधा पाने के बारे में भी जानकारी दी. इसका मतलब है कि यह सुविधा आपके डेटाबेस में ही उपलब्ध है. अगर आपको पहले से नहीं पता है, तो बता दें कि Google Cloud के सभी डेटाबेस में यह सुविधा काम करती है!
- हमने दुनिया के अन्य देशों के मुकाबले, आपको एक कदम आगे बढ़कर यह बताया है कि ScaNN इंडेक्स की मदद से काम करने वाली AlloyDB Vector Search की सुविधा का इस्तेमाल करके, ज़्यादा परफ़ॉर्मेंस और क्वालिटी के साथ वेक्टर सर्च RAG की सुविधा को कैसे लागू किया जा सकता है.
अगर आपने आरएजी के बुनियादी, इंटरमीडिएट, और थोड़े ऐडवांस एक्सपेरिमेंट नहीं पढ़े हैं, तो हम आपको इन तीनों एक्सपेरिमेंट के बारे में पढ़ने का सुझाव देते हैं. इन्हें यहां, यहां, और यहां दिए गए क्रम में पढ़ें.
पेटेंट खोज की सुविधा, उपयोगकर्ता को खोज के लिए इस्तेमाल किए गए टेक्स्ट के हिसाब से, मिलते-जुलते पेटेंट खोजने में मदद करती है. हम इसका एक वर्शन पहले ही बना चुके हैं. अब हम इसे नई और बेहतर RAG सुविधाओं के साथ बनाएंगे. इससे ऐप्लिकेशन के लिए, कॉन्टेक्स्ट के हिसाब से खोज करने की सुविधा मिलेगी. साथ ही, खोज के नतीजों की क्वालिटी को कंट्रोल किया जा सकेगा. आइए, शुरू करते हैं!
नीचे दी गई इमेज में, इस ऐप्लिकेशन में होने वाली पूरी प्रोसेस दिखाई गई है.~ 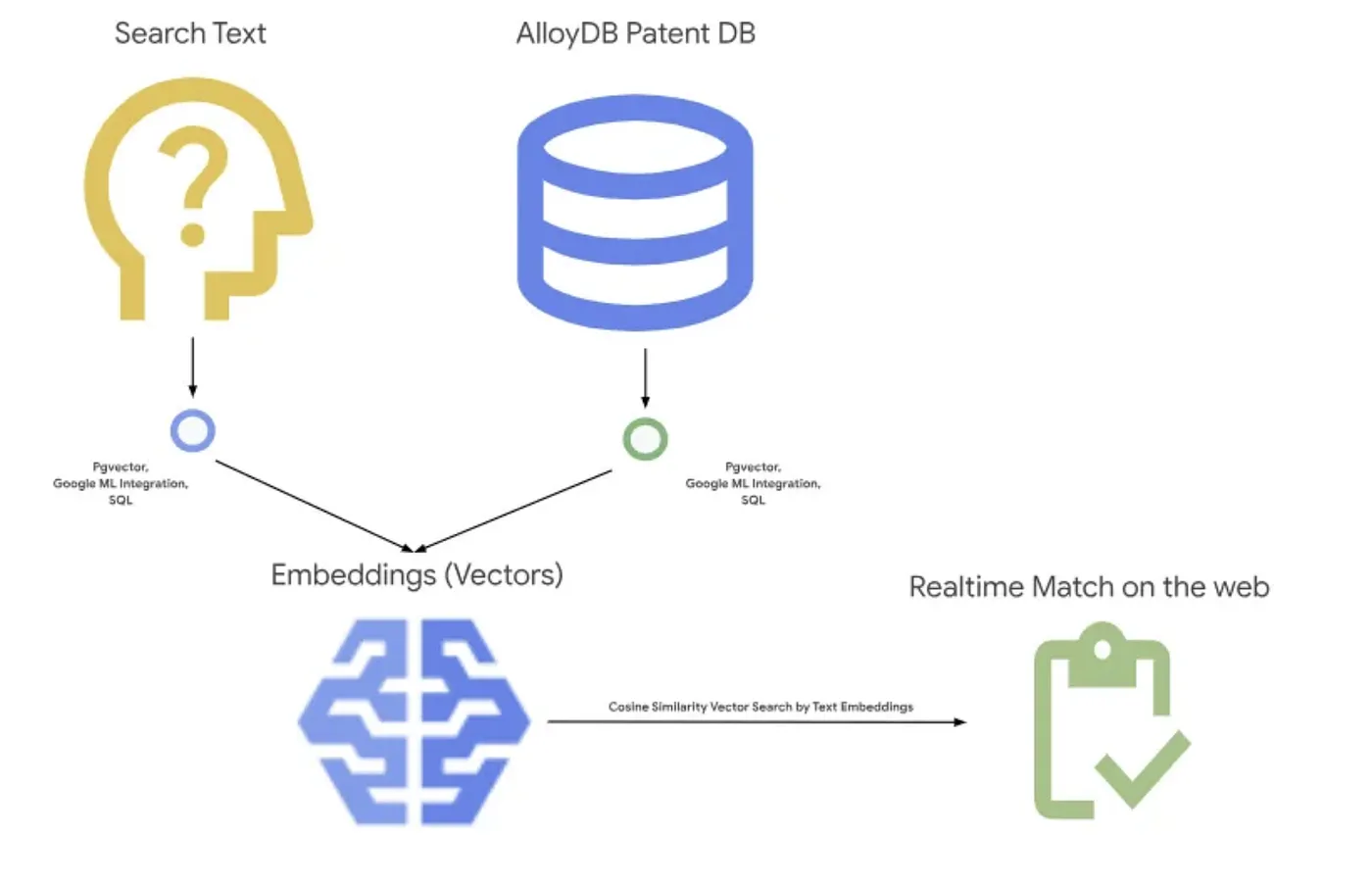
मकसद
किसी उपयोगकर्ता को टेक्स्ट के ब्यौरे के आधार पर पेटेंट खोजने की अनुमति दें. इससे उसे बेहतर परफ़ॉर्मेंस और क्वालिटी मिलेगी. साथ ही, वह AlloyDB की नई RAG सुविधाओं का इस्तेमाल करके, जनरेट किए गए मैच की क्वालिटी का आकलन कर पाएगा.
आपको क्या बनाना है
इस लैब में, आपको ये काम करने होंगे:
- AlloyDB इंस्टेंस बनाना और Patents Public Dataset लोड करना
- मेटाडेटा इंडेक्स और ScaNN इंडेक्स बनाना
- ScaNN की इनलाइन फ़िल्टरिंग की सुविधा का इस्तेमाल करके, AlloyDB में ऐडवांस वेक्टर सर्च लागू करना
- रिकॉल के आकलन की सुविधा लागू करना
- क्वेरी के जवाब का आकलन करना
ज़रूरी शर्तें
2. शुरू करने से पहले
प्रोजेक्ट बनाना
- Google Cloud Console में, प्रोजेक्ट चुनने वाले पेज पर, Google Cloud प्रोजेक्ट चुनें या बनाएं.
- पक्का करें कि आपके Cloud प्रोजेक्ट के लिए बिलिंग चालू हो. किसी प्रोजेक्ट के लिए बिलिंग चालू है या नहीं, यह देखने का तरीका जानें .
- आपको Cloud Shell का इस्तेमाल करना होगा. यह Google Cloud में चलने वाला कमांड-लाइन एनवायरमेंट है. Google Cloud Console में सबसे ऊपर मौजूद, Cloud Shell चालू करें पर क्लिक करें.

- Cloud Shell से कनेक्ट होने के बाद, यह देखने के लिए कि आपकी पुष्टि हो चुकी है और प्रोजेक्ट को आपके प्रोजेक्ट आईडी पर सेट किया गया है, इस कमांड का इस्तेमाल करें:
gcloud auth list
- यह पुष्टि करने के लिए कि gcloud कमांड को आपके प्रोजेक्ट के बारे में पता है, Cloud Shell में यह कमांड चलाएं.
gcloud config list project
- अगर आपका प्रोजेक्ट सेट नहीं है, तो इसे सेट करने के लिए इस निर्देश का इस्तेमाल करें:
gcloud config set project <YOUR_PROJECT_ID>
- ज़रूरी एपीआई चालू करें. Cloud Shell टर्मिनल में gcloud कमांड का इस्तेमाल किया जा सकता है:
gcloud services enable alloydb.googleapis.com compute.googleapis.com cloudresourcemanager.googleapis.com servicenetworking.googleapis.com run.googleapis.com cloudbuild.googleapis.com cloudfunctions.googleapis.com aiplatform.googleapis.com
gcloud कमांड के बजाय, कंसोल का इस्तेमाल करके भी ऐसा किया जा सकता है. इसके लिए, हर प्रॉडक्ट को खोजें या इस लिंक का इस्तेमाल करें.
gcloud कमांड और उनके इस्तेमाल के बारे में जानने के लिए, दस्तावेज़ देखें.
3. डेटाबेस सेटअप करना
इस लैब में, हम पेटेंट के डेटा के लिए AlloyDB का इस्तेमाल करेंगे. यह सभी संसाधनों को सेव करने के लिए, क्लस्टर का इस्तेमाल करता है. जैसे, डेटाबेस और लॉग. हर क्लस्टर में एक प्राइमरी इंस्टेंस होता है, जो डेटा का ऐक्सेस पॉइंट उपलब्ध कराता है. टेबल में असल डेटा होगा.
आइए, एक AlloyDB क्लस्टर, इंस्टेंस, और टेबल बनाएं. इसमें पेटेंट का डेटासेट लोड किया जाएगा.
क्लस्टर और इंस्टेंस बनाना
- Cloud Console में AlloyDB पेज पर जाएं. Cloud Console में ज़्यादातर पेजों को आसानी से ढूंढने के लिए, कंसोल के खोज बार का इस्तेमाल करके उन्हें खोजें.
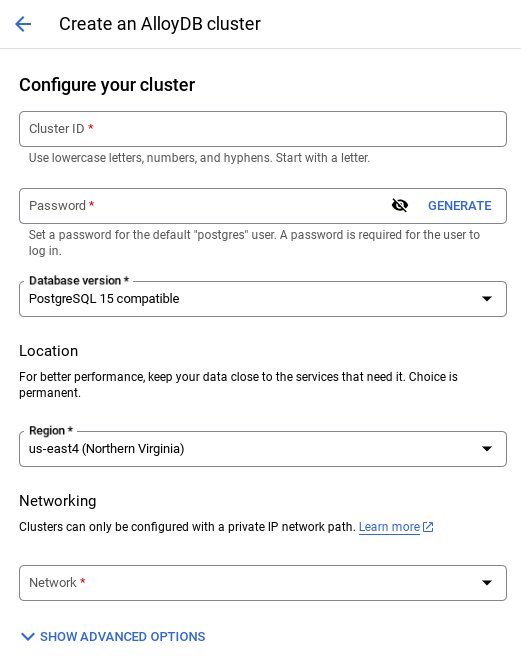
- उस पेज पर जाकर, क्लस्टर बनाएं को चुनें:

- आपको नीचे दी गई इमेज जैसी स्क्रीन दिखेगी. नीचे दी गई वैल्यू का इस्तेमाल करके, क्लस्टर और इंस्टेंस बनाएं. अगर आपको रिपॉज़िटरी से ऐप्लिकेशन कोड क्लोन करना है, तो पक्का करें कि वैल्यू मैच होती हों:
- क्लस्टर आईडी: "
vector-cluster" - password: "
alloydb" - PostgreSQL 15 / सुझाया गया नया वर्शन
- इलाका: "
us-central1" - नेटवर्किंग: "
default"
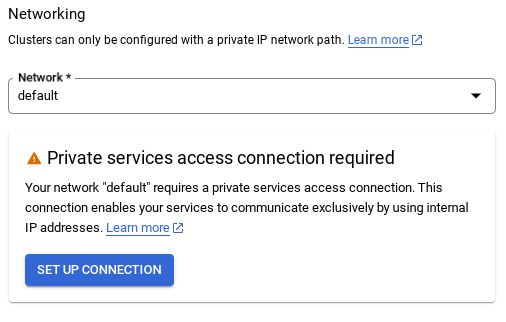
- डिफ़ॉल्ट नेटवर्क चुनने पर, आपको नीचे दी गई इमेज जैसी स्क्रीन दिखेगी.
कनेक्शन सेट अप करें को चुनें.
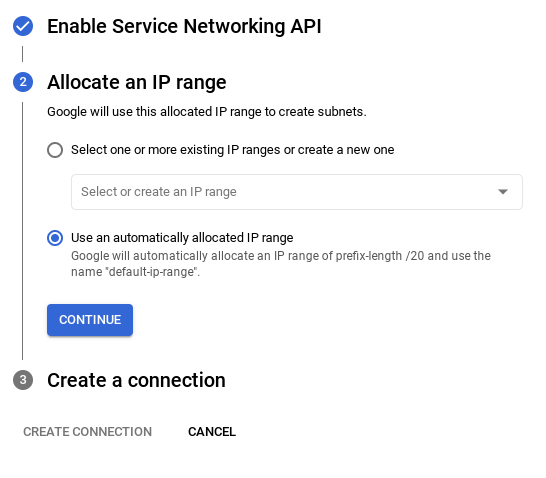
- इसके बाद, "अपने-आप असाइन की गई आईपी रेंज का इस्तेमाल करें" को चुनें और जारी रखें पर क्लिक करें. जानकारी देखने के बाद, कनेक्शन बनाएं को चुनें.
- नेटवर्क सेट अप हो जाने के बाद, क्लस्टर बनाना जारी रखा जा सकता है. नीचे दिए गए तरीके से क्लस्टर सेट अप करने के लिए, क्लस्टर बनाएं पर क्लिक करें:
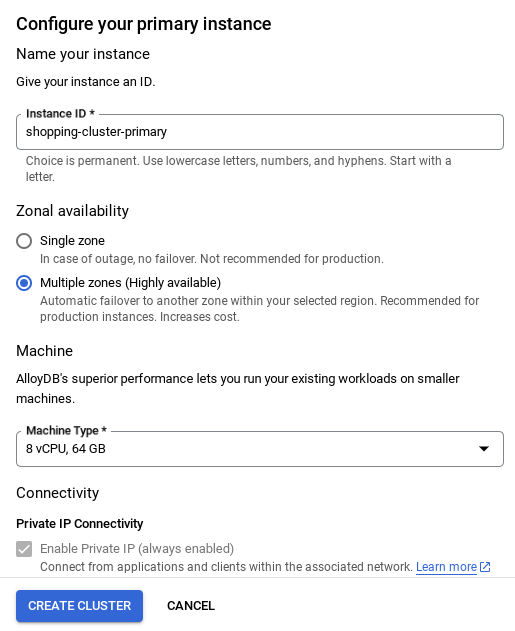
इंस्टेंस आईडी को (यह आपको क्लस्टर / इंस्टेंस को कॉन्फ़िगर करते समय दिखेगा) बदलना न भूलें
vector-instance. अगर इसे बदला नहीं जा सकता, तो आने वाले सभी रेफ़रंस में अपने इंस्टेंस आईडी का इस्तेमाल करना न भूलें.
ध्यान दें कि क्लस्टर बनने में करीब 10 मिनट लगेंगे. प्रोसेस पूरी होने के बाद, आपको एक स्क्रीन दिखेगी. इसमें, आपके बनाए गए क्लस्टर की खास जानकारी दिखेगी.
4. डेटा डालना
अब स्टोर के बारे में जानकारी देने वाली टेबल जोड़ें. AlloyDB पर जाएं. इसके बाद, प्राइमरी क्लस्टर और फिर AlloyDB Studio चुनें:
आपको इंस्टेंस बनने तक इंतज़ार करना पड़ सकता है. इसके बाद, क्लस्टर बनाते समय बनाए गए क्रेडेंशियल का इस्तेमाल करके, AlloyDB में साइन इन करें. PostgreSQL में पुष्टि करने के लिए, इस डेटा का इस्तेमाल करें:
- उपयोगकर्ता नाम : "
postgres" - डेटाबेस : "
postgres" - पासवर्ड : "
alloydb"
AlloyDB Studio में पुष्टि हो जाने के बाद, SQL कमांड को एडिटर में डाला जाता है. आखिरी विंडो के दाईं ओर मौजूद प्लस आइकॉन का इस्तेमाल करके, एक से ज़्यादा एडिटर विंडो जोड़ी जा सकती हैं.
एडिटर विंडो में, AlloyDB के लिए कमांड डाली जाती हैं. इसके लिए, ज़रूरत के हिसाब से 'चलाएं', 'फ़ॉर्मैट करें', और 'मिटाएं' विकल्पों का इस्तेमाल किया जाता है.
एक्सटेंशन चालू करना
इस ऐप्लिकेशन को बनाने के लिए, हम pgvector और google_ml_integration एक्सटेंशन का इस्तेमाल करेंगे. pgvector एक्सटेंशन की मदद से, वेक्टर एम्बेडिंग को सेव किया जा सकता है और उन्हें खोजा जा सकता है. google_ml_integration एक्सटेंशन, ऐसे फ़ंक्शन उपलब्ध कराता है जिनका इस्तेमाल करके, Vertex AI के अनुमान लगाने वाले एंडपॉइंट को ऐक्सेस किया जा सकता है. इससे एसक्यूएल में अनुमान मिलते हैं. इन एक्सटेंशन को चालू करें. इसके लिए, ये DDL चलाएं:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
अगर आपको अपने डेटाबेस पर चालू किए गए एक्सटेंशन देखने हैं, तो यह एसक्यूएल कमांड चलाएं:
select extname, extversion from pg_extension;
टेबल बनाना
AlloyDB Studio में, नीचे दिए गए डीडीएल स्टेटमेंट का इस्तेमाल करके टेबल बनाई जा सकती है:
CREATE TABLE patents_data ( id VARCHAR(25), type VARCHAR(25), number VARCHAR(20), country VARCHAR(2), date VARCHAR(20), abstract VARCHAR(300000), title VARCHAR(100000), kind VARCHAR(5), num_claims BIGINT, filename VARCHAR(100), withdrawn BIGINT, abstract_embeddings vector(768)) ;
abstract_embeddings कॉलम में, टेक्स्ट की वेक्टर वैल्यू सेव की जा सकेंगी.
अनुमति दें
"embedding" फ़ंक्शन को लागू करने की अनुमति देने के लिए, नीचे दिए गए स्टेटमेंट को चलाएं:
GRANT EXECUTE ON FUNCTION embedding TO postgres;
AlloyDB सेवा खाते को Vertex AI User की भूमिका असाइन करना
Google Cloud IAM Console में जाकर, AlloyDB सेवा खाते को "Vertex AI User" की भूमिका का ऐक्सेस दें. यह सेवा खाता इस तरह दिखता है: service-<<PROJECT_NUMBER >>@gcp-sa-alloydb.iam.gserviceaccount.com. PROJECT_NUMBER में आपका प्रोजेक्ट नंबर होगा.
इसके अलावा, Cloud Shell टर्मिनल से नीचे दिया गया कमांड भी चलाया जा सकता है:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
डेटाबेस में पेटेंट का डेटा लोड करना
हमारा डेटासेट, BigQuery पर मौजूद Google Patents के सार्वजनिक डेटासेट का इस्तेमाल करेगा. हम क्वेरी चलाने के लिए, AlloyDB Studio का इस्तेमाल करेंगे. डेटा को इस insert_scripts.sql फ़ाइल में सोर्स किया जाता है. हम इस फ़ाइल को चलाकर पेटेंट का डेटा लोड करेंगे.
- Google Cloud Console में, AlloyDB पेज खोलें.
- बनाया गया नया क्लस्टर चुनें और इंस्टेंस पर क्लिक करें.
- AlloyDB के नेविगेशन मेन्यू में, AlloyDB Studio पर क्लिक करें. अपने क्रेडेंशियल से साइन इन करें.
- दाईं ओर मौजूद, नया टैब आइकॉन पर क्लिक करके, एक नया टैब खोलें.
- ऊपर दी गई
insert_scripts.sqlस्क्रिप्ट सेinsertक्वेरी स्टेटमेंट को कॉपी करके एडिटर में चिपकाएं. इस इस्तेमाल के उदाहरण का तुरंत डेमो देखने के लिए, 10 से 50 इंसर्ट स्टेटमेंट कॉपी किए जा सकते हैं. - चलाएं पर क्लिक करें. आपकी क्वेरी के नतीजे, नतीजे टेबल में दिखते हैं.
ध्यान दें: आपको दिख सकता है कि स्क्रिप्ट डालने के लिए दिए गए कोड में बहुत सारा डेटा है. ऐसा इसलिए है, क्योंकि हमने स्क्रिप्ट डालने की सुविधा में एम्बेड किए गए कॉन्टेंट को शामिल किया है. अगर आपको github में फ़ाइल लोड करने में समस्या आ रही है, तो "View Raw" पर क्लिक करें. ऐसा इसलिए किया जाता है, ताकि अगर Google Cloud के लिए ट्रायल क्रेडिट बिलिंग खाते का इस्तेमाल किया जा रहा है, तो आपको आने वाले चरणों में कुछ से ज़्यादा (जैसे कि ज़्यादा से ज़्यादा 20-25) एम्बेडिंग जनरेट करने में परेशानी न हो.
5. पेटेंट के डेटा के लिए एम्बेडिंग बनाना
सबसे पहले, एम्बेडिंग फ़ंक्शन की जांच करते हैं. इसके लिए, यहां दी गई सैंपल क्वेरी चलाएं:
SELECT embedding('text-embedding-005', 'AlloyDB is a managed, cloud-hosted SQL database service.');
इससे क्वेरी में मौजूद सैंपल टेक्स्ट के लिए, एम्बेडिंग वेक्टर मिलना चाहिए. यह फ़्लोट की एक ऐसी कैटगरी होती है जो ऐरे की तरह दिखती है. यह इस तरह दिखता है:
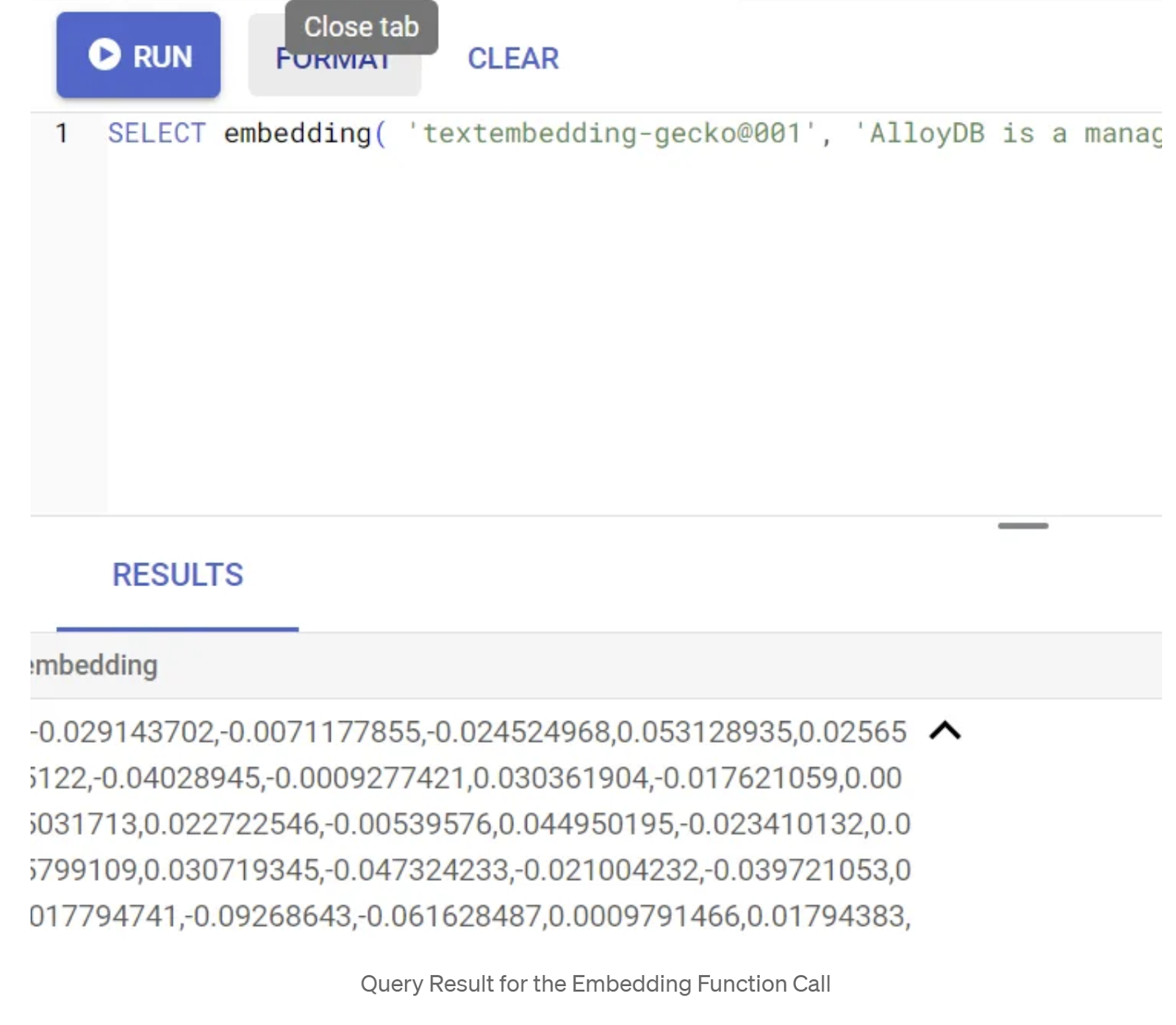
abstract_embeddings वेक्टर फ़ील्ड को अपडेट करना
अगर आपने insert स्क्रिप्ट के हिस्से के तौर पर abstract_embeddings डेटा नहीं डाला है, तो टेबल में पेटेंट के ऐब्स्ट्रैक्ट को अपडेट करने के लिए, नीचे दिए गए डीएमएल को चलाएं. ऐसा सिर्फ़ तब करें, जब आपने abstract_embeddings डेटा नहीं डाला हो:
UPDATE patents_data set abstract_embeddings = embedding( 'text-embedding-005', abstract);
अगर Google Cloud के लिए, बिना किसी शुल्क के आज़माने की सुविधा वाले क्रेडिट बिलिंग खाते का इस्तेमाल किया जा रहा है, तो आपको कुछ से ज़्यादा एम्बेडिंग (जैसे कि ज़्यादा से ज़्यादा 20-25) जनरेट करने में समस्या आ सकती है. इसलिए, हमने पहले से ही इंसर्ट स्क्रिप्ट में एम्बेडिंग शामिल कर दी हैं. अगर आपने "डेटाबेस में पेटेंट का डेटा लोड करें" चरण पूरा कर लिया है, तो आपको यह जानकारी लोड की गई टेबल में मिलनी चाहिए.
6. AlloyDB की नई सुविधाओं की मदद से, बेहतर RAG की सुविधा का इस्तेमाल करना
अब टेबल, डेटा, और एम्बेडिंग तैयार हैं. इसलिए, उपयोगकर्ता के खोज टेक्स्ट के लिए रीयल टाइम वेक्टर सर्च करते हैं. नीचे दी गई क्वेरी चलाकर, इसकी जांच की जा सकती है:
SELECT id || ' - ' || title as title FROM patents_data ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
इस क्वेरी में,
- उपयोगकर्ता ने "भावनाओं का विश्लेषण" खोजा है.
- हम इसे embedding() तरीके में एम्बेडिंग में बदल रहे हैं. इसके लिए, हम मॉडल: text-embedding-005 का इस्तेमाल कर रहे हैं.
- "<=>" का मतलब, COSINE SIMILARITY दूरी के तरीके का इस्तेमाल करना है.
- हम एम्बेड करने के तरीके के नतीजे को वेक्टर टाइप में बदल रहे हैं, ताकि यह डेटाबेस में सेव किए गए वेक्टर के साथ काम कर सके.
- LIMIT 10 का मतलब है कि हम खोजे गए टेक्स्ट से सबसे ज़्यादा मिलते-जुलते 10 नतीजे चुन रहे हैं.
AlloyDB, वेक्टर सर्च RAG को बेहतर बनाता है:
इसमें कई नई सुविधाएं जोड़ी गई हैं. डेवलपर के लिए उपलब्ध दो मुख्य टूल ये हैं:
- इनलाइन फ़िल्टरिंग
- रीकॉल का आकलन करने वाला
इनलाइन फ़िल्टरिंग
डेवलपर के तौर पर, आपको पहले वेक्टर सर्च क्वेरी करनी पड़ती थी. साथ ही, फ़िल्टर करने और वापस पाने की प्रोसेस को मैनेज करना पड़ता था. AlloyDB Query Optimizer, फ़िल्टर के साथ क्वेरी को एक्ज़ीक्यूट करने के तरीके चुनता है. इनलाइन फ़िल्टरिंग, क्वेरी ऑप्टिमाइज़ेशन की एक नई तकनीक है. इससे AlloyDB क्वेरी ऑप्टिमाइज़र, मेटाडेटा फ़िल्टर करने की शर्तों और वेक्टर सर्च, दोनों का एक साथ आकलन कर पाता है. इसके लिए, वह वेक्टर इंडेक्स और मेटाडेटा कॉलम पर मौजूद इंडेक्स, दोनों का इस्तेमाल करता है. इससे रिकॉल परफ़ॉर्मेंस बेहतर हुई है. साथ ही, डेवलपर को AlloyDB की डिफ़ॉल्ट सुविधाओं का फ़ायदा मिल रहा है.
इनलाइन फ़िल्टरिंग, ऐसे मामलों के लिए सबसे सही होती है जिनमें मध्यम स्तर की चुनिंदा जानकारी शामिल होती है. AlloyDB, वेक्टर इंडेक्स में खोज करता है. इसलिए, यह सिर्फ़ उन वेक्टर के बीच की दूरी का हिसाब लगाता है जो मेटाडेटा फ़िल्टर करने की शर्तों से मेल खाते हैं. ये शर्तें, क्वेरी में इस्तेमाल किए गए फ़ंक्शनल फ़िल्टर से मेल खाती हैं. आम तौर पर, इन्हें WHERE क्लॉज़ में हैंडल किया जाता है. इससे इन क्वेरी की परफ़ॉर्मेंस काफ़ी बेहतर हो जाती है. साथ ही, पोस्ट-फ़िल्टर या प्री-फ़िल्टर के फ़ायदे भी मिलते हैं.
- pgvector एक्सटेंशन इंस्टॉल या अपडेट करना
CREATE EXTENSION IF NOT EXISTS vector WITH VERSION '0.8.0.google-3';
अगर pgvector एक्सटेंशन पहले से इंस्टॉल है, तो वेक्टर एक्सटेंशन को 0.8.0.google-3 या इसके बाद के वर्शन पर अपग्रेड करें. इससे आपको रीकॉल इवैल्यूएटर की सुविधाएं मिलेंगी.
ALTER EXTENSION vector UPDATE TO '0.8.0.google-3';
यह चरण सिर्फ़ तब पूरा करना होगा, जब आपका वेक्टर एक्सटेंशन <0.8.0.google-3> हो.
अहम जानकारी: अगर आपकी पंक्ति की संख्या 100 से कम है, तो आपको ScaNN इंडेक्स बनाने की ज़रूरत नहीं होगी. ऐसा इसलिए, क्योंकि यह कम पंक्तियों के लिए लागू नहीं होता. ऐसे में, कृपया यहां दिया गया तरीका न अपनाएं.
- ScaNN इंडेक्स बनाने के लिए, alloydb_scann एक्सटेंशन इंस्टॉल करें.
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
- सबसे पहले, इंडेक्स के बिना और इनलाइन फ़िल्टर चालू किए बिना वेक्टर सर्च क्वेरी चलाएं:
SELECT id || ' - ' || title as title FROM patents_data
WHERE num_claims >= 15
ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
नतीजा कुछ इस तरह का होना चाहिए:
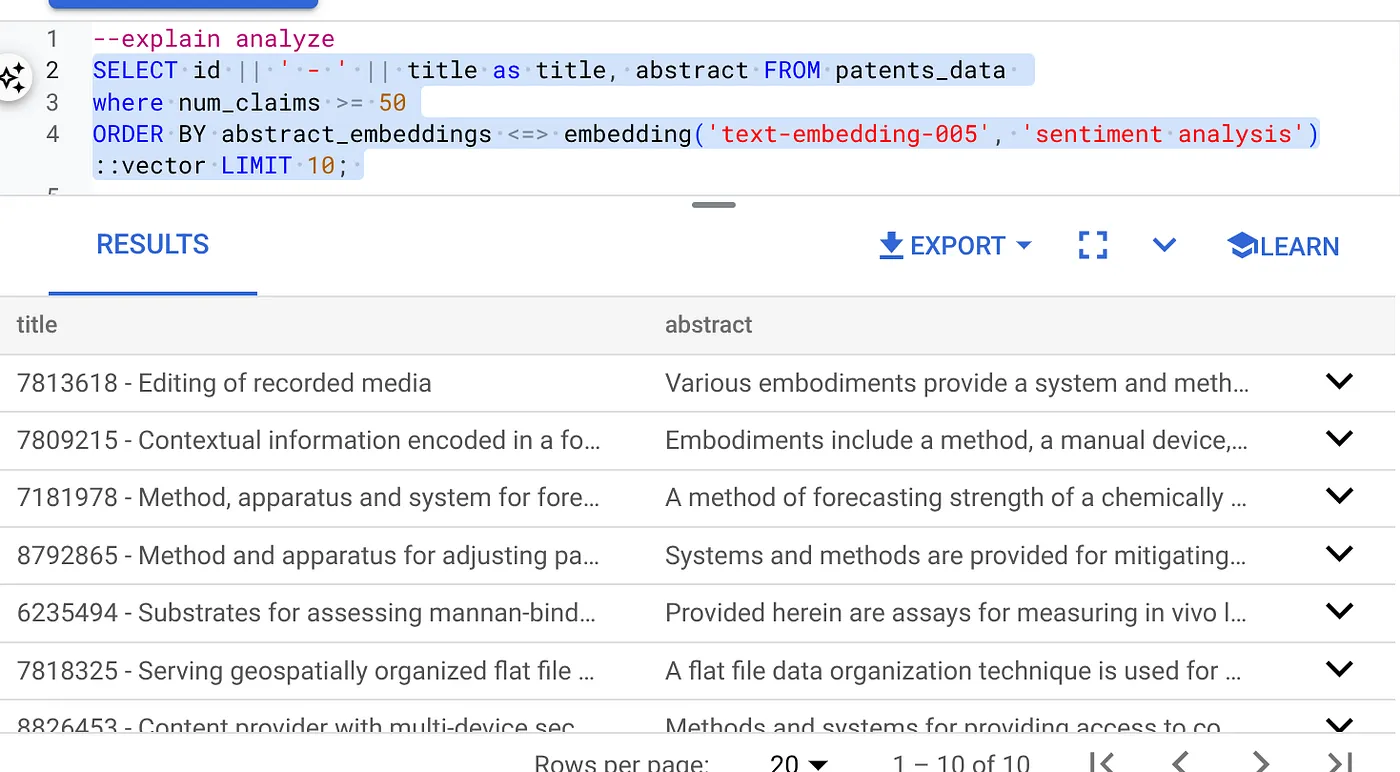
- इस पर 'विश्लेषण के बारे में ज़्यादा जानें' सुविधा का इस्तेमाल करें: (इसमें इंडेक्स या इनलाइन फ़िल्टरिंग का इस्तेमाल नहीं किया गया है)
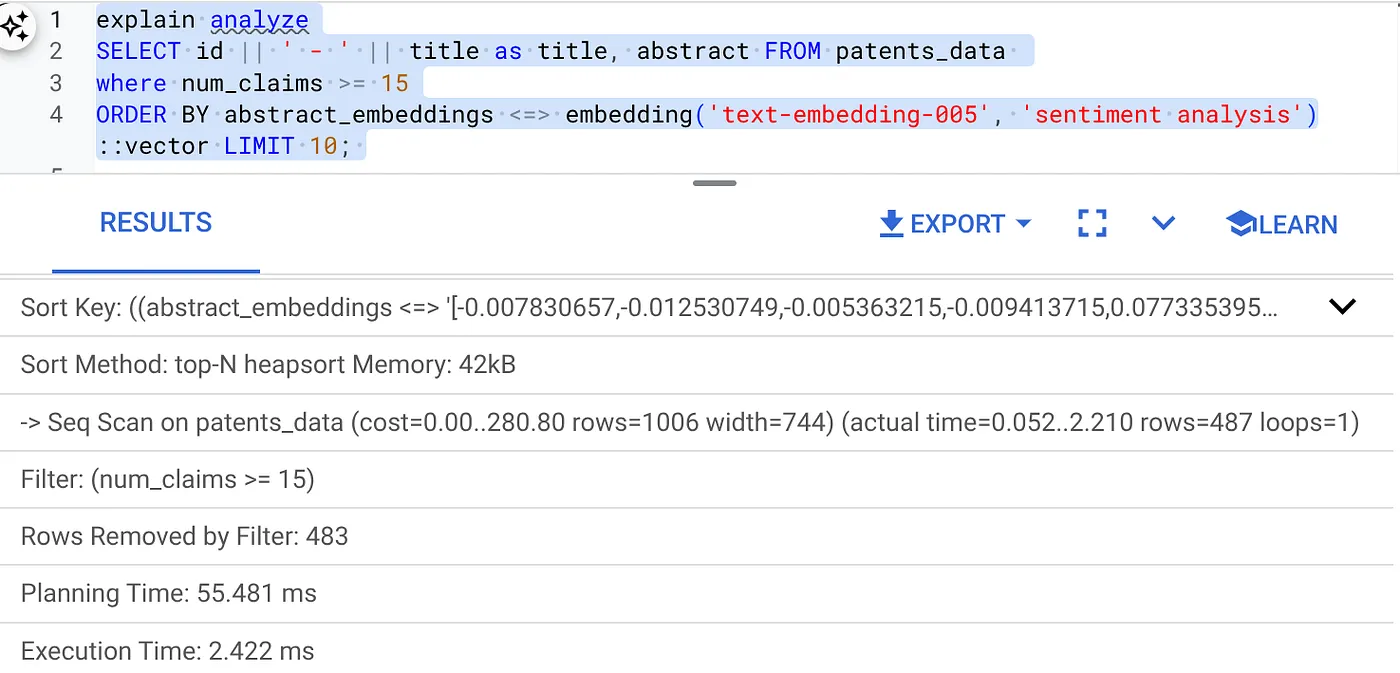
लागू करने में लगने वाला समय 2.4 मि॰से॰ है
- num_claims फ़ील्ड पर एक सामान्य इंडेक्स बनाते हैं, ताकि हम इसके हिसाब से फ़िल्टर कर सकें:
CREATE INDEX idx_patents_data_num_claims ON patents_data (num_claims);
- आइए, पेटेंट खोजने वाले ऐप्लिकेशन के लिए ScaNN इंडेक्स बनाते हैं. AlloyDB Studio से यह कमांड चलाएं:
CREATE INDEX patent_index ON patents_data
USING scann (abstract_embeddings cosine)
WITH (num_leaves=32);
अहम जानकारी: (num_leaves=32) यह हमारे पूरे डेटासेट पर लागू होता है, जिसमें 1,000 से ज़्यादा लाइनें हैं. अगर आपकी पंक्तियों की संख्या 100 से कम है, तो आपको इंडेक्स बनाने की ज़रूरत नहीं होगी, क्योंकि यह कम पंक्तियों पर लागू नहीं होता.
- ScaNN इंडेक्स पर इनलाइन फ़िल्टरिंग की सुविधा चालू करें:
SET scann.enable_inline_filtering = on
- अब, फ़िल्टर और वेक्टर सर्च के साथ एक ही क्वेरी चलाएं:
SELECT id || ' - ' || title as title FROM patents_data
WHERE num_claims >= 15
ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
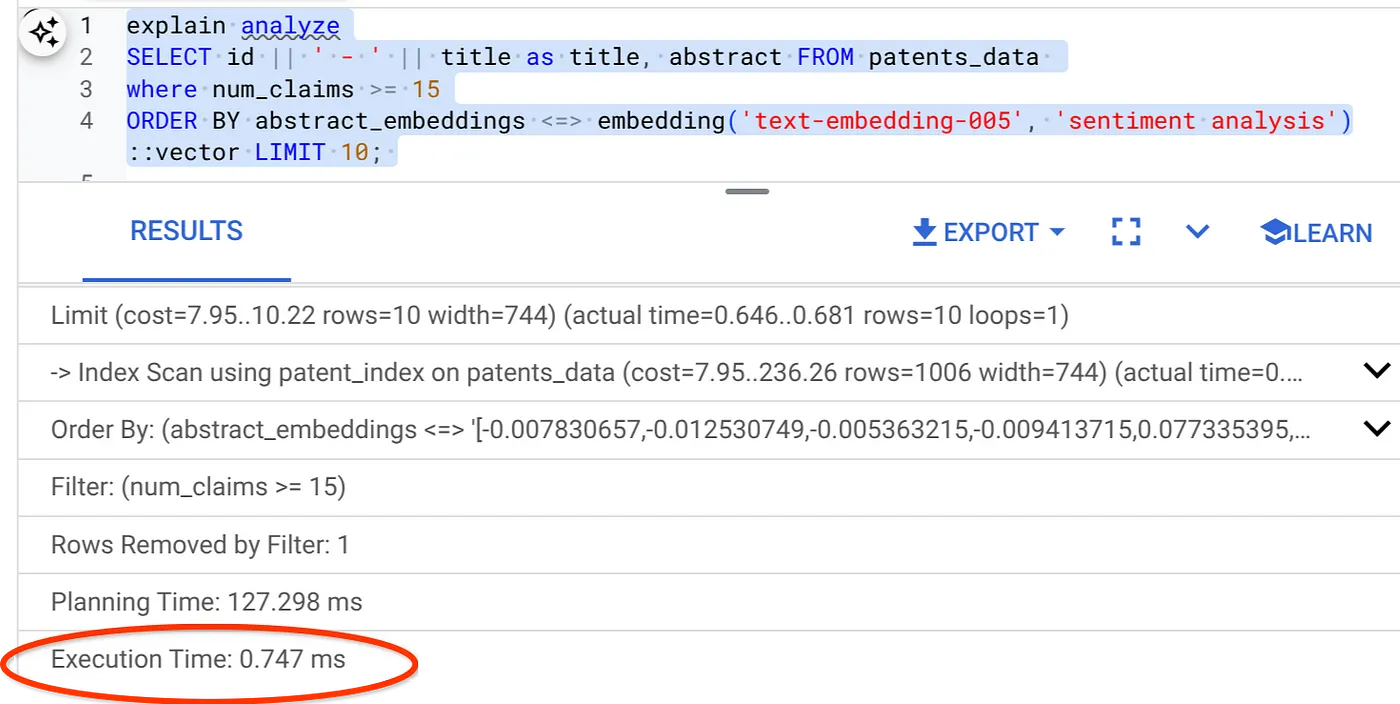
जैसा कि आप देख सकते हैं, एक ही वेक्टर सर्च के लिए एक्ज़ीक्यूशन का समय काफ़ी कम हो गया है. वेक्टर सर्च में ScaNN इंडेक्स के साथ इनलाइन फ़िल्टरिंग की सुविधा उपलब्ध होने की वजह से ऐसा हो पाया है!!!
इसके बाद, ScaNN की सुविधा के साथ काम करने वाली वेक्टर सर्च के लिए, रीकॉल का आकलन करते हैं.
रीकॉल का आकलन करने वाला
मिलती-जुलती इमेज खोजने की सुविधा में रीकॉल, खोज से वापस लाए गए काम के इंस्टेंस का प्रतिशत होता है. इसका मतलब है कि यह ट्रू पॉज़िटिव की संख्या होती है. खोज के नतीजों की क्वालिटी को मेज़र करने के लिए, इस मेट्रिक का सबसे ज़्यादा इस्तेमाल किया जाता है. मिलते-जुलते आइटम को याद न रख पाने की एक वजह, सबसे मिलते-जुलते आइटम को खोजने की अनुमानित सुविधा (एएनएन) और सबसे मिलते-जुलते आइटम को खोजने की सटीक सुविधा (केएनएन) के बीच का अंतर है. AlloyDB के ScaNN जैसे वेक्टर इंडेक्स, aNN एल्गोरिदम लागू करते हैं. इससे बड़े डेटासेट पर वेक्टर सर्च को तेज़ किया जा सकता है. हालांकि, इसके लिए रिकॉल में थोड़ा समझौता करना पड़ता है. अब AlloyDB, आपको अलग-अलग क्वेरी के लिए डेटाबेस में सीधे तौर पर इस ट्रेडऑफ़ को मेज़र करने की सुविधा देता है. साथ ही, यह पक्का करता है कि यह समय के साथ स्थिर रहे. बेहतर नतीजे और परफ़ॉर्मेंस पाने के लिए, इस जानकारी के आधार पर क्वेरी और इंडेक्स पैरामीटर अपडेट किए जा सकते हैं.
खोज के नतीजों को वापस लाने के पीछे क्या लॉजिक है?
वेक्टर सर्च के संदर्भ में, रीकॉल का मतलब उन वेक्टर के प्रतिशत से है जिन्हें इंडेक्स दिखाता है और जो सबसे नज़दीकी वेक्टर होते हैं. उदाहरण के लिए, अगर 20 सबसे नज़दीकी पॉइंट के लिए की गई क्वेरी में, 19 पॉइंट ग्राउंड ट्रुथ के सबसे नज़दीकी पॉइंट के तौर पर मिलते हैं, तो रीकॉल 19/20x100 = 95% होगा. रिकॉल, खोज के नतीजों की क्वालिटी को मापने के लिए इस्तेमाल की जाने वाली मेट्रिक है. इसे ऐसे नतीजों के प्रतिशत के तौर पर तय किया जाता है जो क्वेरी वेक्टर से सबसे ज़्यादा मिलते-जुलते हों.
evaluate_query_recall फ़ंक्शन का इस्तेमाल करके, किसी कॉन्फ़िगरेशन के लिए वेक्टर इंडेक्स पर वेक्टर क्वेरी के लिए रीकॉल का पता लगाया जा सकता है. इस फ़ंक्शन की मदद से, अपने पैरामीटर को इस तरह से ट्यून किया जा सकता है कि आपको वेक्टर क्वेरी रिकॉल के मनमुताबिक नतीजे मिलें.
अहम जानकारी:
अगर आपको यहां दिए गए चरणों में, HNSW इंडेक्स पर अनुमति नहीं होने की गड़बड़ी का सामना करना पड़ रहा है, तो फ़िलहाल रीकॉल का आकलन करने वाले इस पूरे सेक्शन को छोड़ दें. ऐसा हो सकता है कि इस समय ऐक्सेस से जुड़ी पाबंदियां लागू हों, क्योंकि यह सुविधा इस कोडलैब के दस्तावेज़ तैयार होने के समय ही लॉन्च हुई है.
- ScaNN इंडेक्स और HNSW इंडेक्स पर, Enable Index Scan फ़्लैग सेट करें:
SET scann.enable_indexscan = on
SET hnsw.enable_index_scan = on
- AlloyDB Studio में यह क्वेरी चलाएं:
SELECT
*
FROM
evaluate_query_recall($$
SELECT
id || ' - ' || title AS title,
abstract
FROM
patents_data
where num_claims >= 15
ORDER BY
abstract_embeddings <=> embedding('text-embedding-005',
'sentiment analysis')::vector
LIMIT 25 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
evaluate_query_recall फ़ंक्शन, क्वेरी को पैरामीटर के तौर पर लेता है और उसके रीकॉल को दिखाता है. मैंने फ़ंक्शन के इनपुट क्वेरी के तौर पर, उसी क्वेरी का इस्तेमाल किया है जिसका इस्तेमाल मैंने परफ़ॉर्मेंस की जांच करने के लिए किया था. मैंने SCaNN को इंडेक्स के तरीके के तौर पर जोड़ा है. पैरामीटर के ज़्यादा विकल्पों के लिए, दस्तावेज़ देखें.
हम इस Vector Search क्वेरी के लिए इस रिकॉल का इस्तेमाल कर रहे हैं:
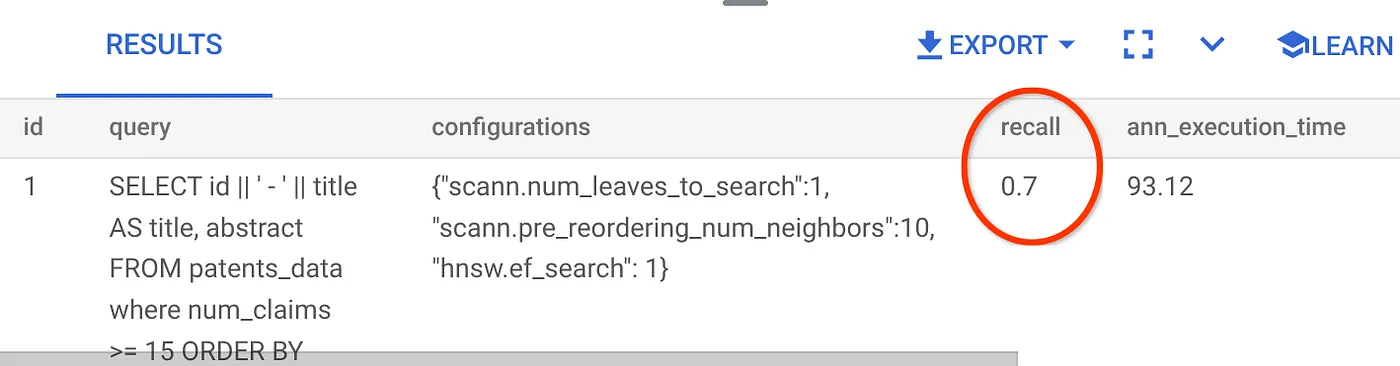
मुझे दिख रहा है कि RECALL 70% है. अब मैं इस जानकारी का इस्तेमाल करके, इंडेक्स पैरामीटर, तरीकों, और क्वेरी पैरामीटर में बदलाव कर सकता/सकती हूं. साथ ही, इस वेक्टर सर्च के लिए अपनी रीकॉल क्षमता को बेहतर बना सकता/सकती हूं!
7. बदले गए क्वेरी और इंडेक्स पैरामीटर के साथ इसकी जांच करें
अब मिले हुए रीकॉल के आधार पर, क्वेरी पैरामीटर में बदलाव करके क्वेरी की जांच करते हैं.
- मैंने नतीजे के सेट में लाइनों की संख्या को 25 से बदलकर 7 कर दिया है. इससे मुझे बेहतर RECALL मिला है, यानी कि 86%.
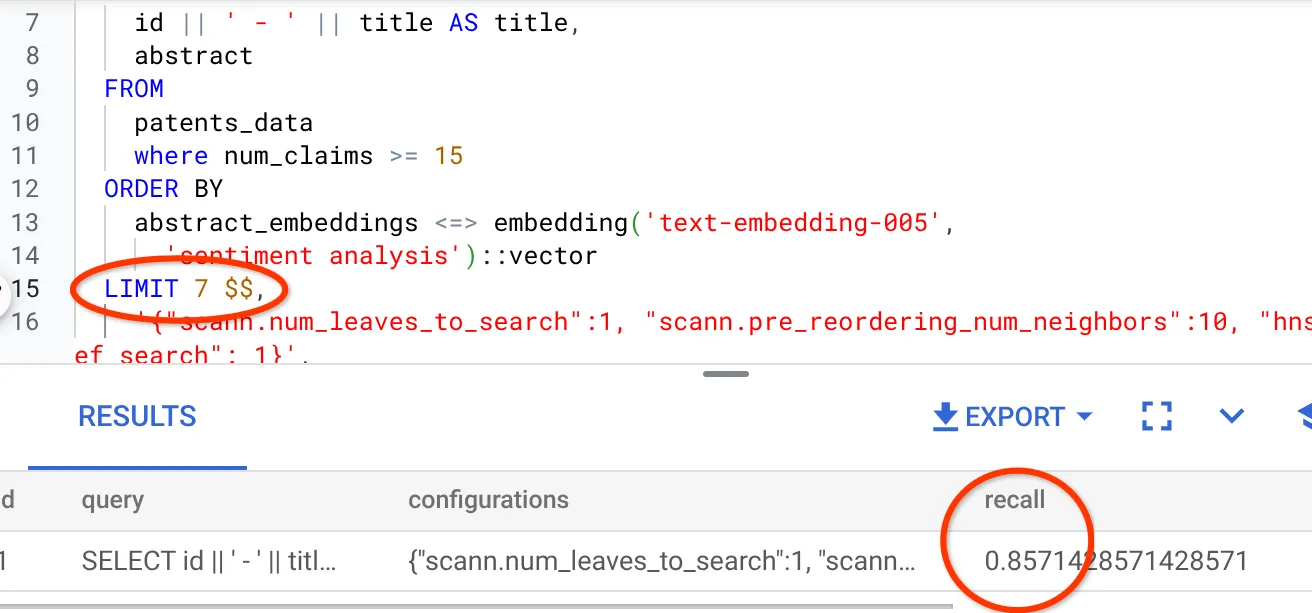
इसका मतलब है कि मैं रीयल-टाइम में, उपयोगकर्ताओं को दिखने वाले मैच की संख्या में बदलाव कर सकता/सकती हूं. इससे, उपयोगकर्ताओं की खोज के संदर्भ के हिसाब से मैच को ज़्यादा काम का बनाया जा सकता है.
- आइए, इंडेक्स पैरामीटर में बदलाव करके इसे फिर से आज़माएं:
इस टेस्ट के लिए, मैं समानता के लिए दूरी का पता लगाने वाले "कोसाइन" फ़ंक्शन के बजाय, "L2 दूरी" फ़ंक्शन का इस्तेमाल करूंगा. मैं क्वेरी की सीमा को भी 10 पर सेट कर दूंगा, ताकि यह दिखाया जा सके कि खोज के नतीजों की संख्या बढ़ने के बावजूद, उनकी क्वालिटी में सुधार हुआ है या नहीं.
[BEFORE] कोसाइन सिमिलैरिटी डिस्टेंस फ़ंक्शन का इस्तेमाल करने वाली क्वेरी:
SELECT
*
FROM
evaluate_query_recall($$
SELECT
id || ' - ' || title AS title,
abstract
FROM
patents_data
where num_claims >= 15
ORDER BY
abstract_embeddings <=> embedding('text-embedding-005',
'sentiment analysis')::vector
LIMIT 10 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
बहुत ज़रूरी सूचना: आपका सवाल हो सकता है कि "हमें कैसे पता चलेगा कि इस क्वेरी में कोसाइन सिमिलैरिटी का इस्तेमाल किया गया है?" कोसाइन दूरी को दिखाने के लिए "<=>" का इस्तेमाल करके, दूरी के फ़ंक्शन की पहचान की जा सकती है.
वेक्टर सर्च के डिस्टेंस फ़ंक्शन के लिए दस्तावेज़ का लिंक.
ऊपर दी गई क्वेरी का नतीजा यह है:
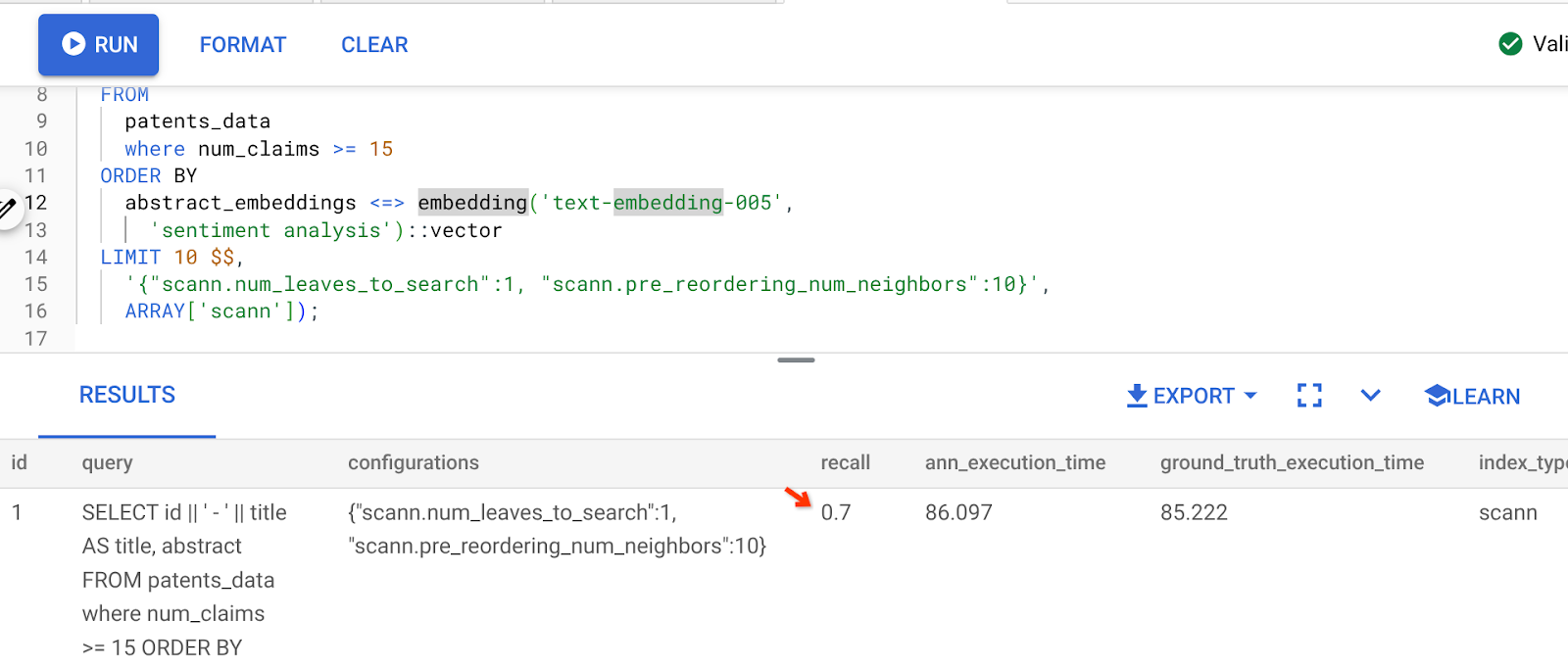
जैसा कि आप देख सकते हैं, इंडेक्स लॉजिक में कोई बदलाव किए बिना, RECALL 70% है. इनलाइन फ़िल्टरिंग सेक्शन के छठे चरण में बनाए गए ScaNN इंडेक्स को याद रखें, "patent_index "? ऊपर दी गई क्वेरी को चलाते समय, वही इंडेक्स अब भी लागू है.
अब हम दूरी के फ़ंक्शन वाली एक अलग क्वेरी के साथ इंडेक्स बनाते हैं: L2 दूरी: <->
drop index patent_index;
CREATE INDEX patent_index_L2 ON patents_data
USING scann (abstract_embeddings L2)
WITH (num_leaves=32);
ड्रॉप इंडेक्स स्टेटमेंट का इस्तेमाल सिर्फ़ यह पक्का करने के लिए किया जाता है कि टेबल पर कोई गैर-ज़रूरी इंडेक्स न हो.
अब, मैं वेक्टर सर्च की सुविधा के डिस्टेंस फ़ंक्शन को बदलने के बाद, RECALL का आकलन करने के लिए यहां दी गई क्वेरी को लागू कर सकता हूं.
[AFTER] कोसाइन सिमिलैरिटी डिस्टेंस फ़ंक्शन का इस्तेमाल करने वाली क्वेरी:
SELECT
*
FROM
evaluate_query_recall($$
SELECT
id || ' - ' || title AS title,
abstract
FROM
patents_data
where num_claims >= 15
ORDER BY
abstract_embeddings <-> embedding('text-embedding-005',
'sentiment analysis')::vector
LIMIT 10 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
ऊपर दी गई क्वेरी का नतीजा यह है:
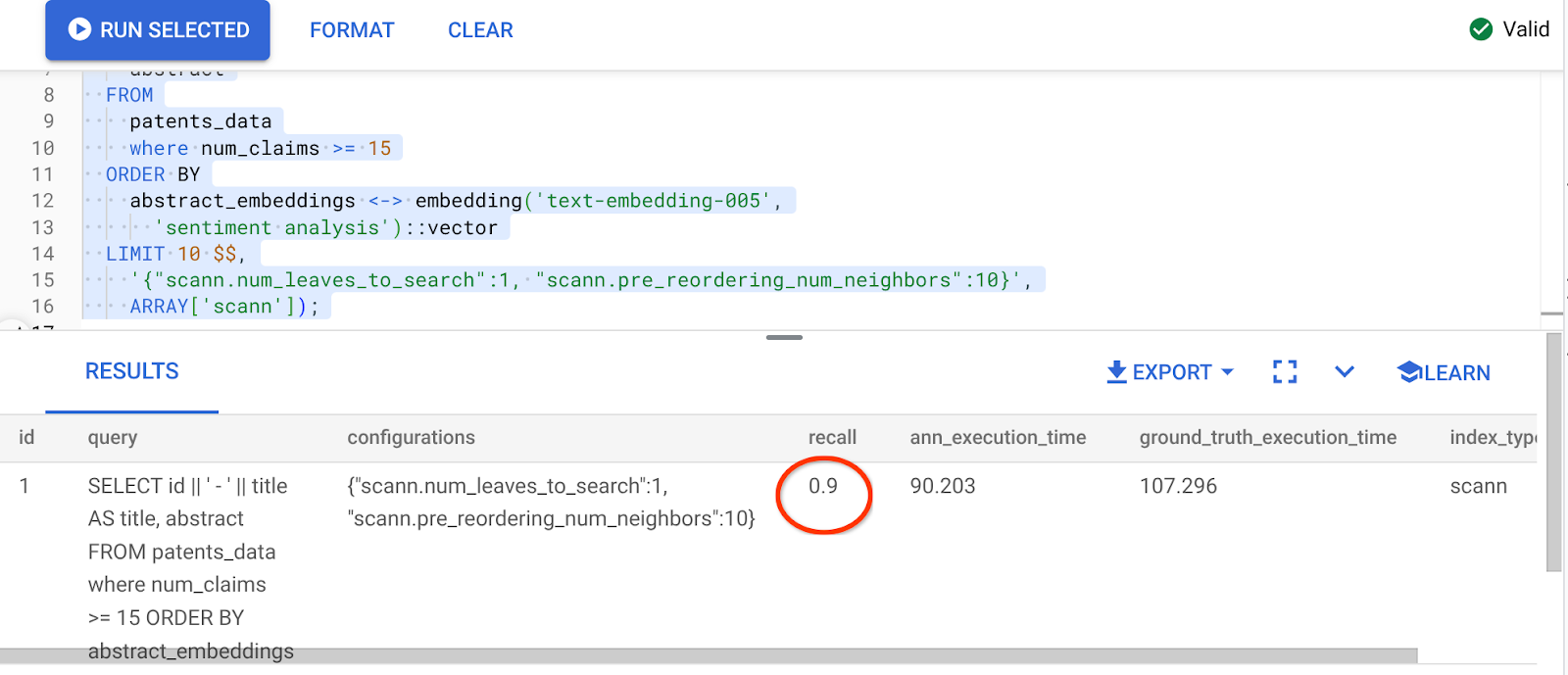
रीकॉल वैल्यू में कितना बड़ा बदलाव हुआ है, 90%!!!
इंडेक्स में कई अन्य पैरामीटर बदले जा सकते हैं. जैसे, num_leaves वगैरह. ये पैरामीटर, आपकी ज़रूरत के हिसाब से रीकॉल वैल्यू और आपके ऐप्लिकेशन के इस्तेमाल किए गए डेटासेट के आधार पर बदले जा सकते हैं.
8. व्यवस्थित करें
इस पोस्ट में इस्तेमाल की गई संसाधनों के लिए, अपने Google Cloud खाते से शुल्क न लिए जाने के लिए, यह तरीका अपनाएं:
- Google Cloud Console में, संसाधन मैनेजर पेज पर जाएं.
- प्रोजेक्ट की सूची में, वह प्रोजेक्ट चुनें जिसे आपको मिटाना है. इसके बाद, मिटाएं पर क्लिक करें.
- डायलॉग बॉक्स में, प्रोजेक्ट आईडी टाइप करें. इसके बाद, प्रोजेक्ट मिटाने के लिए बंद करें पर क्लिक करें.
- इसके अलावा, DELETE CLUSTER बटन पर क्लिक करके, इस प्रोजेक्ट के लिए अभी-अभी बनाए गए AlloyDB क्लस्टर को मिटाया जा सकता है. अगर आपने कॉन्फ़िगरेशन के समय क्लस्टर के लिए us-central1 नहीं चुना था, तो इस हाइपरलिंक में जगह की जानकारी बदलें.
9. बधाई हो
बधाई हो! आपने AlloyDB की बेहतर वेक्टर खोज सुविधा का इस्तेमाल करके, पेटेंट की खोज के लिए कॉन्टेक्स्ट के हिसाब से क्वेरी तैयार कर ली है. इससे आपको बेहतर परफ़ॉर्मेंस मिलेगी और खोज के नतीजे ज़्यादा सटीक होंगे. मैंने क्वालिटी कंट्रोल वाला एक ऐसा ऐप्लिकेशन बनाया है जिसमें कई टूल शामिल हैं. यह ऐप्लिकेशन, ADK और AlloyDB की उन सभी सुविधाओं का इस्तेमाल करता है जिनके बारे में हमने यहां चर्चा की है. इससे, पेटेंट वेक्टर सर्च और विश्लेषण करने वाला एक ऐसा एजेंट बनाया जा सकता है जो बेहतर परफ़ॉर्म करता है और अच्छी क्वालिटी का होता है. इसे यहां देखा जा सकता है: https://youtu.be/Y9fvVY0yZTY
अगर आपको उस एजेंट को बनाने का तरीका जानना है, तो कृपया इस कोडलैब को देखें.