
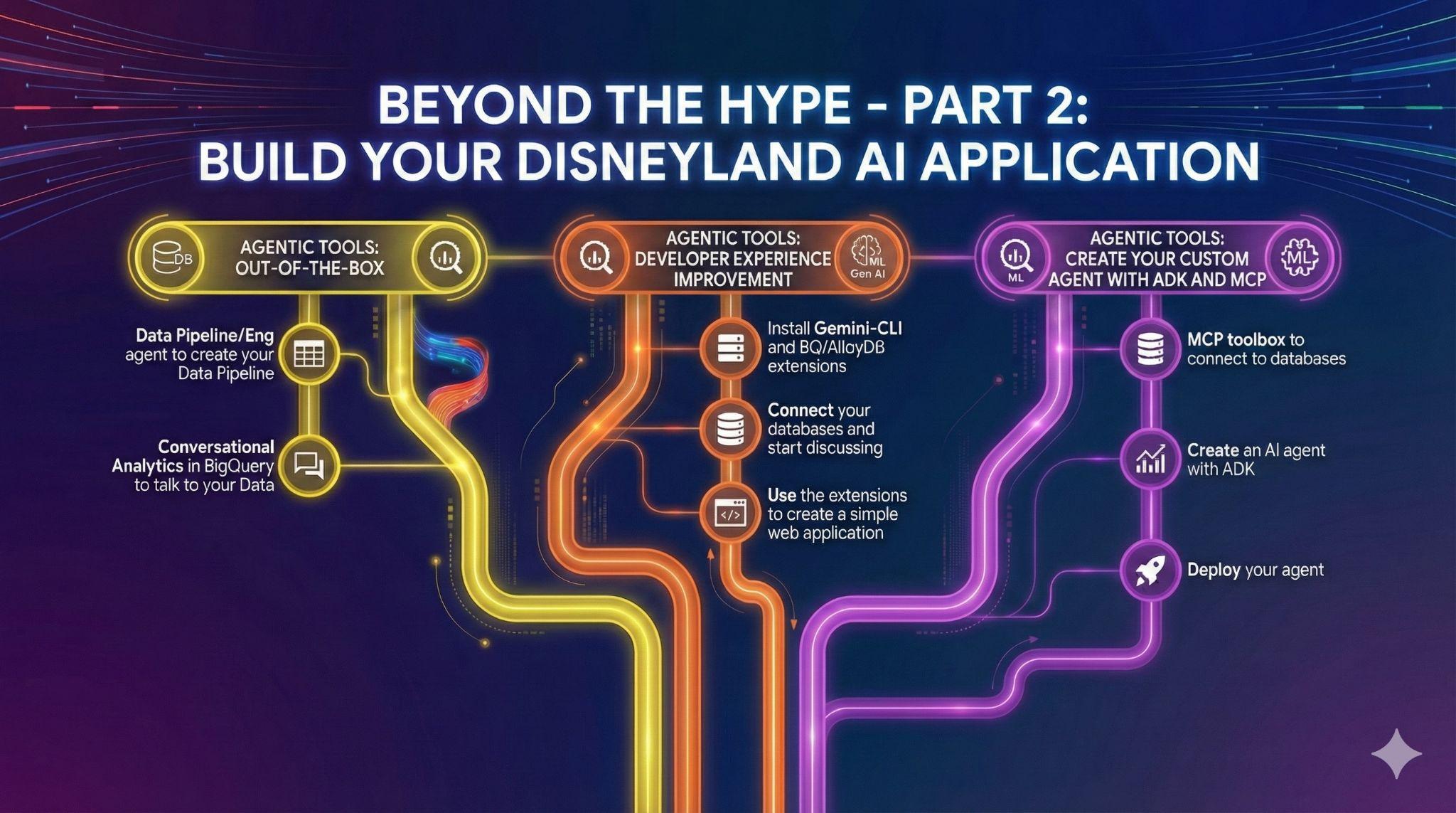
1. 🏰 Disneyland Data Analytics Hackathon (מהדורה שנייה – 3 בדצמבר) 🏰
סיכום | באירוע ההאקתון הזה, תבנו פייפליין של ניתוח נתונים מקצה לקצה, תוך שימוש ביכולות של AI/ML ב-Google Cloud. תטענו נתונים ל-AlloyDB, מסד נתונים מנוהל במלואו שתואם ל-PostgreSQL ומותאם לעומסי עבודה תובעניים. לאחר מכן תשתמשו ב-Datastream, שירות ללא שרת ללכידת נתוני שינוי (CDC), כדי להעביר את הנתונים ל-BigQuery, מחסן נתונים ללא שרת של Google Cloud. ב-BigQuery, תשתמשו ב-BigQuery ML, שמאפשר ליצור ולהפעיל מודלים של למידת מכונה ישירות ב-BigQuery באמצעות SQL סטנדרטי, כדי לנתח את הביקורות ולחזות את מספר המשתתפים. לבסוף, תתנסו בסוכנים, או באמצעות ניתוח נתונים שיחתי וסוכני נתונים, או באמצעות יצירת סוכן בהתאמה אישית, שמבוסס על ערכת הכלים של MCP ועל ערכת פיתוח הסוכנים (ADK), כדי ליצור אינטראקציה בשפה טבעית עם הנתונים. |
categories | docType:Codelab, product:Bigquery |
מחבר | Rayhane Rezgui, Matt Cornillon |
פריסה | גלילה |
רובוטים | noindex |
2. מבוא
ברוכים הבאים, מומחי נתונים לעתיד של דיסני!🪄
לא צריך יותר מדריכי נסיעות מייגעים וגלילה אינסופית בפורומים. תארו לעצמכם שאתם מתכננים את הנסיעה המושלמת לדיסנילנד, עם תובנות מבוססות-נתונים. באיזה פארק אפשר ליהנות מהחוויה הכי טובה? מתי הכי פחות עמוס? אתה יכול לחזות את הזמן הכי טוב להתגבר על התור הארוך הידוע לשמצה?
בהאקתון הזה, אתם יוצרים את כלי התכנון האולטימטיבי לדיסנילנד. יש לנו את הנתונים: ביקורות ממבקרים בסניפים ברחבי העולם, זמני המתנה היסטוריים ונתוני נוכחות. המשימה שלך? הפוך את הנתונים הגולמיים האלה לתובנות פרקטיות:
- איסוף נתונים: טוענים ל-AlloyDB, מסד הנתונים התואם ל-PostgreSQL עם ביצועים גבוהים, נתונים מגוונים כמו ביקורות על דיסנילנד, זמני המתנה ונתוני נוכחות.
- העברה חלקה: אפשר להשתמש ב-Datastream, שירות בלי שרת לסימון נתונים שהשתנו (CDC), כדי להעביר את המידע הדינמי הזה בקלות ל-BigQuery, מחסן הנתונים (data warehouse) העוצמתי בלי שרת של Google Cloud.
- חיזוי הקסם: שימוש ב-BigQuery ML כדי לנתח את הסנטימנט של הביקורות ולחזות את זמני ההמתנה ישירות באמצעות SQL. תוכלו לגלות באילו סניפים תמיד תקבלו שירות טוב, ומהו הזמן האופטימלי לביקור.
- לדבר עם הנתונים – פשוטו כמשמעו: משתמשים בכלים מוכנים מראש שמאפשרים לקבל תובנות בהינף שרביט.
- אינטראקציה חכמה: אפשר להוסיף לסוכנים יכולות חכמות באמצעות MCP Toolbox for Databases ו-ADK (ערכה לפיתוח סוכנים). אפשר לשאול, "What's the best attraction in DisneyLand Paris for space lovers, and what is the best time to join the queue?" ולקבל תשובות מיידיות שמבוססות על נתונים.
מכינים את הקרקע לגלות את הסודות של המקומות הקסומים ביותר בעולם ולבנות צינור לניתוח נתונים שמיקי מאוס היה גאה בו!

3. משימה 1: מפעילות לניתוח; ניתוח ביקורות על דיסנילנד באמצעות Gemini
בשלב הראשוני הזה, תאחזרו את הנתונים ממסד הנתונים התפעולי שלכם ב-AlloyDB ותטענו אותם ל-BigQuery לצורך ניתוח נתונים בהמשך.
בנוסף, תגדירו את כל מה שצריך ב-AlloyDB בשביל הסוכן העתידי שלכם.
טעינת נתונים ב-AlloyDB
קודם כל, בואו נייבא נתונים לאשכול AlloyDB ל-PostgreSQL.
אנחנו הולכים להטמיע 20,000 ביקורות על פארקי שעשועים של דיסנילנד ורשימה של אטרקציות.
אלה השלבים שצריך לבצע:
יצירת טבלאות:
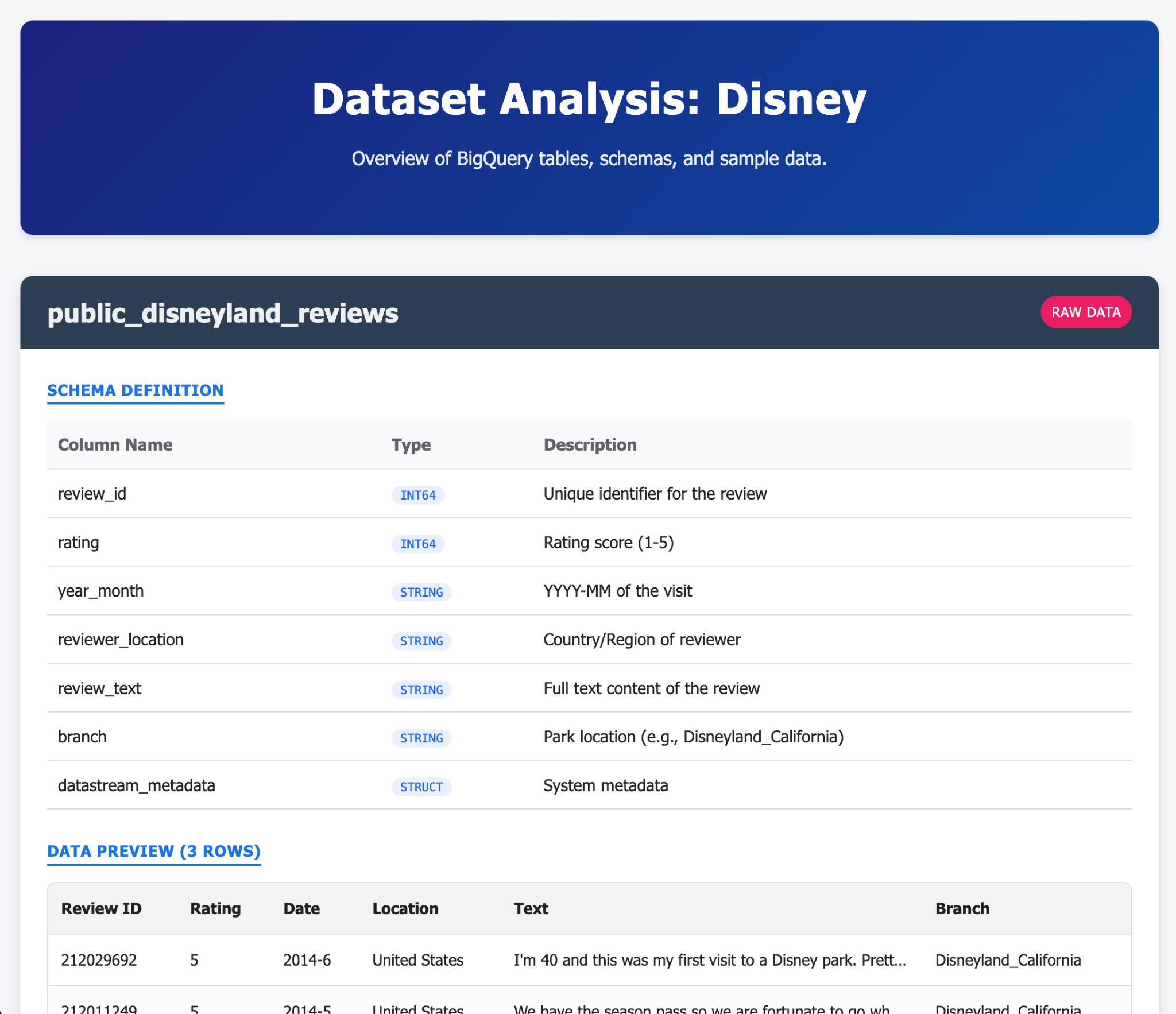
- יוצרים טבלה בשם disneyland_reviews עם 6 עמודות: review_id ו-rating כמספר שלם, year_month, reviewer_location, review_text, branch כטקסט.
- יוצרים טבלה בשם disneyland_attractions עם 4 עמודות: attraction_id (מזהה האטרקציה) כמספר שלם, branch (סניף), name (שם) ו-description (תיאור) כטקסט.
באמצעות הכלי הרצוי, מייבאים נתונים מקובצי ה-CSV:
gs://hackathon_data_disneyland_<YOUR_PROJECT_3DIGITS>/reviews.csvלטבלת הביקורות-
gs://hackathon_data_disneyland_<YOUR_PROJECT_3DIGITS>/attractions.csvלטבלת האטרקציות
כדי לספק המלצות לאטרקציות, אנחנו צריכים ליצור הטבעות של תיאורי האטרקציות:
- התקנת התוסף pgvector ב-AlloyDB
- מוסיפים עמודת וקטור בשם embedding לטבלה attraction
- יצירה ואכלוס של הטמעת התיאורים באמצעות האינטגרציה המובנית בין AlloyDB לבין Vertex AI
מעבר מנתונים תפעוליים לנתונים אנליטיים באמצעות Datastream
כדי להזרים את הנתונים מ-AlloyDB ל-BigQuery, נשתמש ב-Google Datastream. זהו פתרון serverless יעיל שמקשיב לכל השינויים בטבלאות המקור (באמצעות סימון נתונים שהשתנו) ושולח אותם ל-BigQuery.
כדי לשכפל שינויים מ-AlloyDB באמצעות Datastream, צריך ליצור ב-Postgres מה שנקרא פרסום ומשבצת שכפול.
מריצים את השאילתות הבאות באשכול AlloyDB (צריך להריץ אותן אחת בכל פעם):
CREATE PUBLICATION pub_disney FOR TABLE disneyland_reviews, disneyland_attractions;
ALTER USER postgres WITH REPLICATION;
SELECT PG_CREATE_LOGICAL_REPLICATION_SLOT('slot_disney', 'pgoutput');
תצטרכו להשתמש בשם של אתר החדשות וביחידת הקיבולת לשכפול בזרם, אז חשוב לזכור את השמות!
זהו, עכשיו אפשר ליצור שידור!
אלה השלבים שצריך לבצע ב-Datastream:
- יצירת פרופיל מקור לאשכול AlloyDB (שימוש בכתובת ה-IP הציבורית)
- יצירת פרופיל יעד ל-BigQuery
- יוצרים זרם מ-AlloyDB ל-BigQuery.
הנתונים אמורים להיות זמינים ב-BigQuery תוך כמה דקות.
גילוי נתונים ב-BigQuery
עכשיו כשהנתונים שלנו נמצאים ב-BigQuery, כדאי להכיר את השיפורים החדשים בממשק לפני שמתחילים לעבוד!
הוספנו 3 פונקציות חדשות שכבר מופיעות בחלונית הניתוח ב-BigQuery.

- סקירה כללית: מכיל מידע על תכונות של BigQuery, סיורים שיעזרו לכם להתחיל בניתוח נתונים ועוד.
- חיפוש: מבצעים חיפוש סמנטי בנכסי הנתונים.
- נציגים: ששש! נשמור את זה למועד מאוחר יותר 🤫
חיפוש סמנטי של הנתונים ב-BigQuery
עוברים לכרטיסייה Search (חיפוש) בחלונית BigQuery exploration (הכרת BigQuery), ומנסים מונחים שקשורים ל-Disney, כמו 'attractions' (אטרקציות) או 'branch' (סניף).
הדמיה של הנתונים ב-BigQuery
עכשיו אפשר להציג את הנתונים ב-BigQuery ולבצע בהם שינויים. לשם כך, אפשר להריץ את השאילתה הזו בכרטיסיית שאילתה חדשה.
SELECT
*
FROM
[dataset_name].[table_name];
יצירת תובנות לגבי הנתונים בטבלת הביקורות
במשימה הזו תפעילו את התובנות לגבי הנתונים בטבלה disneyland_reviews במערך הנתונים disney.
תובנות לגבי נתונים הוא כלי שמתאים לכל מי שרוצה לבחון את הנתונים שלו ולקבל תובנות בלי לכתוב שאילתות SQL מורכבות.
הפעולה הזו עשויה להימשך כמה דקות.
שאילתה על הטבלה disneyland_reviews ללא SQL
התובנות שיצרתם בקטע הקודם מוכנות עכשיו. במשימה הזו תשתמשו בהנחיה שנוצרה מהתובנות האלה כדי לשלוח שאילתה לטבלה disneyland_reviews בלי להשתמש בקוד.
בוחרים תובנה ומריצים את השאילתה שמשויכת אליה. לדוגמה, אפשר למצוא את השאילתה שמחשבת את ההפרש בדירוג הממוצע בין חודשים עוקבים לכל סניף. הוא ייראה כך:
WITH
monthly_avg AS (
SELECT
branch,
year_month,
AVG(rating) AS avg_rating
FROM
[dataset_name].[table_name]
WHERE
year_month IS NOT NULL
GROUP BY
1,
2 )
SELECT
branch,
year_month,
avg_rating,
avg_rating - LAG(avg_rating, 1, 0) OVER (PARTITION BY branch ORDER BY year_month) AS rating_difference
FROM
monthly_avg
ORDER BY
branch,
year_month;
שימוש במנוע הידע של BigQuery כדי להבין טוב יותר את הנתונים
קודם כול, נתחיל בבדיקה של הכרטיסייה תובנות ברמת מערך הנתונים. כך נוכל לקבל מושג לגבי הקשרים הנסתרים בין הטבלאות במערך הנתונים של דיסני. לאחר מכן,
- יוצרים תיאור של קבוצת הנתונים באמצעות Gemini ומוסיפים אותו לפרטים של קבוצת הנתונים.
- תייצר תיאור של הביקורות והאטרקציות בטבלאות, וגם של כל אחת מהעמודות בטבלאות האלה, ותשמור אותו.
ביצוע סריקת פרופיל של הנתונים
המטרה של הקטע הזה היא לנקות ולהכין את הנתונים. עם זאת, אתם לא מכירים את התפלגות הערכים של כל עמודה. כדי לדעת אילו שלבי טרנספורמציה צריך לבצע בנתונים, צריך ליצור פרופיל של הנתונים.
הקטלוג האוניברסלי של Dataplex ב-Google Cloud מבצע אוטומטית סריקות פרופילים כדי לספק מדדים עקביים של איכות הנתונים. הסטטיסטיקות העיקריות שזוהו כוללות ספירת ערכי null, ערכים ייחודיים, טווחי נתונים והתפלגויות ערכים. אפשר להפעיל סריקת פרופיל דרך ממשק BigQuery.
הפעולה יכולה להימשך כמה דקות, אז אפשר לעבור לקטע הבא בזמן ההמתנה.
עונים על השאלות הבאות:
- מה הדירוג הממוצע של דיסנילנד?
- איפה נמצאים רוב כותבי הביקורות?
- האם כל הביקורות ייחודיות?
- מה אחוז הנתונים החסרים בעמודה Year_Month?
ביצוע סריקה של איכות הנתונים
Dataplex Universal Catalog automatic data quality מאפשר לכם להגדיר ולמדוד את איכות הנתונים בטבלאות BigQuery. אתם יכולים להגדיר שהנתונים ייסרקו אוטומטית, שהנתונים יאומתו בהתאם לכללים מוגדרים, ושיוצגו התראות אם הנתונים לא עומדים בדרישות האיכות. אתם יכולים לנהל את כללי איכות הנתונים ואת הפריסות כקוד, וכך לשפר את תקינות צינורות הנתונים.
על סמך סריקת הפרופיל, מגדירים סריקת איכות (על לא יותר מ-10% מהנתונים כגודל מדגם) שכוללת:
- בודקת אם יש ערכי null בעמודה branch
- הפונקציה מבצעת בדיקת תקינות של הדירוג, כי הוא יכול להיות רק אחד מהערכים הבאים : 1,2,3,4,5
- בודק את הייחודיות של הערך review_id
מוודאים שהתוצאות של הסריקה מיוצאות לטבלה quality_scan_results ב-BigQuery.
כדאי לחשוב על כל הטרנספורמציות הפוטנציאליות שצריך להחיל על הנתונים.
הכנת הנתונים באמצעות הכלי להכנת נתונים של Gemini
אחרי שסיימתם את הסריקות של איכות הנתונים ופרופיל הנתונים, הגיע הזמן לנקות את הנתונים לפני שתנתחו אותם.
הכנת נתונים היא משאב של BigQuery שמשתמש ב-Gemini ב-BigQuery כדי לנתח את הנתונים שלכם ולספק הצעות חכמות לניקוי, לשינוי ולשיפור שלהם. אתם יכולים לצמצם באופן משמעותי את הזמן והמאמץ שנדרשים למשימות ידניות של הכנת נתונים.
בקטע הזה תשתמשו בהכנת נתונים כדי לבצע את הפעולות הבאות בטבלה disneyland_reviews:
- מסננים את השורות שבהן העמודה Branch היא NULL או מחרוזת ריקה.
- החלפת הערך 'missing' בעמודה Year_Month בערך Null.
- החלפת קווים תחתונים ברווחים בעמודת הענף כדי לשפר את הקריאות
- ייצוא לטבלה שעברה טרנספורמציה disneyland_reviews_cleaned
ניתוח ביקורות באמצעות Gemini
אחרי שמנקים את הנתונים, אפשר להתחיל לנתח אותם באמצעות BigQuery ML ומודלים של Gemini. יש לכם שני יעדים:
- חילוץ קטגוריות מביקורות
- ניתוח סנטימנטים של disneyland_reviews
BigQuery ML מאפשר לכם ליצור ולהפעיל מודלים של למידת מכונה (ML) באמצעות שאילתות GoogleSQL. מודלים של BigQuery ML מאוחסנים במערכי נתונים של BigQuery, בדומה לטבלאות ולתצוגות מפורטות. בנוסף, BigQuery ML מאפשר לכם לגשת למודלים של Vertex AI ולממשקי AI ב-Cloud API כדי לבצע משימות של בינה מלאכותית (AI) כמו יצירת טקסט או תרגום אוטומטי. Gemini ל-Google Cloud מספק גם עזרה מבוססת-AI למשימות ב-BigQuery.
אפשר להשתמש ב-ML.GENERATE_TEXT או ב-AI.GENERATE (גרסת טרום-השקה) עם מודלים של Gemini Pro או Flash.
השלבים הבאים יעזרו לכם להשתמש בפונקציה ML.GENERATE_TEXT.
יצירת קישור למשאבים ב-Cloud והקצאת תפקיד IAM
צריך ליצור קישור למשאבים ב-Cloud ב-BigQuery למודלים של Vertex AI, כדי שתוכלו לעבוד עם מודלים של Gemini Pro ו-Gemini Flash. בנוסף, תצטרכו להקצות לחשבון השירות של חיבור משאבי הענן הרשאות IAM באמצעות תפקיד, כדי לאפשר לו גישה לשירותי Vertex AI.
הקצאת התפקיד Vertex AI User לחשבון השירות של החיבור
נותנים לחשבון השירות של החיבור את התפקיד Vertex AI User כדי לאפשר לו להשתמש במודל שבחרתם (לדוגמה, gemini-2.5-flash). ההרשאה תתעדכן תוך דקה.
יצירת מודלים של Gemini ב-BigQuery
יוצרים את המודל באמצעות החיבור שלמעלה. לדוגמה, אפשר להשתמש בנקודת הקצה gemini-2.5-flash.
איך מבקשים מ-Gemini לנתח ביקורות של לקוחות לפי קטגוריות וסנטימנט
במשימה הזו תשתמשו במודל Gemini כדי לנתח כל ביקורת מלקוח לפי קטגוריות וסנטימנט, חיובי או שלילי.
ניתוח הביקורות מלקוחות לפי קטגוריות
הערה: מעכשיו, לצורך הניתוח, נשתמש רק ב-100 שורות, כי קריאה ל-Gemini על 20,000 שורות יכולה לקחת זמן.
Extract categories by modifying and running the following SQL Query:
CREATE OR REPLACE TABLE
[dataset_name].[results_table_name] AS (
SELECT Review_ID, Rating, Year_Month, Reviewer_Location, Review_Text, Branch, ml_generate_text_llm_result AS categories FROM
ML.GENERATE_TEXT(
MODEL [model_name],
(
SELECT Review_ID, Rating, Year_Month, Reviewer_Location, Review_Text, Branch, CONCAT(
'[WRITE YOUR PROMPT HERE].',
Review_Text) AS prompt
FROM (SELECT * FROM [dataset_name].[table_name] LIMIT 100)
),
STRUCT(
0.2 AS temperature, TRUE AS flatten_json_output)));
השאילתה הזו לוקחת ביקורות של לקוחות מהטבלה disneyland_reviews, ויוצרת הנחיות למודל gemini כדי לזהות קטגוריות בכל ביקורת. התוצאות צריכות להישמר בטבלה חדשה reviews_categories
. רק רגע. המודל מעבד את רשומות ביקורות מלקוחות במשך כ-30 שניות, והתוצאות מופיעות בטבלת הפלט.
הצגת התוצאות:
SELECT * FROM [dataset_name].[results_table_name];
כדאי להקדיש זמן לקריאת חלק מהקטגוריות.
ניתוח הסנטימנט של הביקורות מלקוחות כדי לזהות סנטימנט חיובי ושלילי
על סמך שאילתת ה-SQL לחילוץ מילות מפתח, כתוב שאילתה שמנתחת ביקורת לחיובית, שלילית וניטרלית בעמודה בשם 'סנטימנט'.
השאילתה הזו לוקחת ביקורות של לקוחות מהטבלה disneyland_reviews, ויוצרת הנחיות למודל gemini כדי לסווג את הסנטימנט של כל ביקורת. התוצאות נשמרות בטבלה חדשה reviews_analysis, כדי שתוכלו להשתמש בהן בהמשך לניתוח נוסף. צריך להמתין. המודל מעבד את רשומות ביקורות הלקוחות תוך כמה שניות. כשהמודל מסתיים, התוצאה מופיעה בטבלה reviews_analysis שנוצרת.
מעיינים בתוצאות:
SELECT * FROM [...];
בטבלה reviews_analysis יש עמודה בשם Sentiment שמכילה את ניתוח הסנטימנט, והיא כוללת את העמודות social_media_source, review_text, customer_id, location_id ו-review_datetime. כדאי לעיין בחלק מהרשומות. יכול להיות שתבחינו שחלק מהתוצאות של מילות מפתח חיוביות ושליליות לא בפורמט הנכון, וכוללות תווים מיותרים כמו נקודות או רווחים מיותרים. אפשר לנקות את הרשומות באמצעות התצוגה שלמטה.
יצירת תצוגה כדי לנקות את הרשומות
יוצרים תצוגה שמבצעת סניטציה של הערכים בעמודה 'סנטימנט' על ידי:
- שימוש בפונקציה LOWER כדי לוודא שכל הערכים הם באותיות קטנות.
- הסרת סימני פיסוק (נקודה , פסיק ורווח) באמצעות REPLACE
CREATE OR REPLACE VIEW [view_name] AS
SELECT [SANITIZATION_EXPRESSION] AS sentiment,
Review_ID, Rating, Year_Month, Reviewer_Location, Review_Text, Branch,
FROM `disney.reviews_analysis`;
השאילתה יוצרת את התצוגה cleaned_data_view וכוללת את תוצאות הסנטימנט, את הטקסט של הביקורת, Review_ID, Rating, Year_Month, Reviewer_Location, Review_Text and Branch. לאחר מכן, הוא לוקח את תוצאת הסנטימנט (חיובי או שלילי) ומוודא שכל האותיות הן אותיות קטנות, ושהוסרו תווים מיותרים כמו רווחים או נקודות. התצוגה שתתקבל תאפשר לכם לבצע ניתוח נוסף בשלבים הבאים של שיעור ה-Lab הזה.
- כדי לראות את השורות שנוצרו, אפשר להריץ את השאילתה הבאה על התצוגה.
SELECT * FROM [view_name];
יצירת דוח של מספר הביקורות החיוביות והשליליות באמצעות Data Canvas
עכשיו הגיע הזמן לנתח את התוצאות. נתחיל בפעולה ישירות ב-BigQuery, דרך קנבס הנתונים. זהו כלי שמאפשר לכם לחפש נתונים (סמנטיים או מילות מפתח), לשלוח שאילתות ולצרף טבלאות, ליצור גרפים ולקבל תובנות על ידי יצירת תהליך של בד ציור.
המטרה הסופית היא ליצור תרשים של אחוז הביקורות החיוביות לעומת אחוז הביקורות השליליות . לדוגמה:

יצירת תרשים של מספר הביקורות לכל קטגוריה, וגם של התפלגות הביקורות החיוביות והשליליות לכל קטגוריה
טיפ: הפעילו והשתמשו ב-ניתוח מתקדם ב-Data Canvas, שמריץ מחברת Python בתוך אזור עריכה.
4. משימה 2: ניתוח תמונות של פארקי שעשועים כדי לזהות תמונות של דיסנילנד וחילוץ עובדות מעניינות מחוברות מידע על הפארק
ניתוח תמונות ב-BigQuery
יש לכם גישה לכמה תמונות מרתקות ומושכות של פארק השעשועים שצולמו על ידי מבקרים במהלך השנים. אתם כל כך מתרגשים לקראת הנסיעה הקרובה! אבל אתם לא יודעים אילו מהן הן תמונות אמיתיות של דיסנילנד. המשימה שלכם היא לזהות את המשתמשים האלה. התמונות נמצאות ב-gs://hackathon_data_disneyland_<YOUR_PROJECT_3DIGITS>/attraction_parc_photos/.

Is_disneyland: False

Is_disneyland: True
כדי לבצע את הניתוח הזה במהירות. מומלץ להשתמש בטבלאות אובייקטים של BigQuery וב-Gemini באמצעות BigQuery ML (ML.GENERATE_TEXT).
האם תוכל לאמת את הפלט של Gemini על ידי בדיקת כמה תמונות?
יצירת מערכת RAG משלכם באמצעות BigQuery על ברושורים של דיסנילנד
בזמן ההמתנה בתור, אתם רוצים לקבל עובדות מעניינות או פרטים טכניים על האטרקציה שאתם מחכים לה.
ב-gs://hackathon_data_disneyland_<YOUR_PROJECT_3DIGITS>/disneyland_brochures/, אפשר למצוא קובצי PDF עם חוברות מידע על כל הפארקים בעולם.
המטרה: ליצור מערכת Retrieval-Augmented Generation (RAG) בתוך BigQuery, כדי לאפשר למשתמשים לשאול שאלות מורכבות על הפארק על סמך מסמכי PDF מסוימים.
כדי לעשות את זה, אתם צריכים:
- יצירת טבלת אובייקטים של קובצי PDF
- יוצרים פונקציה מוגדרת על ידי המשתמש (UDF) ב-Python כדי לחלק קובצי PDF לחלקים. דוגמה שאפשר להשתמש בה:
CREATE OR REPLACE FUNCTION disney.chunk_pdf(src_json STRING, chunk_size INT64, overlap_size INT64)
RETURNS ARRAY<STRING>
LANGUAGE python
WITH CONNECTION `[LOCATION].[CONN_NAME]`
OPTIONS (entry_point='chunk_pdf', runtime_version='python-3.11', packages=['pypdf'])
AS """
import io
import json
from pypdf import PdfReader # type: ignore
from urllib.request import urlopen, Request
def chunk_pdf(src_ref: str, chunk_size: int, overlap_size: int) -> str:
src_json = json.loads(src_ref)
srcUrl = src_json["access_urls"]["read_url"]
req = urlopen(srcUrl)
pdf_file = io.BytesIO(bytearray(req.read()))
reader = PdfReader(pdf_file, strict=False)
# extract and chunk text simultaneously
all_text_chunks = []
curr_chunk = ""
for page in reader.pages:
page_text = page.extract_text()
if page_text:
curr_chunk += page_text
# split the accumulated text into chunks of a specific size with overlaop
# this loop implements a sliding window approach to create chunks
while len(curr_chunk) >= chunk_size:
split_idx = curr_chunk.rfind(" ", 0, chunk_size)
if split_idx == -1:
split_idx = chunk_size
actual_chunk = curr_chunk[:split_idx]
all_text_chunks.append(actual_chunk)
overlap = curr_chunk[split_idx + 1 : split_idx + 1 + overlap_size]
curr_chunk = overlap + curr_chunk[split_idx + 1 + overlap_size :]
if curr_chunk:
all_text_chunks.append(curr_chunk)
return all_text_chunks
""";
- ניתוח קובץ ה-PDF לחלקים
- יצירת הטמעה אחרי יצירת מודל מרחוק
- הרצת חיפוש וקטורי כדי למצוא את "
Ou manger un repas tex-mex à volonté?" או "where to eat a tex-mex meal buffet-style?" - תשובה מועשרת על סמך תוצאות חיפוש וקטורי לשאלה "
Ou manger un repas tex-mex à volonté?" או "where to eat a tex-mex meal buffet-style?"
5. משימה 3: למידת מכונה בקנה מידה נרחב באמצעות BigQuery: חיזוי, סיווג ודירוג
תחזית לזמני המתנה
התמונות ממש מגניבות! אתם לא יכולים לחכות! כדי לדעת אילו אטרקציות לבחור ואילו אטרקציות כדאי להימנע מהן, אתם רוצים לדעת את זמני ההמתנה בפועל לחלק מהאטרקציות בין פריז לקליפורניה. המשימה שלך היא לחזות את זמני ההמתנה בכל מתקן באמצעות למידת מכונה (Arima plus או TimesFM) כל 30 דקות בשנת 2025.
הנתונים שבהם תשתמשו נמצאים בקובץ ה-CSV הזה: gs://hackathon_data_disneyland_<YOUR_PROJECT_3DIGITS>/waiting_times.csv
השלבים של המשימה:
- טוענים את הקובץ למערך הנתונים ב-BigQuery בטבלה בשם waiting_times.
- אימון מודל חיזוי על הנתונים שלכם (Arima_Plus) או חיזוי ישירות באמצעות AI.Forecast
- הערכת הביצועים של המודל או השוואה בין הנתונים החזויים לבין נתוני הקלט
סיווג הנסיעות לפי עוצמה
אתם מבקרים בדיסנילנד עם חברים, ולמרות שהפארק בדרך כלל מתאים למשפחות, חלק מהמתקנים יכולים להיות עוצמתיים מדי עבור חלק מהאנשים. נשתמש בפונקציות AI מנוהלות של BigQuery כדי לסווג את האטרקציות ולדרג אותן לפי רמת הריגוש והעוצמה, בלי הטיה אנושית, כדי שנוכל להתאים את עצמנו לכולם.
- תשתמש ב-
AI.CLASSIFYכדי לסווג נסיעות על סמך התיאורים שלהן לאחת משלוש קטגוריות קסומות: [קלות, מרגשות, קיצוניות]
דירוג המתקנים לפי רמת הריגוש
- אפשר להשתמש ב-
AI.SCOREכדי להשוות בין האטרקציות ולסדר אותן לפי רמת הריגוש, כאשר דרגה 10 היא הקיצונית ביותר ודרגה 1 היא הנמוכה ביותר.
6. משימה 3 – בונוס: Reverse-ETL, מ-BigQuery ל-AlloyDB
השתמשתם ביכולות המתקדמות של BigQuery כדי להפיק תובנות מכמויות גדולות של נתונים. עכשיו אתם רוצים שהתובנות האלה יהיו פרקטיות באפליקציות התפעוליות שלכם (ובסוכני ה-AI!).
אבל איך? פשוט הולכים בכיוון ההפוך! AlloyDB ל-Postgres מצטיין בהצגת נתונים עם זמן אחזור נמוך ומהירות גבוהה, ומתאים באופן מושלם לאפליקציות קריטיות שפונות למשתמשים. אז בואו נבצע ETL הפוך לנתונים שיצרנו.
כדי לעשות את זה, נשתמש בתכונה חדשה לגמרי, שעדיין נמצאת בתצוגה מקדימה פרטית, שנקראת 'תצוגות BigQuery' ב-AlloyDB. התכונה הזו מאפשרת לכם להריץ שאילתות על נתונים ב-BigQuery ישירות במסד הנתונים של Postgres.
קודם צריך להעניק לחשבון השירות של אשכול AlloyDB את ההרשאות הנדרשות לשליחת שאילתות ל-BigQuery.
gcloud beta alloydb clusters describe <CLUSTER ID> --region=europe-west1
הפלט מכיל את השדה serviceAccountEmail, שהוא חשבון השירות של האשכול הזה.
במסוף Google Cloud, עוברים לדף IAM ומעניקים את ההרשאות הבאות לישות הזו:
- צפייה בנתוני BigQuery (roles/bigquery.dataViewer)
- משתמש בהפעלת קריאה ב-BigQuery (roles/bigquery.readSessionUser)
עכשיו עוברים אל AlloyDB Studio במסוף ומתחברים למסד הנתונים postgres.
מריצים את השאילתות הבאות כדי להתקין ולהגדיר את התכונה החדשה:
CREATE EXTENSION bigquery_fdw;
CREATE SERVER bq_disney FOREIGN DATA WRAPPER bigquery_fdw;
CREATE USER MAPPING FOR postgres SERVER bq_disney ;
עכשיו אפשר ליצור 'טבלה חיצונית' שתמופה לטבלה קיימת ב-BigQuery. משתמשים בכל טבלה שיצרתם במשימה 3. דוגמה לתחביר:
CREATE FOREIGN TABLE reviews_analysis ( "Review_ID" int,
"Sentiment" text) SERVER bq_disney OPTIONS (PROJECT 'bqml-hack25par-xxx',
dataset 'disney',
TABLE 'reviews_analysis');
הכול מוכן, אפשר להריץ שאילתה על הטבלה. מריצים פקודת SELECT ראשונה כדי לאמת את הקישור בין AlloyDB ל-BigQuery, ובסיום יוצרים טבלה חדשה ב-AlloyDB כדי להטמיע את הנתונים מהטבלה החיצונית.
7. משימה 4: סוכני נתונים מוכנים לשימוש
יש לכם חברים שרוצים לתרום לפרויקט של אפליקציית Disneyland. יש להם גישה לנתונים ב-BigQuery, אבל רמות הידע שלהם ב-SQL ובהנדסת נתונים משתנות. אתם רוצים להשתמש בסוכני הנתונים ששולבו לאחרונה בממשק המשתמש של BigQuery כדי לעזור לחברים שלכם:
- יצירת צינורות נתונים.
- שיתוף פעולה בכתיבת קוד SQL.
- לדבר עם הנתונים שלהם.
סוכני הנדסת נתונים לאוטומציה של צינורות עיבוד נתונים
יוצרים תצוגה חדשה average_waiting_time שמבצעת איחוד (join) של הטבלה waiting time והטבלה attractions, ומחשבת את הערך הממוצע של waiting_time לכל attraction, באמצעות סוכן הנדסת הנתונים.
יצירת סוכן לניתוח נתונים שיכול לנהל שיחות ב-BigQuery
מה אם הייתם יכולים ליצור סוכן שידבר עם הנתונים שלכם, בלי קוד, בלי SQL, בלי פריסה ומתוך הממשק של BigQuery? זה היה מגניב, נכון? אפשר לעשות את זה היום באמצעות הכרטיסייה 'סוכנים' ב-BigQuery.

- תצור סוכן בשם my_disney_friend שמתחבר לטבלאות של דיסני. כדי לשפר את הביצועים של הסוכן, אפשר למלא את ההוראות לסוכן. אפשר לשאול שאלות כמו "what percentage of positive vs negative reviews, what's the average waiting time per attraction,etc ... ?"
- מפרסמים את הסוכן ב-BigQuery וב-API (תשתמשו בו בהמשך).
8. משימה 5: שיפור חוויית הפיתוח באמצעות Gemini-CLI
בעידן ה-AI, בניית תוכנה נגישה יותר מאי פעם. יש לכם אלפי רעיונות לאפליקציה שלכם לדיסנילנד, ואתם רוצים להשתמש בנתונים שלכם בצורה הכי יעילה. אתם רוצים לעשות יותר מסתם לדבר עם הנתונים, עכשיו אתם צריכים לפעול!
כדי לעזור לך בדרך הזו, תצטרך עזרה. אנחנו כאן כדי לעזור.
Gemini CLI הוא סוכן AI בקוד פתוח שמאפשר לנצל את היכולות של Gemini ישירות בטרמינל. מפתחים יכולים ליצור אפליקציות עוצמתיות, ובזכות התוספים הם יכולים גם ליצור אינטראקציה עם שרתים שונים של MCP (Model Context Protocol).
בין התוספים האלה, אפשר למצוא גם תוספים לשליחת שאילתות לנתוני AlloyDB או BigQuery.
במשימה הזו, המטרה היא:
- התקנת Gemini-CLI (בטרמינל שלכם או ב-Cloud Shell)
- התקנת תוספים ל-BigQuery ול-AlloyDB Gemini-CLI
- יצירת קובץ סביבה שמאפשר ל-Gemini-CLI להתחבר למופעי BigQuery ו-AlloyDB
- מבקשים מ-Gemini-CLI ליצור דף HTML יחיד ומעוצב שמסביר את התוכן של מסד הנתונים של AlloyDB
- מבצעים את אותה פעולה ב-BigQuery
הנה כמה דוגמאות לתוכן שאפשר ליצור בהנחיה אחת (או בכמה הנחיות) באמצעות Gemini-CLI והתוספים שלו. עכשיו דמיינו שאתם יכולים לעשות את זה עם אפליקציות מהחיים האמיתיים. 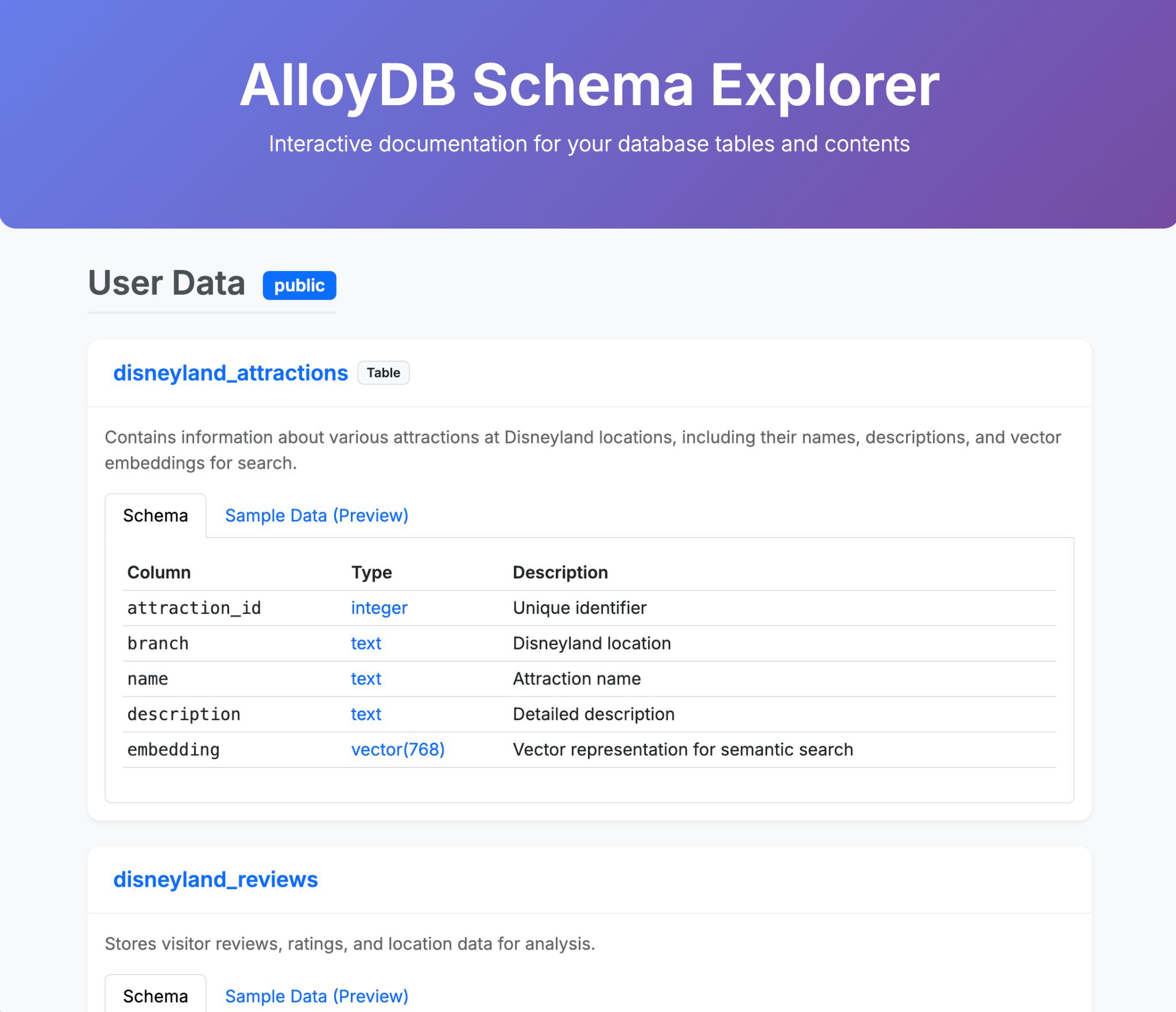
9. משימה 6: יצירת סוכן AI כדי לבצע פעולות לגבי הנתונים
כדי להציע חוויית משתמש חדשה לגמרי למבקרים בדיסנילנד, תיצור עוזר דיגיטלי שיוכל לעזור להם במהלך הטיול. הנציג יוכל:
- רשימה של כל האטרקציות הזמינות בפארק
- המלצה על אטרקציה על סמך ציפיות
- הוספת ביקורות על אטרקציה
- הצגת הערכה של זמן ההמתנה לאטרקציה בשעות הקרובות
- סקירה כללית של הביקורות על אטרקציה ספציפית
תקפיד שהעוזר יוכל לענות רק על שאלות שקשורות לדיסנילנד, ושהתשובות יהיו בנימה ידידותית. כדאי לשנות את ההנחיה לסוכן כדי לוודא שהוא בוחר את הכלים הנכונים לצרכים של המשתמש.
אלה השלבים שצריך לבצע:
- פריסת שרת MCP toolbox for databases שמשתמש ב-AlloyDB וב-BigQuery כמקורות
- תצהיר על 5 כלים שונים לשרת ה-MCP שלך שמבצעים שאילתות ב-AlloyDB וב-BigQuery וממפים את פעולות הסוכן שצוינו קודם
- שימוש בממשק המשתמש של MCP Toolbox כדי לאמת כל אחד מהכלים
- פריסת סוכן באמצעות ערכה לפיתוח סוכנים (ADK) שיכול להשתמש בכלים שנחשפים על ידי שרת MCP toolbox
- מתחברים לממשק האינטרנט של ADK ומציגים דיון מלא עם העוזר הדיגיטלי, כולל כל הכלים הזמינים
שלב בונוס אם מסיימים מוקדם:
הסוכן מוכן? בואו נבצע פריסה ל-Agent Engine!