1. מבוא
ב-Codelab הזה תאמנו מודל לבצע תחזיות על סמך נתונים מספריים שמתארים קבוצת מכוניות.
בתרגיל הזה נדגים שלבים נפוצים לאימון של סוגים רבים ושונים של מודלים, אבל נשתמש במערך נתונים קטן ובמודל פשוט (חלש). המטרה העיקרית היא לעזור לכם להכיר את המונחים הבסיסיים, את המושגים ואת התחביר שקשורים למודלים לאימון באמצעות TensorFlow.js, ולספק לכם צעד נוסף להמשך הלמידה והלמידה.
בגלל שאנחנו מאמנים מודל לחזות מספרים רציפים, המשימה הזו נקראת לפעמים משימת רגרסיה. כדי לאמן את המודל, נציג לו הרבה דוגמאות של קלט יחד עם הפלט הנכון. היא נקראת למידה מונחית.
מה תפַתחו
אתם תיצרו דף אינטרנט שמשתמש ב-TensorFlow.js לאימון מודל בדפדפן. נתון 'כוח סוס' למכונית, המודל ילמד לחזות את "מיילים לגלון" (MPG).
לשם כך:
- טוענים את הנתונים ומכינים אותם לאימון.
- להגדיר את הארכיטקטורה של המודל.
- לאמן את המודל ולעקוב אחרי הביצועים שלו במהלך האימון.
- תוכלו להעריך את המודל שעבר אימון על ידי יצירת תחזיות.
מה תלמדו
- שיטות מומלצות להכנת נתונים ללמידת מכונה, כולל מיון נתונים (shuffle) ונירמול.
- בתחביר של TensorFlow.js ליצירת מודלים באמצעות tf.layers API.
- איך לעקוב אחר אימון בדפדפן באמצעות ספריית tfjs-vis
למה תזדקק?
- גרסה עדכנית של Chrome או דפדפן מתקדם אחר.
- כלי לעריכת טקסט, שפועל באופן מקומי במחשב שלכם או באינטרנט באמצעות משהו כמו Codepen או Glitch.
- ידע ב-HTML, ב-CSS, ב-JavaScript וב-כלי הפיתוח ל-Chrome (או בכלי הפיתוח המועדפים עליכם בדפדפנים).
- הבנה של מושגים ברמה גבוהה של רשתות נוירונים. אם אתם צריכים מבוא או רענון, תוכלו לצפות בסרטון הזה ב-3blue1brown או בסרטון הזה בנושא למידה עמוקה (Deep Learning) ב-JavaScript של אשי קרישנן.
2. להגדרה
יצירת דף HTML והכללת ה-JavaScript
 צריך להעתיק את הקוד הבא לקובץ HTML בשם
צריך להעתיק את הקוד הבא לקובץ HTML בשם
index.html
<!DOCTYPE html>
<html>
<head>
<title>TensorFlow.js Tutorial</title>
<!-- Import TensorFlow.js -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@2.0.0/dist/tf.min.js"></script>
<!-- Import tfjs-vis -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs-vis@1.0.2/dist/tfjs-vis.umd.min.js"></script>
</head>
<body>
<!-- Import the main script file -->
<script src="script.js"></script>
</body>
</html>
יוצרים את קובץ ה-JavaScript בשביל הקוד
- באותה תיקייה שבה נמצא קובץ ה-HTML שלמעלה, יוצרים קובץ בשם script.js ומוסיפים אליו את הקוד הבא.
console.log('Hello TensorFlow');
רוצים לנסות?
עכשיו, אחרי שיצרתם את קובצי ה-HTML וה-JavaScript, כדאי לנסות אותם. פותחים את הקובץ index.html בדפדפן ופותחים את מסוף כלי הפיתוח.
אם הכול פועל, אמורים להיות שני משתנים גלובליים שנוצרו וזמינים במסוף כלי הפיתוח:
tfהוא קובץ עזר של הספרייה TensorFlow.jstfvisהוא קובץ עזר של ספריית tfjs-vis
צריך לפתוח את הכלים למפתחים בדפדפן. בפלט של המסוף אמורה להופיע ההודעה Hello TensorFlow. אם כן, אתם מוכנים לעבור לשלב הבא.
3. טעינה, עיצוב והצגה חזותית של נתוני הקלט
בשלב הראשון, אנחנו יכולים לטעון, לעצב ולהציג את הנתונים שעליהם אנחנו רוצים לאמן את המודל.
אנחנו נטענו את "המכוניות" מערך נתונים מקובץ JSON שאנחנו מארחים. יש בו הרבה תכונות שונות שקשורות לכל מכונית נתונה. עבור מדריך זה, אנחנו רוצים לחלץ נתונים רק לגבי כוח סוס ומייל לגלון.
צריך להוסיף את הקוד הבא אל
script.js קובץ
/**
* Get the car data reduced to just the variables we are interested
* and cleaned of missing data.
*/
async function getData() {
const carsDataResponse = await fetch('https://storage.googleapis.com/tfjs-tutorials/carsData.json');
const carsData = await carsDataResponse.json();
const cleaned = carsData.map(car => ({
mpg: car.Miles_per_Gallon,
horsepower: car.Horsepower,
}))
.filter(car => (car.mpg != null && car.horsepower != null));
return cleaned;
}
הפעולה הזו תסיר גם ערכים שלא הוגדרו בהם מיילים לגלון או כוח סוס. בנוסף, נמחיש את הנתונים בתרשים פיזור כדי לראות איך הם נראים.
צריך להוסיף את הקוד הבא לתחתית המסמך
script.js .
async function run() {
// Load and plot the original input data that we are going to train on.
const data = await getData();
const values = data.map(d => ({
x: d.horsepower,
y: d.mpg,
}));
tfvis.render.scatterplot(
{name: 'Horsepower v MPG'},
{values},
{
xLabel: 'Horsepower',
yLabel: 'MPG',
height: 300
}
);
// More code will be added below
}
document.addEventListener('DOMContentLoaded', run);
כשתרעננו את הדף. בצד ימין של הדף אמורה להופיע חלונית עם פיזור של הנתונים. הוא אמור להיראות כך.
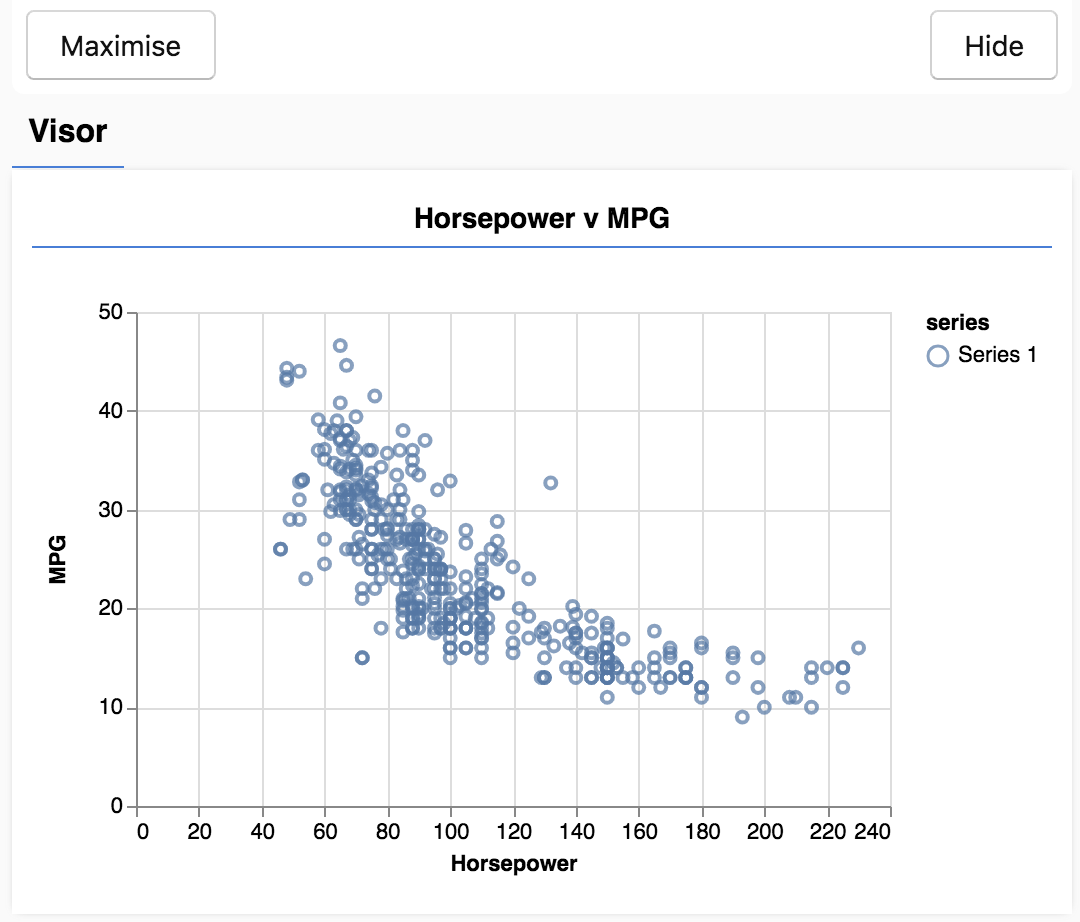
הלוח הזה ידוע בשם המגן, והוא מסופק על ידי tfjs-vis. הוא מספק מקום נוח להציג את הרכיבים החזותיים.
באופן כללי, כשעובדים עם נתונים, כדאי למצוא דרכים לבדוק את הנתונים ולנקות אותם במקרה הצורך. במקרה זה, נאלצנו להסיר מ-carsData רשומות מסוימות שלא הכילו את כל השדות הנדרשים. המחשה חזותית של הנתונים יכולה לתת לנו מושג אם יש מבנה לנתונים שהמודל יכול ללמוד.
מהתרשים שלמעלה ניתן לראות שיש קשר שלילי בין כוח סוס למייל לגלון (MPG), כלומר ככל שכוח הסוס עולה, המכוניות מקבלות פחות מיילים לגלון.
הגדרה של המשימה שלנו
עכשיו נתוני הקלט ייראו כך.
...
{
"mpg":15,
"horsepower":165,
},
{
"mpg":18,
"horsepower":150,
},
{
"mpg":16,
"horsepower":150,
},
...
המטרה שלנו היא לאמן מודל שלוקח מספר אחד וכוח סוס ולומד לחזות מספר אחד, מייל לגלון. חשוב לזכור שהמיפוי אחד לאחד, כי הוא חשוב לקטע הבא.
אנחנו נזין את הדוגמאות האלה, את כוח הסוס והמייל לגלון (MPG), לרשת נוירונים שתלמד מהדוגמאות האלה נוסחה (או פונקציה) כדי לחזות מיילים לגלון כוח סוס. הלמידה הזו מהדוגמאות שיש לנו עבורן את התשובות הנכונות נקראת למידה מבוקרת.
4. הגדרת ארכיטקטורת המודל
בקטע הזה נכתוב קוד שמתאר את ארכיטקטורת המודל. ארכיטקטורת המודלים היא פשוט דרך מיוחדת לומר "אילו פונקציות יפעלו שהמודל יריץ אותו", או "באיזה אלגוריתם ישתמש המודל שלנו כדי לחשב את התשובות שלו".
מודלים של למידת מכונה הם אלגוריתמים שמקבלים קלט ומפיקים פלט. כשמשתמשים ברשתות נוירונים, האלגוריתם הוא קבוצה של שכבות נוירונים עם 'משקולות' (מספרים) שמנהלים את הפלט שלהם. תהליך האימון לומד מהם הערכים האידיאליים למשקולות האלה.
מוסיפים את הפונקציה הבאה
script.js להגדרת ארכיטקטורת המודל.
function createModel() {
// Create a sequential model
const model = tf.sequential();
// Add a single input layer
model.add(tf.layers.dense({inputShape: [1], units: 1, useBias: true}));
// Add an output layer
model.add(tf.layers.dense({units: 1, useBias: true}));
return model;
}
זה אחד המודלים הכי פשוטים שאפשר להגדיר ב-tensorflow.js, בואו נפרק קצת את הפירוט של כל שורה.
הגדרה מיידית של המודל
const model = tf.sequential();
הפעולה הזו יוצרת אובייקט tf.Model. המודל הזה הוא sequential כי הקלט שלו יורד ישירות אל הפלט. לסוגים אחרים של מודלים יכולים להיות הסתעפויות, או אפילו כמה קלט ופלט, אבל במקרים רבים המודלים יהיו רציפים. למודלים של רצף יש גם קל יותר להשתמש ב-API.
הוספת שכבות
model.add(tf.layers.dense({inputShape: [1], units: 1, useBias: true}));
הפעולה הזו מוסיפה שכבת קלט לרשת שלנו, שמחוברת באופן אוטומטי לשכבה dense עם יחידה מוסתרת אחת. שכבה dense היא סוג של שכבה שמכפילה את הקלט שלה במטריצה (שנקראת משקולות) ואז מוסיפה מספר (שנקרא ההטיה) לתוצאה. מכיוון שזו השכבה הראשונה ברשת, עלינו להגדיר את inputShape שלנו. הערך inputShape הוא [1] כי הקלט שלנו הוא מספר 1 (כוח הסוס של מכונית נתונה).
units קובעת את הגודל של מטריצת המשקל בשכבה. כשמגדירים את הערך 1 כאן, אנחנו אומרים שיהיה משקל אחד לכל אחת מתכונות הקלט של הנתונים.
model.add(tf.layers.dense({units: 1}));
הקוד שלמעלה יוצר את שכבת הפלט שלנו. הגדרנו את units ל-1 כי אנחנו רוצים להפיק פלט של מספר 1.
יצירת מופע
צריך להוסיף את הקוד הבא אל
run הפונקציה שהגדרנו קודם.
// Create the model
const model = createModel();
tfvis.show.modelSummary({name: 'Model Summary'}, model);
פעולה זו תיצור מופע של המודל ותציג סיכום של השכבות בדף האינטרנט.
5. הכנת הנתונים לאימון
כדי ליהנות מהיתרונות של TensorFlow.js שבזכותם אימון מודלים של למידת מכונה יהיה מעשי, אנחנו צריכים להמיר את הנתונים שלנו לTensorFlow.js. בנוסף, נבצע כמה טרנספורמציות על הנתונים שלנו שהן שיטות מומלצות, כלומר השמעה אקראית ונירמול.
צריך להוסיף את הקוד הבא אל
script.js קובץ
/**
* Convert the input data to tensors that we can use for machine
* learning. We will also do the important best practices of _shuffling_
* the data and _normalizing_ the data
* MPG on the y-axis.
*/
function convertToTensor(data) {
// Wrapping these calculations in a tidy will dispose any
// intermediate tensors.
return tf.tidy(() => {
// Step 1. Shuffle the data
tf.util.shuffle(data);
// Step 2. Convert data to Tensor
const inputs = data.map(d => d.horsepower)
const labels = data.map(d => d.mpg);
const inputTensor = tf.tensor2d(inputs, [inputs.length, 1]);
const labelTensor = tf.tensor2d(labels, [labels.length, 1]);
//Step 3. Normalize the data to the range 0 - 1 using min-max scaling
const inputMax = inputTensor.max();
const inputMin = inputTensor.min();
const labelMax = labelTensor.max();
const labelMin = labelTensor.min();
const normalizedInputs = inputTensor.sub(inputMin).div(inputMax.sub(inputMin));
const normalizedLabels = labelTensor.sub(labelMin).div(labelMax.sub(labelMin));
return {
inputs: normalizedInputs,
labels: normalizedLabels,
// Return the min/max bounds so we can use them later.
inputMax,
inputMin,
labelMax,
labelMin,
}
});
}
נסביר קצת על מה שקורה כאן.
הצגה אקראית של הנתונים
// Step 1. Shuffle the data
tf.util.shuffle(data);
כאן נארגן את הסדר של הדוגמאות שנזין לאלגוריתם האימון. ערבוב חשוב כי בדרך כלל במהלך האימון מערך הנתונים מחולק לקבוצות משנה קטנות יותר, שנקראות קבוצות משנה, שעליהן מאמנים את המודל. ההשמעה האקראית עוזרת לכל קבוצת נתונים לקבל מגוון רחב של נתונים מהתפלגות הנתונים. כך אנחנו עוזרים למודל:
- לא ללמוד דברים שתלויים לחלוטין בסדר שבו הנתונים הוזנו
- לא להיות רגישים למבנה בקבוצות המשנה (למשל, אם רואים רק מכוניות עם כוח סוס גבוה במחצית הראשונה של האימון, יכול להיות שצריך ללמוד על קשר שלא רלוונטי לשאר מערך הנתונים).
המרה לטינורים
// Step 2. Convert data to Tensor
const inputs = data.map(d => d.horsepower)
const labels = data.map(d => d.mpg);
const inputTensor = tf.tensor2d(inputs, [inputs.length, 1]);
const labelTensor = tf.tensor2d(labels, [labels.length, 1]);
כאן יוצרים שני מערכים, אחד לדוגמאות הקלט שלנו (ערכי כוח הסוס), ואחד לערכי הפלט האמיתיים (שנקראים תוויות בלמידת מכונה).
לאחר מכן אנחנו ממירים כל נתוני מערך לטנזור דו-ממדי. הטנזור יהיה בצורה של [num_examples, num_features_per_example]. כאן יש inputs.length דוגמאות וכל דוגמה כוללת תכונת קלט 1 (כוח הסוס).
נרמול הנתונים
//Step 3. Normalize the data to the range 0 - 1 using min-max scaling
const inputMax = inputTensor.max();
const inputMin = inputTensor.min();
const labelMax = labelTensor.max();
const labelMin = labelTensor.min();
const normalizedInputs = inputTensor.sub(inputMin).div(inputMax.sub(inputMin));
const normalizedLabels = labelTensor.sub(labelMin).div(labelMax.sub(labelMin));
בשלב הבא נציג עוד שיטה מומלצת לאימון של למידת מכונה. אנחנו מנרמלים את הנתונים. כאן אנחנו מנרמלים את הנתונים לטווח המספרי 0-1 באמצעות התאמה מינימלית לעומס. הנירמול חשוב כי המודלים הפנימיים של מודלים רבים של למידת מכונה שתיצרו עם tensorflow.js נועדו לעבוד עם מספרים לא גדולים מדי. טווחים נפוצים לנרמול הנתונים כך שיכללו 0 to 1 או -1 to 1. אם תתרגלו לנרמל את הנתונים לטווח סביר מסוים, יהיה לכם קל יותר באימון המודלים.
החזרת הנתונים וגבולות הנירמול
return {
inputs: normalizedInputs,
labels: normalizedLabels,
// Return the min/max bounds so we can use them later.
inputMax,
inputMin,
labelMax,
labelMin,
}
אנחנו רוצים לשמור את הערכים שבהם השתמשנו לנירמול במהלך האימון, כדי שנוכל לבטל את הנירמול של הפלט כדי להחזיר אותם לקנה המידה המקורי שלנו ולאפשר לנו לנרמל נתוני קלט עתידיים באותה דרך.
6. אימון המודל
לאחר יצירת מופע המודל והנתונים שלנו מיוצגים כמפריעים, יצרנו את כל מה שצריך כדי להתחיל את תהליך האימון.
מעתיקים את הפונקציה הבאה אל
script.js .
async function trainModel(model, inputs, labels) {
// Prepare the model for training.
model.compile({
optimizer: tf.train.adam(),
loss: tf.losses.meanSquaredError,
metrics: ['mse'],
});
const batchSize = 32;
const epochs = 50;
return await model.fit(inputs, labels, {
batchSize,
epochs,
shuffle: true,
callbacks: tfvis.show.fitCallbacks(
{ name: 'Training Performance' },
['loss', 'mse'],
{ height: 200, callbacks: ['onEpochEnd'] }
)
});
}
נסביר קצת.
הכנה להדרכה
// Prepare the model for training.
model.compile({
optimizer: tf.train.adam(),
loss: tf.losses.meanSquaredError,
metrics: ['mse'],
});
אנחנו צריכים 'להדר' את המודל לפני שנאמן אותו. לשם כך, עלינו לציין כמה דברים חשובים מאוד:
optimizer: זהו האלגוריתם שאחראי לניהול העדכונים במודל כפי שיראה דוגמאות. ב-TensorFlow.js יש הרבה כלי אופטימיזציה זמינים. כאן בחרנו בכלי האופטימיזציה של adam כי הוא די יעיל בפועל ולא דורש הגדרה.loss: הפונקציה הזו מראה למודל עד כמה הוא מצליח ללמוד כל אחת מהאצווה (קבוצות המשנה של הנתונים) שהיא מוצגת. כאן אנחנו משתמשים ב-meanSquaredErrorכדי להשוות בין החיזויים שהמודל לבין הערכים האמיתיים.
const batchSize = 32;
const epochs = 50;
לאחר מכן בוחרים גודל אצווה וכמה תקופות של זמן מערכת:
batchSizeמתייחס לגודל של קבוצות המשנה של הנתונים שהמודל יראה בכל איטרציה של האימון. הגדלים הנפוצים של קובצי אצווה הם בדרך כלל בטווח 32-512. אין באמת גודל אידיאלי לכל הבעיות, והוא מעבר להיקף של מדריך זה כדי לתאר את המניעים המתמטיים לגדלים שונים של חבילות.epochsמתייחס למספר הפעמים שהמודל יבחן את כל מערך הנתונים שסיפקתם. כאן נבצע 50 חזרות דרך מערך הנתונים.
התחלת לולאת הרכבת
return await model.fit(inputs, labels, {
batchSize,
epochs,
callbacks: tfvis.show.fitCallbacks(
{ name: 'Training Performance' },
['loss', 'mse'],
{ height: 200, callbacks: ['onEpochEnd'] }
)
});
model.fit היא הפונקציה שאנחנו קוראים להפעלת לולאת האימון. זוהי פונקציה אסינכרונית, לכן אנחנו מחזירים את ההבטחה שהיא נותנת לנו כדי שהמתקשר יוכל לדעת מתי האימון הסתיים.
כדי לעקוב אחרי ההתקדמות באימון, אנחנו מעבירים מספר קריאות חוזרות אל model.fit. אנחנו משתמשים בפונקציה tfvis.show.fitCallbacks כדי ליצור פונקציות שמציגות תרשימים של 'הפסד' ו-mse שציינו קודם.
שילוב של כל המידע
עכשיו צריך לקרוא לפונקציות שהגדרנו מהפונקציה run.
צריך להוסיף את הקוד הבא לתחתית המסמך
run .
// Convert the data to a form we can use for training.
const tensorData = convertToTensor(data);
const {inputs, labels} = tensorData;
// Train the model
await trainModel(model, inputs, labels);
console.log('Done Training');
כשתרעננו את הדף, אחרי כמה שניות אתם אמורים לראות שהתרשימים הבאים מתעדכנים.
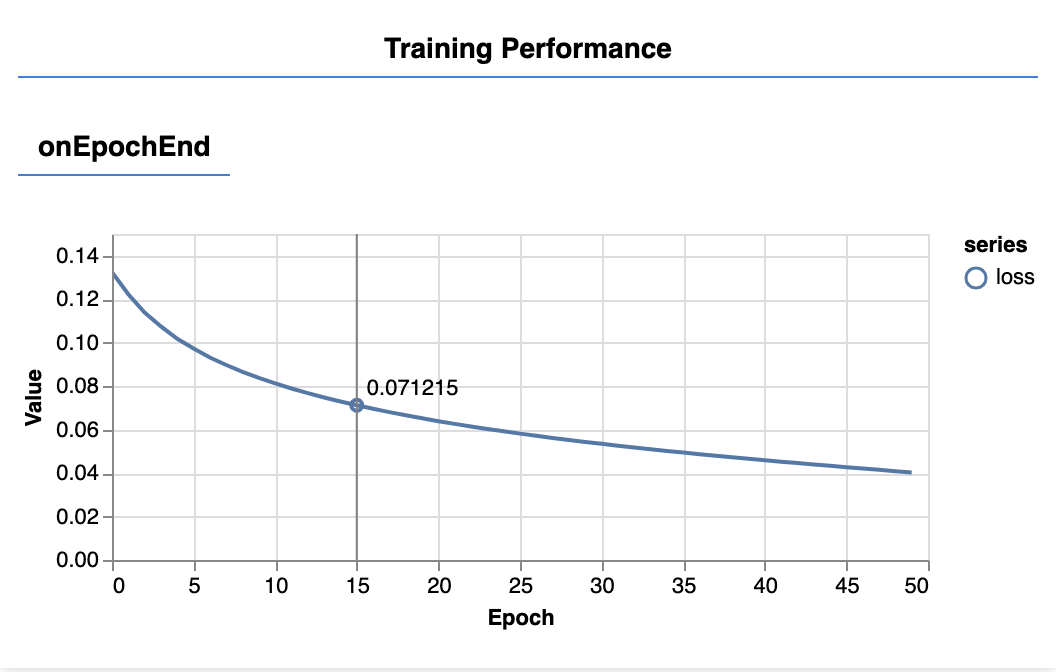
הן נוצרות באמצעות הקריאות החוזרות (callback) שיצרנו קודם. בסוף כל תקופה של בדיקה, היא מציגה את מספר ההפסדים והמסקנות הממוצעים של מערך הנתונים כולו.
כשמאמנים מודל מסוים, אנחנו רוצים לראות כמה הפסדים. במקרה הזה, מאחר שהמדד שלנו הוא מדד של שגיאה, נרצה לראות גם אותו ירידה.
7. ביצוע חיזויים
עכשיו, לאחר אימון המודל שלנו, נרצה לבצע כמה חיזויים. נבחן את המודל לפי חיזוי של טווח מספרים אחיד של כוחות סוס מהנמוך לגבוה.
מוסיפים את הפונקציה הבאה לקובץ script.js
function testModel(model, inputData, normalizationData) {
const {inputMax, inputMin, labelMin, labelMax} = normalizationData;
// Generate predictions for a uniform range of numbers between 0 and 1;
// We un-normalize the data by doing the inverse of the min-max scaling
// that we did earlier.
const [xs, preds] = tf.tidy(() => {
const xsNorm = tf.linspace(0, 1, 100);
const predictions = model.predict(xsNorm.reshape([100, 1]));
const unNormXs = xsNorm
.mul(inputMax.sub(inputMin))
.add(inputMin);
const unNormPreds = predictions
.mul(labelMax.sub(labelMin))
.add(labelMin);
// Un-normalize the data
return [unNormXs.dataSync(), unNormPreds.dataSync()];
});
const predictedPoints = Array.from(xs).map((val, i) => {
return {x: val, y: preds[i]}
});
const originalPoints = inputData.map(d => ({
x: d.horsepower, y: d.mpg,
}));
tfvis.render.scatterplot(
{name: 'Model Predictions vs Original Data'},
{values: [originalPoints, predictedPoints], series: ['original', 'predicted']},
{
xLabel: 'Horsepower',
yLabel: 'MPG',
height: 300
}
);
}
כמה דברים שחשוב לדעת בפונקציה שלמעלה.
const xsNorm = tf.linspace(0, 1, 100);
const predictions = model.predict(xsNorm.reshape([100, 1]));
אנחנו יוצרים 100 'דוגמאות' חדשות כדי להזין למודל. Model.predict הוא האופן שבו אנחנו מזינים את הדוגמאות האלה במודל. חשוב לשים לב שהם צריכים להיות בעלי צורה דומה ([num_examples, num_features_per_example]) כמו באימון.
// Un-normalize the data
const unNormXs = xsNorm
.mul(inputMax.sub(inputMin))
.add(inputMin);
const unNormPreds = predictions
.mul(labelMax.sub(labelMin))
.add(labelMin);
כדי להחזיר את הנתונים לטווח המקורי (במקום 0-1), אנחנו משתמשים בערכים שחיפשנו בזמן הנירמול, אבל פשוט הופכים את הפעולות.
return [unNormXs.dataSync(), unNormPreds.dataSync()];
.dataSync() היא שיטה שבאמצעותה אפשר לשמור typedarray מהערכים שמאוחסנים בארגומנט tensor. כך אנחנו יכולים לעבד את הערכים האלה ב-JavaScript רגיל. זוהי גרסה סינכרונית של השיטה .data() שעדיפה בדרך כלל.
לבסוף, אנחנו משתמשים ב-tfjs-vis כדי להציג את הנתונים המקוריים והחיזויים מהמודל.
צריך להוסיף את הקוד הבא אל
run function.
// Make some predictions using the model and compare them to the
// original data
testModel(model, data, tensorData);
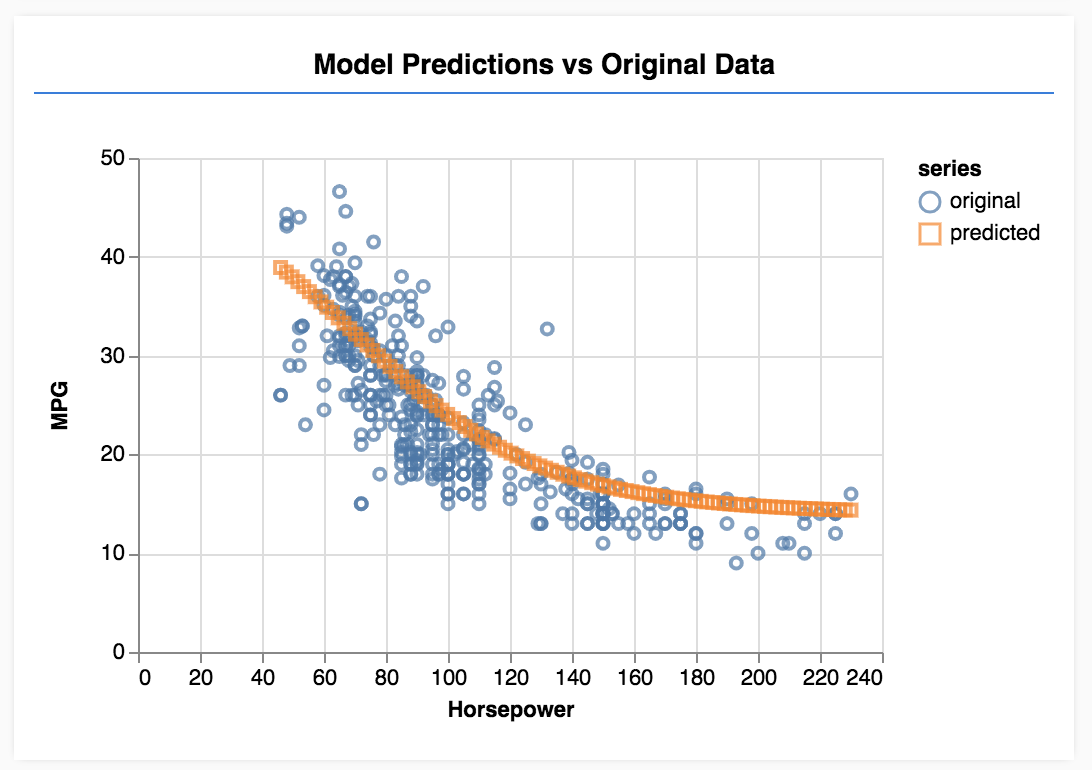
אחרי שהמודל מסיים את האימון, מרעננים את הדף. אתם אמורים לראות משהו כזה.
מזל טוב! בדיוק אימנתם מודל פשוט של למידת מכונה. היא מבצעת כרגע את מה שמכונה רגרסיה ליניארית, שמנסה להתאים קו למגמה הנוכחית בנתוני הקלט.
8. המסקנות העיקריות
השלבים באימון מודל למידת מכונה:
מנסחים את המשימה:
- האם זו בעיית רגרסיה או סיווג?
- האם ניתן לעשות זאת בעזרת למידה מונחית או למידה בלתי מונחית?
- מהי הצורה של נתוני הקלט? איך נתוני הפלט אמורים להיראות?
מכינים את הנתונים:
- כדאי לנקות את הנתונים ולבדוק אותם באופן ידני כדי לאתר דפוסים, אם אפשר
- ערבוב את הנתונים לפני שמשתמשים בהם לאימון.
- נרמל את הנתונים לטווח סביר של רשת הנוירונים. בדרך כלל הערכים 0-1 או -1-1 הם טווחים טובים לנתונים מספריים.
- המרת הנתונים לטנסטורים
בונים ומפעילים את המודל:
- צריך להגדיר את המודל באמצעות
tf.sequentialאוtf.model, ואז להוסיף לו שכבות באמצעותtf.layers.* - בוחרים כלי אופטימיזציה ( adam הוא בדרך כלל שיטה טובה) ופרמטרים כמו גודל הקבוצה ומספר התקופות של זמן המערכת.
- בוחרים פונקציית הפסד מתאימה לבעיה ומדד דיוק שיעזור לכם להעריך את ההתקדמות.
meanSquaredErrorהיא פונקציית הפסד נפוצה בבעיות של רגרסיה. - עקבו אחר האימון כדי לראות אם הירידה בירידה
הערכת המודל
- צריך לבחור מדד הערכה למודל שיהיה אפשר לעקוב אחריו במהלך האימון. אחרי האימון, כדאי לבצע כמה חיזויים של בדיקות כדי להבין את איכות החיזוי.
9. קרדיט נוסף: דברים שכדאי לנסות
- ניסוי לשינוי מספר התקופות של זמן המערכת. כמה תקופות של זמן צריך לצבור לפני שהתרשים יתייצב.
- ניסוי בהגדלת מספר היחידות בשכבה הסמויה.
- מומלץ להתנסות בהוספת שכבות מוסתרות נוספות בין השכבה המוסתרת הראשונה שהוספנו לשכבת הפלט הסופית. הקוד של השכבות הנוספות אמור להיראות בערך כך.
model.add(tf.layers.dense({units: 50, activation: 'sigmoid'}));
הדבר החדש והחשוב ביותר בשכבות הסמויות האלה הוא שהן כוללות פונקציית הפעלה לא ליניארית, במקרה הזה הפעלת sigmoid. מידע נוסף על פונקציות הפעלה זמין במאמר הזה.
בודקים אם אפשר לגרום למודל להפיק פלט כמו בדוגמה הבאה.