1. Введение
В этой кодовой лаборатории вы научите модель делать прогнозы на основе числовых данных, описывающих набор автомобилей.
В этом упражнении будут продемонстрированы шаги, общие для обучения многих различных типов моделей, но будет использоваться небольшой набор данных и простая (неглубокая) модель. Основная цель — помочь вам ознакомиться с базовой терминологией, концепциями и синтаксисом моделей обучения с помощью TensorFlow.js и предоставить стартовую площадку для дальнейшего изучения и обучения.
Поскольку мы обучаем модель прогнозированию непрерывных чисел, эту задачу иногда называют задачей регрессии . Мы будем обучать модель, показывая ей множество примеров входных данных и правильных выходных данных. Это называется контролируемым обучением .
Что вы построите
Вы создадите веб-страницу, которая будет использовать TensorFlow.js для обучения модели в браузере. Учитывая «лошадиную силу» автомобиля, модель научится прогнозировать количество миль на галлон (миль на галлон).
Для этого вам предстоит:
- Загрузите данные и подготовьте их к обучению.
- Определите архитектуру модели.
- Обучайте модель и отслеживайте ее производительность во время обучения.
- Оцените обученную модель, сделав некоторые прогнозы.
Что вы узнаете
- Лучшие практики подготовки данных для машинного обучения, включая перетасовку и нормализацию.
- Синтаксис TensorFlow.js для создания моделей с использованием API tf.layers .
- Как контролировать обучение в браузере с помощью библиотеки tfjs-vis .
Что вам понадобится
- Последняя версия Chrome или другой современный браузер.
- Текстовый редактор, работающий либо локально на вашем компьютере, либо в Интернете через что-то вроде Codepen или Glitch .
- Знание HTML, CSS, JavaScript и инструментов разработчика Chrome (или инструментов разработчика предпочитаемого вами браузера).
- Концептуальное понимание нейронных сетей высокого уровня. Если вам нужно введение или повышение квалификации, рассмотрите возможность просмотра этого видео от 3blue1brown или этого видео о глубоком обучении в Javascript от Аши Кришнана .
2. Настройте
Создайте HTML-страницу и включите JavaScript.
 Скопируйте следующий код в HTML-файл с именем
Скопируйте следующий код в HTML-файл с именем
index.html
<!DOCTYPE html>
<html>
<head>
<title>TensorFlow.js Tutorial</title>
<!-- Import TensorFlow.js -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@2.0.0/dist/tf.min.js"></script>
<!-- Import tfjs-vis -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs-vis@1.0.2/dist/tfjs-vis.umd.min.js"></script>
</head>
<body>
<!-- Import the main script file -->
<script src="script.js"></script>
</body>
</html>
Создайте файл JavaScript для кода.
- В той же папке, что и приведенный выше HTML-файл, создайте файл с именем script.js и поместите в него следующий код.
console.log('Hello TensorFlow');
Проверьте это
Теперь, когда у вас созданы файлы HTML и JavaScript, протестируйте их. Откройте файл index.html в своем браузере и откройте консоль devtools.
Если все работает, должны быть созданы и доступны в консоли devtools две глобальные переменные:
-
tf— это ссылка на библиотеку TensorFlow.js. -
tfvis— это ссылка на библиотеку tfjs-vis.
Откройте инструменты разработчика вашего браузера. В выводе консоли вы должны увидеть сообщение Hello TensorFlow . Если да, то вы готовы перейти к следующему шагу.
3. Загрузите, отформатируйте и визуализируйте входные данные.
В качестве первого шага давайте загрузим, отформатируем и визуализируем данные, на которых мы хотим обучить модель.
Мы загрузим набор данных «автомобили» из файла JSON, который мы разместили для вас. Он содержит множество различных функций о каждом автомобиле. В этом уроке мы хотим извлечь данные только о лошадиных силах и милях на галлон.
Добавьте следующий код в свой
файл script.js
/**
* Get the car data reduced to just the variables we are interested
* and cleaned of missing data.
*/
async function getData() {
const carsDataResponse = await fetch('https://storage.googleapis.com/tfjs-tutorials/carsData.json');
const carsData = await carsDataResponse.json();
const cleaned = carsData.map(car => ({
mpg: car.Miles_per_Gallon,
horsepower: car.Horsepower,
}))
.filter(car => (car.mpg != null && car.horsepower != null));
return cleaned;
}
Это также приведет к удалению всех записей, в которых не определены ни мили на галлон, ни лошадиные силы. Давайте также построим эти данные на диаграмме рассеяния, чтобы увидеть, как они выглядят.
Добавьте следующий код в конец вашего
файл script.js .
async function run() {
// Load and plot the original input data that we are going to train on.
const data = await getData();
const values = data.map(d => ({
x: d.horsepower,
y: d.mpg,
}));
tfvis.render.scatterplot(
{name: 'Horsepower v MPG'},
{values},
{
xLabel: 'Horsepower',
yLabel: 'MPG',
height: 300
}
);
// More code will be added below
}
document.addEventListener('DOMContentLoaded', run);
Когда вы обновляете страницу. В левой части страницы вы должны увидеть панель с диаграммой рассеяния данных. Это должно выглядеть примерно так.
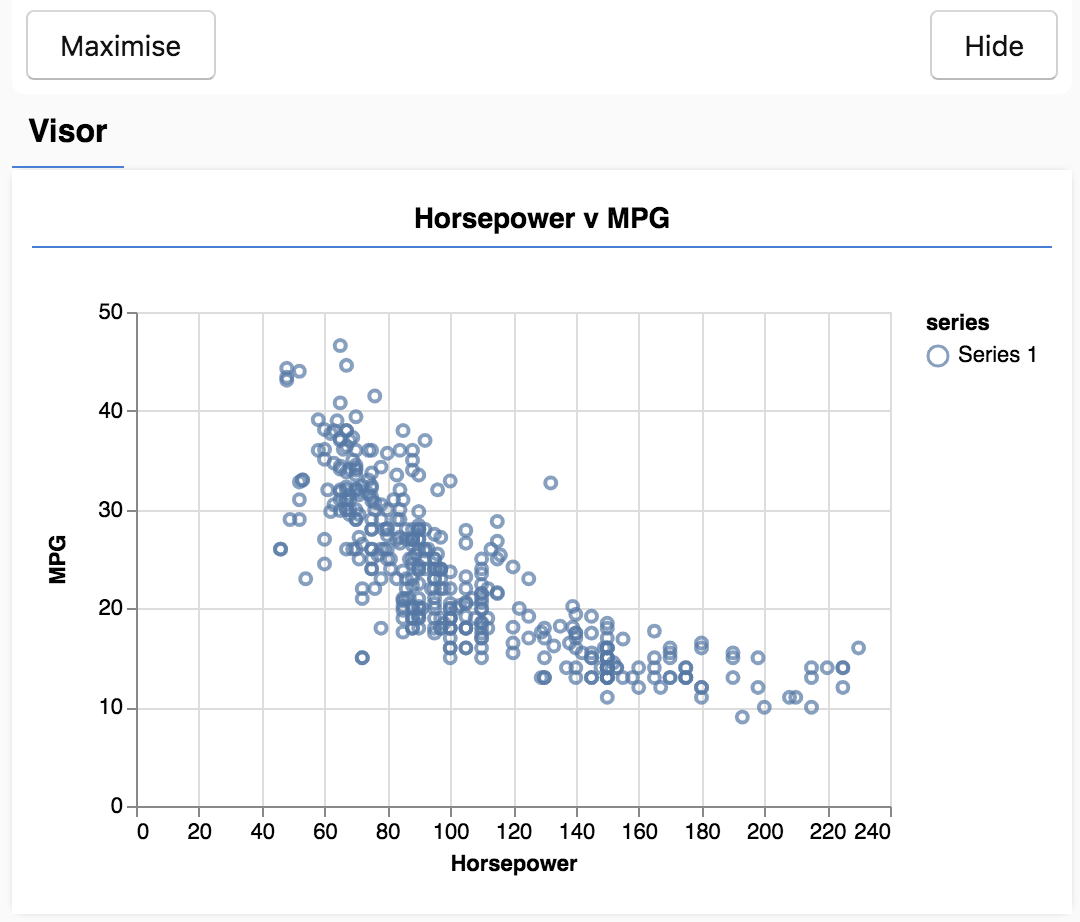
Эта панель называется козырьком и предоставляется tfjs-vis . Он обеспечивает удобное место для отображения визуализаций.
Обычно при работе с данными рекомендуется найти способы просмотреть ваши данные и при необходимости очистить их. В этом случае нам пришлось удалить из carsData некоторые записи, в которых не было всех обязательных полей. Визуализация данных может дать нам представление о том, существует ли какая-либо структура данных, которую может изучить модель.
Из приведенного выше графика мы видим, что существует отрицательная корреляция между мощностью в лошадиных силах и расходом миль на галлон, т. е. по мере увеличения мощности автомобили обычно проезжают меньше миль на галлон.
Концептуализируем нашу задачу
Наши входные данные теперь будут выглядеть так.
...
{
"mpg":15,
"horsepower":165,
},
{
"mpg":18,
"horsepower":150,
},
{
"mpg":16,
"horsepower":150,
},
...
Наша цель — обучить модель, которая будет принимать одно число « Лошадиные силы» и учиться прогнозировать одно число «Миль на галлон» . Помните об этом сопоставлении «один к одному», поскольку оно будет важно для следующего раздела.
Мы собираемся передать эти примеры, мощность в лошадиных силах и расход топлива на галлон, в нейронную сеть, которая на основе этих примеров научится формуле (или функции) для прогнозирования расхода топлива на галлон с учетом мощности в лошадиных силах. Такое обучение на примерах, на которые у нас есть правильные ответы, называется обучением с учителем .
4. Определите архитектуру модели.
В этом разделе мы напишем код для описания архитектуры модели. Архитектура модели — это просто причудливый способ сказать , «какие функции будет выполнять модель во время выполнения» или, альтернативно , «какой алгоритм будет использовать наша модель для вычисления ответов» .
Модели машинного обучения — это алгоритмы, которые принимают входные данные и производят выходные данные. При использовании нейронных сетей алгоритм представляет собой набор слоев нейронов с «весами» (числами), управляющими их выходными данными. В процессе тренировки изучаются идеальные значения этих весов.
Добавьте следующую функцию в свой
script.js для определения архитектуры модели.
function createModel() {
// Create a sequential model
const model = tf.sequential();
// Add a single input layer
model.add(tf.layers.dense({inputShape: [1], units: 1, useBias: true}));
// Add an output layer
model.add(tf.layers.dense({units: 1, useBias: true}));
return model;
}
Это одна из самых простых моделей, которые мы можем определить в tensorflow.js, давайте немного разберем каждую строку.
Создайте экземпляр модели
const model = tf.sequential();
Это создает экземпляр объекта tf.Model . Эта модель является sequential поскольку ее входные данные передаются прямо к выходу. Другие типы моделей могут иметь ветви или даже несколько входов и выходов, но во многих случаях ваши модели будут последовательными. Последовательные модели также имеют более простой в использовании API .
Добавить слои
model.add(tf.layers.dense({inputShape: [1], units: 1, useBias: true}));
Это добавит в нашу сеть входной слой , который автоматически соединяется с dense слоем с одним скрытым блоком. dense слой — это тип слоя, который умножает свои входные данные на матрицу (называемую весами ), а затем добавляет к результату число (называемое смещением ). Поскольку это первый уровень сети, нам нужно определить inputShape . inputShape имеет значение [1] , потому что в качестве входных данных мы имеем 1 число (мощность данного автомобиля).
units устанавливает размер весовой матрицы в слое. Установив здесь значение 1, мы говорим, что для каждой входной функции данных будет 1 вес.
model.add(tf.layers.dense({units: 1}));
Код выше создает наш выходной слой. Мы устанавливаем units измерения на 1 потому что хотим вывести 1 число.
Создать экземпляр
Добавьте следующий код в
функцию run , которую мы определили ранее.
// Create the model
const model = createModel();
tfvis.show.modelSummary({name: 'Model Summary'}, model);
Это создаст экземпляр модели и отобразит сводку слоев на веб-странице.
5. Подготовьте данные для обучения
Чтобы получить преимущества производительности TensorFlow.js, которые делают модели машинного обучения практичными, нам необходимо преобразовать наши данные в тензоры . Мы также выполним ряд преобразований наших данных, которые являются лучшими практиками, а именно перетасовку и нормализацию .
Добавьте следующий код в свой
файл script.js
/**
* Convert the input data to tensors that we can use for machine
* learning. We will also do the important best practices of _shuffling_
* the data and _normalizing_ the data
* MPG on the y-axis.
*/
function convertToTensor(data) {
// Wrapping these calculations in a tidy will dispose any
// intermediate tensors.
return tf.tidy(() => {
// Step 1. Shuffle the data
tf.util.shuffle(data);
// Step 2. Convert data to Tensor
const inputs = data.map(d => d.horsepower)
const labels = data.map(d => d.mpg);
const inputTensor = tf.tensor2d(inputs, [inputs.length, 1]);
const labelTensor = tf.tensor2d(labels, [labels.length, 1]);
//Step 3. Normalize the data to the range 0 - 1 using min-max scaling
const inputMax = inputTensor.max();
const inputMin = inputTensor.min();
const labelMax = labelTensor.max();
const labelMin = labelTensor.min();
const normalizedInputs = inputTensor.sub(inputMin).div(inputMax.sub(inputMin));
const normalizedLabels = labelTensor.sub(labelMin).div(labelMax.sub(labelMin));
return {
inputs: normalizedInputs,
labels: normalizedLabels,
// Return the min/max bounds so we can use them later.
inputMax,
inputMin,
labelMax,
labelMin,
}
});
}
Давайте разберемся, что здесь происходит.
Перемешать данные
// Step 1. Shuffle the data
tf.util.shuffle(data);
Здесь мы рандомизируем порядок примеров, которые мы будем передавать в алгоритм обучения. Перетасовка важна, поскольку обычно во время обучения набор данных разбивается на более мелкие подмножества, называемые пакетами, на которых обучается модель. Перетасовка помогает каждому пакету иметь различные данные из разных источников. Тем самым мы помогаем модели:
- Не изучать вещи, которые полностью зависят от порядка подачи данных.
- Не быть чувствительным к структуре подгрупп (например, если он видит только автомобили с высокой мощностью в первой половине своего обучения, он может изучить взаимосвязь, которая не применима к остальной части набора данных).
Преобразовать в тензоры
// Step 2. Convert data to Tensor
const inputs = data.map(d => d.horsepower)
const labels = data.map(d => d.mpg);
const inputTensor = tf.tensor2d(inputs, [inputs.length, 1]);
const labelTensor = tf.tensor2d(labels, [labels.length, 1]);
Здесь мы создаем два массива: один для наших входных примеров (записи о мощности), а другой для истинных выходных значений (которые в машинном обучении называются метками).
Затем мы конвертируем данные каждого массива в 2d-тензор. Тензор будет иметь форму [num_examples, num_features_per_example] . Здесь у нас есть примеры inputs.length , и каждый пример имеет 1 входную характеристику (лошадиную мощность).
Нормализовать данные
//Step 3. Normalize the data to the range 0 - 1 using min-max scaling
const inputMax = inputTensor.max();
const inputMin = inputTensor.min();
const labelMax = labelTensor.max();
const labelMin = labelTensor.min();
const normalizedInputs = inputTensor.sub(inputMin).div(inputMax.sub(inputMin));
const normalizedLabels = labelTensor.sub(labelMin).div(labelMax.sub(labelMin));
Далее мы применим еще один лучший метод обучения машинному обучению. Нормализуем данные. Здесь мы нормализуем данные в числовом диапазоне 0-1 используя масштабирование min-max . Нормализация важна, поскольку внутренние компоненты многих моделей машинного обучения, которые вы будете строить с помощью tensorflow.js, предназначены для работы с не слишком большими числами. Общие диапазоны для нормализации данных включают 0 to 1 или -1 to 1 . Вы добьетесь большего успеха в обучении своих моделей, если вы привыкнете нормализовать свои данные до некоторого разумного диапазона.
Верните данные и границы нормализации
return {
inputs: normalizedInputs,
labels: normalizedLabels,
// Return the min/max bounds so we can use them later.
inputMax,
inputMin,
labelMax,
labelMin,
}
Мы хотим сохранить значения, которые мы использовали для нормализации во время обучения, чтобы мы могли отменить нормализацию выходных данных, чтобы вернуть их в исходный масштаб, и чтобы мы могли нормализовать будущие входные данные таким же образом.
6. Обучите модель
Когда экземпляр нашей модели создан, а данные представлены в виде тензоров, у нас есть все необходимое для начала процесса обучения.
Скопируйте следующую функцию в свой
файл script.js .
async function trainModel(model, inputs, labels) {
// Prepare the model for training.
model.compile({
optimizer: tf.train.adam(),
loss: tf.losses.meanSquaredError,
metrics: ['mse'],
});
const batchSize = 32;
const epochs = 50;
return await model.fit(inputs, labels, {
batchSize,
epochs,
shuffle: true,
callbacks: tfvis.show.fitCallbacks(
{ name: 'Training Performance' },
['loss', 'mse'],
{ height: 200, callbacks: ['onEpochEnd'] }
)
});
}
Давайте разберем это.
Подготовьтесь к обучению
// Prepare the model for training.
model.compile({
optimizer: tf.train.adam(),
loss: tf.losses.meanSquaredError,
metrics: ['mse'],
});
Нам нужно «скомпилировать» модель, прежде чем обучать ее. Для этого нам необходимо указать ряд очень важных вещей:
-
optimizer: это алгоритм, который будет управлять обновлениями модели по мере просмотра примеров. В TensorFlow.js доступно множество оптимизаторов. Здесь мы выбрали оптимизатор Адама, поскольку он достаточно эффективен на практике и не требует настройки. -
loss: это функция, которая сообщит модели, насколько хорошо она изучает каждый из отображаемых пакетов (подмножеств данных). Здесь мы используемmeanSquaredErrorдля сравнения прогнозов модели с истинными значениями.
const batchSize = 32;
const epochs = 50;
Далее мы выбираем пакетный размер и количество эпох:
-
batchSizeотносится к размеру подмножеств данных, которые модель будет видеть на каждой итерации обучения. Обычные размеры партий обычно находятся в диапазоне 32-512. На самом деле не существует идеального размера пакета для всех задач, и описание математических мотивов для различных размеров пакетов выходит за рамки данного руководства. -
epochsозначают, сколько раз модель будет просматривать весь предоставленный вами набор данных. Здесь мы проведем 50 итераций по набору данных.
Начать цикл поезда
return await model.fit(inputs, labels, {
batchSize,
epochs,
callbacks: tfvis.show.fitCallbacks(
{ name: 'Training Performance' },
['loss', 'mse'],
{ height: 200, callbacks: ['onEpochEnd'] }
)
});
model.fit — это функция, которую мы вызываем для запуска цикла обучения. Это асинхронная функция, поэтому мы возвращаем обещание, которое она нам дает, чтобы вызывающая сторона могла определить, когда обучение завершено.
Чтобы отслеживать ход обучения, мы передаем несколько обратных вызовов в model.fit . Мы используем tfvis.show.fitCallbacks для создания функций, которые строят диаграммы для показателей «потери» и «mse», которые мы указали ранее.
Сложите все это вместе
Теперь нам нужно вызвать функции, которые мы определили, из нашей функции run .
Добавьте следующий код в конец вашего
функция run .
// Convert the data to a form we can use for training.
const tensorData = convertToTensor(data);
const {inputs, labels} = tensorData;
// Train the model
await trainModel(model, inputs, labels);
console.log('Done Training');
Когда вы обновите страницу, через несколько секунд вы увидите обновление следующих графиков.
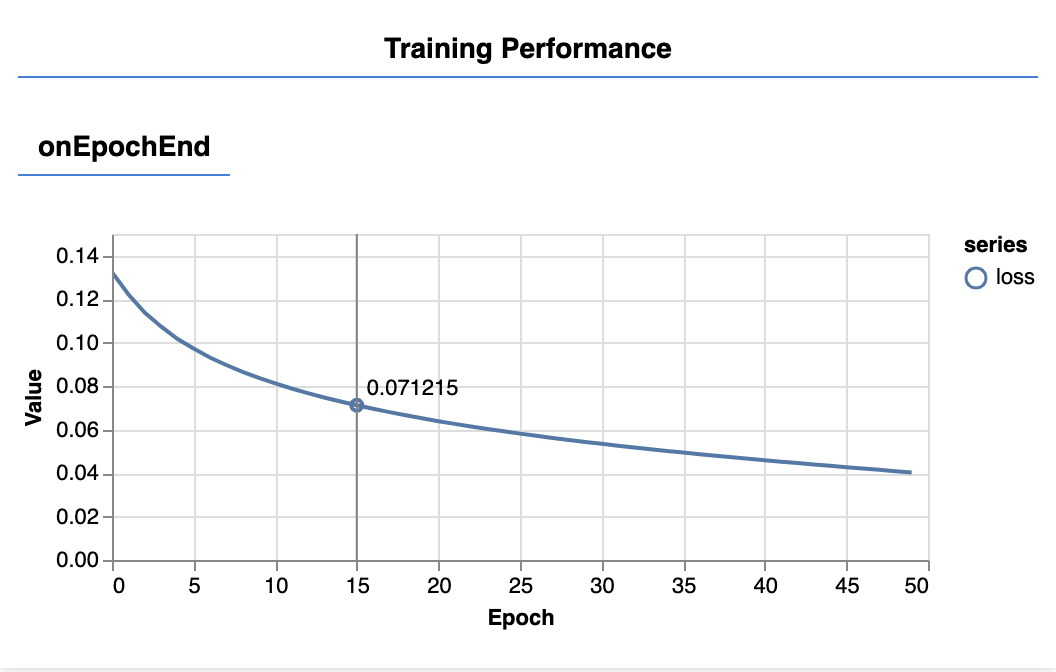
Они создаются обратными вызовами, которые мы создали ранее. Они отображают потери и mse, усредненные по всему набору данных, в конце каждой эпохи.
При обучении модели мы хотим, чтобы потери снизились. В этом случае, поскольку наша метрика является мерой ошибки, мы хотим, чтобы она также снизилась.
7. Делайте прогнозы
Теперь, когда наша модель обучена, мы хотим сделать некоторые прогнозы. Давайте оценим модель, увидев, что она предсказывает для однородного диапазона чисел от низкой до высокой мощности.
Добавьте следующую функцию в ваш файл script.js
function testModel(model, inputData, normalizationData) {
const {inputMax, inputMin, labelMin, labelMax} = normalizationData;
// Generate predictions for a uniform range of numbers between 0 and 1;
// We un-normalize the data by doing the inverse of the min-max scaling
// that we did earlier.
const [xs, preds] = tf.tidy(() => {
const xsNorm = tf.linspace(0, 1, 100);
const predictions = model.predict(xsNorm.reshape([100, 1]));
const unNormXs = xsNorm
.mul(inputMax.sub(inputMin))
.add(inputMin);
const unNormPreds = predictions
.mul(labelMax.sub(labelMin))
.add(labelMin);
// Un-normalize the data
return [unNormXs.dataSync(), unNormPreds.dataSync()];
});
const predictedPoints = Array.from(xs).map((val, i) => {
return {x: val, y: preds[i]}
});
const originalPoints = inputData.map(d => ({
x: d.horsepower, y: d.mpg,
}));
tfvis.render.scatterplot(
{name: 'Model Predictions vs Original Data'},
{values: [originalPoints, predictedPoints], series: ['original', 'predicted']},
{
xLabel: 'Horsepower',
yLabel: 'MPG',
height: 300
}
);
}
Несколько вещей, на которые следует обратить внимание в приведенной выше функции.
const xsNorm = tf.linspace(0, 1, 100);
const predictions = model.predict(xsNorm.reshape([100, 1]));
Мы генерируем 100 новых «примеров» для использования в модели. Model.predict — это то, как мы вводим эти примеры в модель. Обратите внимание, что они должны иметь такую же форму ( [num_examples, num_features_per_example] ), как и во время обучения.
// Un-normalize the data
const unNormXs = xsNorm
.mul(inputMax.sub(inputMin))
.add(inputMin);
const unNormPreds = predictions
.mul(labelMax.sub(labelMin))
.add(labelMin);
Чтобы вернуть данные в исходный диапазон (а не 0–1), мы используем значения, которые мы вычислили при нормализации, но просто инвертируем операции.
return [unNormXs.dataSync(), unNormPreds.dataSync()];
.dataSync() — это метод, который мы можем использовать для получения typedarray значений, хранящихся в тензоре. Это позволяет нам обрабатывать эти значения в обычном JavaScript. Это синхронная версия метода .data() , которая обычно предпочтительнее.
Наконец, мы используем tfjs-vis для построения исходных данных и прогнозов модели.
Добавьте следующий код в свой
функция run .
// Make some predictions using the model and compare them to the
// original data
testModel(model, data, tensorData);
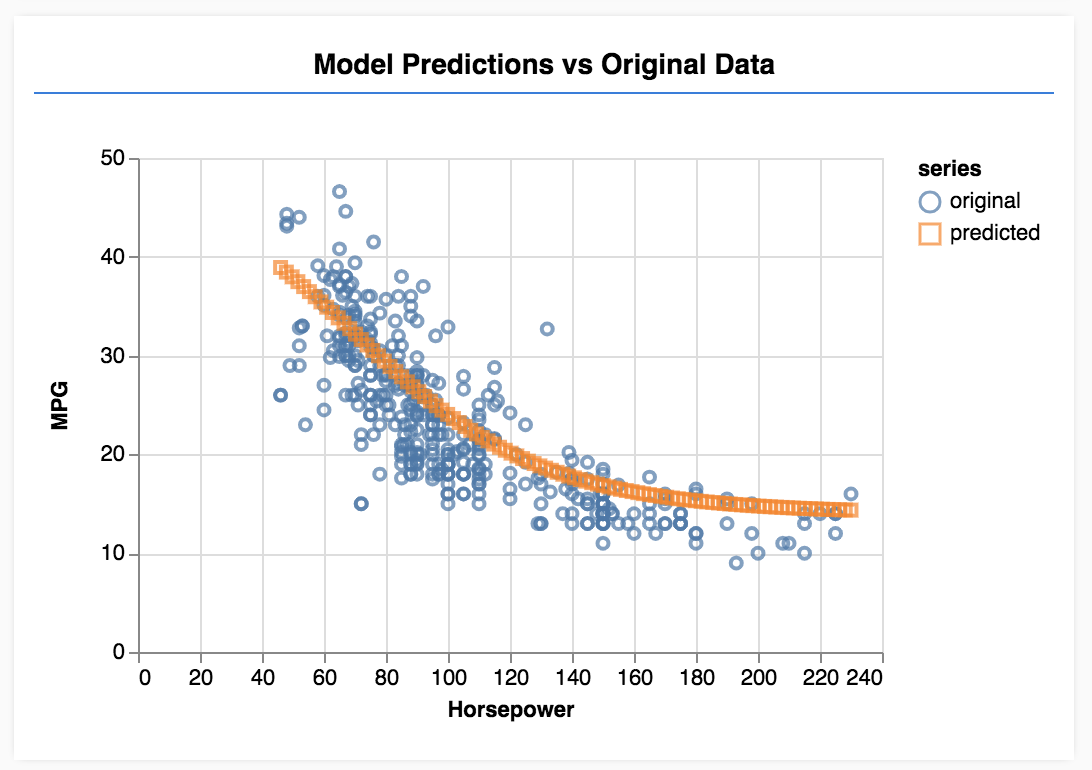
Обновите страницу, и после завершения обучения модели вы должны увидеть что-то вроде следующего.
Поздравляем! Вы только что обучили простую модель машинного обучения. В настоящее время он выполняет так называемую линейную регрессию, которая пытается подогнать линию к тренду, присутствующему во входных данных.
8. Основные выводы
Этапы обучения модели машинного обучения включают в себя:
Сформулируйте свою задачу:
- Это проблема регрессии или классификации?
- Можно ли это сделать с помощью обучения с учителем или обучения без учителя?
- Какова форма входных данных? Как должны выглядеть выходные данные?
Подготовьте данные:
- Очистите данные и, если возможно, вручную проверьте их на наличие закономерностей.
- Перемешайте данные, прежде чем использовать их для обучения.
- Нормализуйте ваши данные в разумном диапазоне для нейронной сети. Обычно 0-1 или -1-1 являются хорошими диапазонами для числовых данных.
- Преобразуйте ваши данные в тензоры
Создайте и запустите свою модель:
- Определите свою модель с помощью
tf.sequentialилиtf.model, а затем добавьте к ней слои с помощьюtf.layers.* - Выберите оптимизатор (обычно хороший Адам ) и такие параметры, как размер пакета и количество эпох.
- Выберите подходящую функцию потерь для вашей проблемы и показатель точности, который поможет вам оценить прогресс.
meanSquaredError— это распространенная функция потерь для задач регрессии. - Следите за тренировками, чтобы увидеть, уменьшаются ли потери
Оцените свою модель
- Выберите метрику оценки для своей модели, которую вы сможете отслеживать во время обучения. После обучения попробуйте сделать несколько тестовых прогнозов, чтобы получить представление о качестве прогнозов.
9. Дополнительный балл: что стоит попробовать
- Поэкспериментируйте, изменяя количество эпох. Сколько эпох вам нужно, чтобы график выровнялся?
- Поэкспериментируйте с увеличением количества объектов в скрытом слое.
- Поэкспериментируйте с добавлением дополнительных скрытых слоев между первым добавленным скрытым слоем и последним выходным слоем. Код этих дополнительных слоев должен выглядеть примерно так.
model.add(tf.layers.dense({units: 50, activation: 'sigmoid'}));
Самым важным нововведением в этих скрытых слоях является то, что они вводят нелинейную функцию активации, в данном случае сигмовидную активацию. Подробнее о функциях активации читайте в этой статье .
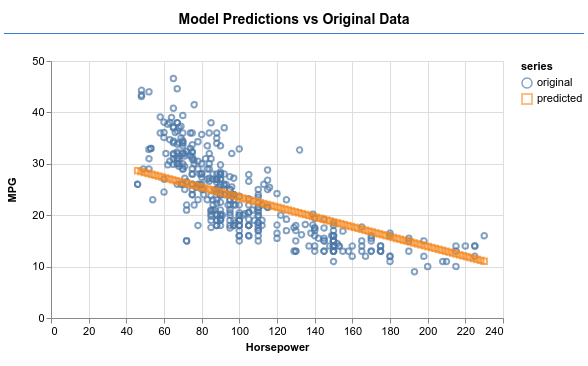
Посмотрите, сможете ли вы заставить модель выдавать выходные данные, как показано на изображении ниже.