1. Giriş
Bu codelab'de, bir dizi arabayı tanımlayan sayısal verilerden tahminlerde bulunacak bir modeli eğiteceksiniz.
Bu alıştırmada, çok sayıda farklı model türünün eğitilmesinde sık kullanılan adımlar gösterilecektir. Ancak bunun için küçük bir veri kümesi ve basit (sığ) bir model kullanılacaktır. Programın birincil amacı, TensorFlow.js ile model eğitimi alanındaki temel terminoloji, kavramlar ve söz dizimi hakkında bilgi edinmenize yardımcı olmak ve daha kapsamlı keşifler ve öğrenim için bir adım atma aşaması sunmaktır.
Bir modeli sürekli sayıları tahmin edecek şekilde eğittiğimizden bu görev bazen regresyon görevi olarak da adlandırılır. Doğru çıkışla birlikte birçok giriş örneği göstererek modeli eğiteceğiz. Buna gözetimli öğrenme adı verilir.
Ne oluşturacaksınız?
Tarayıcıda bir modeli eğitmek için TensorFlow.js kullanan bir web sayfası oluşturacaksınız. "Beygin Gücü" model, "Mil/galon" hesaplamayı öğrenir. (MPG) içerir.
Bunun için:
- Verileri yükleyin ve eğitim için hazırlayın.
- Modelin mimarisini tanımlayın.
- Modeli eğitin ve eğitilirken performansını izleyin.
- Bazı tahminler yaparak eğitilen modeli değerlendirin.
Neler öğreneceksiniz?
- Karıştırma ve normalleştirme dahil olmak üzere makine öğrenimi için veri hazırlamaya yönelik en iyi uygulamalar.
- tf.layers API'yi kullanarak model oluşturmak için TensorFlow.js söz dizimi.
- tfjs-vis kitaplığı kullanılarak tarayıcı içi eğitim nasıl izlenir?
Gerekenler
- Chrome'un son sürümü veya başka bir modern tarayıcı.
- Makinenizde yerel olarak veya Codepen ya da Glitch gibi bir araçla web'de çalışan bir metin düzenleyici.
- HTML, CSS, JavaScript ve Chrome Geliştirici Araçları (veya tercih ettiğiniz tarayıcı geliştirme araçları) hakkında bilgi sahibi olmanız gerekir.
- Nöral Ağlarla ilgili üst düzey kavramsal bir anlayış. Giriş veya bilgilerinizi tazelemek isterseniz 3blue1brown adlı bu videoyu veya Ashi Krishnan'ın JavaScript'te Derin Öğrenme konulu bu videosunu izleyebilirsiniz.
2. Hazırlanın
HTML sayfası oluşturma ve JavaScript'i dahil etme
 Aşağıdaki kodu,
Aşağıdaki kodu,
index.html
<!DOCTYPE html>
<html>
<head>
<title>TensorFlow.js Tutorial</title>
<!-- Import TensorFlow.js -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@2.0.0/dist/tf.min.js"></script>
<!-- Import tfjs-vis -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs-vis@1.0.2/dist/tfjs-vis.umd.min.js"></script>
</head>
<body>
<!-- Import the main script file -->
<script src="script.js"></script>
</body>
</html>
Kod için JavaScript dosyasını oluşturun
- Yukarıdaki HTML dosyasıyla aynı klasörde, script.js adlı bir dosya oluşturun ve aşağıdaki kodu bu dosyaya yerleştirin.
console.log('Hello TensorFlow');
Test edin
HTML ve JavaScript dosyalarınızı oluşturduğunuza göre şimdi test edebilirsiniz. Tarayıcınızda index.html dosyasını açın ve devtools konsolunu açın.
Her şey yolundaysa iki genel değişken oluşturulur ve geliştirici araçları konsolunda kullanılabilir.
tf, TensorFlow.js kitaplığına referanstırtfvis, tfjs-vis kitaplığına referanstır
Tarayıcınızın geliştirici araçlarını açın. Konsol çıkışında Hello TensorFlow yazan bir mesaj görürsünüz. Öyleyse, bir sonraki adıma geçmeye hazırsınız demektir.
3. Giriş verilerini yükleme, biçimlendirme ve görselleştirme
İlk adım olarak, modeli eğitmek istediğimiz verileri yüklememize, biçimlendirmemize ve görselleştirmemize izin verin.
"Arabaları" yükleyeceğiz veri kümesiyle eşleştirilir. Her araçla ilgili birçok farklı özellik içerir. Bu eğitim için yalnızca Beygir Gücü ve Mil/galon ile ilgili verileri ayıklamak istiyoruz.
Aşağıdaki kodu şuraya ekleyin:
script.js dosya
/**
* Get the car data reduced to just the variables we are interested
* and cleaned of missing data.
*/
async function getData() {
const carsDataResponse = await fetch('https://storage.googleapis.com/tfjs-tutorials/carsData.json');
const carsData = await carsDataResponse.json();
const cleaned = carsData.map(car => ({
mpg: car.Miles_per_Gallon,
horsepower: car.Horsepower,
}))
.filter(car => (car.mpg != null && car.horsepower != null));
return cleaned;
}
Bu, mil/galon veya beygir gücü tanımlı olmayan tüm girişleri de kaldıracaktır. Şimdi, bu verileri dağılım grafiğinde göstererek bunların neye benzediğini görelim.
Aşağıdaki kodu sayfanızın altına ekleyin
script.js dosyasını silin.
async function run() {
// Load and plot the original input data that we are going to train on.
const data = await getData();
const values = data.map(d => ({
x: d.horsepower,
y: d.mpg,
}));
tfvis.render.scatterplot(
{name: 'Horsepower v MPG'},
{values},
{
xLabel: 'Horsepower',
yLabel: 'MPG',
height: 300
}
);
// More code will be added below
}
document.addEventListener('DOMContentLoaded', run);
Sayfayı yenilediğinizde. Sayfanın sol tarafında, verilerin dağılım grafiğini içeren bir panel görürsünüz. Şuna benzer bir görünümde olacaktır.
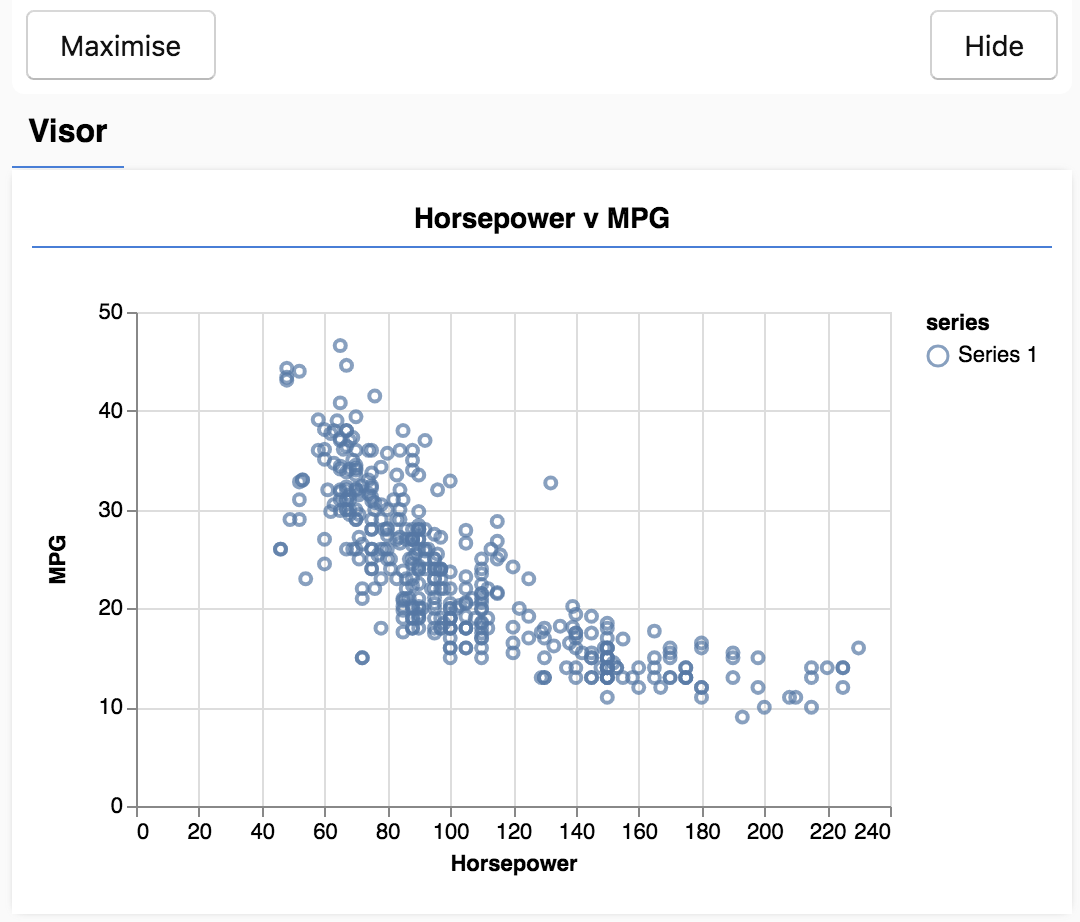
Bu panel, vizör olarak bilinir ve tfjs-vis tarafından sağlanır. Görselleştirmeleri görüntülemek için uygun bir yerdir.
Genel olarak, verilerle çalışırken verilerinize göz atmanın ve gerekirse onları temizlemenin yollarını bulmak iyi bir fikirdir. Bu durumda, gerekli tüm alanlara sahip olmayan bazı girişleri carsData hizmetinden kaldırmak zorunda kaldık. Verileri görselleştirmek, modelin öğrenebileceği verilerin bir yapısı olup olmadığı konusunda bize bir fikir verebilir.
Yukarıdaki grafikten, beygir gücü ile MPG arasında negatif bir bağıntı olduğunu görebiliyoruz. Yani, beygir gücü arttıkça arabalar genellikle galon başına daha az mil alır.
Görevimizi kavramaya dönüştürme
Giriş verilerimiz artık aşağıdaki gibi görünecektir.
...
{
"mpg":15,
"horsepower":165,
},
{
"mpg":18,
"horsepower":150,
},
{
"mpg":16,
"horsepower":150,
},
...
Amacımız bir sayı, beygir gücü olacak ve bir sayıyı Mil/galon tahmin etmeyi öğrenecek bir model eğitmek. Bire bir eşlemenin bir sonraki bölüm için önemli olacağını unutmayın.
Bu örnekleri, beygir gücü ve MPG'yi bir nöral ağa aktaracağız. Bu örneklerden yararlanarak, beygir gücü ile MPG'yi tahmin etmek için bir formül (veya işlev) öğreneceğiz. Doğru cevaplara sahip olduğumuz bu örneklerden öğrendiğimiz, gözetimli öğrenme olarak adlandırılır.
4. Model mimarisini tanımlama
Bu bölümde, model mimarisini açıklamak için kod yazacağız. Model mimarisi, "model çalışırken hangi işlevleri çalıştıracak?" veya "modelimiz yanıtlarını hesaplamak için hangi algoritmayı kullanacak?" gibi süslü bir ifadedir.
ML modelleri, girdi alan ve çıktı üreten algoritmalardır. Nöral ağlar kullanılırken algoritma, içinde "ağırlık" bulunan bir dizi nöron katmanından oluşur (sayılar) kontrol eder. Eğitim süreci, bu ağırlıklar için ideal değerleri öğrenir.
Aşağıdaki işlevi uygulamanıza ekleyin:
script.js dosyasını kullanarak model mimarisini tanımlayın.
function createModel() {
// Create a sequential model
const model = tf.sequential();
// Add a single input layer
model.add(tf.layers.dense({inputShape: [1], units: 1, useBias: true}));
// Add an output layer
model.add(tf.layers.dense({units: 1, useBias: true}));
return model;
}
Bu, tensorflow.js'de tanımlayabileceğimiz en basit modellerden biridir. Şimdi her satırı biraz daha açalım.
Modeli örneklendirme
const model = tf.sequential();
Bu işlem, bir tf.Model nesnesini örneklendirir. Bu modelin girişleri doğrudan çıkışa yönlendirildiği için sequential modelidir. Bazı model türlerinde dallar, hatta birden fazla giriş ve çıkış olabilir, ancak birçok durumda modelleriniz sıralı olacaktır. Sıralı modellerin kullanımı daha kolay API özelliği de vardır.
Katman ekleme
model.add(tf.layers.dense({inputShape: [1], units: 1, useBias: true}));
Bu işlem, ağımıza otomatik olarak tek bir gizli birimi olan dense katmanına bağlanan bir giriş katmanı ekler. dense katmanı, girdilerini bir matrisle çarpan (ağırlıklar denir) ve ardından sonuca bir sayı (önyargı denir) ekleyen bir katman türüdür. Bu, ağın ilk katmanı olduğundan inputShape'mizi tanımlamamız gerekir. inputShape giriş değerimiz 1 olduğundan (belirli bir arabanın beygir gücü) [1].
units, ağırlık matrisinin katmanda ne kadar büyük olacağını belirler. Burada değeri 1 olarak ayarlayarak verilerin her bir giriş özelliği için 1 ağırlık olacağını söyleriz.
model.add(tf.layers.dense({units: 1}));
Yukarıdaki kod, çıkış katmanımızı oluşturur. 1 sayısının çıkışını sağlamak istediğimiz için units öğesini 1 olarak ayarladık.
Örnek oluşturma
Aşağıdaki kodu şuraya ekleyin:
run işlevini tanımlar.
// Create the model
const model = createModel();
tfvis.show.modelSummary({name: 'Model Summary'}, model);
Bu, modelin bir örneğini oluşturur ve web sayfasındaki katmanların bir özetini gösterir.
5. Verileri eğitim için hazırlama
Makine öğrenimi modellerinin eğitimini pratik hale getiren TensorFlow.js performans avantajlarından yararlanmak için verilerimizi tensörlere dönüştürmemiz gerekir. Verilerimizde, karıştırma ve normalleştirme gibi en iyi uygulamalar gibi bir dizi dönüşüm de gerçekleştireceğiz.
Aşağıdaki kodu şuraya ekleyin:
script.js dosya
/**
* Convert the input data to tensors that we can use for machine
* learning. We will also do the important best practices of _shuffling_
* the data and _normalizing_ the data
* MPG on the y-axis.
*/
function convertToTensor(data) {
// Wrapping these calculations in a tidy will dispose any
// intermediate tensors.
return tf.tidy(() => {
// Step 1. Shuffle the data
tf.util.shuffle(data);
// Step 2. Convert data to Tensor
const inputs = data.map(d => d.horsepower)
const labels = data.map(d => d.mpg);
const inputTensor = tf.tensor2d(inputs, [inputs.length, 1]);
const labelTensor = tf.tensor2d(labels, [labels.length, 1]);
//Step 3. Normalize the data to the range 0 - 1 using min-max scaling
const inputMax = inputTensor.max();
const inputMin = inputTensor.min();
const labelMax = labelTensor.max();
const labelMin = labelTensor.min();
const normalizedInputs = inputTensor.sub(inputMin).div(inputMax.sub(inputMin));
const normalizedLabels = labelTensor.sub(labelMin).div(labelMax.sub(labelMin));
return {
inputs: normalizedInputs,
labels: normalizedLabels,
// Return the min/max bounds so we can use them later.
inputMax,
inputMin,
labelMax,
labelMin,
}
});
}
Bu durumun ayrıntılarına göz atalım.
Verileri karıştırma
// Step 1. Shuffle the data
tf.util.shuffle(data);
Burada eğitim algoritmasına ileteceğimiz örneklerin sırasını rastgele hale getiririz. Karıştırma işlemi önemlidir çünkü genellikle eğitim sırasında veri kümesi, modelin eğitildiği daha küçük alt kümelere (gruplar olarak adlandırılır) ayrılır. Karıştırma, her grubun, veri dağıtımından çeşitli verilere sahip olmasına yardımcı olur. Bunu yaparak modelin:
- Tamamen verilerin beslendiği sıraya bağlı olan verileri öğrenmeme
- Alt gruplardaki yapıya karşı duyarlı olmamalıdır (ör. eğitiminin ilk yarısında yalnızca yüksek beygir gücüne sahip arabaları görürse veri kümesinin geri kalanında geçerli olmayan bir ilişki öğrenebilir).
Tensöre dönüştür
// Step 2. Convert data to Tensor
const inputs = data.map(d => d.horsepower)
const labels = data.map(d => d.mpg);
const inputTensor = tf.tensor2d(inputs, [inputs.length, 1]);
const labelTensor = tf.tensor2d(labels, [labels.length, 1]);
Burada, biri giriş örneklerimiz (beygir gücü girişleri) ve diğeri doğru çıkış değerleri (makine öğreniminde etiketler olarak bilinir) için olmak üzere iki dizi oluştururuz.
Daha sonra her dizi verisi 2D tensöre dönüştürülür. Tensörün şekli [num_examples, num_features_per_example] olur. Burada inputs.length örneğimiz vardır ve her örnek 1 giriş özelliğine (beygir gücü) sahiptir.
Verileri normalleştirme
//Step 3. Normalize the data to the range 0 - 1 using min-max scaling
const inputMax = inputTensor.max();
const inputMin = inputTensor.min();
const labelMax = labelTensor.max();
const labelMin = labelTensor.min();
const normalizedInputs = inputTensor.sub(inputMin).div(inputMax.sub(inputMin));
const normalizedLabels = labelTensor.sub(labelMin).div(labelMax.sub(labelMin));
Sırada makine öğrenimi eğitimi için bir en iyi uygulama daha var. Verileri normal hale getiririz. Burada, min-maks. ölçeklendirme yöntemini kullanarak verileri 0-1 sayısal aralığına göre normalleştiririz. tensorflow.js ile derlediğiniz birçok makine öğrenimi modelinin dahili bileşenleri çok büyük olmayan sayılarla çalışacak şekilde tasarlandığından normalleştirme önemlidir. 0 to 1 veya -1 to 1 içerecek şekilde verileri normalleştiren genel aralıklar. Verilerinizi makul bir aralığa kadar normalleştirme alışkanlığı edinirseniz modellerinizi eğitirken daha başarılı olursunuz.
Verileri ve normalleştirme sınırlarını döndürme
return {
inputs: normalizedInputs,
labels: normalizedLabels,
// Return the min/max bounds so we can use them later.
inputMax,
inputMin,
labelMax,
labelMin,
}
Eğitim sırasında normalleştirme için kullandığımız değerleri korumak istiyoruz. Böylece çıkışları normalleştirilerek orijinal ölçeğimize geri dönebilir ve gelecekteki giriş verilerini aynı şekilde normalleştirebiliriz.
6. Modeli eğitme
Model örneğimizin oluşturulması ve verilerimiz tensör olarak temsil edilmesiyle eğitim sürecini başlatmak için her şey hazırdır.
Aşağıdaki işlevi kopyalayıp
script.js dosyasını silin.
async function trainModel(model, inputs, labels) {
// Prepare the model for training.
model.compile({
optimizer: tf.train.adam(),
loss: tf.losses.meanSquaredError,
metrics: ['mse'],
});
const batchSize = 32;
const epochs = 50;
return await model.fit(inputs, labels, {
batchSize,
epochs,
shuffle: true,
callbacks: tfvis.show.fitCallbacks(
{ name: 'Training Performance' },
['loss', 'mse'],
{ height: 200, callbacks: ['onEpochEnd'] }
)
});
}
Şimdi OKR’nin bileşenlerine bakalım.
Eğitime hazırlanma
// Prepare the model for training.
model.compile({
optimizer: tf.train.adam(),
loss: tf.losses.meanSquaredError,
metrics: ['mse'],
});
Herkesi aynı anda eğittiğimiz için teşekkür ederiz. Bunu yapmak için çok önemli bir dizi noktayı belirtmemiz gerekiyor:
optimizer: Bu, örneklerdeki gibi modelde yapılan güncellemeleri yönetecek olan algoritmadır. TensorFlow.js'de birçok optimize edici bulunur. Uygulamada oldukça etkili olduğu ve yapılandırma gerektirmediği için Adam Optimize Edici'yi burada seçtik.loss: Bu, modele gösterildiği grupları (veri alt kümeleri) öğrenmede ne kadar başarılı olduğunu bildiren bir işlevdir. Burada, modelin yaptığı tahminleri doğru değerlerle karşılaştırmak içinmeanSquaredErroryöntemini kullanırız.
const batchSize = 32;
const epochs = 50;
Sonra, birBatchSize ve birkaç dönem seçeceğiz:
batchSize, modelin her eğitim iterasyonunda göreceği veri alt kümelerinin boyutunu ifade eder. Yaygın olarak kullanılan grup sayısı genellikle 32-512 aralığındadır. Tüm problemler için ideal bir grup boyutu yoktur ve çeşitli seri boyutlarına ilişkin matematiksel motivasyonları açıklamak bu eğiticinin kapsamı dışındadır.epochs, modelin sağladığınız veri kümesinin tamamına kaç kez bakacağını ifade eder. Burada, veri kümesinde 50 yineleme gerçekleştireceğiz.
Tren döngüsünü başlatma
return await model.fit(inputs, labels, {
batchSize,
epochs,
callbacks: tfvis.show.fitCallbacks(
{ name: 'Training Performance' },
['loss', 'mse'],
{ height: 200, callbacks: ['onEpochEnd'] }
)
});
model.fit, eğitim döngüsünü başlatmak için çağırdığımız fonksiyondur. Eşzamansız bir işlev olduğundan, çağrının eğitimin ne zaman tamamlandığını belirleyebilmesi için bize verdiği sözü döndürüyoruz.
Eğitimin ilerlemesini izlemek için model.fit geri çağırmaları iletiriz. tfvis.show.fitCallbacks işlevini kullanarak "kayıp" grafiklerini çizen işlevler oluştururuz ve "mse" az önce belirttiğimiz üzere
Öğrendiklerinizin üzerinden geçin
Şimdi, run fonksiyonumuzda tanımladığımız fonksiyonları çağırmamız gerekiyor.
Aşağıdaki kodu sayfanızın altına ekleyin
run işlevi.
// Convert the data to a form we can use for training.
const tensorData = convertToTensor(data);
const {inputs, labels} = tensorData;
// Train the model
await trainModel(model, inputs, labels);
console.log('Done Training');
Sayfayı yenilediğinizde, birkaç saniye sonra aşağıdaki grafiklerin güncellendiğini göreceksiniz.
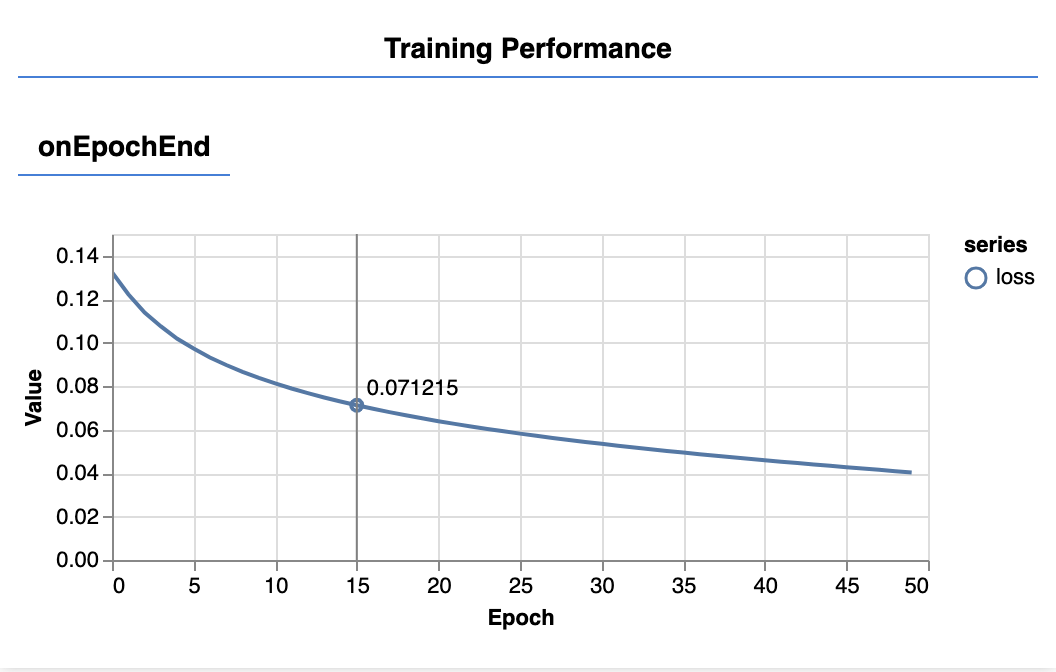
Bu öğeler, daha önce hazırladığımız geri çağırma işlevleriyle oluşturulur. Her bir dönemin sonunda kayıp ve mse'yi, tüm veri kümesi üzerinden ortalaması alınmış olarak gösterirler.
Bir modeli eğitirken kaybın azaldığını görmek istiyoruz. Bu örnekte, metriğimiz bir hata ölçüsü olduğundan, bunun da düşmesini istiyoruz.
7. Tahminlerde Bulunun
Modelimiz eğitildiğine göre bazı tahminlerde bulunmak istiyoruz. Düşükten yüksek beygir gücünün tek tip bir sayı aralığıyla ilgili tahminlerine bakarak modeli değerlendirelim.
Script.js dosyanıza aşağıdaki işlevi ekleyin
function testModel(model, inputData, normalizationData) {
const {inputMax, inputMin, labelMin, labelMax} = normalizationData;
// Generate predictions for a uniform range of numbers between 0 and 1;
// We un-normalize the data by doing the inverse of the min-max scaling
// that we did earlier.
const [xs, preds] = tf.tidy(() => {
const xsNorm = tf.linspace(0, 1, 100);
const predictions = model.predict(xsNorm.reshape([100, 1]));
const unNormXs = xsNorm
.mul(inputMax.sub(inputMin))
.add(inputMin);
const unNormPreds = predictions
.mul(labelMax.sub(labelMin))
.add(labelMin);
// Un-normalize the data
return [unNormXs.dataSync(), unNormPreds.dataSync()];
});
const predictedPoints = Array.from(xs).map((val, i) => {
return {x: val, y: preds[i]}
});
const originalPoints = inputData.map(d => ({
x: d.horsepower, y: d.mpg,
}));
tfvis.render.scatterplot(
{name: 'Model Predictions vs Original Data'},
{values: [originalPoints, predictedPoints], series: ['original', 'predicted']},
{
xLabel: 'Horsepower',
yLabel: 'MPG',
height: 300
}
);
}
Yukarıdaki işlevde dikkat edilmesi gereken birkaç nokta vardır.
const xsNorm = tf.linspace(0, 1, 100);
const predictions = model.predict(xsNorm.reshape([100, 1]));
100 yeni "örnek" oluştururuz modele feed'i de içerir. Model.predict, bu örnekleri modele nasıl aktardığımızı ifade eder. Bu hamlelerin, eğitimimizde olduğu gibi bir şekle ([num_examples, num_features_per_example]) sahip olmaları gerektiğini unutmayın.
// Un-normalize the data
const unNormXs = xsNorm
.mul(inputMax.sub(inputMin))
.add(inputMin);
const unNormPreds = predictions
.mul(labelMax.sub(labelMin))
.add(labelMin);
Verileri orijinal aralığımıza (0-1 yerine) geri getirmek için normalleştirirken hesapladığımız değerleri kullanırız, ancak işlemleri tersine çeviririz.
return [unNormXs.dataSync(), unNormPreds.dataSync()];
.dataSync(), bir tensörde depolanan değerlerin typedarray kadarını almak için kullanabileceğimiz bir yöntemdir. Bu, söz konusu değerleri normal JavaScript'te işlememize olanak tanır. Bu, .data() yönteminin genellikle tercih edilen eşzamanlı bir sürümüdür.
Son olarak, orijinal verileri ve modelden alınan tahminleri çizmek için tfjs-vis'i kullanırız.
Aşağıdaki kodu şuraya ekleyin:
run işlevi.
// Make some predictions using the model and compare them to the
// original data
testModel(model, data, tensorData);
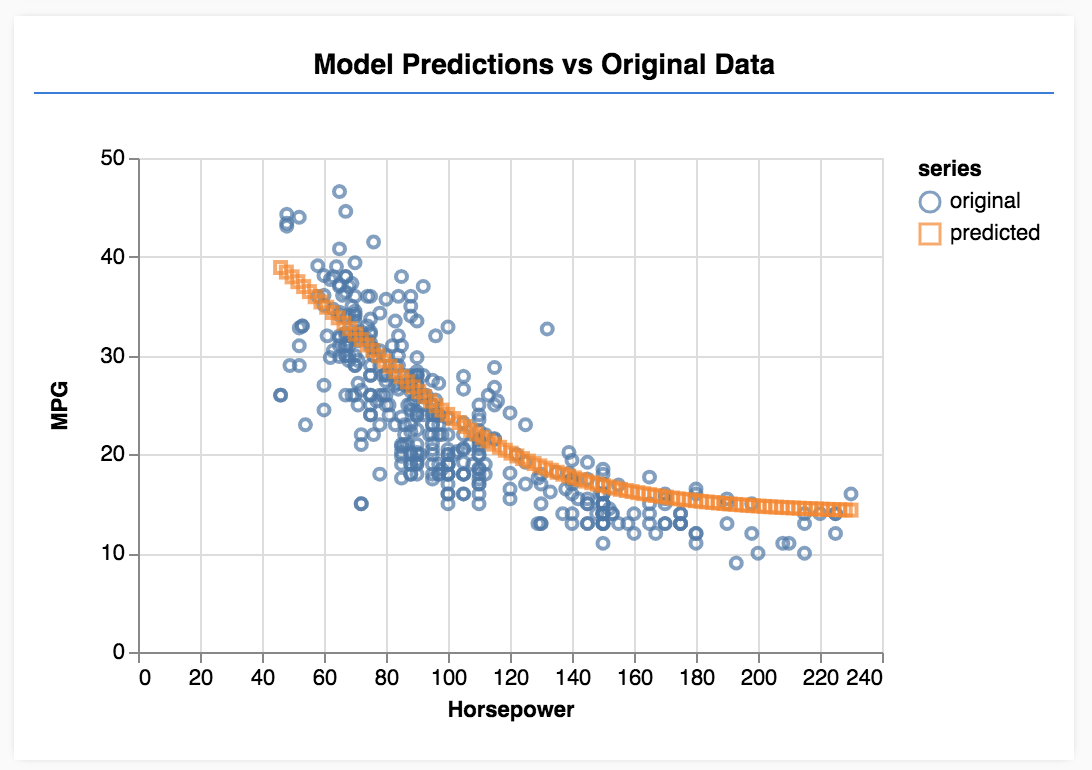
Sayfayı yenilediğinizde, model eğitimini tamamladığında aşağıdakine benzer bir sonuç görürsünüz.
Tebrikler! Basit bir makine öğrenimi modelini eğittiniz. Şu anda, giriş verilerindeki trende göre bir çizgi sığdırmaya çalışan, doğrusal regresyon olarak bilinen işlemi gerçekleştirmektedir.
8. Temel çıkarımlar
Makine öğrenimi modellerini eğitme adımları şunlardır:
Görevinizi formüle edin:
- Regresyon sorunu mu yoksa sınıflandırmayla mı ilgili?
- Bunu gözetimli öğrenmeyle veya gözetimsiz öğrenmeyle yapılabilir mi?
- Girdi verilerinin şekli nedir? Çıkış verileri nasıl olmalı?
Verilerinizi hazırlama:
- Verilerinizi temizleyin ve mümkün olduğunda verilerde kalıp olup olmadığını manuel olarak inceleyin
- Verilerinizi eğitim için kullanmadan önce karıştırma
- Nöral ağ için verilerinizi makul bir aralığa göre normalleştirin. Sayısal veriler için genellikle 0-1 veya -1-1 iyi aralıklardır.
- Verilerinizi tensörlere dönüştürün
Modelinizi derleyin ve çalıştırın:
tf.sequentialveyatf.modelkullanarak modelinizi tanımlayın, ardındantf.layers.*kullanarak modele katmanlar ekleyin- Bir optimize edici ( adam genellikle iyi bir seçenektir) ve grup boyutu ile dönem sayısı gibi parametreler seçin.
- Sorununuz için uygun bir kayıp işlevi ve ilerleme durumunuzu değerlendirmenize yardımcı olması için bir doğruluk metriği seçin.
meanSquaredError, regresyon problemleri için yaygın olarak kullanılan bir kayıp işlevidir. - Kayıpların azalıp azalmadığını görmek için eğitimi izleyin
Modelinizi değerlendirme
- Modeliniz için, eğitim sırasında izleyebileceğiniz bir değerlendirme metriği seçin. Eğitildikten sonra, tahmin kalitesi hakkında bir fikir edinmek için bazı test tahminleri yapmayı deneyin.
9. Ekstra Kredi: Deneyebileceğiniz şeyler
- Dönem sayısını değiştirerek deneme. Grafik düzleşmeden önce kaç döneme ihtiyacınız var?
- Gizli katmandaki birim sayısını artırarak denemeler yapın.
- Eklediğimiz ilk gizli katman ile son çıkış katmanının arasına daha fazla gizli katman ekleyerek denemeler yapın. Bu ekstra katmanların kodu aşağıdakine benzer olmalıdır.
model.add(tf.layers.dense({units: 50, activation: 'sigmoid'}));
Bu gizli katmanlarla ilgili en önemli yeni özellik, doğrusal olmayan bir aktivasyon işlevi (bu örnekte sigmoid etkinleştirmesi) sunmalarıdır. Etkinleştirme işlevleri hakkında daha fazla bilgi edinmek için bu makaleyi inceleyin.
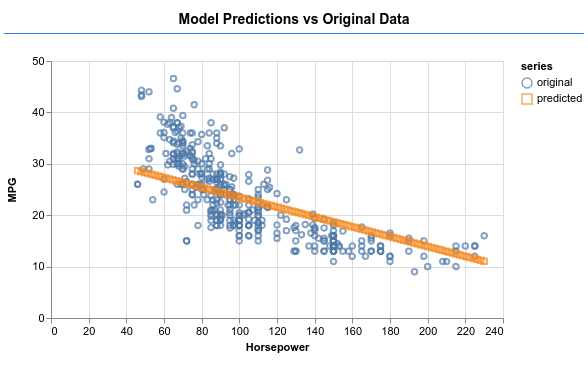
Modelin aşağıdaki resimde gösterildiği gibi çıktı üretmesini sağlayıp sağlayamayacağınıza bakın.