1. Tổng quan
Trong bài tập thực hành này, bạn sẽ tìm hiểu cách sử dụng Vertex AI – nền tảng học máy được quản lý mới ra mắt của Google Cloud – để xây dựng quy trình học máy toàn diện. Bạn sẽ tìm hiểu cách chuyển từ dữ liệu thô sang mô hình đã triển khai và sẵn sàng phát triển cũng như đưa các dự án học máy của riêng bạn vào vận hành thực tế bằng Vertex AI. Trong bài tập thực hành này, chúng ta sẽ sử dụng Cloud Shell để xây dựng một hình ảnh Docker tuỳ chỉnh nhằm minh hoạ các vùng chứa tuỳ chỉnh để huấn luyện bằng Vertex AI.
Mặc dù chúng ta đang sử dụng TensorFlow cho mã mô hình ở đây, nhưng bạn có thể dễ dàng thay thế bằng một khung khác.
Kiến thức bạn sẽ học được
Bạn sẽ tìm hiểu cách:
- Xây dựng và chứa mã huấn luyện mô hình bằng Cloud Shell
- Gửi một công việc huấn luyện mô hình tuỳ chỉnh đến Vertex AI
- Triển khai mô hình đã huấn luyện đến một điểm cuối và sử dụng điểm cuối đó để nhận dự đoán
Tổng chi phí để chạy bài tập thực hành này trên Google Cloud là khoảng 2 USD.
2. Giới thiệu về Vertex AI
Bài tập thực hành này sử dụng sản phẩm AI mới nhất hiện có trên Google Cloud. Vertex AI tích hợp các sản phẩm ML trên Google Cloud để mang lại trải nghiệm phát triển liền mạch. Trước đây, các mô hình được huấn luyện bằng AutoML và các mô hình tuỳ chỉnh có thể truy cập thông qua các dịch vụ riêng biệt. Sản phẩm mới này kết hợp cả hai thành một API duy nhất, cùng với các sản phẩm mới khác. Bạn cũng có thể di chuyển các dự án hiện có sang Vertex AI. Nếu bạn có ý kiến phản hồi, vui lòng xem trang hỗ trợ.
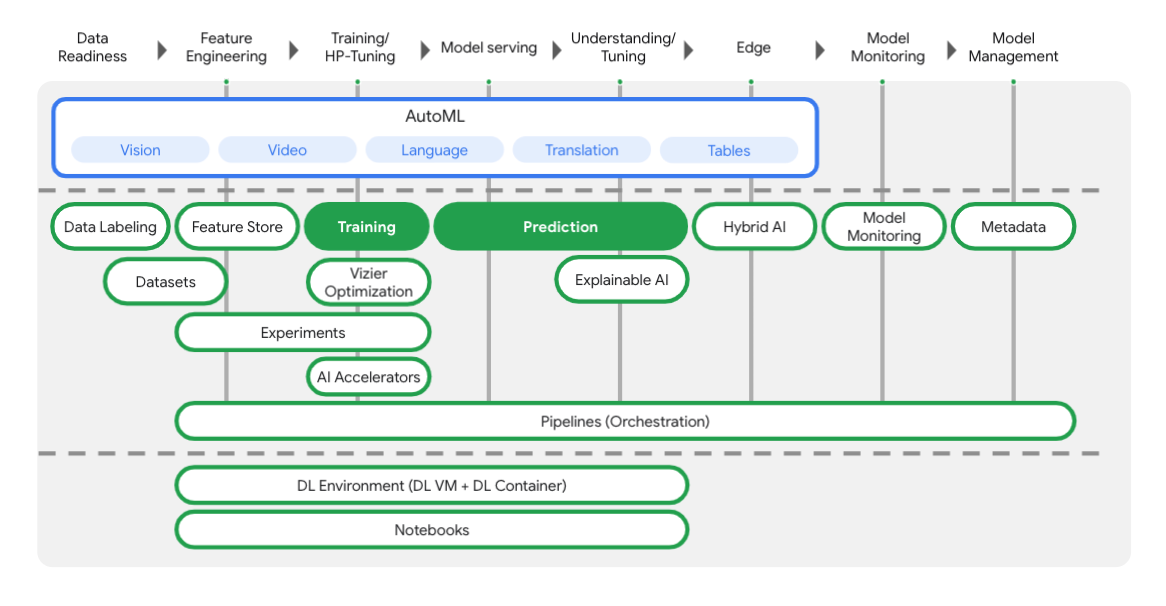
Vertex bao gồm nhiều công cụ khác nhau để giúp bạn ở mỗi giai đoạn của quy trình học máy, như bạn có thể thấy trong biểu đồ bên dưới. Chúng ta sẽ tập trung vào việc sử dụng Vertex Training (Huấn luyện) và Prediction (Dự đoán), được làm nổi bật bên dưới.
3. Thiết lập môi trường
Thiết lập môi trường tự định hướng
Đăng nhập vào Cloud Console rồi tạo một dự án mới hoặc sử dụng lại một dự án hiện có. (Nếu chưa có tài khoản Gmail hoặc Google Workspace, bạn phải tạo một tài khoản.)

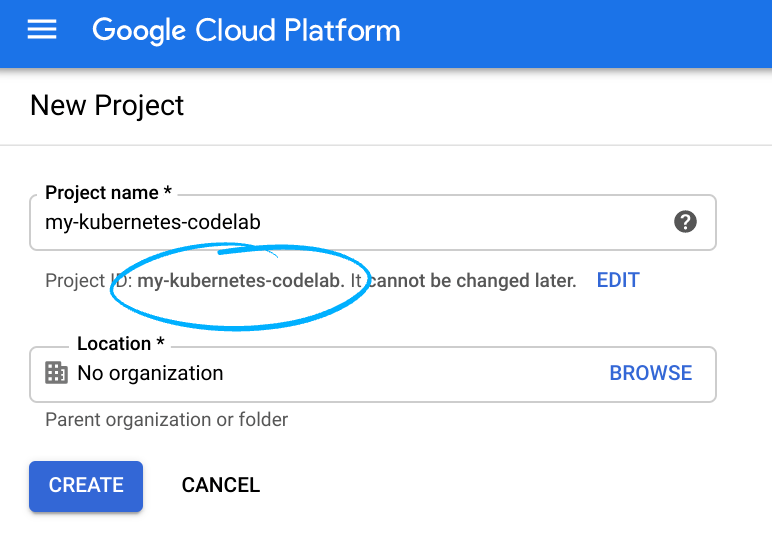
Hãy nhớ mã dự án, một tên duy nhất trên tất cả các dự án Google Cloud (tên ở trên đã được sử dụng và sẽ không hoạt động đối với bạn, xin lỗi!).
Tiếp theo, bạn cần bật tính năng thanh toán trong Cloud Console để sử dụng các tài nguyên của Google Cloud.
Việc chạy lớp học lập trình này sẽ không tốn nhiều chi phí, nếu có. Hãy nhớ làm theo mọi hướng dẫn trong phần "Dọn dẹp" để biết cách tắt các tài nguyên để bạn không phải chịu chi phí thanh toán ngoài hướng dẫn này. Người dùng mới của Google Cloud đủ điều kiện tham gia chương trình Dùng thử miễn phí trị giá 300 USD.
Bước 1: Bắt đầu Cloud Shell
Trong bài tập thực hành này, bạn sẽ làm việc trong một phiên Cloud Shell. Đây là một trình thông dịch lệnh được lưu trữ bởi một máy ảo chạy trong đám mây của Google. Bạn có thể dễ dàng chạy phần này cục bộ trên máy tính của riêng mình, nhưng việc sử dụng Cloud Shell sẽ giúp mọi người có quyền truy cập vào trải nghiệm có thể tái tạo trong một môi trường nhất quán. Sau bài tập thực hành này, bạn có thể thử lại phần này trên máy tính của riêng mình.
Kích hoạt Cloud Shell
Ở trên cùng bên phải của Cloud Console, hãy nhấp vào nút bên dưới để Activate Cloud Shell (Kích hoạt Cloud Shell):

Nếu chưa từng bắt đầu Cloud Shell, bạn sẽ thấy một màn hình trung gian (dưới màn hình đầu tiên) mô tả về Cloud Shell. Nếu vậy, hãy nhấp vào Continue (Tiếp tục) (và bạn sẽ không bao giờ thấy lại màn hình đó). Đây là giao diện của màn hình một lần đó:
Bạn chỉ mất vài phút để cung cấp và kết nối với Cloud Shell.

Máy ảo này được tải tất cả các công cụ phát triển mà bạn cần. Máy ảo này cung cấp một thư mục chính 5 GB liên tục và chạy trong Google Cloud, giúp tăng cường đáng kể hiệu suất mạng và xác thực. Bạn có thể thực hiện hầu hết, nếu không phải là tất cả công việc trong lớp học lập trình này chỉ bằng một trình duyệt hoặc Chromebook.
Sau khi kết nối với Cloud Shell, bạn sẽ thấy rằng mình đã được xác thực và dự án đã được đặt thành mã dự án của bạn.
Chạy lệnh sau trong Cloud Shell để xác nhận rằng bạn đã được xác thực:
gcloud auth list
Đầu ra lệnh
Credentialed Accounts
ACTIVE ACCOUNT
* <my_account>@<my_domain.com>
To set the active account, run:
$ gcloud config set account `ACCOUNT`
Chạy lệnh sau trong Cloud Shell để xác nhận rằng lệnh gcloud biết về dự án của bạn:
gcloud config list project
Đầu ra lệnh
[core] project = <PROJECT_ID>
Nếu không, bạn có thể đặt bằng lệnh này:
gcloud config set project <PROJECT_ID>
Đầu ra lệnh
Updated property [core/project].
Cloud Shell có một vài biến môi trường, bao gồm GOOGLE_CLOUD_PROJECT chứa tên của dự án trên đám mây hiện tại. Chúng ta sẽ sử dụng biến này ở nhiều nơi trong bài tập thực hành này. Bạn có thể xem biến này bằng cách chạy:
echo $GOOGLE_CLOUD_PROJECT
Bước 2: Bật API
Trong các bước sau, bạn sẽ thấy nơi cần các dịch vụ này (và lý do), nhưng hiện tại, hãy chạy lệnh này để cấp cho dự án của bạn quyền truy cập vào các dịch vụ Compute Engine, Container Registry và Vertex AI:
gcloud services enable compute.googleapis.com \
containerregistry.googleapis.com \
aiplatform.googleapis.com
Lệnh này sẽ tạo ra một thông báo thành công tương tự như thông báo này:
Operation "operations/acf.cc11852d-40af-47ad-9d59-477a12847c9e" finished successfully.
Bước 3: Tạo một bộ chứa Cloud Storage
Để chạy một công việc huấn luyện trên Vertex AI, chúng ta cần một bộ chứa lưu trữ để lưu trữ các tài sản mô hình đã lưu. Chạy các lệnh sau trong thiết bị đầu cuối Cloud Shell để tạo một bộ chứa:
BUCKET_NAME=gs://$GOOGLE_CLOUD_PROJECT-bucket
gsutil mb -l us-central1 $BUCKET_NAME
Bước 4: Bí danh Python 3
Mã trong bài tập thực hành này sử dụng Python 3. Để đảm bảo bạn sử dụng Python 3 khi chạy các tập lệnh mà bạn sẽ tạo trong bài tập thực hành này, hãy tạo một bí danh bằng cách chạy lệnh sau trong Cloud Shell:
alias python=python3
Mô hình mà chúng ta sẽ huấn luyện và phân phát trong bài tập thực hành này được xây dựng dựa trên hướng dẫn này trong tài liệu TensorFlow. Hướng dẫn này sử dụng tập dữ liệu Auto MPG từ Kaggle để dự đoán hiệu suất sử dụng nhiên liệu của một chiếc xe.
4. Chứa mã huấn luyện
Chúng ta sẽ gửi công việc huấn luyện này đến Vertex bằng cách đặt mã huấn luyện vào một vùng chứa Docker và đẩy vùng chứa này vào Google Container Registry. Bằng cách sử dụng phương pháp này, chúng ta có thể huấn luyện một mô hình được xây dựng bằng bất kỳ khung nào.
Bước 1: Thiết lập tệp
Để bắt đầu, từ thiết bị đầu cuối trong Cloud Shell, hãy chạy các lệnh sau để tạo các tệp mà chúng ta cần cho Vùng chứa Docker:
mkdir mpg
cd mpg
touch Dockerfile
mkdir trainer
touch trainer/train.py
Giờ đây, bạn sẽ có một thư mục mpg/ có dạng như sau:
+ Dockerfile
+ trainer/
+ train.py
Để xem và chỉnh sửa các tệp này, chúng ta sẽ sử dụng trình soạn thảo mã tích hợp của Cloud Shell. Bạn có thể chuyển đổi qua lại giữa trình chỉnh sửa và thiết bị đầu cuối bằng cách nhấp vào nút trên thanh trình đơn ở trên cùng bên phải trong Cloud Shell:

Bước 2: Tạo Dockerfile
Để chứa mã của mình, trước tiên, chúng ta sẽ tạo một Dockerfile. Trong Dockerfile, chúng ta sẽ đưa vào tất cả các lệnh cần thiết để chạy hình ảnh. Lệnh này sẽ cài đặt tất cả các thư viện mà chúng ta đang sử dụng và thiết lập điểm truy cập cho mã huấn luyện.
Từ trình chỉnh sửa tệp Cloud Shell, hãy mở thư mục mpg/ rồi nhấp đúp để mở Dockerfile:
Sau đó, sao chép nội dung sau vào tệp này:
FROM gcr.io/deeplearning-platform-release/tf2-cpu.2-3
WORKDIR /
# Copies the trainer code to the docker image.
COPY trainer /trainer
# Sets up the entry point to invoke the trainer.
ENTRYPOINT ["python", "-m", "trainer.train"]
Dockerfile này sử dụng hình ảnh Docker TensorFlow Enterprise 2.3 Deep Learning Container. Deep Learning Containers trên Google Cloud được cài đặt sẵn nhiều khung khoa học dữ liệu và ML phổ biến. Hình ảnh mà chúng ta đang sử dụng bao gồm TF Enterprise 2.3, Pandas, Scikit-learn và các hình ảnh khác. Sau khi tải hình ảnh đó xuống, Dockerfile này sẽ thiết lập điểm nhập cho mã huấn luyện mà chúng ta sẽ thêm vào bước tiếp theo.
Bước 3: Thêm mã huấn luyện mô hình
Từ trình chỉnh sửa Cloud Shell, hãy mở tệp train.py rồi sao chép mã bên dưới (mã này được điều chỉnh từ hướng dẫn trong tài liệu TensorFlow).
# This will be replaced with your bucket name after running the `sed` command in the tutorial
BUCKET = "BUCKET_NAME"
import numpy as np
import pandas as pd
import pathlib
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
print(tf.__version__)
"""## The Auto MPG dataset
The dataset is available from the [UCI Machine Learning Repository](https://archive.ics.uci.edu/ml/).
### Get the data
First download the dataset.
"""
"""Import it using pandas"""
dataset_path = "https://storage.googleapis.com/io-vertex-codelab/auto-mpg.csv"
dataset = pd.read_csv(dataset_path, na_values = "?")
dataset.tail()
"""### Clean the data
The dataset contains a few unknown values.
"""
dataset.isna().sum()
"""To keep this initial tutorial simple drop those rows."""
dataset = dataset.dropna()
"""The `"origin"` column is really categorical, not numeric. So convert that to a one-hot:"""
dataset['origin'] = dataset['origin'].map({1: 'USA', 2: 'Europe', 3: 'Japan'})
dataset = pd.get_dummies(dataset, prefix='', prefix_sep='')
dataset.tail()
"""### Split the data into train and test
Now split the dataset into a training set and a test set.
We will use the test set in the final evaluation of our model.
"""
train_dataset = dataset.sample(frac=0.8,random_state=0)
test_dataset = dataset.drop(train_dataset.index)
"""### Inspect the data
Have a quick look at the joint distribution of a few pairs of columns from the training set.
Also look at the overall statistics:
"""
train_stats = train_dataset.describe()
train_stats.pop("mpg")
train_stats = train_stats.transpose()
train_stats
"""### Split features from labels
Separate the target value, or "label", from the features. This label is the value that you will train the model to predict.
"""
train_labels = train_dataset.pop('mpg')
test_labels = test_dataset.pop('mpg')
"""### Normalize the data
Look again at the `train_stats` block above and note how different the ranges of each feature are.
It is good practice to normalize features that use different scales and ranges. Although the model *might* converge without feature normalization, it makes training more difficult, and it makes the resulting model dependent on the choice of units used in the input.
Note: Although we intentionally generate these statistics from only the training dataset, these statistics will also be used to normalize the test dataset. We need to do that to project the test dataset into the same distribution that the model has been trained on.
"""
def norm(x):
return (x - train_stats['mean']) / train_stats['std']
normed_train_data = norm(train_dataset)
normed_test_data = norm(test_dataset)
"""This normalized data is what we will use to train the model.
Caution: The statistics used to normalize the inputs here (mean and standard deviation) need to be applied to any other data that is fed to the model, along with the one-hot encoding that we did earlier. That includes the test set as well as live data when the model is used in production.
## The model
### Build the model
Let's build our model. Here, we'll use a `Sequential` model with two densely connected hidden layers, and an output layer that returns a single, continuous value. The model building steps are wrapped in a function, `build_model`, since we'll create a second model, later on.
"""
def build_model():
model = keras.Sequential([
layers.Dense(64, activation='relu', input_shape=[len(train_dataset.keys())]),
layers.Dense(64, activation='relu'),
layers.Dense(1)
])
optimizer = tf.keras.optimizers.RMSprop(0.001)
model.compile(loss='mse',
optimizer=optimizer,
metrics=['mae', 'mse'])
return model
model = build_model()
"""### Inspect the model
Use the `.summary` method to print a simple description of the model
"""
model.summary()
"""Now try out the model. Take a batch of `10` examples from the training data and call `model.predict` on it.
It seems to be working, and it produces a result of the expected shape and type.
### Train the model
Train the model for 1000 epochs, and record the training and validation accuracy in the `history` object.
Visualize the model's training progress using the stats stored in the `history` object.
This graph shows little improvement, or even degradation in the validation error after about 100 epochs. Let's update the `model.fit` call to automatically stop training when the validation score doesn't improve. We'll use an *EarlyStopping callback* that tests a training condition for every epoch. If a set amount of epochs elapses without showing improvement, then automatically stop the training.
You can learn more about this callback [here](https://www.tensorflow.org/api_docs/python/tf/keras/callbacks/EarlyStopping).
"""
model = build_model()
EPOCHS = 1000
# The patience parameter is the amount of epochs to check for improvement
early_stop = keras.callbacks.EarlyStopping(monitor='val_loss', patience=10)
early_history = model.fit(normed_train_data, train_labels,
epochs=EPOCHS, validation_split = 0.2,
callbacks=[early_stop])
# Export model and save to GCS
model.save(BUCKET + '/mpg/model')
Sau khi sao chép mã ở trên vào tệp mpg/trainer/train.py, hãy quay lại Thiết bị đầu cuối trong Cloud Shell rồi chạy lệnh sau để thêm tên bộ chứa của riêng bạn vào tệp:
sed -i "s|BUCKET_NAME|$BUCKET_NAME|g" trainer/train.py
Bước 4: Xây dựng và kiểm thử vùng chứa cục bộ
Từ Thiết bị đầu cuối, hãy chạy lệnh sau để xác định một biến có URI của hình ảnh vùng chứa trong Google Container Registry:
IMAGE_URI="gcr.io/$GOOGLE_CLOUD_PROJECT/mpg:v1"
Sau đó, xây dựng vùng chứa bằng cách chạy lệnh sau từ gốc của thư mục mpg:
docker build ./ -t $IMAGE_URI
Sau khi xây dựng vùng chứa, hãy đẩy vùng chứa đó vào Google Container Registry:
docker push $IMAGE_URI
Để xác minh rằng hình ảnh của bạn đã được đẩy vào Container Registry, bạn sẽ thấy hình ảnh tương tự như sau khi chuyển đến phần Container Registry của bảng điều khiển:
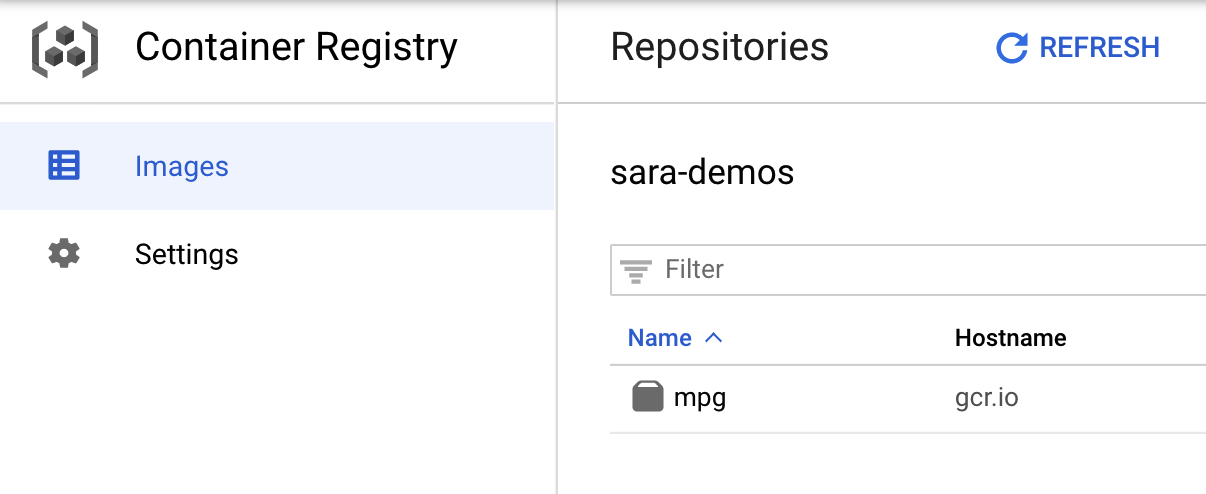
Sau khi đẩy vùng chứa vào Container Registry, chúng ta đã sẵn sàng bắt đầu một công việc huấn luyện mô hình tuỳ chỉnh.
5. Chạy một công việc huấn luyện trên Vertex AI
Vertex cung cấp cho bạn hai lựa chọn để huấn luyện mô hình:
- AutoML: Huấn luyện các mô hình chất lượng cao mà chỉ cần rất ít công sức và chuyên môn về ML.
- Huấn luyện tuỳ chỉnh: Chạy các ứng dụng huấn luyện tuỳ chỉnh của bạn trên đám mây bằng một trong các vùng chứa xây dựng sẵn của Google Cloud hoặc sử dụng vùng chứa của riêng bạn.
Trong bài tập thực hành này, chúng ta sẽ sử dụng tính năng huấn luyện tuỳ chỉnh thông qua vùng chứa tuỳ chỉnh của riêng mình trên Google Container Registry. Để bắt đầu, hãy chuyển đến phần Training (Huấn luyện) trong phần Vertex của bảng điều khiển Cloud:
Bước 1: Bắt đầu công việc huấn luyện
Nhấp vào Create (Tạo) để nhập các tham số cho công việc huấn luyện và mô hình đã triển khai:
- Trong phần Dataset (Tập dữ liệu), hãy chọn No managed dataset (Không có tập dữ liệu được quản lý)
- Sau đó, chọn Custom training (advanced) (Huấn luyện tuỳ chỉnh (nâng cao)) làm phương thức huấn luyện rồi nhấp vào Continue (Tiếp tục).
- Nhập
mpg(hoặc bất kỳ tên nào bạn muốn đặt cho mô hình) cho Model name (Tên mô hình) - Nhấp vào Continue (Tiếp tục)
Trong bước Cài đặt vùng chứa, hãy chọn Custom container (Vùng chứa tuỳ chỉnh):

Trong hộp đầu tiên (Hình ảnh vùng chứa), hãy nhấp vào Browse (Duyệt) rồi tìm vùng chứa mà bạn vừa đẩy vào Container Registry. Đoạn mã sẽ trông giống như sau:
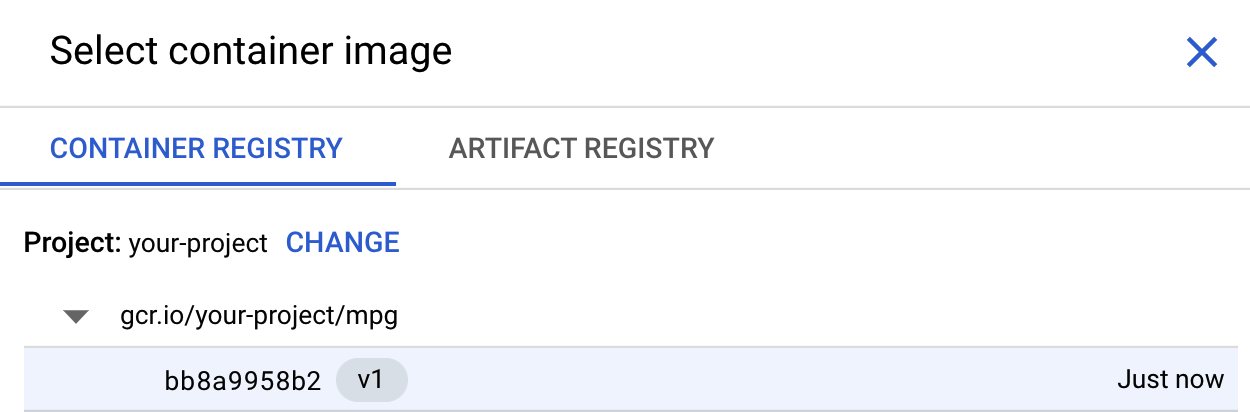
Để trống các trường còn lại rồi nhấp vào Continue (Tiếp tục).
Chúng ta sẽ không sử dụng tính năng điều chỉnh siêu tham số trong hướng dẫn này, vì vậy, hãy bỏ chọn hộp Bật tính năng điều chỉnh siêu tham số rồi nhấp vào Continue (Tiếp tục).
Trong phần Compute and pricing (Tính toán và giá), hãy để nguyên vùng đã chọn và chọn n1-standard-4 làm loại máy:
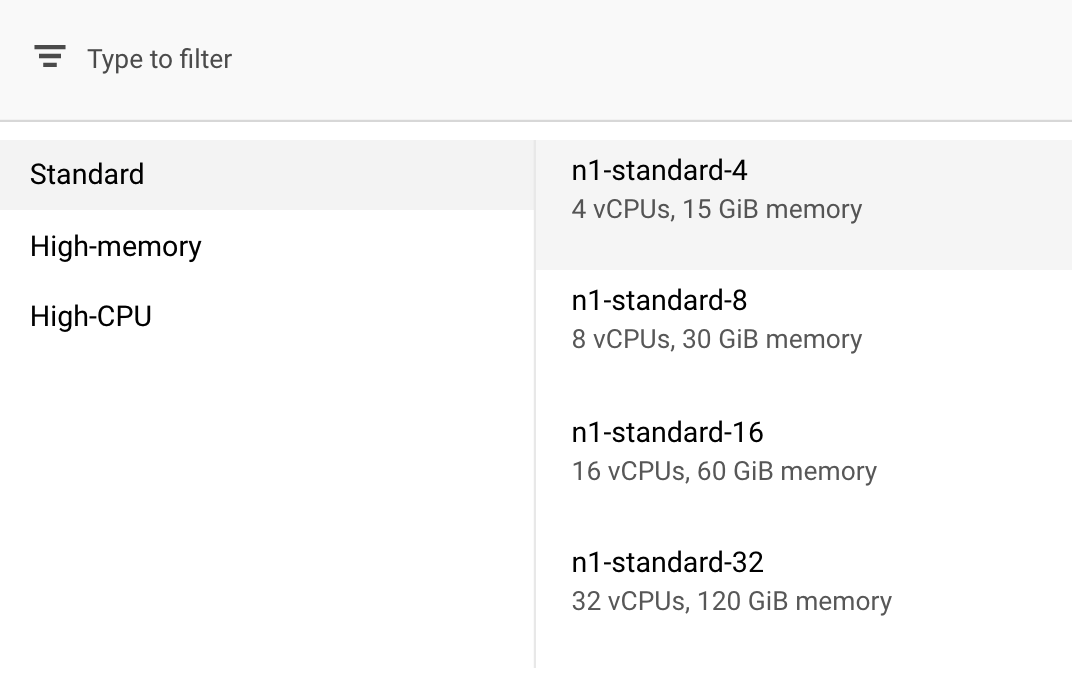
Vì mô hình trong bản minh hoạ này huấn luyện nhanh chóng, nên chúng ta sẽ sử dụng một loại máy nhỏ hơn.
Trong bước Prediction container (Vùng chứa dự đoán), hãy chọn No prediction container (Không có vùng chứa dự đoán):
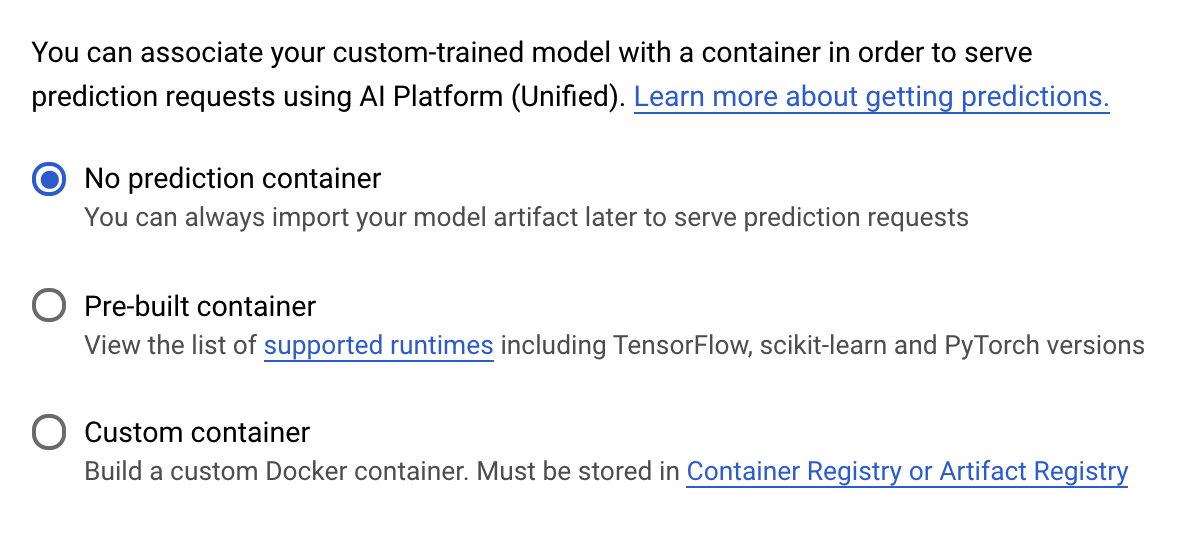
6. Triển khai một điểm cuối mô hình
Trong bước này, chúng ta sẽ tạo một điểm cuối cho mô hình đã huấn luyện. Chúng ta có thể sử dụng điểm cuối này để nhận dự đoán về mô hình của mình thông qua Vertex AI API. Để thực hiện việc này, chúng tôi đã cung cấp một phiên bản của các tài sản mô hình đã huấn luyện được xuất trong một bộ chứa GCS công khai.
Trong một tổ chức, thường có một nhóm hoặc cá nhân chịu trách nhiệm xây dựng mô hình và một nhóm khác chịu trách nhiệm triển khai mô hình đó. Các bước mà chúng ta sẽ thực hiện ở đây sẽ cho bạn thấy cách lấy một mô hình đã được huấn luyện và triển khai mô hình đó để dự đoán.
Ở đây, chúng ta sẽ sử dụng Vertex AI SDK để tạo một mô hình, triển khai mô hình đó đến một điểm cuối và nhận dự đoán.
Bước 1: Cài đặt Vertex SDK
Từ thiết bị đầu cuối Cloud Shell, hãy chạy lệnh sau để cài đặt Vertex AI SDK:
pip3 install google-cloud-aiplatform --upgrade --user
Chúng ta có thể sử dụng SDK này để tương tác với nhiều phần khác nhau của Vertex.
Bước 2: Tạo mô hình và triển khai điểm cuối
Tiếp theo, chúng ta sẽ tạo một tệp Python và sử dụng SDK để tạo một tài nguyên mô hình và triển khai tài nguyên đó đến một điểm cuối. Từ trình chỉnh sửa Tệp trong Cloud Shell, hãy chọn File rồi chọn New File:
Đặt tên cho tệp là deploy.py. Mở tệp này trong trình chỉnh sửa rồi sao chép mã sau:
from google.cloud import aiplatform
# Create a model resource from public model assets
model = aiplatform.Model.upload(
display_name="mpg-imported",
artifact_uri="gs://io-vertex-codelab/mpg-model/",
serving_container_image_uri="gcr.io/cloud-aiplatform/prediction/tf2-cpu.2-3:latest"
)
# Deploy the above model to an endpoint
endpoint = model.deploy(
machine_type="n1-standard-4"
)
Tiếp theo, hãy quay lại Thiết bị đầu cuối trong Cloud Shell, cd quay lại thư mục gốc rồi chạy tập lệnh Python mà bạn vừa tạo:
cd ..
python3 deploy.py | tee deploy-output.txt
Bạn sẽ thấy các bản cập nhật được ghi vào Terminal khi các tài nguyên đang được tạo. Quá trình này sẽ mất 10 – 15 phút để chạy. Để đảm bảo quá trình này hoạt động đúng cách, hãy chuyển đến phần Models (Mô hình) của bảng điều khiển trong Vertex AI:
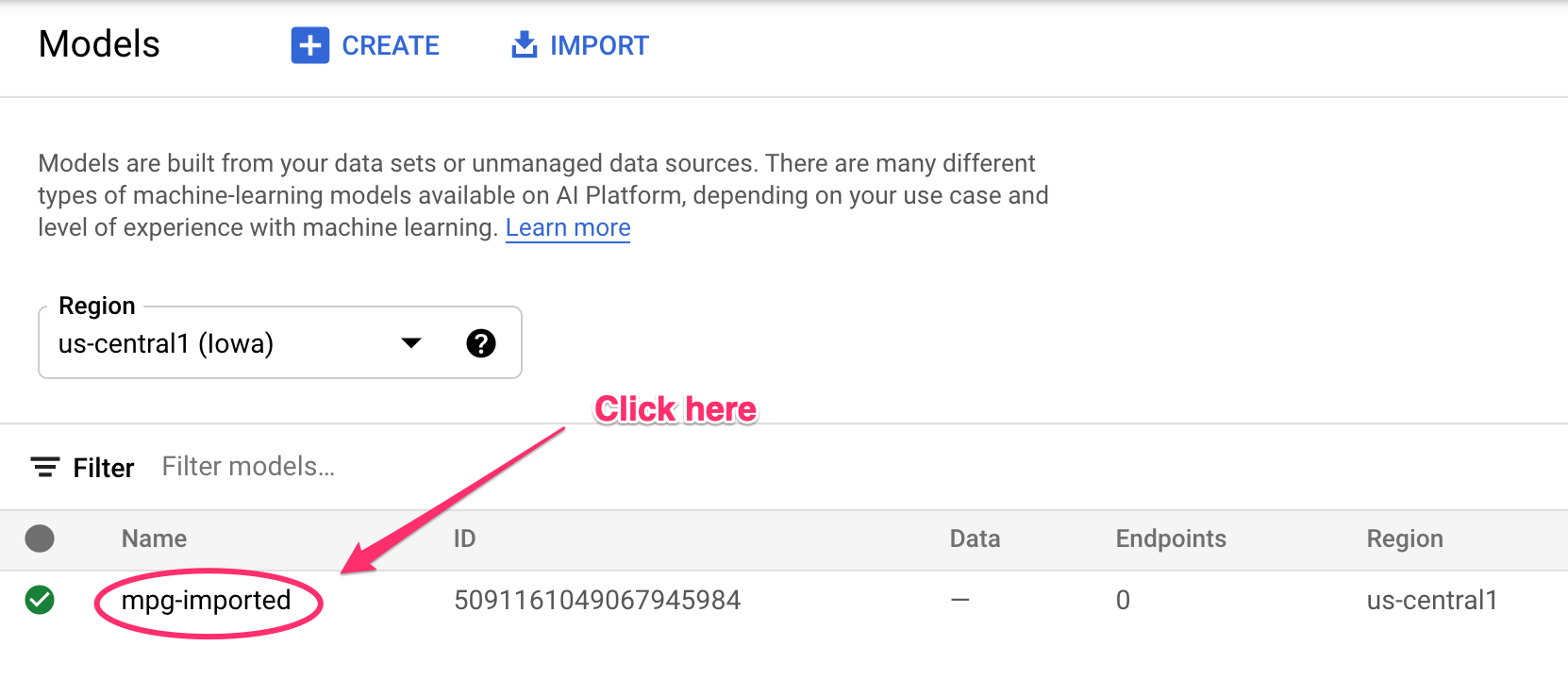
Nhấp vào mgp-imported và bạn sẽ thấy điểm cuối cho mô hình đó đang được tạo:
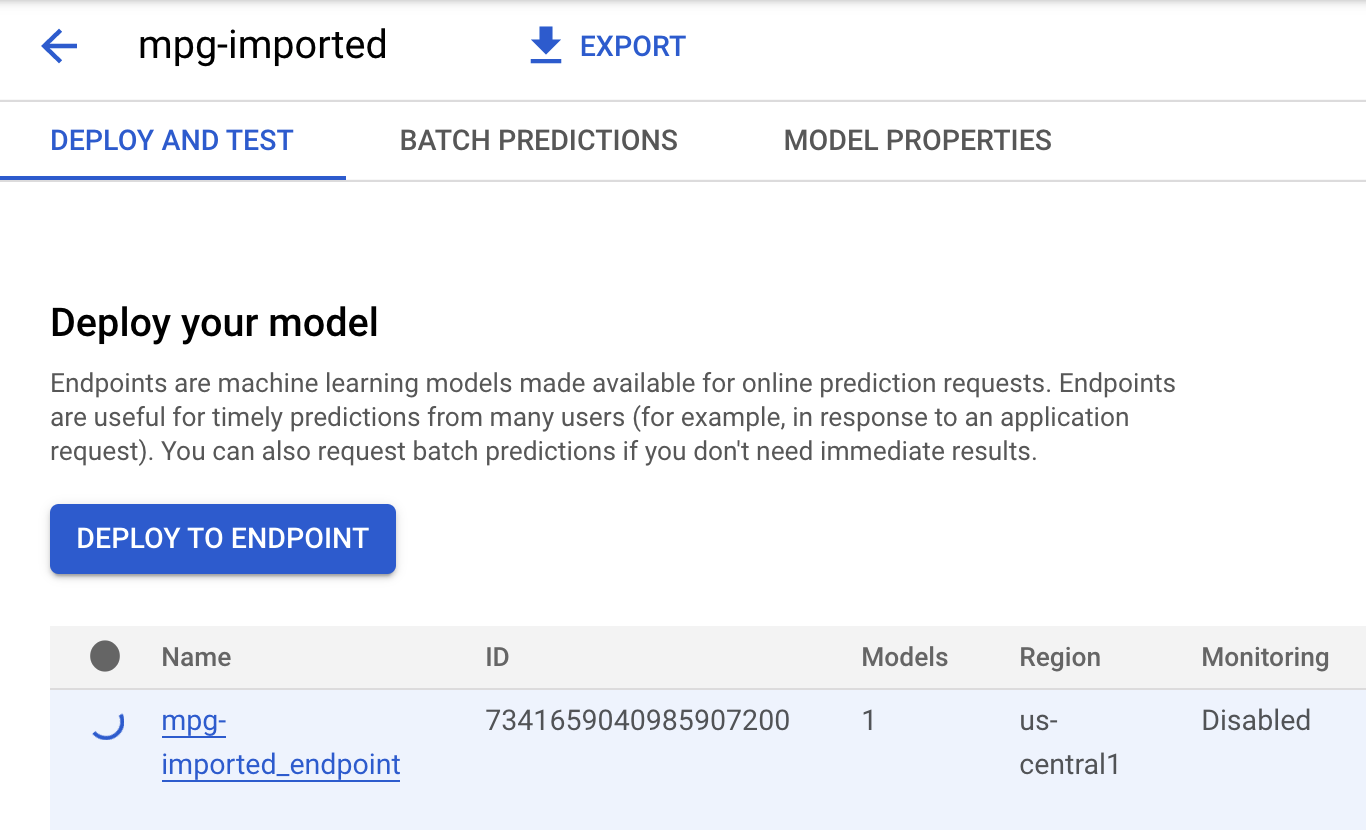
Trong Thiết bị đầu cuối Cloud Shell, bạn sẽ thấy một nhật ký tương tự như sau khi quá trình triển khai điểm cuối hoàn tất:
Endpoint model deployed. Resource name: projects/your-project-id/locations/us-central1/endpoints/your-endpoint-id
Bạn sẽ sử dụng nhật ký này trong bước tiếp theo để nhận dự đoán về điểm cuối đã triển khai.
Bước 3: Nhận dự đoán về điểm cuối đã triển khai
Trong trình chỉnh sửa Cloud Shell, hãy tạo một tệp mới có tên là predict.py:
Mở predict.py rồi dán mã sau vào đó:
from google.cloud import aiplatform
endpoint = aiplatform.Endpoint(
endpoint_name="ENDPOINT_STRING"
)
# A test example we'll send to our model for prediction
test_mpg = [1.4838871833555929,
1.8659883497083019,
2.234620276849616,
1.0187816540094903,
-2.530890710602246,
-1.6046416850441676,
-0.4651483719733302,
-0.4952254087173721,
0.7746763768735953]
response = endpoint.predict([test_mpg])
print('API response: ', response)
print('Predicted MPG: ', response.predictions[0][0])
Tiếp theo, hãy quay lại Thiết bị đầu cuối rồi nhập nội dung sau để thay thế ENDPOINT_STRING trong tệp dự đoán bằng điểm cuối của riêng bạn:
ENDPOINT=$(cat deploy-output.txt | sed -nre 's:.*Resource name\: (.*):\1:p' | tail -1)
sed -i "s|ENDPOINT_STRING|$ENDPOINT|g" predict.py
Bây giờ là lúc chạy tệp predict.py để nhận dự đoán từ điểm cuối mô hình đã triển khai:
python3 predict.py
Bạn sẽ thấy phản hồi của API được ghi lại, cùng với hiệu suất nhiên liệu dự đoán cho dự đoán kiểm thử của chúng ta.
🎉 Xin chúc mừng! 🎉
Bạn đã tìm hiểu cách sử dụng Vertex AI để:
- Huấn luyện một mô hình bằng cách cung cấp mã huấn luyện trong một vùng chứa tuỳ chỉnh. Bạn đã sử dụng mô hình TensorFlow trong ví dụ này, nhưng bạn có thể huấn luyện một mô hình được xây dựng bằng bất kỳ khung nào bằng cách sử dụng các vùng chứa tuỳ chỉnh.
- Triển khai mô hình TensorFlow bằng một vùng chứa xây dựng sẵn như một phần của cùng một quy trình mà bạn đã sử dụng để huấn luyện.
- Tạo một điểm cuối mô hình và tạo dự đoán.
Để tìm hiểu thêm về các phần khác nhau của Vertex AI, hãy xem tài liệu. Nếu bạn muốn xem kết quả của công việc huấn luyện mà bạn đã bắt đầu ở Bước 5, hãy chuyển đến phần huấn luyện của bảng điều khiển Vertex.
7. Dọn dẹp
Để xoá điểm cuối mà bạn đã triển khai, hãy chuyển đến phần Endpoints (Điểm cuối) của bảng điều khiển Vertex rồi nhấp vào biểu tượng xoá:

Để xoá Bộ chứa lưu trữ, hãy sử dụng trình đơn Điều hướng trong Cloud Console, duyệt đến Bộ nhớ, chọn bộ chứa của bạn rồi nhấp vào Xoá: