1. Übersicht
In diesem Lab erfahren Sie, wie Sie mit Vertex AI, der neu angekündigten verwalteten ML-Plattform von Google Cloud, End-to-End-ML-Workflows erstellen. Sie lernen, wie Sie von Rohdaten zu einem bereitgestellten Modell gelangen, und sind nach diesem Workshop bereit, Ihre eigenen ML-Projekte mit Vertex AI zu entwickeln und in die Produktion zu überführen. In diesem Lab verwenden wir Cloud Shell, um ein benutzerdefiniertes Docker-Image zu erstellen und benutzerdefinierte Container für das Training mit Vertex AI zu demonstrieren.
Wir verwenden hier TensorFlow für den Modellcode, aber Sie können ihn problemlos durch ein anderes Framework ersetzen.
Lerninhalte
Die folgenden Themen werden behandelt:
- Modelltrainingscode mit Cloud Shell erstellen und containerisieren
- Benutzerdefinierten Modelltrainingsjob an Vertex AI senden
- Trainiertes Modell auf einem Endpunkt bereitstellen und diesen Endpunkt verwenden, um Vorhersagen zu erhalten
Die Gesamtkosten für die Ausführung dieses Labs in Google Cloud betragen etwa 2$.
2. Einführung in Vertex AI
In diesem Lab wird das neueste KI-Produktangebot von Google Cloud verwendet. Vertex AI vereint die ML-Angebote von Google Cloud in einer nahtlosen Entwicklungsumgebung. Bisher musste auf mit AutoML trainierte und benutzerdefinierte Modelle über verschiedene Dienste zugegriffen werden. Das neue Angebot kombiniert diese und weitere, neue Produkte zu einer einzigen API. Sie können auch vorhandene Projekte zu Vertex AI migrieren. Wenn Sie Feedback haben, rufen Sie die Supportseite auf.
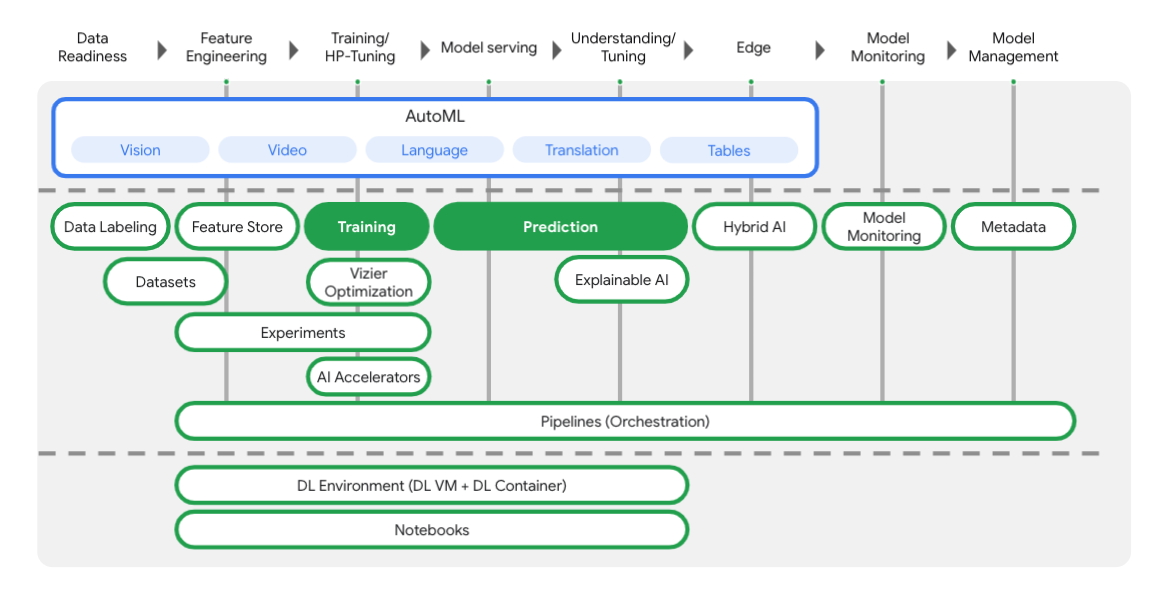
Vertex umfasst viele verschiedene Tools, die Sie in jeder Phase des ML-Workflows unterstützen, wie Sie im folgenden Diagramm sehen. Wir konzentrieren uns auf die Verwendung von Vertex Training und Prediction, die unten hervorgehoben sind.
3. Umgebung einrichten
Umgebung zum selbstbestimmten Lernen einrichten
Melden Sie sich in der Cloud Console an und erstellen Sie ein neues Projekt oder verwenden Sie ein vorhandenes. Wenn Sie noch kein Gmail- oder Google Workspace-Konto haben, müssen Sie eines erstellen.

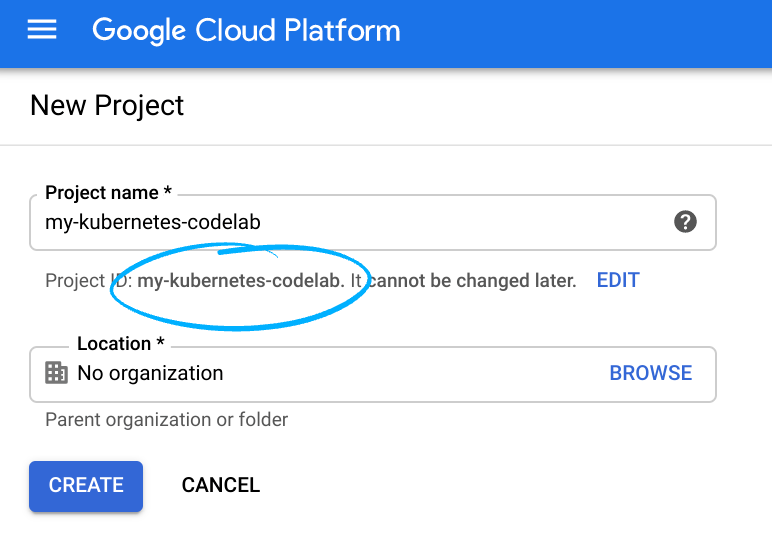
Notieren Sie sich die Projekt-ID, also den projektübergreifend nur einmal vorkommenden Namen eines Google Cloud-Projekts. Der oben angegebene Name ist bereits vergeben und kann leider nicht mehr verwendet werden.
Als Nächstes müssen Sie die Abrechnung in der Cloud Console aktivieren, um Google Cloud-Ressourcen verwenden zu können.
Die Ausführung dieses Codelabs sollte wenig oder gar nichts kosten. Folgen Sie der Anleitung im Abschnitt „Bereinigen“, in der Sie erfahren, wie Sie Ressourcen herunterfahren, damit Ihnen keine Kosten über diese Anleitung hinaus entstehen. Neue Google Cloud-Nutzer können am kostenlosen Testprogramm im Wert von 300$ teilnehmen.
Schritt 1: Cloud Shell starten
In diesem Lab arbeiten Sie in einer Cloud Shell-Sitzung. Das ist ein Befehlsinterpreter, der auf einer virtuellen Maschine in der Google Cloud gehostet wird. Sie könnten diesen Abschnitt auch lokal auf Ihrem eigenen Computer ausführen. Mit Cloud Shell haben jedoch alle Nutzer Zugriff auf eine reproduzierbare Umgebung. Nach dem Lab können Sie diesen Abschnitt gern auf Ihrem eigenen Computer wiederholen.
Cloud Shell aktivieren
Klicken Sie rechts oben in der Cloud Console auf die Schaltfläche Cloud Shell aktivieren:

Wenn Sie Cloud Shell noch nie gestartet haben, wird ein Fenster mit einer Beschreibung eingeblendet. Klicken Sie in diesem Fall einfach auf Weiter. So sieht dieses Fenster aus:
Das Herstellen der Verbindung mit der Cloud Shell sollte nur wenige Augenblicke dauern.

Diese virtuelle Maschine enthält alle Entwicklungstools, die Sie benötigen. Sie bietet ein Basisverzeichnis mit 5 GB nichtflüchtigem Speicher und läuft in Google Cloud, was die Netzwerkleistung und Authentifizierung erheblich verbessert. Die meisten, wenn nicht sogar alle Aufgaben in diesem Codelab können mit einem Browser oder Chromebook erledigt werden.
Sobald die Verbindung mit der Cloud Shell hergestellt ist, sehen Sie, dass Sie bereits authentifiziert sind und für das Projekt schon Ihre Projekt-ID eingestellt ist.
Führen Sie in der Cloud Shell den folgenden Befehl aus, um zu prüfen, ob Sie authentifiziert sind:
gcloud auth list
Befehlsausgabe
Credentialed Accounts
ACTIVE ACCOUNT
* <my_account>@<my_domain.com>
To set the active account, run:
$ gcloud config set account `ACCOUNT`
Führen Sie in der Cloud Shell den folgenden Befehl aus, um zu prüfen, ob der gcloud-Befehl Ihr Projekt kennt:
gcloud config list project
Befehlsausgabe
[core] project = <PROJECT_ID>
Ist dies nicht der Fall, können Sie die Einstellung mit diesem Befehl vornehmen:
gcloud config set project <PROJECT_ID>
Befehlsausgabe
Updated property [core/project].
Cloud Shell hat einige Umgebungsvariablen, darunter GOOGLE_CLOUD_PROJECT, die den Namen unseres aktuellen Cloud-Projekts enthält. Wir verwenden diese Variable an verschiedenen Stellen in diesem Lab. Sie können sie mit folgendem Befehl aufrufen:
echo $GOOGLE_CLOUD_PROJECT
Schritt 2: APIs aktivieren
In späteren Schritten erfahren Sie, wo diese Dienste benötigt werden und warum. Führen Sie jetzt diesen Befehl aus, um Ihrem Projekt Zugriff auf die Dienste Compute Engine, Container Registry und Vertex AI zu gewähren:
gcloud services enable compute.googleapis.com \
containerregistry.googleapis.com \
aiplatform.googleapis.com
Wenn die Aktivierung erfolgreich war, erhalten Sie eine Meldung, die ungefähr so aussieht:
Operation "operations/acf.cc11852d-40af-47ad-9d59-477a12847c9e" finished successfully.
Schritt 3: Cloud Storage-Bucket erstellen
Um einen Trainingsjob in Vertex AI auszuführen, benötigen wir einen Storage-Bucket, in dem wir unsere gespeicherten Modellressourcen speichern können. Führen Sie in Ihrem Cloud Shell-Terminal die folgenden Befehle aus, um einen Bucket zu erstellen:
BUCKET_NAME=gs://$GOOGLE_CLOUD_PROJECT-bucket
gsutil mb -l us-central1 $BUCKET_NAME
Schritt 4: Alias für Python 3 erstellen
Der Code in diesem Lab verwendet Python 3. Damit Sie Python 3 verwenden, wenn Sie die in diesem Lab erstellten Skripts ausführen, erstellen Sie einen Alias, indem Sie Folgendes in Cloud Shell ausführen:
alias python=python3
Das Modell, das wir in diesem Lab trainieren und bereitstellen, basiert auf dieser Anleitung aus der TensorFlow-Dokumentation. In der Anleitung wird das Auto MPG-Dataset von Kaggle verwendet, um den Kraftstoffverbrauch eines Fahrzeugs vorherzusagen.
4. Trainingscode containerisieren
Wir senden diesen Trainingsjob an Vertex, indem wir unseren Trainingscode in einen Docker-Container packen und diesen Container in die Google Container Registry hochladen. Mit diesem Ansatz können wir ein Modell trainieren, das mit einem beliebigen Framework erstellt wurde.
Schritt 1: Dateien einrichten
Führen Sie im Terminal in Cloud Shell die folgenden Befehle aus, um die Dateien zu erstellen, die wir für unseren Docker-Container benötigen:
mkdir mpg
cd mpg
touch Dockerfile
mkdir trainer
touch trainer/train.py
Sie sollten jetzt ein Verzeichnis mpg/ haben, das so aussieht:
+ Dockerfile
+ trainer/
+ train.py
Zum Ansehen und Bearbeiten dieser Dateien verwenden wir den integrierten Code-Editor von Cloud Shell. Sie können zwischen dem Editor und dem Terminal wechseln, indem Sie auf die Schaltfläche in der Menüleiste rechts oben in Cloud Shell klicken:

Schritt 2: Dockerfile erstellen
Um unseren Code zu containerisieren, erstellen wir zuerst ein Dockerfile. In unserem Dockerfile sind alle Befehle enthalten, die zum Ausführen unseres Images erforderlich sind. Es werden alle von uns verwendeten Bibliotheken installiert und der Einstiegspunkt für unseren Trainingscode eingerichtet.
Öffnen Sie im Cloud Shell-Dateieditor das Verzeichnis mpg/ und doppelklicken Sie dann auf das Dockerfile, um es zu öffnen:
Kopieren Sie dann Folgendes in diese Datei:
FROM gcr.io/deeplearning-platform-release/tf2-cpu.2-3
WORKDIR /
# Copies the trainer code to the docker image.
COPY trainer /trainer
# Sets up the entry point to invoke the trainer.
ENTRYPOINT ["python", "-m", "trainer.train"]
Dieses Dockerfile verwendet das Docker-Image TensorFlow Enterprise 2.3 von Deep Learning Container. Die Deep Learning Container in Google Cloud enthalten viele gängige ML- und Data-Science-Frameworks, die vorinstalliert sind. Das von uns verwendete Image enthält unter anderem TF Enterprise 2.3, Pandas und Scikit-learn. Nach dem Herunterladen dieses Images wird in diesem Dockerfile der Einstiegspunkt für unseren Trainingscode eingerichtet, den wir im nächsten Schritt hinzufügen.
Schritt 3: Modelltrainingscode hinzufügen
Öffnen Sie im Cloud Shell-Editor die Datei train.py und kopieren Sie den folgenden Code. Dieser Code wurde aus der Anleitung in der TensorFlow-Dokumentation übernommen.
# This will be replaced with your bucket name after running the `sed` command in the tutorial
BUCKET = "BUCKET_NAME"
import numpy as np
import pandas as pd
import pathlib
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
print(tf.__version__)
"""## The Auto MPG dataset
The dataset is available from the [UCI Machine Learning Repository](https://archive.ics.uci.edu/ml/).
### Get the data
First download the dataset.
"""
"""Import it using pandas"""
dataset_path = "https://storage.googleapis.com/io-vertex-codelab/auto-mpg.csv"
dataset = pd.read_csv(dataset_path, na_values = "?")
dataset.tail()
"""### Clean the data
The dataset contains a few unknown values.
"""
dataset.isna().sum()
"""To keep this initial tutorial simple drop those rows."""
dataset = dataset.dropna()
"""The `"origin"` column is really categorical, not numeric. So convert that to a one-hot:"""
dataset['origin'] = dataset['origin'].map({1: 'USA', 2: 'Europe', 3: 'Japan'})
dataset = pd.get_dummies(dataset, prefix='', prefix_sep='')
dataset.tail()
"""### Split the data into train and test
Now split the dataset into a training set and a test set.
We will use the test set in the final evaluation of our model.
"""
train_dataset = dataset.sample(frac=0.8,random_state=0)
test_dataset = dataset.drop(train_dataset.index)
"""### Inspect the data
Have a quick look at the joint distribution of a few pairs of columns from the training set.
Also look at the overall statistics:
"""
train_stats = train_dataset.describe()
train_stats.pop("mpg")
train_stats = train_stats.transpose()
train_stats
"""### Split features from labels
Separate the target value, or "label", from the features. This label is the value that you will train the model to predict.
"""
train_labels = train_dataset.pop('mpg')
test_labels = test_dataset.pop('mpg')
"""### Normalize the data
Look again at the `train_stats` block above and note how different the ranges of each feature are.
It is good practice to normalize features that use different scales and ranges. Although the model *might* converge without feature normalization, it makes training more difficult, and it makes the resulting model dependent on the choice of units used in the input.
Note: Although we intentionally generate these statistics from only the training dataset, these statistics will also be used to normalize the test dataset. We need to do that to project the test dataset into the same distribution that the model has been trained on.
"""
def norm(x):
return (x - train_stats['mean']) / train_stats['std']
normed_train_data = norm(train_dataset)
normed_test_data = norm(test_dataset)
"""This normalized data is what we will use to train the model.
Caution: The statistics used to normalize the inputs here (mean and standard deviation) need to be applied to any other data that is fed to the model, along with the one-hot encoding that we did earlier. That includes the test set as well as live data when the model is used in production.
## The model
### Build the model
Let's build our model. Here, we'll use a `Sequential` model with two densely connected hidden layers, and an output layer that returns a single, continuous value. The model building steps are wrapped in a function, `build_model`, since we'll create a second model, later on.
"""
def build_model():
model = keras.Sequential([
layers.Dense(64, activation='relu', input_shape=[len(train_dataset.keys())]),
layers.Dense(64, activation='relu'),
layers.Dense(1)
])
optimizer = tf.keras.optimizers.RMSprop(0.001)
model.compile(loss='mse',
optimizer=optimizer,
metrics=['mae', 'mse'])
return model
model = build_model()
"""### Inspect the model
Use the `.summary` method to print a simple description of the model
"""
model.summary()
"""Now try out the model. Take a batch of `10` examples from the training data and call `model.predict` on it.
It seems to be working, and it produces a result of the expected shape and type.
### Train the model
Train the model for 1000 epochs, and record the training and validation accuracy in the `history` object.
Visualize the model's training progress using the stats stored in the `history` object.
This graph shows little improvement, or even degradation in the validation error after about 100 epochs. Let's update the `model.fit` call to automatically stop training when the validation score doesn't improve. We'll use an *EarlyStopping callback* that tests a training condition for every epoch. If a set amount of epochs elapses without showing improvement, then automatically stop the training.
You can learn more about this callback [here](https://www.tensorflow.org/api_docs/python/tf/keras/callbacks/EarlyStopping).
"""
model = build_model()
EPOCHS = 1000
# The patience parameter is the amount of epochs to check for improvement
early_stop = keras.callbacks.EarlyStopping(monitor='val_loss', patience=10)
early_history = model.fit(normed_train_data, train_labels,
epochs=EPOCHS, validation_split = 0.2,
callbacks=[early_stop])
# Export model and save to GCS
model.save(BUCKET + '/mpg/model')
Nachdem Sie den obigen Code in die Datei mpg/trainer/train.py kopiert haben, kehren Sie zum Terminal in Cloud Shell zurück und führen Sie den folgenden Befehl aus, um den Namen Ihres eigenen Buckets zur Datei hinzuzufügen:
sed -i "s|BUCKET_NAME|$BUCKET_NAME|g" trainer/train.py
Schritt 4: Container lokal erstellen und testen
Führen Sie im Terminal den folgenden Befehl aus, um eine Variable mit dem URI Ihres Container-Images in Google Container Registry zu definieren:
IMAGE_URI="gcr.io/$GOOGLE_CLOUD_PROJECT/mpg:v1"
Erstellen Sie dann den Container, indem Sie den folgenden Befehl im Stammverzeichnis von mpg ausführen:
docker build ./ -t $IMAGE_URI
Nachdem Sie den Container erstellt haben, laden Sie ihn in Google Container Registry hoch:
docker push $IMAGE_URI
Wenn Sie prüfen möchten, ob Ihr Image in Container Registry hochgeladen wurde, sollten Sie beim Aufrufen des Abschnitts „Container Registry“ in der Console etwa Folgendes sehen:
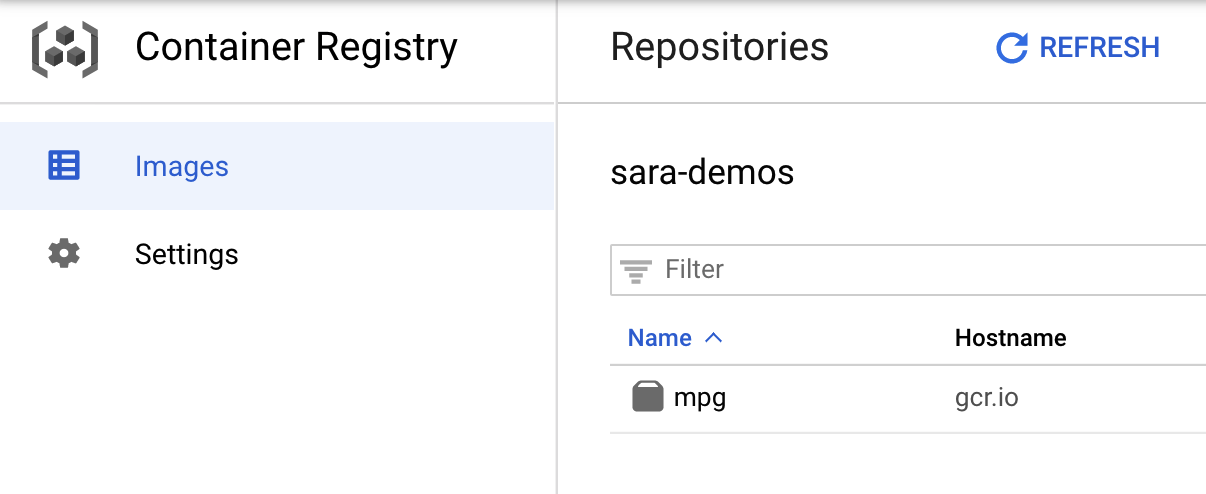
Nachdem unser Container in Container Registry hochgeladen wurde, können wir einen benutzerdefinierten Modelltrainingsjob starten.
5. Trainingsjob in Vertex AI ausführen
Vertex bietet zwei Optionen zum Trainieren von Modellen:
- AutoML: Trainieren Sie mit minimalem Aufwand und minimalen Fachkenntnissen zu maschinellem Lernen hochwertige Modelle.
- Benutzerdefiniertes Training: Führen Sie Ihre benutzerdefinierten Trainingsanwendungen in der Cloud aus. Nutzen Sie dazu einen der vordefinierten Container von Google Cloud oder einen eigenen Container.
In diesem Lab verwenden wir benutzerdefiniertes Training mit unserem eigenen benutzerdefinierten Container in Google Container Registry. Rufen Sie dazu in der Cloud Console im Bereich „Vertex“ den Abschnitt Training auf:
Schritt 1: Trainingsjob starten
Klicken Sie auf Erstellen , um die Parameter für Ihren Trainingsjob und das bereitgestellte Modell einzugeben:
- Wählen Sie unter Dataset die Option Kein verwaltetes Dataset aus.
- Wählen Sie dann Benutzerdefiniertes Training (erweitert) als Trainingsmethode aus und klicken Sie auf Weiter.
- Geben Sie unter Modellname
mpgein (oder einen beliebigen anderen Namen für Ihr Modell). - Klicken Sie auf Weiter.
Wählen Sie im Schritt „Containereinstellungen“ die Option Benutzerdefinierter Container aus:

Klicken Sie im ersten Feld (Container-Image) auf Durchsuchen und suchen Sie den Container, den Sie gerade in Container Registry hochgeladen haben. Die Ausgabe sollte ungefähr so aussehen:
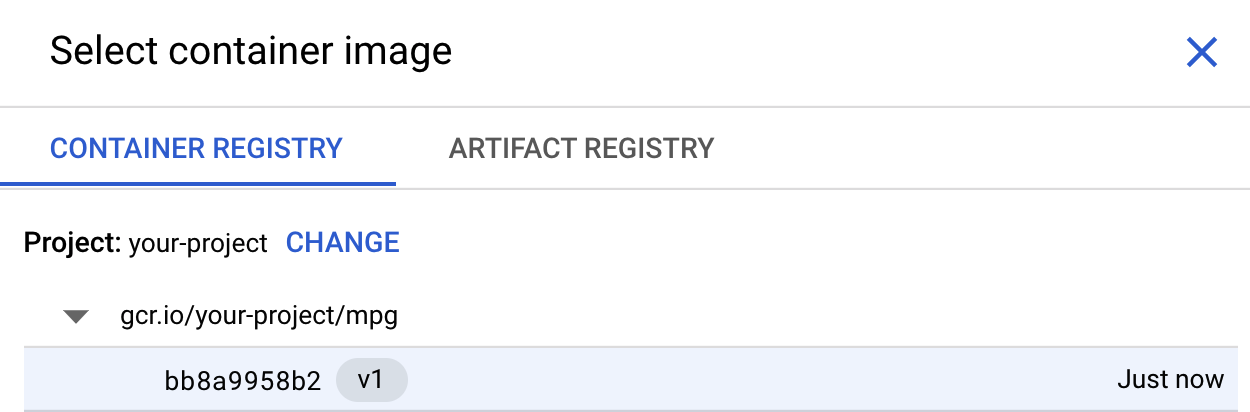
Lassen Sie die übrigen Felder leer und klicken Sie auf Weiter.
In dieser Anleitung verwenden wir keine Hyperparameter-Abstimmung. Lassen Sie das Kästchen Hyperparameter-Abstimmung aktivieren deaktiviert und klicken Sie auf Weiter.
Lassen Sie unter Compute und Preise die ausgewählte Region unverändert und wählen Sie n1-standard-4 als Maschinentyp aus:
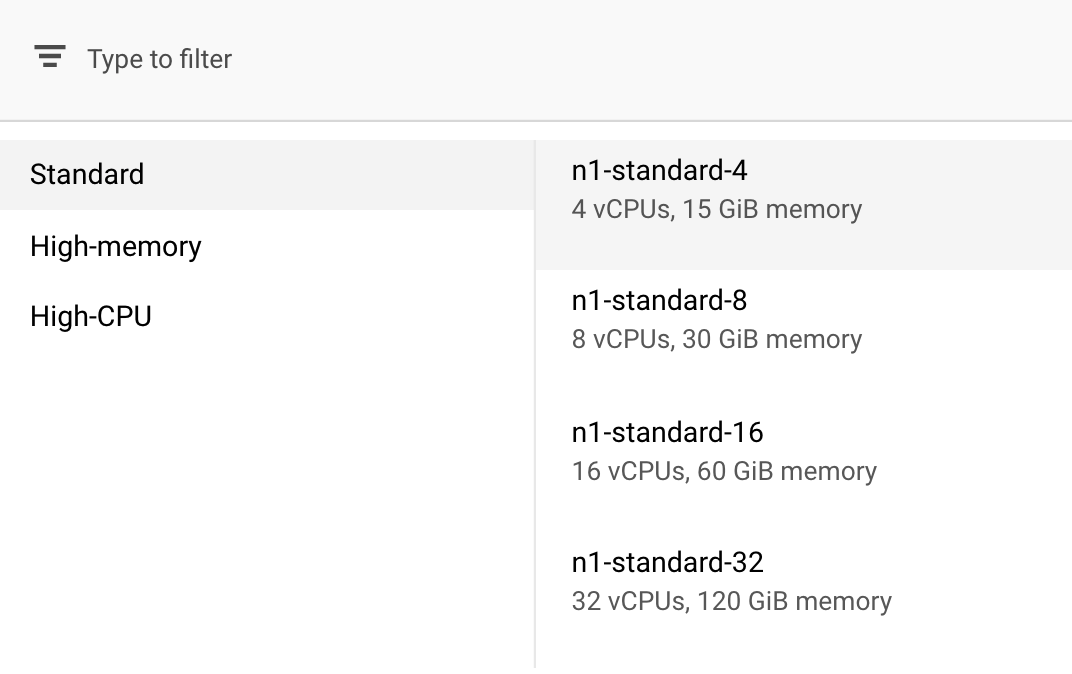
Da das Modell in dieser Demo schnell trainiert wird, verwenden wir einen kleineren Maschinentyp.
Wählen Sie im Schritt Vorhersagecontainer die Option Kein Vorhersagecontainer aus:
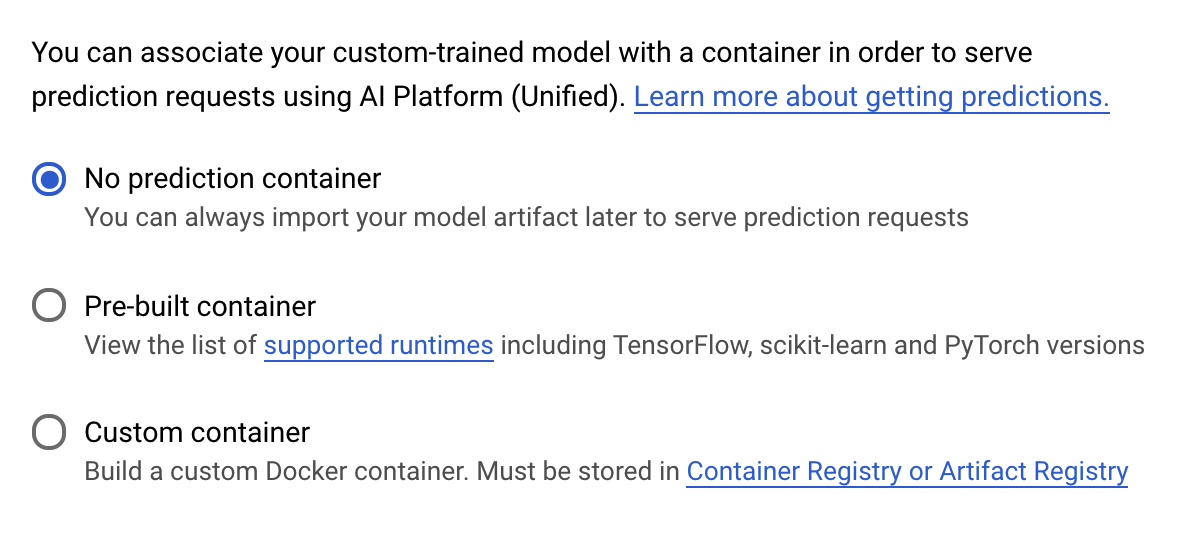
6. Modellendpunkt bereitstellen
In diesem Schritt erstellen wir einen Endpunkt für unser trainiertes Modell. Wir können diesen Endpunkt verwenden, um über die Vertex AI API Vorhersagen für unser Modell zu erhalten. Dazu haben wir eine Version der exportierten trainierten Modellressourcen in einem öffentlichen GCS-Bucket zur Verfügung gestellt.
In einer Organisation ist es üblich, dass ein Team oder eine Person für die Erstellung des Modells und ein anderes Team für die Bereitstellung zuständig ist. In den folgenden Schritten erfahren Sie, wie Sie ein bereits trainiertes Modell bereitstellen, um Vorhersagen zu erhalten.
Hier verwenden wir das Vertex AI SDK, um ein Modell zu erstellen, es auf einem Endpunkt bereitzustellen und eine Vorhersage zu erhalten.
Schritt 1: Vertex SDK installieren
Führen Sie im Cloud Shell-Terminal den folgenden Befehl aus, um das Vertex AI SDK zu installieren:
pip3 install google-cloud-aiplatform --upgrade --user
Mit diesem SDK können wir mit vielen verschiedenen Teilen von Vertex interagieren.
Schritt 2: Modell erstellen und Endpunkt bereitstellen
Als Nächstes erstellen wir eine Python-Datei und verwenden das SDK, um eine Modellressource zu erstellen und sie auf einem Endpunkt bereitzustellen. Wählen Sie im Dateieditor in Cloud Shell Datei und dann Neue Datei aus:
Nennen Sie die Datei deploy.py. Öffnen Sie diese Datei im Editor und kopieren Sie den folgenden Code:
from google.cloud import aiplatform
# Create a model resource from public model assets
model = aiplatform.Model.upload(
display_name="mpg-imported",
artifact_uri="gs://io-vertex-codelab/mpg-model/",
serving_container_image_uri="gcr.io/cloud-aiplatform/prediction/tf2-cpu.2-3:latest"
)
# Deploy the above model to an endpoint
endpoint = model.deploy(
machine_type="n1-standard-4"
)
Kehren Sie dann zum Terminal in Cloud Shell zurück, wechseln Sie mit cd wieder in das Stammverzeichnis und führen Sie dieses gerade erstellte Python-Skript aus:
cd ..
python3 deploy.py | tee deploy-output.txt
Sie sehen Protokollaktualisierungen im Terminal, während Ressourcen erstellt werden. Dieser Vorgang dauert 10 bis 15 Minuten. Um zu prüfen, ob alles richtig funktioniert, rufen Sie in Vertex AI den Abschnitt „Modelle“ in der Console auf:
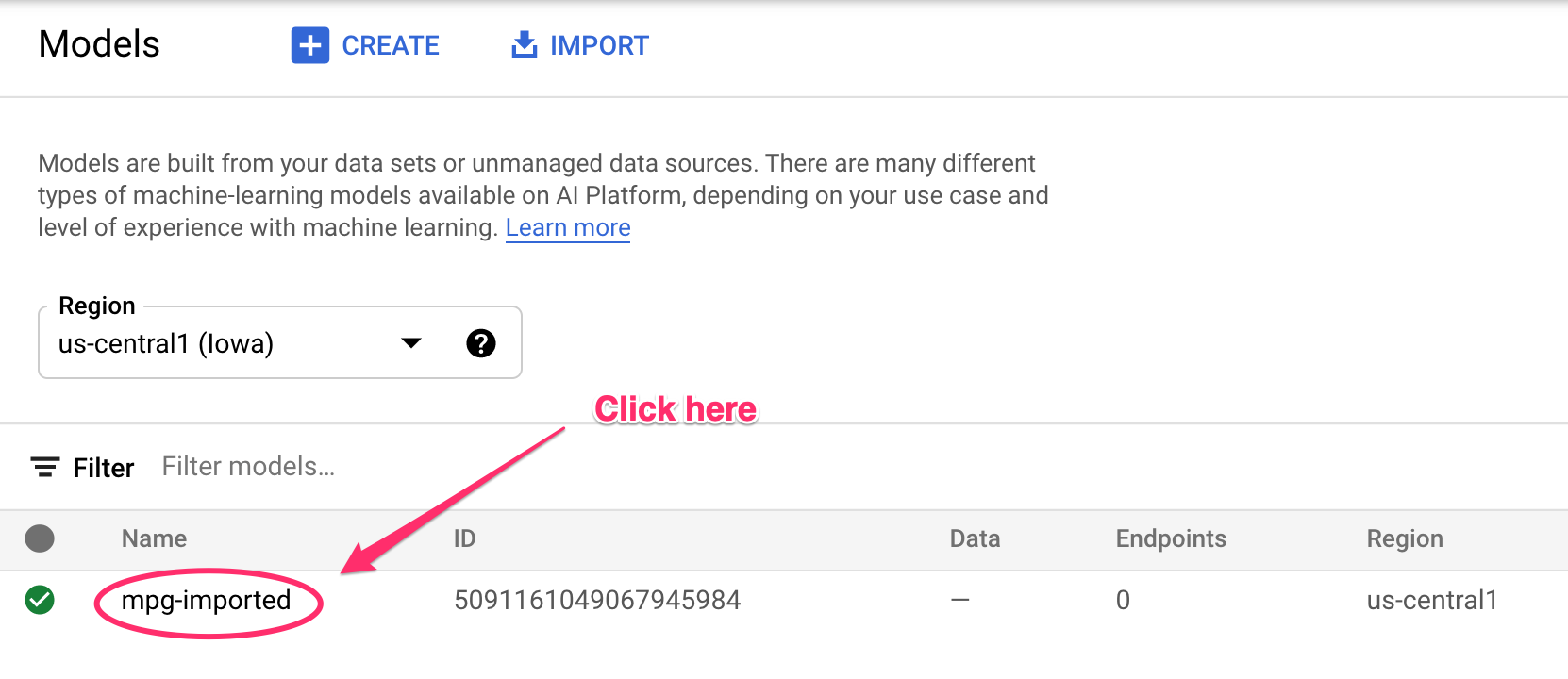
Klicken Sie auf mgp-imported. Sie sollten sehen, dass der Endpunkt für dieses Modell erstellt wird:
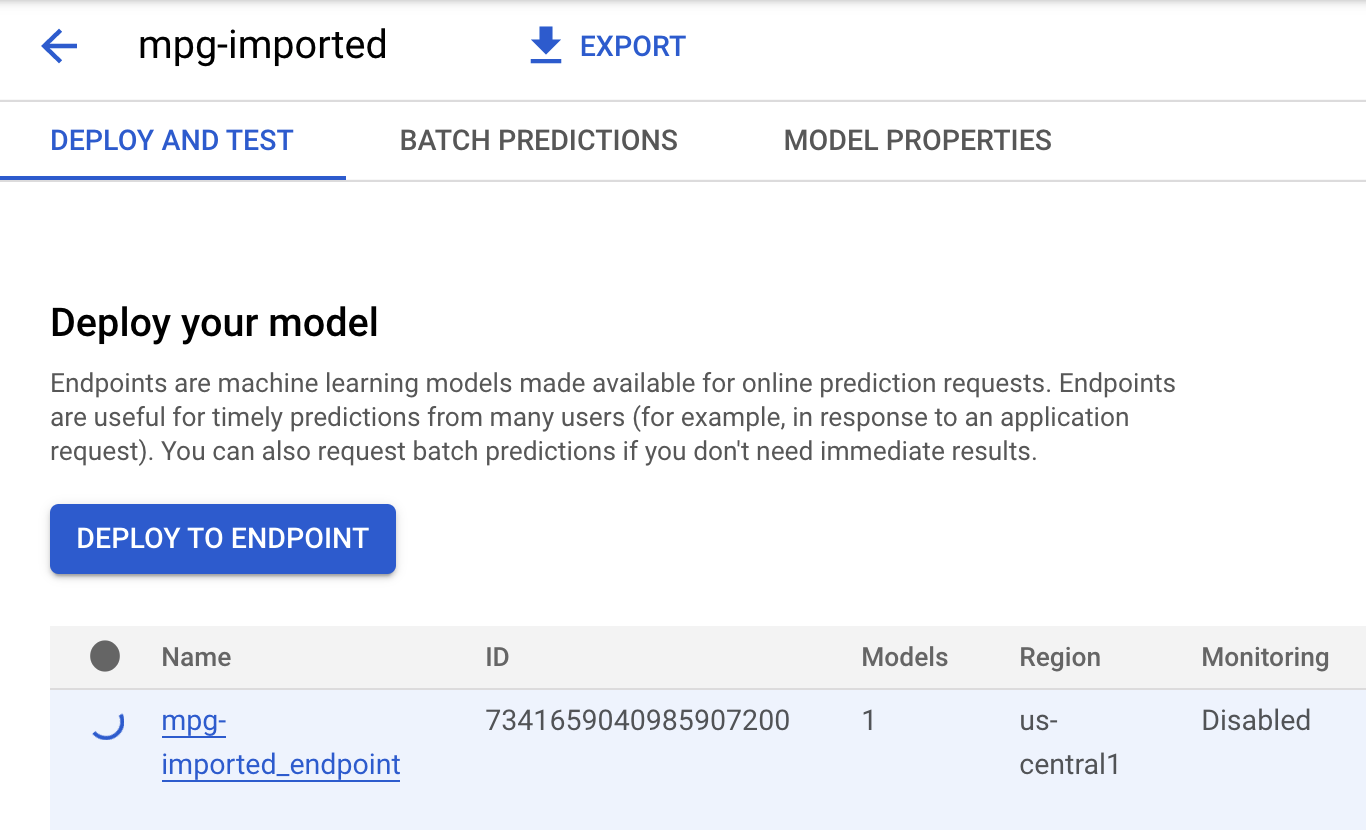
In Ihrem Cloud Shell-Terminal sehen Sie nach Abschluss der Endpunktbereitstellung einen Log wie den folgenden:
Endpoint model deployed. Resource name: projects/your-project-id/locations/us-central1/endpoints/your-endpoint-id
Diesen Log verwenden Sie im nächsten Schritt, um eine Vorhersage für den bereitgestellten Endpunkt zu erhalten.
Schritt 3: Vorhersagen für den bereitgestellten Endpunkt abrufen
Erstellen Sie im Cloud Shell-Editor eine neue Datei mit dem Namen predict.py:
Öffnen Sie predict.py und fügen Sie den folgenden Code ein:
from google.cloud import aiplatform
endpoint = aiplatform.Endpoint(
endpoint_name="ENDPOINT_STRING"
)
# A test example we'll send to our model for prediction
test_mpg = [1.4838871833555929,
1.8659883497083019,
2.234620276849616,
1.0187816540094903,
-2.530890710602246,
-1.6046416850441676,
-0.4651483719733302,
-0.4952254087173721,
0.7746763768735953]
response = endpoint.predict([test_mpg])
print('API response: ', response)
print('Predicted MPG: ', response.predictions[0][0])
Kehren Sie dann zum Terminal zurück und geben Sie Folgendes ein, um ENDPOINT_STRING in der Vorhersagedatei durch Ihren eigenen Endpunkt zu ersetzen:
ENDPOINT=$(cat deploy-output.txt | sed -nre 's:.*Resource name\: (.*):\1:p' | tail -1)
sed -i "s|ENDPOINT_STRING|$ENDPOINT|g" predict.py
Jetzt können Sie die Datei predict.py ausführen, um eine Vorhersage von unserem bereitgestellten Modellendpunkt zu erhalten:
python3 predict.py
Sie sollten die Antwort der API zusammen mit dem vorhergesagten Kraftstoffverbrauch für unsere Testvorhersage sehen.
🎉 Das wars! 🎉
Sie haben gelernt, wie Sie Vertex AI für Folgendes verwenden:
- Modell trainieren, indem Sie den Trainingscode in einem benutzerdefinierten Container bereitstellen. In diesem Beispiel haben Sie ein TensorFlow-Modell verwendet, aber Sie können mit benutzerdefinierten Containern ein Modell trainieren, das mit einem beliebigen Framework erstellt wurde.
- TensorFlow-Modell mit einem vordefinierten Container im selben Workflow bereitstellen, den Sie für das Training verwendet haben.
- Modellendpunkt erstellen und eine Vorhersage generieren.
Weitere Informationen zu den verschiedenen Bereichen von Vertex AI finden Sie in der Dokumentation. Wenn Sie die Ergebnisse des Trainingsjobs sehen möchten, den Sie in Schritt 5 gestartet haben, rufen Sie in der Vertex-Console den Abschnitt „Training“ auf.
7. Bereinigen
Wenn Sie den bereitgestellten Endpunkt löschen möchten, rufen Sie in der Vertex-Console den Abschnitt Endpunkte auf und klicken Sie auf das Löschsymbol:

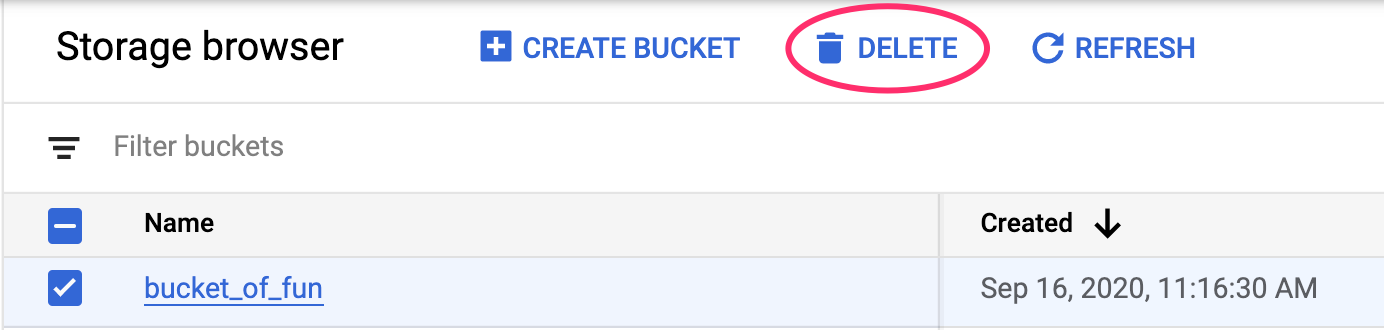
Wenn Sie den Storage-Bucket löschen möchten, rufen Sie in der Cloud Console über das Navigationsmenü „Storage“ auf, wählen Sie den Bucket aus und klicken Sie auf „Löschen“: