
1. قبل البدء
تشكّل النماذج اللغوية الكبيرة (LLM) إحدى أبرز الإنجازات المشوّقة في الآونة الأخيرة في مجال تعلُّم الآلة. يمكن استخدامها لإنشاء النصوص وترجمتها والإجابة عن الأسئلة بطريقة شاملة وغنية بالمعلومات. يتم تدريب النماذج اللغوية الكبيرة، مثل LaMDA وPaLM من Google، على كميات هائلة من البيانات النصية، ما يتيح لها تعلُّم الأنماط الإحصائية والعلاقات بين الكلمات والعبارات. ويتيح لهم ذلك إنشاء نصوص تشبه النصوص التي كتبها الإنسان، وترجمة اللغات بدرجة عالية من الدقة.
إنّ النماذج اللغوية الكبيرة كبيرة جدًا من حيث مساحة التخزين، وتستهلك بشكل عام قدرًا كبيرًا من إمكانيات الحوسبة، ما يعني أنّها تُستخدَم عادةً على السحابة الإلكترونية وتشكّل تحديًا كبيرًا لتعلُّم الآلة على الجهاز (ODML) بسبب القوة الحاسوبية المحدودة على الأجهزة الجوّالة. مع ذلك، من الممكن تشغيل النماذج اللغوية الكبيرة (LLM) ذات الحجم الأصغر (مثل GPT-2) على جهاز Android حديث مع الاستمرار في تحقيق نتائج مبهرة.
في ما يلي عرض توضيحي لتشغيل إصدار نموذج Google PaLM مع 1.5 مليار مَعلمة على Google Pixel 7 Pro بدون زيادة سرعة التشغيل.

في هذا الدرس التطبيقي حول الترميز، ستتعرَّف على التقنيات والأدوات المتاحة لإنشاء تطبيق مستند إلى النموذج اللغوي الكبير (LLM) (باستخدام GPT-2 كمثال على نموذج) باستخدام:
- نظام KerasNLP لتحميل نموذج لغوي كبير (LLM) مدرّب مسبقًا
- نظام KerasNLP لتحسين النموذج اللغوي الكبير
- استخدِم TensorFlow Lite لتحويل النموذج اللغوي الكبير وتحسينه ونشره على Android.
المتطلبات الأساسية
- مستوى معرفة متوسطة ببروتوكول Keras وTensorFlow Lite
- معرفة أساسية بتطوير تطبيقات Android
ما ستتعرَّف عليه
- كيفية استخدام نظام KerasNLP لتحميل نموذج لغوي كبير (LLM) مدرّب مسبقًا وتحسينه
- كيفية قياس النموذج اللغوي الكبير وتحويله إلى TensorFlow Lite
- كيفية تنفيذ الاستنتاج على نموذج TensorFlow Lite الذي تم تحويله
المتطلبات
- الوصول إلى Colab
- أحدث إصدار من استوديو Android
- جهاز Android حديث مزوّد بذاكرة وصول عشوائي (RAM) بسعة أكبر من 4 غيغابايت
2. الإعداد
لتنزيل الرمز الخاص بهذا الدرس التطبيقي حول الترميز:
- انتقِل إلى مستودع GitHub الخاص بهذا الدرس التطبيقي حول الترميز.
- انقر على الرمز > نزِّل الرمز البريدي لتنزيل جميع الرموز الخاصة بهذا الدرس التطبيقي حول الترميز.
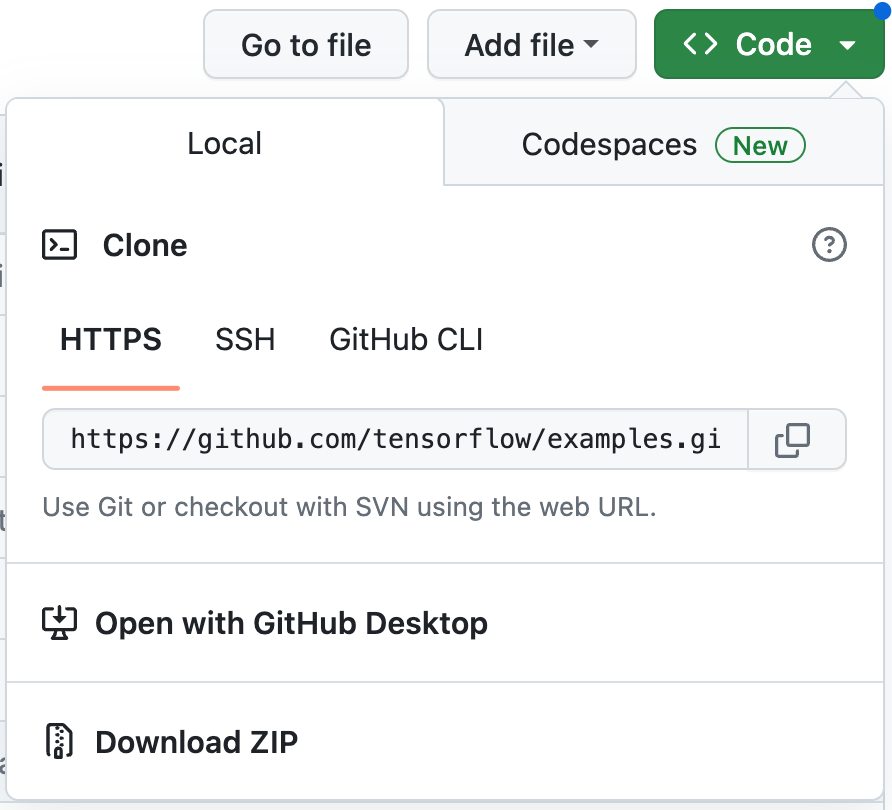
- عليك فك ضغط ملف ZIP الذي تم تنزيله لفك ضغط المجلد الجذر
examplesالذي يحتوي على جميع الموارد التي تحتاج إليها.
3- تشغيل تطبيق إجراء التفعيل
- استيراد مجلد واحد (
examples/lite/examples/generative_ai/android) إلى "استوديو Android" - ابدأ تشغيل محاكي Android، ثم انقر على
 تشغيل في قائمة التنقل.
تشغيل في قائمة التنقل.
تشغيل التطبيق واستكشافه
من المفترض أن يتم تشغيل التطبيق على جهاز Android. يُطلق على التطبيق اسم "الإكمال التلقائي". واجهة المستخدم واضحة جدًا: يمكنك كتابة بعض الكلمات الأساسية في مربّع النص والنقر على إنشاء، بعد ذلك، ينفِّذ التطبيق الاستنتاج على نموذج لغوي كبير (LLM) وينشئ نصًا إضافيًا استنادًا إلى البيانات التي أدخلتها.
في الوقت الحالي، إذا نقرت على إنشاء بعد كتابة بعض الكلمات، لن يحدث شيء. ويرجع ذلك إلى أنّ النموذج اللغوي الكبير (LLM) لا يعمل بعد.
4. إعداد النموذج اللغوي الكبير للنشر على الجهاز
- افتح Colab وتصفّح ورقة الملاحظات (التي تتم استضافتها في مستودع TensorFlow Codelabs GitHub).
5- إكمال عملية إعداد تطبيق Android
الآن بعد أن حولت نموذج GPT-2 إلى TensorFlow Lite، يمكنك نشره في التطبيق في النهاية.
تشغيل التطبيق
- اسحب ملف نموذج
autocomplete.tfliteالذي تم تنزيله من الخطوة الأخيرة إلى مجلدapp/src/main/assets/في "استوديو Android".
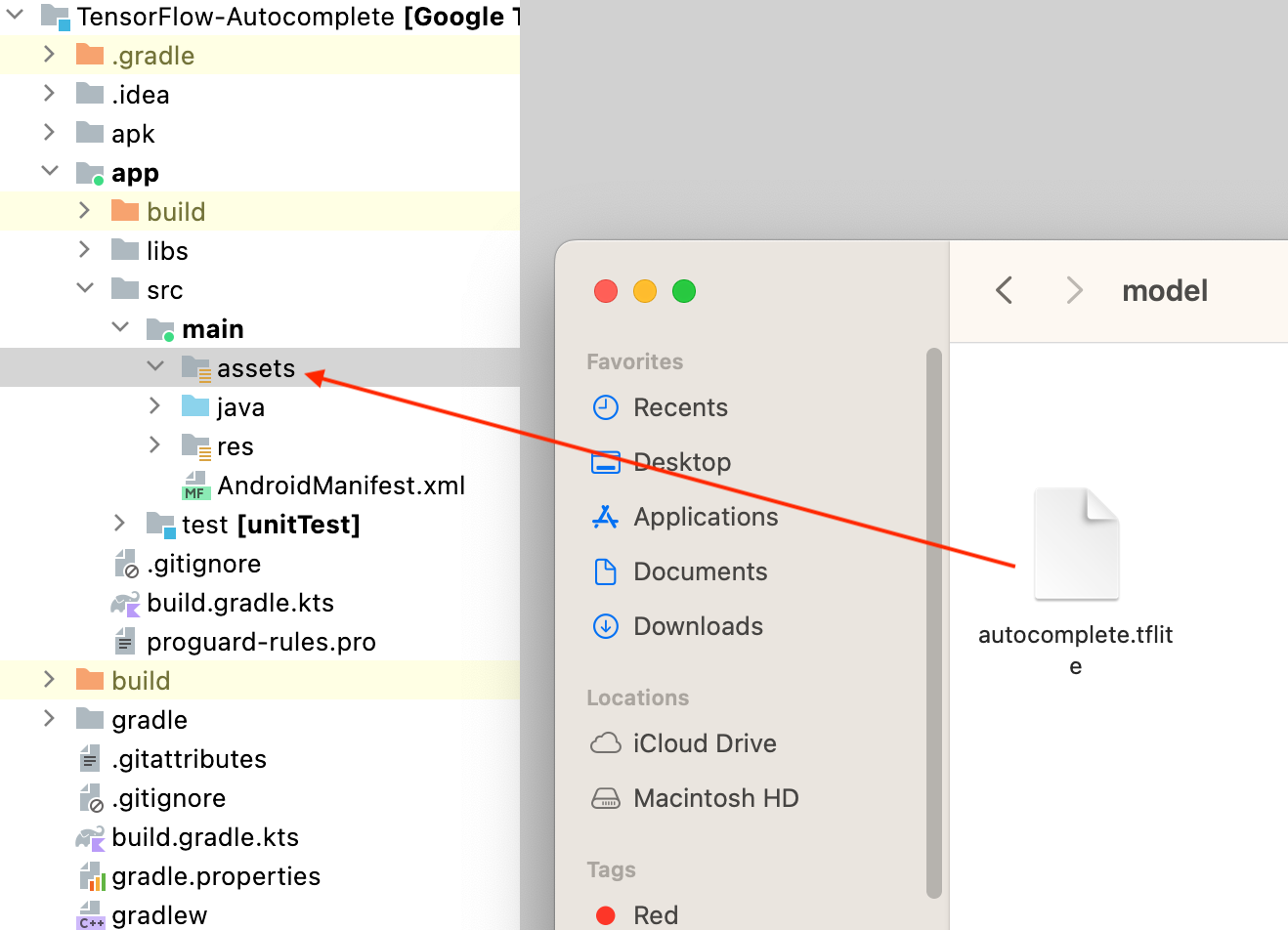
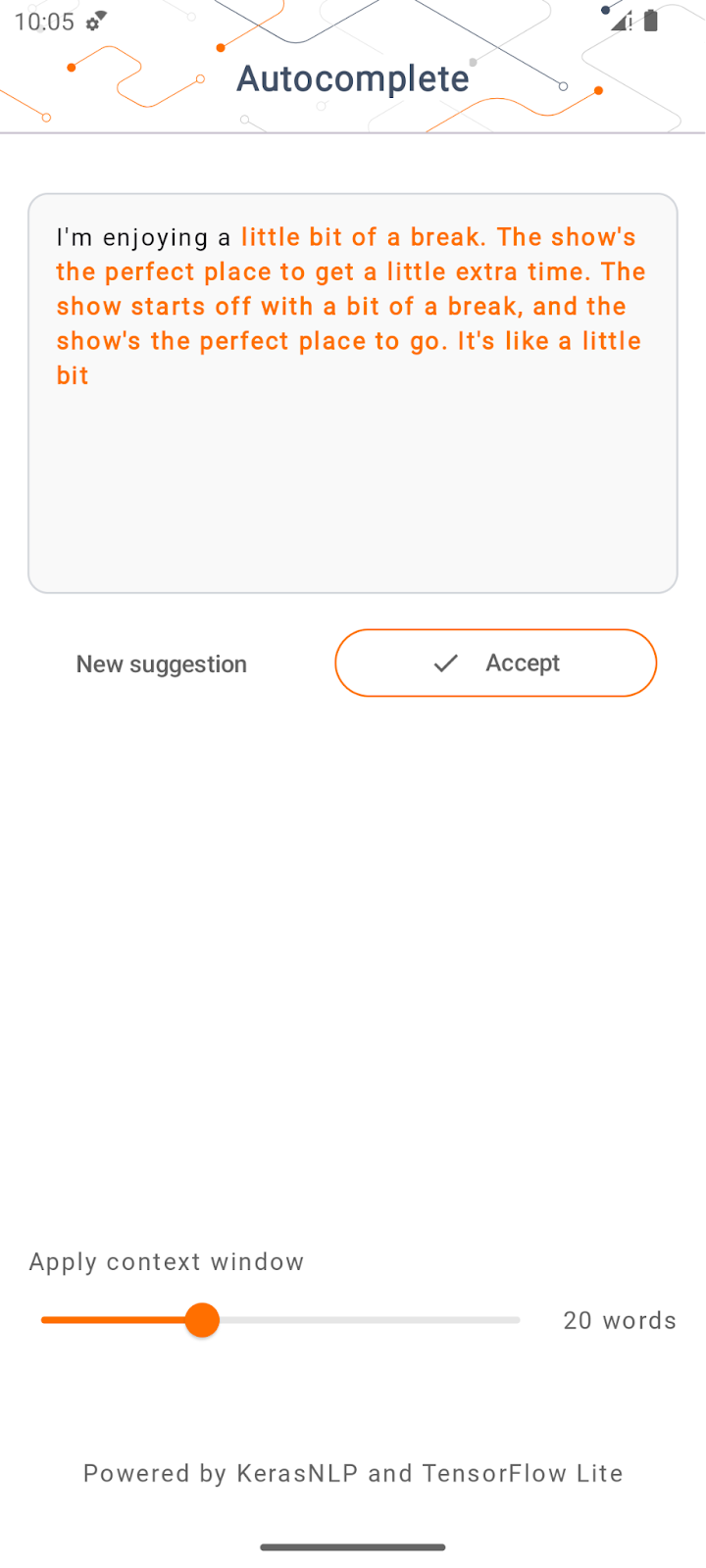
- انقر على تشغيل في قائمة التنقّل، ثم انتظِر إلى أن يتم تحميل التطبيق.
- اكتب بعض الكلمات الأساسية في حقل النص، ثم انقر على إنشاء.
6- ملاحظات حول استخدام الذكاء الاصطناعي بشكل مسؤول
كما هو موضَّح في إشعار GPT-2 من OpenAI الأصلي، هناك محاذير وقيود ملحوظة في نموذج GPT-2. في الواقع، تواجه النماذج اللغوية الكبيرة اليوم تحديات معروفة، مثل الهلوسة والنتائج المسيئة والإنصاف والانحياز. وذلك لأن هذه النماذج مدربة على بيانات العالم الحقيقي، مما يجعلها تعكس مشكلات العالم الحقيقي.
تم إنشاء هذا الدرس التطبيقي حول الترميز فقط لتوضيح كيفية إنشاء تطبيق يستند إلى النماذج اللغوية الكبيرة (LLM) باستخدام أدوات TensorFlow. إنّ النموذج الذي تم إنشاؤه في هذا الدرس التطبيقي حول الترميز مخصّص لأغراض تعليمية فقط، وليس مخصَّصًا للاستخدام في مرحلة الإنتاج.
يتطلّب استخدام إنتاج "النموذج اللغوي الكبير" (LLM) اختيار مجموعة بيانات تدريبية مدروسة وإجراءات شاملة تتعلّق بالسلامة. لمزيد من المعلومات حول الذكاء الاصطناعي المسؤول في سياق النماذج اللغوية الكبيرة، يمكنك مشاهدة الجلسة الفنية للتطوير الآمن والمسؤول باستخدام النماذج اللغوية التوليدية في مؤتمر Google I/O لعام 2023 والاطّلاع على مجموعة أدوات الذكاء الاصطناعي المسؤول.
7. الخاتمة
تهانينا! لقد أنشأت تطبيقًا لإنشاء نص مترابط بناءً على إدخال المستخدم عن طريق تشغيل نموذج لغوي كبير مدرَّب مسبقًا على الجهاز فقط!