
1. نظرة عامة
في مختلف الصناعات، يُعدّ البحث عن براءات الاختراع أداة مهمة لفهم المشهد التنافسي وتحديد فرص الترخيص أو الاستحواذ المحتملة وتجنُّب انتهاك براءات الاختراع الحالية.
إنّ البحث عن براءات الاختراع واسع النطاق ومعقّد. إنّ البحث في عدد لا يحصى من الملخّصات الفنية للعثور على ابتكارات ذات صلة هو مهمة شاقة. غالبًا ما تكون عمليات البحث التقليدية المستندة إلى الكلمات الرئيسية غير دقيقة وتستغرق وقتًا طويلاً. الملخّصات طويلة وفنية، ما يجعل من الصعب فهم الفكرة الأساسية بسرعة. وقد يؤدي ذلك إلى عدم عثور الباحثين على براءات الاختراع الرئيسية أو إضاعة الوقت في نتائج غير ذات صلة.
يكمن سرّ هذا التطوّر في ميزة "البحث المتّجه". بدلاً من الاعتماد على المطابقة البسيطة للكلمات الرئيسية، يحوّل البحث المتّجهي النص إلى تمثيلات رقمية (تضمينات). يتيح لنا ذلك البحث استنادًا إلى معنى طلب البحث، وليس الكلمات المحدّدة المستخدَمة فقط. هذه الميزة ستحدث تغييرًا جذريًا في عالم البحث عن الأعمال الأدبية. تخيّل العثور على براءة اختراع لـ "جهاز مراقبة معدّل نبضات القلب القابل للارتداء" حتى إذا لم يتم استخدام العبارة نفسها في المستند.
الهدف
في هذا الدرس العملي، سنعمل على تسريع عملية البحث عن براءات الاختراع وجعلها أكثر سهولة ودقة من خلال الاستفادة من AlloyDB وإضافة pgvector وGemini 1.5 Pro وEmbeddings وVector Search.
ما ستنشئه
في هذا الدرس التطبيقي، ستنفّذ ما يلي:
- إنشاء مثيل AlloyDB وتحميل بيانات مجموعة البيانات العامة الخاصة ببراءات الاختراع
- تفعيل إضافات pgvector ونموذج الذكاء الاصطناعي التوليدي في AlloyDB
- إنشاء تضمينات من الإحصاءات
- إجراء بحث في الوقت الفعلي عن تشابه جيب التمام لنص بحث المستخدم
- نشر الحل في Cloud Functions بدون خادم
يمثّل الرسم البياني التالي تدفّق البيانات والخطوات المتّبعة في عملية التنفيذ.

High level diagram representing the flow of the Patent Search Application with AlloyDB
المتطلبات
2. قبل البدء
إنشاء مشروع
- في Google Cloud Console، في صفحة اختيار المشروع، اختَر أو أنشِئ مشروعًا على Google Cloud.
- تأكَّد من تفعيل الفوترة لمشروعك على Cloud. تعرَّف على كيفية التحقّق مما إذا كانت الفوترة مفعَّلة في مشروع .
- ستستخدم Cloud Shell، وهي بيئة سطر أوامر تعمل في Google Cloud ومحمّلة مسبقًا بأداة bq. انقر على "تفعيل Cloud Shell" في أعلى "وحدة تحكّم Google Cloud".

- بعد الاتصال بـ Cloud Shell، يمكنك التأكّد من أنّك قد تم التحقّق من هويتك وأنّه تم ضبط المشروع على معرّف مشروعك باستخدام الأمر التالي:
gcloud auth list
- نفِّذ الأمر التالي في Cloud Shell للتأكّد من أنّ أمر gcloud يعرف مشروعك.
gcloud config list project
- إذا لم يتم ضبط مشروعك، استخدِم الأمر التالي لضبطه:
gcloud config set project <YOUR_PROJECT_ID>
- فعِّل واجهات برمجة التطبيقات المطلوبة. يمكنك استخدام أمر gcloud في وحدة Cloud Shell الطرفية:
gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
cloudfunctions.googleapis.com \
aiplatform.googleapis.com
يمكنك بدلاً من استخدام أمر gcloud، البحث عن كل منتج من خلال وحدة التحكّم أو استخدام هذا الرابط.
راجِع المستندات لمعرفة أوامر gcloud وطريقة استخدامها.
3- إعداد قاعدة بيانات AlloyDB
لننشئ مجموعة ومثيل وجدول AlloyDB سيتم تحميل مجموعة بيانات براءات الاختراع فيها.
إنشاء عناصر AlloyDB
أنشئ مجموعة ومثيل باستخدام معرّف المجموعة "patent-cluster" وكلمة المرور "alloydb" وPostgreSQL 15 المتوافق والمنطقة "us-central1"، مع ضبط الشبكات على "default". اضبط معرّف المثيل على "patent-instance". انقر على "إنشاء مجموعة". تتوفّر تفاصيل إنشاء مجموعة في هذا الرابط: https://cloud.google.com/alloydb/docs/cluster-create.
إنشاء جدول
يمكنك إنشاء جدول باستخدام عبارة DDL أدناه في AlloyDB Studio:
CREATE TABLE patents_data ( id VARCHAR(25), type VARCHAR(25), number VARCHAR(20), country VARCHAR(2), date VARCHAR(20), abstract VARCHAR(300000), title VARCHAR(100000), kind VARCHAR(5), num_claims BIGINT, filename VARCHAR(100), withdrawn BIGINT) ;
تفعيل الإضافات
لإنشاء تطبيق "بحث براءات الاختراع"، سنستخدم الإضافتين pgvector وgoogle_ml_integration. تتيح لك إضافة pgvector تخزين عمليات التضمين المتجهة والبحث عنها. توفّر إضافة google_ml_integration دوال يمكنك استخدامها للوصول إلى نقاط نهاية التوقّعات في Vertex AI من أجل الحصول على توقّعات في SQL. فعِّل هذه الإضافات من خلال تنفيذ تعريفات البيانات التالية:
CREATE EXTENSION vector;
CREATE EXTENSION google_ml_integration;
منح الإذن
نفِّذ العبارة أدناه لمنح إذن التنفيذ على الدالة "embedding":
GRANT EXECUTE ON FUNCTION embedding TO postgres;
منح دور "مستخدم Vertex AI" لحساب خدمة AlloyDB
من وحدة تحكّم "إدارة الهوية وإمكانية الوصول" في Google Cloud، امنح حساب خدمة AlloyDB (الذي يبدو على النحو التالي: service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com) إذن الوصول إلى الدور "مستخدم Vertex AI". سيحتوي PROJECT_NUMBER على رقم مشروعك.
يمكنك بدلاً من ذلك منح إذن الوصول باستخدام أمر gcloud:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
تعديل الجدول لإضافة عمود Vector لتخزين عمليات التضمين
نفِّذ عبارة تعريف البيانات (DDL) أدناه لإضافة الحقل abstract_embeddings إلى الجدول الذي أنشأناه للتو. سيسمح هذا العمود بتخزين قيم المتّجه للنص:
ALTER TABLE patents_data ADD column abstract_embeddings vector(3072);
4. تحميل بيانات براءات الاختراع إلى قاعدة البيانات
سيتم استخدام مجموعات البيانات العامة لبراءات اختراع Google على BigQuery كمجموعة البيانات الخاصة بنا. سنستخدم AlloyDB Studio لتشغيل طلبات البحث. يتضمّن مستودع alloydb-pgvector النص البرمجي insert_into_patents_data.sql الذي سننفّذه لتحميل بيانات براءات الاختراع.
- في Google Cloud Console، افتح صفحة AlloyDB.
- اختَر المجموعة التي تم إنشاؤها حديثًا وانقر على الجهاز الظاهري.
- في قائمة التنقّل في AlloyDB، انقر على AlloyDB Studio. سجِّل الدخول باستخدام بيانات اعتمادك.
- افتح علامة تبويب جديدة من خلال النقر على رمز علامة تبويب جديدة على يسار الشاشة.
- انسخ عبارة طلب البحث
insertمن النص البرمجيinsert_into_patents_data.sqlالمذكور أعلاه إلى المحرّر. يمكنك نسخ 50 إلى 100 عبارة إدراج للحصول على عرض توضيحي سريع لحالة الاستخدام هذه. - انقر على تشغيل. تظهر نتائج طلب البحث في جدول النتائج.
5- إنشاء تضمينات لبيانات براءات الاختراع
لنختبر أولاً دالة التضمين من خلال تنفيذ نموذج الاستعلام التالي:
SELECT embedding( 'gemini-embedding-001', 'AlloyDB is a managed, cloud-hosted SQL database service.');
من المفترض أن يعرض هذا الطلب متجه التضمينات، الذي يبدو كصفيف من الأرقام العشرية، للنص النموذجي في الطلب. يظهر على النحو التالي:

تعديل حقل "المتجهات" abstract_embeddings
نفِّذ لغة معالجة البيانات (DML) أدناه لتعديل ملخّصات براءات الاختراع في الجدول باستخدام عمليات التضمين المقابلة:
UPDATE patents_data set abstract_embeddings = embedding( 'gemini-embedding-001', abstract);
6. إجراء بحث عن المتّجهات
بعد أن أصبح الجدول والبيانات والتضمينات جاهزة، لننفّذ الآن عملية "البحث المتّجه" في الوقت الفعلي عن نص بحث المستخدم. يمكنك اختبار ذلك من خلال تنفيذ طلب البحث أدناه:
SELECT id || ' - ' || title as literature FROM patents_data ORDER BY abstract_embeddings <=> embedding('gemini-embedding-001', 'A new Natural Language Processing related Machine Learning Model')::vector LIMIT 10;
في هذا الاستعلام،
- نص بحث المستخدم هو: "نموذج جديد للتعلم الآلي مرتبط بمعالجة اللغات الطبيعية".
- نحوّل النص إلى تضمينات باستخدام الطريقة embedding() وباستخدام النموذج: gemini-embedding-001.
- يمثّل "<=>" استخدام طريقة قياس المسافة COSINE SIMILARITY.
- نحوّل نتيجة طريقة التضمين إلى نوع متّجه لجعلها متوافقة مع المتّجهات المخزّنة في قاعدة البيانات.
- يشير LIMIT 10 إلى أنّنا نختار 10 نتائج مطابقة لنص البحث.
في ما يلي النتيجة:

كما تلاحظ في نتائجك، تكون المطابقات قريبة جدًا من نص البحث.
7. نقل التطبيق إلى الويب
هل أنت مستعد لنقل هذا التطبيق إلى الويب؟ يُرجى اتّباع الخطوات التالية:
- انتقِل إلى Cloud Shell Editor، وانقر على رمز "Cloud Code — تسجيل الدخول" في أسفل يمين أداة التعديل (شريط الحالة). اختَر مشروعك الحالي على Google Cloud الذي تم تفعيل الفوترة فيه، وتأكَّد من تسجيل الدخول إلى المشروع نفسه من Gemini أيضًا (في الزاوية اليمنى من شريط الحالة).
- انقر على رمز Cloud Code وانتظِر إلى أن يظهر مربّع حوار Cloud Code. انقر على "تطبيق جديد" (New Application)، ثم انقر على تطبيق Cloud Functions في النافذة المنبثقة "إنشاء تطبيق جديد" (Create New Application):

في الصفحة 2 من 2 من النافذة المنبثقة "إنشاء تطبيق جديد"، اختَر Java: Hello World وأدخِل اسم مشروعك على النحو التالي: alloydb-pgvector في الموقع الجغرافي المفضّل لديك، ثم انقر على "حسنًا":

- في بنية المشروع الناتجة، ابحث عن pom.xml واستبدِله بالمحتوى من ملف المستودع. يجب أن تتضمّن هذه التبعيات بالإضافة إلى بعض التبعيات الأخرى:

- استبدِل ملف HelloWorld.java بالمحتوى من ملف repo.
يُرجى العِلم أنّه عليك استبدال القيم أدناه بقيمك الفعلية:
String ALLOYDB_DB = "postgres";
String ALLOYDB_USER = "postgres";
String ALLOYDB_PASS = "*****";
String ALLOYDB_INSTANCE_NAME = "projects/<<YOUR_PROJECT_ID>>/locations/us-central1/clusters/<<YOUR_CLUSTER>>/instances/<<YOUR_INSTANCE>>";
//Replace YOUR_PROJECT_ID, YOUR_CLUSTER, YOUR_INSTANCE with your actual values
يُرجى العِلم أنّ الدالة تتوقّع نص البحث كمعلَمة إدخال مع المفتاح "search"، وفي هذا التنفيذ، نعرض تطابقًا واحدًا فقط من قاعدة البيانات:
// Get the request body as a JSON object.
JsonObject requestJson = new Gson().fromJson(request.getReader(), JsonObject.class);
String searchText = requestJson.get("search").getAsString();
//Sample searchText: "A new Natural Language Processing related Machine Learning Model";
BufferedWriter writer = response.getWriter();
String result = "";
HikariDataSource dataSource = AlloyDbJdbcConnector();
try (Connection connection = dataSource.getConnection()) {
//Retrieve Vector Search by text (converted to embeddings) using "Cosine Similarity" method
try (PreparedStatement statement = connection.prepareStatement("SELECT id || ' - ' || title as literature FROM patents_data ORDER BY abstract_embeddings <=> embedding('tgemini-embedding-001', '" + searchText + "' )::vector LIMIT 1")) {
ResultSet resultSet = statement.executeQuery();
resultSet.next();
String lit = resultSet.getString("literature");
result = result + lit + "\n";
System.out.println("Matching Literature: " + lit);
}
writer.write("Here is the closest match: " + result);
}
- لنشر Cloud Function التي أنشأتها للتو، نفِّذ الأمر التالي من وحدة Cloud Shell الطرفية. يُرجى تذكُّر الانتقال إلى مجلد المشروع المناسب أولاً باستخدام الأمر:
cd alloydb-pgvector
بعد ذلك، نفِّذ الأمر التالي:
gcloud functions deploy patent-search --gen2 --region=us-central1 --runtime=java11 --source=. --entry-point=cloudcode.helloworld.HelloWorld --trigger-http
خطوة مهمة:
بعد بدء عملية النشر، من المفترض أن تتمكّن من رؤية الدوال في وحدة تحكّم وظائف Cloud Run من Google. ابحث عن الدالة التي تم إنشاؤها حديثًا وافتحها، ثم عدِّل الإعدادات وغيِّر ما يلي:
- الانتقال إلى إعدادات وقت التشغيل والإنشاء والاتصالات والأمان
- زيادة المهلة إلى 180 ثانية
- انتقِل إلى علامة التبويب "عمليات الربط":

- ضِمن إعدادات Ingress، تأكَّد من اختيار "السماح بكل الزيارات".
- ضمن إعدادات Egress، انقر على القائمة المنسدلة "الشبكة" واختَر الخيار "إضافة أداة ربط VPC جديدة" واتّبِع التعليمات التي تظهر في مربّع الحوار المنبثق:

- قدِّم اسمًا لموصّل VPC وتأكَّد من أنّ المنطقة هي نفسها منطقة المثيل. اترك قيمة "الشبكة" على الوضع التلقائي واضبط "الشبكة الفرعية" على "نطاق IP مخصّص" مع نطاق IP 10.8.0.0 أو نطاق مشابه متوفّر.
- وسِّع SHOW SCALING SETTINGS وتأكَّد من ضبط الإعدادات على ما يلي بالضبط:

- انقر على "إنشاء"، ومن المفترض أن يظهر هذا الرابط في إعدادات الخروج الآن.
- اختَر الموصّل الذي تم إنشاؤه حديثًا
- اختَر توجيه كل حركة البيانات من خلال موصّل شبكة VPC هذا.
8. اختبار التطبيق
بعد نشرها، من المفترض أن يظهر لك عنوان URL النهائي بالتنسيق التالي:
https://us-central1-YOUR_PROJECT_ID.cloudfunctions.net/patent-search
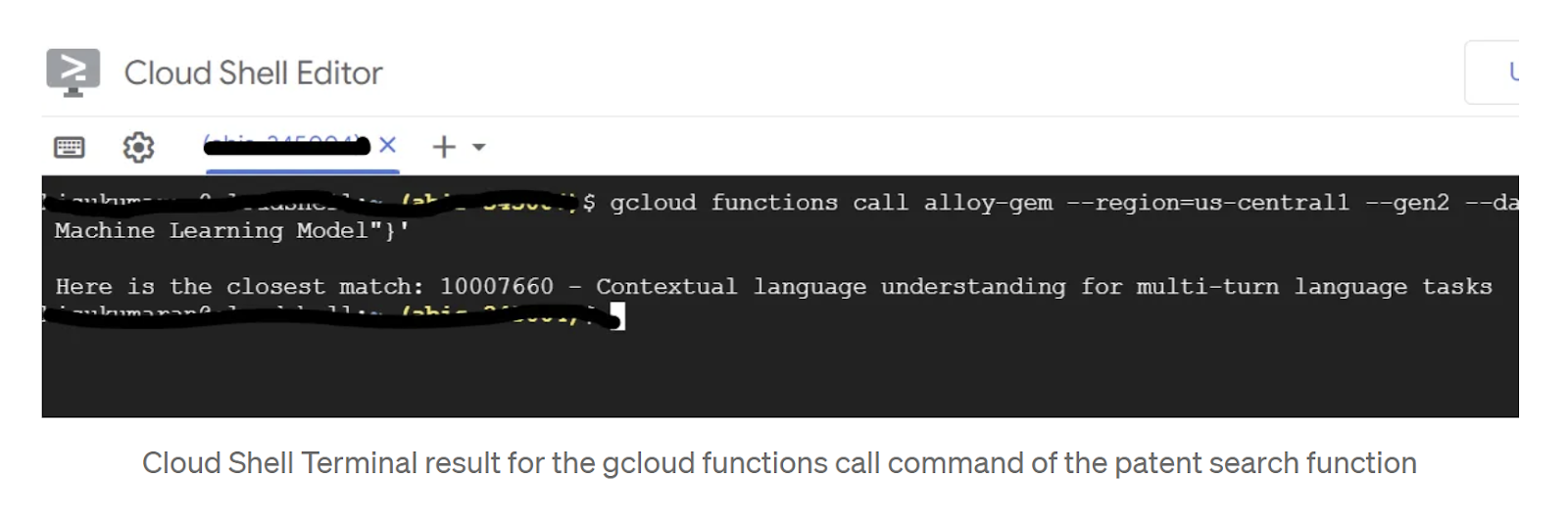
يمكنك اختبارها من "وحدة طرفية Cloud Shell" عن طريق تنفيذ الأمر التالي:
gcloud functions call patent-search --region=us-central1 --gen2 --data '{"search": "A new Natural Language Processing related Machine Learning Model"}'
النتيجة:
يمكنك أيضًا اختبارها من قائمة Cloud Functions. اختَر الدالة التي تم نشرها وانتقِل إلى علامة التبويب "الاختبار". في مربّع النص الخاص بقسم "ضبط حدث التشغيل" لطلب JSON، أدخِل ما يلي:
{"search": "A new Natural Language Processing related Machine Learning Model"}
انقر على الزر "اختبار الدالة" (TEST THE FUNCTION)، وستظهر لك النتيجة على يسار الصفحة:

هذا كل شيء! بهذه البساطة، يمكنك إجراء عملية "البحث عن المتجهات المشابهة" باستخدام نموذج "عمليات التضمين" على بيانات AlloyDB.
9- تَنظيم
لتجنُّب تحمّل رسوم في حسابك على Google Cloud مقابل الموارد المستخدَمة في هذه المشاركة، اتّبِع الخطوات التالية:
10. تهانينا
تهانينا! لقد أجريت بنجاح عملية بحث عن التشابه باستخدام AlloyDB وpgvector و"البحث المتّجه". من خلال الجمع بين إمكانات AlloyDB وVertex AI وVector Search، حقّقنا تقدّمًا كبيرًا في إتاحة عمليات البحث عن المراجع العلمية وفعاليتها وتركيزها على المعنى.