1. परिचय
इस कोडलैब में, मॉडल को कारों के सेट का ब्यौरा देने वाले संख्या वाले डेटा से अनुमान लगाने की ट्रेनिंग दी जाएगी.
इस अभ्यास में, अलग-अलग तरह के कई मॉडल को ट्रेनिंग देने के सामान्य तरीके बताए गए हैं. हालांकि, इसके लिए एक छोटे डेटासेट और एक आसान (उथले) मॉडल का इस्तेमाल किया जाएगा. इसका मुख्य मकसद है, TensorFlow.js की मदद से, ट्रेनिंग मॉडल की बुनियादी शब्दावली, कॉन्सेप्ट, और सिंटैक्स के बारे में आपको अच्छे से समझाना है. साथ ही, आपको आगे जानने और सीखने में मदद करना है.
हम लगातार संख्याओं का अनुमान लगाने के लिए एक मॉडल को ट्रेनिंग दे रहे हैं, इसलिए इस टास्क को कभी-कभी रिग्रेशन टास्क कहा जाता है. हम इस मॉडल को सही आउटपुट के साथ इनपुट के कई उदाहरण दिखाएंगे. इसे सुपरवाइज़्ड लर्निंग कहा जाता है.
आपको क्या बनाना होगा
आपको एक ऐसा वेबपेज बनाना है जो ब्राउज़र में मॉडल को ट्रेनिंग देने के लिए, TensorFlow.js का इस्तेमाल करता है. "हॉर्सपावर" दिया गया यह मॉडल "मील प्रति गैलन" का अनुमान लगाना सीख जाएगा (एमपीजी) के लिए तय किया गया है.
ऐसा करने के लिए:
- डेटा लोड करें और उसे ट्रेनिंग के लिए तैयार करें.
- मॉडल की आर्किटेक्चर तय करें.
- मॉडल को ट्रेनिंग दें और ट्रेनिंग के दौरान इसकी परफ़ॉर्मेंस पर नज़र रखें.
- कुछ अनुमान लगाकर, ट्रेन किए गए मॉडल का आकलन करें.
आपको इनके बारे में जानकारी मिलेगी
- मशीन लर्निंग के लिए डेटा तैयार करने के सबसे सही तरीके, जिनमें शफ़ल करना और नॉर्मलाइज़ेशन शामिल है.
- tf.layers API का इस्तेमाल करके मॉडल बनाने के लिए TensorFlow.js सिंटैक्स.
- tfjs-vis लाइब्रेरी का इस्तेमाल करके, ब्राउज़र में मौजूद ट्रेनिंग पर नज़र रखने का तरीका.
आपको इनकी ज़रूरत होगी
- Chrome या किसी अन्य मॉडर्न ब्राउज़र का नया वर्शन.
- ऐसा टेक्स्ट एडिटर जो कोडपेन या Glitch जैसे टूल के ज़रिए, आपकी मशीन या वेब पर चल रहा हो.
- एचटीएमएल, सीएसएस, JavaScript, और Chrome DevTools (या आपके पसंदीदा ब्राउज़र Devtools) के बारे में जानकारी.
- न्यूरल नेटवर्क के बारे में कॉन्सेप्ट की अच्छी जानकारी. अगर आपको कोई परिचय या रीफ़्रेशर चाहिए, तो 3blue1brown का यह वीडियो या JavaScript में डीप लर्निंग के बारे में आशी कृष्णन का यह वीडियो देखें.
2. सेट अप करें
एचटीएमएल पेज बनाना और उसमें JavaScript को शामिल करना
 इस कोड को एक html फ़ाइल में कॉपी करें, जिसे
इस कोड को एक html फ़ाइल में कॉपी करें, जिसे
index.html
<!DOCTYPE html>
<html>
<head>
<title>TensorFlow.js Tutorial</title>
<!-- Import TensorFlow.js -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@2.0.0/dist/tf.min.js"></script>
<!-- Import tfjs-vis -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs-vis@1.0.2/dist/tfjs-vis.umd.min.js"></script>
</head>
<body>
<!-- Import the main script file -->
<script src="script.js"></script>
</body>
</html>
कोड के लिए JavaScript फ़ाइल बनाएं
- ऊपर दी गई एचटीएमएल फ़ाइल वाले फ़ोल्डर में, script.js नाम की फ़ाइल बनाएं और उसमें यह कोड डालें.
console.log('Hello TensorFlow');
इसे आज़माएं
अब जब आपने एचटीएमएल और JavaScript फ़ाइलें बना ली हैं, तो इनकी जांच करें. अपने ब्राउज़र में index.html फ़ाइल खोलें और devtools कंसोल खोलें.
अगर सब कुछ काम कर रहा है, तो DevTools कंसोल में दो ग्लोबल वैरिएबल बनाए जाने चाहिए और उपलब्ध होने चाहिए.:
tf, TensorFlow.js लाइब्रेरी का रेफ़रंस हैtfvis, tfjs-vis लाइब्रेरी का रेफ़रंस है
अपने ब्राउज़र के डेवलपर टूल खोलें. इसके बाद, कंसोल के आउटपुट में आपको Hello TensorFlow लिखा हुआ मैसेज दिखेगा. अगर ऐसा है, तो आप अगले चरण पर जाने के लिए तैयार हैं.
3. इनपुट डेटा को लोड, फ़ॉर्मैट, और विज़ुअलाइज़ करें
सबसे पहले, हमें वह डेटा लोड, फ़ॉर्मैट, और विज़ुअलाइज़ करने दें जिस पर हम मॉडल को ट्रेनिंग देना चाहते हैं.
हम "कारें" लोड करेंगे डेटासेट को JSON फ़ाइल से इकट्ठा किया गया है, जिसे हमने आपके लिए होस्ट किया है. इसमें मौजूद हर कार के बारे में कई अलग-अलग सुविधाएं होती हैं. इस ट्यूटोरियल के लिए, हम सिर्फ़ हॉर्सपावर और माइल्स प्रति गैलन का डेटा एक्सट्रैक्ट करना चाहते हैं.
यह कोड अपने फ़ोन नंबर में जोड़ें
script.js फ़ाइल
/**
* Get the car data reduced to just the variables we are interested
* and cleaned of missing data.
*/
async function getData() {
const carsDataResponse = await fetch('https://storage.googleapis.com/tfjs-tutorials/carsData.json');
const carsData = await carsDataResponse.json();
const cleaned = carsData.map(car => ({
mpg: car.Miles_per_Gallon,
horsepower: car.Horsepower,
}))
.filter(car => (car.mpg != null && car.horsepower != null));
return cleaned;
}
इससे ऐसी एंट्री भी हट जाएंगी जिनमें मील प्रति गैलन या हॉर्सपावर की कोई जानकारी नहीं है. आइए, इस डेटा को स्कैटरप्लॉट में बनाकर देखें कि यह कैसा दिखता है.
अपने फ़ोन के निचले हिस्से में यह कोड जोड़ें
script.js फ़ाइल.
async function run() {
// Load and plot the original input data that we are going to train on.
const data = await getData();
const values = data.map(d => ({
x: d.horsepower,
y: d.mpg,
}));
tfvis.render.scatterplot(
{name: 'Horsepower v MPG'},
{values},
{
xLabel: 'Horsepower',
yLabel: 'MPG',
height: 300
}
);
// More code will be added below
}
document.addEventListener('DOMContentLoaded', run);
जब पेज को रीफ़्रेश किया जाता है. आपको पेज के बाईं ओर, डेटा के स्कैटरप्लॉट के साथ एक पैनल दिखेगा. यह कुछ ऐसा नज़र आना चाहिए.
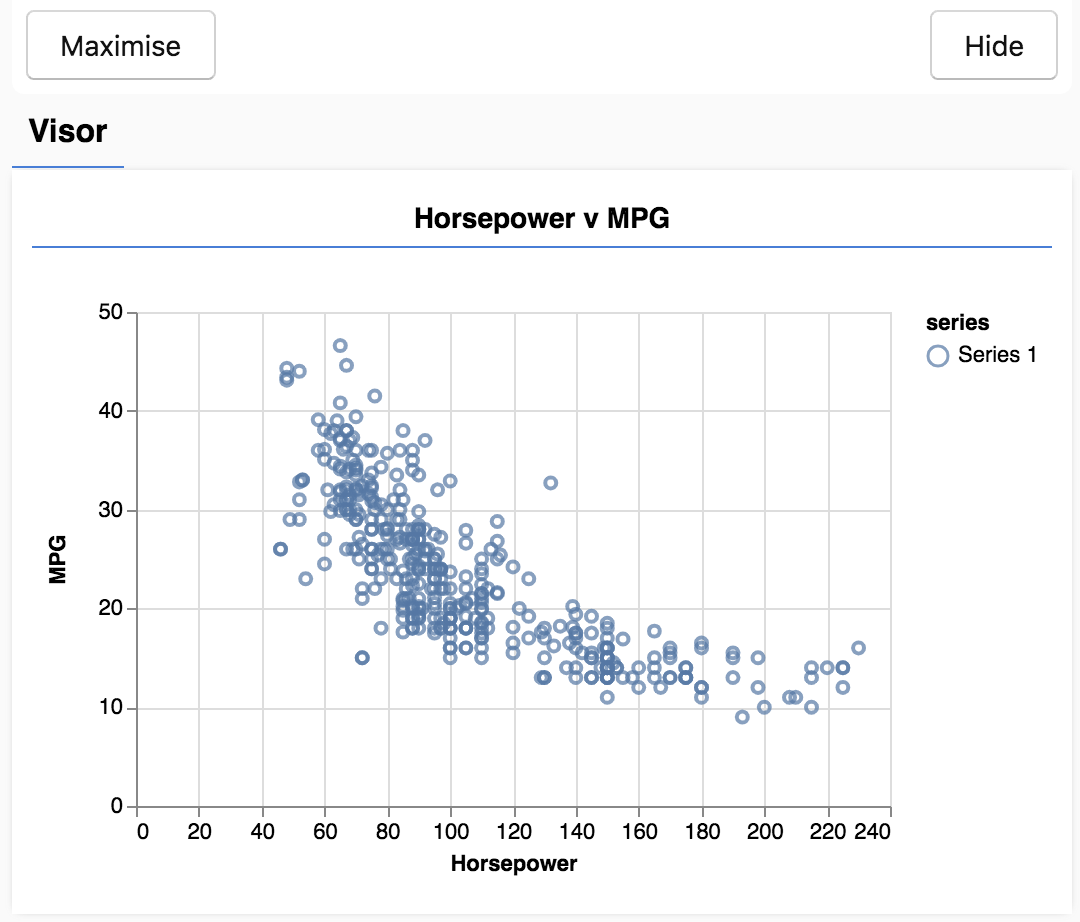
इस पैनल को वाइज़र के तौर पर जाना जाता है और यह tfjs-vis से मिलता है. यह विज़ुअलाइज़ेशन दिखाने के लिए एक सुविधाजनक जगह है.
आम तौर पर, डेटा का इस्तेमाल करते समय अपने डेटा को देखने और ज़रूरत पड़ने पर उसे हटाने के तरीके ढूंढना बेहतर होता है. इस मामले में, हमें carsData से कुछ ऐसी एंट्री हटानी पड़ीं जिनमें सभी ज़रूरी फ़ील्ड नहीं थे. डेटा को विज़ुअलाइज़ करने से हमें पता चलता है कि डेटा का कोई स्ट्रक्चर मौजूद है या नहीं, जिसे मॉडल सीख सकता है.
ऊपर दिए गए प्लॉट से हम यह देख सकते हैं कि हॉर्सपावर और MPG के बीच एक नेगेटिव कोरिलेशन है. इसका मतलब है कि हॉर्सपावर बढ़ने के साथ-साथ, कारों को आम तौर पर एक गैलन में कम मील मिलता है.
हमारे टास्क का सिद्धांत तय करना
हमारा इनपुट डेटा अब ऐसा दिखेगा.
...
{
"mpg":15,
"horsepower":165,
},
{
"mpg":18,
"horsepower":150,
},
{
"mpg":16,
"horsepower":150,
},
...
हमारा लक्ष्य एक ऐसे मॉडल को ट्रेनिंग देना है जो एक नंबर, हॉर्सपावर लेगा और एक नंबर, मील प्रति गैलन का अनुमान लगाना सीखेगा. याद रखें कि वन-टू-वन मैपिंग, क्योंकि यह अगले सेक्शन के लिए अहम होगी.
हम इन उदाहरणों, हॉर्सपावर और एमपीजी को न्यूरल नेटवर्क में फ़ीड करने जा रहे हैं, जो इन उदाहरणों से एक फ़ॉर्मूला (या फ़ंक्शन) सीखेंगे, ताकि एमपीजी के लिए हॉर्सपावर का अनुमान लगाया जा सके. जिन उदाहरणों के सही जवाब हमारे पास हैं उनसे मिली इस लर्निंग को सुपरवाइज़्ड लर्निंग कहा जाता है.
4. मॉडल आर्किटेक्चर तय करें
इस सेक्शन में, हम मॉडल आर्किटेक्चर की जानकारी देने के लिए कोड लिखेंगे. मॉडल आर्किटेक्चर सिर्फ़ यह कहने का एक शानदार तरीका है कि "मॉडल को उसके एक्ज़ीक्यूट करने के दौरान कौनसा फ़ंक्शन चलेगा" या दूसरा विकल्प "हमारा मॉडल अपने जवाबों का हिसाब लगाने के लिए किस एल्गोरिदम का इस्तेमाल करेगा".
एमएल मॉडल ऐसे एल्गोरिदम होते हैं जो इनपुट लेकर आउटपुट देते हैं. न्यूरल नेटवर्क का इस्तेमाल करते समय, एल्गोरिदम 'वेट' वाले न्यूरॉन की लेयर का एक सेट होता है आउटपुट को कंट्रोल करती हैं. ट्रेनिंग की प्रोसेस में, उन महत्वों के सही मान पता किए जाते हैं.
ये फ़ंक्शन अपने में जोड़ें
script.js फ़ाइल का इस्तेमाल करके मॉडल आर्किटेक्चर के बारे में बताएं.
function createModel() {
// Create a sequential model
const model = tf.sequential();
// Add a single input layer
model.add(tf.layers.dense({inputShape: [1], units: 1, useBias: true}));
// Add an output layer
model.add(tf.layers.dense({units: 1, useBias: true}));
return model;
}
यह सबसे सामान्य मॉडल में से एक है, जिसे हम tensorflow.js में तय कर सकते हैं. हमें हर लाइन का कुछ विश्लेषण करने दें.
मॉडल को इंस्टैंशिएट करना
const model = tf.sequential();
यह tf.Model ऑब्जेक्ट को इंस्टैंशिएट करता है. यह मॉडल sequential है, क्योंकि इसके इनपुट सीधे इसके आउटपुट में फ़्लो करते हैं. अन्य तरह के मॉडल में ब्रांच हो सकती हैं या एक से ज़्यादा इनपुट और आउटपुट भी हो सकते हैं. हालांकि, कई मामलों में आपके मॉडल क्रम से वाले होंगे. क्रम में चलने वाले मॉडल में भी एपीआई का इस्तेमाल करना आसान होता है.
लेयर जोड़ें
model.add(tf.layers.dense({inputShape: [1], units: 1, useBias: true}));
इससे हमारे नेटवर्क में एक इनपुट लेयर जुड़ जाता है, जो छिपी हुई यूनिट की dense लेयर से अपने-आप कनेक्ट हो जाता है. dense लेयर, एक तरह की लेयर है, जो अपने इनपुट को मैट्रिक्स (जिन्हें वेट कहा जाता है) से गुणा करती है. इसके बाद, नतीजे में एक संख्या जोड़ती है, जिसे बायस कहा जाता है. यह नेटवर्क की पहली लेयर है, इसलिए हमें अपना inputShape तय करना होगा. inputShape, [1] है, क्योंकि हमारे पास इनपुट के तौर पर 1 नंबर है (किसी कार के लिए हॉर्सपावर).
units सेट करता है कि लेयर में वेट मैट्रिक्स कितना बड़ा होगा. यहां इसे 1 पर सेट करने का मतलब है कि हम डेटा की हर इनपुट सुविधा का एक महत्व देंगे.
model.add(tf.layers.dense({units: 1}));
ऊपर दिया गया कोड हमारा आउटपुट लेयर बनाता है. हमने units को 1 पर सेट किया है, क्योंकि हमें 1 नंबर देना है.
कोई इंस्टेंस बनाना
यह कोड इस कोड में जोड़ें
run फ़ंक्शन जिसके बारे में हमने पहले बताया था.
// Create the model
const model = createModel();
tfvis.show.modelSummary({name: 'Model Summary'}, model);
इससे मॉडल का एक इंस्टेंस बनेगा और वेबपेज पर लेयर की खास जानकारी दिखेगी.
5. ट्रेनिंग के लिए डेटा तैयार करना
TensorFlow.js की मदद से, ट्रेनिंग के मशीन लर्निंग मॉडल को व्यावहारिक बनाने वाले परफ़ॉर्मेंस के फ़ायदे पाने के लिए, हमें अपने डेटा को टेंसर में बदलना होगा. हम अपने डेटा में कई ऐसे बदलाव भी करेंगे जो सबसे सही तरीके हैं. जैसे, शफ़लिंग और नॉर्मलाइज़ेशन.
यह कोड अपने फ़ोन नंबर में जोड़ें
script.js फ़ाइल
/**
* Convert the input data to tensors that we can use for machine
* learning. We will also do the important best practices of _shuffling_
* the data and _normalizing_ the data
* MPG on the y-axis.
*/
function convertToTensor(data) {
// Wrapping these calculations in a tidy will dispose any
// intermediate tensors.
return tf.tidy(() => {
// Step 1. Shuffle the data
tf.util.shuffle(data);
// Step 2. Convert data to Tensor
const inputs = data.map(d => d.horsepower)
const labels = data.map(d => d.mpg);
const inputTensor = tf.tensor2d(inputs, [inputs.length, 1]);
const labelTensor = tf.tensor2d(labels, [labels.length, 1]);
//Step 3. Normalize the data to the range 0 - 1 using min-max scaling
const inputMax = inputTensor.max();
const inputMin = inputTensor.min();
const labelMax = labelTensor.max();
const labelMin = labelTensor.min();
const normalizedInputs = inputTensor.sub(inputMin).div(inputMax.sub(inputMin));
const normalizedLabels = labelTensor.sub(labelMin).div(labelMax.sub(labelMin));
return {
inputs: normalizedInputs,
labels: normalizedLabels,
// Return the min/max bounds so we can use them later.
inputMax,
inputMin,
labelMax,
labelMin,
}
});
}
आइए, यहां इस बारे में बात करते हैं.
डेटा को शफ़ल करना
// Step 1. Shuffle the data
tf.util.shuffle(data);
यहां हम ट्रेनिंग एल्गोरिदम में दिए जाने वाले उदाहरणों का क्रम किसी भी क्रम में लगाते हैं. शफ़ल करना ज़रूरी है, क्योंकि आम तौर पर, ट्रेनिंग के दौरान डेटासेट को छोटे-छोटे सबसेट में बांटा जाता है, जिन्हें बैच कहा जाता है. इन सबसेट के हिसाब से मॉडल को ट्रेनिंग दी जाती है. शफ़ल मोड से हर बैच में, डेटा डिस्ट्रिब्यूशन के दौरान अलग-अलग तरह का डेटा पाने में मदद मिलती है. ऐसा करके हम मॉडल की मदद करते हैं:
- ऐसी चीज़ें नहीं सीखें जो पूरी तरह से उस क्रम पर निर्भर हों जिसमें डेटा फ़ीड किया गया था
- सबग्रुप की बनावट के प्रति संवेदनशील नहीं होनी चाहिए (उदाहरण के लिए, अगर ट्रेनिंग के पहले आधे हिस्से में ही इसे ज़्यादा हॉर्सपावर वाली कार दिखती हैं, तो ऐसा हो सकता है कि वह ऐसे संबंध को समझ पाए जो बाकी डेटासेट पर लागू नहीं होता).
टेंसर में बदलें
// Step 2. Convert data to Tensor
const inputs = data.map(d => d.horsepower)
const labels = data.map(d => d.mpg);
const inputTensor = tf.tensor2d(inputs, [inputs.length, 1]);
const labelTensor = tf.tensor2d(labels, [labels.length, 1]);
यहां हम दो अरे बनाते हैं, एक हमारे इनपुट उदाहरणों (हॉर्सपावर एंट्री) के लिए, और दूसरी सही आउटपुट वैल्यू (जिन्हें मशीन लर्निंग में लेबल के रूप में जाना जाता है) के लिए.
इसके बाद, हम अरे के हर डेटा को 2d टेंसर में बदल देते हैं. टेंसर का आकार [num_examples, num_features_per_example] होगा. यहां हमारे पास inputs.length उदाहरण हैं और हर उदाहरण में 1 इनपुट सुविधा (हॉर्सपावर) है.
डेटा को नॉर्मलाइज़ करें
//Step 3. Normalize the data to the range 0 - 1 using min-max scaling
const inputMax = inputTensor.max();
const inputMin = inputTensor.min();
const labelMax = labelTensor.max();
const labelMin = labelTensor.min();
const normalizedInputs = inputTensor.sub(inputMin).div(inputMax.sub(inputMin));
const normalizedLabels = labelTensor.sub(labelMin).div(labelMax.sub(labelMin));
इसके बाद, हम मशीन लर्निंग ट्रेनिंग के लिए एक और सबसे सही तरीका अपनाते हैं. हम डेटा को नॉर्मलाइज़ करते हैं. यहां हम कम से कम अधिकतम स्केलिंग का इस्तेमाल करके, डेटा को अंकों वाली रेंज 0-1 में सामान्य कर देते हैं. नॉर्मलाइज़ेशन की अहमियत ज़रूरी है, क्योंकि tensorflow.js की मदद से बनाए गए कई मशीन लर्निंग मॉडल के अंदरूनी हिस्सों को ऐसी संख्याओं के साथ काम करने के लिए डिज़ाइन किया गया है जो बहुत बड़ी नहीं होती हैं. 0 to 1 या -1 to 1 को शामिल करने के लिए, डेटा को नॉर्मलाइज़ करने की सामान्य रेंज. अगर आप अपने डेटा को सही रेंज में सामान्य करने की आदत डाल देंगे, तो आपको अपने मॉडल को ट्रेनिंग देने में ज़्यादा कामयाबी मिलेगी.
डेटा वापस करना और नॉर्मलाइज़ेशन की सीमाएं
return {
inputs: normalizedInputs,
labels: normalizedLabels,
// Return the min/max bounds so we can use them later.
inputMax,
inputMin,
labelMax,
labelMin,
}
हम ट्रेनिंग के दौरान नॉर्मलाइज़ेशन के लिए इस्तेमाल की जाने वाली वैल्यू को बनाए रखना चाहते हैं, ताकि हम आउटपुट में होने वाली सामान्य वैल्यू को हटा सकें, ताकि उन्हें हमारे ओरिजनल स्केल पर वापस लाया जा सके. साथ ही, आने वाले समय में इनपुट डेटा को भी इसी तरीके से नॉर्मलाइज़ किया जा सके.
6. मॉडल को ट्रेनिंग दें
हमारा मॉडल इंस्टेंस बना दिया गया है और हमारे डेटा को टेंसर के तौर पर दिखाया गया है. इसलिए, हमारे पास ट्रेनिंग की प्रोसेस शुरू करने के लिए हर चीज़ मौजूद है.
नीचे दिए गए फ़ंक्शन को अपने में कॉपी करें
script.js फ़ाइल.
async function trainModel(model, inputs, labels) {
// Prepare the model for training.
model.compile({
optimizer: tf.train.adam(),
loss: tf.losses.meanSquaredError,
metrics: ['mse'],
});
const batchSize = 32;
const epochs = 50;
return await model.fit(inputs, labels, {
batchSize,
epochs,
shuffle: true,
callbacks: tfvis.show.fitCallbacks(
{ name: 'Training Performance' },
['loss', 'mse'],
{ height: 200, callbacks: ['onEpochEnd'] }
)
});
}
आइए, इस बारे में बात करते हैं.
ट्रेनिंग की तैयारी करें
// Prepare the model for training.
model.compile({
optimizer: tf.train.adam(),
loss: tf.losses.meanSquaredError,
metrics: ['mse';],
});
हमें 'कंपाइल' करना होता है मॉडल को ट्रेनिंग देने से पहले देख सकते हैं. इसके लिए, हमें कई अहम चीज़ों के बारे में बताना होगा:
optimizer: यह एक ऐसा एल्गोरिदम है जो मॉडल के अपडेट को उसी तरह कंट्रोल करता है जिस तरह से मॉडल में अपडेट देखे जाते हैं. TensorFlow.js में कई ऑप्टिमाइज़र उपलब्ध हैं. यहां हमने Adam ऑप्टिमाइज़र को चुना है, क्योंकि यह काफ़ी असरदार है और इसके लिए किसी कॉन्फ़िगरेशन की ज़रूरत नहीं होती.loss: यह एक ऐसा फ़ंक्शन है जिससे मॉडल को यह पता चलता है कि वह दिखाए गए हर बैच (डेटा के सबसेट) को सीखने में कैसा परफ़ॉर्म कर रहा है. यहां हमmeanSquaredErrorका इस्तेमाल करके, मॉडल के लिए बनाए गए अनुमानों की सही वैल्यू से तुलना करते हैं.
const batchSize = 32;
const epochs = 50;
इसके बाद, हम एक बैचसाइज़ और कई epoch चुनते हैं:
batchSizeसे यह पता चलता है कि डेटा के सबसेट का साइज़, मॉडल को ट्रेनिंग के दौरान हर बार दिखेगा. सामान्य बैच साइज़ 32-512 की रेंज में होते हैं. सभी समस्याओं के लिए कोई सही बैच साइज़ नहीं है. अलग-अलग बैच साइज़ के लिए, गणित की वजहों के बारे में जानकारी देना इस ट्यूटोरियल के दायरे से बाहर है.epochsसे पता चलता है कि मॉडल आपके दिए गए पूरे डेटासेट को कितनी बार देखेगा. यहां हम डेटासेट को 50 बार दोहराएँगे.
ट्रेन लूप शुरू करना
return await model.fit(inputs, labels, {
batchSize,
epochs,
callbacks: tfvis.show.fitCallbacks(
{ name: 'Training Performance' },
['loss', 'mse'],
{ height: 200, callbacks: ['onEpochEnd'] }
)
});
model.fit एक ऐसी सुविधा है जिसे हम ट्रेनिंग लूप शुरू करने के लिए कॉल करते हैं. यह एक एसिंक्रोनस फ़ंक्शन है. इसलिए, हम इसके प्रॉमिस को लौटाते हैं, ताकि कॉलर यह तय कर सके कि ट्रेनिंग कब पूरी हो रही है.
ट्रेनिंग की प्रोग्रेस पर नज़र रखने के लिए, हम model.fit को कुछ कॉलबैक करते हैं. हम tfvis.show.fitCallbacks का इस्तेमाल करके, ऐसे फ़ंक्शन जनरेट करते हैं जो 'लॉस' का चार्ट बनाते हैं और ‘mse' मेट्रिक जैसा हमने पहले ही बताया था.
सभी हिस्से एक साथ जोड़ें
अब हमें उन फ़ंक्शन को कॉल करना होगा जिन्हें हमने अपने run फ़ंक्शन से तय किया था.
अपने फ़ोन के निचले हिस्से में यह कोड जोड़ें
run फ़ंक्शन.
// Convert the data to a form we can use for training.
const tensorData = convertToTensor(data);
const {inputs, labels} = tensorData;
// Train the model
await trainModel(model, inputs, labels);
console.log('Done Training');
पेज को रीफ़्रेश करने पर, आपको कुछ सेकंड बाद अपडेट होते हुए नीचे दिए गए ग्राफ़ दिखेंगे.
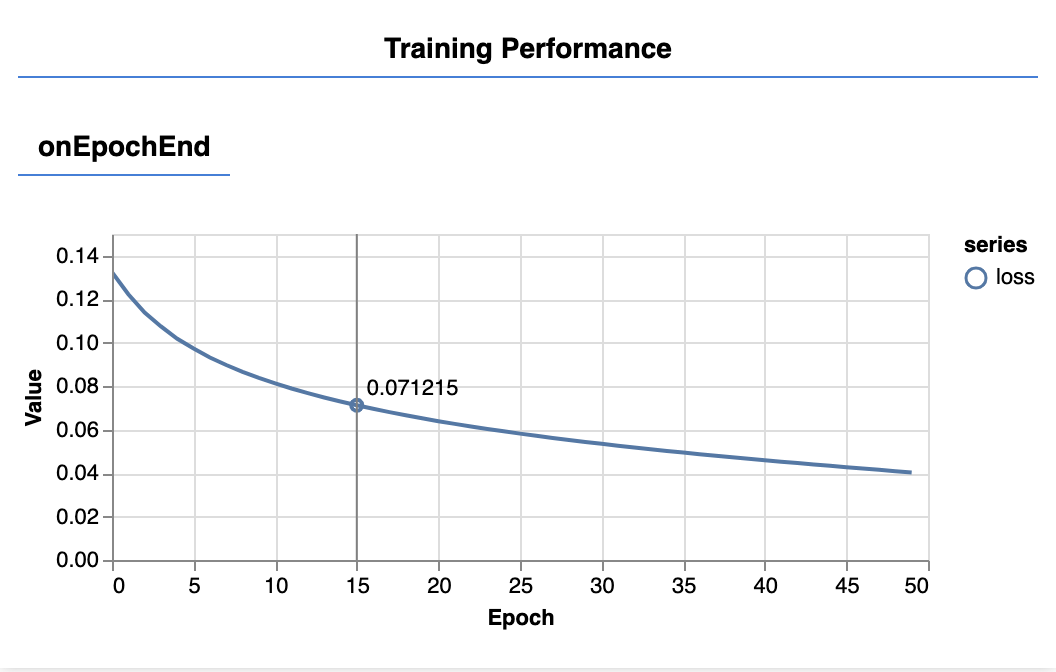
ये उन कॉलबैक से बनाए जाते हैं जो हमने पहले बनाए थे. वे हर epoch के आखिर में, पूरे डेटासेट का औसत नुकसान और एमसे दिखाते हैं.
किसी मॉडल को ट्रेनिंग देते समय हम चाहते हैं कि उस पर होने वाले नुकसान को कम किया जाए. इस मामले में, हमारी मेट्रिक गड़बड़ी का एक पैमाना है, इसलिए हम इसे भी कम होते देखना चाहते हैं.
7. अनुमान लगाएं
अब हमारा मॉडल तैयार हो गया है. इसलिए, हम इसके बारे में कुछ अनुमान लगाना चाहते हैं. इस मॉडल को देखते हुए, यह देखते हैं कि कम से ज़्यादा हॉर्सपावर की एक समान रेंज के लिए यह मॉडल क्या अनुमान लगाता है.
अपनी script.js फ़ाइल में यह फ़ंक्शन जोड़ें
function testModel(model, inputData, normalizationData) {
const {inputMax, inputMin, labelMin, labelMax} = normalizationData;
// Generate predictions for a uniform range of numbers between 0 and 1;
// We un-normalize the data by doing the inverse of the min-max scaling
// that we did earlier.
const [xs, preds] = tf.tidy(() => {
const xsNorm = tf.linspace(0, 1, 100);
const predictions = model.predict(xsNorm.reshape([100, 1]));
const unNormXs = xsNorm
.mul(inputMax.sub(inputMin))
.add(inputMin);
const unNormPreds = predictions
.mul(labelMax.sub(labelMin))
.add(labelMin);
// Un-normalize the data
return [unNormXs.dataSync(), unNormPreds.dataSync()];
});
const predictedPoints = Array.from(xs).map((val, i) => {
return {x: val, y: preds[i]}
});
const originalPoints = inputData.map(d => ({
x: d.horsepower, y: d.mpg,
}));
tfvis.render.scatterplot(
{name: 'Model Predictions vs Original Data'},
{values: [originalPoints, predictedPoints], series: ['original', 'predicted']},
{
xLabel: 'Horsepower',
yLabel: 'MPG',
height: 300
}
);
}
ऊपर दिए गए फ़ंक्शन में ध्यान देने वाली कुछ बातें.
const xsNorm = tf.linspace(0, 1, 100);
const predictions = model.predict(xsNorm.reshape([100, 1]));
हम 100 नए 'उदाहरण' जनरेट करते हैं मॉडल में फ़ीड करने के लिए. Model.predict की मदद से हम उन उदाहरणों को मॉडल में कैसे फ़ीड करते हैं. ध्यान दें कि उनका आकार ([num_examples, num_features_per_example]) वैसा ही होना चाहिए जैसा हमने ट्रेनिंग में किया था.
// Un-normalize the data
const unNormXs = xsNorm
.mul(inputMax.sub(inputMin))
.add(inputMin);
const unNormPreds = predictions
.mul(labelMax.sub(labelMin))
.add(labelMin);
डेटा को अपनी मूल रेंज में वापस लाने के लिए (0-1 के बजाय) हम उन वैल्यू का इस्तेमाल करते हैं जिन्हें नॉर्मलाइज़ करते समय कैलकुलेट किया गया था. हालांकि, हम सिर्फ़ कार्रवाइयों को उलट देते हैं.
return [unNormXs.dataSync(), unNormPreds.dataSync()];
.dataSync() एक ऐसा तरीका है जिसका इस्तेमाल करके, हम किसी टेंसर में स्टोर की गई वैल्यू का typedarray पा सकते हैं. इससे हम उन वैल्यू को सामान्य JavaScript में प्रोसेस कर पाते हैं. यह .data() तरीके का सिंक्रोनस वर्शन है, जिसे आम तौर पर प्राथमिकता दी जाती है.
आखिर में, हम tfjs-vis का इस्तेमाल करके मॉडल के ओरिजनल डेटा और अनुमान दिखाते हैं.
यह कोड अपने फ़ोन नंबर में जोड़ें
run फ़ंक्शन.
// Make some predictions using the model and compare them to the
// original data
testModel(model, data, tensorData);
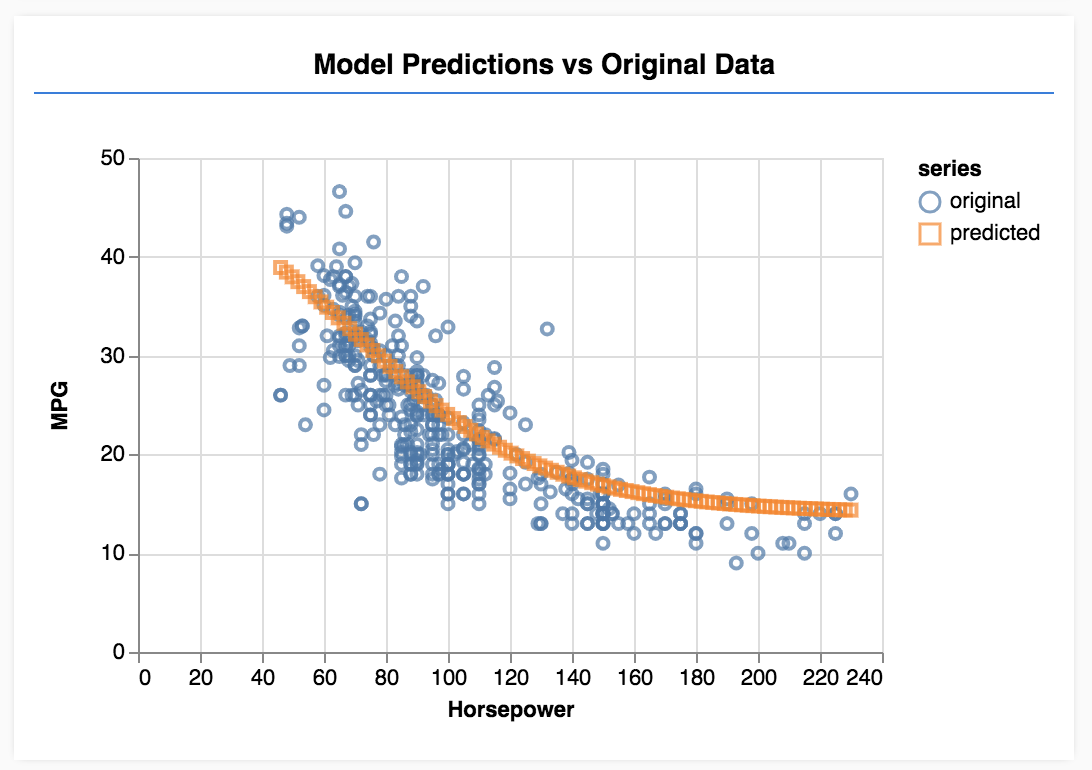
पेज को रीफ़्रेश करें. जब मॉडल की ट्रेनिंग पूरी हो जाएगी, तब आपको ऐसा कुछ दिखेगा.
बधाई हो! आपने अभी-अभी एक आसान मशीन लर्निंग मॉडल को ट्रेनिंग दी है. फ़िलहाल, यह लीनियर रिग्रेशन के नाम से काम करता है. यह इनपुट डेटा में मौजूद रुझान की लाइन में फ़िट करने की कोशिश करता है.
8. सीखने लायक मुख्य बातें
मशीन लर्निंग मॉडल को ट्रेनिंग देने के लिए, ये तरीके अपनाए जाते हैं:
अपना टास्क बनाएं:
- क्या यह कोई रिग्रेशन समस्या है या कोई वर्गीकरण समस्या है?
- क्या इसे सुपरवाइज़्ड लर्निंग या सुपरवाइज़्ड लर्निंग की मदद से पूरा किया जा सकता है?
- इनपुट डेटा का आकार क्या है? आउटपुट डेटा कैसा दिखना चाहिए?
अपना डेटा तैयार करें:
- अपने डेटा को मिटाएँ और पैटर्न का पता लगाने के लिए, मैन्युअल तरीके से उसकी जांच करें
- ट्रेनिंग के लिए इस्तेमाल करने से पहले अपने डेटा को शफ़ल करना
- न्यूरल नेटवर्क के लिए अपने डेटा को उचित रेंज में सामान्य करें. आम तौर पर, अंकों वाले डेटा के लिए 0-1 या -1-1 अच्छे रेंज होते हैं.
- अपने डेटा को टेंसर में बदलना
अपना मॉडल बनाएं और चलाएं:
tf.sequentialयाtf.modelका इस्तेमाल करके अपना मॉडल तय करें. इसके बाद,tf.layers.*का इस्तेमाल करके उसमें लेयर जोड़ें- कोई ऑप्टिमाइज़र चुनें ( आम तौर पर, adam एक अच्छा विकल्प होता है). साथ ही, बैच का साइज़ और epoch की संख्या जैसे पैरामीटर भी चुनें.
- अपनी समस्या के लिए, सही लॉस फ़ंक्शन चुनें. साथ ही, प्रोग्रेस का आकलन करने में मदद के लिए, सटीक मेट्रिक चुनें.
meanSquaredError, रिग्रेशन की समस्याओं के लिए एक सामान्य नुकसान फ़ंक्शन है. - ट्रेनिंग पर नज़र रखकर देखें कि क्या नुकसान कम हो रहा है
अपने मॉडल का मूल्यांकन करना
- अपने मॉडल के लिए इवैलुएशन मेट्रिक चुनें, जिसे ट्रेनिंग के दौरान मॉनिटर किया जा सके. ट्रेनिंग पूरी हो जाने के बाद, अनुमान की क्वालिटी का पता लगाने के लिए, टेस्ट के तौर पर कुछ सुझाव देकर देखें.
9. अतिरिक्त क्रेडिट: आज़माने के लिए चीज़ें
- epoch की संख्या बदलकर देखें. ग्राफ़ के चपटे होने से पहले आपको कितने युगों की ज़रूरत है.
- छिपी हुई लेयर में यूनिट की संख्या बढ़ाकर प्रयोग करें.
- हमारे जोड़ी गई पहली छिपी हुई लेयर और आखिरी आउटपुट लेयर के बीच, ज़्यादा छिपी हुई लेयर जोड़कर प्रयोग करें. इन अतिरिक्त लेयर का कोड कुछ ऐसा दिखना चाहिए.
model.add(tf.layers.dense({units: 50, activation: 'sigmoid'}));
इन छिपी हुई लेयर के बारे में सबसे अहम नई बात यह है कि इनमें नॉन-लीनियर ऐक्टिवेशन फ़ंक्शन दिया गया है, इस मामले में sigmoid ऐक्टिवेशन है. ऐक्टिवेशन फ़ंक्शन के बारे में ज़्यादा जानने के लिए, यह लेख देखें.
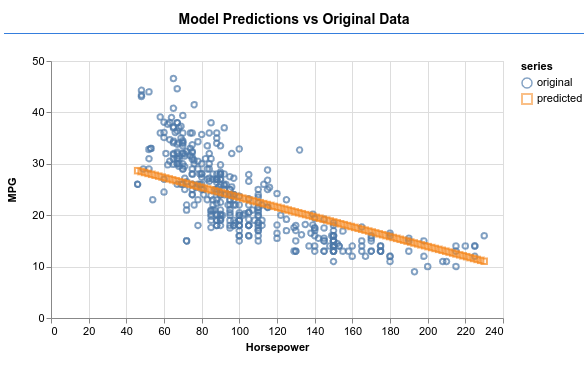
देखें कि क्या नीचे दी गई इमेज में दिए गए मॉडल की तरह, आउटपुट करने के लिए मॉडल का इस्तेमाल किया जा सकता है.