
1. 🏰 Hackathon Disneyland Data Analytics (2e édition, 3 décembre) 🏰
Résumé | Dans ce hackathon, vous allez créer un pipeline d'analyse de données de bout en bout en exploitant les capacités d'IA/de ML sur Google Cloud. Vous chargerez des données dans AlloyDB, une base de données entièrement gérée et compatible avec PostgreSQL, optimisée pour les charges de travail exigeantes. Vous utiliserez ensuite Datastream, un service de capture de données modifiées (CDC) sans serveur, pour les transférer vers BigQuery, l'entrepôt de données sans serveur de Google Cloud. Dans BigQuery, vous appliquerez BigQuery ML, qui vous permet de créer et d'exécuter des modèles de machine learning directement dans BigQuery à l'aide de SQL standard, pour l'analyse des avis et la prévision de la fréquentation. Enfin, vous allez vous familiariser avec les agents, soit prêts à l'emploi grâce à Conversational Analytics et aux agents de données, soit en créant un agent personnalisé à l'aide d'Agent Development Kit et de MCP Toolbox pour interagir avec vos données en langage naturel. |
categories | docType:Codelab, product:Bigquery |
Auteur | Rayhane Rezgui, Matt Cornillon |
Disposition | défilement |
Robots | noindex |
2. Introduction
Bienvenue, futurs magiciens des données Disney !🪄
Oubliez les guides de voyage fastidieux et les forums interminables. Imaginez que vous planifiez le voyage parfait à Disneyland, en vous appuyant sur des insights basés sur les données. Quel parc offre la meilleure expérience ? Quand y a-t-il le moins de monde ? Peux-tu prédire le meilleur moment pour éviter cette file d'attente interminable ?
Dans ce hackathon, vous allez créer l'outil de planification Disneyland ultime. Nous disposons de données telles que les avis des visiteurs dans les différentes succursales du monde, les temps d'attente historiques et les chiffres de fréquentation. Votre mission ? Transformez ces données brutes en insights exploitables :
- Collecter des données : chargez diverses critiques, temps d'attente et chiffres de fréquentation de Disneyland dans AlloyDB, notre base de données hautes performances compatible avec PostgreSQL.
- Transfert fluide : utilisez Datastream, notre service de capture de données modifiées sans serveur, pour transférer facilement ces informations dynamiques vers BigQuery, l'entrepôt de données sans serveur puissant de Google Cloud.
- Prédire la magie : exploitez BigQuery ML pour analyser le sentiment des avis et prévoir les temps d'attente directement avec SQL. Découvrez les agences qui font toujours le bonheur de leurs clients et le meilleur moment pour vous y rendre.
- Parlez à vos données, littéralement ! Utilisez des outils prédéfinis qui vous permettent d'obtenir des insights en un clin d'œil.
- Interaction intelligente : couronnez votre création avec un agent intelligent, optimisé par MCP Toolbox for Databases et ADK (Agent Development Kit). Posez la question "Quelle est la meilleure attraction de Disneyland Paris pour les passionnés de l'espace, et quel est le meilleur moment pour faire la queue ?" et obtenez des réponses instantanées basées sur des données.
Préparez-vous à découvrir les secrets des lieux les plus magiques de la planète et à créer un pipeline d'analyse de données qui ferait la fierté de Mickey !
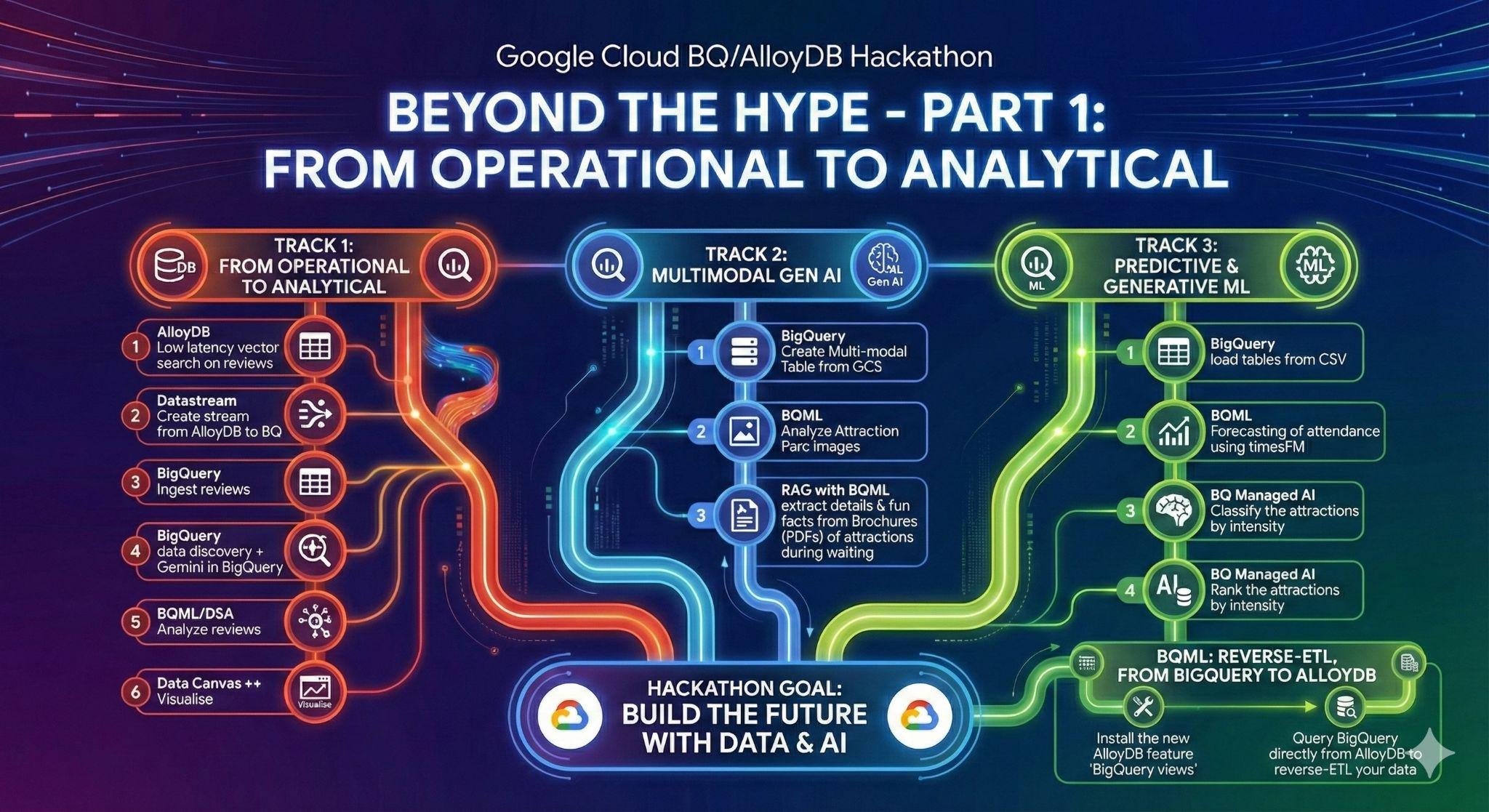
3. Tâche 1 : Passer de l'opérationnel à l'analytique ; analyser les avis sur Disneyland avec Gemini
Pour cette première étape, vous allez récupérer les données de votre base de données opérationnelle AlloyDB et les charger dans BigQuery pour les analyser par la suite.
Vous configurerez également tout ce dont vous aurez besoin dans AlloyDB pour votre futur agent.
Chargement de données dans AlloyDB
Commençons par importer des données dans notre cluster AlloyDB pour PostgreSQL.
Nous allons ingérer 20 000 avis sur les parcs d'attractions Disneyland et une liste d'attractions.
Voici les étapes à suivre :
Création de tableaux :
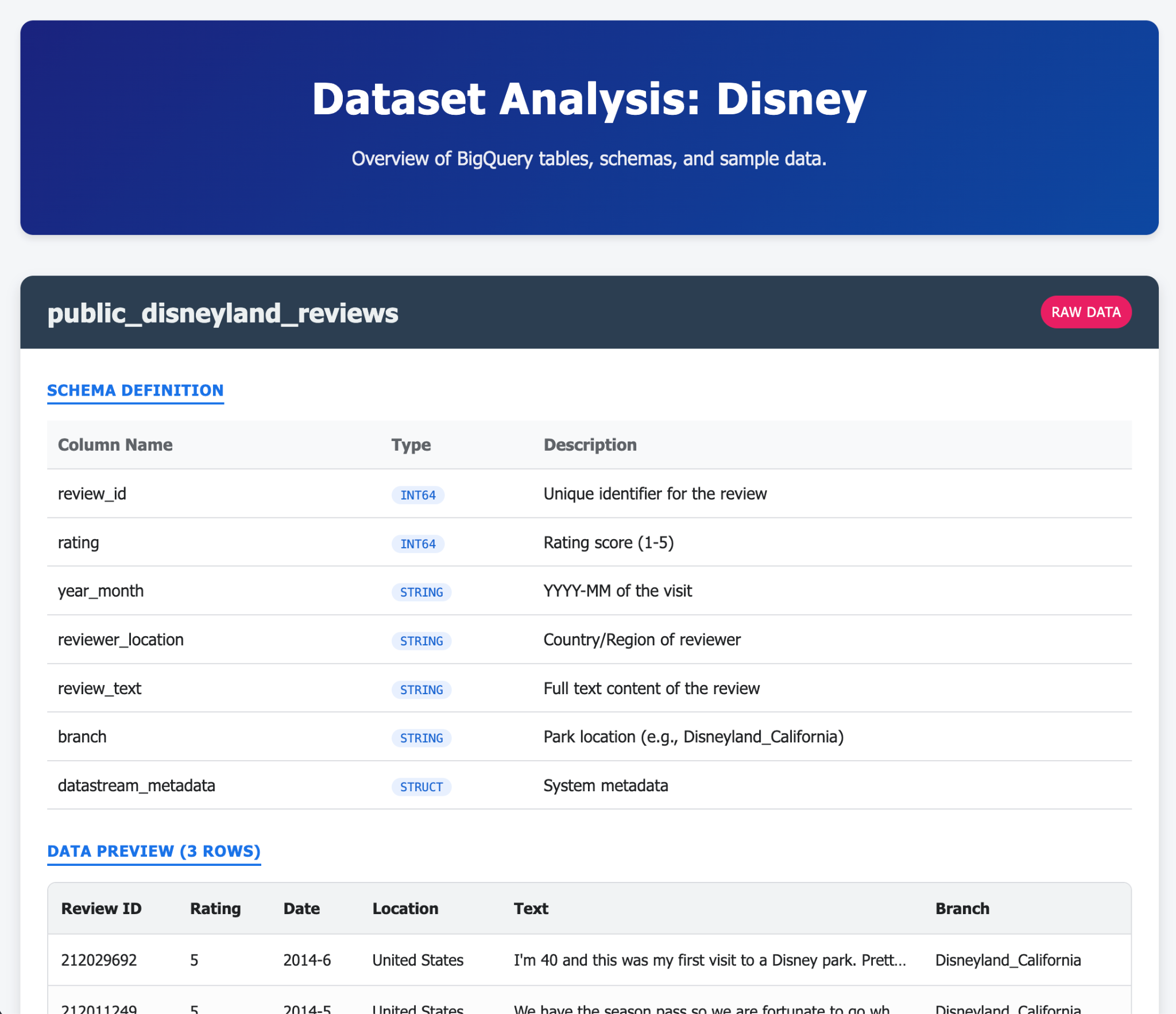
- Créez une table disneyland_reviews avec six colonnes : review_id et rating en tant qu'entiers, year_month, reviewer_location, review_text et branch en tant que texte.
- Créez une table disneyland_attractions avec quatre colonnes : attraction_id (entier), branch, name et description (texte).
À l'aide de l'outil de votre choix, importez les données des fichiers CSV :
gs://hackathon_data_disneyland_<YOUR_PROJECT_3DIGITS>/reviews.csvpour la table des avisgs://hackathon_data_disneyland_<YOUR_PROJECT_3DIGITS>/attractions.csvpour la table "Attractions"
Pour fournir des recommandations d'attractions, nous devons créer des embeddings de leur description :
- Installer l'extension pgvector dans AlloyDB
- Ajoutez une colonne de vecteur appelée "embedding" à votre table "attraction".
- Générez et renseignez l'embedding des descriptions à l'aide de l'intégration native entre AlloyDB et Vertex AI.
Passer des données opérationnelles aux données analytiques avec Datastream
Pour diffuser nos données d'AlloyDB vers BigQuery, nous allons utiliser Google Datastream. Il s'agit d'une solution sans serveur puissante qui écoute toutes les modifications apportées aux tables sources (à l'aide de la capture des données modifiées) et les envoie à BigQuery.
Pour pouvoir répliquer les modifications apportées à AlloyDB avec Datastream, nous devons créer ce que l'on appelle une publication et un emplacement de réplication sur Postgres.
Exécutez les requêtes suivantes sur votre cluster AlloyDB (vous devez les exécuter une par une) :
CREATE PUBLICATION pub_disney FOR TABLE disneyland_reviews, disneyland_attractions;
ALTER USER postgres WITH REPLICATION;
SELECT PG_CREATE_LOGICAL_REPLICATION_SLOT('slot_disney', 'pgoutput');
Vous utiliserez l'emplacement de publication et de réplication dans votre flux. N'oubliez donc pas les noms !
Et voilà, nous pouvons maintenant créer un flux !
Voici les étapes à suivre dans Datastream :
- Créez un profil source pour votre cluster AlloyDB (utilisez l'adresse IP publique).
- Créer un profil de destination pour BigQuery
- Créez un flux d'AlloyDB vers BigQuery.
Les données devraient être disponibles dans BigQuery en quelques minutes.
Découverte des données dans BigQuery
Maintenant que nos données sont dans BigQuery, assurons-nous de connaître les nouvelles améliorations de l'interface avant de nous mettre au travail.
Trois nouvelles fonctions sont déjà disponibles dans le panneau d'exploration BigQuery.

- Présentation : contient des informations sur les fonctionnalités BigQuery, des visites guidées pour commencer à analyser les données, entre autres possibilités.
- Rechercher : effectuez une recherche sémantique sur vos composants de données.
- Agents : Chut ! Nous y reviendrons plus tard 🤫
Effectuer une recherche sémantique dans vos données BigQuery
Accédez à l'onglet "Rechercher" dans le panneau d'exploration BigQuery, puis testez des termes liés à Disney, comme "attractions" ou "succursale".
Visualiser vos données dans BigQuery
Vous pouvez désormais visualiser et manipuler vos données dans BigQuery. Pour ce faire, vous pouvez exécuter cette requête dans un nouvel onglet de requête :
SELECT
*
FROM
[dataset_name].[table_name];
Générer des insights sur les données de la table "reviews"
Dans cette tâche, vous allez activer Data Insights sur la table disneyland_reviews dans l'ensemble de données disney.
Les insights sur les données sont un outil permettant d'explorer des données et d'obtenir des insights sans avoir à écrire des requêtes SQL complexes.
Cela peut prendre quelques minutes.
Interroger la table "disneyland_reviews" sans utiliser de code SQL
Les insights que vous avez générés dans la section précédente sont maintenant prêts. Dans cette tâche, vous allez utiliser un prompt créé à partir de ces insights afin d'interroger la table disneyland_reviews sans utiliser de code.
Sélectionnez un insight et exécutez la requête associée. Par exemple, trouvez la requête qui calcule la différence de note moyenne entre les mois consécutifs pour chaque établissement. Voici un exemple :
WITH
monthly_avg AS (
SELECT
branch,
year_month,
AVG(rating) AS avg_rating
FROM
[dataset_name].[table_name]
WHERE
year_month IS NOT NULL
GROUP BY
1,
2 )
SELECT
branch,
year_month,
avg_rating,
avg_rating - LAG(avg_rating, 1, 0) OVER (PARTITION BY branch ORDER BY year_month) AS rating_difference
FROM
monthly_avg
ORDER BY
branch,
year_month;
Utiliser le moteur de connaissances BigQuery pour mieux comprendre les données
Commençons par examiner l'onglet Insights au niveau de l'ensemble de données. Cela nous donnera une idée des relations cachées entre les tables de l'ensemble de données Disney. Ensuite,
- Générez une description de l'ensemble de données à l'aide de Gemini et ajoutez-la aux détails de l'ensemble de données.
- Génère et enregistre une description des tables "reviews" et "attractions", ainsi que de toutes les colonnes individuelles de ces tables.
Effectuer une analyse de profil de vos données
L'objectif de cette section est de nettoyer et de préparer vos données. Toutefois, vous ne connaissez pas très bien la distribution des valeurs de chaque colonne. Vous devez profiler vos données pour savoir quels types d'étapes de transformation vous devez effectuer.
Dataplex Universal Catalog de Google Cloud automatise les analyses de profilage pour fournir des métriques de qualité des données cohérentes. Les principales statistiques identifiées incluent le nombre de valeurs nulles, les valeurs distinctes, les plages de données et les distributions de valeurs. Vous pouvez activer une analyse de profil via l'interface BigQuery.
Cela peut prendre quelques minutes. Vous pouvez donc consulter la section suivante en attendant.
Répondez aux questions suivantes :
- Quelle est la note moyenne de Disneyland ?
- Où se trouvent la plupart des évaluateurs ?
- Tous les avis sont-ils uniques ?
- Quel est le pourcentage de données manquantes dans la colonne "Year_Month" ?
Effectuer une analyse de la qualité de vos données
La qualité automatique des données de Dataplex Universal Catalog vous permet de définir et de mesurer la qualité des données de vos tables BigQuery. Vous pouvez automatiser l'analyse des données, les valider par rapport à des règles définies et enregistrer des alertes si vos données ne répondent pas aux exigences de qualité. Vous pouvez gérer les règles et les déploiements de qualité des données en tant que code, ce qui améliore l'intégrité des pipelines de production de données.
Sur la base de l'analyse de profilage, définissez une analyse de la qualité (sur un échantillon de données ne dépassant pas 10 %) qui :
- Vérifie les valeurs nulles pour la colonne "branch"
- Effectue un contrôle de validité pour "rating", car il ne peut appartenir qu'à l'ensemble : 1,2,3,4,5
- Vérifie l'unicité de "review_id"
Assurez-vous que l'analyse exporte les résultats vers une table BigQuery quality_scan_results.
Réfléchissez à toutes les transformations potentielles que vous devez appliquer à vos données.
Préparer vos données à l'aide de la préparation des données de Gemini
Après avoir effectué les analyses de qualité et de profilage des données, il est temps de nettoyer les données avant de les analyser.
Les préparations de données sont des ressources BigQuery qui utilisent Gemini dans BigQuery pour analyser vos données et vous fournir des suggestions intelligentes pour les nettoyer, les transformer et les enrichir. Vous pouvez réduire considérablement le temps et les efforts nécessaires aux tâches manuelles de préparation des données.
Dans cette section, vous allez utiliser la préparation des données pour effectuer les opérations suivantes sur votre table "disneyland_reviews" :
- Filtrez les lignes où la colonne "Branch" (Branche) est NULL ou une chaîne vide.
- Remplacez "missing" (manquant) par Null dans Year_Month.
- Remplace les traits de soulignement par des espaces dans la colonne "Branche" pour améliorer la lisibilité.
- Exporter vers la table transformée disneyland_reviews_cleaned
Analyser des avis avec Gemini
Maintenant que vous avez nettoyé vos données, vous pouvez commencer à les analyser à l'aide de BigQuery ML et des modèles Gemini. Vous avez deux objectifs :
- Extraire des catégories à partir d'avis
- Analyse des sentiments des avis sur Disneyland
BigQuery ML vous permet de créer et d'exécuter des modèles de machine learning (ML) à l'aide de requêtes GoogleSQL. Les modèles BigQuery ML sont stockés dans des ensembles de données BigQuery, comme les tables et les vues. BigQuery ML vous permet également d'accéder aux modèles Vertex AI et aux API Cloud AI pour effectuer des tâches d'intelligence artificielle (IA) comme la génération de texte ou la traduction automatique. Gemini pour Google Cloud fournit également une assistance basée sur l'IA pour les tâches BigQuery.
Vous pouvez choisir d'utiliser ML.GENERATE_TEXT ou AI.GENERATE (preview) avec les modèles Gemini Pro ou Flash.
Les étapes suivantes vous guident si vous souhaitez utiliser ML.GENERATE_TEXT.
Créer la connexion à une ressource cloud et attribuer un rôle IAM
Vous devez créer une connexion à une ressource cloud dans BigQuery pour les modèles Vertex AI afin de pouvoir travailler avec les modèles Gemini Pro et Gemini Flash. Vous allez également accorder des autorisations IAM au compte de service de la connexion à la ressource cloud en lui attribuant un rôle, afin de lui permettre d'accéder aux services Vertex AI.
Attribuer le rôle Utilisateur Vertex AI au compte de service de la connexion
Autorisez le compte de service de la connexion à utiliser le modèle de votre choix (par exemple, gemini-2.5-flash) en lui attribuant le rôle Utilisateur Vertex AI. La propagation de l'autorisation prend une minute.
Créer les modèles Gemini dans BigQuery
Créez votre modèle à l'aide de la connexion ci-dessus. Utilisez, par exemple, le point de terminaison gemini-2.5-flash..
Demander à Gemini d'analyser les catégories et les sentiments des avis clients
Dans cette tâche, vous allez utiliser le modèle Gemini pour analyser les catégories et le sentiment de chaque avis client, qu'il soit positif ou négatif.
Analyser les catégories des avis clients
Remarque : À partir de maintenant, pour l'analyse, nous ne prendrons que 100 lignes, car l'appel Gemini sur 20 000 lignes peut prendre un certain temps.
Extract categories by modifying and running the following SQL Query:
CREATE OR REPLACE TABLE
[dataset_name].[results_table_name] AS (
SELECT Review_ID, Rating, Year_Month, Reviewer_Location, Review_Text, Branch, ml_generate_text_llm_result AS categories FROM
ML.GENERATE_TEXT(
MODEL [model_name],
(
SELECT Review_ID, Rating, Year_Month, Reviewer_Location, Review_Text, Branch, CONCAT(
'[WRITE YOUR PROMPT HERE].',
Review_Text) AS prompt
FROM (SELECT * FROM [dataset_name].[table_name] LIMIT 100)
),
STRUCT(
0.2 AS temperature, TRUE AS flatten_json_output)));
Cette requête récupère les avis clients de la table disneyland_reviews et crée des prompts demandant au modèle gemini d'identifier les catégories de chaque avis. Les résultats doivent être stockés dans une nouvelle table reviews_categories.
. Veuillez patienter. Le traitement des enregistrements d'avis clients par le modèle prend environ 30 secondes, et les résultats sont disponibles dans le tableau de sortie.
Afficher les résultats :
SELECT * FROM [dataset_name].[results_table_name];
Prenez le temps de lire certaines catégories.
Analyser les avis clients pour déterminer si le sentiment est positif ou négatif
En vous basant sur la requête SQL pour l'extraction de mots clés, écrivez une requête qui analyse les avis en les classant comme positifs, négatifs ou neutres dans une colonne intitulée "sentiment".
Cette requête récupère les avis clients de la table disneyland_reviews et crée des requêtes demandant au modèle gemini de classer le sentiment de chaque avis. Les résultats sont ensuite stockés dans une nouvelle table reviews_analysis, que vous pourrez utiliser ultérieurement pour réaliser des analyses approfondies. Veuillez patienter. Le traitement des enregistrements d'avis clients par le modèle prend quelques secondes. Lorsque le modèle a terminé cette opération, le résultat se trouve dans la table reviews_analysis qui est créée.
Explorez les résultats :
SELECT * FROM [...];
La table reviews_analysis comporte la colonne Sentiment contenant l'analyse des sentiments, avec les colonnes social_media_source, review_text, customer_id, location_id et review_datetime incluses. Examinez quelques enregistrements. Vous remarquerez peut-être que le format de certains résultats, classés positifs ou négatifs, est incorrect. Ils peuvent par exemple contenir des caractères superflus, tels que des points ou des espaces en trop. Vous pouvez nettoyer les enregistrements en utilisant la vue ci-dessous.
Créer une vue pour nettoyer les enregistrements
Créez une vue qui assainit les valeurs du sentiment de la colonne en :
- Utilisez LOWER pour vous assurer que toutes les valeurs sont en minuscules.
- Supprimer la ponctuation (points , virgules et espaces) à l'aide de REPLACE
CREATE OR REPLACE VIEW [view_name] AS
SELECT [SANITIZATION_EXPRESSION] AS sentiment,
Review_ID, Rating, Year_Month, Reviewer_Location, Review_Text, Branch,
FROM `disney.reviews_analysis`;
La requête crée la vue cleaned_data_view, qui comprend les résultats d'analyse des sentiments, le texte de l'avis et Review_ID, Rating, Year_Month, Reviewer_Location, Review_Text and Branch. Ensuite, elle nettoie le résultat d'analyse des sentiments (positifs ou négatifs), mettant toutes les lettres en minuscules et supprimant les caractères superflus (comme les espaces en trop ou les points). La vue obtenue facilitera les analyses plus approfondies réalisées ultérieurement au cours de cet atelier.
- Vous pouvez interroger la vue avec la requête ci-dessous pour voir les lignes créées.
SELECT * FROM [view_name];
Créer un rapport sur le nombre d'avis positifs et négatifs avec le canevas de données
Il est maintenant temps d'analyser vos résultats. Commençons par le faire directement dans BigQuery, via le canevas de données. Cet outil vous permet de rechercher des données (sémantiquement ou par mot clé), d'interroger et de joindre des tables, de créer des graphiques et d'obtenir des insights en créant un flux de canevas.
Votre objectif final est de créer un graphique de votre choix sur les pourcentages d'avis positifs et négatifs . Exemple :

Créez un graphique du nombre d'avis par catégorie, ainsi que la répartition des avis positifs et négatifs pour chaque catégorie.
Conseil : Activez et utilisez la fonctionnalité Analyse avancée de Data Canvas, qui exécute un notebook Python dans un canevas.
4. Tâche 2 : Analyser des images de parcs d'attractions pour identifier des photos de Disneyland et extraire des anecdotes amusantes des brochures du parc
Analyse d'images dans BigQuery
Vous avez accès à des photos palpitantes et attrayantes du parc d'attractions que les visiteurs ont prises au fil des ans. Vous avez hâte de partir en voyage ! Cependant, vous ne savez pas lesquelles sont de vraies photos de Disneyland. Votre tâche consiste à les identifier. Les images se trouvent dans gs://hackathon_data_disneyland_<YOUR_PROJECT_3DIGITS>/attraction_parc_photos/.

Is_disneyland: : False

Is_disneyland: : True
Pour effectuer rapidement cette analyse, Vous devez utiliser les tables d'objets BigQuery et Gemini via BigQuery ML (ML.GENERATE_TEXT).
Peux-tu vérifier le résultat de Gemini en examinant quelques photos ?
Créer votre propre système RAG avec BigQuery sur les brochures Disneyland
En attendant votre tour, vous souhaitez obtenir des anecdotes ou des informations techniques sur l'attraction.
Dans gs://hackathon_data_disneyland_<YOUR_PROJECT_3DIGITS>/disneyland_brochures/,, vous trouverez des fichiers PDF contenant des brochures pour tous les parcs du monde.
Objectif : créer un système de génération augmentée de récupération (RAG) entièrement dans BigQuery pour permettre aux utilisateurs de poser des questions complexes sur le parc en se basant sur des documents PDF.
Pour ce faire, vous devez :
- Créer une table d'objets de fichiers PDF
- Créez une UDF Python pour segmenter les fichiers PDF. Voici un exemple que vous pouvez utiliser :
CREATE OR REPLACE FUNCTION disney.chunk_pdf(src_json STRING, chunk_size INT64, overlap_size INT64)
RETURNS ARRAY<STRING>
LANGUAGE python
WITH CONNECTION `[LOCATION].[CONN_NAME]`
OPTIONS (entry_point='chunk_pdf', runtime_version='python-3.11', packages=['pypdf'])
AS """
import io
import json
from pypdf import PdfReader # type: ignore
from urllib.request import urlopen, Request
def chunk_pdf(src_ref: str, chunk_size: int, overlap_size: int) -> str:
src_json = json.loads(src_ref)
srcUrl = src_json["access_urls"]["read_url"]
req = urlopen(srcUrl)
pdf_file = io.BytesIO(bytearray(req.read()))
reader = PdfReader(pdf_file, strict=False)
# extract and chunk text simultaneously
all_text_chunks = []
curr_chunk = ""
for page in reader.pages:
page_text = page.extract_text()
if page_text:
curr_chunk += page_text
# split the accumulated text into chunks of a specific size with overlaop
# this loop implements a sliding window approach to create chunks
while len(curr_chunk) >= chunk_size:
split_idx = curr_chunk.rfind(" ", 0, chunk_size)
if split_idx == -1:
split_idx = chunk_size
actual_chunk = curr_chunk[:split_idx]
all_text_chunks.append(actual_chunk)
overlap = curr_chunk[split_idx + 1 : split_idx + 1 + overlap_size]
curr_chunk = overlap + curr_chunk[split_idx + 1 + overlap_size :]
if curr_chunk:
all_text_chunks.append(curr_chunk)
return all_text_chunks
""";
- Analyser le fichier PDF en fragments
- Générer des embeddings après avoir créé un modèle distant
- Exécute une recherche vectorielle pour trouver "
Ou manger un repas tex-mex à volonté?" ou "where to eat a tex-mex meal buffet-style?" - Générer une réponse augmentée par les résultats de recherche vectorielle pour la question "
Ou manger un repas tex-mex à volonté?" ou "where to eat a tex-mex meal buffet-style?"
5. Tâche 3 : Machine learning à grande échelle avec BigQuery : prévision, classification et classement
Prévoir les temps d'attente
Les photos sont très cool ! Vous avez hâte ! Pour savoir quelles attractions choisir et lesquelles éviter, vous souhaitez connaître les temps d'attente réels pour certaines attractions entre Paris et la Californie. Votre tâche consiste à prévoir les temps d'attente de chaque attraction à l'aide du machine learning (Arima Plus ou TimesFM) toutes les 30 minutes en 2025.
Les données que vous allez utiliser se trouvent dans ce fichier CSV : gs://hackathon_data_disneyland_<YOUR_PROJECT_3DIGITS>/waiting_times.csv.
Voici les étapes de votre tâche :
- Chargez le fichier dans votre ensemble de données BigQuery, dans une table appelée "waiting_times".
- Entraînez un modèle de prévision sur vos données (Arima_Plus) ou effectuez des prévisions directement à l'aide d'AI.Forecast.
- Évaluer les performances du modèle ou comparer les données prévisionnelles aux données d'entrée
Classer les trajets par intensité
Vous visitez Disneyland avec des amis. Bien que le parc soit généralement adapté aux familles, certaines attractions peuvent être trop intenses pour certaines personnes. Utilisons les fonctions d'IA gérées de BigQuery pour classer les attractions par niveau de sensations fortes et d'intensité, sans biais humain, afin de satisfaire tout le monde.
- Utilise
AI.CLASSIFYpour classer les manèges en fonction de leur description dans l'une des trois catégories magiques suivantes : [facile, palpitant, extrême].
Classement des attractions selon leur niveau de sensations fortes
- Utilisez
AI.SCOREpour comparer et classer les attractions en fonction de leur niveau de sensations fortes (10 étant le plus élevé et 1 le plus faible).
6. Tâche 3 (bonus) : ETL inversé, de BigQuery à AlloyDB
Vous avez profité des puissantes fonctionnalités de BigQuery pour générer des insights sur de grandes quantités de données. Vous souhaitez désormais que ces insights soient exploitables par vos applications opérationnelles (et vos agents d'IA).
Mais comment y parvenir ? En faisant l'inverse ! AlloyDB pour PostgreSQL est idéal pour diffuser des données avec une faible latence et à grande vitesse, ce qui est parfait pour vos applications critiques destinées aux utilisateurs. Nous allons donc effectuer un reverse-ETL sur les données que nous venons de générer.
Pour ce faire, nous allons utiliser une toute nouvelle fonctionnalité, encore en aperçu privé, appelée "Vues BigQuery" dans AlloyDB. Cette fonctionnalité vous permet d'interroger les données BigQuery directement dans votre base de données Postgres.
Vous devez d'abord accorder à votre compte de service de cluster AlloyDB les droits nécessaires pour interroger BigQuery.
gcloud beta alloydb clusters describe <CLUSTER ID> --region=europe-west1
La sortie contient un champ "serviceAccountEmail", qui correspond au compte de service de ce cluster.
Dans la console Google Cloud, accédez à la page IAM et accordez les privilèges suivants à ce compte principal :
- Lecteur de données BigQuery (roles/bigquery.dataViewer)
- Utilisateur de sessions de lecture BigQuery (roles/bigquery.readSessionUser)
Accédez maintenant à AlloyDB Studio dans la console et connectez-vous à la base de données "postgres".
Exécutez les requêtes suivantes pour installer et configurer la nouvelle fonctionnalité :
CREATE EXTENSION bigquery_fdw;
CREATE SERVER bq_disney FOREIGN DATA WRAPPER bigquery_fdw;
CREATE USER MAPPING FOR postgres SERVER bq_disney ;
Vous pouvez désormais créer une "table externe" qui sera mappée à une table existante dans BigQuery. Utilisez n'importe quelle table que vous avez créée lors de la tâche 3. Voici un exemple de syntaxe :
CREATE FOREIGN TABLE reviews_analysis ( "Review_ID" int,
"Sentiment" text) SERVER bq_disney OPTIONS (PROJECT 'bqml-hack25par-xxx',
dataset 'disney',
TABLE 'reviews_analysis');
C'est parti, interrogeons la table ! Exécutez une première requête SELECT pour valider le lien entre AlloyDB et BigQuery, puis créez une table dans AlloyDB pour ingérer les données de votre table externe.
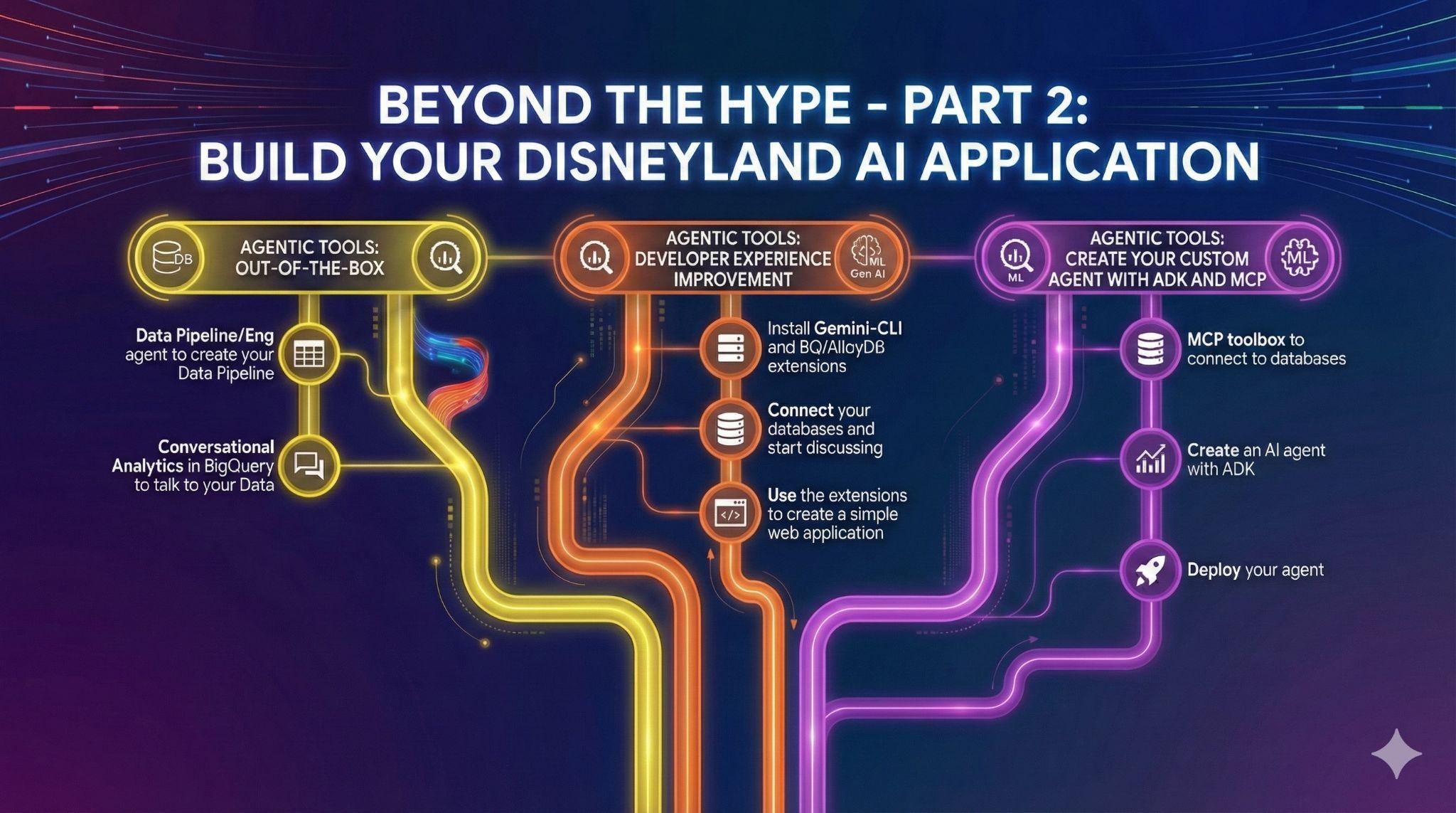
7. Tâche 4 : Agents de données prêts à l'emploi
Vous avez des amis qui souhaitent contribuer au projet d'application Disneyland. Ils ont accès aux données dans BigQuery, mais leur niveau de compétence en SQL et en ingénierie des données varie. Vous souhaitez profiter des dernières annonces de BigQuery concernant les agents de données déjà intégrés à l'UI pour aider vos amis :
- Créez des pipelines de données.
- Collaborer sur du code SQL
- Parlez à vos données.
Agents d'ingénierie des données pour automatiser vos pipelines de données
Créez une vue average_waiting_time qui joint les tables waiting_time et attractions, et calcule le temps d'attente moyen par attraction à l'aide de l'agent Data Engineering.
Créer votre agent Conversational Analytics dans BigQuery
Imaginez pouvoir créer un agent pour discuter avec vos données, sans coder, sans SQL et sans déploiement, directement depuis l'interface de BigQuery. Ce serait génial, non ? C'est désormais possible grâce à l'onglet "Agents" de BigQuery.

- Crée un agent my_disney_friend qui se connecte à tes tables Disney. Vous pouvez améliorer les performances de l'agent en remplissant les instructions de l'agent. Posez des questions comme "Quel est le pourcentage d'avis positifs par rapport aux avis négatifs ? Quel est le temps d'attente moyen par attraction ?"
- Publiez l'agent dans BigQuery et sur l'API (vous l'utiliserez plus tard).
8. Tâche 5 : Améliorer votre expérience de développement avec Gemini-CLI
À l'ère de l'IA, la création de logiciels n'a jamais été aussi accessible. Vous avez des milliers d'idées pour votre application Disneyland et vous souhaitez utiliser vos données à leur plein potentiel. Vous souhaitez aller au-delà de l'analyse des données et passer à l'action ?
Pour vous aider dans cette voie, vous aurez besoin d'aide. Nous sommes là pour vous aider.
Gemini CLI est un agent IA Open Source qui vous permet d'exploiter la puissance de Gemini directement dans votre terminal. Les développeurs peuvent créer des applications puissantes et, grâce aux extensions, interagir avec différents serveurs MCP (Model Context Protocol).
Parmi celles-ci, vous trouverez bien sûr des extensions pour interroger vos données AlloyDB ou BigQuery.
Dans cette tâche, votre objectif est de :
- Installer Gemini CLI (dans votre propre terminal ou dans Cloud Shell)
- Installer les extensions Gemini-CLI BigQuery et AlloyDB
- Créez un fichier d'environnement qui permet à Gemini-CLI de se connecter à vos instances BigQuery et AlloyDB.
- Demandez à Gemini CLI de générer une page HTML unique et élégante qui explique le contenu de votre base de données AlloyDB.
- Faites de même pour BigQuery.
Voici quelques exemples de ce que vous pouvez générer en une ou plusieurs requêtes avec Gemini CLI et ses extensions. Imaginez maintenant que vous puissiez faire cela avec des applications concrètes. 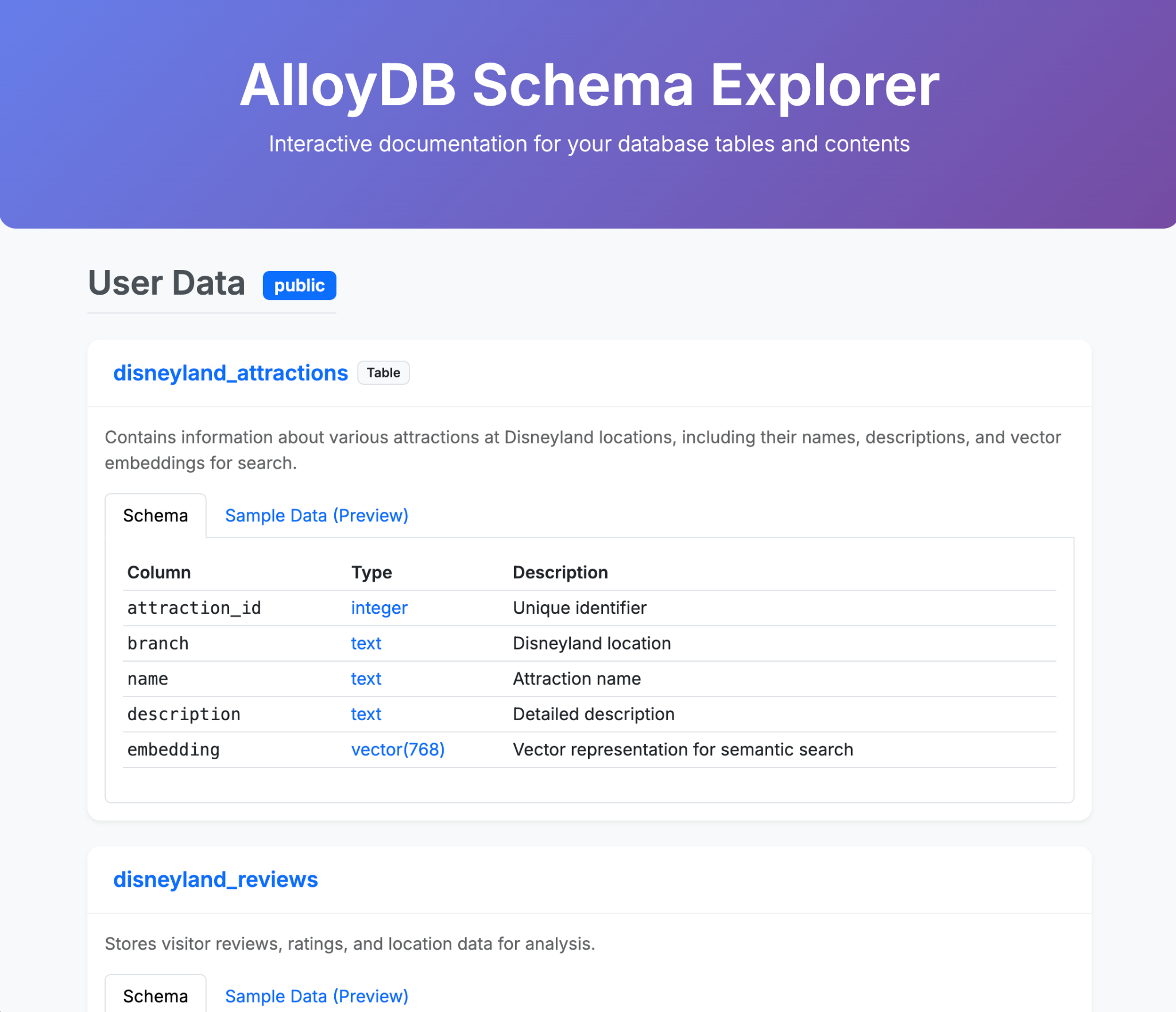
9. Tâche 6 : Créer un agent IA pour interagir avec vos données
Pour offrir une toute nouvelle expérience utilisateur aux visiteurs de Disneyland, vous allez créer un assistant qui pourra les aider pendant leur séjour. Votre agent pourra :
- Lister toutes les attractions disponibles dans le parc
- Recommander une attraction en fonction des attentes
- Ajouter des avis sur une attraction
- Fournir une estimation du temps d'attente pour une attraction dans les prochaines heures
- Fournir un aperçu des avis sur une attraction spécifique
Vous veillerez à ce que votre assistant ne puisse répondre qu'aux questions liées à Disneyland et qu'il adopte un ton amical avec l'utilisateur. Ajustez le prompt de votre agent pour vous assurer qu'il choisit les bons outils en fonction des besoins de l'utilisateur.
Voici les étapes à suivre :
- Déployer un serveur MCP Toolbox for Databases qui utilise AlloyDB et BigQuery comme sources
- Déclarez cinq outils différents pour votre serveur MCP qui interrogent AlloyDB et BigQuery, et mappez les actions de l'agent listées précédemment.
- Utilisez l'UI MCP Toolbox pour valider chacun de vos outils.
- Déployer un agent à l'aide de l'Agent Development Kit, capable d'utiliser les outils exposés par votre serveur MCP Toolbox
- Connectez-vous à votre interface Web ADK et présentez une discussion complète avec votre assistant, y compris tous les outils disponibles.
Étape bonus si vous terminez plus tôt :
Votre agent est-il prêt ? Déployons-le sur Agent Engine !