
1. 🏰 فعالية Disneyland Data Analytics Hackathon (النسخة الثانية - 3 ديسمبر) 🏰
ملخّص | في هذا الهاكاثون، ستنشئ مسارًا متكاملاً لتحليل البيانات يستفيد من إمكانات الذكاء الاصطناعي/تعلُّم الآلة على Google Cloud. ستحمّل البيانات إلى AlloyDB، وهي قاعدة بيانات متوافقة مع PostgreSQL ومُدارة بالكامل ومحسّنة لأحمال العمل الصعبة، ثم تستخدم Datastream، وهي خدمة بدون خادم لتسجيل البيانات المتغيرة (CDC)، لنقلها إلى BigQuery، وهو مستودع بيانات بدون خادم من Google Cloud. في BigQuery، ستستخدم BigQuery ML، ما يتيح لك إنشاء نماذج تعلُّم الآلة وتنفيذها مباشرةً في BigQuery باستخدام لغة SQL العادية، وذلك لتحليل المراجعات وتوقُّع معدّل الحضور. أخيرًا، ستجرّب الوكلاء، إما بشكل جاهز من خلال التحليلات الحوارية ووكلاء البيانات، أو ستنشئ وكيلًا مخصّصًا يستند إلى مجموعة أدوات تطوير الوكلاء وMCP toolbox للتفاعل مع بياناتك باللغة الطبيعية. |
الفئات | docType:Codelab, product:Bigquery |
المؤلف | ريحانة رزقي، مات كورنيون |
التصميم | التمرير |
الروبوتات | noindex |
2. مقدمة
مرحبًا بكم، محللو بيانات Disney المستقبليون!🪄
لا داعي لأدلّة السفر المملّة والتصفّح اللا نهائي للمنتديات. تخيَّل التخطيط لرحلة مثالية إلى Disneyland باستخدام إحصاءات مستنِدة إلى البيانات. أي حديقة تقدّم أفضل تجربة؟ متى يكون عدد الزوّار أقل ما يمكن؟ هل يمكنك التنبؤ بأفضل وقت لتجنُّب الانتظار في هذا الطابور الطويل؟
في هذا الهاكاثون، ستنشئ أداة التخطيط المثالية لرحلتك إلى ديزني لاند. لدينا البيانات: مراجعات من الزوّار في جميع الفروع حول العالم، وأوقات الانتظار السابقة، وأرقام الحضور. مهمتك؟ حوِّل هذه البيانات الأولية إلى إحصاءات قابلة للاستخدام:
- جمع البيانات: حمِّل مراجعات متنوعة عن Disneyland وأوقات الانتظار وأرقام الحضور إلى AlloyDB، وهي قاعدة بيانات عالية الأداء ومتوافقة مع PostgreSQL.
- نقل سلس: استخدِم Datastream، وهي خدمة التقاط البيانات المتغيرة التي لا تتطلّب خادمًا، لنقل هذه المعلومات الديناميكية بسهولة إلى BigQuery، وهو مستودع بيانات قوي لا يتطلّب خادمًا من Google Cloud.
- توقُّع النتائج: يمكنك الاستفادة من BigQuery ML لتحليل آراء المراجعين والتنبؤ بأوقات الانتظار مباشرةً باستخدام لغة SQL. اكتشِف الفروع التي تقدّم خدمة ممتازة باستمرار وأفضل وقت لزيارتها.
- التحدّث إلى بياناتك، حرفيًا: استخدِم أدوات مسبقة الإنشاء تتيح لك الحصول على إحصاءات بنقرة واحدة.
- التفاعل الذكي: يمكنك تتويج إبداعك بوكيل ذكي يستند إلى MCP Toolbox لقواعد البيانات وADK (حزمة تطوير الوكلاء). اطرح السؤال "ما هو أفضل مكان جذب في ديزني لاند باريس لمحبي الفضاء، وما هو أفضل وقت للانضمام إلى قائمة الانتظار؟" واحصل على إجابات فورية مستندة إلى البيانات.
استعدّوا لاستكشاف أسرار أكثر الأماكن سحرًا على وجه الأرض وإنشاء مسار لعملية تحليل البيانات سيجعل "ميكي" فخورًا بكم.
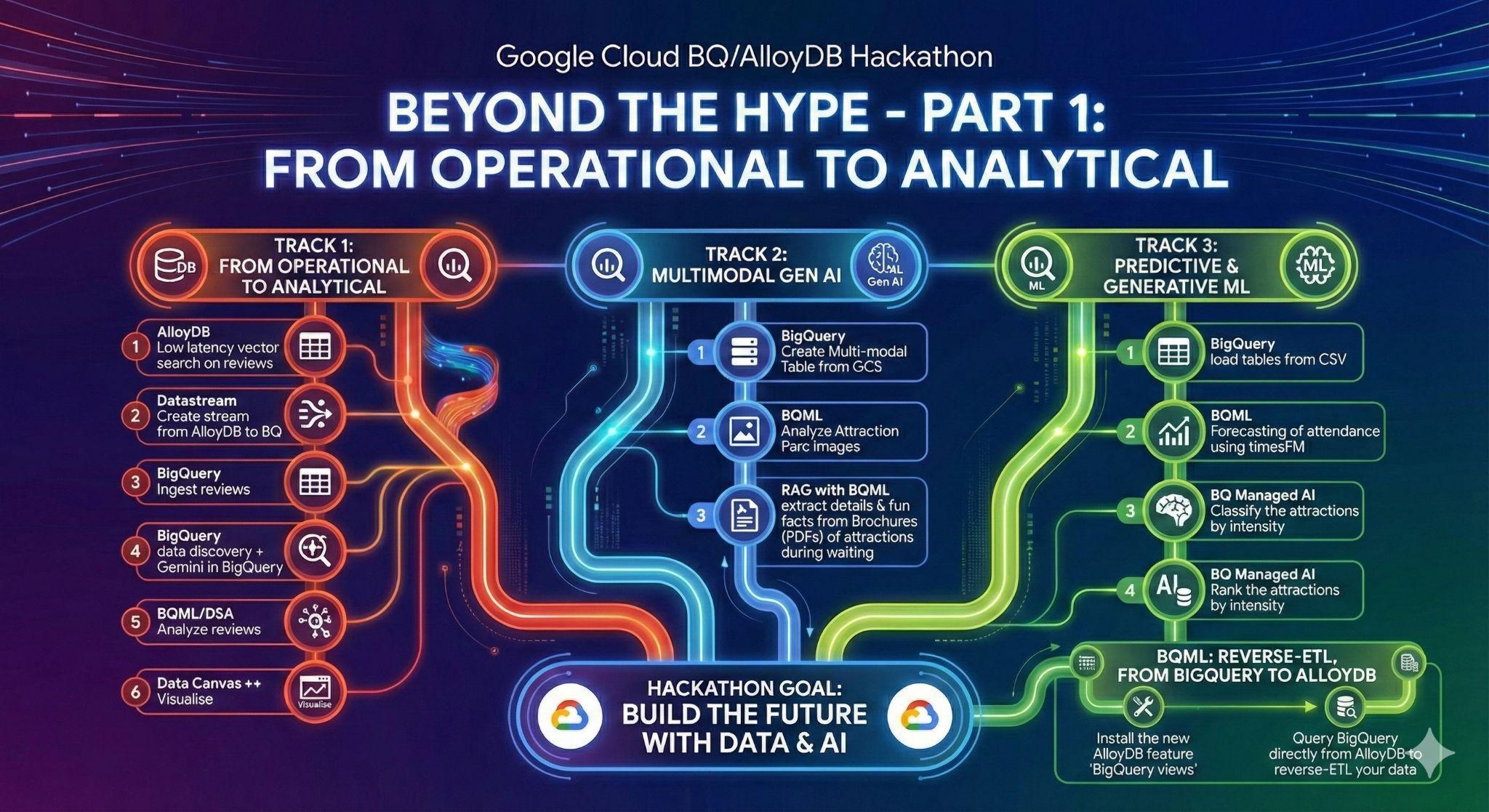

3- المهمة 1: الانتقال من التشغيلية إلى التحليلية: تحليل مراجعات Disneyland باستخدام Gemini
في هذه المرحلة الأولية، ستسترد البيانات من قاعدة بيانات AlloyDB التشغيلية وتحمّلها إلى BigQuery لإجراء تحليل البيانات اللاحق.
ستُعدّ أيضًا كل ما يلزم في AlloyDB للوكيل المستقبلي.
تحميل البيانات في AlloyDB
أولاً، لنستورد بعض البيانات إلى مجموعة AlloyDB for PostgreSQL.
سنستورد 20 ألف مراجعة لمدن ملاهي "ديزني لاند" وقائمة بأماكن الجذب.
في ما يلي الخطوات التي عليك اتّخاذها:
إنشاء الجداول:
- أنشئ جدولاً باسم disneyland_reviews يتضمّن 6 أعمدة: review_id وrating كأعداد صحيحة، وyear_month وreviewer_location وreview_text وbranch كنصوص.
- أنشئ جدولاً باسم disneyland_attractions يتضمّن 4 أعمدة: attraction_id كعدد صحيح، وbranch وname وdescription كنص.
باستخدام الأداة التي تختارها، استورِد البيانات من ملفات CSV:
gs://hackathon_data_disneyland_<YOUR_PROJECT_3DIGITS>/reviews.csvلجدول المراجعاتgs://hackathon_data_disneyland_<YOUR_PROJECT_3DIGITS>/attractions.csvلجدول الأماكن الجاذبة للسياح
لتقديم اقتراحات بشأن أماكن الجذب السياحي، علينا إنشاء تضمينات لوصف أماكن الجذب السياحي:
- تثبيت إضافة pgvector في AlloyDB
- أضِف عمودًا متّجهًا باسم "التضمين" إلى جدول "مناطق الجذب"
- إنشاء تضمين الأوصاف وتعبئته باستخدام عملية الدمج الأصلية بين AlloyDB وVertex AI
من التشغيلية إلى التحليلية باستخدام Datastream
لبث بياناتنا من AlloyDB إلى BigQuery، سنستخدم Google Datastream. وهو حلّ فعّال بدون خادم يستمع إلى جميع التغييرات في جداول المصدر (باستخدام ميزة "التقاط البيانات المتغيرة") ويرسلها إلى BigQuery.
لكي تتمكّن من تكرار التغييرات من AlloyDB باستخدام Datastream، عليك إنشاء ما يُعرف باسم "منشور" و"موضع تكرار" على Postgres.
نفِّذ طلبات البحث التالية على مجموعة AlloyDB (يجب تنفيذها واحدًا تلو الآخر):
CREATE PUBLICATION pub_disney FOR TABLE disneyland_reviews, disneyland_attractions;
ALTER USER postgres WITH REPLICATION;
SELECT PG_CREATE_LOGICAL_REPLICATION_SLOT('slot_disney', 'pgoutput');
ستستخدم خانة النشر والنسخ المتماثل في البث، لذا تذكَّر الأسماء.
هذا كل ما في الأمر، ويمكننا الآن إنشاء بث مباشر.
في ما يلي الخطوات التي عليك اتّخاذها في Datastream:
- إنشاء ملف مصدر لمجموعة AlloyDB (استخدِم عنوان IP المتاح للجميع)
- إنشاء ملف وجهة في BigQuery
- إنشاء مصدر بيانات من AlloyDB إلى BigQuery
من المفترض أن تتوفّر البيانات في BigQuery في غضون بضع دقائق.
استكشاف البيانات في BigQuery
بعد أن أصبحت بياناتنا متوفرة في BigQuery، لنحرص على التعرّف على التحسينات الجديدة في الواجهة قبل البدء في العمل.
لدينا 3 دوال جديدة يمكنك الاطّلاع عليها الآن في لوحة استكشاف BigQuery.

- نظرة عامة: تحتوي على معلومات حول ميزات BigQuery، وجولات إرشادية للبدء في التحليل، وغير ذلك من الإمكانات.
- البحث: يمكنك إجراء بحث دلالي في مواد عرض البيانات.
- الوكلاء: لا داعي للقلق. سنحفظ هذه المعلومات لوقت لاحق 🤫
البحث عن بياناتك دلاليًا في BigQuery
انتقِل إلى علامة التبويب "بحث" في لوحة استكشاف BigQuery، وجرِّب عبارات ذات صلة بـ Disney، مثل "مناطق الجذب" أو "الفرع".
تصوّر بياناتك في BigQuery
يمكنك الآن عرض بياناتك وتنظيمها في BigQuery. لإجراء ذلك، يمكنك تنفيذ هذا الاستعلام في علامة تبويب استعلام جديدة:
SELECT
*
FROM
[dataset_name].[table_name];
إنشاء إحصاءات البيانات في جدول المراجعات
في هذه المهمة، ستفعّل ميزة "إحصاءات البيانات" في جدول disneyland_reviews ضمن مجموعة بيانات disney.
إحصاءات البيانات هي أداة مخصّصة لأي شخص يريد استكشاف بياناته والحصول على إحصاءات بدون كتابة طلبات بحث SQL معقّدة.
قد يستغرق ذلك بضع دقائق.
طلب البحث في جدول disneyland_reviews بدون SQL
أصبحت المعلومات التي أنشأتها في القسم السابق جاهزة الآن. في هذه المهمة، ستستخدم طلبًا تم إنشاؤه من هذه الإحصاءات للاستعلام عن جدول disneyland_reviews بدون استخدام رمز.
اختَر إحصاءً وشغِّل طلب البحث المرتبط به. على سبيل المثال، ابحث عن طلب البحث الذي يحسب الفرق في متوسط التقييم بين الأشهر المتتالية لكل فرع. سيبدو على النحو التالي:
WITH
monthly_avg AS (
SELECT
branch,
year_month,
AVG(rating) AS avg_rating
FROM
[dataset_name].[table_name]
WHERE
year_month IS NOT NULL
GROUP BY
1,
2 )
SELECT
branch,
year_month,
avg_rating,
avg_rating - LAG(avg_rating, 1, 0) OVER (PARTITION BY branch ORDER BY year_month) AS rating_difference
FROM
monthly_avg
ORDER BY
branch,
year_month;
استخدام "محرك المعرفة" في BigQuery لفهم البيانات بشكل أفضل
لنبدأ أولاً بالاطّلاع على علامة التبويب الإحصاءات على مستوى مجموعة البيانات، ما سيعطينا فكرة عن العلاقات المخفية بين الجداول في مجموعة بيانات disney. بعد ذلك، يُرجى اتّباع الخطوات التالية:
- أنشئ وصفًا لمجموعة البيانات باستخدام Gemini وأضِفه إلى تفاصيل مجموعة البيانات.
- أنشئ وصفًا لجداول المراجعات وأماكن الجذب، بالإضافة إلى جميع الأعمدة الفردية في هذه الجداول، ثم احفظه.
إجراء فحص للملف الشخصي لبياناتك
الهدف من هذا القسم هو تنظيف بياناتك وإعدادها. ومع ذلك، أنت لست على دراية كبيرة بتوزيع قيم كل عمود. عليك إنشاء ملف تعريف لبياناتك لمعرفة أنواع خطوات التحويل التي تحتاج إلى تنفيذها على بياناتك.
تتولّى ميزة "الفهرس الشامل" في Dataplex من Google Cloud تنفيذ عمليات فحص تحديد الملفات الشخصية تلقائيًا لتقديم مقاييس متّسقة لجودة البيانات. تشمل الإحصاءات الرئيسية التي تم تحديدها عدد القيم الفارغة والقيم المميزة ونطاقات البيانات وتوزيعات القيم. يمكن تفعيل فحص الملف الشخصي من خلال واجهة BigQuery.
يمكن أن تستغرق هذه العملية بضع دقائق، لذا يمكنك الاطّلاع على القسم التالي أثناء الانتظار.
أجب عن الأسئلة التالية:
- ما هو متوسط تقييم "ديزني لاند"؟
- أين يتواجد معظم المراجعين؟
- هل جميع المراجعات فريدة؟
- ما هي النسبة المئوية للبيانات المفقودة من عمود Year_Month؟
إجراء فحص جودة لبياناتك
تتيح لك ميزة جودة البيانات التلقائية في "الكتالوج الشامل" من Dataplex تحديد جودة البيانات في جداول BigQuery وقياسها. يمكنك إعداد عملية فحص البيانات تلقائيًا، والتحقّق من صحة البيانات استنادًا إلى قواعد محدّدة، وتسجيل التنبيهات إذا كانت بياناتك لا تستوفي متطلبات الجودة. يمكنك إدارة قواعد جودة البيانات وعمليات التفعيل كرمز، ما يؤدي إلى تحسين صحة مسارات التعلّم.
استنادًا إلى فحص الملف الشخصي، حدِّد فحصًا للجودة (على ما لا يزيد عن% 10 من بياناتك كحجم عينة) يفي بالمعايير التالية:
- التحقّق من القيم الفارغة للعمود "الفرع"
- يُجري عملية التحقّق من صحة "التقييم"، لأنّه لا يمكن أن يكون إلا ضمن المجموعة التالية : 1 أو 2 أو 3 أو 4 أو 5
- التحقّق من تفرد "review_id"
تأكَّد من أنّ عملية تصدير نتائج الفحص تتم إلى جدول BigQuery باسم quality_scan_results.
فكِّر في جميع عمليات التحويل المحتملة التي تحتاج إلى تطبيقها على بياناتك.
إعداد بياناتك باستخدام ميزة "إعداد البيانات" في Gemini
بعد عمليات فحص جودة البيانات وتحديد خصائصها التي أجريتها، حان الوقت لتنظيف البيانات قبل تحليلها.
عمليات إعداد البيانات هي موارد BigQuery تستخدم "Gemini في BigQuery" لتحليل بياناتك وتقديم اقتراحات ذكية لتنظيفها وتحويلها وإثرائها. يمكنك تقليل الوقت والجهد المطلوبَين لإجراء مهام إعداد البيانات يدويًا بشكل كبير.
في هذا القسم، ستستخدم أداة "إعداد البيانات" لتنفيذ العمليات التالية على جدول disneyland_reviews:
- فلترَة الصفوف التي يكون فيها عمود "الفرع" إما NULL أو سلسلة فارغة
- استبدِل "missing" في Year_Month بالقيمة Null.
- يستبدل الشرطات السفلية بمسافات في عمود الفرع لتحسين إمكانية القراءة
- تصدير إلى الجدول المحوّل disneyland_reviews_cleaned
تحليل المراجعات باستخدام Gemini
بعد تنظيف بياناتك، يمكنك البدء في تحليلها باستخدام نماذج BigQuery ML وGemini. لديك هدفان:
- استخراج الفئات من المراجعات
- تحليل المشاعر في disneyland_reviews
تتيح لك ميزة BigQuery ML إنشاء نماذج تعلُّم الآلة (ML) وتشغيلها باستخدام طلبات بحث GoogleSQL. يتم تخزين نماذج BigQuery ML في مجموعات بيانات BigQuery، على غرار الجداول وطرق العرض. تتيح لك BigQuery ML أيضًا الوصول إلى نماذج Vertex AI وواجهات Cloud AI API لتنفيذ مهام الذكاء الاصطناعي (AI)، مثل إنشاء النصوص أو الترجمة الآلية. يوفّر "Gemini في Google Cloud" أيضًا مساعدة مستندة إلى الذكاء الاصطناعي في مهام BigQuery.
يمكنك اختيار استخدام ML.GENERATE_TEXT أو AI.GENERATE (نسخة حصرية) مع نماذج Gemini Pro أو Flash.
توضّح لك الخطوات التالية كيفية استخدام ML.GENERATE_TEXT.
إنشاء عملية ربط بمورد السحابة الإلكترونية ومنح دور إدارة الهوية وإمكانية الوصول
عليك إنشاء عملية ربط بمورد على السحابة الإلكترونية في BigQuery بنماذج Vertex AI، حتى تتمكّن من استخدام نماذج Gemini Pro وGemini Flash. ستمنح أيضًا حساب الخدمة الخاص باتصال مورد السحابة الإلكترونية أذونات "إدارة الهوية وإمكانية الوصول" (IAM)، من خلال دور، لتمكينه من الوصول إلى خدمات Vertex AI.
منح دور "مستخدم Vertex AI" لحساب الخدمة الخاص بالربط
اسمح لحساب خدمة الاتصال باستخدام النموذج الذي اخترته (مثل gemini-2.5-flash)، وذلك بمنحه دور "مستخدم Vertex AI". يستغرق نشر الإذن دقيقة واحدة.
إنشاء نماذج Gemini في BigQuery
أنشئ نموذجك باستخدام عملية الربط أعلاه. استخدِم نقطة النهاية gemini-2.5-flash. مثلاً.
طلب تحليل مراجعات العملاء حسب الفئات والانطباعات من Gemini
في هذه المهمة، ستستخدم نموذج Gemini لتحليل كل مراجعة من مراجعات العملاء حسب الفئات والانطباعات، سواء كانت إيجابية أو سلبية.
تحليل مراجعات العملاء للفئات
ملاحظة: من الآن فصاعدًا، سنأخذ 100 صف فقط للتحليل، لأنّ طلب Gemini على 20,000 صف قد يستغرق بعض الوقت.
Extract categories by modifying and running the following SQL Query:
CREATE OR REPLACE TABLE
[dataset_name].[results_table_name] AS (
SELECT Review_ID, Rating, Year_Month, Reviewer_Location, Review_Text, Branch, ml_generate_text_llm_result AS categories FROM
ML.GENERATE_TEXT(
MODEL [model_name],
(
SELECT Review_ID, Rating, Year_Month, Reviewer_Location, Review_Text, Branch, CONCAT(
'[WRITE YOUR PROMPT HERE].',
Review_Text) AS prompt
FROM (SELECT * FROM [dataset_name].[table_name] LIMIT 100)
),
STRUCT(
0.2 AS temperature, TRUE AS flatten_json_output)));
يأخذ هذا الاستعلام مراجعات العملاء من جدول disneyland_reviews، وينشئ طلبات لنموذج gemini لتحديد الفئات ضمن كل مراجعة. يجب تخزين النتائج في جدول جديد reviews_categories
. يُرجى الانتظار. يستغرق النموذج حوالي 30 ثانية لمعالجة سجلات مراجعات العملاء وعرض النتائج في جدول الإخراج.
عرض النتائج:
SELECT * FROM [dataset_name].[results_table_name];
خصِّص بعض الوقت لقراءة بعض الفئات.
تحليل مراجعات العملاء لتحديد الانطباعات الإيجابية والسلبية
استنادًا إلى استعلام لغة الاستعلامات البنيوية (SQL) لاستخراج الكلمات الرئيسية، اكتب استعلامًا يحلّل المراجعة إلى إيجابية وسلبية ومحايدة ضمن عمود باسم "المشاعر".
يأخذ هذا الاستعلام مراجعات العملاء من جدول disneyland_reviews، وينشئ طلبات لنموذج gemini من أجل تصنيف المشاعر في كل مراجعة. يتم بعد ذلك تخزين النتائج في جدول جديد reviews_analysis، حتى تتمكّن من استخدامها لاحقًا لإجراء المزيد من التحليلات. يُرجى الانتظار. يستغرق النموذج بضع ثوانٍ لمعالجة سجلّات مراجعات العملاء. عند انتهاء النموذج، ستظهر النتيجة في جدول reviews_analysis الذي تم إنشاؤه.
استكشاف النتائج:
SELECT * FROM [...];
يحتوي الجدول reviews_analysis على العمود Sentiment الذي يتضمّن تحليل المشاعر، مع تضمين الأعمدة social_media_source وreview_text وcustomer_id وlocation_id وreview_datetime. ألقِ نظرة على بعض السجلات. قد تلاحظ أنّ بعض نتائج التقييمات الإيجابية والسلبية قد لا تكون منسّقة بشكل صحيح، مع أحرف دخيلة مثل النقاط أو المسافات الإضافية. يمكنك تنظيف السجلات باستخدام العرض أدناه.
إنشاء طريقة عرض لتنظيف السجلات
أنشئ طريقة عرض تعمل على تنظيف قيم عمود "المشاعر" من خلال:
- استخدام الدالة LOWER للتأكّد من أنّ جميع القيم مكتوبة بأحرف صغيرة
- إزالة علامات الترقيم (النقطة والفاصلة والمسافة) باستخدام REPLACE
CREATE OR REPLACE VIEW [view_name] AS
SELECT [SANITIZATION_EXPRESSION] AS sentiment,
Review_ID, Rating, Year_Month, Reviewer_Location, Review_Text, Branch,
FROM `disney.reviews_analysis`;
ينشئ طلب البحث طريقة العرض cleaned_data_view ويتضمّن نتائج مدى توافق الآراء ونص المراجعة Review_ID, Rating, Year_Month, Reviewer_Location, Review_Text and Branch. بعد ذلك، تأخذ النتيجة المتعلقة بالآراء (إيجابية أو سلبية) وتتأكّد من تحويل جميع الأحرف إلى أحرف صغيرة وإزالة الأحرف غير الضرورية، مثل المسافات أو النقاط الزائدة. ستسهّل طريقة العرض الناتجة إجراء المزيد من التحليلات في الخطوات اللاحقة ضمن هذا الدرس التطبيقي.
- يمكنك طلب البحث في العرض باستخدام طلب البحث أدناه للاطّلاع على الصفوف التي تم إنشاؤها.
SELECT * FROM [view_name];
إنشاء تقرير بعدد المراجعات الإيجابية والسلبية باستخدام Data Canvas
حان الوقت الآن لتحليل نتائجك. لنبدأ بإجراء ذلك مباشرةً في BigQuery من خلال "لوحة البيانات". هذه أداة تتيح لك البحث عن البيانات (دلاليًا أو باستخدام الكلمات الرئيسية)، والاستعلام عن الجداول ودمجها، وإنشاء رسومات بيانية، والحصول على إحصاءات من خلال إنشاء سير عمل على لوحة العرض.
هدفك النهائي هو إنشاء رسم بياني من اختيارك للنسب المئوية للمراجعات الإيجابية مقابل المراجعات السلبية . وفي ما يلي مثال لذلك:

إنشاء رسم بياني لعدد المراجعات لكل فئة، بالإضافة إلى توزيع المراجعات الإيجابية والسلبية لكل فئة
ملاحظة: فعِّل ميزة التحليل المتقدّم في Data Canvas واستخدِمها، وهي تشغّل دفتر ملاحظات Python داخل لوحة.
4. المهمة 2: تحليل صور لمدن ملاهي لتحديد صور "ديزني لاند" واستخراج معلومات مسلّية من كتيبات المتنزّه
تحليل الصور في BigQuery
يمكنك الوصول إلى بعض الصور المشوّقة والجذابة التي التقطها الزوّار لمتنزّه Attraction على مرّ السنين. أنت متحمّس جدًا لرحلتك القادمة! ومع ذلك، لا تعرف أيّ منها هي صور فعلية لمدينة ديزني لاند. مهمتك هي تحديد هذه الأخطاء. تتوفّر الصور في gs://hackathon_data_disneyland_<YOUR_PROJECT_3DIGITS>/attraction_parc_photos/.

Is_disneyland: False

Is_disneyland: True
لإجراء هذا التحليل بسرعة، عليك استخدام جداول الكائنات في BigQuery وGemini من خلال BigQuery ML (ML.GENERATE_TEXT).
هل يمكنك التحقّق من نتائج Gemini من خلال مراجعة بعض الصور؟
إنشاء نظام RAG خاص بك باستخدام BigQuery على كتيبات Disneyland
أثناء الانتظار في الطابور، تريد الحصول على بعض المعلومات الطريفة أو التفاصيل الفنية حول الجذب السياحي الذي تنتظره.
في gs://hackathon_data_disneyland_<YOUR_PROJECT_3DIGITS>/disneyland_brochures/,، ستعثر على ملفات PDF تحتوي على كتيبات لجميع الحدائق حول العالم.
الهدف: إنشاء نظام "توليد معزّز بالاسترجاع" (RAG) بالكامل ضمن BigQuery للسماح للمستخدمين بطرح أسئلة معقّدة حول الحديقة استنادًا إلى بعض مستندات PDF
لتحقيق ذلك، عليك إجراء ما يلي:
- إنشاء جدول عناصر لملفات PDF
- أنشئ دالة معرَّفة من قِبل المستخدم في Python لتقسيم ملفات PDF إلى أجزاء. إليك مثال يمكنك استخدامه:
CREATE OR REPLACE FUNCTION disney.chunk_pdf(src_json STRING, chunk_size INT64, overlap_size INT64)
RETURNS ARRAY<STRING>
LANGUAGE python
WITH CONNECTION `[LOCATION].[CONN_NAME]`
OPTIONS (entry_point='chunk_pdf', runtime_version='python-3.11', packages=['pypdf'])
AS """
import io
import json
from pypdf import PdfReader # type: ignore
from urllib.request import urlopen, Request
def chunk_pdf(src_ref: str, chunk_size: int, overlap_size: int) -> str:
src_json = json.loads(src_ref)
srcUrl = src_json["access_urls"]["read_url"]
req = urlopen(srcUrl)
pdf_file = io.BytesIO(bytearray(req.read()))
reader = PdfReader(pdf_file, strict=False)
# extract and chunk text simultaneously
all_text_chunks = []
curr_chunk = ""
for page in reader.pages:
page_text = page.extract_text()
if page_text:
curr_chunk += page_text
# split the accumulated text into chunks of a specific size with overlaop
# this loop implements a sliding window approach to create chunks
while len(curr_chunk) >= chunk_size:
split_idx = curr_chunk.rfind(" ", 0, chunk_size)
if split_idx == -1:
split_idx = chunk_size
actual_chunk = curr_chunk[:split_idx]
all_text_chunks.append(actual_chunk)
overlap = curr_chunk[split_idx + 1 : split_idx + 1 + overlap_size]
curr_chunk = overlap + curr_chunk[split_idx + 1 + overlap_size :]
if curr_chunk:
all_text_chunks.append(curr_chunk)
return all_text_chunks
""";
- تقسيم ملف PDF إلى أجزاء
- إنشاء تضمينات بعد إنشاء نموذج عن بُعد
- إجراء بحث متّجه للعثور على "
Ou manger un repas tex-mex à volonté?" أو "where to eat a tex-mex meal buffet-style?" - إنشاء إجابة معزّزة بنتائج البحث المتّجهي للسؤال "
Ou manger un repas tex-mex à volonté?" أو "where to eat a tex-mex meal buffet-style?"
5- المهمة 3: تعلُّم الآلة على نطاق واسع باستخدام BigQuery: التوقّع والتصنيف والترتيب
توقّعات أوقات الانتظار
الصور رائعة جدًا! لا يمكنك الانتظار! الآن، لمعرفة الأماكن التي يجب اختيارها وتلك التي يجب تجنّبها، عليك معرفة أوقات الانتظار الفعلية في بعض الأماكن بين باريس وكاليفورنيا. المطلوب منك هو توقّع waiting_times لكل معلم سياحي باستخدام تعلُّم الآلة (Arima plus أو TimesFM) كل 30 دقيقة في عام 2025.
البيانات التي ستستخدمها موجودة في ملف CSV هذا: gs://hackathon_data_disneyland_<YOUR_PROJECT_3DIGITS>/waiting_times.csv
في ما يلي خطوات مهمتك:
- حمِّل الملف إلى مجموعة بيانات BigQuery ضمن جدول باسم waiting_times.
- تدريب نموذج توقّع على بياناتك (Arima_Plus) أو التوقّع مباشرةً باستخدام AI.Forecast
- تقييم أداء النموذج أو مقارنة البيانات المتوقّعة بالبيانات المُدخَلة
تصنيف الرحلات حسب الشدة
أنت تزور "ديزني لاند" مع أصدقائك، وعلى الرغم من أنّ المتنزّه مناسب للعائلات بشكل عام، إلا أنّ بعض الألعاب قد تكون شديدة الحدة بالنسبة إلى البعض. لنستخدِم وظائف الذكاء الاصطناعي المُدارة من BigQuery لتصنيف مناطق الجذب وترتيبها حسب مستوى الإثارة والتشويق، بدون تحيّز بشري، حتى نتمكّن من تلبية احتياجات الجميع.
- استخدِم
AI.CLASSIFYلتصنيف الرحلات استنادًا إلى أوصافها ضمن إحدى الفئات السحرية الثلاث: [easy-peasy, thrilling, extreme]
ترتيب الألعاب حسب مستوى الإثارة
- استخدِم
AI.SCOREللمقارنة بين مناطق الجذب وترتيبها استنادًا إلى مستوى الإثارة، حيث يمثّل الترتيب 10 أعلى مستوى إثارة والترتيب 1 أدنى مستوى.
6. المهمة 3-مكافأة: عملية عكسية لاستخراج البيانات وتحويلها وتحميلها من BigQuery إلى AlloyDB
لقد استفدت من إمكانات BigQuery الفعّالة لإنشاء إحصاءات حول كميات كبيرة من البيانات. والآن، تريد أن تكون هذه الإحصاءات قابلة للتنفيذ من خلال تطبيقاتك التشغيلية (وبرامج الذكاء الاصطناعي).
ولكن كيف؟ من خلال عكس الترتيب. تتميّز خدمة AlloyDB for Postgres بقدرتها على عرض البيانات بسرعة عالية وبزمن استجابة منخفض، ما يجعلها مثالية لتطبيقاتك المهمة التي تواجه المستخدمين. لذا، لننفّذ عملية عكسية لاستخراج البيانات وتحويلها وتحميلها (ETL) للبيانات التي أنشأناها للتو.
لإجراء ذلك، سنستخدم ميزة جديدة تمامًا لا تزال في مرحلة المعاينة الخاصة، وهي "طرق العرض في BigQuery" في AlloyDB. تتيح لك هذه الميزة طلب بيانات BigQuery مباشرةً في قاعدة بيانات Postgres.
أولاً، عليك منح حساب خدمة مجموعة AlloyDB الأذونات اللازمة للاستعلام عن BigQuery.
gcloud beta alloydb clusters describe <CLUSTER ID> --region=europe-west1
يحتوي الناتج على حقل serviceAccountEmail، وهو حساب الخدمة لهذا المجموعة.
في Google Cloud Console، انتقِل إلى صفحة "إدارة الهوية وإمكانية الوصول" (IAM) وامنح هذا الكيان الأساسي الامتيازات التالية:
- عارِض بيانات في BigQuery (roles/bigquery.dataViewer)
- مستخدم جلسة القراءة في BigQuery (roles/bigquery.readSessionUser)
انتقِل الآن إلى AlloyDB Studio في "وحدة التحكّم" واربط قاعدة البيانات "postgres".
نفِّذ طلبات البحث التالية لتثبيت الميزة الجديدة وإعدادها:
CREATE EXTENSION bigquery_fdw;
CREATE SERVER bq_disney FOREIGN DATA WRAPPER bigquery_fdw;
CREATE USER MAPPING FOR postgres SERVER bq_disney ;
يمكنك الآن إنشاء "جدول خارجي" سيتم ربطه بجدول حالي في BigQuery. استخدِم أي جدول أنشأته في المهمة 3. في ما يلي مثال على بناء الجملة:
CREATE FOREIGN TABLE reviews_analysis ( "Review_ID" int,
"Sentiment" text) SERVER bq_disney OPTIONS (PROJECT 'bqml-hack25par-xxx',
dataset 'disney',
TABLE 'reviews_analysis');
أصبحنا جاهزين، لنطلب البحث في الجدول. نفِّذ عبارة SELECT الأولى للتحقّق من صحة الربط بين AlloyDB وBigQuery، وأنشئ أخيرًا جدولاً جديدًا في AlloyDB لاستيعاب البيانات من الجدول الخارجي.
7. المهمة 4: وكلاء البيانات الجاهزون للاستخدام
لديك أصدقاء يريدون المساهمة في مشروع تطبيق Disneyland. يمكنهم الوصول إلى البيانات في BigQuery، ولكن لديهم مستويات مختلفة في SQL وهندسة البيانات. تريد الاستفادة من إعلانات BigQuery الأخيرة حول وكلاء البيانات المدمجين حاليًا في واجهة المستخدم لمساعدة أصدقائك:
- إنشاء مسارات بيانات
- التعاون في كتابة رمز SQL
- التحدّث إلى بياناتهم
وكلاء هندسة البيانات لأتمتة مسارات البيانات
أنشئ طريقة عرض جديدة average_waiting_time تربط الجدول waiting time بمناطق الجذب، واحتسِب متوسط waiting_time لكل منطقة جذب باستخدام "وكيل هندسة البيانات".
إنشاء وكيل Conversational Analytics في BigQuery
ماذا لو كان بإمكانك إنشاء وكيل للتحدث إلى بياناتك بدون كتابة الرموز البرمجية وبدون SQL وبدون نشر، ومن واجهة BigQuery؟ ألن يكون ذلك رائعًا؟ يمكنك إجراء ذلك اليوم باستخدام علامة التبويب "الوكلاء" في BigQuery.

- أنشئ وكيلاً باسم my_disney_friend، يربط بجداول Disney. يمكنك تحسين أداء الوكيل من خلال ملء تعليمات الوكيل. اطرح أسئلة مثل "ما هي النسبة المئوية للمراجعات الإيجابية مقارنةً بالمراجعات السلبية، وما هو متوسط وقت الانتظار لكل معلم سياحي، وما إلى ذلك؟"
- انشر الوكيل في BigQuery وعلى واجهة برمجة التطبيقات (ستستخدمه لاحقًا).
8. المهمة 5: تحسين تجربة التطوير باستخدام Gemini-CLI
في عصر الذكاء الاصطناعي هذا، أصبح إنشاء البرامج أسهل من أي وقت مضى. لديك آلاف الأفكار لتطبيق "ديزني لاند"، وتريد استخدام بياناتك بأقصى سعة ممكنة. تريد أن تتجاوز مجرد التحدّث إلى البيانات، وتحتاج الآن إلى اتّخاذ إجراء.
للمساعدة في ذلك، ستحتاج إلى مساعدة. ونحن هنا لمساعدتك.
Gemini CLI هو وكيل ذكاء اصطناعي مفتوح المصدر يتيح لك الاستفادة من إمكانات Gemini مباشرةً في نافذة الأوامر على جهازك. يمكن للمطوّرين إنشاء تطبيقات فعّالة، وبفضل الإضافات، يمكنهم أيضًا التفاعل مع خوادم مختلفة لبروتوكول MCP (Model Context Protocol).
ومن بين هذه الأدوات، يمكنك بالطبع العثور على إضافات للاستعلام عن بيانات AlloyDB أو BigQuery.
في هذه المهمة، هدفك هو:
- تثبيت Gemini-CLI (في نافذة الأوامر على جهازك أو في Cloud Shell)
- تثبيت إضافات BigQuery وAlloyDB Gemini-CLI
- إنشاء ملف بيئة يتيح لـ Gemini-CLI الربط بمثيلات BigQuery وAlloyDB
- اطلب من Gemini-CLI إنشاء صفحة HTML واحدة رائعة تشرح محتوى قاعدة بيانات AlloyDB
- اتّبِع الخطوات نفسها في BigQuery
في ما يلي بعض الأمثلة على ما يمكنك إنشاؤه في طلب واحد (أو بضعة طلبات) باستخدام Gemini-CLI وإضافاته. تخيّل الآن أنّه يمكنك إجراء ذلك مع تطبيقات الحياة الواقعية. 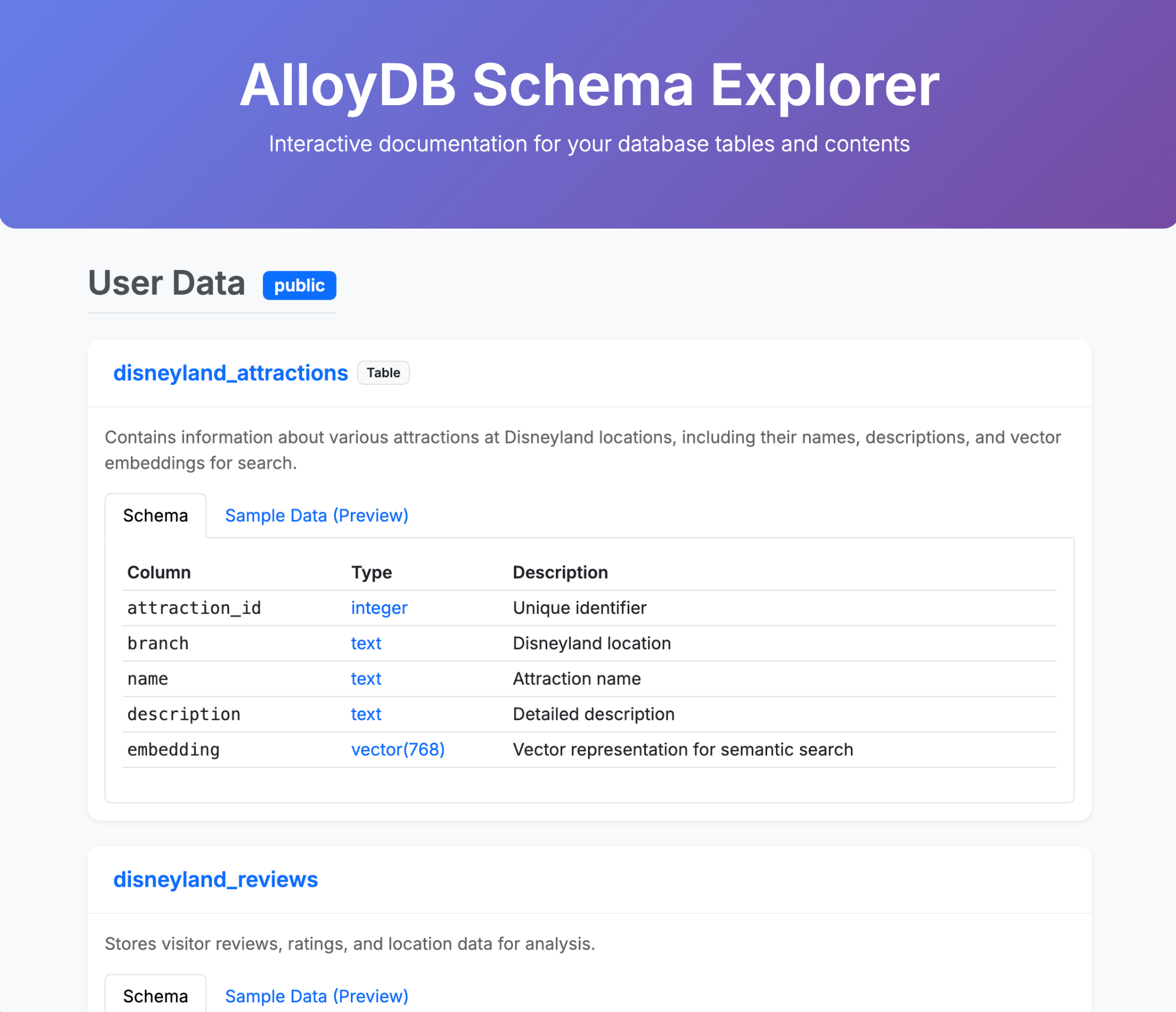

9- المهمة 6: إنشاء وكيل يعمل بالذكاء الاصطناعي للتفاعل مع بياناتك
من أجل تقديم تجربة مستخدم جديدة تمامًا لزوار DisneyLand، عليك إنشاء مساعد يمكنه مساعدتهم أثناء رحلتهم. سيتمكّن الوكيل من إجراء ما يلي:
- إدراج جميع المعالم السياحية المتوفّرة في الحديقة
- اقتراح مكان جذب استنادًا إلى التوقعات
- إضافة مراجعات عن مكان جذب سياحي
- تقديم تقدير لوقت الانتظار في أحد الأماكن الجذابة خلال الساعات القليلة القادمة
- تقديم نظرة عامة على المراجعات الخاصة بمكان جذب معيّن
عليك التأكّد من أنّ مساعدك يمكنه الإجابة عن الأسئلة المتعلّقة بـ "ديزني لاند" فقط، وأنّه يلتزم بنبرة ودودة عند التحدّث مع المستخدم. اضبط طلب وكيلك للتأكّد من أنّه يختار الأدوات المناسبة لاحتياجات المستخدم.
في ما يلي الخطوات التي عليك اتّباعها:
- تفعيل خادم MCP toolbox for databases يستخدم AlloyDB وBigQuery كمصادر
- التعريف بـ 5 أدوات مختلفة لخادم MCP الذي يطلب البحث في AlloyDB وBigQuery ويربط إجراءات الوكيل المُدرَجة سابقًا
- استخدام واجهة مستخدم "مجموعة أدوات MCP" للتحقّق من صحة كل أداة من أدواتك
- نشر وكيل باستخدام حزمة تطوير الوكلاء يمكنه استخدام الأدوات التي يعرضها خادم MCP Toolbox
- الاتصال بواجهة الويب الخاصة بـ ADK وعرض مناقشة كاملة مع مساعدك، بما في ذلك جميع الأدوات المتاحة
خطوة إضافية إذا انتهيت مبكرًا:
هل وكيلك جاهز؟ لننشره في Agent Engine.