
1. Panoramica
I viaggiatori moderni si aspettano esperienze conversazionali. Invece di navigare tra filtri complessi dell'interfaccia utente, vogliono chiedere: "Posso portare il mio cane sull'autobus delle 9:00 per Boston?" Ciò richiede un agente in grado di ragionare su dati non strutturati (norme PDF) e dati strutturati (pianificazioni SQL).
In questo lab, creeremo l'agente di transito Cymbal utilizzando:
- LangChain4j:il principale framework Java per l'orchestrazione dell'AI.
- AlloyDB:un database compatibile con PostgreSQL ad alte prestazioni.
- SDK Java di MCP Toolbox:un modo standardizzato per connettere gli agenti Java a strumenti esterni e origini dati.
Cosa creerai
Cymbal Bus Agent, un'applicazione Java Spring Boot composta da:
- Database AlloyDB e SDK Java di MCP Toolbox per l'orchestrazione degli strumenti con gli agenti.
- Cloud Run per il deployment e l'applicazione di Toolbox (deployment dell'agente).
- Libreria LangChain4J per l'agente e il framework LLM in un'applicazione Spring Boot con Java 17.
Obiettivi didattici
- Come utilizzare LangChain4J per creare agenti e subagenti specializzati orchestrati utilizzando l'SDK Java di MCP Toolbox per i database
- Come configurare e utilizzare AlloyDB per dati e AI.
- Come utilizzare MCP Toolbox per connettere gli agenti agli strumenti di dati di AlloyDB.
- Come eseguire il deployment della soluzione utilizzando Cloud Run o eseguirla localmente.
L'architettura
- AlloyDB per PostgreSQL:funge da database operativo ad alte prestazioni che contiene i nostri record di itinerari, norme e prenotazioni. Alimenta la ricerca e il recupero vettoriali.
- SDK Java di MCP Toolbox for Databases:funge da "maestro dell'orchestrazione", esponendo i dati di AlloyDB come strumenti eseguibili che gli agenti possono chiamare.
L'SDK Java di MCP Toolbox consente di orchestrare gli agenti con gli strumenti di database senza problemi per le applicazioni di livello aziendale.
- LangChain4J:una libreria Java open source che semplifica l'integrazione di modelli linguistici di grandi dimensioni (LLM) nelle applicazioni Java. Fornisce strumenti e astrazioni per la creazione di applicazioni basate sull'AI, tra cui chatbot, agenti e sistemi RAG (Retrieval-Augmented Generation).
- Cloud Run:una piattaforma serverless completamente gestita che ti consente di creare ed eseguire il deployment di app o siti web rapidamente in qualsiasi linguaggio, libreria o binario. Puoi scrivere codice utilizzando il linguaggio, il framework e le librerie che preferisci, pacchettizzarlo come container, eseguire "gcloud run deploy" e la tua app sarà attiva, con tutto ciò di cui ha bisogno per essere eseguita in produzione. La creazione di un container è del tutto facoltativa. Se usi Go, Node.js, Python, Java, .NET Core o Ruby, puoi usare l'opzione di deployment basato sull'origine, che crea il container per te, usando le best practice per il linguaggio che stai utilizzando.
Requisiti
2. Prima di iniziare
Crea un progetto
- Nella console Google Cloud, nella pagina di selezione del progetto, seleziona o crea un progetto Google Cloud.
- Verifica che la fatturazione sia attivata per il tuo progetto Cloud. Scopri come verificare se la fatturazione è abilitata per un progetto.
- Utilizzerai Cloud Shell, un ambiente a riga di comando in esecuzione in Google Cloud. Fai clic su Attiva Cloud Shell nella parte superiore della console Google Cloud.

- Una volta eseguita la connessione a Cloud Shell, verifica di essere già autenticato e che il progetto sia impostato sul tuo ID progetto utilizzando il seguente comando:
gcloud auth list
- Esegui questo comando in Cloud Shell per verificare che il comando gcloud conosca il tuo progetto.
gcloud config list project
- Se il progetto non è impostato, utilizza il seguente comando per impostarlo:
gcloud config set project <YOUR_PROJECT_ID>
- Abilita le API richieste: segui il link e abilita le API.
In alternativa, puoi utilizzare il comando gcloud. Consulta la documentazione per i comandi e l'utilizzo di gcloud.
Aspetti da considerare e risoluzione dei problemi
La sindrome del "progetto fantasma" | Hai eseguito |
La barriera di fatturazione | Hai attivato il progetto, ma hai dimenticato l'account di fatturazione. AlloyDB è un motore ad alte prestazioni; non si avvia se il "serbatoio" (fatturazione) è vuoto. |
Ritardo di propagazione dell'API | Hai fatto clic su "Abilita API", ma la riga di comando indica ancora |
Quota Quags | Se utilizzi un account di prova nuovo di zecca, potresti raggiungere una quota regionale per le istanze AlloyDB. Se |
Service Agent"Nascosto" | A volte all'agente di servizio AlloyDB non viene concesso automaticamente il ruolo |
3. Configurazione del database
Al centro della nostra applicazione si trova AlloyDB per PostgreSQL. Abbiamo sfruttato le sue potenti funzionalità vettoriali e il motore colonnare integrato per generare incorporamenti per oltre 50.000 record SCM. Ciò consente l'analisi vettoriale quasi in tempo reale, consentendo ai nostri agenti di identificare anomalie di inventario o rischi logistici in set di dati di grandi dimensioni in pochi millisecondi.
In questo lab utilizzeremo AlloyDB come database per i dati di test. Utilizza i cluster per contenere tutte le risorse, come database e log. Ogni cluster ha un'istanza primaria che fornisce un punto di accesso ai dati. Le tabelle conterranno i dati effettivi.
Creiamo un cluster, un'istanza e una tabella AlloyDB in cui verrà caricato il set di dati di test.
- Fai clic sul pulsante o copia il link riportato di seguito nel browser in cui hai eseguito l'accesso all'utente della console Google Cloud.
In alternativa, puoi andare al terminale Cloud Shell dal progetto in cui hai riscattato l'account di fatturazione, clonare il repository GitHub e passare al progetto utilizzando i comandi riportati di seguito:
git clone https://github.com/AbiramiSukumaran/easy-alloydb-setup
cd easy-alloydb-setup
- Una volta completato questo passaggio, il repository verrà clonato nell'editor Cloud Shell locale e potrai eseguire il comando riportato di seguito dalla cartella del progetto (è importante assicurarsi di trovarsi nella directory del progetto):
sh run.sh
- Ora utilizza la UI (facendo clic sul link nel terminale o sul link "Anteprima sul web" nel terminale).
- Inserisci i tuoi dati per l'ID progetto, il cluster e i nomi delle istanze per iniziare.
- Prendi un caffè mentre scorrono i log e leggi qui come funziona dietro le quinte.
Aspetti da considerare e risoluzione dei problemi
Il problema della "pazienza" | I cluster di database sono un'infrastruttura pesante. Se aggiorni la pagina o termini la sessione Cloud Shell perché "sembra bloccata", potresti ritrovarti con un'istanza "fantasma" di cui è stato eseguito il provisioning parziale e impossibile da eliminare senza un intervento manuale. |
Regione non corrispondente | Se hai abilitato le API in |
Zombie Clusters | Se in precedenza hai utilizzato lo stesso nome per un cluster e non lo hai eliminato, lo script potrebbe indicare che il nome del cluster esiste già. I nomi dei cluster devono essere univoci all'interno di un progetto. |
Timeout di Cloud Shell | Se la pausa caffè dura 30 minuti, Cloud Shell potrebbe entrare in modalità di sospensione e disconnettere il processo |
4. Provisioning dello schema
Una volta che il cluster e l'istanza AlloyDB sono in esecuzione, vai all'editor SQL di AlloyDB Studio per attivare le estensioni AI e eseguire il provisioning dello schema.

Potrebbe essere necessario attendere il completamento della creazione dell'istanza. Una volta creato, accedi ad AlloyDB utilizzando le credenziali che hai creato durante la creazione del cluster. Utilizza i seguenti dati per l'autenticazione a PostgreSQL:
- Nome utente : "
postgres" - Database : "
postgres" - Password : "
alloydb" (o quella che hai impostato al momento della creazione)
Una volta eseguita l'autenticazione in AlloyDB Studio, i comandi SQL vengono inseriti nell'editor. Puoi aggiungere più finestre dell'editor utilizzando il segno più a destra dell'ultima finestra.

Inserirai i comandi per AlloyDB nelle finestre dell'editor, utilizzando le opzioni Esegui, Formatta e Cancella in base alle esigenze.
Attivare le estensioni
Per creare questa app, utilizzeremo le estensioni pgvector e google_ml_integration. L'estensione pgvector consente di archiviare ed eseguire ricerche di vector embedding. L'estensione google_ml_integration fornisce funzioni che utilizzi per accedere agli endpoint di previsione Vertex AI per ottenere previsioni in SQL. Attiva queste estensioni eseguendo i seguenti DDL:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
Concedi autorizzazione
Esegui l'istruzione riportata di seguito per concedere l'esecuzione della funzione "embedding":
GRANT EXECUTE ON FUNCTION embedding TO postgres;
Concedi il ruolo Utente Vertex AI al service account AlloyDB
Dalla console Google Cloud IAM, concedi al service account AlloyDB (simile a service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com) l'accesso al ruolo "Utente Vertex AI". PROJECT_NUMBER conterrà il numero del tuo progetto.
In alternativa, puoi eseguire il comando riportato di seguito dal terminale Cloud Shell:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Creare una tabella
Puoi creare una tabella utilizzando l'istruzione DDL riportata di seguito in AlloyDB Studio:
DROP TABLE IF EXISTS transit_policies;
DROP TABLE IF EXISTS bus_schedules;
DROP TABLE IF EXISTS bookings;
-- Table 1: Transit Policies (Unstructured Data for RAG)
CREATE TABLE transit_policies (
policy_id SERIAL PRIMARY KEY,
category VARCHAR(50),
policy_text TEXT,
policy_embedding vector(768)
);
-- Table 2: Intercity Bus Schedules (Structured Data)
CREATE TABLE bus_schedules (
trip_id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
origin_city VARCHAR(100),
destination_city VARCHAR(100),
departure_time TIMESTAMP,
arrival_time TIMESTAMP,
available_seats INT DEFAULT 50,
ticket_price DECIMAL(6,2)
);
-- Table 3: Booking Ledger (Transactional Action Data)
CREATE TABLE bookings (
booking_id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
trip_id UUID REFERENCES bus_schedules(trip_id),
passenger_id VARCHAR(100),
status VARCHAR(20) DEFAULT 'CONFIRMED',
booking_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
La colonna policy_embedding consentirà di memorizzare i valori del vettore di alcuni campi di testo.
Importazione dati
Esegui il seguente insieme di istruzioni SQL per inserire in blocco i record nelle rispettive tabelle:
- Inserire politiche non strutturate e GENERARE EMBEDDING REALI in modo nativo in AlloyDB
-- 1. Insert Unstructured Policies and GENERATE REAL EMBEDDINGS natively in AlloyDB
INSERT INTO transit_policies (category, policy_text, policy_embedding)
VALUES
('Pets', 'Service animals are always welcome. Small pets (under 25 lbs) are allowed in secure carriers for a $25 fee. Large dogs are not permitted on standard coaches.', embedding('text-embedding-005', 'Service animals are always welcome. Small pets (under 25 lbs) are allowed in secure carriers for a $25 fee. Large dogs are not permitted on standard coaches.')),
('Luggage', 'Each passenger is allowed one carry-on (up to 15 lbs) and two stowed bags (up to 50 lbs each) free of charge. Additional bags cost $15 each.', embedding('text-embedding-005', 'Each passenger is allowed one carry-on (up to 15 lbs) and two stowed bags (up to 50 lbs each) free of charge. Additional bags cost $15 each.')),
('Refunds', 'Tickets are fully refundable up to 24 hours before departure. Within 24 hours, tickets can be exchanged for travel credit only.', embedding('text-embedding-005', 'Tickets are fully refundable up to 24 hours before departure. Within 24 hours, tickets can be exchanged for travel credit only.'));
- Generare oltre 200 programmi realistici per 7 giorni utilizzando generate_series
-- 2. Generate 200+ Realistic Schedules for the Next 7 Days using generate_series
INSERT INTO bus_schedules (origin_city, destination_city, departure_time, arrival_time, ticket_price, available_seats)
SELECT
origin,
destination,
-- Generate departures every 4 hours starting from tomorrow
(CURRENT_DATE + 1) + (interval '4 hours' * seq) AS dep_time,
(CURRENT_DATE + 1) + (interval '4 hours' * seq) + interval '4.5 hours' AS arr_time,
ROUND((RANDOM() * 30 + 25)::numeric, 2) AS price, -- Random price between $25 and $55
FLOOR(RANDOM() * 50 + 1) AS seats -- Random seats between 1 and 50
FROM
(VALUES
('New York', 'Boston'), ('Boston', 'New York'),
('Philadelphia', 'Washington DC'), ('Washington DC', 'Philadelphia'),
('Seattle', 'Portland'), ('Portland', 'Seattle')
) AS routes(origin, destination)
CROSS JOIN generate_series(1, 40) AS seq; -- 6 routes * 40 time slots = 240 distinct trips ingested!
Genera incorporamenti
Gli embedding vengono coperti automaticamente nell'istruzione di inserimento nella tabella transit_policies utilizzando la funzione "embedding('text-embedding-005', '<<policytext>>')".
Aspetti da considerare e risoluzione dei problemi
Il ciclo "Amnesia della password" | Se hai utilizzato la configurazione "Un clic" e non ricordi la password, vai alla pagina delle informazioni di base dell'istanza nella console e fai clic su "Modifica" per reimpostare la password di |
Errore "Estensione non trovata" | Se |
Problemi di propagazione di IAM | Hai eseguito il comando IAM
|
Mancata corrispondenza delle dimensioni del vettore | La colonna |
Errore di battitura nell'ID progetto | Nella chiamata |
5. Configurazione di strumenti e toolbox
MCP Toolbox for Databases è un server MCP open source per i database. Ti consente di sviluppare strumenti in modo più semplice, rapido e sicuro gestendo le complessità come il pooling di connessioni, l'autenticazione e altro. Toolbox ti aiuta a creare strumenti di AI generativa che consentono agli agenti di accedere ai dati del tuo database.
Utilizziamo Model Context Protocol (MCP) Toolbox for Databases come "direttore d'orchestra". Funge da middleware standardizzato tra i nostri agenti e AlloyDB. Definendo una configurazione tools.yaml, la casella degli strumenti espone automaticamente operazioni di database complesse come strumenti puliti ed eseguibili come find-bus-schedules and routes o query-schedules for specific routes ed esegue azioni autonome come book-ticket. In questo modo si elimina la necessità di raggruppamento manuale delle connessioni o di SQL boilerplate nella logica dell'agente.
Installazione del server Toolbox
Dal terminale Cloud Shell, crea una cartella per salvare il nuovo file YAML degli strumenti e il file binario della toolbox:
mkdir cymbal-bus-toolbox
cd cymbal-bus-toolbox
Dall'interno della nuova cartella, esegui il seguente insieme di comandi:
# see releases page for other versions
export VERSION=0.27.0
curl -L -o toolbox https://storage.googleapis.com/genai-toolbox/v$VERSION/linux/amd64/toolbox
chmod +x toolbox
Poi crea il file tools.yaml all'interno della nuova cartella navigando nell'editor di Cloud Shell e copia i contenuti di questo file repo nel file tools.yaml.
... (Refer to entire file in the repo)
tools:
find-bus-schedules:
kind: postgres-sql
source: alloydb
description: Find all available bus schedules.
statement: |
SELECT CAST(trip_id AS TEXT) trip_id, departure_time, arrival_time, ticket_price, available_seats , origin_city, destination_city
FROM bus_schedules;
query-schedules:
kind: postgres-sql
source: alloydb
description: Find available bus schedules between an origin and destination city.
parameters:
- name: origin
type: string
description: The departure city name.
- name: destination
type: string
description: The arrival city name.
statement: |
SELECT CAST(trip_id AS TEXT) trip_id, departure_time, arrival_time, ticket_price, available_seats
FROM bus_schedules
WHERE lower(origin_city) = lower($1)
AND lower(destination_city) = lower($2)
AND available_seats > 0
ORDER BY departure_time ASC
LIMIT 5;
book-ticket:
kind: postgres-sql
source: alloydb
description: Books a ticket for a specific trip, decrementing available seats and generating a confirmed booking record.
parameters:
- name: trip_id
type: string
description: The UUID of the trip schedule to book.
- name: passenger_name
type: string
description: Name or ID of the passenger (Bound securely via backend or AuthToken).
authServices:
- name: google_auth
field: sub
statement: |
WITH updated_schedule AS (
UPDATE bus_schedules
SET available_seats = available_seats - 1
WHERE trip_id = CAST($1 AS UUID) AND available_seats > 0
RETURNING trip_id
)
INSERT INTO bookings (trip_id, passenger_id)
SELECT trip_id, $2
FROM updated_schedule
RETURNING CAST(booking_id as TEXT) as booking_id, trip_id, passenger_id, status, booking_time;
search-policies:
kind: postgres-sql
source: alloydb
description: Semantic search for transit policies regarding luggage, pets, refunds, and general rules.
parameters:
- name: search_query
type: string
description: The user's question about transit policies to be embedded and searched.
statement: |
SELECT category, policy_text
FROM transit_policies
ORDER BY policy_embedding <=> CAST(embedding('text-embedding-005', $1) AS vector(768))
LIMIT 2;
Nota:
- Nella configurazione di tools.yaml, non dimenticare di includere ipType: "private" nella configurazione dell'origine AlloyDB.
- Ricorda anche di includere l'URL del servizio MCP Toolbox nel parametro clientId per la configurazione di authServices. Potresti ricevere il link solo dopo l'implementazione iniziale, quindi dovrai eseguire i passaggi di implementazione due volte per assicurarti che lo scenario di utilizzo degli strumenti autenticati funzioni.
- Le opzioni riportate di seguito per testare la toolbox localmente non funzioneranno se la connessione AlloyDB è impostata come privata. Devi impostarla come pubblica per testarla localmente o utilizzare un proxy per la connessione. Ma non preoccuparti. Nel nostro caso, lo eseguiremo il deployment direttamente su Cloud Run e poi lo testeremo.
Per testare il file tools.yaml nel server locale:
./toolbox --tools-file "tools.yaml"
In alternativa, puoi testarlo nell'interfaccia utente:
./toolbox --ui
Eseguiamo il deployment in Cloud Run nel seguente modo.
Deployment di Cloud Run
- Imposta la variabile di ambiente PROJECT_ID:
export PROJECT_ID="my-project-id"
- Inizializza gcloud CLI:
gcloud init
gcloud config set project $PROJECT_ID
- Devi aver abilitato le seguenti API:
gcloud services enable run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
secretmanager.googleapis.com
- Crea un account di servizio backend se non ne hai già uno:
gcloud iam service-accounts create toolbox-identity
- Concedi le autorizzazioni per utilizzare Secret Manager:
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/secretmanager.secretAccessor
- Concedi al service account autorizzazioni aggiuntive specifiche per la nostra origine AlloyDB (ruoli roles/alloydb.client e roles/serviceusage.serviceUsageConsumer)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/alloydb.client
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/serviceusage.serviceUsageConsumer
- Carica tools.yaml come secret:
gcloud secrets create tools-cymbal-transit --data-file=tools.yaml
- Se hai già un secret e vuoi aggiornare la versione del secret, esegui il comando seguente:
gcloud secrets versions add tools-cymbal-transit --data-file=tools.yaml
- Imposta una variabile di ambiente sull'immagine container che vuoi utilizzare per Cloud Run:
export IMAGE=us-central1-docker.pkg.dev/database-toolbox/toolbox/toolbox:latest
- Esegui il deployment di Toolbox su Cloud Run utilizzando questo comando:
Se hai abilitato l'accesso pubblico nella tua istanza AlloyDB, segui il comando riportato di seguito per il deployment su Cloud Run:
gcloud run deploy toolbox-cymbal-transit \
--image $IMAGE \
--service-account toolbox-identity \
--region us-central1 \
--set-secrets "/app/tools.yaml=tools-cymbal-transit:latest" \
--args="--tools-file=/app/tools.yaml","--address=0.0.0.0","--port=8080" \
--allow-unauthenticated
Se utilizzi una rete VPC, utilizza il comando riportato di seguito:
gcloud run deploy toolbox-cymbal-transit \
--image $IMAGE \
--service-account toolbox-identity \
--region us-central1 \
--set-secrets "/app/tools.yaml=tools-cymbal-transit:latest" \
--args="--tools-file=/app/tools.yaml","--address=0.0.0.0","--port=8080" \
--network <<YOUR_NETWORK_NAME>> \
--subnet <<YOUR_SUBNET_NAME>> \
--allow-unauthenticated
Nota: una volta eseguito il deployment, vai all'elenco dei servizi Cloud Run e assicurati che nella scheda di sicurezza di quel servizio sia selezionata l'opzione "Consenti accesso pubblico".
6. Configurazione dell'applicazione agente
Clona questo repository nel tuo progetto e analizziamolo.
Per clonare questo progetto, esegui questo comando dal terminale Cloud Shell (nella directory principale o da dove vuoi creare il progetto):
git clone https://github.com/googleapis/mcp-toolbox-sdk-java
Il comando precedente clona l'intero mcp-toolbox-sdk-java. Ci serve solo il progetto di esempio. Vai alla directory root del progetto all'interno del repository:
cd mcp-toolbox-sdk-java/demo-applications/cymbal-transit
- In questo modo dovrebbe essere creato il progetto, che puoi verificare nell'editor di Cloud Shell.

- Apri CymbalTransitController.java e imposta le variabili di ambiente:
- GCP_PROJECT_ID
- GCP_REGION
- GEMINI_MODEL_NAME
- MCP_TOOLBOX_URL
In alternativa (solo a scopo di sviluppo), puoi anche sostituire i segnaposto dei rispettivi valori di riserva.
7. Procedura dettagliata del codice
CymbalTransitController funge da punto di ingresso per il nostro servizio Cloud Run. Gestisce il flusso della conversazione e garantisce che l'agente abbia accesso alla richiesta corrente dell'utente.
L'implementazione segue un'architettura a livelli che separa l'orchestrazione dell'AI, il bridging degli strumenti e la comunicazione MCP di basso livello.
1. Configurazione dell'agente AI (AgentConfiguration)
Questa classe utilizza @Configuration di Spring per eseguire il bootstrap dei componenti AI. Inizializza VertexAiGeminiChatModel e lo associa alla nostra interfaccia Agent.
@Bean
ChatLanguageModel geminiChatModel() {
return VertexAiGeminiChatModel.builder()
.project(projectId)
.location(region)
.modelName(modelName)
.build();
}
@Bean
TransitAgent transitAgent(ChatLanguageModel chatLanguageModel, TransitAgentTools tools) {
return AiServices.builder(TransitAgent.class)
.chatLanguageModel(chatLanguageModel)
.chatMemoryProvider(memoryId -> MessageWindowChatMemory.withMaxMessages(20))
.tools(tools)
.build();
}
Significato: AiServices associa l'interfaccia all'LLM. MessageWindowChatMemory garantisce che l'agente ricordi le preferenze dell'utente (come un trasportino per animali domestici menzionato in precedenza) per un massimo di 20 messaggi all'interno di una singola sessione.
2. Interfaccia dell'agente AI (TransitAgent)
L'annotazione @SystemMessage definisce il "Personaggio" e i vincoli operativi, in particolare una strategia di routing.
@SystemMessage({
"You are the Cymbal Transit Concierge.",
"CRITICAL INSTRUCTION: On your very first interaction, you MUST use the 'findAllSchedules' tool to fetch and memorize the broad bus routes.",
"ONLY if the user asks a specifically narrowed-down question... should you route to the specific tools like 'querySchedules', 'bookTicket', 'searchPolicies'.",
"Don't show any asterisks while listing results. Keep it formatted and numbered or bulleted."
})
String chat(@MemoryId String sessionId, @UserMessage String userMessage);
Significato:questa strategia riduce al minimo la latenza. Recuperando prima i dati generali, l'agente può rispondere a domande generali sul routing utilizzando il contesto interno senza effettuare chiamate di backend ridondanti.
3. Toolbox Bridge (TransitAgentTools)
Questo servizio funge da "mani" dell'agente, traducendo le chiamate agli strumenti LangChain4j in logica di esecuzione.
@Tool("Fetches the initial, broad dataset of all available bus schedules and routes.")
public String findAllSchedules() {
return mcpService.findAllSchedules().join();
}
@Tool("Book a ticket for a passenger using a specific trip ID.")
public String bookTicket(String tripId, String passengerName) {
return mcpService.bookTicket(tripId, passengerName).join();
}
Esecuzione sincrona:sebbene le chiamate MCP siano asincrone (restituiscono CompletableFuture), l'LLM richiede un risultato prima di poter continuare il suo processo di "pensiero". Utilizziamo .join() per fornire risultati sincroni all'agente.
4. Il servizio MCP Toolbox (McpToolboxService)
Questo è il livello di comunicazione che utilizza l'SDK Java di MCP Toolbox per interagire con il backend di AlloyDB.
// Identity Management: Fetching OIDC ID Token for Auth
GoogleCredentials credentials = GoogleCredentials.getApplicationDefault();
this.idToken = ((IdTokenProvider) credentials)
.idTokenWithAudience(targetUrl, Collections.emptyList())
.getTokenValue();
// Dynamic Invocation: Executing a tool by name
public CompletableFuture<String> findAllSchedules() {
return mcpClient.invokeTool("find-bus-schedules", Collections.emptyMap()).thenApply(result -> {
return result.content().stream()
.map(content -> content.text())
.collect(Collectors.joining(", ", "[", "]"));
});
}
Significato: McpToolboxClient gestisce il lavoro pesante della comunicazione JSON-RPC. Il metodo bookTicket mostra in modo specifico la capacità dell'SDK di associare dinamicamente parametri complessi.
5. Il controller REST (TransitAgentController)
L'endpoint finale è radicalmente semplificato perché LangChain4j gestisce lo stato e la logica.
@PostMapping("/chat")
public ResponseEntity<String> handleUserChat(@RequestBody String userMessage, HttpSession session) {
String sessionId = session.getId();
String agentResponse = transitAgent.chat(sessionId, userMessage);
return ResponseEntity.ok(agentResponse);
}
Significato:mappando l'ID HttpSession a @MemoryId, ci assicuriamo che i piani di viaggio di utenti diversi non vengano confusi, mantenendo al contempo il codice del controller pulito e leggibile.
8. MCP Toolbox: significatività e SDK Java
Che cos'è MCP?
Considera il Model Context Protocol (MCP) come un traduttore universale per l'AI. Creato per standardizzare il modo in cui i modelli AI si connettono a strumenti e set di dati esterni, MCP sostituisce gli script di integrazione personalizzati e frammentati con un protocollo universale sicuro. Che l'agente debba eseguire una query SQL transazionale, cercare tra migliaia di documenti di policy o attivare un'API REST, MCP fornisce un'interfaccia singola e unificata.
Strumenti MCP per i database
I team di ingegneria stanno andando oltre i semplici chatbot per creare sistemi agentici che interagiscono direttamente con i database mission-critical. Tuttavia, la creazione di questi agent aziendali spesso comporta l'incontro con un muro di integrazione di codice di collegamento personalizzato, API fragili e logica di database complessa.
Per sostituire questi colli di bottiglia hardcoded con un control plane sicuro e unificato, siamo felici di annunciare l'SDK Java per il toolbox Model Context Protocol (MCP) per i database. Questa release introduce l'orchestrazione di agenti di prima classe e type-safe nell'ecosistema aziendale più adottato al mondo. L'architettura matura di Java è progettata appositamente per queste esigenze rigorose, fornendo l'elevata concorrenza, la rigorosa integrità transazionale e la solida gestione dello stato necessarie per scalare in sicurezza gli agenti AI mission critical in produzione.
Perché l'SDK Java?
L'SDK Java di MCP Toolbox consente agli sviluppatori Java di:
- Consume Tools:connettiti a un server MCP (come MCP Toolbox per AlloyDB) e trasforma automaticamente le sue funzionalità in metodi Java comprensibili a LangChain4j.
- Type Safety:sfrutta la tipizzazione forte di Java per i parametri degli strumenti, riducendo gli errori di "allucinazione" di runtime nelle chiamate degli strumenti.
- Preparazione per l'utilizzo aziendale:integrazione semplice con Spring Boot, Quarkus, Micronaut e così via.
- Connessione senza problemi: evita di scrivere codice JSON-RPC boilerplate.
- Standardizza l'autenticazione:il supporto nativo per i token OIDC di Google Cloud garantisce l'esecuzione sicura degli strumenti.
e molto altro.
Dipendenze: configurazione di pom.xml
Aggiungi la seguente dipendenza al tuo progetto Maven per includere l'ultima versione dell'SDK Java di MCP Toolbox:
<dependency>
<groupId>com.google.cloud.mcp</groupId>
<artifactId>mcp-toolbox-sdk-java</artifactId>
<version>0.2.0</version>
</dependency>
Aggiungi la seguente dipendenza al tuo progetto Maven per includere l'artefatto LangChain4j:
<!-- LangChain4j Core & Gemini -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j</artifactId>
<version>0.35.0</version>
</dependency>
È tutto!!! Abbiamo clonato correttamente il progetto e illustrato i dettagli dell'agente, dell'SDK Java di MCP Toolbox e del contesto.
9. Esecuzione in locale
Per testare l'agente sulla tua macchina, devi indirizzarlo al server MCP Toolbox di cui hai eseguito il deployment.
- Imposta le variabili di ambiente:
export GCP_PROJECT_ID="<<YOUR_PROJECT_ID>>"
export GCP_REGION="us-central1"
export GEMINI_MODEL_NAME="gemini-2.5-flash"
export MCP_TOOLBOX_URL="<<YOUR_TOOLBOX_ENDPOINT_URL>>/mcp"
- Esegui con Maven:
mvn compile
mvn spring-boot:run
In questo modo l'agente dovrebbe avviarsi localmente e dovresti essere in grado di testarlo.
10. Eseguiamo il deployment in Cloud Run
Esegui il deployment su Cloud Run eseguendo questo comando dal terminale Cloud Shell in cui il progetto è clonato e assicurati di trovarti nella cartella principale del progetto.
SE NON TI TROVI NELLA CARTELLA RADICE DEL NOSTRO PROGETTO ATTUALE, esegui questo comando nel terminale Cloud Shell:
cd cymbal-transit
Se ti trovi già nella radice di cymbal-transit, esegui il comando riportato di seguito per eseguire il deployment diretto dell'app su Cloud Run:
gcloud run deploy cymbal-transit --source . --set-env-vars GCP_PROJECT_ID=<<YOUR_PROJECT_ID>>,GCP_REGION=us-central1,GEMINI_MODEL_NAME=gemini-2.5-flash,MCP_TOOLBOX_URL=<<YOUR_MCP_TOOLBOX_URL>> --allow-unauthenticated
Sostituisci i valori dei segnaposto <<YOUR_PROJECT>> and <<YOUR_MCP_TOOLBOX_URL>>
Al termine del comando, verrà visualizzato un URL del servizio. Copialo.
Concedi il ruolo Client AlloyDB al service account Cloud Run.In questo modo, la tua applicazione serverless può creare un tunnel sicuro nel database.
Esegui questo comando nel terminale Cloud Shell:
# 1. Get your Project ID and Project Number
PROJECT_ID=$(gcloud config get-value project)
PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
# 2. Grant the AlloyDB Client role
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$PROJECT_NUMBER-compute@developer.gserviceaccount.com" \
--role="roles/alloydb.client"
Nota: una volta eseguito il deployment, vai all'elenco dei servizi Cloud Run e assicurati che nella scheda di sicurezza di quel servizio sia selezionata l'opzione "Consenti accesso pubblico".
Ora utilizza l'URL del servizio (l'endpoint Cloud Run che hai copiato in precedenza) e testa l'app.
Nota:se riscontri un problema con il servizio e viene indicata la memoria come motivo, prova ad aumentare il limite di memoria allocata a 1 GiB per eseguire il test.
11. Demo
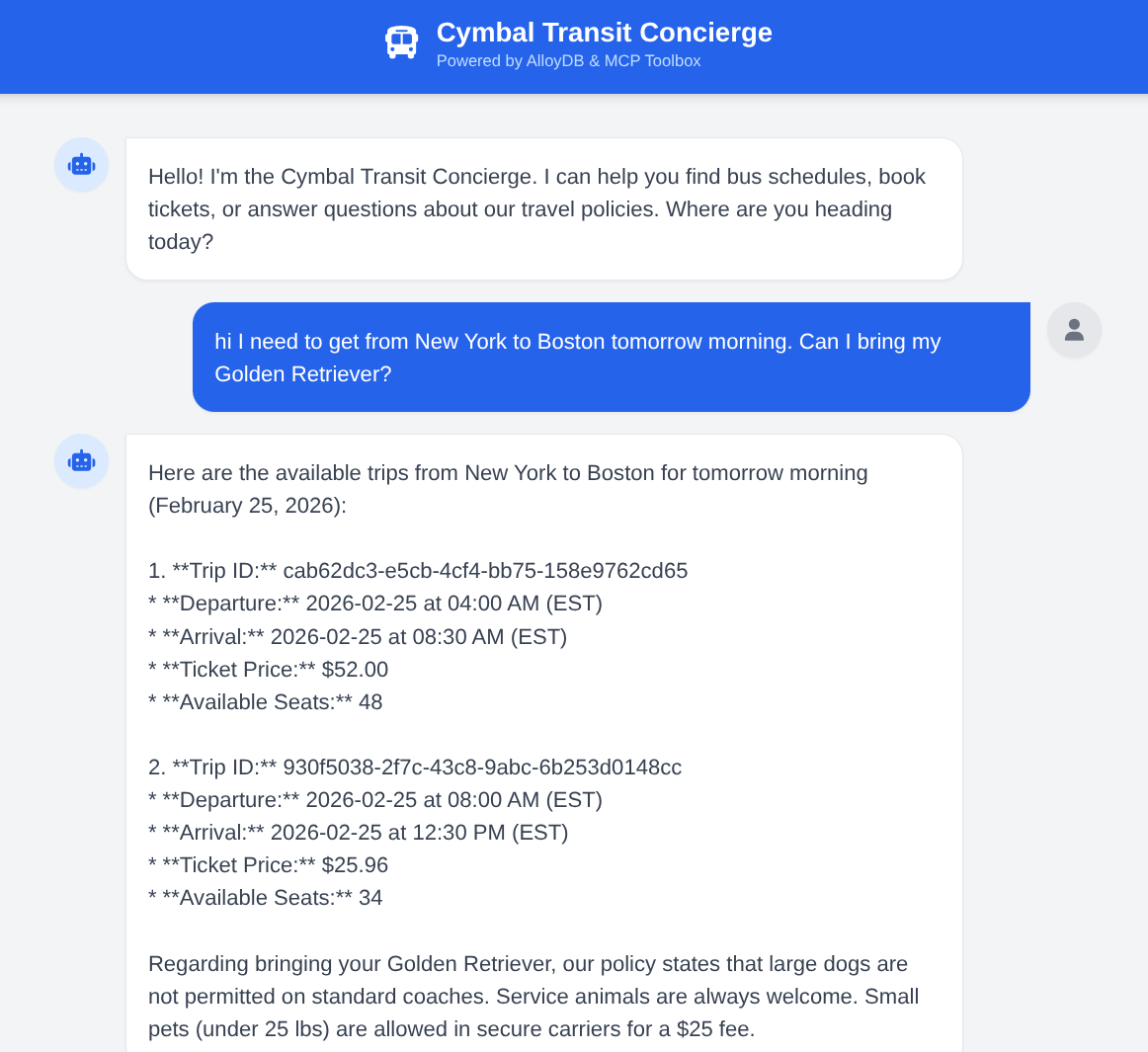
Chiedi all'agente: "Domani mattina devo andare da New York a Boston. Posso portare il mio Golden Retriever?" Osserva come l'agente:
- Cerca le norme per i cani di taglia grande.
- Trova orari specifici.
- Riepiloga il viaggio più veloce con un ID viaggio.
- Prenota anche un biglietto se dai seguito alla richiesta di azione.
12. Esegui la pulizia
Una volta completato questo lab, non dimenticare di eliminare il cluster e l'istanza AlloyDB.
Dovrebbe pulire il cluster insieme alle relative istanze.
13. Complimenti
Hai creato un agente di transito sofisticato basato su Java. Sfruttando LangChain4j per l'orchestrazione e l'SDK Java di MCP Toolbox per la connettività dei dati, hai creato un sistema in grado di ragionare su agenti, strumenti e origini dati. Se vuoi iniziare a orchestrare le tue applicazioni agentic con MCP Toolbox for Databases in più database, anche su più piattaforme, inizia subito a utilizzare l'SDK Java. Qui puoi trovare il blog dell'annuncio di lancio che fornisce informazioni più dettagliate sulla libreria. Se vuoi creare altre applicazioni di questo tipo in modo pratico, senza costi, al tuo ritmo e con la guida di un istruttore, registrati a Code Vipassana all'indirizzo https://codevipassana.dev.