1. Einführung
In diesem Codelab trainieren Sie ein Modell, um Vorhersagen anhand von numerischen Daten zu treffen, die eine Gruppe von Autos beschreiben.
In dieser Übung werden Schritte gezeigt, die für das Training vieler verschiedener Arten von Modellen üblich sind. Es werden jedoch ein kleines Dataset und ein einfaches (oberflächliches) Modell verwendet. Das Hauptziel besteht darin, Sie mit den grundlegenden Begriffen, Konzepten und der Syntax zum Trainieren von Modellen mit TensorFlow.js vertraut zu machen und einen Sprungbrett für weitere Erkundungs- und Lernprozesse zu bieten.
Da wir ein Modell zur Vorhersage kontinuierlicher Zahlen trainieren, wird diese Aufgabe manchmal als Regression bezeichnet. Wir trainieren das Modell, indem wir ihm viele Beispiele für Eingaben und die richtige Ausgabe zeigen. Dies wird als überwachtes Lernen bezeichnet.
Umfang
Sie erstellen eine Webseite, auf der mithilfe von TensorFlow.js ein Modell im Browser trainiert wird. Angegeben: "Pferdestärke" für ein Auto lernt das Modell, „Meilen pro Gallone“ vorherzusagen. (MPG).
Gehen Sie dazu so vor:
- Laden Sie die Daten und bereiten Sie sie für das Training vor.
- Definieren Sie die Architektur des Modells.
- Trainieren Sie das Modell und überwachen Sie seine Leistung während des Trainings.
- Trainiertes Modell anhand einiger Vorhersagen bewerten.
Aufgaben in diesem Lab
- Best Practices für die Datenvorbereitung für maschinelles Lernen, einschließlich Zufallsmix und Normalisierung
- TensorFlow.js-Syntax zum Erstellen von Modellen mit der tf.layers API.
- Browsertraining mit der tfjs-vis-Bibliothek überwachen
Voraussetzungen
- Eine aktuelle Version von Chrome oder einem anderen aktuellen Browser
- Einen Texteditor, der entweder lokal auf Ihrem Computer oder im Web über Codepen oder Glitch ausgeführt wird
- Kenntnisse in HTML, CSS, JavaScript und Chrome-Entwicklertools bzw. den Entwicklertools Ihrer bevorzugten Browser
- Ein konzeptionelles Verständnis von neuronalen Netzwerken. Wenn Sie eine Einführung oder Auffrischung benötigen, können Sie sich dieses Video von 3blue1brown oder dieses Video zu Deep Learning in JavaScript von Ashi Krishnan ansehen.
2. Einrichten
Erstellen Sie eine HTML-Seite und fügen Sie den JavaScript-Code
 Kopieren Sie den folgenden Code in eine HTML-Datei mit dem Namen .
Kopieren Sie den folgenden Code in eine HTML-Datei mit dem Namen .
index.html
<!DOCTYPE html>
<html>
<head>
<title>TensorFlow.js Tutorial</title>
<!-- Import TensorFlow.js -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@2.0.0/dist/tf.min.js"></script>
<!-- Import tfjs-vis -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs-vis@1.0.2/dist/tfjs-vis.umd.min.js"></script>
</head>
<body>
<!-- Import the main script file -->
<script src="script.js"></script>
</body>
</html>
Erstellen Sie die JavaScript-Datei für den Code.
- Erstellen Sie im selben Ordner wie die HTML-Datei oben eine Datei mit dem Namen script.js und fügen Sie den folgenden Code ein.
console.log('Hello TensorFlow');
Jetzt testen
Nachdem Sie nun die HTML- und JavaScript-Dateien erstellt haben, testen Sie sie. Öffnen Sie die Datei „index.html“ in Ihrem Browser und öffnen Sie die Entwicklertools-Konsole.
Wenn alles funktioniert, sollten zwei globale Variablen erstellt und in der Entwicklertools-Konsole verfügbar sein:
tfist ein Verweis auf die TensorFlow.js-Bibliothek.tfvisist ein Verweis auf die tfjs-vis-Bibliothek.
Öffnen Sie die Entwicklertools Ihres Browsers. In der Konsolenausgabe sollte die Meldung Hello TensorFlow angezeigt werden. In diesem Fall können Sie mit dem nächsten Schritt fortfahren.
3. Eingabedaten laden, formatieren und visualisieren
Lassen Sie uns zuerst die Daten laden, formatieren und visualisieren, mit denen das Modell trainiert werden soll.
Wir laden die „cars“ (Autos) aus einer JSON-Datei, die wir für Sie gehostet haben. Es enthält viele verschiedene Merkmale zu jedem Auto. In dieser Anleitung sollen nur Daten zu PS und Meilen pro Gallone extrahiert werden.
Fügen Sie folgenden Code zu Ihrem
script.js Datei
/**
* Get the car data reduced to just the variables we are interested
* and cleaned of missing data.
*/
async function getData() {
const carsDataResponse = await fetch('https://storage.googleapis.com/tfjs-tutorials/carsData.json');
const carsData = await carsDataResponse.json();
const cleaned = carsData.map(car => ({
mpg: car.Miles_per_Gallon,
horsepower: car.Horsepower,
}))
.filter(car => (car.mpg != null && car.horsepower != null));
return cleaned;
}
Dadurch werden auch alle Einträge entfernt, für die weder Meilen pro Gallone noch PS definiert sind. Zeichnen wir diese Daten auch in einem Streudiagramm auf, um zu sehen, wie sie aussehen.
Fügen Sie den folgenden Code unten auf der
script.js Datei.
async function run() {
// Load and plot the original input data that we are going to train on.
const data = await getData();
const values = data.map(d => ({
x: d.horsepower,
y: d.mpg,
}));
tfvis.render.scatterplot(
{name: 'Horsepower v MPG'},
{values},
{
xLabel: 'Horsepower',
yLabel: 'MPG',
height: 300
}
);
// More code will be added below
}
document.addEventListener('DOMContentLoaded', run);
Wenn Sie die Seite aktualisieren. Links auf der Seite sollte ein Steuerfeld mit einem Streudiagramm der Daten angezeigt werden. Die Anzeige sollte ungefähr so aussehen.
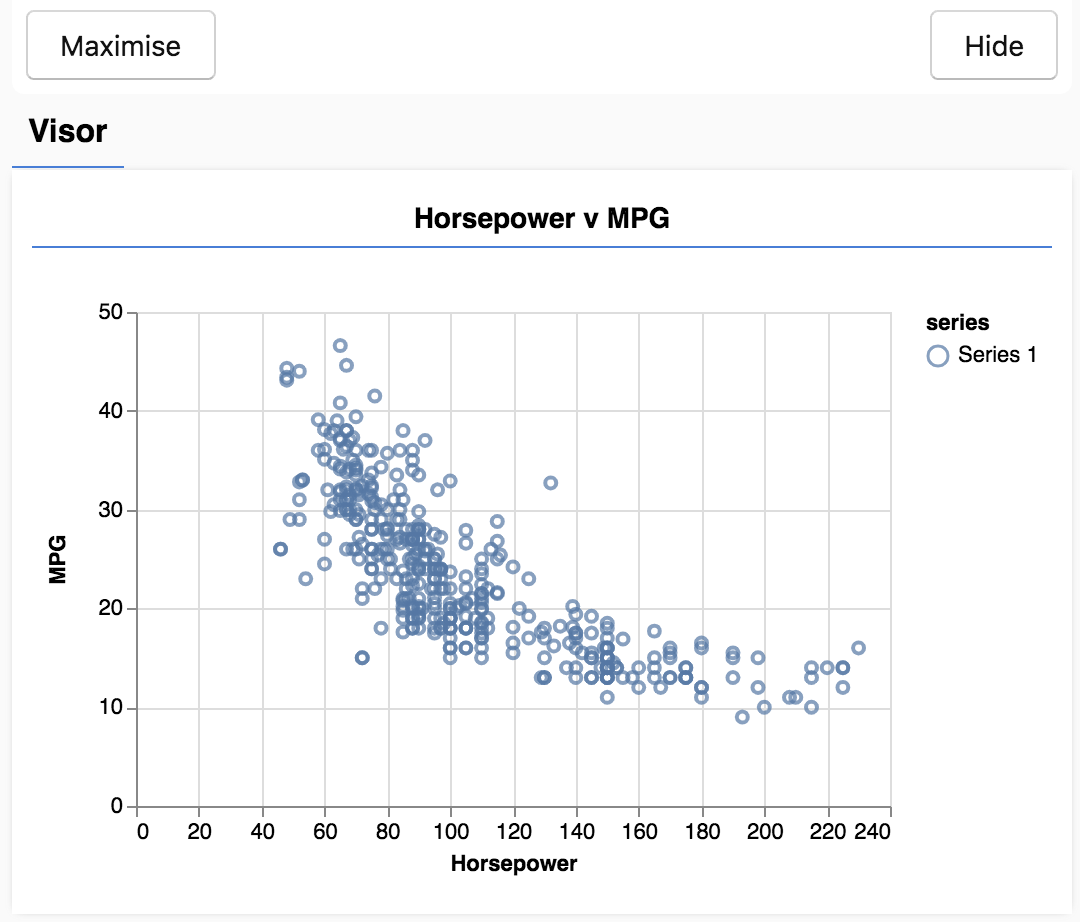
Dieses Panel wird von tfjs-vis bereitgestellt und als Visor bezeichnet. Sie bietet einen praktischen Ort, um Visualisierungen anzuzeigen.
Im Allgemeinen empfiehlt es sich bei der Arbeit mit Daten, Möglichkeiten zu finden, Ihre Daten zu betrachten und bei Bedarf zu bereinigen. In diesem Fall mussten wir bestimmte Einträge aus carsData entfernen, die nicht alle Pflichtfelder enthielten. Durch die Visualisierung der Daten erhalten wir ein Gefühl dafür, ob die Daten eine Struktur haben, die das Modell lernen kann.
Wie Sie im obigen Diagramm sehen können, besteht eine negative Korrelation zwischen PS und Kraftstoffverbrauch, d.h. wenn die PS-Leistung steigt, steigen Autos im Allgemeinen weniger Kilometer pro Gallone.
Unsere Aufgabe formulieren
Unsere Eingabedaten sehen nun so aus.
...
{
"mpg":15,
"horsepower":165,
},
{
"mpg":18,
"horsepower":150,
},
{
"mpg":16,
"horsepower":150,
},
...
Unser Ziel ist es, ein Modell zu trainieren, das eine Zahl, Pferdestärke, benötigt und lernen, eine Zahl, Meilen pro Gallone, vorherzusagen. Denken Sie an die 1:1-Zuordnung, da diese für den nächsten Abschnitt wichtig ist.
Wir werden diese Beispiele, die PS und den Kraftstoffverbrauch, in ein neuronales Netzwerk einspeisen, das aus diesen Beispielen eine Formel (oder Funktion) lernt, um den Kraftstoffverbrauch (PG) für die gegebene PS-Leistung vorherzusagen. Diese Erkenntnis aus Beispielen, auf die wir die richtigen Antworten haben, nennt man überwachtes Lernen.
4. Modellarchitektur definieren
In diesem Abschnitt schreiben wir Code, um die Modellarchitektur zu beschreiben. Die Modellarchitektur ist eine raffinierte Art zu sagen: „Welche Funktionen wird das Modell ausgeführt, wenn es ausgeführt wird?“ oder alternativ „Welchen Algorithmus verwendet unser Modell zur Berechnung seiner Antworten“.
ML-Modelle sind Algorithmen, die anhand einer Eingabe eine Ausgabe generieren. Bei der Verwendung neuronaler Netzwerke besteht der Algorithmus aus einer Reihe von Neuronenschichten mit Gewichten (Zahlen), die ihre Ausgabe steuern. Der Trainingsprozess lernt die idealen Werte für diese Gewichtungen.
Fügen Sie Ihrem die folgende Funktion hinzu:
script.js zum Definieren der Modellarchitektur.
function createModel() {
// Create a sequential model
const model = tf.sequential();
// Add a single input layer
model.add(tf.layers.dense({inputShape: [1], units: 1, useBias: true}));
// Add an output layer
model.add(tf.layers.dense({units: 1, useBias: true}));
return model;
}
Dies ist eines der einfachsten Modelle, die wir in tensorflow.js definieren können. Lassen Sie uns jede Zeile ein wenig aufschlüsseln.
Modell instanziieren
const model = tf.sequential();
Dadurch wird ein tf.Model-Objekt instanziiert. Dieses Modell ist sequential, weil die Eingaben direkt zur Ausgabe führen. Andere Arten von Modellen können Zweige oder sogar mehrere Ein- und Ausgaben haben, aber in vielen Fällen sind Ihre Modelle sequenziell. Sequenzielle Modelle sind außerdem einfacher zu nutzen.
Ebenen hinzufügen
model.add(tf.layers.dense({inputShape: [1], units: 1, useBias: true}));
Dadurch wird unserem Netzwerk eine Eingabeebene hinzugefügt, die automatisch mit einer dense-Ebene mit einer ausgeblendeten Einheit verbunden ist. Eine dense-Ebene ist eine Art von Ebene, die ihre Eingaben mit einer Matrix multipliziert (Gewichtung genannt) und dann dem Ergebnis eine Zahl (Bias) hinzufügt. Da dies die erste Schicht des Netzwerks ist, müssen wir unsere inputShape definieren. inputShape ist [1], weil wir die 1-Zahl als Eingabe haben (die PS-Leistung eines bestimmten Autos).
Mit units wird festgelegt, wie groß die Gewichtungsmatrix in der Ebene ist. Wenn wir den Wert hier auf 1 setzen, sagen wir, dass es nur eine Gewichtung für jedes Eingabemerkmal der Daten gibt.
model.add(tf.layers.dense({units: 1}));
Mit dem Code oben wird die Ausgabeebene erstellt. Wir legen units auf 1 fest, da wir die 1-Zahl ausgeben möchten.
Instanz erstellen
Fügen Sie folgenden Code in das
run -Funktion, die wir zuvor definiert haben.
// Create the model
const model = createModel();
tfvis.show.modelSummary({name: 'Model Summary'}, model);
Dadurch wird eine Instanz des Modells erstellt und eine Zusammenfassung der Ebenen auf der Webseite angezeigt.
5. Daten für das Training vorbereiten
Damit Sie die Leistungsvorteile von TensorFlow.js nutzen können, die das Training von Modellen für maschinelles Lernen praktisch machen, müssen wir unsere Daten in Tensoren umwandeln. Außerdem werden wir eine Reihe von Best Practices an unseren Daten transformieren, nämlich Zufallsmix und Normalisierung.
Fügen Sie folgenden Code zu Ihrem
script.js Datei
/**
* Convert the input data to tensors that we can use for machine
* learning. We will also do the important best practices of _shuffling_
* the data and _normalizing_ the data
* MPG on the y-axis.
*/
function convertToTensor(data) {
// Wrapping these calculations in a tidy will dispose any
// intermediate tensors.
return tf.tidy(() => {
// Step 1. Shuffle the data
tf.util.shuffle(data);
// Step 2. Convert data to Tensor
const inputs = data.map(d => d.horsepower)
const labels = data.map(d => d.mpg);
const inputTensor = tf.tensor2d(inputs, [inputs.length, 1]);
const labelTensor = tf.tensor2d(labels, [labels.length, 1]);
//Step 3. Normalize the data to the range 0 - 1 using min-max scaling
const inputMax = inputTensor.max();
const inputMin = inputTensor.min();
const labelMax = labelTensor.max();
const labelMin = labelTensor.min();
const normalizedInputs = inputTensor.sub(inputMin).div(inputMax.sub(inputMin));
const normalizedLabels = labelTensor.sub(labelMin).div(labelMax.sub(labelMin));
return {
inputs: normalizedInputs,
labels: normalizedLabels,
// Return the min/max bounds so we can use them later.
inputMax,
inputMin,
labelMax,
labelMin,
}
});
}
Schauen wir uns an, was hier vor sich geht.
Daten zufällig anordnen
// Step 1. Shuffle the data
tf.util.shuffle(data);
Hier legen wir eine randomisierte Reihenfolge der Beispiele fest, die wir in den Trainingsalgorithmus einspeisen. Das ist wichtig, da das Dataset während des Trainings in der Regel in kleinere Teilmengen, sogenannte Batches, aufgeteilt wird, mit denen das Modell trainiert wird. Mithilfe der Shuffle-Funktion kann jeder Batch eine Vielzahl von Daten aus der gesamten Datenverteilung haben. Damit helfen Sie dem Modell:
- keine Dinge lernen, die nur von der Reihenfolge abhängen, in der die Daten eingespeist wurden
- Nicht empfindlich auf die Struktur in Untergruppen reagieren (wenn z.B. in der ersten Hälfte des Trainings nur Autos mit hoher Leistung vorhanden sind, lernt es möglicherweise eine Beziehung, die für den Rest des Datasets nicht gilt).
In Tensoren umwandeln
// Step 2. Convert data to Tensor
const inputs = data.map(d => d.horsepower)
const labels = data.map(d => d.mpg);
const inputTensor = tf.tensor2d(inputs, [inputs.length, 1]);
const labelTensor = tf.tensor2d(labels, [labels.length, 1]);
Hier erstellen wir zwei Arrays, eines für unsere Eingabebeispiele (die PS-Einträge) und ein weiteres für die wahren Ausgabewerte (die im maschinellen Lernen als Labels bezeichnet werden).
Anschließend wandeln wir alle Arraydaten in einen 2D-Tensor um. Der Tensor hat die Form [num_examples, num_features_per_example]. Hier sehen Sie inputs.length-Beispiele und jedes Beispiel enthält das Eingabefeature 1 (die PS).
Daten normalisieren
//Step 3. Normalize the data to the range 0 - 1 using min-max scaling
const inputMax = inputTensor.max();
const inputMin = inputTensor.min();
const labelMax = labelTensor.max();
const labelMin = labelTensor.min();
const normalizedInputs = inputTensor.sub(inputMin).div(inputMax.sub(inputMin));
const normalizedLabels = labelTensor.sub(labelMin).div(labelMax.sub(labelMin));
Als Nächstes gibt es eine weitere
Best Practice für das Training von maschinellem Lernen. Die Daten werden normalisiert. Hier normalisieren wir die Daten mithilfe von min-max-Skalierung in den numerischen Bereich 0-1. Normalisierung ist wichtig, weil die Interna vieler ML-Modelle, die Sie mit tensorflow.js erstellen, auf die Arbeit mit nicht zu großen Zahlen ausgelegt sind. Gemeinsame Bereiche zur Normalisierung von Daten, um 0 to 1 oder -1 to 1 einzuschließen. Sie werden mehr Erfolg beim Trainieren Ihrer Modelle haben, wenn Sie es sich zur Gewohnheit machen, Ihre Daten auf einen angemessenen Bereich zu normalisieren.
Daten und Normalisierungsgrenzen zurückgeben
return {
inputs: normalizedInputs,
labels: normalizedLabels,
// Return the min/max bounds so we can use them later.
inputMax,
inputMin,
labelMax,
labelMin,
}
Wir möchten die Werte, die wir während des Trainings für die Normalisierung verwendet haben, beibehalten, damit wir die Ausgaben nicht normalisieren können, um sie wieder in unsere ursprüngliche Skalierung zu bringen und zukünftige Eingabedaten auf die gleiche Weise zu normalisieren.
6. Modell trainieren
Nachdem die Modellinstanz erstellt und die Daten als Tensoren dargestellt wurden, haben wir alles, um mit dem Training zu beginnen.
Kopieren Sie die folgende Funktion in Ihren
script.js Datei.
async function trainModel(model, inputs, labels) {
// Prepare the model for training.
model.compile({
optimizer: tf.train.adam(),
loss: tf.losses.meanSquaredError,
metrics: ['mse'],
});
const batchSize = 32;
const epochs = 50;
return await model.fit(inputs, labels, {
batchSize,
epochs,
shuffle: true,
callbacks: tfvis.show.fitCallbacks(
{ name: 'Training Performance' },
['loss', 'mse'],
{ height: 200, callbacks: ['onEpochEnd'] }
)
});
}
Schauen wir uns das genauer an.
Auf die Schulung vorbereiten
// Prepare the model for training.
model.compile({
optimizer: tf.train.adam(),
loss: tf.losses.meanSquaredError,
metrics: ['mse'],
});
Wir müssen „zusammenstellen“, bevor wir es trainieren. Dazu müssen wir einige sehr wichtige Angaben machen:
optimizer: Dies ist der Algorithmus, der die Aktualisierungen des Modells aus den Beispielen steuert. In TensorFlow.js sind viele Optimierungstools verfügbar. Hier haben wir das Adam-Optimierungstool ausgewählt, da es in der Praxis sehr effektiv ist und keine Konfiguration erfordert.loss: Dies ist eine Funktion, die dem Modell mitteilt, wie gut es die einzelnen Batches (Datenteilmengen) lernt, die es gezeigt hat. Hier verwenden wirmeanSquaredError, um die vom Modell gemachten Vorhersagen mit den tatsächlichen Werten zu vergleichen.
const batchSize = 32;
const epochs = 50;
Als Nächstes wählen wir einen BatchSize und eine Reihe von Epochen aus:
batchSizebezieht sich auf die Größe der Datenteilmengen, die das Modell bei jeder Trainingsdurchlauf sieht. Gängige Batchgrößen liegen in der Regel im Bereich 32 bis 512. Es gibt nicht für alle Probleme die ideale Batchgröße und es würde den Rahmen dieser Anleitung sprengen, die mathematischen Beweggründe für verschiedene Batchgrößen zu beschreiben.epochsgibt an, wie oft sich das Modell das gesamte Dataset ansieht, das Sie ihm zur Verfügung stellen. Hier durchlaufen wir 50 Iterationen des Datasets.
Zugschleife starten
return await model.fit(inputs, labels, {
batchSize,
epochs,
callbacks: tfvis.show.fitCallbacks(
{ name: 'Training Performance' },
['loss', 'mse'],
{ height: 200, callbacks: ['onEpochEnd'] }
)
});
model.fit ist die Funktion, die wir zum Starten der Trainingsschleife aufrufen. Da es sich um eine asynchrone Funktion handelt, geben wir das Versprechen zurück, das sie uns zuweist, damit der Aufrufer feststellen kann, wann das Training abgeschlossen ist.
Um den Trainingsfortschritt zu überwachen, geben wir einige Callbacks an model.fit zurück. Wir verwenden tfvis.show.fitCallbacks, um Funktionen zu generieren, die Diagramme für den Verlust und „mse“. den zuvor angegebenen Messwert.
Praktische Anwendung
Nun müssen wir die Funktionen aufrufen, die wir über die Funktion run definiert haben.
Fügen Sie den folgenden Code unten auf der
run -Funktion.
// Convert the data to a form we can use for training.
const tensorData = convertToTensor(data);
const {inputs, labels} = tensorData;
// Train the model
await trainModel(model, inputs, labels);
console.log('Done Training');
Wenn Sie die Seite aktualisieren, sollten Sie nach einigen Sekunden die folgenden Diagramme sehen.
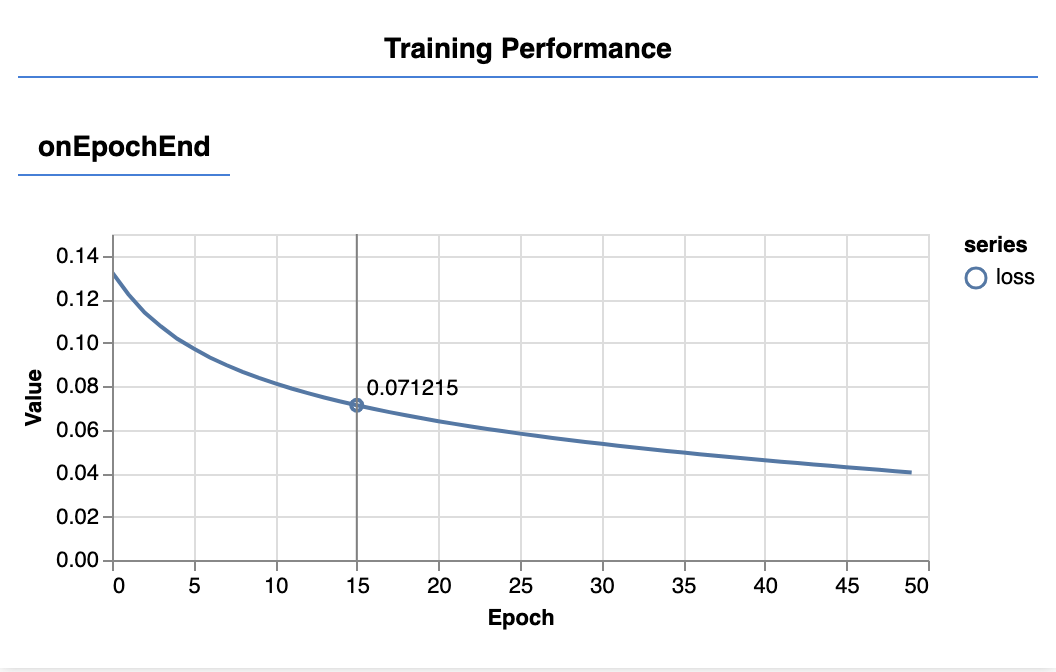
Sie werden durch die zuvor erstellten Callbacks erstellt. Sie zeigen den Verlust und die mse, gemittelt über das gesamte Dataset, am Ende jeder Epoche an.
Beim Trainieren eines Modells möchten wir sehen, dass der Verlust sinkt. Da unser Messwert ein Fehlermaß ist, möchten wir in diesem Fall einen Rückgang sehen.
7. Vorhersagen treffen
Nachdem das Modell nun trainiert ist, möchten wir einige Vorhersagen treffen. Bewerten wir das Modell, indem wir uns ansehen, was es für einen einheitlichen Zahlenbereich von niedrigen bis hohen PS prognostiziert.
Fügen Sie der Datei script.js die folgende Funktion hinzu
function testModel(model, inputData, normalizationData) {
const {inputMax, inputMin, labelMin, labelMax} = normalizationData;
// Generate predictions for a uniform range of numbers between 0 and 1;
// We un-normalize the data by doing the inverse of the min-max scaling
// that we did earlier.
const [xs, preds] = tf.tidy(() => {
const xsNorm = tf.linspace(0, 1, 100);
const predictions = model.predict(xsNorm.reshape([100, 1]));
const unNormXs = xsNorm
.mul(inputMax.sub(inputMin))
.add(inputMin);
const unNormPreds = predictions
.mul(labelMax.sub(labelMin))
.add(labelMin);
// Un-normalize the data
return [unNormXs.dataSync(), unNormPreds.dataSync()];
});
const predictedPoints = Array.from(xs).map((val, i) => {
return {x: val, y: preds[i]}
});
const originalPoints = inputData.map(d => ({
x: d.horsepower, y: d.mpg,
}));
tfvis.render.scatterplot(
{name: 'Model Predictions vs Original Data'},
{values: [originalPoints, predictedPoints], series: ['original', 'predicted']},
{
xLabel: 'Horsepower',
yLabel: 'MPG',
height: 300
}
);
}
Bei der obigen Funktion sind einige Dinge zu beachten.
const xsNorm = tf.linspace(0, 1, 100);
const predictions = model.predict(xsNorm.reshape([100, 1]));
Wir generieren 100 neue „Beispiele“ in das Modell eingespeist werden. Über „Model.predict“ werden diese Beispiele in das Modell eingespeist. Beachten Sie, dass sie eine ähnliche Form ([num_examples, num_features_per_example]) haben müssen wie im Training.
// Un-normalize the data
const unNormXs = xsNorm
.mul(inputMax.sub(inputMin))
.add(inputMin);
const unNormPreds = predictions
.mul(labelMax.sub(labelMin))
.add(labelMin);
Um die Daten wieder in unseren ursprünglichen Bereich (anstatt 0-1) zurückzubekommen, verwenden wir die Werte, die wir während der Normalisierung berechnet haben, aber invertieren wir einfach die Operationen.
return [unNormXs.dataSync(), unNormPreds.dataSync()];
.dataSync() ist eine Methode, mit der wir ein typedarray der in einem Tensor gespeicherten Werte abrufen können. So können diese Werte in regulärem JavaScript verarbeitet werden. Dies ist eine synchrone Version der Methode .data(), die im Allgemeinen bevorzugt wird.
Schließlich verwenden wir tfjs-vis, um die Originaldaten und die Vorhersagen aus dem Modell darzustellen.
Fügen Sie folgenden Code zu Ihrem
run -Funktion.
// Make some predictions using the model and compare them to the
// original data
testModel(model, data, tensorData);
Aktualisieren Sie die Seite. Nachdem das Modell trainiert wurde, sollte Folgendes angezeigt werden:
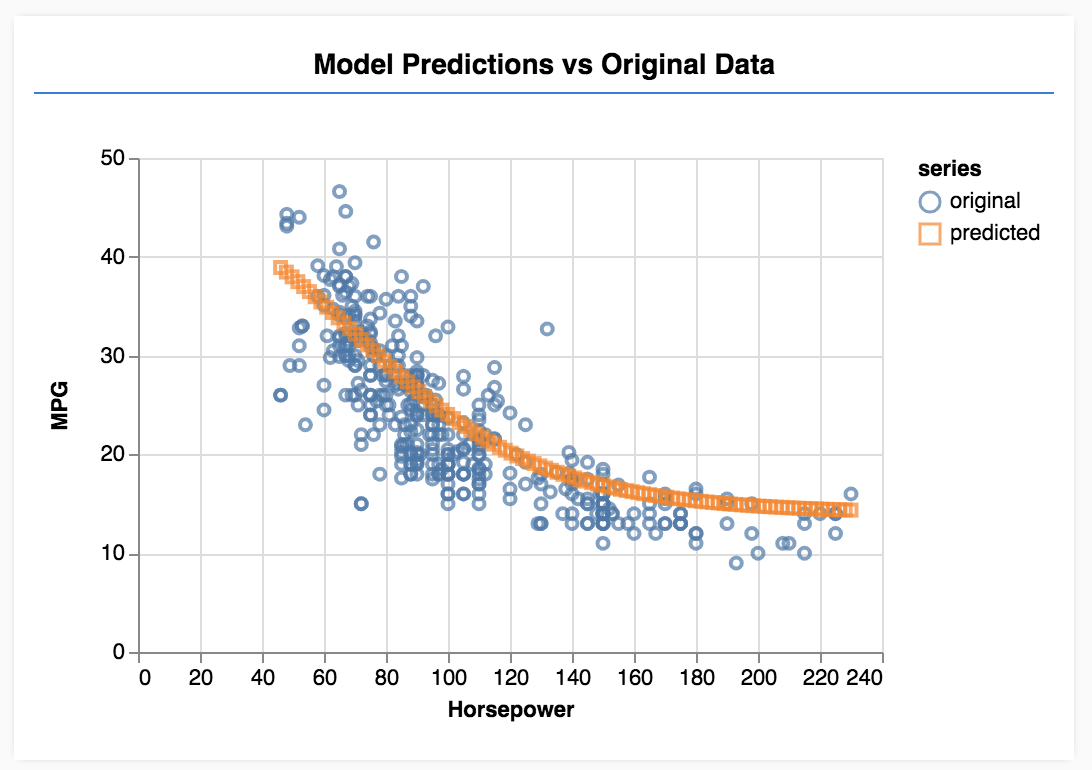
Glückwunsch! Sie haben gerade ein einfaches ML-Modell trainiert. Sie führt derzeit eine sogenannte lineare Regression durch, bei der versucht wird, eine Linie an den Trend in Eingabedaten anzupassen.
8. Wichtigste Erkenntnisse
Das Training eines Modells für maschinelles Lernen umfasst folgende Schritte:
Formulieren Sie Ihre Aufgabe:
- Handelt es sich um ein Regressions- oder ein Klassifizierungsproblem?
- Ist dies durch überwachtes oder unüberwachtes Lernen möglich?
- Welches Format haben die Eingabedaten? Wie sollten die Ausgabedaten aussehen?
Bereiten Sie Ihre Daten vor:
- Bereinigen Sie Ihre Daten und prüfen Sie sie nach Möglichkeit manuell auf Muster
- Daten vor dem Training mischen
- Normalisieren Sie Ihre Daten in einem angemessenen Bereich für das neuronale Netzwerk. Normalerweise sind 0-1 oder -1-1 gute Bereiche für numerische Daten.
- Daten in Tensoren umwandeln
Erstellen Sie Ihr Modell und führen Sie es aus:
- Definieren Sie Ihr Modell mit
tf.sequentialodertf.modelund fügen Sie ihm dann mittf.layers.*Ebenen hinzu - Wählen Sie ein Optimierungstool ( adam ist in der Regel eine gute Wahl) und Parameter wie Batchgröße und Anzahl der Epochen aus.
- Wählen Sie eine geeignete Verlustfunktion für Ihr Problem und einen Genauigkeitsmesswert, um den Fortschritt zu bewerten.
meanSquaredErrorist eine häufige Verlustfunktion für Regressionsprobleme. - Überwachen Sie das Training, um zu sehen, ob der Verlust sinkt
Modell bewerten
- Wählen Sie einen Bewertungsmesswert für Ihr Modell aus, den Sie während des Trainings überwachen können. Versuchen Sie nach dem Training einige Testvorhersagen, um sich ein Bild von der Vorhersagequalität zu machen.
9. Extra Credit: Dinge zum Ausprobieren
- Test: Anzahl der Epochen ändern Wie viele Epochen benötigen Sie, bis sich die Grafik verflacht.
- Experimentieren Sie mit der Erhöhung der Anzahl der Einheiten in der verborgenen Ebene.
- Experimentieren Sie mit dem Hinzufügen weiterer versteckter Ebenen zwischen der ersten ausgeblendeten Ebene, die wir hinzugefügt haben, und der endgültigen Ausgabeebene. Der Code für diese zusätzlichen Layers sollte in etwa so aussehen.
model.add(tf.layers.dense({units: 50, activation: 'sigmoid'}));
Das Wichtigste an diesen verborgenen Ebenen ist, dass sie eine nicht lineare Aktivierungsfunktion einführen, in diesem Fall die Sigmoidaktivierung. Weitere Informationen zu Aktivierungsfunktionen finden Sie in diesem Artikel.
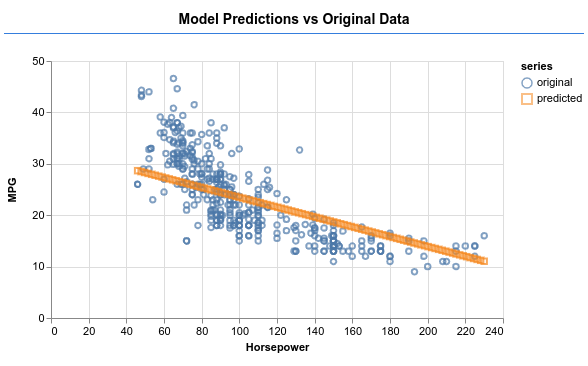
Versuchen Sie, mit dem Modell eine Ausgabe wie im Bild unten zu erzeugen.