
1. 🏰 แฮ็กกาธอนด้านการวิเคราะห์ข้อมูลของดิสนีย์แลนด์ (ครั้งที่ 2 - 3 ธ.ค.) 🏰
สรุป | ใน Hackathon นี้ คุณจะได้สร้างไปป์ไลน์การวิเคราะห์ข้อมูลแบบครบวงจรโดยใช้ประโยชน์จากความสามารถของ AI/ML ใน Google Cloud คุณจะโหลดข้อมูลลงใน AlloyDB ซึ่งเป็นฐานข้อมูลที่เข้ากันได้กับ PostgreSQL ที่มีการจัดการครบวงจรและได้รับการเพิ่มประสิทธิภาพสำหรับภาระงานที่มีความต้องการสูง จากนั้นใช้ Datastream ซึ่งเป็นบริการ Change Data Capture (CDC) แบบ Serverless เพื่อย้ายข้อมูลไปยัง BigQuery ซึ่งเป็นคลังข้อมูลแบบ Serverless ของ Google Cloud ใน BigQuery คุณจะใช้ BigQuery ML ซึ่งช่วยให้คุณสร้างและเรียกใช้โมเดลแมชชีนเลิร์นนิงได้โดยตรงใน BigQuery โดยใช้ SQL มาตรฐานสำหรับการวิเคราะห์รีวิวและการคาดการณ์การเข้าร่วม สุดท้าย คุณจะได้ทดลองใช้ Agent ไม่ว่าจะใช้ Agent ที่พร้อมใช้งานผ่าน Conversational Analytics และ Data Agent หรือสร้าง Agent ที่กำหนดเองโดยใช้ Agent Development Kit และ MCP Toolbox เพื่อโต้ตอบกับข้อมูลของคุณด้วยภาษาธรรมชาติ |
หมวดหมู่ | docType:Codelab, product:Bigquery |
ผู้เขียน | Rayhane Rezgui, Matt Cornillon |
เลย์เอาต์ | การเลื่อน |
หุ่นยนต์ | noindex |
2. บทนำ
ยินดีต้อนรับสู่โลกแห่งการวิเคราะห์ข้อมูลของ Disney ในอนาคต 🪄
ไม่ต้องอ่านคู่มือท่องเที่ยวที่น่าเบื่อและเลื่อนฟอรัมไม่รู้จบอีกต่อไป ลองนึกภาพการวางแผนทริปดิสนีย์แลนด์ที่สมบูรณ์แบบด้วยข้อมูลเชิงลึกที่อิงตามข้อมูลจริง สวนสาธารณะใดมอบประสบการณ์ที่ดีที่สุด ช่วงเวลาที่คนน้อยที่สุด คุณคาดการณ์เวลาที่ดีที่สุดในการต่อคิวที่ยาวเหยียดได้ไหม
ในแฮ็กกาธอนนี้ คุณจะได้สร้างเครื่องมือวางแผน Disneyland ที่ดีที่สุด เรามีข้อมูลรีวิวจากผู้เข้าชมสาขาทั่วโลก เวลาที่ลูกค้ารอคิวในอดีต และสถิติการเข้าชม ภารกิจของคุณคืออะไร เปลี่ยนข้อมูลดิบนี้ให้เป็นข้อมูลเชิงลึกที่นำไปใช้ได้จริง
- รวบรวมข้อมูล: โหลดรีวิว เวลาที่ต้องรอ และตัวเลขผู้เข้าชมดิสนีย์แลนด์ที่หลากหลายลงใน AlloyDB ซึ่งเป็นฐานข้อมูลประสิทธิภาพสูงที่เข้ากันได้กับ PostgreSQL
- การเคลื่อนย้ายที่ราบรื่น: ใช้ Datastream ซึ่งเป็นบริการจับการเปลี่ยนแปลงข้อมูลแบบ Serverless ของเราเพื่อย้ายข้อมูลแบบไดนามิกนี้ไปยัง BigQuery ซึ่งเป็นคลังข้อมูลแบบ Serverless ที่มีประสิทธิภาพของ Google Cloud ได้อย่างง่ายดาย
- คาดการณ์ความเป็นไปได้: ใช้ BigQuery ML เพื่อวิเคราะห์ความรู้สึกจากรีวิวและคาดการณ์เวลารอโดยตรงด้วย SQL ดูว่าสาขาใดที่สร้างรอยยิ้มให้ลูกค้าได้อย่างสม่ำเสมอและเวลาที่เหมาะสมที่สุดในการเข้าชม
- พูดคุยกับข้อมูลของคุณ: ใช้เครื่องมือที่สร้างไว้ล่วงหน้าซึ่งช่วยให้คุณได้รับข้อมูลเชิงลึกเพียงแค่ปัดไม้กายสิทธิ์
- การโต้ตอบอัจฉริยะ: สร้างสรรค์ผลงานของคุณด้วย Agent อัจฉริยะที่ขับเคลื่อนโดย MCP Toolbox สำหรับฐานข้อมูลและ ADK (Agent Development Kit) ถามว่า "สถานที่ท่องเที่ยวที่ดีที่สุดในดิสนีย์แลนด์ปารีสสำหรับคนรักอวกาศคืออะไร และเวลาที่ดีที่สุดในการต่อคิวคือเมื่อใด" แล้วรับคำตอบที่อิงตามข้อมูลได้ทันที
เตรียมพร้อมที่จะไขความลับของสถานที่ที่มีมนต์ขลังที่สุดในโลกและสร้างไปป์ไลน์การวิเคราะห์ข้อมูลที่จะทำให้มิกกี้ภูมิใจ


3. งานที่ 1: จากด้านการดำเนินงานไปสู่ข้อมูลวิเคราะห์: วิเคราะห์รีวิวของดิสนีย์แลนด์ด้วย Gemini
สําหรับระยะเริ่มต้นนี้ คุณจะดึงข้อมูลจากฐานข้อมูลการดําเนินงาน AlloyDB และโหลดลงใน BigQuery เพื่อการวิเคราะห์ข้อมูลในภายหลัง
นอกจากนี้ คุณยังจะได้ตั้งค่าทุกอย่างที่จำเป็นใน AlloyDB สำหรับ Agent ในอนาคตด้วย
การโหลดข้อมูลใน AlloyDB
ก่อนอื่น มานำเข้าข้อมูลบางส่วนลงในคลัสเตอร์ AlloyDB สำหรับ PostgreSQL กัน
เราจะนำเข้ารีวิว 20,000 รายการสำหรับสวนสนุกดิสนีย์แลนด์และรายชื่อสถานที่ท่องเที่ยว
ขั้นตอนที่คุณต้องทำมีดังนี้
การสร้างตาราง:
- สร้างตาราง disneyland_reviews ที่มี 6 คอลัมน์ ได้แก่ review_id และ rating เป็นจำนวนเต็ม, year_month, reviewer_location, review_text, branch เป็นข้อความ
- สร้างตาราง disneyland_attractions ที่มี 4 คอลัมน์ ได้แก่ attraction_id เป็นจำนวนเต็ม, branch, name และ description เป็นข้อความ
ใช้เครื่องมือที่คุณเลือกเพื่อนําเข้าข้อมูลจาก CSV ดังนี้
gs://hackathon_data_disneyland_<YOUR_PROJECT_3DIGITS>/reviews.csvสำหรับตารางรีวิวgs://hackathon_data_disneyland_<YOUR_PROJECT_3DIGITS>/attractions.csvสำหรับตารางสถานที่ท่องเที่ยว
หากต้องการแสดงคำแนะนำเกี่ยวกับสถานที่ท่องเที่ยว เราต้องสร้างการฝังคำอธิบายสถานที่ท่องเที่ยว
- ติดตั้งส่วนขยาย pgvector ใน AlloyDB
- เพิ่มคอลัมน์เวกเตอร์ชื่อ "การฝัง" ลงในตารางสถานที่ท่องเที่ยว
- สร้างและป้อนข้อมูลการฝังของคำอธิบายโดยใช้การผสานรวมดั้งเดิมระหว่าง AlloyDB กับ Vertex AI
ตั้งแต่ด้านการดำเนินงานไปจนถึงข้อมูลวิเคราะห์ด้วย Datastream
หากต้องการสตรีมข้อมูลจาก AlloyDB ไปยัง BigQuery เราจะใช้ Google Datastream ซึ่งเป็นโซลูชันแบบ Serverless ที่มีประสิทธิภาพซึ่งจะรับฟังการเปลี่ยนแปลงทั้งหมดในตารางแหล่งที่มา (ใช้การจับภาพการเปลี่ยนแปลงของข้อมูล) และส่งไปยัง BigQuery
หากต้องการจำลองการเปลี่ยนแปลงจาก AlloyDB ด้วย Datastream เราต้องสร้างสิ่งที่เรียกว่า "การเผยแพร่" และ "ช่องจำลอง" ใน Postgres
เรียกใช้การค้นหาต่อไปนี้ในคลัสเตอร์ AlloyDB (คุณต้องเรียกใช้ทีละรายการ)
CREATE PUBLICATION pub_disney FOR TABLE disneyland_reviews, disneyland_attractions;
ALTER USER postgres WITH REPLICATION;
SELECT PG_CREATE_LOGICAL_REPLICATION_SLOT('slot_disney', 'pgoutput');
คุณจะต้องใช้ช่องการเผยแพร่และช่องเรพลิเคชันในสตรีม ดังนั้นโปรดจำชื่อไว้
เพียงเท่านี้ก็สร้างไลฟ์สดได้แล้ว
ขั้นตอนที่คุณต้องดำเนินการใน Datastream มีดังนี้
- สร้างโปรไฟล์แหล่งที่มาสำหรับคลัสเตอร์ AlloyDB (ใช้ที่อยู่ IP สาธารณะ)
- สร้างโปรไฟล์ปลายทางสำหรับ BigQuery
- สร้างสตรีมจาก AlloyDB ไปยัง BigQuery
ข้อมูลควรพร้อมใช้งานใน BigQuery ภายในไม่กี่นาที
การค้นพบข้อมูลใน BigQuery
ตอนนี้เรามีข้อมูลใน BigQuery แล้ว มาดูการปรับปรุงใหม่ในอินเทอร์เฟซก่อนเริ่มทำงานกัน
เรามีฟังก์ชันใหม่ 3 รายการที่คุณดูได้แล้วในแผงการสํารวจ BigQuery

- ภาพรวม: มีข้อมูลเกี่ยวกับฟีเจอร์ของ BigQuery, ทัวร์เพื่อเริ่มต้นวิเคราะห์ และความเป็นไปได้อื่นๆ
- ค้นหา: ทำการค้นหาเชิงความหมายในชิ้นงานข้อมูล
- Agent: อย่าบอกใครนะ เราจะเก็บเรื่องนี้ไว้ก่อน 🤫
ค้นหาข้อมูลของคุณตามความหมายใน BigQuery
ไปที่แท็บค้นหาในแผงการสำรวจ BigQuery แล้วลองใช้คำที่เกี่ยวข้องกับ Disney เช่น "สถานที่ท่องเที่ยว" หรือ "สาขา"
แสดงภาพข้อมูลใน BigQuery
ตอนนี้คุณสามารถแสดงภาพและจัดการข้อมูลใน BigQuery ได้แล้ว โดยคุณสามารถเรียกใช้การค้นหานี้ในแท็บการค้นหาใหม่ได้
SELECT
*
FROM
[dataset_name].[table_name];
สร้างข้อมูลเชิงลึกเกี่ยวกับข้อมูลในตารางรีวิว
ในงานนี้ คุณจะเปิดใช้ข้อมูลเชิงลึกของข้อมูลในdisneyland_reviewsตารางภายในชุดข้อมูลdisney
ข้อมูลเชิงลึกเป็นเครื่องมือสำหรับทุกคนที่ต้องการสำรวจข้อมูลและรับข้อมูลเชิงลึกโดยไม่ต้องเขียนคิวรี SQL ที่ซับซ้อน
การดำเนินการนี้อาจใช้เวลาสักครู่
ค้นหาตาราง disneyland_reviews โดยไม่ต้องใช้ SQL
ตอนนี้ข้อมูลเชิงลึกที่คุณสร้างไว้ในส่วนก่อนหน้าพร้อมใช้งานแล้ว ในงานนี้ คุณจะใช้พรอมต์ที่สร้างขึ้นจากข้อมูลเชิงลึกเหล่านี้เพื่อค้นหาตาราง disneyland_reviews โดยไม่ต้องใช้โค้ด
เลือกข้อมูลเชิงลึกและเรียกใช้คําค้นหาที่เชื่อมโยงกับข้อมูลเชิงลึกนั้น เช่น ค้นหาคําค้นหาที่คํานวณความแตกต่างของคะแนนเฉลี่ยระหว่างเดือนที่ต่อเนื่องกันสําหรับแต่ละสาขา ซึ่งจะมีลักษณะดังนี้
WITH
monthly_avg AS (
SELECT
branch,
year_month,
AVG(rating) AS avg_rating
FROM
[dataset_name].[table_name]
WHERE
year_month IS NOT NULL
GROUP BY
1,
2 )
SELECT
branch,
year_month,
avg_rating,
avg_rating - LAG(avg_rating, 1, 0) OVER (PARTITION BY branch ORDER BY year_month) AS rating_difference
FROM
monthly_avg
ORDER BY
branch,
year_month;
ใช้เครื่องมือความรู้ของ BigQuery เพื่อทำความเข้าใจข้อมูลได้ดียิ่งขึ้น
ก่อนอื่นเรามาเริ่มดูแท็บข้อมูลเชิงลึกที่ระดับชุดข้อมูลกันก่อน ซึ่งจะช่วยให้เราทราบถึงความสัมพันธ์ที่ซ่อนอยู่ระหว่างตารางต่างๆ ในชุดข้อมูล Disney จากนั้นให้ทำดังนี้
- สร้างคำอธิบายของชุดข้อมูลโดยใช้ Gemini แล้วเพิ่มลงในรายละเอียดชุดข้อมูล
- สร้างคำอธิบายของตาราง รีวิว และสถานที่ท่องเที่ยว รวมถึงคอลัมน์แต่ละคอลัมน์ในตารางเหล่านั้น แล้วบันทึก
ทำการสแกนโปรไฟล์ของข้อมูล
เป้าหมายของส่วนนี้คือการล้างและเตรียมข้อมูล แต่คุณไม่คุ้นเคยกับการกระจายค่าของแต่ละคอลัมน์มากนัก คุณต้องสร้างโปรไฟล์ข้อมูลเพื่อทราบว่าต้องดำเนินการขั้นตอนการเปลี่ยนรูปแบบใดกับข้อมูล
แคตตาล็อกสากล Dataplex ของ Google Cloud จะทำให้ การสแกนการจัดทำโปรไฟล์เป็นไปโดยอัตโนมัติเพื่อแสดงเมตริกคุณภาพของข้อมูลที่สอดคล้องกัน สถิติสำคัญที่ระบุ ได้แก่ จำนวนค่าว่าง ค่าที่ไม่ซ้ำ ช่วงข้อมูล และการกระจายค่า คุณเปิดใช้งานการสแกนโปรไฟล์ผ่านอินเทอร์เฟซ BigQuery ได้
อาจใช้เวลา 2-3 นาที คุณจึงดูส่วนถัดไปขณะรอได้
โปรดตอบคำถามต่อไปนี้
- ดิสนีย์แลนด์มีคะแนนเฉลี่ยเท่าใด
- ผู้ตรวจสอบอยู่ที่ไหนมากที่สุด
- รีวิวทั้งหมดไม่ซ้ำกันใช่ไหม
- เปอร์เซ็นต์ของข้อมูลที่ขาดหายไปจากคอลัมน์ Year_Month คือเท่าใด
ทำการสแกนคุณภาพของข้อมูล
แคตตาล็อกสากลของ Dataplex คุณภาพของข้อมูลอัตโนมัติช่วยให้คุณกำหนดและวัดคุณภาพของข้อมูลในตาราง BigQuery ได้ คุณสามารถทำให้การสแกนข้อมูลเป็นแบบอัตโนมัติ ตรวจสอบข้อมูลกับกฎที่กำหนด และบันทึกการแจ้งเตือนหากข้อมูลไม่เป็นไปตามข้อกำหนดด้านคุณภาพ คุณสามารถจัดการกฎคุณภาพของข้อมูลและการติดตั้งใช้งานเป็นโค้ด ซึ่งจะช่วยปรับปรุงความสมบูรณ์ของไปป์ไลน์การผลิตข้อมูล
จากการสแกนโปรไฟล์ ให้กำหนดการสแกนคุณภาพ (ในข้อมูลไม่เกิน 10% เป็นขนาดตัวอย่าง) ซึ่งมีลักษณะดังนี้
- ตรวจสอบค่า Null สำหรับคอลัมน์ "branch"
- ตรวจสอบความถูกต้องของ "rating" เนื่องจากค่านี้ต้องอยู่ในชุดค่าต่อไปนี้เท่านั้น : 1,2,3,4,5
- ตรวจสอบความไม่ซ้ำกันของ "review_id"
ตรวจสอบว่าการสแกนส่งออกผลลัพธ์ไปยังตาราง BigQuery ที่ชื่อ quality_scan_results
พิจารณาการเปลี่ยนรูปแบบที่อาจต้องใช้กับข้อมูล
เตรียมข้อมูลโดยใช้การเตรียมข้อมูลของ Gemini
หลังจากสแกนคุณภาพของข้อมูลและการจัดทำโปรไฟล์ข้อมูลแล้ว ก็ถึงเวลาทำความสะอาดข้อมูลก่อนวิเคราะห์
การเตรียมข้อมูลคือทรัพยากร BigQuery ซึ่งใช้ Gemini ใน BigQuery เพื่อวิเคราะห์ข้อมูลและให้คำแนะนำอัจฉริยะสำหรับการล้างข้อมูล เปลี่ยนรูปแบบ และเพิ่มคุณค่า คุณสามารถลดเวลาและความพยายามที่ต้องใช้สำหรับงานการเตรียมข้อมูลด้วยตนเองได้อย่างมาก
ในส่วนนี้ คุณจะใช้การเตรียมข้อมูลเพื่อดำเนินการต่อไปนี้ในตาราง disneyland_reviews
- กรองแถวที่คอลัมน์สาขาเป็น NULL หรือสตริงว่างออก
- แทนที่ "missing" ใน Year_Month ด้วย Null
- แทนที่ขีดล่างด้วยช่องว่างในคอลัมน์สาขาเพื่อให้อ่านง่ายขึ้น
- ส่งออกไปยังตารางที่แปลงแล้ว disneyland_reviews_cleaned
วิเคราะห์รีวิวด้วย Gemini
ตอนนี้คุณได้ล้างข้อมูลแล้ว จึงเริ่มวิเคราะห์ข้อมูลได้โดยใช้โมเดล BigQuery ML และ Gemini คุณมี 2 วัตถุประสงค์ดังนี้
- ดึงหมวดหมู่จากรีวิว
- การวิเคราะห์ความเห็นของ disneyland_reviews
BigQuery ML ช่วยให้คุณสร้างและเรียกใช้โมเดลแมชชีนเลิร์นนิง (ML) ได้โดยใช้การค้นหา GoogleSQL ระบบจะจัดเก็บโมเดล BigQuery ML ไว้ในชุดข้อมูล BigQuery เช่นเดียวกับตารางและมุมมอง นอกจากนี้ BigQuery ML ยังให้คุณเข้าถึงโมเดล Vertex AI และ Cloud AI API เพื่อทำงานด้านปัญญาประดิษฐ์ (AI) เช่น การสร้างข้อความหรือการแปลด้วยคอมพิวเตอร์ นอกจากนี้ Gemini สำหรับ Google Cloud ยังให้ความช่วยเหลือที่ทำงานด้วยระบบ AI สำหรับงาน BigQuery ด้วย
คุณเลือกใช้ ML.GENERATE_TEXT หรือ AI.GENERATE (เวอร์ชันตัวอย่าง) กับโมเดล Gemini Pro หรือ Flash ได้
ขั้นตอนต่อไปนี้จะแนะนําคุณหากต้องการใช้ ML.GENERATE_TEXT
สร้างการเชื่อมต่อทรัพยากรระบบคลาวด์และให้บทบาท IAM
คุณต้องสร้างการเชื่อมต่อทรัพยากรระบบคลาวด์ใน BigQuery กับโมเดล Vertex AI เพื่อให้ทำงานกับโมเดล Gemini Pro และ Gemini Flash ได้ นอกจากนี้ คุณยังต้องให้สิทธิ์ IAM ของบัญชีบริการของการเชื่อมต่อทรัพยากรระบบคลาวด์ผ่านบทบาทเพื่อให้เข้าถึงบริการ Vertex AI ได้ด้วย
มอบบทบาทผู้ใช้ Vertex AI ให้กับบัญชีบริการของการเชื่อมต่อ
อนุญาตให้บัญชีบริการของการเชื่อมต่อใช้โมเดลที่คุณเลือก (เช่น gemini-2.5-flash) โดยการมอบบทบาทผู้ใช้ Vertex AI ให้ โดยสิทธิ์จะใช้เวลา 1 นาทีจึงจะมีผล
สร้างโมเดล Gemini ใน BigQuery
สร้างโมเดลโดยใช้การเชื่อมต่อด้านบน เช่น ใช้ปลายทาง gemini-2.5-flash.
เขียนพรอมต์ให้ Gemini วิเคราะห์รีวิวจากลูกค้าตามหมวดหมู่และความรู้สึก
ในงานนี้ คุณจะใช้โมเดล Gemini เพื่อวิเคราะห์รีวิวจากลูกค้าแต่ละรายการตามหมวดหมู่และความรู้สึก ไม่ว่าจะเป็นเชิงบวกหรือเชิงลบ
วิเคราะห์รีวิวจากลูกค้าสำหรับหมวดหมู่
หมายเหตุ: ตั้งแต่นี้เป็นต้นไป เราจะใช้เพียง 100 แถวในการวิเคราะห์ เนื่องจาก Gemini อาจใช้เวลาสักครู่ในการเรียกใช้ 20,000 แถว
Extract categories by modifying and running the following SQL Query:
CREATE OR REPLACE TABLE
[dataset_name].[results_table_name] AS (
SELECT Review_ID, Rating, Year_Month, Reviewer_Location, Review_Text, Branch, ml_generate_text_llm_result AS categories FROM
ML.GENERATE_TEXT(
MODEL [model_name],
(
SELECT Review_ID, Rating, Year_Month, Reviewer_Location, Review_Text, Branch, CONCAT(
'[WRITE YOUR PROMPT HERE].',
Review_Text) AS prompt
FROM (SELECT * FROM [dataset_name].[table_name] LIMIT 100)
),
STRUCT(
0.2 AS temperature, TRUE AS flatten_json_output)));
คําค้นหานี้จะดึงรีวิวจากลูกค้าจากตาราง disneyland_reviews สร้างพรอมต์สําหรับโมเดล gemini เพื่อระบุหมวดหมู่ภายในรีวิวแต่ละรายการ ควรจัดเก็บผลลัพธ์ในตารางใหม่ reviews_categories
. โปรดรอสักครู่ โมเดลใช้เวลาประมาณ 30 วินาทีในการประมวลผลบันทึกรีวิวจากลูกค้าและแสดงผลลัพธ์ในตารางเอาต์พุต
แสดงผลลัพธ์
SELECT * FROM [dataset_name].[results_table_name];
โปรดสละเวลาอ่านหมวดหมู่บางส่วน
วิเคราะห์รีวิวจากลูกค้าเพื่อดูความรู้สึกเชิงบวกและเชิงลบ
เขียนการค้นหาที่วิเคราะห์รีวิวเป็นเชิงบวก เชิงลบ และเป็นกลางภายใต้คอลัมน์ที่ชื่อ "ความรู้สึก" โดยอิงตามการค้นหา SQL สำหรับการแยกคีย์เวิร์ด
การค้นหานี้จะนำรีวิวจากลูกค้าจากตาราง disneyland_reviews มาสร้างพรอมต์สำหรับโมเดล gemini เพื่อจัดประเภทความรู้สึกของรีวิวแต่ละรายการ จากนั้นระบบจะจัดเก็บผลลัพธ์ไว้ในตารางใหม่ reviews_analysis เพื่อให้คุณใช้ในการวิเคราะห์เพิ่มเติมได้ในภายหลัง โปรดรอสักครู่ โมเดลจะใช้เวลา 2-3 วินาทีในการประมวลผลบันทึกรีวิวจากลูกค้า เมื่อโมเดลเสร็จสมบูรณ์แล้ว ผลลัพธ์จะอยู่ในตาราง reviews_analysis ที่สร้างขึ้น
สำรวจผลลัพธ์
SELECT * FROM [...];
ตาราง reviews_analysis มีคอลัมน์ Sentiment ที่มีการวิเคราะห์ความเห็น โดยมีคอลัมน์ social_media_source, review_text, customer_id, location_id และ review_datetime รวมอยู่ด้วย ดูบันทึกบางรายการ คุณอาจสังเกตเห็นว่าผลลัพธ์บางรายการสำหรับค่าบวกและค่าลบอาจมีรูปแบบไม่ถูกต้อง โดยมีอักขระที่ไม่เกี่ยวข้อง เช่น จุด หรือมีช่องว่างเพิ่มเติม คุณล้างข้อมูลระเบียนได้โดยใช้มุมมองด้านล่าง
สร้างมุมมองเพื่อล้างข้อมูลระเบียน
สร้างมุมมองที่ล้างค่าของความรู้สึกในคอลัมน์โดยทำดังนี้
- ใช้ LOWER เพื่อให้แน่ใจว่าค่าทั้งหมดเป็นตัวพิมพ์เล็ก
- การนำเครื่องหมายวรรคตอน (. , และช่องว่าง) ออกโดยใช้ REPLACE
CREATE OR REPLACE VIEW [view_name] AS
SELECT [SANITIZATION_EXPRESSION] AS sentiment,
Review_ID, Rating, Year_Month, Reviewer_Location, Review_Text, Branch,
FROM `disney.reviews_analysis`;
การค้นหาจะสร้างมุมมอง cleaned_data_view และรวมผลลัพธ์ความรู้สึก ข้อความรีวิว Review_ID, Rating, Year_Month, Reviewer_Location, Review_Text and Branch จากนั้นระบบจะใช้ผลการวิเคราะห์ความรู้สึก (เชิงบวกหรือเชิงลบ) และตรวจสอบว่าตัวอักษรทั้งหมดเป็นตัวพิมพ์เล็ก และนำอักขระที่ไม่เกี่ยวข้องออก เช่น ช่องว่างหรือจุด มุมมองที่ได้จะช่วยให้วิเคราะห์เพิ่มเติมในขั้นตอนต่อๆ ไปภายในแล็บนี้ได้ง่ายขึ้น
- คุณสามารถค้นหาข้อมูลในมุมมองด้วยการค้นหาด้านล่างเพื่อดูแถวที่สร้างขึ้น
SELECT * FROM [view_name];
สร้างรายงานจำนวนรีวิวเชิงบวกและเชิงลบด้วย Data Canvas
ตอนนี้ถึงเวลาวิเคราะห์ผลลัพธ์แล้ว มาเริ่มกันด้วยการดำเนินการใน BigQuery โดยตรงผ่าน Data Canvas เครื่องมือนี้ช่วยให้คุณค้นหาข้อมูล (เชิงความหมายหรือคีย์เวิร์ด) ค้นหาและรวมตาราง สร้างกราฟ และรับข้อมูลเชิงลึกได้โดยการสร้างโฟลว์ของ Canvas
เป้าหมายสุดท้ายคือการสร้างกราฟเปอร์เซ็นต์ของรีวิวเชิงบวกเทียบกับรีวิวเชิงลบตามที่คุณเลือก เช่น

สร้างกราฟจำนวนรีวิวต่อหมวดหมู่ รวมถึงการกระจายรีวิวเชิงบวกและเชิงลบสำหรับแต่ละหมวดหมู่
เคล็ดลับ: เปิดใช้งานและใช้การวิเคราะห์ขั้นสูงของ Data Canvas ซึ่งจะเรียกใช้สมุดบันทึก Python ภายใน Canvas
4. งานที่ 2: วิเคราะห์รูปภาพสวนสนุกเพื่อระบุรูปภาพดิสนีย์แลนด์และดึงข้อเท็จจริงที่น่าสนใจจากโบรชัวร์ของสวนสนุก
การวิเคราะห์รูปภาพใน BigQuery
คุณมีสิทธิ์เข้าถึงภาพที่น่าตื่นเต้นและน่าสนใจของ Attraction parc ซึ่งนักท่องเที่ยวถ่ายไว้ตลอดหลายปีที่ผ่านมา คุณตื่นเต้นกับการเดินทางที่กำลังจะมาถึง แต่คุณไม่รู้ว่ารูปไหนเป็นรูปภาพจริงของดิสนีย์แลนด์ คุณมีหน้าที่ระบุตัวตนของบุคคลเหล่านั้น รูปภาพอยู่ใน gs://hackathon_data_disneyland_<YOUR_PROJECT_3DIGITS>/attraction_parc_photos/

Is_disneyland: False

Is_disneyland: True
เพื่อทำการวิเคราะห์นี้อย่างรวดเร็ว คุณควรใช้ตารางออบเจ็กต์ของ BigQuery และ Gemini ผ่าน BigQuery ML (ML.GENERATE_TEXT)
คุณยืนยันเอาต์พุตของ Gemini ได้ไหมโดยตรวจสอบรูปภาพบางรูป
สร้างระบบ RAG ของคุณเองด้วย BigQuery ในโบรชัวร์ของ Disneyland
ขณะต่อคิว คุณต้องการทราบเรื่องน่ารู้/รายละเอียดทางเทคนิคเกี่ยวกับสถานที่ท่องเที่ยวที่คุณกำลังรอ
ใน gs://hackathon_data_disneyland_<YOUR_PROJECT_3DIGITS>/disneyland_brochures/, คุณจะเห็นไฟล์ PDF ที่มีโบรชัวร์ของอุทยานทั่วโลก
เป้าหมาย: สร้างระบบ Retrieval-Augmented Generation (RAG) ภายใน BigQuery ทั้งหมดเพื่อให้ผู้ใช้ถามคำถามที่ซับซ้อนเกี่ยวกับสวนสาธารณะได้โดยอิงตามเอกสาร PDF บางส่วน
หากต้องการบรรลุเป้าหมายนี้ คุณต้องทำดังนี้
- สร้างตารางออบเจ็กต์ของไฟล์ PDF
- สร้าง UDF ของ Python เพื่อแบ่งไฟล์ PDF ออกเป็นส่วนๆ ตัวอย่างที่คุณใช้ได้มีดังนี้
CREATE OR REPLACE FUNCTION disney.chunk_pdf(src_json STRING, chunk_size INT64, overlap_size INT64)
RETURNS ARRAY<STRING>
LANGUAGE python
WITH CONNECTION `[LOCATION].[CONN_NAME]`
OPTIONS (entry_point='chunk_pdf', runtime_version='python-3.11', packages=['pypdf'])
AS """
import io
import json
from pypdf import PdfReader # type: ignore
from urllib.request import urlopen, Request
def chunk_pdf(src_ref: str, chunk_size: int, overlap_size: int) -> str:
src_json = json.loads(src_ref)
srcUrl = src_json["access_urls"]["read_url"]
req = urlopen(srcUrl)
pdf_file = io.BytesIO(bytearray(req.read()))
reader = PdfReader(pdf_file, strict=False)
# extract and chunk text simultaneously
all_text_chunks = []
curr_chunk = ""
for page in reader.pages:
page_text = page.extract_text()
if page_text:
curr_chunk += page_text
# split the accumulated text into chunks of a specific size with overlaop
# this loop implements a sliding window approach to create chunks
while len(curr_chunk) >= chunk_size:
split_idx = curr_chunk.rfind(" ", 0, chunk_size)
if split_idx == -1:
split_idx = chunk_size
actual_chunk = curr_chunk[:split_idx]
all_text_chunks.append(actual_chunk)
overlap = curr_chunk[split_idx + 1 : split_idx + 1 + overlap_size]
curr_chunk = overlap + curr_chunk[split_idx + 1 + overlap_size :]
if curr_chunk:
all_text_chunks.append(curr_chunk)
return all_text_chunks
""";
- แยกวิเคราะห์ไฟล์ PDF เป็นก้อน
- สร้างการฝังหลังจากสร้างโมเดลระยะไกล
- เรียกใช้การค้นหาเวกเตอร์เพื่อค้นหา "
Ou manger un repas tex-mex à volonté?" หรือ "where to eat a tex-mex meal buffet-style?" - สร้างคำตอบที่เสริมด้วยผลการค้นหาแบบเวกเตอร์ของคำถาม "
Ou manger un repas tex-mex à volonté?" หรือ "where to eat a tex-mex meal buffet-style?"
5. งานที่ 3: แมชชีนเลิร์นนิงที่ปรับขนาดได้ด้วย BigQuery: การคาดการณ์ การจัดประเภท และการจัดอันดับ
เวลารอโดยประมาณ
รูปภาพสวยมาก! คุณรอไม่ได้ ตอนนี้คุณอยากรู้เวลาที่ต้องรอจริงสำหรับสถานที่ท่องเที่ยวบางแห่งระหว่างปารีสกับแคลิฟอร์เนีย เพื่อจะได้เลือกสถานที่ท่องเที่ยวที่ควรไปและหลีกเลี่ยงสถานที่ท่องเที่ยวที่ไม่ควรไป งานของคุณคือการคาดการณ์ waiting_times ของสถานที่ท่องเที่ยวทุกแห่งโดยใช้แมชชีนเลิร์นนิง (Arima plus หรือ TimesFM) ทุกๆ 30 นาทีในปี 2025
ข้อมูลที่คุณจะใช้จะอยู่ในไฟล์ CSV นี้: gs://hackathon_data_disneyland_<YOUR_PROJECT_3DIGITS>/waiting_times.csv
ขั้นตอนของงานมีดังนี้
- โหลดไฟล์ลงในชุดข้อมูล BigQuery ในตารางที่ชื่อ waiting_times
- ฝึกโมเดลการคาดการณ์ในข้อมูล (Arima_Plus) หรือคาดการณ์โดยตรงโดยใช้ AI.Forecast
- ประเมินประสิทธิภาพของโมเดลหรือเปรียบเทียบข้อมูลที่คาดการณ์กับข้อมูลอินพุต
จัดประเภทการปั่นตามความเข้มข้น
คุณไปเที่ยวสวนสนุกดิสนีย์แลนด์กับเพื่อนๆ และแม้ว่าโดยทั่วไปแล้วสวนสนุกจะเหมาะสำหรับครอบครัว แต่เครื่องเล่นบางอย่างอาจหวาดเสียวเกินไปสำหรับบางคน มาใช้ฟังก์ชัน AI ที่มีการจัดการของ BigQuery เพื่อจัดประเภทและจัดอันดับสถานที่ท่องเที่ยวตามระดับความตื่นเต้นและความเข้มข้นโดยไม่มีอคติจากมนุษย์ เพื่อให้เราตอบสนองความต้องการของทุกคนได้
- ใช้
AI.CLASSIFYเพื่อจัดหมวดหมู่การขี่ตามคำอธิบายเป็น 1 ใน 3 หมวดหมู่สุดมหัศจรรย์ ได้แก่ [easy-peasy, thrilling, extreme]
จัดอันดับการขี่ตามระดับความตื่นเต้น
- ใช้
AI.SCOREเพื่อเปรียบเทียบและจัดเรียงสถานที่ท่องเที่ยวตามระดับความหวาดเสียว โดยอันดับ 10 คือหวาดเสียวที่สุด และอันดับ 1 คือหวาดเสียวน้อยที่สุด
6. งานที่ 3 - โบนัส: Reverse-ETL จาก BigQuery ไปยัง AlloyDB
คุณได้ใช้ประโยชน์จากความสามารถอันทรงพลังของ BigQuery เพื่อสร้างข้อมูลเชิงลึกเกี่ยวกับข้อมูลจำนวนมาก ตอนนี้คุณต้องการให้ข้อมูลเชิงลึกเหล่านั้นนำไปใช้ได้จริงโดยแอปพลิเคชันด้านการดำเนินงาน (และ AI Agent)
แต่จะทำอย่างไร ด้วยการทำในสิ่งที่ตรงกันข้าม AlloyDB สำหรับ Postgres ทำงานได้ดีในการแสดงข้อมูลที่มีเวลาในการตอบสนองต่ำและความเร็วสูง ซึ่งเหมาะอย่างยิ่งสำหรับแอปพลิเคชันที่สำคัญซึ่งผู้ใช้มองเห็น ดังนั้นเรามาทำ Reverse ETL ข้อมูลที่เราเพิ่งสร้างกัน
เราจะใช้ฟีเจอร์ใหม่ล่าสุดที่ยังอยู่ในเวอร์ชันตัวอย่างแบบส่วนตัวที่เรียกว่า "มุมมอง BigQuery" ใน AlloyDB ฟีเจอร์นี้ช่วยให้คุณค้นหาข้อมูล BigQuery ในฐานข้อมูล Postgres ได้โดยตรง
ก่อนอื่น คุณต้องให้สิทธิ์ที่จำเป็นแก่บัญชีบริการคลัสเตอร์ AlloyDB เพื่อค้นหา BigQuery
gcloud beta alloydb clusters describe <CLUSTER ID> --region=europe-west1
เอาต์พุตจะมีฟิลด์ serviceAccountEmail ซึ่งเป็นบัญชีบริการสำหรับคลัสเตอร์นี้
ในคอนโซล Google Cloud ให้ไปที่หน้า IAM แล้วให้สิทธิ์ต่อไปนี้แก่ผู้รับสิทธิ์นี้
- ผู้ดูข้อมูล BigQuery (roles/bigquery.dataViewer)
- ผู้ใช้เซสชันการอ่าน BigQuery (roles/bigquery.readSessionUser)
ตอนนี้ ให้ไปที่ AlloyDB Studio ใน Console แล้วเชื่อมต่อกับฐานข้อมูล "postgres"
เรียกใช้การค้นหาต่อไปนี้เพื่อติดตั้งและกำหนดค่าฟีเจอร์ใหม่
CREATE EXTENSION bigquery_fdw;
CREATE SERVER bq_disney FOREIGN DATA WRAPPER bigquery_fdw;
CREATE USER MAPPING FOR postgres SERVER bq_disney ;
ตอนนี้คุณสามารถสร้าง "ตารางภายนอก" ที่จะแมปกับตารางปัจจุบันใน BigQuery ได้แล้ว ใช้ตารางที่คุณสร้างในงานที่ 3 ตัวอย่างไวยากรณ์
CREATE FOREIGN TABLE reviews_analysis ( "Review_ID" int,
"Sentiment" text) SERVER bq_disney OPTIONS (PROJECT 'bqml-hack25par-xxx',
dataset 'disney',
TABLE 'reviews_analysis');
พร้อมแล้ว มาค้นหาในตารางกันเลย เรียกใช้ SELECT แรกเพื่อตรวจสอบลิงก์ระหว่าง AlloyDB กับ BigQuery และสุดท้ายสร้างตารางใหม่ใน AlloyDB เพื่อส่งผ่านข้อมูลจากตารางภายนอก
7. งานที่ 4: Data Agent ที่พร้อมใช้งาน
คุณมีเพื่อนที่ต้องการร่วมสร้างโปรเจ็กต์แอปพลิเคชัน Disneyland โดยมีสิทธิ์เข้าถึงข้อมูลใน BigQuery แต่มีระดับความรู้ด้าน SQL และวิศวกรรมข้อมูลที่แตกต่างกัน คุณต้องการใช้ประโยชน์จากการประกาศล่าสุดของ BigQuery เกี่ยวกับเอเจนต์ข้อมูลที่ผสานรวมเข้ากับ UI อยู่แล้วเพื่อช่วยเหลือเพื่อนของคุณ
- สร้าง Data Pipeline
- ทำงานร่วมกันในโค้ด SQL
- พูดคุยกับข้อมูลของพวกเขา
เอเจนต์วิศวกรรมข้อมูลสำหรับการทำให้ไปป์ไลน์ข้อมูลเป็นแบบอัตโนมัติ
สร้างมุมมองใหม่ average_waiting_time ที่รวมตาราง waiting time และ attractions แล้วคํานวณ average waiting_time ต่อสถานที่ท่องเที่ยวโดยใช้ Data Engineering Agent
สร้างเอเจนต์ Conversational Analytics ใน BigQuery
จะดีแค่ไหนหากคุณสร้างเอเจนต์เพื่อพูดคุยกับข้อมูลได้โดยไม่ต้องเขียนโค้ด ไม่ต้องใช้ SQL ไม่ต้องติดตั้งใช้งาน และจากอินเทอร์เฟซของ BigQuery ซึ่งตอนนี้คุณทำได้แล้วด้วยแท็บ "Agent" ใน BigQuery
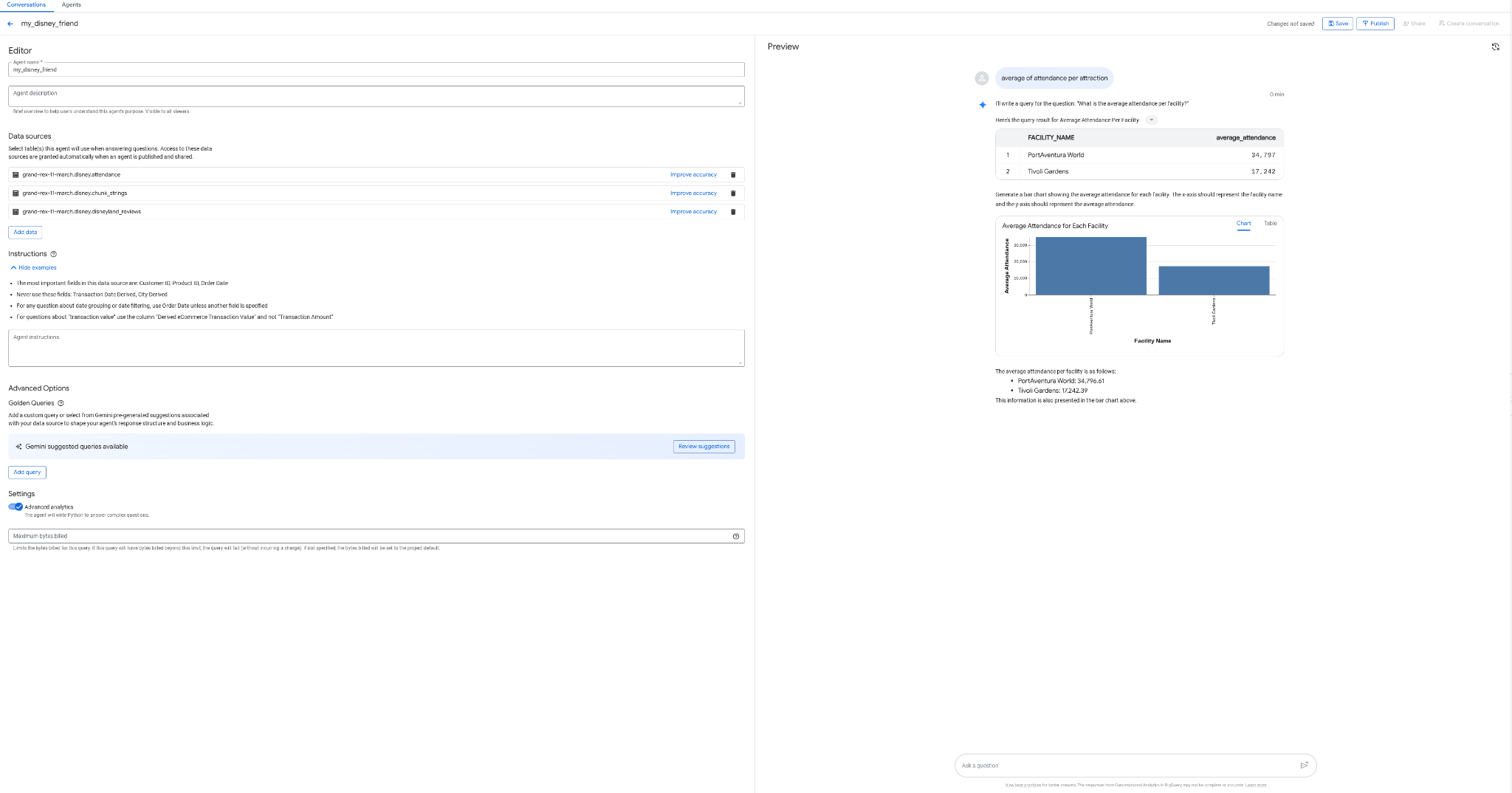
- สร้างเอเจนต์ my_disney_friend ที่เชื่อมต่อกับตาราง disney คุณปรับปรุงประสิทธิภาพของ Agent ได้โดยกรอกวิธีการของ Agent ถามคำถาม เช่น "รีวิวเชิงบวกและเชิงลบมีสัดส่วนเท่าใด เวลาที่ใช้รอโดยเฉลี่ยต่อสถานที่ท่องเที่ยวคือเท่าใด ฯลฯ"
- เผยแพร่ Agent ใน BigQuery และใน API (คุณจะใช้ในภายหลัง)
8. งานที่ 5: ปรับปรุงประสบการณ์การพัฒนาด้วย Gemini-CLI
ในยุค AI นี้ การสร้างซอฟต์แวร์นั้นง่ายกว่าที่เคย คุณมีไอเดียหลายพันรายการสำหรับแอปพลิเคชัน Disneyland และต้องการใช้ข้อมูลอย่างเต็มความสามารถ คุณต้องการทำอะไรมากกว่าแค่พูดคุยกับข้อมูล ตอนนี้คุณต้องการดำเนินการแล้ว
คุณจะต้องได้รับความช่วยเหลือเพื่อก้าวไปในเส้นทางนั้น และเราพร้อมดูแลคุณ
Gemini CLI เป็น AI Agent แบบโอเพนซอร์สที่นำความสามารถของ Gemini มาไว้ในเทอร์มินัลของคุณโดยตรง นักพัฒนาแอปสามารถสร้างแอปพลิเคชันที่มีประสิทธิภาพ และยังโต้ตอบกับเซิร์ฟเวอร์ MCP (Model Context Protocol) ต่างๆ ได้ด้วยส่วนขยาย
ในส่วนดังกล่าว คุณจะพบส่วนขยายเพื่อค้นหาข้อมูล AlloyDB หรือ BigQuery ได้อย่างแน่นอน
ในงานนี้ เป้าหมายของคุณคือ
- ติดตั้ง Gemini-CLI (ในเทอร์มินัลของคุณเองหรือใน Cloud Shell)
- ติดตั้งส่วนขยาย BigQuery และ AlloyDB Gemini-CLI
- สร้างไฟล์สภาพแวดล้อมที่อนุญาตให้ Gemini-CLI เชื่อมต่อกับอินสแตนซ์ BigQuery และ AlloyDB
- ขอให้ Gemini-CLI สร้างหน้า HTML เดียวที่ดูดีซึ่งอธิบายเนื้อหาของฐานข้อมูล AlloyDB
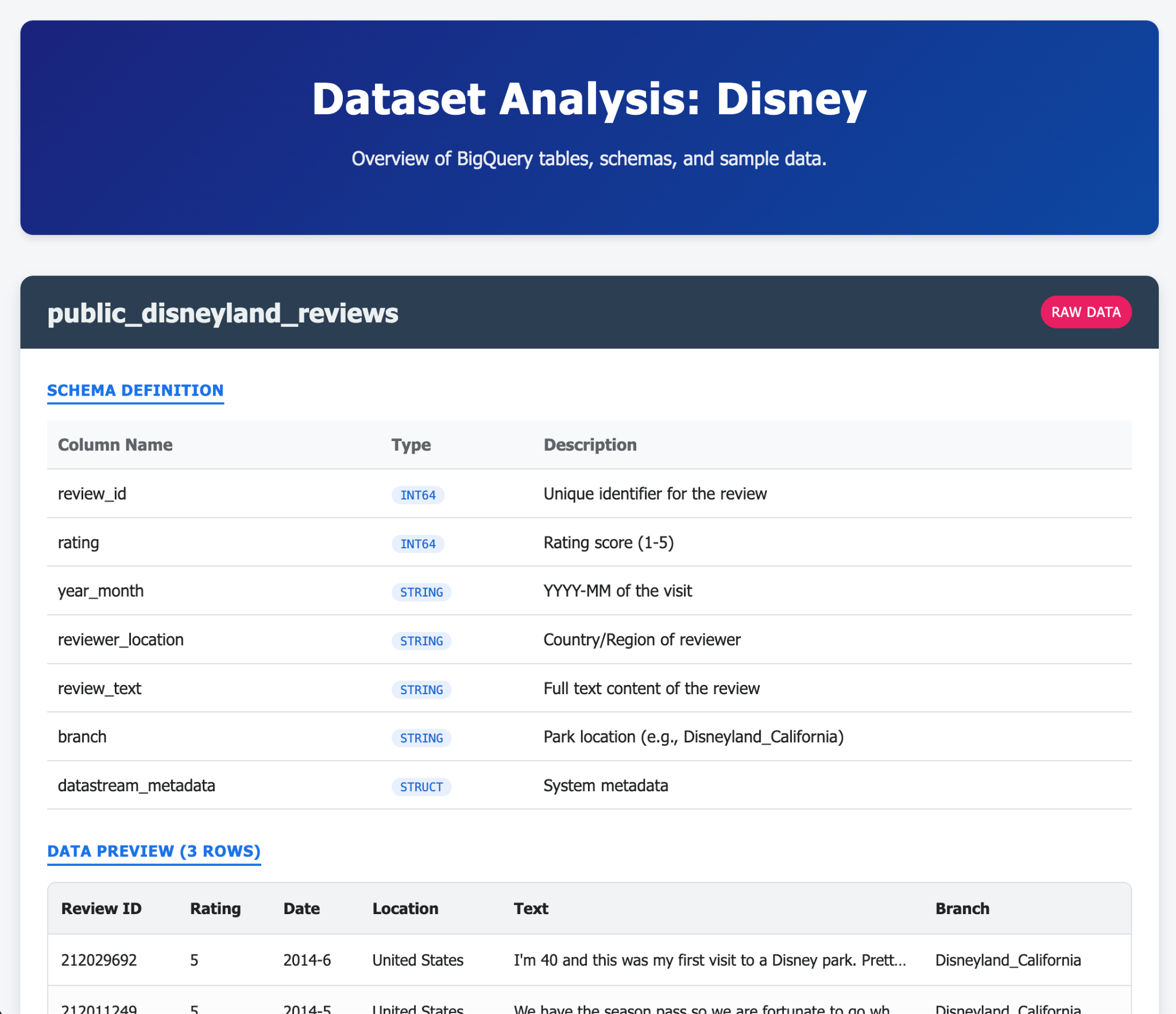
- ทำเช่นเดียวกันกับ BigQuery
ตัวอย่างสิ่งที่คุณสร้างได้ในพรอมต์เดียว (หรือ 2-3 พรอมต์) ด้วย Gemini-CLI และส่วนขยายมีดังนี้ แล้วลองนึกภาพว่าคุณทำแบบนั้นกับแอปพลิเคชันในชีวิตจริงได้ไหม 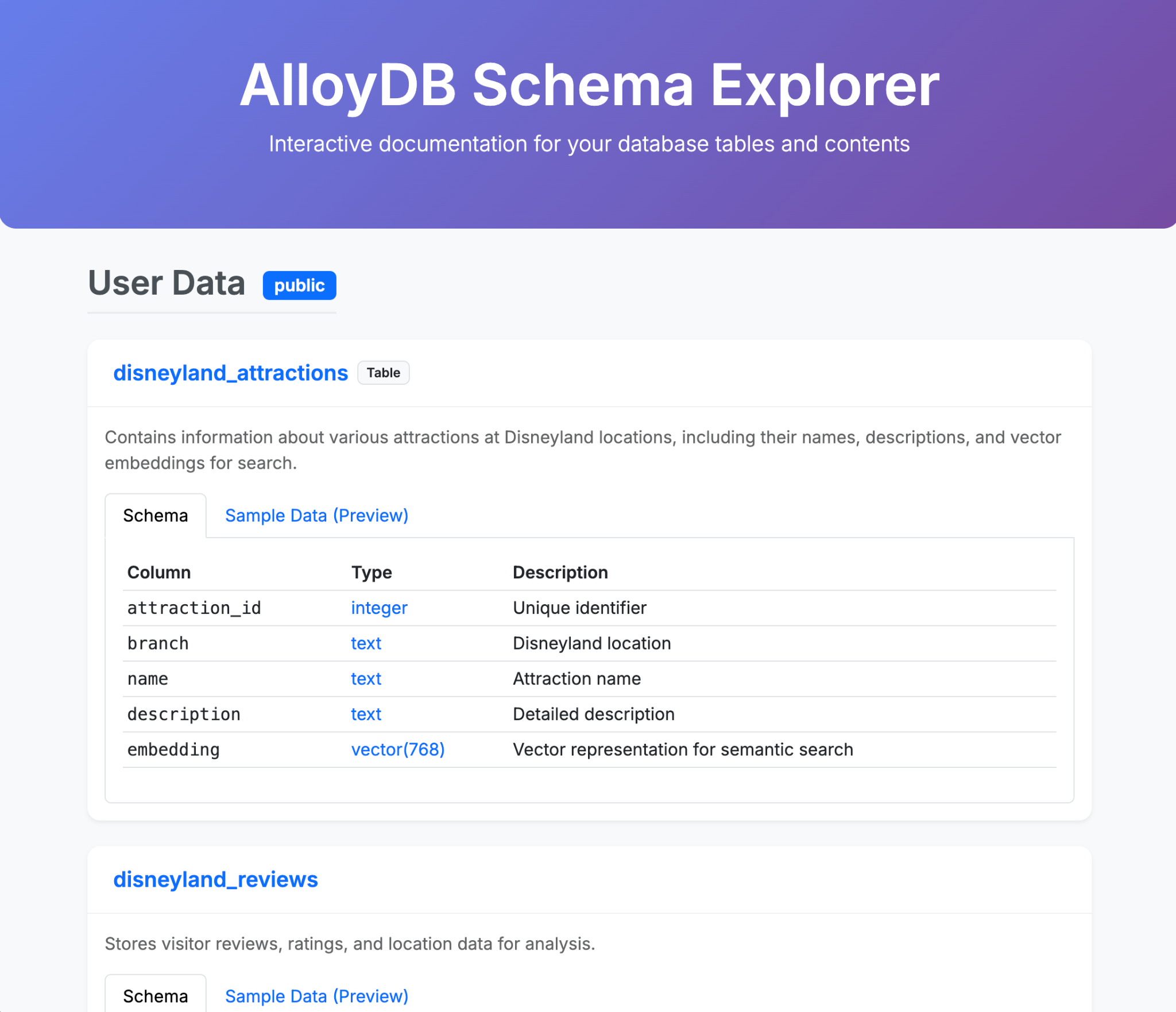
9. งานที่ 6: สร้าง AI Agent เพื่อโต้ตอบกับข้อมูล
คุณจะสร้างผู้ช่วยที่ช่วยผู้เข้าชม Disneyland ได้ตลอดทริปเพื่อมอบประสบการณ์ของผู้ใช้ใหม่ล่าสุด ตัวแทนจะทำสิ่งต่อไปนี้ได้
- แสดงรายการสถานที่ท่องเที่ยวทั้งหมดที่มีในสวนสาธารณะ
- แนะนำสถานที่ท่องเที่ยวตามความคาดหวัง
- เพิ่มรีวิวสำหรับสถานที่ท่องเที่ยว
- ระบุเวลาโดยประมาณที่ต้องรอสำหรับสถานที่ท่องเที่ยวในอีก 2-3 ชั่วโมงข้างหน้า
- ให้ภาพรวมของรีวิวสำหรับสถานที่ท่องเที่ยวที่เฉพาะเจาะจง
คุณจะตรวจสอบว่าผู้ช่วยตอบได้เฉพาะคำถามที่เกี่ยวข้องกับดิสนีย์แลนด์ และใช้ภาษาที่เป็นมิตรกับผู้ใช้ ปรับพรอมต์ของเอเจนต์เพื่อให้แน่ใจว่าเอเจนต์เลือกเครื่องมือที่เหมาะสมกับความต้องการของผู้ใช้
ขั้นตอนที่คุณต้องทำมีดังนี้
- ทำให้ใช้งานได้ MCP Toolbox สำหรับฐานข้อมูลเซิร์ฟเวอร์ที่ใช้ AlloyDB และ BigQuery เป็นแหล่งข้อมูล
- ประกาศเครื่องมือ 5 อย่างที่แตกต่างกันสำหรับเซิร์ฟเวอร์ MCP ที่ค้นหา AlloyDB และ BigQuery และแมปการดำเนินการของ Agent ที่ระบุไว้ก่อนหน้านี้
- ใช้ UI ของกล่องเครื่องมือ MCP เพื่อตรวจสอบเครื่องมือแต่ละรายการ
- ทำให้ใช้งานได้ Agent โดยใช้ Agent Development Kit ที่ใช้เครื่องมือซึ่งเซิร์ฟเวอร์ MCP Toolbox แสดง
- เชื่อมต่อกับอินเทอร์เฟซเว็บของ ADK และแสดงการสนทนาทั้งหมดกับผู้ช่วย รวมถึงเครื่องมือทั้งหมดที่มี
ขั้นตอนเพิ่มเติมหากทำเสร็จก่อนเวลา:
Agent พร้อมใช้งานแล้วใช่ไหม มาทำให้ใช้งานได้กับ Agent Engine กันเลย