
1. Descripción general
En diferentes industrias, la búsqueda contextual es una funcionalidad fundamental que constituye el centro de sus aplicaciones. La generación aumentada por recuperación ha sido un factor clave de esta crucial evolución tecnológica durante bastante tiempo con sus mecanismos de recuperación potenciados por IA generativa. Los modelos generativos, con sus grandes ventanas de contexto y su impresionante calidad de salida, están transformando la IA. La RAG proporciona una forma sistemática de incorporar contexto en las aplicaciones y los agentes de IA, fundamentándolos en bases de datos estructuradas o información de diversos medios. Estos datos contextuales son fundamentales para la claridad de la verdad y la precisión de los resultados, pero ¿qué tan precisos son esos resultados? ¿Tu empresa depende en gran medida de la exactitud y la relevancia de estas coincidencias contextuales? Entonces, este proyecto te encantará.
El secreto a voces de la búsqueda de vectores no es solo crearla, sino saber si las coincidencias de vectores son realmente buenas. A todos nos pasó, mirar fijamente una lista de resultados y preguntarnos: "¿Esto siquiera funciona?". Analicemos cómo evaluar la calidad de tus coincidencias vectoriales. “Entonces, ¿qué cambió en la RAG?”, te preguntarás. Todo! Durante años, la generación mejorada por recuperación (RAG) se sintió como un objetivo prometedor, pero esquivo. Ahora, por fin, tenemos las herramientas para crear aplicaciones de RAG con el rendimiento y la confiabilidad necesarios para las tareas críticas.
Ahora ya tenemos la comprensión fundamental de 3 cosas:
- Qué significa la búsqueda contextual para tu agente y cómo lograrlo con la Búsqueda de vectores
- También profundizamos en cómo lograr la búsqueda de vectores dentro del alcance de tus datos, es decir, dentro de tu propia base de datos (todas las bases de datos de Google Cloud admiten esto, si aún no lo sabías).
- Fuimos un paso más allá que el resto del mundo para explicarte cómo lograr una capacidad de RAG de búsqueda de vectores tan liviana con alto rendimiento y calidad con la capacidad de búsqueda de vectores de AlloyDB potenciada por el índice ScaNN.
Si no has realizado esos experimentos básicos, intermedios y ligeramente avanzados de RAG, te recomiendo que leas estos 3 artículos aquí, aquí y aquí en el orden indicado.
La Búsqueda de patentes ayuda al usuario a encontrar patentes contextualmente relevantes para su texto de búsqueda, y ya creamos una versión de esta función en el pasado. Ahora, la compilaremos con funciones de RAG nuevas y avanzadas que permiten una búsqueda contextual con control de calidad para esa aplicación. Comencemos.
En la siguiente imagen, se muestra el flujo general de lo que sucede en esta aplicación.~ 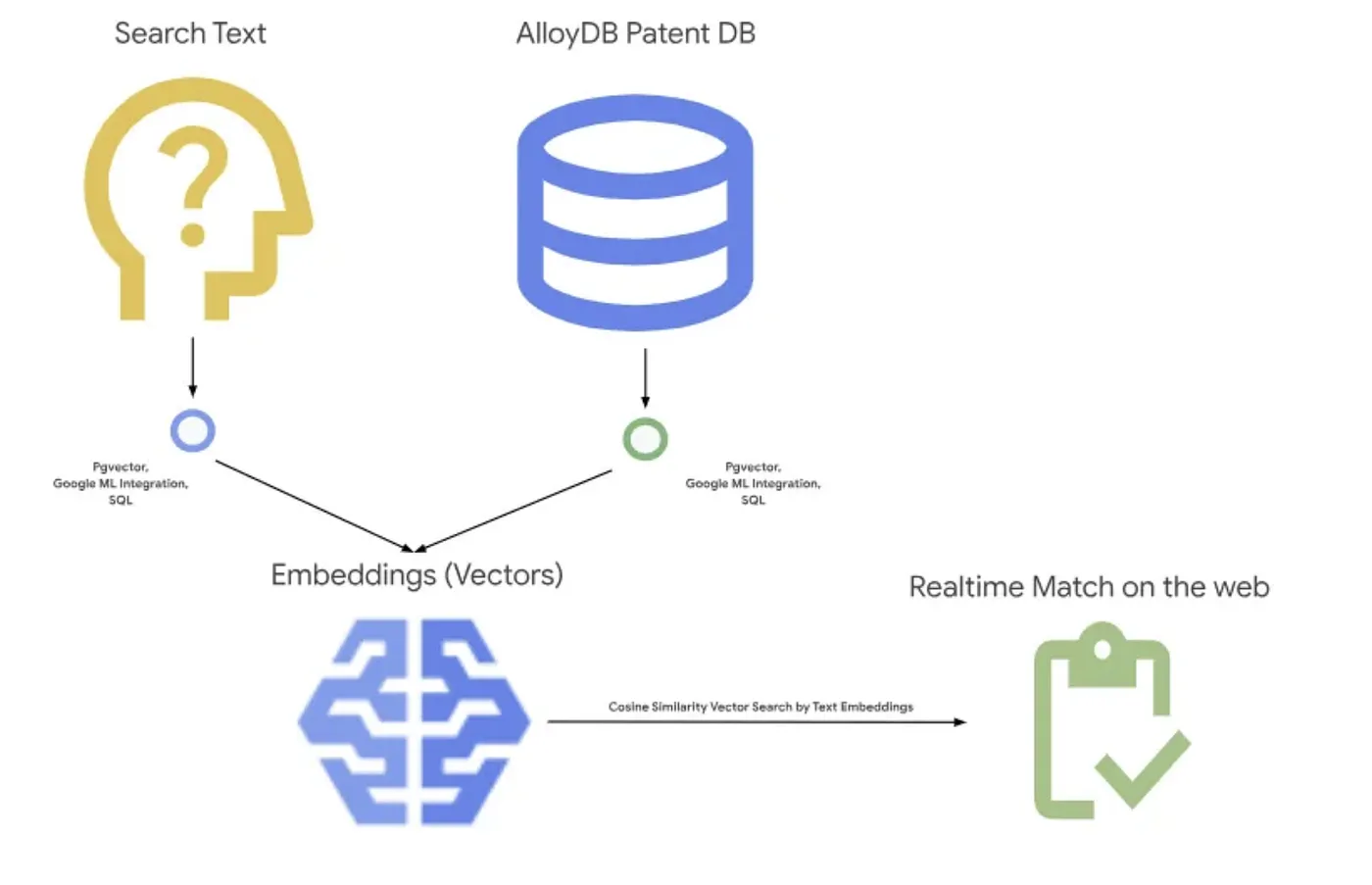
Objetivo
Permite que un usuario busque patentes según una descripción textual con un rendimiento mejorado y una mejor calidad, y, al mismo tiempo, permite evaluar la calidad de las coincidencias generadas con las funciones de RAG más recientes de AlloyDB.
Qué compilarás
Como parte de este lab, harás lo siguiente:
- Crea una instancia de AlloyDB y carga el conjunto de datos públicos de patentes
- Crea un índice de metadatos y un índice de ScaNN
- Implementa la búsqueda de vectores avanzada en AlloyDB con el método de filtrado en línea de ScaNN
- Implementa la función de evaluación de recuperación
- Evalúa la respuesta de la búsqueda
Requisitos
2. Antes de comenzar
Crea un proyecto
- En la página del selector de proyectos de la consola de Google Cloud, selecciona o crea un proyecto de Google Cloud.
- Asegúrate de que la facturación esté habilitada para tu proyecto de Cloud. Obtén información para verificar si la facturación está habilitada en un proyecto .
- Usarás Cloud Shell, un entorno de línea de comandos que se ejecuta en Google Cloud. Haz clic en Activar Cloud Shell en la parte superior de la consola de Google Cloud.

- Una vez que te conectes a Cloud Shell, verifica que ya te autenticaste y que el proyecto se configuró con tu ID del proyecto usando el siguiente comando:
gcloud auth list
- En Cloud Shell, ejecuta el siguiente comando para confirmar que el comando gcloud conoce tu proyecto.
gcloud config list project
- Si tu proyecto no está configurado, usa el siguiente comando para hacerlo:
gcloud config set project <YOUR_PROJECT_ID>
- Habilita las APIs necesarias. Puedes usar un comando de gcloud en la terminal de Cloud Shell:
gcloud services enable alloydb.googleapis.com compute.googleapis.com cloudresourcemanager.googleapis.com servicenetworking.googleapis.com run.googleapis.com cloudbuild.googleapis.com cloudfunctions.googleapis.com aiplatform.googleapis.com
La alternativa al comando de gcloud es buscar cada producto en la consola o usar este vínculo.
Consulta la documentación para ver los comandos y el uso de gcloud.
3. Configuración de la base de datos
En este lab, usaremos AlloyDB como la base de datos para los datos de patentes. Utiliza clústeres para contener todos los recursos, como bases de datos y registros. Cada clúster tiene una instancia principal que proporciona un punto de acceso a los datos. Las tablas contendrán los datos reales.
Creemos un clúster, una instancia y una tabla de AlloyDB en los que se cargará el conjunto de datos de patentes.
Crea un clúster y una instancia
- Navega por la página de AlloyDB en Cloud Console. Una forma sencilla de encontrar la mayoría de las páginas en la consola de Cloud es buscarlas con la barra de búsqueda de la consola.
- Selecciona CREATE CLUSTER en esa página:

- Verás una pantalla como la que se muestra a continuación. Crea un clúster y una instancia con los siguientes valores (asegúrate de que los valores coincidan si clonas el código de la aplicación desde el repo):
- ID del clúster: "
vector-cluster" - contraseña: "
alloydb" - PostgreSQL 15 o la versión recomendada más reciente
- Región: "
us-central1" - Networking: "
default"

- Cuando selecciones la red predeterminada, verás una pantalla como la que se muestra a continuación.
Selecciona CONFIGURAR CONEXIÓN.
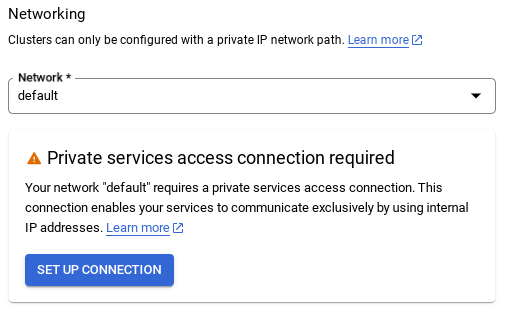
- Allí, selecciona "Usar un rango de IP asignado automáticamente" y haz clic en Continuar. Después de revisar la información, selecciona CREAR CONEXIÓN.
- Una vez que configures tu red, podrás continuar con la creación del clúster. Haz clic en CREATE CLUSTER para completar la configuración del clúster, como se muestra a continuación:
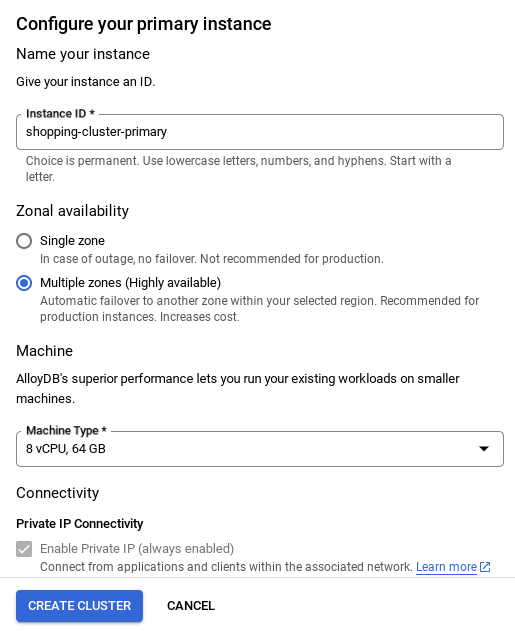
Asegúrate de cambiar el ID de la instancia (que puedes encontrar en el momento de configurar el clúster o la instancia) a
vector-instance. Si no puedes cambiarlo, recuerda usar el ID de tu instancia en todas las referencias futuras.
Ten en cuenta que la creación del clúster tardará alrededor de 10 minutos. Una vez que se complete correctamente, deberías ver una pantalla que muestre el resumen del clúster que acabas de crear.
4. Transferencia de datos
Ahora es momento de agregar una tabla con los datos de la tienda. Navega a AlloyDB, selecciona el clúster principal y, luego, AlloyDB Studio:
Es posible que debas esperar a que termine de crearse la instancia. Una vez que lo hagas, accede a AlloyDB con las credenciales que creaste cuando creaste el clúster. Usa los siguientes datos para autenticarte en PostgreSQL:
- Nombre de usuario : "
postgres" - Base de datos : "
postgres" - Contraseña : "
alloydb"
Una vez que te autentiques correctamente en AlloyDB Studio, ingresa los comandos SQL en el editor. Puedes agregar varias ventanas del editor con el signo más que se encuentra a la derecha de la última ventana.
Ingresarás comandos para AlloyDB en ventanas del editor, y usarás las opciones Ejecutar, Formatear y Borrar según sea necesario.
Habilitar extensiones
Para compilar esta app, usaremos las extensiones pgvector y google_ml_integration. La extensión pgvector te permite almacenar y buscar embeddings de vectores. La extensión google_ml_integration proporciona funciones que usas para acceder a los extremos de predicción de Vertex AI y obtener predicciones en SQL. Habilita estas extensiones ejecutando los siguientes DDL:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
Si quieres verificar las extensiones que se habilitaron en tu base de datos, ejecuta este comando de SQL:
select extname, extversion from pg_extension;
Crea una tabla
Puedes crear una tabla con la siguiente instrucción DDL en AlloyDB Studio:
CREATE TABLE patents_data ( id VARCHAR(25), type VARCHAR(25), number VARCHAR(20), country VARCHAR(2), date VARCHAR(20), abstract VARCHAR(300000), title VARCHAR(100000), kind VARCHAR(5), num_claims BIGINT, filename VARCHAR(100), withdrawn BIGINT, abstract_embeddings vector(768)) ;
La columna abstract_embeddings permitirá almacenar los valores de vector del texto.
Otorgar permiso
Ejecuta la siguiente instrucción para otorgar permiso de ejecución en la función "embedding":
GRANT EXECUTE ON FUNCTION embedding TO postgres;
Otorga el rol de usuario de Vertex AI a la cuenta de servicio de AlloyDB
En la consola de IAM de Google Cloud, otorga a la cuenta de servicio de AlloyDB (que se ve así: service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com) acceso al rol "Usuario de Vertex AI". PROJECT_NUMBER tendrá tu número de proyecto.
Como alternativa, puedes ejecutar el siguiente comando desde la terminal de Cloud Shell:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Carga datos de patentes en la base de datos
Usaremos los conjuntos de datos públicos de patentes de Google en BigQuery como nuestro conjunto de datos. Usaremos AlloyDB Studio para ejecutar nuestras consultas. Los datos se obtienen del archivo insert_scripts.sql y lo ejecutaremos para cargar los datos de patentes.
- En la consola de Google Cloud, abre la página AlloyDB.
- Selecciona el clúster recién creado y haz clic en la instancia.
- En el menú de navegación de AlloyDB, haz clic en AlloyDB Studio. Accede con tus credenciales.
- Haz clic en el ícono Pestaña nueva a la derecha para abrir una pestaña nueva.
- Copia la instrucción de consulta
insertde la secuencia de comandosinsert_scripts.sqlmencionada anteriormente en el editor. Puedes copiar entre 10 y 50 instrucciones de inserción para una demostración rápida de este caso de uso. - Haz clic en Ejecutar. Los resultados de tu consulta aparecen en la tabla Resultados.
Nota: Es posible que observes que la secuencia de comandos de inserción contiene muchos datos. Esto se debe a que incluimos embeddings en las secuencias de comandos de inserción. Haz clic en "Ver sin procesar" en caso de que tengas problemas para cargar el archivo en GitHub. Esto se hace para ahorrarte el trabajo (en los próximos pasos) de generar más de unos pocos embeddings (por ejemplo, entre 20 y 25 como máximo) en caso de que uses una cuenta de facturación de crédito de prueba para Google Cloud.
5. Crea embeddings para los datos de patentes
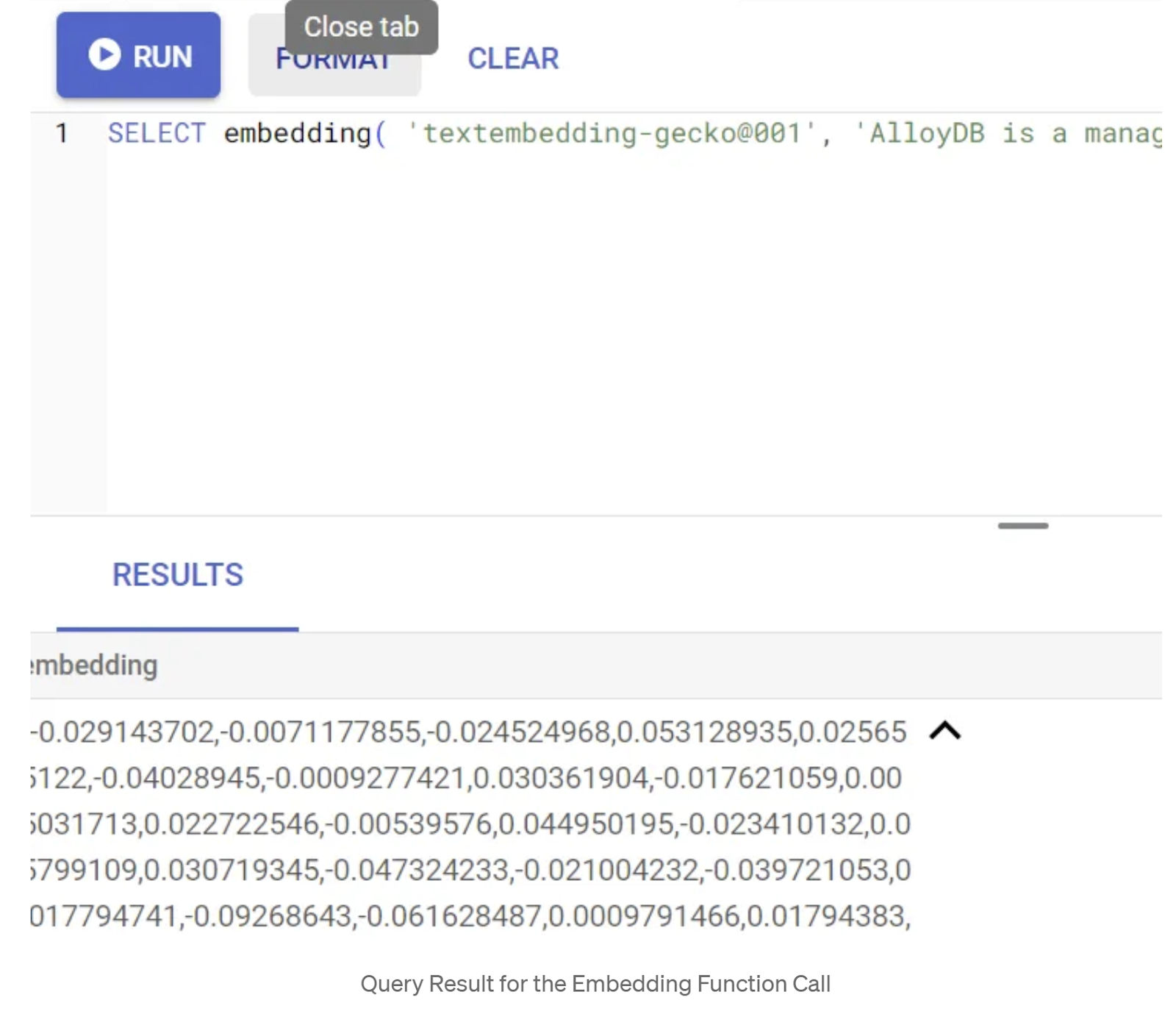
Primero, probemos la función de incorporación ejecutando la siguiente consulta de muestra:
SELECT embedding('text-embedding-005', 'AlloyDB is a managed, cloud-hosted SQL database service.');
Esto debería devolver el vector de embeddings, que se ve como un array de números de punto flotante, para el texto de muestra en la búsqueda. Se ve de la siguiente manera:
Actualiza el campo Vector de abstract_embeddings
Ejecuta el siguiente DML para actualizar los resúmenes de patentes en la tabla con los embeddings correspondientes solo si no insertaste los datos de abstract_embeddings como parte de la secuencia de comandos de inserción:
UPDATE patents_data set abstract_embeddings = embedding( 'text-embedding-005', abstract);
Es posible que tengas problemas para generar más de unos pocos embeddings (por ejemplo, entre 20 y 25 como máximo) si usas una cuenta de facturación de crédito de prueba para Google Cloud. Por ese motivo, ya incluí las incorporaciones en los secuencias de comandos de inserción, y deberías tenerlas cargadas en tu tabla si completaste el paso "Carga datos de patentes en la base de datos".
6. Realiza RAG avanzado con las nuevas funciones de AlloyDB
Ahora que la tabla, los datos y los embeddings están listos, realicemos la búsqueda de vectores en tiempo real para el texto de búsqueda del usuario. Para probarlo, ejecuta la siguiente consulta:
SELECT id || ' - ' || title as title FROM patents_data ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
En esta consulta,
- El texto de búsqueda del usuario es "Análisis de sentimiento".
- Lo convertimos en embeddings en el método embedding() con el modelo text-embedding-005.
- "<=>" representa el uso del método de distancia COSINE SIMILARITY.
- Convertimos el resultado del método de incorporación al tipo de vector para que sea compatible con los vectores almacenados en la base de datos.
- LIMIT 10 representa que seleccionamos las 10 coincidencias más cercanas del texto de búsqueda.
AlloyDB lleva el RAG de búsqueda de vectores al siguiente nivel:
Se introdujeron varias cosas buenas. Dos de las que se enfocan en los desarrolladores son las siguientes:
- Filtrado intercalado
- Evaluador de recuperación
Filtrado intercalado
Anteriormente, como desarrollador, debías realizar la búsqueda de vectores y encargarte del filtrado y la recuperación. El optimizador de consultas de AlloyDB toma decisiones sobre cómo ejecutar una consulta con filtros. El filtrado en línea es una nueva técnica de optimización de consultas que permite que el optimizador de consultas de AlloyDB evalúe las condiciones de filtrado de metadatos y la búsqueda de vectores de forma simultánea, aprovechando los índices de vectores y los índices en las columnas de metadatos. Esto hizo que aumentara el rendimiento de la recuperación, lo que permite a los desarrolladores aprovechar las ventajas que ofrece AlloyDB de inmediato.
El filtrado intercalado es mejor para los casos con selectividad media. A medida que AlloyDB busca en el índice de vectores, solo calcula las distancias para los vectores que coinciden con las condiciones de filtrado de metadatos (tus filtros funcionales en una consulta que, por lo general, se controlan en la cláusula WHERE). Esto mejora enormemente el rendimiento de estas consultas y complementa las ventajas del filtrado posterior o previo.
- Instala o actualiza la extensión pgvector
CREATE EXTENSION IF NOT EXISTS vector WITH VERSION '0.8.0.google-3';
Si la extensión pgvector ya está instalada, actualízala a la versión 0.8.0.google-3 o posterior para obtener capacidades del evaluador de recuperación.
ALTER EXTENSION vector UPDATE TO '0.8.0.google-3';
Este paso solo debe ejecutarse si tu extensión de vectores es <0.8.0.google-3>.
Nota importante: Si el recuento de filas es inferior a 100, no será necesario que crees el índice de ScaNN, ya que no se aplicará para menos filas. En ese caso, omite los siguientes pasos.
- Para crear índices de ScaNN, instala la extensión alloydb_scann.
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
- Primero, ejecuta la consulta de Vector Search sin el índice y sin el filtro intercalado habilitado:
SELECT id || ' - ' || title as title FROM patents_data
WHERE num_claims >= 15
ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
El resultado debería ser similar al siguiente:
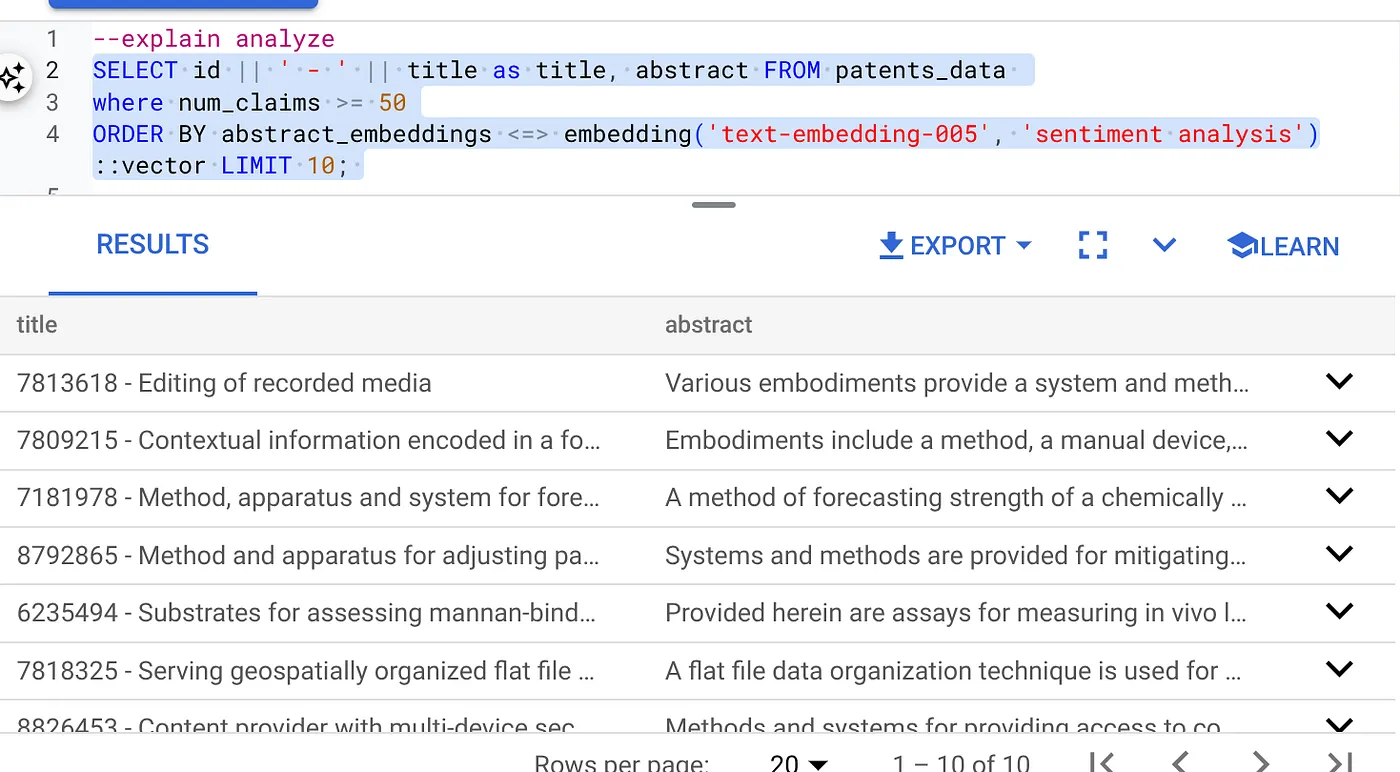
- Ejecuta Explain Analyze en ella (sin indexación ni filtrado intercalado):
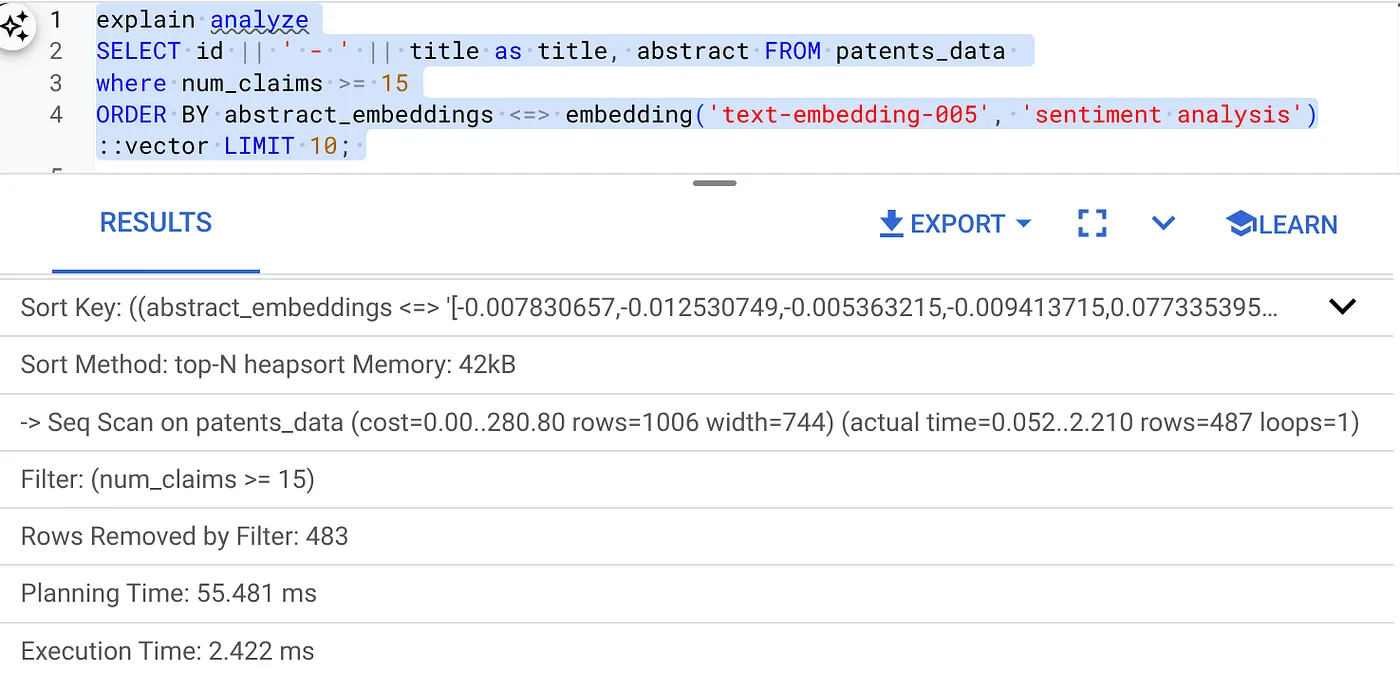
El tiempo de ejecución es de 2.4 ms
- Creemos un índice normal en el campo num_claims para poder filtrarlo:
CREATE INDEX idx_patents_data_num_claims ON patents_data (num_claims);
- Creemos el índice de ScaNN para nuestra aplicación de búsqueda de patentes. Ejecuta lo siguiente desde AlloyDB Studio:
CREATE INDEX patent_index ON patents_data
USING scann (abstract_embeddings cosine)
WITH (num_leaves=32);
Nota importante: (num_leaves=32) se aplica a nuestro conjunto de datos total con más de 1,000 filas. Si el recuento de filas es inferior a 100, no será necesario que crees un índice, ya que no se aplicará para menos filas.
- Establece el filtrado intercalado habilitado en el índice de ScaNN:
SET scann.enable_inline_filtering = on
- Ahora, ejecutemos la misma consulta con el filtro y Vector Search:
SELECT id || ' - ' || title as title FROM patents_data
WHERE num_claims >= 15
ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
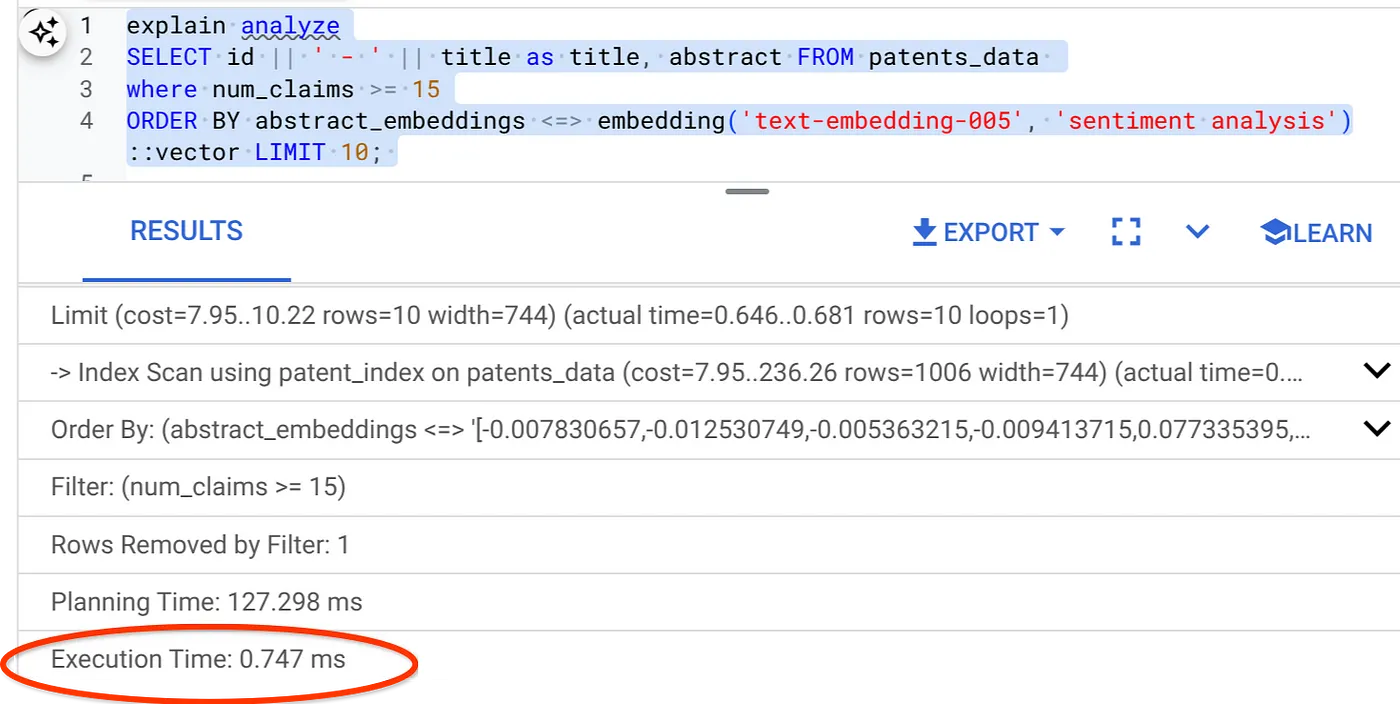
Como puedes ver, el tiempo de ejecución se reduce significativamente para la misma búsqueda vectorial. El índice de ScaNN con filtrado intercalado en Vector Search lo hizo posible.
A continuación, evaluemos la recuperación para esta búsqueda de vectores habilitada para ScaNN.
Evaluador de recuperación
La recuperación en la búsqueda por similitud es el porcentaje de instancias relevantes que se recuperaron de una búsqueda, es decir, la cantidad de verdaderos positivos. Esta es la métrica más común que se usa para medir la calidad de la búsqueda. Una fuente de pérdida de recuperación proviene de la diferencia entre la búsqueda aproximada de vecino más cercano (aNN) y la búsqueda de k vecinos más cercanos (kNN). Los índices de vectores, como ScaNN de AlloyDB, implementan algoritmos de aNN, lo que te permite acelerar la búsqueda de vectores en conjuntos de datos grandes a cambio de una pequeña compensación en la recuperación. Ahora, AlloyDB te permite medir esta compensación directamente en la base de datos para consultas individuales y garantizar que sea estable con el tiempo. Puedes actualizar los parámetros de índice y consulta en respuesta a esta información para obtener mejores resultados y rendimiento.
¿Cuál es la lógica detrás de la recuperación de los resultados de la búsqueda?
En el contexto de la búsqueda vectorial, la recuperación hace referencia al porcentaje de vectores que devuelve el índice y que son vecinos más cercanos verdaderos. Por ejemplo, si una consulta de vecino más cercano para los 20 vecinos más cercanos muestra 19 de los vecinos más cercanos de verdad fundamental, la recuperación será 19/20*100 = 95%. La recuperación es la métrica que se usa para medir la calidad de la búsqueda y se define como el porcentaje de los resultados devueltos que son objetivamente los más cercanos a los vectores de la búsqueda.
Puedes encontrar la recuperación de una búsqueda vectorial en un índice de vectores para una configuración determinada con la función evaluate_query_recall. Esta función te permite ajustar tus parámetros para lograr los resultados de recuperación de la búsqueda vectorial que deseas.
Nota importante:
Si tienes problemas de permisos denegados en el índice HNSW en los siguientes pasos, omite toda la sección de evaluación de recuperación por el momento. Es posible que se deba a restricciones de acceso en este punto, ya que se acaba de lanzar en el momento en que se documenta este codelab.
- Establece la marca Enable Index Scan en el índice de ScaNN y el índice de HNSW:
SET scann.enable_indexscan = on
SET hnsw.enable_index_scan = on
- Ejecuta la siguiente consulta en AlloyDB Studio:
SELECT
*
FROM
evaluate_query_recall($$
SELECT
id || ' - ' || title AS title,
abstract
FROM
patents_data
where num_claims >= 15
ORDER BY
abstract_embeddings <=> embedding('text-embedding-005',
'sentiment analysis')::vector
LIMIT 25 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
La función evaluate_query_recall toma la búsqueda como parámetro y devuelve su recuperación. Uso la misma búsqueda que usé para verificar el rendimiento como la búsqueda de entrada de la función. Agregué SCaNN como método de indexación. Para obtener más opciones de parámetros, consulta la documentación.
La recuperación para esta búsqueda de vectores que hemos estado usando es la siguiente:
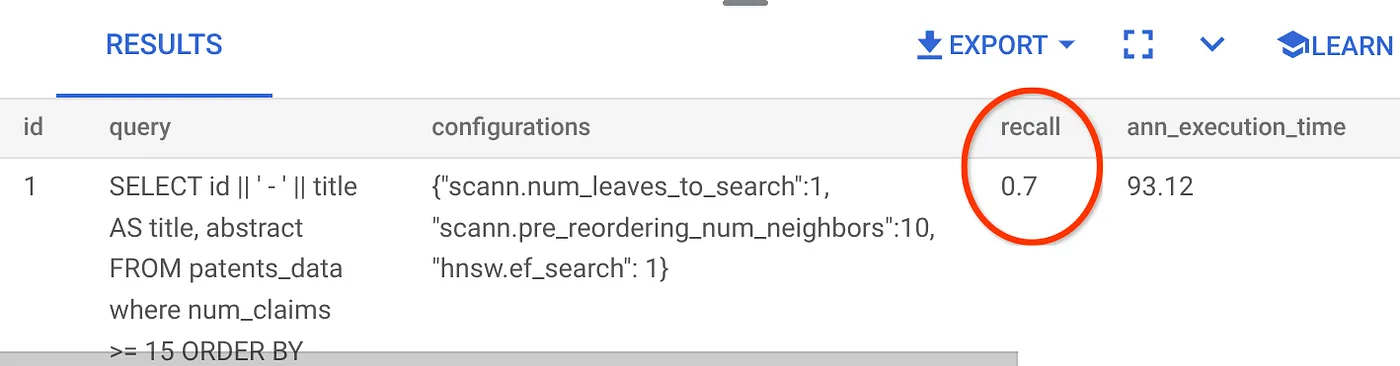
Veo que el RECALL es del 70%. Ahora puedo usar esta información para cambiar los parámetros de índice, los métodos y los parámetros de consulta, y mejorar la recuperación de esta búsqueda vectorial.
7. Probar con parámetros de consulta y de índice modificados
Ahora, probemos la búsqueda modificando los parámetros de búsqueda según la recuperación recibida.
- Modifiqué la cantidad de filas del conjunto de resultados a 7 (antes eran 25) y veo una RECALL mejorada, es decir, del 86%.

Esto significa que, en tiempo real, puedo variar la cantidad de coincidencias que ven mis usuarios para mejorar la relevancia de las coincidencias según el contexto de búsqueda de los usuarios.
- Volvamos a intentarlo modificando los parámetros del índice:
Para esta prueba, usaré la "distancia L2" en lugar de la función de distancia de similitud "coseno". También cambiaré el límite de la búsqueda a 10 para mostrar si hay una mejora en la calidad de los resultados de la búsqueda, incluso con un mayor recuento de conjuntos de resultados de la búsqueda.
[ANTES] Consulta que usa la función de distancia de similitud del coseno:
SELECT
*
FROM
evaluate_query_recall($$
SELECT
id || ' - ' || title AS title,
abstract
FROM
patents_data
where num_claims >= 15
ORDER BY
abstract_embeddings <=> embedding('text-embedding-005',
'sentiment analysis')::vector
LIMIT 10 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
Nota muy importante: Te preguntarás: "¿Cómo sabemos que esta búsqueda usa la similitud de COSENO?". Puedes identificar la función de distancia por el uso de "<=>" para representar la distancia del coseno.
Vínculo a la documentación sobre las funciones de distancia de la Búsqueda de vectores.
El resultado de la consulta anterior es el siguiente:
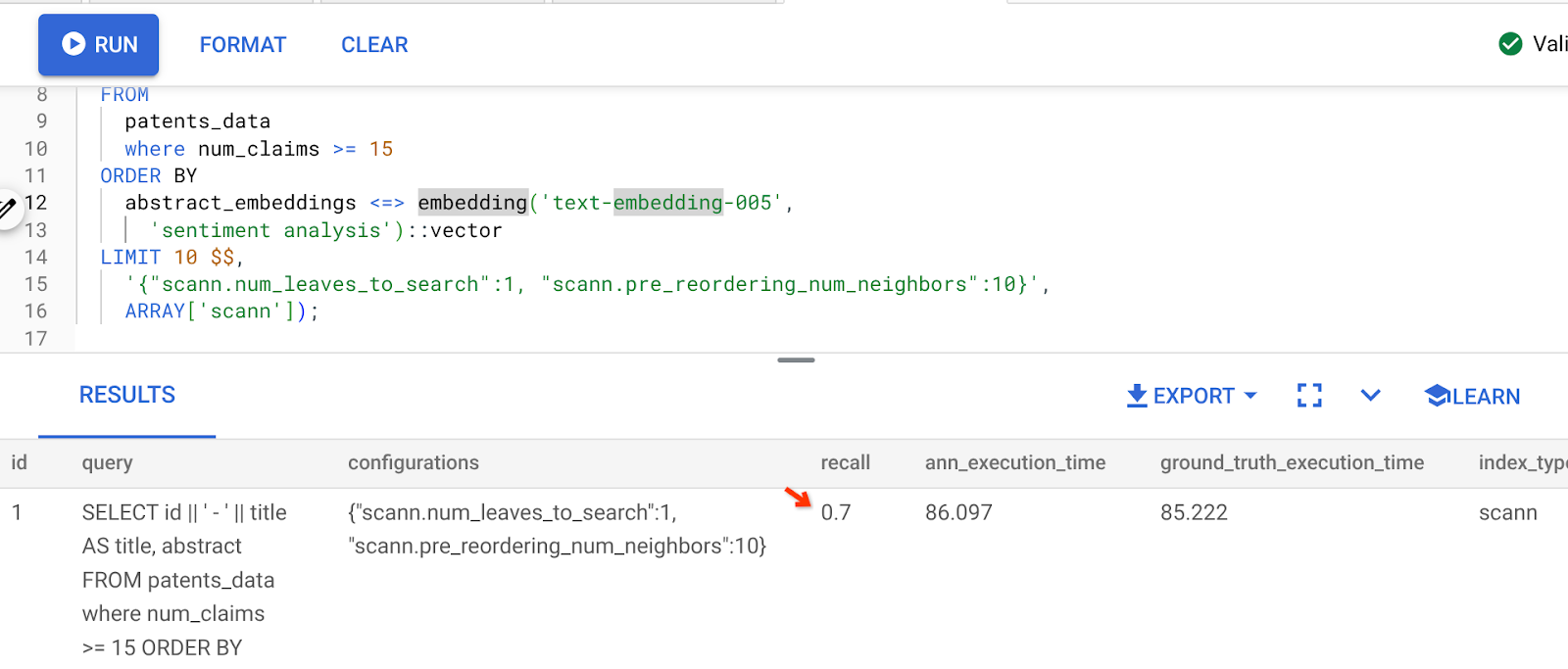
Como puedes ver, la RECALL es del 70% sin ningún cambio en la lógica de nuestro índice. ¿Recuerdas el índice ScaNN que creamos en el paso 6 de la sección Filtrado intercalado, "patent_index "? El mismo índice sigue siendo efectivo mientras ejecutamos la consulta anterior.
Ahora, creemos un índice con una consulta de función de distancia diferente: Distancia L2: <->
drop index patent_index;
CREATE INDEX patent_index_L2 ON patents_data
USING scann (abstract_embeddings L2)
WITH (num_leaves=32);
La instrucción de descarte del índice solo sirve para garantizar que no haya índices innecesarios en la tabla.
Ahora, puedo ejecutar la siguiente consulta para evaluar la RECALL después de cambiar la función de distancia de mi funcionalidad de Vector Search.
[AFTER] Consulta que usa la función de distancia de similitud del coseno:
SELECT
*
FROM
evaluate_query_recall($$
SELECT
id || ' - ' || title AS title,
abstract
FROM
patents_data
where num_claims >= 15
ORDER BY
abstract_embeddings <-> embedding('text-embedding-005',
'sentiment analysis')::vector
LIMIT 10 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
El resultado de la consulta anterior es el siguiente:
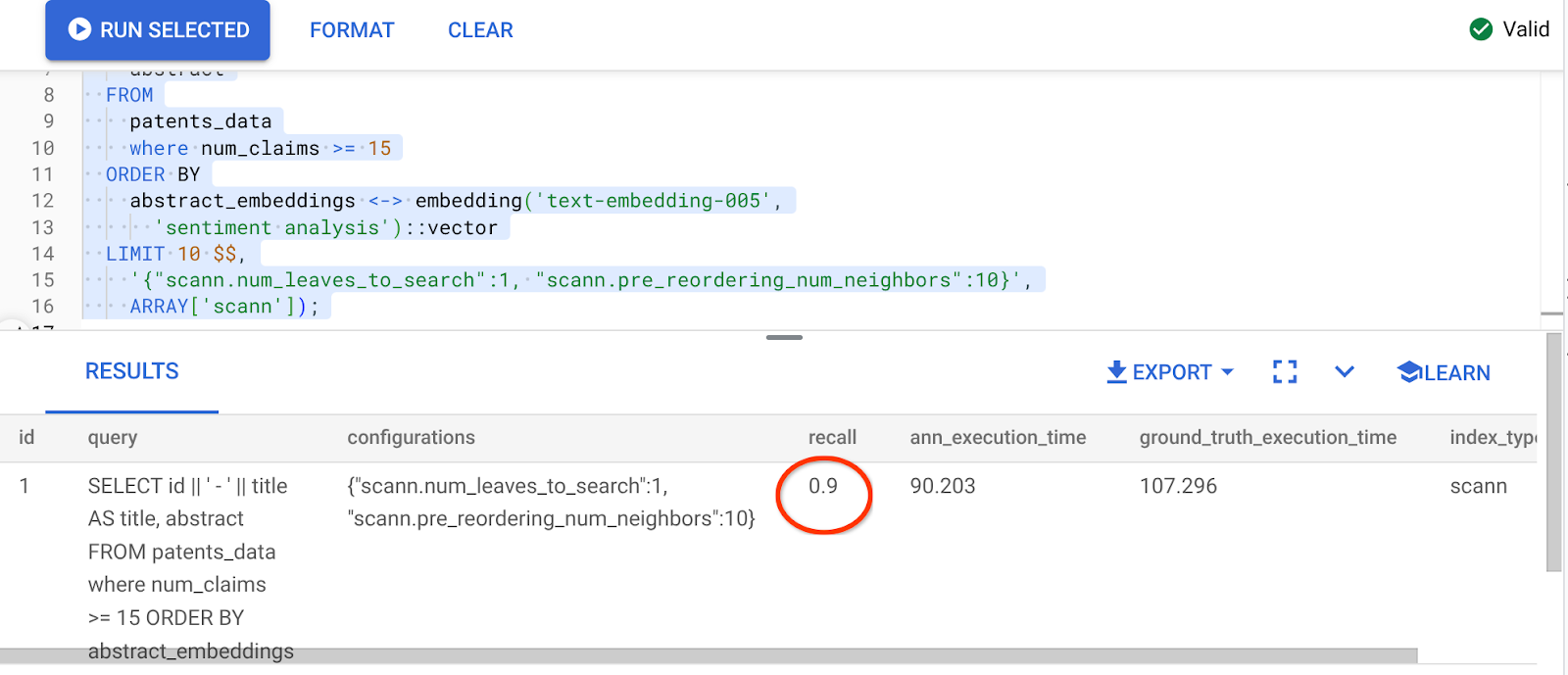
¡Qué transformación en el valor de recuperación, un 90%!!!
Hay otros parámetros que puedes cambiar en el índice, como num_leaves, etc., según el valor de recuperación deseado y el conjunto de datos que usa tu aplicación.
8. Limpia
Sigue estos pasos para evitar que se apliquen cargos a tu cuenta de Google Cloud por los recursos que usaste en esta publicación:
- En la consola de Google Cloud, ve a la página del administrador de recursos.
- En la lista de proyectos, elige el proyecto que deseas borrar y haz clic en Borrar.
- En el diálogo, escribe el ID del proyecto y, luego, haz clic en Cerrar para borrarlo.
- Como alternativa, puedes borrar el clúster de AlloyDB (cambia la ubicación en este hipervínculo si no elegiste us-central1 para el clúster en el momento de la configuración) que acabamos de crear para este proyecto haciendo clic en el botón BORRAR CLÚSTER.
9. Felicitaciones
¡Felicitaciones! Creaste correctamente tu búsqueda de patentes contextual con la búsqueda de vectores avanzada de AlloyDB para obtener un alto rendimiento y que se base en el significado. Creé una aplicación de agente multiherramienta con control de calidad que usa el ADK y todo lo relacionado con AlloyDB que analizamos aquí para crear un agente de análisis y búsqueda de vectores de patentes de alta calidad y rendimiento que puedes ver aquí: https://youtu.be/Y9fvVY0yZTY
Si quieres aprender a compilar ese agente, consulta este codelab.