1. نظرة عامة
في هذا الدرس التطبيقي، ستتعرّف على كيفية استخدام Vertex AI، وهي منصة مُدارة لتعلُّم الآلة أعلنت عنها Google Cloud مؤخرًا، وذلك لإنشاء مهام سير عمل متكاملة لتعلُّم الآلة. ستتعرّف على كيفية الانتقال من البيانات الأولية إلى النموذج الذي تمّ نشره، وستغادر ورشة العمل هذه وأنت مستعد لتطوير مشاريع تعلُّم الآلة الخاصة بك ونشرها باستخدام Vertex AI. في هذه الميزة الاختبارية، سنستخدم Cloud Shell لإنشاء صورة Docker مخصّصة من أجل عرض الحاويات المخصّصة للتدريب باستخدام Vertex AI.
مع أنّنا نستخدم TensorFlow لرمز النموذج هنا، يمكنك استبداله بسهولة بإطار عمل آخر.
ما ستتعلمه
ستتعرَّف على كيفية:
- إنشاء رمز تدريب النموذج وتضمينه في حاوية باستخدام Cloud Shell
- إرسال مهمة تدريب نموذج مخصّص إلى Vertex AI
- فعِّل النموذج المُدرَّب في نقطة نهاية، واستخدِم نقطة النهاية هذه للحصول على توقّعات.
تبلغ التكلفة الإجمالية لتشغيل هذا الدرس التطبيقي على Google Cloud حوالي 2 دولار أمريكي.
2. مقدّمة عن Vertex AI
يستخدم هذا المختبر أحدث منتج مستند إلى الذكاء الاصطناعي متاح على Google Cloud. تدمج Vertex AI عروض تعلُّم الآلة على Google Cloud في تجربة تطوير سلسة. في السابق، كان يمكن الوصول إلى النماذج المدرَّبة باستخدام AutoML والنماذج المخصَّصة من خلال خدمات منفصلة. يجمع العرض الجديد بين كليهما في واجهة برمجة تطبيقات واحدة، بالإضافة إلى منتجات جديدة أخرى. يمكنك أيضًا نقل المشاريع الحالية إلى Vertex AI. إذا كانت لديك أي ملاحظات، يُرجى الانتقال إلى صفحة الدعم.
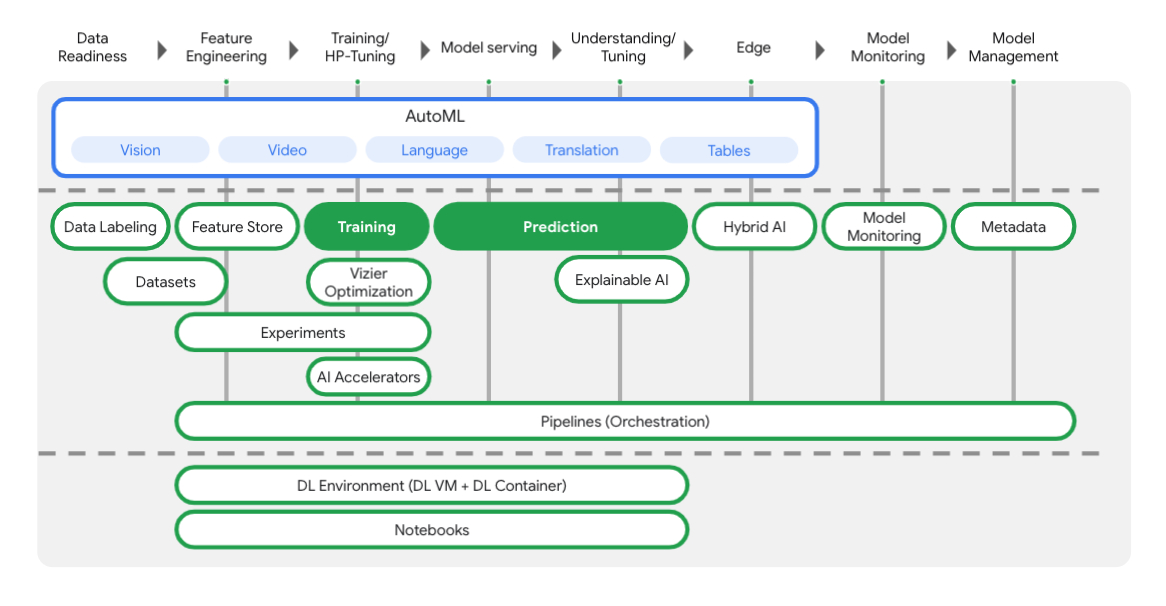
تتضمّن Vertex العديد من الأدوات المختلفة لمساعدتك في كل مرحلة من مراحل سير عمل تعلُّم الآلة، كما هو موضّح في الرسم البياني أدناه. سنركّز على استخدام Vertex Training وPrediction، كما هو موضّح أدناه.
3- إعداد البيئة
إعداد البيئة بوتيرة ذاتية
سجِّل الدخول إلى Cloud Console وأنشِئ مشروعًا جديدًا أو أعِد استخدام مشروع حالي. (إذا لم يكن لديك حساب على Gmail أو Google Workspace، عليك إنشاء حساب).

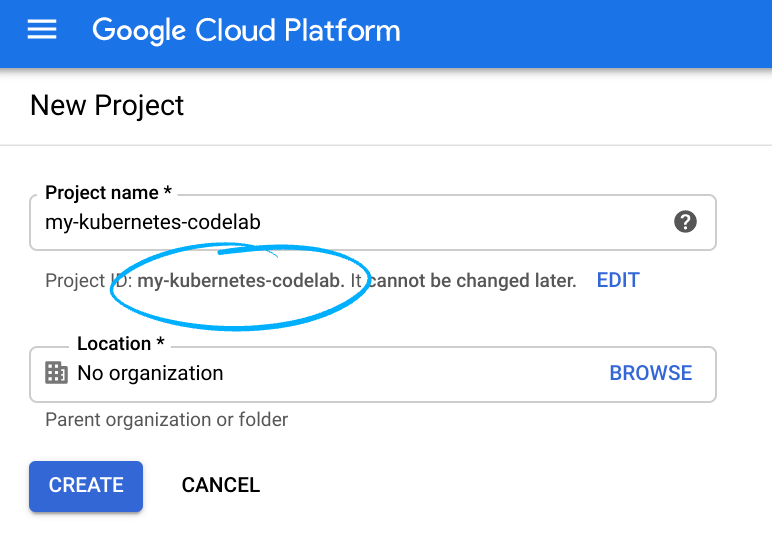
تذكَّر رقم تعريف المشروع، وهو اسم فريد في جميع مشاريع Google Cloud (الاسم أعلاه مستخدَم حاليًا ولن يكون متاحًا لك، نأسف لذلك).
بعد ذلك، عليك تفعيل الفوترة في Cloud Console من أجل استخدام موارد Google Cloud.
لن تكلفك تجربة هذا الدرس البرمجي الكثير من المال، إن لم تكلفك شيئًا على الإطلاق. احرص على اتّباع أي تعليمات في قسم "التنظيف" الذي ينصحك بكيفية إيقاف الموارد حتى لا يتم تحصيل رسوم منك بعد هذا البرنامج التعليمي. يمكن لمستخدمي Google Cloud الجدد الاستفادة من برنامج الفترة التجريبية المجانية بقيمة 300 دولار أمريكي.
الخطوة 1: بدء Cloud Shell
في هذا التمرين، ستعمل في جلسة Cloud Shell، وهي أداة تفسير أوامر تستضيفها آلة افتراضية تعمل في سحابة Google. يمكنك تشغيل هذا القسم بسهولة على جهاز الكمبيوتر الخاص بك، ولكن استخدام Cloud Shell يتيح للجميع الاستفادة من تجربة قابلة للتكرار في بيئة متسقة. بعد انتهاء الجلسة، يمكنك إعادة محاولة إكمال هذا القسم على جهاز الكمبيوتر الخاص بك.
تفعيل Cloud Shell
في أعلى يسار Cloud Console، انقر على الزر أدناه تفعيل Cloud Shell:

إذا لم يسبق لك بدء Cloud Shell، ستظهر لك شاشة وسيطة (الجزء السفلي غير المرئي من الصفحة) توضّح ماهيته. في هذه الحالة، انقر على متابعة (ولن تظهر لك مرة أخرى). في ما يلي الشكل الذي ستظهر به هذه الشاشة لمرة واحدة:
يستغرق توفير Cloud Shell والاتصال به بضع لحظات فقط.

يتم تحميل هذا الجهاز الافتراضي بجميع أدوات التطوير التي تحتاج إليها. توفّر هذه الخدمة دليلًا رئيسيًا دائمًا بسعة 5 غيغابايت وتعمل في Google Cloud، ما يؤدي إلى تحسين أداء الشبكة والمصادقة بشكل كبير. يمكن إنجاز معظم العمل في هذا الدرس البرمجي، إن لم يكن كله، باستخدام متصفّح أو جهاز Chromebook فقط.
بعد الاتصال بـ Cloud Shell، من المفترض أن يظهر لك أنّه تم إثبات هويتك وأنّه تم ضبط المشروع على رقم تعريف مشروعك.
نفِّذ الأمر التالي في Cloud Shell للتأكّد من إكمال عملية المصادقة:
gcloud auth list
ناتج الأمر
Credentialed Accounts
ACTIVE ACCOUNT
* <my_account>@<my_domain.com>
To set the active account, run:
$ gcloud config set account `ACCOUNT`
نفِّذ الأمر التالي في Cloud Shell للتأكّد من أنّ أمر gcloud يعرف مشروعك:
gcloud config list project
ناتج الأمر
[core] project = <PROJECT_ID>
إذا لم يكن كذلك، يمكنك تعيينه من خلال هذا الأمر:
gcloud config set project <PROJECT_ID>
ناتج الأمر
Updated property [core/project].
يحتوي Cloud Shell على بعض متغيرات البيئة، بما في ذلك GOOGLE_CLOUD_PROJECT الذي يحتوي على اسم مشروع على السحابة الإلكترونية الحالي. سنستخدم هذا المتغير في مواضع مختلفة خلال هذا الدرس التطبيقي. يمكنك الاطّلاع عليه من خلال تنفيذ الأمر التالي:
echo $GOOGLE_CLOUD_PROJECT
الخطوة 2: تفعيل واجهات برمجة التطبيقات
في الخطوات اللاحقة، ستعرف الأماكن التي تحتاج فيها إلى هذه الخدمات (والسبب)، ولكن في الوقت الحالي، شغِّل هذا الأمر لمنح مشروعك إذن الوصول إلى خدمات Compute Engine وContainer Registry وVertex AI:
gcloud services enable compute.googleapis.com \
containerregistry.googleapis.com \
aiplatform.googleapis.com
من المفترض أن يؤدي ذلك إلى ظهور رسالة نجاح مشابهة لما يلي:
Operation "operations/acf.cc11852d-40af-47ad-9d59-477a12847c9e" finished successfully.
الخطوة 3: إنشاء حزمة في Cloud Storage
لتشغيل مهمة تدريب على Vertex AI، سنحتاج إلى حزمة تخزين لتخزين مواد عرض النموذج المحفوظ. نفِّذ الأوامر التالية في وحدة Cloud Shell الطرفية لإنشاء حزمة:
BUCKET_NAME=gs://$GOOGLE_CLOUD_PROJECT-bucket
gsutil mb -l us-central1 $BUCKET_NAME
الخطوة 4: إنشاء اسم مستعار لـ Python 3
تستخدم التعليمات البرمجية في هذا التمرين المعملي الإصدار 3 من لغة Python. لضمان استخدام Python 3 عند تشغيل النصوص البرمجية التي ستنشئها في هذا الدرس التطبيقي، أنشئ اسمًا مستعارًا من خلال تنفيذ ما يلي في Cloud Shell:
alias python=python3
يستند النموذج الذي سنتدرّب عليه ونعرضه في هذا الدرس التطبيقي إلى هذا الدليل من مستندات TensorFlow. يستخدم البرنامج التعليمي مجموعة بيانات Auto MPG من Kaggle للتنبؤ بالكفاءة في استهلاك الوقود في مركبة.
4. تضمين رمز التدريب في حاوية
سنرسل مهمة التدريب هذه إلى Vertex من خلال وضع رمز التدريب في حاوية Docker وإرسال هذه الحاوية إلى Google Container Registry. باستخدام هذا الأسلوب، يمكننا تدريب نموذج تم إنشاؤه باستخدام أي إطار عمل.
الخطوة 1: إعداد الملفات
للبدء، شغِّل الأوامر التالية من الوحدة الطرفية في Cloud Shell لإنشاء الملفات التي سنحتاج إليها لحاوية Docker:
mkdir mpg
cd mpg
touch Dockerfile
mkdir trainer
touch trainer/train.py
يجب أن يكون لديك الآن دليل mpg/ بالشكل التالي:
+ Dockerfile
+ trainer/
+ train.py
لعرض هذه الملفات وتعديلها، سنستخدم أداة تعديل الرموز المضمّنة في Cloud Shell. يمكنك التبديل بين المحرّر ونافذة الوحدة الطرفية من خلال النقر على الزر في شريط القائمة أعلى يسار Cloud Shell:

الخطوة 2: إنشاء ملف Dockerfile
لتضمين التعليمات البرمجية في حاوية، سننشئ أولاً ملف Dockerfile. في ملف Dockerfile، سنضمّن جميع الأوامر اللازمة لتشغيل الصورة. سيتم تثبيت جميع المكتبات التي نستخدمها وإعداد نقطة الدخول لرمز التدريب.
من محرِّر ملفات Cloud Shell، افتح الدليل mpg/، ثم انقر مرّتين لفتح Dockerfile:
بعد ذلك، انسخ ما يلي في هذا الملف:
FROM gcr.io/deeplearning-platform-release/tf2-cpu.2-3
WORKDIR /
# Copies the trainer code to the docker image.
COPY trainer /trainer
# Sets up the entry point to invoke the trainer.
ENTRYPOINT ["python", "-m", "trainer.train"]
يستخدم ملف Docker هذا صورة Deep Learning Container TensorFlow Enterprise 2.3 Docker. تتضمّن حزم Deep Learning Containers على Google Cloud العديد من أُطر عمل تعلُّم الآلة وعلم البيانات الشائعة المثبَّتة مسبقًا. يتضمّن الإصدار الذي نستخدمه TF Enterprise 2.3 وPandas وScikit-learn وغيرها. بعد تنزيل هذه الصورة، يضبط ملف Dockerfile نقطة الدخول لرمز التدريب الذي سنضيفه في الخطوة التالية.
الخطوة 3: إضافة رمز تدريب النموذج
من محرِّر Cloud Shell، افتح بعد ذلك الملف train.py وانسخ الرمز أدناه (هذا الرمز مقتبس من البرنامج التعليمي في مستندات TensorFlow).
# This will be replaced with your bucket name after running the `sed` command in the tutorial
BUCKET = "BUCKET_NAME"
import numpy as np
import pandas as pd
import pathlib
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
print(tf.__version__)
"""## The Auto MPG dataset
The dataset is available from the [UCI Machine Learning Repository](https://archive.ics.uci.edu/ml/).
### Get the data
First download the dataset.
"""
"""Import it using pandas"""
dataset_path = "https://storage.googleapis.com/io-vertex-codelab/auto-mpg.csv"
dataset = pd.read_csv(dataset_path, na_values = "?")
dataset.tail()
"""### Clean the data
The dataset contains a few unknown values.
"""
dataset.isna().sum()
"""To keep this initial tutorial simple drop those rows."""
dataset = dataset.dropna()
"""The `"origin"` column is really categorical, not numeric. So convert that to a one-hot:"""
dataset['origin'] = dataset['origin'].map({1: 'USA', 2: 'Europe', 3: 'Japan'})
dataset = pd.get_dummies(dataset, prefix='', prefix_sep='')
dataset.tail()
"""### Split the data into train and test
Now split the dataset into a training set and a test set.
We will use the test set in the final evaluation of our model.
"""
train_dataset = dataset.sample(frac=0.8,random_state=0)
test_dataset = dataset.drop(train_dataset.index)
"""### Inspect the data
Have a quick look at the joint distribution of a few pairs of columns from the training set.
Also look at the overall statistics:
"""
train_stats = train_dataset.describe()
train_stats.pop("mpg")
train_stats = train_stats.transpose()
train_stats
"""### Split features from labels
Separate the target value, or "label", from the features. This label is the value that you will train the model to predict.
"""
train_labels = train_dataset.pop('mpg')
test_labels = test_dataset.pop('mpg')
"""### Normalize the data
Look again at the `train_stats` block above and note how different the ranges of each feature are.
It is good practice to normalize features that use different scales and ranges. Although the model *might* converge without feature normalization, it makes training more difficult, and it makes the resulting model dependent on the choice of units used in the input.
Note: Although we intentionally generate these statistics from only the training dataset, these statistics will also be used to normalize the test dataset. We need to do that to project the test dataset into the same distribution that the model has been trained on.
"""
def norm(x):
return (x - train_stats['mean']) / train_stats['std']
normed_train_data = norm(train_dataset)
normed_test_data = norm(test_dataset)
"""This normalized data is what we will use to train the model.
Caution: The statistics used to normalize the inputs here (mean and standard deviation) need to be applied to any other data that is fed to the model, along with the one-hot encoding that we did earlier. That includes the test set as well as live data when the model is used in production.
## The model
### Build the model
Let's build our model. Here, we'll use a `Sequential` model with two densely connected hidden layers, and an output layer that returns a single, continuous value. The model building steps are wrapped in a function, `build_model`, since we'll create a second model, later on.
"""
def build_model():
model = keras.Sequential([
layers.Dense(64, activation='relu', input_shape=[len(train_dataset.keys())]),
layers.Dense(64, activation='relu'),
layers.Dense(1)
])
optimizer = tf.keras.optimizers.RMSprop(0.001)
model.compile(loss='mse',
optimizer=optimizer,
metrics=['mae', 'mse'])
return model
model = build_model()
"""### Inspect the model
Use the `.summary` method to print a simple description of the model
"""
model.summary()
"""Now try out the model. Take a batch of `10` examples from the training data and call `model.predict` on it.
It seems to be working, and it produces a result of the expected shape and type.
### Train the model
Train the model for 1000 epochs, and record the training and validation accuracy in the `history` object.
Visualize the model's training progress using the stats stored in the `history` object.
This graph shows little improvement, or even degradation in the validation error after about 100 epochs. Let's update the `model.fit` call to automatically stop training when the validation score doesn't improve. We'll use an *EarlyStopping callback* that tests a training condition for every epoch. If a set amount of epochs elapses without showing improvement, then automatically stop the training.
You can learn more about this callback [here](https://www.tensorflow.org/api_docs/python/tf/keras/callbacks/EarlyStopping).
"""
model = build_model()
EPOCHS = 1000
# The patience parameter is the amount of epochs to check for improvement
early_stop = keras.callbacks.EarlyStopping(monitor='val_loss', patience=10)
early_history = model.fit(normed_train_data, train_labels,
epochs=EPOCHS, validation_split = 0.2,
callbacks=[early_stop])
# Export model and save to GCS
model.save(BUCKET + '/mpg/model')
بعد نسخ الرمز أعلاه إلى ملف mpg/trainer/train.py، ارجع إلى Terminal في Cloud Shell ونفِّذ الأمر التالي لإضافة اسم الحزمة إلى الملف:
sed -i "s|BUCKET_NAME|$BUCKET_NAME|g" trainer/train.py
الخطوة 4: إنشاء الحاوية واختبارها محليًا
من "الوحدة الطرفية"، نفِّذ ما يلي لتحديد متغيّر يتضمّن معرّف الموارد المنتظم (URI) لصورة الحاوية في Google Container Registry:
IMAGE_URI="gcr.io/$GOOGLE_CLOUD_PROJECT/mpg:v1"
بعد ذلك، أنشئ الحاوية من خلال تنفيذ الأمر التالي من جذر دليل mpg:
docker build ./ -t $IMAGE_URI
بعد إنشاء الحاوية، يمكنك نقلها إلى Google Container Registry باتّباع الخطوات التالية:
docker push $IMAGE_URI
للتأكّد من أنّه تم إرسال صورتك إلى Container Registry، من المفترض أن يظهر لك ما يلي عند الانتقال إلى قسم Container Registry في وحدة التحكّم:
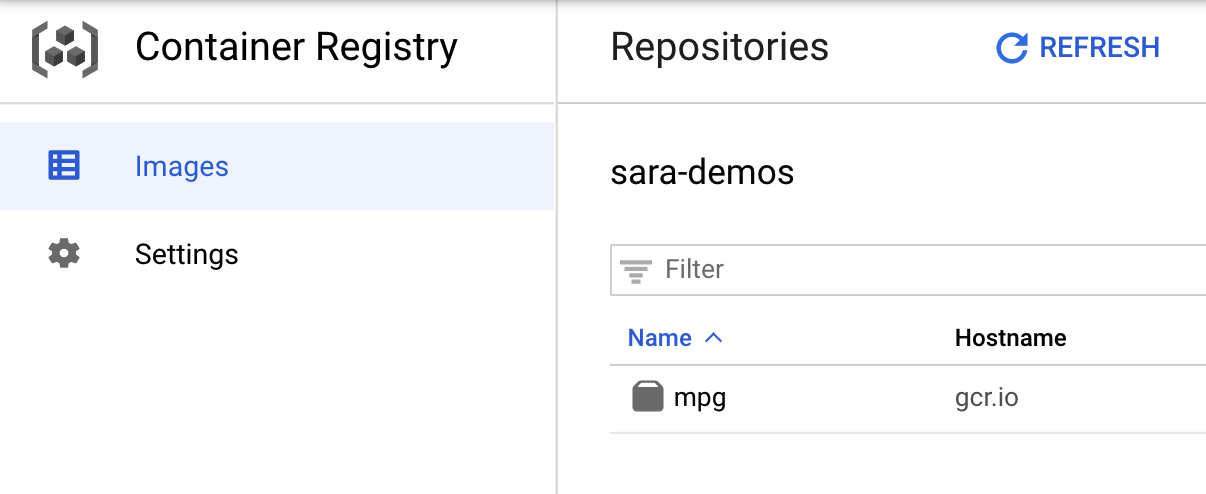
بعد أن تم إرسال الحاوية إلى Container Registry، أصبحنا الآن جاهزين لبدء مهمة تدريب نموذج مخصّص.
5- تنفيذ مهمة تدريب على Vertex AI
توفّر لك Vertex خيارَين لتدريب النماذج:
- AutoML: يمكنك تدريب نماذج عالية الجودة بأقل جهد ممكن وبدون الحاجة إلى خبرة في تعلُّم الآلة.
- التدريب المخصّص: شغِّل تطبيقات التدريب المخصّصة في السحابة الإلكترونية باستخدام إحدى الحاويات المُنشأة مسبقًا من Google Cloud أو استخدِم الحاويات الخاصة بك.
في هذا المختبر، نستخدم التدريب المخصّص من خلال الحاوية المخصّصة الخاصة بنا على Google Container Registry. للبدء، انتقِل إلى قسم التدريب في قسم Vertex في وحدة تحكّم Cloud:
الخطوة 1: بدء مهمة التدريب
انقر على إنشاء لإدخال مَعلمات مهمة التدريب والنموذج الذي تم نشره:
- ضمن مجموعة البيانات، اختَر ما مِن مجموعة بيانات مُدارة.
- بعد ذلك، اختَر التدريب المخصّص (متقدّم) كطريقة التدريب وانقر على متابعة.
- أدخِل
mpg(أو أي اسم آخر تريد إطلاقه على نموذجك) في حقل اسم النموذج - انقر على متابعة.
في خطوة إعدادات الحاوية، اختَر حاوية مخصّصة:

في المربّع الأول (صورة الحاوية)، انقر على تصفّح وابحث عن الحاوية التي دفعتها للتو إلى Container Registry. من المفترض أن تظهر بشكلٍ مشابه لما يلي:
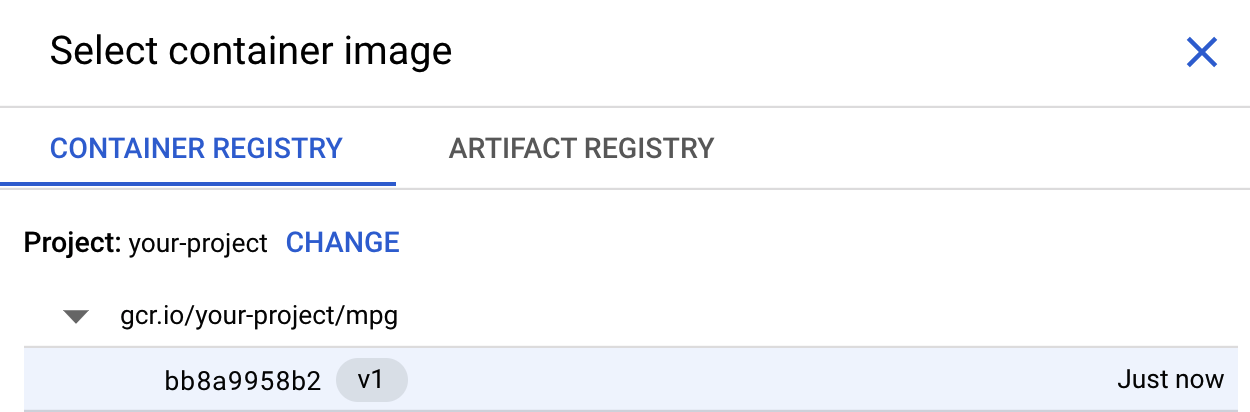
اترك بقية الحقول فارغة وانقر على متابعة.
لن نستخدم ضبط المعلمات الفائقة في هذا البرنامج التعليمي، لذا اترِك المربّع Enable hyperparameter tuning بدون تحديد وانقر على Continue.
في الحوسبة والتسعير، اترك المنطقة المحدّدة كما هي واختَر n1-standard-4 كنوع الجهاز:
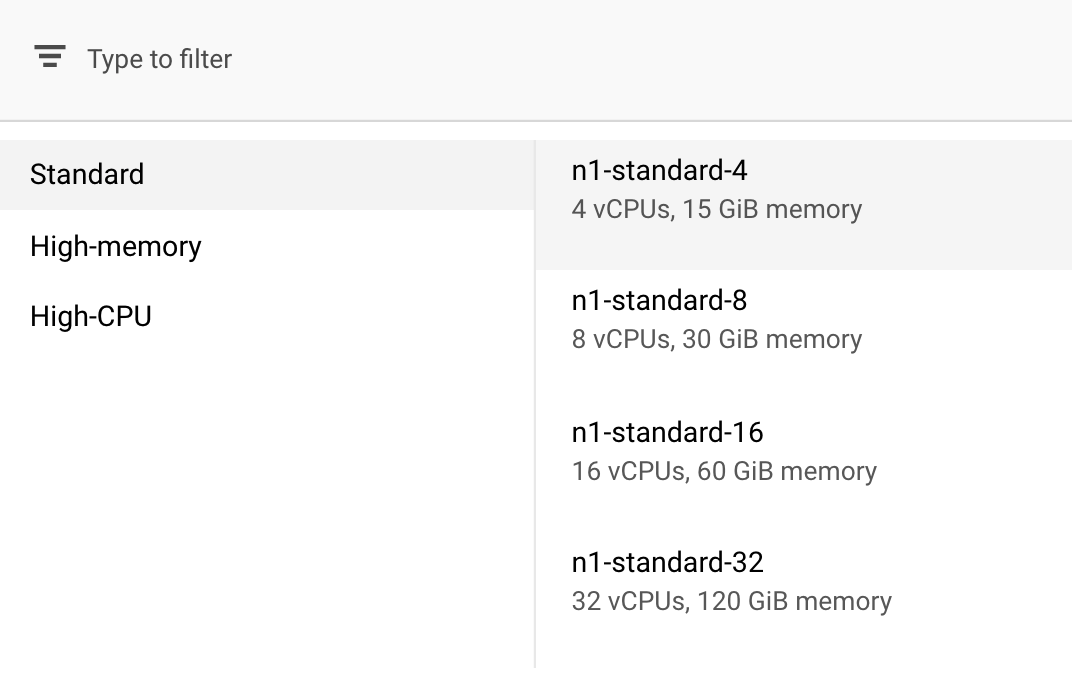
بما أنّ النموذج في هذا العرض التوضيحي يتم تدريبه بسرعة، سنستخدم نوع جهاز أصغر.
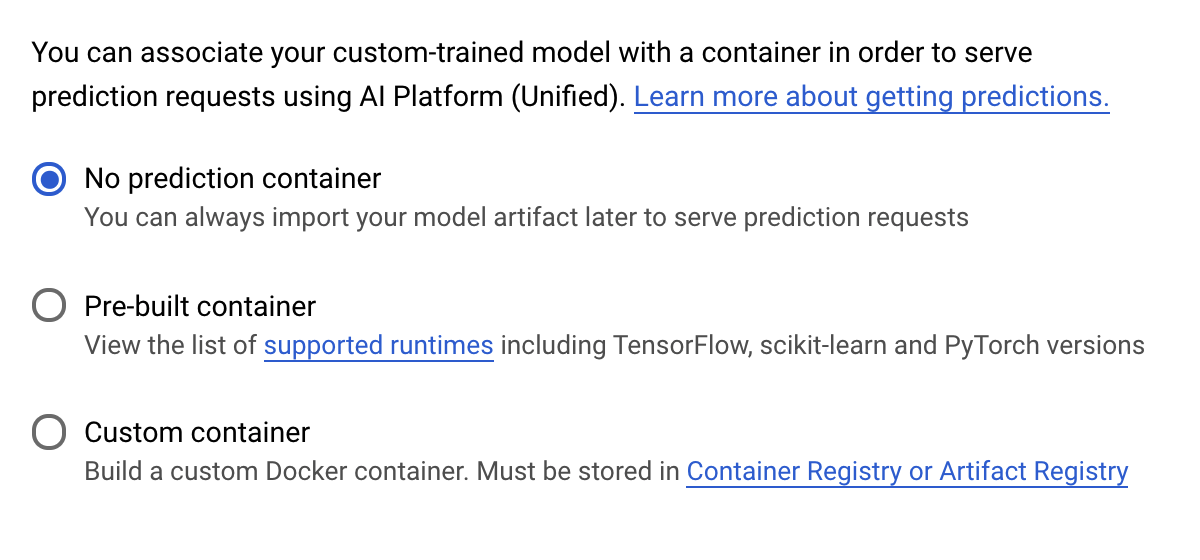
ضمن خطوة حاوية التوقّعات، اختَر بدون حاوية توقّعات:
6. نشر نقطة نهاية نموذج
في هذه الخطوة، سننشئ نقطة نهاية للنموذج المدرَّب. يمكننا استخدام ذلك للحصول على توقّعات بشأن نموذجنا من خلال Vertex AI API. لإجراء ذلك، أتحنا نسخة من مواد عرض النموذج المدرَّب الذي تم تصديره في حزمة GCS عامة.
في المؤسسة، من الشائع أن يكون هناك فريق أو فرد واحد مسؤول عن إنشاء النموذج، وفريق آخر مسؤول عن نشره. ستوضّح لك الخطوات التي سنتّبعها هنا كيفية استخدام نموذج تم تدريبه مسبقًا ونشره لإجراء عمليات التوقّع.
سنستخدم هنا حزمة تطوير البرامج (SDK) الخاصة بمنصة Vertex AI لإنشاء نموذج وتفعيله في نقطة نهاية والحصول على توقّع.
الخطوة 1: تثبيت Vertex SDK
من نافذة Cloud Shell، نفِّذ ما يلي لتثبيت حزمة تطوير البرامج (SDK) الخاصة بـ Vertex AI:
pip3 install google-cloud-aiplatform --upgrade --user
يمكننا استخدام حزمة تطوير البرامج هذه للتفاعل مع العديد من الأجزاء المختلفة في Vertex.
الخطوة 2: إنشاء نموذج ونشر نقطة نهاية
بعد ذلك، سننشئ ملف Python ونستخدم حزمة تطوير البرامج لإنشاء مورد نموذج ونشره في نقطة نهاية. من "محرّر الملفات" في Cloud Shell، انقر على ملف ثم على ملف جديد:
اكتب اسمًا للملف deploy.py. افتح هذا الملف في المحرِّر وانسخ الرمز التالي:
from google.cloud import aiplatform
# Create a model resource from public model assets
model = aiplatform.Model.upload(
display_name="mpg-imported",
artifact_uri="gs://io-vertex-codelab/mpg-model/",
serving_container_image_uri="gcr.io/cloud-aiplatform/prediction/tf2-cpu.2-3:latest"
)
# Deploy the above model to an endpoint
endpoint = model.deploy(
machine_type="n1-standard-4"
)
بعد ذلك، انتقِل مرة أخرى إلى Terminal في Cloud Shell، ثم cd إلى دليل الجذر، وشغِّل نص Python البرمجي الذي أنشأته للتو:
cd ..
python3 deploy.py | tee deploy-output.txt
ستظهر لك التعديلات المسجّلة في نافذة الأوامر أثناء إنشاء الموارد. سيستغرق تنفيذ هذه العملية من 10 إلى 15 دقيقة. للتأكّد من عمله بشكل صحيح، انتقِل إلى قسم "النماذج" في وحدة التحكّم في Vertex AI:
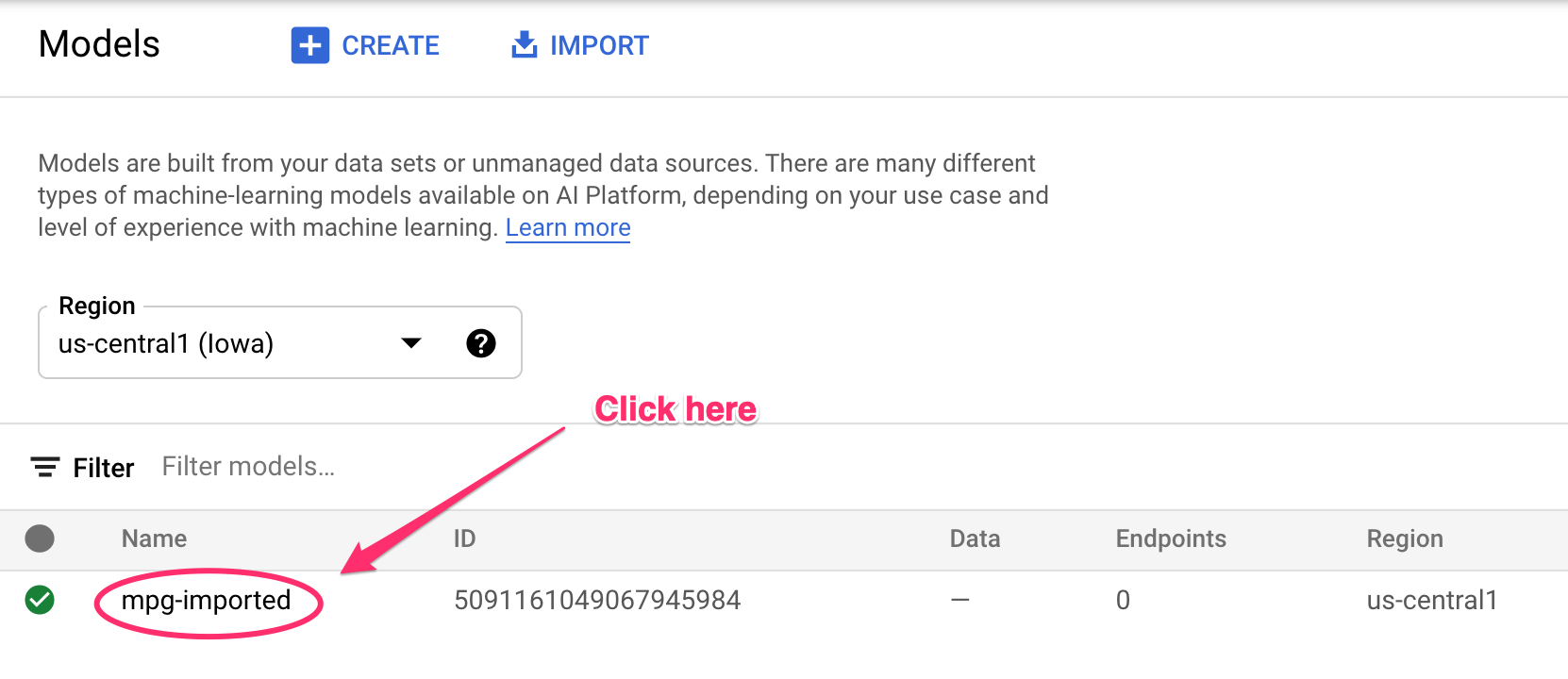
انقر على mgp-imported، وسيظهر لك إنشاء نقطة النهاية لهذا النموذج:
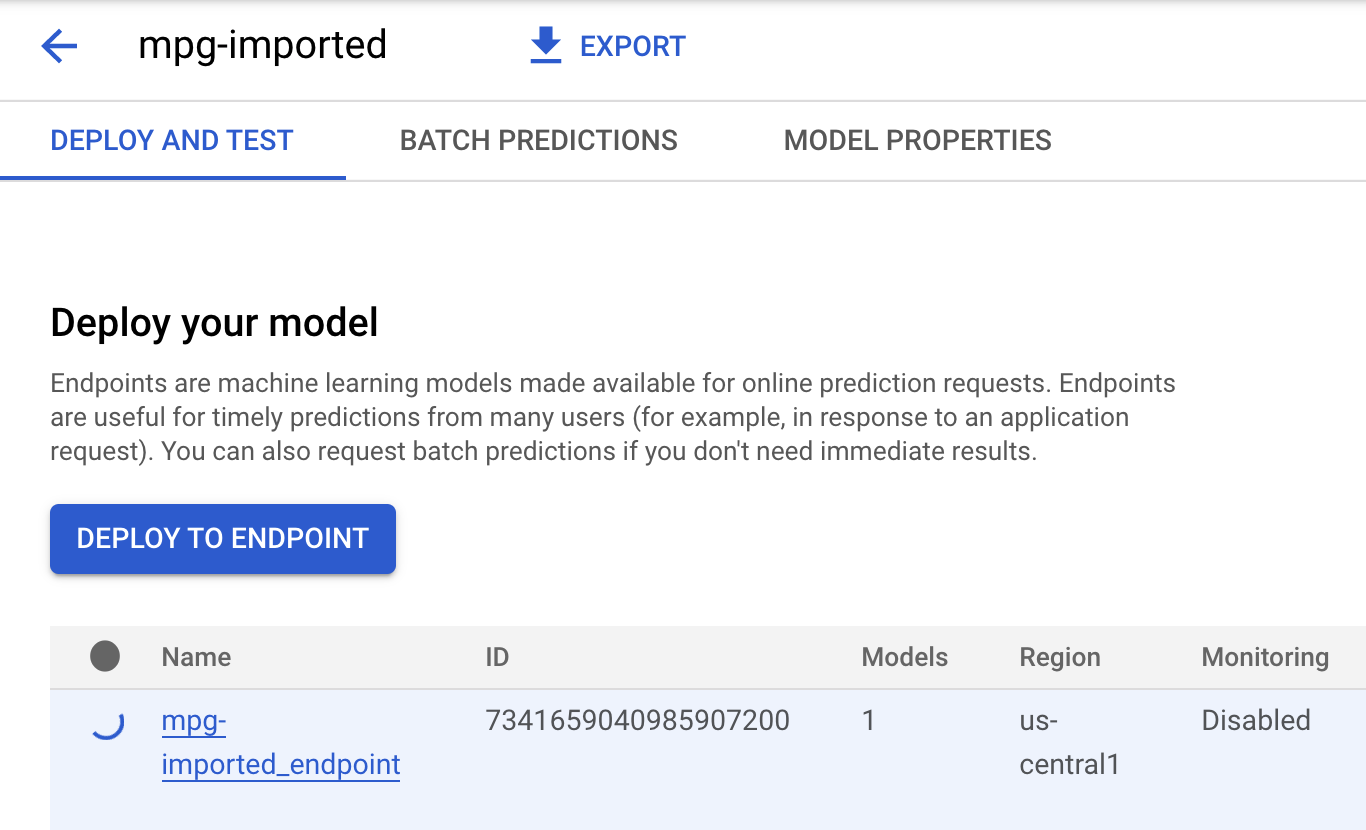
في "وحدة Cloud Shell الطرفية"، سيظهر لك سجلّ مشابه لما يلي عند اكتمال عملية نشر نقطة النهاية:
Endpoint model deployed. Resource name: projects/your-project-id/locations/us-central1/endpoints/your-endpoint-id
ستستخدم هذا الرمز في الخطوة التالية للحصول على توقّع بشأن نقطة النهاية التي تم نشرها.
الخطوة 3: الحصول على توقّعات بشأن نقطة النهاية التي تم نشرها
في محرّر Cloud Shell، أنشئ ملفًا جديدًا باسم predict.py:
افتح predict.py وألصِق الرمز التالي فيه:
from google.cloud import aiplatform
endpoint = aiplatform.Endpoint(
endpoint_name="ENDPOINT_STRING"
)
# A test example we'll send to our model for prediction
test_mpg = [1.4838871833555929,
1.8659883497083019,
2.234620276849616,
1.0187816540094903,
-2.530890710602246,
-1.6046416850441676,
-0.4651483719733302,
-0.4952254087173721,
0.7746763768735953]
response = endpoint.predict([test_mpg])
print('API response: ', response)
print('Predicted MPG: ', response.predictions[0][0])
بعد ذلك، ارجع إلى "الوحدة الطرفية" وأدخِل ما يلي لاستبدال ENDPOINT_STRING في ملف التوقّع بنقطة النهاية الخاصة بك:
ENDPOINT=$(cat deploy-output.txt | sed -nre 's:.*Resource name\: (.*):\1:p' | tail -1)
sed -i "s|ENDPOINT_STRING|$ENDPOINT|g" predict.py
حان الوقت الآن لتشغيل ملف predict.py للحصول على نتيجة توقّعية من نقطة نهاية النموذج الذي تم نشره:
python3 predict.py
من المفترض أن يظهر لك ردّ واجهة برمجة التطبيقات مسجّلاً، بالإضافة إلى الكفاءة في استهلاك الوقود المتوقّعة للتوقّع التجريبي.
🎉 تهانينا! 🎉
تعرّفت على كيفية استخدام Vertex AI من أجل:
- تدريب نموذج من خلال توفير رمز التدريب في حاوية مخصّصة لقد استخدمت نموذج TensorFlow في هذا المثال، ولكن يمكنك تدريب نموذج تم إنشاؤه باستخدام أي إطار عمل باستخدام حاويات مخصّصة.
- يمكنك نشر نموذج TensorFlow باستخدام حاوية معدّة مسبقًا كجزء من سير العمل نفسه الذي استخدمته في التدريب.
- إنشاء نقطة نهاية نموذج وإنشاء توقّع
لمزيد من المعلومات عن الأجزاء المختلفة من Vertex AI، اطّلِع على المستندات. إذا أردت الاطّلاع على نتائج مهمة التدريب التي بدأتها في الخطوة 5، انتقِل إلى قسم التدريب في وحدة تحكّم Vertex.
7. تنظيف
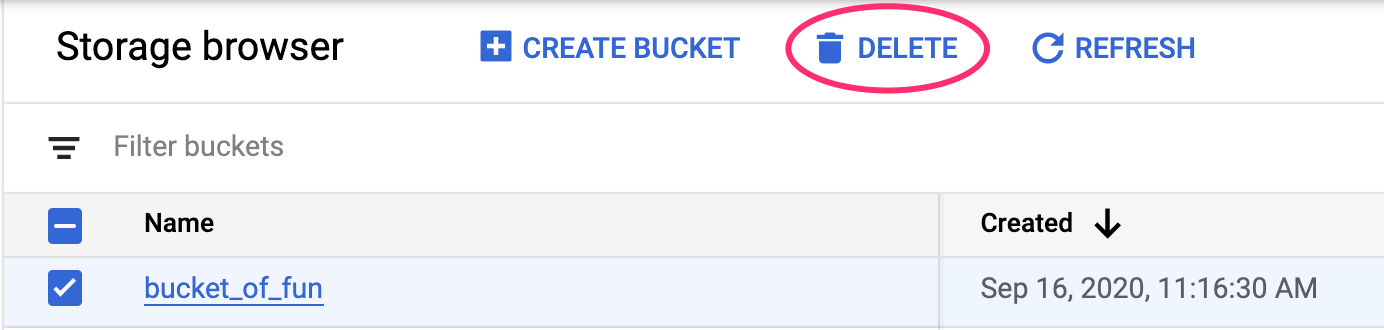
لحذف نقطة النهاية التي نشرتها، انتقِل إلى قسم نقاط النهاية في وحدة تحكّم Vertex وانقر على رمز الحذف:

لحذف حزمة التخزين، استخدِم قائمة التنقّل في Cloud Console، وانتقِل إلى "مساحة التخزين"، واختَر الحزمة، ثم انقر على "حذف":