
1. 🏰 Disneyland Data Analytics Hackathon (2nd Edition - 3rd Dec) 🏰
Podsumowanie | Podczas tego hackathonu zbudujesz kompleksowy potok analizy danych wykorzystujący funkcje AI/ML w Google Cloud. Załadujesz dane do AlloyDB, w pełni zarządzanej bazy danych zgodnej z PostgreSQL i zoptymalizowanej pod kątem wymagających zbiorów zadań, a następnie użyjesz Datastream, bezserwerowej usługi przechwytywania zmian danych (CDC), aby przenieść je do BigQuery, bezserwerowej hurtowni danych Google Cloud. W BigQuery zastosujesz BigQuery ML, które umożliwia tworzenie i uruchamianie modeli uczenia maszynowego bezpośrednio w BigQuery za pomocą standardowej wersji SQL, do analizy opinii i prognozowania frekwencji. Na koniec zapoznasz się z agentami, korzystając z gotowych rozwiązań w ramach analityki konwersacyjnej i agentów danych lub tworząc agenta niestandardowego opartego na pakiecie Agent Development Kit i zestawie narzędzi MCP, który umożliwia interakcję z danymi w języku naturalnym. |
kategorie, | docType:Codelab, product:Bigquery |
Autor | Rayhane Rezgui, Matt Cornillon |
Układ | przewijanie, |
Roboty | noindex |
2. Wprowadzenie
Witamy przyszłych czarodziejów danych z Disneya.🪄
Zapomnij o nudnych przewodnikach i niekończącym się przewijaniu forów. Wyobraź sobie, że planujesz idealną wycieczkę do Disneylandu, korzystając ze statystyk. Wskaż park, który zapewnia najlepsze wrażenia Kiedy jest najmniej tłoczno? Czy możesz przewidzieć najlepszy czas na pokonanie tej notorycznie długiej kolejki?
W tym hackathonie stworzysz najlepsze narzędzie do planowania wizyty w Disneylandzie. Mamy dane: opinie odwiedzających z oddziałów na całym świecie, historyczne czasy oczekiwania i dane o frekwencji. Twoja misja? Przekształć te nieprzetworzone dane w przydatne statystyki:
- Zbieranie danych: załaduj do AlloyDB, naszej bazy danych o wysokiej wydajności zgodnej z PostgreSQL, różne opinie o Disneylandzie, czasy oczekiwania i dane dotyczące frekwencji.
- Płynne przenoszenie: użyj Datastream, naszej bezserwerowej usługi przechwytywania zmian danych, aby bez wysiłku przenieść te dynamiczne informacje do BigQuery, zaawansowanej bezserwerowej hurtowni danych Google Cloud.
- Przewidywanie magicznych chwil: wykorzystaj BigQuery ML do analizowania opinii i prognozowania czasu oczekiwania bezpośrednio za pomocą SQL. Sprawdź, w których oddziałach zawsze możesz liczyć na uśmiech, i wybierz optymalną porę wizyty.
- Rozmawiaj ze swoimi danymi – dosłownie: Korzystaj z gotowych narzędzi, które pozwalają uzyskać statystyki za pomocą jednego kliknięcia.
- Inteligentna interakcja: wzbogać swoje dzieło o inteligentnego agenta opartego na zestawie narzędzi MCP dla baz danych i pakiecie ADK (Agent Development Kit). Zapytaj „Jaka jest najlepsza atrakcja w Disneylandzie w Paryżu dla miłośników kosmosu i kiedy najlepiej ustawić się w kolejce?” i uzyskaj natychmiastowe odpowiedzi oparte na danych.
Przygotuj się na odkrywanie tajemnic najbardziej magicznych miejsc na Ziemi i tworzenie potoku analizy danych, z którego Mickey byłby dumny.
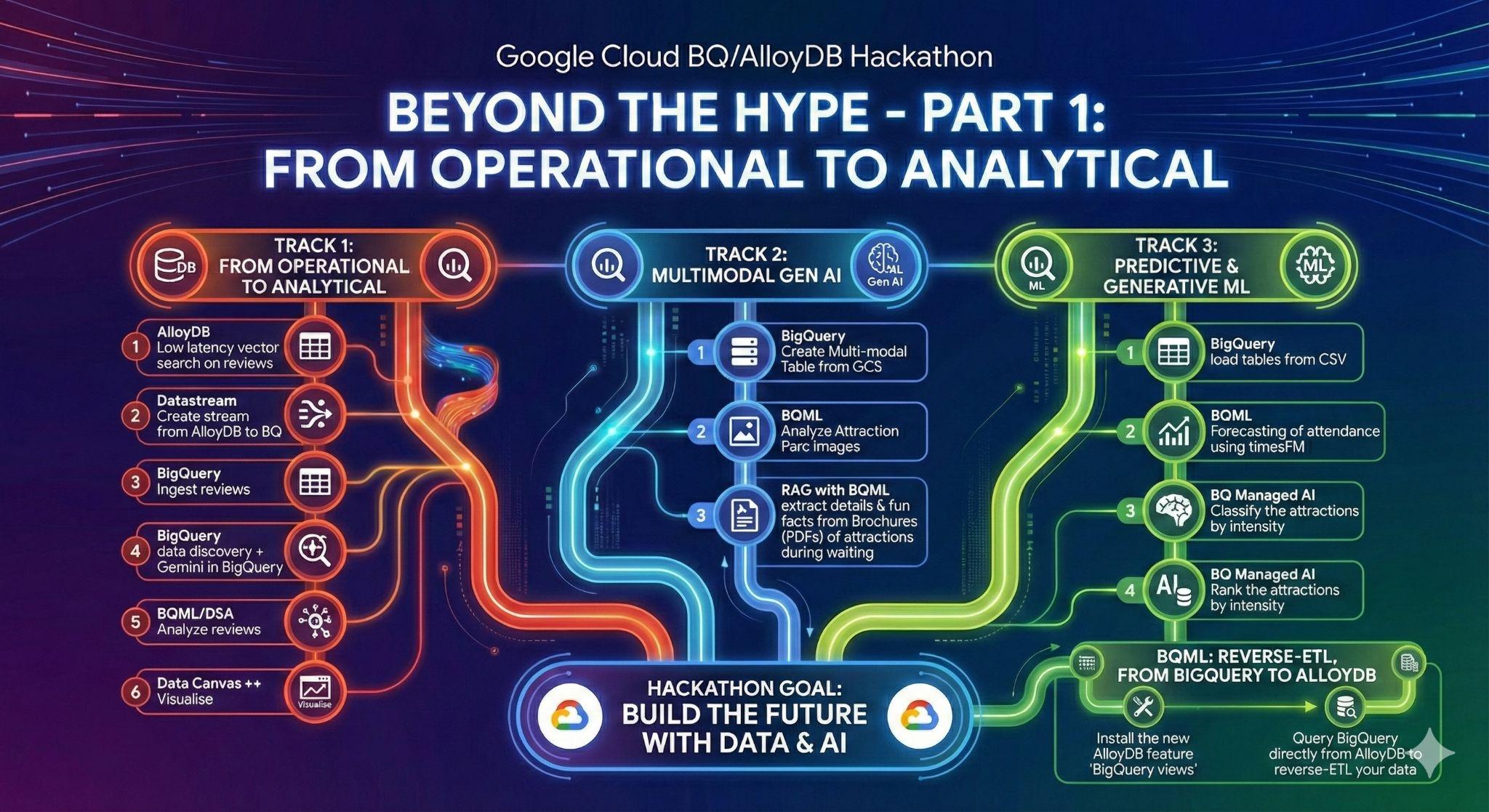

3. Zadanie 1. Od operacyjnego do analitycznego: analiza opinii o Disneylandzie za pomocą Gemini
Na tym początkowym etapie pobierzesz dane z działającej bazy danych AlloyDB i załadujesz je do BigQuery w celu późniejszej analizy.
Skonfigurujesz też wszystko, co będzie potrzebne w AlloyDB dla przyszłego agenta.
Wczytywanie danych w AlloyDB
Najpierw zaimportujmy dane do klastra AlloyDB for PostgreSQL.
Przetworzymy 20 tys. opinii o parkach rozrywki Disneylandu i listę atrakcji.
Musisz wykonać te czynności:
Tworzenie tabel:
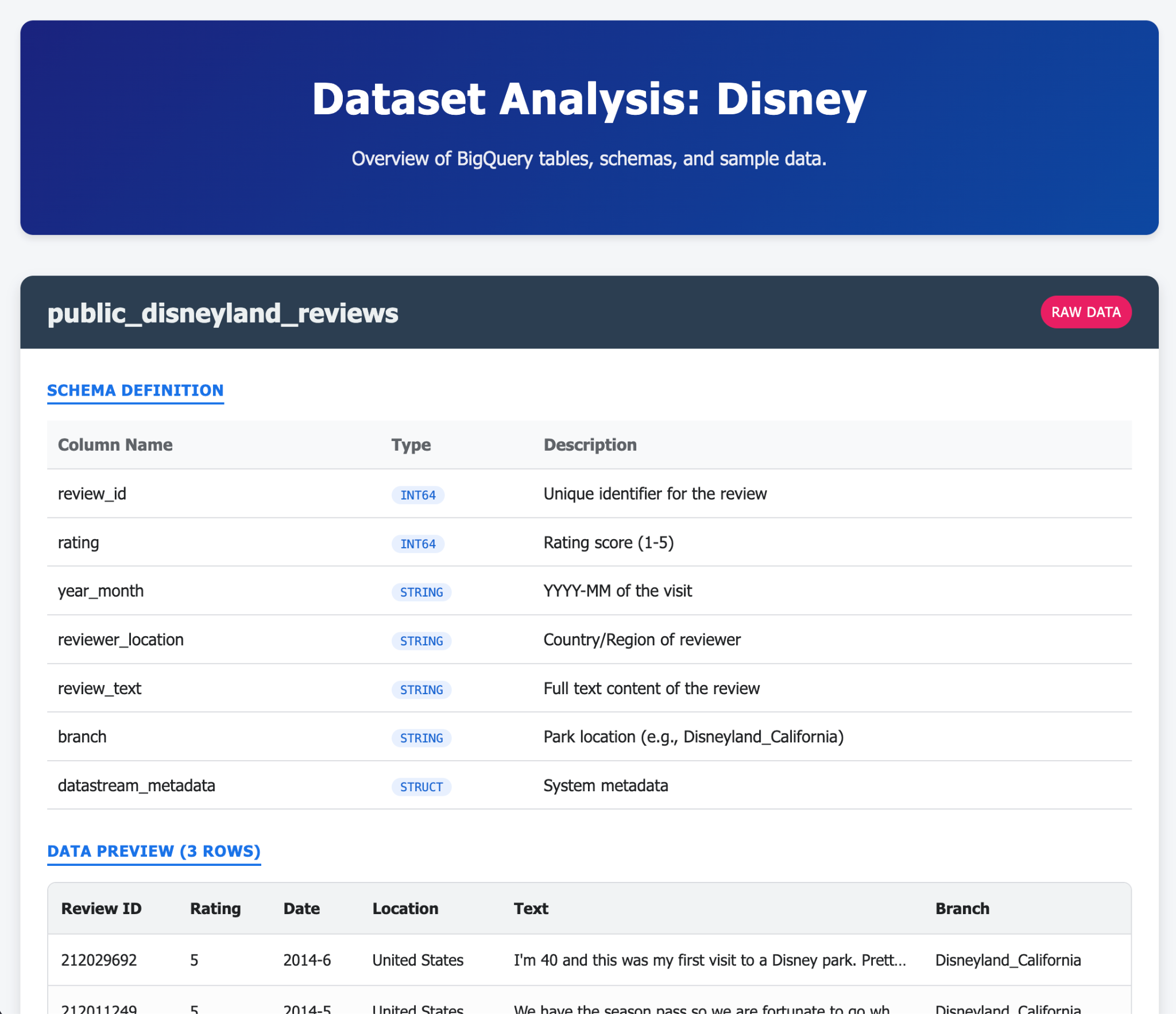
- Utwórz tabelę disneyland_reviews z 6 kolumnami: review_id i rating jako liczby całkowite, year_month, reviewer_location, review_text, branch jako tekst.
- Utwórz tabelę disneyland_attractions z 4 kolumnami: attraction_id jako liczba całkowita, branch, name i description jako tekst.
Za pomocą wybranego narzędzia zaimportuj dane z plików CSV:
gs://hackathon_data_disneyland_<YOUR_PROJECT_3DIGITS>/reviews.csvw przypadku tabeli opinii.gs://hackathon_data_disneyland_<YOUR_PROJECT_3DIGITS>/attractions.csvw przypadku tabeli atrakcji
Aby podać rekomendację atrakcji, musimy utworzyć osadzenia opisu atrakcji:
- Instalowanie rozszerzenia pgvector w AlloyDB
- Dodaj do tabeli atrakcji kolumnę wektorową o nazwie „embedding”.
- generować i wypełniać wektory dystrybucyjne opisów za pomocą natywnej integracji AlloyDB i Vertex AI,
Przejście od danych operacyjnych do analitycznych za pomocą Datastream
Aby przesyłać strumieniowo dane z AlloyDB do BigQuery, użyjemy Google Datastream. Jest to zaawansowane rozwiązanie bezserwerowe, które nasłuchuje wszystkich zmian w tabelach źródłowych (za pomocą funkcji przechwytywania zmian danych) i wysyła je do BigQuery.
Aby móc replikować zmiany z AlloyDB za pomocą Datastream, musimy utworzyć w Postgres tzw. publikację i przedział replikacji.
Wykonaj te zapytania w klastrze AlloyDB (musisz uruchamiać je pojedynczo):
CREATE PUBLICATION pub_disney FOR TABLE disneyland_reviews, disneyland_attractions;
ALTER USER postgres WITH REPLICATION;
SELECT PG_CREATE_LOGICAL_REPLICATION_SLOT('slot_disney', 'pgoutput');
Nazwy publikacji i przedziału replikacji będą używane w strumieniu, więc warto je zapamiętać.
To wszystko. Teraz możemy utworzyć transmisję.
W Datastream musisz wykonać te czynności:
- Utwórz profil źródłowy dla klastra AlloyDB (użyj publicznego adresu IP).
- Tworzenie profilu docelowego dla BigQuery
- Utwórz strumień z AlloyDB do BigQuery.
Dane powinny być dostępne w BigQuery w ciągu kilku minut.
Odkrywanie danych w BigQuery
Teraz, gdy mamy już dane w BigQuery, sprawdźmy nowe ulepszenia w interfejsie, zanim zaczniemy pracę.
Mamy 3 nowe funkcje, które są już widoczne w panelu eksploracji BigQuery.

- Omówienie: zawiera informacje o funkcjach BigQuery, prezentacje, które pomogą Ci rozpocząć analizę, i inne możliwości.
- Wyszukiwanie: przeprowadzaj wyszukiwanie semantyczne w swoich zasobach danych.
- Agent: cicho sza! Zostawimy to na później 🤫
Semantyczne wyszukiwanie danych w BigQuery
Otwórz kartę Wyszukiwanie w panelu eksploracji BigQuery i wypróbuj terminy związane z Disneyem, np. „atrakcje” lub „oddział”.
Wizualizacja danych w BigQuery
Możesz teraz wizualizować dane i wykonywać na nich operacje w BigQuery. W tym celu możesz uruchomić to zapytanie na nowej karcie zapytania:
SELECT
*
FROM
[dataset_name].[table_name];
Generowanie statystyk dotyczących danych w tabeli opinii
W tym zadaniu włączysz statystyki danych w tabeli disneyland_reviews w zbiorze danych disney.
Informacje o danych to narzędzie dla każdego, kto chce badać dane i uzyskiwać informacje bez pisania złożonych zapytań SQL.
Może to potrwać kilka minut.
Wysyłanie zapytań do tabeli disneyland_reviews bez użycia SQL
Statystyki wygenerowane w poprzedniej sekcji są już gotowe. W tym zadaniu użyjesz promptu wygenerowanego na podstawie tych statystyk, aby wysłać zapytanie do tabeli disneyland_reviews bez użycia kodu.
Wybierz statystykę i uruchom powiązane z nią zapytanie. Na przykład znajdź zapytanie, które oblicza różnicę w średniej ocenie między kolejnymi miesiącami w przypadku każdego oddziału. Będzie to wyglądać tak:
WITH
monthly_avg AS (
SELECT
branch,
year_month,
AVG(rating) AS avg_rating
FROM
[dataset_name].[table_name]
WHERE
year_month IS NOT NULL
GROUP BY
1,
2 )
SELECT
branch,
year_month,
avg_rating,
avg_rating - LAG(avg_rating, 1, 0) OVER (PARTITION BY branch ORDER BY year_month) AS rating_difference
FROM
monthly_avg
ORDER BY
branch,
year_month;
Używanie silnika wiedzy BigQuery do lepszego zrozumienia danych
Zacznijmy od karty Statystyki na poziomie zbioru danych. Dzięki temu poznamy ukryte relacje między tabelami w zbiorze danych disney. Następnie:
- Wygeneruj opis zbioru danych za pomocą Gemini i dodaj go do szczegółów zbioru danych.
- Wygeneruj opis tabel opinii i atrakcji oraz wszystkich poszczególnych kolumn w tych tabelach i zapisz go.
Przeprowadzanie skanowania profilującego danych
Celem tej sekcji jest oczyszczenie i przygotowanie danych. Nie znasz jednak dobrze rozkładu wartości w poszczególnych kolumnach. Musisz profilować dane, aby wiedzieć, jakie kroki przekształcenia należy wykonać.
Dataplex Universal Catalog w Google Cloud automatyzuje skanowanie profilowania, aby dostarczać spójne dane dotyczące jakości danych. Wśród zidentyfikowanych kluczowych statystyk znajdują się liczby wartości null, wartości niepowtarzalne, zakresy danych i rozkłady wartości. Skanowanie profilujące można aktywować w interfejsie BigQuery.
Może to potrwać kilka minut, więc w tym czasie możesz zapoznać się z następną sekcją.
Odpowiedz na te pytania:
- Jaka jest średnia ocena Disneylandu?
- Gdzie znajduje się najwięcej recenzentów?
- Czy wszystkie opinie są unikalne?
- Jaki jest odsetek brakujących danych w kolumnie Year_Month?
Przeprowadź skanowanie jakości danych
Automatyczna jakość danych w Dataplex Universal Catalog umożliwia definiowanie i pomiar jakości danych w tabelach BigQuery. Możesz zautomatyzować skanowanie danych, sprawdzać ich poprawność na podstawie zdefiniowanych reguł i rejestrować alerty, jeśli dane nie spełniają wymagań jakościowych. Możesz zarządzać regułami jakości danych i wdrożeniami jako kodem, co zwiększa integralność potoków produkcyjnych danych.
Na podstawie skanowania profilującego zdefiniuj skanowanie jakości (na próbce danych o rozmiarze nie większym niż 10%), które:
- Sprawdza wartości null w kolumnie „branch”.
- Sprawdza, czy wartość „rating” jest prawidłowa, ponieważ może należeć tylko do zbioru : 1, 2, 3, 4, 5.
- Sprawdza unikalność pola „review_id”.
Sprawdź, czy skanowanie eksportuje wyniki do tabeli BigQuery quality_scan_results.
Zastanów się nad wszystkimi przekształceniami, które musisz zastosować do danych.
Przygotowywanie danych za pomocą funkcji przygotowywania danych w Gemini
Po przeprowadzeniu skanowania jakości danych i profilowania czas na ich oczyszczenie przed analizą.
Przygotowania danych to zasoby BigQuery, które używają Gemini in BigQuery do analizowania danych i udzielania inteligentnych sugestii dotyczących ich czyszczenia, przekształcania i wzbogacania. Możesz znacznie skrócić czas i wysiłek potrzebne do ręcznego przygotowywania danych.
W tej sekcji użyjesz funkcji przygotowywania danych, aby wykonać te operacje na tabeli disneyland_reviews:
- Odfiltruj wiersze, w których kolumna Branch ma wartość NULL lub jest pusta.
- Zastąp wartość „missing” w kolumnie Year_Month wartością Null.
- Zastępuje podkreślenia spacjami w kolumnie gałęzi, aby zwiększyć czytelność.
- Eksportowanie do przekształconej tabeli disneyland_reviews_cleaned
Analizowanie opinii za pomocą Gemini
Po oczyszczeniu danych możesz rozpocząć ich analizowanie za pomocą modeli BigQuery ML i Gemini. Masz 2 cele:
- Wyodrębnianie kategorii z opinii
- Analiza nastawienia w przypadku opinii o Disneylandzie
BigQuery ML umożliwia tworzenie i uruchamianie modeli uczenia maszynowego za pomocą zapytań GoogleSQL. Modele BigQuery ML są przechowywane w zbiorach danych BigQuery, podobnie jak tabele i widoki. BigQuery ML umożliwia też dostęp do modeli Vertex AI i interfejsów API AI w Cloud, aby wykonywać zadania związane ze sztuczną inteligencją (AI), takie jak generowanie tekstu czy tłumaczenie maszynowe. Gemini w Google Cloud zapewnia też pomoc opartą na AI w przypadku zadań w BigQuery.
Możesz użyć funkcji ML.GENERATE_TEXT lub AI.GENERATE (wersja testowa) z modelami Gemini Pro lub Flash.
Jeśli chcesz użyć funkcji ML.GENERATE_TEXT, wykonaj te czynności.
Utwórz połączenie z zasobem Cloud i przyznaj rolę IAM
Aby móc korzystać z modeli Gemini Pro i Gemini Flash, musisz utworzyć w BigQuery połączenie z zasobem Cloud z modelami Vertex AI. Przyznasz też kontu usługi połączenia z zasobami w chmurze uprawnienia IAM za pomocą roli, aby umożliwić mu dostęp do usług Vertex AI.
Przyznaj rolę użytkownika Vertex AI kontu usługi połączenia
Umożliw połączenie konta usługi z wybranym modelem (np. gemini-2.5-flash), przyznając mu rolę użytkownika Vertex AI. Rozpowszechnienie uprawnień zajmuje 1 minutę.
Tworzenie modeli Gemini w BigQuery
Utwórz model, korzystając z połączenia powyżej. Użyj na przykład punktu końcowego gemini-2.5-flash.
Poproś Gemini o analizę opinii klientów pod kątem kategorii i nastrojów
W tym zadaniu użyjesz modelu Gemini do analizy każdej opinii klienta pod kątem kategorii i nastawienia (pozytywnego lub negatywnego).
Analizowanie opinii klientów według kategorii
Uwaga: od teraz do analizy będziemy używać tylko 100 wierszy, ponieważ wywołanie Gemini w przypadku 20 tys. wierszy może zająć trochę czasu.
Extract categories by modifying and running the following SQL Query:
CREATE OR REPLACE TABLE
[dataset_name].[results_table_name] AS (
SELECT Review_ID, Rating, Year_Month, Reviewer_Location, Review_Text, Branch, ml_generate_text_llm_result AS categories FROM
ML.GENERATE_TEXT(
MODEL [model_name],
(
SELECT Review_ID, Rating, Year_Month, Reviewer_Location, Review_Text, Branch, CONCAT(
'[WRITE YOUR PROMPT HERE].',
Review_Text) AS prompt
FROM (SELECT * FROM [dataset_name].[table_name] LIMIT 100)
),
STRUCT(
0.2 AS temperature, TRUE AS flatten_json_output)));
To zapytanie pobiera opinie klientów z tabeli disneyland_reviews i tworzy prompty dla modelu gemini, aby zidentyfikować kategorie w każdej opinii. Wyniki powinny być zapisane w nowej tabeli. reviews_categories
. Zaczekaj. Przetworzenie rekordów opinii klientów i wyświetlenie wyników w tabeli wyjściowej zajmuje modelowi około 30 sekund.
Wyświetl wyniki:
SELECT * FROM [dataset_name].[results_table_name];
Poświęć trochę czasu na zapoznanie się z niektórymi kategoriami.
Analizuj opinie klientów pod kątem pozytywnego i negatywnego nastawienia
Na podstawie zapytania SQL do wyodrębniania słów kluczowych napisz zapytanie, które analizuje opinię pod kątem nastawienia pozytywnego, negatywnego i neutralnego w kolumnie o nazwie „sentiment”.
To zapytanie pobiera opinie klientów z tabeli disneyland_reviews i tworzy prompty dla modelu gemini, aby sklasyfikować nastawienie w każdej opinii. Wyniki są następnie zapisywane w nowej tabeli reviews_analysis, aby można było ich później użyć do dalszej analizy. Poczekaj. Przetwarzanie rekordów opinii klientów zajmuje modelowi kilka sekund. Po zakończeniu działania modelu wynik jest dostępny w utworzonej tabeli reviews_analysis.
Przejrzyj wyniki:
SELECT * FROM [...];
Tabela reviews_analysis zawiera kolumnę Sentiment z analizą nastawienia oraz kolumny social_media_source, review_text, customer_id, location_id i review_datetime. Przyjrzyj się niektórym rekordom. Możesz zauważyć, że niektóre wyniki dotyczące wartości dodatnich i ujemnych nie są prawidłowo sformatowane i zawierają niepotrzebne znaki, np. kropki lub dodatkowe spacje. Możesz oczyścić rekordy, korzystając z widoku poniżej.
Tworzenie widoku do oczyszczania rekordów
Utwórz widok, który oczyszcza wartości kolumny sentiment przez:
- Użyj funkcji LOWER, aby upewnić się, że wszystkie wartości są zapisane małymi literami.
- Usuwanie znaków interpunkcyjnych (kropki , przecinka i spacji) za pomocą funkcji ZASTĄP
CREATE OR REPLACE VIEW [view_name] AS
SELECT [SANITIZATION_EXPRESSION] AS sentiment,
Review_ID, Rating, Year_Month, Reviewer_Location, Review_Text, Branch,
FROM `disney.reviews_analysis`;
Zapytanie tworzy widok cleaned_data_view i zawiera wyniki analizy sentymentu, tekst opinii, Review_ID, Rating, Year_Month, Reviewer_Location, Review_Text and Branch. Następnie bierze wynik analizy sentymentu (pozytywny lub negatywny), zamienia wszystkie litery na małe i usuwa zbędne znaki, takie jak dodatkowe spacje czy kropki. Wynikowy widok ułatwi dalszą analizę w kolejnych krokach tego modułu.
- Aby wyświetlić utworzone wiersze, możesz wysłać do widoku zapytanie podane poniżej.
SELECT * FROM [view_name];
Tworzenie raportu z liczbą pozytywnych i negatywnych opinii za pomocą obszaru roboczego danych
Teraz czas na analizę wyników. Zacznijmy od bezpośredniego działania w BigQuery za pomocą obszaru danych. To narzędzie umożliwia wyszukiwanie danych (semantyczne lub na podstawie słów kluczowych), wykonywanie zapytań i łączenie tabel, tworzenie wykresów oraz uzyskiwanie statystyk przez tworzenie przepływu na obszarze roboczym.
Twoim ostatecznym celem jest utworzenie wykresu przedstawiającego wybrane przez Ciebie odsetki pozytywnych i negatywnych opinii . Oto przykład:

Utwórz wykres liczby opinii w poszczególnych kategoriach oraz rozkładu opinii pozytywnych i negatywnych w każdej kategorii.
Wskazówka: aktywuj i używaj zaawansowanej analizy w Data Canvas, która uruchamia notatnik Pythona w obszarze roboczym.
4. Zadanie 2. Analiza zdjęć parków rozrywki w celu zidentyfikowania zdjęć Disneylandu i wyodrębnienia ciekawostek z broszur parku
Analiza obrazów w BigQuery
Masz dostęp do ekscytujących i atrakcyjnych zdjęć parku rozrywki, które odwiedzający zrobili na przestrzeni lat. Nie możesz się doczekać zbliżającego się wyjazdu. Nie wiesz jednak, które z nich przedstawiają Disneyland. Twoim zadaniem jest ich zidentyfikowanie. Zdjęcia znajdują się w gs://hackathon_data_disneyland_<YOUR_PROJECT_3DIGITS>/attraction_parc_photos/.

Is_disneyland: False

Is_disneyland: True
Aby szybko przeprowadzić tę analizę. Powinieneś używać tabel obiektów BigQuery i Gemini za pomocą BigQuery ML (ML.GENERATE_TEXT).
Czy możesz sprawdzić wyniki Gemini, przeglądając kilka zdjęć?
Tworzenie własnego systemu RAG z BigQuery na podstawie broszur Disneylandu
Podczas oczekiwania w kolejce chcesz poznać ciekawostki lub szczegóły techniczne dotyczące atrakcji, na którą czekasz.
W sekcji gs://hackathon_data_disneyland_<YOUR_PROJECT_3DIGITS>/disneyland_brochures/, znajdziesz pliki PDF z broszurami wszystkich parków na świecie.
Cel: utworzenie w całości w BigQuery systemu generowania wspomaganego wyszukiwaniem (RAG), który umożliwi użytkownikom zadawanie złożonych pytań dotyczących parku na podstawie dokumentów PDF.
Aby to osiągnąć, musisz:
- Tworzenie tabeli obiektów z plików PDF
- Utwórz funkcję UDF w Pythonie, aby dzielić pliki PDF na mniejsze części. Oto przykład, z którego możesz skorzystać:
CREATE OR REPLACE FUNCTION disney.chunk_pdf(src_json STRING, chunk_size INT64, overlap_size INT64)
RETURNS ARRAY<STRING>
LANGUAGE python
WITH CONNECTION `[LOCATION].[CONN_NAME]`
OPTIONS (entry_point='chunk_pdf', runtime_version='python-3.11', packages=['pypdf'])
AS """
import io
import json
from pypdf import PdfReader # type: ignore
from urllib.request import urlopen, Request
def chunk_pdf(src_ref: str, chunk_size: int, overlap_size: int) -> str:
src_json = json.loads(src_ref)
srcUrl = src_json["access_urls"]["read_url"]
req = urlopen(srcUrl)
pdf_file = io.BytesIO(bytearray(req.read()))
reader = PdfReader(pdf_file, strict=False)
# extract and chunk text simultaneously
all_text_chunks = []
curr_chunk = ""
for page in reader.pages:
page_text = page.extract_text()
if page_text:
curr_chunk += page_text
# split the accumulated text into chunks of a specific size with overlaop
# this loop implements a sliding window approach to create chunks
while len(curr_chunk) >= chunk_size:
split_idx = curr_chunk.rfind(" ", 0, chunk_size)
if split_idx == -1:
split_idx = chunk_size
actual_chunk = curr_chunk[:split_idx]
all_text_chunks.append(actual_chunk)
overlap = curr_chunk[split_idx + 1 : split_idx + 1 + overlap_size]
curr_chunk = overlap + curr_chunk[split_idx + 1 + overlap_size :]
if curr_chunk:
all_text_chunks.append(curr_chunk)
return all_text_chunks
""";
- Podziel plik PDF na części
- Generowanie wektorów dystrybucyjnych po utworzeniu modelu zdalnego
- Uruchom wyszukiwanie wektorowe, aby znaleźć „
Ou manger un repas tex-mex à volonté?” lub „where to eat a tex-mex meal buffet-style?” - Wygeneruj odpowiedź wzbogaconą o wyniki wyszukiwania wektorowego dla pytania „
Ou manger un repas tex-mex à volonté?” lub „where to eat a tex-mex meal buffet-style?”.
5. Zadanie 3. Uczenie maszynowe na dużą skalę w BigQuery: prognozowanie, klasyfikacja i rankingowanie
Prognozowane czasy oczekiwania
Zdjęcia są świetne. Nie możesz czekać! Aby wiedzieć, które atrakcje wybrać, a których unikać, musisz znać rzeczywisty czas oczekiwania na niektóre atrakcje w parkach w Paryżu i Kalifornii. Twoim zadaniem jest prognozowanie czasu oczekiwania na każdą atrakcję za pomocą uczenia maszynowego (Arima plus lub TimesFM) co 30 minut w 2025 roku.
Dane, których użyjesz, znajdują się w tym pliku CSV: gs://hackathon_data_disneyland_<YOUR_PROJECT_3DIGITS>/waiting_times.csv
Kroki zadania:
- Wczytaj plik do zbioru danych BigQuery w tabeli o nazwie waiting_times.
- Trenowanie modelu prognozowania na podstawie danych (Arima_Plus) lub bezpośrednie prognozowanie za pomocą funkcji AI.Forecast
- ocenić skuteczność modelu lub porównać prognozowane dane z danymi wejściowymi.
Klasyfikowanie przejazdów według intensywności
Odwiedzasz Disneyland ze znajomymi. Park jest ogólnie przyjazny dla rodzin, ale niektóre atrakcje mogą być zbyt intensywne dla niektórych osób. Użyjmy zarządzanych funkcji AI BigQuery, aby sklasyfikować i uszeregować atrakcje według poziomu emocji i intensywności bez ludzkich uprzedzeń, aby każdy mógł znaleźć coś dla siebie.
- Użyj
AI.CLASSIFY, aby podzielić przejażdżki na 3 magiczne kategorie na podstawie ich opisów: [easy-peasy, thrilling, extreme].
Atrakcyjność przejazdu
- Użyj
AI.SCORE, aby porównać i uporządkować atrakcje na podstawie poziomu emocji, gdzie 10 to najbardziej ekstremalna atrakcja, a 1 – najmniej.
6. Zadanie 3 (dodatkowe). Odwrotne ETL z BigQuery do AlloyDB
Wykorzystujesz zaawansowane możliwości BigQuery do generowania statystyk na podstawie dużych ilości danych. Teraz chcesz, aby te statystyki były przydatne dla Twoich aplikacji operacyjnych (i agentów AI).
Ale jak? W inny sposób. AlloyDB for Postgres doskonale sprawdza się w przypadku obsługi danych z krótkim czasem oczekiwania i dużą szybkością, co jest idealne w przypadku najważniejszych aplikacji dla użytkowników. Wykonajmy więc odwrotną transformację ETL danych, które właśnie wygenerowaliśmy.
W tym celu użyjemy nowej funkcji, która jest jeszcze w prywatnej wersji przedpremierowej, o nazwie „Widoki BigQuery” w AlloyDB. Ta funkcja umożliwia wykonywanie zapytań dotyczących danych BigQuery bezpośrednio w bazie danych Postgres.
Najpierw musisz przyznać kontu usługi klastra AlloyDB uprawnienia niezbędne do wykonywania zapytań w BigQuery.
gcloud beta alloydb clusters describe <CLUSTER ID> --region=europe-west1
Dane wyjściowe zawierają pole serviceAccountEmail, które jest kontem usługi dla tego klastra.
W konsoli Google Cloud otwórz stronę Uprawnienia i przyznaj temu podmiotowi te uprawnienia:
- Wyświetlający dane BigQuery (roles/bigquery.dataViewer)
- Użytkownik sesji odczytu BigQuery (roles/bigquery.readSessionUser)
Teraz otwórz AlloyDB Studio w konsoli i połącz się z bazą danych „postgres”.
Aby zainstalować i skonfigurować nową funkcję, wykonaj te zapytania:
CREATE EXTENSION bigquery_fdw;
CREATE SERVER bq_disney FOREIGN DATA WRAPPER bigquery_fdw;
CREATE USER MAPPING FOR postgres SERVER bq_disney ;
Możesz teraz utworzyć „tabelę zewnętrzną”, która będzie mapowana na bieżącą tabelę w BigQuery. Użyj dowolnej tabeli utworzonej w zadaniu 3. Oto przykład składni:
CREATE FOREIGN TABLE reviews_analysis ( "Review_ID" int,
"Sentiment" text) SERVER bq_disney OPTIONS (PROJECT 'bqml-hack25par-xxx',
dataset 'disney',
TABLE 'reviews_analysis');
Wszystko gotowe. Utwórzmy zapytanie do tabeli. Wykonaj pierwsze zapytanie SELECT, aby sprawdzić połączenie między AlloyDB a BigQuery, a na koniec utwórz w AlloyDB nową tabelę, do której zostaną pozyskane dane z tabeli zewnętrznej.
7. Zadanie 4. Gotowe agenty danych
Masz znajomych, którzy chcą współtworzyć projekt aplikacji Disneyland. Mają dostęp do danych w BigQuery, ale różnią się poziomem wiedzy z zakresu SQL i inżynierii danych. Chcesz wykorzystać ostatnie ogłoszenia dotyczące agentów danych w BigQuery, którzy są już zintegrowani z interfejsem, aby pomóc znajomym:
- Tworzenie potoków danych.
- Współpraca nad kodem SQL.
- rozmawiać z ich danymi,
Agenci inżynierii danych do automatyzacji potoków danych
Utwórz nowy widok average_waiting_time, który łączy tabele waiting time i attractions oraz oblicza średni czas oczekiwania (waiting_time) dla każdej atrakcji za pomocą agenta Data Engineering.
Tworzenie agenta analizy konwersacyjnej w BigQuery
A gdyby można było utworzyć agenta do rozmowy z danymi bez kodowania, bez SQL i bez wdrażania, a do tego z interfejsu BigQuery? To byłoby super, prawda? Jest to możliwe dzięki karcie „Agenci” w BigQuery.

- Utwórz agenta my_disney_friend, który łączy się z tabelami Disney. Skuteczność agenta możesz zwiększyć, wypełniając instrukcje agenta. Zadawaj pytania typu „jaki jest odsetek pozytywnych i negatywnych opinii, jaki jest średni czas oczekiwania na atrakcję itp.”
- Opublikuj agenta w BigQuery i w interfejsie API (będziesz go później używać).
8. Zadanie 5. Ulepszanie środowiska programistycznego za pomocą interfejsu wiersza poleceń Gemini
W erze AI tworzenie oprogramowania nigdy nie było tak łatwe. Masz tysiące pomysłów na aplikację Disneylandu i chcesz w pełni wykorzystać swoje dane. Chcesz zrobić coś więcej niż tylko rozmawiać z danymi. Teraz potrzebujesz działania.
Aby Ci w tym pomóc, potrzebujesz pomocy. Chętnie Ci pomożemy.
Interfejs wiersza poleceń Gemini to agent AI o otwartym kodzie źródłowym, który udostępnia możliwości Gemini bezpośrednio w terminalu. Programiści mogą tworzyć zaawansowane aplikacje, a dzięki rozszerzeniom mogą też wchodzić w interakcje z różnymi serwerami MCP (Model Context Protocol).
Wśród nich znajdziesz oczywiście rozszerzenia do wykonywania zapytań na danych AlloyDB lub BigQuery.
W tym zadaniu musisz:
- Zainstaluj interfejs wiersza poleceń Gemini (we własnym terminalu lub w Cloud Shell)
- Instalowanie rozszerzeń interfejsu wiersza poleceń Gemini do BigQuery i AlloyDB
- Utwórz plik środowiska, który umożliwi Gemini-CLI łączenie się z instancjami BigQuery i AlloyDB.
- Poproś Gemini-CLI o wygenerowanie atrakcyjnej pojedynczej strony HTML, która wyjaśnia zawartość bazy danych AlloyDB
- Zrób to samo w przypadku BigQuery.
Oto kilka przykładów tego, co możesz wygenerować za pomocą jednego (lub kilku) promptów w interfejsie wiersza poleceń Gemini i jego rozszerzeniach. Wyobraź sobie, że możesz to zrobić w przypadku aplikacji w rzeczywistym świecie. 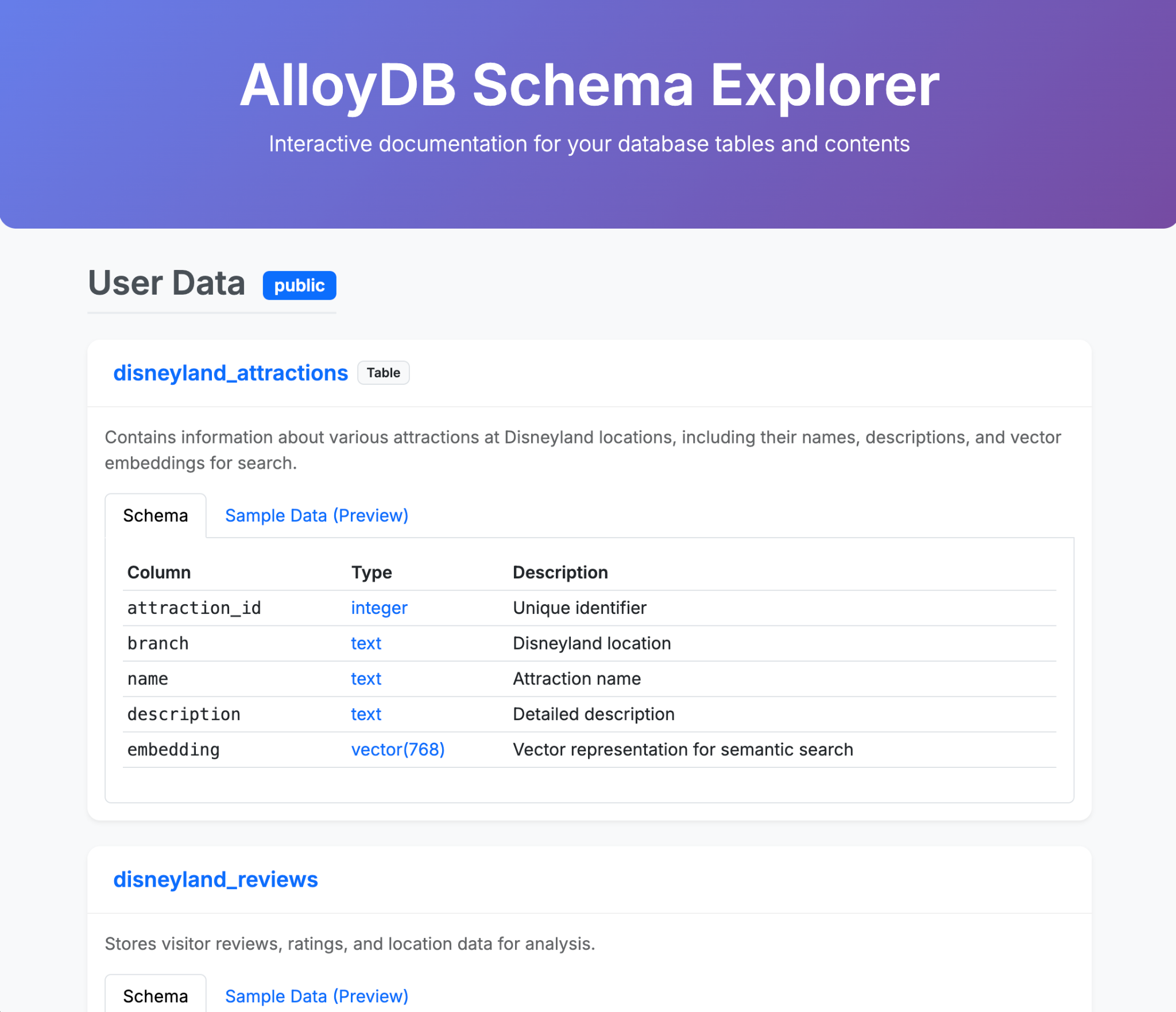
9. Zadanie 6. Utwórz agenta AI do interakcji z danymi
Aby zapewnić odwiedzającym Disneylandu zupełnie nowe wrażenia użytkownika, utworzysz asystenta, który będzie im pomagać podczas wycieczki. Agent będzie mógł:
- Wyświetl listę wszystkich dostępnych atrakcji w parku.
- Polecanie atrakcji na podstawie oczekiwań
- Dodawanie opinii o atrakcji
- podawać szacowany czas oczekiwania na atrakcję w ciągu najbliższych kilku godzin;
- Przedstawienie przeglądu opinii o konkretnej atrakcji
Upewnij się, że Twój asystent może odpowiadać tylko na pytania związane z Disneylandem i zachowuje przyjazny ton w kontaktach z użytkownikiem. Dostosuj prompta agenta, aby mieć pewność, że wybiera on odpowiednie narzędzia do potrzeb użytkownika.
Musisz wykonać te czynności:
- Wdrożenie serwera narzędzi MCP dla baz danych, który używa AlloyDB i BigQuery jako źródeł.
- Zadeklaruj 5 różnych narzędzi dla serwera MCP, które wysyłają zapytania do AlloyDB i BigQuery oraz mapują wymienione wcześniej działania agenta.
- Użyj interfejsu Zestawu narzędzi MCP, aby sprawdzić każde z narzędzi
- Wdrażanie agenta za pomocą pakietu Agent Development Kit, który może korzystać z narzędzi udostępnianych przez serwer zestawu narzędzi MCP.
- Połącz się z interfejsem internetowym ADK i zaprezentuj pełną rozmowę z asystentem, w tym wszystkie dostępne narzędzia.
Dodatkowy krok, jeśli skończysz wcześniej:
Czy agent jest gotowy? Wdróżmy go w Agent Engine.