
1. บทนำ
ในบทแนะนำนี้ เราจะสร้างโมเดล TensorFlow.js เพื่อจดจำตัวเลขที่เขียนด้วยลายมือผ่านโครงข่ายระบบประสาทเทียมแบบ Convolutional อันดับแรก เราจะฝึกตัวแยกประเภทโดยให้มี "ลักษณะ" รูปภาพตัวเลขที่เขียนด้วยลายมือและป้ายชื่อได้หลายพันภาพ จากนั้นเราจะประเมินความแม่นยำของตัวแยกประเภทโดยใช้ข้อมูลทดสอบที่โมเดลไม่เคยเห็นมาก่อน
งานนี้ถือเป็นงานการแยกประเภทเนื่องจากเรากำลังฝึกโมเดลให้กำหนดหมวดหมู่ (ตัวเลขที่ปรากฏในรูปภาพ) ให้กับรูปภาพอินพุต เราจะฝึกโมเดลด้วยการแสดงตัวอย่างอินพุตหลายๆ อย่างพร้อมกับเอาต์พุตที่ถูกต้อง ซึ่งเรียกว่าการเรียนรู้แบบมีการควบคุมดูแล
สิ่งที่คุณจะสร้าง
คุณจะได้สร้างหน้าเว็บที่ใช้ TensorFlow.js เพื่อฝึกโมเดลในเบราว์เซอร์ ด้วยภาพขาวดำที่มีขนาดเฉพาะ ระบบจะจำแนกว่าตัวเลขใดที่ปรากฏในภาพ ขั้นตอนที่เกี่ยวข้องมีดังนี้
- โหลดข้อมูล
- กำหนดสถาปัตยกรรมของโมเดล
- ฝึกโมเดลและตรวจสอบประสิทธิภาพขณะฝึก
- ประเมินโมเดลที่ฝึกโดยทำการคาดการณ์
สิ่งที่คุณจะได้เรียนรู้
- ไวยากรณ์ TensorFlow.js สำหรับการสร้างโมเดล Convolutional โดยใช้ TensorFlow.js Layers API
- การสร้างงานการแยกประเภทใน TensorFlow.js
- วิธีตรวจสอบการฝึกทำงานในเบราว์เซอร์โดยใช้ไลบรารี tfjs-vis
สิ่งที่คุณต้องมี
- Chrome เวอร์ชันล่าสุด หรือเบราว์เซอร์ที่ทันสมัยอื่นที่รองรับโมดูล ES6
- เครื่องมือแก้ไขข้อความ ซึ่งจะทำงานในเครื่องหรือบนเว็บผ่านบางอย่าง เช่น Codepen หรือ Glitch
- ความรู้เกี่ยวกับ HTML, CSS, JavaScript และเครื่องมือสำหรับนักพัฒนาเว็บใน Chrome (หรือเครื่องมือสำหรับนักพัฒนาเว็บในเบราว์เซอร์ที่คุณต้องการ)
- ความเข้าใจในเชิงแนวคิดเกี่ยวกับโครงข่ายระบบประสาทเทียมในระดับสูง หากต้องการข้อมูลเบื้องต้นหรือทบทวนความรู้ โปรดดูวิดีโอนี้โดย 3blue1brown หรือวิดีโอเกี่ยวกับการเรียนรู้เชิงลึกใน JavaScript โดย Ashi Krishnan
และคุณควรคุ้นเคยกับเนื้อหาในบทแนะนำการฝึกอบรมแรกของเราด้วย
2. ตั้งค่า
สร้างหน้า HTML และรวม JavaScript
 คัดลอกโค้ดต่อไปนี้ลงในไฟล์ HTML ชื่อ
คัดลอกโค้ดต่อไปนี้ลงในไฟล์ HTML ชื่อ
index.html
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>TensorFlow.js Tutorial</title>
<!-- Import TensorFlow.js -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@1.0.0/dist/tf.min.js"></script>
<!-- Import tfjs-vis -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs-vis@1.0.2/dist/tfjs-vis.umd.min.js"></script>
<!-- Import the data file -->
<script src="data.js" type="module"></script>
<!-- Import the main script file -->
<script src="script.js" type="module"></script>
</head>
<body>
</body>
</html>
สร้างไฟล์ JavaScript สำหรับข้อมูลและโค้ด
- ในโฟลเดอร์เดียวกับไฟล์ HTML ข้างต้น ให้สร้างไฟล์ชื่อ data.js แล้วคัดลอกเนื้อหาจากลิงก์นี้ไปยังไฟล์ดังกล่าว
- ในโฟลเดอร์เดียวกับขั้นตอนที่ 1 ให้สร้างไฟล์ชื่อ script.js และวางโค้ดต่อไปนี้ลงในไฟล์
console.log('Hello TensorFlow');
ทดสอบเลย
ตอนนี้คุณได้สร้างไฟล์ HTML และ JavaScript แล้ว โปรดทดสอบ เปิดไฟล์ index.html ในเบราว์เซอร์และเปิดคอนโซล Devtools
หากทุกอย่างทำงานเป็นปกติ ควรสร้างตัวแปรร่วม 2 รายการ tf คือการอ้างอิงไลบรารี TensorFlow.js ขณะที่ tfvis จะอ้างอิงไปยังไลบรารี tfjs-vis
คุณควรจะเห็นข้อความว่า Hello TensorFlow, หากเป็นเช่นนั้น คุณก็พร้อมที่จะทำขั้นตอนต่อไปแล้ว
3. โหลดข้อมูล
ในบทแนะนำนี้ คุณจะได้ฝึกโมเดลให้เรียนรู้การรู้จำตัวเลขในภาพเหมือนกับภาพด้านล่าง รูปภาพเหล่านี้เป็นรูปภาพโทนสีเทาขนาด 28x28 พิกเซลจากชุดข้อมูลที่เรียกว่า MNIST

เราได้ให้โค้ดสำหรับโหลดรูปภาพเหล่านี้จากไฟล์สไปรท์พิเศษ (~10 MB) ที่เราสร้างไว้ให้คุณเพื่อให้เราสามารถมุ่งเน้นไปที่ส่วนที่ฝึกได้
คุณสามารถศึกษาไฟล์ data.js เพื่อทำความเข้าใจวิธีโหลดข้อมูลได้ หรือเมื่อคุณทำตามบทแนะนำนี้เสร็จแล้ว ให้สร้างวิธีการโหลดข้อมูลของคุณเอง
โค้ดที่ระบุมีคลาส MnistData ที่มีเมธอดสาธารณะ 2 วิธี ได้แก่
nextTrainBatch(batchSize): แสดงผลกลุ่มรูปภาพแบบสุ่มและป้ายกำกับจากชุดการฝึกnextTestBatch(batchSize): แสดงกลุ่มรูปภาพและป้ายกำกับจากชุดทดสอบ
นอกจากนี้ คลาส MnistData ยังมีขั้นตอนสำคัญในการสับเปลี่ยนและการปรับมาตรฐานข้อมูลด้วย
มีรูปภาพทั้งหมด 65,000 รูป เราจะใช้รูปภาพสูงสุด 55,000 รูปในการฝึกโมเดล และจะบันทึกรูปภาพ 10,000 รูปที่เราใช้เพื่อทดสอบประสิทธิภาพของโมเดลเมื่อดำเนินการเสร็จ และเราจะทำแบบนั้นทั้งหมดในเบราว์เซอร์
มาโหลดข้อมูลและทดสอบว่าโหลดได้ถูกต้องหรือไม่
เพิ่มโค้ดต่อไปนี้ลงในไฟล์ Script.js
import {MnistData} from './data.js';
async function showExamples(data) {
// Create a container in the visor
const surface =
tfvis.visor().surface({ name: 'Input Data Examples', tab: 'Input Data'});
// Get the examples
const examples = data.nextTestBatch(20);
const numExamples = examples.xs.shape[0];
// Create a canvas element to render each example
for (let i = 0; i < numExamples; i++) {
const imageTensor = tf.tidy(() => {
// Reshape the image to 28x28 px
return examples.xs
.slice([i, 0], [1, examples.xs.shape[1]])
.reshape([28, 28, 1]);
});
const canvas = document.createElement('canvas');
canvas.width = 28;
canvas.height = 28;
canvas.style = 'margin: 4px;';
await tf.browser.toPixels(imageTensor, canvas);
surface.drawArea.appendChild(canvas);
imageTensor.dispose();
}
}
async function run() {
const data = new MnistData();
await data.load();
await showExamples(data);
}
document.addEventListener('DOMContentLoaded', run);
รีเฟรชหน้าเว็บ จากนั้นหลังจากผ่านไป 2-3 วินาที คุณจะเห็นแผงทางด้านซ้ายพร้อมด้วยรูปภาพจำนวนหนึ่ง

4. กำหนดแนวคิดของงานของเรา
ข้อมูลอินพุตของเรามีลักษณะดังนี้
เป้าหมายของเราคือการฝึกโมเดลที่ใช้รูปภาพ 1 รูปและเรียนรู้ที่จะคาดการณ์คะแนนของแต่ละคลาสที่เป็นไปได้ทั้ง 10 คลาสที่อาจมีรูปภาพดังกล่าว (ตัวเลข 0-9)
แต่ละภาพมีความกว้าง 28 พิกเซล สูง 28 พิกเซล และมีช่องสี 1 ช่องเช่นเดียวกับรูปภาพสีขาว-ดำ ดังนั้นรูปร่างของแต่ละรูปคือ [28, 28, 1]
อย่าลืมว่าเราสร้างแผนที่แบบ 1 ถึง 10 รวมถึงรูปร่างของตัวอย่างอินพุตแต่ละรายการด้วย เพราะเป็นส่วนสำคัญสำหรับส่วนถัดไป
5. กำหนดสถาปัตยกรรมโมเดล
ในส่วนนี้ เราจะเขียนโค้ดเพื่ออธิบายสถาปัตยกรรมโมเดล สถาปัตยกรรมโมเดลเป็นคำพูดที่ฟังดูเพลินตาในการบอกถึง "โมเดลจะเรียกใช้ฟังก์ชันใดเมื่อโมเดลกำลังทำงาน" หรืออีกทางเลือกหนึ่งคือ "โมเดลของเราจะใช้อัลกอริทึมใดในการคำนวณคำตอบ"
ในแมชชีนเลิร์นนิง เรากำหนดสถาปัตยกรรม (หรืออัลกอริทึม) และให้กระบวนการฝึกเรียนรู้พารามิเตอร์ของอัลกอริทึมนั้น
เพิ่มฟังก์ชันต่อไปนี้ลงใน
script.js ไฟล์เพื่อกำหนดสถาปัตยกรรมโมเดล
function getModel() {
const model = tf.sequential();
const IMAGE_WIDTH = 28;
const IMAGE_HEIGHT = 28;
const IMAGE_CHANNELS = 1;
// In the first layer of our convolutional neural network we have
// to specify the input shape. Then we specify some parameters for
// the convolution operation that takes place in this layer.
model.add(tf.layers.conv2d({
inputShape: [IMAGE_WIDTH, IMAGE_HEIGHT, IMAGE_CHANNELS],
kernelSize: 5,
filters: 8,
strides: 1,
activation: 'relu',
kernelInitializer: 'varianceScaling'
}));
// The MaxPooling layer acts as a sort of downsampling using max values
// in a region instead of averaging.
model.add(tf.layers.maxPooling2d({poolSize: [2, 2], strides: [2, 2]}));
// Repeat another conv2d + maxPooling stack.
// Note that we have more filters in the convolution.
model.add(tf.layers.conv2d({
kernelSize: 5,
filters: 16,
strides: 1,
activation: 'relu',
kernelInitializer: 'varianceScaling'
}));
model.add(tf.layers.maxPooling2d({poolSize: [2, 2], strides: [2, 2]}));
// Now we flatten the output from the 2D filters into a 1D vector to prepare
// it for input into our last layer. This is common practice when feeding
// higher dimensional data to a final classification output layer.
model.add(tf.layers.flatten());
// Our last layer is a dense layer which has 10 output units, one for each
// output class (i.e. 0, 1, 2, 3, 4, 5, 6, 7, 8, 9).
const NUM_OUTPUT_CLASSES = 10;
model.add(tf.layers.dense({
units: NUM_OUTPUT_CLASSES,
kernelInitializer: 'varianceScaling',
activation: 'softmax'
}));
// Choose an optimizer, loss function and accuracy metric,
// then compile and return the model
const optimizer = tf.train.adam();
model.compile({
optimizer: optimizer,
loss: 'categoricalCrossentropy',
metrics: ['accuracy'],
});
return model;
}
มาดูรายละเอียดเพิ่มเติมกัน
คอนโวลูชัน
model.add(tf.layers.conv2d({
inputShape: [IMAGE_WIDTH, IMAGE_HEIGHT, IMAGE_CHANNELS],
kernelSize: 5,
filters: 8,
strides: 1,
activation: 'relu',
kernelInitializer: 'varianceScaling'
}));
เราจะใช้โมเดลตามลำดับ
เราใช้เลเยอร์ conv2d แทนเลเยอร์ที่หนาแน่น เราไม่สามารถลงรายละเอียดทั้งหมดเกี่ยวกับวิธีการทำงานของ Convolution ได้ แต่เรามีแหล่งข้อมูลบางส่วนต่อไปนี้ซึ่งอธิบายการดำเนินการที่สำคัญ
มาดูรายละเอียดของแต่ละอาร์กิวเมนต์ในออบเจ็กต์การกำหนดค่าสำหรับ conv2d กัน
inputShapeรูปร่างของข้อมูลที่จะไหลเข้าสู่เลเยอร์แรกของโมเดล ในกรณีนี้ ตัวอย่างของ MNIST คือรูปภาพขาวดำขนาด 28x28 พิกเซล รูปแบบ Canonical สำหรับข้อมูลรูปภาพคือ[row, column, depth]เราจึงต้องการกำหนดค่ารูปร่าง[28, 28, 1]28 แถวและคอลัมน์สำหรับจำนวนพิกเซลในแต่ละด้าน และความลึก 1 เนื่องจากรูปภาพของเรามีเพียงช่องสีเพียง 1 ช่อง โปรดทราบว่าเราไม่ได้ระบุขนาดกลุ่มในรูปร่างอินพุต เลเยอร์ได้รับการออกแบบมาให้รองรับขนาดกลุ่ม เพื่อให้คุณสามารถส่งผ่าน Tensor ขนาดกลุ่มใดก็ได้ในระหว่างการอนุมานkernelSizeขนาดของหน้าต่างตัวกรองคอนโวลูชันแบบเลื่อนที่จะนำไปใช้กับข้อมูลอินพุต เราตั้งค่าkernelSizeเป็น5ซึ่งระบุหน้าต่างคอนโวลูชันแบบสี่เหลี่ยมจัตุรัส 5x5filtersจำนวนหน้าต่างตัวกรองขนาดkernelSizeที่จะใช้กับข้อมูลอินพุต ในที่นี้เราจะใช้ตัวกรอง 8 รายการกับข้อมูลstrides"ขนาดก้าว" ของหน้าต่างเลื่อน เช่น จำนวนพิกเซลที่ตัวกรองจะเปลี่ยนในแต่ละครั้งที่เลื่อนรูปภาพ ในที่นี้เราจะระบุระยะก้าวเป็น 1 ซึ่งหมายความว่าตัวกรองจะเลื่อนเหนือรูปภาพเป็นขั้นๆ ที่ 1 พิกเซลactivationฟังก์ชันเปิดใช้งานที่จะใช้กับข้อมูลหลังจากคอนโวลูชันเสร็จสมบูรณ์ ในกรณีนี้ เราจะใช้ฟังก์ชัน Rectified Linear Unit (ReLU) ซึ่งเป็นฟังก์ชันเปิดใช้งานที่พบได้ทั่วไปในโมเดล MLkernelInitializerเมธอดที่ใช้ในการเริ่มต้นแบบสุ่มให้น้ำหนักของโมเดล ซึ่งสำคัญมากต่อการฝึกไดนามิก เราจะไม่พูดถึงรายละเอียดของการเริ่มต้นที่นี่ แต่VarianceScaling(ใช้ที่นี่) ถือเป็นตัวเลือกเริ่มต้นที่ดี
ทำให้การแสดงข้อมูลของเราเป็นจำนวนมากขึ้น
model.add(tf.layers.flatten());
รูปภาพเป็นข้อมูลที่มีมิติสูง และการดำเนินการ Convolution มักเพิ่มขนาดของข้อมูลที่มีผลกับรูป ก่อนที่จะส่งข้อมูลไปยังชั้นการจัดประเภทขั้นสุดท้าย เราต้องแยกข้อมูลให้เป็นอาร์เรย์แบบยาว 1 รายการ เลเยอร์ที่หนาแน่น (ซึ่งเราใช้เป็นเลเยอร์สุดท้าย) ใช้เวลาเพียง tensor1d วินาที ดังนั้นขั้นตอนนี้จึงมักเกิดขึ้นในงานแยกประเภทจำนวนมาก
คำนวณการแจกแจงความน่าจะเป็นสุดท้าย
const NUM_OUTPUT_CLASSES = 10;
model.add(tf.layers.dense({
units: NUM_OUTPUT_CLASSES,
kernelInitializer: 'varianceScaling',
activation: 'softmax'
}));
เราจะใช้เลเยอร์แบบหนาแน่นที่มีการเปิดใช้งาน Softmax เพื่อคำนวณการแจกแจงความน่าจะเป็นของคลาสที่เป็นไปได้ทั้ง 10 คลาส ชั้นเรียนที่มีคะแนนสูงสุดจะเป็นตัวเลขที่คาดการณ์ไว้
เลือกฟังก์ชันการเพิ่มประสิทธิภาพและการสูญเสีย
const optimizer = tf.train.adam();
model.compile({
optimizer: optimizer,
loss: 'categoricalCrossentropy',
metrics: ['accuracy'],
});
เรารวบรวมโมเดลที่ระบุเครื่องมือเพิ่มประสิทธิภาพ ฟังก์ชันการสูญเสีย และเมตริกที่ต้องการติดตาม
เราใช้ categoricalCrossentropy เป็นฟังก์ชันการสูญเสียเนื้อหา ซึ่งแตกต่างจากบทแนะนำแรก ซึ่งชื่อจะบ่งบอกลักษณะนี้เมื่อเอาต์พุตของโมเดลเป็นการแจกแจงความน่าจะเป็น categoricalCrossentropy วัดข้อผิดพลาดระหว่างการกระจายความน่าจะเป็นที่สร้างโดยชั้นสุดท้ายของโมเดลของเรากับการกระจายความน่าจะเป็นที่กำหนดโดยป้ายกำกับจริงของเรา
ตัวอย่างเช่น หากตัวเลขของเราแสดงถึง 7 จริงๆ เราอาจได้ผลลัพธ์ต่อไปนี้
ดัชนี | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
ป้ายกำกับจริง | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
การคาดการณ์ | 0.1 | 0.01 | 0.01 | 0.01 | 0.20 | 0.01 | 0.01 | 0.60 | 0.03 | 0.02 |
ครอสเอนโทรปีเชิงหมวดหมู่จะสร้างตัวเลขที่ระบุความใกล้เคียงของเวกเตอร์การคาดการณ์กับเวกเตอร์ป้ายกำกับที่แท้จริงของเรา
การแสดงข้อมูลที่ใช้สำหรับป้ายกำกับที่นี่เรียกว่าการเข้ารหัสแบบฮอตเดียว และพบบ่อยในโจทย์การจัดประเภท แต่ละคลาสมีความน่าจะเป็นที่เกี่ยวข้องสำหรับแต่ละตัวอย่าง เมื่อเรารู้แน่ชัดแล้วว่าควรจะเป็นอะไร เราสามารถตั้งค่าความน่าจะเป็นเป็น 1 และความน่าจะเป็นอื่นๆ เป็น 0 ดูข้อมูลเพิ่มเติมเกี่ยวกับการเข้ารหัสแบบ One-hot ได้ในหน้านี้
เมตริกอื่นที่เราจะตรวจสอบคือ accuracy ซึ่งสำหรับปัญหาการจัดประเภทคือเปอร์เซ็นต์ของการคาดการณ์ที่ถูกต้องจากการคาดการณ์ทั้งหมด
6. ฝึกโมเดล
คัดลอกฟังก์ชันต่อไปนี้ไปยังไฟล์ Script.js
async function train(model, data) {
const metrics = ['loss', 'val_loss', 'acc', 'val_acc'];
const container = {
name: 'Model Training', tab: 'Model', styles: { height: '1000px' }
};
const fitCallbacks = tfvis.show.fitCallbacks(container, metrics);
const BATCH_SIZE = 512;
const TRAIN_DATA_SIZE = 5500;
const TEST_DATA_SIZE = 1000;
const [trainXs, trainYs] = tf.tidy(() => {
const d = data.nextTrainBatch(TRAIN_DATA_SIZE);
return [
d.xs.reshape([TRAIN_DATA_SIZE, 28, 28, 1]),
d.labels
];
});
const [testXs, testYs] = tf.tidy(() => {
const d = data.nextTestBatch(TEST_DATA_SIZE);
return [
d.xs.reshape([TEST_DATA_SIZE, 28, 28, 1]),
d.labels
];
});
return model.fit(trainXs, trainYs, {
batchSize: BATCH_SIZE,
validationData: [testXs, testYs],
epochs: 10,
shuffle: true,
callbacks: fitCallbacks
});
}
จากนั้นเพิ่มโค้ดต่อไปนี้ลงใน
run ฟังก์ชัน
const model = getModel();
tfvis.show.modelSummary({name: 'Model Architecture', tab: 'Model'}, model);
await train(model, data);
รีเฟรชหน้าเว็บ แล้วหลังจากนั้นสักครู่คุณจะเห็นกราฟรายงานความคืบหน้าของการฝึก
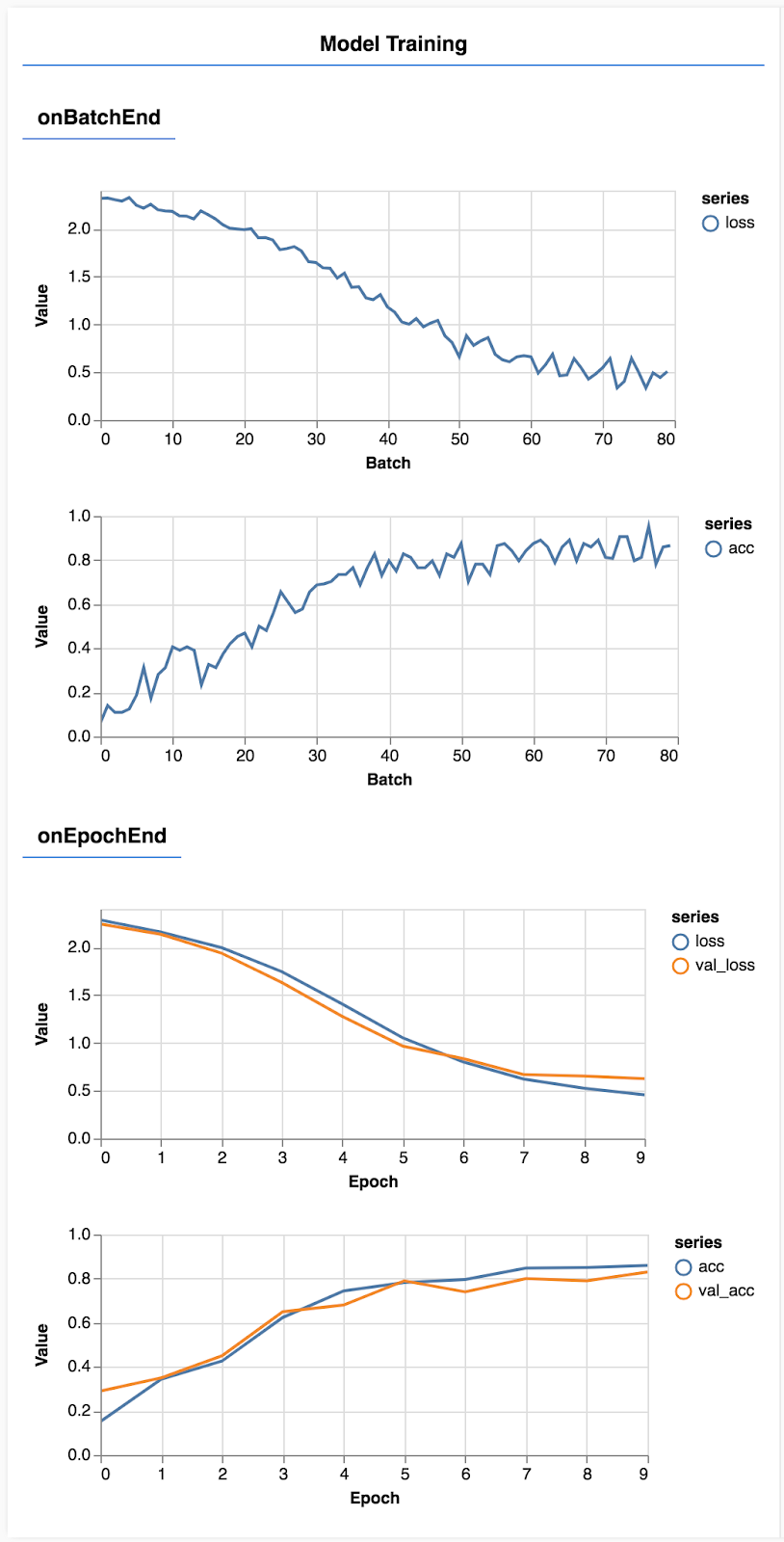
มาดูรายละเอียดเพิ่มเติมกัน
ตรวจสอบเมตริก
const metrics = ['loss', 'val_loss', 'acc', 'val_acc'];
ในส่วนนี้ เราจะตัดสินใจว่าเมตริกใด ที่เราจะตรวจสอบ เราจะตรวจสอบการสูญเสียและความแม่นยำในชุดการฝึก รวมถึงการสูญเสียและความแม่นยำในชุดการตรวจสอบ (val_loss และ val_acc ตามลำดับ) เราจะพูดถึงชุดการตรวจสอบเพิ่มเติมด้านล่าง
เตรียมข้อมูลเป็น Tensor
const BATCH_SIZE = 512;
const TRAIN_DATA_SIZE = 5500;
const TEST_DATA_SIZE = 1000;
const [trainXs, trainYs] = tf.tidy(() => {
const d = data.nextTrainBatch(TRAIN_DATA_SIZE);
return [
d.xs.reshape([TRAIN_DATA_SIZE, 28, 28, 1]),
d.labels
];
});
const [testXs, testYs] = tf.tidy(() => {
const d = data.nextTestBatch(TEST_DATA_SIZE);
return [
d.xs.reshape([TEST_DATA_SIZE, 28, 28, 1]),
d.labels
];
});
เราสร้างชุดข้อมูล 2 ชุด ชุดการฝึกที่เราจะใช้ฝึกโมเดล และชุดการตรวจสอบที่เราจะทดสอบโมเดลในตอนท้ายของแต่ละ Epoch อย่างไรก็ตาม ข้อมูลในชุดการตรวจสอบจะไม่แสดงต่อโมเดลระหว่างการฝึก
คลาสข้อมูลที่เราให้ไว้ช่วยให้คุณรับ Tensor จากข้อมูลรูปภาพได้อย่างง่ายดาย แต่เรายังคงปรับเปลี่ยน Tensor ให้เป็นรูปร่างตามที่โมเดล [num_examples, image_width, image_height, channels] อยู่ก่อนที่จะป้อนสิ่งเหล่านี้ลงในโมเดล สำหรับชุดข้อมูลแต่ละชุด เรามีทั้งอินพุต (X) และป้ายกำกับ (Y)
return model.fit(trainXs, trainYs, {
batchSize: BATCH_SIZE,
validationData: [testXs, testYs],
epochs: 10,
shuffle: true,
callbacks: fitCallbacks
});
เราเรียก model.fit เพื่อเริ่มลูปการฝึก นอกจากนี้เรายังผ่านพร็อพเพอร์ตี้ ValidData เพื่อระบุว่าโมเดลควรใช้ข้อมูลใดเพื่อทดสอบตัวเองหลังจากแต่ละ Epoch (แต่ไม่ใช้สำหรับการฝึก)
หากเราใช้ประโยชน์จากข้อมูลการฝึกได้ดี แต่ไม่ตรงกับข้อมูลการตรวจสอบ นั่นหมายความว่าโมเดลมีแนวโน้มที่จะไม่เหมาะกับข้อมูลการฝึก และจะทำให้ข้อมูลทั่วไปเป็นข้อมูลที่ยังไม่เคยเห็นมาก่อนได้
7. ประเมินโมเดล
ความแม่นยําในการตรวจสอบเป็นการคาดการณ์ที่ดีว่าโมเดลของเราจะดำเนินการกับข้อมูลที่ไม่เคยเห็นมาก่อนได้ดีเพียงใด (ตราบใดที่ข้อมูลดังกล่าวมีลักษณะคล้ายกับชุดการตรวจสอบบางอย่าง) อย่างไรก็ตาม เราอาจต้องการรายละเอียดเพิ่มเติมเกี่ยวกับประสิทธิภาพในชั้นเรียนต่างๆ
มี 2 วิธีใน tfjs-vis ที่ช่วยคุณได้
เพิ่มโค้ดต่อไปนี้ที่ด้านล่างของไฟล์ Script.js
const classNames = ['Zero', 'One', 'Two', 'Three', 'Four', 'Five', 'Six', 'Seven', 'Eight', 'Nine'];
function doPrediction(model, data, testDataSize = 500) {
const IMAGE_WIDTH = 28;
const IMAGE_HEIGHT = 28;
const testData = data.nextTestBatch(testDataSize);
const testxs = testData.xs.reshape([testDataSize, IMAGE_WIDTH, IMAGE_HEIGHT, 1]);
const labels = testData.labels.argMax(-1);
const preds = model.predict(testxs).argMax(-1);
testxs.dispose();
return [preds, labels];
}
async function showAccuracy(model, data) {
const [preds, labels] = doPrediction(model, data);
const classAccuracy = await tfvis.metrics.perClassAccuracy(labels, preds);
const container = {name: 'Accuracy', tab: 'Evaluation'};
tfvis.show.perClassAccuracy(container, classAccuracy, classNames);
labels.dispose();
}
async function showConfusion(model, data) {
const [preds, labels] = doPrediction(model, data);
const confusionMatrix = await tfvis.metrics.confusionMatrix(labels, preds);
const container = {name: 'Confusion Matrix', tab: 'Evaluation'};
tfvis.render.confusionMatrix(container, {values: confusionMatrix, tickLabels: classNames});
labels.dispose();
}
โค้ดนี้ใช้ทำอะไร
- ทำการคาดคะเน
- คำนวณเมตริกความแม่นยำ
- แสดงเมตริก
มาดูรายละเอียดเกี่ยวกับแต่ละขั้นตอนกัน
คาดการณ์
function doPrediction(model, data, testDataSize = 500) {
const IMAGE_WIDTH = 28;
const IMAGE_HEIGHT = 28;
const testData = data.nextTestBatch(testDataSize);
const testxs = testData.xs.reshape([testDataSize, IMAGE_WIDTH, IMAGE_HEIGHT, 1]);
const labels = testData.labels.argMax(-1);
const preds = model.predict(testxs).argMax(-1);
testxs.dispose();
return [preds, labels];
}
ก่อนอื่นเราต้องคาดการณ์ ในส่วนนี้เราจะถ่ายภาพ 500 ภาพและคาดการณ์ตัวเลขที่อยู่ในภาพ (คุณสามารถเพิ่มตัวเลขนี้ในภายหลังเพื่อทดสอบชุดภาพขนาดใหญ่)
ที่สำคัญคือฟังก์ชัน argmax คือสิ่งที่ทำให้เรามีดัชนีของคลาสความน่าจะเป็นสูงสุด อย่าลืมว่าโมเดลจะแสดงความน่าจะเป็นสำหรับแต่ละคลาส ในที่นี้เราจะค้นหาความน่าจะเป็นสูงสุด และกำหนดการใช้งานดังกล่าวเป็นการคาดการณ์
และคุณอาจสังเกตเห็นว่าเราคาดการณ์กับตัวอย่างทั้ง 500 รายการพร้อมกันได้ด้วย นี่คือพลังของการสร้างเวกเตอร์ที่ TensorFlow.js มอบให้
แสดงความแม่นยำตามชั้นเรียน
async function showAccuracy() {
const [preds, labels] = doPrediction();
const classAccuracy = await tfvis.metrics.perClassAccuracy(labels, preds);
const container = { name: 'Accuracy', tab: 'Evaluation' };
tfvis.show.perClassAccuracy(container, classAccuracy, classNames);
labels.dispose();
}
เราสามารถคำนวณความแม่นยำสำหรับแต่ละคลาสได้ด้วยชุดการคาดคะเนและป้ายกำกับ
แสดงเมทริกซ์ความสับสน
async function showConfusion() {
const [preds, labels] = doPrediction();
const confusionMatrix = await tfvis.metrics.confusionMatrix(labels, preds);
const container = { name: 'Confusion Matrix', tab: 'Evaluation' };
tfvis.render.confusionMatrix(container, {values: confusionMatrix, tickLabels: classNames});
labels.dispose();
}
เมทริกซ์ความสับสนคล้ายกับความแม่นยำต่อคลาส แต่จะแบ่งย่อยเพื่อแสดงรูปแบบของการจัดประเภทที่ไม่ถูกต้อง ซึ่งช่วยให้คุณดูได้ว่าโมเดลเกิดความสับสนเกี่ยวกับคลาสคู่ใดหรือไม่
แสดงการประเมิน
เพิ่มโค้ดต่อไปนี้ไว้ที่ด้านล่างของฟังก์ชันการเรียกใช้เพื่อแสดงการประเมิน
await showAccuracy(model, data);
await showConfusion(model, data);
คุณจะเห็นจอแสดงผลที่มีลักษณะดังนี้
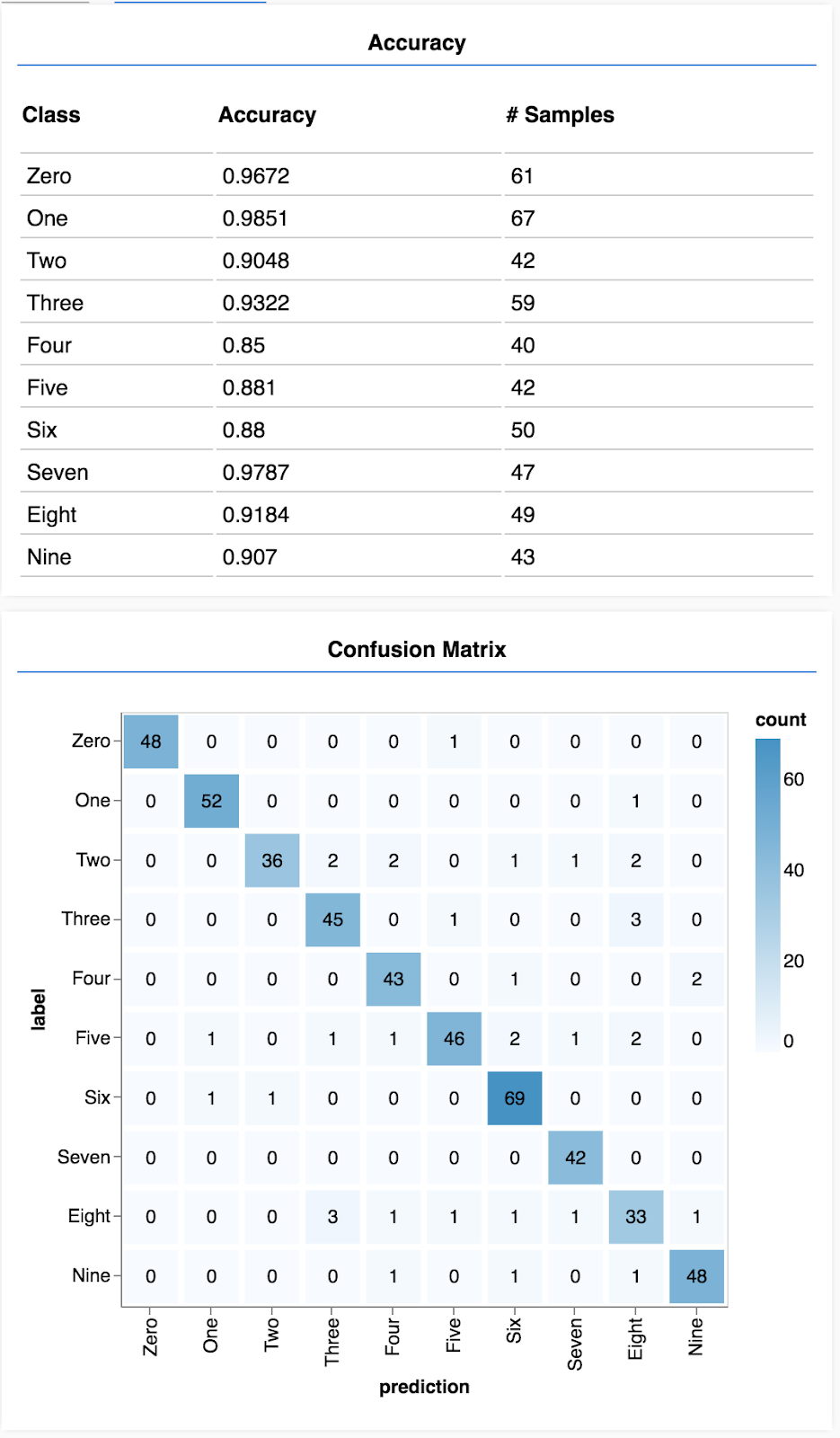
ยินดีด้วย คุณเพิ่งฝึกโครงข่ายประสาทแบบ Convolutional
8. สรุปประเด็นสำคัญ
การคาดการณ์หมวดหมู่สำหรับข้อมูลอินพุตเรียกว่างานการแยกประเภท
งานการแยกประเภทต้องมีการแสดงข้อมูลที่เหมาะสมสำหรับป้ายกำกับ
- การแสดงป้ายกำกับทั่วไปรวมถึงการเข้ารหัสหมวดหมู่แบบ Hot
เตรียมข้อมูลของคุณ:
- คุณควรเก็บข้อมูลบางอย่างไว้ยกเว้นข้อมูลที่โมเดลไม่เคยเห็นระหว่างการฝึก ซึ่งคุณสามารถนำไปใช้เพื่อประเมินโมเดลได้ ซึ่งเรียกว่าชุดการตรวจสอบ
สร้างและเรียกใช้โมเดลโดยทำดังนี้
- ระบบพบว่าโมเดลคอนโวลูชัน (Convolutional) ทำงานได้ดีในงานรูปภาพ
- ปัญหาการจำแนกประเภทมักจะใช้ครอสเอนโทรปีเชิงหมวดหมู่สำหรับหน้าที่ที่สูญเสียไป
- ตรวจสอบการฝึกเพื่อดูว่าการสูญเสียลดลงและความแม่นยำเพิ่มขึ้นหรือไม่
ประเมินโมเดล
- ตัดสินใจเลือกวิธีประเมินโมเดลหลังจากที่ได้รับการฝึกเพื่อดูว่าโมเดลทำงานได้ดีแค่ไหนกับปัญหาแรกเริ่มที่คุณต้องการแก้ไข
- เมทริกซ์ความแม่นยำและความสับสนตามคลาสสามารถดูรายละเอียดประสิทธิภาพของโมเดลได้ละเอียดยิ่งขึ้น ไม่ใช่แค่ความแม่นยำโดยรวม