
1. 🏰 Disneyland Data Analytics Hackathon (第 2 版 - 12 月 3 日) 🏰
摘要 | 在這次黑客松中,您將運用 Google Cloud 的 AI/機器學習功能,建構端對端資料分析管道。您會將資料載入 AlloyDB (與 PostgreSQL 相容的全代管資料庫,專為嚴苛的工作負載而設計),然後使用 Datastream (無伺服器變更資料擷取 (CDC) 服務) 將資料移至 BigQuery (Google Cloud 的無伺服器資料倉儲)。在 BigQuery 中,您將套用 BigQuery ML,直接在 BigQuery 中使用標準 SQL 建立及執行機器學習模型,以進行評論分析和出席預測。最後,您將透過對話式數據分析和資料代理,使用現成代理,或透過 Agent Development Kit 和 MCP 工具箱建立自訂代理,以自然語言與資料互動。 |
類別 | docType:Codelab, product:Bigquery |
作者 | Rayhane Rezgui、Matt Cornillon |
版面配置 | 捲動 |
機器人 | noindex |
2. 簡介
歡迎,未來的 Disney 資料魔法師!🪄
告別枯燥乏味的旅遊指南和無止盡的論壇捲動。想像一下,您要規劃一趟完美的迪士尼樂園之旅,並運用資料驅動的洞察資訊。哪個公園的體驗最好?人潮最少的時間是何時?你能預測何時排隊最省時嗎?
在這次的黑客松中,您將建構終極的迪士尼樂園規劃工具。我們擁有全球分店的訪客評論、歷來等候時間和出席人數等資料。你的任務是將原始資料轉化為可做為行動依據的洞察資料:
- 收集資料:將各種 Disneyland 評論、等待時間和出席人數資料載入 AlloyDB,這是與 PostgreSQL 相容的高效能資料庫。
- 順暢移轉:使用無伺服器變更資料擷取服務 Datastream,輕鬆將這類動態資訊移轉至 Google Cloud 強大的無伺服器資料倉儲 BigQuery。
- 預測魔法:運用 BigQuery ML 分析評論情緒,並直接透過 SQL 預測等待時間。瞭解哪些分店一向能提供優質服務,以及最適合前往的時間。
- 與資料「對話」:使用預先建構的工具,只要揮動魔杖就能取得洞察資料。
- 智慧互動:使用 MCP Toolbox for Databases 和 ADK (Agent Development Kit) 建構智慧型代理,為創作內容畫龍點睛。詢問「巴黎迪士尼樂園最適合太空迷的景點是哪個?排隊的最佳時間是何時?」即可立即獲得以資料為依據的答案。
前置準備解鎖地球上最神奇地點的秘密,並建立連米奇都會引以為傲的資料分析管道!
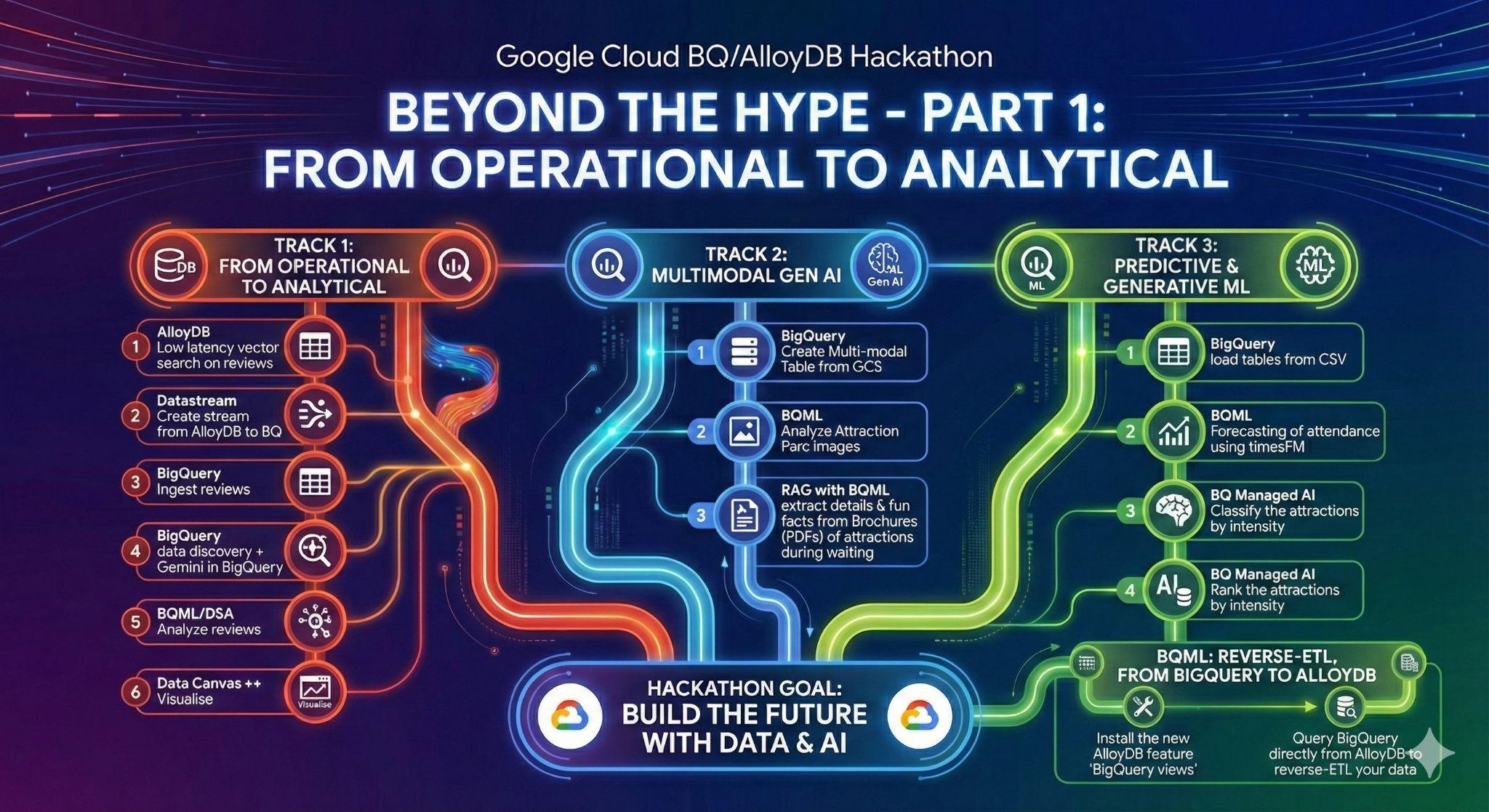

3. 任務 1:從作業到數據分析;使用 Gemini 分析 Disneyland 評論
在初始階段,您會從 AlloyDB 作業資料庫擷取資料,並載入 BigQuery,以利後續進行資料分析。
您也會在 AlloyDB 中設定日後代理程式所需的一切!
在 AlloyDB 中載入資料
首先,請將一些資料匯入 AlloyDB for PostgreSQL 叢集!
我們將擷取迪士尼樂園的 2 萬則評論和景點清單。
請按照下列步驟操作:
建立資料表:
- 建立 disneyland_reviews 資料表,其中包含 6 個資料欄:review_id 和 rating (整數)、year_month、reviewer_location、review_text 和 branch (文字)。
- 建立 disneyland_attractions 資料表,其中包含 4 個資料欄:attraction_id (整數)、branch、name 和 description (文字)。
使用您選擇的工具,從 CSV 檔案匯入資料:
- 評論表格的
gs://hackathon_data_disneyland_<YOUR_PROJECT_3DIGITS>/reviews.csv - 景點表格的
gs://hackathon_data_disneyland_<YOUR_PROJECT_3DIGITS>/attractions.csv
如要提供景點建議,我們需要建立景點說明的嵌入:
- 在 AlloyDB 中安裝 pgvector 擴充功能
- 在表格景點中新增名為「embedding」的向量資料欄
- 透過 AlloyDB 與 Vertex AI 的原生整合功能,生成並填入說明的嵌入
使用 Datastream 將作業資料轉換為分析資料
如要將資料從 AlloyDB 串流至 BigQuery,我們將使用 Google Datastream。這項強大的無伺服器解決方案會監聽來源資料表的所有變更 (使用變更資料擷取),並將變更傳送至 BigQuery。
如要使用 Datastream 複製 AlloyDB 的變更,我們需要在 Postgres 上建立所謂的發布項目和複製運算單元。
在 AlloyDB 叢集上執行下列查詢 (您需要一次執行一個查詢):
CREATE PUBLICATION pub_disney FOR TABLE disneyland_reviews, disneyland_attractions;
ALTER USER postgres WITH REPLICATION;
SELECT PG_CREATE_LOGICAL_REPLICATION_SLOT('slot_disney', 'pgoutput');
您會在串流中使用發布和複製運算單元,因此請記住名稱!
這樣就完成了,現在可以建立串流了!
您需要在 Datastream 中完成下列步驟:
- 為 AlloyDB 叢集建立來源設定檔 (使用公開 IP 位址)
- 為 BigQuery 建立目的地設定檔
- 建立從 AlloyDB 到 BigQuery 的資料串流。
資料應會在幾分鐘內匯入 BigQuery。
BigQuery 中的資料探索
現在資料已匯入 BigQuery,讓我們在開始工作前,先瞭解介面的新功能!
您可以在 BigQuery 探索面板中看到 3 個新函式。

- 總覽:包含 BigQuery 功能的相關資訊,以及開始分析的導覽等。
- 搜尋:對資料資產執行語意搜尋。
- 服務專員:噓,我們稍後會儲存這項資訊 🤫
在 BigQuery 中以語意方式搜尋資料
前往 BigQuery 探索面板的「搜尋」分頁,並試用與 Disney 相關的字詞,例如「景點」或「分店」。
以視覺化方式呈現 BigQuery 中的資料
現在您可以在 BigQuery 中將資料視覺化及操控資料。為此,您可以在新的查詢分頁中執行這項查詢;
SELECT
*
FROM
[dataset_name].[table_name];
生成評論資料表的洞察結果
在這項工作中,您會為 disney 資料集內的 disneyland_reviews 資料表啟用資料深入分析功能。
任何人都能透過資料深入分析工具探索資料,並取得洞察結果,無須編寫複雜的 SQL 查詢。
這可能需要幾分鐘的時間。
不使用 SQL 查詢 disneyland_reviews 資料表
您在上一節生成的洞察結果已可使用。在這項工作中,您會運用根據這些洞察結果生成的提示來查詢 disneyland_reviews 資料表,而且不使用程式碼。
選取洞察結果並執行相關聯的查詢。舉例來說,找出可計算各分店連續幾個月平均評分差異的查詢。程式碼應如下所示:
WITH
monthly_avg AS (
SELECT
branch,
year_month,
AVG(rating) AS avg_rating
FROM
[dataset_name].[table_name]
WHERE
year_month IS NOT NULL
GROUP BY
1,
2 )
SELECT
branch,
year_month,
avg_rating,
avg_rating - LAG(avg_rating, 1, 0) OVER (PARTITION BY branch ORDER BY year_month) AS rating_difference
FROM
monthly_avg
ORDER BY
branch,
year_month;
使用 BigQuery 知識引擎深入瞭解資料
首先,請先查看資料集層級的「洞察」分頁,瞭解 disney 資料集中各個資料表之間隱藏的關係。接著:
- 使用 Gemini 生成資料集說明,並新增至資料集詳細資料。
- 生成資料表評論和景點的說明,以及這些資料表中的所有個別資料欄,然後儲存。
對資料執行剖析掃描
本節的目標是清理及準備資料。不過,您不太瞭解每個資料欄的值分布情形。您需要分析資料,才能瞭解要在資料上執行哪些轉換步驟。
Google Cloud 的 Dataplex Universal Catalog 會自動執行 剖析掃描,提供一致的資料品質指標。系統會找出空值數量、不重複值、資料範圍和值分布情形等重要統計資料。您可以在 BigQuery 介面中啟動剖析掃描作業。
這可能需要幾分鐘的時間,等待時可以先閱讀下一節。
請回答以下問題:
- 迪士尼樂園的平均評分是多少?
- 評論者大多位於哪些地區?
- 所有評論是否都是獨一無二?
- Year_Month 欄的遺漏資料百分比是多少?
對資料執行品質掃描
Dataplex Universal Catalog 的自動資料品質功能可讓您定義及衡量 BigQuery 資料表中的資料品質。您可以自動掃描資料、根據定義的規則驗證資料,以及在資料不符合品質規定時記錄快訊。您可以將資料品質規則和部署作業視為程式碼進行管理,提升資料生產管道的完整性。
根據剖析掃描結果,定義品質掃描 (樣本大小不得超過 10% 的資料),並:
- 檢查「branch」欄的空值
- 對「rating」執行有效性檢查,因為只能是以下值:1、2、3、4、5
- 檢查「review_id」是否為唯一值
確認掃描結果已匯出至 BigQuery 資料表 quality_scan_results。
請思考您需要對資料套用的所有潛在轉換。
使用 Gemini 的資料準備功能準備資料
執行資料品質和剖析掃描後,現在可以開始清理資料,以利後續分析。
資料準備作業是 BigQuery 資源,會使用 Gemini in BigQuery 分析資料,並提供智慧型建議,協助您清理、轉換及補充資料。大幅減少手動準備資料所需的時間和工作量。
在本節中,您將使用資料準備功能,對 disneyland_reviews 資料表執行下列作業:
- 篩除 Branch 資料欄為 NULL 或空字串的資料列。
- 將 Year_Month 中的「missing」替換為 Null。
- 以空格取代分支版本欄中的底線,提高可讀性
- 匯出至轉換後的資料表 disneyland_reviews_cleaned
使用 Gemini 分析評論
現在資料已清理完畢,您可以開始使用 BigQuery ML 和 Gemini 模型分析資料。您有兩個目標:
- 從評論中擷取類別
- disneyland_reviews 的情緒分析
BigQuery ML 可讓您使用 GoogleSQL 查詢,建立及執行機器學習 (ML) 模型。BigQuery ML 模型會儲存在 BigQuery 資料集中,與資料表和檢視區塊類似。您也可以透過 BigQuery ML 存取 Vertex AI 模型和 Cloud AI API,執行文字生成或機器翻譯等人工智慧 (AI) 工作。Gemini 版 Google Cloud 也提供 AI 輔助功能,協助您完成 BigQuery 工作。
您可以選擇使用 ML.GENERATE_TEXT 或 AI.GENERATE (預先發布版) 搭配 Gemini Pro 或 Flash 模型。
如要使用 ML.GENERATE_TEXT,請按照下列步驟操作。
建立 Cloud 資源連結並授予 IAM 角色
您需要在 BigQuery 中建立 Vertex AI 模型適用的 Cloud 資源連結,才能使用 Gemini Pro 和 Gemini Flash 模型。您也將調整角色設定,為雲端資源連線的服務帳戶授予 IAM 權限,這樣該服務帳戶就能使用 Vertex AI 服務。
為連線的服務帳戶授予 Vertex AI 使用者角色
為連線的服務帳戶授予 Vertex AI 使用者角色,允許該帳戶使用您選擇的模型 (例如 gemini-2.5-flash)。權限需要 1 分鐘才會生效。
在 BigQuery 建立 Gemini 模型
使用上述連線建立模型。例如使用端點 gemini-2.5-flash.
提示 Gemini 分析顧客評論的類別和情緒
在這項工作中,您會使用 Gemini 模型分析每則顧客評論的類別和正/負面情緒。
分析顧客評論中的類別
注意:從現在起,為進行分析,我們只會採用 100 列資料,因為對 2 萬列資料呼叫 Gemini 可能需要一段時間。
Extract categories by modifying and running the following SQL Query:
CREATE OR REPLACE TABLE
[dataset_name].[results_table_name] AS (
SELECT Review_ID, Rating, Year_Month, Reviewer_Location, Review_Text, Branch, ml_generate_text_llm_result AS categories FROM
ML.GENERATE_TEXT(
MODEL [model_name],
(
SELECT Review_ID, Rating, Year_Month, Reviewer_Location, Review_Text, Branch, CONCAT(
'[WRITE YOUR PROMPT HERE].',
Review_Text) AS prompt
FROM (SELECT * FROM [dataset_name].[table_name] LIMIT 100)
),
STRUCT(
0.2 AS temperature, TRUE AS flatten_json_output)));
這項查詢會從 disneyland_reviews 資料表中擷取顧客評論,針對 gemini 模型建立提示,找出每個評論中的類別。結果應儲存在新的資料表 reviews_categories
。請稍候。模型約需 30 秒來處理顧客評論記錄,並將結果匯出至輸出資料表。
顯示結果:
SELECT * FROM [dataset_name].[results_table_name];
請花點時間閱讀部分類別。
分析顧客評論的正負面情緒
根據關鍵字擷取的 SQL 查詢,編寫查詢,在名為「sentiment」的欄位中,將評論分析為正面、負面和中性。
這項查詢會從 disneyland_reviews 資料表中擷取顧客評論,針對 gemini 模型建立提示,區分每個評論的情緒。查詢結果會儲存至新資料表 reviews_analysis,稍後可進一步用於分析。請稍候,模型約需幾秒鐘來處理顧客評論記錄。模型處理完畢後,結果會顯示在建立的 reviews_analysis 資料表中。
查看結果:
SELECT * FROM [...];
reviews_analysis 資料表含有 Sentiment 欄,其中包含情緒分析,以及 social_media_source、review_text、customer_id、location_id 和 review_datetime 欄。請查看記錄。您可能會發現某些正負面結果的格式有誤,含有句號或額外空格等不相關的字元。這時可以按照下列指示,使用 view 來清理記錄。
建立 view 來清理記錄
建立檢視畫面,透過下列方式清除資料欄情緒的值:
- 使用 LOWER 確保所有值都是小寫。
- 使用 REPLACE 移除標點符號 (句號、逗號和空格)
CREATE OR REPLACE VIEW [view_name] AS
SELECT [SANITIZATION_EXPRESSION] AS sentiment,
Review_ID, Rating, Year_Month, Reviewer_Location, Review_Text, Branch,
FROM `disney.reviews_analysis`;
這項查詢會建立名為 cleaned_data_view 的 view,內含情緒結果、評論文字、Review_ID, Rating, Year_Month, Reviewer_Location, Review_Text and Branch。接著,查詢會擷取情緒結果 (正面或負面)、確保所有英文字母均改為小寫,並移除額外空格或句號等不相關的字元,這樣就能更輕鬆地在這個實驗室的後續步驟,進一步分析這個 view。
- 您可以對這個 view 執行以下查詢,查看建立的資料列。
SELECT * FROM [view_name];
使用資料畫布建立正負面評論數量的報表
現在可以分析結果了。我們首先要直接在 BigQuery 中透過資料畫布執行這項操作。這個工具可讓您搜尋資料 (語意或關鍵字)、查詢及聯結資料表、建立圖表,以及透過建立畫布流程取得洞察資訊。
最終目標是建立圖表,顯示正面與負面評論的百分比。範例如下:

建立各類別的評論數量圖表,以及各類別正負面評論的分布情況
提示:啟用並使用資料畫布的「進階分析」,在畫布中執行 Python 筆記本。
4. 工作 2:分析遊樂園圖像,找出迪士尼樂園的照片,並從樂園簡介中擷取有趣的事實
在 BigQuery 中進行圖片分析
您可以存取遊客多年來在 Attraction parc 拍下的精彩照片。您很期待即將到來的近期行程!但你不知道哪些是迪士尼樂園的實際相片。您的任務是找出這些問題。圖片位於 gs://hackathon_data_disneyland_<YOUR_PROJECT_3DIGITS>/attraction_parc_photos/。

Is_disneyland:False

Is_disneyland:True
以便快速執行這項分析。您應透過 BigQuery ML (ML.GENERATE_TEXT) 使用 BigQuery 的物件資料表和 Gemini。
你可以查看幾張相片,驗證 Gemini 的輸出結果嗎?
使用 BigQuery 建立自己的 RAG 系統,並以迪士尼樂園宣傳冊為例
排隊等候時,想瞭解等候設施的有趣資訊/技術細節。
在 gs://hackathon_data_disneyland_<YOUR_PROJECT_3DIGITS>/disneyland_brochures/, 中,您會找到包含全球所有公園簡介的 PDF 檔案。
目標:完全在 BigQuery 中建立檢索增強生成 (RAG) 系統,讓使用者根據一些 PDF 文件,提出有關公園的複雜問題。
如要達成這個目標,請按照下列步驟操作:
- 建立 PDF 檔案的物件資料表
- 建立 Python UDF,將 PDF 檔案分塊。您可以參考以下範例:
CREATE OR REPLACE FUNCTION disney.chunk_pdf(src_json STRING, chunk_size INT64, overlap_size INT64)
RETURNS ARRAY<STRING>
LANGUAGE python
WITH CONNECTION `[LOCATION].[CONN_NAME]`
OPTIONS (entry_point='chunk_pdf', runtime_version='python-3.11', packages=['pypdf'])
AS """
import io
import json
from pypdf import PdfReader # type: ignore
from urllib.request import urlopen, Request
def chunk_pdf(src_ref: str, chunk_size: int, overlap_size: int) -> str:
src_json = json.loads(src_ref)
srcUrl = src_json["access_urls"]["read_url"]
req = urlopen(srcUrl)
pdf_file = io.BytesIO(bytearray(req.read()))
reader = PdfReader(pdf_file, strict=False)
# extract and chunk text simultaneously
all_text_chunks = []
curr_chunk = ""
for page in reader.pages:
page_text = page.extract_text()
if page_text:
curr_chunk += page_text
# split the accumulated text into chunks of a specific size with overlaop
# this loop implements a sliding window approach to create chunks
while len(curr_chunk) >= chunk_size:
split_idx = curr_chunk.rfind(" ", 0, chunk_size)
if split_idx == -1:
split_idx = chunk_size
actual_chunk = curr_chunk[:split_idx]
all_text_chunks.append(actual_chunk)
overlap = curr_chunk[split_idx + 1 : split_idx + 1 + overlap_size]
curr_chunk = overlap + curr_chunk[split_idx + 1 + overlap_size :]
if curr_chunk:
all_text_chunks.append(curr_chunk)
return all_text_chunks
""";
- 將 PDF 檔案剖析為區塊
- 建立遠端模型後生成嵌入
- 執行向量搜尋,找出「
Ou manger un repas tex-mex à volonté?」或「where to eat a tex-mex meal buffet-style?」 - 根據「
Ou manger un repas tex-mex à volonté?」或「where to eat a tex-mex meal buffet-style?」的向量搜尋結果生成回覆
5. 工作 3:使用 BigQuery 大規模執行機器學習:預測、分類和排名
預測等待時間
這些照片非常酷!你等不及了!現在,為了瞭解該選擇哪些景點,以及該避開哪些景點,您想知道巴黎和加州之間某些景點的實際等待時間。您的工作是使用機器學習 (Arima Plus 或 TimesFM),預測 2025 年每項遊樂設施每 30 分鐘的等待時間。
您要使用的資料位於這個 CSV 檔案:gs://hackathon_data_disneyland_<YOUR_PROJECT_3DIGITS>/waiting_times.csv
這項工作的步驟如下:
- 將檔案載入 BigQuery 資料集,並放在名為 waiting_times 的資料表下。
- 根據資料訓練預測模型 (Arima_Plus),或直接使用 AI.Forecast 進行預測
- 評估模型成效,或比較預測資料與輸入資料
依強度分類騎乘活動
你和朋友一起去迪士尼樂園玩,雖然樂園大致上適合全家同遊,但有些遊樂設施對某些人來說可能太刺激。讓我們使用 BigQuery 代管 AI 函式,根據刺激和強度等級分類及排序景點,避免人為偏見,讓每個人都能盡情享受。
- 使用
AI.CLASSIFY根據說明將遊樂設施分類為三種魔法類別之一:[easy-peasy、thrilling、extreme]
依據刺激程度排名
- 使用
AI.SCORE依刺激程度比較和排序遊樂設施,其中 10 分最刺激,1 分最不刺激。
6. 工作 3 (加分題):從 BigQuery 反向 ETL 至 AlloyDB
您已運用 BigQuery 的強大功能,從大量資料中產生洞察資料。現在,您希望營運應用程式 (和 AI 代理程式!) 能根據這些洞察資料採取行動。
但該怎麼做呢?方法就是反向操作!AlloyDB for PostgreSQL 擅長以低延遲和高速提供資料,非常適合用於重要的使用者應用程式。現在,我們來反向 ETL 剛才產生的資料。
為此,我們將使用一項全新功能,目前仍處於不公開預先發布階段,稱為 AlloyDB 中的「BigQuery 檢視區塊」。這項功能可讓您直接在 Postgres 資料庫中查詢 BigQuery 資料。
首先,您必須授予 AlloyDB 叢集服務帳戶查詢 BigQuery 的必要權限。
gcloud beta alloydb clusters describe <CLUSTER ID> --region=europe-west1
輸出內容包含 serviceAccountEmail 欄位,這是指這個叢集的服務帳戶。
在 Google Cloud 控制台中,前往「IAM」頁面,然後將下列權限授予這個主體:
- BigQuery 資料檢視者 (roles/bigquery.dataViewer)
- BigQuery 讀取工作階段使用者 (roles/bigquery.readSessionUser)
現在,請前往控制台中的 AlloyDB Studio,然後連線至「postgres」資料庫。
執行下列查詢,安裝及設定新功能:
CREATE EXTENSION bigquery_fdw;
CREATE SERVER bq_disney FOREIGN DATA WRAPPER bigquery_fdw;
CREATE USER MAPPING FOR postgres SERVER bq_disney ;
您現在可以建立「外部資料表」,並對應至 BigQuery 中的現有資料表。使用您在工作 3 中建立的任何資料表。語法範例如下:
CREATE FOREIGN TABLE reviews_analysis ( "Review_ID" int,
"Sentiment" text) SERVER bq_disney OPTIONS (PROJECT 'bqml-hack25par-xxx',
dataset 'disney',
TABLE 'reviews_analysis');
一切就緒,現在來查詢資料表吧!執行第一個 SELECT,驗證 AlloyDB 和 BigQuery 之間的連結,最後在 AlloyDB 中建立新資料表,從外部資料表擷取資料。
7. 工作 4:開箱即用的資料代理程式
有幾位好友想為 Disneyland 應用程式專案貢獻心力,他們可以存取 BigQuery 中的資料,但 SQL 和資料工程的程度不一。您想運用 BigQuery 最近發布的資料代理,這些代理已整合至 UI,可協助您的朋友:
- 建立資料管道。
- 協作處理 SQL 程式碼。
- 與資料對話。
資料工程代理程式,可自動執行資料管道
使用 Data Engineering Agent 建立新的檢視區塊 average_waiting_time,將等待時間和遊樂設施資料表彙整在一起,並計算每個遊樂設施的平均等待時間。
在 BigQuery 中建立對話式數據分析代理程式
如果可以從 BigQuery 介面建立代理程式,與資料對話,不必編寫程式碼、不必使用 SQL,也不必部署,是不是很酷?現在,您可以在 BigQuery 的「代理程式」分頁中執行這項操作。

- 建立代理程式 my_disney_friend,連結至你的 Disney 表格。填寫代理程式指令,有助於提升代理程式效能。提出問題,例如「正面與負面評論的百分比各是多少?每個景點的平均等待時間是多少?」
- 在 BigQuery 和 API 中發布代理程式 (稍後會用到)。
8. 工作 5:使用 Gemini CLI 提升開發體驗
在 AI 時代,軟體開發的門檻大幅降低。您有數千個有關 Disneyland 應用程式的想法,並希望盡可能充分運用資料。您想進一步運用資料,而不只是與資料對話,現在需要採取行動!
為協助你完成這項程序,你需要幫忙。我們也為你設想好了。
Gemini CLI 是開放原始碼 AI 代理,可讓您直接在終端機中使用 Gemini 的強大功能。開發人員可以建構強大的應用程式,並透過擴充功能與各種 MCP (Model Context Protocol) 伺服器互動。
當然,您也可以找到查詢 AlloyDB 或 BigQuery 資料的擴充功能!
在這項工作中,您的目標是:
- 安裝 Gemini CLI (在自己的終端機或 Cloud Shell 中)
- 安裝 BigQuery 和 AlloyDB Gemini-CLI 擴充功能
- 建立環境檔案,讓 Gemini-CLI 連線至 BigQuery 和 AlloyDB 執行個體
- 要求 Gemini CLI 生成精美的單一 HTML 網頁,說明 AlloyDB 資料庫的內容
- 對 BigQuery 執行相同操作
以下列舉幾個範例,說明如何透過 Gemini CLI 及其擴充功能,在單一 (或少數) 提示中生成內容。現在想像一下,如果能將這項技術應用於現實生活,會怎麼樣?

9. 工作 6:建立 AI 代理,與資料互動
為了提供全新的迪士尼樂園使用者體驗,您將建立一個助理,在遊客的旅程中提供協助。代理人可以:
- 列出公園內所有可用的景點
- 根據期望推薦景點
- 新增景點的評論
- 預估未來幾小時內景點的等待時間
- 提供特定景點的評論總覽
請確保助理只能回答與 Disneyland 相關的問題,並以友善的語氣與使用者互動。調整代理提示,確保代理會根據使用者需求選擇合適的工具。
請按照下列步驟操作:
- 部署以 AlloyDB 和 BigQuery 做為來源的資料庫專用 MCP 工具箱伺服器
- 為 MCP 伺服器宣告 5 種不同的工具,查詢 AlloyDB 和 BigQuery,並對應先前列出的代理程式動作
- 使用 MCP Toolbox UI 驗證各項工具
- 使用 Agent Development Kit 部署代理,該代理可使用 MCP 工具箱伺服器公開的工具
- 連線至 ADK 網頁介面,並展示與助理的完整對話,包括所有可用的工具
如果提早完成,可執行額外步驟:
代理已準備就緒?現在就將其部署至 Agent Engine!