
১. গুগল ক্লাউড স্টোরেজ এবং বিগকোয়েরি ব্যবহার করে ডেটাব্রিকস থেকে স্প্যানার পর্যন্ত একটি রিভার্স ইটিএল পাইপলাইন তৈরি করুন।
ভূমিকা
এই কোডল্যাবে, আপনি ডেটাব্রিকস থেকে স্প্যানার পর্যন্ত একটি রিভার্স ইটিএল পাইপলাইন তৈরি করবেন। প্রচলিতভাবে, স্ট্যান্ডার্ড ইটিএল (এক্সট্র্যাক্ট, ট্রান্সফর্ম, লোড) পাইপলাইনগুলো ডেটা অ্যানালিটিক্সের জন্য অপারেশনাল ডেটাবেস থেকে ডেটাব্রিকসের মতো ডেটা ওয়্যারহাউসে ডেটা স্থানান্তর করে। একটি রিভার্স ইটিএল পাইপলাইন এর বিপরীত কাজ করে, অর্থাৎ এটি ডেটা ওয়্যারহাউস থেকে সংগৃহীত ও প্রক্রিয়াজাত ডেটাকে স্প্যানারের মতো অপারেশনাল ডেটাবেসে ফিরিয়ে নিয়ে যায়। স্প্যানার হলো একটি বিশ্বব্যাপী বিতরণকৃত রিলেশনাল ডেটাবেস যা হাই-অ্যাভেইলেবিলিটি অ্যাপ্লিকেশনের জন্য আদর্শ, যেখানে এটি অ্যাপ্লিকেশনগুলোকে শক্তি জোগাতে, ব্যবহারকারী-মুখী ফিচার সরবরাহ করতে, বা রিয়েল-টাইম সিদ্ধান্ত গ্রহণের জন্য ব্যবহৃত হতে পারে।
লক্ষ্য হলো ডেটাব্রিকস আইসবার্গ টেবিল থেকে একটি একত্রিত ডেটাসেটকে স্প্যানার টেবিলে স্থানান্তর করা।
এটি অর্জন করতে, মধ্যবর্তী ধাপ হিসেবে গুগল ক্লাউড স্টোরেজ (GCS) এবং বিগকোয়েরি ব্যবহার করা হয়। নিচে ডেটা প্রবাহের একটি বিশদ বিবরণ এবং এই আর্কিটেকচারের পেছনের যুক্তি তুলে ধরা হলো:

- আইসবার্গ ফরম্যাটে ডেটাব্রিকস থেকে গুগল ক্লাউড স্টোরেজ (GCS):
- প্রথম ধাপ হলো ডেটাব্রিকস থেকে ডেটা একটি উন্মুক্ত ও সুসংজ্ঞায়িত ফরম্যাটে বের করে আনা। টেবিলটি অ্যাপাচি আইসবার্গ ফরম্যাটে এক্সপোর্ট করা হয়। এই প্রক্রিয়ায় মূল ডেটা এক সেট পার্কেট ফাইল হিসেবে এবং টেবিলের মেটাডেটা (স্কিমা, পার্টিশন, ফাইলের অবস্থান) JSON ও অ্যাভ্রো ফাইল হিসেবে লেখা হয়। GCS-এ এই সম্পূর্ণ টেবিল কাঠামোটি স্টেজিং করার ফলে ডেটাটি পোর্টেবল হয় এবং আইসবার্গ ফরম্যাট বোঝে এমন যেকোনো সিস্টেমের কাছে তা অ্যাক্সেসযোগ্য হয়ে ওঠে।
- GCS Iceberg টেবিলগুলোকে BigQuery BigLake এক্সটার্নাল টেবিলে রূপান্তর করুন:
- GCS থেকে সরাসরি স্প্যানারে ডেটা লোড করার পরিবর্তে, BigQuery-কে একটি শক্তিশালী মধ্যস্থতাকারী হিসেবে ব্যবহার করা হয়। BigQuery-তে একটি BigLake এক্সটার্নাল টেবিল তৈরি করা হয়, যা সরাসরি GCS-এর Iceberg মেটাডেটা ফাইলকে নির্দেশ করে। এই পদ্ধতির বেশ কিছু সুবিধা রয়েছে:
- ডেটার পুনরাবৃত্তি হয় না: BigQuery মেটাডেটা থেকে টেবিলের কাঠামো পড়ে এবং Parquet ডেটা ফাইলগুলোকে ইনজেস্ট না করেই সরাসরি কোয়েরি করে, যা উল্লেখযোগ্য পরিমাণে সময় এবং স্টোরেজ খরচ বাঁচায়।
- ফেডারেটেড কোয়েরি: এর মাধ্যমে GCS ডেটার উপর জটিল SQL কোয়েরি চালানো যায়, ঠিক যেমনটি একটি নেটিভ BigQuery টেবিলের ক্ষেত্রে করা হয়।
- BigLake এক্সটার্নাল টেবিলকে স্প্যানারে রিভার্সইটিএল করা:
- চূড়ান্ত ধাপটি হলো BigQuery থেকে Spanner-এ ডেটা স্থানান্তর করা। এটি BigQuery-এর
EXPORT DATAকোয়েরি নামক একটি শক্তিশালী বৈশিষ্ট্যের মাধ্যমে সম্পন্ন করা হয়, যা হলো "রিভার্স ETL" ধাপ। - অপারেশনাল প্রস্তুতি: স্প্যানার ট্রানজ্যাকশনাল ওয়ার্কলোডের জন্য ডিজাইন করা হয়েছে, যা অ্যাপ্লিকেশনগুলির জন্য শক্তিশালী সামঞ্জস্যতা এবং উচ্চ প্রাপ্যতা প্রদান করে। ডেটা স্প্যানারে স্থানান্তর করার মাধ্যমে, এটি ব্যবহারকারী-মুখী অ্যাপ্লিকেশন, এপিআই এবং অন্যান্য অপারেশনাল সিস্টেমগুলির কাছে অ্যাক্সেসযোগ্য হয়ে ওঠে, যেগুলির জন্য কম-লেটেন্সি পয়েন্ট লুকআপ প্রয়োজন।
- স্কেলেবিলিটি: এই প্যাটার্নটি BigQuery-এর বিশ্লেষণাত্মক ক্ষমতাকে কাজে লাগিয়ে বিশাল ডেটাসেট প্রসেস করতে এবং তারপর Spanner-এর বিশ্বব্যাপী স্কেলেবল পরিকাঠামোর মাধ্যমে দক্ষতার সাথে ফলাফল পরিবেশন করতে সাহায্য করে।
পরিষেবা এবং পরিভাষা
- ডেটাব্রিকস - অ্যাপাচি স্পার্ককে কেন্দ্র করে নির্মিত একটি ক্লাউড-ভিত্তিক ডেটা প্ল্যাটফর্ম।
- স্প্যানার - একটি বিশ্বব্যাপী বিতরণকৃত রিলেশনাল ডেটাবেস, যা সম্পূর্ণরূপে গুগল দ্বারা পরিচালিত।
- গুগল ক্লাউড স্টোরেজ - গুগল ক্লাউডের ব্লব স্টোরেজ পরিষেবা।
- BigQuery - অ্যানালিটিক্সের জন্য একটি সার্ভারবিহীন ডেটা ওয়্যারহাউস, যা সম্পূর্ণরূপে গুগল দ্বারা পরিচালিত।
- আইসবার্গ - অ্যাপাচি দ্বারা সংজ্ঞায়িত একটি উন্মুক্ত টেবিল ফরম্যাট যা প্রচলিত ওপেন-সোর্স ডেটা ফাইল ফরম্যাটগুলোর উপর একটি বিমূর্ত ধারণা প্রদান করে।
- পার্কেট - অ্যাপাচি দ্বারা নির্মিত একটি ওপেন-সোর্স কলামভিত্তিক বাইনারি ডেটা ফাইল ফরম্যাট।
আপনি যা শিখবেন
- ডেটাব্রিক্সে আইসবার্গ টেবিল হিসেবে ডেটা লোড করার পদ্ধতি
- কীভাবে একটি GCS বাকেট তৈরি করবেন
- আইসবার্গ ফরম্যাটে ডেটাব্রিকস টেবিলকে জিসিএস-এ কীভাবে এক্সপোর্ট করবেন
- GCS-এর Iceberg টেবিল থেকে BigQuery-তে কীভাবে একটি BigLake এক্সটার্নাল টেবিল তৈরি করবেন
- কীভাবে একটি স্প্যানার ইনস্ট্যান্স সেট আপ করবেন
- BigQuery ব্যবহার করে Spanner-এ BigLake এক্সটার্নাল টেবিলগুলো কীভাবে লোড করবেন
২. স্থাপন, প্রয়োজনীয়তা ও সীমাবদ্ধতা
পূর্বশর্ত
- একটি ডেটাব্রিকস অ্যাকাউন্ট, বিশেষত জিসিপি-তে হলে ভালো হয়।
- BigQuery থেকে Spanner-এ ডেটা এক্সপোর্ট করার জন্য BigQuery Enterprise-tier বা তার চেয়ে উচ্চতর স্তরের রিজার্ভেশনসহ একটি Google Cloud অ্যাকাউন্ট প্রয়োজন।
- ওয়েব ব্রাউজারের মাধ্যমে গুগল ক্লাউড কনসোলে প্রবেশ
- গুগল ক্লাউড সিএলআই কমান্ড চালানোর জন্য একটি টার্মিনাল।
যদি আপনার গুগল ক্লাউড অর্গানাইজেশনে iam.allowedPolicyMemberDomains পলিসিটি সক্রিয় থাকে, তাহলে একজন অ্যাডমিনিস্ট্রেটরকে বাইরের ডোমেইনের সার্ভিস অ্যাকাউন্টগুলোকে অনুমতি দেওয়ার জন্য একটি ব্যতিক্রমী অনুমোদন দিতে হতে পারে। প্রযোজ্য ক্ষেত্রে, এই বিষয়টি পরবর্তী ধাপে আলোচনা করা হবে।
প্রয়োজনীয়তা
- বিলিং সক্ষম একটি গুগল ক্লাউড প্রজেক্ট।
- একটি ওয়েব ব্রাউজার, যেমন ক্রোম
- একটি ডেটাব্রিকস অ্যাকাউন্ট (এই ল্যাবের জন্য ধরে নেওয়া হচ্ছে যে ওয়ার্কস্পেসটি জিসিপি-তে হোস্ট করা আছে)
- EXPORT DATA ফিচারটি ব্যবহার করার জন্য BigQuery ইনস্ট্যান্সটি অবশ্যই এন্টারপ্রাইজ সংস্করণ বা তার উচ্চতর সংস্করণের হতে হবে।
- যদি আপনার গুগল ক্লাউড অর্গানাইজেশনে
iam.allowedPolicyMemberDomainsপলিসিটি সক্রিয় থাকে, তাহলে একজন অ্যাডমিনিস্ট্রেটরকে বাইরের ডোমেইনের সার্ভিস অ্যাকাউন্টগুলোকে অনুমতি দেওয়ার জন্য একটি ব্যতিক্রমী অনুমোদন দিতে হতে পারে। প্রযোজ্য ক্ষেত্রে, এই বিষয়টি পরবর্তী ধাপে আলোচনা করা হবে।
গুগল ক্লাউড প্ল্যাটফর্ম আইএএম অনুমতি
এই কোডল্যাবের সমস্ত ধাপগুলি সম্পাদন করার জন্য গুগল অ্যাকাউন্টের নিম্নলিখিত অনুমতিগুলির প্রয়োজন হবে।
পরিষেবা অ্যাকাউন্ট | ||
| সার্ভিস অ্যাকাউন্ট তৈরি করার সুযোগ দেয়। | |
স্প্যানার | ||
| একটি নতুন স্প্যানার ইনস্ট্যান্স তৈরি করার সুযোগ দেয়। | |
| DDL স্টেটমেন্ট চালানোর মাধ্যমে তৈরি করার অনুমতি দেয় | |
| ডাটাবেসে টেবিল তৈরি করার জন্য DDL স্টেটমেন্ট চালানোর সুযোগ দেয়। | |
গুগল ক্লাউড স্টোরেজ | ||
| এক্সপোর্ট করা Parquet ফাইলগুলো সংরক্ষণ করার জন্য একটি নতুন GCS বাকেট তৈরি করার সুযোগ দেয়। | |
| এক্সপোর্ট করা Parquet ফাইলগুলোকে GCS বাকেটে লেখার অনুমতি দেয়। | |
| BigQuery-কে GCS বাকেট থেকে Parquet ফাইলগুলো পড়ার অনুমতি দেয়। | |
| BigQuery-কে GCS বাকেটে থাকা Parquet ফাইলগুলির তালিকা তৈরি করার অনুমতি দেয়। | |
ডেটাফ্লো | ||
| ডেটাফ্লো থেকে ওয়ার্ক আইটেম দাবি করার সুযোগ দেয়। | |
| ডেটাফ্লো ওয়ার্কারকে ডেটাফ্লো সার্ভিসে বার্তা ফেরত পাঠানোর অনুমতি দেয়। | |
| ডেটাফ্লো ওয়ার্কারদের গুগল ক্লাউড লগিং-এ লগ এন্ট্রি লেখার অনুমতি দেয়। | |
সুবিধার জন্য, এই অনুমতিগুলো অন্তর্ভুক্ত থাকা পূর্বনির্ধারিত ভূমিকাগুলো ব্যবহার করা যেতে পারে।
|
|
|
|
|
|
|
|
গুগল ক্লাউড প্রজেক্ট
প্রজেক্ট হলো গুগল ক্লাউডে ব্যবস্থাপনার একটি মৌলিক একক। যদি কোনো প্রশাসক ব্যবহারের জন্য একটি প্রজেক্ট প্রদান করে থাকেন, তবে এই ধাপটি এড়িয়ে যাওয়া যেতে পারে।
এইভাবে CLI ব্যবহার করে একটি প্রজেক্ট তৈরি করা যায়:
gcloud projects create <your-project-name>
প্রজেক্ট তৈরি ও পরিচালনা সম্পর্কে এখানে আরও জানুন।
সীমাবদ্ধতা
এই পাইপলাইনে যে নির্দিষ্ট সীমাবদ্ধতা এবং ডেটা টাইপের অসামঞ্জস্যতা দেখা দিতে পারে, সে সম্পর্কে সচেতন থাকা গুরুত্বপূর্ণ।
ডেটাব্রিকস আইসবার্গ থেকে বিগকোয়েরি
Databricks দ্বারা পরিচালিত Iceberg টেবিলগুলো (UniForm-এর মাধ্যমে) কোয়েরি করার জন্য BigQuery ব্যবহার করার সময় নিম্নলিখিত বিষয়গুলো মনে রাখবেন:
- স্কিমা বিবর্তন : যদিও ইউনিফর্ম ডেল্টা লেক স্কিমার পরিবর্তনগুলোকে আইসবার্গে ভালোভাবে অনুবাদ করে, জটিল পরিবর্তনগুলো সবসময় প্রত্যাশা অনুযায়ী কার্যকর নাও হতে পারে। উদাহরণস্বরূপ, ডেল্টা লেকে কলামের নাম পরিবর্তন করলে তা আইসবার্গে অনূদিত হয় না, কারণ আইসবার্গ এটিকে একটি
dropএবংaddহিসেবে দেখে। সর্বদা স্কিমার পরিবর্তনগুলো পুঙ্খানুপুঙ্খভাবে পরীক্ষা করুন। - টাইম ট্র্যাভেল : BigQuery ডেল্টা লেকের টাইম ট্র্যাভেল ক্ষমতা ব্যবহার করতে পারে না। এটি শুধুমাত্র আইসবার্গ টেবিলের সর্বশেষ স্ন্যাপশটটি কোয়েরি করবে।
- ডেল্টা লেকের অসমর্থিত বৈশিষ্ট্যসমূহ : ডেল্টা লেকের ডিলিশন ভেক্টর এবং
idমোডের কলাম ম্যাপিং-এর মতো বৈশিষ্ট্যগুলো ইউনিফর্ম ফর আইসবার্গের সাথে সামঞ্জস্যপূর্ণ নয়। ল্যাবটিতে কলাম ম্যাপিং-এর জন্যnameমোড ব্যবহার করা হয়েছে, যা সমর্থিত।
BigQuery থেকে স্প্যানার
BigQuery থেকে Spanner-এ EXPORT DATA কমান্ডটি সব BigQuery ডেটা টাইপ সমর্থন করে না। নিম্নলিখিত টাইপগুলো সহ একটি টেবিল এক্সপোর্ট করলে একটি ত্রুটি দেখা দেবে:
-
STRUCT -
GEOGRAPHY -
DATETIME -
RANGE -
TIME
এছাড়াও, যদি BigQuery প্রজেক্টটি GoogleSQL ডায়ালেক্ট ব্যবহার করে, তাহলে Spanner-এ এক্সপোর্ট করার জন্য নিম্নলিখিত নিউমেরিক টাইপগুলোও সমর্থিত নয়:
-
BIGNUMERIC
সীমাবদ্ধতার একটি সম্পূর্ণ এবং হালনাগাদ তালিকার জন্য, অফিসিয়াল ডকুমেন্টেশন দেখুন: স্প্যানারে এক্সপোর্ট করার সীমাবদ্ধতা ।
সমস্যা সমাধান এবং অপ্রত্যাশিত বিষয়সমূহ
- যদি কোনো GCP Databricks ইনস্ট্যান্সে না থাকে, তাহলে GCS-এ একটি এক্সটার্নাল ডেটা লোকেশন নির্ধারণ করা সম্ভব নাও হতে পারে। সেক্ষেত্রে, ফাইলগুলিকে প্রথমে Databricks ওয়ার্কস্পেসের ক্লাউড প্রোভাইডারের স্টোরেজ সলিউশনে স্টেজ করতে হবে এবং তারপর আলাদাভাবে GCS-এ মাইগ্রেট করতে হবে।
- এটি করার সময় মেটাডেটাতে সমন্বয় করার প্রয়োজন হবে, কারণ তথ্যগুলিতে স্টেজ করা ফাইলগুলির হার্ড কোডেড পাথ থাকবে।
৩. গুগল ক্লাউড স্টোরেজ (GCS) সেটআপ করুন
ডেটাব্রিকস দ্বারা তৈরি পার্কেট ডেটা ফাইলগুলো সংরক্ষণ করতে গুগল ক্লাউড স্টোরেজ (GCS) ব্যবহার করা হবে। এর জন্য, ফাইলগুলোর গন্তব্যস্থল হিসেবে ব্যবহারের জন্য প্রথমে একটি নতুন বাকেট তৈরি করতে হবে।
গুগল ক্লাউড স্টোরেজ
একটি নতুন বালতি তৈরি করা হচ্ছে
- আপনার ক্লাউড কনসোলে থাকা গুগল ক্লাউড স্টোরেজ পেজটিতে যান।
- বাম প্যানেলে, বালতি নির্বাচন করুন:

- তৈরি করুন বোতামে ক্লিক করুন:

- আপনার বালতির বিবরণ পূরণ করুন:
- ব্যবহারের জন্য একটি বাকেটের নাম বেছে নিন। এই ল্যাবের জন্য,
codelabs_retl_databricksনামটি ব্যবহার করা হবে। - বাকেটটি সংরক্ষণের জন্য একটি অঞ্চল নির্বাচন করুন, অথবা ডিফল্ট মানগুলো ব্যবহার করুন।
- স্টোরেজ ক্লাসকে
standardহিসাবে রাখুন - নিয়ন্ত্রণ অ্যাক্সেসের জন্য ডিফল্ট মানগুলি রাখুন
- অবজেক্ট ডেটা সুরক্ষিত রাখতে ডিফল্ট মান রাখুন
- কাজ শেষ হলে
Createবোতামে ক্লিক করুন। সর্বসাধারণের প্রবেশাধিকার রোধ করা হবে কিনা, তা নিশ্চিত করার জন্য একটি অনুরোধ আসতে পারে। অনুগ্রহ করে নিশ্চিত করুন। - অভিনন্দন, একটি নতুন বাকেট সফলভাবে তৈরি করা হয়েছে! আপনাকে বাকেট পৃষ্ঠায় পুনঃনির্দেশিত করা হবে।
- নতুন বাকেট নামটি কোথাও কপি করে রাখুন, কারণ পরবর্তীতে এটির প্রয়োজন হবে।

পরবর্তী পদক্ষেপের জন্য প্রস্তুতি নেওয়া
নিম্নলিখিত বিবরণগুলি লিখে রাখুন, কারণ পরবর্তী পদক্ষেপগুলিতে এগুলির প্রয়োজন হবে:
- গুগল প্রজেক্ট আইডি
- গুগল স্টোরেজ বাকেটের নাম
৪. ডেটাব্রিকস সেটআপ করুন
টিপিসি-এইচ ডেটা
এই ল্যাবের জন্য TPC-H ডেটাসেটটি ব্যবহার করা হবে, যা ডিসিশন সাপোর্ট সিস্টেমের জন্য একটি ইন্ডাস্ট্রি-স্ট্যান্ডার্ড বেঞ্চমার্ক। এর স্কিমাটি গ্রাহক, অর্ডার, সরবরাহকারী এবং যন্ত্রাংশসহ একটি বাস্তবসম্মত ব্যবসায়িক পরিবেশের মডেল তৈরি করে, যা এটিকে বাস্তব জগতের অ্যানালিটিক্স এবং ডেটা মুভমেন্টের দৃশ্যকল্প প্রদর্শনের জন্য নিখুঁত করে তোলে।
কাঁচা, নর্মালাইজড TPC-H টেবিলগুলো ব্যবহার করার পরিবর্তে, একটি নতুন, অ্যাগ্রিগেটেড টেবিল তৈরি করা হবে। এই নতুন টেবিলটি orders , customer এবং nation টেবিলগুলো থেকে ডেটা যুক্ত করে আঞ্চলিক বিক্রয়ের একটি ডিনরমালাইজড ও সংক্ষিপ্ত চিত্র তৈরি করবে। প্রি-অ্যাগ্রিগেশন ধাপটি অ্যানালিটিক্সে একটি প্রচলিত পদ্ধতি, কারণ এটি একটি নির্দিষ্ট ব্যবহারের জন্য ডেটা প্রস্তুত করে—এই ক্ষেত্রে, কোনো অপারেশনাল অ্যাপ্লিকেশনের ব্যবহারের জন্য।
একত্রিত টেবিলের চূড়ান্ত স্কিমাটি হবে:
কর্নেল | প্রকার |
দেশের নাম | স্ট্রিং |
বাজার_বিভাগ | স্ট্রিং |
অর্ডার_বছর | int |
অগ্রাধিকার ক্রম | স্ট্রিং |
মোট_অর্ডার_সংখ্যা | বড় |
মোট_রাজস্ব | দশমিক(২৯,২) |
অনন্য_গ্রাহক_সংখ্যা | বড় |
ডেল্টা লেক ইউনিভার্সাল ফরম্যাট (ইউনিফর্ম) সহ আইসবার্গ সাপোর্ট
এই ল্যাবের জন্য, ডেটাব্রিক্সের ভেতরের টেবিলটি একটি ডেল্টা লেক টেবিল হবে। তবে, বিগকোয়েরির মতো বাহ্যিক সিস্টেম দ্বারা এটিকে পাঠযোগ্য করার জন্য, ইউনিভার্সাল ফরম্যাট (ইউনিফর্ম) নামক একটি শক্তিশালী ফিচার সক্রিয় করা হবে।
টেবিলের ডেটার একটি একক, শেয়ারযোগ্য কপির জন্য UniForm স্বয়ংক্রিয়ভাবে ডেল্টা লেক মেটাডেটার পাশাপাশি আইসবার্গ মেটাডেটাও তৈরি করে। এটি উভয় পদ্ধতির সেরা সুবিধা প্রদান করে:
- ডেটাব্রিক্সের ভেতরে: ডেল্টা লেকের সমস্ত পারফরম্যান্স ও গভর্নেন্স সুবিধা পাওয়া যায়।
- Databricks-এর বাইরে: BigQuery-এর মতো যেকোনো Iceberg-সামঞ্জস্যপূর্ণ কোয়েরি ইঞ্জিন দ্বারা টেবিলটি পড়া যায়, ঠিক যেমনটি একটি নেটিভ Iceberg টেবিল।
এর ফলে ডেটার আলাদা কপি রক্ষণাবেক্ষণ করার বা ম্যানুয়াল রূপান্তর কাজ চালানোর প্রয়োজন হয় না। টেবিল তৈরি করার সময় নির্দিষ্ট টেবিল প্রোপার্টি সেট করার মাধ্যমে ইউনিফর্ম (UniForm) সক্রিয় করা হবে।
ডেটাব্রিকস ক্যাটালগ
ডেটাব্রিকস ক্যাটালগ হলো ডেটাব্রিকসের সমন্বিত গভর্নেন্স সলিউশন, ইউনিটি ক্যাটালগ -এর ডেটার জন্য শীর্ষ-স্তরের কন্টেইনার। ইউনিটি ক্যাটালগ ডেটা অ্যাসেট পরিচালনা, অ্যাক্সেস নিয়ন্ত্রণ এবং ডেটার উৎস ট্র্যাক করার জন্য একটি কেন্দ্রীভূত উপায় প্রদান করে, যা একটি সুশাসিত ডেটা প্ল্যাটফর্মের জন্য অত্যন্ত গুরুত্বপূর্ণ।
এটি ডেটা সংগঠিত করার জন্য একটি তিন-স্তরের নেমস্পেস ব্যবহার করে: catalog.schema.table ।
- ক্যাটালগ: সর্বোচ্চ স্তর, যা পরিবেশ, ব্যবসায়িক ইউনিট বা প্রকল্প অনুযায়ী ডেটা শ্রেণিবদ্ধ করতে ব্যবহৃত হয়।
- স্কিমা (বা ডেটাবেস): একটি ক্যাটালগের অন্তর্গত টেবিল, ভিউ এবং ফাংশনসমূহের যৌক্তিক বিন্যাস।
- টেবিল: যে অবজেক্টটিতে আপনার ডেটা থাকে।
একত্রিত TPC-H টেবিলটি তৈরি করার আগে, এটিকে রাখার জন্য প্রথমে একটি নির্দিষ্ট ক্যাটালগ এবং স্কিমা তৈরি করতে হবে। এটি নিশ্চিত করে যে প্রকল্পটি সুন্দরভাবে সংগঠিত এবং ওয়ার্কস্পেসের অন্যান্য ডেটা থেকে বিচ্ছিন্ন থাকে।
একটি নতুন ক্যাটালগ এবং স্কিমা তৈরি করুন
ডেটাব্রিকস ইউনিটি ক্যাটালগে, একটি ক্যাটালগ ডেটা অ্যাসেটগুলোর সংগঠনের সর্বোচ্চ স্তর হিসেবে কাজ করে, যা একটি সুরক্ষিত কন্টেইনার হিসেবে একাধিক ডেটাব্রিকস ওয়ার্কস্পেস জুড়ে বিস্তৃত হতে পারে। এটি আপনাকে সুস্পষ্টভাবে সংজ্ঞায়িত পারমিশন এবং অ্যাক্সেস কন্ট্রোল সহ বিজনেস ইউনিট, প্রজেক্ট বা এনভায়রনমেন্টের ভিত্তিতে ডেটা সংগঠিত ও পৃথক করতে সক্ষম করে।
একটি ক্যাটালগের মধ্যে, একটি স্কিমা (যা ডেটাবেস নামেও পরিচিত) টেবিল, ভিউ এবং ফাংশনগুলোকে আরও সুসংগঠিত করে। এই শ্রেণিবদ্ধ কাঠামোটি সম্পর্কিত ডেটা অবজেক্টগুলোর সূক্ষ্ম নিয়ন্ত্রণ এবং যৌক্তিক দলবদ্ধকরণের সুযোগ করে দেয়। এই ল্যাবের জন্য, TPC-H ডেটা সংরক্ষণের উদ্দেশ্যে একটি বিশেষ ক্যাটালগ এবং স্কিমা তৈরি করা হবে, যা ডেটার যথাযথ পৃথকীকরণ এবং ব্যবস্থাপনা নিশ্চিত করবে।
একটি ক্যাটালগ তৈরি করা
- যান

- + চিহ্নে ক্লিক করুন এবং তারপর ড্রপডাউন থেকে 'Create a catalog' নির্বাচন করুন।

- নিম্নলিখিত সেটিংস সহ একটি নতুন স্ট্যান্ডার্ড ক্যাটালগ তৈরি করা হবে:
- ক্যাটালগের নাম :
retl_tpch_project - সংরক্ষণের স্থান : ওয়ার্কস্পেসে আগে থেকে সেট করা থাকলে ডিফল্টটি ব্যবহার করুন, অথবা একটি নতুন তৈরি করুন।

একটি স্কিমা তৈরি করা
- যান
- বাম প্যানেল থেকে তৈরি করা নতুন ক্যাটালগটি নির্বাচন করুন।

- ক্লিক করুন
-
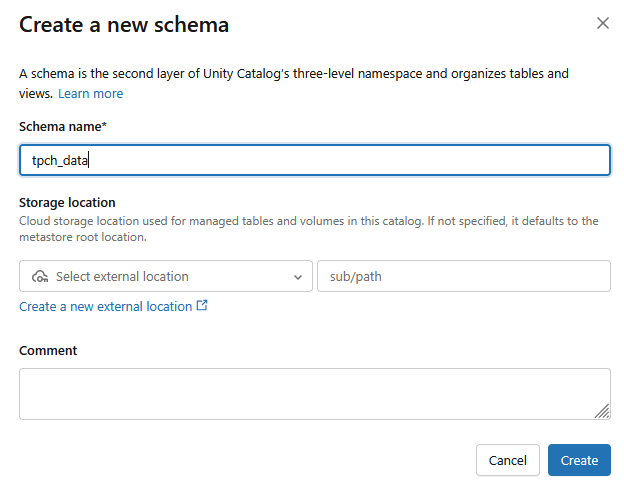
tpch_dataনামে একটি নতুন স্কিমা তৈরি করা হবে।
বাহ্যিক ডেটা সেট আপ করা
Databricks থেকে Google Cloud Storage (GCS)-এ ডেটা এক্সপোর্ট করতে হলে, Databricks-এর মধ্যে এক্সটার্নাল ডেটা ক্রেডেনশিয়াল সেট আপ করতে হবে। এর ফলে Databricks নিরাপদে GCS বাকেট অ্যাক্সেস করতে এবং তাতে লিখতে পারে।
- ক্যাটালগ স্ক্রিন থেকে, ক্লিক করুন

- যদি আপনি '
External Dataঅপশনটি দেখতে না পান, তাহলে এর পরিবর্তে 'Connectড্রপডাউনের অধীনেExternal Locationsতালিকাভুক্ত থাকতে পারে।
- ক্লিক করুন

- নতুন ডায়ালগ উইন্ডোতে, ক্রেডেনশিয়ালগুলির জন্য প্রয়োজনীয় মানগুলি সেট করুন:
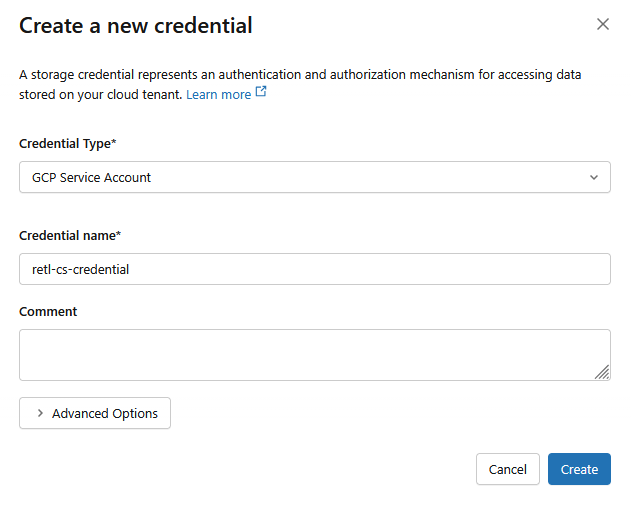
- ক্রেডেনশিয়াল টাইপ :
GCP Service Account - ক্রেডেনশিয়াল নাম :
retl-gcs-credential
- তৈরি করতে ক্লিক করুন
- এরপর, এক্সটার্নাল লোকেশনস ট্যাবে ক্লিক করুন।
- Create location- এ ক্লিক করুন।
- নতুন ডায়ালগ উইন্ডোতে, বাহ্যিক অবস্থানের জন্য প্রয়োজনীয় মানগুলি সেট করুন:
- বাহ্যিক অবস্থানের নাম :
retl-gcs-location - স্টোরেজের ধরণ :
GCP - URL : GCS বাকেটের URL, যা
gs://YOUR_BUCKET_NAMEফরম্যাটে থাকবে। - স্টোরেজ ক্রেডেনশিয়াল : এইমাত্র তৈরি করা
retl-gcs-credentialটি নির্বাচন করুন।

- স্টোরেজ ক্রেডেনশিয়াল নির্বাচন করার পর যে সার্ভিস অ্যাকাউন্টের ইমেলটি স্বয়ংক্রিয়ভাবে পূরণ হয়ে যায়, সেটি লিখে রাখুন, কারণ পরবর্তী ধাপে এটির প্রয়োজন হবে।
- তৈরি করতে ক্লিক করুন
৫. সার্ভিস অ্যাকাউন্টের অনুমতি নির্ধারণ করা
সার্ভিস অ্যাকাউন্ট হলো এক বিশেষ ধরনের অ্যাকাউন্ট, যা অ্যাপ্লিকেশন বা সার্ভিসগুলো গুগল ক্লাউড রিসোর্সে অনুমোদিত এপিআই কল করার জন্য ব্যবহার করে।
এখন GCS-এ নতুন বাকেটটির জন্য তৈরি করা সার্ভিস অ্যাকাউন্টে অনুমতিগুলো যোগ করতে হবে।
- GCS বাকেট পৃষ্ঠা থেকে, অনুমতি ট্যাবটি নির্বাচন করুন।

- প্রিন্সিপাল পৃষ্ঠায় 'অ্যাক্সেস দিন' -এ ক্লিক করুন।
- ডান দিক থেকে স্লাইড করে বেরিয়ে আসা 'Grant Access' প্যানেলে, 'New principals' ফিল্ডে সার্ভিস অ্যাকাউন্ট আইডিটি ইনপুট করুন।
- ‘Assign Roles’-এর অধীনে,
Storage Object AdminএবংStorage Legacy Bucket Readerযোগ করুন। এই রোলগুলো সার্ভিস অ্যাকাউন্টকে স্টোরেজ বাকেটে থাকা অবজেক্টগুলো পড়া, লেখা এবং তালিকাভুক্ত করার অনুমতি দেয়।
TPC-H ডেটা লোড করুন
এখন যেহেতু ক্যাটালগ এবং স্কিমা তৈরি হয়ে গেছে, ডেটাব্রিক্সের অভ্যন্তরে সংরক্ষিত বিদ্যমান samples.tpch টেবিল থেকে TPCH ডেটা লোড করে নতুনভাবে সংজ্ঞায়িত স্কিমার একটি নতুন টেবিলে স্থানান্তর করা যাবে।
আইসবার্গ সাপোর্টের সাহায্যে টেবিল তৈরি করা
ইউনিফর্মের সাথে আইসবার্গের সামঞ্জস্যতা
নেপথ্যে, ডেটাব্রিকস অভ্যন্তরীণভাবে এই টেবিলটিকে একটি ডেল্টা লেক টেবিল হিসেবে পরিচালনা করে, যা ডেটাব্রিকস ইকোসিস্টেমের মধ্যে ডেল্টার পারফরম্যান্স অপটিমাইজেশন এবং গভর্নেন্স ফিচারের সমস্ত সুবিধা প্রদান করে। তবে, ইউনিফর্ম (ইউনিভার্সাল ফরম্যাটের সংক্ষিপ্ত রূপ) সক্রিয় করার মাধ্যমে, ডেটাব্রিকসকে একটি বিশেষ কাজ করার নির্দেশ দেওয়া হয়: প্রতিবার টেবিলটি আপডেট করার সময়, ডেটাব্রিকস ডেল্টা লেক মেটাডেটার পাশাপাশি স্বয়ংক্রিয়ভাবে সংশ্লিষ্ট আইসবার্গ মেটাডেটাও তৈরি ও রক্ষণাবেক্ষণ করে।
এর অর্থ হলো, ডেটা ফাইলের একটি একক, অভিন্ন সেট (পার্কেট ফাইলগুলো) এখন দুই ধরনের মেটাডেটা দ্বারা বর্ণিত হচ্ছে।
- ডেটাব্রিক্সের ক্ষেত্রে: এটি টেবিলটি পড়ার জন্য
_delta_logব্যবহার করে। - এক্সটার্নাল রিডারদের (যেমন BigQuery) জন্য: তারা টেবিলের স্কিমা, পার্টিশনিং এবং ফাইলের অবস্থান বোঝার জন্য আইসবার্গ মেটাডেটা ফাইল (
.metadata.json) ব্যবহার করে।
এর ফলে এমন একটি টেবিল তৈরি হয় যা যেকোনো আইসবার্গ-সচেতন টুলের সাথে সম্পূর্ণ ও স্বচ্ছভাবে সামঞ্জস্যপূর্ণ। এতে কোনো ডেটার পুনরাবৃত্তি হয় না এবং ম্যানুয়াল রূপান্তর বা সিঙ্ক্রোনাইজেশনের প্রয়োজন হয় না। এটি তথ্যের একটি একক উৎস, যা ডেটাব্রিক্সের বিশ্লেষণধর্মী জগৎ এবং উন্মুক্ত আইসবার্গ স্ট্যান্ডার্ড সমর্থনকারী টুলগুলোর বৃহত্তর ইকোসিস্টেম—উভয়ের দ্বারাই নির্বিঘ্নে অ্যাক্সেস করা যায়।
- New- তে ক্লিক করুন, তারপর Query-তে ক্লিক করুন।

- কোয়েরি পেজের টেক্সট ফিল্ডে নিম্নলিখিত SQL কমান্ডটি চালান:
CREATE TABLE retl_tpch_project.tpch_data.regional_sales_iceberg
USING DELTA
LOCATION 'gs://<Your bucket name>/regional_sales_iceberg'
TBLPROPERTIES (
'delta.columnMapping.mode' = 'name',
'delta.enableIcebergCompatV2' = 'true',
'delta.universalFormat.enabledFormats' = 'iceberg'
)
AS
SELECT
n.n_name AS nation_name,
c.c_mktsegment AS market_segment,
YEAR(o.o_orderdate) AS order_year,
o.o_orderpriority AS order_priority,
COUNT(o.o_orderkey) AS total_order_count,
ROUND(SUM(o.o_totalprice), 2) AS total_revenue,
COUNT(DISTINCT c.c_custkey) AS unique_customer_count
FROM samples.tpch.orders AS o
INNER JOIN samples.tpch.customer AS c
ON o.o_custkey = c.c_custkey
INNER JOIN samples.tpch.nation AS n
ON c.c_nationkey = n.n_nationkey
GROUP BY
n.n_name,
c.c_mktsegment,
YEAR(o.o_orderdate),
o.o_orderpriority;
OPTIMIZE retl_tpch_project.tpch_data.regional_sales_iceberg;
DESCRIBE EXTENDED retl_tpch_project.tpch_data.regional_sales_iceberg;
নোট:
- ডেল্টা ব্যবহার - এটি নির্দেশ করে যে আমরা একটি ডেল্টা লেক টেবিল ব্যবহার করছি। ডেটাব্রিক্সে শুধুমাত্র ডেল্টা লেক টেবিলগুলোই এক্সটার্নাল টেবিল হিসেবে সংরক্ষণ করা যায়।
- অবস্থান - টেবিলটি বাহ্যিক হলে, এটি কোথায় সংরক্ষণ করা হবে তা নির্দিষ্ট করে।
- TablePropertoes -
delta.universalFormat.enabledFormats = 'iceberg'বিকল্পটি ডেল্টা লেক ফাইলগুলির পাশাপাশি সামঞ্জস্যপূর্ণ আইসবার্গ মেটাডেটা তৈরি করে। - অপ্টিমাইজ করুন - ইউনিফর্ম মেটাডেটা তৈরি প্রক্রিয়াটি জোরপূর্বক চালু করে, কারণ এটি সাধারণত অ্যাসিঙ্ক্রোনাসভাবে ঘটে থাকে।
- কোয়েরির আউটপুটে নতুন তৈরি করা টেবিলের বিস্তারিত তথ্য দেখানো উচিত।

GCS টেবিলের ডেটা যাচাই করুন
GCS বাকেটে প্রবেশ করলে, নতুন তৈরি করা টেবিলের ডেটা এখন পাওয়া যাবে।
আপনি আইসবার্গ মেটাডেটা metadata ফোল্ডারের মধ্যে পাবেন, যা বাহ্যিক রিডাররা (যেমন BigQuery) ব্যবহার করে। ডেল্টা লেক মেটাডেটা , যা ডেটাব্রিকস অভ্যন্তরীণভাবে ব্যবহার করে, তা _delta_log ফোল্ডারে ট্র্যাক করা হয়।
টেবিলের আসল ডেটা অন্য একটি ফোল্ডারের মধ্যে Parquet ফাইল হিসেবে সংরক্ষিত থাকে, যেটির নাম সাধারণত Databricks দ্বারা এলোমেলোভাবে তৈরি একটি স্ট্রিং দিয়ে রাখা হয়। উদাহরণস্বরূপ, নিচের স্ক্রিনশটে, ডেটা ফাইলগুলো 9M ফোল্ডারে অবস্থিত।

৬. BigQuery এবং BigLake সেটআপ করুন
এখন যেহেতু আইসবার্গ টেবিলটি গুগল ক্লাউড স্টোরেজে রয়েছে, পরবর্তী পদক্ষেপ হলো এটিকে বিগকোয়েরির জন্য অ্যাক্সেসযোগ্য করে তোলা। এটি একটি বিগলেক এক্সটার্নাল টেবিল তৈরি করার মাধ্যমে করা হবে।
BigLake হলো একটি স্টোরেজ ইঞ্জিন যা BigQuery-তে এমন টেবিল তৈরি করতে দেয়, যা Google Cloud Storage-এর মতো বাহ্যিক উৎস থেকে সরাসরি ডেটা পড়তে পারে। এই ল্যাবের জন্য, এটিই মূল প্রযুক্তি যা BigQuery-কে ডেটা ইনজেস্ট করার প্রয়োজন ছাড়াই সদ্য এক্সপোর্ট করা Iceberg টেবিলটি বুঝতে সক্ষম করে।
এটি কার্যকর করতে দুটি উপাদানের প্রয়োজন:
- ক্লাউড রিসোর্স কানেকশন: এটি BigQuery এবং GCS-এর মধ্যে একটি সুরক্ষিত সংযোগ। এটি প্রমাণীকরণ পরিচালনার জন্য একটি বিশেষ সার্ভিস অ্যাকাউন্ট ব্যবহার করে, যা নিশ্চিত করে যে GCS বাকেট থেকে ফাইলগুলি পড়ার জন্য BigQuery-এর প্রয়োজনীয় অনুমতি রয়েছে।
- এক্সটার্নাল টেবিল ডেফিনিশন: এটি BigQuery-কে বলে দেয় যে GCS-এ Iceberg টেবিলের মেটাডেটা ফাইলটি কোথায় খুঁজে পাওয়া যাবে এবং সেটিকে কীভাবে ব্যাখ্যা করা উচিত।
একটি ক্লাউড রিসোর্স সংযোগ তৈরি করুন
প্রথমে, সেই সংযোগটি তৈরি করা হবে যা BigQuery-কে GCS অ্যাক্সেস করার অনুমতি দেবে।
ক্লাউড রিসোর্স কানেকশন তৈরি করার বিষয়ে আরও তথ্য এখানে পাওয়া যাবে।
- BigQuery- তে যান
- এক্সপ্লোরারের অধীনে কানেকশনস -এ ক্লিক করুন
- যদি এক্সপ্লোরার প্লেনটি দেখা না যায়, তাহলে ক্লিক করুন

- সংযোগ পৃষ্ঠায়, ক্লিক করুন
- কানেকশন টাইপের জন্য
Vertex AI remote models, remote functions, BigLake and Spanner (Cloud Resource)বেছে নিন। - কানেকশন আইডি
databricks_retlএ সেট করুন এবং কানেকশনটি তৈরি করুন।

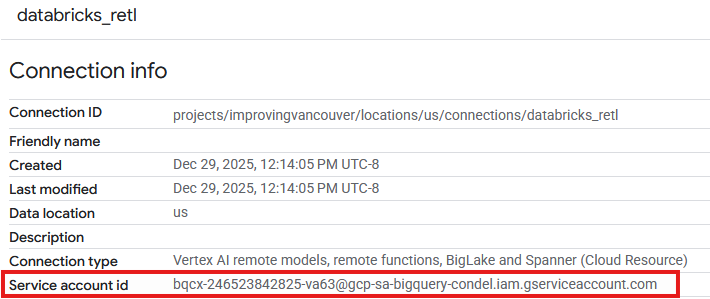
- নতুন তৈরি করা কানেকশনটির একটি এন্ট্রি এখন কানেকশনস টেবিলে দেখা যাবে। কানেকশনের বিস্তারিত দেখতে ওই এন্ট্রিটিতে ক্লিক করুন।

- কানেকশন ডিটেইলস পেজে সার্ভিস অ্যাকাউন্ট আইডিটি লিখে রাখুন, কারণ পরবর্তীতে এটির প্রয়োজন হবে।
কানেকশন সার্ভিস অ্যাকাউন্টে অ্যাক্সেস মঞ্জুর করুন
- IAM ও অ্যাডমিনে যান
- অ্যাক্সেস মঞ্জুর করতে ক্লিক করুন

- 'New principals' ফিল্ডে, উপরে তৈরি করা Connection Resource-এর Service account id-টি প্রবেশ করান।
- ভূমিকার জন্য,
Storage Object Userনির্বাচন করুন এবং তারপরে ক্লিক করুন।
সংযোগ স্থাপিত হলে এবং এর সার্ভিস অ্যাকাউন্টকে প্রয়োজনীয় অনুমতি দেওয়া হলে, এখন বিগলেক এক্সটার্নাল টেবিলটি তৈরি করা যাবে। প্রথমে, নতুন টেবিলটির ধারক হিসেবে কাজ করার জন্য বিগকোয়েরিতে একটি ডেটাসেট প্রয়োজন। তারপর, টেবিলটি তৈরি করা হবে এবং এটিকে GCS বাকেটে থাকা আইসবার্গ মেটাডেটা ফাইলের দিকে নির্দেশ করা হবে।
- BigQuery- তে যান
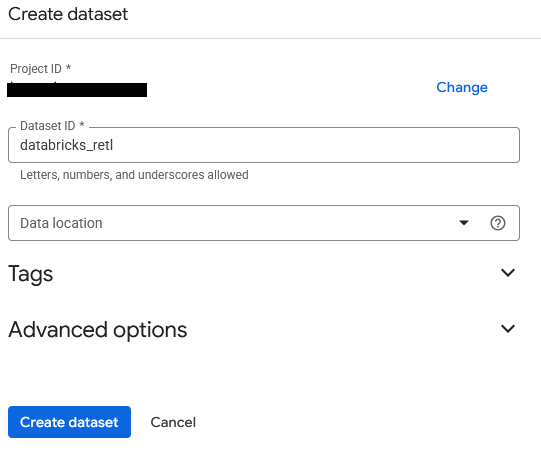
- এক্সপ্লোরার প্যানেলে, প্রজেক্ট আইডিতে ক্লিক করুন, তারপর তিনটি ডটে ক্লিক করে 'Create dataset' নির্বাচন করুন।

- ডেটা সেটটির নাম হবে
databricks_retl। অন্যান্য অপশনগুলো ডিফল্ট হিসেবে রেখে Create dataset বাটনে ক্লিক করুন।
- এখন, এক্সপ্লোরার প্যানেলে নতুন
databricks_retlডেটাসেটটি খুঁজুন। এর পাশে থাকা তিনটি ডটে ক্লিক করুন এবং 'Create table' নির্বাচন করুন।
- টেবিল তৈরির জন্য নিম্নলিখিত সেটিংস পূরণ করুন:
-
Google Cloud Storageথেকে টেবিল তৈরি করুন - GCS বাকেট থেকে ফাইল নির্বাচন করুন অথবা একটি URI প্যাটার্ন ব্যবহার করুন : GCS বাকেটে ব্রাউজ করুন এবং Databricks এক্সপোর্টের সময় তৈরি হওয়া মেটাডেটা JSON ফাইলটি সনাক্ত করুন। পাথটি দেখতে অনেকটা এইরকম হবে:
regional_sales/metadata/v1.metadata.json। - ফাইল ফরম্যাট :
Iceberg - টেবিল :
regional_sales - টেবিলের ধরণ :
External table - সংযোগ আইডি : পূর্বে তৈরি করা
databricks_retlসংযোগটি নির্বাচন করুন। - বাকি মানগুলো অপরিবর্তিত রেখে, 'টেবিল তৈরি করুন' বোতামে ক্লিক করুন।
- তৈরি হয়ে গেলে, নতুন
regional_salesটেবিলটিdatabricks_retlডেটাসেটের অধীনে দেখা যাবে। এখন এই টেবিলটি অন্য যেকোনো BigQuery টেবিলের মতোই সাধারণ SQL ব্যবহার করে কোয়েরি করা যাবে।

৭. স্প্যানারে লোড করুন
পাইপলাইনের চূড়ান্ত এবং সবচেয়ে গুরুত্বপূর্ণ অংশে পৌঁছানো গেছে: বিগলেক এক্সটার্নাল টেবিল থেকে স্প্যানারে ডেটা স্থানান্তর করা। এটি হলো "রিভার্স ইটিএল" ধাপ, যেখানে ডেটা ওয়্যারহাউসে প্রক্রিয়াজাত ও সংকলিত হওয়ার পর, অ্যাপ্লিকেশনগুলোর ব্যবহারের জন্য ডেটা একটি অপারেশনাল সিস্টেমে লোড করা হয়।
স্প্যানার হলো একটি সম্পূর্ণভাবে পরিচালিত, বিশ্বব্যাপী বিতরণযোগ্য রিলেশনাল ডেটাবেস। এটি একটি প্রচলিত রিলেশনাল ডেটাবেসের মতো লেনদেনগত সামঞ্জস্য প্রদান করে, কিন্তু এর সাথে রয়েছে NoSQL ডেটাবেসের মতো অনুভূমিক প্রসারণযোগ্যতা। এই কারণে এটি প্রসারণযোগ্য এবং উচ্চ প্রাপ্যতা সম্পন্ন অ্যাপ্লিকেশন তৈরির জন্য একটি আদর্শ পছন্দ।
প্রক্রিয়াটি হবে:
- একটি স্প্যানার ইনস্ট্যান্স তৈরি করুন, যা হলো রিসোর্সের ভৌত বরাদ্দ।
- ওই ইনস্ট্যান্সের মধ্যে একটি ডাটাবেস তৈরি করুন।
- ডাটাবেসে এমন একটি টেবিল স্কিমা নির্ধারণ করুন যা
regional_salesডেটার কাঠামোর সাথে মেলে। - BigLake টেবিল থেকে সরাসরি Spanner টেবিলে ডেটা লোড করতে একটি BigQuery
EXPORT DATAকোয়েরি চালান।
স্প্যানার ইনস্ট্যান্স, ডেটাবেস এবং টেবিল তৈরি করুন
- স্প্যানারে যান
- ক্লিক করুন
 বিদ্যমান কোনো ইনস্ট্যান্স উপলব্ধ থাকলে নির্দ্বিধায় সেটি ব্যবহার করুন। প্রয়োজন অনুযায়ী ইনস্ট্যান্সের প্রয়োজনীয়তাগুলো সেটআপ করুন। এই ল্যাবের জন্য নিম্নলিখিতগুলো ব্যবহার করা হয়েছিল:
বিদ্যমান কোনো ইনস্ট্যান্স উপলব্ধ থাকলে নির্দ্বিধায় সেটি ব্যবহার করুন। প্রয়োজন অনুযায়ী ইনস্ট্যান্সের প্রয়োজনীয়তাগুলো সেটআপ করুন। এই ল্যাবের জন্য নিম্নলিখিতগুলো ব্যবহার করা হয়েছিল:
সংস্করণ | উদ্যোগ |
ইনস্ট্যান্সের নাম | ডেটাব্রিকস-রেটল |
অঞ্চল কনফিগারেশন | আপনার পছন্দের অঞ্চল |
কম্পিউট ইউনিট | প্রসেসিং ইউনিট (পিইউ) |
ম্যানুয়াল বরাদ্দ | ১০০ |
- তৈরি হয়ে গেলে, স্প্যানার ইনস্ট্যান্স পৃষ্ঠায় যান এবং নির্বাচন করুন
 বিদ্যমান কোনো ডাটাবেস থাকলে নির্দ্বিধায় ব্যবহার করতে পারেন।
বিদ্যমান কোনো ডাটাবেস থাকলে নির্দ্বিধায় ব্যবহার করতে পারেন।
- এই ল্যাবের জন্য একটি ডাটাবেস তৈরি করা হবে
- নাম :
databricks-retl - ডাটাবেস ডায়ালেক্ট :
Google Standard SQL
- ডাটাবেস তৈরি হয়ে গেলে, স্প্যানার ইনস্ট্যান্স পেজ থেকে সেটি নির্বাচন করে স্প্যানার ডাটাবেস পেজে প্রবেশ করুন।
- স্প্যানার ডাটাবেস পৃষ্ঠা থেকে, ক্লিক করুন

- নতুন কোয়েরি পেজে, স্প্যানারে ইম্পোর্ট করার জন্য টেবিলের ডেফিনিশন তৈরি করা হবে। এটি করার জন্য, নিম্নলিখিত SQL কোয়েরিটি চালান।
CREATE TABLE regional_sales (
nation_name STRING(MAX),
market_segment STRING(MAX),
order_year INT64,
order_priority STRING(MAX),
total_order_count INT64,
total_revenue NUMERIC,
unique_customer_count INT64
) PRIMARY KEY (nation_name, market_segment, order_year, order_priority);
- SQL কমান্ডটি কার্যকর হয়ে গেলে, BigQuery-এর মাধ্যমে ডেটা রিভার্স ETL করার জন্য স্প্যানার টেবিলটি প্রস্তুত হয়ে যাবে। স্প্যানার ডেটাবেসের বাম প্যানেলে টেবিলটি তালিকাভুক্ত দেখে এর তৈরি হওয়া যাচাই করা যেতে পারে।

EXPORT DATA ব্যবহার করে স্প্যানারে রিভার্স ইটিএল
এটিই চূড়ান্ত ধাপ। BigQuery BigLake টেবিলে সোর্স ডেটা প্রস্তুত থাকলে এবং Spanner-এ ডেস্টিনেশন টেবিল তৈরি হয়ে গেলে, প্রকৃত ডেটা স্থানান্তর আশ্চর্যজনকভাবে সহজ। একটিমাত্র BigQuery SQL কোয়েরি ব্যবহার করা হবে: EXPORT DATA .
এই কোয়েরিটি বিশেষভাবে এই ধরনের পরিস্থিতির জন্যই ডিজাইন করা হয়েছে। এটি একটি BigQuery টেবিল (BigLake টেবিলের মতো বাহ্যিক টেবিল সহ) থেকে দক্ষতার সাথে একটি বাহ্যিক গন্তব্যে ডেটা এক্সপোর্ট করে। এক্ষেত্রে, গন্তব্যটি হলো স্প্যানার টেবিল। এক্সপোর্ট ফিচারটি সম্পর্কে আরও তথ্য এখানে পাওয়া যাবে।
BigQuery থেকে Spanner Reverse ETL সেট আপ করার বিষয়ে আরও তথ্য এখানে পাওয়া যাবে।
- BigQuery- তে যান
- একটি নতুন কোয়েরি এডিটর ট্যাব খুলুন।
- কোয়েরি পেজে নিম্নলিখিত SQL লিখুন। মনে রাখবেন,
uriএবং টেবিল পাথে থাকা প্রজেক্ট আইডি সঠিক প্রজেক্ট আইডি দিয়ে প্রতিস্থাপন করতে হবে ।
EXPORT DATA OPTIONS(
uri='https://spanner.googleapis.com/projects/YOUR_PROJECT_ID/instances/databricks-retl/databases/databricks-retl',
format='CLOUD_SPANNER',
spanner_options="""{
"table": "regional_sales",
"priority": "MEDIUM"
}"""
) AS
SELECT * FROM `YOUR_PROJECT_ID.databricks_retl.regional_sales`;
- কমান্ডটি সম্পন্ন হলেই, ডেটা সফলভাবে স্প্যানারে এক্সপোর্ট হয়ে যাবে!
৮. স্প্যানারে ডেটা যাচাই করুন
অভিনন্দন! একটি সম্পূর্ণ রিভার্স ইটিএল পাইপলাইন সফলভাবে তৈরি ও কার্যকর করা হয়েছে, যা ডেটাব্রিকস ডেটা ওয়্যারহাউস থেকে একটি চালু স্প্যানার ডেটাবেসে ডেটা স্থানান্তর করছে।
চূড়ান্ত ধাপ হলো ডেটা প্রত্যাশা অনুযায়ী স্প্যানারে পৌঁছেছে কিনা তা যাচাই করা।
- স্প্যানারে যান।
- আপনার
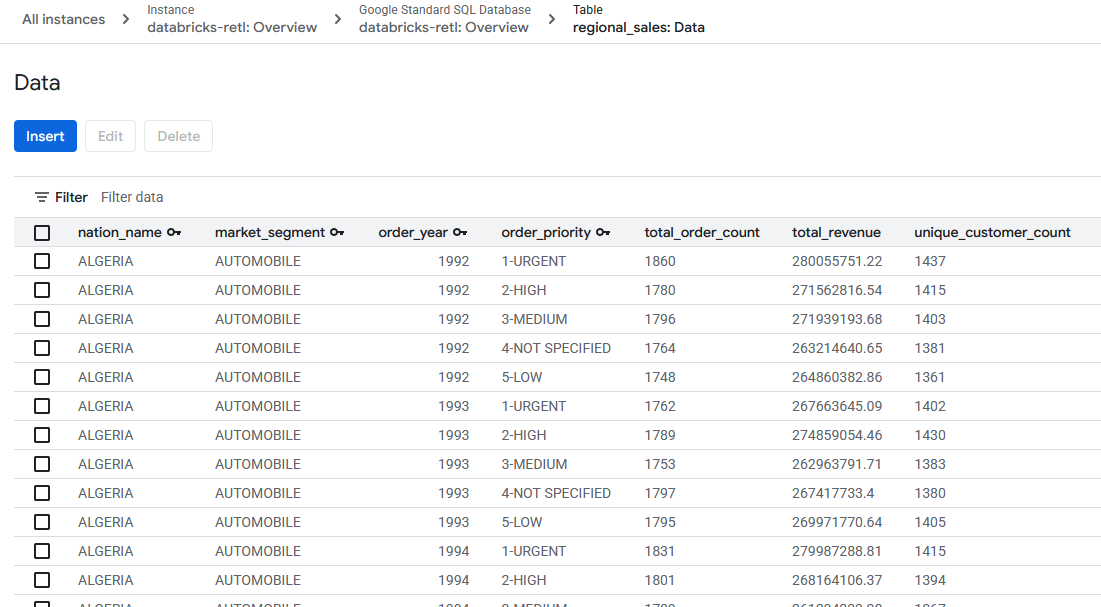
databricks-retlইনস্ট্যান্সে এবং তারপরdatabricks-retlডেটাবেসে যান। - টেবিলের তালিকায়,
regional_salesটেবিলটিতে ক্লিক করুন। - টেবিলের বাম দিকের নেভিগেশন মেনুতে, ডেটা ট্যাবে ক্লিক করুন।

- মূলত ডেটাব্রিকস থেকে প্রাপ্ত একত্রিত বিক্রয় ডেটা এখন স্প্যানার টেবিলে লোড হয়ে ব্যবহারের জন্য প্রস্তুত থাকা উচিত। এই ডেটা এখন একটি কার্যকরী সিস্টেমে রয়েছে, যা একটি লাইভ অ্যাপ্লিকেশন পরিচালনা করতে, একটি ড্যাশবোর্ড পরিবেশন করতে, অথবা একটি এপিআই (API) দ্বারা কোয়েরি করার জন্য প্রস্তুত।
বিশ্লেষণাত্মক এবং পরিচালনগত ডেটা জগতের মধ্যকার ব্যবধান সফলভাবে পূরণ করা হয়েছে।
৯. পরিচ্ছন্নতা
এই ল্যাবের কাজ শেষ হলে যোগ করা সমস্ত টেবিল এবং সংরক্ষিত ডেটা মুছে ফেলুন।
স্প্যানার টেবিল পরিষ্কার করুন
- স্প্যানারে যান
-
databricks-retlনামের তালিকা থেকে এই ল্যাবের জন্য ব্যবহৃত ইনস্ট্যান্সটিতে ক্লিক করুন।

- ইনস্ট্যান্স পৃষ্ঠায়, ক্লিক করুন

- পপ-আপ হওয়া কনফার্মেশন ডায়ালগে
databricks-retlলিখুন এবং ক্লিক করুন।
জিসিএস পরিষ্কার করুন
- GCS- এ যান
- নির্বাচন করুন
 বাম পাশের মেনু থেকে
বাম পাশের মেনু থেকে - `codelabs_retl_databricks` বালতি নির্বাচন করুন
- একবার নির্বাচিত হলে, ক্লিক করুন
 উপরের ব্যানারে যে বোতামটি দেখা যায়
উপরের ব্যানারে যে বোতামটি দেখা যায়

- পপ-আপ হওয়া কনফার্মেশন ডায়ালগে
DELETEটাইপ করুন এবং ক্লিক করুন।
ডেটাব্রিকস পরিষ্কার করুন
ক্যাটালগ/স্কিমা/টেবিল মুছে ফেলুন
- আপনার ডেটাব্রিকস ইনস্ট্যান্সে সাইন ইন করুন
- ক্লিক করুন
 বাম পাশের মেনু থেকে
বাম পাশের মেনু থেকে - পূর্বে তৈরি করা নির্বাচন করুন
 ক্যাটালগ তালিকা থেকে
ক্যাটালগ তালিকা থেকে - স্কিমা তালিকায়, নির্বাচন করুন
 যেটি তৈরি করা হয়েছিল
যেটি তৈরি করা হয়েছিল - পূর্বে তৈরি করা নির্বাচন করুন
 টেবিলের তালিকা থেকে
টেবিলের তালিকা থেকে - ক্লিক করে টেবিলের বিকল্পগুলি প্রসারিত করুন
 এবং
এবং Deleteনির্বাচন করুন - ক্লিক করুন
 টেবিলটি মুছে ফেলার জন্য নিশ্চিতকরণ ডায়ালগে
টেবিলটি মুছে ফেলার জন্য নিশ্চিতকরণ ডায়ালগে - টেবিলটি মুছে ফেলা হলে, আপনাকে আবার স্কিমা পৃষ্ঠায় ফিরিয়ে আনা হবে।
- ক্লিক করে স্কিমা বিকল্পগুলি প্রসারিত করুন এবং
Deleteনির্বাচন করুন - ক্লিক করুন স্কিমা মুছে ফেলার নিশ্চিতকরণ ডায়ালগে
- স্কিমাটি মুছে ফেলা হলে, আপনাকে আবার ক্যাটালগ পৃষ্ঠায় ফিরিয়ে আনা হবে।
- যদি
defaultস্কিমা থেকে থাকে, তবে তা মুছে ফেলার জন্য আবার ৪ থেকে ১১ নম্বর ধাপগুলো অনুসরণ করুন। - ক্যাটালগ পৃষ্ঠা থেকে, ক্লিক করে ক্যাটালগ বিকল্পগুলি প্রসারিত করুন। এবং
Deleteনির্বাচন করুন - ক্লিক করুন ক্যাটালগটি মুছে ফেলার জন্য নিশ্চিতকরণ ডায়ালগে
বাহ্যিক ডেটার অবস্থান / পরিচয়পত্র মুছুন
- ক্যাটালগ স্ক্রিন থেকে, ক্লিক করুন
- যদি আপনি '
External Dataঅপশনটি দেখতে না পান, তাহলে এর পরিবর্তে 'Connect' ড্রপডাউনের অধীনেExternal Locationতালিকাভুক্ত থাকতে পারে। - পূর্বে তৈরি করা
retl-gcs-locationএক্সটার্নাল ডেটা লোকেশনটিতে ক্লিক করুন। - বাহ্যিক অবস্থানের পৃষ্ঠা থেকে, ক্লিক করে অবস্থানের বিকল্পগুলি প্রসারিত করুন। এবং
Deleteনির্বাচন করুন - ক্লিক করুন বাহ্যিক অবস্থানটি মুছে ফেলার জন্য নিশ্চিতকরণ ডায়ালগে
- ক্লিক করুন
- পূর্বে তৈরি করা
retl-gcs-credentialটিতে ক্লিক করুন। - ক্রেডেনশিয়াল পৃষ্ঠা থেকে, ক্লিক করে ক্রেডেনশিয়াল বিকল্পগুলি প্রসারিত করুন। এবং
Deleteনির্বাচন করুন - ক্লিক করুন ক্রেডেনশিয়ালগুলো মুছে ফেলার জন্য কনফার্মেশন ডায়ালগে।
১০. অভিনন্দন
কোডল্যাবটি সম্পন্ন করার জন্য অভিনন্দন।
আমরা যা আলোচনা করেছি
- ডেটাব্রিক্সে আইসবার্গ টেবিল হিসেবে ডেটা লোড করার পদ্ধতি
- কীভাবে একটি GCS বাকেট তৈরি করবেন
- আইসবার্গ ফরম্যাটে ডেটাব্রিকস টেবিলকে জিসিএস-এ কীভাবে এক্সপোর্ট করবেন
- GCS-এর Iceberg টেবিল থেকে BigQuery-তে কীভাবে একটি BigLake এক্সটার্নাল টেবিল তৈরি করবেন
- কীভাবে একটি স্প্যানার ইনস্ট্যান্স সেট আপ করবেন
- BigQuery ব্যবহার করে Spanner-এ BigLake এক্সটার্নাল টেবিলগুলো কীভাবে লোড করবেন