1. Présentation
Dans cet atelier, vous allez apprendre à utiliser Vertex AI, la nouvelle plate-forme de ML gérée de Google Cloud, pour créer des workflows de ML de bout en bout. Vous découvrirez comment passer de données brutes à un modèle déployé. À la fin de cet atelier, vous serez prêt à développer et à mettre en production vos propres projets de ML avec Vertex AI. Dans cet atelier, nous allons utiliser Cloud Shell pour créer une image Docker personnalisée afin de présenter les conteneurs personnalisés pour l'entraînement avec Vertex AI.
Bien que cet atelier utilise TensorFlow pour le code du modèle, vous pourriez aisément le remplacer par un autre framework.
Objectifs
Vous allez apprendre à effectuer les opérations suivantes :
- Créer et conteneuriser du code d'entraînement de modèle à l'aide de Cloud Shell
- Envoyer un job d'entraînement de modèle personnalisé à Vertex AI
- Déployer votre modèle entraîné sur un point de terminaison, et utiliser ce point de terminaison pour obtenir des prédictions
Le coût total d'exécution de cet atelier sur Google Cloud est d'environ 2$.
2. Présentation de Vertex AI
Cet atelier utilise la toute dernière offre de produits d'IA de Google Cloud. Vertex AI simplifie l'expérience de développement en intégrant toutes les offres de ML de Google Cloud. Auparavant, les modèles entraînés avec AutoML et les modèles personnalisés étaient accessibles depuis des services distincts. La nouvelle offre regroupe ces deux types de modèles mais aussi d'autres nouveaux produits en une seule API. Vous pouvez également migrer des projets existants vers Vertex AI. Pour envoyer un commentaire, consultez la page d'assistance.
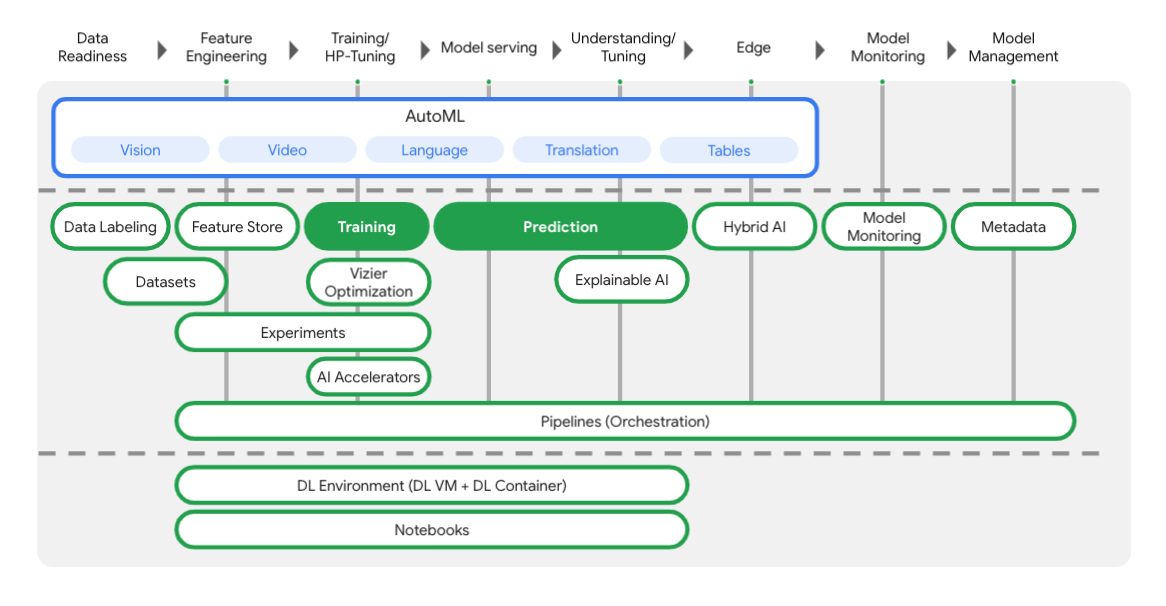
Vertex inclut de nombreux outils différents pour vous aider à chaque étape du workflow de ML, comme vous pouvez le voir dans le schéma ci-dessous. Nous allons nous concentrer sur l'utilisation de Vertex Training et de Prediction, mis en évidence ci-dessous.
3. Configurer votre environnement
Configuration de l'environnement au rythme de chacun
Connectez-vous à la console Cloud, puis créez un projet ou réutilisez un projet existant. (Si vous ne possédez pas encore de compte Gmail ou Google Workspace, vous devez en créer un.)

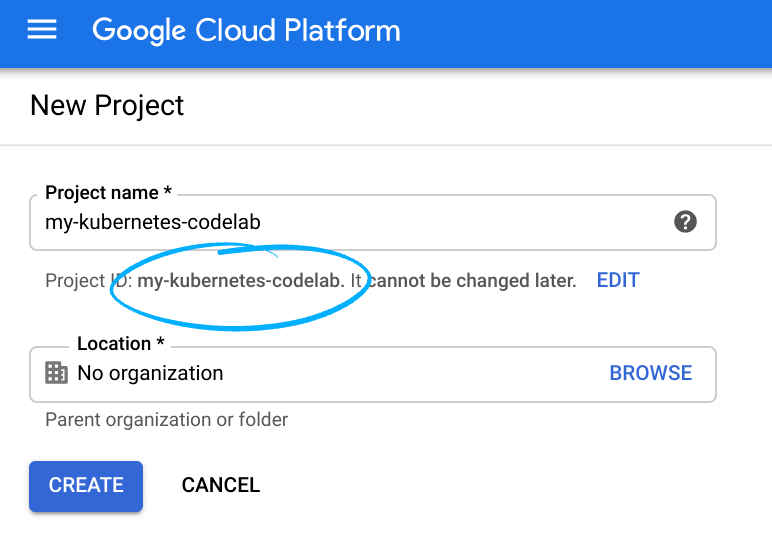
Mémorisez l'ID du projet. Il s'agit d'un nom unique permettant de différencier chaque projet Google Cloud (le nom ci-dessus est déjà pris ; vous devez en trouver un autre).
Vous devez ensuite activer la facturation dans Cloud Console pour pouvoir utiliser les ressources Google Cloud.
L'exécution de cet atelier de programmation est très peu coûteuse, voire sans frais. Veillez à suivre les instructions de la section "Nettoyer" qui indique comment désactiver les ressources afin d'éviter les frais une fois ce tutoriel terminé. Les nouveaux utilisateurs de Google Cloud peuvent bénéficier du programme d'essai sans frais de 300$.
Étape 1 : Démarrer Cloud Shell
Dans cet atelier, vous allez travailler dans une session Cloud Shell. Cet environnement est un interpréteur de commandes hébergé sur une machine virtuelle qui s'exécute dans le cloud de Google. Vous pourriez tout aussi facilement effectuer les tâches de cette section en local sur votre propre ordinateur, mais le fait d'utiliser Cloud Shell permet à chacun de bénéficier d'une expérience reproductible dans un environnement cohérent. Après l'atelier, libre à vous de reproduire cette section sur votre ordinateur.
Activer Cloud Shell
En haut à droite de Cloud Console, cliquez sur le bouton ci-dessous pour activer Cloud Shell :

Si vous n'avez jamais démarré Cloud Shell auparavant, un écran intermédiaire s'affiche en dessous de la ligne de flottaison, décrivant de quoi il s'agit. Si tel est le cas, cliquez sur Continuer. Cet écran ne s'affiche qu'une seule fois. Voici à quoi il ressemble :
Le provisionnement et la connexion à Cloud Shell ne devraient pas prendre plus de quelques minutes.

Cette machine virtuelle contient tous les outils de développement nécessaires. Elle comprend un répertoire d'accueil persistant de 5 Go et s'exécute sur Google Cloud, ce qui améliore nettement les performances du réseau et l'authentification. Vous pouvez réaliser une grande partie, voire la totalité, des activités de cet atelier dans un simple navigateur ou sur votre Chromebook.
Une fois connecté à Cloud Shell, vous êtes en principe authentifié et le projet est défini avec votre ID de projet.
Exécutez la commande suivante dans Cloud Shell pour vérifier que vous êtes authentifié :
gcloud auth list
Résultat de la commande
Credentialed Accounts
ACTIVE ACCOUNT
* <my_account>@<my_domain.com>
To set the active account, run:
$ gcloud config set account `ACCOUNT`
Exécutez la commande suivante dans Cloud Shell pour vérifier que la commande gcloud reconnaît votre projet :
gcloud config list project
Résultat de la commande
[core] project = <PROJECT_ID>
Si vous obtenez un résultat différent, exécutez cette commande :
gcloud config set project <PROJECT_ID>
Résultat de la commande
Updated property [core/project].
Cloud Shell comporte quelques variables d'environnement, parmi lesquelles GOOGLE_CLOUD_PROJECT, qui contient le nom de notre projet Cloud actuel. Nous allons l'utiliser à différents endroits de cet atelier. Pour la voir, exécutez la commande suivante :
echo $GOOGLE_CLOUD_PROJECT
Étape 2 : Activez les API
Dans les étapes suivantes, vous verrez où ces services sont requis (et pourquoi). Mais pour l'instant, exécutez la commande ci-dessous pour autoriser votre projet à accéder aux services Compute Engine, Container Registry et Vertex AI :
gcloud services enable compute.googleapis.com \
containerregistry.googleapis.com \
aiplatform.googleapis.com
Un message semblable à celui qui suit s'affiche pour vous indiquer que l'opération s'est correctement déroulée :
Operation "operations/acf.cc11852d-40af-47ad-9d59-477a12847c9e" finished successfully.
Étape 3 : Créez un bucket Cloud Storage
Pour exécuter un job d'entraînement sur Vertex AI, nous avons besoin d'un bucket de stockage dans lequel enregistrer les ressources de modèle. Exécutez les commandes suivantes dans votre terminal Cloud Shell afin de créer un bucket :
BUCKET_NAME=gs://$GOOGLE_CLOUD_PROJECT-bucket
gsutil mb -l us-central1 $BUCKET_NAME
Étape 4 : Créez un alias pour Python 3
Le code de cet atelier utilise Python 3. Pour vous assurer d'utiliser Python 3 lorsque vous exécutez les scripts que vous allez créer dans cet atelier, créez un alias en exécutant la commande suivante dans Cloud Shell :
alias python=python3
Le modèle que nous allons entraîner et diffuser dans cet atelier est basé sur ce tutoriel de la documentation TensorFlow. Ce tutoriel utilise l'ensemble de données Auto MPG de Kaggle pour prédire le rendement énergétique d'un véhicule.
4. Conteneuriser le code d'entraînement
Nous allons envoyer ce job d'entraînement à Vertex AI. Pour ce faire, nous allons en premier lieu placer notre code d'entraînement dans un conteneur Docker, puis transmettre ce conteneur à Google Container Registry. Cette approche nous permet d'entraîner un modèle créé avec n'importe quel framework.
Étape 1 : Configurez les fichiers
Pour commencer, dans le terminal de Cloud Shell, exécutez les commandes suivantes pour créer les fichiers dont nous aurons besoin pour notre conteneur Docker :
mkdir mpg
cd mpg
touch Dockerfile
mkdir trainer
touch trainer/train.py
Vous devriez maintenant disposer d'un répertoire mpg/ semblable à celui-ci :
+ Dockerfile
+ trainer/
+ train.py
Pour afficher et modifier ces fichiers, nous allons utiliser l'éditeur de code intégré de Cloud Shell. Vous pouvez passer de l'éditeur au terminal (et vice versa) en cliquant sur le bouton situé dans la barre de menu en haut à droite de Cloud Shell :

Étape 2 : Créez un Dockerfile
Pour conteneuriser notre code, nous allons d'abord créer un Dockerfile. Nous allons placer dans ce Dockerfile toutes les commandes requises pour l'exécution de l'image. Ce fichier servira à installer toutes les bibliothèques requises et à configurer le point d'entrée de notre code d'entraînement.
Dans l'éditeur de fichiers Cloud Shell, ouvrez votre répertoire mpg/, puis double-cliquez pour ouvrir le Dockerfile :
Copiez ensuite le contenu suivant dans ce fichier :
FROM gcr.io/deeplearning-platform-release/tf2-cpu.2-3
WORKDIR /
# Copies the trainer code to the docker image.
COPY trainer /trainer
# Sets up the entry point to invoke the trainer.
ENTRYPOINT ["python", "-m", "trainer.train"]
Ce Dockerfile utilise l'image Docker de TensorFlow Enterprise 2.3 comme conteneur de deep learning. Les conteneurs de deep learning de Google Cloud sont fournis avec de nombreux frameworks de ML et de data science courants préinstallés. Celui que nous utilisons inclut TF Enterprise 2.3, Pandas, Scikit-learn, etc. Une fois l'image téléchargée, ce Dockerfile configure le point d'entrée de notre code d'entraînement, que nous allons ajouter à l'étape suivante.
Étape 3 : Ajoutez le code d'entraînement du modèle
Dans l'éditeur Cloud Shell, ouvrez ensuite le fichier train.py et copiez-y le code fourni ci-dessous (ce contenu a été adapté à partir du tutoriel disponible dans la documentation de TensorFlow).
# This will be replaced with your bucket name after running the `sed` command in the tutorial
BUCKET = "BUCKET_NAME"
import numpy as np
import pandas as pd
import pathlib
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
print(tf.__version__)
"""## The Auto MPG dataset
The dataset is available from the [UCI Machine Learning Repository](https://archive.ics.uci.edu/ml/).
### Get the data
First download the dataset.
"""
"""Import it using pandas"""
dataset_path = "https://storage.googleapis.com/io-vertex-codelab/auto-mpg.csv"
dataset = pd.read_csv(dataset_path, na_values = "?")
dataset.tail()
"""### Clean the data
The dataset contains a few unknown values.
"""
dataset.isna().sum()
"""To keep this initial tutorial simple drop those rows."""
dataset = dataset.dropna()
"""The `"origin"` column is really categorical, not numeric. So convert that to a one-hot:"""
dataset['origin'] = dataset['origin'].map({1: 'USA', 2: 'Europe', 3: 'Japan'})
dataset = pd.get_dummies(dataset, prefix='', prefix_sep='')
dataset.tail()
"""### Split the data into train and test
Now split the dataset into a training set and a test set.
We will use the test set in the final evaluation of our model.
"""
train_dataset = dataset.sample(frac=0.8,random_state=0)
test_dataset = dataset.drop(train_dataset.index)
"""### Inspect the data
Have a quick look at the joint distribution of a few pairs of columns from the training set.
Also look at the overall statistics:
"""
train_stats = train_dataset.describe()
train_stats.pop("mpg")
train_stats = train_stats.transpose()
train_stats
"""### Split features from labels
Separate the target value, or "label", from the features. This label is the value that you will train the model to predict.
"""
train_labels = train_dataset.pop('mpg')
test_labels = test_dataset.pop('mpg')
"""### Normalize the data
Look again at the `train_stats` block above and note how different the ranges of each feature are.
It is good practice to normalize features that use different scales and ranges. Although the model *might* converge without feature normalization, it makes training more difficult, and it makes the resulting model dependent on the choice of units used in the input.
Note: Although we intentionally generate these statistics from only the training dataset, these statistics will also be used to normalize the test dataset. We need to do that to project the test dataset into the same distribution that the model has been trained on.
"""
def norm(x):
return (x - train_stats['mean']) / train_stats['std']
normed_train_data = norm(train_dataset)
normed_test_data = norm(test_dataset)
"""This normalized data is what we will use to train the model.
Caution: The statistics used to normalize the inputs here (mean and standard deviation) need to be applied to any other data that is fed to the model, along with the one-hot encoding that we did earlier. That includes the test set as well as live data when the model is used in production.
## The model
### Build the model
Let's build our model. Here, we'll use a `Sequential` model with two densely connected hidden layers, and an output layer that returns a single, continuous value. The model building steps are wrapped in a function, `build_model`, since we'll create a second model, later on.
"""
def build_model():
model = keras.Sequential([
layers.Dense(64, activation='relu', input_shape=[len(train_dataset.keys())]),
layers.Dense(64, activation='relu'),
layers.Dense(1)
])
optimizer = tf.keras.optimizers.RMSprop(0.001)
model.compile(loss='mse',
optimizer=optimizer,
metrics=['mae', 'mse'])
return model
model = build_model()
"""### Inspect the model
Use the `.summary` method to print a simple description of the model
"""
model.summary()
"""Now try out the model. Take a batch of `10` examples from the training data and call `model.predict` on it.
It seems to be working, and it produces a result of the expected shape and type.
### Train the model
Train the model for 1000 epochs, and record the training and validation accuracy in the `history` object.
Visualize the model's training progress using the stats stored in the `history` object.
This graph shows little improvement, or even degradation in the validation error after about 100 epochs. Let's update the `model.fit` call to automatically stop training when the validation score doesn't improve. We'll use an *EarlyStopping callback* that tests a training condition for every epoch. If a set amount of epochs elapses without showing improvement, then automatically stop the training.
You can learn more about this callback [here](https://www.tensorflow.org/api_docs/python/tf/keras/callbacks/EarlyStopping).
"""
model = build_model()
EPOCHS = 1000
# The patience parameter is the amount of epochs to check for improvement
early_stop = keras.callbacks.EarlyStopping(monitor='val_loss', patience=10)
early_history = model.fit(normed_train_data, train_labels,
epochs=EPOCHS, validation_split = 0.2,
callbacks=[early_stop])
# Export model and save to GCS
model.save(BUCKET + '/mpg/model')
Une fois que vous avez copié le code ci-dessus dans le fichier mpg/trainer/train.py, revenez au terminal de votre Cloud Shell et exécutez la commande suivante pour ajouter le nom de votre bucket au fichier :
sed -i "s|BUCKET_NAME|$BUCKET_NAME|g" trainer/train.py
Étape 4 : Créez et testez le conteneur localement
Depuis votre terminal, exécutez la commande suivante pour définir une variable avec l'URI de votre image de conteneur dans Google Container Registry :
IMAGE_URI="gcr.io/$GOOGLE_CLOUD_PROJECT/mpg:v1"
Ensuite, créez le conteneur en exécutant la commande suivante à partir de la racine de votre répertoire mpg :
docker build ./ -t $IMAGE_URI
Une fois le conteneur créé, transférez-le vers Google Container Registry :
docker push $IMAGE_URI
Pour vérifier que votre image a bien été transférée vers Container Registry, vous devriez voir un résultat semblable à celui-ci lorsque vous accédez à la section Container Registry de votre console :
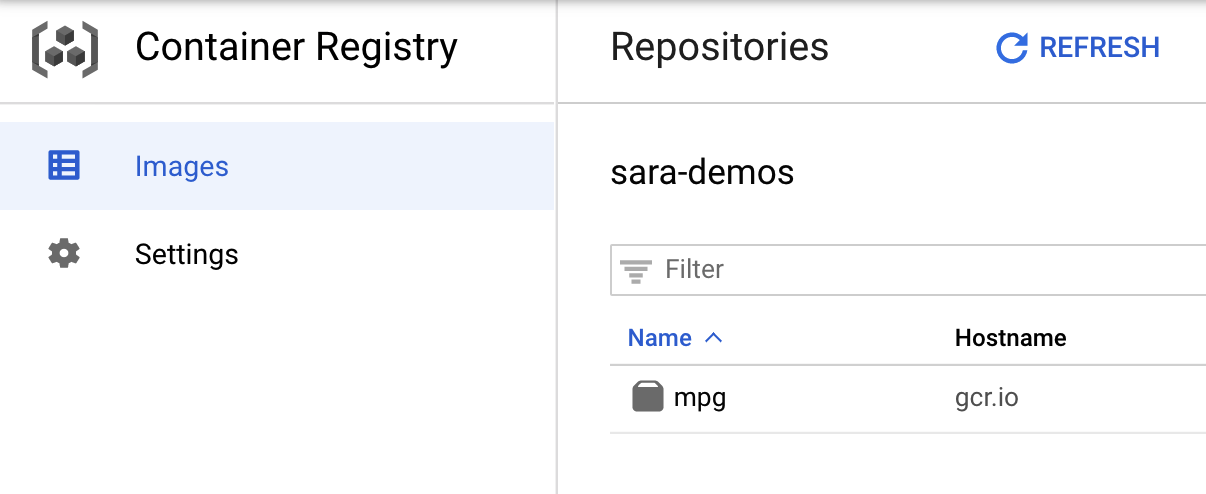
Maintenant que le conteneur a été transmis à Container Registry, nous pouvons démarrer un job d'entraînement de modèle personnalisé.
5. Exécuter un job d'entraînement sur Vertex AI
Vertex vous offre deux options pour entraîner des modèles :
- AutoML : entraînez des modèles de grande qualité avec un minimum d'effort et d'expertise en ML.
- Entraînement personnalisé : exécutez vos applications d'entraînement personnalisées dans le cloud à l'aide de l'un des conteneurs prédéfinis de Google Cloud ou du vôtre.
Dans cet atelier, nous allons utiliser l'entraînement personnalisé via notre propre conteneur personnalisé sur Google Container Registry. Pour commencer, accédez à l'onglet Entraînement de la section Vertex de votre console Cloud :
Étape 1 : Démarrez le job d'entraînement
Cliquez sur Créer pour saisir les paramètres du job d'entraînement et du modèle déployé :
- Sous Ensemble de données, sélectionnez Aucun ensemble de données géré
- Sélectionnez ensuite Entraînement personnalisé (avancé) comme méthode d'entraînement, puis cliquez sur Continuer.
- Saisissez
mpg(ou le nom que vous souhaitez attribuer à votre modèle) pour Nom du modèle. - Cliquez sur Continuer.
À l'étape des paramètres du conteneur, sélectionnez Conteneur personnalisé :

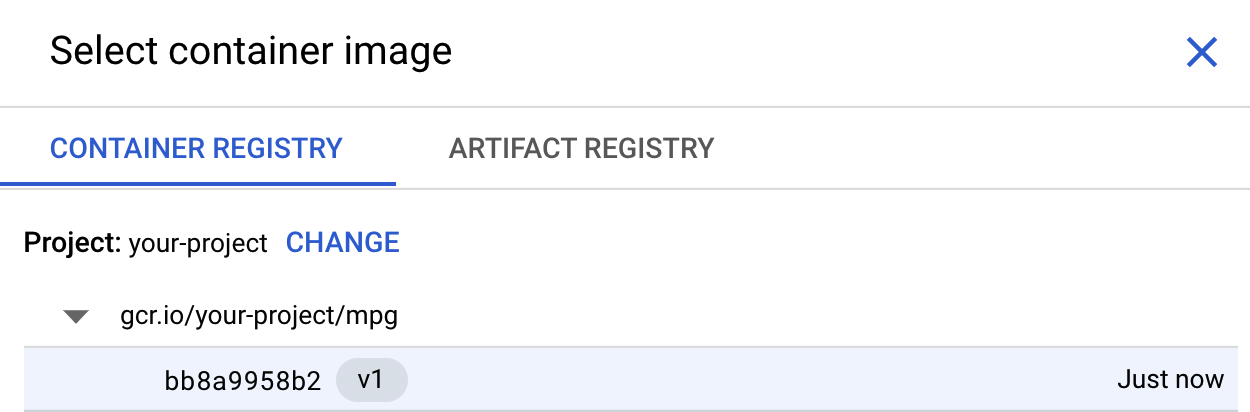
Dans la première zone (Image du conteneur), cliquez sur Parcourir et recherchez le conteneur que vous venez de transférer vers Container Registry. Exemple :
Laissez les autres champs vides et cliquez sur Continuer.
Le réglage des hyperparamètres n'est pas utilisé dans cet atelier. Laissez la case Activer le réglage des hyperparamètres décochée et cliquez sur Continuer.
Dans Options de calcul et tarifs, ne modifiez pas la région sélectionnée et choisissez n1-standard-4 comme type de machine :
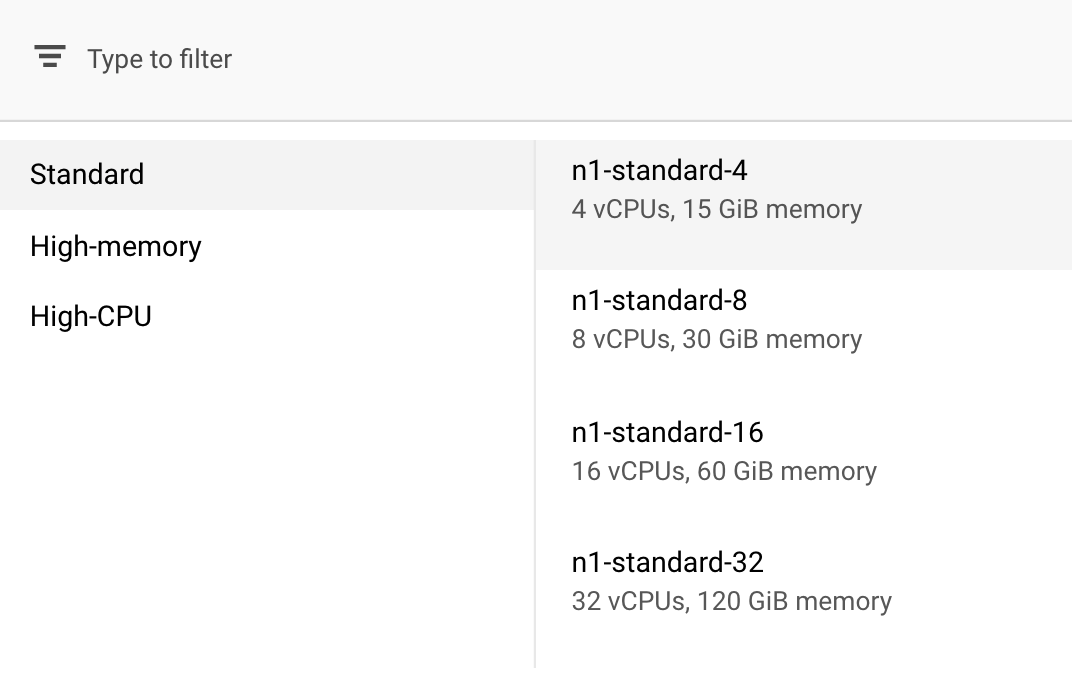
Comme le modèle de cette démonstration peut être entraîné rapidement, nous pouvons utiliser un type de machine de plus petite taille.
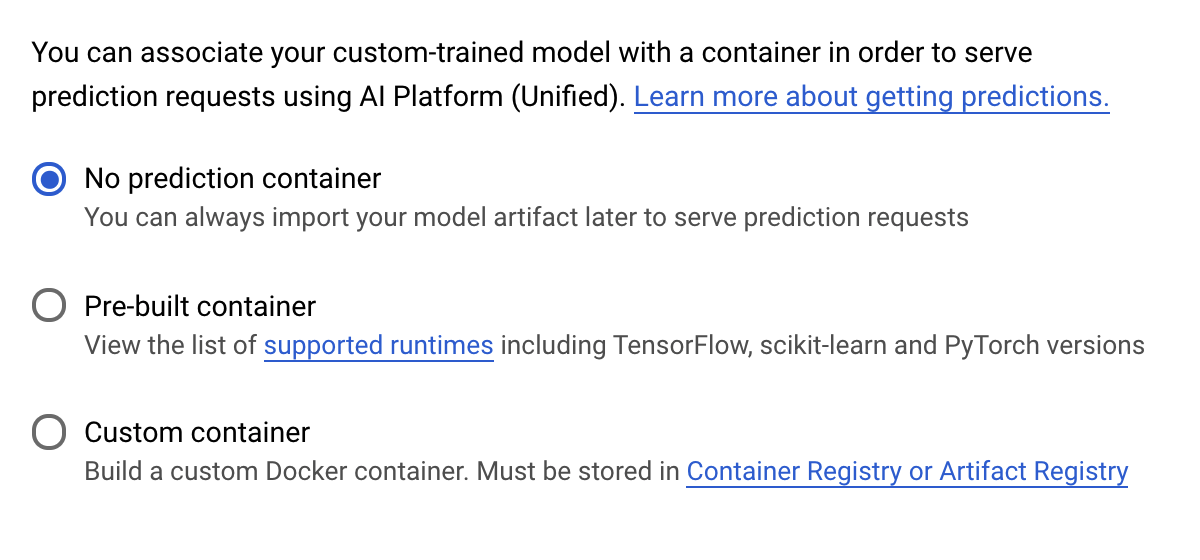
À l'étape Conteneur de prédiction, sélectionnez Aucun conteneur de prédiction :
6. Déployer un point de terminaison du modèle
Au cours de cette étape, nous allons créer un point de terminaison pour le modèle entraîné. Nous pouvons l'utiliser pour obtenir des prédictions à partir du modèle via l'API Vertex AI. Pour ce faire, nous avons mis à disposition une version des ressources de modèle entraîné exportées dans un bucket GCS public.
Dans une organisation, il est courant qu'une équipe ou une personne soit chargée de créer le modèle, et qu'une autre équipe soit chargée de le déployer. Les étapes que nous allons suivre ici vous montreront comment prendre un modèle déjà entraîné et le déployer pour la prédiction.
Nous allons utiliser le SDK Vertex AI pour créer un modèle, le déployer sur un point de terminaison et obtenir une prédiction.
Étape 1 : Installez le SDK Vertex
Dans votre terminal Cloud Shell, exécutez la commande suivante pour installer le SDK Vertex AI :
pip3 install google-cloud-aiplatform --upgrade --user
Nous pouvons utiliser ce SDK pour interagir avec de nombreuses parties différentes de Vertex.
Étape 2 : Créez un modèle et déployez un point de terminaison
Nous allons ensuite créer un fichier Python et utiliser le SDK pour créer une ressource de modèle et la déployer sur un point de terminaison. Dans l'éditeur de fichiers de Cloud Shell, sélectionnez Fichier , puis Nouveau fichier :
Attribuez le nom deploy.py au fichier. Ouvrez ce fichier dans votre éditeur et copiez le code suivant :
from google.cloud import aiplatform
# Create a model resource from public model assets
model = aiplatform.Model.upload(
display_name="mpg-imported",
artifact_uri="gs://io-vertex-codelab/mpg-model/",
serving_container_image_uri="gcr.io/cloud-aiplatform/prediction/tf2-cpu.2-3:latest"
)
# Deploy the above model to an endpoint
endpoint = model.deploy(
machine_type="n1-standard-4"
)
Revenez ensuite au terminal de Cloud Shell, cd à nouveau à votre répertoire racine et exécutez le script Python que vous venez de créer :
cd ..
python3 deploy.py | tee deploy-output.txt
Des mises à jour seront enregistrées dans votre terminal à mesure que les ressources seront créées. L'exécution prendra entre 10 et 15 minutes. Pour vous assurer que tout fonctionne correctement, accédez à la section "Modèles" de votre console dans Vertex AI :
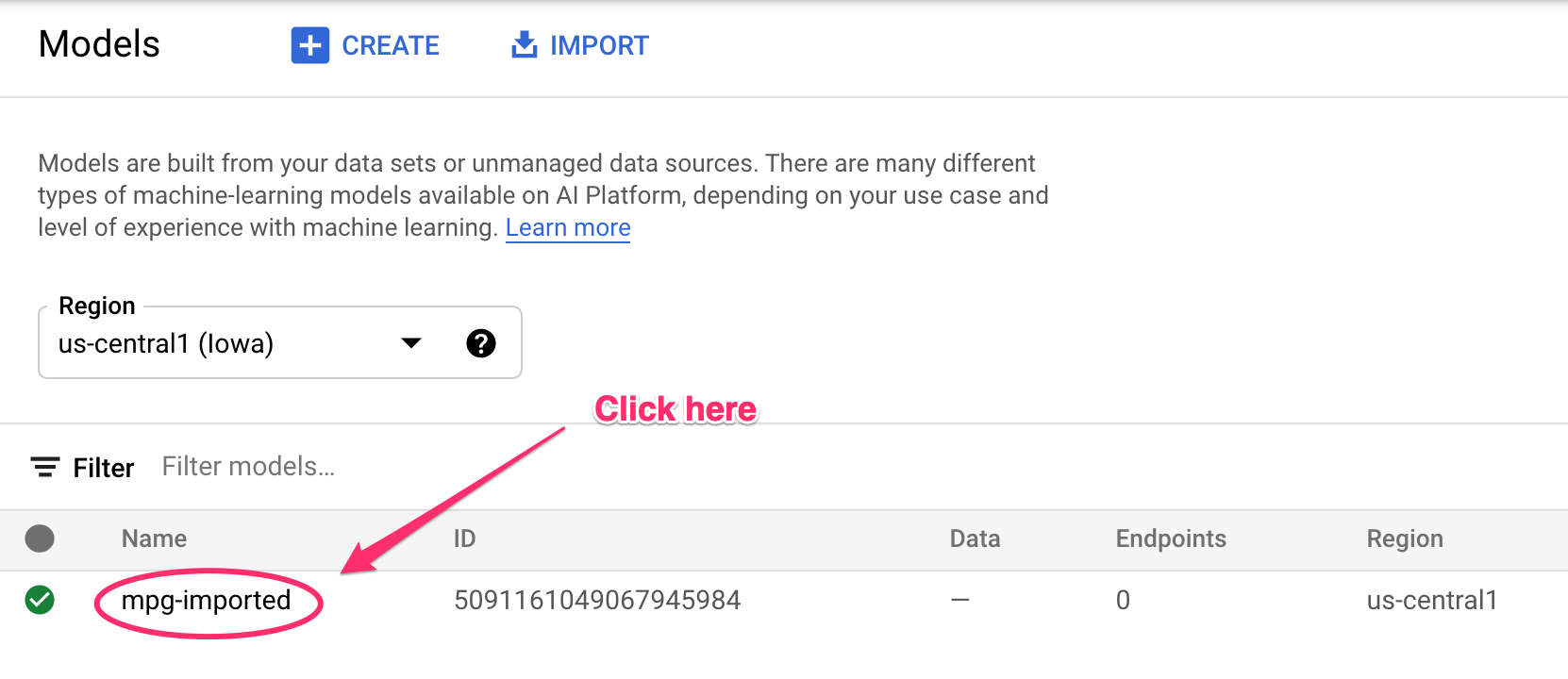
Cliquez sur mgp-imported . Vous devriez voir le point de terminaison de ce modèle en cours de création :
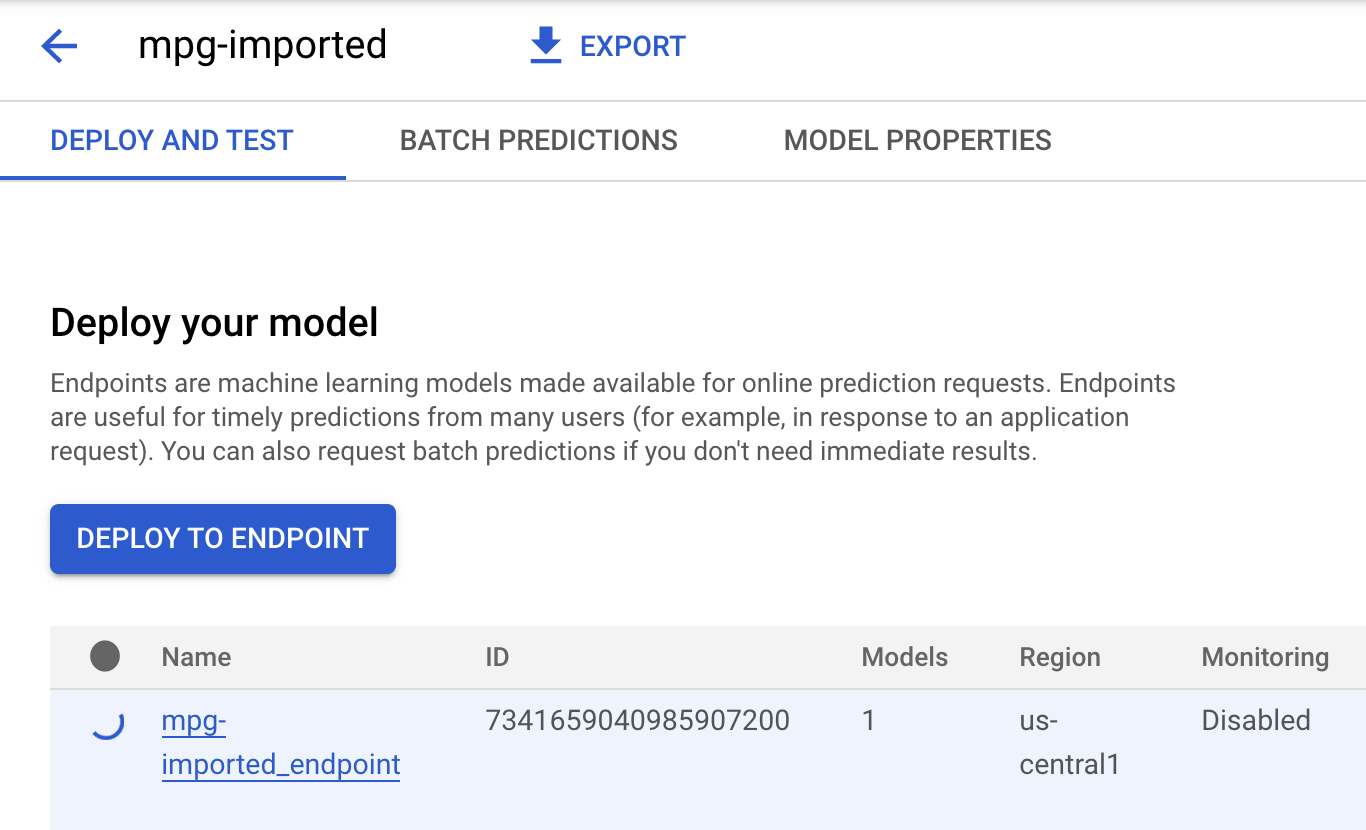
Dans votre terminal Cloud Shell, vous verrez un journal semblable à celui-ci une fois le déploiement de votre point de terminaison terminé :
Endpoint model deployed. Resource name: projects/your-project-id/locations/us-central1/endpoints/your-endpoint-id
Vous l'utiliserez à l'étape suivante pour obtenir une prédiction sur votre point de terminaison déployé.
Étape 3 : Obtenez des prédictions sur le point de terminaison déployé
Dans votre éditeur Cloud Shell, créez un fichier nommé predict.py :
Ouvrez predict.py et collez-y le code suivant :
from google.cloud import aiplatform
endpoint = aiplatform.Endpoint(
endpoint_name="ENDPOINT_STRING"
)
# A test example we'll send to our model for prediction
test_mpg = [1.4838871833555929,
1.8659883497083019,
2.234620276849616,
1.0187816540094903,
-2.530890710602246,
-1.6046416850441676,
-0.4651483719733302,
-0.4952254087173721,
0.7746763768735953]
response = endpoint.predict([test_mpg])
print('API response: ', response)
print('Predicted MPG: ', response.predictions[0][0])
Revenez ensuite à votre terminal et saisissez la commande suivante pour remplacer ENDPOINT_STRING dans le fichier de prédiction par votre propre point de terminaison :
ENDPOINT=$(cat deploy-output.txt | sed -nre 's:.*Resource name\: (.*):\1:p' | tail -1)
sed -i "s|ENDPOINT_STRING|$ENDPOINT|g" predict.py
Il est maintenant temps d'exécuter le fichier predict.py pour obtenir une prédiction à partir de notre point de terminaison de modèle déployé :
python3 predict.py
La réponse de l'API s'affiche, ainsi que le rendement énergétique prédit pour notre prédiction de test.
🎉 Félicitations ! 🎉
Vous savez désormais utiliser Vertex AI pour :
- Entraîner un modèle en fournissant le code d'entraînement dans un conteneur personnalisé : dans cet exemple, vous avez utilisé un modèle TensorFlow, mais vous pouvez entraîner un modèle créé avec n'importe quel framework à l'aide de conteneurs personnalisés.
- Déployer un modèle TensorFlow à l'aide d'un conteneur préconfiguré dans le cadre du workflow que vous avez déjà utilisé pour l'entraînement
- Créer un point de terminaison de modèle et générer une prédiction
Pour en savoir plus sur les différentes parties de Vertex AI, consultez la documentation. Si vous souhaitez afficher les résultats du job d'entraînement que vous avez démarré à l'étape 5, accédez à la section Entraînement de votre console Vertex.
7. Nettoyage
Pour supprimer le point de terminaison que vous avez déployé, accédez à la section Points de terminaison de votre console Vertex et cliquez sur l'icône de suppression :

Pour supprimer le bucket de stockage, utilisez le menu de navigation de la console Cloud pour accéder à Stockage, sélectionnez votre bucket puis cliquez sur "Supprimer" :