
1. 简介与设置
Web 功能
我们希望缩小 Web 应用与原生应用之间的功能差距,让开发者能够轻松在开放 Web 平台上打造绝佳体验。我们坚信,每位开发者都应有权使用所需的功能来打造出色的 Web 体验,并且我们致力于打造功能更强大的 Web。
不过,有些功能(例如文件系统访问和空闲检测)可供原生应用使用,但无法在 Web 上使用。缺少这些功能意味着某些类型的应用无法在 Web 上交付,或者实用性较低。
我们将以公开透明的方式设计和开发这些新功能,在迭代设计时使用现有的开放式 Web 平台标准流程,同时从开发者和其他浏览器供应商处获取早期反馈,以确保设计具有互操作性。
构建内容
在此 Codelab 中,您将体验一些全新或仅在标志后提供的 Web API。因此,本 Codelab 侧重于 API 本身以及这些 API 带来的用例,而不是构建特定的最终产品。
学习内容
在此 Codelab 中,您将学习一些前沿 API 的基本机制。请注意,这些机制尚未完全确定,我们非常欢迎您就开发者流程提供反馈。
所需条件
由于此 Codelab 中介绍的 API 非常新颖,因此每个 API 的要求各不相同。请务必仔细阅读每个部分开头的兼容性信息。
如何完成 Codelab
此 Codelab 不一定需要按顺序完成。每个部分代表一个独立的 API,您可以随意择优挑选 (cherry-pick) 自己最感兴趣的部分。
2. Badging API
徽章 API 的目的是让用户注意到在后台发生的事情。为简化此 Codelab 中的演示,我们使用该 API 来吸引用户注意前台发生的事情。然后,您就可以将这种思维转移到后台发生的事情上。
安装 Airhorner
要使此 API 正常运行,您需要将 PWA 安装到主屏幕,因此第一步是安装 PWA,例如臭名昭著、闻名世界的 airhorner.com。点击右上角的安装按钮,或使用三点状菜单手动安装。
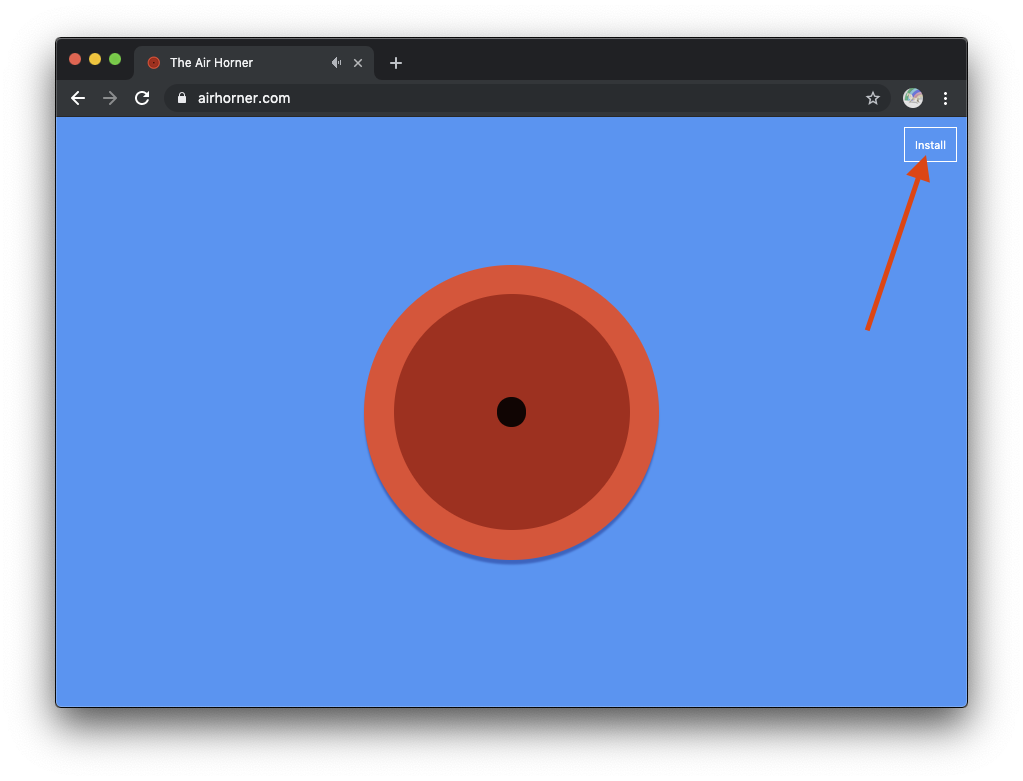
系统随即会显示确认提示,点击安装。

现在,您的操作系统 Dock 中会显示一个新图标。点击该图标即可启动 PWA。它将拥有自己的应用窗口,并以独立模式运行。
|
|

设置徽章
现在您已安装 PWA,接下来需要一些数字数据(徽章只能包含数字)来显示在徽章上。在《The Air Horner》中,最容易统计的是叹息,也就是按喇叭的次数。实际上,在安装 Airhorner 应用后,尝试鸣喇叭并检查徽章。每次按喇叭时,该计数器都会加 1。

那么,此功能是如何运作的?从本质上讲,代码如下:
let hornCounter = 0;
const horn = document.querySelector('.horn');
horn.addEventListener('click', () => {
navigator.setExperimentalAppBadge(++hornCounter);
});
按几次气喇叭,然后检查 PWA 的图标:每次按气喇叭时,该图标都会更新。就是这么简单。

清除徽章
计数器会递增到 99,然后重新开始。您也可以手动重置。打开开发者工具控制台标签页,粘贴以下代码行,然后按 Enter 键。
navigator.setExperimentalAppBadge(0);
或者,您也可以通过显式清除徽章来移除它,如以下代码段所示。现在,PWA 的图标应再次呈现清晰且没有标记的初始状态。
navigator.clearExperimentalAppBadge();

反馈
您觉得此 API 怎么样?请简要回答这份调查问卷,帮助我们改进服务:
此 API 是否直观易用?
您是否已成功运行示例?
还有其他意见吗?是否存在缺少的功能?请在这份调查问卷中提供快速反馈。谢谢!
3. Native File System API
借助 Native File System API,开发者可以构建功能强大的 Web 应用,让这些应用与用户本地设备上的文件进行交互。用户向 Web 应用授予访问权限后,此 API 让 Web 应用可以直接读取用户设备上的文件和文件夹内容,或者保存对这些内容的更改。
读取文件
Native File System API 的“Hello, world”示例是读取本地文件并获取文件内容。创建一个纯 .txt 文件,并输入一些文本。接下来,前往任意安全网站(即通过 HTTPS 提供的网站),例如 example.com,然后打开开发者工具控制台。将以下代码段粘贴到控制台中。由于 Native File System API 需要用户手势,因此我们在文档上附加了一个双击处理程序。我们稍后需要使用文件句柄,因此只需将其设为全局变量即可。
document.ondblclick = async () => {
window.handle = await window.chooseFileSystemEntries();
const file = await handle.getFile();
document.body.textContent = await file.text();
};
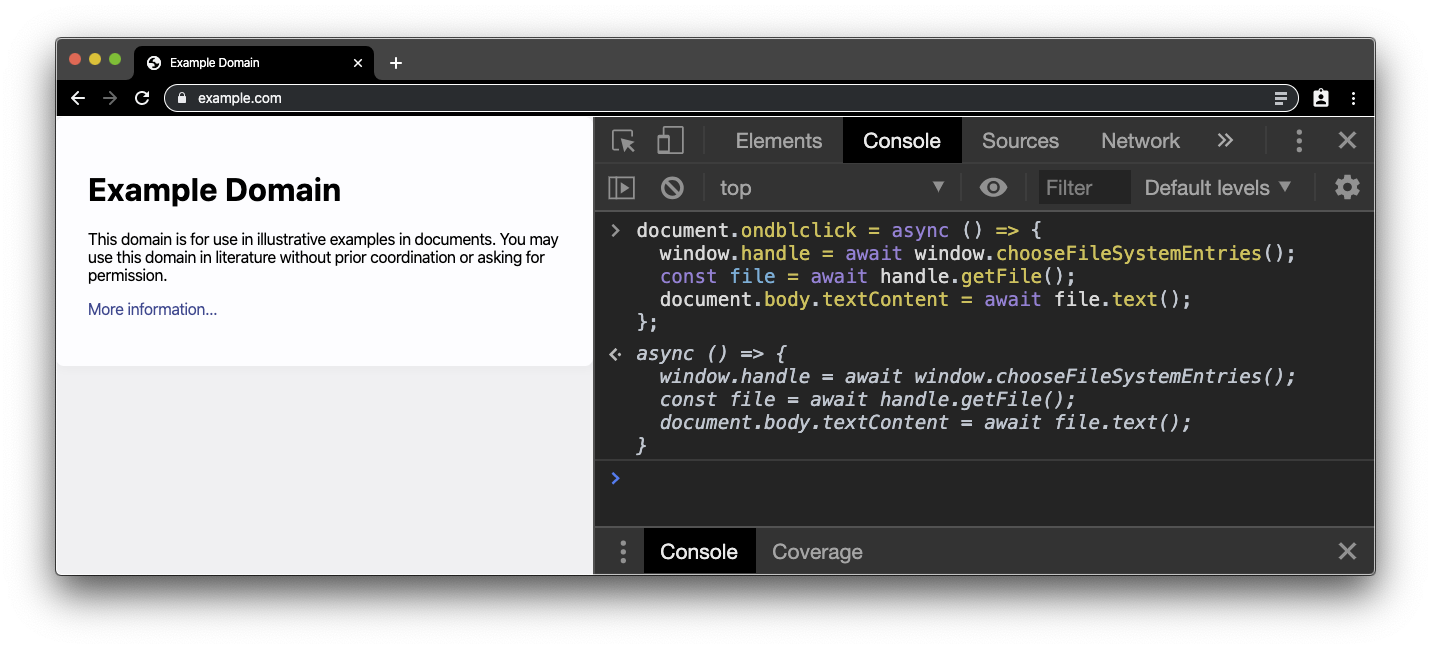
然后,当您双击 example.com 页面中的任意位置时,系统会显示文件选择器。

选择您之前创建的 .txt 文件。然后,文件内容将替换 example.com 的实际 body 内容。

保存文件
接下来,我们想做一些更改。因此,我们通过粘贴以下代码段来使 body 可编辑。现在,您可以像在文本编辑器中一样编辑文字。
document.body.contentEditable = true;

现在,我们要将这些更改写回原始文件。因此,我们需要文件句柄上的写入器,可以通过在控制台中粘贴以下代码段来获取该写入器。同样,我们需要用户手势,因此这次我们等待主文档上的点击。
document.onclick = async () => {
const writer = await handle.createWriter();
await writer.truncate(0);
await writer.write(0, document.body.textContent);
await writer.close();
};

现在,当您点击(而非双击)该文档时,系统会显示权限提示。授予权限后,文件的内容将是您之前在 body 中编辑的内容。在其他编辑器中打开该文件,验证更改是否已生效(或者再次双击该文档,重新打开文件,以重新开始该流程)。


恭喜!您刚刚创建了世界上最小的文本编辑器 [citation needed]。
反馈
您觉得此 API 怎么样?请简要回答这份调查问卷,帮助我们改进服务:
此 API 是否直观易用?
您是否已成功运行示例?
还有其他意见吗?是否存在缺少的功能?请在这份调查问卷中提供快速反馈。谢谢!
4. Shape Detection API
Shape Detection API 可用于访问加速的形状检测器(例如,用于检测人脸),并且适用于静态图片和/或实时图像源。操作系统具有高性能且高度优化的特征检测器,例如 Android FaceDetector。Shape Detection API 会开放这些原生实现,并通过一组 JavaScript 接口公开它们。
目前,支持的功能包括通过 FaceDetector 接口进行人脸检测、通过 BarcodeDetector 接口进行条形码检测,以及通过 TextDetector 接口进行文本检测(光学字符识别)。
人脸检测
Shape Detection API 的一项令人着迷的功能是人脸检测。为了测试它,我们需要一个包含人脸的网页。此页面显示了作者的脸,这是一个不错的开端。它将类似于以下屏幕截图所示。在受支持的浏览器中,系统会识别出人脸的边界框和人脸地标。
您可以复刻或修改 Glitch 项目(尤其是 script.js 文件),了解实现此效果所需的代码量。

如果您想实现完全动态的效果,而不仅仅是使用作者的脸部,请在私密标签页或以访客模式打开此 Google 搜索结果页面,其中包含大量人脸。现在,在该页面上,右键点击任意位置,然后点击检查,打开 Chrome 开发者工具。接下来,在“控制台”标签页中,粘贴以下代码段。该代码将使用半透明的红色框突出显示检测到的人脸。
document.querySelectorAll('img[alt]:not([alt=""])').forEach(async (img) => {
try {
const faces = await new FaceDetector().detect(img);
faces.forEach(face => {
const div = document.createElement('div');
const box = face.boundingBox;
const computedStyle = getComputedStyle(img);
const [top, right, bottom, left] = [
computedStyle.marginTop,
computedStyle.marginRight,
computedStyle.marginBottom,
computedStyle.marginLeft
].map(m => parseInt(m, 10));
const scaleX = img.width / img.naturalWidth;
const scaleY = img.height / img.naturalHeight;
div.style.backgroundColor = 'rgba(255, 0, 0, 0.5)';
div.style.position = 'absolute';
div.style.top = `${scaleY * box.top + top}px`;
div.style.left = `${scaleX * box.left + left}px`;
div.style.width = `${scaleX * box.width}px`;
div.style.height = `${scaleY * box.height}px`;
img.before(div);
});
} catch(e) {
console.error(e);
}
});
您会注意到,系统会显示一些 DOMException 消息,并且并非所有图片都会被处理。这是因为首屏内容中的图片以内嵌数据 URI 的形式存在,因此可以访问,而首屏下方内容中的图片来自未配置为支持 CORS 的其他网域。为了演示,我们无需担心这一点。
人脸特征点检测
除了人脸本身,macOS 还支持检测人脸特征点。如需测试人脸地标检测,请将以下代码段粘贴到控制台中。提醒:由于存在 crbug.com/914348,地标的排列并不完美,但您可以了解此功能的未来发展方向以及它可能带来的强大功能。
document.querySelectorAll('img[alt]:not([alt=""])').forEach(async (img) => {
try {
const faces = await new FaceDetector().detect(img);
faces.forEach(face => {
const div = document.createElement('div');
const box = face.boundingBox;
const computedStyle = getComputedStyle(img);
const [top, right, bottom, left] = [
computedStyle.marginTop,
computedStyle.marginRight,
computedStyle.marginBottom,
computedStyle.marginLeft
].map(m => parseInt(m, 10));
const scaleX = img.width / img.naturalWidth;
const scaleY = img.height / img.naturalHeight;
div.style.backgroundColor = 'rgba(255, 0, 0, 0.5)';
div.style.position = 'absolute';
div.style.top = `${scaleY * box.top + top}px`;
div.style.left = `${scaleX * box.left + left}px`;
div.style.width = `${scaleX * box.width}px`;
div.style.height = `${scaleY * box.height}px`;
img.before(div);
const landmarkSVG = document.createElementNS('http://www.w3.org/2000/svg', 'svg');
landmarkSVG.style.position = 'absolute';
landmarkSVG.classList.add('landmarks');
landmarkSVG.setAttribute('viewBox', `0 0 ${img.width} ${img.height}`);
landmarkSVG.style.width = `${img.width}px`;
landmarkSVG.style.height = `${img.height}px`;
face.landmarks.map((landmark) => {
landmarkSVG.innerHTML += `<polygon class="landmark-${landmark.type}" points="${
landmark.locations.map((point) => {
return `${scaleX * point.x},${scaleY * point.y} `;
}).join(' ')
}" /></svg>`;
});
div.before(landmarkSVG);
});
} catch(e) {
console.error(e);
}
});
条形码检测
Shape Detection API 的第二个功能是条形码检测。与之前类似,我们需要一个包含条形码的网页,例如此网页。在浏览器中打开该文件后,您会看到各种已解码的二维码。复刻或修改 Glitch 项目,尤其是 script.js 文件,了解具体做法。

如果您想要更动态的图片,可以再次使用 Google 图片搜索。这次,在浏览器中,以无痕式标签页或访客模式前往此 Google 搜索结果页面。现在,将以下代码段粘贴到 Chrome 开发者工具的“控制台”标签页中。稍等片刻,系统会使用原始值和条形码类型对识别出的条形码进行注释。
document.querySelectorAll('img[alt]:not([alt=""])').forEach(async (img) => {
try {
const barcodes = await new BarcodeDetector().detect(img);
barcodes.forEach(barcode => {
const div = document.createElement('div');
const box = barcode.boundingBox;
const computedStyle = getComputedStyle(img);
const [top, right, bottom, left] = [
computedStyle.marginTop,
computedStyle.marginRight,
computedStyle.marginBottom,
computedStyle.marginLeft
].map(m => parseInt(m, 10));
const scaleX = img.width / img.naturalWidth;
const scaleY = img.height / img.naturalHeight;
div.style.backgroundColor = 'rgba(255, 255, 255, 0.75)';
div.style.position = 'absolute';
div.style.top = `${scaleY * box.top + top}px`;
div.style.left = `${scaleX * box.left - left}px`;
div.style.width = `${scaleX * box.width}px`;
div.style.height = `${scaleY * box.height}px`;
div.style.color = 'black';
div.style.fontSize = '14px';
div.textContent = `${barcode.rawValue}`;
img.before(div);
});
} catch(e) {
console.error(e);
}
});
文本检测
Shape Detection API 的最后一个功能是文本检测。现在,您应该已经知道操作流程了:我们需要一个包含文字的图片页面,例如这个页面,其中包含 Google 图书扫描结果。在支持的浏览器中,您会看到识别出的文字以及在文字段落周围绘制的边界框。复刻或修改 Glitch 项目,尤其是 script.js 文件,了解具体做法。

如需动态测试此功能,请在私密标签页或以访客模式前往此搜索结果页。现在,将以下代码段粘贴到 Chrome 开发者工具的“控制台”标签页中。稍等片刻,系统就会识别出部分文字。
document.querySelectorAll('img[alt]:not([alt=""])').forEach(async (img) => {
try {
const texts = await new TextDetector().detect(img);
texts.forEach(text => {
const div = document.createElement('div');
const box = text.boundingBox;
const computedStyle = getComputedStyle(img);
const [top, right, bottom, left] = [
computedStyle.marginTop,
computedStyle.marginRight,
computedStyle.marginBottom,
computedStyle.marginLeft
].map(m => parseInt(m, 10));
const scaleX = img.width / img.naturalWidth;
const scaleY = img.height / img.naturalHeight;
div.style.backgroundColor = 'rgba(255, 255, 255, 0.75)';
div.style.position = 'absolute';
div.style.top = `${scaleY * box.top + top}px`;
div.style.left = `${scaleX * box.left - left}px`;
div.style.width = `${scaleX * box.width}px`;
div.style.height = `${scaleY * box.height}px`;
div.style.color = 'black';
div.style.fontSize = '14px';
div.innerHTML = text.rawValue;
img.before(div);
});
} catch(e) {
console.error(e);
}
});
反馈
您觉得此 API 怎么样?请简要回答这份调查问卷,帮助我们改进服务:
此 API 是否直观易用?
您是否已成功运行示例?
还有其他意见吗?是否存在缺少的功能?请在这份调查问卷中提供快速反馈。谢谢!
5. Web Share Target API
借助 Web Share Target API,已安装的 Web 应用可以向底层操作系统注册为共享目标,以接收来自 Web Share API 或系统事件(例如操作系统级共享按钮)的共享内容。
安装 PWA 以分享到
首先,您需要一个可以分享到的 PWA。这次,Airhorner(幸运的是)不会完成这项工作,但 Web Share Target 演示版应用会为您提供支持。将应用安装到设备的主屏幕。

向 PWA 分享内容
接下来,您需要分享内容,例如 Google 相册中的照片。使用“分享”按钮,然后选择剪贴簿 PWA 作为分享目标。

点按应用图标后,您将直接进入 Scrapbook PWA,并且照片就在那里。

那么,此功能是如何运作的?如需了解详情,请探索 Scrapbook PWA 的Web 应用清单。用于使 Web Share Target API 正常运行的配置位于清单的 "share_target" 属性中,该属性在其 "action" 字段中指向一个网址,该网址会使用 "params" 中列出的参数进行修饰。
然后,分享方会相应地填充此网址模板(通过分享操作或由开发者使用 Web Share API 以编程方式控制),以便接收方随后可以提取参数并对其执行某些操作,例如显示这些参数。
{
"action": "/_share-target",
"enctype": "multipart/form-data",
"method": "POST",
"params": {
"files": [{
"name": "media",
"accept": ["audio/*", "image/*", "video/*"]
}]
}
}
反馈
您觉得此 API 怎么样?请简要回答这份调查问卷,帮助我们改进服务:
此 API 是否直观易用?
您是否已成功运行示例?
还有其他意见吗?是否存在缺少的功能?请在这份调查问卷中提供快速反馈。谢谢!
6. Wake Lock API
为避免消耗电池电量,大多数设备在处于空闲状态时会快速进入休眠模式。虽然大多数情况下这样做都没什么问题,但有些应用需要使屏幕或设备保持唤醒状态,才能完成工作。Wake Lock API 提供了一种防止设备屏幕变暗和锁定或防止设备进入休眠状态的方法。借助此功能,您可以打造迄今为止需要原生应用才能实现的新体验。
设置屏保
如需测试 Wake Lock API,您必须先确保设备会进入休眠状态。因此,请在操作系统的偏好设置窗格中激活所选的屏保,并确保该屏保在 1 分钟后启动。让设备闲置相应的时间,确保该功能正常运行(我知道,这很痛苦)。以下屏幕截图显示的是 macOS,但您当然可以在 Android 设备或任何受支持的桌面平台上尝试此操作。

设置屏幕唤醒锁定
现在,您已了解屏保可以正常运行,接下来将使用 "screen" 类型的唤醒锁定来阻止屏保执行其任务。前往 唤醒锁定演示版应用,然后点击激活
screen 唤醒锁定复选框。

从那一刻起,唤醒锁定处于有效状态。如果您有耐心让设备保持不动一分钟,您会发现屏保确实没有启动。
那么,这种方式是如何运作的呢?如需了解详情,请前往 Wake Lock 演示版应用 的 Glitch 项目,然后查看 script.js。以下代码段中显示了代码的要点。打开一个新标签页(或使用您恰好打开的任何标签页),然后将以下代码粘贴到 Chrome 开发者工具控制台中。点击窗口后,您应该会看到一个有效时间正好为 10 秒的唤醒锁定(请参阅控制台日志),并且屏幕保护程序不应启动。
if ('wakeLock' in navigator && 'request' in navigator.wakeLock) {
let wakeLock = null;
const requestWakeLock = async () => {
try {
wakeLock = await navigator.wakeLock.request('screen');
wakeLock.addEventListener('release', () => {
console.log('Wake Lock was released');
});
console.log('Wake Lock is active');
} catch (e) {
console.error(`${e.name}, ${e.message}`);
}
};
requestWakeLock();
window.setTimeout(() => {
wakeLock.release();
}, 10 * 1000);
}

反馈
您觉得此 API 怎么样?请简要回答这份调查问卷,帮助我们改进服务:
此 API 是否直观易用?
您是否已成功运行示例?
还有其他意见吗?是否存在缺少的功能?请在这份调查问卷中提供快速反馈。谢谢!
7. Contact Picker API
我们非常期待的一项 API 是联系人选择工具 API。它允许 Web 应用从设备的原生联系人管理器访问联系人,因此您的 Web 应用可以访问联系人的姓名、电子邮件地址和电话号码。您可以指定是只需要一个联系人还是多个联系人,以及是需要所有字段还是只需要名称、电子邮件地址和电话号码的一部分。
隐私注意事项
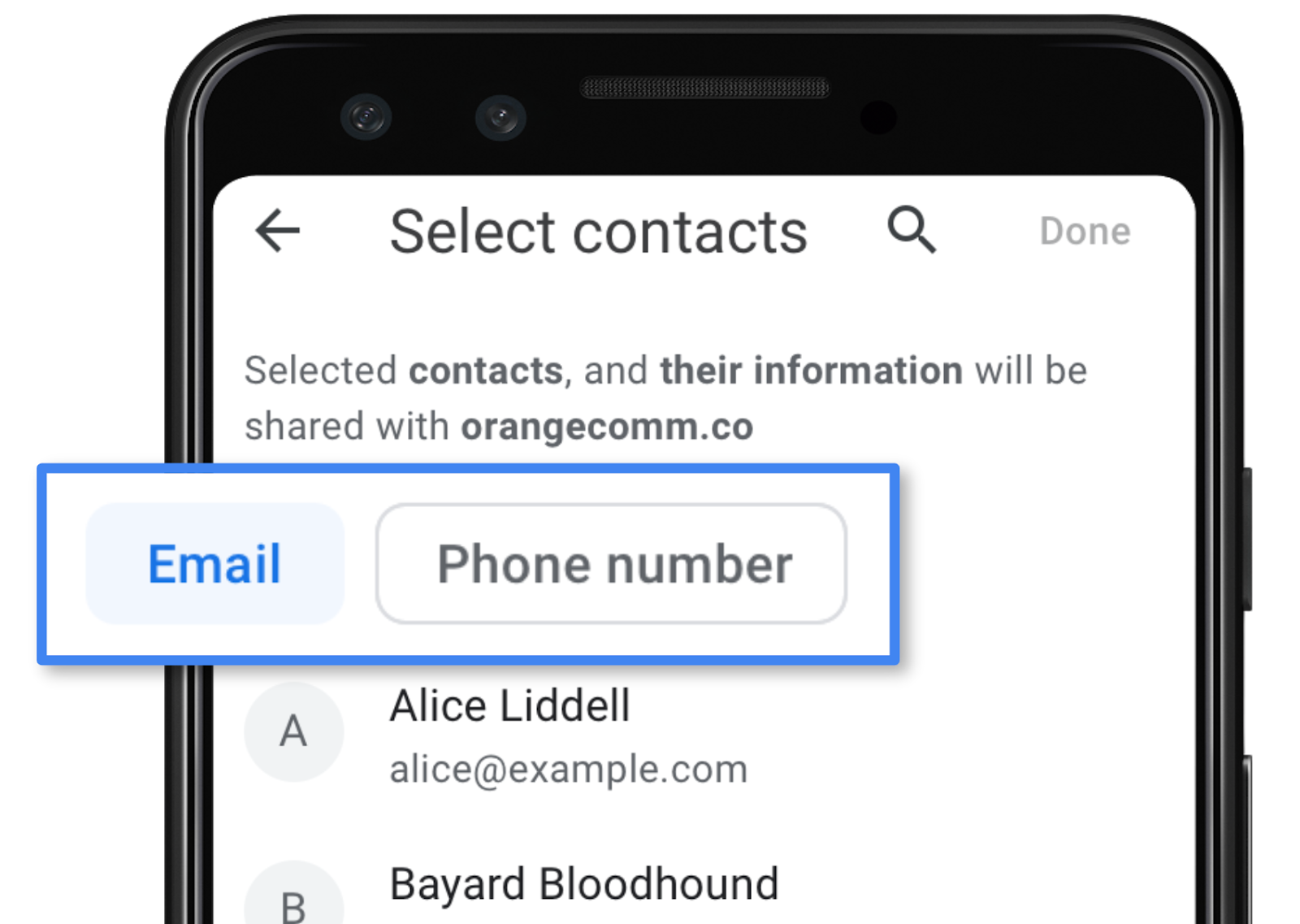
选择器打开后,您可以选择要分享的联系人。您会注意到,没有“全选”选项,这是有意为之:我们希望分享是一项有意识的决定。同样,访问权限不是持续的,而是一次性决定。
访问联系人
访问联系人信息是一项简单的任务。在选择器打开之前,您可以指定所需的字段(选项为 name、email 和 telephone),以及是想访问多个联系人还是仅访问一个联系人。您可以在 Android 设备上通过打开演示应用来测试此 API。源代码的相关部分基本上就是下面的代码段:
getContactsButton.addEventListener('click', async () => {
const contacts = await navigator.contacts.select(
['name', 'email'],
{multiple: true});
if (!contacts.length) {
// No contacts were selected, or picker couldn't be opened.
return;
}
console.log(contacts);
});
8. Async Clipboard API
复制和粘贴文字
在此之前,无法以编程方式将图片复制并粘贴到系统剪贴板。最近,我们为 Async Clipboard API 添加了图片支持,
这样,您现在就可以复制和粘贴图片了。新功能是,您还可以将图片写入剪贴板。异步剪贴板 API 已经支持文本复制和粘贴有一段时间了。您可以通过调用 navigator.clipboard.writeText() 将文本复制到剪贴板,然后通过调用 navigator.clipboard.readText() 粘贴该文本。
复制和粘贴图片
现在,您还可以将图片写入剪贴板。为此,您需要将图片数据作为 BLOB 传递给剪贴板项构造函数。最后,您可以通过调用 navigator.clipboard.write() 来复制此剪贴板项。
// Copy: Writing image to the clipboard
try {
const imgURL = 'https://developers.google.com/web/updates/images/generic/file.png';
const data = await fetch(imgURL);
const blob = await data.blob();
await navigator.clipboard.write([
new ClipboardItem(Object.defineProperty({}, blob.type, {
value: blob,
enumerable: true
}))
]);
console.log('Image copied.');
} catch(e) {
console.error(e, e.message);
}
从剪贴板粘贴回图片看起来很复杂,但实际上只是从剪贴板项中获取 Blob。由于可能存在多个,您需要循环遍历它们,直到找到您感兴趣的那个。出于安全考虑,目前仅支持 PNG 图片,但未来可能会支持更多图片格式。
async function getClipboardContents() {
try {
const clipboardItems = await navigator.clipboard.read();
for (const clipboardItem of clipboardItems) {
try {
for (const type of clipboardItem.types) {
const blob = await clipboardItem.getType(type);
console.log(URL.createObjectURL(blob));
}
} catch (e) {
console.error(e, e.message);
}
}
} catch (e) {
console.error(e, e.message);
}
}
您可以在演示版应用中看到此 API 的实际应用,其源代码的相关代码段已嵌入到上方。无需获得许可即可将图片复制到剪贴板,但您需要授予访问权限才能粘贴剪贴板中的内容。

授予访问权限后,您就可以从剪贴板读取图片并将其粘贴到应用中:

9. 大功告成!
恭喜,您已完成了本 Codelab 的学习。再次提醒您,大多数 API 仍在不断变化,我们也在积极改进。因此,该团队非常感谢您的反馈,因为只有与像您这样的人互动,才能帮助我们完善这些 API。
我们还建议您经常访问我们的功能着陆页。我们会及时更新此列表,其中包含指向我们所处理的 API 的所有深度文章的指针。继续摇滚吧!
Tom 和整个 Capabilities 团队 🐡