
1. 🏰 Hackathon de análisis de datos de Disneyland (2ª edición, 3 de diciembre) 🏰
Resumen | En este hackathon, crearás una canalización de análisis de datos de extremo a extremo que aproveche las capacidades de IA/AA en Google Cloud. Cargarás datos en AlloyDB, una base de datos completamente administrada y compatible con PostgreSQL optimizada para cargas de trabajo exigentes, y, luego, usarás Datastream, un servicio de captura de datos modificados (CDC) sin servidores, para trasladarlos a BigQuery, el almacén de datos sin servidores de Google Cloud. En BigQuery, aplicarás BigQuery ML, que te permite crear y ejecutar modelos de aprendizaje automático directamente en BigQuery con SQL estándar, para el análisis de opiniones y la previsión de asistencia. Por último, experimentarás con agentes, ya sea de forma predeterminada a través de Análisis conversacional y agentes de datos, o bien crearás un agente personalizado, potenciado por el Kit de desarrollo de agentes y el kit de herramientas de MCP para la interacción en lenguaje natural con tus datos. |
categorías | docType:Codelab, product:Bigquery |
Autor | Rayhane Rezgui y Matt Cornillon |
Diseño | Desplazamiento |
Robots | noindex |
2. Introducción
¡Te damos la bienvenida, futuro mago de los datos de Disney!🪄
Olvídate de las tediosas guías de viaje y de desplazarte sin parar por los foros. Imagina que planificas el viaje perfecto a Disneyland, equipado con estadísticas basadas en datos. ¿Qué parque ofrece la mejor experiencia? ¿Cuándo hay menos gente? ¿Puedes predecir el mejor momento para superar esa fila notoriamente larga?
En este hackathon, crearás tu herramienta de planificación definitiva para Disneyland. Tenemos los datos: opiniones de los visitantes de las sucursales de todo el mundo, tiempos de espera históricos y cifras de asistencia. ¿Tu misión? Transforma estos datos sin procesar en estadísticas prácticas:
- Recopila datos: Carga diversas opiniones, tiempos de espera y cifras de asistencia de Disneyland en AlloyDB, nuestra base de datos de alto rendimiento compatible con PostgreSQL.
- Movimiento sin inconvenientes: Usa Datastream, nuestro servicio de captura de datos de cambio sin servidores, para transferir sin esfuerzo esta información dinámica a BigQuery, el potente almacén de datos sin servidores de Google Cloud.
- Predice la magia: Libera BigQuery ML para analizar el sentimiento de las opiniones y predecir los tiempos de espera directamente con SQL. Descubre qué sucursales brindan sonrisas de forma constante y cuál es el momento óptimo para tu visita.
- Habla con tus datos, literalmente: Usa herramientas prediseñadas que te permiten obtener estadísticas con un solo toque.
- Interacción inteligente: Corona tu creación con un agente inteligente, potenciado por el kit de herramientas de MCP para bases de datos y el ADK (Kit de desarrollo de agentes). Pregunta: "¿Cuál es la mejor atracción de Disneyland París para los amantes del espacio y cuál es el mejor momento para hacer fila?" y obtén respuestas instantáneas basadas en datos.
Prepárate para descubrir los secretos de los lugares más mágicos de la Tierra y crear una canalización de análisis de datos que haría sentir orgulloso a Mickey.

3. Tarea 1: De lo operativo a lo analítico: analiza las opiniones sobre Disneyland con Gemini
En esta etapa inicial, recuperarás los datos de tu base de datos operativa de AlloyDB y los cargarás en BigQuery para el análisis de datos posterior.
También configurarás todo lo necesario en AlloyDB para tu futuro agente.
Carga de datos en AlloyDB
En primer lugar, importemos algunos datos a nuestro clúster de AlloyDB para PostgreSQL.
Vamos a incorporar 20,000 opiniones sobre los parques de diversiones de Disneyland y una lista de atracciones.
Estos son los pasos que debes seguir:
Creación de tablas:
- Crea una tabla disneyland_reviews con 6 columnas: review_id y rating como números enteros, year_month, reviewer_location, review_text y branch como texto.
- Crea una tabla disneyland_attractions con 4 columnas: attraction_id como número entero, branch, name y description como texto.
Con la herramienta que elijas, importa los datos de los archivos CSV:
gs://hackathon_data_disneyland_<YOUR_PROJECT_3DIGITS>/reviews.csvpara la tabla de opinionesgs://hackathon_data_disneyland_<YOUR_PROJECT_3DIGITS>/attractions.csvpara la tabla de atracciones
Para proporcionar recomendaciones de atracciones, debemos crear incorporaciones de la descripción de las atracciones:
- Instala la extensión pgvector en AlloyDB
- Agrega una columna de vectores llamada "embedding" a tu tabla attraction
- Genera y completa el embedding de las descripciones con la integración nativa entre AlloyDB y Vertex AI
De lo operativo a lo analítico con Datastream
Para transmitir nuestros datos de AlloyDB a BigQuery, usaremos Google Datastream. Es una potente solución sin servidores que detectará todos los cambios en las tablas de origen (a través de la captura de datos modificados) y los enviará a BigQuery.
Para poder replicar los cambios de AlloyDB con Datastream, debemos crear lo que se denomina una publicación y una ranura de replicación en Postgres.
Ejecuta las siguientes consultas en tu clúster de AlloyDB (debes ejecutarlas una a la vez):
CREATE PUBLICATION pub_disney FOR TABLE disneyland_reviews, disneyland_attractions;
ALTER USER postgres WITH REPLICATION;
SELECT PG_CREATE_LOGICAL_REPLICATION_SLOT('slot_disney', 'pgoutput');
Usarás la ranura de publicación y replicación en tu transmisión, así que recuerda los nombres.
Eso es todo. Ahora podemos crear una transmisión.
Estos son los pasos que debes seguir en Datastream:
- Crea un perfil de origen para tu clúster de AlloyDB (usa la dirección IP pública)
- Crea un perfil de destino para BigQuery
- Crea una transmisión de AlloyDB a BigQuery.
Los datos deberían estar disponibles en BigQuery en unos minutos.
Descubrimiento de datos en BigQuery
Ahora que tenemos nuestros datos en BigQuery, asegurémonos de conocer las nuevas mejoras en la interfaz antes de comenzar a trabajar.
Tenemos 3 funciones nuevas que ya puedes ver en el panel de exploración de BigQuery.

- Overview: Contiene información sobre las funciones de BigQuery, recorridos para comenzar a realizar análisis, entre otras posibilidades.
- Búsqueda: Realiza búsquedas semánticas en tus recursos de datos.
- Agentes: ¡Shhh! Lo guardaremos para más tarde 🤫
Cómo buscar tus datos de forma semántica en BigQuery
Ve a la pestaña Search en el panel de exploración de BigQuery y experimenta con términos relacionados con Disney, como "atracciones" o "sucursal".
Visualiza tus datos en BigQuery
Ahora puedes visualizar y manipular tus datos en BigQuery. Para ello, puedes ejecutar esta consulta en una pestaña de consulta nueva.
SELECT
*
FROM
[dataset_name].[table_name];
Genera estadísticas de datos en la tabla de opiniones
En esta tarea, habilitarás estadísticas de datos en la tabla disneyland_reviews del conjunto de datos disney.
Estadísticas de datos es una herramienta para cualquier persona que quiera explorar sus datos y obtener estadísticas sin tener que escribir consultas en SQL complejas.
Esto podría demorar unos minutos.
Consulta la tabla disneyland_reviews sin SQL
Las estadísticas que generaste en la sección anterior ya están listas. En esta tarea, usarás una instrucción generada a partir de estas estadísticas para consultar la tabla disneyland_reviews sin usar código.
Selecciona una estadística y ejecuta la consulta asociada a ella. Por ejemplo, busca la consulta que calcula la diferencia en la calificación promedio entre meses consecutivos para cada sucursal. Se vería de la siguiente manera:
WITH
monthly_avg AS (
SELECT
branch,
year_month,
AVG(rating) AS avg_rating
FROM
[dataset_name].[table_name]
WHERE
year_month IS NOT NULL
GROUP BY
1,
2 )
SELECT
branch,
year_month,
avg_rating,
avg_rating - LAG(avg_rating, 1, 0) OVER (PARTITION BY branch ORDER BY year_month) AS rating_difference
FROM
monthly_avg
ORDER BY
branch,
year_month;
Usa el motor de conocimiento de BigQuery para comprender mejor los datos
Primero, comencemos por observar la pestaña Estadísticas a nivel del conjunto de datos. Esto nos dará una idea de las relaciones ocultas entre las tablas del conjunto de datos de Disney. Luego, haz lo siguiente:
- Genera una descripción del conjunto de datos con Gemini y agrégala a los detalles del conjunto de datos.
- Genera una descripción de las tablas reviews y attractions, así como de todas las columnas individuales de esas tablas, y guárdala.
Realiza un análisis de perfil de tus datos
El objetivo de esta sección es limpiar y preparar tus datos. Sin embargo, no conoces muy bien la distribución de los valores de cada columna. Debes crear un perfil de tus datos para saber qué tipo de pasos de transformación debes realizar en ellos.
Dataplex Universal Catalog de Google Cloud automatiza los análisis de generación de perfiles para proporcionar métricas de calidad de los datos coherentes. Las estadísticas clave identificadas incluyen recuentos de valores nulos, valores distintos, rangos de datos y distribuciones de valores. Es posible activar un análisis de perfil a través de la interfaz de BigQuery.
Puede tardar un par de minutos, así que puedes consultar la siguiente sección mientras esperas.
Responde las siguientes preguntas:
- ¿Cuál es la calificación promedio de Disneyland?
- ¿Dónde se encuentran la mayoría de los revisores?
- ¿Todas las opiniones son únicas?
- ¿Qué porcentaje de datos faltantes hay en la columna Year_Month?
Realiza un análisis de calidad de tus datos
La calidad automática de los datos de Dataplex Universal Catalog te permite definir y medir la calidad de los datos en tus tablas de BigQuery. Puedes automatizar el análisis de los datos, validarlos según las reglas definidas y registrar alertas si no cumplen con los requisitos de calidad. Puedes administrar las reglas y las implementaciones de calidad de los datos como código, lo que mejora la integridad de las canalizaciones de producción de datos.
Según el análisis del perfil, define un análisis de calidad (en no más del 10% de tus datos como tamaño de la muestra) que haga lo siguiente:
- Verifica si hay valores nulos en la columna "branch".
- Realiza una verificación de validez para la "calificación", ya que solo puede estar en el conjunto de : 1,2,3,4,5
- Verifica la unicidad de "review_id".
Asegúrate de que el análisis exporte los resultados a una tabla de BigQuery llamada quality_scan_results.
Piensa en todas las transformaciones posibles que necesitas aplicar a tus datos.
Prepara tus datos con la función de preparación de datos de Gemini
Después de los análisis de calidad y creación de perfiles de los datos que realizaste, es hora de limpiarlos antes de analizarlos.
Las preparaciones de datos son recursos de BigQuery que usan Gemini en BigQuery para analizar tus datos y proporcionar sugerencias inteligentes para limpiarlos, transformarlos y enriquecerlos. Puedes reducir significativamente el tiempo y el esfuerzo necesarios para las tareas manuales de preparación de datos.
En esta sección, usarás la Preparación de datos para realizar las siguientes operaciones en tu tabla disneyland_reviews:
- Filtra las filas en las que la columna Branch es NULL o una cadena vacía.
- Reemplaza "missing" en Year_Month por Null.
- Se reemplazan los guiones bajos por espacios en la columna de la rama para mejorar la legibilidad.
- Exporta a la tabla transformada disneyland_reviews_cleaned
Analiza opiniones con Gemini
Ahora que limpiaste tus datos, puedes comenzar a analizarlos con BigQuery ML y los modelos de Gemini. Tienes dos objetivos:
- Extrae categorías de las opiniones
- Análisis de opiniones de disneyland_reviews
BigQuery ML te permite crear y ejecutar modelos de aprendizaje automático (AA) con consultas de GoogleSQL. Los modelos de BigQuery ML se almacenan en conjuntos de datos de BigQuery, de forma similar a las tablas y las vistas. BigQuery ML también te permite acceder a modelos de Vertex AI y APIs de Cloud AI para realizar tareas de inteligencia artificial (IA), como la generación de texto o la traducción automática. Gemini para Google Cloud también proporciona asistencia potenciada por IA para las tareas de BigQuery.
Puedes usar ML.GENERATE_TEXT o AI.GENERATE (versión preliminar) con los modelos Gemini Pro o Flash.
Los siguientes pasos te guiarán si deseas usar ML.GENERATE_TEXT.
Crea la conexión de recursos de Cloud y otorga el rol de IAM
Debes crear una conexión de recursos de Cloud en BigQuery a los modelos de Vertex AI para trabajar con los modelos de Gemini Pro y Gemini Flash. También otorgarás los permisos de IAM a la cuenta de servicio de la conexión al recurso de Cloud, a través de un rol, para habilitar el acceso a los servicios de Vertex AI.
Otorga el rol de usuario de Vertex AI a la cuenta de servicio de la conexión
Otorga a la cuenta de servicio de la conexión el rol de usuario de Vertex AI para permitirle usar el modelo que elegiste (por ejemplo, gemini-2.5-flash). El permiso tarda 1 minuto en propagarse.
Crea los modelos de Gemini en BigQuery
Crea tu modelo con la conexión anterior. Por ejemplo, usa el extremo gemini-2.5-flash..
Enviar una instrucción a Gemini para que analice las opiniones de los clientes en busca de categorías y del sentimiento
En esta tarea, usarás el modelo de Gemini para analizar cada opinión del cliente en busca de categorías y sentimientos, ya sean positivos o negativos.
Analiza las opiniones de los clientes por categorías
Nota: A partir de ahora, para el análisis, solo tomaremos 100 filas, ya que la llamada a Gemini en 20,000 filas puede tardar un tiempo.
Extract categories by modifying and running the following SQL Query:
CREATE OR REPLACE TABLE
[dataset_name].[results_table_name] AS (
SELECT Review_ID, Rating, Year_Month, Reviewer_Location, Review_Text, Branch, ml_generate_text_llm_result AS categories FROM
ML.GENERATE_TEXT(
MODEL [model_name],
(
SELECT Review_ID, Rating, Year_Month, Reviewer_Location, Review_Text, Branch, CONCAT(
'[WRITE YOUR PROMPT HERE].',
Review_Text) AS prompt
FROM (SELECT * FROM [dataset_name].[table_name] LIMIT 100)
),
STRUCT(
0.2 AS temperature, TRUE AS flatten_json_output)));
Esta consulta toma las opiniones de los clientes de la tabla disneyland_reviews y crea instrucciones para el modelo gemini para identificar categorías dentro de cada opinión. Los resultados se deben almacenar en una tabla nueva reviews_categories.
. Espera un momento. El modelo tarda alrededor de 30 segundos en procesar los registros de las opiniones de los clientes y en tener los resultados en la tabla de salida.
Muestra los resultados:
SELECT * FROM [dataset_name].[results_table_name];
Tómate un tiempo para leer algunas de las categorías.
Analiza las opiniones de los clientes en busca de sentimiento positivo y negativo
Según la consulta en SQL para la extracción de palabras clave, escribe una consulta que analice las opiniones como positivas, negativas y neutras en una columna llamada "sentimiento".
Esta consulta toma las opiniones de los clientes de la tabla disneyland_reviews y crea instrucciones para el modelo gemini para clasificar el sentimiento de cada opinión. Luego, los resultados se almacenan en una tabla nueva reviews_analysis, de modo que puedas usarla más tarde para realizar un análisis más profundo. Espera un momento. El modelo tarda unos segundos en procesar los registros de las opiniones de los clientes. Cuando el modelo finalice, el resultado se encontrará en la tabla reviews_analysis que se creó.
Explora los resultados:
SELECT * FROM [...];
La tabla reviews_analysis tiene la columna Sentiment que contiene el análisis de opiniones, con las columnas social_media_source, review_text, customer_id, location_id y review_datetime incluidas. Analiza algunos de los registros. Es posible que observes que algunos de los resultados para sentimiento positivo y negativo no tengan el formato correcto y contengan caracteres extraños, como puntos o espacios adicionales. Para limpiar los registros, puedes usar la vista que figura a continuación.
Crea una vista para limpiar los registros
Crea una vista que sanee los valores de la columna de opinión de la siguiente manera:
- Usa LOWER para asegurarte de que todos los valores estén en minúsculas.
- Cómo quitar signos de puntuación (puntos , comas y espacios) con REPLACE
CREATE OR REPLACE VIEW [view_name] AS
SELECT [SANITIZATION_EXPRESSION] AS sentiment,
Review_ID, Rating, Year_Month, Reviewer_Location, Review_Text, Branch,
FROM `disney.reviews_analysis`;
La consulta crea la vista cleaned_data_view y, además, incluye los resultados del sentimiento, el texto de la opinión y Review_ID, Rating, Year_Month, Reviewer_Location, Review_Text and Branch. Luego, se toma el resultado de sentimiento (positivo o negativo), se garantiza que todas las letras estén en minúsculas y se quitan los caracteres extraños, como espacios adicionales o puntos. La vista resultante facilitará un análisis más profundo en los pasos posteriores de este lab.
- Para ver las filas que se crearon, puedes consultar la vista con la consulta que figura a continuación.
SELECT * FROM [view_name];
Crea un informe de recuentos de opiniones positivas y negativas con el lienzo de datos
Ahora es el momento de analizar tus resultados. Comencemos por hacerlo directamente en BigQuery, a través del lienzo de datos. Es una herramienta que te permite buscar datos (semánticamente o por palabras clave), consultar y unir tablas, crear gráficos y obtener estadísticas creando un flujo de lienzo.
Tu objetivo final es crear un gráfico de los porcentajes de opiniones positivas y negativas que elijas . Por ejemplo:

Crea un gráfico de la cantidad de opiniones por categoría, así como la distribución de opiniones positivas y negativas para cada categoría
Sugerencia: Activa y usa el Análisis avanzado de Data Canvas, que ejecuta un notebook de Python dentro de un lienzo.
4. Tarea 2: Analiza imágenes de parques de atracciones para identificar fotos de Disneyland y extraer datos curiosos de los folletos del parque
Análisis de imágenes en BigQuery
Tienes acceso a algunas imágenes emocionantes y atractivas del parque de atracciones que los visitantes tomaron a lo largo de los años. ¡Estás muy emocionado por tu próximo viaje! Sin embargo, no sabes cuáles son fotos reales de Disneyland. Tu tarea es identificarlos. Las imágenes se encuentran en gs://hackathon_data_disneyland_<YOUR_PROJECT_3DIGITS>/attraction_parc_photos/.

Is_disneyland: False

Is_disneyland: Verdadero
Para realizar este análisis rápidamente Debes usar las tablas de objetos de BigQuery y Gemini a través de BigQuery ML (ML.GENERATE_TEXT).
¿Puedes verificar el resultado de Gemini revisando algunas fotos?
Crea tu propio sistema de RAG con BigQuery en folletos de Disneyland
Mientras esperas en la fila, quieres conocer algunos datos curiosos o detalles técnicos sobre la atracción.
En gs://hackathon_data_disneyland_<YOUR_PROJECT_3DIGITS>/disneyland_brochures/,, encontrarás archivos PDF que contienen folletos de todos los parques del mundo.
Objetivo: Crear un sistema de generación aumentada por recuperación (RAG) completamente dentro de BigQuery para permitir que los usuarios hagan preguntas complejas sobre el parque en función de algunos documentos PDF.
Para lograrlo, debes hacer lo siguiente:
- Crea una tabla de objetos de archivos PDF
- Crea una UDF de Python para dividir archivos PDF en fragmentos. Aquí tienes un ejemplo que puedes usar:
CREATE OR REPLACE FUNCTION disney.chunk_pdf(src_json STRING, chunk_size INT64, overlap_size INT64)
RETURNS ARRAY<STRING>
LANGUAGE python
WITH CONNECTION `[LOCATION].[CONN_NAME]`
OPTIONS (entry_point='chunk_pdf', runtime_version='python-3.11', packages=['pypdf'])
AS """
import io
import json
from pypdf import PdfReader # type: ignore
from urllib.request import urlopen, Request
def chunk_pdf(src_ref: str, chunk_size: int, overlap_size: int) -> str:
src_json = json.loads(src_ref)
srcUrl = src_json["access_urls"]["read_url"]
req = urlopen(srcUrl)
pdf_file = io.BytesIO(bytearray(req.read()))
reader = PdfReader(pdf_file, strict=False)
# extract and chunk text simultaneously
all_text_chunks = []
curr_chunk = ""
for page in reader.pages:
page_text = page.extract_text()
if page_text:
curr_chunk += page_text
# split the accumulated text into chunks of a specific size with overlaop
# this loop implements a sliding window approach to create chunks
while len(curr_chunk) >= chunk_size:
split_idx = curr_chunk.rfind(" ", 0, chunk_size)
if split_idx == -1:
split_idx = chunk_size
actual_chunk = curr_chunk[:split_idx]
all_text_chunks.append(actual_chunk)
overlap = curr_chunk[split_idx + 1 : split_idx + 1 + overlap_size]
curr_chunk = overlap + curr_chunk[split_idx + 1 + overlap_size :]
if curr_chunk:
all_text_chunks.append(curr_chunk)
return all_text_chunks
""";
- Analiza el archivo PDF en fragmentos
- Genera embeddings después de crear un modelo remoto
- Ejecuta una búsqueda de vectores para encontrar "
Ou manger un repas tex-mex à volonté?" o "where to eat a tex-mex meal buffet-style?". - Genera una respuesta aumentada por los resultados de la búsqueda vectorial de la pregunta "
Ou manger un repas tex-mex à volonté?" o "where to eat a tex-mex meal buffet-style?".
5. Tarea 3: Aprendizaje automático a gran escala con BigQuery: previsión, clasificación y ranking
Previsión de tiempos de espera
¡Las fotos son geniales! ¡No puedes esperar! Ahora, para saber qué atracciones elegir y cuáles evitar, debes conocer los tiempos de espera reales de algunas de las atracciones entre París y California. Tu tarea es predecir los tiempos de espera de cada atracción con aprendizaje automático (Arima Plus o TimesFM) cada 30 minutos en 2025.
Los datos que usarás se encuentran en este archivo CSV: gs://hackathon_data_disneyland_<YOUR_PROJECT_3DIGITS>/waiting_times.csv
Estos son los pasos de tu tarea:
- Carga el archivo en tu conjunto de datos de BigQuery en una tabla llamada waiting_times.
- Entrena un modelo de previsión con tus datos (Arima_Plus) o realiza previsiones directamente con AI.Forecast
- Evalúa el rendimiento del modelo o compara los datos previstos con los datos de entrada.
Clasifica los viajes según su intensidad
Estás visitando Disneyland con amigos y, si bien el parque es apto para familias, algunas atracciones pueden ser demasiado intensas para algunas personas. Usemos las funciones de IA administradas de BigQuery para clasificar y ordenar las atracciones según el nivel de emoción e intensidad, sin sesgos humanos, de modo que podamos satisfacer a todos.
- Usa
AI.CLASSIFYpara categorizar los viajes según sus descripciones en una de las tres categorías mágicas: [fácil, emocionante, extremo]
Clasifica los viajes según el nivel de emoción
- Usa
AI.SCOREpara comparar y ordenar las atracciones según un nivel de emoción, en el que el rango 10 es el más extremo y el rango 1 es el menos.
6. Tarea 3 (bonificación): ETL inverso, de BigQuery a AlloyDB
Aprovechaste las potentes capacidades de BigQuery para generar estadísticas sobre grandes cantidades de datos. Ahora quieres que tus aplicaciones operativas (y agentes de IA) puedan aplicar esas estadísticas.
¿Pero cómo? ¡Dando la vuelta! AlloyDB para PostgreSQL es ideal para entregar datos con baja latencia y alta velocidad, lo que lo hace perfecto para tus aplicaciones críticas orientadas al usuario. Así que hagamos una ETL inversa de los datos que acabamos de generar.
Para ello, usaremos una función completamente nueva, que aún está en versión preliminar privada, llamada "Vistas de BigQuery" en AlloyDB. Esta función te permite consultar datos de BigQuery directamente en tu base de datos de Postgres.
Primero, debes otorgar a la cuenta de servicio de tu clúster de AlloyDB los privilegios necesarios para consultar BigQuery.
gcloud beta alloydb clusters describe <CLUSTER ID> --region=europe-west1
El resultado contiene un campo serviceAccountEmail, que es la cuenta de servicio de este clúster.
En la consola de Google Cloud, ve a la página de IAM y otorga los siguientes privilegios a esta principal:
- Visualizador de datos de BigQuery (roles/bigquery.dataViewer)
- Usuario de sesión de lectura de BigQuery (roles/bigquery.readSessionUser)
Ahora, ve a AlloyDB Studio en la consola y conéctate a la base de datos "postgres".
Ejecuta las siguientes consultas para instalar y configurar la nueva función:
CREATE EXTENSION bigquery_fdw;
CREATE SERVER bq_disney FOREIGN DATA WRAPPER bigquery_fdw;
CREATE USER MAPPING FOR postgres SERVER bq_disney ;
Ahora puedes crear una "tabla externa" que se asignará a una tabla actual en BigQuery. Usa cualquier tabla que hayas creado en la Tarea 3. Este es un ejemplo de la sintaxis:
CREATE FOREIGN TABLE reviews_analysis ( "Review_ID" int,
"Sentiment" text) SERVER bq_disney OPTIONS (PROJECT 'bqml-hack25par-xxx',
dataset 'disney',
TABLE 'reviews_analysis');
Ya está todo listo. Consultemos la tabla. Ejecuta un primer SELECT para validar la vinculación entre AlloyDB y BigQuery, y, por último, crea una tabla nueva en AlloyDB para transferir los datos de tu tabla externa.
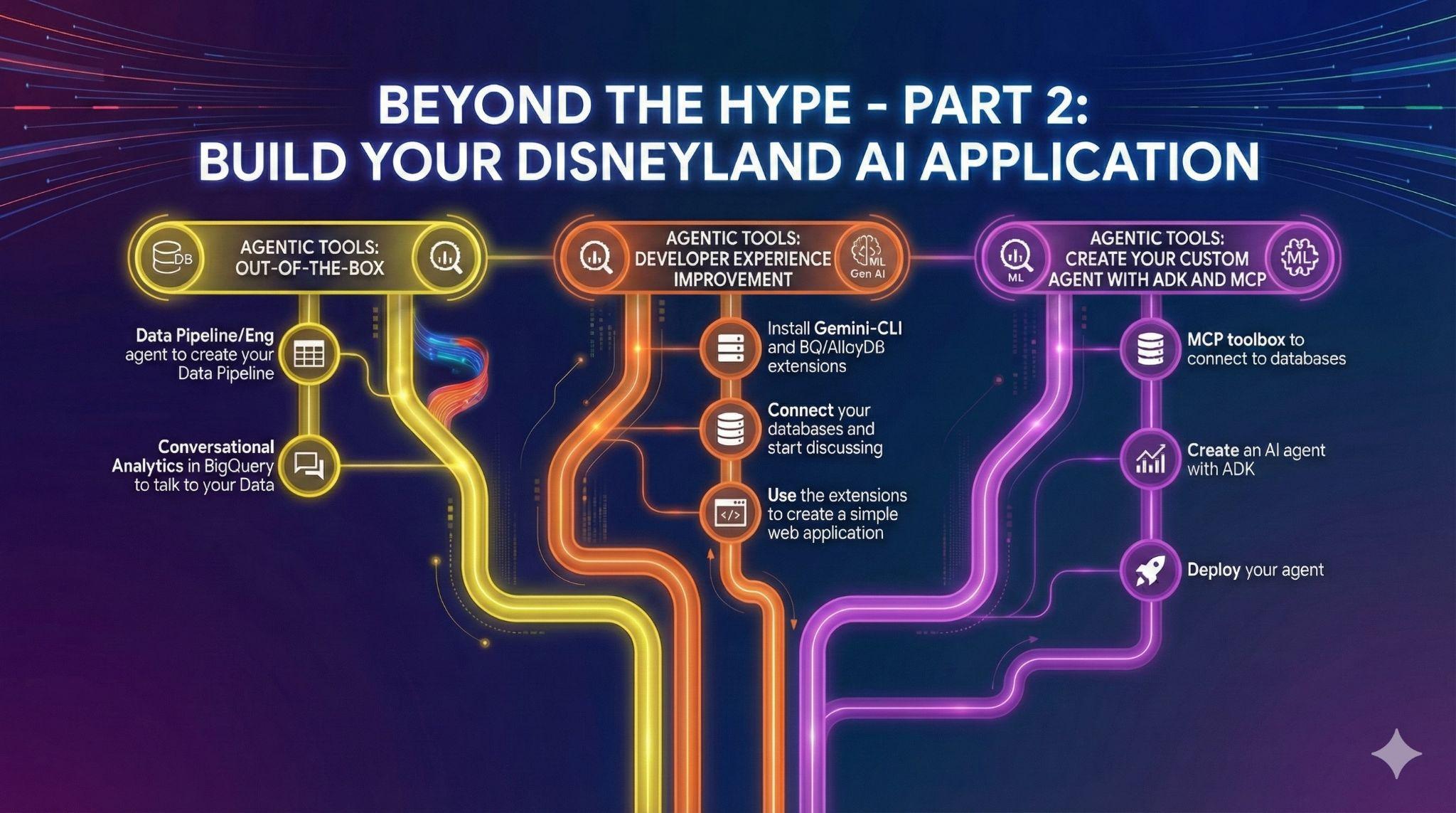
7. Tarea 4: Agentes de datos listos para usar
Tienes amigos que quieren contribuir al proyecto de la aplicación de Disneyland. Tienen acceso a los datos en BigQuery, pero tienen diferentes niveles de conocimiento de SQL y de ingeniería de datos. Quieres aprovechar los anuncios recientes de BigQuery sobre los agentes de datos que ya están integrados en la IU para ayudar a tus amigos:
- Crear canalizaciones de datos
- Colaborar en código SQL
- Habla con sus datos.
Agentes de ingeniería de datos para automatizar tus canalizaciones de datos
Crea una vista nueva average_waiting_time que una la tabla waiting_time y las atracciones, y calcula el promedio de waiting_time por atracción con el agente de ingeniería de datos.
Crea tu agente de Conversational Analytics en BigQuery
¿Qué pasaría si pudieras crear un agente para hablar con tus datos, sin código, sin SQL, sin implementación y desde la interfaz de BigQuery? ¿No sería genial? Bueno, hoy es posible con la pestaña "Agentes" en BigQuery.

- Crea un agente my_disney_friend que se conecte a tus tablas de Disney. Puedes mejorar el rendimiento del agente completando las instrucciones del agente. Haz preguntas como "¿Qué porcentaje de opiniones son positivas y qué porcentaje son negativas? ¿Cuál es el tiempo de espera promedio por atracción?, etcétera".
- Publica el agente en BigQuery y en la API (lo usarás más adelante).
8. Tarea 5: Mejora tu experiencia de desarrollo con Gemini CLI
En esta era de la IA, crear software nunca fue tan accesible. Tienes miles de ideas para tu aplicación de Disneyland y quieres usar tus datos al máximo. Quieres ir más allá de solo hablar con los datos, ahora necesitas acción.
Para ayudarte en ese camino, necesitarás ayuda. Y nosotros te ayudaremos.
Gemini CLI es un agente de IA de código abierto que lleva el poder de Gemini directamente a tu terminal. Los desarrolladores pueden crear aplicaciones potentes y, gracias a las extensiones, también pueden interactuar con varios servidores de MCP (Protocolo de contexto del modelo).
Entre ellas, por supuesto, puedes encontrar extensiones para consultar tus datos de AlloyDB o BigQuery.
En esta tarea, tu objetivo es hacer lo siguiente:
- Instala Gemini CLI (en tu propia terminal o en Cloud Shell)
- Instala las extensiones de Gemini CLI para BigQuery y AlloyDB
- Crea un archivo de entorno que permita que Gemini CLI se conecte a tus instancias de BigQuery y AlloyDB
- Pídele a Gemini CLI que genere una sola página HTML elegante que explique el contenido de tu base de datos de AlloyDB
- Haz lo mismo para BigQuery
Estos son algunos ejemplos de lo que podrías generar con una sola instrucción (o algunas) con Gemini CLI y sus extensiones. Ahora imagina que podrías hacer eso con aplicaciones de la vida real. 

9. Tarea 6: Crea un agente de IA para interactuar con tus datos
Para ofrecer una experiencia de usuario completamente nueva a los visitantes de Disneyland, crearás un asistente que pueda ayudarlos durante su viaje. Tu agente podrá hacer lo siguiente:
- Enumera todas las atracciones disponibles en el parque
- Recomienda una atracción según las expectativas
- Agrega opiniones sobre una atracción
- Proporcionar una estimación del tiempo de espera para una atracción en las próximas horas
- Proporciona una descripción general de las opiniones sobre una atracción específica
Te asegurarás de que tu asistente solo pueda responder preguntas relacionadas con Disneyland y mantenga un tono amigable con el usuario. Ajusta la instrucción del agente para asegurarte de que el agente elija las herramientas adecuadas para las necesidades del usuario.
Estos son los pasos que debes seguir:
- Implementa un servidor de caja de herramientas de MCP para bases de datos que use AlloyDB y BigQuery como fuentes.
- Declara 5 herramientas diferentes para tu servidor de MCP que consulten AlloyDB y BigQuery, y asigna las acciones del agente que se mencionaron anteriormente.
- Usa la IU de MCP Toolbox para validar cada una de tus herramientas
- Implementa un agente con el Kit de desarrollo de agentes que pueda usar las herramientas expuestas por el servidor del kit de herramientas de MCP.
- Conéctate a la interfaz web del ADK y muestra una conversación completa con tu asistente, incluidas todas las herramientas disponibles.
Paso adicional si terminas antes:
¿Tu agente está listo? Implementémoslo en Agent Engine.