이 Codelab에서는 자동차 세트를 설명하는 수치 데이터로 예측을 수행하도록 모델을 학습시킵니다.
이 연습에서는 다양한 종류의 모델을 학습시키는 일반적인 단계를 보여주지만 작은 데이터 세트와 간단한 모델(깊이가 얕은) 모델을 사용합니다. 기본 목표는 TensorFlow.js를 사용한 학습 모델에 대한 기본 용어, 개념, 구문에 익숙해지도록 돕고 추가 탐색 및 학습을 위한 발판을 마련하는 것입니다.
연속적인 숫자를 예측하도록 모델을 학습시키기 때문에 이 작업을 회귀 작업이라고도 합니다. 많은 입력 예시와 올바른 출력을 인식시켜 모델을 학습시키는데 이러한 학습을 지도 학습이라고 합니다.
빌드 대상
TensorFlow.js를 사용해 브라우저에서 모델을 학습시키는 웹페이지를 만듭니다. 자동차의 '마력'이 주어지면 모델은 '갤런당 마일'(MPG)을 예측하는 방법을 학습합니다.
이를 위해 다음과 같이 진행합니다.
- 데이터를 로드하고 학습에 사용할 수 있도록 준비합니다.
- 모델의 아키텍처를 정의합니다.
- 모델을 학습시키고 학습하는 동안 성능을 모니터링합니다.
- 몇 가지 예측을 수행하여 학습된 모델을 평가합니다.
학습 내용
- 셔플, 정규화 등 머신러닝을 위한 데이터 준비 권장사항
- tf.layers API를 사용해 모델을 만드는 TensorFlow.js 구문
- tfjs-vis 라이브러리를 사용해 브라우저 내 학습을 모니터링하는 방법
필요한 사항
- 최신 버전의 Chrome 또는 다른 최신 브라우저
- 머신에서 로컬로 실행되거나 Codepen 또는 Glitch 등을 통해 웹에서 실행되는 텍스트 편집기
- HTML, CSS, 자바스크립트, Chrome DevTools(또는 선호하는 브라우저의 개발 도구)에 대한 지식
- 신경망에 대한 대략적인 개념 이해. 소개 또는 복습이 필요하다면 3blue1brown의 동영상 또는 아시 크리슈난의 자바스크립트 딥 러닝 동영상을 확인하세요.
HTML 페이지 작성 및 자바스크립트 포함
 아래 이름의 html 파일에 다음 코드를 복사합니다.
아래 이름의 html 파일에 다음 코드를 복사합니다.
index.html
<!DOCTYPE html>
<html>
<head>
<title>TensorFlow.js Tutorial</title>
<!-- Import TensorFlow.js -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@2.0.0/dist/tf.min.js"></script>
<!-- Import tfjs-vis -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs-vis@1.0.2/dist/tfjs-vis.umd.min.js"></script>
<!-- Import the main script file -->
<script src="script.js"></script>
</head>
<body>
</body>
</html>
코드를 위한 자바스크립트 파일 만들기
- 위의 HTML 파일이 있는 폴더에 script.js라는 파일을 만든 후 이 파일에 다음 코드를 입력합니다.
console.log('Hello TensorFlow');
테스트
HTML 및 자바스크립트 파일을 만들었으므로 이제 테스트해 보겠습니다. 브라우저에서 index.html 파일을 열고 DevTools 콘솔을 엽니다.
모든 항목이 제대로 작동한다면 2개의 전역 변수가 생성되어 DevTools 콘솔에서 사용할 수 있게 됩니다.
tf는 TensorFlow.js 라이브러리의 참조입니다.tfvis는 tfjs-vis 라이브러리의 참조입니다.
브라우저의 개발자 도구를 열면 콘솔 출력에 Hello TensorFlow라는 메시지가 표시됩니다. 메시지가 나타나면 다음 단계를 진행할 준비가 된 것입니다.
첫 번째 단계에서는 모델 학습에 사용할 데이터를 로드하고, 형식을 지정하고, 시각화해 보겠습니다.
Google에서 호스팅한 JSON 파일에서 'cars' 데이터 세트를 로드합니다. 이 데이터 세트에는 주어진 각 자동차에 대한 다양한 특징이 많이 포함되어 있습니다. 이 튜토리얼에서는 마력과 갤런당 마일에 대한 데이터만 추출하려고 합니다.
다음 코드를
script.js 파일에 추가합니다.
/**
* Get the car data reduced to just the variables we are interested
* and cleaned of missing data.
*/
async function getData() {
const carsDataResponse = await fetch('https://storage.googleapis.com/tfjs-tutorials/carsData.json');
const carsData = await carsDataResponse.json();
const cleaned = carsData.map(car => ({
mpg: car.Miles_per_Gallon,
horsepower: car.Horsepower,
}))
.filter(car => (car.mpg != null && car.horsepower != null));
return cleaned;
}
그러면 갤런당 마일이나 마력이 정의되지 않은 항목이 삭제됩니다. 이 데이터를 산점도에 그려서 데이터가 어떻게 표시되는지 확인해 보겠습니다.
다음 코드를
script.js 파일의 하단에 추가합니다.
async function run() {
// Load and plot the original input data that we are going to train on.
const data = await getData();
const values = data.map(d => ({
x: d.horsepower,
y: d.mpg,
}));
tfvis.render.scatterplot(
{name: 'Horsepower v MPG'},
{values},
{
xLabel: 'Horsepower',
yLabel: 'MPG',
height: 300
}
);
// More code will be added below
}
document.addEventListener('DOMContentLoaded', run);
페이지를 새로고침하면 페이지 왼쪽에 데이터의 산점도가 포함된 패널이 표시됩니다. 다음과 같이 나타납니다.
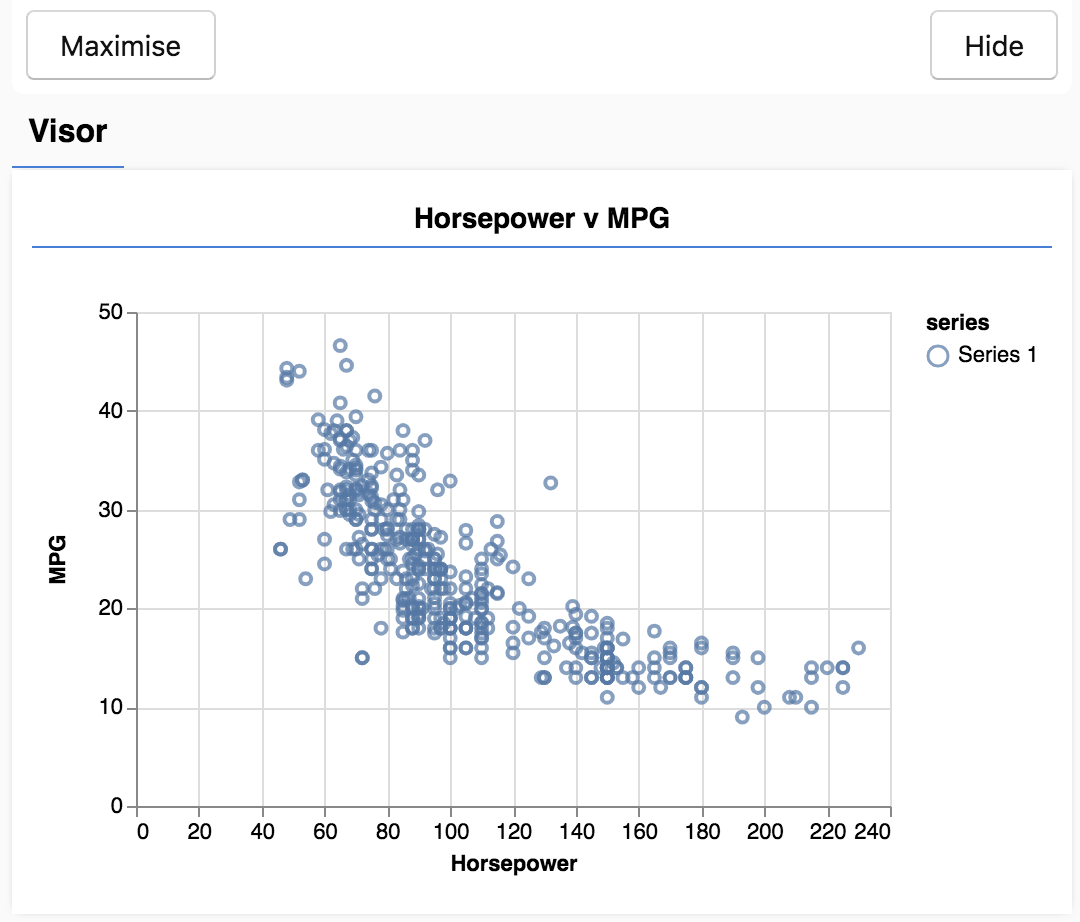
이 패널을 바이저라고 하며 tfjs-vis에서 제공합니다. 이 패널에 시각화를 편리하게 표시할 수 있습니다.
일반적으로 데이터로 작업할 때는 데이터를 시각적으로 표시할 방법을 찾고 필요한 경우 데이터를 정리하는 것이 좋습니다. 이 경우에는 필수 필드 중 일부가 포함되지 않은 carsData의 특정 항목을 삭제해야 했습니다. 데이터를 시각화하면 모델이 학습할 수 있는 데이터에 어떤 구조가 있는지 파악할 수 있습니다.
위 산점도에서는 마력과 MPG 사이에 음의 상관관계가 있음을 알 수 있습니다. 즉, 마력이 증가하면 일반적으로 자동차의 갤런당 마일이 감소합니다.
작업 개념화
이제 입력 데이터가 다음과 같이 표시됩니다.
...
{
"mpg":15,
"horsepower":165,
},
{
"mpg":18,
"horsepower":150,
},
{
"mpg":16,
"horsepower":150,
},
...
목표는 숫자 1개, 마력을 가져와 숫자 1개, 갤런당 마일을 예측하도록 모델을 학습시키는 것입니다. 일대일 매핑에 대해 작업하고 있다는 것을 잊지 마세요. 이 내용은 다음 섹션에서 중요합니다.
이 예시와 마력, MPG를 신경망에 제공하면 신경망은 이러한 예시로부터 마력에 따른 MPG를 예측하는 공식(또는 함수)을 학습합니다. 올바른 답변을 가지고 있는 예시로부터 학습하는 방법을 지도 학습이라고 합니다.
이 섹션에서는 모델 아키텍처를 설명하는 코드를 작성합니다. 모델 아키텍처란 '모델이 실행될 때 모델이 실행하는 함수' 또는 '응답을 계산하기 위해 모델에서 사용하는 알고리즘'으로 표현할 수 있습니다.
ML 모델은 입력을 받고 출력을 생성하는 알고리즘입니다. 신경망을 사용할 때 이 알고리즘은 출력에 적용되는 '가중치'(숫자)가 있는 뉴런 레이어의 집합이며 학습 프로세스는 이러한 가중치에 이상적인 값을 학습합니다.
다음 함수를
script.js 파일에 추가하여 모델 아키텍처를 정의합니다.
function createModel() {
// Create a sequential model
const model = tf.sequential();
// Add a single input layer
model.add(tf.layers.dense({inputShape: [1], units: 1, useBias: true}));
// Add an output layer
model.add(tf.layers.dense({units: 1, useBias: true}));
return model;
}
이 모델은 tensorflow.js에서 정의할 수 있는 가장 간단한 모델 중 하나이며 각 줄을 분석해 보겠습니다.
모델 인스턴스화
const model = tf.sequential();
tf.Model 객체를 인스턴스화합니다. 이 모델은 입력이 출력으로 곧바로 흘러가므로 sequential 모델입니다. 다른 종류의 모델에는 분기 또는 여러 입력 및 출력이 있을 수 있지만 대부분의 경우 모델은 순차적입니다. 순차 모델에는 더욱 사용하기 쉬운 API도 있습니다.
레이어 추가
model.add(tf.layers.dense({inputShape: [1], units: 1, useBias: true}));
이렇게 하면 Google의 네트워크에 입력 레이어가 추가되며 이 레이어는 숨겨진 단위 하나가 있는 dense 레이어에 자동으로 연결됩니다. dense 레이어는 행렬(가중치라고 함)에 입력을 곱한 후 그 결과에 숫자(편향이라고 함)를 더하는 레이어 유형입니다. 네트워크의 첫 번째 레이어이므로 inputShape를 정의해야 합니다. inputShape는 입력(특정 자동차의 마력)으로 숫자 1이 있으므로 [1]입니다.
units는 레이어에서 가중치 행렬의 크기를 설정합니다. 1로 설정하면 데이터의 입력 특징별로 가중치가 1이 됩니다.
model.add(tf.layers.dense({units: 1}));
위의 코드는 출력 레이어를 생성합니다. 숫자 1을 출력하려고 하므로 units를 1로 설정합니다.
인스턴스 만들기
다음 코드를
앞에서 정의한 run 함수에 추가합니다.
// Create the model
const model = createModel();
tfvis.show.modelSummary({name: 'Model Summary'}, model);
그러면 모델의 인스턴스가 생성되고 웹페이지에 레이어 요약이 표시됩니다.
머신러닝 모델 학습을 실용적으로 활용하는 TensorFlow.js의 성능 이점을 얻기 위해서는 데이터를 텐서로 변환해야 합니다. 데이터에 대해 셔플 및 정규화와 같은 권장되는 다양한 변환을 수행합니다.
다음 코드를
script.js 파일에 추가합니다.
/**
* Convert the input data to tensors that we can use for machine
* learning. We will also do the important best practices of _shuffling_
* the data and _normalizing_ the data
* MPG on the y-axis.
*/
function convertToTensor(data) {
// Wrapping these calculations in a tidy will dispose any
// intermediate tensors.
return tf.tidy(() => {
// Step 1. Shuffle the data
tf.util.shuffle(data);
// Step 2. Convert data to Tensor
const inputs = data.map(d => d.horsepower)
const labels = data.map(d => d.mpg);
const inputTensor = tf.tensor2d(inputs, [inputs.length, 1]);
const labelTensor = tf.tensor2d(labels, [labels.length, 1]);
//Step 3. Normalize the data to the range 0 - 1 using min-max scaling
const inputMax = inputTensor.max();
const inputMin = inputTensor.min();
const labelMax = labelTensor.max();
const labelMin = labelTensor.min();
const normalizedInputs = inputTensor.sub(inputMin).div(inputMax.sub(inputMin));
const normalizedLabels = labelTensor.sub(labelMin).div(labelMax.sub(labelMin));
return {
inputs: normalizedInputs,
labels: normalizedLabels,
// Return the min/max bounds so we can use them later.
inputMax,
inputMin,
labelMax,
labelMin,
}
});
}
자세히 살펴보겠습니다.
데이터 셔플링
// Step 1. Shuffle the data
tf.util.shuffle(data);
여기서는 학습 알고리즘에 제공할 예시의 순서를 무작위로 지정합니다. 일반적으로 학습하는 동안 데이터 세트는 모델이 학습할 크기가 작은 하위 집합(배치라고 함)으로 분할되기 때문에 셔플이 중요합니다. 셔플은 각 배치에 전체 데이터 분포의 데이터가 다양하게 포함되도록 하는 데 도움이 됩니다. 데이터가 다양하게 포함되도록 하면 모델에 다음과 같은 이점이 있습니다.
- 제공된 데이터의 순서에만 의존하여 학습하지 않도록 합니다.
- 하위 그룹의 구조에 민감해지지 않도록 합니다. 예를 들어 학습의 전반부에만 높은 마력의 자동차가 있다면 나머지 데이터 세트에는 적용되지 않는 관계를 학습할 수 있습니다.
텐서로 변환
// Step 2. Convert data to Tensor
const inputs = data.map(d => d.horsepower)
const labels = data.map(d => d.mpg);
const inputTensor = tf.tensor2d(inputs, [inputs.length, 1]);
const labelTensor = tf.tensor2d(labels, [labels.length, 1]);
여기서는 두 개의 배열을 만듭니다. 하나는 입력 예시(마력 항목)용이고 다른 하나는 실제 출력 값(머신러닝에서 라벨이라고 함)을 위한 배열입니다.
그런 다음 각 배열 데이터를 2D 텐서로 변환합니다. 텐서의 모양은 [num_examples, num_features_per_example]입니다. 여기에는 inputs.length 예시가 있으며 각 예시에는 1 입력 특징(마력)이 있습니다.
데이터 정규화
//Step 3. Normalize the data to the range 0 - 1 using min-max scaling
const inputMax = inputTensor.max();
const inputMin = inputTensor.min();
const labelMax = labelTensor.max();
const labelMin = labelTensor.min();
const normalizedInputs = inputTensor.sub(inputMin).div(inputMax.sub(inputMin));
const normalizedLabels = labelTensor.sub(labelMin).div(labelMax.sub(labelMin));
다음으로 머신러닝 학습을 위한 또 다른 권장사항을 수행합니다. Google에서는 데이터를 정규화합니다. 여기서는 최소-최대 조정을 사용하여 데이터를 숫자 범위 0-1로 정규화합니다. Tensorflow.js로 빌드할 많은 머신러닝 모델의 내부는 너무 크지 않은 숫자에 대해 작동하도록 설계되기 때문에 정규화가 중요합니다. 데이터를 정규화하는 일반적인 범위는 0 to 1 또는 -1 to 1입니다. 데이터를 합당한 범위로 정규화하는 습관을 들이면 모델을 보다 성공적으로 학습시키게 됩니다.
데이터 및 정규화 경계 반환
return {
inputs: normalizedInputs,
labels: normalizedLabels,
// Return the min/max bounds so we can use them later.
inputMax,
inputMin,
labelMax,
labelMin,
}
출력을 정규화하지 않은 원래의 상태로 다시 되돌려서 원래의 조정으로 가져오고 향후 입력 데이터를 동일한 방식으로 정규화할 수 있도록 학습 중에 정규화에 사용한 값을 유지하려고 합니다.
모델 인스턴스를 생성하고 데이터를 텐서로 표현했으니 학습 프로세스를 시작할 모든 준비를 마쳤습니다.
다음 함수를
script.js 파일에 복사합니다.
async function trainModel(model, inputs, labels) {
// Prepare the model for training.
model.compile({
optimizer: tf.train.adam(),
loss: tf.losses.meanSquaredError,
metrics: ['mse'],
});
const batchSize = 32;
const epochs = 50;
return await model.fit(inputs, labels, {
batchSize,
epochs,
shuffle: true,
callbacks: tfvis.show.fitCallbacks(
{ name: 'Training Performance' },
['loss', 'mse'],
{ height: 200, callbacks: ['onEpochEnd'] }
)
});
}
구체적으로 설명하면 다음과 같습니다.
학습 준비
// Prepare the model for training.
model.compile({
optimizer: tf.train.adam(),
loss: tf.losses.meanSquaredError,
metrics: ['mse'],
});
모델을 학습하기 전에 먼저 '컴파일'해야 합니다. 그러려면 다음과 같이 매우 중요한 항목들을 지정해야 합니다.
optimizer: 모델이 예시를 보면서 업데이트하는 데 적용될 알고리즘입니다. TensorFlow.js에는 다양한 옵티마이저가 있지만 여기에서는 실제로 매우 효과적이며 구성이 필요 없는 adam 옵티마이저를 선택했습니다.loss: 표시되는 각 배치(데이터 하위 집합)를 얼마나 잘 학습하고 있는지 모델에 알려줄 함수입니다. 여기서는meanSquaredError를 사용해 모델이 수행한 예측을 실제 값과 비교합니다.
const batchSize = 32;
const epochs = 50;
다음으로 batchSize와 세대의 수를 선택합니다.
batchSize는 각 학습 반복에서 모델이 보게 될 데이터 하위 집합의 크기를 나타냅니다. 일반적인 배치 크기는 32~512 범위입니다. 모든 문제에 맞는 이상적인 배치 크기는 없으며 다양한 배치 크기의 수학적 연계성에 대한 설명은 이 튜토리얼에서 다루지 않습니다.epochs는 모델이 제공된 전체 데이터 세트를 볼 횟수입니다. 여기서는 데이터 세트를 50번 반복합니다.
학습 루프 시작
return await model.fit(inputs, labels, {
batchSize,
epochs,
callbacks: tfvis.show.fitCallbacks(
{ name: 'Training Performance' },
['loss', 'mse'],
{ height: 200, callbacks: ['onEpochEnd'] }
)
});
model.fit은 학습 루프를 시작하기 위해 호출하는 함수입니다. 비동기 함수이므로 제공된 프라미스를 반환하여 학습이 완료되는 시기를 호출자가 결정할 수 있습니다.
학습 진행 상황을 모니터링하기 위해 model.fit에 일부 콜백을 전달합니다. tfvis.show.fitCallbacks를 사용해 앞에서 지정한 '손실' 및 'MSE' 측정항목에 대한 차트를 그리는 함수를 생성합니다.
종합해 보기
이제 run 함수에서 정의한 함수를 호출해야 합니다.
다음 코드를
run 함수의 하단에 추가합니다.
// Convert the data to a form we can use for training.
const tensorData = convertToTensor(data);
const {inputs, labels} = tensorData;
// Train the model
await trainModel(model, inputs, labels);
console.log('Done Training');
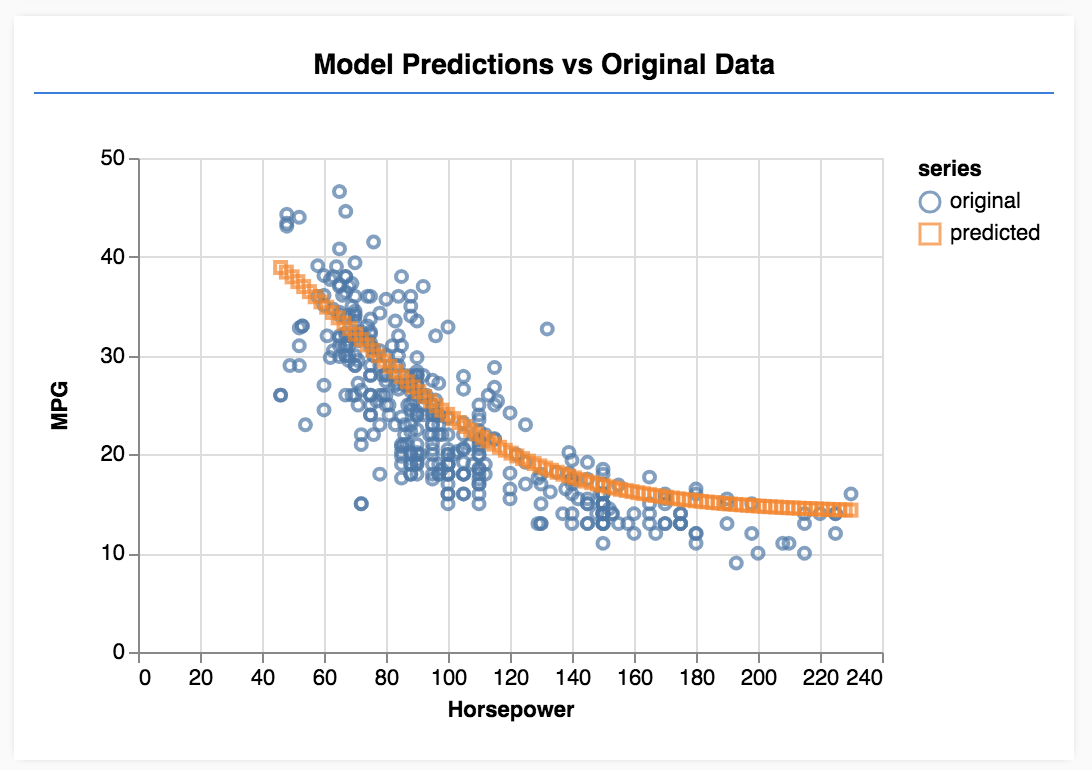
페이지를 새로고침하면 몇 초 후에 다음과 같은 업데이트된 그래프가 표시됩니다.
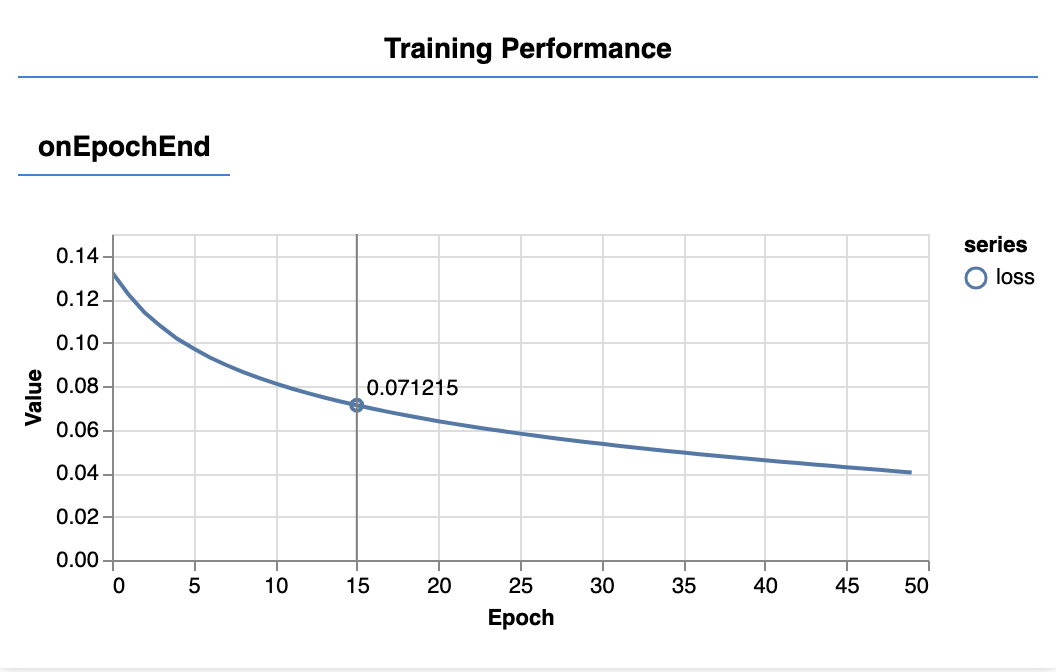
이 그래프는 앞에서 만든 콜백에 의해 생성되며 각 세대가 끝나면 전체 데이터 세트의 평균 손실 및 MSE를 표시합니다.
모델을 학습시킬 때 손실이 감소하는지 확인하고 싶다면 이 경우 측정항목은 오차를 나타내므로 측정항목도 함께 감소하는지 확인하려고 합니다.
이제 모델이 학습되었으니 몇 가지 예측을 해 보겠습니다. 마력이 낮은 것부터 높은 것까지 일정한 범위의 숫자를 어떻게 예측하는지 확인하여 모델을 평가해 보겠습니다.
script.js 파일에 다음 함수를 추가합니다.
function testModel(model, inputData, normalizationData) {
const {inputMax, inputMin, labelMin, labelMax} = normalizationData;
// Generate predictions for a uniform range of numbers between 0 and 1;
// We un-normalize the data by doing the inverse of the min-max scaling
// that we did earlier.
const [xs, preds] = tf.tidy(() => {
const xs = tf.linspace(0, 1, 100);
const preds = model.predict(xs.reshape([100, 1]));
const unNormXs = xs
.mul(inputMax.sub(inputMin))
.add(inputMin);
const unNormPreds = preds
.mul(labelMax.sub(labelMin))
.add(labelMin);
// Un-normalize the data
return [unNormXs.dataSync(), unNormPreds.dataSync()];
});
const predictedPoints = Array.from(xs).map((val, i) => {
return {x: val, y: preds[i]}
});
const originalPoints = inputData.map(d => ({
x: d.horsepower, y: d.mpg,
}));
tfvis.render.scatterplot(
{name: 'Model Predictions vs Original Data'},
{values: [originalPoints, predictedPoints], series: ['original', 'predicted']},
{
xLabel: 'Horsepower',
yLabel: 'MPG',
height: 300
}
);
}
위 함수에서 고려해야 할 사항이 있습니다.
const xs = tf.linspace(0, 1, 100);
const preds = model.predict(xs.reshape([100, 1]));
모델에 제공할 새 '예시'를 100개 생성합니다. Model.predict는 이러한 예시를 모델에 제공하는 방법입니다. 학습할 때와 유사한 형태([num_examples, num_features_per_example])여야 합니다.
// Un-normalize the data
const unNormXs = xs
.mul(inputMax.sub(inputMin))
.add(inputMin);
const unNormPreds = preds
.mul(labelMax.sub(labelMin))
.add(labelMin);
데이터를 0~1이 아닌 원래 범위로 되돌리려면 정규화 중에 계산한 값을 사용하고 연산을 반전시킵니다.
return [unNormXs.dataSync(), unNormPreds.dataSync()];
.dataSync()는 텐서에 저장된 값의 typedarray를 가져오는 데 사용할 수 있는 메서드입니다. 이 메서드를 통해 일반 자바스크립트에서 해당 값을 처리할 수 있습니다. 일반적으로 권장되는 .data() 메서드의 동기식 버전입니다.
마지막으로 tfjs-vis를 사용해 원본 데이터와 모델의 예측을 표시합니다.
다음 코드를
run 함수에 추가합니다.
// Make some predictions using the model and compare them to the
// original data
testModel(model, data, tensorData);
페이지를 새로고침하면 모델 학습이 완료된 후 다음과 같은 내용이 표시됩니다.
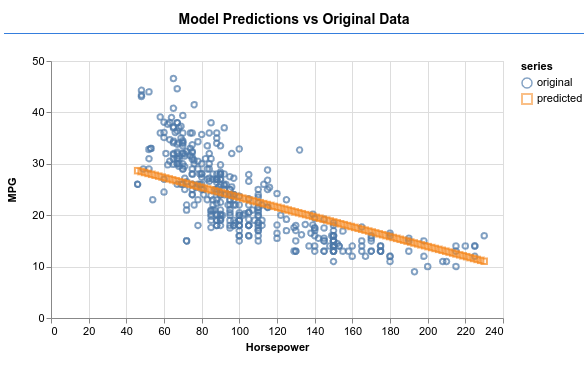
수고하셨습니다. 간단한 머신러닝 모델을 학습시켰습니다. 이 모델은 현재 선형 회귀를 수행합니다. 선형 회귀란 입력 데이터에 나타나는 추세에 선을 맞추려고 시도하는 방법입니다.
머신러닝 모델을 학습시키는 단계는 다음과 같습니다.
작업을 체계적으로 정리:
- 회귀 문제인가, 분류 문제인가?
- 지도 학습을 통해 수행할 수 있는가, 아니면 비지도 학습을 통해 수행할 수 있는가?
- 입력 데이터의 모양은 어떤가? 출력 데이터는 어떻게 표시되어야 하는가?
데이터 준비:
- 가능하면 데이터를 정리하고 수동으로 패턴을 검사합니다.
- 학습에 사용하기 전에 데이터를 셔플링합니다.
- 신경망에 합당한 범위로 데이터를 정규화합니다. 일반적으로 수치 데이터에는 0~1 또는 -1~1이 적합합니다.
- 데이터를 텐서로 변환합니다.
모델 빌드 및 실행:
tf.sequential또는tf.model을 사용하여 모델을 정의한 다음tf.layers.*를 사용하여 모델에 레이어를 추가합니다.- 옵티마이저(일반적으로 adam이 적합함), 매개변수(배치 크기, 세대 수 등)를 선택합니다.
- 문제에 적합한 손실 함수를 선택하고 진행 상황을 평가하는 데 도움이 되는 정확도 측정항목을 선택합니다.
meanSquaredError는 회귀 문제의 일반적인 손실 함수입니다. - 손실이 감소하는지 학습을 모니터링합니다.
모델 평가
- 학습 중에 모니터링할 수 있는 모델의 평가 측정항목을 선택합니다. 학습이 완료되면 예측 품질을 파악할 수 있도록 테스트 예측을 시도합니다.
- 세대 수를 변경하여 실험합니다. 그래프가 평탄화되기까지 몇 개의 세대가 필요한가요?
- 히든 레이어의 단위 수를 늘려 실험합니다.
- 처음에 추가한 히든 레이어와 최종 출력 레이어 사이에 히든 레이어를 추가하는 실험을 진행합니다. 이러한 추가 레이어의 코드는 다음과 같은 형태여야 합니다.
model.add(tf.layers.dense({units: 50, activation: 'sigmoid'}));
이러한 히든 레이어의 가장 중요하고 새로운 특징은 비선형 활성화 함수를 도입한다는 점입니다. 이 경우에는 시그모이드 활성화입니다. 활성화 함수에 대한 자세한 내용은 이 도움말을 참고하세요.
모델이 아래 이미지와 같은 출력을 생성할 수 있는지 확인하세요.