
১. 🏰 ডিজনিল্যান্ড ডেটা অ্যানালিটিক্স হ্যাকাথন (২য় সংস্করণ - ৩রা ডিসেম্বর) 🏰
সারসংক্ষেপ | এই হ্যাকাথনে, আপনি গুগল ক্লাউডে AI/ML সক্ষমতা ব্যবহার করে একটি এন্ড-টু-এন্ড ডেটা অ্যানালিটিক্স পাইপলাইন তৈরি করবেন। আপনি AlloyDB- তে ডেটা লোড করবেন, যা একটি সম্পূর্ণ-পরিচালিত, PostgreSQL-উপযোগী ডেটাবেস এবং উচ্চ চাহিদার কাজের জন্য অপ্টিমাইজ করা। এরপর, আপনি Datastream ব্যবহার করে, যা একটি সার্ভারলেস চেঞ্জ ডেটা ক্যাপচার (CDC) পরিষেবা, সেই ডেটাকে গুগল ক্লাউডের সার্ভারলেস ডেটা ওয়্যারহাউস BigQuery- তে স্থানান্তর করবেন। BigQuery-তে, আপনি BigQuery ML প্রয়োগ করবেন, যা আপনাকে স্ট্যান্ডার্ড SQL ব্যবহার করে সরাসরি BigQuery-তে মেশিন লার্নিং মডেল তৈরি এবং কার্যকর করার সুযোগ দেয়, এবং এটি রিভিউ বিশ্লেষণ ও উপস্থিতি পূর্বাভাসের জন্য ব্যবহৃত হবে। সবশেষে, আপনি এজেন্ট নিয়ে কাজ করবেন, হয় কনভারসেশনাল অ্যানালিটিক্স ও ডেটা এজেন্টস-এর মাধ্যমে তৈরি এজেন্ট ব্যবহার করে অথবা এজেন্ট ডেভেলপমেন্ট কিট এবং MCP টুলবক্স দ্বারা চালিত একটি কাস্টম এজেন্ট তৈরি করে আপনার ডেটার সাথে স্বাভাবিক ভাষায় মিথস্ক্রিয়া করবেন। |
বিভাগগুলি | ডকটাইপ:কোডল্যাব, পণ্য:বিগকোয়েরি |
লেখক | রায়হানে রেজগুই, ম্যাট কর্নিলন |
লেআউট | স্ক্রোলিং |
রোবট | কোনো সূচক নেই |
২. ভূমিকা
স্বাগতম, ভবিষ্যতের ডিজনি ডেটা উইজার্ডরা!🪄
ক্লান্তিকর ভ্রমণ নির্দেশিকা এবং ফোরামে অবিরাম স্ক্রোল করার কথা ভুলে যান। ডেটা-ভিত্তিক তথ্যের সাহায্যে একটি নিখুঁত ডিজনিল্যান্ড ভ্রমণের পরিকল্পনা করার কথা ভাবুন। কোন পার্কটি সেরা অভিজ্ঞতা দেয়? কখন ভিড় সবচেয়ে কম থাকে? সেই কুখ্যাত দীর্ঘ লাইনটি পার করার সেরা সময় কি আপনি অনুমান করতে পারবেন?
এই হ্যাকাথনে, আপনি আপনার সর্বাধুনিক ডিজনিল্যান্ড পরিকল্পনা টুল তৈরি করছেন। আমাদের কাছে ডেটা আছে: বিশ্বজুড়ে বিভিন্ন শাখার দর্শনার্থীদের রিভিউ, অতীতের অপেক্ষার সময় এবং উপস্থিতির পরিসংখ্যান। আপনার কাজ? এই কাঁচা ডেটাকে কার্যকরী তথ্যে রূপান্তরিত করা।
- তথ্য সংগ্রহ করুন: ডিজনিল্যান্ডের বিভিন্ন রিভিউ, অপেক্ষার সময় এবং উপস্থিতির পরিসংখ্যান আমাদের উচ্চ-ক্ষমতাসম্পন্ন, PostgreSQL-উপযোগী ডেটাবেস AlloyDB-তে লোড করুন।
- নির্বিঘ্ন স্থানান্তর: আমাদের সার্ভারলেস চেঞ্জ ডেটা ক্যাপচার সার্ভিস, ডেটাস্ট্রিম (Datastream) ব্যবহার করে এই পরিবর্তনশীল তথ্যকে অনায়াসে গুগল ক্লাউডের শক্তিশালী সার্ভারলেস ডেটা ওয়্যারহাউস, বিগকোয়েরি (BigQuery)-তে স্থানান্তর করুন।
- জাদুর পূর্বাভাস দিন: সরাসরি SQL ব্যবহার করে রিভিউয়ের মনোভাব বিশ্লেষণ করতে এবং অপেক্ষার সময়ের পূর্বাভাস দিতে BigQuery ML-এর ব্যবহার শুরু করুন। জেনে নিন কোন শাখাগুলো ধারাবাহিকভাবে সন্তুষ্টি দেয় এবং আপনার পরিদর্শনের জন্য সর্বোত্তম সময় কোনটি।
- আপনার ডেটার সাথে কথা বলুন - আক্ষরিক অর্থেই!: আগে থেকে তৈরি এমন টুল ব্যবহার করুন যা আপনাকে এক টানেই গুরুত্বপূর্ণ তথ্য পেতে সাহায্য করবে।
- বুদ্ধিদীপ্ত মিথস্ক্রিয়া: ডেটাবেসের জন্য এমসিপি টুলবক্স এবং এডিকে (এজেন্ট ডেভেলপমেন্ট কিট) দ্বারা চালিত একটি বুদ্ধিমান এজেন্টের মাধ্যমে আপনার সৃষ্টিকে চূড়ান্ত রূপ দিন। জিজ্ঞাসা করুন, "মহাকাশপ্রেমীদের জন্য ডিজনিল্যান্ড প্যারিসের সেরা আকর্ষণ কোনটি, এবং লাইনে দাঁড়ানোর সেরা সময় কোনটি?" এবং তাৎক্ষণিক, ডেটা-ভিত্তিক উত্তর পান।
পৃথিবীর সবচেয়ে জাদুকরী স্থানগুলোর রহস্য উন্মোচন করতে এবং এমন একটি ডেটা অ্যানালিটিক্স পাইপলাইন তৈরি করতে প্রস্তুত হন যা মিকিকেও গর্বিত করবে!

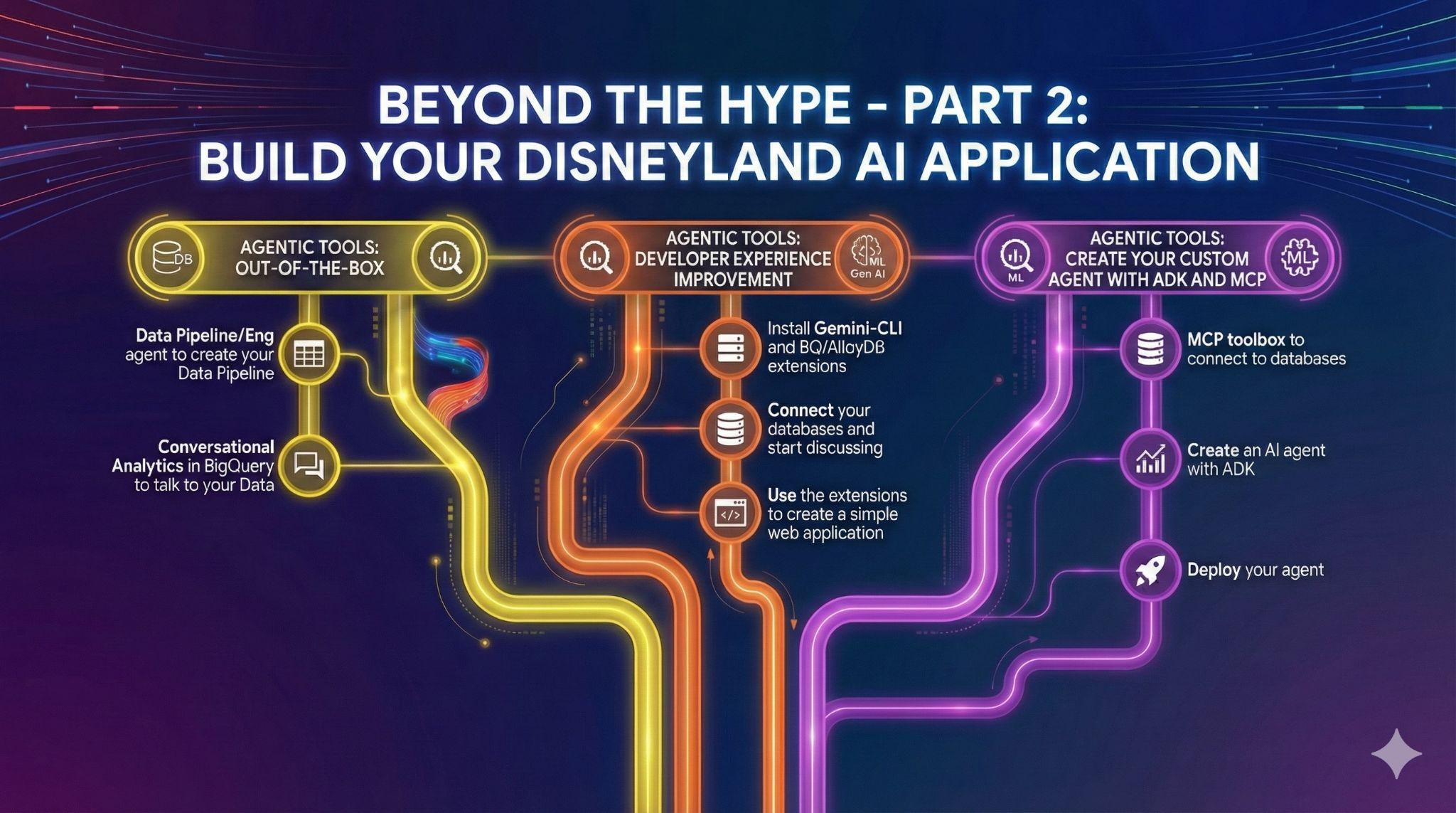
৩. কাজ ১: পরিচালনগত থেকে বিশ্লেষণাত্মক; জেমিনির সাহায্যে ডিজনিল্যান্ডের রিভিউ বিশ্লেষণ করুন
এই প্রাথমিক পর্যায়ে, আপনি আপনার AlloyDB অপারেশনাল ডেটাবেস থেকে ডেটা সংগ্রহ করে পরবর্তী ডেটা বিশ্লেষণের জন্য BigQuery-তে লোড করবেন।
আপনার ভবিষ্যৎ এজেন্টের জন্য AlloyDB-তে প্রয়োজনীয় সবকিছুও আপনাকে সেট আপ করতে হবে!
AlloyDB-তে ডেটা লোড করা হচ্ছে
প্রথমেই, চলুন আমাদের AlloyDB for PostgreSQL ক্লাস্টারে কিছু ডেটা ইম্পোর্ট করি!
আমরা ডিজনিল্যান্ড অ্যামিউজমেন্ট পার্কের ২০ হাজার রিভিউ এবং আকর্ষণীয় স্থানগুলোর একটি তালিকা সংগ্রহ করব।
আপনাকে যে পদক্ষেপগুলো নিতে হবে তা নিম্নরূপ:
টেবিল তৈরি:
- disneyland_reviews নামে একটি টেবিল তৈরি করুন, যাতে review_id ও rating (পূর্ণসংখ্যা হিসেবে), year_month, reviewer_location, review_text এবং branch (টেক্সট হিসেবে) এই ৬টি কলাম থাকবে।
- disneyland_attractions নামে একটি টেবিল তৈরি করুন, যাতে চারটি কলাম থাকবে: attraction_id (পূর্ণসংখ্যা), branch, name এবং description (টেক্সট)।
আপনার পছন্দের টুল ব্যবহার করে CSV ফাইলগুলো থেকে ডেটা ইম্পোর্ট করুন:
- রিভিউ টেবিলের জন্য
gs://hackathon_data_disneyland_<YOUR_PROJECT_3DIGITS>/reviews.csv - আকর্ষণ সারণীর জন্য
gs://hackathon_data_disneyland_<YOUR_PROJECT_3DIGITS>/attractions.csv
দর্শনীয় স্থানের সুপারিশ প্রদান করার জন্য, আমাদের দর্শনীয় স্থানের বিবরণের এমবেডিং তৈরি করতে হবে:
- AlloyDB-তে pgvector এক্সটেনশনটি ইনস্টল করুন
- আপনার টেবিল অ্যাট্রাকশনে 'embedding' নামে একটি ভেক্টর কলাম যোগ করুন।
- AlloyDB এবং Vertex AI-এর মধ্যকার নেটিভ ইন্টিগ্রেশন ব্যবহার করে বর্ণনাগুলোর এমবেডিং তৈরি ও পূরণ করুন।
ডেটাস্ট্রিমের মাধ্যমে অপারেশনাল থেকে অ্যানালিটিক্যাল
AlloyDB থেকে BigQuery-তে আমাদের ডেটা স্ট্রিম করার জন্য, আমরা Google Datastream ব্যবহার করব। এটি একটি শক্তিশালী সার্ভার-বিহীন সমাধান যা সোর্স টেবিলের সমস্ত পরিবর্তন (Change Data Capture ব্যবহার করে) পর্যবেক্ষণ করে এবং সেগুলোকে BigQuery-তে পাঠিয়ে দেয়।
Datastream ব্যবহার করে AlloyDB থেকে পরিবর্তনগুলো প্রতিলিপি করতে হলে, আমাদের Postgres-এ একটি পাবলিকেশন এবং রেপ্লিকেশন স্লট তৈরি করতে হবে।
আপনার AlloyDB ক্লাস্টারে নিম্নলিখিত কোয়েরিগুলি চালান (আপনাকে এগুলি এক এক করে চালাতে হবে):
CREATE PUBLICATION pub_disney FOR TABLE disneyland_reviews, disneyland_attractions;
ALTER USER postgres WITH REPLICATION;
SELECT PG_CREATE_LOGICAL_REPLICATION_SLOT('slot_disney', 'pgoutput');
আপনি আপনার স্ট্রিমে পাবলিকেশন এবং রেপ্লিকেশন স্লট ব্যবহার করবেন, তাই নামগুলো মনে রাখবেন!
ব্যাস, হয়ে গেল, এখন আমরা একটি স্ট্রিম তৈরি করতে পারি!
ডেটাস্ট্রিমে আপনাকে যে পদক্ষেপগুলো নিতে হবে তা নিম্নরূপ:
- আপনার AlloyDB ক্লাস্টারের জন্য একটি সোর্স প্রোফাইল তৈরি করুন (পাবলিক আইপি অ্যাড্রেস ব্যবহার করুন)।
- BigQuery-এর জন্য একটি গন্তব্য প্রোফাইল তৈরি করুন
- AlloyDB থেকে BigQuery-তে একটি স্ট্রিম তৈরি করুন।
কয়েক মিনিটের মধ্যেই ডেটা BigQuery-তে পাওয়া যাবে।
BigQuery-তে ডেটা আবিষ্কার
এখন যেহেতু আমাদের ডেটা BigQuery-তে আছে, কাজ শুরু করার আগে চলুন ইন্টারফেসের নতুন উন্নতিগুলো সম্পর্কে জেনে নিই!
আমাদের ৩টি নতুন ফাংশন রয়েছে যা আপনি ইতিমধ্যেই BigQuery এক্সপ্লোরেশন প্যানেলে দেখতে পাচ্ছেন।
- সংক্ষিপ্ত বিবরণ: এতে BigQuery-এর বৈশিষ্ট্য, বিশ্লেষণ শুরু করার জন্য নির্দেশিকা এবং অন্যান্য সম্ভাবনা সম্পর্কে তথ্য রয়েছে।
- অনুসন্ধান: আপনার ডেটা সম্পদগুলিতে শব্দার্থিক অনুসন্ধান চালান।
- এজেন্টরা: চুপ! এটা আমরা পরে দেখাবো 🤫
BigQuery-তে আপনার ডেটা শব্দার্থগতভাবে অনুসন্ধান করুন।
BigQuery এক্সপ্লোরেশন প্যানেলের সার্চ ট্যাবে যান এবং ডিজনির সাথে সম্পর্কিত শব্দ, যেমন 'attractions' বা 'branch' নিয়ে পরীক্ষা-নিরীক্ষা করুন।
BigQuery-তে আপনার ডেটা ভিজ্যুয়ালাইজ করুন
এখন আপনি BigQuery-তে আপনার ডেটা দেখতে ও পরিচালনা করতে পারবেন। এর জন্য, আপনি একটি নতুন কোয়েরি ট্যাবে এই কোয়েরিটি চালাতে পারেন;
SELECT
*
FROM
[dataset_name].[table_name];
রিভিউ টেবিলে ডেটা ইনসাইট তৈরি করুন
এই টাস্কে, আপনি disney ডেটাসেটের অন্তর্গত disneyland_reviews টেবিলের উপর ডেটা ইনসাইটস সক্রিয় করবেন।
যারা জটিল SQL কোয়েরি না লিখে নিজেদের ডেটা বিশ্লেষণ করতে ও তার থেকে গুরুত্বপূর্ণ তথ্য জানতে চান, ডেটা ইনসাইটস তাদের জন্য একটি টুল।
এতে কয়েক মিনিট সময় লাগতে পারে।
SQL ছাড়া disneyland_reviews টেবিলটি কোয়েরি করুন
পূর্ববর্তী বিভাগে আপনি যে ইনসাইটগুলো তৈরি করেছেন, সেগুলো এখন প্রস্তুত। এই টাস্কে, আপনি এই ইনসাইটগুলো থেকে তৈরি একটি প্রম্পট ব্যবহার করে কোড ছাড়াই disneyland_reviews টেবিলটি কোয়েরি করবেন।
একটি ইনসাইট নির্বাচন করুন এবং এর সাথে যুক্ত কোয়েরিটি চালান। উদাহরণস্বরূপ, সেই কোয়েরিটি খুঁজুন যা প্রতিটি শাখার জন্য পরপর মাসগুলোর গড় রেটিং-এর পার্থক্য গণনা করে। এটি দেখতে এইরকম হবে:
WITH
monthly_avg AS (
SELECT
branch,
year_month,
AVG(rating) AS avg_rating
FROM
[dataset_name].[table_name]
WHERE
year_month IS NOT NULL
GROUP BY
1,
2 )
SELECT
branch,
year_month,
avg_rating,
avg_rating - LAG(avg_rating, 1, 0) OVER (PARTITION BY branch ORDER BY year_month) AS rating_difference
FROM
monthly_avg
ORDER BY
branch,
year_month;
ডেটা আরও ভালোভাবে বোঝার জন্য BigQuery নলেজ ইঞ্জিন ব্যবহার করুন।
প্রথমেই, ডেটাসেট লেভেলে Insights ট্যাবটি দেখা যাক; এটি আমাদের ডিজনি ডেটাসেটের টেবিলগুলোর মধ্যেকার লুকানো সম্পর্কগুলো সম্পর্কে একটি ধারণা দেবে। তারপর,
- Gemini ব্যবহার করে ডেটাসেটটির একটি বিবরণ তৈরি করুন এবং সেটি ডেটাসেটের বিবরণে যোগ করুন।
- 'রিভিউ' এবং 'আকর্ষণ' টেবিলগুলোর পাশাপাশি ঐ টেবিলগুলোর প্রতিটি কলামের একটি বিবরণ তৈরি করুন এবং তা সংরক্ষণ করুন।
আপনার ডেটার প্রোফাইল স্ক্যান করুন।
এই অংশের উদ্দেশ্য হলো আপনার ডেটা পরিষ্কার ও প্রস্তুত করা। তবে, প্রতিটি কলামের মানগুলোর বিন্যাস সম্পর্কে আপনি খুব বেশি পরিচিত নন। আপনার ডেটার উপর কী ধরনের রূপান্তর পদক্ষেপ গ্রহণ করতে হবে, তা জানার জন্য আপনাকে আপনার ডেটার প্রোফাইলিং করতে হবে।
গুগল ক্লাউডের ডেটাপ্লেক্স ইউনিভার্সাল ক্যাটালগ সামঞ্জস্যপূর্ণ ডেটা কোয়ালিটি মেট্রিক্স প্রদানের জন্য প্রোফাইলিং স্ক্যান স্বয়ংক্রিয় করে। শনাক্তকৃত প্রধান পরিসংখ্যানগুলোর মধ্যে রয়েছে নাল কাউন্ট, ডিসটিংক্ট ভ্যালু, ডেটা রেঞ্জ এবং ভ্যালু ডিস্ট্রিবিউশন। বিগকোয়েরি ইন্টারফেসের মাধ্যমে একটি প্রোফাইল স্ক্যান সক্রিয় করা সম্ভব।
এতে কয়েক মিনিট সময় লাগতে পারে, তাই অপেক্ষা করার সময় আপনি পরের অংশটি দেখতে পারেন।
নিম্নলিখিত প্রশ্নগুলোর উত্তর দিন:
- ডিজনিল্যান্ডের গড় রেটিং কত?
- পর্যালোচকদের বেশিরভাগই কোথায় থাকেন?
- সব রিভিউ কি স্বতন্ত্র?
- Year_Month কলামে অনুপস্থিত ডেটার শতকরা হার কত?
আপনার ডেটার গুণগত মান যাচাই করুন।
ডেটাপ্লেক্স ইউনিভার্সাল ক্যাটালগের স্বয়ংক্রিয় ডেটা কোয়ালিটি আপনাকে আপনার BigQuery টেবিলের ডেটার গুণমান নির্ধারণ ও পরিমাপ করতে দেয়। আপনি ডেটা স্ক্যানিং স্বয়ংক্রিয় করতে পারেন, নির্ধারিত নিয়মের সাথে ডেটা যাচাই করতে পারেন এবং আপনার ডেটা গুণমানের প্রয়োজনীয়তা পূরণ না করলে অ্যালার্ট লগ করতে পারেন। আপনি ডেটা কোয়ালিটির নিয়ম এবং ডেপ্লয়মেন্ট কোড হিসাবে পরিচালনা করতে পারেন, যা ডেটা প্রোডাকশন পাইপলাইনের অখণ্ডতা উন্নত করে।
প্রোফাইল স্ক্যানের উপর ভিত্তি করে, একটি কোয়ালিটি স্ক্যান নির্ধারণ করুন (নমুনা আকার হিসাবে আপনার ডেটার ১০%-এর বেশি নয়) যা:
- ' branch ' কলামের জন্য নাল (null) মান পরীক্ষা করা হয়।
- " রেটিং "-টির বৈধতা যাচাই করা হয়, কারণ এটি শুধুমাত্র ১, ২, ৩, ৪, ৫ এই সেটের মধ্যেই থাকতে পারে।
- " review_id "-এর অনন্যতা যাচাই করে
নিশ্চিত করুন যে স্ক্যানটি তার ফলাফল 'quality_scan_results' নামের একটি BigQuery টেবিলে এক্সপোর্ট করে।
আপনার ডেটাতে প্রয়োগ করার জন্য প্রয়োজনীয় সমস্ত সম্ভাব্য রূপান্তরগুলো সম্পর্কে চিন্তা করুন।
জেমিনির ডেটা প্রিপারেশন ব্যবহার করে আপনার ডেটা প্রস্তুত করুন।
আপনার করা ডেটার গুণমান এবং প্রোফাইলিং স্ক্যানগুলোর পর, এখন ডেটা বিশ্লেষণ করার আগে তা পরিষ্করণ করার সময় এসেছে।
ডেটা প্রিপারেশন হলো BigQuery-এর একটি রিসোর্স, যা BigQuery-এর Gemini ব্যবহার করে আপনার ডেটা বিশ্লেষণ করে এবং এটিকে পরিষ্করণ, রূপান্তর ও সমৃদ্ধ করার জন্য বুদ্ধিদীপ্ত পরামর্শ প্রদান করে। এর মাধ্যমে আপনি ম্যানুয়াল ডেটা প্রিপারেশন কাজের জন্য প্রয়োজনীয় সময় ও শ্রম উল্লেখযোগ্যভাবে কমাতে পারেন।
এই অংশে, আপনি ডেটা প্রিপারেশন ব্যবহার করে আপনার disneyland_reviews টেবিলের উপর এই অপারেশনগুলো সম্পাদন করবেন:
- যেসব সারির 'Branch' কলামের মান NULL অথবা একটি খালি স্ট্রিং, সেগুলোকে ফিল্টার করে বাদ দিন।
- Year_Month-এ থাকা 'missing'-কে Null দ্বারা প্রতিস্থাপন করুন।
- পাঠযোগ্যতা উন্নত করার জন্য শাখা কলামে আন্ডারস্কোরকে স্পেস দিয়ে প্রতিস্থাপন করা হয়।
- রূপান্তরিত টেবিল disneyland_reviews_cleaned-এ রপ্তানি করুন
জেমিনি দিয়ে রিভিউ বিশ্লেষণ করুন
এখন যেহেতু আপনি আপনার ডেটা পরিষ্কার করে ফেলেছেন, আপনি BigQuery ML এবং Gemini মডেল ব্যবহার করে এটি বিশ্লেষণ করা শুরু করতে পারেন। আপনার দুটি উদ্দেশ্য রয়েছে:
- রিভিউ থেকে ক্যাটাগরিগুলো বের করুন
- ডিজনিল্যান্ড রিভিউগুলির অনুভূতি বিশ্লেষণ
BigQuery ML আপনাকে GoogleSQL কোয়েরি ব্যবহার করে মেশিন লার্নিং (ML) মডেল তৈরি ও চালানোর সুযোগ দেয়। BigQuery ML মডেলগুলো টেবিল এবং ভিউ-এর মতোই BigQuery ডেটাসেটে সংরক্ষিত থাকে। BigQuery ML আপনাকে টেক্সট জেনারেশন বা মেশিন ট্রান্সলেশনের মতো কৃত্রিম বুদ্ধিমত্তার (AI) কাজ সম্পাদনের জন্য Vertex AI মডেল এবং Cloud AI API অ্যাক্সেস করার সুযোগও দেয়। Gemini for Google Cloud-ও BigQuery-এর কাজগুলোর জন্য AI-চালিত সহায়তা প্রদান করে।
আপনি জেমিনি প্রো বা ফ্ল্যাশ মডেলের সাথে ML.GENERATE_TEXT অথবা AI.GENERATE (প্রিভিউ) ব্যবহার করতে পারেন।
আপনি যদি ML.GENERATE_TEXT ব্যবহার করতে চান, তাহলে নিম্নলিখিত ধাপগুলো আপনাকে পথ দেখাবে।
ক্লাউড রিসোর্স সংযোগ তৈরি করুন এবং IAM ভূমিকা মঞ্জুর করুন
Gemini Pro এবং Gemini Flash মডেলগুলির সাথে কাজ করার জন্য, আপনাকে BigQuery-তে Vertex AI মডেলগুলির সাথে একটি ক্লাউড রিসোর্স কানেকশন তৈরি করতে হবে। এছাড়াও, Vertex AI পরিষেবাগুলি অ্যাক্সেস করার সুযোগ দেওয়ার জন্য, আপনাকে একটি রোলের মাধ্যমে ক্লাউড রিসোর্স কানেকশনের সার্ভিস অ্যাকাউন্টকে IAM পারমিশন প্রদান করতে হবে।
কানেকশনের সার্ভিস অ্যাকাউন্টে Vertex AI User রোল প্রদান করুন
কানেকশনের সার্ভিস অ্যাকাউন্টকে আপনার নির্বাচিত মডেল (যেমন gemini-2.5-flash ) ব্যবহার করার অনুমতি দিতে, এটিকে Vertex AI User রোলটি প্রদান করুন। অনুমতিটি কার্যকর হতে ১ মিনিট সময় লাগে।
BigQuery-তে Gemini মডেলগুলি তৈরি করুন
উপরের সংযোগটি ব্যবহার করে আপনার মডেলটি তৈরি করুন। উদাহরণস্বরূপ gemini-2.5-flash.
গ্রাহকদের পর্যালোচনার বিভাগ এবং মনোভাব বিশ্লেষণ করতে জেমিনিকে নির্দেশ দিন।
এই কাজে, আপনি জেমিনি মডেল ব্যবহার করে প্রতিটি গ্রাহক পর্যালোচনার বিভাগ এবং ইতিবাচক বা নেতিবাচক অনুভূতি বিশ্লেষণ করবেন।
বিভাগগুলির জন্য গ্রাহক পর্যালোচনাগুলি বিশ্লেষণ করুন
দ্রষ্টব্য: এখন থেকে বিশ্লেষণের জন্য আমরা কেবল ১০০টি সারি নেব , কারণ ২০ হাজার সারির ডেটা প্রসেস করতে জেমিনির কিছুটা সময় লাগতে পারে।
-
Extract categories by modifying and running the following SQL Query:
CREATE OR REPLACE TABLE
[dataset_name].[results_table_name] AS (
SELECT Review_ID, Rating, Year_Month, Reviewer_Location, Review_Text, Branch, ml_generate_text_llm_result AS categories FROM
ML.GENERATE_TEXT(
MODEL [model_name],
(
SELECT Review_ID, Rating, Year_Month, Reviewer_Location, Review_Text, Branch, CONCAT(
'[WRITE YOUR PROMPT HERE].',
Review_Text) AS prompt
FROM (SELECT * FROM [dataset_name].[table_name] LIMIT 100)
),
STRUCT(
0.2 AS temperature, TRUE AS flatten_json_output)));
এই কোয়েরিটি disneyland_reviews টেবিল থেকে গ্রাহকদের রিভিউ গ্রহণ করে এবং প্রতিটি রিভিউর মধ্যে ক্যাটাগরি শনাক্ত করার জন্য gemini মডেলের জন্য প্রম্পট তৈরি করে। ফলাফলগুলো reviews_categories নামক একটি নতুন টেবিলে সংরক্ষণ করা হবে।
অনুগ্রহ করে অপেক্ষা করুন । মডেলটির গ্রাহক পর্যালোচনার রেকর্ডগুলো প্রক্রিয়াকরণ করতে এবং আউটপুট টেবিলে ফলাফল দেখাতে প্রায় ৩০ সেকেন্ড সময় লাগে।
ফলাফল প্রদর্শন করুন:
SELECT * FROM [dataset_name].[results_table_name];
কিছু সময় নিয়ে বিভাগগুলো পড়ুন।
গ্রাহকদের মতামতের ইতিবাচক ও নেতিবাচক দিকগুলো বিশ্লেষণ করুন।
কীওয়ার্ড নিষ্কাশনের জন্য ব্যবহৃত SQL কোয়েরির উপর ভিত্তি করে এমন একটি কোয়েরি লিখুন, যা 'sentiment' নামক একটি কলামের অধীনে রিভিউগুলোকে পজিটিভ, নেগেটিভ এবং নিউট্রাল—এই তিন ভাগে বিশ্লেষণ করবে।
এই কোয়েরিটি disneyland_reviews টেবিল থেকে গ্রাহকের রিভিউগুলো নেয় এবং প্রতিটি রিভিউর সেন্টিমেন্ট শ্রেণীবদ্ধ করার জন্য gemini মডেলের জন্য প্রম্পট তৈরি করে। এরপর ফলাফলগুলো reviews_analysis একটি নতুন টেবিলে সংরক্ষণ করা হয়, যাতে আপনি পরবর্তীতে আরও বিশ্লেষণের জন্য এটি ব্যবহার করতে পারেন। অনুগ্রহ করে অপেক্ষা করুন। মডেলটির গ্রাহকের রিভিউ রেকর্ডগুলো প্রসেস করতে কয়েক সেকেন্ড সময় লাগে। মডেলটির কাজ শেষ হলে, তৈরি হওয়া reviews_analysis টেবিলে ফলাফলটি পাওয়া যাবে।
ফলাফলগুলো পর্যালোচনা করুন:
SELECT * FROM [...];
reviews_analysis টেবিলটিতে Sentiment কলাম রয়েছে, যেখানে social_media_source , review_text , customer_id , location_id এবং review_datetime কলামগুলো সহ সেন্টিমেন্ট অ্যানালাইসিস দেওয়া আছে। রেকর্ডগুলোর কয়েকটি দেখুন। আপনি হয়তো লক্ষ্য করবেন যে, পজিটিভ এবং নেগেটিভের কিছু ফলাফল সঠিকভাবে ফরম্যাট করা নাও থাকতে পারে, যেখানে পিরিয়ড বা অতিরিক্ত স্পেসের মতো অনাকাঙ্ক্ষিত অক্ষর রয়েছে। আপনি নিচের ভিউটি ব্যবহার করে রেকর্ডগুলো সংশোধন করতে পারেন।
রেকর্ডগুলো পরিমার্জন করার জন্য একটি ভিউ তৈরি করুন।
এমন একটি ভিউ তৈরি করুন যা 'sentiment' কলামের মানগুলোকে নিম্নলিখিত উপায়ে পরিমার্জন করে:
- সমস্ত মান ছোট হাতের অক্ষরে নিশ্চিত করতে LOWER ব্যবহার করা হয়।
- REPLACE ব্যবহার করে বিরামচিহ্ন (., , এবং স্পেস) অপসারণ করা।
CREATE OR REPLACE VIEW [view_name] AS
SELECT [SANITIZATION_EXPRESSION] AS sentiment,
Review_ID, Rating, Year_Month, Reviewer_Location, Review_Text, Branch,
FROM `disney.reviews_analysis`;
কোয়েরিটি cleaned_data_view নামের একটি ভিউ তৈরি করে এবং এতে সেন্টিমেন্টের ফলাফল, রিভিউ টেক্সট, Review_ID, Rating, Year_Month, Reviewer_Location, Review_Text and Branch অন্তর্ভুক্ত থাকে। এরপর এটি সেন্টিমেন্টের ফলাফল (ইতিবাচক বা নেতিবাচক) গ্রহণ করে এবং নিশ্চিত করে যে সমস্ত অক্ষর ছোট হাতের অক্ষরে লেখা হয়েছে এবং অতিরিক্ত স্পেস বা পিরিয়ডের মতো অপ্রয়োজনীয় অক্ষরগুলো সরিয়ে ফেলা হয়েছে। এই ল্যাবের পরবর্তী ধাপগুলোতে প্রাপ্ত ভিউটি আরও বিশ্লেষণ করা সহজ করে তুলবে।
- তৈরি হওয়া সারিগুলো দেখতে, আপনি নিচের কোয়েরিটি ব্যবহার করে ভিউটি কোয়েরি করতে পারেন।
SELECT * FROM [view_name];
ডেটা ক্যানভাস ব্যবহার করে ইতিবাচক ও নেতিবাচক পর্যালোচনার সংখ্যার একটি প্রতিবেদন তৈরি করুন।
এখন, আপনার ফলাফল বিশ্লেষণ করার সময় এসেছে। চলুন, সরাসরি BigQuery-তে, Data Canvas-এর মাধ্যমে কাজটি শুরু করা যাক। এটি এমন একটি টুল যা আপনাকে ক্যানভাসের একটি ফ্লো তৈরি করার মাধ্যমে ডেটা অনুসন্ধান (অর্থগতভাবে বা কীওয়ার্ড অনুসারে), টেবিল কোয়েরি ও জয়েন করা, গ্রাফ তৈরি করা এবং ইনসাইট পেতে সাহায্য করে।
আপনার চূড়ান্ত লক্ষ্য হলো ইতিবাচক ও নেতিবাচক পর্যালোচনার শতাংশের উপর ভিত্তি করে আপনার পছন্দমতো একটি গ্রাফ তৈরি করা। এখানে একটি উদাহরণ দেওয়া হলো:

প্রতিটি ক্যাটাগরি অনুযায়ী পর্যালোচনার সংখ্যার একটি গ্রাফ তৈরি করুন, সেইসাথে প্রতিটি ক্যাটাগরির জন্য ইতিবাচক ও নেতিবাচক পর্যালোচনার বিন্যাসও দেখান।
পরামর্শ: ডেটা ক্যানভাসের অ্যাডভান্সড অ্যানালাইসিস সক্রিয় করে ব্যবহার করুন, যা একটি ক্যানভাসের ভিতরে একটি পাইথন নোটবুক চালায়।
৪. কাজ ২: ডিজনিল্যান্ডের ছবি শনাক্ত করতে অ্যাট্রাকশন পার্কের ছবি বিশ্লেষণ করুন এবং পার্কের ব্রোশিওর থেকে মজার তথ্য বের করুন।
BigQuery-তে চিত্র বিশ্লেষণ
আপনার কাছে অ্যাট্রাকশন পার্কের কিছু রোমাঞ্চকর ও আকর্ষণীয় ছবি রয়েছে, যা বছরের পর বছর ধরে দর্শনার্থীরা তুলেছেন। আপনি আপনার আসন্ন ভ্রমণ নিয়ে খুবই উত্তেজিত! তবে, আপনি জানেন না এর মধ্যে কোনগুলো ডিজনিল্যান্ডের আসল ছবি। আপনাকে সেগুলো শনাক্ত করার দায়িত্ব দেওয়া হয়েছে। ছবিগুলো gs://hackathon_data_disneyland_<YOUR_PROJECT_3DIGITS>/attraction_parc_photos/ অবস্থিত।

ডিজনিল্যান্ড: মিথ্যা

ডিজনিল্যান্ড: সত্য
এই বিশ্লেষণটি দ্রুত সম্পন্ন করার জন্য, আপনার BigQuery ML ( ML.GENERATE_TEXT ) এর মাধ্যমে BigQuery-এর অবজেক্ট টেবিল এবং Gemini ব্যবহার করা উচিত।
আপনি কি কিছু ছবি দেখে জেমিনির আউটপুট যাচাই করতে পারবেন?
ডিজনিল্যান্ড ব্রোশারের উপর ভিত্তি করে BigQuery দিয়ে আপনার নিজস্ব RAG সিস্টেম তৈরি করুন
লাইনে অপেক্ষা করার সময়, আপনি যে আকর্ষণটির জন্য অপেক্ষা করছেন, সেটির বিষয়ে কিছু মজার তথ্য বা প্রযুক্তিগত বিবরণ জেনে নিতে পারেন।
gs://hackathon_data_disneyland_<YOUR_PROJECT_3DIGITS>/disneyland_brochures/, আপনি সারা বিশ্বের সমস্ত পার্কের ব্রোশার সম্বলিত পিডিএফ ফাইল পাবেন।
লক্ষ্য: বিগকোয়েরি (BigQuery)-এর সম্পূর্ণ পরিসরে একটি রিট্রিভাল-অগমেন্টেড জেনারেশন (RAG) সিস্টেম তৈরি করা, যা ব্যবহারকারীদের কিছু পিডিএফ ডকুমেন্টের উপর ভিত্তি করে পার্কটি সম্পর্কে জটিল প্রশ্ন জিজ্ঞাসা করার সুযোগ দেবে।
এটি অর্জন করতে হলে আপনাকে যা করতে হবে:
- পিডিএফ ফাইলগুলির একটি অবজেক্ট টেবিল তৈরি করুন
- পিডিএফ ফাইলগুলোকে খণ্ডে খণ্ডে ভাগ করার জন্য একটি পাইথন ইউডিএফ তৈরি করুন। এখানে একটি উদাহরণ দেওয়া হলো যা আপনি ব্যবহার করতে পারেন:
CREATE OR REPLACE FUNCTION disney.chunk_pdf(src_json STRING, chunk_size INT64, overlap_size INT64)
RETURNS ARRAY<STRING>
LANGUAGE python
WITH CONNECTION `[LOCATION].[CONN_NAME]`
OPTIONS (entry_point='chunk_pdf', runtime_version='python-3.11', packages=['pypdf'])
AS """
import io
import json
from pypdf import PdfReader # type: ignore
from urllib.request import urlopen, Request
def chunk_pdf(src_ref: str, chunk_size: int, overlap_size: int) -> str:
src_json = json.loads(src_ref)
srcUrl = src_json["access_urls"]["read_url"]
req = urlopen(srcUrl)
pdf_file = io.BytesIO(bytearray(req.read()))
reader = PdfReader(pdf_file, strict=False)
# extract and chunk text simultaneously
all_text_chunks = []
curr_chunk = ""
for page in reader.pages:
page_text = page.extract_text()
if page_text:
curr_chunk += page_text
# split the accumulated text into chunks of a specific size with overlaop
# this loop implements a sliding window approach to create chunks
while len(curr_chunk) >= chunk_size:
split_idx = curr_chunk.rfind(" ", 0, chunk_size)
if split_idx == -1:
split_idx = chunk_size
actual_chunk = curr_chunk[:split_idx]
all_text_chunks.append(actual_chunk)
overlap = curr_chunk[split_idx + 1 : split_idx + 1 + overlap_size]
curr_chunk = overlap + curr_chunk[split_idx + 1 + overlap_size :]
if curr_chunk:
all_text_chunks.append(curr_chunk)
return all_text_chunks
""";
- পিডিএফ ফাইলটিকে খণ্ডে খণ্ডে ভাগ করুন
- রিমোট মডেল তৈরি করার পরে এমবেডিং তৈরি করুন
- "
Ou manger un repas tex-mex à volonté?" অথবা "where to eat a tex-mex meal buffet-style?" খুঁজে বের করার জন্য একটি ভেক্টর সার্চ চালান। - "
Ou manger un repas tex-mex à volonté?" অথবা ""where to eat a tex-mex meal buffet-style?" প্রশ্নটির ভেক্টর সার্চ ফলাফলের উপর ভিত্তি করে একটি উত্তর তৈরি করুন।
৫. টাস্ক ৩: BigQuery ব্যবহার করে বৃহৎ পরিসরে মেশিন লার্নিং: পূর্বাভাস, শ্রেণিবিন্যাস এবং র্যাঙ্কিং
পূর্বাভাস অপেক্ষার সময়
ছবিগুলো খুব দারুণ! আপনি আর অপেক্ষা করতে পারছেন না! এখন, কোন আকর্ষণগুলো বেছে নেবেন এবং কোনগুলো এড়িয়ে চলবেন, তা জানার জন্য আপনার প্যারিস এবং ক্যালিফোর্নিয়ার মধ্যবর্তী কিছু আকর্ষণের প্রকৃত অপেক্ষার সময় জানা প্রয়োজন। আপনার কাজ হলো মেশিন লার্নিং (Arima plus বা TimesFM) ব্যবহার করে ২০২৫ সালে প্রতি ৩০ মিনিট অন্তর প্রতিটি আকর্ষণের অপেক্ষার সময়ের পূর্বাভাস দেওয়া।
আপনার প্রয়োজনীয় ডেটা এই csv ফাইলটিতে রয়েছে: gs://hackathon_data_disneyland_<YOUR_PROJECT_3DIGITS>/waiting_times.csv
আপনার কাজের ধাপগুলো হলো:
- ফাইলটি আপনার BigQuery ডেটাসেটের waiting_times নামের টেবিলে লোড করুন।
- আপনার ডেটার উপর একটি পূর্বাভাস মডেলকে প্রশিক্ষণ দিন (Arima_Plus) অথবা AI.Forecast ব্যবহার করে সরাসরি পূর্বাভাস দিন।
- মডেলের কর্মক্ষমতা মূল্যায়ন করুন অথবা পূর্বাভাসিত ডেটার সাথে ইনপুট ডেটার তুলনা করুন ।
তীব্রতা অনুসারে রাইডগুলোকে শ্রেণীবদ্ধ করুন
আপনি বন্ধুদের সাথে ডিজনিল্যান্ডে বেড়াতে এসেছেন, এবং পার্কটি সাধারণত পরিবার-বান্ধব হলেও, কিছু রাইড কারও কারও জন্য একটু বেশিই রোমাঞ্চকর হতে পারে। আসুন, মানুষের পক্ষপাতিত্ব ছাড়াই BigQuery Managed AI ফাংশন ব্যবহার করে রাইডগুলোকে রোমাঞ্চ ও তীব্রতার মাত্রা অনুযায়ী শ্রেণিবদ্ধ ও র্যাঙ্ক করি, যাতে আমরা সকলের প্রয়োজন মেটাতে পারি।
-
AI.CLASSIFYব্যবহার করে রাইডগুলোর বিবরণের ওপর ভিত্তি করে সেগুলোকে তিনটি জাদুকরী বিভাগের যেকোনো একটিতে শ্রেণীবদ্ধ করুন: [অত্যন্ত সহজ, রোমাঞ্চকর, চরম]
রোমাঞ্চের মাত্রা অনুযায়ী রাইড র্যাঙ্ক করুন
-
AI.SCOREব্যবহার করে রোমাঞ্চের মাত্রা অনুযায়ী আকর্ষণগুলোর তুলনা ও ক্রম নির্ধারণ করুন, যেখানে র্যাঙ্ক ১০ হলো সবচেয়ে চরম এবং র্যাঙ্ক ১ হলো সবচেয়ে কম।
৬. টাস্ক ৩-বোনাস: বিগকোয়েরি থেকে অ্যালয়ডিবি-তে রিভার্স-ইটিএল।
আপনি বিপুল পরিমাণ ডেটা থেকে অন্তর্দৃষ্টি তৈরি করতে BigQuery-এর শক্তিশালী সক্ষমতার সুবিধা নিয়েছেন। এখন আপনি চান সেই অন্তর্দৃষ্টিগুলো আপনার অপারেশনাল অ্যাপ্লিকেশন (এবং এআই এজেন্ট!) দ্বারা কার্যকর হোক।
কিন্তু কীভাবে? উল্টো পথে! AlloyDB for Postgres কম-লেটেন্সি এবং উচ্চ গতিতে ডেটা পরিবেশন করতে পারদর্শী, যা আপনার গুরুত্বপূর্ণ ব্যবহারকারী-মুখী অ্যাপ্লিকেশনগুলির জন্য উপযুক্ত। তাই চলুন, আমরা এইমাত্র তৈরি করা ডেটা রিভার্স-ETL করি।
এটি করার জন্য, আমরা অ্যালয়ডিবি-র "বিগকোয়েরি ভিউস" নামক একটি একেবারে নতুন ফিচার ব্যবহার করব, যা এখনও প্রাইভেট প্রিভিউ পর্যায়ে রয়েছে। এই ফিচারটি আপনাকে সরাসরি আপনার পোস্টগ্রেস ডেটাবেসে বিগকোয়েরি ডেটা কোয়েরি করার সুযোগ দেয়।
প্রথমে, BigQuery-তে কোয়েরি করার জন্য আপনাকে আপনার AlloyDB ক্লাস্টার সার্ভিস অ্যাকাউন্টকে প্রয়োজনীয় প্রিভিলেজ প্রদান করতে হবে।
gcloud beta alloydb clusters describe <CLUSTER ID> --region=europe-west1
আউটপুটে একটি serviceAccountEmail ফিল্ড থাকে, যা এই ক্লাস্টারের সার্ভিস অ্যাকাউন্ট।
Google Cloud Console-এ, IAM পৃষ্ঠায় যান এবং এই প্রিন্সিপালকে নিম্নলিখিত বিশেষাধিকারগুলি প্রদান করুন:
- BigQuery ডেটা ভিউয়ার (roles/bigquery.dataViewer)
- BigQuery সেশন ব্যবহারকারী পড়ুন (roles/bigquery.readSessionUser)
এখন, কনসোলে AlloyDB Studio-তে যান এবং "postgres" ডাটাবেসের সাথে সংযোগ করুন।
নতুন ফিচারটি ইনস্টল ও কনফিগার করতে নিম্নলিখিত কোয়েরিগুলো চালান:
CREATE EXTENSION bigquery_fdw;
CREATE SERVER bq_disney FOREIGN DATA WRAPPER bigquery_fdw;
CREATE USER MAPPING FOR postgres SERVER bq_disney ;
আপনি এখন একটি 'ফরেন টেবিল' তৈরি করতে পারেন যা BigQuery-এর একটি বর্তমান টেবিলের সাথে ম্যাপ করা হবে। টাস্ক ৩-এ তৈরি করা যেকোনো টেবিল ব্যবহার করুন। সিনট্যাক্সের একটি উদাহরণ নিচে দেওয়া হলো:
CREATE FOREIGN TABLE reviews_analysis ( "Review_ID" int,
"Sentiment" text) SERVER bq_disney OPTIONS (PROJECT 'bqml-hack25par-xxx',
dataset 'disney',
TABLE 'reviews_analysis');
সবকিছু প্রস্তুত, চলুন টেবিলটি কোয়েরি করা যাক! AlloyDB এবং BigQuery-এর মধ্যে সংযোগ যাচাই করার জন্য প্রথমে একটি SELECT কোয়েরি চালান, এবং সবশেষে আপনার ফরেন টেবিল থেকে ডেটা গ্রহণ করার জন্য AlloyDB-তে একটি নতুন টেবিল তৈরি করুন।
৭. কাজ ৪: রেডিমেড ডেটা এজেন্ট
আপনার এমন কিছু বন্ধু আছেন যারা ডিজনিল্যান্ড অ্যাপ্লিকেশন প্রকল্পে অবদান রাখতে চান। BigQuery-তে থাকা ডেটাতে তাদের অ্যাক্সেস আছে, কিন্তু SQL এবং ডেটা ইঞ্জিনিয়ারিং-এ তাদের দক্ষতার স্তর ভিন্ন। আপনি আপনার বন্ধুদের সাহায্য করার জন্য BigQuery-এর ডেটা এজেন্ট সম্পর্কিত সাম্প্রতিক ঘোষণাগুলো কাজে লাগাতে চান, যা ইতিমধ্যেই UI-তে ইন্টিগ্রেটেড রয়েছে।
- ডেটা পাইপলাইন তৈরি করুন।
- SQL কোডে যৌথভাবে কাজ করুন।
- তাদের ডেটার সাথে কথা বলুন।
আপনার ডেটা পাইপলাইন স্বয়ংক্রিয় করার জন্য ডেটা ইঞ্জিনিয়ারিং এজেন্ট
ডেটা ইঞ্জিনিয়ারিং এজেন্ট ব্যবহার করে, 'waiting time' এবং 'atractions' টেবিল দুটিকে যুক্ত করে 'average_waiting_time' নামে একটি নতুন ভিউ তৈরি করুন এবং প্রতিটি আকর্ষণের গড় অপেক্ষার সময় (average waiting_time) গণনা করুন।
BigQuery-তে আপনার কনভারসেশনাল অ্যানালিটিক্স এজেন্ট তৈরি করুন
কেমন হতো যদি আপনি কোডিং, SQL বা ডেপ্লয়মেন্ট ছাড়াই, এবং BigQuery-এর ইন্টারফেস থেকেই আপনার ডেটার সাথে কথা বলার জন্য একটি এজেন্ট তৈরি করতে পারতেন? ব্যাপারটা কতটা চমৎকার হতো, তাই না? BigQuery-এর 'Agents' ট্যাবের মাধ্যমে আজ এটি সম্ভব।

- my_disney_friend নামে একজন এজেন্ট তৈরি করুন, যিনি আপনার ডিজনি টেবিলগুলোর সাথে সংযুক্ত থাকবেন। এজেন্টের নির্দেশাবলী পূরণ করে আপনি তার কর্মক্ষমতা উন্নত করতে পারেন। "ইতিবাচক বনাম নেতিবাচক পর্যালোচনার শতাংশ কত, প্রতিটি আকর্ষণের জন্য গড় অপেক্ষার সময় কত, ইত্যাদি...?"-এর মতো প্রশ্ন জিজ্ঞাসা করুন।
- BigQuery এবং API-তে এজেন্টটি প্রকাশ করুন (আপনি এটি পরে ব্যবহার করবেন)।
৮. কাজ ৫: Gemini-CLI ব্যবহার করে আপনার ডেভেলপমেন্ট অভিজ্ঞতা উন্নত করুন।
এই এআই যুগে, সফটওয়্যার তৈরি করা আগের চেয়ে অনেক বেশি সহজলভ্য হয়েছে। আপনার ডিজনিল্যান্ড অ্যাপ্লিকেশনের জন্য আপনার কাছে হাজার হাজার ধারণা আছে, এবং আপনি আপনার ডেটাকে তার সর্বোচ্চ ক্ষমতায় ব্যবহার করতে চান। আপনি শুধু ডেটার সাথে কথা বলার চেয়েও আরও এগিয়ে যেতে চান, এখন আপনার প্রয়োজন কাজ!
সেই পথে আপনাকে সাহায্য করতে আপনার সাহায্যের প্রয়োজন হবে। আর আমরা আপনার পাশে আছি।
জেমিনি সিএলআই হলো একটি ওপেন-সোর্স এআই এজেন্ট যা জেমিনির ক্ষমতা সরাসরি আপনার টার্মিনালে নিয়ে আসে। ডেভেলপাররা এর মাধ্যমে শক্তিশালী অ্যাপ্লিকেশন তৈরি করতে পারেন এবং এক্সটেনশনের কল্যাণে বিভিন্ন এমসিপি (মডেল কনটেক্সট প্রোটোকল) সার্ভারের সাথেও যোগাযোগ করতে পারেন।
সেগুলোর মধ্যে আপনি অবশ্যই আপনার AlloyDB বা BigQuery ডেটা কোয়েরি করার জন্য এক্সটেনশনও খুঁজে পাবেন!
এই কাজে আপনার লক্ষ্য হলো:
- Gemini-CLI ইনস্টল করুন (আপনার নিজের টার্মিনালে অথবা ক্লাউড শেলে)
- BigQuery এবং AlloyDB Gemini-CLI এক্সটেনশনগুলি ইনস্টল করুন
- একটি এনভায়রনমেন্ট ফাইল তৈরি করুন যা Gemini-CLI-কে আপনার BigQuery এবং AlloyDB ইনস্ট্যান্সগুলির সাথে সংযোগ করার অনুমতি দেবে।
- আপনার AlloyDB ডাটাবেসের বিষয়বস্তু ব্যাখ্যা করে এমন একটি আকর্ষণীয় একক HTML পৃষ্ঠা তৈরি করতে Gemini-CLI-কে নির্দেশ দিন।
- BigQuery-এর ক্ষেত্রেও একই কাজ করুন।
জেমিনি-সিএলআই এবং এর এক্সটেনশনগুলো ব্যবহার করে একটি (বা কয়েকটি) প্রম্পটেই আপনি কী কী তৈরি করতে পারেন, তার কিছু উদাহরণ এখানে দেওয়া হলো। এবার কল্পনা করুন, বাস্তব জীবনের অ্যাপ্লিকেশনগুলোতেও যদি আপনি এটা করতে পারতেন? 

৯. কাজ ৬: আপনার ডেটার সাথে মিথস্ক্রিয়া করার জন্য একটি এআই এজেন্ট তৈরি করুন।
ডিজনিল্যান্ডের দর্শনার্থীদের একটি সম্পূর্ণ নতুন ব্যবহারকারীর অভিজ্ঞতা দেওয়ার জন্য, আপনি এমন একজন সহকারী তৈরি করবেন যিনি তাদের ভ্রমণকালে সাহায্য করতে পারবেন। আপনার এজেন্ট নিম্নলিখিত কাজগুলো করতে সক্ষম হবে:
- পার্কে উপলব্ধ সমস্ত আকর্ষণীয় স্থানগুলির তালিকা করুন।
- প্রত্যাশার ভিত্তিতে একটি আকর্ষণীয় স্থানের সুপারিশ করুন
- একটি আকর্ষণের জন্য পর্যালোচনা যোগ করুন
- আগামী কয়েক ঘণ্টার মধ্যে কোনো একটি দর্শনীয় স্থানের জন্য অপেক্ষার আনুমানিক সময় জানান।
- একটি নির্দিষ্ট আকর্ষণ কেন্দ্রের পর্যালোচনাগুলোর একটি সংক্ষিপ্ত বিবরণ দিন।
আপনাকে নিশ্চিত করতে হবে যে আপনার অ্যাসিস্ট্যান্ট যেন শুধুমাত্র ডিজনিল্যান্ড সম্পর্কিত প্রশ্নের উত্তর দিতে পারে এবং ব্যবহারকারীর সাথে বন্ধুত্বপূর্ণ আচরণ করে। আপনার এজেন্টের নির্দেশিকাটি এমনভাবে সাজিয়ে নিন, যাতে এজেন্ট ব্যবহারকারীর প্রয়োজন অনুযায়ী সঠিক টুলগুলো বেছে নিতে পারে।
আপনাকে যে ধাপগুলো অনুসরণ করতে হবে তা হলো:
- AlloyDB এবং BigQuery উৎস হিসেবে ব্যবহার করে এমন ডাটাবেস সার্ভারের জন্য একটি MCP টুলবক্স স্থাপন করুন।
- আপনার MCP সার্ভারের জন্য ৫টি ভিন্ন টুল ঘোষণা করুন যেগুলো AlloyDB ও BigQuery-কে কোয়েরি করে এবং পূর্বে তালিকাভুক্ত এজেন্ট অ্যাকশনগুলোকে ম্যাপ করে।
- আপনার প্রতিটি টুল যাচাই করতে এমসিপি টুলবক্স ইউআই ব্যবহার করুন।
- এজেন্ট ডেভেলপমেন্ট কিট ব্যবহার করে এমন একটি এজেন্ট স্থাপন করুন যা আপনার এমসিপি টুলবক্স সার্ভার দ্বারা উপলব্ধ টুলগুলি ব্যবহার করতে পারে।
- আপনার ADK ওয়েব ইন্টারফেসে সংযোগ করুন এবং আপনার সহকারীর সাথে উপলব্ধ সমস্ত সরঞ্জাম সহ একটি সম্পূর্ণ আলোচনা উপস্থাপন করুন।
আগে শেষ করলে বোনাস ধাপ:
আপনার এজেন্ট কি প্রস্তুত? চলুন, এটিকে এজেন্ট ইঞ্জিনে ডেপ্লয় করা যাক!