在此 Codelab 中,您将训练模型,使之能够根据描述一组汽车的数值数据做出预测。
本练习将演示训练许多不同类型的模型的常见步骤,但将使用小型数据集和简单(浅显)模型。主要目标是帮助您熟悉有关使用 TensorFlow.js 训练模型的基本术语、概念和语法,让您为进一步探索和学习打下良好的基础。
由于我们训练模型来预测连续数字,因而此任务有时称为回归任务。我们将通过向模型展示输入的多个样本和正确的输出来训练模型。这称为监督式学习。
您将构建的模型
您将创建一个使用 TensorFlow.js 在浏览器中训练模型的网页。如果提供汽车的“马力”,模型将学习预测“每加仑的英里数”(MPG)。
为了实现此目的,您需要:
- 加载数据,并准备将其用于训练。
- 定义模型的架构。
- 训练模型并监控其训练时的性能。
- 通过进行一些预测来评估经过训练的模型。
学习内容
- 准备用于机器学习的数据的最佳做法,包括重排和归一化。
- TensorFlow.js 语法:只有掌握了这些语法,才能使用 tf.layers API 创建模型。
- 如何使用 tfjs-vis 库监控浏览器内训练。
所需条件
- 最新版的 Chrome 或其他新型浏览器。
- 文本编辑器(可以在机器的本地运行,也可以通过 Codepen 或 Glitch 等工具在 web 中运行)。
- 了解 HTML、CSS、JavaScript 和 Chrome 开发者工具(或您的首选浏览器 DevTools)。
- 大致了解神经网络的概念。如果您需要了解简介或回顾内容,请考虑观看这部由 3blue1brown 制作的视频,或 Ashi Krishnan 这部有关使用 JavaScript 构建深度学习应用的视频。
创建 HTML 网页并添加 JavaScript
 将以下代码复制到名为 index.html 的 HTML 文件中
将以下代码复制到名为 index.html 的 HTML 文件中
index.html
<!DOCTYPE html>
<html>
<head>
<title>TensorFlow.js Tutorial</title>
<!-- Import TensorFlow.js -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@2.0.0/dist/tf.min.js"></script>
<!-- Import tfjs-vis -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs-vis@1.0.2/dist/tfjs-vis.umd.min.js"></script>
<!-- Import the main script file -->
<script src="script.js"></script>
</head>
<body>
</body>
</html>
为代码创建 JavaScript 文件
- 在上述 HTML 文件所在的文件夹中,创建一个名为 script.js 的文件,并将以下代码复制到其中。
console.log('Hello TensorFlow');
开始测试
现在,您已经创建了 HTML 和 JavaScript 文件,接下来可以对其进行测试。在浏览器中打开 index.html 文件,然后打开 Devtools 控制台。
如果一切正常,系统应该在 DevTools 控制台中创建并且提供两个全局变量:
tf是对 TensorFlow.js 库的引用tfvis是对 tfjs-vis 库的引用
打开浏览器的开发者工具,您应该会在控制台输出中看到一条内容为“Hello TensorFlow”的消息。如果是这样,那么您可以继续执行下一步操作。
我们首先加载要用于训练模型的数据、设置其格式并让数据直观呈现出来。
我们将从为您托管的 JSON 文件中加载“cars”数据集。它包含与每辆指定汽车有关的多个不同特征。在本教程中,我们只希望提取有关马力和每加仑英里数的数据。
将以下代码添加到您的
script.js 文件中
/**
* Get the car data reduced to just the variables we are interested
* and cleaned of missing data.
*/
async function getData() {
const carsDataResponse = await fetch('https://storage.googleapis.com/tfjs-tutorials/carsData.json');
const carsData = await carsDataResponse.json();
const cleaned = carsData.map(car => ({
mpg: car.Miles_per_Gallon,
horsepower: car.Horsepower,
}))
.filter(car => (car.mpg != null && car.horsepower != null));
return cleaned;
}
这样还会移除尚未定义每加仑的英里数或马力的所有条目。让我们以散点图的形式绘制这些数据,以查看其呈现样式。
将以下代码添加到
script.js 文件的底部。
async function run() {
// Load and plot the original input data that we are going to train on.
const data = await getData();
const values = data.map(d => ({
x: d.horsepower,
y: d.mpg,
}));
tfvis.render.scatterplot(
{name: 'Horsepower v MPG'},
{values},
{
xLabel: 'Horsepower',
yLabel: 'MPG',
height: 300
}
);
// More code will be added below
}
document.addEventListener('DOMContentLoaded', run);
刷新页面时,您应该会在页面左侧看到一个面板,其中显示了数据的散点图。应如下所示。
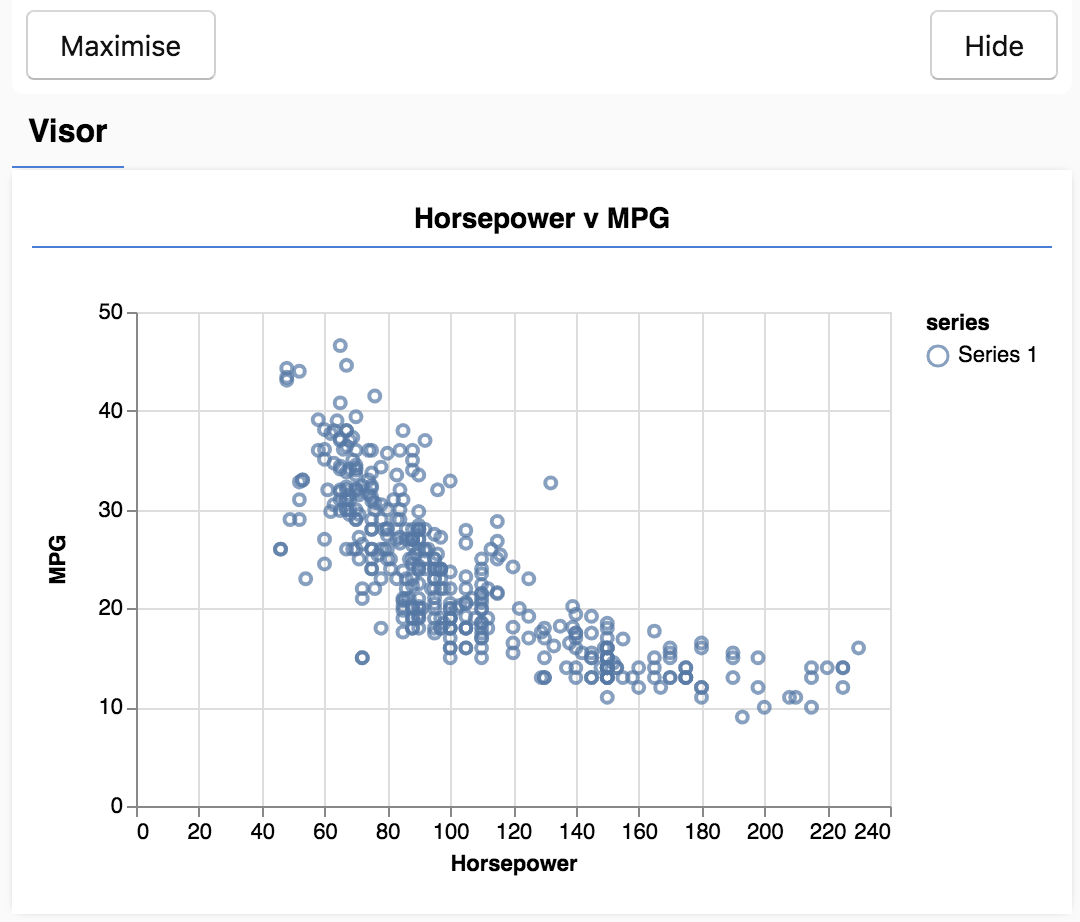
此面板称为 visor,由 tfjs-vis 提供,可便利地直观显示数据形状。
通常,在处理数据时,建议您设法查看数据并在必要时清理这些数据。在本例,我们必须从 carsData 中移除某些不包含所有必填字段的条目。直观呈现数据可让我们了解模型可以学习的数据是否存在任何结构。
从上图中可以看出,马力与 MPG 之间成反比,也就是说,随着马力越大,汽车耗用一加仑汽油能行使的英里数通常越少。
形成任务的概念
现在,输入数据将如下所示。
...
{
"mpg":15,
"horsepower":165,
},
{
"mpg":18,
"horsepower":150,
},
{
"mpg":16,
"horsepower":150,
},
...
我们的目标是训练一个模型,该模型将获取一个一个数字“马力”,并学习预测一个数字“每加仑的英里数”。请注意,这是一对一的映射,该映射对于下一部分非常重要。
我们将这些样本(马力和 MPG)提供给神经网络,神经网络将通过这些样本学习一个公式(或函数),以预测汽车在指定马力下的 MPG。这种通过从我们提供正确答案的样本来学习的方式称为监督式学习。
在本部分中,我们将编写代码来描述模型架构。模型架构其实就是“模型在执行时会运行的函数”,换一种说法就是“我们的模型将用于计算答案的算法”。
机器学习模型是指接受输入并生成输出的算法。使用神经网络时,算法是一组神经元层,其中权重(数字)控制着其输出。训练过程会学习这些权重的理想值。
将以下函数添加到您的
script.js 文件来定义模型架构。
function createModel() {
// Create a sequential model
const model = tf.sequential();
// Add a single input layer
model.add(tf.layers.dense({inputShape: [1], units: 1, useBias: true}));
// Add an output layer
model.add(tf.layers.dense({units: 1, useBias: true}));
return model;
}
这是我们在 tensorflow.js 中定义的一个最简单的模型,让我们来详细介绍每一行。
实例化模型
const model = tf.sequential();
这样会实例化 tf.Model 对象。此模型是 sequential,因为其输入直接向下流至其输出。其他类型的模型可以有分支,甚至可以有多个输入和输出,但在许多情况下,模型将是贯序的。贯序模型还更易于使用 API。
添加层
model.add(tf.layers.dense({inputShape: [1], units: 1, useBias: true}));
此操作会向我们的网络添加输入层,从而自动连接到包含一个隐藏单元的 dense 层。 dense 是一种层,可将输入与矩阵(称为“权重”)相乘,并向结果添加一个数字(称为“偏差”)。由于这是网络的第一层,因此我们需要定义 inputShape。inputShape 是 [1],因为我们将 1 数字用作输入(某辆指定汽车的马力)。
units 用于设置权重矩阵在层中的大小。将其设置为 1 即表示数据的每个输入特征的权重为 1。
model.add(tf.layers.dense({units: 1}));
上述代码用于创建我们的输出层。我们将 units 设置为 1,因为我们想要输出数字 1。
创建实例
将以下代码添加到
我们之前定义的 run 函数。
// Create the model
const model = createModel();
tfvis.show.modelSummary({name: 'Model Summary'}, model);
这样将创建模型的实例,并显示网页上各层的摘要。
为了享有 TensorFlow.js 的性能优势,从而让训练机器学习模型切实可行,我们需要将数据转换为张量。我们还会对数据执行许多转换(这是最佳做法),即重排和归一化。
将以下代码添加到您的
script.js 文件中
/**
* Convert the input data to tensors that we can use for machine
* learning. We will also do the important best practices of _shuffling_
* the data and _normalizing_ the data
* MPG on the y-axis.
*/
function convertToTensor(data) {
// Wrapping these calculations in a tidy will dispose any
// intermediate tensors.
return tf.tidy(() => {
// Step 1. Shuffle the data
tf.util.shuffle(data);
// Step 2. Convert data to Tensor
const inputs = data.map(d => d.horsepower)
const labels = data.map(d => d.mpg);
const inputTensor = tf.tensor2d(inputs, [inputs.length, 1]);
const labelTensor = tf.tensor2d(labels, [labels.length, 1]);
//Step 3. Normalize the data to the range 0 - 1 using min-max scaling
const inputMax = inputTensor.max();
const inputMin = inputTensor.min();
const labelMax = labelTensor.max();
const labelMin = labelTensor.min();
const normalizedInputs = inputTensor.sub(inputMin).div(inputMax.sub(inputMin));
const normalizedLabels = labelTensor.sub(labelMin).div(labelMax.sub(labelMin));
return {
inputs: normalizedInputs,
labels: normalizedLabels,
// Return the min/max bounds so we can use them later.
inputMax,
inputMin,
labelMax,
labelMin,
}
});
}
我们来详细了解一下发生哪些情况。
重排数据
// Step 1. Shuffle the data
tf.util.shuffle(data);
我们会随机排列提供给训练算法的样本的顺序。数据重排很重要,因为在训练期间,数据集通常会被拆分成较小的子集(称为批次),以用于训练模型。借助重排,每个批次可从分布的所有数据中获取各种数据。通过这样做,我们可以帮助模型:
- 不学习纯粹依赖于数据输入顺序的东西
- 对子组中的结构不敏感(例如,如果模型在训练的前半部分仅看到高马力汽车,可能会学习一种不适用于数据集其余部分的关系)。
转换为张量
// Step 2. Convert data to Tensor
const inputs = data.map(d => d.horsepower)
const labels = data.map(d => d.mpg);
const inputTensor = tf.tensor2d(inputs, [inputs.length, 1]);
const labelTensor = tf.tensor2d(labels, [labels.length, 1]);
我们会创建两个数组,一个用于输入样本(马力条目),另一个用于真实输出值(在机器学习中称为标签)。
然后,将每个数组数据转换为 2d 张量。张量的形状将为 [num_examples, num_features_per_example]。我们使用的是 inputs.length 样本,每个样本都具有 1 输入特征(马力)。
对数据进行归一化
//Step 3. Normalize the data to the range 0 - 1 using min-max scaling
const inputMax = inputTensor.max();
const inputMin = inputTensor.min();
const labelMax = labelTensor.max();
const labelMin = labelTensor.min();
const normalizedInputs = inputTensor.sub(inputMin).div(inputMax.sub(inputMin));
const normalizedLabels = labelTensor.sub(labelMin).div(labelMax.sub(labelMin));
接下来,我们将实施另一种最佳做法来进行机器学习训练。我们会对数据进行归一化。我们使用最小-最大缩放比例将数据归一化为数值范围 0-1。归一化至关重要,因为您将使用 tensorflow.js 构建的许多机器学习模型的内部构件旨在处理不太大的数字。对数据进行归一化以包含 0 to 1 或 -1 to 1 的通用范围。如果您养成将数据归一化到某合理范围内的习惯,那么在训练模型时就更有可能取得成功。
返回数据和归一化边界
return {
inputs: normalizedInputs,
labels: normalizedLabels,
// Return the min/max bounds so we can use them later.
inputMax,
inputMin,
labelMax,
labelMin,
}
我们希望保留训练期间用于归一化的值,以便我们可以将输出取消归一化,以使其恢复到原始比例,并且使我们能以相同方式对今后的输入数据进行归一化。
创建模型实例并将数据表示为张量之后,我们就可以开始训练过程了。
将以下函数复制到您的
script.js 文件中。
async function trainModel(model, inputs, labels) {
// Prepare the model for training.
model.compile({
optimizer: tf.train.adam(),
loss: tf.losses.meanSquaredError,
metrics: ['mse'],
});
const batchSize = 32;
const epochs = 50;
return await model.fit(inputs, labels, {
batchSize,
epochs,
shuffle: true,
callbacks: tfvis.show.fitCallbacks(
{ name: 'Training Performance' },
['loss', 'mse'],
{ height: 200, callbacks: ['onEpochEnd'] }
)
});
}
我们来详细介绍一下。
为训练做好准备
// Prepare the model for training.
model.compile({
optimizer: tf.train.adam(),
loss: tf.losses.meanSquaredError,
metrics: ['mse'],
});
在我们训练模型之前,我们必须对其进行“编译”。为此,我们必须指定一些非常重要的事项:
optimizer:这是用于控制模型更新的算法,如样本所示。TensorFlow.js 中提供了许多优化器。我们选择了 Adam 优化器,因为它在实际使用中非常有效,无需进行任何配置。loss:这是一个函数,用于告知模型在学习所显示的各个批次(数据子集)时的表现如何。我们使用meanSquaredError将模型所做的预测与真实值进行比较。
const batchSize = 32;
const epochs = 50;
接下来,我们将选择 batchSize 和多个周期:
batchSize是指模型在每次训练迭代时会看到的数据子集的大小。常见的批次大小通常介于 32-512 之间。对于所有问题,实际上并没有理想的批次大小,并且描述各种批次大小的数学动机超出了本教程的范围。epochs表示模型查看您提供的整个数据集的次数。我们将对数据集执行 50 次迭代。
启动训练循环
return await model.fit(inputs, labels, {
batchSize,
epochs,
callbacks: tfvis.show.fitCallbacks(
{ name: 'Training Performance' },
['loss', 'mse'],
{ height: 200, callbacks: ['onEpochEnd'] }
)
});
model.fit 是您为了启动训练循环而调用的函数。这是一个异步函数,因此我们会返回它提供的 promise,以便调用方确定训练何时完成。
为了监控训练进度,我们会将一些回调传递给 model.fit。我们使用 tfvis.show.fitCallbacks 来生成可为我们之前指定的“损失”和“均方误差'”指标绘制图表的函数。
综合应用
现在,我们必须调用通过 run 函数定义的函数。
将以下代码添加到
run 函数的底部。
// Convert the data to a form we can use for training.
const tensorData = convertToTensor(data);
const {inputs, labels} = tensorData;
// Train the model
await trainModel(model, inputs, labels);
console.log('Done Training');
刷新页面几秒钟后,您应该会看到以下图表更新。
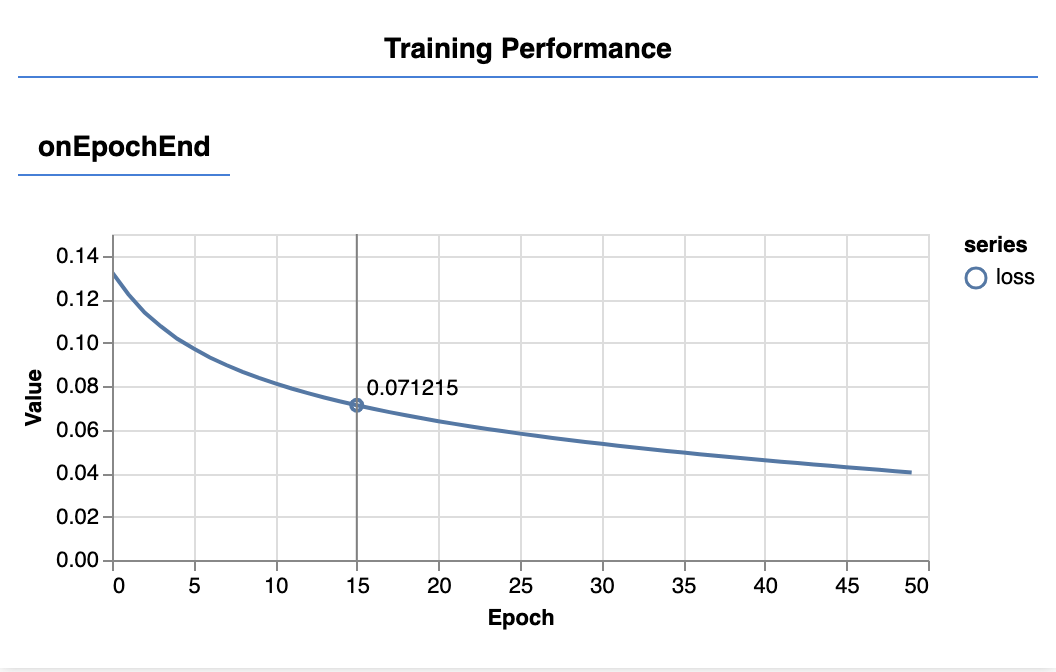
这是由我们之前创建的回调创建的。它们显示每个周期结束时整个数据集的平均损失和均方误差。
在训练模型时,我们希望看到损失下降。在本例中,由于我们的指标是用来衡量错误的,因此我们还希望看到该指标下降。
现在模型已经过训练,我们需要进行一些预测。让我们查看模型对均匀范围内的数字(从低到高的马力)的预测情况,从而对其进行评估。
将以下函数添加到您的 script.js 文件中
function testModel(model, inputData, normalizationData) {
const {inputMax, inputMin, labelMin, labelMax} = normalizationData;
// Generate predictions for a uniform range of numbers between 0 and 1;
// We un-normalize the data by doing the inverse of the min-max scaling
// that we did earlier.
const [xs, preds] = tf.tidy(() => {
const xs = tf.linspace(0, 1, 100);
const preds = model.predict(xs.reshape([100, 1]));
const unNormXs = xs
.mul(inputMax.sub(inputMin))
.add(inputMin);
const unNormPreds = preds
.mul(labelMax.sub(labelMin))
.add(labelMin);
// Un-normalize the data
return [unNormXs.dataSync(), unNormPreds.dataSync()];
});
const predictedPoints = Array.from(xs).map((val, i) => {
return {x: val, y: preds[i]}
});
const originalPoints = inputData.map(d => ({
x: d.horsepower, y: d.mpg,
}));
tfvis.render.scatterplot(
{name: 'Model Predictions vs Original Data'},
{values: [originalPoints, predictedPoints], series: ['original', 'predicted']},
{
xLabel: 'Horsepower',
yLabel: 'MPG',
height: 300
}
);
}
在上述函数中需要注意的一些事项。
const xs = tf.linspace(0, 1, 100);
const preds = model.predict(xs.reshape([100, 1]));
我们生成了 100 个新“样本”,以提供给模型。Model.predict 是我们将这些样本提供给模型的方式。请注意,它们必须具有与训练时相似的形状 ([num_examples, num_features_per_example])。
// Un-normalize the data
const unNormXs = xs
.mul(inputMax.sub(inputMin))
.add(inputMin);
const unNormPreds = preds
.mul(labelMax.sub(labelMin))
.add(labelMin);
要将数据恢复到原始范围(而非 0-1),我们会使用归一化过程中计算的值,但只是进行逆运算。
return [unNormXs.dataSync(), unNormPreds.dataSync()];
.dataSync() 是一种用于获取张量中存储的值的 typedarray 的方法。这使我们能够在常规 JavaScript 中处理这些值。这是通常首选的 .data() 方法的同步版本。
最后,我们使用 tfjs-vis 来绘制原始数据和模型的预测。
将以下代码添加到您的
run 函数中。
// Make some predictions using the model and compare them to the
// original data
testModel(model, data, tensorData);
刷新页面,您应会在模型完成训练后看到如下内容。
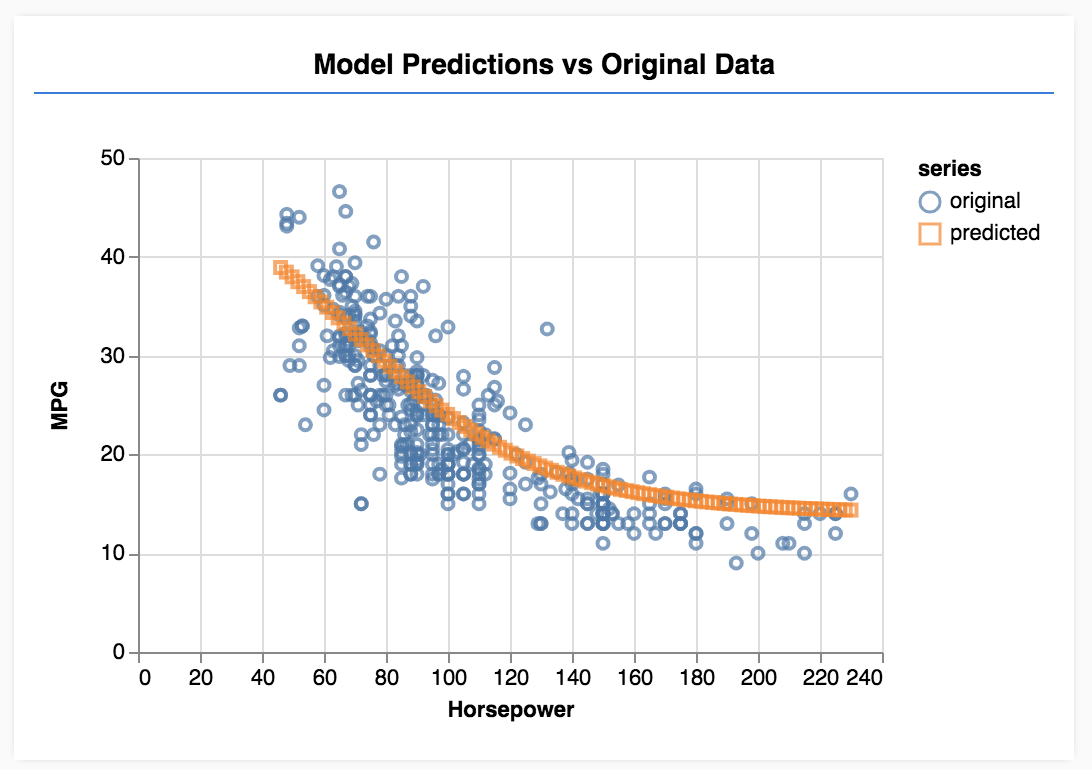
恭喜!您刚刚训练了一个简单的机器学习模型。目前,它会执行所谓的线性回归,从而尝试将一条线与输入数据中的趋势拟合。
训练机器学习模型的步骤包括:
制定任务:
- 是回归问题还是分类问题?
- 可以通过监督式学习还是非监督式学习来完成?
- 输入数据的形状是什么?输出数据应该是什么样的?
准备数据:
- 清理数据并尽可能手动检查它是否存在任何模式
- 在使用数据进行训练之前对数据进行重排
- 将数据归一化为神经网络的合理范围。通常,对于数值数据,0-1 或 -1-1 是合适的范围。
- 将数据转换为张量
构建并运行您的模型:
- 使用
tf.sequential或tf.model定义模型,然后使用tf.layers.*向模型中添加层 - 选择优化器(adam 通常是一个不错的选择),以及批次大小和周期数等参数。
- 为您的问题选择合适的损失函数,并选择准确率指标来帮助您评估进度。
meanSquaredError是处理回归问题的常见损失函数。 - 监控训练,看看损失是否降低
评估模型
- 为您的模型选择一个评估指标,您可以在训练过程中对模型进行监控。训练完成后,请尝试进行一些测试预测,以了解预测质量。
- 更改周期数的实验。在图表数据变化趋缓之前,您需要经历的周期数。
- 尝试增加隐藏层中的单元数量。
- 尝试在我们添加的第一个隐藏层与最终输出层之间添加更多隐藏层。这些额外层的代码应如下所示。
model.add(tf.layers.dense({units: 50, activation: 'sigmoid'}));
关于这些隐藏层最重要的一条新信息是它们引入了非线性激活函数(在这种情况下是 sigmoid 激活函数)。如需详细了解激活函数,请参阅这篇文章。
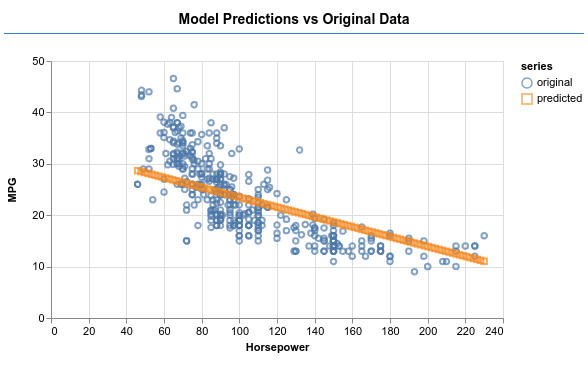
看看是否可以使模型生成如下图所示的输出。